One fundamental difference between the similarity computation in
user-based CF and item-based CF is that in case of user-based CF the
similarity is computed along the rows of the matrix
but in case of the item-based CF the similarity is
computed along the columns i.e., each pair in the co-rated set
corresponds to a different user (Figure 2). Computing similarity
using basic cosine measure in item-based case has one important drawback-the
difference in rating scale between different users are not taken into
account. The adjusted cosine similarity offsets this drawback by
subtracting the corresponding user average from each co-rated
pair. Formally, the similarity between items i and j using this
scheme is given by
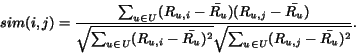
Here
![]() is the average of the u-th user's ratings.
is the average of the u-th user's ratings.