| Red Hat Docs > Manuals > Red Hat High Availability Server Manuals > |
| Red Hat Linux 6.2: The Official Red Hat High Availability Server Installation Guide | ||
|---|---|---|
| Prev | Chapter 7. Failover Services (FOS) | Next |
While the architecture of an FOS cluster consists of relatively few components, it is important to completely understand how these components work together to provide highly-available services. This section discusses FOS in more detail.
A node in an FOS cluster is defined as being either a primary or a backup system. The two types operate identically except in two situations:
In cases where both nodes of a two node cluster attempt to declare themselves as actively providing services (a quorum tie), the primary node will always win the stalemate and force the backup system to become an inactive standby.
An FOS cluster will always have a primary node; there are no configuration options to eliminate it. If a single-node cluster is defined (a configuration allowed by Piranha for use with other components, but of no value in an FOS setup), then that single node must be configured as a primary. Note that this is not the same situation as when a two node cluster has one node down — in that case the remaining node will be either a primary or backup, depending on which node failed, and which is still running.
All nodes in a running FOS cluster will be operating in one of the following states at any point in time:
Table 7-1. FOS Node States
| State | Description |
|---|---|
| Active | The node is providing the configured IP services to the public users. Only one node in an FOS cluster is allowed to be the active node at any point in time. |
| Inactive | The node is acting as a standby system while the other node (sometimes referred to as its partner) is active. The inactive node monitors the services on the active node, and will become the active node if it detects one of those services failing to respond. |
| Dead | The node is down, or its services are non-responsive. |
Each of the cluster nodes send a periodic heartbeat message to the network, with an indication of whether that node is currently active or inactive. Each node expects to see a heartbeat message from its partner. If it is not received, this is considered a failure of that system and may result in a failover of services. This test is independent of the IP service monitoring.
When the inactive node fails to see the heartbeat of the active node, it treats the missing heartbeat as indicating a cluster failure, and will perform a failover of all services. If the active node fails to see a heartbeat from the inactive node, the inactive system is logged as being unavailable for failover, while the services continue normal operation on the active node.
Failover in an FOS cluster is accomplished through the use of VIP (Virtual IP) addresses. They are virtual because they exist as additional IP addresses to the node's regular host IP address. In other words, a node can have multiple IP addresses, all on the same network interface. A node can be accessed by its VIP address(es) as well as by its regular host address.
VIP addresses are a feature of Linux and can be defined on any network interface present. For FOS, the VIP addresses and their network interfaces have to be accessible by the clients on the public network.
Each service defined in FOS requires a VIP address, a port number, a start command (or script name), and a stop/shutdown command (or script name). Each service can be defined as having a different VIP address, or some (or all) can use the same VIP address. Services currently cannot failover individually — when one service fails, they all failover to the inactive system. This means that in most cases there is little value in specifying individual VIP addresses for services. However, there are some cases where this may be desirable:
You have an existing environment where the IP services are already being provided by different servers, and you are using FOS to consolidate them to a single, more fault-tolerant cluster. In this case, using their previous IP addresses as VIP addresses will allow you to migrate without needing to change any client systems.
You anticipate long-term growth in the use of each service. Using different VIP addresses now may make it easier to migrate the individual services to separate, dedicated FOS clusters in the future, while reducing the possible impact of changes on client systems.
In general, however, it is recommended that you use the same VIP address for all FOS services. Because a single VIP address means only one VIP address must be moved from the active node to the inactive node during failover, a single VIP address means faster, more reliable failovers.
Each service is also allowed two optional parameters: a send string and an expect string. If specified, these strings will be used as part of the service monitoring that will test whether the service is actually responding. If they are not specified, the service will be considered functional if a socket connection attempt to it succeeds.
On the inactive node, a monitoring daemon is run for each FOS service on the active node. Each monitoring daemon, called nanny, periodically tests a service on the active node. The test goes through the following steps:
The first test is whether a connection to that service's tcp/ip port is successful or not. If an error results, that service is considered dysfunctional and a failover occurs. Otherwise, the test continues.
If it has been supplied, a character string (the send string) is sent to service's port. If an error occurs, the service is considered dysfunctional, and a failover occurs. Otherwise, the test continues.
