µÚ2Ơ °ü×°Íâ¹Û£¨Wrapper Facade£©£ºÓĂÓÚÔÚÀàÖĐ·â×°º¯ÊưµÄ½á¹¹ĐÍģʽ
¡¡
Douglas C. Schmidt
¡¡¡¡±¾ÂÛÎÄĂèÊö°ü×°Íâ¹Ûģʽ¡£¸ĂģʽµÄ̉âͼÊÇͨ¹ưĂæỊ̈¶ÔÏó£¨OO£©Àà½Ó¿ÚÀ´·â×°µÍ¼¶º¯ÊưºÍÊư¾Ư½á¹¹¡£³£¼ûµÄ°ü×°Íâ¹ÛģʽµÄÀư×ÓÊÇÏñMFC¡¢ACEºÍAWTƠâÑùµÄÀà¿â£¬ËüĂÇ·â×°±¾µØµÄOS C API£¬±ÈÈçsocket¡¢pthreads»̣GUIº¯Êư¡£
¡¡¡¡Ö±½Ó¶Ô±¾µØOS C API½øĐбà³̀»áʹÍøÂçÓ¦ÓĂ·±Ëö¡¢²»½¡×³¡¢²»¿É̉ÆÖ²£¬Ç̉ÄÑ̉Ôά»¤£¬̣̉ΪӦÓĂ¿ª·¢ƠßĐè̉ªÁ˽âĐí¶àµÍ¼¶¡¢̉×´íµÄϸ½Ú¡£±¾ÂÛÎIJûÊÍ°ü×°Íâ¹ÛģʽÔơÑùʹƠâĐ©ÀàĐ͵ÄÓ¦ÓñäµĂ¸üΪ¼̣½à¡¢½¡×³¡¢¿É̉ÆÖ²ºÍ¿Éά»¤¡£
¡¡¡¡±¾ÂÛÎı»×éÖ¯ÈçÏ£º2.2ÏêϸĂèÊöʹÓĂÎ÷ĂÅ×Ó¸ñʽ[1]µÄ°ü×°Íâ¹Ûģʽ£¬2.3¸ø³ö½áÊøÓï¡£
¡¡
¡¡
¡¡¡¡ÔÚ¸üΪ¼̣½à¡¢½¡×³¡¢¿É̉ÆÖ²ºÍ¿Éά»¤µÄ½Ï¸ß¼¶ĂæỊ̈¶ÔÏóÀà½Ó¿ÚÖĐ·â×°µÍ¼¶º¯ÊưºÍÊư¾Ư½á¹¹¡£
¡¡
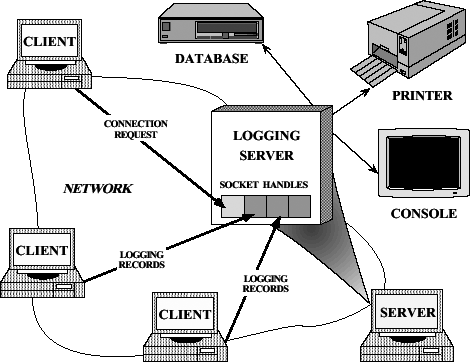
¡¡¡¡Îª²ûÊÍ°ü×°Íâ¹Ûģʽ£¬¿¼ÂÇͼ2-1ÖĐËùʾµÄ·Ö²¼Ê½ÈƠÖ¾·₫ÎñµÄ·₫ÎñÆ÷¡£¿Í»§Ó¦ÓĂʹÓĂÈƠÖ¾·₫ÎñÀ´¼Ç¼¹ØÓÚËüĂÇÔÚ·Ö²¼Ê½»·¾³ÖеÄÖ´ĐĐ×´̀¬µÄĐÅÏ¢¡£ƠâЩ״̀¬ĐÅϢͨ³£°üÀ¨´íÎó֪ͨ¡¢µ÷ÊÔ¸ú×ÙºÍĐÔÄÜƠï¶Ï¡£ÈƠÖ¾¼Ç¼±»·¢Ë͵½ÖĐÑëÈƠÖ¾·₫ÎñÆ÷£¬ÓÉËü½«¼ÇÂ¼Đ´µ½¸÷ÖÖÊä³öÉ豸£¬±ÈÈçÍøÂç¹ÜÀí¿ØÖÆ̀¨¡¢´̣Ó¡»ú»̣Êư¾Ư¿â¡£
¡¡
¡¡
ͼ2-1 ·Ö²¼Ê½ÈƠÖ¾·₫Îñ
¡¡
¡¡¡¡Í¼2-1ËùʾµÄÈƠÖ¾·₫ÎñÆ÷´¦Àí¿Í»§·¢Ë͵ÄÁ¬½ÓÇëÇóºÍÈƠÖ¾¼Ç¼¡£ÈƠÖ¾¼Ç¼ºÍÁ¬½ÓÇëÇó¿É̉Ô²¢·¢µØÔÚ¶à¸ösocket¾ä±úÉϵ½´ï¡£¸÷¸ö¾ä±ú±êʶÔÚOSÖĐ¹ÜÀíµÄÍøÂçͨĐÅ×ÊÔ´¡£
¡¡¡¡¿Í»§Ê¹ÓĂÏñTCP[2]ƠâÑùµÄĂæỊ̈Á¬½ÓĐ̉éÓëÈƠÖ¾·₫ÎñÆ÷ͨĐÅ¡£̣̉¶ø£¬µ±¿Í»§Ïë̉ª¼Ç¼ÈƠÖ¾Êư¾Ưʱ£¬Ëü±ØĐëÊ×ÏÈỊ̈ÈƠÖ¾·₫ÎñÆ÷·¢ËÍÁ¬½ÓÇëÇó¡£·₫ÎñÆ÷ʹÓĂ¾ä±ú¹¤³§£¨handle factory£©À´½ÓÊÜÁ¬½ÓÇëÇ󣬾ä±ú¹¤³§ÔÚ¿Í»§ÖªµÀµÄÍøÂçµØÖ·ÉϽøĐĐỚ̀ư¡£µ±Á¬½ÓÇëÇóµ½´ïʱ£¬OS¾ä±ú¹¤³§½ÓÊÜ¿Í»§µÄÁ¬½Ó£¬²¢´´½¨±íʾ¸Ă¿Í»§µÄÁ¬½Ó¶ËµăµÄsocket¾ä±ú¡£¸Ă¾ä±ú±»·µ»Ø¸øÈƠÖ¾·₫ÎñÆ÷£¬ºóƠßÔÚƠâ¸ö¾ä±úºÍÆäËû¾ä±úÉϵȴư¿Í»§ÈƠÖ¾ÇëÇóµ½´ï¡£̉»µ©¿Í»§±»Á¬½Ó£¬ËüĂÇ¿É̉Ô·¢ËÍÈƠÖ¾¼Ç¼¸ø·₫ÎñÆ÷¡£·₫ÎñÆ÷ͨ¹ửÑÁ¬½ÓµÄsocket¾ä±úÀ´½ÓÊƠƠâĐ©¼Ç¼£¬´¦Àí¼Ç¼£¬²¢½«ËüĂÇĐ´µ½ËüĂǵÄÊä³öÉ豸¡£
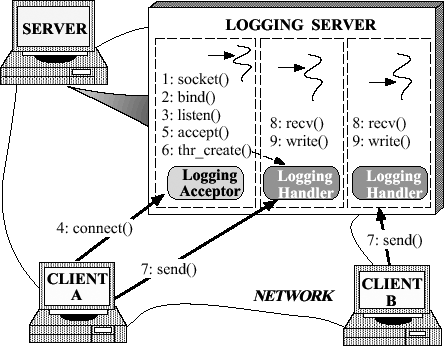
¡¡¡¡¿ª·¢²¢·¢´¦Àí¶à¸ö¿Í»§µÄÈƠÖ¾·₫ÎñÆ÷µÄ³£¼û·½·¨ÊÇʹÓĂµÍ¼¶CÓïÑÔº¯ÊưºÍÊư¾Ư½á¹¹À´Íê³ÉÏß³̀¡¢Í¬²½¼°ÍøÂçͨĐŵȲÙ×÷¡£ÀưÈ磬ͼ2-2ÑƯʾÔơÑù½«SolarisÏß³̀[3]ºÍsocket[4]ÍøÂç±à³̀APIÓĂÓÚ¿ª·¢¶àÏß³̀ÈƠÖ¾·₫ÎñÆ÷¡£
¡¡
¡¡
¡¡
ͼ2-2 ¶àÏß³̀ÈƠÖ¾·₫ÎñÆ÷
¡¡
¡¡¡¡ÔÚ´ËÉè¼ÆÖĐ£¬ÈƠÖ¾·₫ÎñÆ÷µÄ¾ä±ú¹¤³§ÔÚËüµÄÖ÷Ïß³̀ÖĐ½ÓÊÜ¿Í»§ÍøÂçÁ¬½Ó¡£ËüËæ¼´ÅÉÉú̉»¸öĐÂÏß³̀£¬ÔÚµ¥¶ÀµÄÁ¬½ÓÖĐÔËĐĐlogging_handlerº¯Êư¡¢̉Ô´¦ÀíÀ´×ÔĂ¿¸ö¿Í»§µÄÈƠÖ¾¼Ç¼¡£ÏÂĂæµÄÁ½¸öCº¯ÊưÑƯʾÔơÑùʹÓĂsocket¡¢»¥³ầåºÍÏß³̀µÄ±¾µØSolaris OS APIÀ´ÊµÏÖ´ËÈƠÖ¾·₫ÎñÆ÷Éè¼Æ¡£
¡¡
// At file
scope.
