As mentioned before, Web Services are the technology of choice for Internet-based applications with loosely coupled clients and servers. That makes them the natural choice for building the next generation of grid-based applications. However, remember Web Services do have certain limitations. In fact, plain Web Services (as currently specified by the W3C) wouldn't be very helpful for building a grid application. Enter Grid Services, which are basically Web Services with improved characteristics and services.
We'll take a brief look at the main improvements introduced in OGSI:
Stateful and potentially transient services
Service Data
Notifications
Service Groups
portType extension
Lifecycle management
GSH & GSR
This first feature is probably one of the most important improvement with regard to Web Services. Let's see what this feature is all about by using a simple example. Imagine your organization has a really big cluster capable of performing the most mind-boggling calculations. However, this cluster is located in your central headquarters in Chicago, and you need employees from your offices in New York, Los Angeles, and Seattle to conveniently use the cluster's computational power. This looks like a perfect scenario for a Web Service!
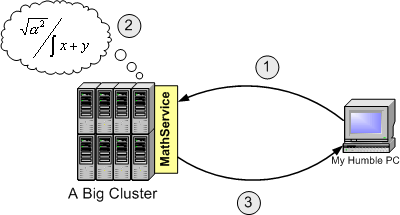
We could implement a Math Web Service called MathService which offered operations such as SolveReallyBigSystem(), SolveFermatsLastTheorem(), etc. At first, we would be able to perform typical Web Service invocations:
Invoke MathService, asking it to perform a certain operation.
MathService will instruct the cluster to perform that operation.
MathService will return the result of the operation.
So far, so good. However, let's be a bit more realistic. If you're going to access a remote cluster to perform complex mathematical operations, you probably won't perform a single operation, but rather a chain of operations, which will all be related to each other. However, Web Services are stateless. "Stateless" means that Web Services can't remember what you've done from one invocation to another. If we wanted to perform a chain of operations, we would have to get the result of one operation and send it as a parameter to the next operation.
Furthermore, even if we solved the stateless problem (some Web Services containers actually work around this problem), Web Services are still non-transient, which means that they outlive all their clients. Web Services are also referred to as persistent (as opposed to transient; this doesn't mean 'persistent' in the sense of 'persisting data to secondary storage, a hard drive, etc.') because their lifetime is bound to the Web Services container (a Web Service is available from the moment the server is started, and doesn't go down until the server is stopped) In any case, this implies that, after one client is done using a Web Service, all the information the Web Service is remembering could be accessed by the next clients. In fact, while one client is using the Web Service, another client could access the Web Service and potentially mess up the first client's operations. This certainly isn't a very elegant solution!
Grid Services solve both problems by allowing programmers to use a factory/instance approach to Web Services. Instead of having one big stateless MathService shared by all users, we could have a central MathService factory in charge of maintaining a bunch of MathService instances. When a client wants to invoke a MathService operation, it will talk to the instance, not to the factory. When a client needs a new instance to be created (or destroyed) it will talk to the factory.
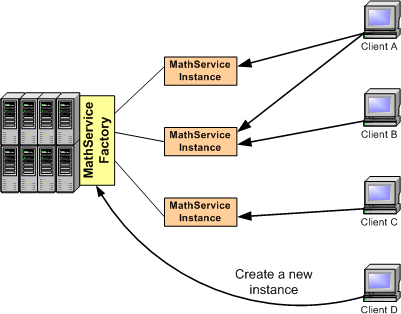
This diagram shows how there doesn't necessarily have to be one instance per client. One instance could be shared by two clients, and one client could have access to two instances. These instances are transient, because they have a limited lifetime which isn't bound to the lifetime of the Grid Services' container. In other words, we can create and destroy instances at will whenever we need them (instead of having one persistent service permanently available). The actual lifecycle of an instance can vary from application to application. Usually, we'll want instances to live only as long as a client has any use for them. This way, every client has its own personal instance to work with. However, there are other scenarios where we might want an instance to be shared by several users, and to self-destruct after no clients have accessed it for a certain time.
Finally, notice how Grid Services are potentially transient. This means that not all Grid Services have to use (by definition) a factory/instance approach. A Grid Service can be persistent, just like a normal Web Service. Choosing between persistent Grid Services or factory/instance Grid Services depends entirely on the requirements of your application.
