| ˇˇ | Win32 | |
| Winnie | ||
| Generic | ||
| Controls | ||
| Dialog-bsd App | ||
| Generic Dialog | ||
| Canvas | ||
| Pens/Brushes | ||
| Threads | ||
| Folder Watcher | ||
| Shell API | ||
| OLE/COM | ||
| Smart OLE | ||
| OLE Automation | ||
| Splitter Bar | ||
| Bitmaps | ||
| Direct Draw | ||
| ˇˇ |
What's Wrong with OLE?ˇˇThe Insider's storyYou might have heard or read critical opinions about OLE. Programmers mostly complain about the complex system of reference counting and the lack of support for inheritance. Microsoft evangelists counter this by saying that there is no other way, and that it's for your own good1. Interfaces, it is said, have to be refcounted, and there is a clever hack called aggregation (fondly called aggravation by OLE programmers) that provides the same functionality as inheritance. Maybe they are right, maybe the problem of interacting with run-time-loadable objects is so complex that there simply isn't any better way? On the other hand, maybe OLE has a fatal flaw that just keeps popping up all over the place.
Technically this interface jumping it is done by having every interface inherit from the mother of all interfaces, IUnknown. IUnknown has the fatal method QueryInterface that is supposed to return any interface supported by the current object. This single assumption precludes any possibility of having simple implementation of inheritance. Let me explain why. Suppose that you have an object FooObj with an interface IFoo. This situation is easily modeled in C++ by having an abstract class (all methods pure virtual) IFoo and a concrete class FooObj that inherits from IFoo and implements all its methods. Now you would like to extend this object by adding support for another interface IBar. In C++ it's trivial, you just define a class FooBarObj that inherits from FooObj and IBar. This new class supports the IFoo interface together with its implementation through inheritance from FooObj. It also supports the interface IBar and provides the implementation of IBar methods. 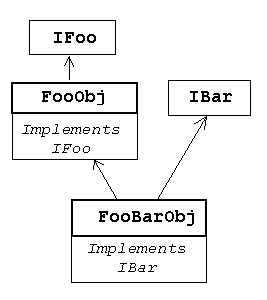 Anybody who knows C++ can do it with their eyes closed. So why can't you do the same in OLE? Here comes the Flaw. You have to be able to obtain the IBar interface from the IFoo interface using its QueryInterface. But, wait a minute, the object FooObj that provides the implementation of all methods of IFoo, including QueryInterface, had no clue about IBar! It could have been created long before anyone even thought about the possibility of IBar. So how can it provide access to IBar? Good question. I'm not going to go into the gory details of the aggregation hack that is supposed to solve this problem. Given the constraints of the flawed initial design, it is a truly ingenious hack. So is there a better design? Read on... Have you ever noticed how one is forced to distinguish between the object that implements interfaces and the interfaces themselves? These are two completely different notions. You can't explain anything in OLE without talking about objects, sometimes called components. Interfaces are important, but objects are even more important. When can you get one interface from another? When they share the same underlying object. You can change the state of an object using one interface and then examine this state through another interface. It's obviously the same object! In my example I described two interfaces, IFoo and IBar, and two objects (or classes of objects), FooObject and FooBarObject. In fact, anybody who's the implementor of interfaces (whether in C++, C, or Basic) has to deal with objects. Nevertheless, this very important abstraction is completely absent from the client's view of OLE. All that the client sees are interfaces. The underlying object is like a ghost. But it's not a ghost, it is physically present in the address space of your program, either directly, or as a forwarding stub. So why hide it? Indeed, wouldn't OLE be simpler with the explicit notion of an object? Let's see how it would work. The client of this "smart OLE" would call CoCreateInstance or ClassFactory::CreateInstance to obtain a pointer to an object (not an interface!). Using this pointer, the client would call QueryInterface to obtain an interface. If the client wanted to obtain another interface, he or she would make another QueryInterface call through the object, not through the interface. You could not obtain an interface from another interface. Only the object would have the ability to dispense interfaces. Bye, bye IUnknown! Let me show you some hypothetical code in this new "smart OLE."
I purposely omitted all the error checking and reference counting. In fact, I wouldn't write code like this in a serious application, I'd use smart pointers and exceptions. But notice one thing, in "smart OLE" inheritance is as simple as in C++. Since there is no way to jump from interface to interface and there is no IUnknown; extending FooObject by adding IBar requires no more work than having FooBarObject inherit from FooObject and IBar, implementing IBar methods and overriding the QueryInterface method of CoObject. I assume that all "smart OLE" objects inherit from the abstract class CoObject and override its QueryInterface method (it's very much different from having every interface inherit from IUnknown!). What about reference counting? The truth is, there is very little need for refcounting as long as you agree not to destroy the object while you are using its interfaces. That's not such a big deal--we do it all the time when we are using methods in C++. We don't think it's an especially harsh requirement, not to destroy the object while we are using its methods. If we were to follow OLE's current model to its full extent, we should require the client to get a refcount of any method he or she is planning to use, and then release it after the call? It would be absurd, wouldn't it? So why does OLE so meticulously count references? Simple--it's because it is hiding the object from the client. The OLE object is created implicitly when you get its first interface, and destroyed implicitly when you release its last interface. You see, OLE is doing you a big favor by hiding this bookkeeping from you. Or is it? Funny you'd ask.
Here's the best part of the story. You might think, "Oh, right, big deal! It's easy to come up with these ideas now, after OLE has been on the market for almost a decade." What if I told you that yours truly, who worked for Microsoft back then, soon after OLE 1.0 was released, had these ideas written down and sent to the responsible people. To make the long story short, the ideas were accepted as valid, but rejected on the premise that there already had been too much code written to the OLE specification (mostly at Microsoft). No manager was willing to take the risk of redesigning OLE. So here we are now, reference counting, aggregating and all. The moral of the story is,
But can we have the cake and eat it too? In other words, is it possible to build "smart OLE" on top of "the other OLE"? You bet! Go straight to the next tutorial. 1It really cracked me up when I read the introduction to the chapter on Aggregation in the otherwise fine (although somehow dorky) book "Inside COM" by Dale Rogerson. If he knew the real story, he wouldn't be so adamant in his defense of aggregation. |