NLP and Big Data
Using NLTK and Hadoop
NLP needs Big Data
The science that has been developed around the facts of language passed through three stages before finding its true and unique object. First something called "grammar" was studied. This study, initiated by the Greeks and continued mainly by the French, was based on logic. It lacked a scientific approach and was detached from language itself. Its only aim was to give rules for distinguishing between correct and incorrect forms; it was a normative discipline, far removed from actual observation, and its scope was limited.
-- Ferdinand de Saussure
NLP needs Big Data
Using Hadoop with NLTK
- Computational Lingusitics methodologies are stochastic
- Examples are easier to create than rules
- Rules and Logic miss frequency and language dynamics
- Humans use lots of data for the same task- It's AI!
- More data is better - relevance is in the long tail
- If you don't have enough data - hire a knowledge engineer
Big Data will need NLP
Big Data will need NLP
Using NLTK with Hadoop
- Hadoop is great at massive amounts of text data
- However, current methods aren't really NLP
- Indexing, Co-Occurrence, even N-Gram Modeling is search
- We haven't exhausted frequency analysis yet
- But when we do, we're going to want semantic analyses
Domain Knowledge is IMPORTANT



- Stochastic methods are not universal
- Domain specific training sets and knowledge required
Capitol Words
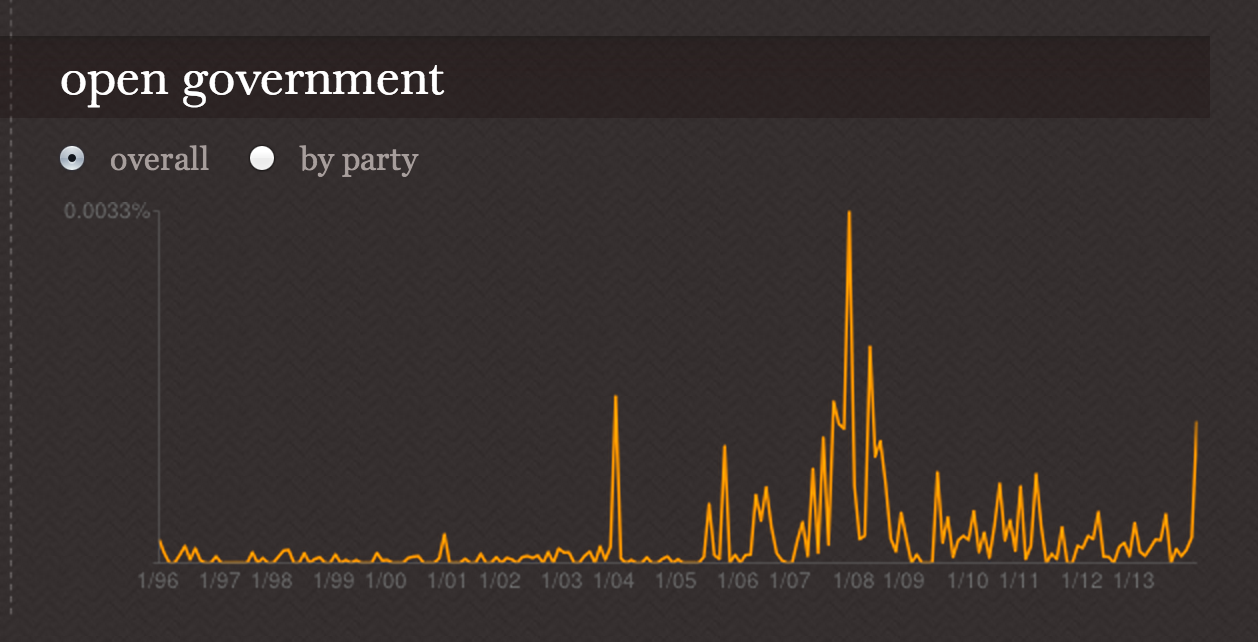
The Foo of Big Data
Given a large data set and domain specific knowledge:
- Form hypothesis (a data product)
- Mix in NLP techniques and machine learning tools
- Perform computation and test hypothesis
- Add to data set and domain knowledge
- Repeat
We have a wealth of data and can iterate rapidly!
Why NLTK?

- It's not Stanford
- It's Open Source (the price is right)
- The blessing (and curse) of choice
- It lets you use your domain knowledge (it forces you to)
Why Hadoop?

