Configuring Java and CORBA for Successful Database Application Integration
Thomas W. Hetherington
Applied Research Laboratories
The University of Texas at Austin
Lane B. Warshaw
Department of Computer Sciences and Applied Research Laboratories
The University of Texas at Austin
Lance Obermeyer
Applied Research Laboratories
The University of Texas at Austin
Daniel P. Miranker
Department of Computer Sciences and Applied Research Laboratories
The University of Texas at Austin
Abstract
Modern software engineering practices dictate decomposing large applications into smaller modules, with communication between modules occurring via formal interfaces. A recent technology, the Common Object Request Broker Architecture (CORBA), provides interface infrastructure to facilitate this communication. CORBA has two fundamental features, an interface definition language (called IDL) to define formal interfaces and an implementation mechanism to manage module communication. This allows application functionality to be distributed to different processes within the same machine or to different machines across a network. Database applications have long followed this model of distributed computing by supporting database functionality on large server class machines and interface functionality on smaller client class machines. Thus a current area of research is whether database applications can benefit from CORBA technology, and if so, how.
One benefit of using CORBA technology is language independence. Modules can be written in nearly any language; the CORBA mechanism will handle any inter-language integration. In essence, modules written in languages such as Ada and C++ may be "linked" together into a single application. This extends to the currently popular Java language.
This paper reports on our experiments linking client software written in Java and C++ with database servers via CORBA interfaces. Starting from the result of a similar study, the "MASTR Prototype Study", prepared for the Air Force Studies and Analysis Agency, we evaluated the throughput of a number of configurations. Client options include Java clients and C++ clients running on NT and Unix machines. Server options include Oracle version 7.3 on an NT server and Sybase version 11 on a Unix server. In all cases, Iona’s ORBIX product was used as the CORBA implementation. Our experiments include different record lengths and block sizes.
The best configuration achieved to date is capable of almost 2,800 records per second. It is this configuration that serves as the distributed infrastructure for the Order of Battle Data Interchange Format (OBDIF) project, a demonstration project for the standardization and transmission of Order of Battle data for modeling and simulation uses. The OBDIF effort currently demonstrates reading data from two separate databases hosted on different machines. OBDIF includes facilities for data display and semantic conflict resolution. As such, it serves as a valid test bed for evaluating CORBA technology with respect to data warehouse and data mart applications.
1. Introduction
In 1996, the Java programming language from Sun emerged as the preferred way to enhance web pages with complicated behavior. Since its initial beachhead as a web programming language, Java's appeal has broadened to where it is now considered an acceptable, even recommended, language for all client side computing. Therefore, there is now interest in making data stored in databases accessible via Java client programs.
There are several techniques for making database managed data available to Java. Java versions 1.1 and later natively support accessing relational databases through the Java database connectivity (JDBC) package, a Java equivalent to the traditional open database connectivity (ODBC) interface supported by most databases. JDBC allows a Java program to embed SQL commands within Java programs. This has the advantage that JDBC is a core function of Java; programmers may simply call the JDBC API from their programs.
However, application specific logic that is too complicated to express in SQL or database stored procedures must therefore be encoded in the Java client. This has two weaknesses. First, the logic must be implemented on the client side, even when a more natural location might be the server side. Second, the logic is restricted to Java programs. Client programs written in other languages, such as C++ or Visual Basic, must duplicate the logic. A further complication concerns Java security restrictions when running as an applet under a browser. In this environment, a Java applet (without a trusted digital signature or from versions prior to 1.1) is only allowed to connect back to the host from which its source code was retrieved (e.g. the machine running the web server). If this is not the machine with the database, then a proxy process must exist to exchange information between the applet and the database.
The Common Object Request Broker Architecture (CORBA), a standard for distributed computing promulgated by the Object Management Group (OMG), provides solutions to the above problems. CORBA provides a mechanism to write generic object interfaces, generate code in the desired implementation language and provide access to these objects to any number of machines in a heterogeneous network. Hence, complicated application specific logic can be implemented in a CORBA object written in the most appropriate language that serves multiples clients, each of which may be written in a different language, on different machines.
