![[*]](footnote.png)
Pavan Deolasee
Amol Katkar
Ankur Panchbudhe
Krithi Ramamritham
Prashant Shenoy
Copyright is held by the author/owner(s).
WWW10, May 1-5, 2001, Hong Kong.
ACM 1-58113-348-0/01/0006.
Department of Computer Science and Engineering.
Department of Computer Science
Indian Institute of Technology Bombay
University of Massachusetts
Mumbai, India 400076
Amherst, MA 01003
{pavan,amolk,ankurp,krithi}@cse.iitb.ernet.in
{krithi,shenoy}@cs.umass.edu
![]()
In the rest of this section, we (a) describe the problem of temporal coherency maintenance in detail, (b) show the need to go beyond the canonical Push- and Pull-based data dissemination, and (c) outline the key contributions of this paper, namely, the development and evaluation of adaptive protocols for disseminating dynamic i.e., time-varying data.
Suppose users obtain their time-varying data from a proxy cache. To
maintain coherency of the cached data, each cached item must be
periodically refreshed with the copy at the server.
We assume that a user specifies a temporal coherency requirement
(![]() ) for each cached item of interest. The value of
) for each cached item of interest. The value of ![]() denotes the maximum
permissible deviation of the cached value from the value at the server
and thus constitutes the user-specified tolerance. Observe that
denotes the maximum
permissible deviation of the cached value from the value at the server
and thus constitutes the user-specified tolerance. Observe that ![]() can be specified in units of time (e.g., the item should never be
out-of-sync by more than 5 minutes) or value (e.g., the stock
price should never be out-of-sync by more than a dollar). In this
paper, we only consider temporal coherency requirements specified in
terms of the value of the object (maintaining temporal coherency
specified in units of time is a simpler problem that requires
less sophisticated techniques). As shown in Figure
1, let
can be specified in units of time (e.g., the item should never be
out-of-sync by more than 5 minutes) or value (e.g., the stock
price should never be out-of-sync by more than a dollar). In this
paper, we only consider temporal coherency requirements specified in
terms of the value of the object (maintaining temporal coherency
specified in units of time is a simpler problem that requires
less sophisticated techniques). As shown in Figure
1, let ![]() ,
, ![]() and
and ![]() denote the value of the data
item at the server, proxy cache and the user, respectively. Then, to maintain
temporal coherency we should have
denote the value of the data
item at the server, proxy cache and the user, respectively. Then, to maintain
temporal coherency we should have
![]()
The fidelity of the data seen by users depends on the degree to
which their coherency needs are met. We define the fidelity ![]() observed by a user to be the total length of time that the above
inequality holds (normalized by the total length of the
observations). In addition to specifying the coherency requirement
observed by a user to be the total length of time that the above
inequality holds (normalized by the total length of the
observations). In addition to specifying the coherency requirement
![]() , users can also specify their fidelity requirement
, users can also specify their fidelity requirement ![]() for each
data item so that an algorithm that is capable of handling users'
fidelity and temporal coherency
requirements (
for each
data item so that an algorithm that is capable of handling users'
fidelity and temporal coherency
requirements (![]() s) can adapt to users' needs.
s) can adapt to users' needs.
In this paper we develop adaptive push- and pull-based data dissemination techniques that maintain user-specified coherency and fidelity requirements. We focus on the path between a server and a proxy, assuming that push is used by proxies to disseminate data to end-users. Since proxies act as immediate clients to servers, henceforth, we use the terms proxy and client interchangeably (unless specified otherwise, the latter term is distinct from the ultimate end-users of data).
In the case of servers adhering to the HTTP protocol, proxies need to periodically pull the data based on the dynamics of the data and a user's coherency requirements. In contrast, servers that possess push capability maintain state information pertaining to clients and push only those changes that are of interest to a user/proxy.
The first contribution of this paper is an extensive evaluation of the
canonical push- and pull-based techniques using traces of real-world
dynamic data. Our results, reported in Section
2.3 and summarized in Table 1,
show that these two
canonical techniques have complementary properties with respect to
resiliency to (server) failures, the level of temporal coherency
maintained, communication overheads, state space overheads, and
computation overheads.
Specifically, our results indicate that
These properties indicate that a push-based approach is suitable when a client requires its coherency requirements to be satisfied with a high fidelity, or when the communication overheads are the bottleneck. A pull-based approach is better suited to less frequently changing data or for less stringent coherency requirements, and when resilience to failures is important.
![]() s of clients may vary across clients and bandwidth availability
may vary with time, so a static solution to the problem of
disseminating dynamic, i.e., time-varying, data will not be responsive
to client needs or load/bandwidth changes. We need an intelligent and adaptive approach that can be tuned according
to the client requirements and conditions prevailing in the network or
at the server/proxy. Moreover, the approach should not sacrifice the
scalability of the server (under load) or reduce the resiliency of the
system to failures. One solution to this problem is to combine push-
and pull-based dissemination so as to realize the best features of
both approaches while avoiding their disadvantages. The goal of this
paper therefore is to develop techniques that combine push and pull in
an intelligent and adaptive manner while offering good
resiliency and scalability.
