 |
| Figure 2.1: Decomposition of Linux System into Major Subsystems |
Available at: http://www.grad.math.uwaterloo.ca/~itbowman/CS746G/a1/
Keywords: Software architecture, conceptual architecture, Linux
This paper describes the abstract or conceptual software architecture of the Linux kernel. This level of architecture is concerned with the large-scale subsystems within the kernel, but not with particular procedures or variables. One of the purposes of such an abstract architecture is to form a mental model for Linux developers and architects. The model may not reflect the as-built architecture perfectly, but it provides a useful way to think about the overall structure. This model is most useful for entry-level developers, but is also a good way for experienced developers to maintain a consistent and accurate system vocabulary.
The architecture presented here is the result of reverse engineering an existing Linux implementation; the primary sources of information used were the documentation and source code. Unfortunately, no developer interviews were used to extract the live architecture of the system.
The Linux kernel is composed of five main subsystems that communicate using procedure calls. Four of these five subsystems are discussed at the module interconnection level, and we discuss the architectural style in the sense used by Garlan and Shaw. At all times the relation of particular subsystems to the overall Linux system is considered.
The architecture of the kernel is one of the reasons that Linux has been successfully adopted by many users. In particular, the Linux kernel architecture was designed to support a large number of volunteer developers. Further, the subsystems that are most likely to need enhancements were architected to easily support extensibility. These two qualities are factors in the success of the overall system.
| Figure 2.1: | Decomposition of Linux System into Major Subsystems |
| Figure 2.2: | Kernel Subsystem Overview |
| Figure 2.3: | Division of Developer Responsibilities |
| Figure 3.1: | Process Scheduler Subsystem in Context |
| Figure 3.2: | Memory Manager subsystem in context |
| Figure 3.3: | Virtual File System in Context |
| Figure 3.4: | Network Interface Subsystem in Context |
The goal of this paper is to present the abstract architecture of the Linux kernel. This is described by Soni ([Soni 1995]) as being the conceptual architecture. By concentrating on high-level design, this architecture is useful to entry-level developers that need to see the high level architecture before understanding where their changes fit in. In addition, the conceptual architecture is a good way to create a formal system vocabulary that is shared by experienced developers and system designers. This architectural description may not perfectly reflect the actual implementation architecture, but can provide a useful mental model for all developers to share. Ideally, the conceptual architecture should be created before the system is implemented, and should be updated to be an ongoing system conscience in the sense of [Monroe 1997], showing clearly the load-bearing walls as described in [Perry 1992].
This presentation is somewhat unusual, in that the conceptual architecture is usually formed before the as-built architecture is complete. Since the author of this paper was not involved in either the design or implementation of the Linux system, this paper is the result of reverse engineering the Slackware 2.0.27 kernel source and documentation. A few architectural descriptions were used (in particular, [Rusling 1997] and [Wirzenius 1997] were quite helpful), but these descriptions were also based on the existing system implementation. By deriving the conceptual architecture from an existing implementation, this paper probably presents some implementation details as conceptual architecture.
In addition, the mechanisms used to derive the information in this paper omitted the best source of information -- the live knowledge of the system architects and developers. For a proper abstraction of the system architecture, interviews with these individuals would be required. Only in this way can an accurate mental model of the system architecture be described.
Despite these problems, this paper offers a useful conceptualization of the Linux kernel software, although it cannot be taken as an accurate depiction of the system as implemented.
The next section describes the overall objective and architecture of the Linux kernel as a whole. Next, each individual subsystem is elaborated to the module level, with a discussion of the relations between modules in a subsystem and to other subsystems. Finally, we discuss how the architecture of the Linux kernel was useful in the implementation of the system and contributed to the overall success of the system.
