Strategies for CORBA Middleware-Based Load Balancing
Ossama
Othman, Carlos O'Ryan, and Douglas C. Schmidt
University of California, Irvine
The growth of online Internet services during the past decade has increased the demand for scalable and dependable distributed computing systems. E-commerce and online stock trading systems are examples. These systems concurrently serve many clients that transmit a large, often "bursty," number of requests and have stringent quality of service requirements. To protect hardware investments and avoid overcomitting resources, such systems scale incrementally by connecting servers through high-speed networks.
An increasingly popular and cost effective technique to improve networked server performance is load balancing, where hardware or software mechanisms determine which server will execute each client request. Load balancing helps improve system scalability by ensuring that client application requests are distributed and processed equitably across a group of servers. Likewise, it helps improve system dependability by adapting dynamically to system configuration changes that arise from hardware or software failures. Load balancing also helps ensure all resources are used efficiently and that new servers are purchased or cycles are leased only when necessary.
This article describes the strategies and architectures for CORBA load balancing, introduces a CORBA load balancing service we designed, and provides performance benchmarks. A second installment of this article (appearing in the April 2001 issue of DS Online) provides more detail regarding the specific load balancing service we designed using TAO?he ACE (Adaptive Communication Environment) ORB.
Load balancing for distributed systems
Load balancing mechanisms distribute client workload equitably among back-end servers to improve overall system responsiveness. These mechanisms can be provided in any or all of the following layers in a distributed system:
-
Network-based load balancing: IP routers and domain name servers that service a pool of host machines provide this type of load balancing. For example, when a client resolves a hostname, the DNS can assign a different IP address to each request dynamically based on current load conditions. The client then contacts the designated back-end server, unaware that a different server could be selected for its next DNS resolution. Routers can also bind a TCP flow to any back-end server based on the current load conditions and then use that binding for the duration of the flow. High volume Web sites often use network-based load balancing at the network layer (layer 3) and transport layer (layer 4). Layer 3 and 4 load balancing (referred to as switching1) use the IP address/hostname and port, respectively, to determine where to forward packets. Load balancing at these layers is somewhat limited, however, because they do not take into account the content of client requests. Instead, higher-layer mechanisms?he so called layer 5 switching described below?erform load balancing in accordance with the content of requests, such as pathname information within a URL.
-
OS-based load balancing: Distributed OSs provide this type of load balancing through clustering, load sharing (load sharing should not be confused with load balancing; for example, processing resources can be shared among processors but not necessarily balanced), and process migration2 mechanisms. Clustering is a cost effective way to achieve high availability and high performance by combining many commodity computers to improve overall system processing power. Processes can then be distributed transparently among computers in the cluster. Clusters generally employ load sharing and process migration. Process migration mechanisms balance load across processors?r, more generally, across network nodes?y transferring the state of a process between nodes.3 Transferring process states requires significant platform infrastructure support to handle platform differences between nodes. It can also limit applicability to programming languages based on virtual machines, such as Java.
- Middleware-based load balancing: This type of load balancing is performed in middleware, often on a per-session or per-request basis. For example, layer 5 switching1 has become a popular technique to determine which Web server should receive a client request for a particular URL. This strategy can also detect "hot spots"?requently accessed URLs?o that additional resources can be allocated to handle the large number of requests for such URLs.
Advantages of middleware-based load balancing
Network-based and OS-based load balancing architectures suffer from several limitations including lack of flexibility and adaptability. The lack of flexibility arises from the inability to support application-defined metrics at run time when making load balancing decisions. The lack of adaptability occurs due to the absence of load-related feedback from a given set of replicas (duplicate instances of a particular object on a server that is managed by a load balancer), as well as the inability to control if and when a given replica should accept additional requests. Neither network-based nor OS-based load balancing solutions provide as straightforward, portable, and economical a means of adapting load balancing decisions based on application-level request characteristics, such as content and duration, as middleware-based load balancing does.
