
献给对
P2P网络感兴趣的朋友们:
Peer to Peer ( P2P ) 综述
罗杰文
中科院计算技术研究所
2005-11-3
最近几年,对等计算
( Peer-to-Peer,简称P2P) 迅速成为计算机界关注的热门话题之一,财富杂志更将P2P列为影响Internet未来的四项科技之一。目前,在学术界、工业界对于P2P没有一个统一的定义,下面列举几个常用的定义供参考:
定义:1、Peer-to-peer is a type of Internet network allowing a group of computer users with the same networking program to connect with each other for the purposes of directly accessing files from one another's hard drives.
2、Peer-to-peer networking (P2P) is an application that runs on a personal computer and shares files with other users across the Internet. P2P networks work by connecting individual computers together to share files instead of having to go through a central server.
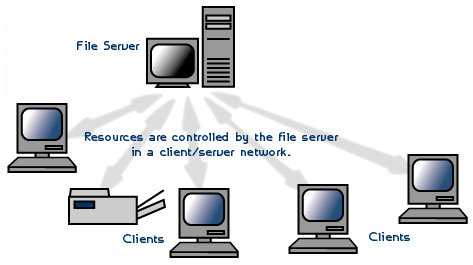
3、P2P是一种分布式网络,网络的参与者共享他们所拥有的一部分硬件资源(处理能力、存储能力、网络连接能力、打印机等),这些共享资源需要由网络提供服务和内容,能被其它对等节点(Peer)直接访问而无需经过中间实体。在此网络中的参与者既是资源(服务和内容)提供者(Server),又是资源(服务和内容)获取者(Client)。
虽然上述定义稍有不同,但共同点都是P2P打破了传统的Client/Server (C/S)模式,在网络中的每个结点的地位都是对等的。每个结点既充当服务器,为其他结点提供服务,同时也享用其他结点提供的服务。P2P与C/S模式的对比如下图所示:
|
|
| Client/Server模式 | Peer to Peer 模式 |
P2P技术的特点体现在以下几个方面。
非中心化(Decentralization):网络中的资源和服务分散在所有结点上,信息的传输和服务的实现都直接在结点之间进行,可以无需中间环节和服务器的介入,避免了可能的瓶颈。P2P的非中心化基本特点,带来了其在可扩展性、健壮性等方面的优势。
可扩展性:在
健壮性:
高性能
隐私保护: 在P2P网络中,由于信息的传输分散在各节点之间进行而无需经过某个集中环节,用户的隐私信息被窃听和泄漏的可能性大大缩小。此外,目前解决Internet隐私问题主要采用中继转发的技术方法,从而将通信的参与者隐藏在众多的网络实体之中。在传统的一些匿名通信系统中,实现这一机制依赖于某些中继服务器节点。而在P2P中,所有参与者都可以提供中继转发的功能,因而大大提高了匿名通讯的灵活性和可靠性,能够为用户提供更好的隐私保护。
负载均衡: P2P 网络环境下由于每个节点既是服务器又是客户机,减少了对传统C/S结构服务器计算能力、存储能力的要求,同时因为资源分布在多个节点,更好的实现了整个网络的负载均衡。
与传统的分布式系统相比,P2P技术具有无可比拟的优势。同时,P2P技术具有广阔的应用前景。Internt上各种P2P应用软件层出不穷,用户数量急剧增加。2004年3月来自www.slyck.com的数据显示,大量P2P软件的用户使用数量分布从几十万、几百万到上千万并且急剧增加,并给Internet带宽带来巨大冲击。P2P计算技术正不断应用到军事领域,商业领域,政府信息,通讯等领域。
根据具体应用不同,可以把P2P分为以下这些类型:
挖掘P2P对等计算能力和存储共享能力,例如SETI@home、Avaki、Popular Power等;
基于P2P方式的协同处理与服务共享平台,例如JXTA、Magi、Groove、.NET My Service等;
即时通讯交流,包括ICQ、OICQ、Yahoo Messenger等;
安全的P2P通讯与信息共享,例如Skype、Crowds、Onion Routing等。
拓扑结构是指分布式系统中各个计算单元之间的物理或逻辑的互联关系,结点之间的拓扑结构一直是确定系统类型的重要依据。目前互联网络中广泛使用集中式、层次式等拓扑结构,
Interne本身是世界上最大的非集中式的互联网络,但是九十年代所建立的一些网络应用系统却是完全的集中式的系统、很多Web应用都是运行在集中式的服务器系统上。集中式拓扑结构系统目前面临着过量存储负载、Dos攻击等一些难以解决的问题。P2P系统一般要构造一个非集中式的拓扑结构,在构造过程中需要解决系统中所包含的大量结点如何命名、组织以及确定结点的加入/离开方式、出错恢复等问题。
根据拓扑结构的关系可以将P2P研究分为4种形式:中心化拓扑(Centralized Topology);全分布式非结构化拓扑(Decentralized Unstructured Topology);全分布式结构化拓扑(Decentralized Structured Topology,也称作DHT网络)和半分布式拓扑(Partially Decentralized Topology)。
其中,中心化拓扑最大的优点是维护简单发现效率高。由于资源的发现依赖中心化的目录系统,发现算法灵活高效并能够实现复杂查询。最大的问题与传统客户机/服务器结构类似,容易造成单点故障,访问的“热点”现象和法律等相关问题,这是第一代P2P网络采用的结构模式,经典案例就是著名的MP3共享软件Napster。
