Copyright is held by the author/owner.
WWW10, May 1-5, 2001, Hong Kong.
ACM 1-58113-348-0/01/0005.
Content understanding is a crucial issue for website adaptation. In this paper we present a Function-based Object Model (FOM) that attempts to understand authors' intention by identifying Object function instead of semantic understanding. Every Object in a website serves for certain functions (Basic and Specific Function) which reflect authors' intention towards the purpose of an Object. Based on this consideration we have proposed the FOM model for website understanding. FOM includes two complementary parts: Basic FOM based on the basic functional properties of Object and Specific FOM based on the category of Object. An automatic approach to detect the functional properties and category of Object is presented for FOM generation. Two level adaptation rules (general rules and specific rules) based on FOM are combined for practical adaptation. A system for web content adaptation over Wireless Application Protocol (WAP) is developed as an application example of the proposed model. Experiments have shown satisfactory results and extensibility.
The increasing diversity in terms of devices, protocols, networks and user preferences in today's web has made adaptive capability critical for Internet applications. Many efforts have addressed this problem and various solutions have been proposed [1]-[5].
To achieve adequate adaptation it is crucial to understand website structure and content function that reflect authors' intention directly. However, most of the previous works achieve adaptation only under some special conditions due to the lack of structural information. Some works tried to extract semantic structural information from HTML tag either manually [6] - [9] or automatically [10] [11]. But these approaches lack an overview of the whole website. In addition, they are only suitable for HTML contents. Furthermore, most of them do not work effectively even for HTML pages because HTML was designed for both presentational and structural representation of content. Further misuses of structural HTML tags for layout purpose make the situation even worse. Cascade Style Sheet (CSS) [12] compensates this situation by representing the presentation information separately, but its application is quite limited. Moreover, the difficulty of extracting semantic structure from HTML tags is still not solved by CSS. Therefore, the results of semantic rules based approaches for HTML contents are not so stable for general web pages. Smith et al. proposed InfoPyramid model [13] to represent the structural information of multimedia contents. However, InfoPyramid does not exist in current web contents. XML provides a semantic structural description to content by Document Type Description (DTD) [14]. However, DTD is not a general solution because each application area would require its special DTD, and XML takes no consideration to the function of content. Besides, although XSL [15] provides a flexible way of presenting the same content in different devices, it needs be generated manually, which would be a labor-intensive work for authors.Instead of semantic understanding, in this paper we present a Function-based Object Model (FOM) for website adaptation. Taking semantic understanding a task of XML, FOM attempts to understand authors' intention by identifying Object function and category. In FOM Objects are classified into Basic Object (BO) and Composite Object (CO). Each Object in a website serves certain functions including Basic Function and Specific Function. They both reflect authors' intention towards the purpose of an Object, which is a crucial clue for web content adaptation. Based on this observation, we propose the FOM model for website understanding. FOM includes two complementary parts: Basic FOM and Specific FOM. Basic FOM represents an Object by its basic functional properties and Specific FOM represents an Object by its category. Combining Basic FOM and Specific FOM together, we can obtain a thorough understanding of authors' intention towards a web site.
Since authors tend not to give more description on Object function and category, in this paper an automatic approach to detect the functional properties and categories of Objects is presented for FOM generation, which is crucial for the application of FOM.FOM provides two level guidelines for web content adaptation: general rules based on Basic FOM and specific rules based on Specific FOM. An example of web content adaptation over Wireless Application Protocol (WAP) is presented in this paper, and experiments have shown satisfactory results.
In Section 2, we present the concept of FOM. This is followed by the description of automatic FOM generation scheme in Section 3. In Section 4, we present general adaptation rules based on Basic FOM and specific adaptation rules for WAP devices based on Specific FOM as an example. Conclusions are given in Section 5.Object is the basic element of a hypermedia system. It is a piece or a set of information to perform some certain functions. According to the number of content bodies an Object contains, Object can be classified into Basic Object (BO) and Composite Object (CO). In the following two sub-sections we will illustrate Basic FOM and Specific FOM for Object, respectively.
In a hypermedia system, a Basic Object is the smallest information body that cannot be further divided. Only as a whole can it perform certain functions.
1) Function of BO
A BO generally performs one or more of the following basic functions:
It may provide some semantic information to users or guide users to other Object with a hyperlink. Besides, it may also serve for beautifying a page or have interface for users to communicate with the system.