In contrast, middleware-based load balancing offers several advantages over network- or OS-based load balancing. Middleware-based load balancing architectures?articularly those based on standard CORBA4?ave the following advantages:
-
Middleware-based load balancing can be used in conjunction with specialized network-based and OS-based load balancing mechanisms.
-
It can also be applied on top of commodity-off-the-shelf networks and OSs, which helps reduce cost.
-
In addition, it can provide semantically-rich customization hooks to perform load balancing based on a wide range of application-specific load balancing conditions, such as runtime I/O versus CPU overhead conditions.
This article focuses on middleware-based load balancing supported by CORBA object request brokers. ORB middleware lets clients invoke operations on distributed objects without concern for object location, programming language, OS platform, communication protocols and interconnects, and hardware.5 Moreover, ORBs can determine which client requests to route to which object replicas on which servers.
An example of CORBA middleware-based load balancing
To illustrate the benefits of middleware-based load balancing, consider the following CORBA-based online stock trading system (see Figure 1). A distributed online stock trading system creates sessions through which trading is conducted. This system consists of multiple back-end servers (replicas) that process the session creation requests that clients send over a network. A replica is an object that can perform the same tasks as the original object. Server replicas that perform the same operations can be grouped together into back-end server groups, which are also known as replica groups or object groups.
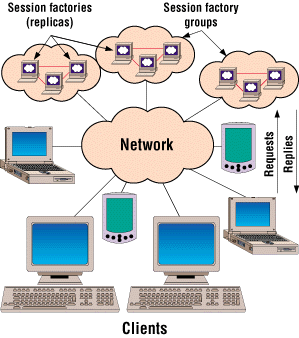
Figure 1. A distributed online stock trading system places heavy demands on resources while requiring instantaneous scalability and 24-7 dependability.
Figure 1 replicates a session factory6 in an effort to reduce the load on any given factory. The load in this case is a combination of the average number of session creation requests per unit time and the total amount of resources employed currently to create sessions at a given location. Loads are then balanced across all replicas in the session factory replica group. The replicas need not reside at the same location.
The sole purpose of session factories is to create stock trading sessions. Therefore, factories need not retain state, (they are stateless). Moreover, in this type of system, client requests arrive dynamically?/FONT>not deterministically?nd the duration of each request many not be known a priori.
These conditions require that the distributed online stock trading system redistribute requests to replicas dynamically. Otherwise, one or more replicas might become overloaded while others will be underutilized. In other words, the system must adapt to changing load conditions. In theory, applying adaptivity in conjunction with multiple back-end servers can
-
increase the system's scalability and dependability;
-
reduce the initial investment when the number of clients is small; and
-
let the system scale up gracefully to handle more clients and processing workload in larger configurations.
In practice, achieving this degree of scalability and dependability requires a sophisticated load balancing service. Ideally, this service should be transparent to existing online stock trading components. Moreover, if incoming requests arrive dynamically, a load balancing service might not benefit from a priori QoS specifications, scheduling, or admission control and must therefore adapt dynamically to changes in runtime conditions.
Strategies and architectures for CORBA load balancing
Although CORBA provides solutions for many distributed system challenges, such as predictability, security, transactions, and fault tolerance, it still lacks standard solutions to tackle other important challenges distributed systems architects and developers face.
Strategies
We classify strategies for designing CORBA load balancing services along the following orthogonal dimensions:
Client binding granularity
A load balancer
binds a client request to a replica each time it makes a load
balancing decision. Specifically, a client's requests are bound to
the replica the load balancer selects. Client binding mechanisms
include modifications to the standard CORBA services, ad hoc
proprietary protocols and interfaces, or use of the LOCATION_FORWARD message in the OMG standard GIOP
protocol. Regardless of the mechanism, we can classify client binding
according to its granularity as follows:
-
Per-session?lient requests will continue to be issued to the same replica for the duration of a session (in the context of CORBA, a session defines the period of time during which a client is connected to a given server for the purpose of invoking remote operations on objects in that server), and is usually defined by the client's lifetime.7
-
Per-request?ach client request will be forwarded to a potentially different replica?hat is, bound to a replica each time a request is invoked.
