ABSTRACT
WebQuilt is a web logging and visualization system that helps web design teams run usability tests (both local and remote) and analyze the collected data. Logging is done through a proxy, overcoming many of the problems with server-side and client-side logging. Captured usage traces can be aggregated and visualized in a zooming interface that shows the web pages people viewed. The visualization also shows the most common paths taken through the website for a given task, as well as the optimal path for that task as designated by the designer. This paper discusses the architecture of WebQuilt and also describes how it can be extended for new kinds of analyses and visualizations.
Categories and Subject Descriptors
H.1.2 [Models and Principles]: User/Machine Systems – Human factors; H.3.5 [Information Storage and Retrieval] Online Information Services – Web-based services; H.5.2 [Information Interfaces and Presentation] User Interfaces – Evaluation / methodology; H.5.4 [Information Interfaces and Presentation] Hypertext/Hypermedia – User issues
General Terms
Measurement, Design, Experimentation, Human Factors
Keywords
usability evaluation, log file analysis, web visualization, web proxy, WebQuilt
1. INTRODUCTION
There are two problems all web designers face: understanding what tasks people are trying to accomplish on a website and figuring out what difficulties people encounter in completing these tasks. Just knowing one or the other is insufficient. For example, a web designer could know that someone wants to find and purchase gifts, but this isn’t useful unless the web designer also knows what problems are preventing the individual from completing the task. Likewise, the web designer could know that this person left the site at the checkout process, but this isn’t meaningful unless the designer also knows that he truly intended to buy something and is not simply browsing.
There are a variety of methods for discovering what people want to do on a website, such as structured interviews, ethnographic observations, and questionnaires (for example, see [3]). Instead, we focus here on techniques for tackling the other problem, that is understanding what obstacles people are facing on a website. [1]
Traditionally, this kind of information is gathered by running usability tests on a website. A usability specialist brings in several participants to a usability lab and asks them to complete a few predefined tasks. The usability engineer observes what stumbling blocks people come across and follows up with a survey and an interview to gain more insights into the issues.
The drawback to this traditional approach is that it is very time consuming to run usability tests with large numbers of people: it takes a considerable amount of work to schedule participants, observe them, and analyze the results. Consequently, the data tends to reflect only a few people and is mostly qualitative. These small numbers also make it hard to cover all of the possible tasks on a site. Furthermore, small samples are less convincing when asking management to make potentially expensive changes to a site. Lastly, a small set of participants may not find the majority of usability problems. Despite previous claims that around five participants are enough to find the majority of usability problems [14, 19], a recent study by Spool and Schroeder suggests that this number may be nowhere near enough [17]. Better techniques and tools are needed to increase the number of participants and tasks that can be managed for a usability test.

Figure 1. Server-side logging is done on the web server, but the data is available only to the owners of the server.
In contrast to traditional usability testing, server log analysis (See Figure 1) is one way of quantitatively understanding what large numbers of people are doing on a website. Nearly every web server logs page requests, making server log analysis quite popular. In fact, there are over 90 research, commercial, and freeware tools currently available [1]. Server logging also has the advantage of letting test participants work remotely in their own environments: instead of coming to a single place, usability test participants can evaluate a website from any location on their own time, using their own equipment and network connection.
However, from the perspective of the web design team, there are two problems with server logs. The first is with deployment. Access to server logs are often restricted to just the owners of the web server. This can make it difficult to analyze subsites that exist on a server. For example, a company may own a single web server with different subsites owned by separate divisions. For the same reason, it is also impractical to do a log file analysis of a competitor’s website. A competitive analysis is important in understanding what features people consider important, as well as learning what parts of your site are easy-to-use and which are not in comparison to a competitor’s site.

Figure 2. Client-side logging is done on the client computer, but requires special software running in the background or having a special web browser.
Client-side logging has been developed to overcome these deployment problems. In this approach, participants remotely test a website by downloading special software that records web usage (See Figure 2). However, client-side logging has two weaknesses. First, the design team must deploy the special software and have end-users install it. Second, this technique makes it hard to achieve compatibility with a range of operating systems and web browsers. What is needed is a logging technique that is easy to deploy for any website and is compatible with a number of operating systems and browsers.
