Part II:词法分析器
我总是说在学一个东西的时候例子总是不能足够简单.这就是为什么当我想要设计一个包含所有完整编译器应该有的特性的简单的编译器时感到很累.我拼凑了一个字符串处理语言,它使用象C那样的语法,有BASIC那样的功能.下面是用我们的语言的正确编写的一个程序.
| print "Please enter your name > "; input name; if (name == "Jan") { // string comparison name = "my creator"; // string assignment happy = "yes"; } print "Thank you, " + name + "!\n" + // string concatenation "You've just made a simple program very happy!"; |
就象你看到的,他没有构造象函数,类等等那样的功能,它甚至没有数值类型.这就是最终的东西,但是,他是很容易扩展的.
但是在接触那个之前我们还一很长的路要走--记得上次的组件列表吗?今天我们将实现第一个:词法分析器或称短语分析器.这是一个很好的热身,因为它不是编译器中真正难的部分.
OK,准备好了吗?
首先我猜你想要知道词法分析器是什么和为什么我们要用它?词法分析器的任务是把源文件的字符流转换成记号流.本质上它查看连续的字符然后把它们识别为"单词".
我们当然可以写一个函数用来把源文件当前位置取得的字符串与我们的所有关键字比较,但是这将是不可忍受的慢.所以我们使用有限自动机来识别单词(燕良注:就是DFA了,设计过程是正则式==>NFA==>DFA==>最小化).如果你不知道它是什么,好吧,你不需要知道(燕良注:如果你想知道,请看本文最后的附注).
关于词法分析器的一个基本情况是我们不需要作实际的艰苦的工作,我们使用一个叫作"LEX"的程序生成词法分析器.这是一个标准的UNIX程序,他也有几个win 32的版本(燕良注:我有一个FLEX.exe).这里有完整的LEX手册的HTML版.
好的,现在你知道了词法分析器作什么和我们将如何制作它.现在你可以下载 *tut2.zip*并且看一眼那些代码.这部分的源程序是string.l(燕良注:LEX源程序)和main.cpp以及几个头文件.请注意ZIP文件中含有目录结构,flex.exe在主目录,这部分的代码在tut2\目录.
LEX需要一些简单的规则来生成我们的词法分析器.在介绍规则之前,先让我们看一下LEX源程序的分段.
| 说明部分 %% 规则部分 %% 辅助程序部分 |
<说明部分>包含一些正则式(regular expression )的宏(正则式在LEX手册中有解释,想彻底了解它请看这里).这些告诉LEX我们使用的LETTER,DIGIT, IDENT(标识符,通常定义为字母开头的字母数字串)和STR(字符串常量,通常定义为双引号括起来的一串字符)是什么意思.(燕良注:呵呵,多熟悉呀.)
这部分也可以包含一些初始化代码.例如用#include来使用标准的头文件和前向说明(forward references).这些代码应该再标记"%{"和"%}"之间,你马上将看到我include了一个lexsymb.h 文件.
<规则部分>可以包括任何你想用来分析的代码;我们这里包括了忽略所有注释中字符的功能,传送ID名称和字符串常量内容到主调函数和main函数的功能.
lexsymb.h 文件声明了词法分析器函数将要返回的记号的符号.它还声明了一个'yylval' 共用体(union),用来传送额外的信息(例如标识符的名字)到主调函数;这里我们使用这个特殊的共用体可以使下一部分更清晰些.
现在让我们看一下实际的规则.我使用/* */作注释;LEX是一个相当老的程序,所以它着支持//引导的注释.顺便提一下,我们将使用LEX生成C程序,C++版的LEX程序也有,但是标准的UNIX LEX产生C代码.我们想要使这东西便携,不是吗? (燕良注: LEX源文件 .L--->FLEX--->C源文件,默认文件名是lex.yy.c)
| "if" {return IF;} "=" {return ASSIGN;} ";" {return END_STMT;} {IDENT} {Identifier (); /* identifier: copy name */ return ID;} {STR} {StringConstant (); /* string constant: copy contents */ return STRING;} "//" {EatComment();} /* comment: skip */ \n {lineno++;} /* newline: count lines */ {WSPACE} {} /* whitespace: (do nothing) */ . {return ERROR_TOKEN;} /* other char: error, illegal token */ |
我删去了一些非常简单的规则.就象你看到的那样,每一条规则开始部分是LEX将要识别的样式,接下来是一些代码告诉LEX当规则匹配后作什么(这部分代码可以包含C++代码,因为LEX只是简单把它们的拷贝到输出文件中).记住最顶端的规则被最优先评估,这通常很重要.