- On-demand?lient requests can be re-bound to another replica whenever the load balancer deems it necessary. This design forces a client to issue its requests to a replica other than the one to which it currently sends requests.
Balancing policy
When designing a load balancing service, it is important to select an appropriate algorithm that decides which replica will process each incoming request. For example, applications in which all requests generate nearly identical amounts of load can use a simple round-robin algorithm, while applications in which the load generated by each request cannot be predicted in advance might require more advanced algorithms. In general, we can classify load balancing policies into one of two categories:
- Nonadaptive? load balancer can use nonadaptive policies, such as a simple round-robin algorithm or a randomization algorithm, to select which replica will handle a particular request.
- Adaptive? load balancer can use adaptive policies that utilize runtime information, such as the amount of idle CPU available on each back-end server, to select the replica that will handle a particular request.
Architectures for CORBA load balancing
By combining the strategies we just described in various ways, you can create the alternative load balancing architectures we describe below. Figure 2 illustrates three of the primary architectures.

Figure 2. Various architectures for load balancing: (a) nonadaptive per-session, (b) adaptive per-request, and (c) adaptive on-demand.
Nonadaptive per-session architectures
One way to design a CORBA load balancer is make to the load balancer select the target replica when a client?erver session is first established?hat is, when a client obtains an object reference to a CORBA object (namely the replica) and connects to that object, as Figure 2a shows.
Note that the balancing policy in this architecture is nonadaptive, because the client interacts with the same server to which it was directed originally, regardless of that server's load conditions. This architecture is suitable for load balancing policies that implement round-robin or randomized balancing algorithms.
Different clients can be directed to different object replicas either using a middleware activation daemon, such as a CORBA Implementation Repository,8 or a lookup service, such as the CORBA Naming or Trading services. For example, ORBIX9 provides an extension to the CORBA Naming Service that returns references to object replicas in either a random or round-robin order.
Load balancing services based on a per-session client binding architecture can satisfy requirements for application transparency, increased system dependability, minimal overhead, and CORBA interoperability. The primary benefit of per-session client binding is that it incurs less runtime overhead than the alternative architectures we describe in the following sections.
Nonadaptive per-session architectures do not, however, satisfy the requirement to handle dynamic client operation request patterns adaptively. In particular, forwarding is performed only when the client binds to the object?hat is, when it invokes its first request. Therefore, overall system performance might suffer if multiple clients that impose high loads are bound to the same server, even if other servers are less loaded. Unfortunately, nonadaptive per-session architectures have no provisions to reassign their clients to available servers.
Nonadaptive per-request architectures
A nonadaptive per-request architecture shares many characteristics with the nonadaptive per-session architecture. The primary difference is that a client is bound to a replica each time a request is invoked in the nonadaptive per-request architecture, rather than just once during the initial request binding. This architecture has the disadvantage of degrading performance due to increased communication overhead.
Nonadaptive on-demand architectures
Nonadaptive on-demand architectures have the same characteristics as their per-session counterparts. However, nonadaptive on-demand architectures allow reshuffling of client bindings at an arbitrary point in time. Note that run-time information, such as CPU load, is not used to decide when to rebind clients. Instead, clients could be re-bound at regular time intervals, for example.
Adaptive per-session architecture
This architecture is similar to the nonadaptive per-session approach. The primary difference is that an adaptive per-session can use runtime load information to select the replica, thereby alleviating the need to bind new clients to heavily loaded replicas. This strategy only represents a slight improvement, however, because the load generated by clients can change after binding decisions are made. In this situation, the adaptive on-demand architecture offers a clear advantage, because it can respond to dynamic changes in client load.