The Linux kernel is useless in isolation; it participates as one part in a larger system that, as a whole, is useful. As such, it makes sense to discuss the kernel in the context of the entire system. Figure 2.1 shows a decomposition of the entire Linux operating system:
|
| Figure 2.1: Decomposition of Linux System into Major Subsystems |
The Linux operating system is composed of four major subsystems:
This decomposition follows Garlan and Shaw's Layered style discussed in [Garlan 1994]; each subsystem layer can only communicate with the subsystem layers that are immediately adjacent to it. In addition, the dependencies between subsystems are from the top down: layers pictured near the top depend on lower layers, but subsystems nearer the bottom do not depend on higher layers.
Since the primary interest of this paper is the Linux kernel, we will completely ignore the User Applications subsystem, and only consider the Hardware and O/S Services subsystems to the extent that they interface with the Linux kernel subsystem.
The Linux kernel presents a virtual machine interface to user processes. Processes are written without needing any knowledge of what physical hardware is installed on a computer -- the Linux kernel abstracts all hardware into a consistent virtual interface. In addition, Linux supports multi-tasking in a manner that is transparent to user processes: each process can act as though it is the only process on the computer, with exclusive use of main memory and other hardware resources. The kernel actually runs several processes concurrently, and is responsible for mediating access to hardware resources so that each process has fair access while inter-process security is maintained.
The Linux kernel is composed of five main subsystems:
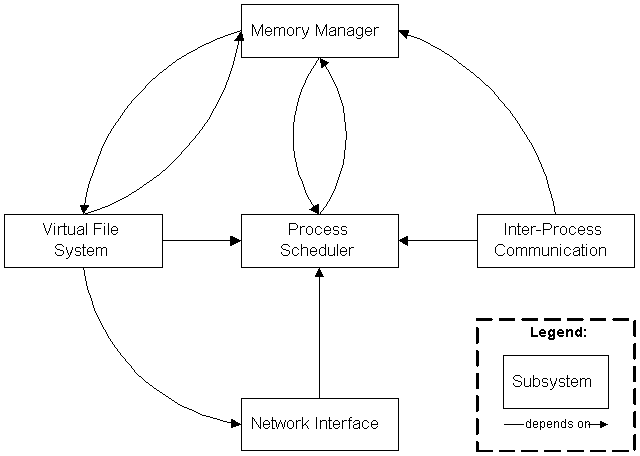
Figure 2.2 shows a high-level decomposition of the Linux kernel, where lines are drawn from dependent subsystems to the subsystems they depend on:
 |
| Figure 2.2: Kernel Subsystem Overview |
This diagram emphasizes that the most central subsystem is the process scheduler: all other subsystems depend on the process scheduler since all subsystems need to suspend and resume processes. Usually a subsystem will suspend a process that is waiting for a hardware operation to complete, and resume the process when the operation is finished. For example, when a process attempts to send a message across the network, the network interface may need to suspend the process until the hardware has completed sending the message successfully. After the message has been sent (or the hardware returns a failure), the network interface then resumes the process with a return code indicating the success or failure of the operation. The other subsystems (memory manager, virtual file system, and inter-process communication) all depend on the process scheduler for similar reasons.
The other dependencies are somewhat less obvious, but equally important:
In addition to the dependencies that are shown explicitly, all subsystems in the kernel rely on some common resources that are not shown in any subsystem. These include procedures that all kernel subsystems use to allocate and free memory for the kernel's use, procedures to print warning or error messages, and system debugging routines. These resources will not be referred to explicitly since they are assumed ubiquitously available and used within the kernel layer of Figure 2.1.
The architectural style at this level resembles the Data Abstraction style discussed by Garlan and Shaw in [Garlan 1994]. Each of the depicted subsystems contains state information that is accessed using a procedural interface, and the subsystems are each responsible for maintaining the integrity of their managed resources.