Another problem with using either server- or client-side web logs to inform web design is that existing server log analysis tools do not help web designers understand what visitors are trying to do on a website. Most of these tools produce aggregate reports, such as “number of transfers by date” and “most popular pages.” This kind of information resembles footsteps in the forest: you know someone has been there and where they went, but you have no idea what they were trying to do and whether they were successful. What is needed are logging tools that can be used in conjunction with known tasks, as well as sophisticated methods for analyzing and visualizing the logged data.
To recap, there are four things that could greatly streamline current practices in web usability evaluations:
1. A way of logging web usage that is fast and easy to deploy on any website
2. A way of logging that is compatible with a range of operating systems and web browsers
3. A way of logging where the task is already known
4. Tools for analyzing and visualizing the captured data
To address these needs, we developed WebQuilt, a tool for capturing, analyzing, and visualizing web usage. To address the first and second needs, we developed a proxy-based approach to logging that is faster and easier to deploy than traditional log analysis techniques (See Figure 3). This proxy has better compatibility with existing operating systems and browsers and requires no downloads on the part of end-users. It will also be easier to make compatible with future operating systems and browsers, such as those found on handheld devices and cellular phones.

Figure 3. Proxy-based logging is done on an intermediate computer, and avoids many of the deployment problems faced by client-side and server-side logging.
To address the third need, we designed the proxy to be flexible enough that it can be used in conjunction with existing tools, such as those offering participant recruitment and online surveys. With these existing tools, we can know who the users are, what tasks they are trying to accomplish, and whether they were satisfied with how the site supported these tasks (for example, tools like these are provided by NetRaker [6]).
To address the fourth need, we designed a visualization that aggregates data from several test sessions and displays the web pages people viewed and the paths they took. However, we knew that we would not immediately have all of the solutions for analyzing the resulting data, so we also designed WebQuilt to be extensible enough so that new tools and visualizations could be implemented to help web designers understand the captured data.
WebQuilt is designed for task-based usability tests. Test participants are given specific tasks to perform, such as browsing for a specific piece of information or finding and purchasing an item. The WebQuilt proxy can track the participants’ actions, whether they are local or remote. After a number of web usage traces have been captured, tools developed with the WebQuilt framework can be used to analyze and visualize the results, pointing to both problem areas and successful parts of the site. It is important that a task be attached to the test participants’ interactions, because otherwise one must interpret the intent of visitors, something difficult to do based on web usage traces alone.
In the rest of this paper, we describe the architecture of WebQuilt and give a description of our current visualization tool. We then close with a discussion of related work and directions we plan to take in the future.
2. WEBQUILT ARCHITECTURE
WebQuilt is separated into five independent components: the Proxy Logger, the Action Inferencer, the Graph Merger, the Graph Layout, and the Visualization (See Figure 4). The Proxy Logger mediates between the client browser and the web server and logs all communication between the two. The Action Inferencer takes a log file for a single session and converts it into a list of actions, such as “clicked on a link” or “hit the back button.” The Graph Merger combines multiple lists of actions, aggregating what multiple people did on a website into a directed graph where the nodes represent web pages and the edges represent page requests. The Graph Layout component takes the combined graph of actions and assigns a location to each node. The Visualization component takes the results from the Graph Layout component and provides an interactive display.
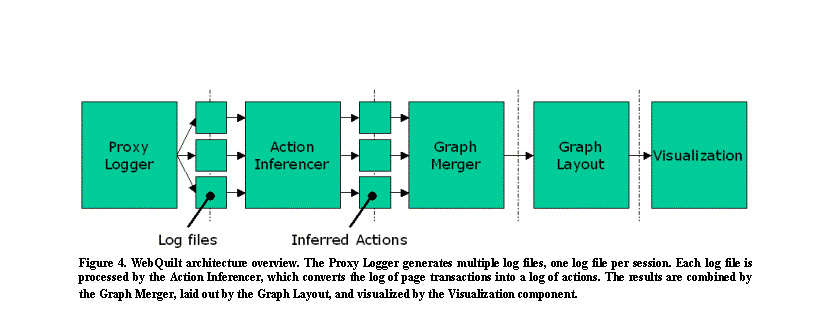
Each of these components was designed to be as independent of each other as
possible. There is a minimal amount of communication between each component,
to make it as easy as possible to replace components as better algorithms
and techniques are developed. In the rest of this section, we describe each
of these components in detail.