Adaptive per-request architectures
Figure 2b shows a more adaptive request architecture for CORBA load balancing. This design introduces a front-end server, which is a proxy10 that receives all client requests. In this case, the front-end server is the load balancer. The load balancer selects an appropriate back-end server replica in accordance with its load balancing policy and forwards the request to that replica. The front-end server proxy waits for the replica's reply to arrive and then returns it to the client. Informational messages?alled load advisories?re sent from the load balancer to replicas when attempting to balance loads. These advisories cause the replicas to either accept requests or redirect them back to the load balancer.
The primary benefit of an adaptive request forwarding architecture is its potential for greater scalability and fairness. For example, the front-end server proxy can examine the current load on each replica before selecting the target of each request, which might let it distribute the load more equitably. Hence, this forwarding architecture is suitable for use with adaptive load balancing policies.
Unfortunately, this architecture can also introduce excessive latency and network overhead because a front-end server processes each request. Moreover, it introduces two new network messages:
-
the request from the front-end server to the replica; and
- the corresponding reply from the back-end server (replica) to the front-end server.
Adaptive on-demand architecture
As Figure
2c shows, clients receive an object reference to the load
balancer initially. Using CORBA's standard LOCATION_FORWARD
mechanism, the load balancer can redirect the initial client request
to the appropriate target server replica. CORBA clients will continue
to use the new object reference obtained as part of the LOCATION_FORWARD message to communicate with this
replica directly until they are redirected again or finish their
conversation.
Unlike the nonadaptive architectures described earlier, adaptive load balancers that forward requests on demand can monitor replica load continuously. Using this load information and the policies specified by an application, a load balancer can determine how equitably the load is distributed. When the load becomes unbalanced, the load balancer can communicate with one or more replicas and request them to redirect subsequent clients back to the load balancer. The load balancer will then redirect the client to a less loaded replica.
Using this architecture, the overall distributed object computing system can recover from inequitable client/replica bindings while amortizing the additional network and processing overhead over multiple requests. This strategy satisfies most of the requirements outlined previously. In particular, it requires minimal changes to the application initialization code and no changes to the object implementations (servants) themselves.
The primary drawback with adaptive on-demand architectures is that server replicas must be prepared to receive messages from a load balancer and redirect clients to that load balancer. Although the required changes do not affect application logic, application developers must modify a server's initialization and activation components to respond to the load advisory messages we mentioned.
CORBA adaptive on-demand load balancing using TAO
The CORBA-based load balancing service TAO (for more information on TAO, see the related article highlighted in this issue of DS Online) provides lets distributed applications be load balanced adaptively and efficiently. This service increases overall system throughput by distributing requests across multiple back-end server replicas without increasing round-trip latency substantially or assuming predictable or homogeneous loads. As a result, developers can concentrate on their core application behavior, rather than wrestling with complex infrastructure mechanisms needed to make their application distributed, scalable, and dependable.
We based TAO's load balancing service implementation entirely on standard features in CORBA, which demonstrates that CORBA technology has matured to the point where many higher-level services can be implemented efficiently without requiring extensions to the ORB or its communication protocols. Exploiting the rich set of primitives available in CORBA still requires specialized skills, however, along with the use of somewhat poorly documented features. We believe that further research and documentation of the effective architectures and design patterns used in the implementation of higher-level CORBA services is required to advance the state of the practice and to let application developers make better decisions when designing their systems.
To overcome the drawbacks related to the adaptive on-demand architecture, we applied standard CORBA portable interceptors.11 Likewise, we implemented our load balancing solution based on the patterns12 in the CORBA component model13 to avoid changing application code. In the CCM, a container is responsible for configuring the portable object adapter5 that manages a component. Thus, TAO's adaptive on-demand load balancer just requires enhancing standard CCM containers so they support load balancing and does not require changes to application code. More extensive discussion of our design for an adaptive CORBA load balancing service using TAO will be included in the April 2001 issue of DS Online.
