|
Columbia University New York, NY 10027 eugene@cs.columbia.edu |
NEC Research Institute Princeton, NJ 08540 |
Columbia University New York, NY 10027 |
Copyright is held by the author/owner.
WWW10, May 2-5, 2001, Hong Kong
ACM 1-58113-348-0/01/0005.
We introduce a method for learning query transformations that improves the ability to retrieve answers to questions from an information retrieval system. During the training stage the method involves automatically learning phrase features for classifying questions into different types, automatically generating candidate query transformations from a training set of question/answer pairs, and automatically evaluating the candidate transforms on target information retrieval systems such as real-world general purpose search engines. At run time, questions are transformed into a set of queries, and re-ranking is performed on the documents retrieved. We describe a prototype search engine, Tritus, that applies the method to web search engines. Blind evaluation on a set of real queries from a web search engine log shows that the method significantly outperforms the underlying web search engines as well as a commercial search engine specializing in question answering.
Web search engines such as AltaVista (www.altavista.com) and Google (www.google.com) typically treat a natural language question as a list of terms and retrieve documents similar to the original query. However, documents with the best answers may contain few of the terms from the original query and be ranked low by the search engine. These queries could be answered more precisely if a search engine recognized them as questions.
Consider the question ``What is a hard disk?''. The best documents
for this query are probably not company websites of disk storage manufacturers,
which may be returned by a general-purpose search engine, but rather hardware
tutorials or glossary pages with definitions or descriptions of hard disks.
A good response might contain an answer such as:
``Hard Disk: One or
more rigid magnetic disks rotating about a central axle with associated
read/write heads and electronics, used to store data...''. This definition
can be retrieved by transforming the original question into a query ![]() ``hard
disk'' NEAR ``used to''
``hard
disk'' NEAR ``used to''![]() .
Intuitively, by requiring the phrase ``used to'', we can bias most
search engines towards retrieving this answer as one of the top-ranked
documents.
.
Intuitively, by requiring the phrase ``used to'', we can bias most
search engines towards retrieving this answer as one of the top-ranked
documents.
We present a new system, Tritus, that automatically learns to transform natural language questions into queries containing terms and phrases expected to appear in documents containing answers to the questions (Section 3). We evaluate Tritus on a set of questions chosen randomly from the Excite query logs, and compare the quality of the documents retrieved by Tritus with documents retrieved by other state-of-the-art systems (Section 4) in a blind evaluation (Section 5).
The first part of the task, relevant to our work here, is to retrieve promising documents from a collection. The systems in the latest TREC evaluation submitted the original questions to various information retrieval systems for this task [22].
A number of systems aim to extract answers from documents. For example, Abney et al. [1] describe a system in which documents returned by the SMART information retrieval system are processed to extract answers. Questions are classified into one of a set of known ``question types'' that identify the type of entity corresponding to the answer. Documents are tagged to recognize entities, and passages surrounding entities of the correct type for a given question are ranked using a set of heuristics. Moldovan et al., and Aliod et al. [13,2] present systems that re-rank and postprocess the results of regular information retrieval systems with the goal of returning the best passages. Cardie et al. [7] describe a system that combines statistical and linguistic knowledge for question answering and employs sophisticated linguistic filters to postprocess the retrieved documents and extract the most promising passages to answer a question.
The systems above use the general approach of retrieving documents or passages that are similar to the original question with variations of standard TF-IDF term weighting schemes [18]. The most promising passages are chosen from the documents returned using heuristics and/or hand-crafted regular expressions. This approach is not optimal, because documents that are similar to the question are initially retrieved. However, the user is actually looking for documents containing an answer and these documents may contain few of the terms used to ask the original question. This is particularly important when retrieving documents is expensive or limited to a certain number of documents, as is the case with web search engines.