2.1 Proxy Logger
The goal of the Proxy Logger is to capture user actions on the web. As a proxy, it lies between clients and servers, with the assumption that clients will make all requests through the proxy. In this section we first discuss problems with current logging techniques, describe how WebQuilt’s proxy approach addresses these problems, and then continue with a description of the proxy’s architecture.
2.1.1 Problems with Existing Logging Techniques
Currently, there are two common ways of capturing and generating web usage logs: server-side and client-side logging. Server-side logs have the advantage of being easy to capture and generate, since all transactions go through the server. However, there are several downsides to server-side logging, as pointed out by Etgen and Cantor [9] and by Davison [8]. One problem is that web caches, both client browser caches and Intranet or ISP caches, can intercept requests for web pages. If the requested page is in the cache then the request will never reach the server and is thus not logged. Another problem is that multiple people can also share the same IP address, making it difficult to distinguish who is requesting what pages (for example, America Online, the United States’ largest ISP, does this). A third problem with server-side logging is with dynamically assigned IP addresses, where a computer’s IP address changes every time it connects to the Internet. This can make it quite difficult to determine what an individual user is doing since IP addresses are often used as identifiers.
One alternative to gathering data on the server is to collect it on the client. Clients are instrumented with special software so that all usage transactions will be captured. Clients can be modified either by running software that transparently records user actions whenever the web browser is being used (as in [5]), by modifying an existing web browser (as in [18] and [13]), or by creating a custom web browser specifically for capturing usage information (as with [20]).
The advantage to client-side logging is that literally everything can be recorded, from low-level events such as keystrokes and mouse clicks to higher-level events such as page requests. However, there are several drawbacks to client-side logging. First, special software must be installed on the client, which end-users may be unwilling or unable to do. This can severely limit the usability test participants to experienced users, which may not be representative of the target audience. Second, there needs to be some mechanism for sending the logged data back to the team that wants to collect the logs. Third, the software is platform dependent, meaning that the software only works for a specific operating system or specific browser.
WebQuilt’s logging software differs from the server-side and client-side approaches by using a proxy for logging instead. The proxy approach has three key advantages over the server-side approach. First, the proxy represents a separation of concerns. Any special modifications needed for tracking purposes can be done on the proxy, leaving the server to deal with just serving content. This makes it easier to deploy, since the server and its content do not have to be modified in any way.
Second, the proxy allows anyone to run usability tests on any website, even people that do not own that website. One can simply set up a proxy and ask testers to go through the proxy first. The proxy simply modifies the URL of the targeted site to instead go through the proxy. End users do not have to change any settings to get started. Again, this makes it easy to run and log usability tests on a competitor’s site.
Finally, having testers go through a proxy allows web designers to “tag” and uniquely identify each test participant. This way designers can know who the tester was, what they were trying to do, and afterwards can ask them how well they thought the site supported them in accomplishing their task.
The proxy approach is also better than the client-side approach. It does not require any special software on the client beyond a web browser, making it faster to deploy. The proxy also makes it easier to test a site with a wide variety of test participants, including novice users who may be unable or afraid to download special software. The proxy approach is also more compatible with a wider range of operating systems and web browsers than a client-side approach would be, as it works by modifying the HTML in a platform-independent way. Again, this permits testing with a more realistic sample of participants, devices, and browsers.
2.1.2 WebQuilt Proxy Logger Implementation
Our current implementation uses Java Servlet technology. The key to this component, though, is the log file format, as it is the log files that are processed by the Action Inferencer in the next step. To use our analysis tools, it actually does not matter what technologies are used for logging or whether the logger lies on the server, on a proxy, or on the client, as long as the log format is followed. Presently, the WebQuilt Proxy Logger creates one log file per test participant session.
