Integrating NAS, Netscape Extensions and CORBA
Abstract
This paper explains how to integrate a CORBA application into the Netscape
Application Server (NAS). It describes the various ways, how a NAS programmer
can use the features the Common Object Request Broker Architecture (CORBA)
provides for implementing services and for communication between remote
programs. Beginning with AppLogics connecting to a CORBA server, we then
use Netscape extensions to establish a connection to a CORBA server, and
finally show how to convert a CORBA service into a NAS service. While this
paper gives an overview of the background and the integration techniques
themselves and discusses the pros and cons of the solutions, it also provides
links to so-called cookbooks, where the solutions
are explained in detail. Nevertheless we assume that the reader is familiar
with NAS, Netscape extensions and CORBA.
Table of Content
Introduction
A NAS application consists of a set of AppLogics implementing business
logic like accessing a database and generating a report from the resulting
data set. The NAS client, which can be an HTML page in a Web browser, calls
a certain AppLogic in the NAS directory and passes some information to it.
The AppLogic extracts the data from the database using the passed page
information and sends the results of the database query back to the Web
browser. In case of a thin client, which communicates with NAS through
IIOP, the client calls an AppLogic in NAS also passing some parameters
and receives the results in an output parameter list, which it processes
and presents to the user. Figure 1 shows a NAS application represented
by the small orange ovals inside the Netscape Application Server and its
environment represented by the user interface, which is embedded in the
Web browser and supplied by the Web Server or implemented as Thin-Client,
communicating through the Internet InterORB Protocol (IIOP), and the Databases
and Legacy Systems at the other end bearing the data or additional business
logic.
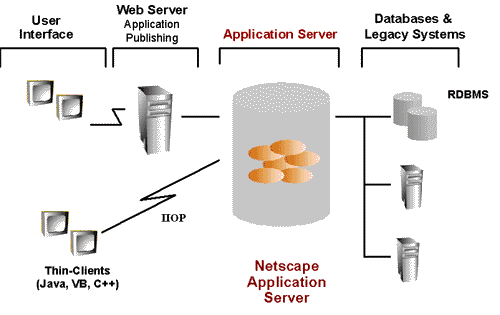 Figure 1: The Netscape Application Server
Figure 1: The Netscape Application Server
Now, assume that you have a CORBA application which provides you with
additional features like a bank, which manages accounts and allows to deposit
and withdraw money from specific accounts. This CORBA application, also
called CORBA server, receives requests from remote clients, so-called CORBA
clients, calls the appropriate methods on its objects and returns the results
to the clients. The CORBA clients contain the business logic, like searching
for certain accounts and making deposits and withdrawals of certain amounts.
Besides sending requests to a specific CORBA application service, Figure
2 shows, that the clients and the bank server also can make use of CORBA
services like for example the Naming Service, Event Service or Transaction
Service.
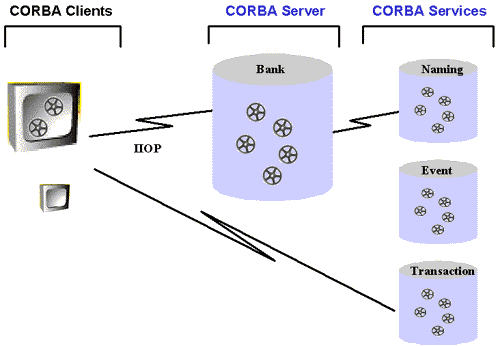 Figure 2: A CORBA Server and Its Clients
Figure 2: A CORBA Server and Its Clients
According to Figure 1, we could think of incorporating
the CORBA server into the Databases & Legacy Systems tier, allowing
to use the functionality of the CORBA server from within NAS. Now, as Figure
3 shows, the Bank service is accessible like the databases and legacy systems.
The NAS client is able to connect to the Bank server through NAS and to
manage the accounts in the Bank.
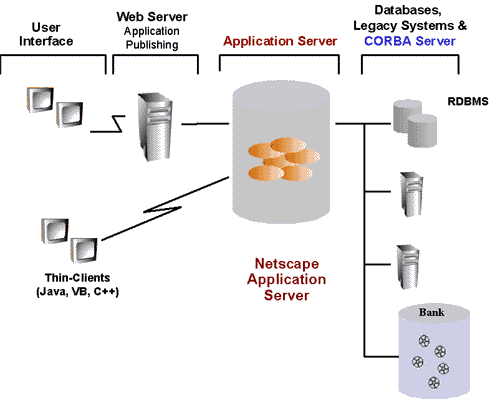 Figure 3: NAS connecting to a CORBA server
Figure 3: NAS connecting to a CORBA server
According to Figure 2, this turns NAS into a
CORBA client, which raises the question, what part of NAS actually the
CORBA client is. Since NAS applications consist of AppLogics, the first
solution will be to connect to the Bank server from within the AppLogics.