Since we are now dealing with services that have non-trivial lifecycles (if we use a factory/instance model, instances can be created and destroyed at any time), lifecycle management mechanisms are provided in Grid Services. OGSI itself only supplies some very basic mechanisms, which are complemented by additional mechanisms in GT3, as we'll see later on.
Service Data, along with statefulness and transience, ranks very high in the list of 'the best things Grid Services add to Web Services'. In fact, Service Data is my personal favorite extension!
Service Data allows us to easily include a set of structured data to any service, which can then be accessed directly through its interface. Since plain Web Services only allow operations to be included in the WSDL interface, you could think of Service Data as an extension that allows us to include not only operations in the WSDL interface, but also attributes. However, Service Data is much more than simple attributes, since we can easily include any type of data (fundamental types, classes, arrays, etc.)
In general, the Service Data we include in a service will fall into one of two categories:
State information: Provides information on the current state of the service, such as operation results, intermediate results, runtime information, etc.
Service metadata: Information on the service itself, such as system data, supported interfaces, cost of using the service, etc.
If you're not too sure what service data is, don't worry: a much more detailed explanation will be given when we start coding Grid Services with service data.
A Grid Service can be configured to be a notification source, and certain clients to be notification sinks (or subscribers). This means that if a change occurs in the Grid Service, that change is notified to all the subscribers (not all changes are notified, only the ones the Grid Services programmer wants to). In the MathService example, suppose that all the clients perform certain calculations using a variable called InterestingCoefficient which is stored in the Grid Service. Any of the clients can modify that value to improve the overall calculation. However, all clients must be notified of that change when it occurs. We can achieve this easily with the Grid Services notifications.
Later on, we'll see that notifications in OGSI are very closely related to service data.
Any service can be configured to act as a service group which aggregates other services. We can easily perform operations such as 'add new service to group', 'remove this service from group', and (more importantly) 'find a service in the group that meets condition FOOBAR'. Although the service group functionality included in OGSI is pretty simple, it is nonetheless the base of more powerful directory services (such as GT3's IndexService) which allow us to group different services together and access them through a single point of entry (the service group).
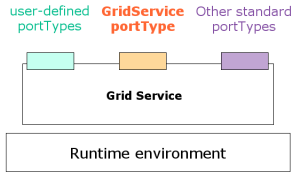
In the previous page we saw that a Web Service exposes its interface (the operations it can perform) through a WSDL document. The interface is usually called portType (due to a WSDL tag of the same name). A normal Web Service can have only one portType. Grid Services, on the other hand, support portType extension, which means we can define a portType as an extension of a previously existing portType.
For example, the OGSI specification mandates that all Grid Services must extend from a standard portType called GridService:
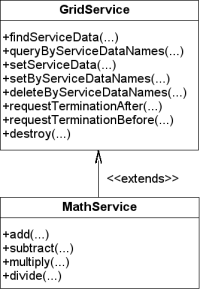
Thanks to portType extension, we can simply define our own portType as an extension of GridService. With plain web services, we would need to include the declaration of all the operations (including the GridService operations) in a single portType.
Besides the standard GridService portType, OGSI defines a lot of other standard portTypes we can extend from to add functionality to our grid service. For example, there is a NotificationSource portType which we can extend from if we want our service to act as a notification source (we'll take a close look at this portType and other standard portTypes when we start working with code). Notice how NotificationSource itself extends from GridService:
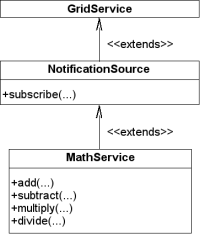
In general, we'll find that grid services can have three types of portTypes:
In the previous page we saw that Web Services are addressed with URIs. Since Grid Service are Web Services, they are also addressed with URIs. However, OGSI introduces a more powerful addressing scheme.
A "Grid Service URI" is called the Grid Service Handle, or simply GSH. Each GSH must be unique. There cannot be two Grid Services with the same GSH. The only problem with the GSH is that it tells me where the Grid Service is, but doesn't give me any information on how to communicate with the Grid Service (what methods it has, what kind of messages it accepts/receives, etc.). To do this, we need the Grid Service Reference, or GSR. In theory, the GSR can take many different forms, but since we will usually use SOAP to communicate with a Grid Service, the GSR will be a WSDL file (remember that WSDL describes a Web Service: what methods it has, etc.). In fact, in this tutorial we will only handle WSDL as a GSR format.