Table 1 shows a sample log. The Time field is the time in milliseconds the page is first returned to a client, where 0 is the start time of the session. The From TID and the To TID fields are transaction identifiers. In WebQuilt, a transaction ID represents the Nth page that a person has requested. The From TID field represents the page that a person came from, and the To TID field represents the current page the person is at. The transaction ID numbers are used by the Action Inferencer for inferring when a person used the browser back button and where they went back.
The HTTP Response field is just the response from the server, such as “200 ok” and “404 not found.” The Link ID field specifies which link was clicked on according to the Document Object Model (DOM). In this representation, the first link in the HTML has link ID of 0, the second has link ID of 1, and so on. This data is useful for understanding which links people are following on a given page. The last field is the Current URL field, which represents the current page the person is at.
This log format supports some of the same things that other log formats do. For example, the first row shows a start time of 20 msec and the second row 17825 msec. This means that the person spent about 17 seconds looking at the page http://www.yahoo.com. However, this format supports two things that other tools and formats do not. The first is the Link ID. Without this information, it can be difficult to tell which link a person clicked on if there are redundant links to the same page, which is a common practice in web design. This can be important in understanding which links users are following and which are being ignored. The second is exactly where a person used the back button. The highlighted cells in Table 1 show an example of where the person used the back button to go from transaction ID of 3 back to transaction ID of 1, and then forward again, this time to a different destination.
The proxy works by dynamically modifying all requested pages in four ways:
· Link URLs are modified to go through the proxy
· Transaction IDs are added to link URLs
· Link IDs are added to link URLs
· Base HREF is added to point to the original site
The proxy modifies all link URLs in a page to use the proxy again on the next page request. Thus, once a person has started to use the proxy, all of the links thereafter will automatically be rewritten to continue using the proxy. The proxy also adds Transaction IDs to each link. Again, Transaction IDs represent the Nth page that a person has requested. Embedding the transaction ID into a link’s URL lets the proxy identify exactly what page a person came from. Link IDs are also added to each link URL. This allows the proxy to identify exactly which link in the page a person clicked on. Lastly, a Base HREF tag is added to the top of the page, in order to display images correctly.
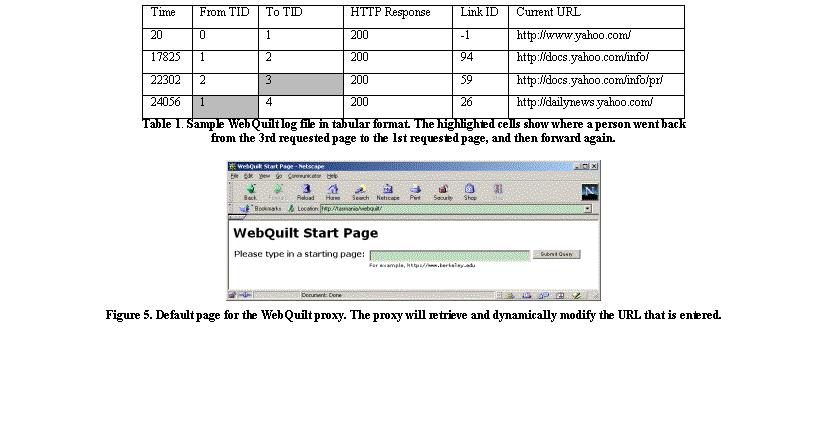
There are two ways a person can start using the proxy. The first is by requesting
the proxy’s default web page and submitting a URL to the proxy (See Figure
5). The other way a person could start using the proxy is by using a link
to a proxied page. For example, suppose you wanted to run a usability study
on Yahoo’s website. If the proxy’s URL was:
http://tasmania.cs.berkeley.edu/webquilt,
then participants could just use the following link:
http://tasmania.cs.berkeley.edu/webquilt/redirect.jsp?replace=http://www.yahoo.com.