In later chapters we will see, that there exists several other possibilities
to implement this connection, we could use the Netscape extensions to provide
the access to the CORBA server and we could also reimplement the Bank server
as NAS service by again using the extension concept. But first let's have
a closer look, how AppLogics can use the functionality of a CORBA server.
Accessing CORBA Servers Using AppLogics
The purpose of a CORBA server is to provide methods, which can be called
remotely from CORBA clients. These methods are described by interfaces
in the Interface Definition Language (IDL), the CORBA client knows and
uses, and are implemented by classes, the CORBA server owns. The Bank server,
for example, which allows the CORBA client to
- open, find and delete an account in the bank and to
- check the balance and make a deposit or a withdrawal,
provides two interfaces, see bank.idl,
where bank contains the methods
-
newAccount, which takes a String
object and returns an account object,
- findAccount, which takes a String
object and returns an account object and
- deleteAccount, which takes an account
object,
and account contains two read-only
attributes name and balance and the methods
- makeLodgement, which takes a Float
object,
- makeWithdrawal, which takes a Float
object,
- get_name, which returns a String
object and
- get_balance, which returns a Float
object.
The Java implementation of the Bank server consists of a set of Java interfaces
and classes, which are partially generated by the IDL compiler and implemented
by the server programmer, see bankDir.
A CORBA client can request a bank
object from the Bank server and call newAccount("John")
on this object, see the small wheels in Figure 4.
This returns an account object
the client can call makeLodgement( 1000)
on. The client code contains any reasonable series of these calls, like
- find all accounts and print the names on the screen,
- open a new account and make a lodgement or
- find an account and make a lodgement or a withdrawal,
depending on the interaction with the user. Thus the CORBA client contains
the business logic, but uses remote objects instead of local objects. The
CORBA server provides an application service, here a Bank service, the
CORBA client is an application using the application service.
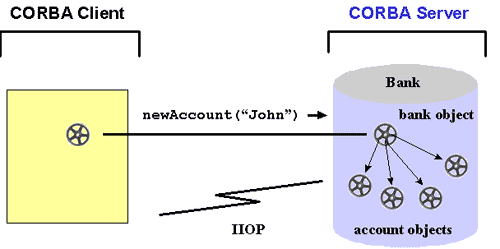 Figure 4: A CORBA client's request
Figure 4: A CORBA client's request
This is a two-tier architecture, a CORBA client and a CORBA server.
Now, when NAS is involved, we got a three-tier architecture, the NAS clients,
the AppLogics in NAS and the CORBA server as shown in Figure
3. The CORBA server remains unchanged. It still provides the interfaces
and their implementations, it remains an application service. The NAS clients
interact with the user, reading the user input, like the request "find
an account" and the name "John" of the owner, call an AppLogic to handle
the request and show the result, e.g. an HTML page showing the balance
of John's account and allowing to make a lodgement or a withdrawal. So
the NAS client is the application. But, what do the AppLogics inbetween?
The Design of the CORBA AppLogics
The AppLogics, the oval balls inside the Application Server in Figure
5, make the calls to the remote objects in the CORBA server, receive
the results from these calls and pass the data to the NAS clients as HTML
pages or as output parameters of the request. The part of the AppLogic,
which delegates the call to the remote object, is like a service - it is
independent of the client application, but depends on the interface of
the application server. It receives a request and has to call the appropriate
method. The other part, which interprets the results of the remote call
and generates the HTML page or the output parameters contains business
logic, so it depends on the client application. The AppLogic is a hybrid,
it is both a client application containing business logic and an application
service.
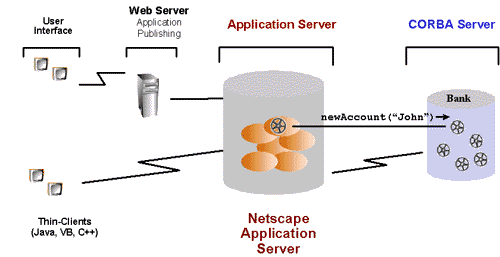 Figure 5: An AppLogic's request
Figure 5: An AppLogic's request
Let's visualize this by an example, shown in Figure
6. The user wants to open a new account for "John". The HTML page allows
to enter the name, "John", and then calls the AppLogic newAccountAppLogic.