If an expect string is supplied, an attempt to receive a response takes place. If an error occurs, a response is not received, or the response does not match the expect string, the service is considered dysfunctional, and a failover occurs. Otherwise, the service is considered functional.
When nanny monitors a service, it connects using the active node's host IP address rather than the VIP address of the service. This is done to ensure cluster reliability. There are windows during service failure (and the subsequent failover) where the VIP address may exist on both cluster nodes, or be missing altogether. Using the host IP address instead of the VIP address to monitor a service ensures that the correct system is always being examined and tested.
The following diagram illustrates the service monitoring logic used by FOS:
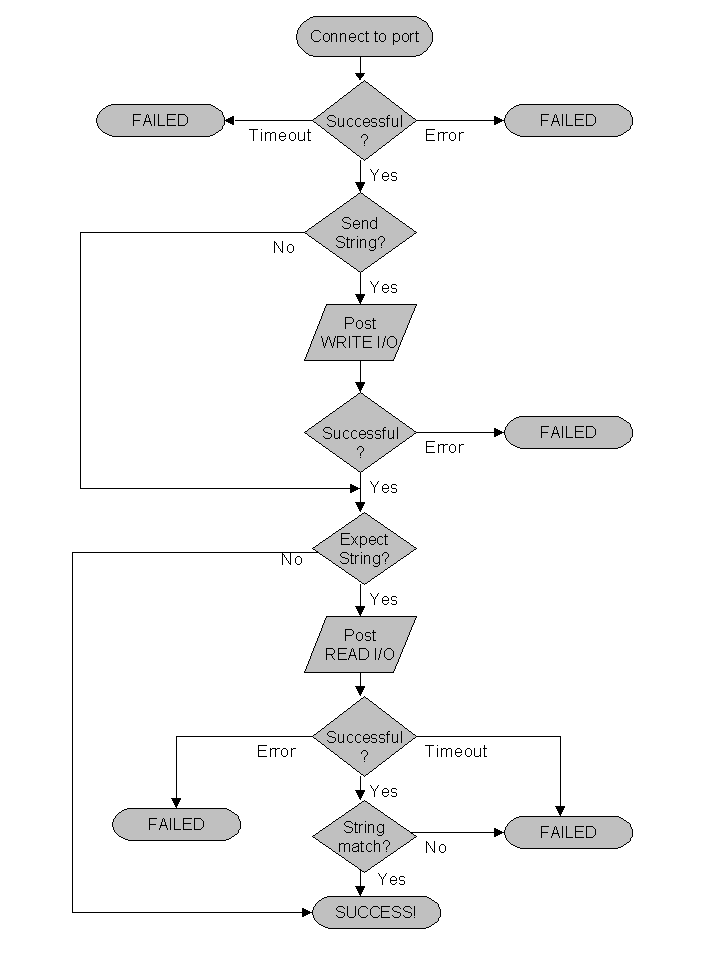
Figure 7-1. Service Monitoring Logic
FOS automatically creates, deletes, or moves VIP addresses based on the information in its configuration file. Each time FOS changes a VIP address, ARP broadcasts are sent out to inform the connected network that the MAC address for the VIP address has changed. If an end-user accesses a service by referring to its VIP address and port, it will be transparent which system is actually providing that service.