Other systems attempt to modify queries in order to improve the chance of retrieving answers. Lawrence and Giles [11] introduced Specific Expressive Forms, where questions are transformed into specific phrases that may be contained in answers. For example, the question ``what is x'' may be transformed into phrases such as ``x is'' or ``x refers to''. The main difference from our current work is that in [11] the transforms are hand crafted (hard coded) and the same set of queries is submitted to all search engines used, except for the differences in query syntax between search engines. Joho and Sanderson [10] use a set of hand-crafted query transformations in order to retrieve documents containing descriptive phrases of proper nouns. Harabagiu et al. [8] describe a system that transforms questions using a hierarchy of question types. The hierarchy is built semi-automatically using a bootstrapping technique. Schiffman and McKeown [19] describe experiments in automatically building a lexicon of phrases from a collection of documents with the goal of building an index of the collection that is better suited for question answering.
Also related is a large body of research (e.g., [12]) that describes methods for automatically expanding queries based on the relevance of terms in the top-ranked documents. An interesting approach presented in [23] describes how to automatically expand a query based on the co-occurrence of terms in the query with the terms in the top-ranked documents for the original query. In general, automatic query expansion systems expand queries at run time on a query-by-query basis using an initial set of top-ranked documents returned by the information system in response to the original query.
In contrast to the previous research, we present a system that automatically learns multiple query transformations, optimized specifically for each search engine, with the goal of maximizing the probability of an information retrieval system returning documents that contain answers to a given question. We exploit the inherent regularity and power of natural language by transforming natural language questions into sets of effective search engine queries.
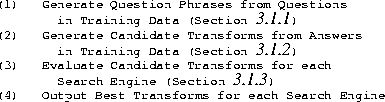 |
| Figure 1: Outline of the process used to train the Tritus system. |
The input to this stage is a set of questions. These questions and their corresponding answers constitute the training data. We generate potential question phrases by computing the frequency of all n-grams (phrases) of length minQtokens to maxQtokens words, with all n-grams anchored at the beginning of the questions. We use all resulting n-grams that occur at least minQphraseCount times.
The output of this stage is a set of question phrases that can be used to quickly classify questions into respective question types. Sample question phrases, automatically generated from questions in the training collection described later, are shown in Table 1.
|
||||||||||
| Table 1: Question type phrases used for evaluation (Section 4). |
This method of selecting question phrases can produce many phrases, which may include a significant number of phrases that are too specific to be widely applicable. Because the following stages of the training process are relatively expensive and we have limited resources for training, we chose to limit the training for the results reported here to phrases that match the regular expressions shown in Figure 2. The regular expressions match common questions, and allow us to concentrate our resources on the most useful phrases. Feature selection techniques, part-of-speech tagging, and other natural language processing techniques may be used to fine-tune the filtering of generated question phrases.
|
|
| Figure 2: The regular expressions used to filter the automatically generated question phrases that are candidates for transformation. |
Although alternative approaches can be used to identify categories of questions, our n-gram approach has a number of advantages. This approach is relatively inexpensive computationally, allowing the processing of large training sets. The approach is also domain independent, and will work for many languages with only minor modifications. Additionally, when evaluating a question at run time (Section 3.2), categorizing a question using phrase matching can be incorporated with negligible overhead in the overall processing time of queries.
For this stage of the learning process we use a collection of <Question, Answer> pairs. A sample of the original collection is given in Figure 5. As we will describe next, this stage of the learning process operates over a collection that has been tagged with a part-of-speech tagger, which assigns a syntactic part of speech (e.g., noun, verb) to each word in the text. We use Brill's part-of-speech tagger [4], which is widely used in the natural language processing community and is available at http://www.cs.jhu.edu/~ brill/.
For each <Question, Answer> pair in the training collection where a prefix of Question matches QP, we generate all possible potential answer phrases from all of the words in the prefix of Answer. For this we use n-grams of length minAtokens to maxAtokens words, starting at every word boundary in the first maxLen bytes of the Answer text. A sample of answer phrases generated after this step is shown in Table 2. These phrases are heavily biased towards electronics or the computer domain. These phrases were generated because a large portion of the documents in the training collection were on technology related topics. If we used these phrases in transforms, we may change the intended topic of a query. Recall that the transformations we are trying to learn should improve accuracy of the retrieved set of documents, yet preserve the topic of the original query. Therefore we would need to filter out phrases such as ``telephone'', which intuitively would not be good transformations for general questions (e.g., ``What is a rainbow?'').