2) Property of BO
According to its function, a BO has the following properties:
Presentation: the way a BO shows itself to users, which includes Media Type, Layout Format and Encoding Format.
Semanteme: the content meaning of a BO. Since XML has a good scheme for describing the semantic meaning of contents, here semanteme is more at semantic layer instead.
Decoration: to what extent a BO serves for beautifying the web page. Decoration value of a BO is indicated as x, (0«x«1). The higher x is, the Object serves more for decoration. If x equals to 1, the BO serves only for decoration without any other information. If x equals to 0, the BO has no intention for decoration.
Hyperlink: the Object a BO points to, which has the following cases: No Hyperlink, Hyperlink to Other Object and Hyperlink to Other Application.
Interaction: the interaction method of a BO, which has the following cases: Display (for presenting information), Button (for selecting list item or submitting information) and Input (for inputting information).
3) FOM of BO
Based on the properties above, the FOM of a BO is as following:
BO (Presentation, Semanteme, Decoration, Hyperlink, Interaction)
Presentation:
Layout Format: Left aligned...Media Type: Text
Encoding: Language: English; Content Type: Text/HTML...
Semanteme: Abstract
Hyperlink: NONE
Decoration: 0
Interaction: Display
A Composite Object is a set of Objects (BO or CO) that perform some certain functions together. These Objects are combined under some basic clustering rules. Since a web page is composed of COs and BOs, and a website is a set of web pages, both of them are COs.
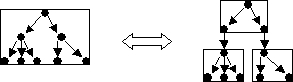
Unfolding all the child COs inside a CO, and repeating this process until all the leaves of the original CO are BOs, we have a tree-like representation of the CO, which is called the Full Representation of the CO. Root Child is a child that connects with the root directly. And Root Children are Brother Objects to each other.
1) Function of CO
Besides the basic functions of BOs, a CO has also clustering function. The Root Children of a CO are clustered based on some basic rules to perform certain goals that reflect authors' intention towards the relationship and hierarchy of Root Children.
2) Property of CO
Based on the clustering function, a CO has its basic properties as following:
Clustering Relationship
Presentation Relationship: presentation order (time and space) of Root Children inside a CO, and whether the Root Children are separable when they are presented.
3) FOM of CO
Based on the properties above, the FOM of a CO is as following:
CO = {Oi, Clustering Relationship, Presentation Relationship | Oi is the Root Children of the CO, i=1, 2, ..., NR}, where NR is the total number of Root Children of the CO.
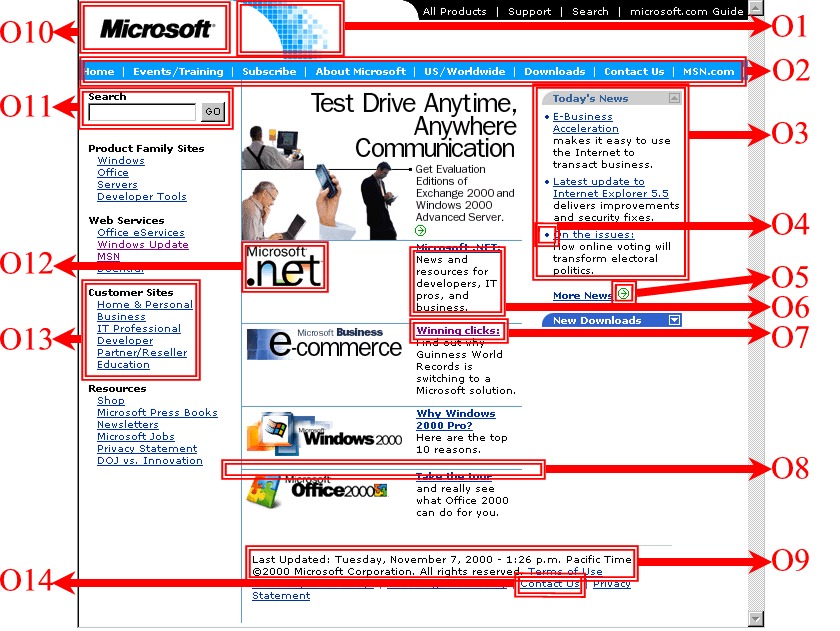
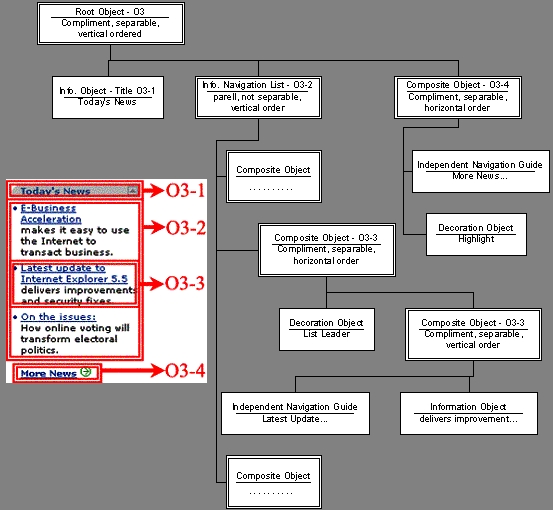
For example, the FOM of O3 in Figure1 is:
Root Children: O3-1, O3-2, O3-4
Clustering Relationship: Complement
Presentation Relationship: Vertical; Separable
Figure 2 is the Full representation of O3.