This approach makes it easy to deploy the proxy, as the link can just be emailed to people. Again, we expect other tools to be used for recruiting participants and specifying tasks for them to do. The proxy is flexible enough that it can easily be used with such other usability evaluation tools.
The base case of handling standard HTTP and HTML is straightforward. However, there are many special cases that must be dealt with. For example, cookies are typically sent from web servers to client browsers. These cookies are sent back to the web server whenever a client browser makes a page request. The problem is that, for security and privacy reasons, web browsers only send cookies to certain web servers (ones in the same domain as the web server that created the cookie in the first place). To address this, the proxy logger manages all cookies for a user throughout a session. It keeps a table of cookies, mapping from users to domains. When a page request is made through the proxy, it simply looks up the user, sees if there are any cookies associated with the requested web server or page, and forwards these cookies along in its request to the web server.
Another special case that must be dealt with is secure HTTPS. HTTPS uses SSL (Secure Socket Layer) to secure page requests and page data. The proxy logger handles HTTPS connections by creating two HTTPS connections, one from the client browser to the proxy, and another from the proxy to the web server.
Currently, the proxy logger does not handle server-side image maps, JavaScript window popups, Java applets, and style sheets.
2.2 Action Inferencer
Action Inferencers transform a log of page requests into a log of inferred actions, where an action is currently defined as either requesting a page, going back by hitting the back button, or going forward by hitting the forward button. The reason the actions must be inferred is that the log generated by the proxy only captures page requests. The proxy cannot capture where a person uses the back or forward buttons to do navigation, since pages are loaded from the local browser cache.
WebQuilt comes with a default Action Inferencer, but the architecture is designed such that developers can create and plug in new ones. It should be noted that given our logging approach, the inferencer can be certain of when pages were requested and can be certain of when the back button was used, but cannot be certain of back and forward combinations.
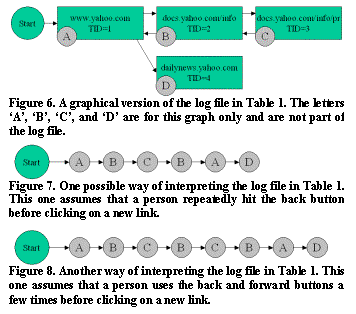
As an example, figure 6 shows a graph of the log file shown in Table 1. Figure 7 shows how the default Action Inferencer interprets the actions in the log file. We know that this person had to have gone back to Transaction ID 1, but we don’t know exactly how many times he hit the back and forward buttons. Figure 7 shows what happens if we assume that the person went directly back from TID 3 to TID 1, before going on to TID 4.
Figure 8 shows another valid way of inferring what happened with the same log file. The person could have gone back and forth between TID 2 and 3 a few times before returning to TID 1.
2.3 Graph Merger
The Graph Merger takes all of the actions inferred by the Action Inferencer
and merges them together. In other words, it merges multiple log files together,
aggregating all of the actions that people did. A graph of web pages (nodes)
and actions (edges) is available once this step is completed.
2.4 Graph Layout
Once the log files have been aggregated, they are passed to the Graph Layout component, which prepares the data for visualization. The goal of this step is to give an (x,y) location to all of the web pages. Since there are a variety of graph layout algorithms available, we have simply defined a way for developers to plug-in new algorithms. Currently, WebQuilt uses a simple force-directed placement algorithm as its default. This algorithm tries to place connected pages a fixed distance apart, and tries to spread out unconnected web pages at a reasonable distance.
2.5 Visualization
The final part of the WebQuilt framework is the visualization component. There are many ways of visualizing the information. We have built one visualization that shows the web pages traversed and paths taken (See Figures 9 and 10).
Web pages are represented by screenshots of that page as rendered in a web browser. Arrows are used to indicate traversed links and where people hit the back button. Thicker arrows indicate more heavily traversed paths. Color is used to indicate the average amount of time spent before traversing a link, with colors closer to green meaning short amounts of time and colors closer to red meaning longer amounts of time. Zooming is used to see the URL for a web page and to see a detailed image of individual pages (See Figure 10).