Napster是最早出现的P2P系统之一,并在短期内迅速成长起来。Napster实质上并非是纯粹的P2P系统,它通过一个中央服务器保存所有Napster用户上传的音乐文件索引和存放位置的信息。当某个用户需要某个音乐文件时,首先连接到Napster服务器,在服务器进行检索,并由服务器返回存有该文件的用户信息;再由请求者直接连到文件的所有者传输文件。
Napster首先实现了文件查询与文件传输的分离,有效地节省了中央服务器的带宽消耗,减少了系统的文件传输延时。这种方式最大的隐患在中央服务器上,如果该服务器失效,整个系统都会瘫痪。当用户数量增加到105或者更高时,Napster的系统性能会大大下降。另一个问题在于安全性上,Napster并没有提供有效的安全机制。
在Napster模型中,一群高性能的中央服务器保存着网络中所有活动对等计算机共享资源的目录信息。当需要查询某个文件时,对等机会向一台中央服务器发出文件查询请求。中央服务器进行相应的检索和查询后,会返回符合查询要求的对等机地址信息列表。查询发起对等机接收到应答后,会根据网络流量和延迟等信息进行选择,和合适的对等机建立连接,并开始文件传输。Napster的工作原理如图1所示。
这种对等网络模型存在很多问题,主要表现为:
(1)中央服务器的瘫痪容易导致整个网络的崩馈,可靠性和安全性较低。
(2)随着网络规模的扩大,对中央索引服务器进行维护和更新的费用将急剧增加,所需成本过高。
(3)中央服务器的存在引起共享资源在版权问题上的纠纷,并因此被攻击为非纯粹意义上的P2P网络模型。对小型网络而言,集中目录式模型在管理和控制方面占一定优势。但鉴于其存在的种种缺陷,该模型并不适合大型网络应用。
 |
 |
|
Napster结构 |
Napster界面 |
全分布非结构化网络在重叠网络(
overlay)采用了随机图的组织方式,结点度数服从"Power-law"[a][b]规律,从而能够较快发现目的结点,面对网络的动态变化体现了较好的容错能力,因此具有较好的可用性。同时可以支持复杂查询,如带有规则表达式的多关键词查询,模糊查询等,最典型的案例是Gnutella。Gnutella是一个P2P文件共享系统,它和Napster最大的区别在于Gnutella是纯粹的P2P系统,没有索引服务器,它采用了基于完全随机图的洪泛(Flooding)发现和随机转发(Random Walker)机制。为了控制搜索消息的传输,通过TTL (Time To Live)的减值来实现。具体协议参照[Gnutella协议中文版]
在Gnutella分布式对等网络模型N中,每一个联网计算机在功能上都是对等的,既是客户机同时又是服务器,所以被称为对等机(Servent,Server+Client的组合)。
随着联网节点的不断增多,网络规模不断扩大,通过这种洪泛方式定位对等点的方法将造成网络流量急剧增加,从而导致网络中部分低带宽节点因网络资源过载而失效。所以在初期的Gnutella网络中,存在比较严重的分区,断链现象。也就是说,一个查询访问只能在网络的很小一部分进行,因此网络的可扩展性不好。所以,解决Gnutella网络的可扩展性对该网络的进一步发展至关重要。
由于没有确定拓扑结构的支持,非结构化网络无法保证资源发现的效率。即使需要查找的目的结点存在发现也有可能失败。由于采用
TTL(Time-to-Live)、洪泛(Flooding)、随机漫步或有选择转发算法,因此直径不可控,可扩展性较差。因此发现的准确性和可扩展性是非结构化网络面临的两个重要问题。目前对此类结构的研究主要集中于改进发现算法和复制策略以提高发现的准确率和性能。
|
|
 |
|
最初的Gnutella采用的Flooding搜索算法示意图 |
采用第二代Gnutella协议最经典的软件-Bearshare |
由于非结构化网络将重叠网络认为是一个完全随机图,结点之间的链路没有遵循某些预先定义的拓扑来构建。这些系统一般不提供性能保证,但容错性好,支持复杂的查询,并受结点频繁加入和退出系统的影响小。但是查询的结果可能不完全,查询速度较慢,采用广播查询的系统对网络带宽的消耗非常大,并由此带来可扩展性差等问题。
另外,由于非结构化系统中的随机搜索造成的不可扩展性,大量的研究集中在如何构造一个高度结构化的系统。目前研究的重点放在了如何有效地查找信息上,最新的成果都是基于DHT的分布式发现和路由算法。这些算法都避免了类似Napster的中央服务器,也不是像Gnutella那样基于广播进行查找,而是通过分布式散列函数,将输入的关键字惟一映射到某个结点上,然后通过某些路由算法同该结点建立连接。
最新的研究成果体现在采用分布式散列表(
DHT)[a]的完全分布式结构化拓扑网络。分布式散列表(DHT)实际上是一个由广域范围大量结点共同维护的巨大散列表。散列表被分割成不连续的块,每个结点被分配给一个属于自己的散列块,并成为这个散列块的管理者。
DHT的结点既是动态的结点数量也是巨大的,因此非中心化和原子自组织成为两个设计的重要目标。通过加密散列函数,一个对象的名字或关键词被映射为128位或160位的散列值。一个采用DHT的系统内所有结点被映射到一个空间分布式散列表起源于
SDDS(Scalable Distribute Data Structures)[a]研究,Gribble等实现了一个高度可扩展,容错的SDDS集群。最近的研究集中在采用新的拓扑图构建重叠路由网络,以减少路由表容量和路由延时。这些新的拓扑关系的基本原理是在
DHT表一维空间的基础上引入更多的拓扑结构图来反映底层网络的结构。DHT类结构能够自适应结点的动态加入/退出,有着良好的可扩展性、鲁棒性、结点ID分配的均匀性和自组织能力。由于重叠网络采用了确定性拓扑结构,DHT可以提供精确的发现。只要目的结点存在于网络中DHT总能发现它,发现的准确性得到了保证,最经典的案例是Tapestry,Chord,CAN,和Pastry。