// Keep track
of number of logging requests.
static int
request_count;
// Lock to
protect request_count.
static mutex_t
lock;
// Forward
declaration.
static void
*logging_handler (void *);
// Port number
to listen on for requests.
static const
int logging_port = 10000;
¡¡
// Main driver
function for the multi-threaded
// logging
server. Some error handling has been
// omitted to
save space in the example.
int main (int
argc, char *argv[])
{
struct
sockaddr_in sock_addr;
¡¡
// Handle
UNIX/Win32 portability differences.
#if defined
(_WINSOCKAPI_)
SOCKET
acceptor;
#else
int acceptor;
#endif /*
_WINSOCKAPI_ */
¡¡
// Create a
local endpoint of communication.
acceptor =
socket (PF_INET, SOCK_STREAM, 0);
¡¡
// Set up the
address to become a server.
memset
(reinterpret_cast <void *> (&sock_addr), 0, sizeof sock_addr);
sock_addr.sin_family
= AF_INET;
sock_addr.sin_port
= htons (logging_port);
sock_addr.sin_addr.s_addr
= htonl (INADDR_ANY);
¡¡
// Associate
address with endpoint.
bind (acceptor,
reinterpret_cast <struct
sockaddr *>
(&sock_addr),
sizeof sock_addr);
¡¡
// Make
endpoint listen for connections.
listen
(acceptor, 5);
¡¡
// Main server
event loop.
for (;;)
{
thread_t t_id;
¡¡
// Handle UNIX/Win32 portability
differences.
#if defined
(_WINSOCKAPI_)
SOCKET h;
#else
int h;
#endif /*
_WINSOCKAPI_ */
¡¡
// Block waiting for clients to
connect.
int h = accept (acceptor, 0, 0);
¡¡
// Spawn a new thread that runs the
// <logging_handler> entry
point and
// processes client logging records
on
// socket handle <h>.
thr_create (0, 0,
logging_handler,
reinterpret_cast <void *>
(h),
THR_DETACHED,
&t_id);
}
¡¡
/* NOTREACHED
*/
return 0;
}
¡¡
logging_handlerº¯ÊưÔËĐĐÔÚµ¥¶ÀµÄÏß³̀¿ØÖÆÖĐ£¬̉²¾ÍÊÇ£¬Ă¿¸ö¿Í»§̉»¸öÏß³̀¡£ËüÔÚ¸÷¸öÁ¬½ÓÉϽÓÊƠ²¢´¦ÀíÈƠÖ¾¼Ç¼£¬ÈçÏÂËùʾ£º
¡¡
// Entry point
that processes logging records for
// one client
connection.
void
*logging_handler (void *arg)
{
// Handle
UNIX/Win32 portability differences.
#if defined
(_WINSOCKAPI_)
SOCKET h =
reinterpret_cast <SOCKET> (arg);
#else
int h =
reinterpret_cast <int> (arg);
#endif /*
_WINSOCKAPI_ */
for (;;)
{
UINT_32 len; // Ensure a 32-bit
quantity.
char log_record[LOG_RECORD_MAX];
¡¡
// The first <recv> reads the
length
// (stored as a 32-bit integer) of
// adjacent logging record. This
code
// does not handle
"short-<recv>s".
ssize_t n = recv
(h,
reinterpret_cast <char *>
(&len),
sizeof len, 0);
¡¡
// Bail out if we don¡¯t get the
expected len.
if (n <= sizeof len) break;
len = ntohl (len); // Convert
byte-ordering.
if (len > LOG_RECORD_MAX) break;
¡¡
// The second <recv> then
reads <len>
// bytes to obtain the actual
record.
// This code handles
"short-<recv>s".
for (size_t nread = 0;
nread < len;
nread += n)
{
n = recv (h, log_record + nread,
len - nread, 0);
// Bail out if an error occurs.
if (n <= 0) return 0;
}
¡¡
mutex_lock (&lock);
¡¡
// Execute following two statements
in a
// critical section to avoid race
conditions
// and scrambled output,
respectively.
++request_count; // Count # of
requests received.
¡¡
if (write (1, log_record, len) ==
-1)
// Unexpected error occurred, bail
out.
break;
¡¡
mutex_unlock (&lock);
}
¡¡
close (h);
return 0;
}
¡¡
×¢̉âÈ«²¿µÄÏß³̀¡¢Í¬²½¼°ÍøÂç´úÂëÊÇÔơÑùʹÓĂSolaris²Ù×÷ϵͳËù̀ṩµÄµÍ¼¶Cº¯ÊưºÍÊư¾Ư½á¹¹À´±àĐ´µÄ¡£
¡¡
¡¡¡¡·ĂÎÊÓɵͼ¶º¯ÊưºÍÊư¾Ư½á¹¹Ëù̀ṩ·₫ÎñµÄÓ¦ÓĂ¡£
¡¡
¡¡¡¡ÍøÂçÓ¦ÓĂ³£³£Ê¹ÓĂ2.2.2ÖĐËùÑƯʾµÄµÍ¼¶º¯ÊưºÍÊư¾Ư½á¹¹À´±àĐ´¡£¾¡¹ÜƠâÊÇ̉»ÖÖ¹ßÓĂ·½·¨£¬ÓÉÓÚ²»Äܽâ¾ö̉ÔÏÂÎỀ⣬Ëü»á¸øÓ¦ÓĂ¿ª·¢ƠßỐ³ÉĐí¶àÎỀ⣺
¡¡
