The cache result code appears in the fourth column of Squid's native access.log format. It indicates how the request was handled by Squid.
The following codes, beginning with TCP_, are for requests to the HTTP port (3128).
A valid copy of the requested object is in the cache. Squid does not forward the request.
The requested object is not in the cache.
The object is in the cache, but stale. Squid has forwarded an If-Modified-Since request and received a Not Modified response.
The object is in the cache, but stale. Squid has forwarded an If-Modified-Since request but it failed (e.g. connection timeout), so Squid sends the old (stale) object to the client.
The object is in the cache, but stale. Squid has forwarded an If-Modified-Since request and received a response with the new content.
The client issued a request with the no-cache pragma, so Squid forwards the request.
The client issued an If-Modified-Since request and the object is in the cache, and still fresh. Squid does not forward the request.
The client issued an If-Modified-Since request for a stale object. Squid forwards the request as a miss.
The object is believed to be in the cache, but could not be accessed, so Squid forwards the request.
Access is denied for this request.
The following codes, beginning with UDP_, are for requests to the ICP port (3130).
A fresh copy of the requested object is in the cache.
Same as UDP_HIT, but the object data is small enough to also be sent in the UDP reply packet.
The requested object is either stale or not in the cache at all.
Access is denied for this request.
An invalid request is received.
The replying cache recommends that this request NOT be made at this time. Squid uses this reply code when reloading metadata at startup, and when the failure ratio exceeds its threshold.
There are also numerous error codes, which begin with ERR_, for requests to the HTTP port. We will not discuss these codes here.
Every HTTP response includes a status code on the first line. This three-digit numeric code also appears in the fourth column of Squid's native access.log. Section 6.1.1 of the HTTP/1.1 RFC includes a full list of these codes. We are primarily interested in only two of them.
This, the most common status code, indicates a successful request.
This means the request included an If-Modified-Since header with a timestamp, and the resource has not been modified since the given time.
The ninth column of Squid's native access.log is a code that indicates how the next-hop cache was selected.
Squid forwards the request directly to the origin server.
Squid forwards the request directly to the origin server because the origin server's IP address is inside your firewall.
Squid forwards the request to the parent cache with the fastest weighted round trip time.
Squid forwards the request to the first available parent in your list.
Squid forwards the request directly to the origin server because the origin server's IP address matched your local_ip list.
Squid forwards the request to a sibling cache that sent us a UDP_HIT reply.
Squid cannot forward the request because of firewall restrictions and no parent caches are available.
Squid forwards the request to a parent cache that sent us a UDP_HIT reply.
The request is forwarded to the only parent cache appropriate for this request. Also requires that single_parent_bypass be enabled.
Squid forwards the request to the origin server because its source_ping reply arrived first.
Squid received the object in a UDP_HIT_OBJ reply from a parent cache.
Squid received the object in a UDP_HIT_OBJ reply from a sibling cache.
Squid forwarded the request to a default parent, without sending any ICP queries first.
Squid forwarded the request to the round-robin parent with the lowest use count, without sending any ICP queries first.
Squid forwarded the request to the the parent whose ICP_MISS reply has the lowest measured RTT to the origin server. This only appears with query_icmp enabled in the configuration file.
Squid forwarded the request directly to the origin server because Squid measured a lower RTT to the origin than any of its parent caches.
Squid does not forward the request at all.
Note, when the two second timeout occurs waiting for ICP replies, the word TIMEOUT_ is prepended to the hierarchy code.
We find it useful to categorize request forwarding through the hierarchy in one of five ways. For the NLANR caches, we examine the access.log fields for some of the codes mentioned in the previous sections. This analysis is somewhat specific to our cache configuration. For example, we do not use the default option, and therefore do not need to look for DEFAULT_PARENT requests. Much of our information comes from utilizing ICP.