In normal operation, an FOS system will have one active node with running services (and their associated VIP addresses), and an inactive node monitoring the services on the active node. This is illustrated below:
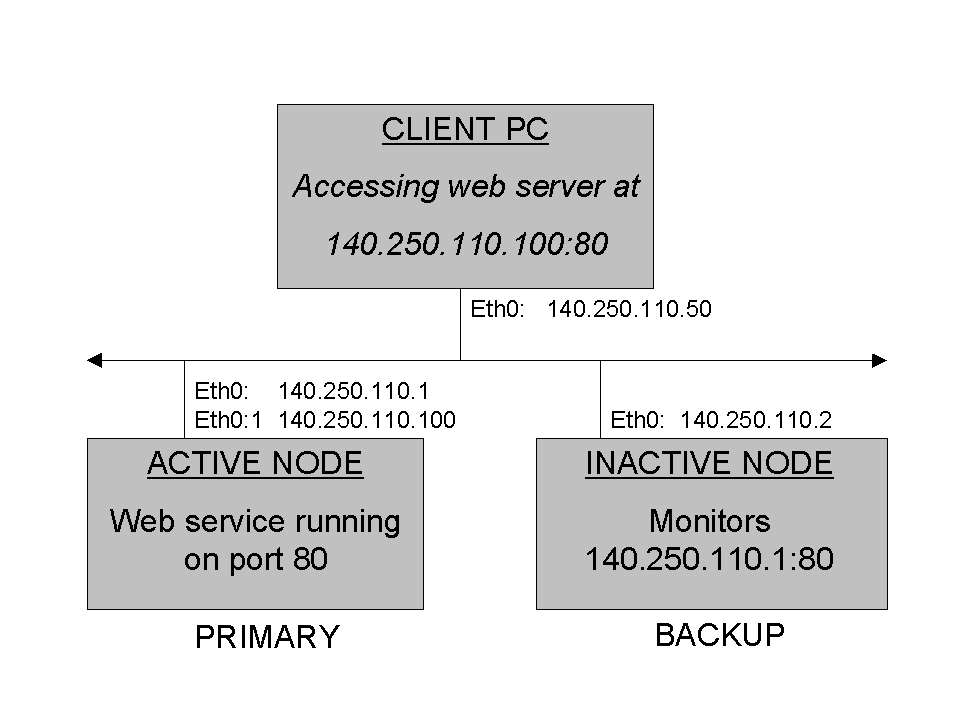
Figure 7-2. Running FOS Cluster Before Failover
When a failover occurs, the service VIP addresses are recreated on the inactive node, and the inactive node becomes active by starting the services. The originally-active system is notified (by heartbeat) that it should become inactive (if possible, depending on the failure situation). If it does go inactive, it will stop all services, start the monitoring programs, and become eligible for a failover should the new active system suffer an outage. This is illustrated below:
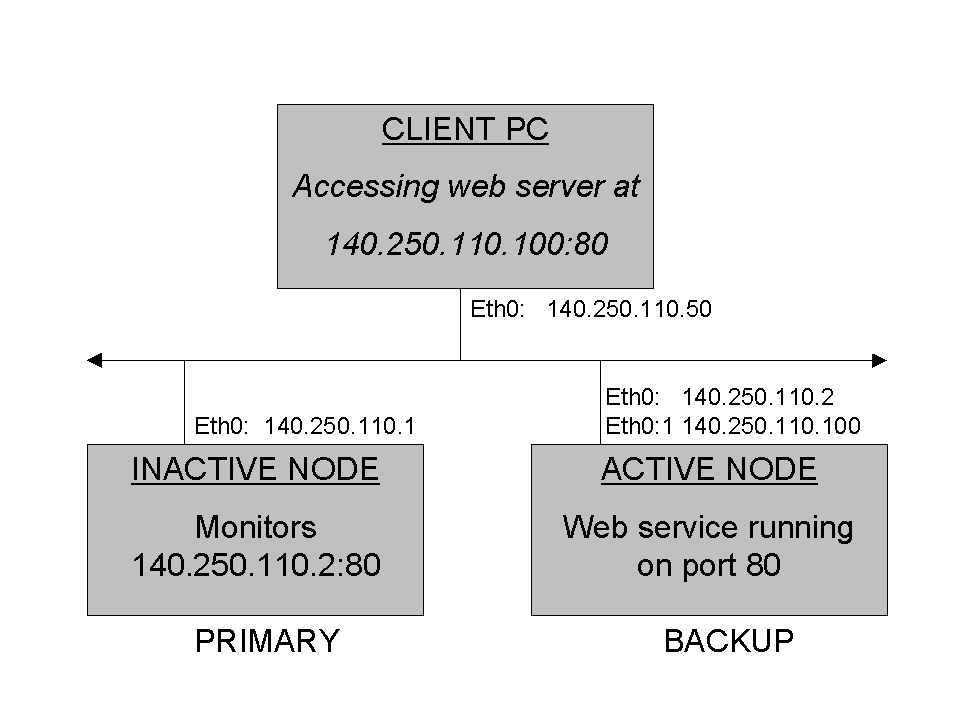
Figure 7-3. Running FOS Cluster After Failover
If, for some reason, the services on the originally-active system cannot be stopped, it does not interfere with the cluster, because the VIP addresses have been moved to the new active system, directing all traffic away from the originally-active system.