Tapestry提供了一个分布式容错查找和路由基础平台,在此平台基础之上,可以开发各种P2P应用(OceanStore即是此平台上的一个应用) 。Tapestry的思想来源于Plaxton。在Plaxton中,结点使用自己所知道的邻近结点表,按照目的ID来逐步传递消息。Tapestry基于Plaxtion的思想,加入了容错机制,从而可适应P2P的动态变化的特点。OceanStore是以Tapestry为路由和查找基础设施的P2P平台。它是一个适合于全球数据存储的P2P应用系统。任何用户均可以加入OceanStore系统,或者共享自己的存储空间,或者使用该系统中的资源。通过使用复制和缓存技术,OceanStore可提高查找的效率。最近,Tapstry为适应P2P网络的动态特性,作了很多改进,增加了额外的机制实现了网络的软状态(soft state),并提供了自组织、鲁棒性、可扩展性和动态适应性,当网络高负载且有失效结点时候性能有限降低,消除了对全局信息的依赖、根结点易失效和弹性(resilience)差的问题。
Pastry是微软研究院提出的可扩展的分布式对象定位和路由协议,可用于构建大规模的P2P系统。在Pastry中,每个结点分配一个128位的结点标识符号(nodeID) ,所有的结点标识符形成了一个环形的nodeID空间,范围从0到2128 - 1 ,结点加入系统时通过散列结点IP地址在128位nodeID空间中随机分配。
在MIT,开展了多个与P2P相关的研究项目:Chord,GRID和RON。Chord项目的目标是提供一个适合于P2P环境的分布式资源发现服务,它通过使用DHT技术使得发现指定对象只需要维护O(logN)长度的路由表。
在DHT技术中,网络结点按照一定的方式分配一个唯一结点标识符(Node ID) ,资源对象通过散列运算产生一个唯一的资源标识符(Object ID) ,且该资源将存储在结点ID与之相等或者相近的结点上。需要查找该资源时,采用同样的方法可定位到存储该资源的结点。因此,Chord的主要贡献是提出了一个分布式查找协议,该协议可将指定的关键字(Key) 映射到对应的结点(Node) 。从算法来看,Chord是相容散列算法的变体。MIT的GRID和RON项目则提出了在分布式广域网中实施查找资源的系统框架。
AT&T ACIRI中心的CAN(Content Addressable Networks) 项目独特之处在于采用多维的标识符空间来实现分布式散列算法。CAN将所有结点映射到一个n维的笛卡尔空间中,并为每个结点尽可能均匀的分配一块区域。CAN采用的散列函数通过对(key, value) 对中的key进行散列运算,得到笛卡尔空间中的一个点,并将(key, value) 对存储在拥有该点所在区域的结点内。CAN采用的路由算法相当直接和简单,知道目标点的坐标后,就将请求传给当前结点四邻中坐标最接近目标点的结点。CAN是一个具有良好可扩展性的系统,给定N个结点,系统维数为d,则路由路径长度为O(n1/d) ,每结点维护的路由表信息和网络规模无关为O(d) 。
DHT类结构最大的问题是DHT的维护机制较为复杂,尤其是结点频繁加入退出造成的网络波动(Churn)会极大增加DHT的维护代价。DHT所面临的另外一个问题是DHT仅支持精确关键词匹配查询,无法支持内容/语义等复杂查询。
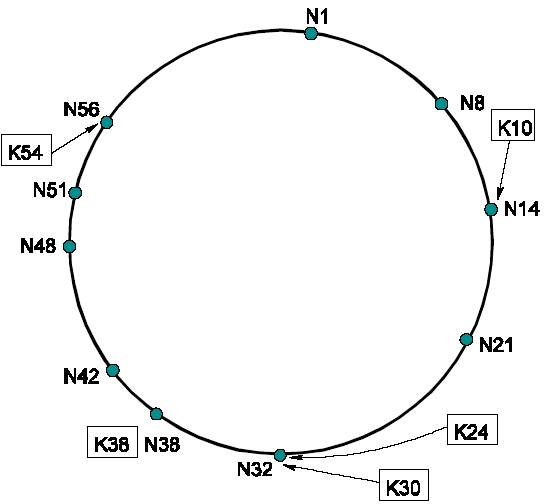 |
 |
|
Chord的Identifier Circle |
Pastry的消息路由 |
半分布式结构(有的文献称作 Hybrid Structure)吸取了中心化结构和全分布式非结构化拓扑的优点,选择性能较高(处理、存储、带宽等方面性能)的结点作为超级点(
英文文献中多称作:SuperNodes, Hubs),在各个超级点上存储了系统中其他部分结点的信息,发现算法仅在超级点之间转发,超级点再将查询请求转发给适当的叶子结点。半分布式结构也是一个层次式结构,超级点之间构成一个高速转发层,超级点和所负责的普通结点构成若干层次。最典型的案例就是KaZaa。KaZaa是现在全世界流行的几款p2p软件之一。根据CA公司统计,全球KaZaa的下载量超过2.5亿次。使用KaZaa软件进行文件传输消耗了互联网40%的带宽。之所以它如此的成功,是因为它结合了Napster和Gnutella共同的优点。从结构 上来说,它使用了Gnutella的全分布式的结构,这样可以是系统更好的扩展,因为它无需中央索引服务器存储文件名,它是自动的把性能好的机器成为SuperNode,它存储着离它最近的叶子节点的文件信息,这些SuperNode,再连通起来形成一个Overlay Network. 由于SuperNode的索引功能,使搜索效率大大提高。
 |
 |
|
半分布式结构(含有SuperNode) |
kaZaa界面 |
半分布式结构的优点是性能、可扩展性较好,较容易管理,但对超级点依赖性大,易于受到攻击,容错性也受到影响。下表
比较了4种结构的综合性能,比较结果如表1-1所示。表
1:4种结构的性能比较
|
比较标准/拓扑结构 |
中心化拓扑 |
全分布式非结构化拓扑 |
全分布式结构化拓扑 |
半分布式拓扑 |
|
可扩展性 |
差 |
差 |
好 |
中 |
|
可靠性 |
差 |
好 |
好 |
中 |
|
可维护性 |
最好 |
最好 |
好 |
中 |
|
发现算法效率 |
最高 |
中 |
高 |
中 |
|
复杂查询 |
支持 |
支持 |
不支持 |
支持 |
学术机构研发
Maze 是北京大学网络实验室开发的一个中心控制与对等连接相融合的对等计算文件共享系统,在结构上类似Napster,对等计算搜索方法类似于Gnutella。网络上的一台计算机,不论是在内网还是外网,可以通过安装运行Maze的客户端软件自由加入和退出Maze系统。每个节点可以将自己的一个或多个目录下的文件共享给系统的其他成员,也可以分享其他成员的资源。Maze支持基于关键字的资源检索,也可以通过好友关系直接获得。
清华大学―Granary
Granary是清华大学自主开发的对等计算存储服务系统。它以对象格式存储数据。另外,Granary设计了专门的结点信息收集算法PeerWindow的结构化覆盖网络路由协议Tourist。