We address this problem by filtering out candidate transform phrases containing nouns. We observe that in most of the queries the nouns are content words, or words expressing the topic of the query. For example, in the query ``what is a rainbow'', the term ``rainbow'' is a noun and a content word. Likewise, the word ``telephone'' is a noun. Thus, we filter candidate transform phrases by checking if a generated answer phrase contains a noun, and if it does, the phrase is discarded. We use the part of speech information, which is computed once for the whole collection as described in the beginning of this subsection.
|
||||||||||||||||||
Of the resulting n-grams, we keep the topKphrases with the highest frequency counts. We then apply IR techniques for term weighting to rank these candidate transforms.
The initial term weights are assigned to each candidate transform phrase, ti, by applying the term weighting scheme described in [16]. These term weights were used in the Okapi BM25 document ranking formula (used by the state-of-the-art Okapi information retrieval system participating in TREC conferences since TREC-3). Many information retrieval systems use the vector space model [18] to compute similarity between documents. In this model, similarity is computed as a dot product between vectors representing each document. The elements of each vector are calculated as a combination of the term weight and term frequency of each term in the document. The BM25 metric [17] uses a similar idea. In the original definition of BM25, each term ti in the document is assigned the Robertson-Spark Jones term weight w(1)i [15] with respect to a specific query topic and is calculated as:
| (1) |
where r is the number of relevant documents containing ti, N is the number of documents in the collection, R is the number of relevant documents, and n is the number of documents containing ti. Intuitively, this weight is designed to be high for terms that tend to occur in many relevant documents and few non-relevant documents, and is smoothed and normalized to account for potential sparseness of relevance information in the training data.
In the original definition of BM25, term weight wi(1) is specific to each query topic. We apply this metric to our task of weighting candidate transforms by incorporating two modifications. First, we interpret query topic as question type. In this interpretation, a relevant document is one of the answers in the training collection that corresponds to the question phrase (question type). Therefore wi(1) is an estimate of the selectivity of a candidate transform ti with respect to the specific question type. Second, we extend the term weighting scheme to phrases. We apply the same, consistent weighting scheme to phrases, and treat them in the same way as single word terms. We compute this weight for each candidate transform tri by computing the count of <Question, Answer> pairs w+here tri appears in the Answer to a question matching QP as the number of relevant documents, and consider the number of the remaining <Question, Answer> pairs where tri appears in the Answer as non-relevant, and apply the formula in Equation 1.
We then compute the term selection weights, wtri, for each candidate transform tri, as described in [14] in the context of selecting terms for automatic query expansion as:
| (2) |
where qtfi is the co-occurrence count of tri with QP, and wi(1) is the relevance-based term weight of tri computed with respect to QP. This term ranking strategy exploits both co-occurrence statistics and relevance weights with the aim of filtering out noise. While wi(1) assigns higher weight to terms and phrases with high discriminatory power, qtf is a measure of how often a phrase occurs in answers to relevant question types. For example, while in Table 3 the phrase ``named after'' is a better discriminator for the question phrase ``what is a'', it does not occur as often as those ultimately ranked higher. This tradeoff between discrimination and frequency of occurrence, or expected precision and recall, may be explored in future work. Sample output of this stage is shown in Table 3.
|
||||||||||||||||||||||||||||||||||||||||
| Table 3: Sample candidate transforms along with their frequency count qtfi, BM25 term weight w(1)i, and the resulting term selection weight wtri. |
Finally, the candidate transforms are sorted into buckets according to the number of words in the transform phrase, and up to maxBucket transforms with the highest values of wtri are kept from each bucket. In general, we expect that longer phrases may be processed differently by the search engines, and this step was done in order to include such longer, potentially higher precision transforms in the set of candidate transforms, whereas primarily shorter transforms with higher frequency counts may be chosen otherwise. In Table 4, we show a sample of phrases with the highest selection weights from each candidate transform bucket.