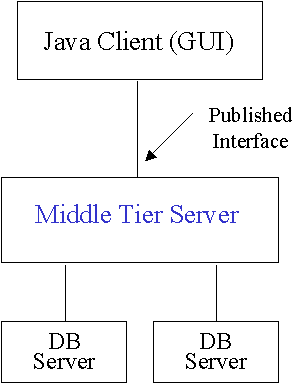
This work has been performed in the context of the Order of Battle Data Interchange Format (OBDIF) project [1], done under the direction of the Defense Modeling and Simulation Office (DMSO). OBDIF is a software tool that integrates disparate order of battle databases into a single virtual database. The OBDIF tool set provides access and manipulation functions that allow users to extract order of battle information in specialized formats for loading into simulations. OBDIF employs a three tier architecture (see Figure 1) with a thin Java client as the top tier providing the user GUI. The middle tier does the heavy duty work of fetching data from the constituent databases and performing any necessary physical and semantic integration while the bottom tier consists of just the constituent databases. With Java used in the top tier, CORBA connecting the tiers and potentially hundreds of megabytes of constituent data, we were clearly quite concerned about the performance of the Java/CORBA environment.
Figure 1: OBDIF Architecture
2. Configurations
The design space of ways to configure a system consisting of a Java client connecting to a database server via a CORBA communication channel is amazingly large.
CORBA
Interface Type. CORBA provides several different methods of managing objects.
The basic method uses the client/server paradigm. An object lives inside a server, and is accessible by its published interface. This interface is described by an interface definition in the IDL language. Objects are distributed to other users by reference, not by value. Thus clients of an object do not hold a copy of an object, but rather hold a proxy to an object. Conceptually, this proxy contains the host address of the server machine, process id of the server that maintains the object and a physical pointer to the object. In the interface method, clients access data values of an object by calling automatically generated accessor functions. These functions are applied to the proxy object within the address space of the client. This object forwards the call to the host of the object, the call is executed on the host machine, and the result is returned to the proxy, which returns the result to the client.
An alternative to the interface method is the structure method. A structure in IDL is simply a formatted block of bytes. Structures are passive objects that do not support method calls. Further, they are passed to clients by value, not by proxy, hence no additional network traffic is generated. For these two reasons, structures are more applicable than interfaces for passing static data from databases to clients.
Size. Databases work best when accessing blocks of information. CORBA supports grouping information into a block called a sequence, which is essentially an array. Transferring information by block is generally faster than transferring by record.
Granularity. Database access libraries generally offer the ability to extract information not only by row, but also by column within a row. This is an important capability when accessing data from ad hoc queries, where the number of columns can vary.
This capability can be simulated within CORBA by creating a server object using the interface technique that supports next row and next column iteration functions as well as a fetch data function.
This method, while flexible, is excruciatingly slow. Each call to an interface method (e.g. next row, next column, and fetch) requires a message be sent to and from the server, encountering latency at each stage.
In summary, an access scheme where records are formatted into structures representing an entire record and fed to the client in blocks will provide the highest throughput through the CORBA channel.
Hosts
There are three primary entities involved with extracting data from a database, forming it into CORBA objects, and retrieving it on the client. These entities are the database engine itself, the CORBA server, and the client. How these entities are mapped to actual machines (and processes) affects the performance of the resulting system.
The standard configuration will host the client on its own machine, typically a personal computer running a Java enabled web browser like Netscape Navigator or Microsoft Internet Explorer. At the other end, the database engine lives on a machine, typically a server class machine or a server cluster with large locally mounted disks.
The location of the CORBA server is flexible, however. In an environment where the Java code runs under a web browser as an applet, security restrictions require the CORBA server to run on the same machine as the web server. Assuming this is the case, there are two possibilities, the CORBA/web server runs on the same machine as the database engine, or the CORBA/web server runs on an entirely different machine. Both configurations have advantages and disadvantages.
Hosting both sets of services on the same machine, especially if the machine is a multiprocessor, reduces the communication costs between the CORBA server process and the database server process, thus reducing latency. Hosting the services on separate machines, however, may increase responsiveness if there are users of the web service that do not also use the database service, or vice versa. Additionally, security may be enhanced if the CORBA/web server machine is isolated from the database server machine by a firewall.
3. Experimental Results
We report on two families of experiments, one that closely matches the Air Force's MASTR study [2], and one based on the TPC-D database benchmark suite.
The test database systems are a Dell dual Pentium 166 database server running Windows NT 4.0 and Oracle version 7.3 and a Hewlett Packard 755 running HP-UX 10.20 and Sybase version 11. Test client systems are a Sun UltraSparc running Solaris 2.5 and a Dell Pentium 166 running Windows NT 4.0. The CORBA implementation was Iona Technologies' Orbix for C++ and OrbixWeb for Java.
