Notifications are nothing new. It's a very popular software design pattern, although you might know it with a different name: Observer/Observable, Model-View-Controller, etc. Let's suppose that our software had several distinct parts (e.g. a GUI and the application logic, a client and a server, etc.) and that one of the parts of the software needs to be aware of the changes that happen in one of the other parts. For example, the GUI might need to know when a value is changed in a database, so that the new value is immediately displayed to the user. Taking this to the client/server world is easy: suppose a client needs to know when the server reaches a certain state, so the client can make a set of specific calls to the server.
The most crude approach to keep the client informed is a polling approach. The client periodically polls the server (asks if there are any changes). For example, let's suppose we have a server where clients can sign up for a special newsletter. The newsletter is sent as soon as a certain number of clients have signed up, but the newsletter e-mails are sent by another server. This other server needs to know when enough clients have signed up, so it can send the e-mails. The first server is called the observable part, and the second server is called the observer part. The polling approach would go like this:
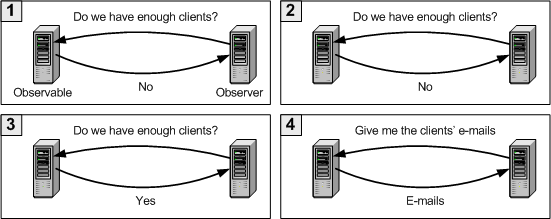
The observer asks the observable if there are any changes. The observable replies "No", so the observer waits a while before making another call.
Once again, the observer asks the observable if there are any changes. The observable replies "No", so the observer waits a while before making another call.
Once again, the observer asks the observable if there are any changes. This time the observable replies "Yes".
Now that the data is available, the observer asks the observable for the e-mails.
This approach isn't very efficient, specially if you consider the following:
If the time between calls is very small, the amount of network traffic and CPU use increases.
There can be more than one observer. If we have dozens of observers, the observable could get saturated with calls asking it if there are any changes.
The answer to this problem is actually terribly simple (and common sense). Instead of periodically asking the observable if there are any changes, we make an initial call asking the observable to notify whenever there are any changes. The observable will contact us as soon as a change occurs, and then we can act accordingly. This is the notification approach.
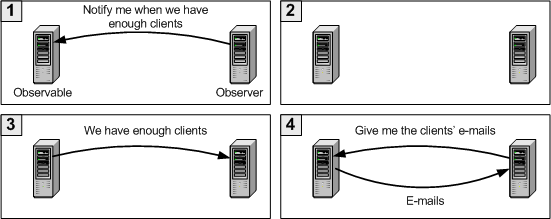
The observer asks the server to notify him as soon as there are enough clients. The observable keeps a list of all its registered observers. This step is normally called the subscription or registration step.
The observer and the observable go about their business. So far, there aren't enough clients.
Enough clients have subscribed. The observable notifies all its observers (remember, there can be more than one) that there are enough clients.
The observer asks the observable to send the e-mail addresses.
As you can see, this approach is much more efficient (in this simple example, network traffic has been sliced in half with respect to the polling approach).
There are two ways of applying the Observer/Observable design pattern: the pull approach or the push approach. Each approach has its advantages and its disadvantages.
Pull: The pull approach is the one shown in the above diagrams. In a strict implementation, the observable will simply tell the observers that 'a change' has occurred. The notification can specify what type of change it is (e.g. "We have enough clients") but will never include the information relative to that change. Notice how, after the notification, the observer must make another call to the observable to get the e-mails. This might seem like a redundant call (we could have sent the e-mails along with the notification), but this approach is useful in the following cases:
Each observer needs to get different information from the observable once a change occurs.
When a notification doesn't imply that the observer will request data from the observable (the observer might choose to ignore the notification)
Push: In this approach, we allow data to travel along with the notification. In our example, the notification would include all the e-mail addresses. This approach is useful when:
Each observer needs to obtain the same information once a change occurs.
In general, the pull approach gives the client more control over the data it will get after the notification. The push approach limits what information the client receives, but is more efficient since we save an extra trip to the observable.
Notifications in GT3 are closely related to service data. In fact, the observers don't subscribe to a whole service, but to a particular Service Data Element (SDE) in that service. The following diagram shows how a MathService has a single SDE, and how several clients subscribe to it.
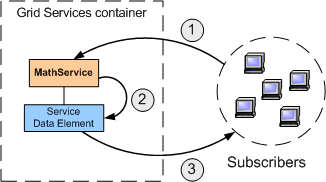
addListener: This call subscribes the calling client to a particular SDE (which is specified in the call)
notifyChange: Whenever a change happens, the MathService will ask the SDE to notify its subscribers.
deliverNotification: The SDE notifies the subscribers that a change had happened.
This notification sent in the third step includes the actual service data, so the subscriber doesn't need to make any more calls to the service. Of course, this is a push notification pattern. GT3 only supports push notifications, although it is possible to implement a pull notification by subscribing to a 'dummy SDE' with no data (consequently, no data would be sent with the notification).
Finally, take into account that (in GT3 jargon) the observables are usually called the notification sources and the observers are usually called the notification sinks.