
Overview and Status of Current GT Performance Studies
| Overview of Current Performance Work | High-Level Description of Study | High-Level Summary of Current Findings | Summary of Planned Near-Term Work | Update Date of this Entry | Link to Detailed Current and Historical Data |
|---|---|---|---|---|---|
| WS GRAM Study #1 |
MEJS throughput fork JT1 - details | sustained job throughput achieved by the MJES for Fork scheduler, submitting a simple job (/bin/date): no delegation, no staging, no cleanup, no stdout/err streaming | maximum throughput achieved 77 jobs per minute | 01/21/05 | 3.9.4
results Bottleneck investigation Delegation reuse improvement |
| WS GRAM Study #2 |
pre-ws JM throughput fork JT1 - details | sustained job throughput achieved by the pre-ws Job manager for Fork scheduler, submitting a simple job (/bin/date): no delegation, no staging, no cleanup, no stdout/err streaming | maximum throughput achieved nn jobs per minute | 12/15/04 | need results |
| WS GRAM Study #3 |
MEJS burst fork JT1 - details | simultaneous job submissions to the same MEJS for the Fork scheduler, submitting a simple job: no delegation, no staging, no cleanup, no stdout/err streaming | n jobs of n total jobs processed successfully | 12/15/04 | need results |
| WS GRAM Study #4 |
MEJS max concurrency fork JT1 - details | Maximum job submissions to the same MEJS for the Fork scheduler, submitting a long running sleep job: no delegation, no staging, no cleanup, no stdout/err streaming | Maximum concurrency achieved was 8000 jobs, but no failures, so limit still not know | 01/21/05 | find current limit |
| WS GRAM Study #4.1 |
MEJS max concurrency condor JT1 - details | Maximum job submissions to the same MEJS for the Condor scheduler, submitting a long running sleep job: no delegation, no staging, no cleanup, no stdout/err streaming | Maximum concurrency achieved was 32,000 jobs, due to system limitation. mkdir: cannot create directory `bar': Too many links | 04/06/05 | 32,000 job limit |
| WS GRAM Study #5 |
MEJS long run fork JT2 - details | Keep a moderate load (10 jobs?) on the service for one month duration. Job should perform all tasks: delegation, stage in, out, cleanup, in order to get the most GT service code coverage. relevant to bug 2479 | number of jobs submitted. Test duration n hours or n days | 04/06/05 | 23 days 500,000+ sequential jobs submitted without container crash |
| WS GRAM Study #n |
|||||
| WS MDS Long Running Index |
Long Running Index Server (4.0.0), zero entry index | Ran for 8,338,435 secs (96 days) til server reboot, Processed 623,395,877requests, | Oct 10, 2005 | Perf slides available in a talk here | |
| WS MDS Long Running Index |
Long Running Index Server (4.0.1), 100 entry index | running for 2,860,028 seconds (33 days) as of Sept 30 and continuing, Processed 14,686,638 queries | Test ongoing | Oct 10, 2005 | Perf slides available in a talk here |
| WS MDS Index Scalabilty |
Index Server (4.0.1) Scalability wrt number of users | Throughput is stable at ~2,000 queries per minute for 10-800 users | ongoing | Oct 10, 2005 | Perf slides available in a talk here |
| Java WS Core Study #1 |
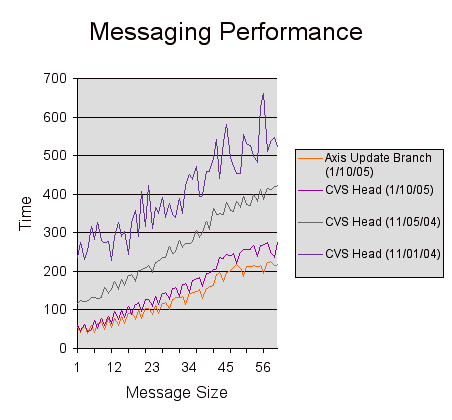
Core Messaging Performance | Timing a roundtrip WS GRAM job creation like message with and without resource dispatch. Timing is measured as a function of the number of typical sub-job descriptions in the input message. | 02/21/2005 | Results (no resource dispatch) | |
| Java WS Core Study #2 |
Core WSRF/WSN Operation Performance | Timing of various WSRF and WSN operations on a simple service | 02/21/2005 | Details & Results | |
| Java WS Core Study #3 |
|||||
| C WS Core Study #1 |
|||||
| GridFTP Study #1 |
TeraGrid Bandwidth Study | 90% utilization (27 Gbs on a 30 Gbs link) memory to memory with 32 nodes; 17.5 Gbs disk to disk with 64 nodes, limited by the SAN. | work with SAN folks to improve disk to disk, but low priority. Our bandwidth performance is good enough for now. | 2004-12-06 | Excel Spreadsheet |
| GridFTP Study #2 |
Long running (stability) Test | Single client instance and single server instance with cached connections | Ran for about a week. Slowly increased memory usage and lost bandwidth (BW) then crashed. Restarted, has now been running for about two weeks, still lost performance, but it looks like the BW has stabilized, need to check on the memory. Looking into this. | 2005-01-04 | BW MRTG Graph (shows bandwidth) |
| GridFTP Study #3 |
|||||
| RFT Study #1 |
{kind=link}
General description of the Tests
- In all cases, you must be clear what process you intend to test (for instance the the client or the service). You must then ensure that process is the bottleneck and not something else. For example, if your intent is to test the load that a client host can handle, if you submit all the client requests against the same service, the service may well fail before the client; therefore, you may need multiple services over which you can distribute the load.
- All tests should record the input parameters to the test.
- We also need a way to either profile the process while it is running, or do a postmortem.
- Things such as CPU load and memory usage should be recorded if at all possible.
- On the C side, the time command actually has a whole range of statistics it can provide.
Test 1: Max Concurrent Test
This test is designed to see how many of a particular process a host can handle. The idea here is to run long jobs that will not end during the duration of the test. Continue to increase the number until failure. This test can be conducted using the throughput tester as long as the run time of a job is longer than the duration of the test. The results of this test should be the number at which failure occurred and the mode of the failure (container out of memory, connection refused, etc).
Test 2: Max Load Test
This test is designed to simulate a heavily loaded client or server host. The difference between this and Test #1 is that jobs should complete and be re-submitted so that there is turnover. This is essentially the test that the GRAM threaded throughput tester and the Mats C client accomplishes. This test ramps the number of jobs up to the specified load and then holds it there, starting a new job for every job that completes, for the duration of the test. This is iterated, increasing the load, until the tested process fails. The results from this test would be the load at which the tested process fails, the actual time the test ran, and the desired test parameters.
Test 3: Burst Test
This test is identical to Test #2 except that all of the tests should be synchronized so that they start as close to the same time as possible. This simulates a "job storm" - a sudden spike where many jobs hit simultaneously. This may give identical results to Test #2 and if so, we will discontinue one or the other of the tests.
Test 4: Robustness Test
This test is intended to keep the tested process alive and moderately busy for a long period of time. How long will vary from component to component, but initially we are thinking one week for a GRAM client, and one month for a service. The throughput tester can be used for this as well, but the load is set constant at some moderate load, not ramped until failure. Failure in this case would be caused by things such as memory leaks, or other issues that slowly increase over time. The results of this test would be total hours it was up and the number of jobs completed.