s of clients may vary across clients and bandwidth availability
may vary with time, so a static solution to the problem of
disseminating dynamic, i.e., time-varying, data will not be responsive
to client needs or load/bandwidth changes. We need an intelligent and adaptive approach that can be tuned according
to the client requirements and conditions prevailing in the network or
at the server/proxy. Moreover, the approach should not sacrifice the
scalability of the server (under load) or reduce the resiliency of the
system to failures. One solution to this problem is to combine push-
and pull-based dissemination so as to realize the best features of
both approaches while avoiding their disadvantages. The goal of this
paper therefore is to develop techniques that combine push and pull in
an intelligent and adaptive manner while offering good
resiliency and scalability.
| Algorithm | Resiliency | Temporal Coherency | Overheads (Scalability) | ||
|
|
(fidelity) | Communication | Computation | State Space | |
| Push | Low | High | Low | High | High |
| Pull | High | Low (for small |
High | Low | Low |
| High (for large |
|||||
| PaP | Graceful degradation | Adjustable | Low/Medium | Low/Medium | High |
| (fine grain) | |||||
| PoP | Delayed graceful degradation | Adjustable | Low/Medium | Low/Medium | Low/Medium |
| (coarse grain) | |||||
| PoPoPaP | Graceful degradation | Adjustable | Low/Medium | Low/Medium | Low/Medium |
In this paper, we propose two different techniques for combining push- and pull-based dissemination.
We have implemented our algorithms into a prototype server and a proxy. We demonstrate the efficacy of our approaches via simulations and an experimental evaluation. Complete source code for our prototype implementation and the simulator as well as the data used in our experiments is available from our web site[11].
Table 1 summarizes the properties of our PaP and PoP algorithms vis-a-vis the canonical push and pull approaches.
The semantics of most of the entries in the table are self-evident even though the reason behind the stated properties of PaP and PoP will be clear only after they are described and evaluated. But a few words of explanation are in order.
In this section, we present a comparison of push- and pull-based data dissemination and evaluate their tradeoffs. These techniques will form the basis for our combined push-pull algorithms.
To achieve temporal coherency using a pull-based approach, a proxy can compute a
Time To Refresh (TTR) attribute with each cached data item. The
TTR denotes the next time at which the proxy should poll the
server so as to refresh the data item if it has changed in the
interim. A proxy can compute the TTR values based
on the rate of change of the data and the user's coherency
requirements. Rapidly changing data items and/or stringent coherency
requirements result in a smaller TTR, whereas infrequent changes
or less stringent coherency requirement require less frequent polls to
the server, and hence, a larger TTR.Observe that a proxy need not pull every single change to the data
item, only those changes that are of interest to the user need to be
pulled from the server (and the TTR is computed accordingly).
Clearly, the success of the pull-based technique hinges on the accurate estimation of the TTR value. Next, we summarize a set of techniques for computing the TTR value that have their origins in [21]. Given a user's coherency requirement, these techniques allow a proxy to adaptively vary the TTR value based on the rate of change of the data item. The TTR decreases dynamically when a data item starts changing rapidly and increases when a hot data item becomes cold. To achieve this objective, the Adaptive TTR approach takes into account (a) static bounds so that TTR values are not set too high or too low, (b) the most rapid changes that have occurred so far and (c) the most recent changes to the polled data.
In what follows, we use ![]() ,
, ![]() ,
,
![]() ,
, ![]() to denote the values of a data item
to denote the values of a data item ![]() at the server
in chronological order. Thus,
at the server
in chronological order. Thus, ![]() is the latest value of data item
is the latest value of data item
![]() .
.
![]() is computed as:
is computed as:
![]()
where
In a push-based approach, the proxy registers with a server,
identifying the data of interest and the associated ![]() , i.e., the
value
, i.e., the
value ![]() . Whenever the value of the data changes, the server uses
the
. Whenever the value of the data changes, the server uses
the ![]() value
value ![]() to determine if the new value should be pushed to
the proxy; only those changes that are of interest to the user (based
on the
to determine if the new value should be pushed to
the proxy; only those changes that are of interest to the user (based
on the ![]() ) are actually pushed. Formally, if
) are actually pushed. Formally, if ![]() was the last
value that was pushed to the proxy, then the current value
was the last
value that was pushed to the proxy, then the current value ![]() is
pushed if and only if
is
pushed if and only if
![]() ,
,
![]() .
To achieve this objective, the server needs to maintain state
information consisting of a list of proxies interested in each data
item, the
.
To achieve this objective, the server needs to maintain state
information consisting of a list of proxies interested in each data
item, the ![]() of each proxy and the last update sent to that proxy.
of each proxy and the last update sent to that proxy.
The key advantage of the push-based approach is that it can meet stringent coherency requirements--since the server is aware of every change, it can precisely determine which changes to push and when.
In what follows, we compare the push and pull approaches along several dimensions: maintenance of temporal coherency, communication overheads, computational overheads, space overheads, and resiliency.
These algorithms were evaluated using a prototype server/proxy that employed trace replay. For Pull, we used a vanilla HTTP web server with our prototype proxy. For Push, we used a prototype server that uses unicast and connection-oriented sockets to push data to proxies. All experiments were done on a local intranet. We also ran carefully instrumented experiments on the internet and the trends observed were consistent with our results.