·±Ëö¡¢²»½¡×³µÄ³̀Đ̣£ºÖ±½Ó¶ÔµÍ¼¶º¯ÊưºÍÊư¾Ư½á¹¹±à³̀µÄÓ¦ÓĂ¿ª·¢Ơß±ØĐë·´¸´µØÖØĐ´´óÁ¿Èß³¤·¦Î¶µÄÈí¼₫Âß¼¡£̉»°ă¶øÑÔ£¬±àĐ´ºÍά»¤ÆđÀ´ºÜ·¦Î¶µÄ´úÂë³£³£º¬ÓĐ΢Ăî¶øÓĐº¦µÄ´íÎó¡£
ÀưÈ磬ÔÚ2.2.2µÄmainº¯ÊưÖĐ´´½¨ºÍ³ơʼ»¯½ÓÊÜÆ÷socketµÄ´úÂëÊÇÈỬ׳ö´íµÄ£¬±ÈÈçĂ»ÓжÔsock_addrÇåÁă£¬»̣Ă»ÓжÔlogging_portºÅʹÓĂhtons[5]¡£mutex_lockºÍmutex_unlock̉²ÈỬ×±»ÎóÓĂ¡£ÀưÈ磬Èç¹ûwriteµ÷ÓĂ·µ»Ø-1£¬logging_handler´úÂë¾Í»á²»ÊÍ·Å»¥³âËø¶ø̀ø³öÑ»·¡£Í¬ÑùµØ£¬Èç¹ûǶ̀×µÄforÑ»·ÔÚÓöµ½´íÎóʱ·µ»Ø£¬socket¾ä±úh¾Í²»»á±»¹Ø±Ơ¡£
¡¡
ȱ·¦¿É̉ÆÖ²ĐÔ£ºÊ¹ÓĂµÍ¼¶º¯ÊưºÍÊư¾Ư½á¹¹±àĐ´µÄÈí¼₫³£³£²»ÄÜÔÚ²»Í¬µÄOSƽ̀¨ºÍ±à̉ëÆ÷¼ä̉ÆÖ²¡£¶øÇ̉£¬ËüĂÇÉơÖÁ³£³£²»ÄÜÔÚͬ̉»OS»̣±à̉ëÆ÷µÄ²»Í¬°æ±¾¼ä̉ÆÖ²¡£²»¿É̉ÆÖ²ĐÔÔ´ÓÚ̉₫²ØÔÚ»ùÓڵͼ¶APIµÄº¯ÊưºÍÊư¾Ư½á¹¹ÖеÄĐÅÏ¢ØÑ·¦¡£
ÀưÈ磬ÔÚ2.2.2ÖеÄÈƠÖ¾·₫ÎñÆ÷ʵÏÖ̉ѾӲ±àÂëÁ˶ÔÈô¸É²»¿É̉ÆÖ²µÄ±¾µØOSÏß³̀ºÍÍøÂç±à³̀C APIµÄ̉ÀÀµ¡£̀رđµØ£¬¶Ôthr_create¡¢mutex_lockºÍmutex_unlockµÄʹÓĂ²»ÄÜ̉ÆÖ²µ½·ÇSolaris OSƽ̀¨ÉÏ¡£Í¬ÑùµØ£¬̀ض¨µÄsocket̀ØĐÔ£¬±ÈÈçʹÓĂint±íʾsocket¾ä±ú£¬²»ÄÜ̉ÆÖ²µ½ÏñWin32µÄWinSockƠâÑùµÄ·ÇUnixƽ̀¨ÉÏ£»WinSock½«socket¾ä±ú±íʾΪָƠë¡£
¡¡
¸ßά»¤¿ªÏú£ºCºÍC++¿ª·¢Ơßͨ³£Í¨¹ưʹÓĂ#ifdefÔÚËûĂǵÄÓ¦ÓĂÔ´ÂëÖĐÏÔʽµØÔö¼Ó̀ơ¼₫±à̉ëÖ¸ÁîÀ´»ñµĂ¿É̉ÆÖ²ĐÔ¡£µ«ÊÇ£¬Ê¹ÓẰơ¼₫±à̉ëÀ´´¦Àíƽ̀῭ØÓеıäÖÖÔÚ¸÷·½Ă涼Ôö¼ÓÁËÓ¦ÓĂÔ´ÂëµÄÎïÀíÉè¼Æ¸´ÔÓĐÔ[6]¡£¿ª·¢ƠßÄÑ̉Ôά»¤ºÍÀ©Ơ¹ƠâÑùµÄÈí¼₫£¬̣̉Ϊƽ̀῭ØÓеÄʵÏÖϸ½Ú·ÖÉ¢ÔÚÓ¦ÓĂÔ´Îļ₫µÄ¸÷¸öµØ·½¡£
ÀưÈ磬´¦ÀísocketÊư¾ƯÀàĐ͵ÄWin32ºÍUNIX¿É̉ÆÖ²ĐÔ£¨̉²¾ÍÊÇ£¬SOCKET vs. int£©µÄ#ifdef·Á°ÁË´úÂëµÄ¿É¶ÁĐÔ¡£¶ÔÏñƠâÑùµÄµÍ¼¶C API½øĐбà³̀µÄ¿ª·¢Ơß±ØĐëÊ®·ÖẾϤĐí¶àOSƽ̀῭ØĐÔ£¬²ÅÄܱàĐ´ºÍά»¤¸Ă´úÂë¡£
ÓÉÓÚÓĐƠâĐ©È±µă£¬Í¨¹ư¶ÔµÍ¼¶º¯ÊưºÍÊư¾Ư½á¹¹Ö±½Ó½øĐбà³̀À´¿ª·¢Ó¦ÓĂ³£³£²¢·ÇÊÇÓĐЧµÄÉè¼ÆÑ¡Ôñ¡£
¡¡
¡¡¡¡È·±£Ó¦ÓĂ²»Ö±½Ó·ĂÎʵͼ¶º¯ÊưºÍÊư¾Ư½á¹¹µÄ̉»ÖÖÓĐĐ§Í¾¾¶ÊÇʹÓĂ°ü×°Íâ¹Ûģʽ¡£¶ÔÓÚĂ¿̉»×éÏà¹ØµÄº¯ÊưºÍÊư¾Ư½á¹¹£¬´´½¨̉»»̣¶à¸ö°ü×°Íâ¹ÛÀ࣬ÔÚ°ü×°Íâ¹Û½Ó¿ÚËù̀ṩµÄ¸üΪ¼̣½à¡¢½¡×³¡¢¿É̉ÆÖ²ºÍ¿Éά»¤µÄ·½·¨ÖĐ·â×°µÍ¼¶º¯ÊưºÍÊư¾Ư½á¹¹¡£
¡¡
¡¡¡¡°ü×°Íâ¹ÛģʽµÄ²ÎÓëƠߵĽṹÔÚͼ2-1ÖеÄUMLÀàͼÖĐÑƯʾ£º
¡¡

¡¡
ͼ2-1 °ü×°Íâ¹ÛģʽµÄ²ÎÓëƠߵĽṹ
¡¡
°ü×°Íâ¹ÛģʽÖĐµÄ¹Ø¼ü²ÎÓëƠß°üÀ¨£º
¡¡
º¯Êư£¨Function£©£ºº¯ÊưÊÇÏÖÓĐµÄµÍ¼¶º¯ÊưºÍÊư¾Ư½á¹¹£¬ËüĂÇ̀ṩÄھ۵ģ¨cohesive£©·₫Îñ¡£
¡¡
°ü×°Íâ¹Û£¨Wrapper
Fa?ade£©£º°ü×°Íâ¹ÛÊÇ·â×°º¯ÊưºÍÓëÆäÏà¹ØÁªµÄÊư¾Ư½á¹¹µÄ̉»¸ö»̣̉»×éÀà¡£°ü×°Íâ¹Û̀ṩµÄ·½·¨½«¿Í»§µ÷ÓĂת·¢¸ø̉»»̣¶à¸öµÍ¼¶º¯Êư¡£
¡¡
¡¡¡¡Í¼2-2ÑƯʾ°ü×°Íâ¹ÛģʽÖеĸ÷ÖÖĐ×÷£º
¡¡

¡¡
ͼ2-2 °ü×°Íâ¹ÛģʽÖеÄĐ×÷
¡¡
¡¡¡¡ÈçÏÂËùÊö£¬ƠâĐ©Đ×÷ÊÇÊ®·Ö¼̣µ¥Ă÷Á˵ģº
¡¡
1.
¿Í»§µ÷ÓĂ£¨Client invocation£©£º¿Í»§Í¨¹ư°ü×°Íâ¹ÛµÄʵÀưÀ´µ÷ÓĂ·½·¨¡£
2.
ת·¢£¨Forwarding£©£º°ü×°Íâ¹Û·½·¨½«ÇëÇóת·¢¸øËü·â×°µÄ̉»»̣¶à¸öµ×²ăº¯Êư£¬²¢´«µƯº¯ÊưËùĐèµÄÈκÎÄÚ²¿Êư¾Ư½á¹¹¡£
¡¡
¡¡¡¡Ơẩ»²¿·Ö½âÊÍͨ¹ư°ü×°Íâ¹ÛģʽʵÏÖ×é¼₫ºÍÓ¦ÓĂËùÉæ¼°µÄ²½Öè¡£Î̉Ăǽ«²ûÊÍƠâĐ©°ü×°Íâ¹ÛÊÇÔơÑù¿Ë·₫·±Ëö¡¢²»½¡×³µÄ³̀Đ̣¡¢È±·¦¿É̉ÆÖ²ĐÔ£¬̉Ô¼°¸ßά»¤¿ªÏúµÈÎỀâµÄ£»ƠâĐ©ÎỀâƠÛÄ¥×ÅʹÓĂµÍ¼¶º¯ÊưºÍÊư¾Ư½á¹¹µÄ½â¾ö·½°¸¡£
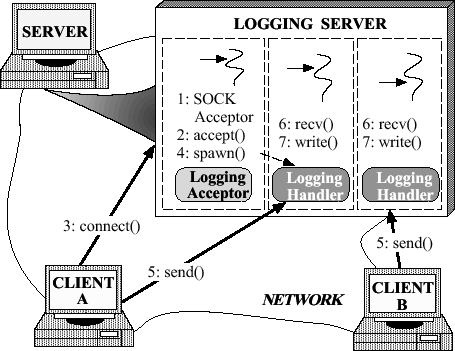
¡¡¡¡ƠâÀï½éÉܵÄÀư×Ó»ùÓÚ2.2.2ĂèÊöµÄÈƠÖ¾·₫ÎñÆ÷£¬Í¼2-3ÑƯʾ´ËÀưÖĐµÄ½á¹¹ºÍ²ÎÓëƠß¡£Ơẩ»²¿·ÖÖеÄÀư×ÓÓ¦ÓĂÁËÀ´×ÔACE¹¹¼Ü[7]µÄ¿É¸´ÓĂ×é¼₫¡£ACÈṩ̉»×é·á¸»µÄ¿É¸´ÓĂC++°ü×°ºÍ¹¹¼Ü×é¼₫£¬̉Ô¿çÔ½¹ă·ºµÄOSƽ̀¨Íê³É³£¼ûµÄͨĐÅÈí¼₫ÈÎÎñ¡£
¡¡
¡¡
ͼ2-3 ¶àÏß³̀ÈƠÖ¾·₫ÎñÆ÷
¡¡
¡¡¡¡¿É²ÉÈ¡ÏÂĂæµÄ²½ÖèÀ´ÊµÏÖ°ü×°Íâ¹Ûģʽ£º
¡¡
1.
È·¶¨ÏÖÓĐº¯Êư¼äµÄÄھ۵ijéÏóºÍ¹Øϵ£ºÏñWin32¡¢POSIX»̣X WindowsƠâÑù±»ÊµÏÖΪ¶ÀÁ¢µÄº¯ÊưºÍÊư¾Ư½á¹¹µÄ´«Í³APÌṩĐí¶àÄھ۵ijéÏ󣬱ÈÈçÓĂÓÚÍøÂç±à³̀¡¢Í¬²½ºÍÏß³̀£¬̉Ô¼°GUI¹ÜÀíµÄ»úÖÆ¡£µ«ÊÇ£¬ÓÉÓÚÔÚÏñCƠâÑùµÄµÍ¼¶ÓïÑÔÖĐȱ·¦Êư¾Ư³éÏóÖ§³Ö£¬¿ª·¢Ơß³£³£²¢²»ÄÜÂíÉÏĂ÷ÁËƠâĐ©ÏÖÓĐµÄº¯ÊưºÍÊư¾Ư½á¹¹ÊÇÔơÑù»¥Ïà¹ØÁªµÄ¡£̣̉´Ë£¬Ó¦ÓĂ°ü×°Íâ¹ÛµÄµÚ̉»²½¾ÍÊÇÈ·¶¨ÏÖÓĐAPIÖĐµÄ½ÏµÍ¼¶º¯ÊưÖ®¼äµÄÄھ۵ijéÏóºÍ¹Øϵ¡£»»¾ä»°Ëµ£¬Î̉ĂÇͨ¹ư½«ÏÖÓĐµÄµÍ¼¶APIº¯ÊưºÍÊư¾Ư½á¹¹¾ÛºÏ½ø̉»»̣¶à¸öÀàÖĐÀ´¶¨̉å̉»ÖÖ¡°¶ÔÏóÄ£ĐÍ¡±¡£
ÔÚÎ̉ĂǵÄÈƠÖ¾Àư×ÓÖĐ£¬Î̉ĂÇ´Ó×Đϸ¼́²éÎ̉ĂÇÔÀ´µÄÈƠÖ¾·₫ÎñÆ÷ʵÏÖ¿ªÊ¼¡£¸ĂʵÏÖʹÓĂÁËĐí¶àµÍ¼¶º¯Êư£¬ÓÉËüĂÇʵ¼ỀṩÈô¸ÉÄھ۵ķ₫Îñ£¬±ÈÈçͬ²½ºÍÍøÂçͨĐÅ¡£ÀưÈ磬mutex_lockºÍmutex_unlockº¯ÊưÓ뻥³ầåͬ²½³éÏóÏà¹ØÁª¡£Í¬ÑùµØ£¬socket¡¢bind¡¢listenºÍacceptº¯Êư°çÑƯÁËÍøÂç±à³̀³éÏóµÄ¶àÖÖ½ÇÉ«¡£
2.