|
||||||||||||||||||||||||
| Table 4: A sample of candidate transforms grouped into buckets according to the transform length. These transforms were generated for the question phrase ``what is a''. |
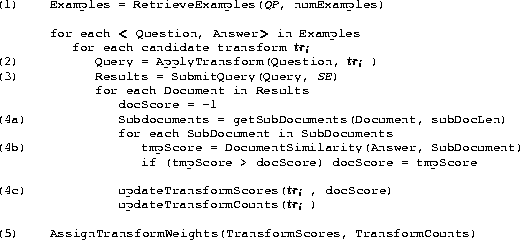 |
| Figure 3: Automatically evaluating the effectiveness of candidate transforms. |
In Step (1) of the algorithm we retrieve a set of <Question, Answer> pairs to be used as training examples. This is done by sorting all of the <Question, Answer> pairs in the collection in order of increasing answer length, and using up to numExamples of the first <Question, Answer> pairs that contain questions beginning with QP. The sorting step is done because we believe the evaluation may be more accurate for questions that have shorter answers; however, this is a topic for future research.
For each of the example <Question, Answer> pairs, and the
set of candidate transforms generated in the previous stage of the
process, we apply each transform ![]() to the Question one at a time (Step (2)). Consider a question Question
=
to the Question one at a time (Step (2)). Consider a question Question
= ![]() QP
C
QP
C![]() ,
where QP is the question phrase, and C are the remaining
terms in the question. Using transform tri we remove
the question phrase QP and rewrite Question as Query =
,
where QP is the question phrase, and C are the remaining
terms in the question. Using transform tri we remove
the question phrase QP and rewrite Question as Query = ![]() C
AND tri
C
AND tri![]() .
For example, consider the candidate transform ``refers to'' for the question
phrase ``what is a'', and the <Question, Answer> pair
<``what is a lisp machine (lispm)'', ``A Lisp Machine (lispm)
is a computer optimized for running Lisp programs, ...''>. Applying
the transform to the Question we obtain a rewritten query Query
= ``
.
For example, consider the candidate transform ``refers to'' for the question
phrase ``what is a'', and the <Question, Answer> pair
<``what is a lisp machine (lispm)'', ``A Lisp Machine (lispm)
is a computer optimized for running Lisp programs, ...''>. Applying
the transform to the Question we obtain a rewritten query Query
= `` ![]() (lisp
machine lispm) AND (``refers to'')
(lisp
machine lispm) AND (``refers to'')![]() .''
We use the appropriate query syntax for each search engine. We also encode
the transforms so that they are treated as phrases by each search
engine.
.''
We use the appropriate query syntax for each search engine. We also encode
the transforms so that they are treated as phrases by each search
engine.
The syntax of the querying interface varies for each search engine.
For AltaVista we use the NEAR operator instead of AND because
we found the NEAR operator to produce significantly better results
in preliminary experiments. In the example above, the actual query submitted
to AltaVista would be `` ![]() (lisp
machine lispm) NEAR (``refers to'')
(lisp
machine lispm) NEAR (``refers to'')![]() .''
Google treats all the terms submitted in a query with implicit AND
semantics in the absence of an explicit OR operator. Note that Google
incorporates the proximity of query terms in the document ranking [5]
and may discard some words that appear in its stopword list.
.''
Google treats all the terms submitted in a query with implicit AND
semantics in the absence of an explicit OR operator. Note that Google
incorporates the proximity of query terms in the document ranking [5]
and may discard some words that appear in its stopword list.
There are other possibilities for rewriting Question, for example, requiring or not requiring parts of the query in matching pages, and combining multiple transformations into a single query. In Step (3) of Figure 3 the rewritten query Query is submitted to the search engine SE. At most 10 of the top results returned by SE are retrieved. Each of the returned documents D is analyzed in Steps (4a), (4b), and (4c). In Step (4a), subdocuments of D are generated. In Step (4b), the subdocuments in D most similar to Answer are found. In Step (4c), the scores and counts for tri are updated based on the similarity of D with respect to Answer. More details on these steps follow.
In Step (4a) we generate subdocuments from a document to calculate
a more accurate similarity measure. Consider original answer
A and
a document D, one of the documents retrieved using the transformed
query. We make an assumption that answers are localized, i.e., that
the key information/set of phrases will appear in close proximity of each
other - within subdocuments of length
subDocLen. The subdocuments
overlap by subDocLen/2 words, to minimize the possibility that an
answer will not be entirely within one of the subdocuments. In other words,
given query Q, document
D, and subDocLen = N,
we break D into overlapping subdocuments D1,
D2,
D3,
D4,
..., each starting at successive positions 0, N/2,
N, ![]()
In Step (4b) we calculate the score of document D with respect
to
Answer. We define docScore(Answer, D) as the maximum of
the similarities of each of the subdocuments Di in
D.