华中科技大学―AnySee
AnySee是华中科大设计研发的视频直播系统。它采用了一对多的服务模式,支持部分NAT和防火墙的穿越,提高了视频直播系统的可扩展性;同时,它利用近播原则、分域调度的思想,使用Landmark路标算法直接建树的方式构建应用层上的组播树,克服了ESM等一对多模式系统由联接图的构造和维护带来的负载影响。
更详细介绍见[中国计算机学会通讯 Page 38-51 郑纬民等 对等计算研究概论]
企业研发产品
广州数联软件技术有限公司-Poco
POCO 是中国最大的 P2P用户分享平台 , 是有安全、流量控制力的,无中心服务器的第三代 P2P 资源交换平台 , 也是世界范围内少有的盈利的 P2P 平台。目前已经形成了 2600 万海量用户,平均在线 58.5 万,在线峰值突破 71 万,并且全部是宽带用户的用户群。 成为中国地区第一的 P2P 分享平台。[a]
深圳市点石软件有限公司-OP
OP-又称为Openext Media Desktop,一个网络娱乐内容平台,Napster的后继者,它可以最直接的方式找到您想要的音乐、影视、软件、游戏、图片、书籍以及各种文档,随时在线共享文件容量数以亿计“十万影视、百万音乐、千万图片”。OP整合了Internet
Explorer、Windows Media Player、RealOne Player和ACDSee
,是国内的网络娱乐内容平台。[a]
基于P2P的在线电视直播-PPLive
PPLive是一款用于互联网上大规模视频直播的共享软件。它使用网状模型,有效解决了当前网络视频点播服务的带宽和负载有限 问题,实现用户越多,播放越流畅的特性,整 体服务质量大大提高!(2005年的超级女声决赛期间,这款软件非常的火爆,同时通过它看湖南卫视的有上万观众)
其他商业软件这里不一一列举,请访问P2P门户网站
http://www.ppcn.net/
国外开展
P2P研究的学术团体主要包括P2P工作组(P2PWG) 、全球网格论坛(Global Grid Forum ,GGF) 。P2P工作组成立的主要目的是希望加速P2P计算基础设施的建立和相应的标准化工作。P2PWG成立之后,对P2P计算中的术语进行了统一,也形成相关的草案,但是在标准化工作方面工作进展缓慢。目前P2PWG已经和GGF合并,由该论坛管理P2P计算相关的工作。GGF负责网格计算和P2P计算等相关的标准化工作。从国外公司对
P2P计算的支持力度来看,Microsoft公司、Sun公司和Intel公司投入较大。Microsoft公司成立了Pastry项目组,主要负责P2P计算技术的研究和开发工作。目前Microsoft公司已经发布了基于Pastry的软件包SimPastry/ VisPastry。Rice大学也在Pastry的基础之上发布了FreePastry软件包。在
2000年8月,Intel公司宣布成立P2P工作组,正式开展P2P的研究。工作组成立以后,积极与应用开发商合作,开发P2P应用平台。2002年Intel发布了. Net基础架构之上的Accelerator Kit (P2P加速工具包) 和P2P安全API软件包,从而使得微软. NET开发人员能够迅速地建立P2P安全Web应用程序。Sun公司以Java技术为背景,开展了JXTA项目。JXTA是基于Java的开源P2P平台,任何个人和组织均可以加入该项目。因此,该项目不仅吸引了大批P2P研究人员和开发人员,而且已经发布了基于JXTA的即时聊天软件包。JXTA定义了一组核心业务:认证、资源发现和管理。在安全方面,JXTA加入了加密软件包,允许使用该加密包进行数据加密,从而保证消息的隐私、可认证性和完整性。在JXTA核心之上,还定义了包括内容管理、信息搜索以及服务管理在内的各种其它可选JXTA服务。在核心服务和可选服务基础上,用户可以开发各种JXTA平台上的P2P应用。
P2P实际的应用主要体现在以下几个方面:
P2P
分布式存储P2P分布式存储系统是一个用于对等网络的数据存储系统,它可以提供高效率的、鲁棒的和负载平衡的文件存取功能。这些研究包括:OceanStore,Farsite等。其中,基于超级点结构的半分布式P2P应用如Kazza、Edonkey、Morpheus、Bittorrent等也是属于分布式存储的范畴,并且用户数量急剧增加。
计算能力的共享
加入对等网络的结点除了可以共享存储能力之外,还可以共享
CPU处理能力。目前已经有了一些基于对等网络的计算能力共享系统。比如SETI@home。目前SETI@home采用的仍然是类似于Napster的集中式目录策略。Xenoservers向真正的对等应用又迈进了一步。这种计算能力共享系统可以用于进行基因数据库检索和密码破解等需要大规模计算能力的应用。P2P
应用层组播。应用层组播,就是在应用层实现组播功能而不需要网络层的支持。这样就可以避免出现由于网络层迟迟不能部署对组播的支持而使组播应用难以进行的情况。应用层组播需要在参加的应用结点之间实现一个可扩展的,支持容错能力的重叠网络,而基于
DHT的发现机制正好为应用层组播的实现提供了良好的基础平台。Internet
间接访问基础结构(Internet Indirection Infrastructure)。为了使
Internet更好地支持组播、单播和移动等特性,Internet间接访问基础结构提出了基于汇聚点的通信抽象。在这一结构中,并不把分组直接发向目的结点,而是给每个分组分配一个标识符,而目的结点则根据标识符接收相应的分组。标识符实际上表示的是信息的汇聚点。目的结点把自己想接收的分组的标识符预先通过一个触发器告诉汇聚点,当汇聚点收到分组时,将会根据触发器把分组转发该相应的目的结点。Internet间接访问基础结构实际上在Internet上构成了一个重叠网络,它需要对等网络的路由系统对它提供相应的支持。P2P技术从出现到各个领域的应用展开,仅用了几年的时间。从而证明了P2P技术具有非常广阔的应用前景。