NewAccountAppLogic has to forward
the request to the remote bank object. This can be done by calling the
method newAccount of the interface
bank on a bank object passing the
parameter "John" received from the page. The newAccount
returns an account object. Now,
the AppLogic has to generate the next HTML page. This could be a page to
open another new account or one containing the data of the new created
account and allowing to make a lodgement or withdrawal or delete the account.
The next AppLogic then should refer to the new created account object.
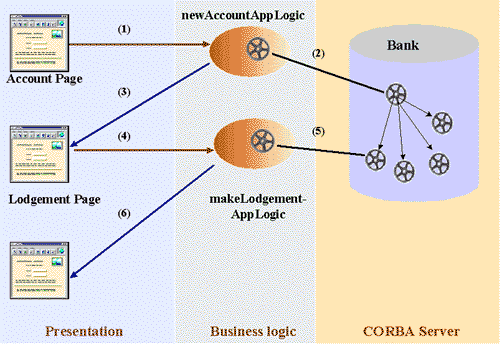 Figure 6: Series of HTML pages and AppLogics
connected to a CORBA server
Figure 6: Series of HTML pages and AppLogics
connected to a CORBA server
Beside the business logic, the AppLogics implement the connection to
the CORBA server, which is the same all CORBA clients do, calling the remote
methods.
Methods are organized in interfaces and these again in modules, whereas
AppLogics are organized in applications, which correspond to modules. When
we associate AppLogics with methods, as we did above with newAccountAppLogic
and newAccount, we miss one level,
the interface level. This could lead to a name collision, if there are two
different methods with the same name in two interfaces of the same module.
To solve the problem we add the name of the interface as prefix to the
AppLogic name and obtain for example bankNewAccountAppLogic
and accountMakeLodgementAppLogic.
Which AppLogics have to be defined?
Since the AppLogics are hybrids between client applications and application
services - they contain business logic and implement the connection to
the CORBA server in delegating the call -, it is difficult to decide, which
AppLogics have to be defined. If they were pure business logic, we would
define them like all the others. If they were pure application service,
for every interface method we would define an AppLogic delegating this
method call. But in this case, we come from both ends and have to meet
the requirements from both sides by defining the AppLogics.
We suggest that you begin with the application service end in defining
an AppLogic for every method of every interface of the CORBA server. The
bank example would lead to seven AppLogics called
bankNewAccountAppLogic,
bankFindAccountAppLogic, bankDeleteAccountAppLogic,
accountMakeLodgementAppLogic, accountMakeWithdrawalAppLogic,
accountGet_nameAppLogic, accountGet_balanceAppLogic.
The application programmer then adds the business logic code to the AppLogics
and decides whether he/she needs additional AppLogics with the same application
service method but different business logic code. It might also happen
that an AppLogic wants to call several methods alternatively like makeLodgement
or makeWithdrawal or has to call
several methods in a series like newAccount
and then makeLodgement. The programmer
then has to implement these straightforward. There is no possible generalization.
Details of the CORBA AppLogic Implementation
Every remote call from an AppLogic to the CORBA server has to be invoked
on an object reference, which is a proxy for the remote object. Without
NAS, as shown in Figure 7, a CORBA client creates the proxies for the remote
objects by binding to a named CORBA object or by receiving an object reference
as a result of a method call. A bank application would first bind to a
bank object like "BankOfAmerica:bankServer",
which returns a bank proxy, e.
g. theBank, and then call newAccount("John")
on this bank proxy, e. g. anAccount
= theBank.newAccount( "John"),
receiving now an account proxy,
which can be used to call the method makeLodgement, e. g. anAccount.makeLodgement(
1000). The client programmer has to manage all these proxies and
to make sure that he/she keeps access to these.
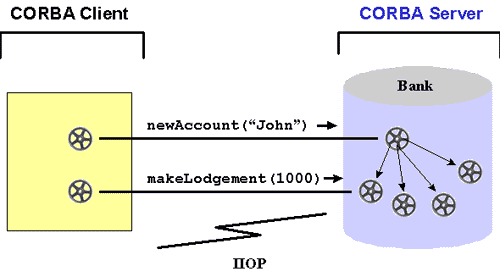 Figure 7: CORBA clients with proxy objects and the CORBA
server with remote objects
Figure 7: CORBA clients with proxy objects and the CORBA
server with remote objects
When the CORBA clients end up, the proxies are lost, unless they became
persistent by storing them in a persistent memory.
Involving NAS, as shown in Figure 8, moves the role of the CORBA client
to the AppLogics. Now, the AppLogics create the proxies and have to keep
access to them. But each AppLogic implements, beside the business logic,
mostly a method of the application service in calling the appropriate method
on the remote object. It then prepares the result page and ends up, possibly
loosing the access to a proxy the method call returned and other AppLogics
would want to access later in the business logic flow. Unlike the "normal"
CORBA client the AppLogics are independent parts, which are combined by
the NAS client to build the whole application.