More formally,
docScore(Answer, D) = Max(BM25![]() (Answer,
Di)) where BM25
(Answer,
Di)) where BM25![]() is an extension of the BM25 metric [16]
modified to incorporate phrase weights, calculated as in Equation 1.
is an extension of the BM25 metric [16]
modified to incorporate phrase weights, calculated as in Equation 1.
The original BM25 metric uses relevance weights wi(1) and topic frequencies as described previously, and is defined as:
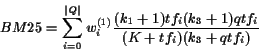 |
(3) |
where k1 = 1.2, k3 = 1000, ![]() ,
b=0.5,
dl
is the document length in tokens, avdl is the average document length
in tokens, and wi(1) and qtfi
are the relevance weight and query topic frequency as described previously1.
,
b=0.5,
dl
is the document length in tokens, avdl is the average document length
in tokens, and wi(1) and qtfi
are the relevance weight and query topic frequency as described previously1.
In the BM25![]() metric, the ``terms'' in the summation (Equation 3)
include phrases, with weights learned over the training data as in the
previous subsection. The weight for a term or phrase t is calculated
as follows:
metric, the ``terms'' in the summation (Equation 3)
include phrases, with weights learned over the training data as in the
previous subsection. The weight for a term or phrase t is calculated
as follows:
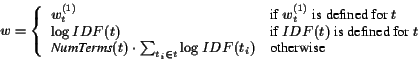
This multi-step assignment procedure is used because terms encountered may not be present in the training collection. We use IDF (Inverse Document Frequency, which is high for rare terms, and low for common terms) weights derived from a much larger sample (one million web pages, obtained from the collection of pages used in the TREC Web Track [9]). The last, fall-back case is necessary in order to handle phrases not present in the training data. Intuitively, it assigns the weight of phrase t inversely proportional to the probability that all the terms in t appear together, scaled to weight occurrences of query phrases higher. This heuristic worked well in our preliminary experiments, but clearly may be improved on with further work.
While document ranking is important during run time operation of the system described in Section 3.2, re-ranking of the result set of documents was not the focus of this work.
The overall goal of ranking candidate transforms is to weight highly the transforms that tend to return many relevant documents (similar to the original Answers) and few non-relevant documents. In Step (5) we calculate weight WTi of a transform tri as the average similarity between the original training answers and the documents returned in response to the transformed query:
| (4) |
where the sum is calculated over all of the <Question, Answer> pairs in the set of examples.
The result of this final stage of training is a set of transforms, automatically ranked with respect to their effectiveness in retrieving answers for questions matching QP from search engine SE. Two samples of highly ranked transforms for QP = ``what is a'', the first optimized for the AltaVista search engine and the second for the Google search engine, are shown in Table 5.
In Step (1a), the system determines if it can reformulate the question by matching known question phrases, with preference for longer (more specific) phrases. For example, ``what is the'' would be preferred over ``what is''. In Step (1b), the corresponding set of transforms is retrieved. Only the top numTransforms transforms are used.
 |
|
Figure 4: Evaluating questions at run time. |
In Step (2) each transform is used to rewrite the original question, one transform at a time, resulting in a new query. In Step (3) the transformed queries are submitted to the search engine and the first page of results is retrieved.
In Steps (4a), (4b), and (4c) the returned documents are analyzed and scored based on the similarity of the documents with respect to the transformed query. The process of scoring the document is the same as described in Section 3.1.3. The important difference is in Step (4c). If a document is retrieved through the application of multiple transforms, then the final score for the document is the maximum of each of the individual document scores. In Step (5) the returned documents are ranked with respect to their final document scores, and in Step (6) the top ranked topKdocs documents are returned as the final result produced by the Tritus system.