MASTR Motivated Experiment
In October 1996, the Air Force Studies and Analysis Agency distributed a technical report documenting their experience using Java and CORBA to retrieve data from a relational database. Their report, the MASTR Prototype Study, documented a series of experiments aimed at porting the existing MASTR (Modeling, Analysis, Simulation and TRaining) system to a Java/CORBA environment. In general, the authors reported a negative result, with the Java/CORBA combination consistently too slow to be practical.
We were surprised by this result, and examined their methodology and result in some detail. This examination unveiled several important points that, while appropriate for the MASTR application, are inappropriate for more generic applications.
A summary of the architecture and performance results from the MASTR prototype study appears in Figure 2. After close examination of the architecture we proposed several changes in an attempt to gain acceptable performance for more general applications. First, network transfer and latency times are known problems and we sought to minimize them by locating the CORBA object server on the same machine as the database. Second, one of the more useful features of CORBA is that there is no requirement for client code to be written in the same language as server code. So, we decided to take advantage of the relatively static nature of the database server object and code it in C++ for greater performance than Java. Java 1.0 originally averaged 20 times slower than C++ (with wide variations depending on problem type) [3] but recent advances in just-in-time (JIT) compilers and native compilers can reduce that to as little as a factor of 1.5 in certain special cases. Next, we sought to reduce overhead by fetching data in blocks of records rather than one column at a time. Finally, we eliminated all post processing of the query results, including writing the results to a file. While it is true that most real applications require some amount of post processing we felt that it was not appropriate to include post processing in measurements of the performance of Java/CORBA database transfer.
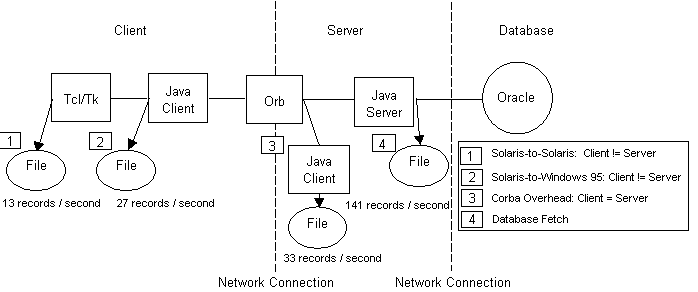
Figure 2: MASTR Prototype Study
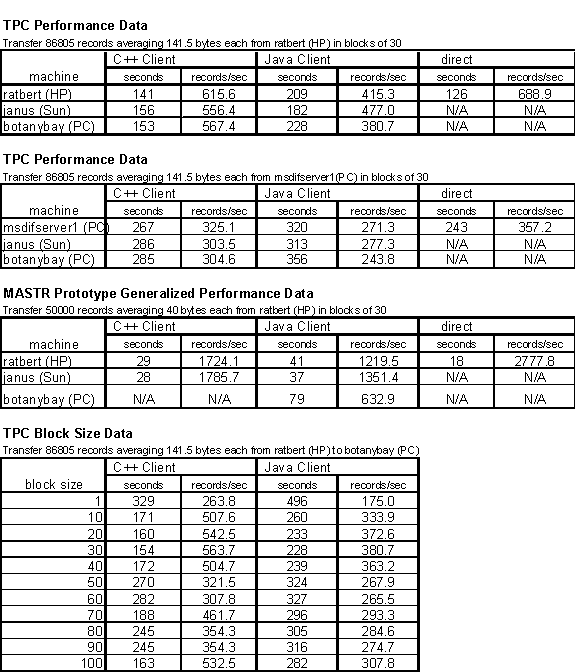
Figure 3 shows our generalized version of the MASTR prototype architecture and the corresponding performance figures. We included data for C++ versions of the client in order to provide a direct comparison of Java with a traditional, higher performance programming language. The best case performance of 2,778 records per second occurred, not surprisingly, at point C, the direct connection to the database without any CORBA ORB overhead or network transfer latencies. The worst case performance of 1,220 records per second was at point D, not point A as we had expected. This anomaly can probably be explained by some combination of resource contention on the server machine and the client machine being much faster (dual processor Sun UltraSparc versus single processor HP 9000/755). The performance figures from our generalized version indicate that the Java/CORBA environment imposes at most a 50% penalty over a direct connection to the database and should be sufficient for a much wider range of applications than the initial MASTR prototype.
