2.1
Principle
[Home] [Top] [Next]
1. Linear Space
& Physical
Space
在硬件工程师和普通用户看来,内存就是插在或固化在主板上的内存条,它们有一定的容量――比如64
MB。但在应用程序员眼中,并不过度关心插在主板上的内存容量,而是他们可以使用的内存空间――他们可以开发一个需要占用1
GB内存的程序,并让其在OS平台上运行,哪怕这台运行主机上只有128
MB的物理内存条。而对于OS开发者而言,则是介于二者之间,他们既需要知道物理内存的细节,也需要提供一套机制,为应用程序员提供另一个内存空间,这个内存空间的大小可以和实际的物理内存大小之间没有任何关系。
我们将主板上的物理内存条所提供的内存空间定义为物理内存空间;将应用程序员看到的内存空间定义为线性空间。物理内存空间大小在不同的主机上可以是不一样的,随着主板上所插的物理内存条的容量不同而不同;但为应用程序员提供的线性空间却是固定的,不会随物理内存的变化而变化,这样才能保证应用程序的可移植性。尽管物理内存的大小可以影响应用程序运行的性能,并且很多情况下对物理内存的大小有一个最低要求,但这些因素只是为了让一个OS可以正常的运行。
线性空间的大小在32-bit平台上为4
GB的固定大小,对于每个进程都是这样(一个应用可以是多进程的,在OS眼中,是以进程为单位的)。也就是说线性空间不是进程共享的,而是进程隔离的,每个进程都有相同大小的4
GB线性空间。一个进程对于某一个内存地址的访问,与其它进程对于同一内存地址的访问绝不冲突。比如,一个进程读取线性空间地址1234ABCDh可以读出整数8,而另外一个进程读取线性空间地址1234ABCDh可以读出整数20,这取决于进程自身的逻辑。
在任意一个时刻,在一个CPU上只有一个进程在运行。所以对于此CPU来讲,在这一时刻,整个系统只存在一个线性空间,这个线性空间是面向此进程的。当进程发生切换的时候,线性空间也随着切换。所以结论就是每个进程都有自己的线性空间,只有此进程运行的时候,其线性空间才被运行它的CPU所知。在其它时刻,其线性空间对于CPU来说,是不可知的。所以尽管每个进程都可以有4
GB的线性空间,但在CPU眼中,只有一个线性空间的存在。线性空间的变化,随着进程切换而变化。
尽管线性空间的大小和物理内存的大小之间没有任何关系,但使用线性空间的应用程序最终还是要运行在物理内存中。应用所给出的任何线性地址最终必须被转化为物理地址,才能够真正的访问物理内存。所以,线性内存空间必须被映射到物理内存空间中,这个映射关系需要通过使用硬件体系结构所规定的数据结构来建立。我们不妨先称其为映射表。一个映射表的内容就是某个线性内存空间和物理内存空间之间的映射关系。OS
Kernel一旦告诉某个CPU一个映射表的位置,那么这个CPU需要去访问一个线性空间地址时,就根据这张映射表的内容,将这个线性空间地址转化为物理空间地址,并将此物理地址送到地址线,毕竟地址线只知道物理地址。
所以,我们很容易得出一个结论,如果我们给出不同的映射表,那么CPU将某一线性空间地址转化的物理地址也会不同。所以我们为每一个进程都建立一张映射表,将每个进程的线性空间根据自己的需要映射到物理空间上。既然某一时刻在某一CPU上只能有一个应用在运行,那么当任务发生切换的时候,将映射表也更换为响应的映射表就可以实现每个进程都有自己的线性空间而互不影响。所以,在任意时刻,对于一个CPU来说,也只需要有一张映射表,以实现当前进程的线性空间到物理空间的转化。
2. OS Kernel Space &
Process Space
由于OS
Kernel在任意时刻都必须存在于内存中,而进程却可以切换,所以在任意时刻,内存中都存在两部分,OS
Kernel和用户进程。而在任意时刻,对于一个CPU来说只存在一个线性空间,所以这个线性空间必须被分成两部分,一部分供OS
Kernel使用,另一部分供用户进程使用。既然OS Kernel在任何时候都占用线性空间中的一部分,那么对于所有进程的线性空间而言,它们为OS
Kernel所留出的线性空间可以是完全相同的,也就是说,它们各自的映射表中,也分为两部分,一部分是进程私有映射部分,对于OS
Kernel映射部分的内容则完全相同。
从这个意义上来说,我们可以认为,对于所有的进程而言,它们共享OS
Kernel所占用的线性空间部分,而每个进程又各自有自己私有的线性空间部分。假如,我们将任意一个4 GB线性空间分割为1 GB的OS Kernel空间部分和3