Note that it is possible to use multicast for push; however, we assumed that unicast communication is used to push data to each client (thus, results for push are conservative upper-bounds; the message overheads will be lower if multicast is used).
Quantitative performance characteristics are evaluated using real
world stock price streams as exemplars of dynamic data. The
presented
results are based on stock price traces (i.e., history of stock
prices) of a few companies obtained from
http://finance.yahoo.com. The traces were collected at a rate of 2 or
3 stock quotes per second. Since stock prices only change once every
few seconds, the traces can be
considered to be ``real-time'' traces. For empirical and repetitive
evaluations, we ``cut out'' the history for the time intervals listed
in table 2 and experimented with the different mechanisms by
determining the stock prices they would have observed had the source
been live. A trace that is 2 hours long, has approximately 15000 data
values. All curves portray the averages of the plotted metric over
all these traces. Few of the experiments were done with
quotes obtained in real-time, but the difference was found to be
negligible when compared to
the results with the traces.
The Pull approach was evaluated using
the Adaptive TTR algorithm with an ![]() value of 0.9,
value of 0.9, ![]() of 1
second and three
of 1
second and three ![]() values of 10, 30 and 60 seconds.
values of 10, 30 and 60 seconds.
| Company | Date | Time |
| Dell | Jun 1, 2000 | 21:56-22:53 IST |
| UTSI | Jun 1, 2000 | 22:41-23:15 IST |
| CBUK | Jun 2, 2000 | 18:31-21:57 IST |
| Intel | Jun 2, 2000 | 22:14-01:42 IST |
| Cisco | Jun 6, 2000 | 18:48-22:20 IST |
| Oracle | Jun 7, 2000 | 00:01-01:59 IST |
| Veritas | Jun 8, 2000 | 21:20-23:48 IST |
| Microsoft | Jun 8, 2000 | 21:02-23:48 IST |
Since a push-based server communicates every change of interest to a
connected client, a client's ![]() is never violated as long as the
server does not fail or is so overloaded that the pushes are delayed.
Thus, a push-based server is well suited to achieve a fidelity value of 1.
On the other hand, in the case of a pull-based server, the frequency
of the pulls (translated in our case to the assignment of TTR values)
determines the degree to which client needs are met. We quantify the
achievable fidelity of pull-based approaches in terms of the
probability that user's
is never violated as long as the
server does not fail or is so overloaded that the pushes are delayed.
Thus, a push-based server is well suited to achieve a fidelity value of 1.
On the other hand, in the case of a pull-based server, the frequency
of the pulls (translated in our case to the assignment of TTR values)
determines the degree to which client needs are met. We quantify the
achievable fidelity of pull-based approaches in terms of the
probability that user's ![]() will be met.
To do so, we measure the durations when
will be met.
To do so, we measure the durations when
![]() . Let
. Let
![]() denote these durations when user's
denote these durations when user's
![]() is violated. Let
is violated. Let
![]() denote the total time
for which data was observed by a user. Then fidelity is
denote the total time
for which data was observed by a user. Then fidelity is
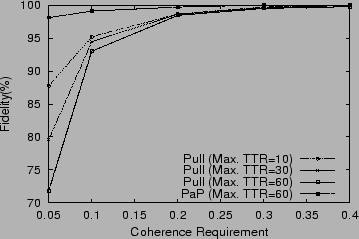
Figure 2 shows the fidelity for a pull-based algorithm that employs adaptive TTRs. Recall that the Push algorithm offers a fidelity of 100%. In contrast, the Figure shows that the pull algorithm has a fidelity of 70-80% for stringent coherency requirements and its fidelity improves as the coherency requirements become less stringent. (The curve marked PaP is for the PaP algorithm that combines Push and Pull and is described in Section 3.1.)
In a push-based approach, the number of messages transferred over the
network is equal to the number of times the user is informed of data
changes so that the user specified temporal coherency is maintained.
(In a network that supports multicasting, a single push message may be
able to serve multiple clients.) A pull-based approach requires two
messages--an HTTP IMS request, followed by a response--per poll.
Moreover, in the pull approach, a proxy polls the server based on
its estimate of how frequently the data is changing. If the data
actually changes at a slower rate, then the proxy might poll more
frequently than necessary. Hence a
pull-based approach is liable to impose a larger load on the network.
However, a push-based approach may push to clients who are no longer
interested in a piece of information, thereby incurring unnecessary
message overheads. We quantify communication overheads in terms of
the number of messages exchanged between server and proxy.
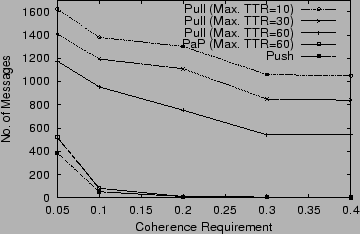
Figure 3
shows the variation in the number of messages with
coherence requirement
![]() .
As seen in Figure 3,
the
Push approach incurs a small communication overhead
because only values of interest to a client are transferred over the network.
The Pull approach, on the other hand, imposes a significantly
higher overhead.
.
As seen in Figure 3,
the
Push approach incurs a small communication overhead
because only values of interest to a client are transferred over the network.
The Pull approach, on the other hand, imposes a significantly
higher overhead.