The specific function of an Object in a given application environment is represented by its category, which reflects authors' intention directly. There are many Objects categories according to various purposes. Here we take the HTML content of Figure 1 as an example to describe Object categories.
1) Information Object: presents content information. (O6)
2) Navigation Object: provides navigation guide. (O12)
3) Interaction Object: provides user side interaction. It has the following formats: User Selection (for selecting items from a list of available information), User Query (for inputting query information, O11) and User Submission (for uploading information).
4) Decoration Object: serves for decoration purpose only. (O1). Decoration Object may have the following format: Separator (O8), List Leader (O4), Highlight (O5) and Background.
5) Special Function Object: performs special functions such as AD, Logo, Contact, Copyright, Reference, etc.
6) Page Object: serves as the basic document of a website for presenting related information. It has two basic categories: Index Page and Content Page. Index Page serves mainly as navigation guide to other pages. Figure 1 is an example. The purpose of Content Page is to deliver semantic information. See Figure 11 for an example.
Note: websites can also be considered as COs. However, due to the complexity of websites, we leave the category analysis of websites for future research.
Although it is desirable that additional information be added for the generation of FOM in the authoring phase, authors actually tend not to do so. Thus, it is important that we can automatically analyze the function of contents in a website. Here we present an automatic method for the generation of Basic and Specific FOM in Section 3.1 and 3.2, respectively. Although our analysis is based on HTML websites, it is easy to extend to other languages.
Object detection is a necessary step before the generation of FOM.
In HTML content, a BO is a non-breakable element within two tags or an embedded Object. There is no other tag inside the content of a BO. According to this criteria it is easy to find out all the BOs inside a website.
COs can be detected by layout analysis of web pages. The basic idea is that Objects in the same category generally have consistent visual styles and they are separated by apparent visual boundaries from Objects in other categories. According to this observation, we first render the visual image in our system. Then a visual similarity pattern detection algorithm based on DBSCAN [16] is applied to extract Objects in the same category. The distance between different objects in this algorithm is measured by their visual similarity.
The functional properties of a BO are generally included in its HTML source content. Following are some basic rules for the Basic FOM generation of BO:
1) Presentation Property can be determined by analyzing HTML source and tags to extract Media Type, Encoding Format and Layout information of an Object.
2) Semanteme Property can be determined by analyzing the content itself to extract the semantic layer.
3) Navigation Property is the destination of the hyperlink contained in a BO.
4) Decoration Property varies between [0,1] according to presentation and Semanteme property. Text/Video Objects normally have lower decoration value. And the following Objects generally have higher value to indicate that their main purpose is for decoration: general decoration symbols, lines and separators between Objects and Object with "background" property in HTML tag.
5) Interaction Property of a BO may be one of the following three categories:
Following are some basic rules for the Basic FOM generation of CO:
1) Clustering Relationship, may be one of the following three categories:
2) Presentation Relationship
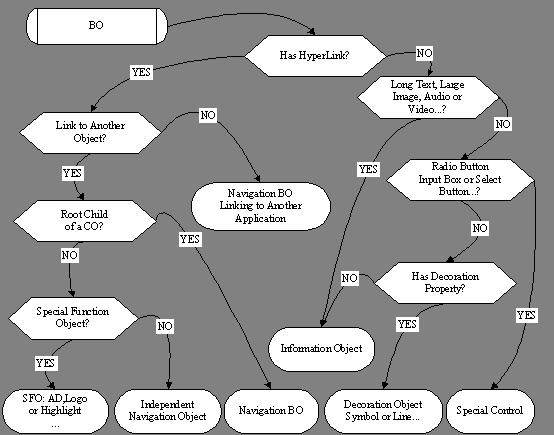
As described above, Specific FOM represents an Object with its category. For a BO, its category is mainly determined by the major properties of the BO, the properties of the Father/Brother Objects. A rule based decision tree is applied to determine the category of BO. Figure 3 illustrates the basic idea of BO category detection.
