Neural Networks¶
ML implements feed-forward artificial neural networks or, more particularly, multi-layer perceptrons (MLP), the most commonly used type of neural networks. MLP consists of the input layer, output layer, and one or more hidden layers. Each layer of MLP includes one or more neurons directionally linked with the neurons from the previous and the next layer. The example below represents a 3-layer perceptron with three inputs, two outputs, and the hidden layer including five neurons:
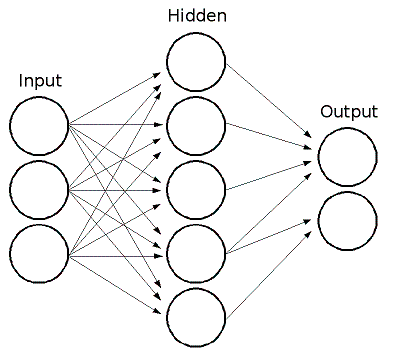
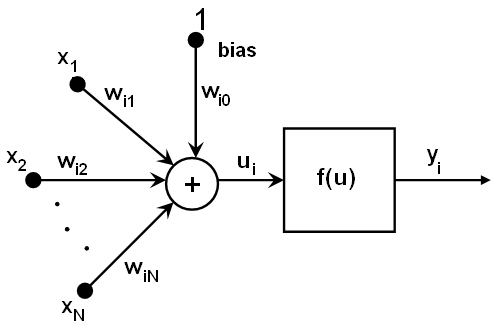
All the neurons in MLP are similar. Each of them has several input links (it takes the output values from several neurons in the previous layer as input) and several output links (it passes the response to several neurons in the next layer). The values retrieved from the previous layer are summed up with certain weights, individual for each neuron, plus the bias term. The sum is transformed using the activation function
 that may be also different for different neurons.
that may be also different for different neurons.
In other words, given the outputs
 of the layer
of the layer
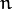 , the outputs
, the outputs
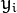 of the layer
of the layer
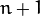 are computed as:
are computed as:
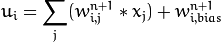
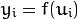
Different activation functions may be used. ML implements three standard functions:
Identity function (
CvANN_MLP::IDENTITY):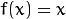
Symmetrical sigmoid (
CvANN_MLP::SIGMOID_SYM):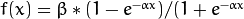 ), which is the default choice for MLP. The standard sigmoid with
), which is the default choice for MLP. The standard sigmoid with
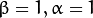 is shown below:
is shown below: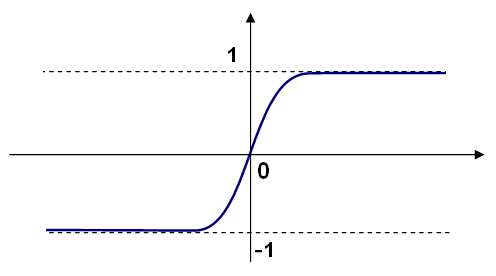
Gaussian function (
CvANN_MLP::GAUSSIAN):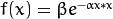 , which is not completely supported at the moment.
, which is not completely supported at the moment.
In ML, all the neurons have the same activation functions, with the same free parameters (
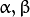 ) that are specified by user and are not altered by the training algorithms.
) that are specified by user and are not altered by the training algorithms.
So, the whole trained network works as follows:
- Take the feature vector as input. The vector size is equal to the size of the input layer.
- Pass values as input to the first hidden layer.
- Compute outputs of the hidden layer using the weights and the activation functions.
- Pass outputs further downstream until you compute the output layer.
So, to compute the network, you need to know all the
weights
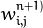 . The weights are computed by the training
algorithm. The algorithm takes a training set, multiple input vectors
with the corresponding output vectors, and iteratively adjusts the
weights to enable the network to give the desired response to the
provided input vectors.
. The weights are computed by the training
algorithm. The algorithm takes a training set, multiple input vectors
with the corresponding output vectors, and iteratively adjusts the
weights to enable the network to give the desired response to the
provided input vectors.
The larger the network size (the number of hidden layers and their sizes) is,
the more the potential network flexibility is. The error on the
training set could be made arbitrarily small. But at the same time the
learned network also “learns” the noise present in the training set,
so the error on the test set usually starts increasing after the network
size reaches a limit. Besides, the larger networks are trained much
longer than the smaller ones, so it is reasonable to pre-process the data,
using
PCA::operator() or similar technique, and train a smaller network
on only essential features.
