Copyright is held by the author/owner.
WWW10, May 1-5, 2001, Hong Kong.
ACM 1-58113-348-0/01/0005.
In order to find more precise answers to a query, a new generation of search engines - or question answering systems - have appeared on the Web (e.g. AskJeeves, http://www.askjeaves.com/). Unlike the traditional search engines that only use keywords to match documents, this new generation of systems tries to "understand" the user's question, and suggest some similar questions that other people have often asked and for which the system has the correct answers. In fact, the correct answers have been prepared or checked by human editors in most cases. It is then guaranteed that, if one of the suggested questions is truly similar to that of the user, the answers provided by the system will be relevant. The assumption behind such a system is that many people are interested in the same questions - the Frequently Asked Questions/Queries (FAQs). If the system can correctly answer these questions, then an important part of users' questions will be answered precisely. However, the queries submitted by users are very different, both in form and in intention. How human editors can determine which queries are FAQs is still an open issue. A closely related question is: how can a system judge if two questions are similar? The classic approaches to information retrieval (IR) would suggest a similarity calculation according to their keywords. However, this approach has some known drawbacks due to the limitations of keywords.
At the retrieval level, traditional approaches are also limited by the fact that they require a document to share some keywords with the query to be retrieved. In reality, it is known that users often use keywords or terms that are different from the documents. There are then two different term spaces, one for the users, and another for the documents. How to create relationships for the related terms between the two spaces is an important issue. This problem can also be viewed as the creation of a live online thesaurus. The creation of such relationships would allow the system to match queries with relevant documents, even though they contain different terms. Again, with a large amount of user logs, this may be possible.
In this paper, we propose a new approach to query clustering using user logs. The principles are as follows. 1) If users clicked on the same documents for different queries, then the queries are similar. 2) If a set of documents is often selected for a set of queries, then the terms in these documents are related to the terms of the queries to some extent. These principles are used in combination with the traditional approaches based on query contents (i.e. keywords). Our preliminary results are very encouraging: many queries that we consider similar are actually clustered together using our approach. In addition, we notice that many similar questions would have been grouped into different clusters by traditional clustering approaches because they do not share any common keywords. This study demonstrates the usefulness of user logs for query clustering, and the feasibility of an automatic tool to detect FAQs for a search engine.
Encarta contains a great number of documents organized in a hierarchy. A document is written on a specific topic, for instance, about a country. It is further divided into sections (and subsections) on different aspects of the topic. For example, there is usually a section about the population of a country, another section on its culture, etc. One should point out that the quality of the documents is consistently high, in contrast with other documents on the Web. The current search engine used on Encarta uses some advanced strategies to retrieve relevant documents. Although it suffers from some common problems of search engines, the result list does provide a good indication of the document contents. Therefore, when a user clicks on one of the documents in the result list, he/she has a good idea about what can be found in the document. This provides us with a solid basis for using user clicks as an indication of document's relevance.
Encarta is not a static encyclopedia, as are the printed ones. It evolves in time. In fact, a number of human editors are working on the improvement of the encyclopedia so that users can find more information from Encarta and in a more precise way. Their work mainly concerns the following two aspects: 1) If Encarta does not provide sufficient information for some often asked questions, the editors will add more documents to answer these questions. 2) If many users asked the same questions (FAQ) in a certain period of time (a hot topic), then the answers to these questions will be checked manually and directly linked to the questions. This second aspect is also found in many new-generation search engines, such as AskJeeves. Our current study concerns this aspect. The first goal is to develop a clustering system that helps the editors quickly identify the FAQs. The key problem is to determine an adequate similarity function so that truly similar queries can be grouped together using a clustering algorithm. Our second goal is to create a live online thesaurus that links the terms found in the users to those used by the documents, again through an analysis of user logs. Given a large amount of user logs, the relationships created could help the system match user queries and relevant documents despite differences in the terms they use.
session := query text [clicked document]*
Each session corresponds to one query and the documents the user clicked on. A query may be a well-formed natural language question, or one or more keywords or phrases. In Encarta, once a user query is input, a list of documents is presented to the user, together with the document titles. Because the document titles in Encarta are carefully chosen, they give the user a good idea of the contents of the documents. Therefore, if a user clicks on a document, it is likely that the document is relevant to the query, or at least related to it to some extent. Therefore, for our purposes, we do consider a clicked document to be relevant to the query. This assumption does not only apply to Encarta, but to most search engines. In fact, if among a set of documents provided by the system, the user chooses to click on some of them, it is because the user considers that these documents are more relevant than the others, based on the information provided in the document list (e.g. document title). Even if they are not all relevant, we can still affirm that they are usually more relevant than the other documents. In a long run, we can still extract interesting relationships from them.
