Data Service job editor
Data Service editor contains three tabs (located at the bottom section of the editor):
- Endpoint configuration: configuration of service endpoint, service deployment controls
- Data Service REST Job: logic of the service, implemented as CloverETL graph
- Source: XML source code of the job logic and endpoint configuration
Endpoint Configuration
Contains configuration of the REST endpoint: job name, URL and HTTP methods that this endpoint will respond to.
When connected to Server sandbox, the Endpoint Configuration shows the current status of service deployment. The service will respond to incoming requests only when published.
Data Service jobs can be published directly from Designer if connected to a Server sandbox.
Designer will attempt to redeploy the service whenever the job or the endpoint configuration is changed. The redeploy happens when you save changes in job, however the deployment may fail, if the configuration is invalid.
Due to potential failures, the automatic redeployment of the service is useful mostly during development,
when changes to the jobs are frequent and you want to quickly test the service behavior.
In production environment, it is recommended to upload the service .rjob files to Server sandbox
and deploy the service using CloverETL Server management console instead. This way, you can make sure it has been deployed correctly.
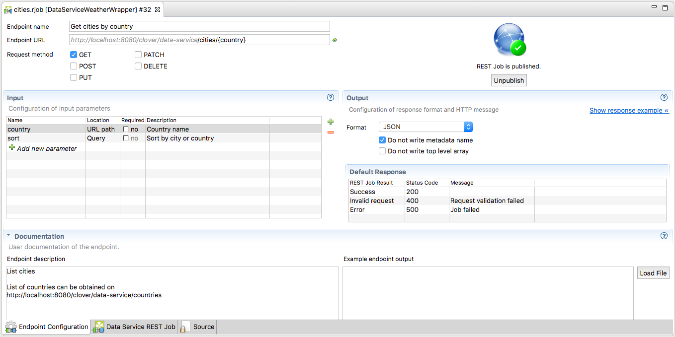
Figure 50.1. Main .rjob editor
| Enpoint configuration | |
| Endpoint name | Title of a job. It should be a human-readable title. Displayed in a documentation and user interface. |
| Endpoint URL |
URL of REST job endpoint where it listens for connections. Grayed part cannot be changed and is automatically derived from CloverETL Server URL. URL may contain a specification of URL path parameters using a {param_name} syntax. |
| Request method |
The list of HTTP methods this endpoint will respond to. If client uses an HTTP method unsupported by the endpoint, they receive a response code: 404 - Not found. |
| Input | |
| Specification of input HTTP parameters. | |
| Name | Name of parameter |
| Location | URL path or Query |
| Required | Data Service job automatically validates the presence of required parameters. If any of the required parameters are missing, the result is Invalid request. |
| Description | Human-readable description of a parameter. Will be displayed in a service documentation. |
| Output | |
| Specification of a response format and HTTP status codes. See the Generating response content section for more details about the output. | |
| Format | One of data formats for automatic serialization (JSON, XML) or “Custom” for user-controlled data serialization. |
| JSON-specific settings |
Additional settings for JSON payloads, affecting the formatting; can be used to simplify the parsing of the response on consumer side for typical payloads: Do not write metadata name causes the JSON formatter to omit the top-level object and only send an anonymous array instead. Use this option when your REST response contains only one type of record (metadata), i.e. when you connected edge to only single port on the response component. Do not write top level array omits the top-level array and generates only single object. Enable this option for services that return only single output record. The graph will fail, if the option is enabled and multiple output records arrive. Both options simplify output and make it easier to parse. |
| Default Response |
HTTP status code and reason phrase. Success is returned after the job finishes, Invalid Request is returned in case of a missing required parameter, Error is returned in case of any other failure. Default success status code is 200. It is recommended to use more specific status codes based on the functionality of your job. For example 201 - Created, 202 - Accepted or 204 - No content. Error responses are described in section Exceptions and Error handling. Note: Using setResponseStatus CTL function in any of the job’s components overrides the default response status code with a code specified in the function. |
| Response example |
Displayed after clicking on the link “Show response example”. Shows an artificial example response and how it is affected when additional JSON formatting options are enabled. |
| Documentation | |
|
Documentation elements do not have any effect on the job functionality. Description and Example endpoint output are included in generated the service documentation to help consumers use your REST endpoint. Example endpoint output is currently just a placeholder and is not reflected in the service documentation. | |
Data Service REST Job logic
Data Service REST Job tab displays the data transformation logic used to implement your service. The logic can use any of the CloverETL data transformation components as well as subgraphs.
LIMITATIONS
- It is not possible to access HTTP request or service response from subgraph, i.e. subgraph can’t be used as a direct ‘reader’ or ‘writer’ in job logic. It can however be used as a ‘transforming’ component anywhere in the flow.
- Similarly, if you use Jobflow components like ExecuteGraph or ExecuteJobflow to launch a separate graph, the HTTP context will not be passed to the spawned child job.