We use the following simple Perl script to parse Squid's native access.log and output the percentage of each category:
#!/usr/local/bin/perl
while (<>) {
chop;
@F = split;
$L = $F[3]; # local cache result code
$H = $F[8]; # hierarchy code
next unless ($L =~ /TCP_/); # skip UDP and errors
$N++;
$timeout++ if ($H =~ /TIMEOUT/);
if ($L =~ /HIT/) {
$local_hit++;
} elsif ($H =~ /HIT/) {
$remote_hit++;
} elsif ($H =~ /MISS/) {
$remote_miss++;
} elsif ($H =~ /DIRECT/) {
$direct++;
} else {
$other++;
}
}
printf "TCP-REQUESTS %d\n", $N;
printf "TIMEOUT %f\n", 100*$timeout/$N;
printf "LOCAL-HIT %f\n", 100*$local_hit/$N;
printf "REMOTE-HIT %f\n", 100*$remote_hit/$N;
printf "REMOTE-MISS %f\n", 100*$remote_miss/$N;
printf "DIRECT %f\n", 100*$direct/$N;
printf "OTHER %f\n", 100*$other/$N;
This script may or may not be appropriate to your particular
situation, but should help you get started developing one of your own.
Next we present a case study analysis of the NLANR cache hierarchy. Presently there are six cache servers in our top-level configuration, distributed across the U.S., with two on the Eastern coast, two in the Central region, and two on the West coast. Five of these caches communicate with each other via the vBNS, an unsaturated nationwide OC3/OC12 network with roughly 40 millisecond round-trip times between sites. The other cache, `SV', is located at FIX-West, a popular exchange point in Silicon Valley, California.
The five vBNS caches use multicast to send ICP queries to one another for almost every request. The `SV' cache does not send ICP to the other five because of the congested, commodity Internet paths between them. However, `SV' and all of the other caches do have parent relationships with caches located in other countries.
The NLANR caches are all configured as mutual parents. That is, every cache is a parent for every other. Normally this would result in forwarding loops, but we eliminate them with the cache_host_acl directive:
cache_host nlanr.mcast.ircache.net multicast 3128 3130 ttl=4
acl nlanr_peers src it.cache.nlanr.net
acl nlanr_peers src pb.cache.nlanr.net
acl nlanr_peers src uc.cache.nlanr.net
acl nlanr_peers src bo.cache.nlanr.net
acl nlanr_peers src sd.cache.nlanr.net
cache_host_acl nlanr.mcast.ircache.net !nlanr_peers
which lets us query the multicast group, unless the request
is from one of our own caches.
Also, for the five vBNS caches, we use the proxy-only option to effect a large, distributed cache. We also use the ICMP measurements to route requests to the closest neighbour.
Note that one of the machines, `SD', is currently out of operation due to hardware failure, so we are unable to present its statistics here.
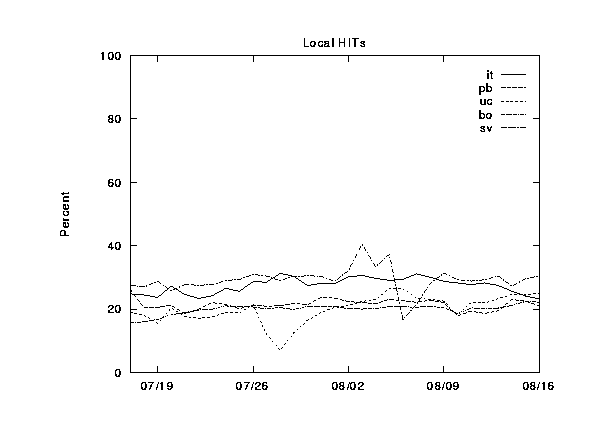
Here we present graphs of the hierarchy category values for the NLANR caches, plotted over a 30-day time period. These are figures 2--6.