An FOS system consists of the following components:
Table 7-2. FOS Components
| Component | Description |
|---|---|
| Piranha Web Interface | A graphical interface for creating and maintaining the cluster configuration file. (Please read Chapter 9 for more information on the Piranha Web Interface.) |
| /etc/lvs.cf | The cluster configuration file. Can be any filename desired; this is the default. The FOS-related contents of this file are detailed later in this document. |
| /usr/sbin/pulse | Main Piranha program and daemon process. Provides and tests for a heartbeat between the cluster nodes. Also starts and stops the fos daemon process as needed. |
| /etc/rc.d/init.d/pulse | Start and stop script for the pulse program. |
| /usr/sbin/fos | Main FOS program and daemon. Started by pulse, this program operates in two modes. On the active node, it is started using a --active option which causes it to automatically start and stop the IP service(s). On the inactive node, it is started with a --monitor option which causes it to start and stop the nanny service monitoring daemon(s). When a failure is detected by the inactive node, the fos daemon initiates a failover by exiting, which in turn causes pulse to restart it using the --active option, and to notify the partner cluster node that it is to go inactive. |
| /usr/sbin/nanny | Service monitoring program and daemon. Started by fos, there is one nanny daemon for each defined service to monitor. The nanny processes only run on the inactive system, and monitor the services on the active system for failure. If a failure is detected, the nanny daemon notifies the fos daemon of the failure by exiting, which in turn causes fos to terminate all other nanny processes. Then fos exits to notify the pulse daemon that a failure has occurred. |
| /usr/sbin/send_arp | Program used by fos to broadcast to the public network which system is currently providing the service for a VIP address. |
The components on a running FOS system supporting two services looks like this:
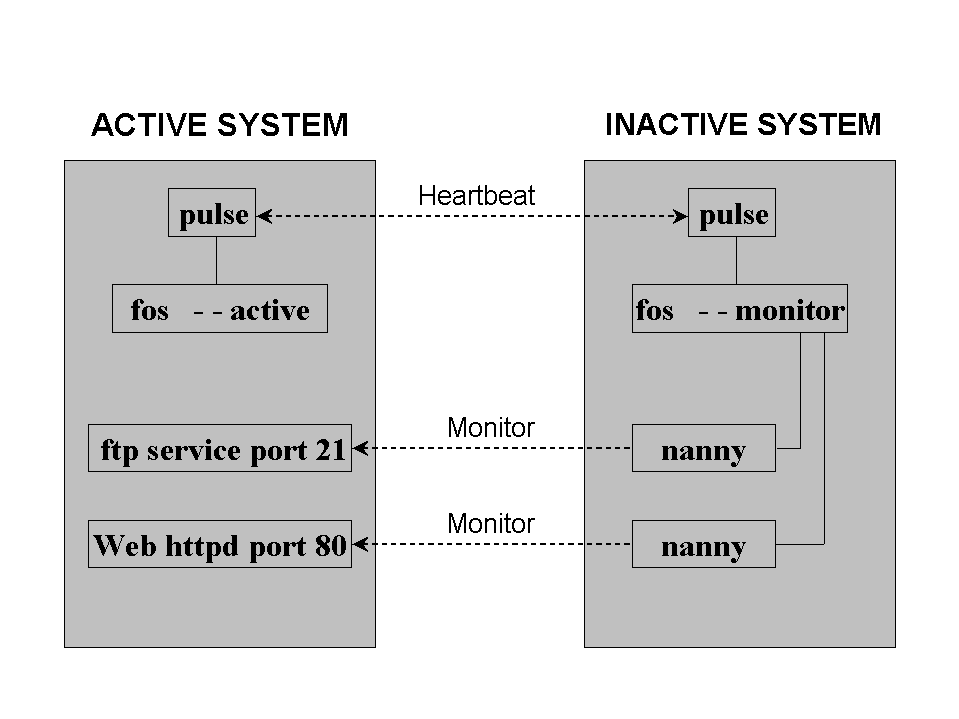
Figure 7-4. Components of a Running FOS Cluster