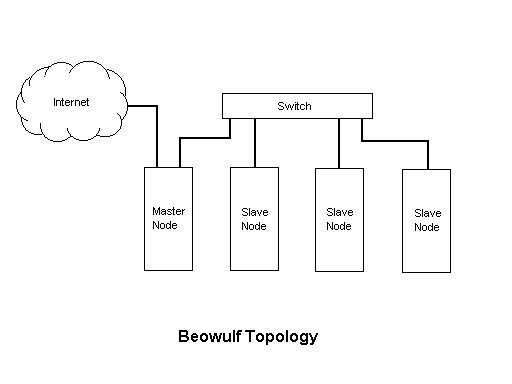
Now it's time to test the cluster to see if the nodes can talk to
each other via MPI. Run the tstmachines script in the sbin/ directory
under the mpich directory to verify this. It will help to use the -v option
to get more info. If this works, it's time to run a program on the cluster.
Under the distribution tree for mpich you'll find an examples directory.
Inside that, under the basic directory, you'll find the cpi program. This
program calculates the value of Pi, and is a good tool for verifying the
cluster is working properly. Run 'make cpi' in the basic directory to
build the executable. Run the program using the mpirun command. Here's
what I used to test mini-wulf:
mpirun -np 3 -nolocal cpi
Note: I put /usr/local/mpich-1.2.4/bin in my path before doing this, so the
machine could find mpirun. Also, the -nolocal flag was needed on my cluster
to keep it from trying to run all the processes on the master node. I don't
understand why this is, but it works for me.
Update: the -nolocal flag is only needed when the 'outside' name of the
node is included in the loopback line in /etc/hosts, which linux does by
default. Change the loopback line to read '127.0.0.1 localhost.localdomain localhost'
and MPICH won't require the flag.
The -np flag tells mpirun how
many processors to use to run the program, 3 in this case. Here's the output
I got:
% mpirun -np 3 -nolocal cpi
Process 0 of 3 on (outside IP).rwic.und.edu
pi is approximately 3.1415926535899121, Error is 0.0000000000001190
wall clock time = 2.800307
Process 1 of 3 on alpha.rwic.und.edu
Process 2 of 3 on bravo.rwic.und.edu
Note: I changed cpi.c to add more loop cycles to the program to get a longer
run time. This helped make the difference between using more nodes less
influenced by communication lags and overhead. Looks like we're actually using
all processors, but let's try some other configurations just to make sure:
% mpirun -np 1 -nolocal cpi
Process 0 of 1 on (outside IP).rwic.und.edu
pi is approximately 3.1415926535897309, Error is 0.0000000000000622
wall clock time = 8.395115
%
% mpirun -np 2 -nolocal cpi
Process 0 of 2 on (outside IP).rwic.und.edu
pi is approximately 3.1415926535899850, Error is 0.0000000000001918
wall clock time = 4.197473
Process 1 of 2 on alpha.rwic.und.edu
Yep, looks like mpirun is calling on the specified number of CPUs to run the program,
and the time savings using more CPUs is what you'd expect. Using two CPUs runs the
program in 49.9% of the time it took one, and three runs it in 33.4%. This is a
beautiful 1/N progression for the runtime vs. number of CPUs, but don't expect it to
hold for more complex programs or huge numbers of cluster nodes.
Installing LAM/MPI:
Since MPICH has some issues with NFS, and the
Klingon Bird of Prey cluster
Mini-Wulf is based on runs it, I decided to install the
LAM/MPI implementation
of MPI.
Running
./configure --prefix=/usr/local/lam_mpi --with-rsh=/usr/bin/ssh
revealed no problems, since LAM/MPI supports native FreeBSD. The INSTALL file
did instruct me to run make with the '-i' option under FreeBSD, since 'BSDs
version doesn't always handle script result codes the way they'd like. The
usual 'make -i' and 'make -i install' followed. After adding /usr/local/lam_mpi/bin
to my path, I also built the examples via 'make -i examples'.