½«Äھ۵ĺ¯Êư×é¾ÛºÏ½ø°ü×°Íâ¹ÛÀàºÍ·½·¨ÖĐ£º¸Ă²½Öè¿É»®·ÖΪ̉ÔÏÂ×Ó²½Ö裺
Ôڴ˲½ÖèÖĐ£¬Î̉ĂÇÎªĂ¿×éÏà¹ØÓÚ̀ض¨³éÏóµÄº¯ÊưºÍÊư¾Ư½á¹¹¶¨̉å̉»»̣¶à¸ö°ü×°Íâ¹ÛÀà¡£
¡¡
A. ´´½¨ÄÚ¾ÛµÄÀࣺÎ̉ĂÇ´ÓÎªĂ¿×éÏà¹ØÓÚ̀ض¨³éÏóµÄº¯ÊưºÍÊư¾Ư½á¹¹¶¨̉å̉»»̣¶à¸ö°ü×°Íâ¹ÛÀ࿪ʼ¡£ÓĂÓÚ´´½¨ÄÚ¾ÛµÄÀàµÄÈô¸É³£Óñê×¼°üÀ¨£º
¡¡
- ½«¾ßÓиßÄÚ¾ÛĐÔ£¨cohesion£©µÄº¯ÊưºÏ²¢½ø¶ÀÁ¢µÄÀàÖĐ£¬Í¬Ê±Ê¹ÀàÖ®¼ä²»±Ø̉ªµÄñîºÏ×îĐ¡»¯¡£
- È·¶¨ÔÚµ×²ăº¯ÊưÖĐÊ²Ă´ÊÇͨÓõÄÊ²Ă´ÊǿɱäµÄ£¬²¢°Ñº¯Êư·Ö×é½øÀàÖĐ£¬´Ó¶ø½«±ä»¯¸ôÀëÔÚͳ̉»µÄ½Ó¿ÚºóĂæ¡£
¡¡
̉»°ă¶øÑÔ£¬Èç¹ûÔÀ´µÄAPIº¬ÓĐ¹ă·ºµÄÏà¹Øº¯Êư£¬¾ÍÓĐ¿ÉÄܱØĐë´´½¨Èô¸É°ü×°Íâ¹ÛÀàÀ´Êʵ±µØ¶ÔÊÂÎñ½øĐĐ·ÖÀí¡£
¡¡
B. ½«¶à¸ö¶ÀÁ¢º¯ÊưºÏ²¢½øÀà·½·¨ÖĐ£º³ưÁ˽«ÏÖÓĐº¯Êư·Ö×é½øÀàÖĐ£¬ÔÚĂ¿¸ö°ü×°ÀàÖĐ½«¶à¸ö¶ÀÁ¢º¯Êư×éºÏ½øÊưÄ¿¸üÉٵķ½·¨ÖĐ³£³£̉²ÊÇÓĐ̉æµÄ¡£ÀưÈ磬Ϊȷ±£̉»×éµÍ¼¶º¯ÊửÔÊʵ±µÄ˳Đ̣±»µ÷ÓĂ£¬¿ÉÄܱØĐë̉ª²ÉÓĂ´ËÉè¼Æ¡£
¡¡
C. Ñ¡Ôñ¼ä½Ó²ă´Î£º´ó¶àÊư°ü×°Íâ¹ÛÀà¼̣µ¥µØ½«ËüĂǵķ½·¨µ÷ÓĂÖ±½Óת·¢¸øµ×²ăµÄµÍ¼¶º¯Êư¡£Èç¹û°ü×°Íâ¹Û·½·¨ÊÇÄÚÁªµÄ£¬ÓëÖ±½Óµ÷ÓĂµÍ¼¶º¯ÊưÏà±È£¬¿ÉÄܲ¢Ă»ÓжîÍâµÄ¼ä½Ó²ă´Î¡£ÎªÔöÇ¿¿ÉÀ©Ơ¹ĐÔ£¬»¹¿É̉Ôͨ¹ư¶¯̀¬·ÖÅÉ°ü×°Íâ¹Û·½·¨ÊµÏÖÀ´Ôö¼ÓÁíÍâµÄ¼ä½Ó²ă´Î¡£ÔÚƠâÖÖÇé¿öÏ£¬°ü×°Íâ¹ÛÀà°çÑƯÇŽӣ¨Bridge£©Ä£Ê½[8]ÖĐµÄ³éÏó£¨Abstraction£©½ÇÉ«¡£
¡¡
D. È·¶¨ÔÚÄÄÀï´¦Àíƽ̀῭ØÓеıäÖÖ£ºÊ¹Æ½̀῭ØÓеÄÓ¦ÓĂ´úÂë×îÉÙ»¯ÊÇʹÓĂ°ü×°Íâ¹ÛģʽµÄÖØ̉ªºĂ´¦¡£̣̉¶ø£¬¾¡¹Ü°ü×°Íâ¹ÛÀà·½·¨µÄʵÏÖÔÚ²»Í¬µÄOSƽ̀¨ÉÏ¿É̉Ô²»Í¬£¬ËüĂÇÓ¦¸Ằṩͳ̉»µÄ¡¢Æ½̀¨Î̃¹ØµÄ½Ó¿Ú¡£
´¦Àíƽ̀῭ØÓбäÖÖµÄ̉»ÖÖ²ßÂÔÊÇÔÚ°ü×°Íâ¹ÛÀà·½·¨ÊµÏÖÖĐʹÓĂ#ifdef¡£ÔÚÁªºÏʹÓĂ#ifdefºÍ×Ô¶¯ÅäÖĂ¹¤¾ß£¨±ÈÈçGNU autoconf£©Ê±£¬¿É̉Ôͨ¹ưµ¥̉»µÄÔ´ÂëÊ÷´´½¨Í³̉»µÄ¡¢²»̉ÀÀµÓÚƽ̀¨µÄ°ü×°Íâ¹Û¡£Áí̉»ÖÖ¿ÉÑ¡²ßÂÔÊǽ«²»Í¬µÄ°ü×°Íâ¹ÛÀàʵÏÖ·Ö½â½ø·ÖÀëµÄĿ¼ÖĐ£¨ÀưÈç£¬Ă¿¸öƽ̀¨ÓĐ̉»¸öĿ¼£©£¬²¢ÅäÖĂÓïÑÔ´¦Àí¹¤¾ß£¬̉ÔÔÚ±à̉ëʱ½«Êʵ±µÄ°ü×°Íâ¹ÛÀà°üº¬½øÓ¦ÓĂÖĐ¡£
Ñ¡Ôñ̀ض¨µÄ²ßÂÔÔںܴó³̀¶ÈÉÏÈ¡¾öÓÚ°ü×°Íâ¹Û·½·¨ÊµÏֱ䶯µÄƵ¶È¡£ÀưÈ磬Èç¹ûËüĂÇƵ·±±ä¶¯£¬ÎªĂ¿¸öƽ̀¨ƠưÈ·µØ¸üĐÂ#ifdef¿ÉÄÜÊǵ¥µ÷·¦Î¶µÄ¡£Í¬ÑùµØ£¬ËùÓĐ̉ÀÀµÓÚ¸ĂÎļ₫µÄÎļ₫¿ÉÄܶ¼Đè̉ªÖرà̉룬¼´Ê¹±ä¶¯½ö½ö¶Ổ»¸öƽ̀¨À´ËµÊDZØĐèµÄ¡£
¡¡
¡¡ÔÚÎ̉ĂǵÄÈƠÖ¾Àư×ÓÖĐ£¬Î̉Ăǽ«Îª»¥³ầå¡¢socketºÍÏß³̀¶¨̉å°ü×°Íâ¹ÛÀ࣬̉ÔÑƯÊ¾Ă¿̉»×Ó²½ÖèÊÇÔơÑù±»ÊµÊ©µÄ¡£ÈçÏÂËùʾ£º
¡¡
- »¥³ầå°ü×°Íâ¹Û£ºÎ̉ĂÇÊ×Ïȶ¨̉åThread_Mutex³éÏó£¬ÔÚͳ̉»ºÍ¿É̉ÆÖ²µÄÀà½Ó¿ÚÖĐ·â×°Solaris»¥³ầ庯Êư£º
¡¡
class
Thread_Mutex
{
public:
Thread_Mutex
(void)
{
mutex_init (&mutex_, 0, 0);
}
¡¡
?Thread_Mutex
(void)
{
mutex_destroy (&mutex_);
}
¡¡
int acquire
(void)
{
return mutex_lock (&mutex_);
}
¡¡
int release
(void)
{
return mutex_unlock (&mutex_);
}
¡¡
private:
//
Solaris-specific Mutex mechanism.
mutex_t mutex_;
¡¡
// = Disallow
copying and assignment.
Thread_Mutex
(const Thread_Mutex &);
void operator=
(const Thread_Mutex &);
};
¡¡
¡¡¡¡Í¨¹ư¶¨̉åThread_MutexÀà½Ó¿Ú£¬²¢ËæÖ®±àĐ´Ê¹ÓĂËü¡¢¶ø²»Êǵͼ¶±¾µØOS C
APIµÄÓ¦ÓĂ£¬Î̉ĂÇ¿É̉ÔºÜÈỬ׵ؽ«Î̉Ăǵİü×°Íâ¹Û̉ÆÖ²µ½ÆäËûƽ̀¨¡£ÀưÈ磬ÏÂĂæµÄThread_MutexʵÏÖÔÚWin32ÉϹ¤×÷£º
¡¡
class
Thread_Mutex
{
public:
Thread_Mutex
(void)
{
InitializeCriticalSection
(&mutex_);
}
¡¡
?Thread_Mutex
(void)
{
DeleteCriticalSection
(&mutex_);
}
¡¡
int acquire
(void)
{
EnterCriticalSection (&mutex_);
return 0;
}
¡¡
int release
(void)
{
LeaveCriticalSection (&mutex_);
return 0;
}
¡¡
private:
//
Win32-specific Mutex mechanism.