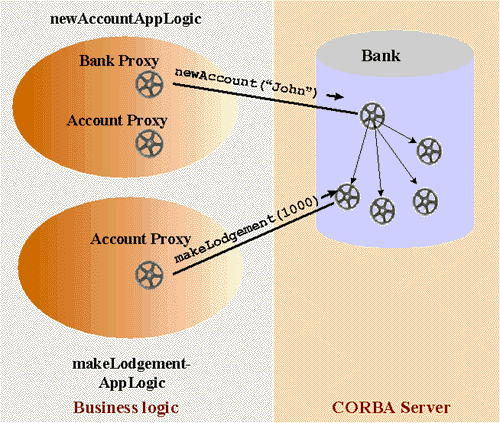 Figure 8: AppLogics with proxy objects and the CORBA server
with remote objects
Figure 8: AppLogics with proxy objects and the CORBA server
with remote objects
When an AppLogic calls a method on a proxy object, it has to have access
to this proxy object, which is probably created by another AppLogic. The
bankNewAccountAppLogic for example
creates a new account resulting in a new account
proxy, which has to be used by the accountMakeLodgmentAppLogic
to call the method makeLodgement.
Obviously, we need a mechanism to pass data between AppLogics.
There are two ways to pass data from one AppLogic to another AppLogic:
-
the session object can store data, which can be shared between AppLogics,
and
-
the NAS client can pass data to an AppLogic it has received prior from
another AppLogic.
We will use the combination of the two approaches, to make sure, that every
required proxy object is available in the appropriate AppLogics.
Using Hidden Values and the Session Object to
Pass Proxies Between AppLogics
A session object, an instance of the Session2
class, which implements the ISession2
interface, is associated with an application and is managed by NAS. It
stores session data determined by the application programmer, which can
be accessed by every AppLogic of the application. The session object can
store a stringified version of the proxies the AppLogics had created when
calling methods on remote objects, actually on proxies for the remote objects.
The programmer then has to manage all proxies in the session object and
has to distinguish them. Assuming that during a session, the user was dealing
with two accounts, John's account and Bill's account, the programmer has
to manage two account proxies,
which he can store in the session object. Since the user of the bank application
decides, which account he/she wants to clear, John's account or Bill's
account, these names or an identification of the accounts have to be passed
to the accountMakeLodgementAppLogic,
which has to retrieve the appropriate account
proxy from the session object and to call the remote makeLodgement
method.
We decided to assign every proxy object a unique identification (UID),
which we store in the session object together with the stringified object
reference. Some UIDs are also passed to the client. In the case of a Web
browser, where we return an HTML page, we store the UIDs of the proxy objects
as hidden values in the page. Thus every page gets back the whole chain
of proxy identifications having been created during a "transaction", beginning
from choosing the bank to searching an account, and it passes this data
to the AppLogic it calls next. A thin client receives the UIDs in its output
parameter list and can manage these in its own memory.
If now the user hits the "Back" button and returns to a page, the associated
account had been deleted, i. e. an AppLogic was responsible to remove the
corresponding UID proxy pair from the session object, the programmer can
implement this case by sending a message to the users screen, saying that
this action is not allowed. The programmer could also use the session object
to hold the "current" proxies, the ones the user is dealing with at the
moment. This would allow him/her to realize, that the user hit the "Back"
button, and to react in a suitable way, like sending a message that this
would be an invalid action.
Evaluation of the AppLogic to CORBA approach
Connecting a CORBA server from within AppLogics is done by defining AppLogics,
which call methods on the CORBA objects, receive the results and prepare
the return pages, resp. the output parameters for the thin client. The
NAS application consisting of a set of HTML pages, resp. a thin client,
and a set of AppLogics has therefore to manage the references to the CORBA
objects between several different address spaces: the client browser, resp.
the thin client, and all the execution processes in NAS and between multiple
NASs involved in the application process. This can be done by storing the
stringified CORBA object references together with a unique identifier in
the session object and by passing the unique identifiers to the pages,
resp. the thin client. This approach allows the programmer to fully control
the application, even hitting the "Back" button, which results in a thread
apart from the normal business logic flow.
The implementation of this kind of NAS application requires to "program"
CORBA in the AppLogics, as it is required for programming every CORBA client.
In addition, the programmer has to design the AppLogics, which all together
build the application, but also break it into several pieces, which makes
the design and the memory management more complicated, than the "normal"
CORBA client programming requires.