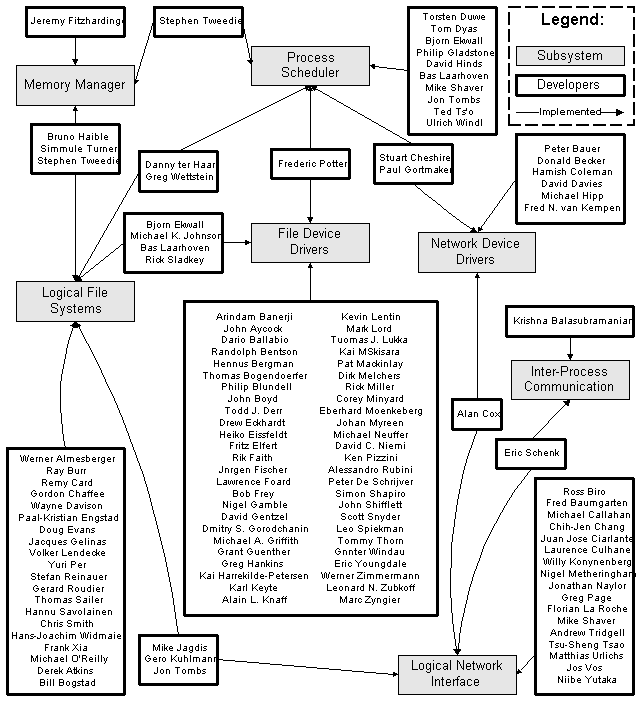
The Linux system was developed by a large number of volunteers (the current CREDITS file lists 196 developers that have worked on the Linux system). The large number of developers and the fact that they are volunteers has an impact on how the system should be architected. With such a large number of geographically dispersed developers, a tightly coupled system would be quite difficult to develop -- developers would be constantly treading on each others code. For this reason, the Linux system was architected to have the subsystems that were anticipated to need the most modification -- the file systems, hardware interfaces, and network system -- designed to be highly modular. For example, an implementation of Linux can be expected to support many hardware devices which each have distinct interfaces; a naive architecture would put the implementation of all hardware devices into one subsystem. An approach that better supports multiple developers is to separate the code for each hardware device into a device driver that is a distinct module in the file system. Analyzing the credits file gives Figure 2.3:
 |
| Figure 2.3: Division of Developer Responsibilities |
Figure 2.3 shows most of the developers who have worked on the Linux kernel, and the areas that they appeared to have implemented. A few developers modified many parts of the kernel; for clarity, these developers were not included. For example, Linus Torvalds was the original implementor of most of the kernel subsystems, although subsequent development was done by others. This diagram can't be considered accurate because developer signatures were not maintained consistently during the development of the kernel, but it gives a general idea of what systems developers spent most of their effort implementing.
This diagram confirms the large-scale structure of the kernel as outlined earlier. It is interesting to note that very few developers worked on more than one system; where this did occur, it occurred mainly where there is a subsystem dependency. The organization supports the well-known rule of thumb stated by Melvin Conway (see [Raymond 1993]) that system organization often reflects developer organization. Most of the developers worked on hardware device drivers, logical file system modules, network device drivers, and network protocol modules. It's not surprising that these four areas of the kernel have been architected to support extensibility the most.
The process scheduler maintains a block of data for each process that is active. These blocks of data are stored in a linked list called the task list; the process scheduler always maintains a current pointer that indicates the current process that is active.
The memory manager stores a mapping of virtual to physical addresses on a per-process basis, and also stores additional information on how to fetch and replace particular pages. This information is stored in a memory-map data structure that is stored in the process scheduler's task list.
The Virtual File System uses index-nodes (i-nodes) to represent files on a logical file system. The i-node data structure stores the mapping of file block numbers to physical device addresses. I-node data structures can be shared across processes if two processes have the same file open. This sharing is accomplished by both task data blocks pointing to the same i-node.
All of the data structures are rooted at the task list of the process scheduler. Each process on the system has a data structure containing a pointer to its memory mapping information, and also pointers to the i-nodes representing all of the opened files. Finally, the task data structure also contains pointers to data structures representing all of the opened network connections associated with each task.