CRITICAL_SECTION
mutex_;
¡¡
// = Disallow
copying and assignment.
Thread_Mutex
(const Thread_Mutex &);
void operator=
(const Thread_Mutex &);
};
¡¡
¡¡¡¡ÈçÔçÏÈËùĂèÊöµÄ£¬Î̉ĂÇ¿É̉Ôͨ¹ưÔÚThread_Mutex·½·¨ÊµÏÖÖĐʹÓĂ#ifdef̉Ô¼°×Ô¶¯ÅäÖĂ¹¤¾ß£¨±ÈÈçGUN autoconf£©À´Ö§³Ö¶à¸öOSƽ̀¨£¬̉ÔʹÓõ¥̉»Ô´ÂëÊ÷̀ṩͳ̉»µÄ¡¢Æ½̀¨Î̃¹ØµÄ»¥³ầå³éÏó¡£Ïà·´£¬Î̉ĂÇ̉²¿É̉Ô½«²»Í¬µÄThread_MutexʵÏÖ·Ö½â½ø·ÖÀëµÄĿ¼ÖĐ£¬²¢Ö¸Ê¾Î̉ĂǵÄÓïÑÔ´¦Àí¹¤¾ßÔÚ±à̉ëʱ½«Êʵ±µÄ°æ±¾°üº¬½øÎ̉ĂǵÄÓ¦ÓĂÖĐ¡£
¡¡¡¡³ưÁ˸ÄÉÆ¿É̉ÆÖ²ĐÔ£¬Î̉ĂǵÄThread_Mutex°ü×°Íâ¹Û»¹̀ṩ±ÈÖ±½Ó±à³̀µÍ¼¶Solarisº¯ÊưºÍmutex_tÊư¾Ư½á¹¹¸ü²»ÈỬ׳ö´íµÄ»¥³ầå½Ó¿Ú¡£ÀưÈ磬Î̉ĂÇ¿É̉ÔʹÓĂC++ private·ĂÎÊ¿ØÖÆָʾ·ûÀ´½ûÖ¹»¥³ầåµÄ¿½±´ºÍ¸³Öµ£»ƠâÑùµÄʹÓĂÊÇ´íÎóµÄ£¬µ«È´²»»á±»²»ÄÇĂ´Ç¿ÀàĐÍ»¯µÄC±à³̀APIËù×èÖ¹¡£
¡¡
- socket°ü×°Íâ¹Û£ºsocket API±ÈSolaris»¥³ầåAPỈª´óµĂ¶à£¬̉²ÓбíÏÖÁ¦µĂ¶à[5]¡£̣̉´Ë£¬Î̉ĂDZØĐ붨̉å̉»×éÏà¹ØµÄ°ü×°Íâ¹ÛÀàÀ´·â×°socket¡£Î̉Ăǽ«´Ó¶¨̉åÏÂĂæµÄ´¦ÀíUNIX/Win32¿É̉ÆÖ²ĐÔ²î̉́µÄtypedef¿ªÊ¼£º
¡¡
#if !defined
(_WINSOCKAPI_)
typedef int
SOCKET;
#define
INVALID_HANDLE_VALUE -1
#endif /*
_WINSOCKAPI_ */
¡¡
½ÓÏÂÀ´£¬Î̉Ăǽ«¶¨̉åINET_AddrÀ࣬·â×°InternetỌ́µØÖ·½á¹¹£º
¡¡
class INET_Addr
{
public:
INET_Addr
(u_short port, long addr)
{
// Set up the address to become a
server.
memset (reinterpret_cast <void
*> (&addr_), 0, sizeof addr_);
addr_.sin_family = AF_INET;
addr_.sin_port = htons (port);
addr_.sin_addr.s_addr = htonl
(addr);
}
¡¡
u_short
get_port (void) const
{
return addr_.sin_port;
}
¡¡
long
get_ip_addr (void) const
{
return addr_.sin_addr.s_addr;
}
¡¡
sockaddr *addr
(void) const
{
return reinterpret_cast
<sockaddr *>(&addr_);
}
¡¡
size_t size
(void) const
{
return sizeof (addr_);
}
// ...
¡¡
private:
sockaddr_in
addr_;
};
¡¡
¡¡¡¡×¢̉âINET_Addr¹¹ỐÆ÷ÊÇÔơÑùͨ¹ư½«sockaddr_inỌ́ÇåÁă£¬²¢È·±£¶Ë¿ÚºÍIPµØÖ·±»×ª»»ÎªÍøÂç×Ö½ÚĐ̣£¬Ïû³ưÈô¸É³£¼ûµÄsocket±à³̀´íÎóµÄ¡£
¡¡¡¡ÏẨ»¸ö°ü×°Íâ¹ÛÀ࣬SOCK_Stream£¬¶ÔÓ¦ÓĂ¿ÉÔÚ̉ÑÁ¬½Ósocket¾ä±úÉϵ÷ÓõÄI/O²Ù×÷£¨±ÈÈçrecvºÍsend£©½øĐĐ·â×°£º
¡¡
class
SOCK_Stream
{
public:
// =
Constructors.
// Default
constructor.
SOCK_Stream
(void)
: handle_ (INVALID_HANDLE_VALUE) {}
¡¡
// Initialize
from an existing HANDLE.
SOCK_Stream
(SOCKET h): handle_ (h) {}
¡¡
//
Automatically close the handle on destruction.
?SOCK_Stream (void)
{ close (handle_); }
¡¡
void set_handle
(SOCKET h) { handle_ = h; }
SOCKET
get_handle (void) const { return handle_; }
¡¡
// = I/O
operations.
int recv (char
*buf, size_t len, int flags = 0);
int send (const
char *buf, size_t len, int flags = 0);
// ...
¡¡
private:
// Handle for
exchanging socket data.
SOCKET handle_;
};
¡¡
×¢̉â´ËÀàÊÇÔơÑùÈ·±£socket¾ä±úÔÚSOCK_Stream¶ÔÏó³ö×÷ÓĂỌ́ʱ±»×Ô¶¯¹Ø±ƠµÄ¡£
¡¡¡¡SOCK_Stream¶ÔÏóÓÉÁ¬½Ó¹¤³§SOCK_Acceptor´´½¨£¬ºóƠß·â×°±»¶¯µÄÁ¬½Ó½¨Á¢Âß¼[9]¡£SOCK_Acceptor¹¹ỐÆ÷³ơʼ»¯±»¶¯Ä£Ê½½ÓÊÜÆ÷socket£¬̉ÔÔÚsock_addrµØÖ·ÉϽøĐĐỚ̀ư¡£Í¬ÑùµØ£¬accept¹¤³§·½·¨Í¨¹ưĐ½ÓÊܵÄÁ¬½ÓÀ´³ơʼ»¯SOCK_Stream£¬ÈçÏÂËùʾ£º
¡¡
class
SOCK_Acceptor
{
public:
SOCK_Acceptor
(const INET_Addr &sock_addr)
{
// Create a local endpoint of
communication.
handle_ = socket (PF_INET,
SOCK_STREAM, 0);
¡¡
// Associate address with endpoint.
bind (handle_, sock_addr.addr (), sock_addr.size
());
¡¡
// Make endpoint listen for
connections.
listen (handle_, 5);
};
¡¡
// Accept a
connection and initialize
// the
<stream>.
int accept
(SOCK_Stream &stream)
{
stream.set_handle (accept (handle_,
0, 0));
if (stream.get_handle () ==
INVALID_HANDLE_VALUE)
return -1;
else return 0;
}
¡¡
private:
// Socket
handle factory.
SOCKET handle_;
};
¡¡
×¢̉âSOCK_AcceptorµÄ¹¹ỐÆ÷ÊÇÔơÑùÈ·±£µÍ¼¶µÄsocket¡¢bindºÍlistenº¯Êư×ÜÊÇ̉ÔƠưÈ·µÄ´ÎĐ̣±»µ÷ÓĂµÄ¡£
¡¡¡¡ÍêƠûµÄsocket°ü×°Íâ¹Û¼¯»¹°üÀ¨SOCK_Connector£¬·â×°Ö÷¶¯µÄÁ¬½Ó½¨Á¢Âß¼[9]¡£
¡¡
- Ïß³̀Íâ¹Û£ºÔÚ²»Í¬µÄOSƽ̀¨ÉÏÓĐĐí¶àÏß³̀API¿ÉÓĂ£¬°üÀ¨SolarisÏß³̀¡¢POSIX PthreadsºÍWin32Ïß³̀¡£ƠâĐ©APIÏÔʾ³ö΢ĂîµÄÓï·¨ºÍÓï̉å²î̉́£¬ÀưÈ磬SolarisºÍPOSIXÏß³̀¿É̉Ô¡°·ÖÀ롱£¨detached£©Ä£Ê½±»ÅÉÉú£¬¶øWin32Ïß³̀Ộ²»ĐĐ¡£µ«ÊÇ£¬¿É̉ỒṩThread_Manager°ü×°Íâ¹Û£¬ÔÚͳ̉»µÄAPIÖĐ·â×°ƠâĐ©²î̉́¡£ÈçÏÂËùʾ£º
¡¡
class
Thread_Manager
{
public:
int spawn (void
*(*entry_point) (void *),
void *arg,
long flags,
long stack_size = 0,
void *stack_pointer = 0,
thread_t *t_id = 0)
{
thread_t t;
if (t_id == 0)
t_id = &t;
¡¡
return thr_create (stack_size,
stack_pointer,
entry_point,
arg,
flags,
t_id);
}
// ...