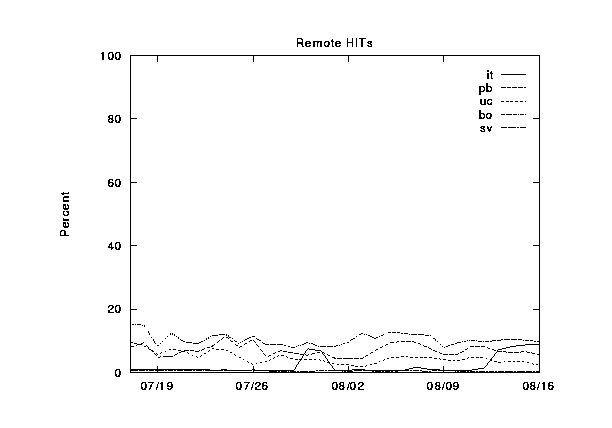
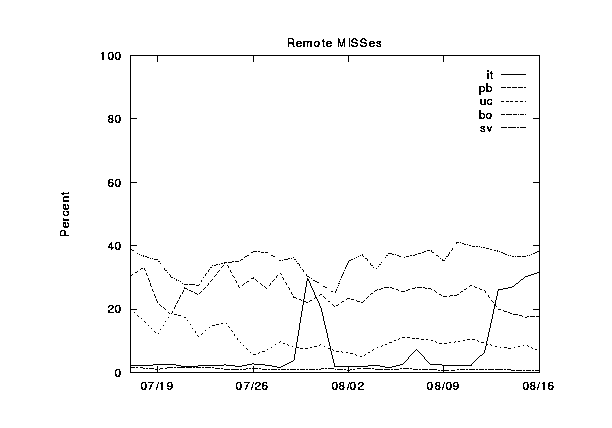
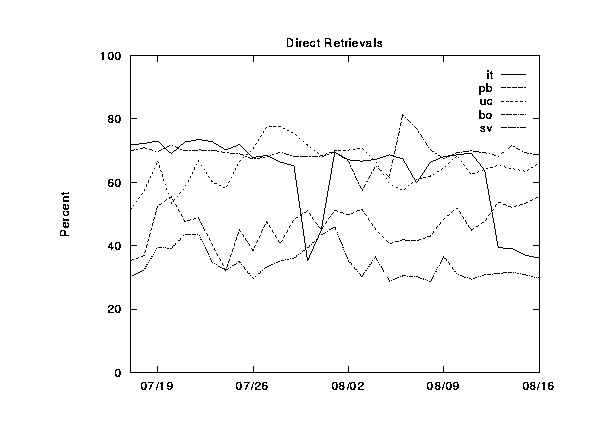
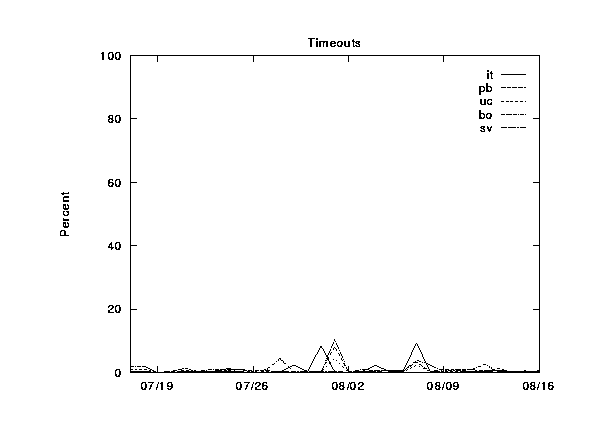
In figures 7--11 we show the same information, except this time grouped by cache instead of by category. The categories are shown cumulatively in each graph: (1) local hits, (2) remote hits, (3) remote misses, (4) direct retrievals, and (5) other. For each graph, the final sum should lie at exactly 100%. Note that the plots for direct and other coincide exactly because the other category is very near zero.