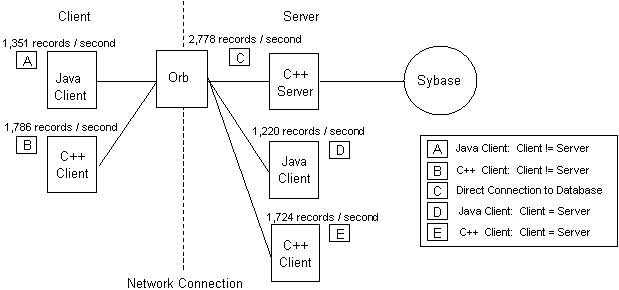
Figure 3: MASTR Prototype Study Generalized
In summary, the MASTR prototype study results, while accurate, are extremely application specific and should not be projected to other projects with different requirements.
TPC-D Motivated Experiment
Introduction. Despite the positive results of our generalized MASTR prototype architecture we were still somewhat uncomfortable claiming acceptable performance for the general case. Our reluctance was due to the extreme simplicity of the data that was being queried (4 columns of fixed length character data, only 5000 records, no indices).
The Transaction Processing Performance Council (TPC) [4] distributes a series of widely used and highly regarded database benchmark suites (all copyrighted and trademarked by the TPC). These suites allow users to accurately compare the performance and cost of systems from different database vendors. One of the benchmark suites is TPC-D, which comprises a database schema, a set of decision support oriented queries, and a data generator. This experiment uses portions of the TPC-D schema and data generator as the data source. It must be emphasized that this experiment does not constitute a TPC-D result. It merely uses the TPC-D schema and data generator as a source of realistic database contents.
The TPC-D schema consists of eight tables representing a generic order entry system. We used a scale factor of 0.01 with the data generator to create a set of sample tables that have 86,805 total records and average approximately 140 bytes per record. We used this data and the generalized MASTR prototype architecture described above as the basis for this experiment. We expanded the scope somewhat to include multiple commercial databases, multiple database host machines and multiple heterogeneous clients. The test query consisted of simply fetching each record from each table once.
TPC-D on Sybase/HP. Figure 4 summarizes the architecture and performance results with the TPC-D data stored in Sybase on a HP 9000/755. The raw numbers for records per second transfer do not seem to agree with those from Figure 2 until the relative difference in record size is taken into account. Once that is done the results agree quite nicely. The best case performance of 689 records per second occurs at point C as before while the worst case performance of 381 records per second occurs at point A (NT). Note that the same anomaly with respect to point D and point A (Sun) occurs here as it did in the generalized MASTR prototype.
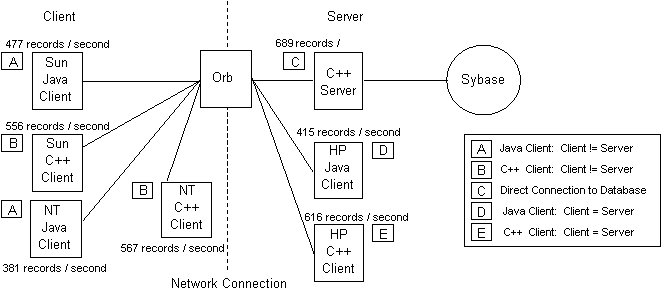
Figure 4: TPC-D Study on Sybase/HP
TPC-D on Oracle/NT. Figure 5 summarizes the architecture and performance results with the TPC-D data stored in Oracle on a Dell dual Pentium 166 NT PC. The results here track quite well with the TPC-D on Sybase/HP except they are approximately a factor of two slower. We are not sure if this is due to differences in the commercial databases or differences in the machines themselves. This discrepancy was repeatable and was also noticeable running identical queries from the command line SQL utilities that come with each database. The best case performance of 357 records per second occurs at point C as before while the worst case performance of 244 records per second occurs at point A (NT). Note that the same anomaly with respect to point D and point A (Sun) occurs here as it did in the generalized MASTR prototype and TPC-D on Sybase/HP.