- Silly question at a Big Data talk?
- Who doesn't have a distribution? Intel has one!
- NLP is embarrassingly parallel, perfect for Map Reduce.
- You've got a cluster in your closet.
Does Hadoop really do native tokenization?

- Word count is your first Hadoop program
- (sometimes also called segmentation or chunking)
- Not as simple as splitting on punctuation and whitespace
- Different NLP tasks require different kinds of tokenization
You're not going to the U.S.A. in that super-zeppelin, Dr. Stoddard?
Preprocessing Unstructured Text

- Hadoop stores output as it's own file
- Map/Reduce jobs are now essentially built-in preprocessors
- Last-mile computation can be done in 100GB of Memory
- Hadoop is best for a series of jobs that transform data to something machine tractable
- In NLP this means: text → tokenized → tagged → parsed → Treebank

Hadoop is Java and NLTK is Python, how to make them play?
Comic Attribution: askrahul.com
Now We Start Typing
- Intro to Hadoop Streaming with Python
- An NLP token count with Dumbo
Hadoop Streaming
- Supply any executable to Hadoop as the mapper or reducer
- Key Value pairs read from
stdinand pushed tostdout - All Hadoopy-ness still exists, only the mapper and reducer get to be replaced
mapper.py
import sys
class Mapper(object):
def __init__(self, infile=sys.stdin, separator='\t'):
self.infile = infile
self.sep = separator
def emit(self, key, value):
sys.stdout.write("%s%s%s\n" % (key, self.sep, value))
def map(self):
for line in self:
for word in line.split():
self.emit(word, 1)
def __iter__(self):
for line in self.infile:
yield line
if __name__ == "__main__":
mapper = Mapper()
mapper.map()reducer.py
import sys
from itertools import groupby
from operator import itemgetter
class Reducer(object):
def __init__(self, infile=sys.stdin, separator="\t"):
self.infile = infile
self.sep = separator
def emit(self, key, value):
sys.stdout.write("%s%s%s\n" % (key, self.sep, value))
def reduce(self):
for current, group in groupby(self, itemgetter(0)):
try:
total = sum(int(count) for current, count in group)
self.emit(current, total)
except ValueError:
pass
def __iter__(self):
for line in self.infile:
yield line.rstrip().split(self.sep, 1)
if __name__ == "__main__":
reducer = Reducer()
reducer.reduce()Running the Job
hduser@ubuntu:/usr/local/hadoop$ bin/hadoop jar contrib/streaming/hadoop-*streaming*.jar \
-file /home/hduser/mapper.py -mapper /home/hduser/mapper.py \
-file /home/hduser/reducer.py -reducer /home/hduser/reducer.py \
-input /user/hduser/gutenberg/* -output /user/hduser/gutenberg-outputtoken_count.py
import nltk
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import wordpunct_tokenize
class Mapper(object):
def __init__(self):
if 'stopwords' in self.params:
with open(self.params['stopwords'], 'r') as excludes:
self._stopwords = set(line.strip() for line in excludes)
else:
self._stopwords = None
self.lemmatizer = WordNetLemmatizer()
def __call__(self, key, value):
for word in self.tokenize(value):
if not word in self.stopwords:
yield word, 1
def normalize(self, word):
word = word.lower()
return self.lemmatizer.lemmatize(word)
def tokenize(self, sentence):
for word in wordpunct_tokenize(sentence):
yield self.normalize(word)
@property
def stopwords(self):
if not self._stopwords:
self._stopwords = nltk.corpus.stopwords.words('english')
return self._stopwords
def reducer(key, values):
yield key, sum(values)
def runner(job):
job.additer(Mapper, reducer, reducer)
def starter(prog):
excludes = prog.delopt("stopwords")
if excludes: prog.addopt("param", "stopwords="+excludes)
if __name__ == "__main__":
import dumbo
dumbo.main(runner, starter)Running the job
hduser@ubuntu:~$ dumbo start token_count.py \
-input /user/hduser/gutenberg
-output /user/hduser/gutenberg-output
-hadoop $HADOOP_BIN
-hadooplib $HADOOP_CLASSPATHImportant Notes
- An Interpreter is loaded for every job (no multiprocessing)
- NLTK data loading only happens ONCE!
- Use generators to save on memory
- Other Libraries exist for quickly creating tools.
Pro Tips

- Reusable tasks for generating domain-specific knowledge
- NLTK Trainer loads from Pickled Data
- We generated tag data sets, lexicons, PCFGs
- 10-fold training/test/validation on your corpus