Computational overheads for a pull-based server result from the need
to deal with individual pull requests. After getting a pull request
from the proxy, the server has to just look up the latest data value
and respond. On the other hand, when the server has to push changes to
the proxy, for each change that occurs, the server has to check if the
![]() for any of the proxies has been violated. This computation is
directly proportional to the rate of arrival of new data values and
the number of unique temporal coherency requirements associated with
that data value. Although this is
a time varying quantity in the sense that the rate of arrival of data
values as well as number of connections change with time, it is easy
to see that push is computationally more demanding than pull. On
the other hand, it is important to remember that servers respond to
individual pull requests and so may incur queueing related overheads.
for any of the proxies has been violated. This computation is
directly proportional to the rate of arrival of new data values and
the number of unique temporal coherency requirements associated with
that data value. Although this is
a time varying quantity in the sense that the rate of arrival of data
values as well as number of connections change with time, it is easy
to see that push is computationally more demanding than pull. On
the other hand, it is important to remember that servers respond to
individual pull requests and so may incur queueing related overheads.
The above results are summarized in Table 1. In what follows, we present two approaches that strive to achieve the benefits of the two complementary approaches by adaptively combining Push and Pull.
In this section, we present Push-and-Pull (PaP) -- a new algorithm that simultaneously employs both push and pull to achieve the advantages of both approaches. The algorithm has tunable parameters that determine the degree to which push and pull are employed and allow the algorithm to span the entire range from a push approach to a pull approach. Our algorithm is motivated by the following observations.
The pull-based adaptive TTR algorithm described in Section 2.1
can react to variations in the rate of change of a data item. When a
data item starts changing more rapidly, the algorithm uses smaller
TTRs (resulting in more frequent polls). Similarly,
the changes are slow, TTR values tend to get larger.
If the algorithm detects a violation in the coherency requirement
(i.e.,
![]() ), then it responds by
using a smaller TTR for the next pull. A further violation will reduce
the TTR even further. Thus, successive violations indicate that the data
item is changing rapidly and the proxy gradually decreases the TTR
until the TTR becomes sufficiently small to keep up with the rapid
changes. Experiments reported in [21] show that the
algorithm gradually ``learns'' about such ``clubbed'' (i.e., successive)
violations and reacts appropriately. So, what
we need is a way to prevent even the small number of temporal coherency violations
that occur due to the delay in this gradual learning process.
Furthermore, if a rapid change occurs at the
source and then the data goes back to its original value before the
next pull, this ``spike'' will go undetected by a pull-based
algorithm. The PaP approach described next helps the TTR
algorithm to ``catch'' all the ``clubbed'' violations properly;
moreover ``spikes'' also get detected. This is achieved by endowing
push capabilities to servers and having the server push changes that a proxy
is unable to detect. This increases the fidelity for clients at the
cost of endowing push capability to servers. Note that, sinc`e
proxies continue to have the the ability to pull, the approach is
more resilient to failures than a push approach (which loses all
state information on a failure).
), then it responds by
using a smaller TTR for the next pull. A further violation will reduce
the TTR even further. Thus, successive violations indicate that the data
item is changing rapidly and the proxy gradually decreases the TTR
until the TTR becomes sufficiently small to keep up with the rapid
changes. Experiments reported in [21] show that the
algorithm gradually ``learns'' about such ``clubbed'' (i.e., successive)
violations and reacts appropriately. So, what
we need is a way to prevent even the small number of temporal coherency violations
that occur due to the delay in this gradual learning process.
Furthermore, if a rapid change occurs at the
source and then the data goes back to its original value before the
next pull, this ``spike'' will go undetected by a pull-based
algorithm. The PaP approach described next helps the TTR
algorithm to ``catch'' all the ``clubbed'' violations properly;
moreover ``spikes'' also get detected. This is achieved by endowing
push capabilities to servers and having the server push changes that a proxy
is unable to detect. This increases the fidelity for clients at the
cost of endowing push capability to servers. Note that, sinc`e
proxies continue to have the the ability to pull, the approach is
more resilient to failures than a push approach (which loses all
state information on a failure).
Suppose a client registers with a server and intimates its coherency
requirement ![]() . Assume that the client pulls data from the server
using an algorithm, say
. Assume that the client pulls data from the server
using an algorithm, say ![]() , to decide its TTR values (e.g., Adaptive TTR). After initial
synchronization, server also runs algorithm
, to decide its TTR values (e.g., Adaptive TTR). After initial
synchronization, server also runs algorithm ![]() . Under this scenario,
the server is aware of when the client will be pulling next. With
this, whenever server sees that the client must be notified of a new
data value, the server pushes the data value to the proxy if and only
if it determines that the client will take time to poll next.
The state maintained by this algorithm is a soft state in the sense
that even if push connection is lost or the clients' state is lost due
to server failure, the client will
continue to be served at least as well as under
. Under this scenario,
the server is aware of when the client will be pulling next. With
this, whenever server sees that the client must be notified of a new
data value, the server pushes the data value to the proxy if and only
if it determines that the client will take time to poll next.
The state maintained by this algorithm is a soft state in the sense
that even if push connection is lost or the clients' state is lost due
to server failure, the client will
continue to be served at least as well as under ![]() .