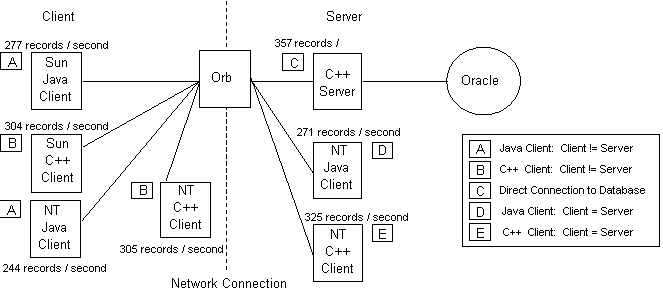
Figure 5: TPC-D Study on Oracle/NT
Block Size Study. One of our changes to the original MASTR prototype architecture was to transfer data in blocks of records. This brought up the question of what block size would perform the best. So we ran an experiment to give us a general idea what block size to use. Using the TPC-D data on Sybase/HP we ran the NT client in both Java and C++. The results can be seen in Figure 6. It was pleasant to see that the numbers from Java and C++ agreed so well and we selected a block size of 30 records for all of the experiments described in the previous sections. It is interesting to note that there appear to be local maxima in transfer rate near 70 and 100, perhaps suggesting a cyclical trend.
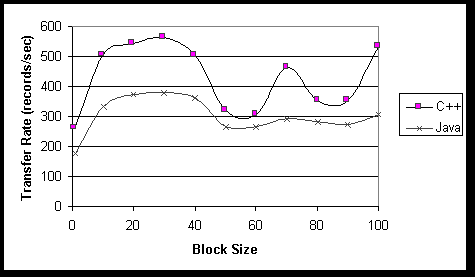
Figure 6: Block Size Study
4. Conclusion
The emergence of Java as a preferred language for client side computing has increased the interest in CORBA as a means of communication with the server side, mostly due to CORBA's language independence. This paper presented a brief overview of ways to configure communication between a Java client and a database server via a CORBA communication channel. Several of the configurations were tested to determine the throughput rates that can be expected. The results showed that, done well, CORBA could successfully be used for moderate throughput client communication with the database.
Appendix
References
[1] OBDIF Homepage: http://ratbert.arlut.utexas.edu/obdif
[2] MASTR Prototype Study. Technical Report, Air Force Studies & Analysis Agency, October 2, 1996.
[3] David Flanagan, Java in a Nutshell, O’Reilly & Associates, Inc., 1996.
[4] Transaction Processing Performance Council Homepage: http://www.tpc.org/
Biographies
Thomas W. Hetherington
P.O. Box 8029, Austin, TX 78713-8029, (512) 835-3137, FAX (512) 835-3670, [email protected]
Mr. Hetherington is a research engineer at Applied Research Laboratories, The University of Texas at Austin (ARL:UT), and has experience with implementing compiled rule systems and RF signal propagation computation/analysis. He is currently working on design and implementation of a heterogeneous multi-database system featuring a three-tier architecture. Mr. Hetherington has a bachelor’s degree in electrical engineering and a master’s degree in computer sciences from UT Austin.
Lane B. Warshaw
P.O. Box 8029, Austin, TX 78713-8029, (512) 835-3840, FAX (512) 835-3670, [email protected]
Mr. Warshaw is a research assistant at ARL:UT where he helps to further develop and maintain a declarative, C++ derived and embedded rule-based compiler called "Venus." His current research lies in the area of extensible rule-base query optimizer and distributed database technologies. Mr. Warshaw received a bachelor’s degree in computer sciences from UT Austin, and is currently a candidate for a master’s degree at the same institution.
Lance Obermeyer
P.O. Box 8029, Austin, TX 78713-8029, (512) 835-3837, FAX (512) 835-3670, [email protected]
Mr. Obermeyer is the project lead for the Order of Battle Data Interchange Format (OBDIF) at ARL:UT. This project is an effort towards extracting data from heterogeneous databases for modeling and simulation uses. He is also interested in high-performance production rule environments, including active databases and active multi-databases. Mr. Obermeyer received a bachelor’s degree in finance from Florida State and a master’s degree in computer sciences at UT Austin, where he is currently pursuing a Ph.D. in computer sciences.
Daniel P. Miranker, Ph.D.
P.O. Box 1188, Austin TX 78712-1188, (512) 471-9541, FAX (512) 471-8885, [email protected]
Dr. Miranker has considerable expertise in the areas of parallel computer architecture; active, expert, and heterogeneous databases; and high-performance artificial intelligence systems. He received his doctorate in computer sciences from Columbia University, and is currently an associate professor in the department of computer sciences and a research scientist at the University of Texas at Austin.