随着
P2P应用的蓬勃发展,作为P2P应用中核心问题的发现技术除了遵循技术本身的逻辑以外,也受到某些技术的发展趋势、需求趋势的深刻影响。1.3.1 度数和直径的折衷关系(tradeoff)对发现算法的影响
如上所述,
DHT发现技术完全建立在确定性拓扑结构的基础上,从而表现出对网络中路由的指导性和网络中结点与数据管理的较强控制力。但是,对确定性结构的认识又限制了发现算法效率的提升。研究分析了目前基于DHT的发现算法,发现衡量发现算法的两个重要参数度数(表示邻居关系数、路由表的容量)和链路长度(发现算法的平均路径长度)之间存在渐进曲线的关系。研究者
采用图论中度数(Degree)和直径(Diameter)两个参数研究DHT发现算法,发现这些DHT发现算法在度数和直径之间存在渐进曲线关系,如下图所示。在N个结点网络中,图中直观显示出当度数为N时,发现算法的直径为O(1);当每个结点仅维护一个邻居时,发现算法的直径为O(N)。这是度数和直径关系的2种极端情况。同时,研究以图论的理论分析了O(d)的度和O(d)的直径的算法是不可能的。 |
| 度数和直径之间的渐进曲线关系 |
从渐进曲线关系可以看出,如果想获得更短的路径长度,必然导致度数的增加;而网络实际连接状态的变化造成大度数邻居关系的维护复杂程度增加。另外,研究者
证明O(logN)甚至O(logN/loglogN)的平均路径长度也不能满足状态变化剧烈的网络应用的需求。新的发现算法受到这种折衷关系制约的根本原因在于DHT对网络拓扑结构的确定性认识。1.3.2 Small world 理论对P2P发现技术的影响
非结构化
P2P系统中发现技术一直采用洪泛转发的方式,与DHT的启发式发现算法相比,可靠性差,对网络资源的消耗较大。最新的研究从提高发现算法的可靠性和寻找随机图中的最短路径两个方面展开。也就是对重叠网络的重新认识。其中,small world特征和幂规律证明实际网络的拓扑结构既不是非结构化系统所认识的一个完全随机图,也不是DHT发现算法采用的确定性拓扑结构。实际网络体现的幂规律分布的含义可以简单解释为在网络中有少数结点有较高的“度”,多数结点的“度”较低。度较高的结点同其他结点的联系比较多,通过它找到待查信息的概率较高。
Small-world[a][b]模型的特性:网络拓扑具有高聚集度和短链的特性。在符合small world特性的网络模型中,可以根据结点的聚集度将结点划分为若干簇(Cluster),在每个簇中至少存在一个度最高的结点为中心结点。大量研究证明了以Gnutella为代表的P2P网络符合small world特征,也就是网络中存在大量高连通结点,部分结点之间存在“短链”现象。
因此,P2P发现算法中如何缩短路径长度的问题变成了如何找到这些“短链”的问题。尤其是在DHT发现算法中,如何产生和找到“短链”是发现算法设计的一个新的思路。small world特征的引入会对P2P发现算法产生重大影响。
现有
DHT算法由于采用分布式散列函数,所以只适合于准确的查找,如果要支持目前Web上搜索引擎具有的多关键字查找的功能,还要引入新的方法。主要的原因在于DHT的工作方式。基于
DHT的P2P系统采用相容散列函数根据精确关键词进行对象的定位与发现。散列函数总是试图保证生成的散列值均匀随机分布,结果两个内容相似度很高但不完全相同的对象被生成了完全不同的散列值,存放到了完全随机的两个结点上。因此,DHT可以提供精确匹配查询,但是支持语义是非常困难的。目前在
DHT基础上开展带有语义的资源管理技术的研究还非常少。由于DHT的精确关键词映射的特性决定了无法和信息检索等领域的研究成果结合,阻碍了基于DHT的P2P系统的大规模应用。[a]P2P发现技术中最重要的研究成果应该是基于small world理论的非结构化发现算法和基于DHT的结构化发现算法。尤其是DHT及其发现技术为资源的组织与查找提供了一种新的方法。
随着P2P系统实际应用的发展,物理网络中影响路由的一些因素开始影响P2P发现算法的效率。一方面,实际网络中结点之间体现出较大的差异,即异质性。由于客户机/服务器模式在Internet和分布式领域十几年的应用和大量种类的电子设备的普及,如手提电脑、移动电话或PDA。这些设备在计算能力、存储空间和电池容量上差别很大。另外,实际网络被路由器和交换机分割成不同的自治区域,体现出严密的层次性。
另一方面,网络波动的程度严重影响发现算法的效率。网络波动(Churn、fluctuation of network)包括结点的加入、退出、失败、迁移、并发加入过程、网络分割等。DHT的发现算法如Chord、CAN、Koorde等都是考虑网络波动的最差情况下的设计与实现。由于每个结点的度数尽量保持最小,这样需要响应的成员关系变化的维护可以比较小,从而可以快速恢复网络波动造成的影响。但是每个结点仅有少量路由状态的代价是发现算法的高延时,因为每一次查找需要联系多个结点,在稳定的网络中这种思路是不必要的。
同时,作为一种资源组织与发现技术必然要支持复杂的查询,如关键词、内容查询等。尽管信息检索和数据挖掘领域提供了大量成熟的语义查询技术,由于DHT精确关键词映射的特性阻碍了DHT在复杂查询方面的应用。
2复杂P2P网络拓扑模型
Internet作为当今人类社会信息化的标志,其规模正以指数速度高速增长.如今Internet的“面貌”已与其原型ARPANET大相径庭,依其高度的复杂性,可以将其看作一个由计算机构成的“生态系统”.虽然Internet是人类亲手建造的,但却没有人能说出这个庞然大物看上去到底是个什么样子,运作得如何.Internet拓扑建模研究就是探求在这个看似混乱的网络之中蕴含着哪些还不为我们所知的规律.发现Internet拓扑的内在机制是认识Internet的必然过程,是在更高层次上开发利用Internet的基础.然而,Internet与生俱来的异构性动态性发展的非集中性以及如今庞大的规模都给拓扑建模带来巨大挑战.Internet拓扑建模至今仍然是一个开放性问题,在计算机网络研究中占有重要地位.