While the mighty P90 CPU chewed on this task, I started another shell and edited
the /usr/local/lam_mpi/etc/lam-bhost.def file, which contains a list of all the
processor nodes in the cluster. This defaults to just one, the node that LAM is
built on. I added the other two nodes in the cluster.
After the examples were built and the lam-bhost.def file adjusted, it was time to test!
LAM runs a little differently than MPICH, in that it runs daemons on each node in
the cluster to facilitate the message-passing. This means that the LAM executables
must be on every node. I ran 'recon -v -a' to test the remote nodes, and got
errors when they wouldn't run the LAM program 'tkill' (which is what recon uses
to test the cluster). Since I hadn't shared out the /usr/local/lam_mpi directory
on the master node, the slaves couldn't find it. I debated doing the NFS share,
but for the moment just copied the directory to the remote nodes using scp. This
keeps NFS traffic down, although it would make cluster maintainance more labor-intensive.
(Note: I've since shared out the /usr/local/lam_mpi directory and NFS mounted
it on the slaves. This makes things a lot easier for upgrades later)
I also had to end up setting the LAMHOME environment variable to /usr/local/lam_mpi, since both recon and
lamboot were having trouble finding executables (although putting the $prefix/bin
directory in my PATH should have taken care of it. Oh well, whatever works). After
that, I ran 'lamboot' and got the required output.
Now that LAM was actually running, it was time to actually run some parallel programs
to test the cluster. I went to the examples/pi directory, and fired off my old friend,
the cpi program. LAM syntax is a bit different to start:
mpirun C cpi
The output was huge! This version of cpi was a bit different than the other I had
tested, so I copied that one (from the MPICH distro) to the local directory, compiled
it using mpicc, and ran that version using LAM. Here's the output:
> mpirun C cpi
Process 0 of 3 on (outside IP).rwic.und.edu
Process 1 of 3 on alpha.rwic.und.edu
Process 2 of 3 on bravo.rwic.und.edu
pi is approximately 3.1415926535899121, Error is 0.0000000000001190
wall clock time = 2.805890
So, it looks like the LAM version of MPI is running. It also compiles code written for
MPICH with no modifications, and runs the resultant executable in a very similar elapsed
time. Very satisfactory.
LAM requires one last step that MPICH doesn't: you have to shut down the LAM daemons on
all the nodes. This is accomplished via the 'lamhalt' command. There seems to be no man
page for this command, but you can do a man on the older 'wipe' command, which will give
you more info.
Status: June 28, 2002
At this point the cluster is functional, and can be used as is.
Most production clusters, however, need more than just the bare-bones of message-
passing. Mini-wulf at this point would be fine for a single or small number of
users running a small number of programs, but when you start adding lots of users
and/or having more programs running, management of the cluster becomes a chore.
Bigger clusters use tools for batch processing programs so that all programs get
a fair share of the CPU cycles of the cluster. Also, using good old 'adduser' on
each node to keep track of user accounts gets tedious.
Adding these tools to mini-wulf will be explored at a later date.
Status: July 1, 2002
Mini-wulf is currently off-line waiting for upgrades. I say, "waiting for upgrades."
because it sounds better than "scavenged for parts." I had a need for a server at work, and
since Mini was available, I concatenated together some of its parts to make the server. The
slave nodes are basically intact, with one CPU downgraded from an AMD K6-2 400 to a Pentium 120,
but I'll need to find a new master node. I've got a box in mind, I just have to make time to
configure it.
Status: July 3, 2002
Mini-wulf is back in operation! After mucking about with a cranky 3Com 509 NIC, I got
the new master node configured and functional. The Bravo node is still only running as a
Pentium 100, even though the CPU was only downgraded to a P120. More investigation is needed.
