Part IV:符号表 & 语法树
如果我们想要用上两部分我们建立的词法分析器和语法分析器来作些有用的事的话,那么我们需要把我们从程序中收集的的信息存储到数据结构中.这就是下面我们要作的.这包括两个重要的组件: 符号表和语法树.
符号表,顾名思义,它是我们的程序中用来存储所有符号的一个表;在我们这里,包括所有的字符串变量,还有常量字符串.如果你的语言含有函数和类,他们的符号也将被存储的符号表.
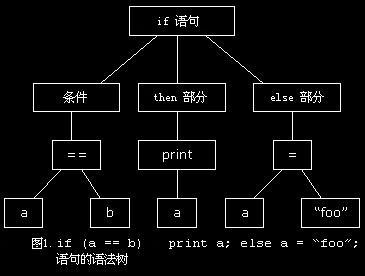
语法树是程序结构的一个树形表示;请看下图.在下一部分中我们使用这个表示来生成中间代码.尽管不是必须建立一个语法树(我们已经从语法分析器中得到了所有关于程序结构的信息),但是我认为这可以使编译器更透明(燕良注:原文是tranparent,我猜是拼写错误,所以按transparent译的,不知道那是否是什么术语...),这正是在这个系列文章中我所要达到的目标.
这是包括"真正的"代码的第一部分,在我们观察它之前请让我澄清一点:这些代码在写时应该更易懂而不是结构好.它对于我们这里制作的编译器是合格的,但是如果是一个真正的编译器,你需要作很多不同的东西.当我们碰到这些问题时我会试着说明它们.
显而易见,我们必须在我们的语法分析器中添加功能;例如,当我们发现一个符号时我们把它送人符号表--但是我们还希望它的"父"规则(事实上使用此标识符的规则)在符号描述中也要能够被访问.
我们在建立一个语法树时需要某些近似的东西:我们需要父规则有一个指针指向他的"孩子结点"(构成父规则的那些规则)
还记得yylval共用体吗?Yacc也使用他在规则之间传递信息.每一个规则能够使用yylval共用体的一个域;这是规则的类型.在string.y的顶部,你能看到类似下面的类型说明:
%type <symbol> identifier string
%type <tnode> statement expression
symbol和tnode是那个共用体的新成员;他们分别描述一个指向符号描述的指针和一个指向语法树的指针.
现在语句的规则象下面这样使用这些类型:
| expression END_STMT {$$ = new TreeNode (EXPR_STMT, $1);}
它的意思是:如果你发现了一个expression语句,构造一个EXPR_STMT类型的新的树结点(并且返回新的结点指针),他带有一个"孩子":组成这个语句的表达式.$$代表一个规则的返回值,$1是规则定义中的第一个符号返回的值(expression).在这里$2没有意义,因为词法分析器没有为END_STMT记号设置一个yylval成员.
我希望这样的解释够清楚了,因为这很重要.本质上,规则是分层的,每一条规则能够返回一个值到"更高层"的规则.
现在让我们看一下符号表和语法树使用什么样的数据结构.
符号表在我们例子中至包含很少的信息;基本上它只是变量名和它第一次被声明的行.后面我们会使用它来存储更多的数据.
实现非常的简单:它只是当我们取回一个符号时(看一眼symtab.cpp)为符号的描述建立一个单链表(singly-linked list)并且线性的查找这个链表.对于一个真正的编译器,符号表通常被实现为一个binary search tree 或 hash table,以便能够更快的找到符号.
你要作的是当语法分析器发现这个时把我们的符号送入那个表:
| identifier : ID { $$ = st.Find ($1); if ($$ == NULL) { // doesn't exist yet; create it $$ = new SymDesc ($1, STR_VAR, NULL, lineno); st.Add ($$); } } ; |
我们把字符串常量处理成常量,我们为他们生成一个名字然后把他们送入那个表.注意:一个更高级些的编译器可能会让词法分析器来存储和取回标识符.这是因为复杂的语言中标识符可能有很多不同的含义:变量,函数,类型,等等.词法分析器可以取回标识符的描述,并直接把相应的记号返回给语法分析器.因为我们标识符肯定是变量,所以我们只使用语法分析器来处理他们.
我为语法树建立了一个非常简单的TreeNode类.它只存储指向孩子的指针和一些附加信息(结点类型,如果可用还有一个符号的连接).看看吧,这没什么复杂的.
象你前面看到的,我们可以从已经验证的语法规则轻松的建立语法树:
| equal_expression : expression EQUAL assign_expression {$$ = newTreeNode(EQUAL_EXPR, $1, $3);} | assign_expression {$$ = $1;} ; |
你会看到在某些时候我们只是无变化的从孩子规则到父规则传递信息;如果你的equal_expression 事实上就是一个assign_expression,就没有必要为它建立一个新的结点;你只使用在assign_expression中建立的那个.记住我们使用这么多表达式规则的唯一的原因是为了清楚的处理操作符的优先级.
编译这部分(和下面的部分)使用与前面相同的方法.程序还是接受语法结构上正确的程序,但是现在转储到它建立的符号表和语法树中.
OK,它读程序并且分析它.但是它没有对程序作任何真正聪明或有用的事,不是吗?
是的,依然是.我们还有更多的组件要实现.下一部分将涉及语义检查和中间代码的生成.这将是一条通向编译程序的漫漫长路.
我希望你不要认为它进展的太慢,我只是想要集中到每一个分立的组件,而不是走马观花.如果你很快理解了这些东西,实验一下他们吧.
下次再见.

(Part of the Guide entry on the Babel Fish)
"Now it is such a bizarrely improbable coincidence that anything so mindboggingly
useful could have evolved purely by chance that some thinkers have chosen to see it as the
final and clinching proof of the non-existence of God.
The argument goes something like this: `I refuse to prove that I exist,' says God, `for
proof denies faith, and without faith I am nothing.'
`But,' says Man, `The Babel fish is a dead giveaway, isn't it? It could not have evolved
by chance. It proves you exist, and so therefore, by your own arguments, you don't. QED.'
"
HHG 1:6
Download the tutorial code (tut4.zip) (8k)
返回目录
diamond Garden制作 2000年1月