};
¡¡
Thread_Manager»¹̀ṩÁª½Ó£¨join£©ºÍÈ¡ÏûÏß³̀µÄ·½·¨¡£
¡¡
1.
È·¶¨´íÎó´¦Àí»úÖÆ£ºµÍ¼¶µÄCº¯ÊưAPIͨ³£Ê¹ÓĂ·µ»ØÖµºÍƠûĐÍ´úÂ루±ÈÈçerrno£©À´½«´íÎó֪ͨ¸øËüĂǵĵ÷ÓĂƠß¡£µ«ÊÇ£¬´Ë¼¼ÊơÊÇÈỬ׳ö´íµÄ£¬̣̉Ϊµ÷ÓĂƠß¿ÉÄÜ»áÍü¼Ç¼́²éËüĂǵĺ¯Êưµ÷Óõķµ»Ø×´̀¬¡£
¸üΪÓÅÑŵı¨¸æ´íÎóµÄ·½Ê½ÊÇʹÓẲ́³£´¦Àí¡£Đí¶à±à³̀ÓïÑÔ£¬±ÈÈçC++ºÍJava£¬Ê¹ÓẲ́³£´¦ÀíÀ´×÷Ϊ´íÎ󱨸æ»úÖÆ¡£Ëü̉²±»Ä³Đ©²Ù×÷ϵͳËùʹÓĂ£¬±ÈÈçWin32¡£
ʹÓẲ́³£´¦Àí×÷Ϊ°ü×°Íâ¹ÛÀàµÄ´íÎó´¦Àí»úÖÆÓĐÈô¸ÉºĂ´¦£º
¡¡
- ËüÊÇ¿ÉÀ©Ơ¹µÄ£ºÏÖ´ú±à³̀ÓïÑÔÔÊĐíͨ¹ư¶ÔÏÖÓĐ½Ó¿ÚºÍʹÓøÉÈż«ÉÙµÄ̀ØĐÔÀ´À©Ơ¹̉́³£´¦Àí²ßÂԺͻúÖÆ¡£ÀưÈ磬C++ºÍJavaʹÓĂ¼̀³ĐÀ´¶¨̉å̉́³£ÀàµÄ²ă´Î¡£
- Ëüʹ´íÎó´¦ÀíÓëƠư³£´¦ÀíµẲԸɾ»µØÈ¥ñîºÏ£ºÀưÈ磬´íÎó´¦ÀíĐÅÏ¢²»»áÏÔʽµØ´«µƯ¸ø²Ù×÷¡£¶øÇ̉£¬Ó¦ÓĂ²»»ạ́̉ÎªĂ»ÓĐ¼́²éº¯Êư·µ»ØÖµ¶øżȻµØºöÂỔ́³£¡£
- Ëü¿É̉ÔÊÇÀàĐÍ°²È«µÄ£ºÔÚÏñC++ºÍJavaƠâÑùµÄÓïÑÔÖĐ£¬̉́³£̉Ổ»ÖÖÇ¿ÀàĐÍ»¯µÄ·½Ê½±»ÈÓ³öºÍ²¶×½£¬̉ÔÔöÇ¿´íÎó´¦Àí´úÂëµÄ×éÖ¯ºÍƠưÈ·ĐÔ¡£Ïà¶ÔÓÚÏÔʽµØ¼́²éÏß³̀רÓеĴíÎóÖµ£¬±à̉ëÆ÷»áÈ·±£¶ÔÓÚĂ¿ÖÖÀàĐ͵Ä̉́³££¬½«Ö´ĐĐƠưÈ·µÄ´¦ÀíÆ÷¡£
¡¡
µ«ÊÇ£¬Îª°ü×°Íâ¹ÛÀàʹÓẲ́³£´¦Àí̉²ÓĐÈô¸Éȱµă£º
¡¡
- Ëü²»ÊÇͨÓĂµÄ£º²»ÊÇËùÓĐÓïÑÔ¶¼̀ṩ̉́³£´¦Àí¡£ÀưÈç£¬Ä³Đ©C++±à̉ëÆ÷Ă»ÓĐʵÏÖ̉́³£¡£Í¬ÑùµØ£¬µ±OS̀ṩ̉́³£·₫Îñʱ£¬ËüĂDZØĐë±»ÓïÑÔÀ©Ơ¹ËùÖ§³Ö£¬´Ó¶ø½µµÍÁË´úÂëµÄ¿É̉ÆÖ²ĐÔ¡£
- Ëüʹ¶àÖÖÓïÑÔµÄʹÓñäµĂ¸´ÔÓ»¯£º̣̉ΪÓïÑỔÔ²»Í¬µÄ·½Ê½ÊµÏÖ̉́³££¬»̣¸ù±¾²»ÊµÏÖ̉́³££¬Èç¹û̉Ô²»Í¬ÓïÑÔ±àĐ´µÄ×é¼₫ÈÓ³ö̉́³££¬¿ÉÄܺÜÄÑ°ÑËüĂǼ¯³ÉÔÚ̉»Æđ¡£Ïà·´£¬Ê¹ÓĂƠûĐÍÖµ»̣½á¹¹À´±¨¸æ´íÎóĐÅÏ¢̀ṩÁ˸üΪͨÓĂµÄ½â¾ö·½°¸¡£
- Ëüʹ×ÊÔ´¹ÜÀí±äµĂ¸´ÔÓ»¯£ºÈç¹ûÔÚC++»̣Java´úÂë¿éÖĐÓжà¸öÍ˳ö·¾¶£¬×ÊÔ´¹ÜÀí¿ÉÄÜ»á±äµĂ¸´ÔÓ»¯[10]¡£̣̉¶ø£¬Èç¹ûÓïÑÔ»̣±à³̀»·¾³²»Ö§³ÖÀ¬»øÊƠ¼¯£¬±ØĐë×¢̉âÈ·±£ÔÚÓĐ̉́³£ÈÓ³öʱɾ³ư¶¯̀¬·ÖÅäµÄ¶ÔÏó¡£
- ËüÓĐ×ÅDZÔÚµÄʱ¼äºÍ/»̣¿Ơ¼äµÍЧµÄ¿ÉÄÜĐÔ£º¼´Ê¹Ă»ÓĐ̉́³£ÈÓ³ö£¬̉́³£´¦ÀíµÄÔă¸âʵÏÖ̉²»á´øÀ´Ê±¼äºÍ/»̣¿Ơ¼äµÄ¹ư¶È¿ªÏú[10]¡£¶ÔÓÚ±ØĐë¾ßÓиßЧºÍµÍÄÚ´æƠ¼ÓẰØĐÔµÄǶÈëʽϵͳÀ´Ëµ£¬ƠâÑùµÄ¿ªÏú¿ÉÄÜ»á̀رđµØ³ÉÎỀâ¡£
¡¡
¡¡¡¡¶ÔÓÚ·â×°Äں˼¶É豸Çư¶¯³̀Đ̣»̣µÍ¼¶µÄ±¾µØOS API£¨ËüĂDZØĐë±»̉ÆÖ²µ½Đí¶àƽ̀¨ÉÏ£©µÄ°ü×°Íâ¹ÛÀ´Ëµ£¬̉́³£´¦ÀíµÄȱµẳ²ÊÇ̀رđ³ÉÎỀâµÄ¡£¶ÔÓÚƠâĐ©ÀàĐ͵İü×°Íâ¹Û£¬¸üΪ¿É̉ÆÖ²¡¢¸ßЧºÍÏß³̀°²È«µÄ´¦Àí´íÎóµÄ·½Ê½ÊǶ¨̉å´íÎó´¦ÀíÆ÷³éÏó£¬ÏÔʽµØά»¤¹ØÓÚ²Ù×÷µÄ³É¹¦»̣ʧ°ÜµÄĐÅÏ¢¡£Ê¹ÓĂÏß³̀רÓĐ´æ´¢£¨Thread-Specific Storage£©Ä£Ê½[11]ÊDZ»¹ă·ºÓĂÓÚƠâĐ©ÏµÍ³¼¶°ü×°Íâ¹ÛµÄ½â¾ö·½°¸¡£
¡¡
1.
¶¨̉åÏà¹ØÖúÊÖÀࣨ¿ÉÑ¡£©£º̉»µ©µÍ¼¶º¯ÊưºÍÊư¾Ư½á¹¹±»·â×°ÔÚÄھ۵İü×°Íâ¹ÛÀàÖĐ£¬³£³£ÓĐ¿ÉÄÜ´´½¨ÆäËûÖúÊÖÀàÀ´½ø̉»²½¼̣»¯Ó¦ÓĂ¿ª·¢¡£Í¨³£̉ªÔÚ°ü×°Íâ¹Ûģʽ̉ѱ»Ó¦ÓĂÓÚ½«µÍ¼¶º¯ÊưºÍÓëÆä¹ØÁªµÄÊư¾Ư¾ÛºÏ½øÀàÖĐÖ®ºó£¬ƠâĐ©ÖúÊÖÀàµÄЧÓĂ²Å±äµĂĂ÷ÏÔÆđÀ´¡£
ÀưÈ磬ÔÚÎ̉ĂǵÄÈƠÖ¾Àư×ÓÖĐ£¬Î̉ĂÇ¿É̉ÔÓĐЧµØÀûÓĂÏÂĂæµÄʵÏÖC++ Scoped
LockingÏ°ÓïµÄGuardÀࣻ¸ĂÏ°ÓïÈ·±£Thread_Mutex±»Êʵ±µØÊÍ·Å£¬²»¹Ü³̀Đ̣µÄ¿ØÖÆÁ÷ÊÇÔơÑùÍ˳ö×÷ÓĂỌ́µÄ¡£
¡¡
template
<class LOCK>
class Guard
{
public:
Guard (LOCK
&lock): lock_ (lock)
{
lock_.acquire ();
}
¡¡
?Guard (void)
{
lock_.release ();
}
¡¡
private:
// Hold the
lock by reference to avoid
// the use of
the copy constructor...