Performance results
For load balancing to improve the overall performance of CORBA-based systems significantly, the load balancing service must incur minimal overhead. This section describes the design and results of several experiments we performed to measure the benefits of TAO's strategy empirically, as well as to demonstrate limitations with the alternative load balancing strategies. The first set of experiments show the overhead incurred by the request forwarding architectures described in this article. The second set of experiments demonstrates how TAO's load balancer can maintain balanced loads dynamically and efficiently, whereas alternative load balancing strategies cannot.
Hardware/software platform
We ran benchmarks using three 733 MHz dual CPU Intel Pentium III workstations, and one 400 MHz quad CPU Intel Pentium II Xeon workstation, all running Debian GNU/Linux "potato" (glibc 2.1), with Linux kernel version 2.2.16. GNU/Linux is an open source OS that supports kernel-level multitasking, multithreading, and symmetric multiprocessing. All workstations are connected through a 100 Mbps Ethernet switch.
We ran all benchmarks in the POSIX real-time thread scheduling class.14 This scheduling class improved the integrity of our results by ensuring the threads created during the experiment were not preempted arbitrarily during their execution.
Benchmark tests
The core
benchmarking software is based on the "Latency"
performance test distributed with the TAO open source software
release. (See $TAO_ROOT/performance-tests/Latency/ in the TAO release for
the source code of this benchmark.) All benchmarks use one of the
following variations of the Latency test:
1. Classic Latency test: In this benchmark, we use high-resolution OS timers to measure the throughput, latency, and jitter of requests made on an instance of a CORBA object that verifies a given integer is prime. Prime number factorization provides a suitable workload for our load balancing tests, because each operation runs for a relatively long time. In addition, it is a stateless service that shields the results from transitional effects that would otherwise occur when transferring state between load balanced stateful replicas.
2. Latency
test with a nonadaptive per-request load balancing strategy: This
variant of the Latency test was designed to
demonstrate the performance and scalability of optimal load balancing
using per-request forwarding as the underlying request forwarding
architecture. This variant added a specialized "forwarding server"
to the test, whose sole purpose was to forward requests to a target
server at the fastest possible rate. No changes were made to the
client.
3. Latency
test with TAO's adaptive on-demand load balancing strategy: This
variant of the Latency test added support for
TAO's adaptive on-demand load balancer to the classic Latency
test. The Latency test client code
remained unchanged, thereby preserving client transparency. This
variant quantified the performance and scalability impact of TAO's
adaptive on-demand load balancer.
Benchmarking the overhead of load balancing mechanisms
These benchmarks measure the degree of end-to-end overhead incurred by adding load balancing to CORBA applications.
The overhead experiments presented in this article compute the throughput, latency, and jitter incurred to communicate between a single-threaded client and a single-threaded server (that is, one replica) using the following four request forwarding architectures:
No load
balancing: To establish a performance baseline without load
balancing, the Latency performance test was
first run between a single-threaded client and a single-threaded
server (one replica) residing on separate workstations. These results
reflect the baseline performance of a TAO client?erver application.
A nonadaptive
per-session client binding architecture: We then configured TAO's
load balancer to use the nonadaptive per-session load balancing
strategy when balancing loads on a Latency
test server. We added the registration code to the Latency
test server implementation, which causes the replica to register
itself with the load balancer so that it could be load balanced. No
changes to the core Latency test implementation
were made. Because the replica sends no feedback to the load
balancer, this benchmark establishes a baseline for the best
performance a load balancer can achieve that utilizes a per-session
client binding granularity.
A nonadaptive
per-request client binding architecture: Next, we added a
specialized nonadaptive per-request forwarding server to the original Latency
test. This server just forwards client requests to an unmodified
backend server. The forwarding server resided on a different machine
than either the client or backend server, which themselves each ran
on separate workstations. Because the forwarding server is
essentially a lightweight load balancer, this benchmark provides a
baseline for the best performance a load balancer can achieve using a
per-request client binding granularity.