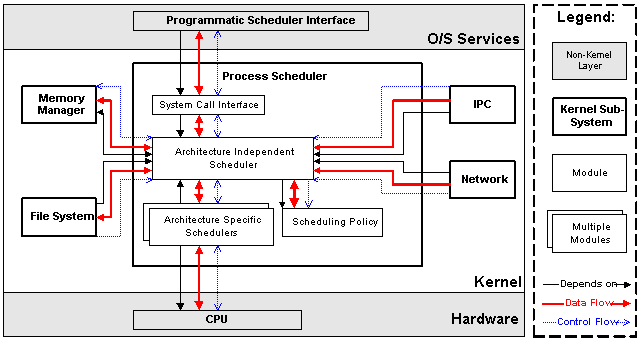
The process scheduler is the most important subsystem in the Linux kernel. Its purpose is to control access to the computer's CPU(s). This includes not only access by user processes, but also access for other kernel subsystems.
The scheduler is divided into four main modules:
The system call interface module permits user processes access to only those resources that are explicitly exported by the kernel. This limits the dependency of user processes on the kernel to a well-defined interface that rarely changes, despite changes in the implementation of other kernel modules.
 |
| Figure 3.1: Process Scheduler Subsystem in Context |
The scheduler maintains a data structure, the task list, with one entry for each active process. This data structure contains enough information to suspend and resume the processes, but also contains additional accounting and state information. This data structure is publicly available throughout the kernel layer
The process scheduler calls the memory manager subsystem as mentioned earlier; because of this, the process scheduler subsystem depends on the memory manager subsystem. In addition, all of the other kernel subsystems depend on the process scheduler to suspend and resume processes while waiting for hardware requests to complete. These dependencies are expressed through function calls and access to the shared task list data structure. All kernel subsystems read and write the data structure representing the current task, leading to bi-directional data flow throughout the system.
In addition to the data and control flow within the kernel layer, the O/S services layer provides an interface for user processes to register for timer notification. This corresponds to the implicit execution architectural style described in [Garlan 1994]. This leads to a flow of control from the scheduler to the user processes. The usual case of resuming a dormant process is not considered a flow of control in the normal sense because the user process cannot detect this operation. Finally, the scheduler communicates with the CPU to suspend and resume processes; this leads to a data flow, and a flow of control. The CPU is responsible for interrupting the currently executing process and allowing the kernel to schedule another process.
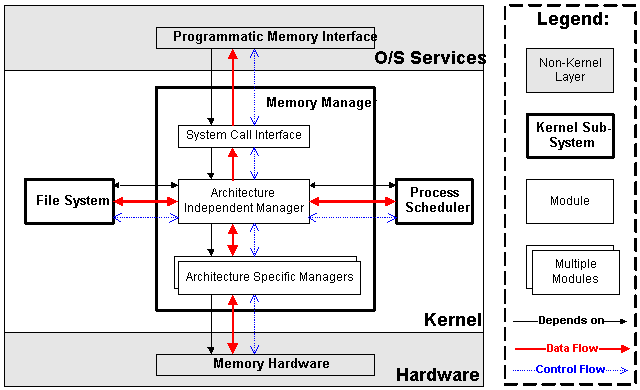
The memory manager subsystem is responsible for controlling process access to the hardware memory resources. This is accomplished through a hardware memory-management system that provides a mapping between process memory references and the machine's physical memory. The memory manager subsystem maintains this mapping on a per process basis, so that two processes can access the same virtual memory address and actually use different physical memory locations. In addition, the memory manager subsystem supports swapping; it moves unused memory pages to persistent storage to allow the computer to support more virtual memory than there is physical memory.