The size of the query logs is very large. There are about 1 million queries per week that are submitted to Encarta. About half of query sessions have document clicks. Out of these sessions, about 90% of them have 1-2 document clicks. Even if some of the document clicks are erroneous, we can expect that most users do click on relevant documents.
The first criterion is similar to those used in traditional approaches to document clustering methods based on keywords. We formulate it as the following principle:
Principle 1 (using query contents): If two queries contain the same or similar terms, they denote the same or similar information needs.
Obviously, the longer the queries, the more reliable the principle 1 is. However, users often submit short queries to search engines. A typical query on the web usually contains one or two words. In many cases, there is not enough information to deduce users information needs correctly. Therefore, the second criterion is used as a complement.
The second criterion is similar to the intuition underlying document clustering in IR. Classically, it is believed that closely associated documents tend to correspond to the same query [13]. In our case, we use the intuition in the reverse way as follows:
Principle 2 (using document clicks): If two queries lead to the selection of the same document (which we call a document click), then they are similar.
Document clicks are comparable to user relevance feedback in a traditional IR environment, except that document clicks denote implicit and not always valid relevance judgments.
The two criteria have their own advantages. In using the first criterion, we can group together queries of similar compositions. In using the second criterion, we benefit from user's judgments. This second criterion has also been used in [1] to cluster user queries. However, in that work, only user clicks were used. In our approach, we combine both user clicks and document and query contents to determine the similarity. Better results should result from this combination. We will discuss the use of these criteria in more detail in section 4.
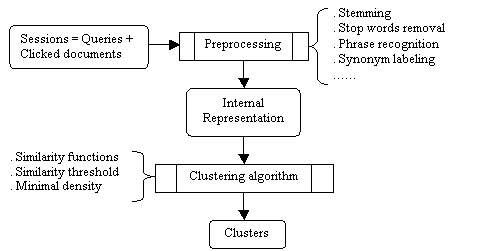
We adopted DBSCAN and IncrementalDBSCAN as the core algorithms to construct a comprehensive query clustering tool. This clustering tool is organized as shown in Figure 1.
Special attention is paid to such words in Query Answering (QA) [12][5], where they are used as prominent indicators of question type. The whole question is represented as a template in accordance with the question type. The building of templates is crucial. In fact, one has to predefine a set of possible template forms for a given application. During question evaluation, the question template may be expanded using a thesaurus (e.g. Wordnet [7]) or morphological transformations. In our case, only a small portion of the queries are well-formed natural language questions. Most of queries are simply short phrases or keywords (e.g. "population of U.S."). The approach used in QA is therefore not completely applicable to our case. However, if words denoting a question type do appear in a complete question, these words should be taken into account.
Apart from document and query clustering based on keywords, there is still another group of approaches, which uses user's relevance feedback as an indication of similarity. The principle is as follows: if two documents are judged relevant to the same query, then there is reason to believe that these documents talk about some common topic, and therefore can be included in the same cluster. This approach to document clustering may solve some of the problems in using keywords, due to the implication of user judgments. However, in a traditional IR environment, the amount of relevance feedback information is too limited to allow for a reasonable coverage of documents. The situation in our case makes this approach feasible. In the Web environment, we have abundant queries and user clicks. As we mentioned previously, user clicks represent implicit relevance feedback. Although they are not as accurate as explicit relevance feedback and may even be erroneous, they do represent the fact the selected documents are thought of as being related to the query by the user. This forms the basis of our second clustering principle, which clearly distinguishes the current work from previous studies.
![]()
where kn(.) is the number of keywords in a query, KN(p, q) is the number of common keywords in two queries.
If query terms are weighted, the following modified formula can be used instead:
![]()
where w(ki(p)) is the weight of the i-th common keyword in query p and kn(.) becomes the sum of weights of the keywords in a query. In our case, we use tf*idf for keyword weighting.
The above measures can be easily extended to phrases. Phrases are a more precise representation of meaning than single words. Therefore, if we can identify phrases in queries, we can obtain a more accurate calculation of query similarity. For example, the two queries history of China and history of the United States are very close queries (both asking about the history of a country). Their similarity is 0.33 on the basis of keywords. If we can recognize the United States as a phrase and take it as a single term, the similarity between these two queries is increased to 0.5. The calculation of phrase-based similarity is similar to formulas (1) and (2). We only need to recognize phrases in a query. There are two main methods for doing this. One is by using a noun phrase recognizer based on some syntactic rules [6]. Another way is to use a phrase dictionary. In Encarta, there is such a dictionary. It contains a great number of phrases and proper nouns that appear in Encarta documents. This dictionary provides us with a simple way to recognize phrases in queries. However, it may not be complete. In the future, it will be supplemented by an automatic phrase recognizer based on a syntactic and statistical analysis.