Figure 5: Sample question-answer pairs from the training collection. |
|
|||||||||||||||||||||
| Table 6: The number of training questions for each question type. |
Tritus uses a number of parameters in the training process. We performed some experimentation with the different values of these parameters resulting in the parameters shown in Table 7. We did not test parameters exhaustively and further fine-tuning may improve the performance of the system.
|
||||||||||||||||||||||||||||||||||||
| Table 7: Tritus training parameters. |
To measure recall over a collection we need to mark every document in the collection as either relevant or non-relevant for each evaluation query. This, of course, is a daunting task for any large document collection, and is essentially impossible for the web, which contains billions of documents. Researchers have addressed this problem by developing standard document collections with queries and associated relevance judgments, and by limiting the domain of documents that are judged [21].
Recently, TREC has incorporated a Web Track [9] that employs a collection of web documents (small relative to the size of the web). This collection of documents is a valuable resource to evaluate information retrieval algorithms over web data. However, the collection is not well suited to evaluate a system like Tritus, where we aim to transform user queries to obtain improved results from existing search engines like Google and AltaVista, which operate over the web at large. Consequently, to evaluate Tritus rigorously we needed to define an alternative experimental setting.
To evaluate Tritus we inspect the top K pages returned by the various systems that we compare (Section 4.2) for each query that we consider (Section 4.4). We describe how we computed relevance judgments for these documents in Section 4.4. Using these relevance judgments, we evaluate the answers that the systems produce using the following metrics.
Definition 1 The precision at K of a retrieval system S for a query q is the percentage of documents relevant to q among the top K documents returned by S for q.
Example 1 Consider a query q and the top 10
documents returned by Google for this query. If we judge that 8 of these
10 documents are relevant to
q then the precision at 10 of Google
for q is ![]() .
.
We also compute the percentage of questions where a given system provides the best performance of all systems tested:
Definition 2 Consider systems ![]() and query q. A system Si at document cutoff K for a query q
is considered (one of) the best performing systems if Si has
the highest number of relevant documents among the top K documents that
it produced, compared to all other systems. Note that multiple systems
may have identical performance on a given question, in which case they
may all be considered the best.
and query q. A system Si at document cutoff K for a query q
is considered (one of) the best performing systems if Si has
the highest number of relevant documents among the top K documents that
it produced, compared to all other systems. Note that multiple systems
may have identical performance on a given question, in which case they
may all be considered the best.
Example 2 Consider a query q, the top 10 documents returned by Google for q, and the top 10 documents returned by AltaVista for the same query. If there are 7 documents relevant to q among the top 10 Google documents and only 5 among the top 10 AltaVista documents, then Google is considered to have the best performance at document cutoff 10 for q. Intuitively, Google gets a ``vote'' for q because it was the best of the two retrieval systems for that query.
The set of test questions was generated by scanning for the question phrases in the query log. A random sample of 50 questions was chosen for each question type. The sample was manually filtered to remove queries that might be offensive or are likely to return offensive documents. We also checked that the questions were not present verbatim in our training collection. None of the test questions were used for tuning the parameters of Tritus.
Table 8: The number of questions of each question type in the Excite query log. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Table 9: Parameters used for evaluation. |
The test questions of each type (Table 8) are submitted to all of the five systems (Section 4.2) without any modifications to the original question. From each system, we retrieve up to 10 top-ranked URLs. The rank for each of the result URLs is stored. The top 10 documents (or all documents if fewer than 10) are retrieved as follows:
The volunteers were told to use the following criteria to judge documents. A good page is one that contains an answer to the test question on the page. If a page is not relevant, or only contains links to the useful information, even if links are to other documents on the same site, the page is judged ``bad.'' If a page could not be viewed for any reason (e.g., server error, broken link), the result is ``ignore.''