Thus, compared to a Push-based server, this strategy provides for
graceful degradation.
.
Thus, compared to a Push-based server, this strategy provides for
graceful degradation.
In practice, we are likely to face problems of synchronization between server and client because of variable network delays. Also, the server will have the additional computational load imposed by the need to run the TTR algorithm for all the connections it has with its clients. The amount of additional state required to be maintained by the server cannot be ignored either. One could argue that we might as well resort to Push which will have the added advantage of reducing the number of messages on the network. However, we will have to be concerned with the effects of loss of state information or of connection loss on the maintenance of temporal coherency.
Fortunately, for the advantages of this technique to accrue, the
server need not run the full-fledged TTR algorithm. A good
approximation to computing the client's next TTR will suffice.
For example, the server can compute the difference between the times
of the last two pulls (![]() ) and assume that the next pull will occur after a
similar
) and assume that the next pull will occur after a
similar ![]() , at
, at
![]() .
Suppose
.
Suppose ![]() is the time of the most recent
value. The server computes
is the time of the most recent
value. The server computes ![]() , the next predicted pulling time as follows:
, the next predicted pulling time as follows:
In practice, the server should allow the client to pull data if the
changes of interest to the client occur close to the client's expected
pulling time.
So, the server waits, for a duration of
![]() , a small quantity close to
, a small quantity close to ![]() , for the client to
pull. If a client does not pull when server expects it to, the server
extends the push duration by adding (
, for the client to
pull. If a client does not pull when server expects it to, the server
extends the push duration by adding (
![]() ) to
) to
![]() . It is obvious that if
. It is obvious that if ![]() , PaP
reduces to push approach; if
, PaP
reduces to push approach; if ![]() is large then the approach
works similar to a pull approach. Thus, the value of
is large then the approach
works similar to a pull approach. Thus, the value of ![]() can
be varied so that the number of pulls and pushes is balanced properly.
can
be varied so that the number of pulls and pushes is balanced properly.
![]() is hence one of the factors which decides the temporal coherency
properties of the PaP algorithm as well as the number of
messages sent over the network.
is hence one of the factors which decides the temporal coherency
properties of the PaP algorithm as well as the number of
messages sent over the network.
The arguments at the beginning of this section suggest that it is a
good idea to let the proxy pull when it is polling frequently anyway
and violations are occurring rapidly. Suppose, starting at ![]() a
series of rapid changes occurs to data
a
series of rapid changes occurs to data ![]() . This can lead to a
sequence of ``clubbed'' violations of
. This can lead to a
sequence of ``clubbed'' violations of ![]() unless steps are taken.
The adaptive TTR algorithm triggers a decrease in the TTR value at the
proxy. Let this TTR value be
unless steps are taken.
The adaptive TTR algorithm triggers a decrease in the TTR value at the
proxy. Let this TTR value be ![]() . The proxy polls next at
. The proxy polls next at
![]() . According to the PaP algorithm, the server
pushes any data changes above
. According to the PaP algorithm, the server
pushes any data changes above ![]() during
during ![]() . Since a
series of rapid changes occurs, the probability that some violation(s)
may occur in
. Since a
series of rapid changes occurs, the probability that some violation(s)
may occur in ![]() is very high and thus these changes will
also be pushed by the server further forcing a decrease in the TTR at
the proxy and causing frequent polls from the proxy. Now, the TTR
value at the proxy will tend towards
is very high and thus these changes will
also be pushed by the server further forcing a decrease in the TTR at
the proxy and causing frequent polls from the proxy. Now, the TTR
value at the proxy will tend towards ![]() and
and ![]() will also
approach zero, thus making the durations of possible pushes from the
server close to zero. It is evident that if rapid changes occur, after
a few pushes,
the push interval will be zero, and client will pull almost all the
rapid changes thereafter. Thus the server has helped the proxy pull
sooner than it would otherwise. This leads to better fidelity of data
at the proxy than with a pull approach.
will also
approach zero, thus making the durations of possible pushes from the
server close to zero. It is evident that if rapid changes occur, after
a few pushes,
the push interval will be zero, and client will pull almost all the
rapid changes thereafter. Thus the server has helped the proxy pull
sooner than it would otherwise. This leads to better fidelity of data
at the proxy than with a pull approach.
If an isolated rapid change (i.e., spike) occurs, then the server will push it to the proxy leading to a decrease in the TTR used next by the proxy. It will poll sooner but will not find any more violations and that in turn will lead to an increase in the TTR.
Thus, the proxy will tend to pull nearly all but the first few in a
series of rapid changes helped by the initial pushes from the server,
while all ``spikes'' will be pushed by the server to the proxy. The
result is that all violations will be caught by the PaP
algorithm in the ideal case (e.g., with the server running the adaptive
TTR algorithm in parallel with the proxy). In case the server is
estimating the proxy's next TTR, the achieved temporal coherency can be made to be
as close to the ideal, as exemplified by Pure Push, by proper choice of
![]() .
.
Overall, since the proxy uses the pushed (as well as pulled) information to determine TTR values, the adaptation of the TTRs would be much better than with a pull-based algorithm alone.