Internet拓扑作为Internet这个自组织系统的“骨骼”,与流量协议共同构成模拟Internet的3个组成部分,即在拓扑网络中节点间执行协议,形成流量.Internet拓扑模型是建立Internet系统模型的基础,由此而体现的拓扑建模意义也可以说就是Internet建模的意义,即作为一种工具,人们用其来对Internet进行分析预报决策或控制.Internet模型中的拓扑部分刻画的是Internet在宏观上的特征,反映一种总体趋势,所以其应用也都是在大尺度上展开的.对Internet拓扑模型的需求主要来自以下几个方面:(1) 许多新应用或实验不适合直接应用于Internet,其中一些具有危害性,如蠕虫病毒在大规模网络上的传播模拟;(2) 对于一些依赖于网络拓扑的协议(如多播协议),在其研发阶段,当前Internet拓扑只能提供一份测试样本,无法对协议进行全面评估,需要提供多个模拟拓扑环境来进行实验;(3) 从国家安全角度考虑,需要在线控制网络行为,如美国国防高级研究计划局(DARPA)的NMS(network modeling and simulation)项目.
随机网络是由
N个顶点构成的图中,可以存在2.1.2随机网络参数
描述随机网络有一些重要的参数。一个节点所拥有的度是该节点与其他节点相关联的边数,度是描述网络局部特性的基本参数。网络中并不是所有节点都具有相同的度,系统中节点度的分布情况,可以用分布函数
聚集系数是描述与第三个节点连接的一对节点被连接的概率。从连接节点的边的意义上,若

Internet拓扑模型可分为两类:一类是描述Internet拓扑特征,包括Waxman模型,Tiers,Transit -Stub和幂律;另一类是描述拓扑特征形成的机理,包括Barabási与Albert提出的BA和ESF以及一种改进模型GLP.由于后一类模型对Internet幂律形成机理的描述还不成熟,更多的是作为一种产生幂律的图生成算法。对于第1类模型来说,Internet拓扑特征的发现,实际上就是刻画该特征的度量(metric)的发现.一个属于第一类的拓扑模型就是包含若干已存在的或新发现的度量,然后根据实际的Internet拓扑数据求出这些度量的值.因此,对这类模型进行评价需要从两方面入手:一方面,对它所采用的拓扑数据进行评价;另一方面,对其度量进行评价.在所有已经发现的Internet拓扑度量中,最为基本的就是节点出度频率fd.其分布是判断一幅拓扑图是否与Internet拓扑相类似的最重要的依据.在研究早期,研究人员或者认为Internet节点出度是完全随机的(如Waxman模型),或者认为节点出度是正规的(如Tiers模型).而幂律的发现证明了Internet拓扑结构介于两者之间,呈幂率分布.根据对出度频率分布的刻画,可将Internet拓扑模型分为以下3类:
(1) 随机型,即认为Internet拓扑图处于一个完全无序的状态,在大尺度上是均一的.Waxman模型,是一种类似于Erds-Rényi模型的随机模型,出度频率呈泊松分布.这个模型有两个版本:RG1,先将节点随机布置在直角坐标网格中,节点间的距离就是其欧几里德距离;RG2,依据(0,L)均匀随机分布为节点对指定距离.两个版本中,节点间相接的概率P(u,v)与其距离相关,服从泊松分布,距离越近,概率越大.
![]()
其中
,d(u,v)表示节点u与v之间的距离,L为节点间最长距离,á与a取值范围是(0,1).(2) 层次型,来自对Internet结构所具有的层次特征的认识,在同一层上的节点出度接近,不同层间节点出度差别很大.对同一层上的节点布置借用Waxman模型方法.Tiers(等级)模型将Internet划分为LAN(局域网),MAN(城域网)和WAN(广域网)3个层次.在该模型中,WAN只有一个,通过指定LAN和MAN数量以及各自内部所包含节点的数量来构造拓扑图.Transit-Stub模型将AS域划分为Transit类和Stub类.在该模型中,Transit节点彼此互联构成一个节点群,一个或多个Transit节点群构成拓扑图的核心,而Stub节点分布在Transit节点群四周与Transit节点相连.Transit -Stub是GT-ITM(georgia tech Internetwork topology models)软件包的一部分,有时GT-ITM也就是指Transit-Stub模型.