In any case, the overall performance of the cluster has suffered a bit. Here's the output
from a cpi run in the new configuration:
Process 0 of 3 on (outside ip).rwic.und.edu
Process 1 of 3 on alpha.rwic.und.edu
Process 2 of 3 on bravo.rwic.und.edu
pi is approximately 3.1415926535899121, Error is 0.0000000000001190
wall clock time = 3.301860
I thought that upgrading the weakest machine would help the overall performance, but as you
can see, the clock time for the program is about one second longer. This result is consistant
over several test runs. The new master node has only 32M of RAM, so there may be some disk
swap going on before the program is passed out and run on the LAN. More testing will be
conducted as I have time.
Status: July 5, 2002
Since the new master node was so pathetic, I just had to move stuff around again.
I shuffled NICs and made the old alpha node the new master, since it now had the largest
hard drive and most RAM. After fussing about with NFS mounts, rc.conf and hosts files,
I finally got everything running properly. I shared out the /usr/local/lam_mpi directory
to the slaves via NFS, since I had to end up rebuilding LAM due to damage I did during
the move. I also added set prompt = '%n@%m:%/%# '
to my .cshrc
file,
since doing the wrong commands on the wrong nodes is what messed me up in the first place.
Hint: never try to scp a directory on to itself, it corrupts all the files and generally
makes you unhappy. The cluster actually runs a bit faster now, interestingly enough:
Process 0 of 3 on (outside ip).rwic.und.edu
Process 1 of 3 on alpha.rwic.und.edu
Process 2 of 3 on bravo.rwic.und.edu
pi is approximately 3.1415926535899121, Error is 0.0000000000001190
wall clock time = 2.526050
I also ran the lam test suite, just to verify that the package was properly built and
installed. No problems at this point.
Status: July 16, 2002
I've been running the Pallas benchmark
on miniwulf for about a
week in various configurations. The Results are rather interesting.
They indicate that the choice of MPI implementation and even hardware is dependent on
your code and application of the cluster.
Status: September 3, 2002
Over the long weekend, I decided I wanted to try running some other
distributed computer clients on the slave nodes (
www.distributed.net). Since these clients were designed to run on single computers
attached to the internet, and miniwulf's slave nodes couldn't access the internet,
I had some adjusting to do. I decided to setup NAT (network address translation) on
the master node. This would allow the slave nodes with their unroutable IP numbers
to pass packets to the master, which would strip off the old IPs and use its own,
routable IP on the packets. When the packets return from the internet, natd uses
its tables to figure out which slave the packet originated from, and puts the internal
IP back on it. It's pretty slick, but under FreeBSD requires jumping through some hoops.
I had to build a custom kernel with ipfw firewall capability, and write a simple firewall
ruleset. It's ipfw that actually passes the packets off to natd. Also, the /etc/rc.conf
file has to have a few adjustments as well, such as enabling forwarding and activating
the firewall. Instructions for doing all this is available at
www.freebsd.org.
The NAT routing makes the slave nodes think they're connected directly to the internet, but
blocks any outside hosts from accessing the nodes. The cluster is thus still fairly secure,
and can still run the MPI software without any problems.
Status: October 14, 2002
Mini-wulf continues to evolve. Since the distributed.net project was completed (at
least the RC5-64 section that I was interested in), I removed the client programs from the
nodes. I left the natd functionality intact, however, to allow easier upgrades and other
maintainance of the cluster nodes.
Mini-wulf has finally been used for the purpose for which it was built: education. I enrolled
in an online MPI programming course offered by the
Ohio Supercomputer Center. Mini-wulf has been very handy for
doing homework problems for this course. It's also interesting to note that programs run with
more than three processors, which is all mini-wulf has, work just fine. This does cause more
than one process to be run on each node, but for simple programs that don't require huge
amounts of computing power, that's not a problem. Of course, a single computer with MPI
installed could also be used to run simple MPI programs to teach and demonstrate message
passing, but that would leave out all the fun of building the cluster :).