Another MLP feature is an inability to handle categorical
data as is. However, there is a workaround. If a certain feature in the
input or output (in case of n -class classifier for
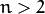 ) layer is categorical and can take
) layer is categorical and can take
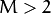 different values, it makes sense to represent it as a binary tuple of
different values, it makes sense to represent it as a binary tuple of M elements, where the i -th element is 1 if and only if the
feature is equal to the i -th value out of M possible. It
increases the size of the input/output layer but speeds up the
training algorithm convergence and at the same time enables “fuzzy” values
of such variables, that is, a tuple of probabilities instead of a fixed value.
ML implements two algorithms for training MLP’s. The first algorithm is a classical random sequential back-propagation algorithm. The second (default) one is a batch RPROP algorithm.
| [BackPropWikipedia] | http://en.wikipedia.org/wiki/Backpropagation. Wikipedia article about the back-propagation algorithm. |
| [LeCun98] |
|
| [RPROP93] |
|
CvANN_MLP_TrainParams¶
-
struct
CvANN_MLP_TrainParams¶ Parameters of the MLP training algorithm. You can initialize the structure by a constructor or the individual parameters can be adjusted after the structure is created.
The back-propagation algorithm parameters:
-
double
bp_dw_scale¶ Strength of the weight gradient term. The recommended value is about 0.1.
-
double
bp_moment_scale¶ Strength of the momentum term (the difference between weights on the 2 previous iterations). This parameter provides some inertia to smooth the random fluctuations of the weights. It can vary from 0 (the feature is disabled) to 1 and beyond. The value 0.1 or so is good enough
The RPROP algorithm parameters (see [RPROP93] for details):
-
double
rp_dw0¶ Initial value
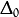 of update-values
of update-values 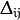 .
.
-
double
rp_dw_plus¶ Increase factor
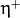 . It must be >1.
. It must be >1.
-
double
rp_dw_minus¶ Decrease factor
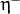 . It must be <1.
. It must be <1.
-
double
rp_dw_min¶ Update-values lower limit
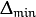 . It must be positive.
. It must be positive.
-
double
rp_dw_max¶ Update-values upper limit
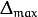 . It must be >1.
. It must be >1.
-
double
CvANN_MLP_TrainParams::CvANN_MLP_TrainParams¶
The constructors.
-
C++:
CvANN_MLP_TrainParams::CvANN_MLP_TrainParams()¶
-
C++:
CvANN_MLP_TrainParams::CvANN_MLP_TrainParams(CvTermCriteria term_crit, int train_method, double param1, double param2=0 )¶ Parameters: - term_crit – Termination criteria of the training algorithm. You can specify the maximum number of iterations (
max_iter) and/or how much the error could change between the iterations to make the algorithm continue (epsilon). - train_method –
Training method of the MLP. Possible values are:
- CvANN_MLP_TrainParams::BACKPROP The back-propagation algorithm.
- CvANN_MLP_TrainParams::RPROP The RPROP algorithm.
- param1 – Parameter of the training method. It is
rp_dw0forRPROPandbp_dw_scaleforBACKPROP. - param2 – Parameter of the training method. It is
rp_dw_minforRPROPandbp_moment_scaleforBACKPROP.
- term_crit – Termination criteria of the training algorithm. You can specify the maximum number of iterations (
By default the RPROP algorithm is used:
CvANN_MLP_TrainParams::CvANN_MLP_TrainParams()
{
term_crit = cvTermCriteria( CV_TERMCRIT_ITER + CV_TERMCRIT_EPS, 1000, 0.01 );
train_method = RPROP;
bp_dw_scale = bp_moment_scale = 0.1;
rp_dw0 = 0.1; rp_dw_plus = 1.2; rp_dw_minus = 0.5;
rp_dw_min = FLT_EPSILON; rp_dw_max = 50.;
}
CvANN_MLP¶
-
class
CvANN_MLP: publicCvStatModel¶
MLP model.
Unlike many other models in ML that are constructed and trained at once, in the MLP model these steps are separated. First, a network with the specified topology is created using the non-default constructor or the method CvANN_MLP::create(). All the weights are set to zeros. Then, the network is trained using a set of input and output vectors. The training procedure can be repeated more than once, that is, the weights can be adjusted based on the new training data.
CvANN_MLP::CvANN_MLP¶
The constructors.
-
C++:
CvANN_MLP::CvANN_MLP()¶
-
C++:
CvANN_MLP::CvANN_MLP(const CvMat* layerSizes, int activateFunc=CvANN_MLP::SIGMOID_SYM, double fparam1=0, double fparam2=0 )¶
-
Python:
cv2.ANN_MLP([layerSizes[, activateFunc[, fparam1[, fparam2]]]]) → <ANN_MLP object>¶
The advanced constructor allows to create MLP with the specified topology. See CvANN_MLP::create() for details.
