我们已经为您展示了如何在对集合持久化时使用延迟装载(lazy initialization)。对于通常的对象引用,使用CGLIB代理可以达到类似的效果。我们也提到过Hibernate在Session级别缓存持久化对象。还有更多先进的缓存策略,你可以为每一个类单独配置。
这一章里,我们来教你如何使用这些特性,在必要的时候得到高得多的性能。
Hibernate使用动态字节码增强技术来实现持久化对象的延迟装载代理(使用优秀的CGLIB库)。
映射文件为每一个类声明一个类或者接口作为代理接口。建议使用这个类自身:
<class name="eg.Order" proxy="eg.Order">
运行时的代理应该是Order的子类。注意被代理的类必须实现一个默认的构造器,并且至少在包内可见。
在扩展这种方法来对应多形的类时,要注意一些细节,比如:
<class name="eg.Cat" proxy="eg.Cat">
......
<subclass name="eg.DomesticCat" proxy="eg.DomesticCat">
.....
</subclass>
</class>首先,Cat永远不能被强制转换为DomesticCat,即使实际上该实例就是一个DomesticCat实例。
Cat cat = (Cat) session.load(Cat.class, id); // instantiate a proxy (does not hit the db)
if ( cat.isDomesticCat() ) { // hit the db to initialize the proxy
DomesticCat dc = (DomesticCat) cat; // Error!
....
}其次,代理的==可能不再成立。
Cat cat = (Cat) session.load(Cat.class, id); // instantiate a Cat proxy
DomesticCat dc =
(DomesticCat) session.load(DomesticCat.class, id); // required new DomesticCat proxy!
System.out.println(cat==dc); // false虽然如此,这种情况并不像看上去得那么糟。虽然我们现在有两个不同的引用来指向不同的代理对象,实际上底层的实例应该是同一个对象:
cat.setWeight(11.0); // hit the db to initialize the proxy System.out.println( dc.getWeight() ); // 11.0
第三,你不能对final的类或者具有final方法的类使用CGLIB代理。
最后,假如你的持久化对象在实例化的时候需要某些资源(比如,在实例化方法或者默认构造方法中),这些资源也会被代理需要。代理类实际上是持久化类的子类。
这些问题都来源于Java的单根继承模型的天生限制。如果你希望避免这些问题,你的每个持久化类必须抽象出一个接口,声明商业逻辑方法。你应该在映射文件中指定这些接口,比如:
<class name="eg.Cat" proxy="eg.ICat">
......
<subclass name="eg.DomesticCat" proxy="eg.IDomesticCat">
.....
</subclass>
</class>这里Cat实现ICat接口,并且DomesticCat实现IDomesticCat接口。于是 load()或者iterate()就会返回Cat和DomesticCat的实例的代理。(注意find()不会返回代理。)
ICat cat = (ICat) session.load(Cat.class, catid);
Iterator iter = session.iterate("from cat in class eg.Cat where cat.name='fritz'");
ICat fritz = (ICat) iter.next();关系也是延迟装载的。这意味着你必须把任何属性声明为ICat类型,而非Cat。
某些特定操作不需要初始化代理
equals(), 假如持久化类没有重载equals()
hashCode(), 假如持久化类没有重载hashCode()
标识符的get方法
Hibernate会识别出重载了equals() 或者 hashCode()方法的持久化类。
在初始化代理的时候发生的异常会被包装成LazyInitializationException。
有时候我们需要保证在Session关闭前某个代理或者集合已经被初始化了。当然,我们总是可以通过调用cat.getSex()或者 cat.getKittens().size()之类的方法来确保这一点。但是这样程序可读性不佳,也不符合通常的代码规范。静态方法Hibernate.initialize()和Hibernate.isInitialized()给你的应用程序一个正常的途径来加载集合或代理。Hibernate.initialize(cat) 会强制初始化一个代理,cat,只要它的Session仍然打开。Hibernate.initialize( cat.getKittens() )对kittens的集合具有同样的功能。
HibernateSession是事务级别的持久化数据缓存。再为每个类或者每个集合配置一个集群或者JVM级别(SessionFactory级别)的缓存也是有可能的。你甚至可以插入一个集群的缓存。要小心,缓存永远不会知道其他进程可能对持久化仓库(数据库)进行的修改(即使他们可能设定为经常对缓存的数据进行失效)。
默认情况下,Hibernate使用EHCache进行JVM级别的缓存。但是,对JCS的支持现在已经被废弃了,未来版本的Hibernate将会去掉它。通过hibernate.cache.provider_class属性,你也可以指定其他缓存,只要其实现了net.sf.hibernate.cache.CacheProvider接口。
Table 12.1. Cache Providers
| Cache | Provider class | Type | Cluster Safe | Query Cache Supported |
|---|---|---|---|---|
| Hashtable (not intended for production use) | net.sf.hibernate.cache.HashtableCacheProvider | memory | yes | |
| EHCache | net.sf.ehcache.hibernate.Provider | memory, disk | yes | |
| OSCache | net.sf.hibernate.cache.OSCacheProvider | memory, disk | yes | |
| SwarmCache | net.sf.hibernate.cache.SwarmCacheProvider | clustered (ip multicast) | yes (clustered invalidation) | |
| JBoss TreeCache | net.sf.hibernate.cache.TreeCacheProvider | clustered (ip multicast), transactional | yes (replication) |
类或者集合映射的<cache>元素可能有下列形式:
<cache 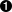 usage="transactional|read-write|nonstrict-read-write|read-only" />
usage="transactional|read-write|nonstrict-read-write|read-only" /> | usage 指定了缓存策略: transactional, read-write, nonstrict-read-write 或者 read-only |
另外 (推荐首选?), 你可以在hibernate.cfg.xml中指定<class-cache> 和 <collection-cache> 元素。
usage属性指明了缓存并发策略(cache concurrency strategy)。
如果你的应用程序需要读取一个持久化类的实例,但是并不打算修改它们,可以使用read-only 缓存。这是最简单,也是实用性最好的策略。甚至在集群中,它也能完美地运作。
<class name="eg.Immutable" mutable="false">
....