Status: January 22, 2003
"Charlie" node added. Mini is finally a four node cluster! When an old samba server
underwent an upgrade (pronounced 'replacement'), I found myself with a fully fuctional
Pentium 133 based FreeBSD box. After a quick re-read of this document, I made the necessary
adjustments to the old box's network and NFS settings, plugged it into the Mini-wulf LAN,
powered up, and away it went! Benchmarking with the pi calculation program, Mini's crunching
abilities have increased 25%. Not the 33% I would have expected, but perhaps I'm basing my
expectations on some dodgy math. It's still very gratifying that the cluster is so easy to
upgrade.
I have room left on the hub and power strip for one more system to be added to
Mini. However I don't know how likely it is that I'll do this. While Mini-wulf has been
great fun and very educational to build, computationally it gets its butt whupped by our
dual Pentium 3 Xeon system. I'm now starting the process of building our 'real'
Beowulf cluster that will have some serious MFLOPs and storage. Mini taught me many of
the things I needed to know to build the big cluster, but it will most likely be used
for 'hot storage' of old hardware from now on. It's always possible students may want to
use Mini for experimental purposes, but as a high-powered number cruncher it's just too
limited to be useful for big problem solving.
Status: January 24, 2003
I modified the pi calculation program to include a crude
MFLOP (million floating
point operation) calculator, just so I could do some simple benchmarking. Since the pi
program doesn't do any trig or other heavy math, the results should be used more as a
relative guide rather than absolute. Here are the results using different numbers of nodes:
Number of nodes MFLOPS
--------------- ------
1 12.2
2 20.1
3 22.6
4 30.1
It should be remembered that the number three node is a pentium 100, while the others are
133s. Even so, it's a bit bizzare that the addition of the third node only increased the
performance by about 12%.
The same code running on a dual 1.7GHz Pentium III Xeon system gave:
Number of nodes MFLOPS
--------------- ------
1 235.6
2 471.3
As you can see, a modern dual-processor computer beats Mini's crunching capability by about an
order of magnitude. I theorize the nice doubling of performance on the dually is because the
interprocess communication is taking place on the bus, rather than across a network.
Status: March 25, 2003
Upgraded cluster OS to latest FreeBSD security branch.
Status: March 26, 2003
Installed ATLAS linear algebra math
library.
Status: April 25, 2003
Ran Pi MFLOP benchmark again, this time for up to 20 processes (the cluster still
has only 4 nodes).
Number of processes MFLOPS
------------------- ------
1 12.2
2 23.7
3 27.4
4 36.6
5 25.0
6 30.1
7 32.0
8 36.6
9 30.1
10 33.4
11 31.3
12 34.1
13 32.6
14 35.1
15 30.9
16 32.7
17 34.1
18 36.1
19 30.7
20 32.4
Graphical version.
Status: May 12, 2003
Mini is up and operational again. During the previous week a critical server
failed, so I was forced to borrow the charlie node to fill in for it until a replacement
could be built.
Over the weekend I built Deuce, a two-node cluster running
Redhat Linux 9.0. Since Zeus
will be running this OS, I wanted to get some clustering experience with it.
Status: May 23, 2003
Since Mini is now a four node cluster, I reran the
Pallas benchmark on it. Here
are the results. These are for MPICH running on a 10bT hub.
Status: August 5, 2003
Delta node added. Yet another pentium 133 was retired from active service and was
added to Mini. This makes 5 nodes total, and fills the Addtron 10bT hub (and the power
strip) to capacity. This is likely the last node I'll add to Mini. I do have an 8-port
10bT hub I could use for the LAN, but the counter where I have the cluster installed is
running short on space. Since most of my energies as far as Beowulfs are concerned are
being spent on Zeus, Mini is mostly a curiosity for me these days.