![]()
The advantage of this measure is that it takes into account the word order, as well as words that denote query types such as "who" and "what" if they appear in a query. This method is more flexible than those used in QA systems, which rely on special recognition mechanisms for different types of questions. It is therefore more suitable to our situation.
In our preliminary experiments, we found that this measure is very useful for long and complete questions in natural language. Below are some queries that are grouped into one cluster:
In the similarity calculations described above, we can further incorporate a dictionary of synonyms. Following Wordnet, we call a set of synonyms a synset. If two words/terms are in the same synset, their similarity is set at a predetermined value (0.8 in our current implementation). It is easy to incorporate this similarity between synonyms into the calculation of query similarity.
![]()
![]()
Similarity based on user clicks follows the following principle: If ![]() then documents d_cij1 , d_cij2 ,
, d_cijtrepresent
the
common topics of queries qi and qj.
Therefore, a similarity between queries qi and qj
is determined by
then documents d_cij1 , d_cij2 ,
, d_cijtrepresent
the
common topics of queries qi and qj.
Therefore, a similarity between queries qi and qj
is determined by ![]()
There are two ways to consider Encarta documents: in isolation, or in terms of each document placed in its hierarchy (because of the hierarchical organization of documents in Encarta ).
![]()
where rd(.) is the number of clicked documents for a query, RD(p, q) is the number of document clicks in common.
In despite of its simplicity, this measure demonstrates a surprising ability to cluster semantically related queries that contain different words. Below are some queries from one such cluster:
In addition, this measure is also very useful in distinguishing between queries that happen to be worded similarly but stem from different information needs. For example, if one user asked for law and clicked on the articles about legal problems, and another user asked law and clicked the articles about the order of nature, the two cases can be easily distinguished through user clicks. This kind of distinction can be exploited for sense disambiguation in a user interface. This is an aspect we will investigate in the future.
![]()
In particular, s(di, di) = 1; and s(di, dj) = 0 if F(di, dj) = root.
Now let us incorporate this document similarity measure into the calculation
of query similarity. Let ![]() and
and ![]() be the clicked documents
for queries p and q respectively, and rd(p) and rd(q) the
number of document clicks for each query. The concept-based similarity
is defined as follows:
be the clicked documents
for queries p and q respectively, and rd(p) and rd(q) the
number of document clicks for each query. The concept-based similarity
is defined as follows:
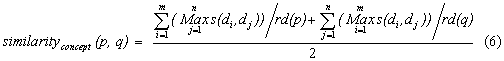
Using formula (6), the following two queries are recognized as being similar:
Query 1: <query text> image processingBoth documents have a common parent node Computer Science & Electronics. According to formula (5), the similarity between the two documents is 0.66. If these were the only two documents selected for the two queries, then the similarity between the queries is also 0.66 according to formula (6). In contrast, their similarity based on formula (4) using common clicks is 0. Hence, we see that this new similarity function can recognize a wider range of similar queries.<relevant documents> ID: 761558022 Title: Computer Graphics
Query 2: <query text> image rendering
<relevant documents> ID: 761568805 Title: Computer Animation
Since user information needs may be partially captured by both query texts and relevant documents, we would like to define a combined measures that takes advantage of both strategies. A simple way to do this is to combine both measures linearly, as follows:
![]()
This raises the question of how to set parameters a and b. We believe that these parameters should be set according to editor's objectives. It is difficult to determine them in advance; they can be adjusted over time and in light of the system's use. In what follows, we give a simple example to show the possible effects of different measures, as well as their combination.
Let us consider the 4 queries shown in table 1. Assume that the similarity
threshold is set at 0.6. The ideal result would be to group Queries 1 and
2 in a cluster, and Queries 3 and 4 in another.
| Query 1: <query text> law of thermodynamics
<clicked documents> ID: 761571911 Title: Thermodynamics ID: 761571262 Title: Conservation Laws |
| Query 2: <query text> conservation laws
<clicked documents> ID: 761571262 Title: Conservation Laws ID: 761571911 Title: Thermodynamics |
| Query 3: <query text> Newton law
<clicked documents> ID: 761573959 Title: Newton, Sir Isaac ID: 761573872 Title: Ballistics |
| Query 4: <query text> Newton law
<clicked documents> ID: 761556906 Title: Mechanics ID: 761556362 Title: Gravitation |
Cluster 1: Query 1
Cluster 2: Query 2
Cluster 3: Query 3 and Query 4
Queries 1 and 2 are not clustered together.