The category of a CO is determined by the major properties of the CO/Root Children and the application environment. Each category needs a specific detection algorithm. In this section and next section we give two examples on Normal Navigation Bar (NNB) detection and page category detection, respectively. The methods can be easily extended to related categories.
According to its media type, NNB can be classified into Text and Image NNB. Here we focus on the detection of Text NNB. Image NNB can also be detected with similar method.
To find out the Text NNB in a website, we have the following rules by statistical analysis:
The constant variables above such as Hmin, Lmax, Rmin and Dmax are experimental values, which may vary in different websites according to the practical detection result.
Based on the rules above, we can easily set up the algorithm for Text NNB Finding. Small deviations are allowed for the binary conditions in practical detection. That is, even if one of the values is slightly on the wrong side of a threshold, the corresponding Text NNB can be accepted if all the other values are well away from their thresholds.
Experimental results of NNB detection can be found in Figure 11, where the NNB is removed in adapted content. For more results please refer to our website listed in Section 4.2. Experimental results show that our detection algorithm is pretty precise for Text NNB.
As described above, web page has two basic categories: Index Page and Content Page. Here we present a hyperlink based page category detection algorithm, which is effective for all languages based on XML.
We first define the Out Degree (OD) and In Degree (ID) of a web page. OD is the number of hyperlinks inside the page. ID is the number of web pages with hyperlinks to the current page in the whole website.
By statistical analysis, we find that a page with relatively large OD or ID may be an Index Page and a page with relatively small OD and ID may be a Content Page. That is, for a page with Out Degree OD and In Degree ID, the following rules exist:
If OD > OD0 or ID > ID0, the page can be considered as an Index Page;
If OD < OD0 and ID < ID0, the page can be considered as a Content Page,
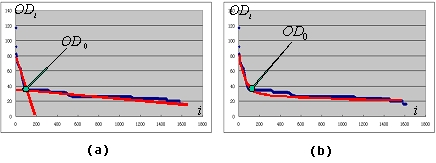
where OD0 and ID0 are two constant variables determined by the website. To find OD0 and ID0, we first sort the pages by OD and ID in descending order, respectively, and draw the corresponding OD(i)-i and ID(i)-i diagram of a website (i is the ordered number of a web page). Figure 4 gives an example of OD(i)-i and ID(i)-i diagram for Yahoo! Chinese news website (1,615 pages). By statistical analysis to many websites we find that OD0 and ID0 are generally the inflexions in OD(i)-i and ID(i)-i diagram as shown in Figure 4.
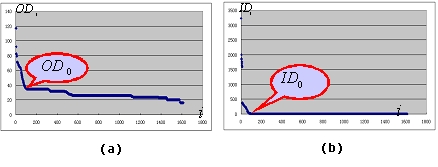
1) Beeline simulation. As shown in Figure 5(a), we simulate the diagram with two beelines. That is, the average distance between the beelines and the original curve of OD is minimized. Then the y-coordinate of the intersection of the two lines is OD0.
2) Polynomial simulation. As shown in Figure 5(b), we simulate the diagram with a polynomial curve (second power or more). That is, the average distance between the polynomial and the original curve of OD is minimized. Then the y-coordinate of the inflexion with the largest curvature of the polynomial curve is OD0.
Following is an example of our experiment results to an English news website:
Total number of web pages: 73, in which number of Index/Content Pages: 5/68
OD0 =22, ID0 =4
Detection Precision: 100%
Figure 10 and Figure 11 give examples of an Index Page (OD=36, ID=76) and a Content Page (OD=8, ID=3) in this website. Experiments to other websites have also shown promising results. For more results please refer to our website listed in Section 4.2.
Since Navigation Bars may exist in both Index Pages and Content Pages, we can take them away from web pages before calculating OD and ID of each page to eliminate the influence of Navigation Bar. With this method, we have even higher precision for page category detection. Compared to other approaches [21], our method has not only a higher precision but also good extensibility.
For practical adaptation, FOM has two level guidelines. Section 4.1 presents the general rules based on Basic FOM. The specific rules for web adaptation over WAP based on Specific FOM are illustrated in Section 4.2 as an example.