CvANN_MLP::create¶
Constructs MLP with the specified topology.
-
C++:
CvANN_MLP::create(const Mat& layerSizes, int activateFunc=CvANN_MLP::SIGMOID_SYM, double fparam1=0, double fparam2=0 )¶
-
C++:
CvANN_MLP::create(const CvMat* layerSizes, int activateFunc=CvANN_MLP::SIGMOID_SYM, double fparam1=0, double fparam2=0 )¶
-
Python:
cv2.ANN_MLP.create(layerSizes[, activateFunc[, fparam1[, fparam2]]]) → None¶ Parameters: - layerSizes – Integer vector specifying the number of neurons in each layer including the input and output layers.
- activateFunc – Parameter specifying the activation function for each neuron: one of
CvANN_MLP::IDENTITY,CvANN_MLP::SIGMOID_SYM, andCvANN_MLP::GAUSSIAN. - fparam1 – Free parameter of the activation function,
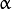 . See the formulas in the introduction section.
. See the formulas in the introduction section. - fparam2 – Free parameter of the activation function,
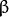 . See the formulas in the introduction section.
. See the formulas in the introduction section.
The method creates an MLP network with the specified topology and assigns the same activation function to all the neurons.
CvANN_MLP::train¶
Trains/updates MLP.
-
C++:
CvANN_MLP::train(const Mat& inputs, const Mat& outputs, const Mat& sampleWeights, const Mat& sampleIdx=Mat(), CvANN_MLP_TrainParams params=CvANN_MLP_TrainParams(), int flags=0 )¶
-
C++:
CvANN_MLP::train(const CvMat* inputs, const CvMat* outputs, const CvMat* sampleWeights, const CvMat* sampleIdx=0, CvANN_MLP_TrainParams params=CvANN_MLP_TrainParams(), int flags=0 )¶
-
Python:
cv2.ANN_MLP.train(inputs, outputs, sampleWeights[, sampleIdx[, params[, flags]]]) → retval¶ Parameters: - inputs – Floating-point matrix of input vectors, one vector per row.
- outputs – Floating-point matrix of the corresponding output vectors, one vector per row.
- sampleWeights – (RPROP only) Optional floating-point vector of weights for each sample. Some samples may be more important than others for training. You may want to raise the weight of certain classes to find the right balance between hit-rate and false-alarm rate, and so on.
- sampleIdx – Optional integer vector indicating the samples (rows of
inputsandoutputs) that are taken into account. - params – Training parameters. See the
CvANN_MLP_TrainParamsdescription. - flags –
Various parameters to control the training algorithm. A combination of the following parameters is possible:
- UPDATE_WEIGHTS Algorithm updates the network weights, rather than computes them from scratch. In the latter case the weights are initialized using the Nguyen-Widrow algorithm.
- NO_INPUT_SCALE Algorithm does not normalize the input vectors. If this flag is not set, the training algorithm normalizes each input feature independently, shifting its mean value to 0 and making the standard deviation equal to 1. If the network is assumed to be updated frequently, the new training data could be much different from original one. In this case, you should take care of proper normalization.
- NO_OUTPUT_SCALE Algorithm does not normalize the output vectors. If the flag is not set, the training algorithm normalizes each output feature independently, by transforming it to the certain range depending on the used activation function.
This method applies the specified training algorithm to computing/adjusting the network weights. It returns the number of done iterations.
The RPROP training algorithm is parallelized with the TBB library.
If you are using the default cvANN_MLP::SIGMOID_SYM activation function then the output should be in the range [-1,1], instead of [0,1], for optimal results.
CvANN_MLP::predict¶
Predicts responses for input samples.
-
C++:
CvANN_MLP::predict(const Mat& inputs, Mat& outputs)const¶
-
C++:
CvANN_MLP::predict(const CvMat* inputs, CvMat* outputs)const¶
-
Python:
cv2.ANN_MLP.predict(inputs[, outputs]) → retval, outputs¶ Parameters: - inputs – Input samples.
- outputs – Predicted responses for corresponding samples.
The method returns a dummy value which should be ignored.
If you are using the default cvANN_MLP::SIGMOID_SYM activation function with the default parameter values fparam1=0 and fparam2=0 then the function used is y = 1.7159*tanh(2/3 * x), so the output will range from [-1.7159, 1.7159], instead of [0,1].
CvANN_MLP::get_layer_count¶
Returns the number of layers in the MLP.
-
C++:
CvANN_MLP::get_layer_count()¶
Help and Feedback
You did not find what you were looking for?- Ask a question on the Q&A forum.
- If you think something is missing or wrong in the documentation, please file a bug report.