Component Allocation
This attribute is taken into account only on CloverETL Cluster environment.
Allocation attribute is common for all ETL components. This attribute is used for cluster graph processing to plan how many instances of the component will be executed and on which cluster nodes. Allocation is our basic concept for parallelization of data processing and inter-cluster-node data routing.
Allocation can be specified in three different ways:
based on number of workers - component will be executed in requested instances on some cluster nodes, which are preferred by CloverETL Cluster
based on reference on a partitioned sandbox - component will be executed on all cluster nodes where the partitioned sandbox has a location
![[Note]](figures/note.png)
Note This allocation type is transparently used as a default for most of data readers and data writers which refers to a file in a partitioned sandbox.
allocation defined by list of cluster node identifiers (a cluster node can be used more times)
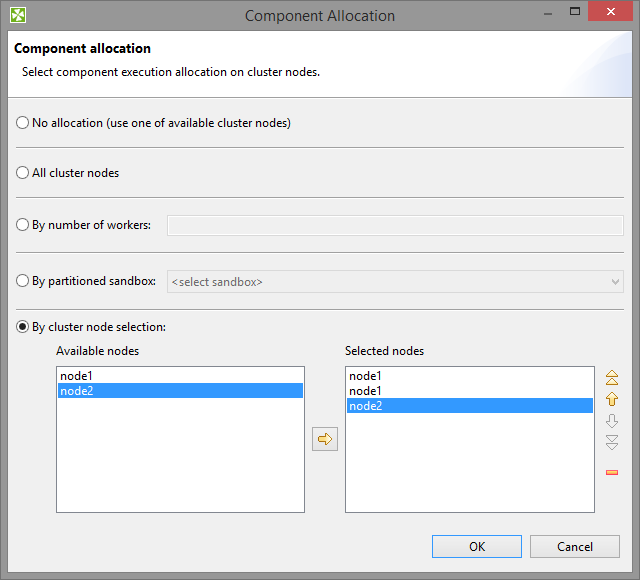
Figure 30.11. Component allocation dialog
Allocation is automatically inherited from neighboring components. Therefore, continuous graph may have only single component with an allocation and this allocation is used by all other components as well. All components of clustered graphs are decorated by number of instances (x3) in which the component will be finally executed - so called allocation cardinality. These annotations are updated on graph save operation. Allocation cardinality derived from neighbors is indicated in gray italic font and the cardinality derived from allocation defined right on the component is printed out with a solid font.

Figure 30.12. Allocation cardinality decorator
Two interconnected components have to have compatible allocations - number of specified workers has to be equal. Only exception from this rule are cluster components, which are dedicated just to change level of parallelism. Parallel Partitioners change single-worker allocation to multi-worker allocation. On the other hand Parallel Gatherers change multi-worker allocation to single-worker allocation.
More details about clustered graph processing are available in CloverETL Server Documentation in Cluster part.