2) If we use the measure based on individual documents (formula (4)), we obtain:
Cluster 1: Query 1 and Query 2
Cluster 2: Query 3
Cluster 3: Query 4
Now Queries 3 and 4 are not judged similar.
3) Now we use the measure on document hierarchy.
The document similarities according to formula (5) are shown in table 2.
| (1) | (2) | (3) | (4) | (5) | (6) | |
| (1) Thermodynamics | 1.0 | 0.66 | 0.33 | 0.33 | 0.66 | 0.66 |
| (2) Conservation laws | 0.66 | 1.0 | 0.33 | 0.33 | 0.66 | 0.66 |
| (3) Newton, Sir Isaac | 0.33 | 0.33 | 1.0 | 0.33 | 0.33 | 0.33 |
| (4) Ballistics | 0.33 | 0.33 | 0.33 | 1.0 | 0.33 | 0.33 |
| (5) Mechanics | 0.66 | 0.66 | 0.33 | 0.33 | 1.0 | 0.66 |
| (6) Gravitation | 0.66 | 0.66 | 0.33 | 0.33 | 0.66 | 1.0 |
Cluster 1: Query 1, Query 2, and Query 4
Cluster 2: Query 3
We see that it is not possible to separate Query 4 from Queries 1 and 2.
4) Now let us use formula (7) with similaritycontent = similaritykeyword and similarityfeedback = similarityconcept. Both a and b are set to 0.5. The queries are now clustered in the desired way:
Cluster 1: Query 1 and Query 2
Cluster 2: Query 3 and Query 4
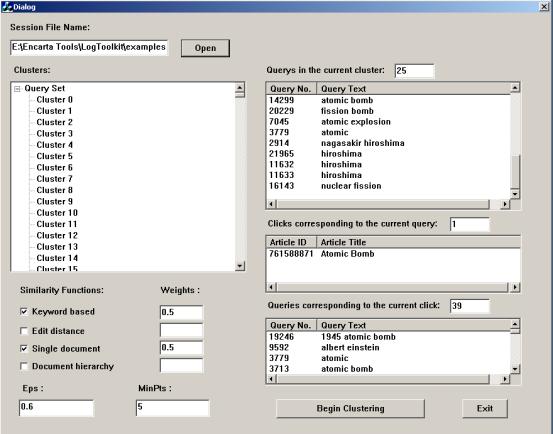
The purpose of this example is only to show that each similarity calculation focuses on a specific aspect. By combining them in a reasonable way, better results can be obtained. Therefore, by trying different combinations, the editors will have a better chance of locating desired FAQs. Our current implementation includes all the similarity measures described above. An interface allows the editors to choose different functions and to set different combination parameters (see figure 2).
Our project is still ongoing, and there is certainly room for further improvement:
[2] M. Ester, H. Kriegel, J. Sander and X. Xu. A density-based algorithm for discovering clusters in large spatial databases with noise. Proc. 2nd Int. Conf. on Knowledge Discovery and Data Mining. Portland, OR. 1996, pp. 226-231.
[3] M. Ester, H. Kriegel, J. Sander, M. Wimmer and X. Xu. Incremental clustering for mining in a data warehousing environment. Proc. of the 24th VLDB Conf. New York, USA, 1998.
[4] D. Gusfield. Algorithms on strings, trees, and sequences: computer science and computational biology. Part III. Inexact matching, sequence alignment, and dynamic programming. Press of Cambridge University. 1997.
[5] V.A. Kulyukin, K.J. Hammond and R.D. Burke. Answering questions for an organization online, Proc. of AAAI'98, 1998.
[6] D.D. Lewis and W.B. Croft. Term clustering of syntactic phrases, ACM-SIGIR, pp. 385-404, 1990.
[7] G. Miller (Ed.) Wordnet: an on-line lexical database. International Journal of Lexicography. 1990.
[8] R. Ng and J. Han. Efficient and effective clustering method for spatial data mining. In Proc. 1994 Int. Conf. Very Large Data Bases, pp. 144--155, Santiago, Chile, September 1994.
[9] S.E. Robertson, M.E. Maron and W.S. Cooper. Probability of relevance: a unification of two competing models for document retrieval. Information Technology: Research and Development, 1(1-21). 1982.
[10] M. Porter. An algorithm for suffix stripping. Program, Vol. 14(3), pp. 130137, 1980
[11] G. Salton and M.J. McGill. Introduction to modern information retrieval, McGraw-Hill Book Company, 1983.
[12] R. Srihari and W. Li. Question answering supported by information extraction. Proc. of TREC8, pp. 75-85, 1999.
[13] C.J. van Rijsbergen. Information Retrieval. Butterworths, 1979.