Since every NAS application programmer has to deal with CORBA programming
when connecting to a CORBA server, we should consider the possibility to
hide the CORBA specific parts from the AppLogic programmer. This approach
could yield in programming the CORBA parts only once, which would be independent
of the NAS application, and using these parts in every NAS application
connecting to the CORBA server. To implement this approach we need a concept,
which provides application independent access to programs outside NAS.
The Netscape Extensions are the appropriate concept, since they allow to
hide functionality behind an exposed interface and to connect to remote
programs. So, the next step will be to build the connection to a CORBA
server by using extensions.
Connecting to a CORBA Server
through an Extension
A NAS extension accessing a remote program allows to provide the functionality
of the remote program without reimplementing the program, but it also allows
to wrap the calls to the remote system. The NAS application uses the remote
program through the extension, as shown in Figure 9, without getting direct
contact to the remote system, in our case the CORBA server.
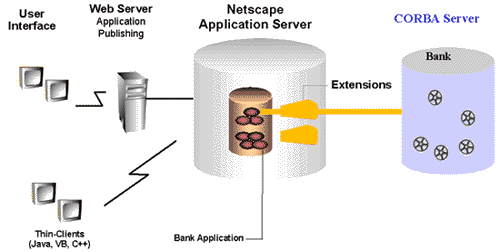 Figure 9: Connecting to a CORBA server through extensions
Figure 9: Connecting to a CORBA server through extensions
Inspecting this new architecture it turns out that we got another tier
inside NAS, instead of having AppLogics connecting directly to the CORBA
server, they pass their requests through the extension. This determines
the task extensions have to fulfill:
-
they don't implement the application service functionality, this is done
by the remote program,
-
they don't implement the client side of the application, this is done by
the AppLogics and the NAS clients,
-
they only provide the connection by passing the requests from the AppLogics
to the remote program and hiding some CORBA programming.
Now the responsibility of extensions is determined, we can discuss their
design and implementation.
Design and Implementation of the CORBA
Extension
Extensions represent a layer or tier between the AppLogics and the remote
program. They expose the same interfaces as the remote program and implement
them by forwarding the request from the AppLogics to the remote program.
The extension classes doing the forwarding are part of the CORBA client
and call methods on remote objects. As we know, method calls on remote
objects are always done through proxies. These proxies are objects of proxy
classes generated by the CORBA IDL compiler. So we are faced with two kinds
of classes, extension classes and proxy classes, which we have to combine.
A common approach is to use delegation, which is implemented by defining
an association between every pair of extension and proxy classes.
Figure 10 shows, that two objects, an extension object and a proxy object
linked to it maintain the connection between an AppLogic and the CORBA
server.
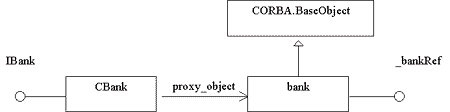
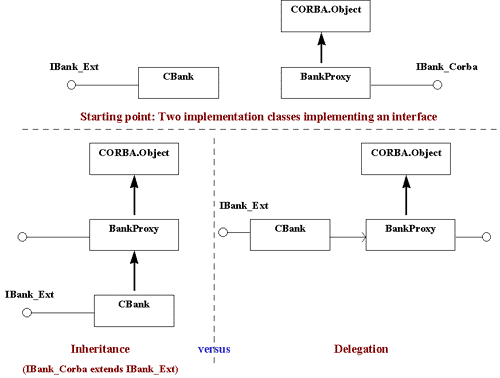 Figure 10: Extension using delegation
Figure 10: Extension using delegation
Using the delegation mechanism as shown in Figure 11 means, that every
implementation class is associated to a proxy class and implements every
method the proxy class defines. The association can be implemented by an
attribute, e. g. proxy_object. Each method will be implemented by calling
the corresponding method on the linked proxy object. You always have to
maintain the pairs, each time a proxy object is returned by a method,
an instance of an implementation class has to be created and linked to
this proxy object. CORBA programmer know how to handle this when applying
the Tie approach.
Figure 11: Delegation between extension and proxy classes
From our discussion in Accessing CORBA
Servers Using AppLogics we know, that the AppLogics, now referring
to extension objects, loose these, when they end up. If, for example, the
newAccount AppLogic ends, it cuts
its reference to its account extension
object. The next called makeLodgement
AppLogic won't get the access to this account
extension object. This happens, because we don't manage the object references.
We got two possibilities to redress,
-
we use object pooling, to collect the object references or
-
we let the manager class object manage the object references.