(3) 幂率型.1999年,Faloutsos等人对NLANR(National Lab for Applied Network Research)在1997~1998年间的3份BGP数据以及1995年的一份traceroute测量数据进行分析,发现Internet拓扑中存在着4条幂律.
幂律是指形如
近似幂律
(hop-plot指数H):h跳内节点对(pairs of nodes)的数量与h的H次幂成比例.幂律3(特征指数E):特征值li与其次序i的E次幂成比例.
在现实的
Internet环境中,网络拓扑并不完全满足随机网络拓扑。Watt和Strogatz发现,只需要在规则网络上稍作随机改动就可以同时具备以上两个性质。改动的方法是,对于规则网络的每一个顶点的所有边,以概率p断开一个端点,并重新连接,连接的新的端点从网络中的其他顶点里随机选择,如果所选的顶点已经与此顶点相连,则再随机选择别的顶点来重连。当p = 0时就是规则网络,p = 1则为随机网络,对于0 < p < 1的情况,存在一个很大的p的区域,同时拥有较大的集聚程度和较小的最小距离。Small World网络的几何性质如图所示。

|
|
p值不同的small world网络 |
(1)平均路径。图中被随机选择又重新连结后的线称为捷径,它对整个网络的平均路径有着很大影响,分析表明:当p>=21(NK),即在保证系统中至少出现一条捷径的情况下,系统的平均路径开始下降。即使是相当少的捷径也能够显著地减小网络的平均路径长度。这是因为每出现一条捷径,它对整个系统的影响是非线性的,它不仅影响到被这条线直接连着的两点,也影响到了这两点的最近邻、次近邻,以及次次近邻等。
(2) WS网络的集团系数。r1初始固定的节点数可计算t1{ p=0时规则网络的聚集系数为C(0), C(0)取决于网络结构而与尺寸N无关,因此有相对较大的值。随着边按一定的概率p随机化,聚集系数在CYO}的附近变化。
(3)度分布。WS模型是介于规则网络和随机网络之间的模型,p-O时规则网络的度分布是中心点位于K=k的8函数,P=1时随机网络Poisson分布,在K=k点达到极大值。P从。变化到1的过程中,原来S函数形式的度分布逐渐拓宽最终形成Poisson分布。在Small World网络的研究兴起之后,越来越多的科学家投入到复杂网络的研究中去。大家发现其实更多的其他几何量的特征也具有很大程度上的普适性和特定的结构功能关系。Scale Free网络就是其中的一个重要方面。Scale Free网络指的是网络的度分布符合幂率分布,由于其缺乏一个描述问题的特征尺度而被称为无标度网络。我们都知道在统计物理学相变与临界现象,以及在自组织临界性(SOC)中幂率具有特殊地位。Scale-free 其实也具有small world 的特性。
按照搜索策略,可以分为两大类:盲目搜索和信息搜索。盲目搜索通过在网络中传播查询信息并且把这些信息不断扩散给每个节点。通过这种洪泛方式来搜索想要的资源。而信息搜索在搜索的过程中利用一些已有的信息来辅助查找过程。由于信息搜索对资源的存储有一些知识,所以信息搜索能够比较快的找到资源。
3.1 Blind search
在最初的
Gnutella协议中,使用的Flooding方法,就是一种典型的盲目搜索。在网络中,每个节点都不知道其他节点的资源。当它要寻找某个文件,把这个查询信息传递给它的相邻节点,如果相邻节点含有这个资源,就返回一个QueryHit的信息给Requester。如果它相邻的节点都没有命中这个被查询文件,就把这条消息转发给自己的相邻节点。这种方式像洪水在网络中各个节点流动一样,所以叫做Flooding搜索。由于这种搜索策略是首先遍历自己的邻接点,然后再向下传播,所以又称为宽度优先搜索方法(BFS)。BFS搜索把消息传播给所有的邻接点,它消耗了大量的网络带宽,使消息堵塞严重,效率比较低,扩展性不好。一些人在BFS的基础上进行改进,它的方法是随机抽取一定比例的相邻节点传递消息,而不是像Flooding一样把查询信息传播给所有邻接点。这种修正的极大地减少了网络中的查询信息,但是在命中率上不如BFS。
Iterative Deepening:这种搜索策略是在初始阶段,给TTL一个很小的值,如果在TTL减为0,还没有搜索到资源,则给TTL重新赋更高的值。这种策略可以减少搜索的半径,但是在最坏的情况下,延迟很大。
Random Walk: 在随机漫步中,请求者发出K个查询请求给随机挑选的K个相邻节点。然后每个查询信息在以后的漫步过程中直接与请求者保持联系,询问是否还要继续下一步。如果请求者同意继续漫步,则又开始随机选择下一步漫步的节点,否则中止搜索。
Gnutella2: 建立super-node,它存储着离它最近的叶子节点的文件信息,这些SuperNode,再连通起来形成一个Overlay Network.当叶子节点需要查询文件,它首先从它连接的SuperNode的索引中寻找,如果找到了文件,则直接根据文件所存储的机器的IP地址建立连接,如果没有找到,则SuperNode把这个查询请求发给它连接的其他超级节点,直到得到想要的资源。

这种方法不同于盲目搜索很大的地方在与它在每个节点上,不管是中央节点还是简单节点都存有路径信息。这就是Cache的思路。新的搜索并不需要直接达到资源的存储地,只要在搜索的路径中找到以前搜索的记录也就是在它以前的搜索的基础上找到源IP地址,就可以把请求消息返回。这样可以极大的减少搜索的消息,提高效率。
3.2.2 Mobile Agent based Method
移动Agent是一个能在异构网络中自主地从一台主机迁移到另一台主机,并可与其他Agent或资源进行交互的程序。Agent非常适合在网络环境中来帮助用户完成信息检索的任务。现在意大利的一些研究人员在Mobile Agent 结合P2P方面做了一些前沿的研究,其中的一些想法,就是通过在P2P软件中嵌入Agent的运行时环境。当有节点需要搜索的时候,它发送一个移动Agent 给它相邻的节点,移动Agent记录着它的一些搜索的信息。当这个Agent到达一台新的机器上,然后在这个机器上进行资源搜索任务,如果这台机器上没有它想要的资源,则它把这些搜索的信息传给它的邻节点,如果找到资源,则返回给请求的机器。