An adaptive
on-demand client binding architecture: Finally, we included TAO's
adaptive on-demand client binding granularity in the experiment by
adding the load monitor to the Latency
test server. This enhancement let TAO's load balancer react to the
current load on the Latency test server. TAO's load
balancer, the client, and the server each ran on separate
workstations (three workstations were involved in this benchmark). No
changes were made to the client portion of the Latency
test, nor were any substantial changes made to the core servant
implementation.
The overhead
benchmark results illustrated in Figure 3
quantify the latency imposed by adding load balancing?pecifically
request forwarding?o the Latency performance test. All overhead
benchmarks were run with 200,000 iterations. As shown in this figure,
a nonadaptive per-session approach imposes essentially no latency
overhead to the classic Latency test. In contrast, the
nonadaptive per-request approach more than doubles the average
latency. TAO's adaptive on-demand approach adds little latency. The
slight increase in latency TAO's approach incurred is caused by
-
the additional processing resources the load monitor needs to perform load monitoring; and
-
the resources used when sending periodic load reports to the load balancer?hat is, "push-based" load monitoring.
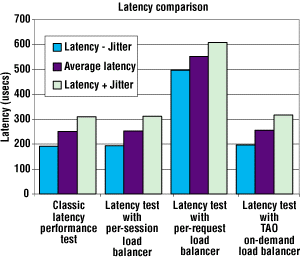
Figure 3. Load balancing latency overhead.
These results clearly show that it is possible to minimize latency overhead, yet still provide adaptive load balancing. As Figure 3 shows, the jitter did not change appreciably between each of the test cases, which illustrates that load balancing hardly affects the time required for client requests to complete.
Figure 4 shows how the average throughput differs between each load balancing strategy. Again, we used only one client and one server for this experiment.
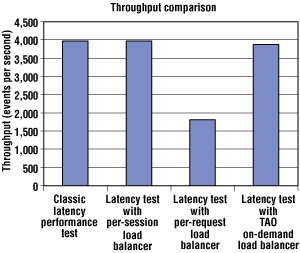
Figure 4. Load balancing throughput overhead.
Not surprisingly, the throughput remained basically unchanged for the nonadaptive per-session approach because only one out of 200,000 requests was forwarded. The remaining requests were all sent to directly to the server?ll requests were running at their maximum speed.
Figure 4 illustrates that throughput decreases dramatically in the per-request strategy because it forwards requests on behalf of the client and forwards replies received from the replica to the client, thereby doubling the communication required to complete a request. This architecture is clearly not suitable for throughput-sensitive applications.
In contrast, the throughput in TAO's load balancing approach only decreased slightly with respect to the case where no load balancing was performed. The slight decrease in throughput can be attributed to the same factors that caused the slight in increase in latency described above?dditional resources the load monitor used and the communication between the load balancer and the load monitor.
Load balancing strategy effectiveness
The following
benchmarks quantify how effective each load balancing strategy is at
maintaining balanced load across a given set of replicas. In all
cases, we used the Latency test from the overhead
benchmarks for the experiments.
The goal of the effectiveness benchmark was to overload certain replicas in a group and then measure how different load balancing strategies handled the imbalanced loads. We hypothesized that loads across replicas should remain imbalanced when using nonadaptive per-session load balancing strategies. Conversely, when using adaptive load balancing strategies, such as TAO's adaptive load balancing strategy, loads across replicas should be balanced shortly after imbalances are detected.
To create this
situation, we registered our Latency test server replicas?ach with a
dedicated CPU?ith TAO's load balancer during each effectiveness
experiment. We then launched eight Latency
test clients. Half the clients issued requests at a higher rate than
the other half. For example, the first client issued requests at a
rate of 10 requests per-second, the second client issued requests at
a rate of five requests per-second, the third at 10 requests
per-second, and so forth. The actual load was not important for this
set of experiments. Instead, it was the relative load on each
replica that was important?n other words, a well-balanced set of
replicas should have relatively similar loads, regardless of the
actual values of the load.