We consider object pooling not the proper technique for managing the object
references, because it is designed to manage a few objects, which are very
expensive in constructing, like a connection to a database. But we consider
the account objects, which could
be thousand, not expensive to construct. Nevertheless, we can always manage
them by the manager class through assigning and storing UIDs. The manager
class object collects the extension objects and every extension object
keeps the reference to one proxy object. The AppLogics receive the UIDs
and pass them through the HTML pages to other AppLogics, which bind to
the manager class object and ask for the extension objects. Instead of
collecting the extension objects, the manager class object could also collect
the proxy objects and had to create an extension object and to link it
to the proxy object when asked for the extension object. You can deal with
the extension objects linked to the proxy objects in the same way as you
do with the Tie objects linked to the objects of the implementation classes
using CORBA.
If the extension objects have to be shared between different NAS or
multiple KJS/KCSs in one NAS, we have to store them in the session
object as we did with the proxy object in Accessing
CORBA Servers Using AppLogics. Since in our case the extension objects
are simple objects, they only refer to a proxy object, which can be stringified,
we can write them to a string by ourselves. This requires every extension
class to provide an externalization and an internalization method. The
externalization method returns a string, which consists of the name of
the class and the stringified object reference it refers to.
When an AppLogic wants to stringify an extension object, it calls externalize
on the object and receives the string. When an AppLogic wants to get back
an extension object, it has to pass the string to the manager class object
of the extension, which extracts the name of the class and creates an object,
which has to receive the reference to the approriate proxy object. The
latter is implemented by the internalization method of the class.
These methods would allow us to convert all objects created by
an extension in a stringified form and to store them for distribution.
If the programmer chooses to collect only the proxy objects and to create
the corresponding extension objects, every time these are retrieved, he/she
only has to store the proxy objects, which we already did in Accessing
CORBA Servers Using AppLogics.
When we implement the delegation approach, we face the problems, that
we have to match the Netscape and the CORBA interfaces, because we want
to provide most of the functionality of the CORBA server through the extension.
We also might have to deal with calls to CORBAservices, like the Naming
Service. The following is a complete list of problems, we have to solve:
-
The extension interfaces are defined in Netscape IDL (N-IDL). The interfaces
of the CORBA server are defined in an IDL, specified by the OMG, let's
call it CORBA-IDL . The differences are listed in Appendix
A. To name just a few:
-
In N-IDL you cannot specify the return type of a method, it is always HRESULT
(= int).
-
In N-IDL (to Java) you are restricted to one output parameter. The Java
language mapping of CORBA-IDL defines so-called holder classes for every
interface to store the object reference. These are used for output parameters.
-
N-IDL doesn't know exceptions, CORBA-IDL allows to specify an interface
to raise an exception.
The first step in developing the extension has to map the C-IDL to the
N-IDL, where the latter is less expressive.
-
The extension has to present the same interface the AppLogic knows from
the CORBA server and only to forward the requests to the CORBA server.
Which ends up in duplicating the interface of the CORBA server plus the
interface of the Object Request Broker, which is used by CORBA clients,
plus the interfaces of the CORBA Services as interfaces of the extension
and to implement the methods of the helper classes. See Appendix
B for a list of all interfaces, which had to be provided.
-
In addition to the interfaces the CORBA server provides for its clients,
the extension has to define a manager class that holds one object by which
the AppLogic binds to the extension. This has to be different from the
CORBA server "main class" like the bank
class, because the CORBA client might bind to many objects of this class,
whereas the extension doesn't allow binding to many objects. Since all
extension classes implement interfaces, an interface for the manager class
has to be defined.
-
Extensions don't share their objects with other servers in a NAS and not
between different NASs. To share the objects of an extension, the extension
has to distribute the objects through the Session and State Management
service.
Let's summarize this aspects.
Evaluation of the Extension Approach
Implementing the connection to a CORBA server can be done by reimplementing
the interfaces of the CORBA server in the extension classes, which delegate
the method calls to the linked proxy objects. The proxy objects can be
managed by the manager class object, which stores the UID and the object
reference and passes the UIDs to the AppLogics, or the UID together with
the stringified object references are stored in the session object.
The delegation approach is the selected approach, when you want to hide
CORBA specifics. It allows you to wrap the access and all calls to the
CORBA server. So you can decide, which CORBA features you want to expose
and which you want to hide.
All solutions, we considered up to this point, keep the CORBA server
outside NAS, and transform a NAS application into a CORBA client. There
is still one remaining combination of NAS and CORBA for discussion: the
service, which was originally provided by the CORBA server, implemented
as NAS service.