关于搜索方法综述:参照[ Chonggang Wang Bo Li: Peer-to-Peer Overlay Networks: A Survey]
[Hybrid Search Schemes for Unstructured Peer-to-Peer Networks]
在P2P共享网络中普遍存在着知识产权保护问题。尽管目前Gnutella、Kazaa等P2P共享软件宣传其骨干服务器上并没有存储任何涉及产权保护的内容的备份,而仅仅是保存了各个内容在互联网上的存储索引。但无疑的是,P2P共享软件的繁荣加速了盗版媒体的分发,提高了知识产权保护的难点。美国唱片工业协会RIAA(Recording
Industry Association of
America)与这些共享软件公司展开了漫长的官司拉锯战,著名的Napster便是这场战争的第一个牺牲者。另一个涉及面很关的战场则是RIAA和使用P2P来交换正版音乐的平民。从2004年1月至今RIAA已提交了1000份有关方面的诉讼。尽管如此,至今每个月仍然有超过150,000,000的歌曲在网络上被自由下载。后Napster时代的P2P共享软件较Napster更具有分散性,也更难加以控制。即使P2P共享软件的运营公司被判违法而关闭,整个网络仍然会存活,至少会正常工作一段时间。
另一方面,Napster以后的P2P共享软件也在迫切寻找一个和媒体发布厂商的共生互利之道。如何更加合法合理的应用这些共享软件,是一个新时代的课题。毕竟P2P除了共享盗版软件,还可以共享相当多的有益的信息。
网络社会与自然社会一样,其自身具有一种自发地在无序和有序之间寻找平衡的趋势。P2P技术为网络信息共享带来了革命性的改进,而这种改进如果想要持续长期地为广大用户带来好处,必须以不损害内容提供商的基本利益为前提。这就要求在不影响现有P2P共享软件性能的前提下,一定程度上实现知识产权保护机制。目前,已经有些P2P厂商和其它公司一起在研究这样的问题。这也许将是下一代P2P共享软件面临的挑战性技术问题之一。
随着计算机网络应用的深入发展,计算机病毒对信息安全的威胁日益增加。特别是在P2P环境下,方便的共享和快速的选路机制,为某些网络病毒提供了更好的入侵机会。
由于P2P网络中逻辑相邻的节点,地理位置可能相隔很远,而参与P2P网络的节点数量
又非常大,因此通过P2P系统传播的病毒,波及范围大,覆盖面广,从而造成的损失会很大。
在P2P网络中,每个节点防御病毒的能力是不同的。只要有一个节点感染病毒,就可以通过内部共享和通信机制将病毒扩散到附近的邻居节点。在短时间内可以造成网络拥塞甚至瘫痪,共享信息丢失,机密信息失窃,甚至通过网络病毒可以完全控制整个网络。
一个突出的例子就是2003年通过即时通讯(Instant Message)软件传播病毒的案例显著增多。包括Symantec公司和McAfee公司的高层技术主管都预测即时通讯软件将会成为网络病毒传播和黑客攻击的主要载体之一。
随着P2P技术的发展,将来会出现各种专门针对P2P系统的网络病毒。利用系统漏洞,达到迅速破坏、瓦解、控制系统的目的。因此,网络病毒的潜在危机对P2P系统安全性和健壮性提出了更高的要求,迫切需要建立一套完整、高效、安全的防毒体系。
其它信息安全问题还包括反动影片、色情影片的在P2P泛滥,对国家、青少年造成的负面影响。
详细可参照[程学旗等 信息技术快报 2004年第三期 P2P技术与信息安全]
5 结尾
5.1 P2P一些资源
http://www.ppcn.net/ 中国的P2P门户网站
http://iptps05.cs.cornell.edu/IPTPS_cfp.htm P2P领域著名的国际会议
http://www.jxta.org/ Java P2P 技术网站
http://www.hpl.hp.com/techreports/2002/HPL-2002-57R1.pdf 非常经典的P2P综述文章
http://david.weekly.org/code/napster.php3 第一个P2P 软件-Napster 协议
http://www.globus.org/alliance/publications/papers/kazaa.pdf 非常著名的kaZaa软件解析
http://p2p.weblogsinc.com/ 比较著名的p2p weblog
http://www.google.com
最后,当然是好帮手 Google 了 :)
5.2 致谢和建议
这篇文章是我在中科院计算所的一篇技术报告的部分内容(修改)。最先是在2005-4-25号挂在自己的个人主页上。目的是让更多的朋友通过阅读对P2P技术有一个大概的了解。为了让文章变得通俗易懂,我删除了其中非常细节的部分,这次又对第一版进行了修改。承蒙厚爱,在这期间,我收到了很多朋友,包括学校的同学、公司的技术人员给我写的email,表达对文章的肯定,希望一起探讨p2p的问题,这里表示感谢。
因为P2P技术包括很多方面,以一篇文章之力肯定不能面面俱到,所以要想对P2P进行深入的研究,个人觉得,一定多看Paper,多看程序。记得刚写这篇文章时候,包括从Google, Citeseer,IEEE , ACM,Wanfang期刊网等搜索了624篇paper(英文610篇,中文14篇),然后对其进行了分类,包括各种综述、拓扑网络、搜索算法、安全等等。这绝对是一个必由之路。另外,由于大多数P2P软件都是开源的,所以通过看源码可以对其进行更深的了解。
2005-4-25 第一版
2005-11-3 修改版
作者希望在以后的版本中更加完善,同时也希望文章能给大家带来一些帮助。