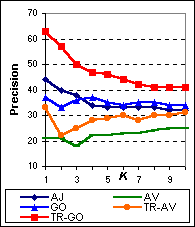
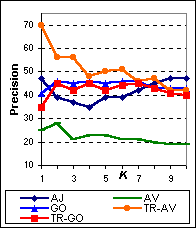
Figure 6 shows the average precision at K for varying K of AskJeeves (AJ), AltaVista (AV), Google (GO), Tritus-Google (TR-GO), and Tritus-AltaVista (TR-AV) over the 89 test questions. As we can see, Tritus optimized for Google has the highest precision at all values of document cutoff K. Also note that both TR-GO and TR-AV perform better than the underlying search engine used. TR-AV shows a large improvement over AltaVista.
 |
| Figure 6: Average precision at K of AskJeeves ( AJ), AltaVista ( AV), Google ( GO) and Tritus ( TR-AV, TR-GO) over 89 test queries, for varying number of top documents examined K. Tritus consistently outperforms the underlying search engine that it is based on, and Tritus-Google is the best performing system. |
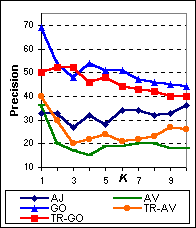
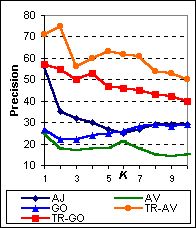
Figure 7 shows the percentage of questions where each system performed the best in terms of the number of relevant documents returned at document cutoff K, over all 89 test questions. As we can see, TR-GO performs the best on more questions than any other system. Even though TR-AV performs relatively poorly on this metric, its performance is comparable to the original AltaVista search engine. Because the lower performing systems perform best for only a small number of questions, comparison of the lower performing systems on this metric is not very meaningful.
 |
| Figure 7: The percentage of questions for which each system returns the most relevant documents for varying number of top documents examined K. The search engines are AskJeeves ( AJ), AltaVista ( AV), Google ( GO) and Tritus ( TR-AV, TR-GO) over 89 test queries. When the highest number of relevant documents for a given question is returned by multiple search engines, all of these engines are considered to have returned the most relevant documents. Because the lower performing systems perform best for only a small number of questions, comparison of the lower performing systems on this metric is not very meaningful. |
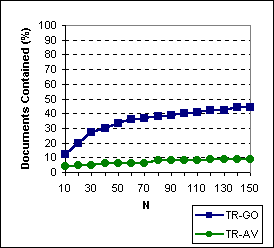
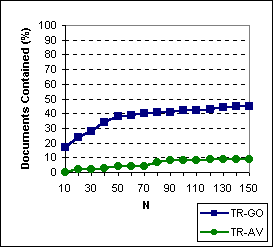
We considered the possibility that the documents returned by Tritus
could also be retrieved simply by examining more documents returned by
the search engines for the original query. We report the percentage of
Tritus
documents contained in response to the original query as more documents
are examined in Figure 8. In Figure
8(a)
we report the percentage of all
Tritus documents (without re-ranking)
that are contained in the top N (10-150) search-engine responses
for the original query. In Figure 8(b)
we plot the percentage of top 10 Tritus documents (after reranking)
contained in the original search engine results, and in Figure 8(c)
we show percentage of relevant Tritus documents contained in the
original search engine results. Only the top 10 Tritus documents
had relevance judgments assigned. The figures show that for TR-AV
there is very little overlap between result sets retrieved in response
to the transformed queries, and the documents retrieved for the original
query. For TR-GO, the overlap is low for all of TR-GO documents
(without re-ranking), but slowly increases and levels off at around 45%
for the top 10 and relevant Tritus documents as more of the original
Google documents are examined. These experiments indicate that a significant
fraction of the relevant documents retrieved by Tritus would not
be found using an underlying search engine.
 |
 |
 |
| (a) | (b) | (c) |
In Table 10 we report the average precision (%) at K of the document sets retrieved by AJ, AV, GO, TR-GO, and TR-AV. The results are separated by question phrase. As we examine documents with lower ranks, precision in general decreases. In the case of AskJeeves, the reason may be that the top-ranked documents could be selected by human editors as answers to the questions. Note that at least one of the Tritus systems has higher precision than AskJeeves even for the top ranked document alone in 6 out of 7 question phrases
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Table 10: Average precision at K for AskJeeves ( AJ), AltaVista ( AV), Google ( GO) and Tritus ( TR-AV, TR-GO) separated by question type and question phrase, for K = 1, 2, 3, 5 and 10 documents. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
 |
 |
 |
|
|
|
|
|
In Figure 9 we report the average precision
(%) at K of the document sets retrieved by AskJeeves
(AJ),
AltaVista (AV), Google (GO), Tritus-Google
(TR-GO),
and Tritus-AltaVista (TR-AV) separated by question type. Note that
at least one of the Tritus systems has the highest precision at
K
for 3 out of 4 question types (What, Where, and Who in Figures 9(a),
(c) and (d)) for ![]() ,
while Google has the highest precision for How2.