<jcs-cache usage="read-only"/>
</class>如果应用程序需要更新数据,可能read-write缓存比较合适。如果需要可序列化事务隔离级别(serializable transaction isolation level),这种缓存决不能使用。如果在JTA环境中使用这种缓存,你必须指定hibernate.transaction.manager_lookup_class属性的值,给出得到JTA TransactionManager的策略。在其它环境中,你必须确保在Session.close()或者Session.disconnect()调用前,事务已经结束了。 如果你要在集群环境下使用这一策略,你必须确保底层的缓存实现支持锁定(locking)。内置的缓存提供器并不支持。
<class name="eg.Cat" .... >
<jcs-cache usage="read-write"/>
....
<set name="kittens" ... >
<jcs-cache usage="read-write"/>
....
</set>
</class>如果程序偶尔需要更新数据(也就是说,出现两个事务同时更新同一个条目的现象很不常见),也不需要十分严格的事务隔离,可能适用nonstrict-read-write缓存。如果在JTA环境中使用这种缓存,你必须指定hibernate.transaction.manager_lookup_class属性的值,给出得到JTA TransactionManager的策略。在其它环境中,你必须确保在Session.close()或者Session.disconnect()调用前,事务已经结束了。
transactional缓存策略提供了对全事务缓存提供,比如JBoss TreeCache的支持。这样的缓存只能用于JTA环境,你必须指定hibernate.transaction.manager_lookup_class。
没有一种缓存提供器能够支持所有的缓存并发策略。下面的表列出每种提供器与各种并发策略的兼容性。
不管何时你传递一个对象给save(), update()或者 saveOrUpdate() ,或者不管何时你使用load(), find(), iterate()或者filter()取得一个对象的时候,该对象被加入到Session的内部缓存中。当后继的flush()被调用时,对象的状态会和数据库进行同步。如果你在处理大量对象并且需要有效的管理内存的时候,你可能不希望发生这种同步,evict()方法可以从缓存中去掉对象和它的集合。
Iterator cats = sess.iterate("from eg.Cat as cat"); //a huge result set
while ( cats.hasNext() ) {
Cat cat = (Cat) iter.next();
doSomethingWithACat(cat);
sess.evict(cat);
}Session也提供了一个contains()方法来判断是否一个实例处于这个session的缓存中。
要把所有的对象从session缓存中完全清除,请调用Session.clear()。
For the JVM-level JCS cache, there are methods defined on SessionFactory for evicting the cached state of an instance, entire class, collection instance or entire collection role.
对于第二层缓存来说,在SessionFactory中定义了一些方法来从缓存中清除一个实例、整个类、集合实例或者整个集合。
查询结果集也可以被缓存。只有当经常使用同样的参数进行查询时,这才会有些用处。要使用查询缓存,首先你要打开它,设置hibernate.cache.use_query_cache=true这个属性。这样会创建两个缓存区域——一个保存查询结果集(net.sf.hibernate.cache.QueryCache),另一个保存最近查询的表的时间戳(net.sf.hibernate.cache.UpdateTimestampsCache)。请注意查询缓存并不缓存结果集中包含实体的状态;它只缓存标识符属性的值和值类型的结果。所以查询缓存通常会和第二层缓存一起使用。
大多数查询并不会从缓存中获得什么好处,所以默认查询是不进行缓存的。要进行缓存,调用 Query.setCacheable(true)。这个调用会让查询在执行时去从缓存中查找结果,或者把结果集放到缓存去。
如果你要对查询缓存的失效政策进行精确的控制,你必须调用Query.setCacheRegion()来为每个查询指定一个命名的缓存区域。
List blogs = sess.createQuery("from Blog blog where blog.blogger = :blogger order by blog.datetime desc")
.setEntity("blogger", blogger)
.setMaxResults(15)
.setCacheable(true)
.setCacheRegion("frontpages")
.list();