GB的进程空间部分,那么所有进程的4 GB线性空间中1 GB的OS Kernel空间是共享的,而剩余的3
GB进程空间部分则是各个进程私有的。Linux就是这么做的,而Windows NT则是让OS Kernel和进程各使用2 GB线性空间。
3. Segment Mapping &
Page Mapping
所有的线性空间的内容只有被放置到物理内存中才能够被真正的运行和操作。所以,尽管OS
Kernel和进程都被放在线性空间中,但它们最终必须被放置到物理内存中。所以OS
Kernel和所有的进程都最终共享物理内存。在现阶段,物理内存远没有线性空间那么大――线性空间是4
GB,而物理内存空间往往只有几百兆,甚至更小。另外即使物理内存有4 GB,但由于每个进程都可以有3 GB线性空间(假如进程私有线性空间是3
GB的话),如果把所有进程的线性空间内容都放在物理内存中,明显是不现实的。所以OS
Kernel必须将某些进程暂时用不到的数据或代码放在物理内存之外,将有限的内存提供给当前最需要的进程。另外,由于OS
Kernel在任何时候都有可能运行,所以OS Kernel最好被永远放在物理内存中。我们仅仅将进程数据进行换入换出。
从线性空间到物理空间的映射需要映射表,映射表的内容是将某段线性空间映射到相同大小的物理内存空间上。从理论上,我们可以使用两种映射方法:变长映射,和定长映射。变长映射指的是根据不同的需要,将一个一个变长段映射到物理内存上,其格式可以如下(线性空间段起始地址,物理空间段起始地址,段长度)。假如一个进程有3个段:10M的数据段,5M的代码段,和8K的堆栈段,那么就可以在映射表中建立3项内容,每一项针对一个段。这看起来没有问题。但假如现在我们的实际的内存只有32M,其中10M被内核占用,留给进程的物理空间只有22M,那么此进程在运行时,就占据了10M+5M+8K的内存空间。随后当进程发生切换时,假如另一个进程和其有相同的内存要求,那么剩余的22M-(10M+5M+8K)明显就不够用了,这时只能将原进程的某些段换出,并且必须是整段的换出。这就意味着我们必须至少换出一个10M的数据段,而换出的成本很高,因为我们必须将这10M的内容拷贝到磁盘上,磁盘I/O是很慢的。
所以,使用变长的段映射的结果就是一个段要么被全部换入,要么被全部换出。但在现实中,一个程序中并非所有的代码和数据都能够被经常访问,往往被经常访问的只占全部代码数据的一部分,甚至是一小部分。所以更有效的策略是我们最好只换出那些并不经常使用的部分,而保留那些经常被使用的部分。而不是整个段的换入换出。这样可以避免大块的慢速磁盘操作。
这就是定长映射策略,我们将内存空间分割为一个个定长块,每个定长块被称为一个页。映射表的基本格式为(物理空间页起始地址),由于页是定长的,所以不需要指出它的长度,另外,我们不需要在映射表中指定线性地址,我们可以将线性地址作为索引,到映射表中检索出相应的物理地址。当使用页时,其策略为:当换出的时候,我们只将那些不活跃的,也就是不经常使用的页换出,而保留那些活跃的页。在换入的时候,只有被请求访问的页才被换入,没有被请求访问的页将永远不会被换入到物理内存。这就是请求页(Demand
Page)算法的核心思想。
这就引出一个页大小的问题:首先我们不可能以字节为单位,这样映射表的大小和线性空间大小相同――假如整个线性空间都被映射的话――我们不可能将全部线性空间用作存放这个映射表。由此,我们也可以得知,页越小,则映射表的容量越大。而我们不能让映射表占用太多的空间。但如果页太大,则面临着和不定长段映射同样的问题,每次换出一个页,都需要大量的磁盘操作。另外,由于为一个进程分配内存的最小单位是页,假如我们的页大小为4
MB,那么即使一个进程只需要使用4 KB的内存,也不得不占用整个4 MB页,这明显是一种很大的浪费。所以我们必须在两者之间进行折衷,一般平台所规定的页大小为1
KB到8 KB,IA-32所规定的页大小为4 KB。(IA-32也支持4 MB页,你可以根据你的OS的用途进行选择,一般都是使用4 KB页)。
假如使用4 KB的页,那么对于4
GB的线性空间,则需要1,048,576个页表实体,每个表项占用4个字节,则需要4,194,304个字节。仅仅页表就占用4
MB空间,这是一个很大的需求。但如果确确实实一个进程需要使用全部线性空间的话,那么这4 MB的页表空间投入也是必要的。
但在现实中,很少有那个程序需要使用这么大空间,一般的程序往往很小,从几KB到几MB,再使用这么大的页表就纯粹是一种浪费。那我们该怎么办?