Although the amount of state maintained is nearly equal to push, the state is a soft state. This means that even if the state is lost due to some reason or the push connection with a proxy is lost, the performance will be at least as good as that of TTR algorithm running at the proxy as clients will keep pulling.
Figure 2
shows that for PaP algorithm, the fidelity offered is more than 98% for
stringent ![]() and 100% for less stringent
and 100% for less stringent ![]() .
From Figure 3,
we see that compared to Pull, the PaP algorithm has very little network overhead because of the
push component. Its network overheads are, however, slightly higher
than that of Push.
.
From Figure 3,
we see that compared to Pull, the PaP algorithm has very little network overhead because of the
push component. Its network overheads are, however, slightly higher
than that of Push.
The value of ![]() needs to be chosen to
balance the number of pushes and pulls.
Experimental results (not shown here) indicate, as one would expect,
that when
needs to be chosen to
balance the number of pushes and pulls.
Experimental results (not shown here) indicate, as one would expect,
that when ![]() is large
the number of successful pushes is large, but as we decrease
is large
the number of successful pushes is large, but as we decrease
![]() , the number of pushes decreases slowly until a point
where pulls start dominating.
, the number of pushes decreases slowly until a point
where pulls start dominating.
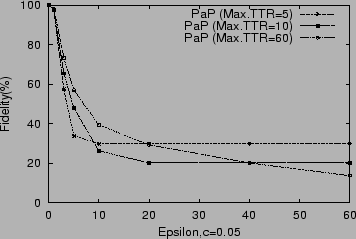
Figure 4
shows the variation in fidelity when ![]() is
varied. When
is
varied. When ![]() is zero, the algorithm reduces to push and
hence fidelity is 100%. But as we start increasing the value of
is zero, the algorithm reduces to push and
hence fidelity is 100%. But as we start increasing the value of
![]() the fidelity starts suffering. For values of
the fidelity starts suffering. For values of ![]() , the fidelity is above 75%. And for
, the fidelity is above 75%. And for
![]() ,
fidelity is approximately 99%. For values of
,
fidelity is approximately 99%. For values of ![]() closer to
closer to
![]() (in this case 60), fidelity is low as the pulls overtake
pushes and the algorithm behaves like a TTR algorithm.
(in this case 60), fidelity is low as the pulls overtake
pushes and the algorithm behaves like a TTR algorithm.
Figure 4
also shows the effect of changing ![]() in conjunction with
in conjunction with ![]() on the fidelity offered by the
algorithm.
As
on the fidelity offered by the
algorithm.
As ![]() decreases, pulls increase. As pulls become more dominant, the server
has less chance to push the data values, and a bigger
decreases, pulls increase. As pulls become more dominant, the server
has less chance to push the data values, and a bigger ![]() gives
the server fewer opportunities to push. This explains the effect in Figure
4
for
gives
the server fewer opportunities to push. This explains the effect in Figure
4
for ![]() or
or ![]() . As pulls increase
and the server has less and less chance to push, fidelity suffers and
decreases more rapidly than in the case of
. As pulls increase
and the server has less and less chance to push, fidelity suffers and
decreases more rapidly than in the case of ![]() . It can also
be observed that, as
. It can also
be observed that, as ![]() takes values greater than
takes values greater than ![]() ,
fidelity offered becomes constant. This is because even if server sets
,
fidelity offered becomes constant. This is because even if server sets
![]() greater than
greater than ![]() client will keep polling at the
maximum rate of
client will keep polling at the
maximum rate of ![]() . In effect, setting
. In effect, setting ![]() greater
than
greater
than ![]() is equivalent to setting it to
is equivalent to setting it to ![]() . This
explains the crossover of curves in Figure 4.
. This
explains the crossover of curves in Figure 4.
As expected, as ![]() is increased the number of pulls
become higher and higher. For
is increased the number of pulls
become higher and higher. For ![]() , there are no pulls and
for
, there are no pulls and
for
![]() there are no pushes.
More fidelity
requires more number of pushes and for the case where number of pushes
is equal to number of pulls, fidelity is close to 50%. The more we
increase the number of pulls (i.e.,
there are no pushes.
More fidelity
requires more number of pushes and for the case where number of pushes
is equal to number of pulls, fidelity is close to 50%. The more we
increase the number of pulls (i.e., ![]() ), the lower the obtained
fidelity.
), the lower the obtained
fidelity.
One of the primary goals of our work was to have an adaptive and intelligent approach which can be tuned according to conditions prevailing in the system. From the previous analysis of the PaP algorithm it is clear that it has a set of tunable parameters using which one can achieve Push capability or Pull capability or anything in between. So it is fairly flexible.
Some of the typical scenarios are:
PaP achieves its adaptiveness through the adjustment of
parameters such as ![]() and
and ![]() , and thereby obtains a
range of behaviors with push and pull at the two extremes. We now
describe a somewhat simpler approach wherein, based on the
availability of resources and the data and temporal coherency needs of users, a
server chooses push or pull for a particular client. Consequently, we
refer to our approach as Push-or-Pull (PoP).
, and thereby obtains a
range of behaviors with push and pull at the two extremes. We now
describe a somewhat simpler approach wherein, based on the
availability of resources and the data and temporal coherency needs of users, a
server chooses push or pull for a particular client. Consequently, we
refer to our approach as Push-or-Pull (PoP).