LOCK
&lock_;
}
¡¡
GuardÀàÓ¦ÓĂÁË[12]ÖĐĂèÊöµÄC++Ï°Ó½å´Ë£¬ÔÚ̉»¶¨×÷ÓĂỌ́ÖĐ¡°¹¹ỐÆ÷»ñÈ¡×ÊÔ´¶øÎö¹¹Æ÷ÊÍ·ÅËüĂÇ¡±¡£ÈçÏÂËùʾ£º
¡¡
// ...
{
// Constructor
of <mon> automatically
// acquires the
<mutex> lock.
Guard<Thread_Mutex>
mon (mutex);
¡¡
// ...
operations that must be serialized ...
¡¡
// Destructor
of <mon> automatically
// releases the
<mutex> lock.
}
// ...
¡¡
¡¡¡¡̣̉ΪÎ̉ĂÇʹÓĂÁËÏñThread_Mutex°ü×°Íâ¹ÛƠâÑùµÄÀ࣬Î̉ĂÇ¿É̉ÔºÜÈỬ×µØ̀æ»»²»Í¬ÀàĐ͵ÄËø¶¨»úÖÆ£¬Óë´ËͬʱÈÔÈ»¸´ÓĂGuardµÄ×Ô¶¯Ëø¶¨/½âËøĐ̉é¡£ÀưÈ磬Î̉ĂÇ¿É̉ÔÓĂProcess_MutexÀàÀ´È¡´úThread_MutexÀ࣬ÈçÏÂËùʾ£º
¡¡
// Acquire a
process-wide mutex.
Guard<Process_Mutex>
mon (mutex);
¡¡
¡¡¡¡Èç¹ûʹÓĂCº¯ÊưºÍÊư¾Ư½á¹¹¡¢¶ø²»ÊÇC++À࣬»ñµĂƠâÖÖ³̀¶ÈµÄ¡°¿É²åĐÔ¡±£¨pluggability£©̉ªÀ§ÄÑµĂ¶à¡£
¡¡
¡¡¡¡ÏÂĂæµÄ´úÂëÑƯʾÈƠÖ¾·₫ÎñÆ÷µÄmainº¯Êư£¬Ëü̉ÑʹÓĂ2.2.8ĂèÊöµÄ»¥³ầå¡¢socketºÍÏß³̀µÄ°ü×°Íâ¹ÛÖØĐ´¡£
¡¡
// At file
scope.
// Keep track
of number of logging requests.
static int
request_count;
¡¡
// Manage
threads in this process.
static
Thread_Manager thr_mgr;
¡¡
// Lock to protect
request_count.
static
Thread_Mutex lock;
¡¡
// Forward
declaration.
static void
*logging_handler (void *);
¡¡
// Port number
to listen on for requests.
static const
int logging_port = 10000;
¡¡
// Main driver
function for the multi-threaded
// logging
server. Some error handling has been
// omitted to
save space in the example.
int main (int
argc, char *argv[])
{
// Internet
address of server.
INET_Addr addr
(port);
¡¡
// Passive-mode
acceptor object.
SOCK_Acceptor
server (addr);
¡¡
SOCK_Stream
new_stream;
¡¡
// Wait for a
connection from a client.
for (;;)
{
// Accept a connection from a
client.
server.accept (new_stream);
¡¡
// Get the underlying handle.
SOCKET h = new_stream.get_handle
();
¡¡
// Spawn off a
thread-per-connection.
thr_mgr.spawn (logging_handler,
reinterpret_cast <void *>
(h),
THR_DETACHED);
}
}
¡¡
logging_handlerº¯ÊưÔËĐĐÔÚµ¥¶ÀµÄÏß³̀¿ØÖÆÖĐ£¬̉²¾ÍÊÇ£¬Ă¿¸öÏàÁ¬¿Í»§ÓĐ̉»¸öÏß³̀¡£ËüÔÚ¸÷¸öÁ¬½ÓÉϽÓÊƠ²¢´¦ÀíÈƠÖ¾¼Ç¼£¬ÈçÏÂËùʾ£º
¡¡
// Entry point
that processes logging records for
// one client
connection.
void
*logging_handler (void *arg)
{
SOCKET h =
reinterpret_cast <SOCKET> (arg);
¡¡
// Create a
<SOCK_Stream> object from SOCKET <h>.
SOCK_Stream
stream (h);
for (;;)
{
UINT_32 len; // Ensure a 32-bit
quantity.
char log_record[LOG_RECORD_MAX];
¡¡
// The first <recv_n> reads
the length
// (stored as a 32-bit integer) of
// adjacent logging record. This
code
// handles
"short-<recv>s".
ssize_t n = stream.recv_n
(reinterpret_cast <char *>
(&len),
sizeof len);
¡¡
// Bail out if we¡¯re shutdown or
// errors occur unexpectedly.
if (n <= 0) break;
len = ntohl (len); // Convert
byte-ordering.
if (len > LOG_RECORD_MAX) break;
¡¡
// The second <recv_n> then
reads <len>
// bytes to obtain the actual
record.
// This code handles
"short-<recv>s".
n = stream.recv_n (log_record,
len);
¡¡
// Bail out if we¡¯re shutdown or
// errors occur unexpectedly.
if (n <= 0) break;
¡¡
{
// Constructor of Guard
automatically
// acquires the lock.
Guard<Thread_Mutex> mon
(lock);
¡¡
// Execute following two statements
in a
// critical section to avoid race
conditions
// and scrambled output,
respectively.
++request_count; // Count # of
requests
¡¡
if (write (STDOUT, log_record, len)
== -1)
break;
¡¡
// Destructor of Guard
automatically
// releases the lock, regardless of
// how we exit this block!
}
}
¡¡
// Destructor
of <stream> automatically
// closes down
<h>.
return 0;
}
¡¡
×¢̉âÉÏĂæµÄ´úÂëÊÇÔơÑù½â¾ö2.2.2Ëùʾ´úÂëµÄ¸÷ÖÖÎỀâµÄ¡£ÀưÈ磬SOCK_StreamºÍGuardµÄÎö¹¹Æ÷»á·Ö±đ¹Ø±Ơsocket¾ä±úºÍÊÍ·ÅThread_Mutex£¬¶ø²»¹Ü´úÂë¿éÊÇÔơÑùÍ˳öµÄ¡£Í¬ÑùµØ£¬´Ë´úÂë̉ªÈỬ×̉ÆÖ²ºÍά»¤µĂ¶à£¬̣̉ΪËüĂ»ÓĐʹÓĂƽ̀῭ØÓеÄAPI¡£
¡¡¡¡±¾ÂÛÎÄÖеÄÀư×Ó¾Û½¹ÓÚ²¢·¢ÍøÂç±à³̀¡£µ«ÊÇ£¬°ü×°Íâ¹Ûģʽ̉ѱ»Ó¦Óõ½ÆäËûµÄĐí¶àÁ́Ọ́£¬±ÈÈçGUI¹¹¼ÜºÍÊư¾Ư¿âÀà¿â¡£ÏÂĂæÊÇ°ü×°Íâ¹ÛģʽµÄ̉»Đ©¹ăΪÈËÖªµÄÓ¦ÓĂ£º
¡¡
Microsoft Foundation Class£¨MFC£©£ºMFC̀ṩ̉»×é·â×°´ó¶àÊưµÍ¼¶C Win32 APIµÄ°ü×°Íâ¹Û£¬Ö÷̉ª¼¯ÖĐÓÚ̀ṩʵÏÖMicrosoftÎĵµ/Ä£°å̀åϵ½á¹¹µÄGUI×é¼₫¡£
¡¡
ACE¹¹¼Ü£º2.2.8ĂèÊöµÄ»¥³ầå¡¢Ïß³̀ºÍsocketµÄ°ü×°Íâ¹Û·Ö±đ»ùÓÚACE¹¹¼ÜÖеÄ×é¼₫[7]£ºACE_Thread_Mutex¡¢ACE_Thread_ManagerºÍACE_SOCK*Àà¡£
¡¡