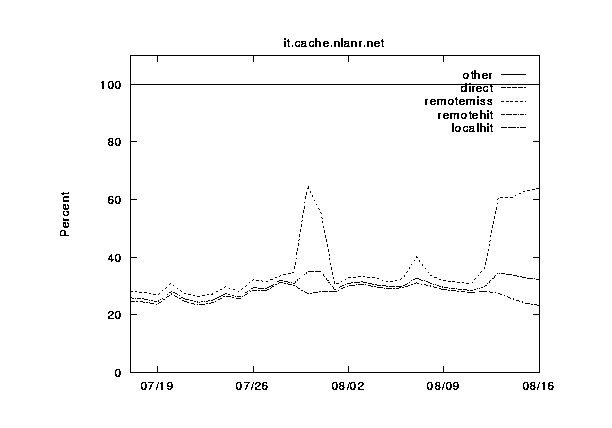
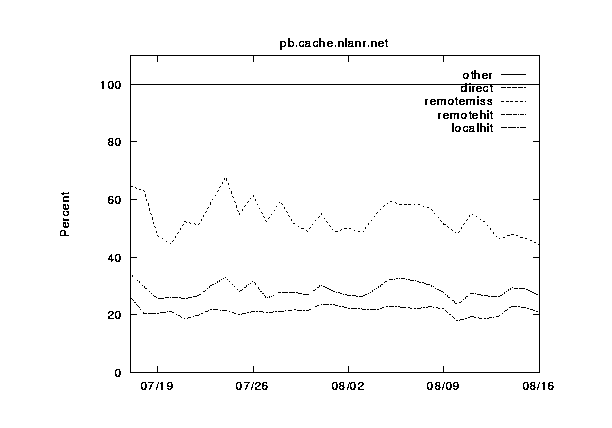
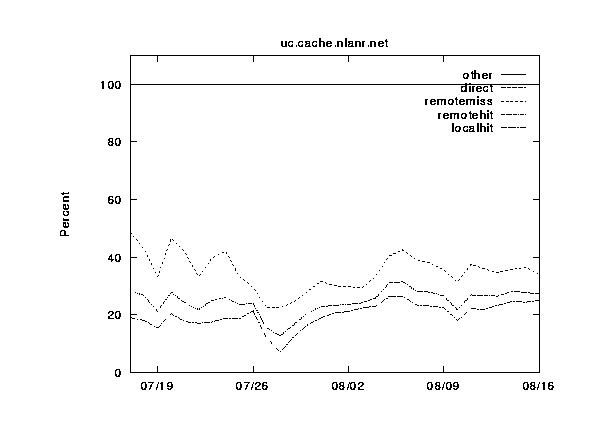
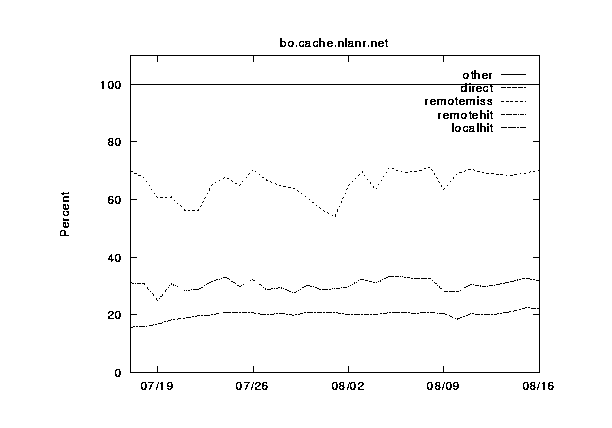
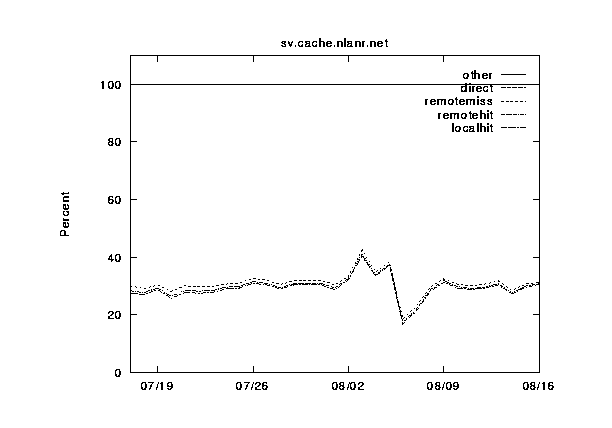
During this 30-day period, three of the caches were upgraded from 256 to 512 MB of RAM, and from 8 to 16 Gbytes of disk allocated for caching. Can you spot any corresponding changes in these graphs? Although difficult to detect, there are slight increases (roughly 5%) in the local hit rates for the three caches which were upgraded (`IT', `UC', and `BO'). This highlights another interesting thing about caching; doubling your capacity of a given resource does not necessarily double your hit rates!
If you are a sibling for another cache, you can use a simple command to search for anomalous requests. You should expect that a request from a sibling would result in a cache hit for you. If the IP address of the other cache is 10.0.0.1, then this command will locate any questionable requests:
awk '$2 == "10.0.0.1" && $4 ~ /MISS/' access.log
A few such requests likely does not merit concern; ICP and HTTP do not match up perfectly in all situations, so some of these requests may slip by. However, if you see a large number of anomalous access.log entries, the other cache could be using you as a parent instead of a sibling.