Data Types
In the object hierarchy under any database, you will find Data Types. Data Types can be added by selecting CREATE DATA TYPE from the Data Types context menu. Once a data type has been created, it can also be commented on and dropped. This section describes how to create, comment on, and drop a data type with RHDB Administrator.
In this example, you will create a data type called my_data_type.
A data type is an object under a database, so to create a data type, first expand the database under which you wish to create the data type (click the + beside the database name).
Right-click on Data Types and select CREATE DATA TYPE.
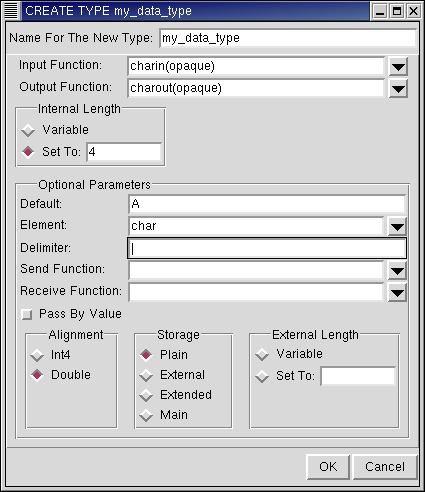
The first field is the name of the data type. Type the name: my_data_type.
Next, you must define the Input Function and Output Function. The Input Function is the function that converts the external representation of the user-defined data type into an internal representation for PostgreSQL's use. The Output Function describes the function that converts data from the internal representation to an external form that is analogous to the user-defined type.
For this example, use charin(opaque) as the input function, and charout(opaque) as the output function.

Generally, the input and output functions are selected to take in "opaque" (any type) as an argument. However there are other limited options that may be used. Refer to the Red Hat Database SQL Guide and Reference for more information.
Specify the Internal Length of the new data type. Variable allows the length to vary depending on the data being stored. If a value is entered in the Set To field, then that many bytes are used to store the data type, regardless of how much space it would have otherwise taken.
For this example, set the Internal Length to 4.
The Default field specifies the default value for the data type. The value entered in this field is used in instances that make use of this data type but where the value for the type was not specified. For example, if a column was created with this data type and an entry was made into the table containing that column with the value for the column left blank, then the value would automatically be set to this "default value" of the data type. (Note that if you have specified the default value for that column, that takes precedence and the default value for the data type is ignored.)
For this example, set the Default to A.
The Element field is used when the type being created is to be an array of another type; this field holds that other type.
This example will use char as the Element, so the Data Type that is created is an array of characters.
When a data type is created, PostgreSQL automatically creates another data type that is an array of the newly created type, so when this data type is created, the backend will automatically create a type called "_my_data_type", which is an array of type my_data_type.)
Next is the Delimiter field. When creating an array of a user-defined type, a delimiter needs to be specified so that the elements can be distinguished. If a value is entered in the Delimiter field of the Create dialog, that value can then be used as the delimiter when specifying arrays of the user type. If no delimiter is specified, comma (,) is used as the delimiter.
For this example, use '|' as a delimiter.
The Send Function and Receive Function are not currently implemented in the backend. The Input Function and Output Function are used for conversion between internal and external representation and vice versa. The Send and Receive functions may someday be used to specify machine-independent binary representations.
The Pass By Value check box signifies how the data type is passed around. If checked, the data type's "value" is passed around. If left unchecked, a reference to the data type is passed around. Pass By Value may be specified only when the internal length of the data type is less than the width of the datum on the machine running the database server.
For this example, leave Pass By Value unchecked.
Alignment specifies the storage alignment required for the data type. If the data type has a variable internal length, the Alignment must be at least 4 bytes because the Variable length uses at least 4 bytes.
For this example, specify the alignment; as the internal length has been set to 4, set the Alignment to Double.
Storage specifies the storage strategy for the data type. If the data type is of fixed-length, only Plain Storage can be used. If not specified, Plain is used as the default by the backend.
The External Length specifies the external representation length. The current backend does not support specific external lengths and considers all external lengths to be variable.
Click OK to create the data type.
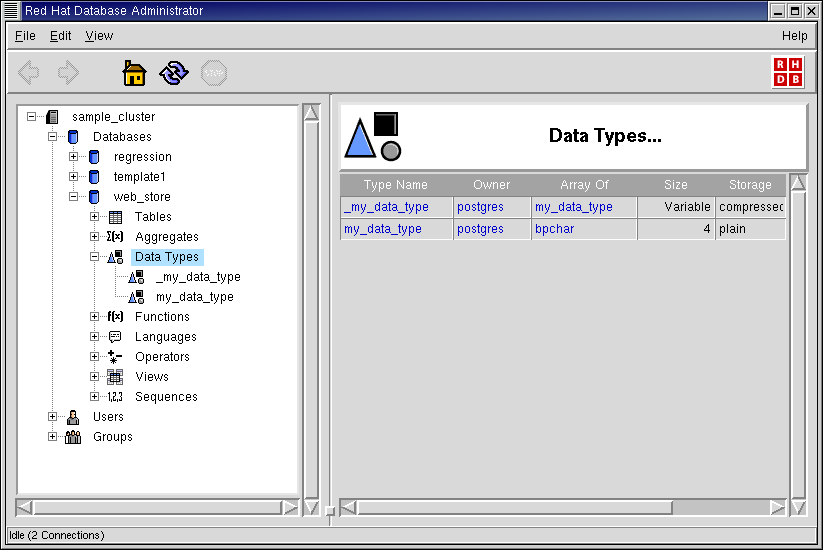
Note that the data type my_data_type has been added under the Data Types node in the Tree View.
RHDB Administrator also enables you to perform the following operations on existing data types:
- Dropping
To drop a user data type, right-click on the the data type and select DROP DATA TYPE. If View -> Ask For Confirmations is enabled, you are asked to confirm that you want the data type dropped; if it is disabled, the data type is dropped immediately. This action cannot be undone.
- Commenting
PostgreSQL allows commenting on data types, which makes it easier to identify the data types. To comment on a data type, right-click on it, and select COMMENT. A dialog asks for the comment. If there is already a comment on the data type, this comment is displayed. Type the new comment in the edit box and click OK (or press
[Enter] ) to save the new comment.
Refer to the Red Hat Database SQL Guide and Reference for more information on data types.