To provide users with the same browsing experience, we have the following basic criteria.
Following are the general adaptation rules based on basic FOM.
1) Presentation Property should be considered together with device capability and language difference to generate the most suitable Media Type, Encoding Format and Layout Format for an Object.
2) Semanteme Property helps to select the most appropriate semantic layer of an Object.
3) Decoration values of different Objects are compared to decide whether an Object should be removed (Decided by Decision Engine [17]). If the value is 0, the Object should be retained. Otherwise, it can be removed if necessary.
4) Rules for Hyperlink Property:
5) Rules for Interaction Property:
6) Rules for Clustering Property (for COs only):
![]()

The rules above are just basic guidelines. They should be combined with specific rules based on Specific FOM and application environment for content adaptation. Following we present an example of adapting web content over WAP to illustrate the specific rules based on Specific FOM.
WAP environment is quite different from that of web, which requires content re-authoring and truncation to enable WAP users to browse the web content. However, the narrow bandwidth, small memory, different protocol and poor presentation capability (small screen size, poor support for multimedia, etc.) of WAP device prohibit the delivery of normal web contents, and a web page originally designed for desktops has to be divided into several decks for WAP devices. All these make web content adaptation over WAP a significant hard problem.
Many research results have been presented in this area. W3C's "HTML 4.0 Guidelines for Mobile Access" [18] is a series of suggestions of adapted authoring for WAP. However, it has no consideration to the existing web contents. Marcin, etc. [19] defined some tag-based conversion rules, but it is not a general method. Eija, etc. [20] designed an HTML/WML conversion proxy server. However, the proxy server only works for some certain applications.
Generally speaking, most of the previous approaches are Tag/Page based. They are only suitable for HTML documents and lack an overview of the whole website. Our FOM based approach provides a good solution towards these problems. Following are the specific rules for WAP adaptation based on Specific FOM.
a. In Index Page: since Index Pages mainly serve as navigation guide, Navigation Bar should be retained. Text NNB can be retained without change. Image NNB, Frame, Menu or Map should be converted into Text NNB.
b. In Content Page: since the purpose of Content Page is to deliver semantic information, Navigation Bar can be discarded. Otherwise, the small screen of WAP device would be filled with redundant information.
a. Normal List/Info. List/Intro. List: no change
b. Map: convert to hyperlink text list
a. Highlight: replaced with big font text
b. Separator/List Leader/Background: discard
In addition to the specific adaptation rules, we have also language conversion rules (HTML to WML). Since this is not much related to FOM, here we just introduce four basic rules:
Besides, to help users locate information quickly, the most important information should be delivered first. This can be achieved by reorganizing the web content into WML decks.
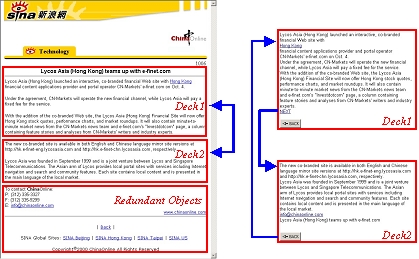
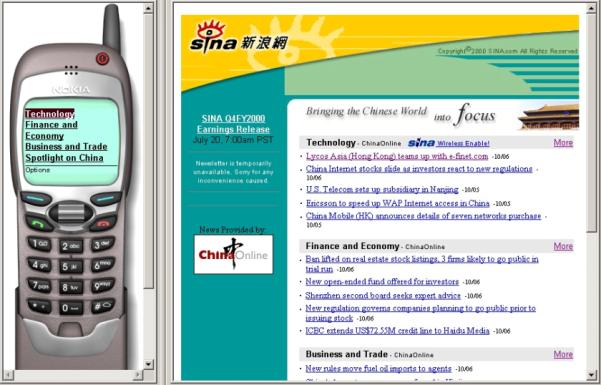
Figure 10 shows an adaptation example for an Index Page, in which contents with unsupported media type are removed, and several new decks are generated to show the original content at different layer. The Index Deck is an outline of the original page. Detailed contents are in Deck 1-6. To simplify the adaptation process, here we only use decks to present the adapted content for WAP device, and cards are not considered. Figure 12 shows the adaptation result in a WAP simulator. Figure 11 shows the adaptation result of a Content Page, in which redundant contents are removed, and the original page is divided into two decks because of the memory limitation of WAP device. The two examples in Figures 10 and 11 are all practical adaptation results for an existing website. For more results please visit our website:
Compared to other approaches, our approach has more satisfactory results and brings the same browsing experience to users. Since authors' intention is well understood through FOM analysis, our adaptation is quite reasonable. For example, page function analysis (index/content page) has helped to decide whether to keep a navigation bar or not for WAP device (See Figures 10 and 11). Since the major purpose of an index page is to provide navigation guide to users, the navigation bar is retained in the index page (Figure 10). On the contrary, the major purpose of the content page is to provide information to users, and the navigation bar can be considered as redundant information, therefore, it is removed in the content page (Figure 11). Another example is the generation of the index deck (Figure 10). The system first detects the navigation lists in the index page through FOM analysis. At the same time, the parallel clustering relationship of these navigation lists are also detected. Then the system can extract the abstract information from these navigation lists and list them equally to generate the new index deck, which enables users to navigate the adapted content easily.