Using the same traces given in table 2 we evaluated PoP. The experiments were performed by running the server on a load free Pentium-II machine and simulating clients from four different load free Pentium-II machines. There were 56 users on each client machine, accessing 3-4 data items. Keeping the server's communication resources constant, the ratio of push to pull connections was varied and the effect on average fidelity experienced by clients in pull mode as well as across all the clients was measured.
As expected, experimental results indicate that the communication overheads drop when the percentage of push sockets is increased. This is to be expected because push algorithms are optimum in terms of communication overheads. As we increase the percentage of push sockets, while the push clients may be able to experience 100% coherence, the percentage of pull requests that are denied due to queue overflow grows exponentially. These results indicate that a balance between pull and push connections must be struck if we want to achieve scalability while achieving high coherency.
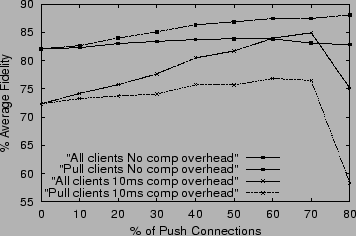
We measured the effect of increasing the percentage of push connections on fidelity. As the number of push connections increases, proxies which were serving the largest number of data items or data items with stringent temporal coherency requirements are moved from pull to push mode. The implemented system worked with a fixed number of clients/data items and so the results below do not reflect the effect of admission control (i.e. request denial based on server load and client profile, which includes its requirements, volume of data served to it and its network status) that is part of PoP. The results are plotted in Figure 6 for two cases of computational overheads per pull request: (1) no computational overheads, except for those connected with the use of the socket, and (2) a 10 msec computational overhead per pull request, in addition to the socket handling overheads.
When the computational overheads for a pull are negligible, average fidelity across all clients improves gradually as we increase the percentage of push clients. When a small computational overhead of 10 msecs per pull is added, while fidelity improves up to a point, when the number of pull connections becomes small, some of the pull requests experience denial of service thereby affecting the average fidelity across all clients. In fact, the overall fidelity drops nearly 10%.
Recall that all push clients experience 100% fidelity. So, the above drop in fidelity is all due to the pull clients. This is clear when we study the variation of the average fidelity of pull clients. With zero computational overheads for pulls, as we increase the number of push clients, fidelity for pull clients improves from 82% to 84% before dropping to 83%. The improvement as well as drop is more pronounced under 10 msec pull overheads. When a large percentage of the clients are in pull mode, the number of pull requests is very high. This increases the average response time for each client, which in effect, decreases the fidelity for pull clients. This scalability problem is due to computation load at the server when a large number of pull clients are present. As more and more clients switch to push mode, the number of pull requests drops, the response time of the server improves, and better fidelity results. The fidelity for pull clients peaks and then starts deteriorating. At this point the incoming requests cause overflows in the socket queues and the corresponding requests are denied. These again cause an increase in the effective response time of the client and fidelity decreases. The last portion of the curve clearly brings out the scalability issue arising because of resource constraints.
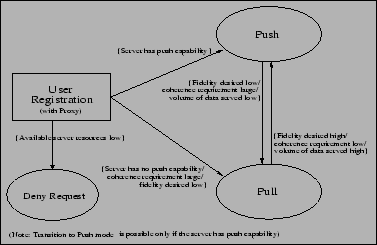
These results clearly identify the need for the system to allocate push and pull connections intelligently. An appropriate allocation of push and pull connections to the registered clients will provide the temporal coherency and fidelity desired by them. In addition, when clients request access to the server and the requisite server resources are unavailable to meet needs of the client, access must be denied. As Figure 5 indicates, this is precisely what PoP is designed to do.
It is clear from the results plotted in Figure 6, that the way in which clients are categorized as push and pull clients affects the performance of PoP. So the system must dynamically and intelligently allocate the available resources amongst push and pull clients. For example, (a) when the system has to scale to accommodate more clients, it should preempt a few push clients (ideally, those which can tolerate some loss in fidelity) and give those resources to pull clients; (b) if the number of clients accessing the server is very small, a server can allocate maximum resources to push clients thus ensuring high fidelity. Thus, by varying the allocation of resources, a server can either ensure high fidelity or greater scalability.
Together, these arguments motivate the properties of PoPoPaP mentioned in Table 1: by adaptively choosing pull or PaP for its clients, PoPoPaP can be designed to achieve the desired temporal coherency, scalability desired for a system[11].
Several research efforts have investigated the design of push-based and pull-based dissemination protocols from the server to the proxy, on the one hand, and the proxy to the client, on the other. Push-based techniques that have been recently developed include broadcast disks [1], continuous media streaming [3], publish/subscribe applications [19,4], web-based push caching [14], and speculative dissemination [5]. Research on pull-based techniques has spanned the areas of web proxy caching and collaborative applications [6,7,21]. Whereas each of these efforts has focused on a particular dissemination protocol, few have focused on supporting multiple dissemination protocols in web environment.