The CORBA server inside NAS
Since CORBA servers host services - a set of objects, which receive methods
calls, execute them and return the results - it should be obvious to implement
a CORBA service inside NAS as a NAS service. If we want to provide the
CORBA bank server inside NAS, we have to implement it as NAS service. There
are already a few pre-built NAS services like the Session service, the
State Management service, the Data Access service and the Transaction Management
service.
A NAS service consists of a set of interfaces it exposes to the AppLogics.
The Session service for example provides the ISession2
interface with several methods like getSessionData
or setSessionData. This interface
is implemented by a class, in this case the Session2
class. To build your own service you have to define the interfaces and
to implement these by classes. As NAS service, the Bank service would provide
the same functionality as the CORBA service, it would let the client bind
to a bank, open or find accounts, make lodgements or withdrawals and delete
accounts. It would expose the same interfaces bank
and account and had to implement
these by a set of classes.
When implementing a service, you provide the interfaces of the service,
the implementation of the interface methods and the attributes of the implementation
objects. You also have to provide a mechanism, which keeps your service
objects referable. All this is done in a CORBA server in connection with
an Object Request Broker (ORB). Now, assuming you implemented your service
in a CORBA server, how can you integrate this service in NAS? NAS only
knows system-defined services like Data Access Service etc. and AppLogics.
The Applogics are small programs, which get started in a thread of a KJS/KCS
and end up at the end of the execute
method loosing all their objects. They are not the proper concept to implement
a service.
The proper concept to provide a service is given by the Netscape extensions.
They allow to expose interfaces, to implement the interfaces by classes,
to create an object, when NAS is started, and to hand over this object
to an AppLogic, which then calls the methods on the object. So both, CORBA
server and Netscape extensions, do similar things, however the implementation
is different. How can the application service of a CORBA server be provided
by an extension?
Reimplementing a CORBA Server as an Extension
If you own the source code of the implementation classes of the CORBA service,
you can adapt this code to define a Netscape extension of NAS. The programming
concepts are very similar, although the underlying mechanisms are different.
Table 1 shows the common concepts:
| Netscape Extension |
CORBA Server |
| Define the interfaces in N-IDL. |
Define the interfaces in the CORBA Interface Definition Language (C-IDL). |
| Let the N-IDL compiler generate the method stubs of the implementation classes. |
Let the C-IDL compiler generate the method stubs for the CORBA client and the method skeletons for the CORBA server. |
| Implement the methods of the implementation classes by filling the stubs with code. |
Implement the methods of the implementation classes by subclassing the skeletons (BOA approach), or define your implementation
classes and implement the methods using Tie objects (Tie approach). |
| The N-IDL compiler also generates an accessor class to let the AppLogics bind to the only one manager class object. |
Implement the server main class, which will create one or several objects, the clients can bind to. The main method will also
make calls to the Object Request Broker (ORB), like obj_is_ready
or impl_is_ready. |
Table 1: Comparison of Netscape extension and CORBA server
Without addressing several problems, which we will discuss later, the
following steps show how to transform a CORBA server into a NAS service:
- From C-IDL interfaces produce N-IDL interfaces.
- Let the N-IDL compiler generate the interface files and the implementation classes with empty stubs.
- To transform the CORBA server implementation classes to extension classes,
- exchange the interface names for the extension interface names, exchange the implementation class names for the extension class names,
- if the implementation classes use the Tie approach, delete the creation of Tie objects, always pass and return an object of the extension class instead of the Tie class,
- strip the methods off any call to the ORB.
- From every CORBA server implementation class take the code of every method body and fill it into the corresponding method stub of the appropriate extension class.
Now, write your AppLogics, which use the new service. They should be similiar
to the Applogics we developed in Accessing
a CORBA Server by Using AppLogics, besides that they don't connect
to a CORBA server but a NAS service. So, every of these AppLogics has to
get access to the extension objects, which is normally done through the
"entry point", the accessor object. But this means, that an AppLogic, which
wants to make a deposit in an account, has first to find the appropriate
account object, which then it calls
makeLodgement on. To find an account
object the findAccount method is
called, which is also called by the corresponding findAccount
AppLogic. Do the AppLogics have to repeat calls other AppLogics already
do? It looks like, if the AppLogics aren't able to store references to
extension objects.
Unlike the CORBA object references, the extension objects don't have
an object identification. So the only reasonable solution would be to implement
an object identification and locator in the extension, preferable
the extension manager class. This locator creates a unique identifier for
every object, which is accessed by an AppLogic and stores this identifier
together with the reference of the object. Here, we rebuild the functionality
of the Basic Object Adapter (BOA) of CORBA! Then the AppLogics are able
to store and pass the identifier between themselves. When an AppLogic wants
to make a lodgement in an account, it first has to transform the object
identifier into a reference to an extension object, which it also has to
do for all objects, it wants to send as parameter with a method. This can
be provided by the manager class object, which stores all identifiers and
references to extension objects.