,
while Google has the highest precision for How2.
Google's impressive performance on the How questions may be due to a common practice on the web of linking to the pages that people find useful for solving specific problems, which by their nature contain good answers to How types of questions. Since Google exploits anchor text for document retrieval, it achieves high results for this type of question.
It is interesting to note that the systems do not perform uniformly well across different question types, or even across different subtypes of the basic question type. We can explain this phenomenon by observing that questions such as ``What are'' and ``What is a'', even though both questions fall into the What questions type, are typically used to express different purposes. ``What is a'' usually indicates a request for a definition or explanation of a term or concept, while ``What are'' often indicates a request for a list of characteristics or features of a concept.
Also note that TR-GO performs better than TR-AV on What and How types of questions, while TR-AV is clearly better at Where and Who questions. This suggests an approach of routing the questions to particular search engine(s) that perform well for a given question type and transforming the question in a manner optimal for that search engine. Note that the relatively small number of questions in each category limits the accuracy of the results for individual question types.
In summary, we have introduced a method for learning query transformations that improves the ability to retrieve answers to questions from an information retrieval system. The method involves classifying questions into different question types, generating candidate query transformations from a training set of question/answer pairs, and evaluating the candidate transforms on the target information retrieval systems. This technique for processing natural language questions could be applicable to a wide range of information retrieval systems. We have implemented and evaluated the method as applied to web search engines. Blind evaluation on a set of real queries from a web search engine shows that the method significantly outperforms the underlying web search engines for common question types.
Finally we would like to thank all the great people who took time off from their busy schedules to help evaluate our system: Regina Barzilay, Nicolas Bruno, Adiel Cohen, Junyan Ding, Noemie Elhadad, Rakan El-Khalil, Eleazar Eskin, David Evans, John Gassner, Eric Glover, Tobias Hoellerer, Panagiotis Ipeirotis, Min-Yen Kan, Sharon Kroo, Amelie Marian, Eugene Mesgar, Yoko Nitta, Gedalia Pasternak, Dmitry Rubanovich, Carl Sable, Roman Shimanovich, Alexey Smirnov, Viktoria Sokolova, Michael Veynberg, Brian Whitman, Kazi Zaman, and an anonymous benefactor.
 |
Eugene Agichtein is a Ph.D. student in the Computer Science Department, Columbia University. He received his M.S. degree from Columbia University and his B.S. degree from the Cooper Union for the Advancement of Science and Art, New York. Eugene's research interests are in text mining, information retrieval, machine learning, databases, and digital libraries. His work is currently focused on search, extraction, and integration of information from the web and unstructured (text) sources. |
 |
Dr. Steve Lawrence is a Research Scientist at NEC Research Institute, Princeton, NJ. His research interests include information retrieval and machine learning. Dr. Lawrence has published over 50 papers in these areas, including articles in Science, Nature, CACM, and IEEE Computer. He has been interviewed by over 100 news organizations including the New York Times, Wall Street Journal, Washington Post, Reuters, Associated Press, CNN, MSNBC, BBC, and NPR. Hundreds of articles about his research have appeared worldwide in over 10 different languages. |
 |
Luis Gravano has been an Assistant Professor in the Computer Science Department, Columbia University since September 1997, and a Senior Research Scientist at Google, Inc. since January 2001. He received his Ph.D. degree in Computer Science from Stanford University in 1997. He also holds an M.S. degree from Stanford University and a B.S. degree from the Escuela Superior Latinoamericana de Informatica (ESLAI), Argentina. Luis is the recipient of a CAREER award from the National Science Foundation. His current areas of research interest include text databases and digital libraries. Further details can be found from http://www.cs.columbia.edu/~gravano |