The memory manager subsystem is composed of three modules:
The memory manager stores a per-process mapping of physical addresses to virtual addresses. This mapping is stored as a reference in the process scheduler's task list data structure. In addition to this mapping, additional details in the data block tell the memory manager how to fetch and store pages. For example, executable code can use the executable image as a backing store, but dynamically allocated data must be backed to the system paging file. Finally, the memory manager stores permissions and accounting information in this data structure to ensure system security.
 |
| Figure 3.2: Memory Manager subsystem in context |
The memory manager controls the memory hardware, and receives a notification from the hardware when a page fault occurs -- this means that there is bi-directional data and control flow between the memory manager modules and the memory manager hardware. Also, the memory manager uses the file system to support swapping and memory mapped I/O. This requirement means that the memory manager needs to make procedure calls to the file system to store and fetch memory pages from persistent storage. Because the file system requests cannot be completed immediately, the memory manager needs to suspend a process until the memory is swapped back in; this requirement causes the memory manager to make procedure calls into the process scheduler. Also, since the memory mapping for each process is stored in the process scheduler's data structures, there is a bi-directional data flow between the memory manager and the process scheduler. User processes can set up new memory mappings within the process address space, and can register themselves for notification of page faults within the newly mapped areas. This introduces a control flow from the memory manager, through the system call interface module, to the user processes. There is no data flow from user processes in the traditional sense, but user processes can retrieve some information from the memory manager using select system calls in the system call interface module.
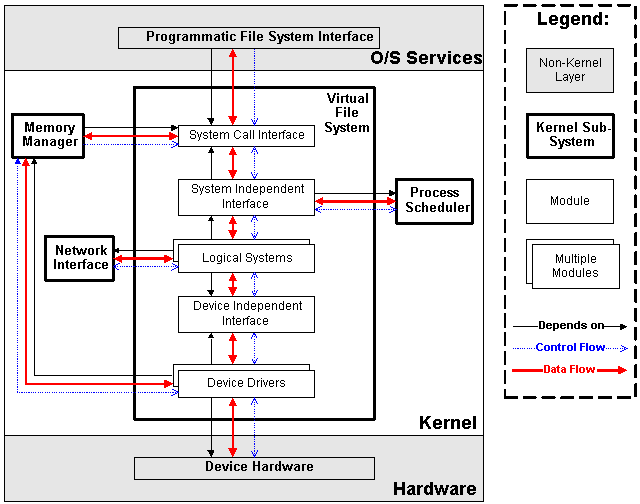 |
| Figure 3.3: Virtual File System in Context |
The virtual file system is designed to present a consistent view of data as stored on hardware devices. Almost all hardware devices in a computer are represented using a generic device driver interface. The virtual file system goes further, and allows the system administrator to mount any of a set of logical file systems on any physical device. Logical file systems promote compatibility with other operating system standards, and permit developers to implement file systems with different policies. The virtual file system abstracts the details of both physical device and logical file system, and allows user processes to access files using a common interface, without necessarily knowing what physical or logical system the file resides on.
In addition to traditional file-system goals, the virtual file system is also responsible for loading new executable programs. This responsibility is accomplished by the logical file system module, and this allows Linux to support several executable formats.
All files are represented using i-nodes. Each i-node structure contains location information for specifying where on the physical device the file blocks are. In addition, the i-node stores pointers to routines in the logical file system module and device driver that will perform required read and write operations. By storing function pointers in this fashion, logical file systems and device drivers can register themselves with the kernel without having the kernel depend on any specific module.
One specific device driver is a ramdisk; this device allocates an area of main memory and treats it as a persistent-storage device. This device driver uses the memory manager to accomplish its tasks, and thus there is a dependency, control flow, and data flow between the file system device drivers and the memory manager.
One of the specific logical file systems that is supported is the network file system (as a client only). This file system accesses files on another machine as if they were part of the local machine. To accomplish this, one of the logical file system modules uses the network subsystem to complete its tasks. This introduces a dependency, control flow, and data flow between the two subsystems.