What remains is the question, who induces the manager class object to
create and store an object identifier. Without locator, the method newAccount
of the bank class creates an account
object and returns it to the calling AppLogic. With the locator the newAccount
method has to ask the manager class object to generate an identifier, which
it then returns to the AppLogic. From this, we can conclude, that every
method, which returns objects has instead to return an object identifier
generated by the locator.
Evaluation of Reimplementing the CORBA Server
Reimplementing a CORBA server as NAS service makes you independent of CORBA
or any other middleware, but you have to solve the following problems:
- There is no specification of N-IDL.
The Netscape Extension Builder (NEB) Toolkit generates the IDL code.
- A CORBA implementation is usually based on interfaces defined in CORBA-IDL.
The CORBA-IDL compiler generates so-called skeletons, which will be extended
by the user-defined implementation classes.
Problem: N-IDL and CORBA-IDL are different. The differences are listed
in the Appendix A.To name just a few:
- In N-IDL you cannot specify the return type of a method, it is always HRESULT (= int).
- In N-IDL (to Java) you are restricted to one output parameter. The Java
language mapping of CORBA-IDL defines so-called holder classes for every
interface to store the object reference. These are used for output parameters.
- N-IDL doesn't know exceptions, CORBA-IDL allows to specify an interface to raise an exception.
- CORBA servers consist of a main class, which has to create the server objects
the CORBA clients bind to. These could be several with different names
and also objects of different classes. The client can bind to any or to
a specific by using the name. Extensions allow only one manager class of
which only one object is automatically created and returned by the accessor class.
- Implement an object identificator and locator system.
- Extensions don't share their objects with other servers in a NAS and not
between different NAS. To share the objects of an extension, the extension
has to distribute the objects through the Session and State Management
service. But these accept only GXVAL objects, i. e. strings, integers and
BLOBs. If your extension objects are not of this kind you have to externalize
and internalize their state. This could be a huge effort.
- The methods of the CORBA implementation classes could use a CORBA service,
like the naming service. Since ou don't own the source code of the CORBA
services, you cannot integrate the CORBA services into NAS as NAS services.
You have to leave the CORBA services outside NAS and use the same mechanism
of calling from within an extension to a CORBA service as we did from within
AppLogics, see Accessing CORBA Servers Using AppLogics.
The only way to place the CORBA service inside NAS is by reemplementing
the CORBA server as an extension. But, if you don't own the source code
of the implementation, it is not possible. Since extensions are part of
a KJS, which is a process that runs a method called on an extension object
in a thread, and since CORBA server are processes, there is no way to put
a CORBA server as a whole into a KJS or NAS.
Conclusion
In this paper we presented three approaches to combine NAS and CORBA. The
first one accesses the CORBA server from within AppLogics. The development
of this solution also served us to clarify how to keep the references to
CORBA objects referable for all AppLogics during the execution of an NAS
application. We store the stringified object references together with a
unique identifier in the session object and pass the unique identifiers
to the HTML pages or thin clients. This enables the NAS application to
behave like a "normal" CORBA client, which retrieves object references
from the CORBA server and keeps them referable in its memory as long as
they are needed. On the other hand, the AppLogic programmer has to "programm"
CORBA, we cannot relieve him/her from calling bind
or narrow, but he/she has also
access to every CORBA feature even the CORBAservices.
The second approach, where the CORBA server is accessed through an extension,
succeeds in hiding the CORBA specific calls from the AppLogic programmer.
He/she then has to deal exclusively with the extension, i. e. has to get
access to the extension. The extension objects delegate the method calls
to the CORBA server. But, in implementing the extension we have to match
the interfaces defined in CORBA IDL to interfaces defined in Netscape IDL.
Every CORBA IDL construct, which is not supported by Netscape IDL has to
be simulated, see the Writing Extensions
Connecting to a CORBA Server for more information. In case we want
to provide additional CORBA features, like methods belonging to the ORB
interface, access methods to the interface repository, the dynamic invocation
interface or the CORBAservices, we have to define them as extension interfaces.
The third approach reimplements the CORBA server as NAS server, which
is only possible, if you own the source code. The advantage of this approach
is the independence of CORBA and the release of "programming" CORBA, while
you also give up all the benefits of CORBA.
For the latest technical information on Sun-Netscape Alliance products, go to: http://developer.iplanet.com
For more Internet development resources, try Netscape TechSearch.
Copyright © 1999 Netscape Communications Corporation.
This site powered by: Netscape Enterprise Server and Netscape Compass Server.