Netscape has recently added push and pull capabilities to its Navigator browser specifically for dynamic documents [20]. Netscape Navigator 1.1 gives two new open standards-based mechanisms for handling dynamic documents. The mechanisms are (a) Server push, where the server sends a chunk of data; the browser displays the data but leaves the connection open; whenever the server desires, it continues to send more data and the browser displays it, leaving the connection open; and (b) Client pull where the server sends a chunk of data, including a directive (in the HTTP response or the document header) that says ``reload this data in 5 seconds'', or ``go load this other URL in 10 seconds''. After the specified amount of time has elapsed, the client does what it was told - either reloading the current data or getting new data. In server push, a HTTP connection is held open for an indefinite period of time (until the server knows it is done sending data to the client and sends a terminator, or until the client interrupts the connection). Server push is accomplished by using a variant of the MIME message format ``multipart/mixed'', which lets a single message (or HTTP response) contain many data items. Client pull is accomplished by an HTTP response header (or equivalent HTML tag) that tells the client what to do after some specified time delay. The computation, state space and bandwidth requirements in case of Server push will be at least as much as was discussed in section 2.3. In addition, since we are using HTTP MIME messages, the message overhead will be more (on average MIME messages are bigger than raw data). Because of the same reason, it is not feasible to use this scheme for highly dynamic data, where the changes are small and occur very rapidly. Also, it would be very difficult to funnel multiple connections into one connection as envisaged in our model 1 (see equation 1). This will clearly increase the space and computation requirements at the server. For the Client pull case, for reasons discussed in Section 6.2, it is very difficult to use this approach for highly dynamic data. Still, these mechanisms may be useful for implementing the algorithms discussed in this paper as they are supported by standard browsers.
Turning to the caching of dynamic data, techniques discussed in [16] primarily use push-based invalidation and employ dependence graphs to track the dependence between cached objects to determine which invalidations to push to a proxy and when. In contrast, we have looked at the problem of disseminating individual time-varying objects from servers to proxies.
Several research groups and startup companies have designed adaptive techniques for web workloads [2,6,13]. Whereas these efforts focus on reacting to network loads and/or failures as well dynamic routing of requests to nearby proxies, our effort focuses on adapting the dissemination protocol to changing system conditions.
The design of coherency mechanisms for web workloads has also received significant attention recently. Proposed techniques include strong and weak consistency [17] and the leases approach [9,22]. Our contribution in this area lie in the definition of temporal coherency in combination with the fidelity requirements of users.
Finally, work on scalable and available replicated servers [23] and distributed servers [8] are also related to our goals. Whereas [23] addresses the issue of adaptively varying the consistency requirement in replicated servers based on network load and application-specific requirements, we focus on adapting the dissemination protocol for time-varying data.
We end this section with a detailed comparison of two alternatives to our approaches: Leases [9,12], a technique that also combines aspects from pull-based and push-based approaches, and Server-based prediction (instead of our client-based prediction) for setting Time-to-Live attributes for Web objects [10,15,17].
Though the Server-Prediction approach looks like a better option than PaP, it runs into following problems:
In summary, so far dynamic data has been handled at the server end [16,10]; our approaches are motivated by the goal of offloading this work to proxies.
Since the frequency of changes of time-varying web data can itself vary over time (as hot objects become cold and vice versa), in this paper, we argued that it is a priori difficult to determine whether a push- or pull-based approach should be employed for a particular data item. To address this limitation, we proposed two techniques that combine push- and pull-based approaches to adaptively determine which approach is best suited at a particular instant. Our first technique (PaP) is inherently pull-based and maintains soft state at the server. The proxy is primarily responsible for pulling those changes that are of interest; the server, by virtue of its soft state, may optionally push additional updates the proxy, especially when there is a sudden surge in the rate of change that is yet to be detected by the proxy. Since the server maintains only soft state, it is neither required to push such updates to the proxy, nor does it need to recover this state in case of a failure. Our second technique (PoP) allows a server to adaptively choose between a push- or pull-based approach on a per-connection basis (depending on observed rate of change of the data item or the coherency requirements). We also showed how PoP can be extended to use PaP for some of its connections, leading to the algorithm PopoPap.
Another contribution of our work is the design of algorithms that allow
a proxy or a server to efficiently determine when to switch from
a pull-based approach to push and vice versa. These decisions are made
based on (i) a client's temporal coherency requirements (![]() ), (ii)
characteristics of the data item, and (iii) capabilities of servers
and proxies (e.g., a pure HTTP-based server precludes the use of
push-based dissemination and necessitates the use of a pull-based
approach by a proxy).
), (ii)
characteristics of the data item, and (iii) capabilities of servers
and proxies (e.g., a pure HTTP-based server precludes the use of
push-based dissemination and necessitates the use of a pull-based
approach by a proxy).
Our techniques have several characteristics that are desirable for
time-varying data: they are user-cognizant (i.e., aware of user
and application requirements), intelligent (i.e., have the
ability to dynamically choose the most efficient set of mechanisms to
service each application), and adaptive (i.e., have the ability
to adapt a particular mechanism to changing network and workload
characteristics). Our experimental results demonstrated that such
tailored data dissemination is essential to meet diverse temporal
coherency requirements, to be resilient to failures, and for the
efficient and scalable utilization of server and network resources.
Currently we are extending the algorithms developed in this paper to design algorithms suitable for cooperative proxies and also for disseminating the results of continual queries [18] posed over dynamic data.