一种策略是建立变长页表――我们只建立所需长度的页表。但这种策略带来很大的限制,并且仍然会造成比较大的空间浪费。由于页表机制是使用线性地址作为索引,到页表中进行检索。那么如果我们想让OS
Kernel使用C0000000h-FFFFFFFFh,也就是3 GB-4 GB之间的线性空间,那么页表的3
MB以上部分肯定被使用,那么页表还是不得不占用大于3 MB空间的空间,即使这个进程仅仅使用1 KB的线性空间。除非我们把OS
Kernel放在0h-3FFFFFFFh,也就是第一个1 GB线性空间。即使是这样,我们的页表也必须至少占用1 MB的空间,尽管实际上我们的内核可能只有4
MB,只需要1024个表项,也就是4
KB表项空间――因为进程私有的线性空间是从40000000h开始的。另外,对于共享库而言,它们一般被放在物理内存的某个位置,同时映射到某个线性空间位置,这个映射关系对所有的进程都是一致的。每个进程都将所需共享库的映射关系放在自己的页表中。为了给用户进程留出足够的空间,共享库一般被映射到较高的线性空间,比如2
GB的位置。那么页表则至少需要2 MB以上的空间。总之,变长页表无法真正解决页表空间浪费的问题。
另外一种策略是使用多级页表。我们以4
KB页的二级页表为例来说明多级页表的原理。
二级页表的第一级称为页目录(Page
Directory),第二级称为页表(Page Table)。
如果使用一级页表,则对于4
KB页的来说,其起始地址都是以4
KB=2^12对齐的,所以一个线性地址的低12-bit用来做页内寻址。高20-bit被用来做页表索引。而如果使用2级页表,则将其高20-bit分为两部分,比如我们分为2个10-bit,高位的10-bit用来做Page
Directory的索引,用于定位Page Table;低位10-bit用来做Page
Table的索引,用于定位Page;最低的12-bit用于定位页内Offset。所以通过3部分的组合,一个32-bit的线性地址就最终转化为一个32-bit的物理地址。
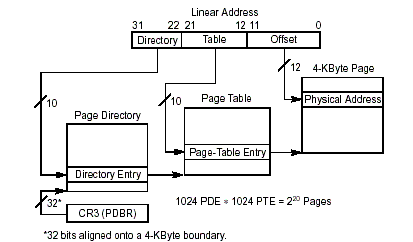
在整个2级页表架构中,只存在一个Page
Directory,由于页目录索引是10-bit,所以页目录中有2^10=1024个页目录表项(Directory Entry)。一个Directory
Entry占4个字节,所以页目录大小为1024*4 = 4 KB,恰好被放在一个页中。每一个Directory
Entry指向一个页表,所以最多有1024个Page Table,但并非所有Page Table都需要存在。每一个Page
Table的索引也是10-bit,所以一个Page Table中有2^10=1024个页表表项(Page-Table
Entry);一个Page-Table Entry占4个字节,所以一个Page Table大小为1024*4 =
4 KB,也恰好被放在一个页中。所以一个Directory Entry的高20-bit加上全为0的低12-bit,就是其所指向的Page
Table所在页的起始地址。一个Page-Table Entry的高20-bit加上全为0的低12-bit,就是其所指向的Page的起始地址。
这样,当我们给出一个32-bit的线性地址时,首先取出高10-bit作为Page Directory的索引,找到相应的Directory
Entry,然后根据此Directory Entry的高20-bit找到相应的Page
Table所在的Page,再根据线性地址的中间10-bit作为索引,在此Page Table中找到相应的Page-Table
Entry,然后根据此Page-Table Entry的高20-bit找到相应的Page,最后根据线性地址的低12-bit作为Offset,加上Page
Base Address就转化成了32-bit的物理地址。
这就是2级页表的线性地址到物理地址的映射机制。在2级页表中,Page Directory占用4
KB字节,这是2级页表的最小内存需求。Page Table则根据实际的需要而创建。假如OS Kernel被放在3 GB的位置,大小为4
MB,则只需要创建一个Page Table,然后将Page Directory的第768个Directory Entry设为指向此Page
Table所在的页基地址。如果进程自身占用4 MB,占用线性地址0-4MB,则只需要再创建一个Page Table,然后将Page
Directory的第0个Directory Entry设为指向此Page Table所在的页基地址。其它的线性地址没有被使用,所以不需要再创建其它的Page
Table,而将Page Directory中的其它Directory Entry都设为空。这种情况下,页表所占据的空间就是4 KB*3=12
KB。而如果使用1级页表,即使是变长的,也需要3M+4K。所以使用2级页表很大的节省了页表空间。
基于绝大多数程序都是几百KB或一两兆的事实,为了更进一步的节省页表空间,可以使用三级或多级页表。但这样同时也造成对一个线性地址到物理地址的转换层次过多。另外,对于大型程序来说,其占用的页表空间可能更多。所以,很少有系统使用3级以上页表。