Rogue WaveÀà¿â£ºRogue WaveµÄNet.h++ºÍThreads.h++Àà¿âÔÚĐí¶àOSƽ̀¨ÉÏʵÏÖÁËsocket¡¢Ïß³̀ºÍͬ²½»úÖƵİü×°Íâ¹Û¡£
¡¡
ObjectSpace System<Toolkit>£º¸Ă¹¤¾ß°ü̉²̀ṩÁËsocket¡¢Ïß³̀ºÍͬ²½»úÖƵİü×°Íâ¹Û¡£
¡¡
JavaĐéÄâ»úºÍJava»ù´¡Àà¿â£ºJavaĐéÄâ»ú£¨JVM£©ºÍ¸÷ÖÖJava»ù´¡Àà¿â£¬±ÈÈçAWTºÍSwing£¬̀ṩÁË̉»×é·â×°´ó¶àÊưµÍ¼¶µÄ±¾µØOSϵͳµ÷ÓĂºÍGUI APIµÄ°ü×°Íâ¹Û¡£
¡¡
¡¡¡¡°ü×°Íâ¹Ûģʽ̀ṩ̉ÔÏÂºĂ´¦£º
¡¡
¸üΪ¼̣½àºÍ½¡×³µÄ±à³̀½Ó¿Ú£º°ü×°Íâ¹ÛģʽÔÚ̉»×é¸üΪ¼̣½àµÄOOÀà·½·¨ÖĐ·â×°Đí¶àµÍ¼¶º¯Êư¡£Ơâ¼ơÉÙÁËʹÓĂµÍ¼¶º¯ÊưºÍÊư¾Ư½á¹¹¿ª·¢Ó¦ÓĂµÄ¿ƯÔïĐÔ£¬´Ó¶ø½µµÍÁË·¢Éú±à³̀´íÎóµÄDZÔÚ¿ÉÄÜĐÔ¡£
¡¡
¸ÄÉÆÓ¦ÓĂ¿É̉ÆÖ²ĐԺͿÉά»¤ĐÔ£º°ü×°Íâ¹ÛÀàµÄʵÏÖ¿ÉÓẲÔʹӦÓĂ¿ª·¢ƠßÓëµÍ¼¶º¯ÊưºÍÊư¾Ư½á¹¹µÄ²»¿É̉ÆÖ²µÄ·½ĂæÆÁ±Î¿ªÀ´¡£¶øÇ̉£¬Í¨¹ưÓĂ»ùÓÚÂß¼Éè¼Æʵ̀壨±ÈÈç»ùÀà¡¢×ÓÀ࣬̉Ô¼°ËüĂǵĹØϵ£©µÄÓ¦ÓĂÅäÖĂ²ßÂÔÈ¡´ú»ùÓÚÎïÀíÉè¼Æʵ̀壨±ÈÈçÎļ₫ºÍ#ifdef£©µÄ²ßÂÔ[6]£¬°ü×°Íâ¹Ûģʽ¸ÄÉÆÁËÈí¼₫½á¹¹¡£̉»°ă¶øÑÔ£¬¸ù¾ƯÓ¦ÓõÄÂß¼Éè¼Æ¡¢¶ø²»ÊÇÎïÀíÉè¼ÆÀ´Àí½âºÍά»¤ËüĂÇ̉ª¸üΪÈỬ×̉»Đ©¡£
¡¡
¸ÄÉÆÓ¦ÓõÄÄ£¿éĐÔ¡¢¿É¸´ÓĂĐԺͿÉÅäÖĂĐÔ£ºÍ¨¹ưʹÓĂÏñ¼̀³ĐºÍ²ÎÊư»¯ÀàĐÍƠâÑùµÄOOÓïÑỒØĐÔ£¬°ü×°Íâ¹Ûģʽ´´½¨µÄ¿É¸´ÓĂÀà×é¼₫¿É̉Ổ»ÖÖƠû̀巽ʽ±»¡°²åÈ롱ÆäËû×é¼₫£¬»̣´ÓÖĐ¡°°Î³ö¡±¡£Ïà·´£¬²»ÇóÖúÓÚ´ÖÁ£¶ÈµÄOS¹¤¾ß£¬±ÈÈçÁ´½ÓÆ÷»̣Îļ₫ϵͳ£¬̀æ»»³É×éµÄº¯ÊửªÄÑµĂ¶à¡£
¡¡
°ü×°Íâ¹ÛģʽÓĐ̉ÔÏÂȱµă£º
¡¡
¶îÍâµÄ¼ä½ÓĐÔ£¨Indirection£©£ºÓëÖ±½ÓʹÓĂµÍ¼¶µÄº¯ÊưºÍÊư¾Ư½á¹¹Ïà±È£¬°ü×°Íâ¹Ûģʽ¿ÉÄÜ´øÀ´¶îÍâµÄ¼ä½Ó¡£µ«ÊÇ£¬Ö§³ÖÄÚÁªµÄÓïÑÔ£¬±ÈÈçC++£¬¿É̉ÔÎ̃ĐèÏÔÖøµÄ¿ªÏú¶øʵÏÖ¸Ăģʽ£¬̣̉Ϊ±à̉ëÆ÷¿É̉ÔÄÚÁªÓĂÓÚʵÏÖ°ü×°Íâ¹ÛµÄ·½·¨µ÷ÓĂ¡£
¡¡¡¡°ü×°Íâ¹ÛģʽÓëÍâ¹ÛģʽÊÇÀàËƵÄ[8]¡£Íâ¹ÛģʽµÄ̉âͼÊǼ̣»¯×ÓϵͳµÄ½Ó¿Ú¡£°ü×°Íâ¹ÛģʽµÄ̉âͼỘ¸üΪ¾ß̀壺Ëǜṩ¼̣½à¡¢½¡×³¡¢¿É̉ÆÖ²ºÍ¿Éά»¤µÄÀà½Ó¿Ú£¬·â×°µÍ¼¶µÄº¯ÊưºÍÊư¾Ư½á¹¹£¬±ÈÈç±¾µØOS»¥³ầå¡¢socket¡¢Ïß³̀ºÍGUI CÓïÑÔAPI¡£̉»°ă¶øÑÔ£¬Íâ¹Û½«¸´ÔÓµÄÀà¹Øϵ̉₫²ØÔÚ¸ü¼̣µ¥µÄAPIºóĂ棬¶ø°ü×°Íâ¹Û½«¸´Ôӵĺ¯ÊưºÍÊư¾Ư½á¹¹¹Øϵ̉₫²ØÔÚ¸ü·á¸»µÄÀàAPIºóĂæ¡£
¡¡¡¡Èç¹û¶¯̀¬·ÖÅɱ»ÓĂÓÚʵÏÖ°ü×°Íâ¹Û·½·¨£¬°ü×°Íâ¹Ûģʽ¿ÉʹÓĂÇŽÓģʽ[8]À´ÊµÏÖ£»°ü×°Íâ¹Û·½·¨ÔÚÇŽÓģʽÖĐ°çÑƯ³éÏó£¨Abstraction£©½ÇÉ«¡£
¡¡
¡¡¡¡±¾ÂÛÎÄĂèÊö°ü×°Íâ¹Ûģʽ£¬²¢¸ø³öÁËÏêϸµÄÀư×ÓÑƯʾÔơÑùʹÓĂËü¡£ÔÚ±¾ÂÛÎÄÖĐĂèÊöµÄACE°ü×°Íâ¹Û×é¼₫µÄʵÏÖ¿ÉÔÚACE[7]Èí¼₫·¢²¼ÖĐ×ÔÓÉ»ñÈ¡£¨URL£ºhttp://www.cs.wustl.edu/~schmidt/ACE.html£©¡£¸Ă·¢²¼º¬ÓĐÔÚʥ·̉×˹»ªÊ¢¶Ù´óѧ¿ª·¢µÄÍêƠûµÄC++Ô´Âë¡¢ÎĵµºÍ²âÊÔÀư×ÓÇư¶¯³̀Đ̣¡£Ä¿Ç°ACEƠưÔÚÓĂÓÚĐí¶à¹«Ë¾£¨ÏñBellcore¡¢²¨̉ô¡¢DEC¡¢°®Á¢ĐÅ¡¢¿Â´ï¡¢ÀÊѶ¡¢Ä¦ÍĐẪÀ¡¢SAICºÍÎ÷ĂÅ×Ó£©µÄͨĐÅÈí¼₫ÏîÄ¿ÖĐ¡£
¡¡¡¡¸ĐĐ»Hans Rohnert¡¢Regine Meunier¡¢Michael Stal¡¢Christa Schwanninger¡¢Frank BuschmannºÍBrad Appleton£¬ËûĂǵĴóÁ¿̉â¼û¼«´óµØ¸ÄÉÆÁË°ü×°Íâ¹ÛģʽĂèÊöµÄĐÎʽºÍÄÚÈƯ¡£
¡¡
[1] F.
Buschmann, R. Meunier, H. Rohnert, P. Sommerlad, and M. Stal, Pattern-Oriented
Software Architecture - A System of Patterns. Wiley and Sons, 1996.
[2]
W.R.Stevens,UNIX Network Programming, First Edition. Englewood Cliffs,
NJ: Prentice Hall, 1990.
[3] J.
Eykholt, S. Kleiman, S. Barton, R. Faulkner, A. Shivalin-giah, M. Smith, D.
Stein, J. Voll, M. Weeks, and D. Williams, ¡°Beyond Multiprocessing...
Multithreading the SunOS Ker-nel,¡± in Proceedings of the Summer USENIX
Conference,(San Antonio, Texas), June 1992.
[4]
W.R.Stevens,UNIX Network Programming, Second Edition. Englewood Cliffs,
NJ: Prentice Hall, 1997.
[5] D. C.
Schmidt, ¡°IPC SAP: An Object-Oriented Interface to Interprocess Communication
Services,¡± C++ Report,vol.4, November/December 1992.
[6] J.
Lakos, Large-scale Software Development with C++. Reading, MA:
Addison-Wesley, 1995.
[7] D. C.
Schmidt, ¡°ACE: an Object-Oriented Framework for Developing Distributed
Applications,¡± in Proceedings of the 6th USENIX C++ Technical
Conference, (Cambridge, Mas-sachusetts), USENIX Association, April 1994.
[8] E.
Gamma, R. Helm, R. Johnson, and J. Vlissides, Design Pat-terns: Elements of
Reusable Object-Oriented Software. Read-ing, MA: Addison-Wesley, 1995.
[9] D. C.
Schmidt, ¡°Acceptor and Connector: Design Patterns for Initializing
Communication Services,¡± in Pattern Languages of Program Design (R.
Martin, F. Buschmann, and D. Riehle, eds.), Reading, MA: Addison-Wesley, 1997.
[10] H.
Mueller, ¡°Patterns for Handling Exception Handling Suc-cessfully,¡± C++ Report,
vol. 8, Jan. 1996.
[11] D. C.
Schmidt, T. Harrison, and N. Pryce, ¡°Thread-Specific Storage ¨C An Object
Behavioral Pattern for Accessing per-Thread State Efficiently,¡± C++ Report,vol.9,Novem-ber/December
1997.
[12]
Bjarne Stroustrup, The C++ Programming Language, 3rd Edition.
Addison-Wesley, 1998.
¡¡