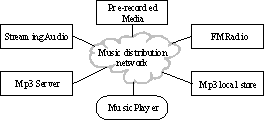
Figure 1: Music Delivery Infrastructure
Keywords: Personalisation, Radio, Moods, User EvaluationCopyright is held by the author/owner(s).
WWW10, May 1-5, 2001, Hong Kong.
ACM 1-58113-348-0/01/0005.
Abstract: Automated Personalised Audio is a relatively new concept, currently making its debut on the Web. Personalised audio relies on the existence of information about the music (music metadata) and information about the users (listener profiles). By gathering profile information, personalised audio systems attempt to select appropriate content for each user. This paper introduces the Personal DJ architecture for personalised audio. An evaluation of the concept is presented on the basis of data gathered from user tests. These tests were performed with a prototype developed from this architecture using simple mood based music metadata. 3
The aim of the Personal DJ is to make optimal choices between content from various sources including network servers, local disk, and radio broadcast. Both the user and the content provider(s) control the scheduling objectives directly or indirectly, and the relevant business rules (e.g. Digital Millennium Copyright Act [10]) are maintained throughout.
Figure 1: Music Delivery Infrastructure
Figure 2 shows the system architecture. The following is a brief explanation of the main data flows in the system: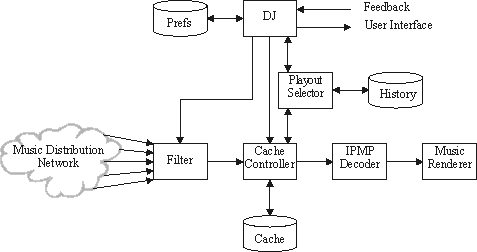
Figure 2: Diagram of System Architecture
A brief description of the modules of the system follows.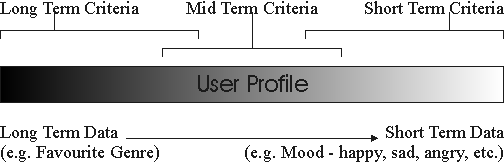
Figure 3: User Profile and Criteria
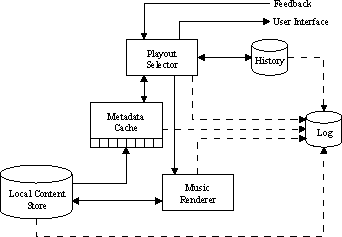
Figure 4: Prototype Functional Architecture
The functionality of components of the interface are detailed below: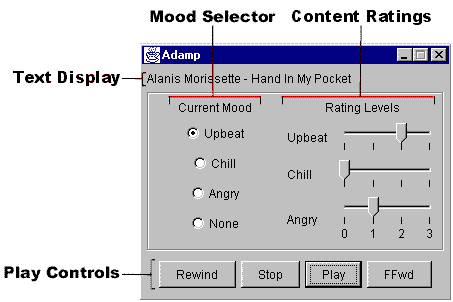
Figure 5: Prototype User Interface
The ratings implement one of two user feedback methods. This mechanical feedback method runs during the test, to constantly collect evaluations from the user.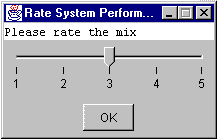
Figure 6: Prototype Rating Window
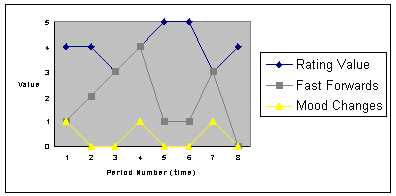
Figure 7: Chart of captured user data
www.www9.org.www.www9.org.http:// decweb.ethz.ch/ WWW6/.http:// nitin.www.media.mit.edu/ people/
nitin/ NomadicRadio/.This document was translated from LATEX by HEVEA.