For testing nonadaptive per-session load balancing effectiveness, TAO's load balancer was configured to use its round-robin load balancing strategy. This strategy does not perform any analysis on reported loads but simply forwards client requests to a given replica. The client then continues to issue requests to the same replica over the lifetime of that replica. The load balancer thus applies the nonadaptive per-session strategy?hat is, it is only involved during the initial client request.
Figure
5 illustrates the loads incurred on each of the Latency
server replicas using nonadaptive per-session load balancing. The
results quantify the degree to which loads across replicas become
unbalanced by using this strategy. Because there is no feedback loop
between the replicas and the load balancer, it is not possible to
shift load from highly loaded replicas to less heavily loaded
replicas.

Figure 5. Effectiveness of nonadaptive per-session load balancing.
Two of the replicas (3 and 4) had the same load. The line representing the load on replica 4 obscures the line representing the load on replica 3. In addition, each client issued the same number of iterations. Because some clients issued requests at a faster rate (10 Hz), however, those clients completed their execution before the clients with the lower request rates (5 Hz). This difference in request rate accounts for the sudden drop in load half way before the slower (low load) clients completed their execution.
This test for TAO's adaptive load balancing strategy effectiveness demonstrated the benefits of an adaptive load balancing strategy. Therefore, we increased the load each client imposed and increased the number of iterations from 200,000 to 750,000. Four clients running at 100 Hz and another four running at 50 Hz were started and ended simultaneously.
We increase client request rates to exaggerate load imbalance and to make the load balancing more obvious as it progresses. It was necessary to increase the number of iterations in this experiment because of the higher client request rates. If the number of iterations were capped at the 200,000 used in the overhead experiments, the experiment could have ended before balancing the loads across the replicas.
As Figure 6 illustrates, the loads across all four replicas fluctuated for a short period of time until reaching an equilibrium load of 150 Hz. (The 150 Hz equilibrium load corresponds to one 100 Hz client and one 50 Hz client on each of the four replicas.) The initial load fluctuations result from the load balancer periodically rebinding clients to less loaded replicas. By the time a given rebind completed, the replica load had become imbalanced, at which point the client was re-bound to another replica.

Figure 6. Effectiveness of adaptive on-demand load balancing.
The load balancer required several iterations to balance the loads across the replicas (to stabilize). Had it not been for the dampening built into TAO's adaptive on-demand load balancing strategy, it is likely that replica loads would have oscillated for the duration of the experiment. Dampening prevents the load balancer from basing its decisions on instantaneous replica loads, and forces it to use average loads instead.
It is instructive to compare the results in Figure 6 to the nonadaptive per-session load balancing architecture results in Figure 5. Loads in the nonadaptive approach remained imbalanced. Using the adaptive on-demand approach, the overhead is minimized and loads remained balanced.
After it was obvious that the loads were balanced?quilibrium was reached?e terminated the experiment. This accounts for the uniform drops in load depicted in Figure 6. Contrast this to the nonuniform drops in the load that occurred in the overhead experiments, where clients were allowed to complete all iterations. In both cases, the number of iterations is less important than the fact that the iterations were executed to illustrate the effects of load balancing and to ensure that the overall results were not subject to transient effects, such as periodic execution of operating system tasks.
The actual time required to reach the equilibrium load depends greatly on the load balancing strategy. The example above was based on the minimum dispersion strategy. This strategy minimizes the differences in relative loads between replicas. We could have employed a more sophisticated adaptive load balancing strategy to improve the time to reach equilibrium. Regardless of the complexity of the adaptive load balancing strategy, these results show that adaptive load balancing strategies can maintain balanced loads across a given set of replicas.
As the results of our
benchmarks show, CORBA load balancing services using TAO provide many
advantages and increase system scalability and dependability.
TAO and TAO's load balancing service have been applied to a wide
range of distributed applications, including many telecommunication
systems, aerospace and military systems, online trading systems,
medical systems, and manufacturing process control systems. All the
source code, examples, and documentation for TAO, its load balancing
service, and its other CORBA services is freely available at http://www.cs.wustl.edu/~schmidt/TAO.html.