头3条规则十分的简单,它们只是识别一个字符串,然后返回相对应记号的符号.你可以改变这些字符串,例如你想使用":="来作赋值操作符.
第4行是第一条有趣的规则:它使用了IDENT宏,它识别不满足前面的条件的字母/数字串.如果匹配,它将调用Identifier()函数,此函数把yytext(保存当前记号的文本)的内容赋复制到一个新字符数组.词法分析器返回ID记号,主调函数可以使用'yylval->str'指针来访问标识符非名称.STR对于字符常量实现同样的功能.
下一行规则处理注释,换行和空白.注意行号将被计数,将来我们在出错信息中将使用它.最后一行告诉LEX如果输入不能满足上面所有的规则(表达式"."的意思是:除了'\n'以外的所有字符),我们应该返回一个错误记号,然后让主调函数决定作什么.
LEX的源程序可以使用下面的命令行来编译成LEX.CPP:
flex -olex.cpp string.l
ZIP中还包含一个MSVC 6.0 (string.dsp)的Project文件,我相信它在5.0中也能工作,但是我不确定.Project为string.l设置了一个自定义命令行,所以它可以被自动编译.
不幸的是LEX使用一个非标准的头文件,unistd.h,它不能在windows中使用.在主目录中有一个空的unistd.h文件,请添加主目录到include路径中(in MSVC:Tools->Options->Directories->Include).
lex.cpp包含一个满足我们规则的完整的词法分析器.它是那么简单!主程序只是使用词法分析函数读取一个记号,然后显示记号的名字和值(它是ID还是STR).你可以试着加入一些测试数据,然后观察词法分析器如何处理它们;随机的字符序列通常被识别为ID,我们不使用的字符,例如'$'引发一个ERROR_TOKEN.你也可以试试example.str (在主目录).
好吧,我们现在有了一个可以"读"的程序.遗憾的是它对它读的是什么和这些是否符合我们的标准依然没有概念.它只是接受它知道的一些记号.
看来它需要知道语法,惊人的巧合,语法正是我们下一部分将要讨论的.下一个组件是语法分析器,它的功能是找出程序的结构并且检查语法.
这样就变得真正有趣了.我们将能使程序成为一个编译器,它将接受一些东西,并不只是因为它可以接受几乎所有东西,而是因为它知道这个程序的语法是正确的.我知道你肯定和我一样激动,但是我不得不等到下一部分...
Quote!
![]()
"And so it was only with the advent of pocket computers that the startling truth
became finally apparent, and it was this:
Numbers written on restaurant bills within the confines of restaurants do not follow the
same mathematical laws as numbers written on any other pieces of paper in any other parts
of the Universe.
This single fact took the scientific world by storm. It completely revolutionized it. So
many mathematical conferences got held in such good restaurants that many of the finest
minds of a generation died of obesity and heart failure and the science of maths was put
back by years."
HHG 2:7
程序的功能是把下面这些实常数转换成相应的科学计数表示:
设计思路:
Pi,E,Degree可以当作关键字来处理,不是本程序的主要部分,本程序的主要功能是识别一下各种形式的实常数:
识别上述形式实常数的DFA为: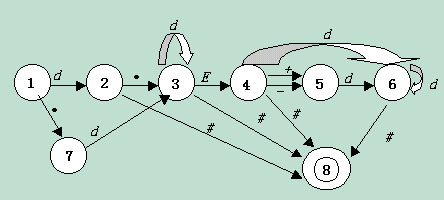
参见程序:CONSTANT.zip
附送另一个程序,识别C语言源程序的LEX源程序.
返回目录
diamond Garden制作 2000年1月