As mentioned in section 3.2, the memory manager uses the virtual file system to accomplish memory swapping and memory-mapped I/O. Also, the virtual file system uses the process scheduler to disable processes while waiting for hardware requests to complete, and resume them once the request has been completed. Finally, the system call interface allows user processes to call in to the virtual file system to store or retrieve data. Unlike the previous subsystems, there is no mechanism for users to register for implicit invocation, so there is no control flow from the virtual file system towards user processes (resuming processes is not considered control flow).
The network subsystem allows Linux systems to connect to other systems over a network. There are a number of possible hardware devices that are supported, and a number of network protocols that can be used. The network subsystem abstracts both of these implementation details so that user processes and other kernel subsystems can access the network without necessarily knowing what physical devices or protocol is being used.
Finally, the system calls interface module restricts the exported routines that user processes can access.
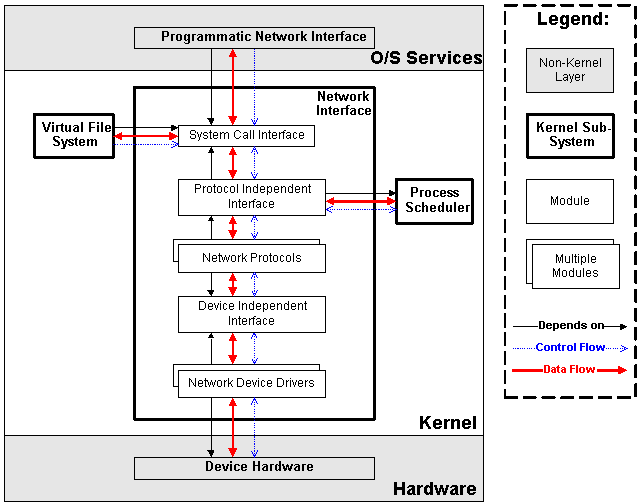 |
| Figure 3.4: Network Interface Subsystem in Context |
Each network object is represented as a socket. Sockets are associated with processes in the same way that i-nodes are associated; sockets can be share amongst processes by having both of the task data structures pointing to the same socket data structure.
The network subsystem uses the process scheduler to suspend and resume processes while waiting for hardware requests to complete (leading to a subsystem dependency and control and data flow). In addition, the network subsystem supplies the virtual file system with the implementation of a logical file system (NFS) leading to the virtual file system depending on the network interface and having data and control flow with it.
The architecture of the inter-process communication subsystem is omitted for brevity since it is not as interesting as the other subsystems.
The Linux kernel is one layer in the architecture of the entire Linux system. The kernel is conceptually composed of five major subsystems: the process scheduler, the memory manager, the virtual file system, the network interface, and the inter-process communication interface. These subsystems interact with each other using function calls and shared data structures.
At the highest level, the architectural style of the Linux kernel is closes to Garlan and Shaw's Data Abstraction style ([Garlan1994]); the kernel is composed of subsystems that maintain internal representation consistency by using a specific procedural interface. As each of the subsystems is elaborated, we see an architectural style that is similar to the layered style presented by Garlan and Shaw. Each of the subsystems is composed of modules that communicate only with adjacent layers.
The conceptual architecture of the Linux kernel has proved its success; essential factors for this success were the provision for the organization of developers, and the provision for system extensibility. The Linux kernel architecture was required to support a large number of independent volunteer developers. This requirement suggested that the system portions that require the most development -- the hardware device drivers and the file and network protocols -- be implemented in an extensible fashion. The Linux architect chose to make these systems be extensible using a data abstraction technique: each hardware device driver is implemented as a separate module that supports a common interface. In this way, a single developer can add a new device driver, with minimal interaction required with other developers of the Linux kernel. The success of the kernel implementation by a large number of volunteer developers proves the correctness of this strategy.
Another important extension to the Linux kernel is the addition of more supported hardware platforms. The architecture of the system supports this extensibility by separating all hardware-specific code into distinct modules within each subsystem. In this way, a small group of developers can effect a port of the Linux kernel to a new hardware architecture by re-implementing only the machine-specific portions of the kernel.