Besides, based on visual information and functional property analysis instead of tag analysis, our method is a general approach to various websites. It not only is able to handle HTML based websites, but also can be easily extended to other web environment. For all the contents we listed in our website, we always get relatively stable and reasonable adaptation results. Compared to our approach, previous tag-based approaches are limited to some certain applications due to the misuse of HTML tags.

This paper presents Function-based Object Model for website adaptation. By representing Objects with their functional properties and categories, FOM effectively avoids the ineffectiveness and limitation of approaches based on semantic structure analysis. Experiment results show that our approach has more reasonable adaptation results and can be applied to various web contents and applications. As a general approach, FOM can be easily extended to the whole website and other application environment. In addition, the automatic FOM generation method also enables our approach quite effective.
Further research includes extending FOM to website function analysis, combining FOM with semantic representation model (such as XML) and user model to provide a more personalized service. Besides, we will also try to set up an automatic test bed so that users can submit the links of web pages that they are interested in and test the adapted results.
Jinlin Chen joined Microsoft Research China in 1999 as an Associate Researcher in the Media Computing Group. From 1997 to 1998 he was a visiting scholar in Dept. of EE & Info. Tech., Technical University of Munich, Germany. He obtained a PhD in 1999 from Dept. of Automation, Tsinghua Univ., a B.Eng and a second B. Economics from Tsinghua Univ. in 1994. His research interests include Adaptive Web/WAP Content Delivery, User Modeling, Embedded System and Intelligent House.
Baoyao Zhou is a Master candidate in Dept. of Automation, Tsinghua University. He received a B.S. in School of Information Science and Technology, Tsinghua University in 1999. He is currently a Visiting Student in Media Computing Group, Microsoft Research, China. His research interests include Adaptive Web/WAP Content Delivery.
Jin Shi is a Visiting Student in Media Computing Group, Microsoft Research, China. He received a B.S. in School of Information Science and Technology, Tsinghua University in 2000. His research interests include Adaptive Web/WAP Content Delivery.
Hongjiang Zhang joined Microsoft Research, China as Assistant Director from Hewlett-Packard Labs, Palo Alto, CA. He obtained a Ph.D. from the Technical University of Denmark, and his B.S. from Zhengzhou University, China, both in Electrical Engineering. Throughout his academic career, HongJiang has been actively engaged in research and development activities in the areas of video and image analysis, processing and retrieval, media compression and streaming, computer vision and their applications consumer and enterprise markets. He is widely known in the multimedia research community for his pioneering work in video and image content analysis, representation, retrieval and browsing. At HP Labs, HongJiang was a research manager, worked in the areas of multimedia content retrieval and management technologies; intelligent image and video processing; and Internet media. Before joining HP Labs in 1995, Dr. Zhang worked with the Institute of Systems Science, National University of Singapore. He also worked at MIT's Media Lab in 1994 as a visiting researcher. HongJiang is a Senior Member of IEEE and a member of ACM. He has authored two books, over 80 referred papers and book chapters, 14 US patents or pending applications, and numerous special issues of professional journals in multimedia processing, content-based retrieval, and Internet media.
Qiufeng Wu is a professor in School of Information Science and Technology, Tsinghua Univ. He was a visiting scholar at Boston Univ. in 1985. He obtained his B.S. form Tsinghua University in Dept. of Electrical Engineering in 1959. Throughout his academic career, Prof. Wu has been actively engaged in research and education activities in the areas of Computer Integration Manufacturing System, Network Communication and Multimedia Network.