See next month's DS Online for an in-depth discussion on the
design of TAO's adaptive CORBA load balancing service.
Acknowledgments
Automated Trading Desk, BBN, Cisco, DARPA contract 9701516,
and Siemens MED provided part of the funding for this work.
References
- E. Johnson and ArrowPoint Communications, "A Comparative Analysis of Web Switching Architectures," 1998, http://www.arrowpoint.com/solutions/white_papers/ws_archV6.html (current 6 Mar. 2001)
- G. Coulouris, J. Dollimore, and T. Kindberg, Distributed Systems: Concepts and Design, Pearson Education, Ltd., Harlow, England, 2001.
- F. Douglis and J. Ousterhout, "Process Migration in the Sprite Operating System,"Proc. Intl. Conf. Distributed Computing Systems, IEEE CS Press, Los Alamitos, Calif., 1987, pp. 18?5.
- Object Management Group, The Common Object Request Broker: Architecture and Specification, 2.3 ed., OMG, Needham, Mass., June 1999.
- E. Gamma et al., Design Patterns: Elements of Reusable Object-Oriented Software, Addison-Wesley, Reading, Mass., 1995.
- N. Pryce, "Abstract Session," Pattern Languages of Program Design, Addison-Wesley, Reading, Mass., 1999.
- M. Henning, "Binding, Migration, and Scalability in CORBA," Comm. of the ACM, vol. 41, no. 10, Oct. 1998
- S. Baker, CORBA Distributed Objects using Orbix, Addison-Wesley, Reading, Mass., 1997.
- F. Buschmann et. al., Pattern-Oriented Software Architecture? System of Patterns, John Wiley and Sons, New York, 1996.
- Adiron, LLC, et. al., Portable Interceptor Working Draft?oint Revised Submission, Object Management Group, OMG Document orbos/99-10-01 ed., Oct. 1999.
- D.C. Schmidt et. al., Pattern-Oriented Software Architecture: Patterns for Concurrency and Distributed Objects, Volume 2, John Wiley & Sons, New York, 2000.
- BEA Systems, et. Al., CORBA Component Model Joint Revised Submission, Object Management Group, OMG Document orbos/99-07-01 edl, July 1999.
- S. Khanna et al., "Realtime Scheduling in SunOS 5.0," Proc. USENIX Winter Conf., USENIX Association, 1992, pp. 375?90.
Ossama Othman is a research assistant at the Distributed Object Computing Laboratory in the Department of Electrical and Computer Engineering, University of California at Irvine. He is currently pursuing his PhD studies and research in the field of secure, scalable and high availability CORBA-based middleware. As part of this work, he is one of the core development team members for the open source CORBA ORB, TAO. Contact him at The Department of Electrical and Computer Engineering, 355 Engineering Tower, The University of California at Irvine, Irvine, CA 92697-2625, [email protected].
Carlos O'Ryan is a research assistant at the Distributed Object Computing Laboratory and a graduate student in the Department of Computer Engineering, University of California at Irvine. He participates in the development of TAO, and open source, real-time, high-performance, CORBA-compliant ORB. He obtained a BS in mathematics from the Pontificia Universidad Catolica de Chiled and an MS. in computer science from Washington University. Contact him at The Department of Electrical and Computer Engineering, 355 Engineering Tower, The University of California at Irvine, Irvine, CA 92697-2625, [email protected].
Douglas C. Schmidt is an associate professor in the Department of Electrical and Computer Engineering at the University of California at Irvine. He is currently serving as a program manager at the DARPA Information Technology Office, where he is leading the national effort on distributed object computing middleware research. His research focuses on patterns, optimization principles, and empirical analyses of object-oriented techniques that facilitate the development of high-performance, real-time distributed object computing middleware on parallel processing platforms running over high-speed ATM networks and embedded system interconnects. Contact him at The Department of Electrical and Computer Engineering, 616E Engineering Tower, The University of California at Irvine, Irvine, CA 92697-2625, [email protected].