I did run my Pi MFLOP benchmark on the new configuration, and
found a ~24% increase in maximum
MFLOPS over the 4-node configuration. Here are the results:
Number of processes MFLOPS
------------------- ------
1 12.1
2 24.2
3 22.6
4 29.6
5 37.6
6 36.2
7 42.4
8 30.1
9 33.8
10 37.6
11 41.4
12 45.1
13 32.6
14 35.1
15 37.6
16 40.1
17 42.6
18 33.8
19 35.7
20 37.6
Graphical Version
It's interesting to note the changes in the maximum performance, which show up at 12 processes on the
5-node cluster, but at 8 processes on the 4-node. It should be noted that I've switched back to the MPICH
implementation of MPI for this test, while the previous one was made using LAM/MPI. This could
certainly have an effect on the response of the cluster to different processing loads.
Status: August 13, 2003
Clusters must be some sort of disease, or perhaps addictive. I just couldn't leave well enough alone.
Another box became available, so I replaced the Bravo node with a K6/2 333. After a few abortive
attempts, I replaced the 3Com ISA NIC with a PCI version, and got it working. Before the dust had
settled, I renamed the old Bravo node to Echo, swapped out the 5-port hub for an 8-port, adjusted all
the /etc/hosts files (strange things happen if all your nodes don't know about each other) and
/usr/local/mpich-1.2.4/share/machines.freebsd, and ran the
MFLOP benchmark for 20 processes again. This resulted in a peak performance jump
of about 26% over the 5-node cluster configuration. Here's the output:
Number of processes MFLOPS
------------------- ------
1 12.2
2 24.4
3 36.4
4 40.1
5 50.1
6 45.2
7 42.6
8 48.1
9 54.1
10 50.1
11 55.1
12 45.2
13 48.9
14 52.7
15 56.4
16 53.4
17 56.8
18 45.2
19 47.6
20 50.2
Graphical Version
Changing the weak node from the second in line to the sixth has changed the shape of the repeating part
of the performance graph. I haven't tested the benchmark code on the new K6/2 node individually yet,
but it does look like it stacks up favorably to the Pentium 133s.
Looking back over this document I see that Mini is just
over one year old, has doubled in size and almost doubled in computational power. It's come a long way
since it began as an unsanctioned after-hours experiment with a few old computers I was going to
surplus and some obsolete network gear. I remember searching the web for hours, trying to figure out
what a Beowulf was and how it worked, and scratching for the little info available on FreeBSD 'wulfs amid
the comparitive wealth on Linux clusters. When I first ran the Pi program on Mini, I was totally stoked.
I started this web page and sent the URL to my Boss, who wasn't exactly bubbling over with enthusiasm
("Let's not waste too much time on this."). Since that time, however, he's become a cluster convert,
and was willing to fund the building of Zeus. While neither of us think Beowulf
clusters will send big-iron supercomputer builders packing, they do allow cash-strapped researchers
some decent computational horsepower for certain algorithms that they are suited for.
Status: September 2, 2003
A sad day. Miniwulf has been given its marching orders. The counter where the cluster stood
was needed for another project (a lab we were using to build stuff was needed again for teaching). Mini's
master node was also used as a DNS and NTP server, so it had its secondary NIC removed, configuration
adjusted, and was moved to a different machine room. The compute nodes were shut down and moved into
a storage area. It is possible that another master node could be built from one of the compute nodes,
and the cluster set up elsewhere. This will have to wait until I have sufficient free time and can
find space and power/network resources to run the cluster. Given the lack of computational power Mini
suffered from, the incentive to reassemble it is not terribly high.
So, 15 months. That's about how long Miniwulf was operational. It's been a fun and educational ride.
I took a final snapshot of the critical configuration files that went into building Mini:
Status: September 18, 2003
I've pretty much accepted the fact that Miniwulf will most likely never be reassembled.
I've raided the collection of compute nodes for replacement PCs and parts, and with the cost of
much more powerful PCs as low as they are, it just doesn't make sense to rebuild a Beowulf
that was based on Pentium 133s and 10bT ethernet. Mini's purpose was education: helping me
learn how to build, program, and manage a cluster, and now that that purpose is fufilled,
it's time to move on.
Links:
Other Clusters:
Tools for building clusters:
Other cluster stuff: