Table of Contents
- 14.1. Setting the Storage Engine
- 14.2. The
InnoDBStorage Engine - 14.2.1. Getting Started with
InnoDB - 14.2.2. Creating and Using
InnoDBTables and Indexes - 14.2.3. Administering
InnoDB - 14.2.4.
InnoDBConcepts and Architecture - 14.2.5.
InnoDBPerformance Tuning and Troubleshooting - 14.2.6.
InnoDBFeatures for Flexibility, Ease of Use and Reliability - 14.2.7.
InnoDBStartup Options and System Variables - 14.2.8. Limits on
InnoDBTables - 14.2.9. MySQL and the ACID Model
- 14.2.10.
InnoDBIntegration with memcached
- 14.2.1. Getting Started with
- 14.3. The
MyISAMStorage Engine - 14.4. The
MEMORYStorage Engine - 14.5. The
CSVStorage Engine - 14.6. The
ARCHIVEStorage Engine - 14.7. The
BLACKHOLEStorage Engine - 14.8. The
MERGEStorage Engine - 14.9. The
FEDERATEDStorage Engine - 14.10. The
EXAMPLEStorage Engine - 14.11. Other Storage Engines
- 14.12. Overview of MySQL Storage Engine Architecture
Storage engines are MySQL components that handle the SQL operations
for different table types. InnoDB is
the most general-purpose storage engine, and Oracle recommends using
it for tables except for specialized use cases. (The
CREATE TABLE statement in MySQL
5.6 creates InnoDB tables by
default.)
MySQL Server uses a pluggable storage engine architecture that enables storage engines to be loaded into and unloaded from a running MySQL server.
To determine which storage engines your server supports, use the
SHOW ENGINES statement. The value in
the Support column indicates whether an engine
can be used. A value of YES,
NO, or DEFAULT indicates that
an engine is available, not available, or available and currently
set as the default storage engine.
This chapter primarily describes the features and performance
characteristics of InnoDB tables. It also covers
the use cases for the special-purpose MySQL storage engines, except
for NDBCLUSTER which is covered in
MySQL Cluster NDB 7.2. For advanced users, it
also contains a description of the pluggable storage engine
architecture (see Section 14.12, “Overview of MySQL Storage Engine Architecture”).
For information about storage engine support offered in commercial MySQL Server binaries, see MySQL Enterprise Server 5.6, on the MySQL Web site. The storage engines available might depend on which edition of Enterprise Server you are using.
For answers to some commonly asked questions about MySQL storage engines, see Section B.2, “MySQL 5.6 FAQ: Storage Engines”.
MySQL 5.6 Supported storage Engines
InnoDB: A transaction-safe (ACID compliant) storage engine for MySQL that has commit, rollback, and crash-recovery capabilities to protect user data.InnoDBrow-level locking (without escalation to coarser granularity locks) and Oracle-style consistent nonlocking reads increase multi-user concurrency and performance.InnoDBstores user data in clustered indexes to reduce I/O for common queries based on primary keys. To maintain data integrity,InnoDBalso supportsFOREIGN KEYreferential-integrity constraints.InnoDBis the default storage engine in MySQL 5.6.MyISAM: These tables have a small footprint. Table-level locking limits the performance in read/write workloads, so it is often used in read-only or read-mostly workloads in Web and data warehousing configurations.Memory: Stores all data in RAM, for fast access in environments that require quick lookups of non-critical data. This engine was formerly known as theHEAPengine. Its use cases are decreasing;InnoDBwith its buffer pool memory area provides a general-purpose and durable way to keep most or all data in memory, andNDBCLUSTERprovides fast key-value lookups for huge distributed data sets.CSV: Its tables are really text files with comma-separated values. CSV tables let you import or dump data in CSV format, to exchange data with scripts and applications that read and write that same format. Because CSV tables are not indexed, you typically keep the data inInnoDBtables during normal operation, and only use CSV tables during the import or export stage.Archive: These compact, unindexed tables are intended for storing and retrieving large amounts of seldom-referenced historical, archived, or security audit information.Blackhole: The Blackhole storage engine accepts but does not store data, similar to the Unix/dev/nulldevice. Queries always return an empty set. These tables can be used in replication configurations where DML statements are sent to slave servers, but the master server does not keep its own copy of the data.Merge: Enables a MySQL DBA or developer to logically group a series of identicalMyISAMtables and reference them as one object. Good for VLDB environments such as data warehousing.Federated: Offers the ability to link separate MySQL servers to create one logical database from many physical servers. Very good for distributed or data mart environments.Example: This engine serves as an example in the MySQL source code that illustrates how to begin writing new storage engines. It is primarily of interest to developers. The storage engine is a “stub” that does nothing. You can create tables with this engine, but no data can be stored in them or retrieved from them.
You are not restricted to using the same storage engine for an
entire server or schema. You can specify the storage engine for any
table. For example, an application might use mostly
InnoDB tables, with one CSV
table for exporting data to a spreadsheet and a few
MEMORY tables for temporary workspaces.
Choosing a Storage Engine
The various storage engines provided with MySQL are designed with different use cases in mind. The following table provides an overview of some storage engines provided with MySQL:
Table 14.1. Storage Engines Feature Summary
| Feature | MyISAM | Memory | InnoDB | Archive | NDB |
|---|---|---|---|---|---|
| Storage limits | 256TB | RAM | 64TB | None | 384EB |
| Transactions | No | No | Yes | No | Yes |
| Locking granularity | Table | Table | Row | Table | Row |
| MVCC | No | No | Yes | No | No |
| Geospatial data type support | Yes | No | Yes | Yes | Yes |
| Geospatial indexing support | Yes | No | No | No | No |
| B-tree indexes | Yes | Yes | Yes | No | Yes |
| Hash indexes | No | Yes | No[a] | No | Yes |
| Full-text search indexes | Yes | No | Yes[b] | No | No |
| Clustered indexes | No | No | Yes | No | No |
| Data caches | No | N/A | Yes | No | Yes |
| Index caches | Yes | N/A | Yes | No | Yes |
| Compressed data | Yes[c] | No | Yes[d] | Yes | No |
| Encrypted data[e] | Yes | Yes | Yes | Yes | Yes |
| Cluster database support | No | No | No | No | Yes |
| Replication support[f] | Yes | Yes | Yes | Yes | Yes |
| Foreign key support | No | No | Yes | No | No |
| Backup / point-in-time recovery[g] | Yes | Yes | Yes | Yes | Yes |
| Query cache support | Yes | Yes | Yes | Yes | Yes |
| Update statistics for data dictionary | Yes | Yes | Yes | Yes | Yes |
|
[a] InnoDB utilizes hash indexes internally for its Adaptive Hash Index feature. [b] InnoDB support for FULLTEXT indexes is available in MySQL 5.6.4 and higher. [c] Compressed MyISAM tables are supported only when using the compressed row format. Tables using the compressed row format with MyISAM are read only. [d] Compressed InnoDB tables require the InnoDB Barracuda file format. [e] Implemented in the server (via encryption functions), rather than in the storage engine. [f] Implemented in the server, rather than in the storage engine. [g] Implemented in the server, rather than in the storage engine. | |||||
When you create a new table, you can specify a special-purpose
storage engine to use by adding an ENGINE table
option to the CREATE TABLE
statement:
-- ENGINE=INNODB not needed unless you have set a different default storage engine. CREATE TABLE t1 (i INT) ENGINE = INNODB; -- Simple table definitions can be switched from one to another. CREATE TABLE t2 (i INT) ENGINE = CSV; -- Some storage engines have their own specific clauses in CREATE TABLE syntax. CREATE TABLE t3 (i INT) ENGINE = MEMORY USING BTREE;
When you omit the ENGINE option, the default
storage engine is used. The default engine is
InnoDB in MySQL 5.6. You
can specify the default engine by using the
--default-storage-engine server
startup option, or by setting the
default-storage-engine option in
the my.cnf configuration file.
You can set the default storage engine for the current session by
setting the
default_storage_engine variable:
SET default_storage_engine=NDBCLUSTER;
As of MySQL 5.6.3, the storage engine for
TEMPORARY tables created with
CREATE TEMPORARY
TABLE can be set separately from the engine for
permanent tables by setting the
default_tmp_storage_engine,
either at startup or at runtime. Before MySQL 5.6.3,
default_storage_engine sets the
engine for both permanent and TEMPORARY tables.
To convert a table from one storage engine to another, use an
ALTER TABLE statement that
indicates the new engine:
ALTER TABLE t ENGINE = InnoDB;
See Section 13.1.14, “CREATE TABLE Syntax”, and
Section 13.1.6, “ALTER TABLE Syntax”.
If you try to use a storage engine that is not compiled in or that
is compiled in but deactivated, MySQL instead creates a table
using the default storage engine. For example, in a replication
setup, perhaps your master server uses InnoDB
tables for maximum safety, but the slave servers use other storage
engines for speed at the expense of durability or concurrency.
By default, a warning is generated whenever
CREATE TABLE or
ALTER TABLE cannot use the default
storage engine. To prevent confusing, unintended behavior if the
desired engine is unavailable, enable the
NO_ENGINE_SUBSTITUTION SQL mode.
If the desired engine is unavailable, this setting produces an
error instead of a warning, and the table is not created or
altered. See Section 5.1.7, “Server SQL Modes”.
For new tables, MySQL always creates an .frm
file to hold the table and column definitions. The table's index
and data may be stored in one or more other files, depending on
the storage engine. The server creates the
.frm file above the storage engine level.
Individual storage engines create any additional files required
for the tables that they manage. If a table name contains special
characters, the names for the table files contain encoded versions
of those characters as described in
Section 9.2.3, “Mapping of Identifiers to File Names”.
- 14.2.1. Getting Started with
InnoDB - 14.2.2. Creating and Using
InnoDBTables and Indexes - 14.2.3. Administering
InnoDB - 14.2.4.
InnoDBConcepts and Architecture - 14.2.5.
InnoDBPerformance Tuning and Troubleshooting - 14.2.6.
InnoDBFeatures for Flexibility, Ease of Use and Reliability - 14.2.7.
InnoDBStartup Options and System Variables - 14.2.8. Limits on
InnoDBTables - 14.2.9. MySQL and the ACID Model
- 14.2.10.
InnoDBIntegration with memcached
InnoDB is a general-purpose storage engine that
balances high reliability and high performance. In MySQL
5.6, issuing the CREATE
TABLE statement with no ENGINE= clause
creates an InnoDB table.
Key advantages of InnoDB tables include:
Its DML operations follow the ACID model, with transactions featuring commit, rollback, and crash-recovery capabilities to protect user data.
Row-level locking and Oracle-style consistent reads increase multi-user concurrency and performance.
InnoDBtables arrange your data on disk to optimize queries based on primary keys.To maintain data integrity,
InnoDBalso supportsFOREIGN KEYconstraints. Inserts, updates, and deletes are all checked to ensure they do not result in inconsistencies across different tables.You can freely mix
InnoDBtables with tables from other MySQL storage engines, even within the same statement. For example, you can use a join operation to combine data fromInnoDBandMEMORYtables in a single query.The latest
InnoDBoffers significant new features over MySQL 5.1 and earlier. These features focus on performance and scalability, reliability, flexibility, and usability:Fast index creation: add or drop indexes without copying the data.
Data compression: shrink tables, to significantly reduce storage and I/O.
More efficient storage for large column values: fully off-page storage of long
BLOB,TEXT, andVARCHARcolumns.Barracuda file format: enables new features while protecting upward and downward compatibility
INFORMATION_SCHEMAtables: information about compression and lockingPerformance and scalability enhancements: includes features such as multiple background I/O threads, multiple buffer pools, and group commit.
Other changes: for flexibility, ease of use and reliability.
Table 14.2. InnoDB Storage Engine
Features
| Storage limits | 64TB | Transactions | Yes | Locking granularity | Row |
| MVCC | Yes | Geospatial data type support | Yes | Geospatial indexing support | No |
| B-tree indexes | Yes | Hash indexes | No[a] | Full-text search indexes | Yes[b] |
| Clustered indexes | Yes | Data caches | Yes | Index caches | Yes |
| Compressed data | Yes[c] | Encrypted data[d] | Yes | Cluster database support | No |
| Replication support[e] | Yes | Foreign key support | Yes | Backup / point-in-time recovery[f] | Yes |
| Query cache support | Yes | Update statistics for data dictionary | Yes | ||
|
[a] InnoDB utilizes hash indexes internally for its Adaptive Hash Index feature. [b] InnoDB support for FULLTEXT indexes is available in MySQL 5.6.4 and higher. [c] Compressed InnoDB tables require the InnoDB Barracuda file format. [d] Implemented in the server (via encryption functions), rather than in the storage engine. [e] Implemented in the server, rather than in the storage engine. [f] Implemented in the server, rather than in the storage engine. | |||||
InnoDB has been designed for maximum performance
when processing large data volumes. Its CPU efficiency is probably
not matched by any other disk-based relational database engine.
The InnoDB storage engine maintains its own
buffer pool for caching data
and indexes in main memory. By default, with the
innodb_file_per_table setting
enabled, each new InnoDB table and its associated
indexes are stored in a separate file. When the
innodb_file_per_table option is
disabled, InnoDB stores all its tables and
indexes in the single system
tablespace, which may consist of several files (or raw disk
partitions). InnoDB tables can handle large
quantities of data, even on operating systems where file size is
limited to 2GB.
InnoDB is published under the same GNU GPL
License Version 2 (of June 1991) as MySQL. For more information on
MySQL licensing, see http://www.mysql.com/company/legal/licensing/.
Additional Resources
For
InnoDB-related terms and definitions, see Appendix F, MySQL Glossary.A forum dedicated to the
InnoDBstorage engine is available at http://forums.mysql.com/list.php?22.
MySQL has a well-earned reputation for being easy-to-use and delivering performance and scalability. In previous versions of MySQL, MyISAM was the default storage engine. In our experience, most users never changed the default settings. With MySQL 5.5, InnoDB becomes the default storage engine. Again, we expect most users will not change the default settings. But, because of InnoDB, the default settings deliver the benefits users expect from their RDBMS: ACID Transactions, Referential Integrity, and Crash Recovery. Let's explore how using InnoDB tables improves your life as a MySQL user, DBA, or developer.
Trends in Storage Engine Usage
In the first years of MySQL growth, early web-based applications didn't push the limits of concurrency and availability. In 2010, hard drive and memory capacity and the performance/price ratio have all gone through the roof. Users pushing the performance boundaries of MySQL care a lot about reliability and crash recovery. MySQL databases are big, busy, robust, distributed, and important.
InnoDB hits the sweet spot of these top user priorities. The trend of storage engine usage has shifted in favor of the more scalable InnoDB. Thus MySQL 5.5 is the logical transition release to make InnoDB the default storage engine.
MySQL continues to work on addressing use cases that formerly required MyISAM tables. In MySQL 5.6 and higher:
InnoDB can perform full-text search using the
FULLTEXTindex type. See Section 14.2.4.12.3, “FULLTEXTIndexes” for details.InnoDB now performs better with read-only or read-mostly workloads. Automatic optimizations apply to InnoDB queries in autocommit mode, and you can explicitly mark transactions as read-only with the syntax
START TRANSACTION READ ONLY. See Section 14.2.5.2.2, “Optimizations for Read-Only Transactions” for details.Applications distributed on read-only media can now use InnoDB tables. See Section 14.2.6.1, “Support for Read-Only Media” for details.
Consequences of InnoDB as Default MySQL Storage Engine
Starting from MySQL 5.5.5, the default storage engine for new
tables is InnoDB. This change applies to newly created tables
that don't specify a storage engine with a clause such as
ENGINE=MyISAM. (Given this change of default
behavior, MySQL 5.5 might be a logical point to evaluate whether
your tables that do use MyISAM could benefit from switching to
InnoDB.)
The mysql and
information_schema databases, that implement
some of the MySQL internals, still use MyISAM. In particular,
you cannot switch the grant tables to use InnoDB.
Benefits of InnoDB Tables
If you use MyISAM tables but aren't tied to
them for technical reasons, you'll find many things more
convenient when you use InnoDB tables in
MySQL 5.5:
If your server crashes because of a hardware or software issue, regardless of what was happening in the database at the time, you don't need to do anything special after restarting the database. InnoDB crash recovery automatically finalizes any changes that were committed before the time of the crash, and undoes any changes that were in process but not committed. Just restart and continue where you left off. This process is now much faster than in MySQL 5.1 and earlier.
The InnoDB buffer pool caches table and index data as the data is accessed. Frequently used data is processed directly from memory. This cache applies to so many types of information, and speeds up processing so much, that dedicated database servers assign up to 80% of their physical memory to the InnoDB buffer pool.
If you split up related data into different tables, you can set up foreign keys that enforce referential integrity. Update or delete data, and the related data in other tables is updated or deleted automatically. Try to insert data into a secondary table without corresponding data in the primary table, and the bad data gets kicked out automatically.
If data becomes corrupted on disk or in memory, a checksum mechanism alerts you to the bogus data before you use it.
When you design your database with appropriate primary key columns for each table, operations involving those columns are automatically optimized. It is very fast to reference the primary key columns in
WHEREclauses,ORDER BYclauses,GROUP BYclauses, and join operations.Inserts, updates, deletes are optimized by an automatic mechanism called change buffering. InnoDB not only allows concurrent read and write access to the same table, it caches changed data to streamline disk I/O.
Performance benefits are not limited to giant tables with long-running queries. When the same rows are accessed over and over from a table, a feature called the Adaptive Hash Index takes over to make these lookups even faster, as if they came out of a hash table.
Best Practices for InnoDB Tables
If you have been using InnoDB for a long
time, you already know about features like transactions and
foreign keys. If not, read about them throughout this chapter.
To make a long story short:
Specify a primary key for every table using the most frequently queried column or columns, or anauto-increment value if there is no obvious primary key.
Embrace the idea of joins, where data is pulled from multiple tables based on identical ID values from those tables. For fast join performance, define foreign keys on the join columns, and declare those columns with the same data type in each table. The foreign keys also propagate deletes or updates to all affected tables, and prevent insertion of data in a child table if the corresponding IDs are not present in the parent table.
Turn off autocommit. Committing hundreds of times a second puts a cap on performance (limited by the write speed of your storage device).
Group sets of related DML operations into transactions, by bracketing them with
START TRANSACTIONandCOMMITstatements. While you don't want to commit too often, you also don't want to issue huge batches ofINSERT,UPDATE, orDELETEstatements that run for hours without committing.Stop using
LOCK TABLEstatements. InnoDB can handle multiple sessions all reading and writing to the same table at once, without sacrificing reliability or high performance. To get exclusive write access to a set of rows, use theSELECT ... FOR UPDATEsyntax to lock just the rows you intend to update.Enable the
innodb_file_per_tableoption to put the data and indexes for individual tables into separate files, instead of in a single giant system tablespace. (This setting is required to use some of the other features, such as table compression and fast truncation.)Evaluate whether your data and access patterns benefit from the new InnoDB table compression feature (
ROW_FORMAT=COMPRESSEDon theCREATE TABLEstatement. You can compress InnoDB tables without sacrificing read/write capability.Run your server with the option
--sql_mode=NO_ENGINE_SUBSTITUTIONto prevent tables being created with a different storage engine if there is an issue with the one specified in theENGINE=clause ofCREATE TABLE.
Recent Improvements for InnoDB Tables
If you have experience with InnoDB, but from MySQL 5.1 or
earlier, read about the latest InnoDB enhancements in
Section 14.2.5.2, “InnoDB Performance and Scalability Enhancements” and
Section 14.2.6, “InnoDB Features for Flexibility, Ease of Use and
Reliability”. To make a long story
short:
You can compress tables and associated indexes.
You can create and drop indexes with much less performance or availability impact than before.
Truncating a table is very fast, and can free up disk space for the operating system to reuse, rather than freeing up space within the system tablespace that only InnoDB could reuse.
The storage layout for table data is more efficient for BLOBs and long text fields, with the
DYNAMICrow format.You can monitor the internal workings of the storage engine by querying
INFORMATION_SCHEMAtables.You can monitor the performance details of the storage engine by querying
performance_schematables.There are many many performance improvements. In particular, crash recovery, the automatic process that makes all data consistent when the database is restarted, is fast and reliable. (Now much much faster than long-time InnoDB users are used to.) The bigger the database, the more dramatic the speedup.
Most new performance features are automatic, or at most require setting a value for a configuration option. For details, see Section 14.2.5.2, “InnoDB Performance and Scalability Enhancements”. For InnoDB-specific tuning techniques you can apply in your application code, see Section 8.5, “Optimizing for
InnoDBTables”. Advanced users can review Section 14.2.7, “InnoDBStartup Options and System Variables”.
Testing and Benchmarking with InnoDB as Default Storage Engine
Even before completing your upgrade from MySQL 5.1 or earlier to
MySQL 5.5 or higher, you can preview whether your database
server or application works correctly with InnoDB as the default
storage engine. To set up InnoDB as the default storage engine
with an earlier MySQL release, either specify on the command
line --default-storage-engine=InnoDB, or add
to your my.cnf file
default-storage-engine=innodb in the
[mysqld] section, then restart the server.
Since changing the default storage engine only affects new
tables as they are created, run all your application
installation and setup steps to confirm that everything installs
properly. Then exercise all the application features to make
sure all the data loading, editing, and querying features work.
If a table relies on some MyISAM-specific feature, you'll
receive an error; add the ENGINE=MyISAM
clause to the CREATE TABLE statement to avoid
the error. (For example, tables that rely on full-text search
must be MyISAM tables rather than InnoDB ones.)
If you did not make a deliberate decision about the storage
engine, and you just want to preview how certain tables work
when they're created under InnoDB, issue the command
ALTER TABLE table_name ENGINE=InnoDB; for
each table. Or, to run test queries and other statements without
disturbing the original table, make a copy like so:
CREATE TABLE InnoDB_Table (...) ENGINE=InnoDB AS SELECT * FROM MyISAM_Table;
Since there are so many performance enhancements in InnoDB in MySQL 5.5 and higher, to get a true idea of the performance with a full application under a realistic workload, install the latest MySQL server and run benchmarks.
Test the full application lifecycle, from installation, through heavy usage, and server restart. Kill the server process while the database is busy to simulate a power failure, and verify that the data is recovered successfully when you restart the server.
Test any replication configurations, especially if you use different MySQL versions and options on the master and the slaves.
Verifying that InnoDB is the Default Storage Engine
To know what the status of InnoDB is, whether you're doing what-if testing with an older MySQL or comprehensive testing with the latest MySQL:
Issue the command
SHOW ENGINES;to see all the different MySQL storage engines. Look forDEFAULTin the InnoDB line.If InnoDB is not present at all, you have a
mysqldbinary that was compiled without InnoDB support and you need to get a different one.If InnoDB is present but disabled, go back through your startup options and configuration file and get rid of any
skip-innodboption.
The first decisions to make about InnoDB configuration involve
how to lay out InnoDB data files, and how much memory to
allocate for the InnoDB storage engine. You record these choices
either by recording them in a configuration file that MySQL
reads at startup, or by specifying them as command-line options
in a startup script. The full list of options, descriptions, and
allowed parameter values is at
Section 14.2.7, “InnoDB Startup Options and System Variables”.
Overview of InnoDB Tablespace and Log Files
Two important disk-based resources managed by the
InnoDB storage engine are its tablespace data
files and its log files. If you specify no
InnoDB configuration options, MySQL creates
an auto-extending 10MB data file named
ibdata1 and two 5MB log files named
ib_logfile0 and
ib_logfile1 in the MySQL data directory. To
get good performance, explicitly provide
InnoDB parameters as discussed in the
following examples. Naturally, edit the settings to suit your
hardware and requirements.
The examples shown here are representative. See
Section 14.2.7, “InnoDB Startup Options and System Variables” for additional information
about InnoDB-related configuration
parameters.
Considerations for Storage Devices
In some cases, database performance improves if the data is not
all placed on the same physical disk. Putting log files on a
different disk from data is very often beneficial for
performance. The example illustrates how to do this. It places
the two data files on different disks and places the log files
on the third disk. InnoDB fills the
tablespace beginning with the first data file. You can also use
raw disk partitions (raw devices) as InnoDB
data files, which may speed up I/O. See
Section 14.2.3.3, “Using Raw Disk Partitions for the Shared Tablespace”.
InnoDB is a transaction-safe (ACID
compliant) storage engine for MySQL that has commit, rollback,
and crash-recovery capabilities to protect user data.
However, it cannot do so if
the underlying operating system or hardware does not work as
advertised. Many operating systems or disk subsystems may
delay or reorder write operations to improve performance. On
some operating systems, the very fsync()
system call that should wait until all unwritten data for a
file has been flushed might actually return before the data
has been flushed to stable storage. Because of this, an
operating system crash or a power outage may destroy recently
committed data, or in the worst case, even corrupt the
database because of write operations having been reordered. If
data integrity is important to you, perform some
“pull-the-plug” tests before using anything in
production. On Mac OS X 10.3 and up, InnoDB
uses a special fcntl() file flush method.
Under Linux, it is advisable to disable
the write-back cache.
On ATA/SATA disk drives, a command such hdparm -W0
/dev/hda may work to disable the write-back cache.
Beware that some drives or disk
controllers may be unable to disable the write-back
cache.
If reliability is a consideration for your data, do not
configure InnoDB to use data files or log
files on NFS volumes. Potential problems vary according to OS
and version of NFS, and include such issues as lack of
protection from conflicting writes, and limitations on maximum
file sizes.
Specifying the Location and Size for InnoDB Tablespace Files
To set up the InnoDB tablespace files, use
the innodb_data_file_path
option in the [mysqld] section of the
my.cnf option file. On Windows, you can use
my.ini instead. The value of
innodb_data_file_path should be
a list of one or more data file specifications. If you name more
than one data file, separate them by semicolon
(“;”) characters:
innodb_data_file_path=datafile_spec1[;datafile_spec2]...
For example, the following setting explicitly creates a tablespace having the same characteristics as the default:
[mysqld] innodb_data_file_path=ibdata1:10M:autoextend
This setting configures a single 10MB data file named
ibdata1 that is auto-extending. No location
for the file is given, so by default, InnoDB
creates it in the MySQL data directory.
Sizes are specified using K,
M, or G suffix letters to
indicate units of KB, MB, or GB.
A tablespace containing a fixed-size 50MB data file named
ibdata1 and a 50MB auto-extending file
named ibdata2 in the data directory can be
configured like this:
[mysqld] innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
The full syntax for a data file specification includes the file name, its size, and several optional attributes:
file_name:file_size[:autoextend[:max:max_file_size]]
The autoextend and max
attributes can be used only for the last data file in the
innodb_data_file_path line.
If you specify the autoextend option for the
last data file, InnoDB extends the data file
if it runs out of free space in the tablespace. The increment is
8MB at a time by default. To modify the increment, change the
innodb_autoextend_increment
system variable.
If the disk becomes full, you might want to add another data
file on another disk. For tablespace reconfiguration
instructions, see
Section 14.2.3.2, “Adding, Removing, or Resizing InnoDB Data and Log
Files”.
InnoDB is not aware of the file system
maximum file size, so be cautious on file systems where the
maximum file size is a small value such as 2GB. To specify a
maximum size for an auto-extending data file, use the
max attribute following the
autoextend attribute. Use the
max attribute only in cases where
constraining disk usage is of critical importance, because
exceeding the maximum size causes a fatal error, possibly
including a crash. The following configuration permits
ibdata1 to grow up to a limit of 500MB:
[mysqld] innodb_data_file_path=ibdata1:10M:autoextend:max:500M
InnoDB creates tablespace files in the MySQL
data directory by default. To specify a location explicitly, use
the innodb_data_home_dir
option. For example, to use two files named
ibdata1 and ibdata2
but create them in the /ibdata directory,
configure InnoDB like this:
[mysqld] innodb_data_home_dir = /ibdata innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
InnoDB does not create directories, so make
sure that the /ibdata directory exists
before you start the server. This is also true of any log file
directories that you configure. Use the Unix or DOS
mkdir command to create any necessary
directories.
Make sure that the MySQL server has the proper access rights to create files in the data directory. More generally, the server must have access rights in any directory where it needs to create data files or log files.
InnoDB forms the directory path for each data
file by textually concatenating the value of
innodb_data_home_dir to the
data file name, adding a path name separator (slash or
backslash) between values if necessary. If the
innodb_data_home_dir option is
not specified in my.cnf at all, the default
value is the “dot” directory
./, which means the MySQL data directory.
(The MySQL server changes its current working directory to its
data directory when it begins executing.)
If you specify
innodb_data_home_dir as an
empty string, you can specify absolute paths for the data files
listed in the
innodb_data_file_path value.
The following example is equivalent to the preceding one:
[mysqld] innodb_data_home_dir = innodb_data_file_path=/ibdata/ibdata1:50M;/ibdata/ibdata2:50M:autoextend
Specifying InnoDB Configuration Options
Sample my.cnf file
for small systems. Suppose that you have a computer
with 512MB RAM and one hard disk. The following example shows
possible configuration parameters in my.cnf
or my.ini for InnoDB,
including the autoextend attribute. The
example suits most users, both on Unix and Windows, who do not
want to distribute InnoDB data files and log
files onto several disks. It creates an auto-extending data file
ibdata1 and two InnoDB
log files ib_logfile0 and
ib_logfile1 in the MySQL data directory.
[mysqld] # You can write your other MySQL server options here # ... # Data files must be able to hold your data and indexes. # Make sure that you have enough free disk space. innodb_data_file_path = ibdata1:10M:autoextend # # Set buffer pool size to 50-80% of your computer's memory innodb_buffer_pool_size=256M innodb_additional_mem_pool_size=20M # # Set the log file size to about 25% of the buffer pool size innodb_log_file_size=64M innodb_log_buffer_size=8M # innodb_flush_log_at_trx_commit=1
Note that data files must be less than 2GB in some file systems. The combined size of the log files can be up to 512GB. The combined size of data files must be at least 10MB.
Setting Up the InnoDB System Tablespace
When you create an InnoDB system tablespace
for the first time, it is best that you start the MySQL server
from the command prompt. InnoDB then prints
the information about the database creation to the screen, so
you can see what is happening. For example, on Windows, if
mysqld is located in C:\Program
Files\MySQL\MySQL Server 5.6\bin, you
can start it like this:
C:\> "C:\Program Files\MySQL\MySQL Server 5.6\bin\mysqld" --console
If you do not send server output to the screen, check the
server's error log to see what InnoDB prints
during the startup process.
For an example of what the information displayed by
InnoDB should look like, see
Section 14.2.3.1, “Creating the InnoDB Tablespace”.
Editing the MySQL Configuration File
You can place InnoDB options in the
[mysqld] group of any option file that your
server reads when it starts. The locations for option files are
described in Section 4.2.3.3, “Using Option Files”.
If you installed MySQL on Windows using the installation and
configuration wizards, the option file will be the
my.ini file located in your MySQL
installation directory. See Section 2.3.3, “Installing MySQL on Microsoft Windows Using MySQL Installer”.
If your PC uses a boot loader where the C:
drive is not the boot drive, your only option is to use the
my.ini file in your Windows directory
(typically C:\WINDOWS). You can use the
SET command at the command prompt in a
console window to print the value of WINDIR:
C:\> SET WINDIR
windir=C:\WINDOWS
To make sure that mysqld reads options only
from a specific file, use the
--defaults-file option as the
first option on the command line when starting the server:
mysqld --defaults-file=your_path_to_my_cnf
Sample my.cnf file
for large systems. Suppose that you have a Linux
computer with 2GB RAM and three 60GB hard disks at directory
paths /, /dr2 and
/dr3. The following example shows possible
configuration parameters in my.cnf for
InnoDB.
[mysqld] # You can write your other MySQL server options here # ... innodb_data_home_dir = # # Data files must be able to hold your data and indexes innodb_data_file_path = /db/ibdata1:2000M;/dr2/db/ibdata2:2000M:autoextend # # Set buffer pool size to 50-80% of your computer's memory, # but make sure on Linux x86 total memory usage is < 2GB innodb_buffer_pool_size=1G innodb_additional_mem_pool_size=20M innodb_log_group_home_dir = /dr3/iblogs # # Set the log file size to about 25% of the buffer pool size innodb_log_file_size=250M innodb_log_buffer_size=8M # innodb_flush_log_at_trx_commit=1 innodb_lock_wait_timeout=50 # # Uncomment the next line if you want to use it #innodb_thread_concurrency=5
Determining the Maximum Memory Allocation for InnoDB
On 32-bit GNU/Linux x86, be careful not to set memory usage
too high. glibc may permit the process heap
to grow over thread stacks, which crashes your server. It is a
risk if the value of the following expression is close to or
exceeds 2GB:
innodb_buffer_pool_size + key_buffer_size + max_connections*(sort_buffer_size+read_buffer_size+binlog_cache_size) + max_connections*2MB
Each thread uses a stack (often 2MB, but only 256KB in MySQL
binaries provided by Oracle Corporation.) and in the worst
case also uses sort_buffer_size +
read_buffer_size additional memory.
Tuning other mysqld server parameters. The following values are typical and suit most users:
[mysqld]
skip-external-locking
max_connections=200
read_buffer_size=1M
sort_buffer_size=1M
#
# Set key_buffer to 5 - 50% of your RAM depending on how much
# you use MyISAM tables, but keep key_buffer_size + InnoDB
# buffer pool size < 80% of your RAM
key_buffer_size=value
On Linux, if the kernel is enabled for large page support,
InnoDB can use large pages to allocate memory
for its buffer pool and additional memory pool. See
Section 8.11.4.2, “Enabling Large Page Support”.
- 14.2.2.1. Managing InnoDB Tablespaces
- 14.2.2.2. Grouping DML Operations with Transactions
- 14.2.2.3. Converting Tables from Other Storage Engines to
InnoDB - 14.2.2.4.
AUTO_INCREMENTHandling inInnoDB - 14.2.2.5.
FOREIGN KEYConstraints - 14.2.2.6. Online DDL for
InnoDBTables - 14.2.2.7.
InnoDBData Compression - 14.2.2.8.
InnoDBFile-Format Management - 14.2.2.9. How
InnoDBStores Variable-Length Columns
To create an InnoDB table, use the
CREATE TABLE statement without any
special clauses. Formerly, you needed the
ENGINE=InnoDB clause, but not anymore now that
InnoDB is the default storage engine. (You
might still use that clause if you plan to use
mysqldump or replication to replay the
CREATE TABLE statement on a server
running MySQL 5.1 or earlier, where the default storage engine is
MyISAM.)
-- Default storage engine = InnoDB. CREATE TABLE t1 (a INT, b CHAR (20), PRIMARY KEY (a)); -- Backwards-compatible with older MySQL. CREATE TABLE t2 (a INT, b CHAR (20), PRIMARY KEY (a)) ENGINE=InnoDB;
Depending on the file-per-table setting, InnoDB
creates each table and associated primary key index either in the
system tablespace,
or in a separate tablespace (represented by a
.ibd file) for each table.
MySQL creates t1.frm and
t2.frm files in the test
directory under the MySQL database directory. Internally,
InnoDB adds an entry for the table to its own
data dictionary. The entry includes the database name. For
example, if test is the database in which the
t1 table is created, the entry is for
'test/t1'. This means you can create a table of
the same name t1 in some other database, and
the table names do not collide inside InnoDB.
To see the properties of these tables, issue a
SHOW TABLE STATUS statement:
SHOW TABLE STATUS FROM test LIKE 't%';
In the status output, you see the
row format property of
these first tables is Compact. Although that
setting is fine for basic experimentation, to take advantage of
the most powerful InnoDB performance features,
you will quickly graduate to using other row formats such as
Dynamic
and
Compressed.
Using those values requires a little bit of setup first:
set global innodb_file_per_table=1; set global innodb_file_format=barracuda; CREATE TABLE t3 (a INT, b CHAR (20), PRIMARY KEY (a)) row_format=dynamic; CREATE TABLE t4 (a INT, b CHAR (20), PRIMARY KEY (a)) row_format=compressed;
Always set up a primary
key for each InnoDB table, specifying
the column or columns that:
Are referenced by the most important queries.
Are never left blank.
Never have duplicate values.
Rarely if ever change value once inserted.
For example, in a table containing information about people, you
would not create a primary key on (firstname,
lastname) because more than one person can have the same
name, some people have blank last names, and sometimes people
change their names. With so many constraints, often there is not
an obvious set of columns to use as a primary key, so you create a
new column with a numeric ID to serve as all or part of the
primary key. You can declare an
auto-increment column
so that ascending values are filled in automatically as rows are
inserted:
-- The value of ID can act like a pointer between related items in different tables. CREATE TABLE t5 (id INT AUTO_INCREMENT, b CHAR (20), PRIMARY KEY (id)); -- The primary key can consist of more than one column. Any autoinc column must come first. CREATE TABLE t6 (id INT AUTO_INCREMENT, a INT, b CHAR (20), PRIMARY KEY (id,a));
Although the table works correctly without
you defining a primary key, the primary key is involved with many
aspects of performance and is a crucial design aspect for any
large or frequently used table. Make a habit of always specifying
one in the CREATE TABLE statement.
(If you create the table, load data, and then do
ALTER TABLE to add a primary key
later, that operation is much slower than defining the primary key
when creating the table.)
Historically, all InnoDB tables and indexes
were stored in the system
tablespace. This monolithic approach was targeted at
machines dedicated entirely to database processing, with
carefully planned data growth, where any disk storage allocated
to MySQL would never be needed for other purposes.
InnoDB's
file-per-table mode
is a more flexible alternative, where you store each
InnoDB table and its indexes in a separate
file. Each such
.ibd
file represents a separate
tablespace. This mode is
controlled by the
innodb_file_per_table
configuration option, and is the default in MySQL 5.6.6 and
higher.
Multiple tablespaces are useful in a number of situations:
You can reclaim disk space when truncating or dropping a table. For tables created when file-per-table mode is turned off, truncating or dropping them creates free space internally in the ibdata files. That free space can only be used for new
InnoDBdata.You can store specific tables on separate storage devices, for I/O optimization, space management, or backup purposes.
You can copy individual
InnoDBtables from one MySQL instance to another (known as the transportable tablespace feature).You can enable compression for table and index data, using the compressed row format.
You can enable more efficient storage for tables with large BLOB or text columns using the dynamic row format.
You can back up or restore a single table quickly, without interrupting the use of other
InnoDBtables, using the MySQL Enterprise Backup product. See Restoring a Single.ibdFile for the procedure and restrictions.
To make file-per-table mode the default for a MySQL server,
start the server with the
--innodb_file_per_table
command-line option, or add this line to the
[mysqld] section of
my.cnf:
[mysqld] innodb_file_per_table
You can also issue the command while the server is running:
SET GLOBAL innodb_file_per_table=1;
With file-per-table mode enabled, InnoDB
stores each newly created table in its own
tbl_name.ibdMyISAM storage engine, with its separate
tbl_name.MYDtbl_name.MYIInnoDB stores
the data and the indexes together in a single
.ibd file. The
tbl_name.frm
If you remove
innodb_file_per_table from
your startup options and restart the server, or turn it off
with the SET GLOBAL command,
InnoDB creates any new tables inside the
system tablespace.
You can always read and write any InnoDB
tables, regardless of the file-per-table setting.
To move a table from the system tablespace to its own
tablespace, or vice versa, change the
innodb_file_per_table setting
and rebuild the table:
-- Move table from system tablespace to its own tablespace. SET GLOBAL innodb_file_per_table=1; ALTER TABLEtable_nameENGINE=InnoDB; -- Move table from its own tablespace to system tablespace. SET GLOBAL innodb_file_per_table=0; ALTER TABLEtable_nameENGINE=InnoDB;
InnoDB always needs the system tablespace
because it puts its internal
data dictionary
and undo logs there.
The .ibd files are not sufficient for
InnoDB to operate.
When a table is moved out of the system tablespace into its
own .ibd file, the data files that make
up the system tablespace remain the same size. The space
formerly occupied by the table can be reused for new
InnoDB data, but is not reclaimed for use
by the operating system. When moving large
InnoDB tables out of the system
tablespace, where disk space is limited, you might prefer to
turn on innodb_file_per_table and then
recreate the entire instance using the
mysqldump command.
To create a new InnoDB table in a specific
location outside the MySQL data directory, use the
DATA DIRECTORY =
clause of the absolute_path_to_directoryCREATE TABLE
statement. The directory you specify could be on another
storage device with particular performance or capacity
characteristics, such as a fast
SSD or a high-capacity
HDD.
Within the destination directory, MySQL creates a subdirectory
corresponding to the database name, and within that a
.ibd file for the new
table. In the database directory underneath the MySQL
DATADIR directory, MySQL
creates a
table_name.isl.isl file is treated by MySQL like a
symbolic link. (Using actual
symbolic links has never been supported for
InnoDB tables.)
The following example shows how you might run a small
development or test instance of MySQL on a laptop with a
primary hard drive that is 95% full, and place a new table
EXTERNAL on a different storage device with
more free space. The shell commands show the different paths
to the LOCAL table in its default location
under the DATADIR directory, and the
EXTERNAL table in the location you
specified:
mysql> \! df -k . Filesystem 1024-blocks Used Available Capacity iused ifree %iused Mounted on /dev/disk0s2 244277768 231603532 12418236 95% 57964881 3104559 95% / mysql> use test; Database changed mysql> show variables like 'innodb_file_per_table'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_file_per_table | ON | +-----------------------+-------+ 1 row in set (0.00 sec) mysql> \! pwd /usr/local/mysql mysql> create table local (x int unsigned not null primary key); Query OK, 0 rows affected (0.03 sec) mysql> \! ls -l data/test/local.ibd -rw-rw---- 1 cirrus staff 98304 Nov 13 15:24 data/test/local.ibd mysql> create table external (x int unsigned not null primary key) data directory = '/volumes/external1/data'; Query OK, 0 rows affected (0.03 sec) mysql> \! ls -l /volumes/external1/data/test/external.ibd -rwxrwxrwx 1 cirrus staff 98304 Nov 13 15:34 /volumes/external1/data/test/external.ibd mysql> select count(*) from local; +----------+ | count(*) | +----------+ | 0 | +----------+ 1 row in set (0.01 sec) mysql> select count(*) from external; +----------+ | count(*) | +----------+ | 0 | +----------+ 1 row in set (0.01 sec)
MySQL initially holds the
.ibdfile open, preventing you from dismounting the device, but might eventually close the table if the server is busy. Be careful not to accidentally dismount the external device while MySQL is running, or to start MySQL while the device is disconnected. Attempting to access a table when the associated.ibdfile is missing causes a serious error that requires a server restart.The server restart might fail if the
.ibdfile is still not at the expected path. In this case, manually remove thetable_name.islDROP TABLEto delete the.frmfile and remove the information about the table from the data dictionary.Do not put MySQL tables on an NFS-mounted volume. NFS uses a message-passing protocol to write to files, which could cause data inconsistency if network messages are lost or received out of order.
If you use an LVM snapshot, file copy, or other file-based mechanism to back up the
.ibdfile, always use theFLUSH TABLES ... FOR EXPORTstatement first to make sure all changes that were buffered in memory are flushed to disk before the backup occurs.The
DATA DIRECTORYclause is a supported alternative to using symbolic links, which has always been problematic and was never supported for individualInnoDBtables.
There are many reasons why you might copy an
InnoDB table to a different database
server:
To run reports without putting extra load on a production server.
To set up identical data for a table on a new slave server.
To restore a backed-up version of a table after a problem or mistake.
As a faster way of moving data around than importing the results of a mysqldump command. the data is available immediately, rather than having to be re-inserted and the indexes rebuilt.
Use the FLUSH
TABLES statement with the FOR
EXPORT clause. This puts the corresponding
.ibd files into a consistent state so that
they can be copied to another server. You copy a
.cfg file along with the
.ibd file; this extra file is used by
ALTER TABLE ...
IMPORT TABLESPACE to make any necessary adjustments
within the tablespace file during the import process. See
Section 13.7.6.3, “FLUSH Syntax” for the SQL semantics.
Although tablespace management typically involves files holding tables and indexes, you can also divide the undo log into separate undo tablespace files. This layout is different from the default configuration where the undo log is part of the system tablespace. See Section 14.2.5.2.3, “Separate Tablespaces for InnoDB Undo Logs” for details.
By default, connection to the MySQL server begins with autocommit mode enabled, which automatically commits every SQL statement as you execute it. This mode of operation might be unfamiliar if you have experience with other database systems, where it is standard practice to issue a sequence of DML statements and commit them or roll them back all together.
To use multiple-statement
transactions, switch
autocommit off with the SQL statement SET autocommit =
0 and end each transaction with
COMMIT or
ROLLBACK as
appropriate. To leave autocommit on, begin each transaction with
START
TRANSACTION and end it with
COMMIT or
ROLLBACK. The
following example shows two transactions. The first is
committed; the second is rolled back.
shell>mysql testmysql>CREATE TABLE customer (a INT, b CHAR (20), INDEX (a));Query OK, 0 rows affected (0.00 sec) mysql>-- Do a transaction with autocommit turned on.mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO customer VALUES (10, 'Heikki');Query OK, 1 row affected (0.00 sec) mysql>COMMIT;Query OK, 0 rows affected (0.00 sec) mysql>-- Do another transaction with autocommit turned off.mysql>SET autocommit=0;Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO customer VALUES (15, 'John');Query OK, 1 row affected (0.00 sec) mysql>INSERT INTO customer VALUES (20, 'Paul');Query OK, 1 row affected (0.00 sec) mysql>DELETE FROM customer WHERE b = 'Heikki';Query OK, 1 row affected (0.00 sec) mysql>-- Now we undo those last 2 inserts and the delete.mysql>ROLLBACK;Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM customer;+------+--------+ | a | b | +------+--------+ | 10 | Heikki | +------+--------+ 1 row in set (0.00 sec) mysql>
Transactions in Client-Side Languages
In APIs such as PHP, Perl DBI, JDBC, ODBC, or the standard C
call interface of MySQL, you can send transaction control
statements such as COMMIT to the
MySQL server as strings just like any other SQL statements such
as SELECT or
INSERT. Some APIs also offer
separate special transaction commit and rollback functions or
methods.
If you have existing tables, and applications that use them,
that you want to convert to InnoDB for better
reliability and scalability, use the following guidelines and
tips. This section assumes most such tables were originally
MyISAM, which was formerly the default.
Plan the Storage Layout
To get the best performance from InnoDB
tables, you can adjust a number of parameters related to storage
layout.
When you convert MyISAM tables that are
large, frequently accessed, and hold vital data, investigate and
consider the
innodb_file_per_table,
innodb_file_format, and
innodb_page_size configuration
options, and the
ROW_FORMAT
and KEY_BLOCK_SIZE clauses of the
CREATE TABLE statement.
During your initial experiments, the most important setting is
innodb_file_per_table. Enabling
this option before creating new InnoDB tables
ensures that the InnoDB
system tablespace
files do not allocate disk space permanently for all the
InnoDB data. With
innodb_file_per_table enabled,
DROP TABLE and
TRUNCATE TABLE free disk space as
you would expect.
Converting an Existing Table
To convert a non-InnoDB table to use
InnoDB use ALTER
TABLE:
ALTER TABLE table_name ENGINE=InnoDB;
Do not convert MySQL system tables in the
mysql database (such as
user or host) to the
InnoDB type. This is an unsupported
operation. The system tables must always be of the
MyISAM type.
Cloning the Structure of a Table
You might make an InnoDB table that is a clone of a MyISAM
table, rather than doing the ALTER
TABLE conversion, to test the old and new table
side-by-side before switching.
Create an empty InnoDB table with identical
column and index definitions. Use show create table
to see the
full table_name\GCREATE TABLE statement to
use. Change the ENGINE clause to
ENGINE=INNODB.
Transferring Existing Data
To transfer a large volume of data into an empty
InnoDB table created as shown in the previous
section, insert the rows with INSERT INTO
.
innodb_table SELECT * FROM
myisam_table ORDER BY
primary_key_columns
You can also create the indexes for the
InnoDB table after inserting the data.
Historically, creating new secondary indexes was a slow
operation for InnoDB, but now you can create the indexes after
the data is loaded with relatively little overhead from the
index creation step.
If you have UNIQUE constraints on secondary
keys, you can speed up a table import by turning off the
uniqueness checks temporarily during the import operation:
SET unique_checks=0;... import operation ...
SET unique_checks=1;
For big tables, this saves disk I/O because
InnoDB can use its
insert buffer to write
secondary index records as a batch. Be certain that the data
contains no duplicate keys.
unique_checks permits but does
not require storage engines to ignore duplicate keys.
To get better control over the insertion process, you might insert big tables in pieces:
INSERT INTO newtable SELECT * FROM oldtable WHERE yourkey >somethingAND yourkey <=somethingelse;
After all records have been inserted, you can rename the tables.
During the conversion of big tables, increase the size of the
InnoDB buffer pool to reduce disk I/O, to a
maximum of 80% of physical memory. You can also increase the
sizes of the InnoDB log files.
Storage Requirements
By this point, as already mentioned, you should already have the
innodb_file_per_table option
enabled, so that if you temporarily make several copies of your
data in InnoDB tables, you can recover all
that disk space by dropping unneeded tables afterward.
Whether you convert the MyISAM table directly
or create a cloned InnoDB table, make sure
that you have sufficient disk space to hold both the old and new
tables during the process. InnoDB tables
require more disk space than MyISAM tables.
If an ALTER TABLE operation runs
out of space, it starts a rollback, and that can take hours if
it is disk-bound. For inserts, InnoDB uses
the insert buffer to merge secondary index records to indexes in
batches. That saves a lot of disk I/O. For rollback, no such
mechanism is used, and the rollback can take 30 times longer
than the insertion.
In the case of a runaway rollback, if you do not have valuable
data in your database, it may be advisable to kill the database
process rather than wait for millions of disk I/O operations to
complete. For the complete procedure, see
Section 14.2.5.6, “Starting InnoDB on a Corrupted Database”.
Application Performance Considerations
The extra reliability and scalability features of
InnoDB do require more disk storage than
equivalent MyISAM tables. You might change
the column and index definitions slightly, for better space
utilization, reduced I/O and memory consumption when processing
result sets, and better query optimization plans making
efficient use of index lookups.
Consider adding a primary key to any table that does not already have one. Use the smallest practical numeric type based on the maximum projected size of the table. This can make each row slightly more compact, which can yield substantial savings for tens of millions of rows. The space savings are multiplied if the table has any secondary indexes, because the primary key value is repeated in each secondary index entry.
If the table already has a primary key on some longer column,
such as a VARCHAR, consider adding a new
unsigned AUTO_INCREMENT column and switching
the primary key to that, even if that column is not referenced
in queries. This design change can produce substantial space
savings in the secondary indexes. You can designate the former
primary key columns as UNIQUE NOT NULL to
enforce the same constraints as the PRIMARY
KEY clause, that is, to prevent duplicate or null
values across all those columns.
If you do set up a numeric ID column for the primary key, use
that value to cross-reference with related values in any other
tables, particularly for join
queries. For example, rather than accepting a country name as
input and doing queries searching for the same name, do one
lookup to determine the country ID, then do other queries (or a
single join query) to look up relevant information across
several tables. Rather than storing a customer or catalog item
number as a string of digits, potentially using up several
bytes, convert it to a numeric ID for storing and querying. A
4-byte unsigned INT column can
index over 4 billion items (with the US meaning of billion: 1000
million). For the ranges of the different integer types, see
Section 11.2.1, “Integer Types (Exact Value) - INTEGER,
INT, SMALLINT,
TINYINT, MEDIUMINT,
BIGINT”.
InnoDB provides an optimization that
significantly improves scalability and performance of SQL
statements that insert rows into tables with
AUTO_INCREMENT columns. To use the
AUTO_INCREMENT mechanism with an
InnoDB table, an
AUTO_INCREMENT column
ai_col must be defined as part of an
index such that it is possible to perform the equivalent of an
indexed SELECT
MAX( lookup on the
table to obtain the maximum column value. Typically, this is
achieved by making the column the first column of some table
index.
ai_col)
This section provides background information on the original
(“traditional”) implementation of auto-increment
locking in InnoDB, explains the configurable
locking mechanism, documents the parameter for configuring the
mechanism, and describes its behavior and interaction with
replication.
The original implementation of auto-increment handling in
InnoDB uses the following strategy to
prevent problems when using the binary log for statement-based
replication or for certain recovery scenarios.
If you specify an AUTO_INCREMENT column for
an InnoDB table, the table handle in the
InnoDB data dictionary contains a special
counter called the auto-increment counter that is used in
assigning new values for the column. This counter is stored
only in main memory, not on disk.
InnoDB uses the following algorithm to
initialize the auto-increment counter for a table
t that contains an
AUTO_INCREMENT column named
ai_col: After a server startup, for the
first insert into a table t,
InnoDB executes the equivalent of this
statement:
SELECT MAX(ai_col) FROM t FOR UPDATE;
InnoDB increments the value retrieved by
the statement and assigns it to the column and to the
auto-increment counter for the table. By default, the value is
incremented by one. This default can be overridden by the
auto_increment_increment
configuration setting.
If the table is empty, InnoDB uses the
value 1. This default can be overridden by
the auto_increment_offset
configuration setting.
If a SHOW TABLE STATUS
statement examines the table t before the
auto-increment counter is initialized,
InnoDB initializes but does not increment
the value and stores it for use by later inserts. This
initialization uses a normal exclusive-locking read on the
table and the lock lasts to the end of the transaction.
InnoDB follows the same procedure for
initializing the auto-increment counter for a freshly created
table.
After the auto-increment counter has been initialized, if you
do not explicitly specify a value for an
AUTO_INCREMENT column,
InnoDB increments the counter and assigns
the new value to the column. If you insert a row that
explicitly specifies the column value, and the value is bigger
than the current counter value, the counter is set to the
specified column value.
If a user specifies NULL or
0 for the AUTO_INCREMENT
column in an INSERT,
InnoDB treats the row as if the value was
not specified and generates a new value for it.
The behavior of the auto-increment mechanism is not defined if you assign a negative value to the column, or if the value becomes bigger than the maximum integer that can be stored in the specified integer type.
When accessing the auto-increment counter,
InnoDB uses a special table-level
AUTO-INC lock that it keeps to the end of
the current SQL statement, not to the end of the transaction.
The special lock release strategy was introduced to improve
concurrency for inserts into a table containing an
AUTO_INCREMENT column. Nevertheless, two
transactions cannot have the AUTO-INC lock
on the same table simultaneously, which can have a performance
impact if the AUTO-INC lock is held for a
long time. That might be the case for a statement such as
INSERT INTO t1 ... SELECT ... FROM t2 that
inserts all rows from one table into another.
InnoDB uses the in-memory auto-increment
counter as long as the server runs. When the server is stopped
and restarted, InnoDB reinitializes the
counter for each table for the first
INSERT to the table, as
described earlier.
A server restart also cancels the effect of the
AUTO_INCREMENT =
table option in
NCREATE TABLE and
ALTER TABLE statements, which
you can use with InnoDB tables to set the
initial counter value or alter the current counter value.
You may see gaps in the sequence of values assigned to the
AUTO_INCREMENT column if you roll back
transactions that have generated numbers using the counter.
As described in the previous section,
InnoDB uses a special lock called the
table-level AUTO-INC lock for inserts into
tables with AUTO_INCREMENT columns. This
lock is normally held to the end of the statement (not to the
end of the transaction), to ensure that auto-increment numbers
are assigned in a predictable and repeatable order for a given
sequence of INSERT statements.
In the case of statement-based replication, this means that
when an SQL statement is replicated on a slave server, the
same values are used for the auto-increment column as on the
master server. The result of execution of multiple
INSERT statements is
deterministic, and the slave reproduces the same data as on
the master. If auto-increment values generated by multiple
INSERT statements were
interleaved, the result of two concurrent
INSERT statements would be
nondeterministic, and could not reliably be propagated to a
slave server using statement-based replication.
To make this clear, consider an example that uses this table:
CREATE TABLE t1 ( c1 INT(11) NOT NULL AUTO_INCREMENT, c2 VARCHAR(10) DEFAULT NULL, PRIMARY KEY (c1) ) ENGINE=InnoDB;
Suppose that there are two transactions running, each
inserting rows into a table with an
AUTO_INCREMENT column. One transaction is
using an INSERT
... SELECT statement that inserts 1000 rows, and
another is using a simple
INSERT statement that inserts
one row:
Tx1: INSERT INTO t1 (c2) SELECT 1000 rows from another table ...
Tx2: INSERT INTO t1 (c2) VALUES ('xxx');
InnoDB cannot tell in advance how many rows
will be retrieved from the
SELECT in the
INSERT statement in Tx1, and it
assigns the auto-increment values one at a time as the
statement proceeds. With a table-level lock, held to the end
of the statement, only one
INSERT statement referring to
table t1 can execute at a time, and the
generation of auto-increment numbers by different statements
is not interleaved. The auto-increment value generated by the
Tx1 INSERT ...
SELECT statement will be consecutive, and the
(single) auto-increment value used by the
INSERT statement in Tx2 will
either be smaller or larger than all those used for Tx1,
depending on which statement executes first.
As long as the SQL statements execute in the same order when
replayed from the binary log (when using statement-based
replication, or in recovery scenarios), the results will be
the same as they were when Tx1 and Tx2 first ran. Thus,
table-level locks held until the end of a statement make
INSERT statements using
auto-increment safe for use with statement-based replication.
However, those locks limit concurrency and scalability when
multiple transactions are executing insert statements at the
same time.
In the preceding example, if there were no table-level lock,
the value of the auto-increment column used for the
INSERT in Tx2 depends on
precisely when the statement executes. If the
INSERT of Tx2 executes while
the INSERT of Tx1 is running
(rather than before it starts or after it completes), the
specific auto-increment values assigned by the two
INSERT statements are
nondeterministic, and may vary from run to run.
InnoDB can avoid using the table-level
AUTO-INC lock for a class of
INSERT statements where the
number of rows is known in advance, and still preserve
deterministic execution and safety for statement-based
replication. Further, if you are not using the binary log to
replay SQL statements as part of recovery or replication, you
can entirely eliminate use of the table-level
AUTO-INC lock for even greater concurrency
and performance, at the cost of permitting gaps in
auto-increment numbers assigned by a statement and potentially
having the numbers assigned by concurrently executing
statements interleaved.
For INSERT statements where the
number of rows to be inserted is known at the beginning of
processing the statement, InnoDB quickly
allocates the required number of auto-increment values without
taking any lock, but only if there is no concurrent session
already holding the table-level AUTO-INC
lock (because that other statement will be allocating
auto-increment values one-by-one as it proceeds). More
precisely, such an INSERT
statement obtains auto-increment values under the control of a
mutex (a light-weight lock) that is not
held until the statement completes, but only for the duration
of the allocation process.
This new locking scheme enables much greater scalability, but
it does introduce some subtle differences in how
auto-increment values are assigned compared to the original
mechanism. To describe the way auto-increment works in
InnoDB, the following discussion defines
some terms, and explains how InnoDB behaves
using different settings of the
innodb_autoinc_lock_mode
configuration parameter, which you can set at server startup.
Additional considerations are described following the
explanation of auto-increment locking behavior.
First, some definitions:
“
INSERT-like” statementsAll statements that generate new rows in a table, including
INSERT,INSERT ... SELECT,REPLACE,REPLACE ... SELECT, andLOAD DATA.“Simple inserts”
Statements for which the number of rows to be inserted can be determined in advance (when the statement is initially processed). This includes single-row and multiple-row
INSERTandREPLACEstatements that do not have a nested subquery, but notINSERT ... ON DUPLICATE KEY UPDATE.“Bulk inserts”
Statements for which the number of rows to be inserted (and the number of required auto-increment values) is not known in advance. This includes
INSERT ... SELECT,REPLACE ... SELECT, andLOAD DATAstatements, but not plainINSERT.InnoDBwill assign new values for theAUTO_INCREMENTcolumn one at a time as each row is processed.“Mixed-mode inserts”
These are “simple insert” statements that specify the auto-increment value for some (but not all) of the new rows. An example follows, where
c1is anAUTO_INCREMENTcolumn of tablet1:INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d');
Another type of “mixed-mode insert” is
INSERT ... ON DUPLICATE KEY UPDATE, which in the worst case is in effect anINSERTfollowed by aUPDATE, where the allocated value for theAUTO_INCREMENTcolumn may or may not be used during the update phase.
There are three possible settings for the
innodb_autoinc_lock_mode
parameter:
innodb_autoinc_lock_mode = 0(“traditional” lock mode)This lock mode provides the same behavior as before
innodb_autoinc_lock_modeexisted. For all “INSERT-like” statements, a special table-levelAUTO-INClock is obtained and held to the end of the statement. This assures that the auto-increment values assigned by any given statement are consecutive.This lock mode is provided for:
Backward compatibility.
Performance testing.
Working around issues with “mixed-mode inserts”, due to the possible differences in semantics described later.
innodb_autoinc_lock_mode = 1(“consecutive” lock mode)This is the default lock mode. In this mode, “bulk inserts” use the special
AUTO-INCtable-level lock and hold it until the end of the statement. This applies to allINSERT ... SELECT,REPLACE ... SELECT, andLOAD DATAstatements. Only one statement holding theAUTO-INClock can execute at a time.With this lock mode, “simple inserts” (only) use a new locking model where a light-weight mutex is used during the allocation of auto-increment values, and no table-level
AUTO-INClock is used, unless anAUTO-INClock is held by another transaction. If another transaction does hold anAUTO-INClock, a “simple insert” waits for theAUTO-INClock, as if it too were a “bulk insert”.This lock mode ensures that, in the presence of
INSERTstatements where the number of rows is not known in advance (and where auto-increment numbers are assigned as the statement progresses), all auto-increment values assigned by any “INSERT-like” statement are consecutive, and operations are safe for statement-based replication.Simply put, the important impact of this lock mode is significantly better scalability. This mode is safe for use with statement-based replication. Further, as with “traditional” lock mode, auto-increment numbers assigned by any given statement are consecutive. In this mode, there is no change in semantics compared to “traditional” mode for any statement that uses auto-increment, with one important exception.
The exception is for “mixed-mode inserts”, where the user provides explicit values for an
AUTO_INCREMENTcolumn for some, but not all, rows in a multiple-row “simple insert”. For such inserts,InnoDBwill allocate more auto-increment values than the number of rows to be inserted. However, all values automatically assigned are consecutively generated (and thus higher than) the auto-increment value generated by the most recently executed previous statement. “Excess” numbers are lost.innodb_autoinc_lock_mode = 2(“interleaved” lock mode)In this lock mode, no “
INSERT-like” statements use the table-levelAUTO-INClock, and multiple statements can execute at the same time. This is the fastest and most scalable lock mode, but it is not safe when using statement-based replication or recovery scenarios when SQL statements are replayed from the binary log.In this lock mode, auto-increment values are guaranteed to be unique and monotonically increasing across all concurrently executing “
INSERT-like” statements. However, because multiple statements can be generating numbers at the same time (that is, allocation of numbers is interleaved across statements), the values generated for the rows inserted by any given statement may not be consecutive.If the only statements executing are “simple inserts” where the number of rows to be inserted is known ahead of time, there will be no gaps in the numbers generated for a single statement, except for “mixed-mode inserts”. However, when “bulk inserts” are executed, there may be gaps in the auto-increment values assigned by any given statement.
The auto-increment locking modes provided by
innodb_autoinc_lock_mode have
several usage implications:
Using auto-increment with replication
If you are using statement-based replication, set
innodb_autoinc_lock_modeto 0 or 1 and use the same value on the master and its slaves. Auto-increment values are not ensured to be the same on the slaves as on the master if you useinnodb_autoinc_lock_mode= 2 (“interleaved”) or configurations where the master and slaves do not use the same lock mode.If you are using row-based replication, all of the auto-increment lock modes are safe. Row-based replication is not sensitive to the order of execution of the SQL statements.
“Lost” auto-increment values and sequence gaps
In all lock modes (0, 1, and 2), if a transaction that generated auto-increment values rolls back, those auto-increment values are “lost”. Once a value is generated for an auto-increment column, it cannot be rolled back, whether or not the “
INSERT-like” statement is completed, and whether or not the containing transaction is rolled back. Such lost values are not reused. Thus, there may be gaps in the values stored in anAUTO_INCREMENTcolumn of a table.Gaps in auto-increment values for “bulk inserts”
With
innodb_autoinc_lock_modeset to 0 (“traditional”) or 1 (“consecutive”), the auto-increment values generated by any given statement will be consecutive, without gaps, because the table-levelAUTO-INClock is held until the end of the statement, and only one such statement can execute at a time.With
innodb_autoinc_lock_modeset to 2 (“interleaved”), there may be gaps in the auto-increment values generated by “bulk inserts,” but only if there are concurrently executing “INSERT-like” statements.For lock modes 1 or 2, gaps may occur between successive statements because for bulk inserts the exact number of auto-increment values required by each statement may not be known and overestimation is possible.
Auto-increment values assigned by “mixed-mode inserts”
Consider a “mixed-mode insert,” where a “simple insert” specifies the auto-increment value for some (but not all) resulting rows. Such a statement will behave differently in lock modes 0, 1, and 2. For example, assume
c1is anAUTO_INCREMENTcolumn of tablet1, and that the most recent automatically generated sequence number is 100. Consider the following “mixed-mode insert” statement:INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d');
With
innodb_autoinc_lock_modeset to 0 (“traditional”), the four new rows will be:+-----+------+ | c1 | c2 | +-----+------+ | 1 | a | | 101 | b | | 5 | c | | 102 | d | +-----+------+
The next available auto-increment value will be 103 because the auto-increment values are allocated one at a time, not all at once at the beginning of statement execution. This result is true whether or not there are concurrently executing “
INSERT-like” statements (of any type).With
innodb_autoinc_lock_modeset to 1 (“consecutive”), the four new rows will also be:+-----+------+ | c1 | c2 | +-----+------+ | 1 | a | | 101 | b | | 5 | c | | 102 | d | +-----+------+
However, in this case, the next available auto-increment value will be 105, not 103 because four auto-increment values are allocated at the time the statement is processed, but only two are used. This result is true whether or not there are concurrently executing “
INSERT-like” statements (of any type).With
innodb_autoinc_lock_modeset to mode 2 (“interleaved”), the four new rows will be:+-----+------+ | c1 | c2 | +-----+------+ | 1 | a | |
x| b | | 5 | c | |y| d | +-----+------+The values of
xandywill be unique and larger than any previously generated rows. However, the specific values ofxandywill depend on the number of auto-increment values generated by concurrently executing statements.Finally, consider the following statement, issued when the most-recently generated sequence number was the value 4:
INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d');
With any
innodb_autoinc_lock_modesetting, this statement will generate a duplicate-key error 23000 (Can't write; duplicate key in table) because 5 will be allocated for the row(NULL, 'b')and insertion of the row(5, 'c')will fail.
InnoDB supports foreign keys, which let you
cross-reference related data across tables, and
foreign key
constraints, which help keep this spread-out data
consistent. The syntax for an InnoDB foreign
key constraint definition in the CREATE
TABLE or ALTER TABLE
statement looks like this:
[CONSTRAINT [symbol]] FOREIGN KEY [index_name] (index_col_name, ...) REFERENCEStbl_name(index_col_name,...) [ON DELETEreference_option] [ON UPDATEreference_option]reference_option: RESTRICT | CASCADE | SET NULL | NO ACTION
index_name represents a foreign key
ID. If given, this is ignored if an index for the foreign key is
defined explicitly. Otherwise, if InnoDB
creates an index for the foreign key, it uses
index_name for the index name.
Foreign keys definitions are subject to the following conditions:
Foreign key relationships involve a parent table that holds the central data values, and a child table with identical values pointing back to its parent. The
FOREIGN KEYclause is specified in the child table. The parent and child tables must both beInnoDBtables. They must not beTEMPORARYtables.Corresponding columns in the foreign key and the referenced key must have similar internal data types inside
InnoDBso that they can be compared without a type conversion. The size and sign of integer types must be the same. The length of string types need not be the same. For nonbinary (character) string columns, the character set and collation must be the same.InnoDBrequires indexes on foreign keys and referenced keys so that foreign key checks can be fast and not require a table scan. In the referencing table, there must be an index where the foreign key columns are listed as the first columns in the same order. Such an index is created on the referencing table automatically if it does not exist. This index might be silently dropped later, if you create another index that can be used to enforce the foreign key constraint.index_name, if given, is used as described previously.InnoDBpermits a foreign key to reference any index column or group of columns. However, in the referenced table, there must be an index where the referenced columns are listed as the first columns in the same order.Index prefixes on foreign key columns are not supported. One consequence of this is that
BLOBandTEXTcolumns cannot be included in a foreign key because indexes on those columns must always include a prefix length.If the
CONSTRAINTclause is given, thesymbolsymbolvalue must be unique in the database. If the clause is not given,InnoDBcreates the name automatically.
Referential Actions
This section describes how foreign keys play an important part in safeguarding referential integrity.
InnoDB rejects any
INSERT or
UPDATE operation that attempts to
create a foreign key value in a child table if there is no a
matching candidate key value in the parent table.
When an UPDATE or
DELETE operation affects a key
value in the parent table that has matching rows in the child
table, the result depends on the referential
action specified using ON UPDATE
and ON DELETE subclauses of the
FOREIGN KEY clause. InnoDB
supports five options regarding the action to be taken. If
ON DELETE or ON UPDATE are
not specified, the default action is
RESTRICT.
CASCADE: Delete or update the row from the parent table, and automatically delete or update the matching rows in the child table. BothON DELETE CASCADEandON UPDATE CASCADEare supported. Between two tables, do not define severalON UPDATE CASCADEclauses that act on the same column in the parent table or in the child table.NoteCurrently, cascaded foreign key actions do not activate triggers.
SET NULL: Delete or update the row from the parent table, and set the foreign key column or columns in the child table toNULL. BothON DELETE SET NULLandON UPDATE SET NULLclauses are supported.If you specify a
SET NULLaction, make sure that you have not declared the columns in the child table asNOT NULL.RESTRICT: Rejects the delete or update operation for the parent table. SpecifyingRESTRICT(orNO ACTION) is the same as omitting theON DELETEorON UPDATEclause.NO ACTION: A keyword from standard SQL. In MySQL, equivalent toRESTRICT.InnoDBrejects the delete or update operation for the parent table if there is a related foreign key value in the referenced table. Some database systems have deferred checks, andNO ACTIONis a deferred check. In MySQL, foreign key constraints are checked immediately, soNO ACTIONis the same asRESTRICT.SET DEFAULT: This action is recognized by the parser, butInnoDBrejects table definitions containingON DELETE SET DEFAULTorON UPDATE SET DEFAULTclauses.
InnoDB supports foreign key references
between one column and another within a table. (A column cannot
have a foreign key reference to itself.) In these cases,
“child table records” really refers to dependent
records within the same table.
Examples of Foreign Key Clauses
Here is a simple example that relates parent
and child tables through a single-column
foreign key:
CREATE TABLE parent (id INT NOT NULL,
PRIMARY KEY (id)
) ENGINE=INNODB;
CREATE TABLE child (id INT, parent_id INT,
INDEX par_ind (parent_id),
FOREIGN KEY (parent_id) REFERENCES parent(id)
ON DELETE CASCADE
) ENGINE=INNODB;
A more complex example in which a
product_order table has foreign keys for two
other tables. One foreign key references a two-column index in
the product table. The other references a
single-column index in the customer table:
CREATE TABLE product (category INT NOT NULL, id INT NOT NULL,
price DECIMAL,
PRIMARY KEY(category, id)) ENGINE=INNODB;
CREATE TABLE customer (id INT NOT NULL,
PRIMARY KEY (id)) ENGINE=INNODB;
CREATE TABLE product_order (no INT NOT NULL AUTO_INCREMENT,
product_category INT NOT NULL,
product_id INT NOT NULL,
customer_id INT NOT NULL,
PRIMARY KEY(no),
INDEX (product_category, product_id),
FOREIGN KEY (product_category, product_id)
REFERENCES product(category, id)
ON UPDATE CASCADE ON DELETE RESTRICT,
INDEX (customer_id),
FOREIGN KEY (customer_id)
REFERENCES customer(id)) ENGINE=INNODB;
InnoDB enables you to add a new foreign key
constraint to a table by using ALTER
TABLE:
ALTER TABLEtbl_nameADD [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (index_col_name, ...) REFERENCEStbl_name(index_col_name,...) [ON DELETEreference_option] [ON UPDATEreference_option]
The foreign key can be self referential (referring to the same
table). When you add a foreign key constraint to a table using
ALTER TABLE, remember
to create the required indexes first.
Foreign Keys and ALTER TABLE
InnoDB supports the use of
ALTER TABLE to drop foreign keys:
ALTER TABLEtbl_nameDROP FOREIGN KEYfk_symbol;
If the FOREIGN KEY clause included a
CONSTRAINT name when you created the foreign
key, you can refer to that name to drop the foreign key.
Otherwise, the fk_symbol value is
internally generated by InnoDB when the
foreign key is created. To find out the symbol value when you
want to drop a foreign key, use the SHOW
CREATE TABLE statement. For example:
mysql>SHOW CREATE TABLE ibtest11c\G*************************** 1. row *************************** Table: ibtest11c Create Table: CREATE TABLE `ibtest11c` ( `A` int(11) NOT NULL auto_increment, `D` int(11) NOT NULL default '0', `B` varchar(200) NOT NULL default '', `C` varchar(175) default NULL, PRIMARY KEY (`A`,`D`,`B`), KEY `B` (`B`,`C`), KEY `C` (`C`), CONSTRAINT `0_38775` FOREIGN KEY (`A`, `D`) REFERENCES `ibtest11a` (`A`, `D`) ON DELETE CASCADE ON UPDATE CASCADE, CONSTRAINT `0_38776` FOREIGN KEY (`B`, `C`) REFERENCES `ibtest11a` (`B`, `C`) ON DELETE CASCADE ON UPDATE CASCADE ) ENGINE=INNODB CHARSET=latin1 1 row in set (0.01 sec) mysql>ALTER TABLE ibtest11c DROP FOREIGN KEY `0_38775`;
You cannot add a foreign key and drop a foreign key in separate
clauses of a single ALTER TABLE
statement. Separate statements are required.
If ALTER TABLE for an
InnoDB table results in changes to column
values (for example, because a column is truncated),
InnoDB's FOREIGN KEY
constraint checks do not notice possible violations caused by
changing the values.
How Foreign Keys Work with Other MySQL Commands
The InnoDB parser permits table and column
identifiers in a FOREIGN KEY ... REFERENCES
... clause to be quoted within backticks.
(Alternatively, double quotation marks can be used if the
ANSI_QUOTES SQL mode is
enabled.) The InnoDB parser also takes into
account the setting of the
lower_case_table_names system
variable.
InnoDB returns a child table's foreign key
definitions as part of the output of the
SHOW CREATE TABLE statement:
SHOW CREATE TABLE tbl_name;
mysqldump also produces correct definitions of tables in the dump file, including the foreign keys for child tables.
To make it easier to reload dump files for tables that have
foreign key relationships, mysqldump
automatically includes a statement in the dump output to set
foreign_key_checks to 0. This
avoids problems with tables having to be reloaded in a
particular order when the dump is reloaded. It is also possible
to set this variable manually:
mysql>SET foreign_key_checks = 0;mysql>SOURCEmysql>dump_file_name;SET foreign_key_checks = 1;
This enables you to import the tables in any order if the dump
file contains tables that are not correctly ordered for foreign
keys. It also speeds up the import operation. Setting
foreign_key_checks to 0 can
also be useful for ignoring foreign key constraints during
LOAD DATA and
ALTER TABLE operations. However,
even if foreign_key_checks = 0,
InnoDB does not permit the creation of a foreign key constraint
where a column references a nonmatching column type. Also, if an
InnoDB table has foreign key constraints,
ALTER TABLE cannot be used to
change the table to use another storage engine. To alter the
storage engine, drop any foreign key constraints first.
You cannot issue DROP TABLE for
an InnoDB table that is referenced by a
FOREIGN KEY constraint, unless you do
SET foreign_key_checks = 0. When you drop a
table, the constraints that were defined in its create statement
are also dropped.
If you re-create a table that was dropped, it must have a definition that conforms to the foreign key constraints referencing it. It must have the right column names and types, and it must have indexes on the referenced keys, as stated earlier. If these are not satisfied, MySQL returns error number 1005 and refers to error 150 in the error message.
If MySQL reports an error number 1005 from a
CREATE TABLE statement, and the
error message refers to error 150, table creation failed because
a foreign key constraint was not correctly formed. Similarly, if
an ALTER TABLE fails and it
refers to error 150, that means a foreign key definition would
be incorrectly formed for the altered table. To display a
detailed explanation of the most recent
InnoDB foreign key error in the server, issue
SHOW ENGINE INNODB
STATUS.
For users familiar with the ANSI/ISO SQL Standard, please note
that no storage engine, including InnoDB,
recognizes or enforces the MATCH clause
used in referential-integrity constraint definitions. Use of
an explicit MATCH clause will not have the
specified effect, and also causes ON DELETE
and ON UPDATE clauses to be ignored. For
these reasons, specifying MATCH should be
avoided.
The MATCH clause in the SQL standard
controls how NULL values in a composite
(multiple-column) foreign key are handled when comparing to a
primary key. InnoDB essentially implements
the semantics defined by MATCH SIMPLE,
which permit a foreign key to be all or partially
NULL. In that case, the (child table) row
containing such a foreign key is permitted to be inserted, and
does not match any row in the referenced (parent) table. It is
possible to implement other semantics using triggers.
Additionally, MySQL and InnoDB require that
the referenced columns be indexed for performance. However,
the system does not enforce a requirement that the referenced
columns be UNIQUE or be declared
NOT NULL. The handling of foreign key
references to nonunique keys or keys that contain
NULL values is not well defined for
operations such as UPDATE or
DELETE CASCADE. You are advised to use
foreign keys that reference only UNIQUE and
NOT NULL keys.
Furthermore, InnoDB does not recognize or
support “inline REFERENCES
specifications” (as defined in the SQL standard) where
the references are defined as part of the column
specification. InnoDB accepts
REFERENCES clauses only when specified as
part of a separate FOREIGN KEY
specification. For other storage engines, MySQL Server parses
and ignores foreign key specifications.
Deviation from SQL standards:
If there are several rows in the parent table that have the same
referenced key value, InnoDB acts in foreign
key checks as if the other parent rows with the same key value
do not exist. For example, if you have defined a
RESTRICT type constraint, and there is a
child row with several parent rows, InnoDB
does not permit the deletion of any of those parent rows.
InnoDB performs cascading operations through
a depth-first algorithm, based on records in the indexes
corresponding to the foreign key constraints.
Deviation from SQL standards: A
FOREIGN KEY constraint that references a
non-UNIQUE key is not standard SQL. It is an
InnoDB extension to standard SQL.
Deviation from SQL standards:
If ON UPDATE CASCADE or ON UPDATE
SET NULL recurses to update the same
table it has previously updated during the cascade,
it acts like RESTRICT. This means that you
cannot use self-referential ON UPDATE CASCADE
or ON UPDATE SET NULL operations. This is to
prevent infinite loops resulting from cascaded updates. A
self-referential ON DELETE SET NULL, on the
other hand, is possible, as is a self-referential ON
DELETE CASCADE. Cascading operations may not be nested
more than 15 levels deep.
Deviation from SQL standards:
Like MySQL in general, in an SQL statement that inserts,
deletes, or updates many rows, InnoDB checks
UNIQUE and FOREIGN KEY
constraints row-by-row. When performing foreign key checks,
InnoDB sets shared row-level locks on child
or parent records it has to look at. InnoDB
checks foreign key constraints immediately; the check is not
deferred to transaction commit. According to the SQL standard,
the default behavior should be deferred checking. That is,
constraints are only checked after the entire SQL
statement has been processed. Until
InnoDB implements deferred constraint
checking, some things will be impossible, such as deleting a
record that refers to itself using a foreign key.
You can perform several kinds of
online DDL operations on
InnoDB tables: that is, without rebuilding the
entire table, allowing DML
operations on the table while the
DDL is in progress, or both. This
enhancement has the following benefits:
It improves responsiveness and availability in busy production environments, where making a table unavailable for minutes or hours whenever you modify its column definitions or indexes is not practical.
It avoids temporary increases in disk space usage by doing the changes in-place where possible, rather than creating a new copy of the table.
It lets you adjust the balance between performance and concurrency during the DDL operation, by choosing whether to block access to the table entirely, allow queries but not DML, or allow full query and DML access to the table.
Historically, many DDL operations
on InnoDB tables were expensive. Many
ALTER TABLE operations worked by
creating a new, empty table defined with the requested table
options and indexes, then copying the existing rows to the new
table one-by-one, updating the indexes as the rows were inserted.
After all rows from the original table were copied, the old table
was dropped and the copy was renamed with the name of the original
table.
MySQL 5.5, and MySQL 5.1 with the InnoDB Plugin, optimized
CREATE INDEX and DROP INDEX
to avoid the table-copying behavior. That feature was known as
Fast Index Creation. MySQL 5.6 enhances many other types of
ALTER TABLE operations to avoid
copying the table. Another enhancement allows
SELECT queries and
INSERT,
UPDATE, and
DELETE
(DML) statements to proceed while
the table is being altered. This combination of features is now
known as online DDL.
The online DDL enhancements in MySQL 5.6 improve many DDL
operations that formerly required a table copy, blocked DML
operations on the table, or both. The DDL operations enhanced by
this feature are these variations on the
ALTER TABLE statement:
Table 14.3. Summary of Online Status for DDL Operations
| Operation | In-Place? | Concurrent DML? | Notes |
|---|---|---|---|
| CREATE INDEX, ADD INDEX | Yes* | Yes* | Creating a FULLTEXT index cannot be done in-place, and does not allow concurrent DML. |
| DROP INDEX | Yes | Yes | |
| Set default value for a column | Yes* | Yes | Modifies .frm file only, not the data file. |
| Change auto-increment value for a column | Yes | Yes | |
| Add a foreign key constraint | Yes* | Yes | To avoid copying the table, disable foreign_key_checks during constraint creation. |
| Drop a foreign key constraint | Yes | Yes | The foreign_key_checks option can be enabled or disabled. |
| Rename a column | Yes | Yes* | To allow concurrent DML, keep the same data type and only change the column name. |
| Add a column | No | Yes* | Concurrent DML not allowed when adding an auto-increment column. |
| Drop a column | No | Yes | |
| Reorder columns | No | Yes | |
| Rebuild with FORCE option | No | Yes | |
| Change ROW_FORMAT property | No | Yes | |
| Change KEY_BLOCK_SIZE property | No | Yes | |
| Make column NULL or NOT NULL | No | Yes | |
| Change data type of column | No | No | |
| Add primary key | Yes* | Yes | Although ALGORITHM=INPLACE is allowed, the data is reorganized substantially, so it is still an expensive operation. |
| Drop primary key | Maybe | Yes | Only allowed in-place when you add a new primary key in the same ALTER TABLE. |
| Convert character set | Maybe | No | Rebuilds the table if the new character encoding is different. |
| Specify character set | Maybe | No | Rebuilds the table if the new character encoding is different. |
| Add a partition | Maybe | No | Avoids copying the table when partitioned by LIST or RANGE. |
| Drop a partition | Maybe | No | Avoids copying the table when partitioned by LIST or RANGE. |
| Truncate a partition | Yes | No | |
| Coalesce a partition | No | No | |
| Reorganize a partition | No | No | |
| Exchange a partition | No | No | |
| Analyze a partition | No | No | |
| Check a partition | No | No | |
| Optimize a partition | No | No | |
| Rebuild a partition | No | No | |
| Repair a partition | No | No | |
| Remove a partition | No | No |
The following list shows the basic syntax, and usage notes related to online DDL, for each of the major operations that can be performed in-place, with concurrent DML, or both:
Create secondary indexes:
CREATE INDEXornameONtable(col_list)ALTER TABLE. (Creating a primary key or atableADD INDEXname(col_list)FULLTEXTindex still requires locking the table.)Drop secondary indexes:
DROP INDEXornameONtable;ALTER TABLEtableDROP INDEXnameCreating and dropping secondary indexes on
InnoDBtables has avoided the table-copying behavior since the days of MySQL 5.1 with theInnoDBPlugin. Now, the table remains available for read and write operations while the index is being created or dropped. TheCREATE INDEXorDROP INDEXstatement only finishes after all transactions that are modifying the table are completed, so that the initial state of the index reflects the most recent contents of the table.Previously, modifying the table while an index was being created or dropped typically resulted in a deadlock that cancelled the insert, update, or delete statement on the table.
Changing the auto-increment value for a column:
ALTER TABLEtableAUTO_INCREMENT=next_value;Especially in a distributed system using replication or sharding, you sometimes reset the auto-increment counter for a table to a specific value. The next row inserted into the table uses the specified value for its auto-increment column. You might also use this technique in a data warehousing environment where you periodically empty all the tables and reload them, and you can restart the auto-increment sequence from 1.
Adding or dropping a foreign key constraint:
ALTER TABLE
tbl1ADD CONSTRAINTfk_nameFOREIGN KEYindex(col1) REFERENCEStbl2(col2)referential_actions; ALTER TABLEtblDROP FOREIGN KEYfk_name;Dropping a foreign key can be performed online with the
foreign_key_checksoption enabled or disabled. Creating a foreign key online requiresforeign_key_checksto be disabled.If you do not know the names of the foreign key constraints on a particular table, issue the following statement and find the constraint name in the
CONSTRAINTclause for each foreign key:show create table
table\GOr, query the
information_schema.table_constraintstable and use theconstraint_nameandconstraint_typecolumns to identify the foreign key names.As a consequence of this enhancement, you can now also drop a foreign key and its associated index in a single statement, which previously required separate statements in a strict order:
ALTER TABLE
tableDROP FOREIGN KEYconstraint, DROP INDEXindex;Renaming a column:
ALTER TABLEtblCHANGEold_col_namenew_col_namedatatypeWhen you keep the same data type and only change the column name, this operation can always be performed online.
As part of this enhancement, you can now rename a column that is part of a foreign key constraint, which was not allowed before. The foreign key definition is automatically updated to use the new column name. Renaming a column participating in a foreign key only works with the in-place mode of
ALTER TABLE. If you use theALGORITHM=COPYclause, or some other condition causes the command to perform a table copy, theALTER TABLEstatement will fail.Some other
ALTER TABLEoperations are non-blocking, and are faster than before because the table-copying operation is optimized, even though a table copy is still required:Adding, dropping, or reordering columns.
Changing the
ROW_FORMATorKEY_BLOCK_SIZEproperties for a table.Changing the nullable status for a column.
As your database schema evolves with new columns, data types,
constraints, indexes, and so on, keep your
CREATE TABLE statements up to
date with the latest table definitions. Even with the
performance improvements of online DDL, it is more efficient to
create stable database structures at the beginning, rather than
creating part of the schema and then issuing
ALTER TABLE statements afterward.
The main exception to this guideline is for secondary indexes on tables with large numbers of rows. It is typically most efficient to create the table with all details specified except the secondary indexes, load the data, then create the secondary indexes.
Whatever sequence of CREATE
TABLE, CREATE INDEX,
ALTER TABLE, and similar
statements went into putting a table together, you can capture
the SQL needed to reconstruct the current form of the table by
issuing the statement SHOW CREATE TABLE
(uppercase
table\G\G required for tidy formatting). This output
shows clauses such as numeric precision, NOT
NULL, and CHARACTER SET that are
sometimes added behind the scenes, and you might otherwise leave
out when cloning the table on a new system or setting up foreign
key columns with identical type.
With MySQL 5.5 and higher, or MySQL 5.1 with the InnoDB Plugin,
creating and dropping
secondary indexes for
InnoDB tables is much faster than before. Historically, adding or
dropping an index on a table with existing data could be very
slow. The CREATE INDEX and
DROP INDEX statements worked by
creating a new, empty table defined with the requested set of
indexes, then copying the existing rows to the new table
one-by-one, updating the indexes as the rows are inserted. After
all rows from the original table were copied, the old table was
dropped and the copy was renamed with the name of the original
table.
The performance speedup from in-place DDL applies to operations on secondary indexes, not to the primary key index. The rows of an InnoDB table are stored in a clustered index organized based on the primary key, forming what some database systems call an “index-organized table”. Because the table structure is so closely tied to the primary key, redefining the primary key still requires copying the data.
This new mechanism also means that you can generally speed the overall process of creating and loading a table and associated indexes by creating the table with without any secondary indexes, then adding the secondary indexes after the data is loaded.
Although no syntax changes are required in the
CREATE INDEX or
DROP INDEX commands, some factors
affect the performance, space usage, and semantics of this
operation (see Section 14.2.2.6.8, “Limitations of Online DDL”).
Online DDL improves several aspects of MySQL operation, such as performance, concurrency, availability, and scalability:
Because queries and DML operations on the table can proceed while the DDL is in progress, applications that access the table are more responsive. Reduced locking and waiting for other resources all throughout the MySQL server leads to greater scalability, even for operations not involving the table being altered.
For in-place operations, by avoiding the disk I/O and CPU cycles to rebuild the table, you minimize the overall load on the database and maintain good performance and high throughput during the DDL operation.
For in-place operations, because less data is read into the buffer pool than if all the data was copied, you avoid purging frequently accessed data from memory, which formerly caused a temporary performance dip after a DDL operation.
Locking Options for Online DDL
While an InnoDB table is being changed by a DDL operation, the
table may or may not be locked, depending on the
LOCK clause of the ALTER
TABLE statement. If the LOCK clause
specifies a level of locking that is not available for that
specific kind of DDL operation, such as
LOCK=SHARED or LOCK=NONE
while creating or dropping a primary key, the statement fails with
an error. The following list shows the different possibilities for
the LOCK clause, from the most permissive to
the most restrictive:
For DDL operations with
LOCK=NONE, both queries and concurrent DML are allowed. This clause makes theALTER TABLEfail if the kind of DDL operation cannot be performed with the requested type of locking, so specifyLOCK=NONEif keeping the table fully available is vital and it is OK to cancel the DDL if that is not possible. For example, you might use this clause in DDLs for tables involving customer signups or purchases, to avoid making those tables unavailable by mistakenly issuing an expensiveALTER TABLEstatement.For DDL operations with
LOCK=SHARED, any writes to the table (that is, DML operations) are blocked, but the data in the table can be read. This clause makes theALTER TABLEfail if the kind of DDL operation cannot be performed with the requested type of locking, so specifyLOCK=SHAREDif keeping the table available for queries is vital and it is OK to cancel the DDL if that is not possible. For example, you might use this clause in DDLs for tables in a data warehouse, where it is OK to delay data load operations until the DDL is finished, but queries cannot be delayed for long periods.For DDL operations with
LOCK=DEFAULT, or with theLOCKclause omitted, MySQL uses the lowest level of locking that is available for that kind of operation, allowing concurrent queries, DML, or both wherever possible. This is the setting to use when making pre-planned, pre-tested changes that you know will not cause any availability problems based on the workload for that table.For DDL operations with
LOCK=EXCLUSIVE, both queries and DML operations are blocked. This clause makes theALTER TABLEfail if the kind of DDL operation cannot be performed with the requested type of locking, so specifyLOCK=EXCLUSIVEif the primary concern is finishing the DDL in the shortest time possible, and it is OK to make applications wait when they try to access the table. You might also useLOCK=EXCLUSIVEif the server is supposed to be idle, to avoid unexpected accesses to the table.
An online DDL statement for an InnoDB table always waits for currently executing transactions that are accessing the table to commit or roll back, because it requires exclusive access to the table for a brief period while the DDL statement is being prepared. Likewise, it requires exclusive access to the table for a brief time before finishing. Thus, an online DDL statement waits for any transactions that are started while the DDL is in progress, and query or modify the table, to commit or roll back before the DDL completes.
Because there is some processing work involved with recording the changes made by concurrent DML operations, then applying those changes at the end, an online DDL operation could take longer overall than the old-style mechanism that blocks table access from other sessions. The reduction in raw performance is balanced against better responsiveness for applications that use the table. When evaluating the ideal techniques for changing table structure, consider end-user perception of performance, based on factors such as load times for web pages.
A newly created InnoDB secondary index contains only the committed
data in the table at the time the CREATE
INDEX or ALTER TABLE
statement finishes executing. It does not contain any uncommitted
values, old versions of values, or values marked for deletion but
not yet removed from the old index.
Performance of In-Place versus Table-Copying DDL Operations
The raw performance of an online DDL operation is largely determined by whether the operation is performed in-place, or requires copying and rebuilding the entire table. See Table 14.3, “Summary of Online Status for DDL Operations” to see what kinds of operations can be performed in-place, and any requirements for avoiding table-copy operations.
To judge the relative performance of online DDL operations, you
can run such operations on a big InnoDB table
using current and earlier versions of MySQL. You can also run all
the performance tests under the latest MySQL version, simulating
the previous DDL behavior for the “before” results,
by setting the old_alter_table
system variable. Issue the statement set
old_alter_table=1 in the session, and measure DDL
performance to record the “before” figures. Then
set old_alter_table=0 to re-enable the newer,
faster behavior, and run the DDL operations again to record the
“after” figures.
For a basic idea of whether a DDL operation does its changes in-place or performs a table copy, look at the “rows affected” value displayed after the command finishes. For example, here are lines you might see after doing different types of DDL operations:
Changing the default value of a column (super-fast, does not affect the table data at all):
Query OK, 0 rows affected (0.07 sec)
Adding an index (takes time, but
0 rows affectedshows that the table is not copied):Query OK, 0 rows affected (21.42 sec)
Changing the data type of a column (takes substantial time and does require rebuilding all the rows of the table):
Query OK, 1671168 rows affected (1 min 35.54 sec)
For example, before running a DDL operation on a big table, you might check whether the operation will be fast or slow as follows:
Clone the table structure.
Populate the cloned table with a tiny amount of data.
Run the DDL operation on the cloned table.
Check whether the “rows affected” value is zero or not. A non-zero value means the operation will require rebuilding the entire table, which might require special planning. For example, you might do the DDL operation during a period of scheduled downtime, or on each replication slave server one at a time.
For a deeper understanding of the reduction in MySQL processing,
examine the performance_schema and
INFORMATION_SCHEMA tables related to
InnoDB before and after DDL operations, to see
the number of physical reads, writes, memory allocations, and so
on.
Typically, you do not need to do anything special to enable
online DDL when using the
ALTER TABLE statement for
InnoDB tables. See
Table 14.3, “Summary of Online Status for DDL Operations” for the kinds of
DDL operations that can be performed in-place, allowing concurrent
DML, or both. Some variations require particular combinations of
configuration settings or ALTER
TABLE clauses.
You can control the various aspects of a particular online DDL
operation by using the LOCK and
ALGORITHM clauses of the
ALTER TABLE statement. These
clauses come at the end of the statement, separated from the table
and column specifications by commas. The LOCK
clause is useful for fine-tuning the degree of concurrent access
to the table. The ALGORITHM clause is primarily
intended for performance comparisons and as a fallback to the
older table-copying behavior in case you encounter any issues with
existing DDL code. For example:
To avoid accidentally making the table unavailable for reads, writes, or both, you could specify a clause on the
ALTER TABLEstatement such asLOCK=NONE(allow both reads and writes) orLOCK=SHARED(allow reads). The operation halts immediately if the requested level of concurrency is not available.To compare performance, you could run one statement with
ALGORITHM=INPLACEand another withALGORITHM=COPY, as an alternative to setting theold_alter_tableconfiguration option.To avoid the chance of tying up the server by running an
ALTER TABLEthat copied the table, you could includeALGORITHM=INPLACEso the statement halts immediately if it cannot use the in-place mechanism. See Table 14.3, “Summary of Online Status for DDL Operations” for a list of the DDL operations that can or cannot be performed in-place.
See Section 14.2.2.6.2, “Performance and Concurrency Considerations for Online DDL” for more
details about the LOCK clause. For full
examples of using online DDL, see
Section 14.2.2.6.5, “Examples of Online DDL”.
Before the introduction of online
DDL, it was common practice to combine many DDL operations
into a single ALTER TABLE
statement. Because each ALTER TABLE
statement involved copying and rebuilding the table, it was more
efficient to make several changes to the same table at once, since
those changes could all be done with a single rebuild operation
for the table. The downside was that SQL code involving DDL
operations was harder to maintain and to reuse in different
scripts. If the specific changes were different each time, you
might have to construct a new complex ALTER
TABLE for each slightly different scenario.
For DDL operations that can be done in-place, as shown in
Table 14.3, “Summary of Online Status for DDL Operations”, now you can
separate them into individual ALTER
TABLE statements for easier scripting and maintenance,
without sacrificing efficiency. For example, you might take a
complicated statement such as:
alter table t1 add index i1(c1), add unique index i2(c2), change c4_old_name c4_new_name integer unsigned;
and break it down into simpler parts that can be tested and performed independently, such as:
alter table t1 add index i1(c1); alter table t1 add unique index i2(c2); alter table t1 change c4_old_name c4_new_name integer unsigned not null;
You might still use multi-part ALTER
TABLE statements for:
Operations that must be performed in a specific sequence, such as creating an index followed by a foreign key constraint that uses that index.
Operations all using the same specific
LOCKclause, that you want to either succeed or fail as a group.Operations that cannot be performed in-place, that is, that still copy and rebuild the table.
Operations for which you specify
ALGORITHM=COPYorold_alter_table=1, to force the table-copying behavior if needed for precise backward-compatibility in specialized scenarios.
Original Fast Index Creation Examples
You can create multiple indexes on a table with one
ALTER TABLE statement. This is
relatively efficient, because the clustered index of the table
needs to be scanned only once (although the data is sorted
separately for each new index). For example:
CREATE TABLE T1(A INT PRIMARY KEY, B INT, C CHAR(1)) ENGINE=InnoDB; INSERT INTO T1 VALUES (1,2,'a'), (2,3,'b'), (3,2,'c'), (4,3,'d'), (5,2,'e'); COMMIT; ALTER TABLE T1 ADD INDEX (B), ADD UNIQUE INDEX (C);
The above statements create table T1 with the
primary key on column A, insert several rows,
then build two new indexes on columns B and
C. If there were many rows inserted into
T1 before the ALTER
TABLE statement, this approach is much more efficient
than creating all the secondary indexes before loading the data.
Because dropping InnoDB secondary indexes also does not require
any copying of table data, it is equally efficient to drop
multiple indexes with a single ALTER
TABLE statement or multiple DROP
INDEX statements:
ALTER TABLE T1 DROP INDEX B, DROP INDEX C;
or:
DROP INDEX B ON T1; DROP INDEX C ON T1;
Restructuring the clustered index in InnoDB always requires
copying the data in the table. For example, if you create a table
without a primary key, InnoDB chooses one for you, which can be
the first UNIQUE key defined on NOT
NULL columns, or a system-generated key. Defining a
PRIMARY KEY later causes the data to be copied,
as in the following example:
CREATE TABLE T2 (A INT, B INT) ENGINE=InnoDB; INSERT INTO T2 VALUES (NULL, 1); ALTER TABLE T2 ADD PRIMARY KEY (B);
When you create a UNIQUE or PRIMARY
KEY index, MySQL must do some extra work. For
UNIQUE indexes, MySQL checks that the table
contains no duplicate values for the key. For a PRIMARY
KEY index, MySQL also checks that none of the
PRIMARY KEY columns contains a
NULL. It is best to define the primary key when
you create a table, so you need not rebuild the table later.
Here are code examples showing some operations whose performance, concurrency, and scalability are improved by the latest online DDL enhancements.
Example 14.1, “Schema Setup Code for Online DDL Experiments” sets up tables named
BIG_TABLEandSMALL_TABLEused in the subsequent examples.Example 14.2, “Speed and Efficiency of CREATE INDEX and DROP INDEX” illustrates the performance aspects of creating and dropping indexes.
Example 14.3, “Concurrent DML During CREATE INDEX and DROP INDEX” shows queries and DML statements running during a
DROP INDEXoperation.Example 14.4, “Renaming a Column” demonstrates the speed improvement for renaming a column, and shows the care needed to keep the data type precisely the same when doing the rename operation.
Example 14.5, “Dropping Foreign Keys” demonstrates how foreign keys work with online DDL. Because two tables are involved in foreign key operations, there are extra locking considerations. Thus, tables with foreign keys sometimes have restrictions for online DDL operations.
Example 14.6, “Changing Auto-Increment Value” demonstrates how auto-increment columns work with online DDL. Tables with auto-increment columns sometimes have restrictions for online DDL operations.
Example 14.7, “Controlling Concurrency with the
LOCKClause” demonstrates the options to permit or restrict concurrent queries and DML operations while an online DDL operation is in progress. It shows the situations when the DDL statement might wait, or the concurrent transaction might wait, or the concurrent transaction might cancel a DML statement due to a deadlock error.
Example 14.1. Schema Setup Code for Online DDL Experiments
Here is the code that sets up the initial tables used in these demonstrations:
/* Setup code for the online DDL demonstration: - Set up some config variables. - Create 2 tables that are clones of one of the INFORMATION_SCHEMA tables that always has some data. The "small" table has a couple of thousand rows. For the "big" table, keep doubling the data until it reaches over a million rows. - Set up a primary key for the sample tables, since we are demonstrating InnoDB aspects. */ set autocommit = 0; set foreign_key_checks = 1; set global innodb_file_per_table = 1; set old_alter_table=0; prompt mysql: use test; \! echo "Setting up 'small' table:" drop table if exists small_table; create table small_table as select * from information_schema.columns; alter table small_table add id int unsigned not null primary key auto_increment; select count(id) from small_table; \! echo "Setting up 'big' table:" drop table if exists big_table; create table big_table as select * from information_schema.columns; show create table big_table\G insert into big_table select * from big_table; insert into big_table select * from big_table; insert into big_table select * from big_table; insert into big_table select * from big_table; insert into big_table select * from big_table; insert into big_table select * from big_table; insert into big_table select * from big_table; insert into big_table select * from big_table; insert into big_table select * from big_table; insert into big_table select * from big_table; commit; alter table big_table add id int unsigned not null primary key auto_increment; select count(id) from big_table;
Running this code gives this output, condensed for brevity and with the most important points bolded:
Setting up 'small' table:
Query OK, 0 rows affected (0.01 sec)
Query OK, 1678 rows affected (0.13 sec)
Records: 1678 Duplicates: 0 Warnings: 0
Query OK, 1678 rows affected (0.07 sec)
Records: 1678 Duplicates: 0 Warnings: 0
+-----------+
| count(id) |
+-----------+
| 1678 |
+-----------+
1 row in set (0.00 sec)
Setting up 'big' table:
Query OK, 0 rows affected (0.16 sec)
Query OK, 1678 rows affected (0.17 sec)
Records: 1678 Duplicates: 0 Warnings: 0
*************************** 1. row ***************************
Table: big_table
Create Table: CREATE TABLE `big_table` (
`TABLE_CATALOG` varchar(512) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_SCHEMA` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`ORDINAL_POSITION` bigint(21) unsigned NOT NULL DEFAULT '0',
`COLUMN_DEFAULT` longtext CHARACTER SET utf8,
`IS_NULLABLE` varchar(3) CHARACTER SET utf8 NOT NULL DEFAULT '',
`DATA_TYPE` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`CHARACTER_MAXIMUM_LENGTH` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_OCTET_LENGTH` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_PRECISION` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_SCALE` bigint(21) unsigned DEFAULT NULL,
`DATETIME_PRECISION` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_SET_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLLATION_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLUMN_TYPE` longtext CHARACTER SET utf8 NOT NULL,
`COLUMN_KEY` varchar(3) CHARACTER SET utf8 NOT NULL DEFAULT '',
`EXTRA` varchar(30) CHARACTER SET utf8 NOT NULL DEFAULT '',
`PRIVILEGES` varchar(80) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_COMMENT` varchar(1024) CHARACTER SET utf8 NOT NULL DEFAULT ''
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
Query OK, 1678 rows affected (0.09 sec)
Records: 1678 Duplicates: 0 Warnings: 0
Query OK, 3356 rows affected (0.07 sec)
Records: 3356 Duplicates: 0 Warnings: 0
Query OK, 6712 rows affected (0.17 sec)
Records: 6712 Duplicates: 0 Warnings: 0
Query OK, 13424 rows affected (0.44 sec)
Records: 13424 Duplicates: 0 Warnings: 0
Query OK, 26848 rows affected (0.63 sec)
Records: 26848 Duplicates: 0 Warnings: 0
Query OK, 53696 rows affected (1.72 sec)
Records: 53696 Duplicates: 0 Warnings: 0
Query OK, 107392 rows affected (3.02 sec)
Records: 107392 Duplicates: 0 Warnings: 0
Query OK, 214784 rows affected (6.28 sec)
Records: 214784 Duplicates: 0 Warnings: 0
Query OK, 429568 rows affected (13.25 sec)
Records: 429568 Duplicates: 0 Warnings: 0
Query OK, 859136 rows affected (28.16 sec)
Records: 859136 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.03 sec)
Query OK, 1718272 rows affected (1 min 9.22 sec)
Records: 1718272 Duplicates: 0 Warnings: 0
+-----------+
| count(id) |
+-----------+
| 1718272 |
+-----------+
1 row in set (1.75 sec)
Example 14.2. Speed and Efficiency of CREATE INDEX and DROP INDEX
Here is a sequence of statements demonstrating the relative
speed of CREATE INDEX and
DROP INDEX statements. For a
small table, the elapsed time is less than a second whether we
use the fast or slow technique, so we look at the “rows
affected” output to verify which operations can avoid the
table rebuild. For a large table, the difference in efficiency
is obvious because skipping the table rebuild saves substantial
time.
\! clear -- Make sure we're using the new-style fast DDL. -- Outside of benchmarking and troubleshooting, you would -- never enable the old_alter_table setting. set old_alter_table=0; \! echo "=== Create and drop index (small table, new/fast technique) ===" \! echo \! echo "Data size (kilobytes) before index created: " \! du -k data/test/small_table.ibd create index i_dtyp_small on small_table (data_type); \! echo "Data size after index created: " \! du -k data/test/small_table.ibd drop index i_dtyp_small on small_table; -- Revert to the older slower DDL for comparison. set old_alter_table=1; \! echo "=== Create and drop index (small table, old/slow technique) ===" \! echo \! echo "Data size (kilobytes) before index created: " \! du -k data/test/small_table.ibd create index i_dtyp_small on small_table (data_type); \! echo "Data size after index created: " \! du -k data/test/small_table.ibd drop index i_dtyp_small on small_table; -- In the above example, we examined the "rows affected" number, -- ideally looking for a zero figure. Let's try again with a larger -- sample size, where we'll see that the actual time taken can -- vary significantly. -- Back to the new/fast behavior: set old_alter_table=0; \! echo "=== Create and drop index (big table, new/fast technique) ===" \! echo \! echo "Data size (kilobytes) before index created: " \! du -k data/test/big_table.ibd create index i_dtyp_big on big_table (data_type); \! echo "Data size after index created: " \! du -k data/test/big_table.ibd drop index i_dtyp_big on big_table; -- Let's see that again, in slow motion: set old_alter_table=1; \! echo "=== Create and drop index (big table, old/slow technique) ===" \! echo \! echo "Data size (kilobytes) before index created: " \! du -k data/test/big_table.ibd create index i_dtyp_big on big_table (data_type); \! echo "Data size after index created: " \! du -k data/test/big_table.ibd drop index i_dtyp_big on big_table;
Running this code gives this output, condensed for brevity and with the most important points bolded:
Query OK, 0 rows affected (0.00 sec) === Create and drop index (small table, new/fast technique) === Data size (kilobytes) before index created: 384 data/test/small_table.ibd Query OK, 0 rows affected (0.04 sec) Records: 0 Duplicates: 0 Warnings: 0 Data size after index created: 432 data/test/small_table.ibd Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 Query OK, 0 rows affected (0.00 sec) === Create and drop index (small table, old/slow technique) === Data size (kilobytes) before index created: 432 data/test/small_table.ibd Query OK, 1678 rows affected (0.12 sec) Records: 1678 Duplicates: 0 Warnings: 0 Data size after index created: 448 data/test/small_table.ibd Query OK, 1678 rows affected (0.10 sec) Records: 1678 Duplicates: 0 Warnings: 0 Query OK, 0 rows affected (0.00 sec) === Create and drop index (big table, new/fast technique) === Data size (kilobytes) before index created: 315392 data/test/big_table.ibd Query OK, 0 rows affected (33.32 sec) Records: 0 Duplicates: 0 Warnings: 0 Data size after index created: 335872 data/test/big_table.ibd Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 Query OK, 0 rows affected (0.00 sec) === Create and drop index (big table, old/slow technique) === Data size (kilobytes) before index created: 335872 data/test/big_table.ibd Query OK, 1718272 rows affected (1 min 5.01 sec) Records: 1718272 Duplicates: 0 Warnings: 0 Data size after index created: 348160 data/test/big_table.ibd Query OK, 1718272 rows affected (46.59 sec) Records: 1718272 Duplicates: 0 Warnings: 0
Example 14.3. Concurrent DML During CREATE INDEX and DROP INDEX
Here are some snippets of code that I ran in separate
mysql sessions connected to the same
database, to illustrate DML statements (insert, update, or
delete) running at the same time as CREATE
INDEX and DROP INDEX.
/* CREATE INDEX statement to run against a table while insert/update/delete statements are modifying the column being indexed. */ -- We'll run this script in one session, while simultaneously creating and dropping -- an index on test/big_table.table_name in another session. use test; create index i_concurrent on big_table(table_name);
/* DROP INDEX statement to run against a table while insert/update/delete statements are modifying the column being indexed. */ -- We'll run this script in one session, while simultaneously creating and dropping -- an index on test/big_table.table_name in another session. use test; drop index i_concurrent on big_table;
/* Some queries and insert/update/delete statements to run against a table while an index is being created or dropped. Previously, these operations would have stalled during the index create/drop period and possibly timed out or deadlocked. */ -- We'll run this script in one session, while simultaneously creating and dropping -- an index on test/big_table.table_name in another session. -- In our test instance, that column has about 1.7M rows, with 136 different values. -- Sample values: COLUMNS (20480), ENGINES (6144), EVENTS (24576), FILES (38912), TABLES (21504), VIEWS (10240). set autocommit = 0; use test; select distinct character_set_name from big_table where table_name = 'FILES'; delete from big_table where table_name = 'FILES'; select distinct character_set_name from big_table where table_name = 'FILES'; -- I'll issue the final rollback interactively, not via script, -- the better to control the timing. -- rollback;
Running this code gives this output, condensed for brevity and with the most important points bolded:
mysql: source concurrent_ddl_create.sql Database changed Query OK, 0 rows affected (1 min 25.15 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql: source concurrent_ddl_drop.sql Database changed Query OK, 0 rows affected (24.98 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql: source concurrent_dml.sql Query OK, 0 rows affected (0.00 sec) Database changed +--------------------+ | character_set_name | +--------------------+ | NULL | | utf8 | +--------------------+ 2 rows in set (0.32 sec) Query OK, 38912 rows affected (1.84 sec) Empty set (0.01 sec) mysql: rollback; Query OK, 0 rows affected (1.05 sec)
Example 14.4. Renaming a Column
Here is a demonstration of using ALTER
TABLE to rename a column. We use the new, fast DDL
mechanism to change the name, then the old, slow DDL mechanism
(with old_alter_table=1) to restore the
original column name.
Notes:
Because the syntax for renaming a column also involves re-specifying the data type, be very careful to specify exactly the same data type to avoid a costly table rebuild. In this case, we checked the output of
show create tableand copied any clauses such astable\GCHARACTER SETandNOT NULLfrom the original column definition.Again, renaming a column for a small table is fast enough that we need to examine the “rows affected” number to verify that the new DDL mechanism is more efficient than the old one. With a big table, the difference in elapsed time makes the improvement obvious.
/* Run through a sequence of 'rename column' statements. Because this operation involves only metadata, not table data, it is fast for big and small tables, with new or old DDL mechanisms. */ \! clear \! echo "Rename column (fast technique, small table):" set old_alter_table=0; alter table small_table change `IS_NULLABLE` `NULLABLE` varchar(3) character set utf8 not null; \! echo "Rename back to original name (slow technique):" set old_alter_table=1; alter table small_table change `NULLABLE` `IS_NULLABLE` varchar(3) character set utf8 not null; \! echo "Rename column (fast technique, big table):" set old_alter_table=0; alter table big_table change `IS_NULLABLE` `NULLABLE` varchar(3) character set utf8 not null; \! echo "Rename back to original name (slow technique):" set old_alter_table=1; alter table big_table change `NULLABLE` `IS_NULLABLE` varchar(3) character set utf8 not null; set old_alter_table=0;
Running this code gives this output, condensed for brevity and with the most important points bolded:
Rename column (fast technique, small table): Query OK, 0 rows affected (0.05 sec) Query OK, 0 rows affected (0.13 sec) Records: 0 Duplicates: 0 Warnings: 0 Rename back to original name (slow technique): Query OK, 0 rows affected (0.00 sec) Query OK, 1678 rows affected (0.35 sec) Records: 1678 Duplicates: 0 Warnings: 0 Rename column (fast technique, big table): Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.11 sec) Records: 0 Duplicates: 0 Warnings: 0 Rename back to original name (slow technique): Query OK, 0 rows affected (0.00 sec) Query OK, 1718272 rows affected (1 min 0.00 sec) Records: 1718272 Duplicates: 0 Warnings: 0 Query OK, 0 rows affected (0.00 sec)
Example 14.5. Dropping Foreign Keys
Here is a demonstration of foreign keys, including improvement to the speed of dropping a foreign key constraint.
/* Demonstrate aspects of foreign keys that are or aren't affected by the DDL improvements. - Create a new table with only a few values to serve as the parent table. - Set up the 'small' and 'big' tables as child tables using a foreign key. - Verify that the ON DELETE CASCADE clause makes changes ripple from parent to child tables. - Drop the foreign key constraints, and optionally associated indexes. (This is the operation that is sped up.) */ \! clear -- Make sure foreign keys are being enforced, and allow -- rollback after doing some DELETEs that affect both -- parent and child tables. set foreign_key_checks = 1; set autocommit = 0; -- Create a parent table, containing values that we know are already present -- in the child tables. drop table if exists schema_names; create table schema_names (id int unsigned not null primary key auto_increment, schema_name varchar(64) character set utf8 not null, index i_schema (schema_name)) as select distinct table_schema schema_name from small_table; show create table schema_names\G show create table small_table\G show create table big_table\G -- Creating the foreign key constraint still involves a table rebuild when foreign_key_checks=1, -- as illustrated by the "rows affected" figure. alter table small_table add constraint small_fk foreign key i_table_schema (table_schema) references schema_names(schema_name) on delete cascade; alter table big_table add constraint big_fk foreign key i_table_schema (table_schema) references schema_names(schema_name) on delete cascade; show create table small_table\G show create table big_table\G select schema_name from schema_names order by schema_name; select count(table_schema) howmany, table_schema from small_table group by table_schema; select count(table_schema) howmany, table_schema from big_table group by table_schema; -- big_table is the parent table. -- schema_names is the parent table. -- big_table is the child table. -- (One row in the parent table can have many "children" in the child table.) -- Changes to the parent table can ripple through to the child table. -- For example, removing the value 'test' from schema_names.schema_name will -- result in the removal of 20K or so rows from big_table. delete from schema_names where schema_name = 'test'; select schema_name from schema_names order by schema_name; select count(table_schema) howmany, table_schema from small_table group by table_schema; select count(table_schema) howmany, table_schema from big_table group by table_schema; -- Because we've turned off autocommit, we can still get back those deleted rows -- if the DELETE was issued by mistake. rollback; select schema_name from schema_names order by schema_name; select count(table_schema) howmany, table_schema from small_table group by table_schema; select count(table_schema) howmany, table_schema from big_table group by table_schema; -- All of the cross-checking between parent and child tables would be -- deadly slow if there wasn't the requirement for the corresponding -- columns to be indexed! -- But we can get rid of the foreign key using a fast operation -- that doesn't rebuild the table. -- If we didn't specify a constraint name when setting up the foreign key, we would -- have to find the auto-generated name such as 'big_table_ibfk_1' in the -- output from 'show create table'. -- For the small table, we'll drop the foreign key and the associated index. -- Having an index on a small table is less critical. \! echo "DROP FOREIGN KEY and INDEX from small_table:" alter table small_table drop foreign key small_fk, drop index small_fk; -- For the big table, we'll drop the foreign key and leave the associated index. -- If we are still doing queries that reference the indexed column, the index is -- very important to avoid a full table scan of the big table. \! echo "DROP FOREIGN KEY from big_table:" alter table big_table drop foreign key big_fk; show create table small_table\G show create table big_table\G
Running this code gives this output, condensed for brevity and with the most important points bolded:
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)
Query OK, 4 rows affected (0.03 sec)
Records: 4 Duplicates: 0 Warnings: 0
*************************** 1. row ***************************
Table: schema_names
Create Table: CREATE TABLE `schema_names` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`schema_name` varchar(64) CHARACTER SET utf8 NOT NULL,
PRIMARY KEY (`id`),
KEY `i_schema` (`schema_name`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
*************************** 1. row ***************************
Table: small_table
Create Table: CREATE TABLE `small_table` (
`TABLE_CATALOG` varchar(512) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_SCHEMA` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`ORDINAL_POSITION` bigint(21) unsigned NOT NULL DEFAULT '0',
`COLUMN_DEFAULT` longtext CHARACTER SET utf8,
`IS_NULLABLE` varchar(3) CHARACTER SET utf8 NOT NULL,
`DATA_TYPE` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`CHARACTER_MAXIMUM_LENGTH` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_OCTET_LENGTH` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_PRECISION` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_SCALE` bigint(21) unsigned DEFAULT NULL,
`DATETIME_PRECISION` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_SET_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLLATION_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLUMN_TYPE` longtext CHARACTER SET utf8 NOT NULL,
`COLUMN_KEY` varchar(3) CHARACTER SET utf8 NOT NULL DEFAULT '',
`EXTRA` varchar(30) CHARACTER SET utf8 NOT NULL DEFAULT '',
`PRIVILEGES` varchar(80) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_COMMENT` varchar(1024) CHARACTER SET utf8 NOT NULL DEFAULT '',
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1679 DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
*************************** 1. row ***************************
Table: big_table
Create Table: CREATE TABLE `big_table` (
`TABLE_CATALOG` varchar(512) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_SCHEMA` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`ORDINAL_POSITION` bigint(21) unsigned NOT NULL DEFAULT '0',
`COLUMN_DEFAULT` longtext CHARACTER SET utf8,
`IS_NULLABLE` varchar(3) CHARACTER SET utf8 NOT NULL,
`DATA_TYPE` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`CHARACTER_MAXIMUM_LENGTH` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_OCTET_LENGTH` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_PRECISION` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_SCALE` bigint(21) unsigned DEFAULT NULL,
`DATETIME_PRECISION` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_SET_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLLATION_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLUMN_TYPE` longtext CHARACTER SET utf8 NOT NULL,
`COLUMN_KEY` varchar(3) CHARACTER SET utf8 NOT NULL DEFAULT '',
`EXTRA` varchar(30) CHARACTER SET utf8 NOT NULL DEFAULT '',
`PRIVILEGES` varchar(80) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_COMMENT` varchar(1024) CHARACTER SET utf8 NOT NULL DEFAULT '',
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`),
KEY `big_fk` (`TABLE_SCHEMA`)
) ENGINE=InnoDB AUTO_INCREMENT=1718273 DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
Query OK, 1678 rows affected (0.10 sec)
Records: 1678 Duplicates: 0 Warnings: 0
Query OK, 1718272 rows affected (1 min 14.54 sec)
Records: 1718272 Duplicates: 0 Warnings: 0
*************************** 1. row ***************************
Table: small_table
Create Table: CREATE TABLE `small_table` (
`TABLE_CATALOG` varchar(512) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_SCHEMA` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`ORDINAL_POSITION` bigint(21) unsigned NOT NULL DEFAULT '0',
`COLUMN_DEFAULT` longtext CHARACTER SET utf8,
`IS_NULLABLE` varchar(3) CHARACTER SET utf8 NOT NULL,
`DATA_TYPE` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`CHARACTER_MAXIMUM_LENGTH` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_OCTET_LENGTH` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_PRECISION` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_SCALE` bigint(21) unsigned DEFAULT NULL,
`DATETIME_PRECISION` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_SET_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLLATION_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLUMN_TYPE` longtext CHARACTER SET utf8 NOT NULL,
`COLUMN_KEY` varchar(3) CHARACTER SET utf8 NOT NULL DEFAULT '',
`EXTRA` varchar(30) CHARACTER SET utf8 NOT NULL DEFAULT '',
`PRIVILEGES` varchar(80) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_COMMENT` varchar(1024) CHARACTER SET utf8 NOT NULL DEFAULT '',
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`),
KEY `small_fk` (`TABLE_SCHEMA`),
CONSTRAINT `small_fk` FOREIGN KEY (`TABLE_SCHEMA`) REFERENCES `schema_names` (`schema_name`) ON DELETE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=1679 DEFAULT CHARSET=latin1
1 row in set (0.12 sec)
*************************** 1. row ***************************
Table: big_table
Create Table: CREATE TABLE `big_table` (
`TABLE_CATALOG` varchar(512) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_SCHEMA` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`ORDINAL_POSITION` bigint(21) unsigned NOT NULL DEFAULT '0',
`COLUMN_DEFAULT` longtext CHARACTER SET utf8,
`IS_NULLABLE` varchar(3) CHARACTER SET utf8 NOT NULL,
`DATA_TYPE` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`CHARACTER_MAXIMUM_LENGTH` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_OCTET_LENGTH` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_PRECISION` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_SCALE` bigint(21) unsigned DEFAULT NULL,
`DATETIME_PRECISION` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_SET_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLLATION_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLUMN_TYPE` longtext CHARACTER SET utf8 NOT NULL,
`COLUMN_KEY` varchar(3) CHARACTER SET utf8 NOT NULL DEFAULT '',
`EXTRA` varchar(30) CHARACTER SET utf8 NOT NULL DEFAULT '',
`PRIVILEGES` varchar(80) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_COMMENT` varchar(1024) CHARACTER SET utf8 NOT NULL DEFAULT '',
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`),
KEY `big_fk` (`TABLE_SCHEMA`),
CONSTRAINT `big_fk` FOREIGN KEY (`TABLE_SCHEMA`) REFERENCES `schema_names` (`schema_name`) ON DELETE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=1718273 DEFAULT CHARSET=latin1
1 row in set (0.01 sec)
+--------------------+
| schema_name |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.00 sec)
+---------+--------------------+
| howmany | table_schema |
+---------+--------------------+
| 563 | information_schema |
| 286 | mysql |
| 786 | performance_schema |
| 43 | test |
+---------+--------------------+
4 rows in set (0.01 sec)
+---------+--------------------+
| howmany | table_schema |
+---------+--------------------+
| 576512 | information_schema |
| 292864 | mysql |
| 804864 | performance_schema |
| 44032 | test |
+---------+--------------------+
4 rows in set (2.10 sec)
Query OK, 1 row affected (1.52 sec)
+--------------------+
| schema_name |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
+--------------------+
3 rows in set (0.00 sec)
+---------+--------------------+
| howmany | table_schema |
+---------+--------------------+
| 563 | information_schema |
| 286 | mysql |
| 786 | performance_schema |
+---------+--------------------+
3 rows in set (0.00 sec)
+---------+--------------------+
| howmany | table_schema |
+---------+--------------------+
| 576512 | information_schema |
| 292864 | mysql |
| 804864 | performance_schema |
+---------+--------------------+
3 rows in set (1.74 sec)
Query OK, 0 rows affected (0.60 sec)
+--------------------+
| schema_name |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.00 sec)
+---------+--------------------+
| howmany | table_schema |
+---------+--------------------+
| 563 | information_schema |
| 286 | mysql |
| 786 | performance_schema |
| 43 | test |
+---------+--------------------+
4 rows in set (0.01 sec)
+---------+--------------------+
| howmany | table_schema |
+---------+--------------------+
| 576512 | information_schema |
| 292864 | mysql |
| 804864 | performance_schema |
| 44032 | test |
+---------+--------------------+
4 rows in set (1.59 sec)
DROP FOREIGN KEY and INDEX from small_table:
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
DROP FOREIGN KEY from big_table:
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
*************************** 1. row ***************************
Table: small_table
Create Table: CREATE TABLE `small_table` (
`TABLE_CATALOG` varchar(512) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_SCHEMA` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`ORDINAL_POSITION` bigint(21) unsigned NOT NULL DEFAULT '0',
`COLUMN_DEFAULT` longtext CHARACTER SET utf8,
`IS_NULLABLE` varchar(3) CHARACTER SET utf8 NOT NULL,
`DATA_TYPE` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`CHARACTER_MAXIMUM_LENGTH` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_OCTET_LENGTH` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_PRECISION` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_SCALE` bigint(21) unsigned DEFAULT NULL,
`DATETIME_PRECISION` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_SET_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLLATION_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLUMN_TYPE` longtext CHARACTER SET utf8 NOT NULL,
`COLUMN_KEY` varchar(3) CHARACTER SET utf8 NOT NULL DEFAULT '',
`EXTRA` varchar(30) CHARACTER SET utf8 NOT NULL DEFAULT '',
`PRIVILEGES` varchar(80) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_COMMENT` varchar(1024) CHARACTER SET utf8 NOT NULL DEFAULT '',
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1679 DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
*************************** 1. row ***************************
Table: big_table
Create Table: CREATE TABLE `big_table` (
`TABLE_CATALOG` varchar(512) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_SCHEMA` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`TABLE_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_NAME` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`ORDINAL_POSITION` bigint(21) unsigned NOT NULL DEFAULT '0',
`COLUMN_DEFAULT` longtext CHARACTER SET utf8,
`IS_NULLABLE` varchar(3) CHARACTER SET utf8 NOT NULL,
`DATA_TYPE` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '',
`CHARACTER_MAXIMUM_LENGTH` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_OCTET_LENGTH` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_PRECISION` bigint(21) unsigned DEFAULT NULL,
`NUMERIC_SCALE` bigint(21) unsigned DEFAULT NULL,
`DATETIME_PRECISION` bigint(21) unsigned DEFAULT NULL,
`CHARACTER_SET_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLLATION_NAME` varchar(32) CHARACTER SET utf8 DEFAULT NULL,
`COLUMN_TYPE` longtext CHARACTER SET utf8 NOT NULL,
`COLUMN_KEY` varchar(3) CHARACTER SET utf8 NOT NULL DEFAULT '',
`EXTRA` varchar(30) CHARACTER SET utf8 NOT NULL DEFAULT '',
`PRIVILEGES` varchar(80) CHARACTER SET utf8 NOT NULL DEFAULT '',
`COLUMN_COMMENT` varchar(1024) CHARACTER SET utf8 NOT NULL DEFAULT '',
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`),
KEY `big_fk` (`TABLE_SCHEMA`)
) ENGINE=InnoDB AUTO_INCREMENT=1718273 DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
Example 14.6. Changing Auto-Increment Value
Here is an illustration of increasing the
auto-increment lower
limit for a table column, demonstrating how this operation now
avoids a table rebuild, plus some other fun facts about
InnoDB auto-increment columns.
/*
If this script is run after foreign_key.sql, the schema_names table is
already set up. But to allow this script to run multiple times without
running into duplicate ID errors, we set up the schema_names table
all over again.
*/
\! clear
\! echo "=== Adjusting the Auto-Increment Limit for a Table ==="
\! echo
drop table if exists schema_names;
create table schema_names (id int unsigned not null primary key auto_increment, schema_name varchar(64) character set utf8 not null, index i_schema (schema_name)) as select distinct table_schema schema_name from small_table;
\! echo "Initial state of schema_names table. AUTO_INCREMENT is included in SHOW CREATE TABLE output."
\! echo "Note how MySQL reserved a block of IDs, but only needed 4 of them in this transaction, so the next inserted values would get IDs 8 and 9."
show create table schema_names\G
select * from schema_names order by id;
\! echo "Inserting even a tiny amount of data can produce gaps in the ID sequence."
insert into schema_names (schema_name) values ('eight'), ('nine');
set old_alter_table=0;
\! echo "Bumping auto-increment lower limit to 20 (fast mechanism):"
alter table schema_names auto_increment=20;
\! echo "Inserting 2 rows that should get IDs 20 and 21:"
insert into schema_names (schema_name) values ('foo'), ('bar');
commit;
set old_alter_table=1;
\! echo "Bumping auto-increment lower limit to 30 (slow mechanism):"
alter table schema_names auto_increment=30;
\! echo "Inserting 2 rows that should get IDs 30 and 31:"
insert into schema_names (schema_name) values ('bletch'),('baz');
commit;
select * from schema_names order by id;
set old_alter_table=0;
\! echo "Final state of schema_names table. AUTO_INCREMENT value shows the next inserted row would get ID=32."
show create table schema_names\GRunning this code gives this output, condensed for brevity and with the most important points bolded:
=== Adjusting the Auto-Increment Limit for a Table ===
Query OK, 0 rows affected (0.01 sec)
Query OK, 4 rows affected (0.02 sec)
Records: 4 Duplicates: 0 Warnings: 0
Initial state of schema_names table. AUTO_INCREMENT is included in SHOW CREATE TABLE output.
Note how MySQL reserved a block of IDs, but only needed 4 of them in this transaction, so the next inserted values would get IDs 8 and 9.
*************************** 1. row ***************************
Table: schema_names
Create Table: CREATE TABLE `schema_names` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`schema_name` varchar(64) CHARACTER SET utf8 NOT NULL,
PRIMARY KEY (`id`),
KEY `i_schema` (`schema_name`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
+----+--------------------+
| id | schema_name |
+----+--------------------+
| 1 | information_schema |
| 2 | mysql |
| 3 | performance_schema |
| 4 | test |
+----+--------------------+
4 rows in set (0.00 sec)
Inserting even a tiny amount of data can produce gaps in the ID sequence.
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Bumping auto-increment lower limit to 20 (fast mechanism):
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
Inserting 2 rows that should get IDs 20 and 21:
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Bumping auto-increment lower limit to 30 (slow mechanism):
Query OK, 8 rows affected (0.02 sec)
Records: 8 Duplicates: 0 Warnings: 0
Inserting 2 rows that should get IDs 30 and 31:
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.01 sec)
+----+--------------------+
| id | schema_name |
+----+--------------------+
| 1 | information_schema |
| 2 | mysql |
| 3 | performance_schema |
| 4 | test |
| 8 | eight |
| 9 | nine |
| 20 | foo |
| 21 | bar |
| 30 | bletch |
| 31 | baz |
+----+--------------------+
10 rows in set (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Final state of schema_names table. AUTO_INCREMENT value shows the next inserted row would get ID=32.
*************************** 1. row ***************************
Table: schema_names
Create Table: CREATE TABLE `schema_names` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`schema_name` varchar(64) CHARACTER SET utf8 NOT NULL,
PRIMARY KEY (`id`),
KEY `i_schema` (`schema_name`)
) ENGINE=InnoDB AUTO_INCREMENT=32 DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
Example 14.7. Controlling Concurrency with the LOCK Clause
This example shows how to use the LOCK clause
of the ALTER TABLE statement to
allow or deny concurrent access to the table while an online DDL
operation is in progress. The clause has settings that allow
queries and DML statements (LOCK=NONE), just
queries (LOCK=SHARED), or no concurrent
access at all (LOCK=EXCLUSIVE).
In one session, we run a succession of
ALTER TABLE statements to create
and drop an index, using different values for the
LOCK clause to see what happens with waiting
or deadlocking in either session. We are using the same
BIG_TABLE table as in previous examples,
starting with approximately 1.7 million rows. For illustration
purposes, we will index and query the
IS_NULLABLE column. (Although in real life it
would be silly to make an index for a tiny column with only 2
distinct values.)
mysql: desc big_table;
+--------------------------+---------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------------------+---------------------+------+-----+---------+----------------+
| TABLE_CATALOG | varchar(512) | NO | | | |
| TABLE_SCHEMA | varchar(64) | NO | | | |
| TABLE_NAME | varchar(64) | NO | | | |
| COLUMN_NAME | varchar(64) | NO | | | |
| ORDINAL_POSITION | bigint(21) unsigned | NO | | 0 | |
| COLUMN_DEFAULT | longtext | YES | | NULL | || IS_NULLABLE | varchar(3) | NO | | | |
...
+--------------------------+---------------------+------+-----+---------+----------------+
21 rows in set (0.14 sec)
mysql: alter table big_table add index i1(is_nullable);
Query OK, 0 rows affected (20.71 sec)
mysql: alter table big_table drop index i1;
Query OK, 0 rows affected (0.02 sec)
mysql: alter table big_table add index i1(is_nullable), lock=exclusive;
Query OK, 0 rows affected (19.44 sec)
mysql: alter table big_table drop index i1;
Query OK, 0 rows affected (0.03 sec)
mysql: alter table big_table add index i1(is_nullable), lock=shared;
Query OK, 0 rows affected (16.71 sec)
mysql: alter table big_table drop index i1;
Query OK, 0 rows affected (0.05 sec)
mysql: alter table big_table add index i1(is_nullable), lock=none;
Query OK, 0 rows affected (12.26 sec)
mysql: alter table big_table drop index i1;
Query OK, 0 rows affected (0.01 sec)
... repeat statements like the above while running queries ...
... and DML statements at the same time in another session ...
Nothing dramatic happens in the session running the DDL
statements. Sometimes, an ALTER
TABLE takes unusually long because it is waiting for
another transaction to finish, when that transaction modified
the table during the DDL or queried the table before the DDL:
mysql: alter table big_table add index i1(is_nullable), lock=none;Query OK, 0 rows affected (59.27 sec) mysql: -- The previous ALTER took so long because it was waiting for all the concurrent mysql: -- transactions to commit or roll back. mysql: alter table big_table drop index i1; Query OK, 0 rows affected (41.05 sec) mysql: -- Even doing a SELECT on the table in the other session first causes mysql: -- the ALTER TABLE above to stall until the transaction mysql: -- surrounding the SELECT is committed or rolled back.
Here is the log from another session running concurrently, where
we issue queries and DML statements against the table before,
during, and after the DDL operations shown in the previous
listings. This first listing shows queries only. We expect the
queries to be allowed during DDL operations using
LOCK=NONE or LOCK=SHARED,
and for the query to wait until the DDL is finished if the
ALTER TABLE statement includes
LOCK=EXCLUSIVE.
mysql: show variables like 'autocommit'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | autocommit | ON | +---------------+-------+ 1 row in set (0.01 sec) mysql: -- A trial query before any ADD INDEX in the other session: mysql: -- Note: because autocommit is enabled, each mysql: -- transaction finishes immediately after the query. mysql: select distinct is_nullable from big_table; +-------------+ | is_nullable | +-------------+ | NO | | YES | +-------------+ 2 rows in set (4.49 sec) mysql: -- Index is being created with LOCK=EXCLUSIVE on the ALTER statement. mysql: -- The query waits until the DDL is finished before proceeding. mysql: select distinct is_nullable from big_table; +-------------+ | is_nullable | +-------------+ | NO | | YES | +-------------+2 rows in set (17.26 sec) mysql: -- Index is being created with LOCK=SHARED on the ALTER statement. mysql: -- The query returns its results while the DDL is in progress. mysql: -- The same thing happens with LOCK=NONE on the ALTER statement. mysql: select distinct is_nullable from big_table; +-------------+ | is_nullable | +-------------+ | NO | | YES | +-------------+ 2 rows in set (3.11 sec) mysql: -- Once the index is created, and with no DDL in progress, mysql: -- queries referencing the indexed column are very fast: mysql: select count(*) from big_table where is_nullable = 'YES'; +----------+ | count(*) | +----------+ | 411648 | +----------+ 1 row in set (0.20 sec) mysql: select distinct is_nullable from big_table; +-------------+ | is_nullable | +-------------+ | NO | | YES | +-------------+ 2 rows in set (0.00 sec)
Now in this concurrent session, we run some transactions
including DML statements, or a combination of DML statements and
queries. We use DELETE statements
to illustrate predictable, verifiable changes to the table.
Because the transactions in this part can span multiple
statements, we run these tests with
autocommit turned off.
mysql: set global autocommit = off; Query OK, 0 rows affected (0.00 sec) mysql: -- Count the rows that will be involved in our DELETE statements: mysql: select count(*) from big_table where is_nullable = 'YES'; +----------+ | count(*) | +----------+ | 411648 | +----------+ 1 row in set (0.95 sec) mysql: -- After this point, any DDL statements back in the other session mysql: -- stall until we commit or roll back. mysql: delete from big_table where is_nullable = 'YES' limit 11648; Query OK, 11648 rows affected (0.14 sec) mysql: select count(*) from big_table where is_nullable = 'YES'; +----------+ | count(*) | +----------+ | 400000 | +----------+ 1 row in set (1.04 sec) mysql: rollback; Query OK, 0 rows affected (0.09 sec) mysql: select count(*) from big_table where is_nullable = 'YES'; +----------+ | count(*) | +----------+ | 411648 | +----------+ 1 row in set (0.93 sec) mysql: -- OK, now we're going to try that during index creation with LOCK=NONE. mysql: delete from big_table where is_nullable = 'YES' limit 11648; Query OK, 11648 rows affected (0.21 sec) mysql: -- We expect that now there will be 400000 'YES' rows left: mysql: select count(*) from big_table where is_nullable = 'YES'; +----------+ | count(*) | +----------+ | 400000 | +----------+ 1 row in set (1.25 sec) mysql: -- In the other session, the ALTER TABLE is waiting before finishing, mysql: -- because _this_ transaction hasn't committed or rolled back yet. mysql: rollback; Query OK, 0 rows affected (0.11 sec) mysql: select count(*) from big_table where is_nullable = 'YES'; +----------+ | count(*) | +----------+ | 411648 | +----------+ 1 row in set (0.19 sec) mysql: -- The ROLLBACK left the table in the same state we originally found it. mysql: -- Now let's make a permanent change while the index is being created, mysql: -- again with ALTER TABLE ... , LOCK=NONE. mysql: -- First, commit so the DROP INDEX in the other shell can finish; mysql: -- the previous SELECT started a transaction that accessed the table. mysql: commit; Query OK, 0 rows affected (0.00 sec) mysql: -- Now we add the index back in the other shell, then issue DML in this one mysql: -- while the DDL is running. mysql: delete from big_table where is_nullable = 'YES' limit 11648; Query OK, 11648 rows affected (0.23 sec) mysql: commit; Query OK, 0 rows affected (0.01 sec) mysql: -- In the other shell, the ADD INDEX has finished. mysql: select count(*) from big_table where is_nullable = 'YES'; +----------+ | count(*) | +----------+ | 400000 | +----------+ 1 row in set (0.19 sec) mysql: -- At the point the new index is finished being created, it contains entries mysql: -- only for the 400000 'YES' rows left when all concurrent transactions are finished. mysql: mysql: -- Now we will run a similar test, while ALTER TABLE ... , LOCK=SHARED is running. mysql: -- We expect a query to complete during the ALTER TABLE, but for the DELETE mysql: -- to run into some kind of issue. mysql: commit; Query OK, 0 rows affected (0.00 sec) mysql: -- As expected, the query returns results while the LOCK=SHARED DDL is running: mysql: select count(*) from big_table where is_nullable = 'YES'; +----------+ | count(*) | +----------+ | 400000 | +----------+ 1 row in set (2.07 sec) mysql: -- The DDL in the other session is not going to finish until this transaction mysql: -- is committed or rolled back. If we tried a DELETE now and it waited because mysql: -- of LOCK=SHARED on the DDL, both transactions would wait forever (deadlock). mysql: -- MySQL detects this condition and cancels the attempted DML statement. mysql: delete from big_table where is_nullable = 'YES' limit 100000; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction mysql: -- The transaction here is still going, so in the other shell, the ADD INDEX operation mysql: -- is waiting for this transaction to commit or roll back. mysql: rollback; Query OK, 0 rows affected (0.00 sec) mysql: -- Now let's try issuing a query and some DML, on one line, while running mysql: -- ALTER TABLE ... , LOCK=EXCLUSIVE in the other shell. mysql: -- Notice how even the query is held up until the DDL is finished. mysql: -- By the time the DELETE is issued, there is no conflicting access mysql: -- to the table and we avoid the deadlock error. mysql: select count(*) from big_table where is_nullable = 'YES'; delete from big_table where is_nullable = 'YES' limit 100000; +----------+ | count(*) | +----------+ | 400000 | +----------+1 row in set (15.98 sec) Query OK, 100000 rows affected (2.81 sec) mysql: select count(*) from big_table where is_nullable = 'YES'; +----------+ | count(*) | +----------+ | 300000 | +----------+ 1 row in set (0.17 sec) mysql: rollback; Query OK, 0 rows affected (1.36 sec) mysql: select count(*) from big_table where is_nullable = 'YES'; +----------+ | count(*) | +----------+ | 400000 | +----------+ 1 row in set (0.19 sec) mysql: commit; Query OK, 0 rows affected (0.00 sec) mysql: -- Next, we try ALTER TABLE ... , LOCK=EXCLUSIVE in the other session mysql: -- and only issue DML, not any query, in the concurrent transaction here. mysql: delete from big_table where is_nullable = 'YES' limit 100000; Query OK, 100000 rows affected (16.37 sec) mysql: -- That was OK because the ALTER TABLE did not have to wait for the transaction mysql: -- here to complete. The DELETE in this session waited until the index was ready. mysql: select count(*) from big_table where is_nullable = 'YES'; +----------+ | count(*) | +----------+ | 300000 | +----------+ 1 row in set (0.16 sec) mysql: commit; Query OK, 0 rows affected (0.00 sec)
In the preceding example listings, we learned that:
The
LOCKclause forALTER TABLEis set off from the rest of the statement by a comma.Online DDL operations might wait before starting, until any prior transactions that access the table are committed or rolled back.
Online DDL operations might wait before completing, until any concurrent transactions that access the table are committed or rolled back.
While an online DDL operation is running, concurrent queries are relatively straightforward, as long as the
ALTER TABLEstatement usesLOCK=NONEorLOCK=SHARED.Pay attention to whether
autocommitis turned on or off. If it is turned off, be careful to end transactions in other sessions (even just queries) before performing DDL operations on the table.With
LOCK=SHARED, concurrent transactions that mix queries and DML could encounter deadlock errors and have to be restarted after the DDL is finished.With
LOCK=NONE, concurrent transactions can freely mix queries and DML. The DDL operation waits until the concurrent transactions are committed or rolled back.With
LOCK=NONE, concurrent transactions can freely mix queries and DML, but those transactions wait until the DDL operation is finished before they can access the table.
InnoDB has two types of indexes: the clustered index and secondary indexes. Since the clustered index contains the data values in its B-tree nodes, adding or dropping a clustered index does involve copying the data, and creating a new copy of the table. A secondary index, however, contains only the index key and the value of the primary key. This type of index can be created or dropped without copying the data in the clustered index. Because each secondary index contains copies of the primary key values (used to access the clustered index when needed), when you change the definition of the primary key, all secondary indexes are recreated as well.
Dropping a secondary index is simple. Only the internal InnoDB system tables and the MySQL data dictionary tables are updated to reflect the fact that the index no longer exists. InnoDB returns the storage used for the index to the tablespace that contained it, so that new indexes or additional table rows can use the space.
To add a secondary index to an existing table, InnoDB scans the table, and sorts the rows using memory buffers and temporary files in order by the values of the secondary index key columns. The B-tree is then built in key-value order, which is more efficient than inserting rows into an index in random order. Because the B-tree nodes are split when they fill, building the index in this way results in a higher fill-factor for the index, making it more efficient for subsequent access.
Background Information
Historically, the MySQL server and InnoDB have
each kept their own metadata about table and index structures. The
MySQL server stores this information in
.frm files that are not
protected by a transactional mechanism, while
InnoDB has its own
data dictionary as
part of the system
tablespace. If a DDL operation was interrupted by a crash
or other unexpected event partway through, the metadata could be
left inconsistent between these two locations, causing problems
such as startup errors or inability to access the table that was
being altered. Now that InnoDB is the default
storage engine, addressing such issues is a high priority. These
enhancements to DDL operations reduce the window of opportunity
for such issues to occur.
Although no data is lost if the server crashes while an
ALTER TABLE statement is executing,
the crash recovery
process is different for
clustered indexes and
secondary indexes.
If the server crashes while creating an InnoDB secondary index,
upon recovery, MySQL drops any partially created indexes. You must
re-run the ALTER TABLE or
CREATE INDEX statement.
When a crash occurs during the creation of an InnoDB clustered index, recovery is more complicated, because the data in the table must be copied to an entirely new clustered index. Remember that all InnoDB tables are stored as clustered indexes. In the following discussion, we use the word table and clustered index interchangeably.
MySQL creates the new clustered index by copying the existing data from the original InnoDB table to a temporary table that has the desired index structure. Once the data is completely copied to this temporary table, the original table is renamed with a different temporary table name. The temporary table comprising the new clustered index is renamed with the name of the original table, and the original table is dropped from the database.
If a system crash occurs while creating a new clustered index, no data is lost, but you must complete the recovery process using the temporary tables that exist during the process. Since it is rare to re-create a clustered index or re-define primary keys on large tables, or to encounter a system crash during this operation, this manual does not provide information on recovering from this scenario. Instead, please see the InnoDB web site: http://www.innodb.com/support/tips.
Take the following considerations into account when creating or dropping InnoDB indexes:
During an online DDL operation that copies the table, files are written to the temporary directory (
$TMPDIRon Unix,%TEMP%on Windows, or the directory specified by the--tmpdirconfiguration variable). Each temporary file is large enough to hold one column in the new table or index, and each one is removed as soon as it is merged into the final table or index.The table is copied, rather than using Fast Index Creation when you create an index on a
TEMPORARY TABLE. This has been reported as MySQL Bug #39833.InnoDB handles error cases when users attempt to drop indexes needed for foreign keys. See section Section 14.2.6.9, “Better Error Handling when Dropping Indexes” for details.
The
ALTER TABLEclauseLOCK=NONEis not allowed if there areON...CASCADEorON...SET NULLconstraints on the table.During each online DDL
ALTER TABLEstatement, regardless of theLOCKclause, there are brief periods at the beginning and end requiring an exclusive lock on the table (the same kind of lock specified by theLOCK=EXCLUSIVEclause). Thus, an online DDL operation might wait before starting if there is a long-running transaction performing inserts, updates, deletes, orSELECT ... FOR UPDATEon that table; and an online DDL operation might wait before finishing if a similar long-running transaction was started while theALTER TABLEwas in progress.
By setting InnoDB configuration options, you can create tables where the data is stored in compressed form. The compression means less data is transferred between disk and memory, and takes up less space in memory. The benefits are amplified for tables with secondary indexes, because index data is compressed also. Compression can be especially important for SSD storage devices, because they tend to have lower capacity than HDD devices.
Because processors and cache memories have increased in speed more than disk storage devices, many workloads are I/O-bound. Data compression enables smaller database size, reduced I/O, and improved throughput, at the small cost of increased CPU utilization. Compression is especially valuable for read-intensive applications, on systems with enough RAM to keep frequently-used data in memory.
An InnoDB table created with
ROW_FORMAT=COMPRESSED can use a smaller
page size on disk than the
usual 16KB default. Smaller pages require less I/O to read from
and write to disk, which is especially valuable for
SSD devices.
The page size is specified through the
KEY_BLOCK_SIZE parameter. The different page
size means the table must be in its own .ibd
file rather than the system tablespace, which requires enabling
the innodb_file_per_table option. The level of
compression is the same regardless of the
KEY_BLOCK_SIZE value. As you specify smaller
values for KEY_BLOCK_SIZE, you get the I/O
benefits of increasingly smaller pages. But if you specify a value
that is too small, there is additional overhead to reorganize the
pages when data values cannot be compressed enough to fit multiple
rows in each page. There is a hard limit on how small
KEY_BLOCK_SIZE can be for a table, based on the
lengths of the key columns for each of its indexes. Specify a
value that is too small, and the CREATE
TABLE or ALTER TABLE
statement fails.
In the buffer pool, the compressed data is held in small pages,
with a page size based on the KEY_BLOCK_SIZE
value. For extracting or updating the column values, InnoDB also
creates a 16KB page in the buffer pool with the uncompressed data.
Within the buffer pool, any updates to the uncompressed page are
also re-written back to the equivalent compressed page. You might
need to size your buffer pool to accommodate the additional data
of both compressed and uncompressed pages, although the
uncompressed pages are
evicted from the buffer pool
when space is needed, and then uncompressed again on the next
access.
The default uncompressed size of InnoDB data pages is 16KB. You
can use the attributes ROW_FORMAT=COMPRESSED,
KEY_BLOCK_SIZE, or both in the
CREATE TABLE and
ALTER TABLE statements to enable
table compression. Depending on the combination of option values,
InnoDB uses a page size of 1KB, 2KB, 4KB, 8KB, or 16KB for the
.ibd file of the table. (The actual compression
algorithm is not affected by the KEY_BLOCK_SIZE
value.)
Compression is applicable to tables, not to individual rows,
despite the option name ROW_FORMAT.
To create a compressed table, you might use a statement like this:
CREATE TABLEname(column1 INT PRIMARY KEY) ENGINE=InnoDB ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=4;
If you specify ROW_FORMAT=COMPRESSED but not
KEY_BLOCK_SIZE, the default compressed page
size of 8KB is used. If KEY_BLOCK_SIZE is
specified, you can omit the attribute
ROW_FORMAT=COMPRESSED.
Setting KEY_BLOCK_SIZE=16 typically does not
result in much compression, since the normal InnoDB page size is
16KB. This setting may still be useful for tables with many long
BLOB, VARCHAR or
TEXT columns, because such values often do
compress well, and might therefore require fewer
“overflow” pages as described in
Section 14.2.2.7.4, “
Compressing BLOB, VARCHAR and TEXT Columns
”.
All indexes of a table (including the clustered index) are
compressed using the same page size, as specified in the
CREATE TABLE or
ALTER TABLE statement. Table
attributes such as ROW_FORMAT and
KEY_BLOCK_SIZE are not part of the
CREATE INDEX syntax, and are
ignored if they are specified (although you see them in the output
of the SHOW CREATE TABLE statement).
Compressed tables are stored in a format that previous versions
of InnoDB cannot process. To preserve downward compatibility of
database files, compression can be specified only when the
Barracuda data file format
is enabled using the configuration parameter
innodb_file_format.
Table compression is also not available for the InnoDB system
tablespace. The system tablespace (space 0, the
ibdata* files) may contain user data, but it
also contains internal InnoDB system information, and therefore
is never compressed. Thus, compression applies only to tables
(and indexes) stored in their own tablespaces.
To use compression, enable the
file-per-table
mode using the configuration parameter
innodb_file_per_table and
enable the Barracuda disk file format using the parameter
innodb_file_format. If
necessary, you can set these parameters in the MySQL option file
my.cnf or my.ini, or with
the SET statement without shutting down the
MySQL server.
Specifying ROW_FORMAT=COMPRESSED or
KEY_BLOCK_SIZE in CREATE
TABLE or ALTER TABLE
statements produces these warnings if the Barracuda file format
is not enabled. You can view them with the SHOW
WARNINGS statement.
| Level | Code | Message |
|---|---|---|
| Warning | 1478 | InnoDB: KEY_BLOCK_SIZE requires
innodb_file_per_table. |
| Warning | 1478 | InnoDB: KEY_BLOCK_SIZE requires innodb_file_format=1 |
| Warning | 1478 | InnoDB: ignoring
KEY_BLOCK_SIZE= |
| Warning | 1478 | InnoDB: ROW_FORMAT=COMPRESSED requires
innodb_file_per_table. |
| Warning | 1478 | InnoDB: assuming ROW_FORMAT=COMPACT. |
These messages are only warnings, not errors, and the table is
created as if the options were not specified. When InnoDB
“strict mode” (see
Section 14.2.6.7, “InnoDB Strict Mode”) is
enabled, InnoDB generates an error, not a warning, for these
cases. In strict mode, the table is not created if the current
configuration does not permit using compressed tables.
The “non-strict” behavior is intended to permit you
to import a mysqldump file into a database
that does not support compressed tables, even if the source
database contained compressed tables. In that case, MySQL
creates the table in ROW_FORMAT=COMPACT
instead of preventing the operation.
When you import the dump file into a new database, if you want
to have the tables re-created as they exist in the original
database, ensure the server has the proper settings for the
configuration parameters
innodb_file_format and
innodb_file_per_table,
The attribute KEY_BLOCK_SIZE is permitted
only when ROW_FORMAT is specified as
COMPRESSED or is omitted. Specifying a
KEY_BLOCK_SIZE with any other
ROW_FORMAT generates a warning that you can
view with SHOW WARNINGS. However, the table
is non-compressed; the specified
KEY_BLOCK_SIZE is ignored).
| Level | Code | Message |
|---|---|---|
| Warning | 1478 | InnoDB: ignoring KEY_BLOCK_SIZE= |
If you are running in InnoDB strict mode, the combination of a
KEY_BLOCK_SIZE with any
ROW_FORMAT other than
COMPRESSED generates an error, not a warning,
and the table is not created.
Table 14.4, “Meaning of CREATE TABLE and
ALTER TABLE options”
summarizes how the various options on
CREATE TABLE and
ALTER TABLE are handled.
Table 14.4. Meaning of CREATE TABLE and
ALTER TABLE options
| Option | Usage | Description |
|---|---|---|
ROW_FORMAT=REDUNDANT | Storage format used prior to MySQL 5.0.3 | Less efficient than ROW_FORMAT=COMPACT; for backward
compatibility |
ROW_FORMAT=COMPACT | Default storage format since MySQL 5.0.3 | Stores a prefix of 768 bytes of long column values in the clustered index page, with the remaining bytes stored in an overflow page |
ROW_FORMAT=DYNAMIC | Available only with
innodb_file_format=Barracuda | Store values within the clustered index page if they fit; if not, stores only a 20-byte pointer to an overflow page (no prefix) |
ROW_FORMAT=COMPRESSED | Available only with
innodb_file_format=Barracuda | Compresses the table and indexes using zlib to default compressed page
size of 8K bytes; implies
ROW_FORMAT=DYNAMIC |
KEY_BLOCK_SIZE= | Available only with
innodb_file_format=Barracuda | Specifies compressed page size of 1, 2, 4, 8 or 16K bytes; implies
ROW_FORMAT=DYNAMIC and
ROW_FORMAT=COMPRESSED |
Table 14.5, “CREATE/ALTER TABLE Warnings and Errors when InnoDB
Strict Mode is OFF”
summarizes error conditions that occur with certain combinations
of configuration parameters and options on the
CREATE TABLE or
ALTER TABLE statements, and how
the options appear in the output of SHOW TABLE
STATUS.
When InnoDB strict mode is OFF, InnoDB
creates or alters the table, but may ignore certain settings, as
shown below. You can see the warning messages in the MySQL error
log. When InnoDB strict mode is ON, these
specified combinations of options generate errors, and the table
is not created or altered. You can see the full description of
the error condition with SHOW ERRORS. For
example:
mysql>CREATE TABLE x (id INT PRIMARY KEY, c INT)->ENGINE=INNODB KEY_BLOCK_SIZE=33333;ERROR 1005 (HY000): Can't create table 'test.x' (errno: 1478) mysql>SHOW ERRORS;+-------+------+-------------------------------------------+ | Level | Code | Message | +-------+------+-------------------------------------------+ | Error | 1478 | InnoDB: invalid KEY_BLOCK_SIZE=33333. | | Error | 1005 | Can't create table 'test.x' (errno: 1478) | +-------+------+-------------------------------------------+ 2 rows in set (0.00 sec)
Table 14.5. CREATE/ALTER TABLE Warnings and Errors when InnoDB
Strict Mode is OFF
| Syntax | Warning or Error Condition | Resulting ROW_FORMAT, as shown in SHOW TABLE
STATUS |
|---|---|---|
ROW_FORMAT=REDUNDANT | None | REDUNDANT |
ROW_FORMAT=COMPACT | None | COMPACT |
ROW_FORMAT=COMPRESSED or
ROW_FORMAT=DYNAMIC or
KEY_BLOCK_SIZE is specified | Ignored unless both
innodb_file_format=Barracuda
and
innodb_file_per_table
are enabled | COMPACT |
Invalid KEY_BLOCK_SIZE is specified (not 1, 2, 4, 8
or 16) | KEY_BLOCK_SIZE is ignored | the requested one, or COMPACT by default |
ROW_FORMAT=COMPRESSED and valid
KEY_BLOCK_SIZE are specified | None; KEY_BLOCK_SIZE specified is used, not the 8K
default | COMPRESSED |
KEY_BLOCK_SIZE is specified with
REDUNDANT, COMPACT
or DYNAMIC row format | KEY_BLOCK_SIZE is ignored | REDUNDANT, COMPACT or
DYNAMIC |
ROW_FORMAT is not one of
REDUNDANT,
COMPACT, DYNAMIC
or COMPRESSED | Ignored if recognized by the MySQL parser. Otherwise, an error is issued. | COMPACT or N/A |
When InnoDB strict mode is ON
(innodb_strict_mode=1), InnoDB rejects
invalid ROW_FORMAT or
KEY_BLOCK_SIZE parameters. For compatibility
with earlier versions of InnoDB, strict mode is not enabled by
default; instead, InnoDB issues warnings (not errors) for
ignored invalid parameters.
Note that it is not possible to see the chosen
KEY_BLOCK_SIZE using SHOW TABLE
STATUS. The statement SHOW CREATE
TABLE displays the KEY_BLOCK_SIZE
(even if it was ignored by InnoDB). The real compressed page
size inside InnoDB cannot be displayed by MySQL.
Most often, the internal optimizations in InnoDB described in Section 14.2.2.7.4, “ InnoDB Data Storage and Compression ” ensure that the system runs well with compressed data. However, because the efficiency of compression depends on the nature of your data, there are some factors you should consider to get best performance. You need to choose which tables to compress, and what compressed page size to use. You might also adjust the size of the buffer pool based on run-time performance characteristics, such as the amount of time the system spends compressing and uncompressing data.
When to Use Compression
In general, compression works best on tables that include a reasonable number of character string columns and where the data is read far more often than it is written. Because there are no guaranteed ways to predict whether or not compression benefits a particular situation, always test with a specific workload and data set running on a representative configuration. Consider the following factors when deciding which tables to compress.
Data Characteristics and Compression
A key determinant of the efficiency of compression in reducing the
size of data files is the nature of the data itself. Recall that
compression works by identifying repeated strings of bytes in a
block of data. Completely randomized data is the worst case.
Typical data often has repeated values, and so compresses
effectively. Character strings often compress well, whether
defined in CHAR, VARCHAR,
TEXT or BLOB columns. On the
other hand, tables containing mostly binary data (integers or
floating point numbers) or data that is previously compressed (for
example JPEG or PNG images)
may not generally compress well, significantly or at all.
You choose whether to turn on compression for each InnoDB tables.
A table and all of its indexes use the same (compressed) page
size. It might be that the primary key (clustered) index, which
contains the data for all columns of a table, compresses more
effectively than the secondary indexes. For those cases where
there are long rows, the use of compression might result in long
column values being stored “off-page”, as discussed
in Section 14.2.2.9.3, “DYNAMIC and COMPRESSED Row Formats”. Those overflow
pages may compress well. Given these considerations, for many
applications, some tables compress more effectively than others,
and you might find that your workload performs best only with a
subset of tables compressed.
Experimenting is the only way to determine whether or not to
compress a particular table. InnoDB compresses data in 16K chunks
corresponding to the uncompressed page size, and in addition to
user data, the page format includes some internal system data that
is not compressed. Compression utilities compress an entire stream
of data, and so may find more repeated strings across the entire
input stream than InnoDB would find in a table compressed in 16K
chunks. But you can get a sense of how compression efficiency by
using a utility that implements LZ77 compression (such as
gzip or WinZip) on your data file.
Another way to test compression on a specific table is to copy
some data from your uncompressed table to a similar, compressed
table (having all the same indexes) and look at the size of the
resulting file. When you do so (if nothing else using compression
is running), you can examine the ratio of successful compression
operations to overall compression operations. (In the
INNODB_CMP table, compare
COMPRESS_OPS to
COMPRESS_OPS_OK. See
INNODB_CMP
for more information.) If a high percentage of compression
operations complete successfully, the table might be a good
candidate for compression.
Compression and Application and Schema Design
Decide whether to compress data in your application or in the InnoDB table. It is usually not sensible to store data that is compressed by an application in an InnoDB compressed table. Further compression is extremely unlikely, and the attempt to compress just wastes CPU cycles.
Compressing in the Database
The InnoDB table compression is automatic and applies to all
columns and index values. The columns can still be tested with
operators such as LIKE, and sort operations can
still use indexes even when the index values are compressed.
Because indexes are often a significant fraction of the total size
of a database, compression could result in significant savings in
storage, I/O or processor time. The compression and decompression
operations happen on the database server, which likely is a
powerful system that is sized to handle the expected load.
Compressing in the Application
If you compress data such as text in your application, before it is inserted into the database, You might save overhead for data that does not compress well by compressing some columns and not others. This approach uses CPU cycles for compression and uncompression on the client machine rather than the database server, which might be appropriate for a distributed application with many clients, or where the client machine has spare CPU cycles.
Hybrid Approach
Of course, it is possible to combine these approaches. For some applications, it may be appropriate to use some compressed tables and some uncompressed tables. It may be best to externally compress some data (and store it in uncompressed InnoDB tables) and allow InnoDB to compress (some of) the other tables in the application. As always, up-front design and real-life testing are valuable in reaching the right decision.
Workload Characteristics and Compression
In addition to choosing which tables to compress (and the page
size), the workload is another key determinant of performance. If
the application is dominated by reads, rather than updates, fewer
pages need to be reorganized and recompressed after the index page
runs out of room for the per-page “modification log”
that InnoDB maintains for compressed data. If the updates
predominantly change non-indexed columns or those containing
BLOBs or large strings that happen to be stored
“off-page”, the overhead of compression may be
acceptable. If the only changes to a table are
INSERTs that use a monotonically increasing
primary key, and there are few secondary indexes, there is little
need to reorganize and recompress index pages. Since InnoDB can
“delete-mark” and delete rows on compressed pages
“in place” by modifying uncompressed data,
DELETE operations on a table are relatively
efficient.
For some environments, the time it takes to load data can be as important as run-time retrieval. Especially in data warehouse environments, many tables may be read-only or read-mostly. In those cases, it might or might not be acceptable to pay the price of compression in terms of increased load time, unless the resulting savings in fewer disk reads or in storage cost is significant.
Fundamentally, compression works best when the CPU time is available for compressing and uncompressing data. Thus, if your workload is I/O bound, rather than CPU-bound, you might find that compression can improve overall performance. When you test your application performance with different compression configurations, test on a platform similar to the planned configuration of the production system.
Configuration Characteristics and Compression
Reading and writing database pages from and to disk is the slowest aspect of system performance. Compression attempts to reduce I/O by using CPU time to compress and uncompress data, and is most effective when I/O is a relatively scarce resource compared to processor cycles.
This is often especially the case when running in a multi-user environment with fast, multi-core CPUs. When a page of a compressed table is in memory, InnoDB often uses an additional 16K in the buffer pool for an uncompressed copy of the page. The adaptive LRU algorithm attempts to balance the use of memory between compressed and uncompressed pages to take into account whether the workload is running in an I/O-bound or CPU-bound manner. Still, a configuration with more memory dedicated to the InnoDB buffer pool tends to run better when using compressed tables than a configuration where memory is highly constrained.
Choosing the Compressed Page Size
The optimal setting of the compressed page size depends on the type and distribution of data that the table and its indexes contain. The compressed page size should always be bigger than the maximum record size, or operations may fail as noted in Section 14.2.2.7.4, “ Compression of B-Tree Pages ”.
Setting the compressed page size too large wastes some space, but the pages do not have to be compressed as often. If the compressed page size is set too small, inserts or updates may require time-consuming recompression, and the B-tree nodes may have to be split more frequently, leading to bigger data files and less efficient indexing.
Typically, you set the compressed page size to 8K or 4K bytes.
Given that the maximum InnoDB record size is around 8K,
KEY_BLOCK_SIZE=8 is usually a safe choice.
Monitoring Compression at Runtime
Overall application performance, CPU and I/O utilization and the size of disk files are good indicators of how effective compression is for your application.
To dig deeper into performance considerations for compressed tables, you can monitor compression performance at run time. using the Information Schema tables described in Example 14.9, “Using the Compression Information Schema Tables”. These tables reflect the internal use of memory and the rates of compression used overall.
The INNODB_CMP tables report information about
compression activity for each compressed page size
(KEY_BLOCK_SIZE) in use. The information in
these tables is system-wide, and includes summary data across all
compressed tables in your database. You can use this data to help
decide whether or not to compress a table by examining these
tables when no other compressed tables are being accessed.
The key statistics to consider are the number of, and amount of
time spent performing, compression and uncompression operations.
Since InnoDB must split B-tree nodes when they are too full to
contain the compressed data following a modification, compare the
number of “successful” compression operations with
the number of such operations overall. Based on the information in
the INNODB_CMP tables and overall application
performance and hardware resource utilization, you might make
changes in your hardware configuration, adjust the size of the
InnoDB buffer pool, choose a different page size, or select a
different set of tables to compress.
If the amount of CPU time required for compressing and uncompressing is high, changing to faster CPUs, or those with more cores, can help improve performance with the same data, application workload and set of compressed tables. Increasing the size of the InnoDB buffer pool might also help performance, so that more uncompressed pages can stay in memory, reducing the need to uncompress pages that exist in memory only in compressed form.
A large number of compression operations overall (compared to the
number of INSERT, UPDATE and
DELETE operations in your application and the
size of the database) could indicate that some of your compressed
tables are being updated too heavily for effective compression. If
so, choose a larger page size, or be more selective about which
tables you compress.
If the number of “successful” compression operations
(COMPRESS_OPS_OK) is a high percentage of the
total number of compression operations
(COMPRESS_OPS), then the system is likely
performing well. If the ratio is low, then InnoDB is reorganizing,
recompressing, and splitting B-tree nodes more often than is
desirable. In this case, avoid compressing some tables, or
increase KEY_BLOCK_SIZE for some of the
compressed tables. You might turn off compression for tables that
cause the number of “compression failures” in your
application to be more than 1% or 2% of the total. (Such a failure
ratio might be acceptable during a temporary operation such as a
data load).
This section describes some internal implementation details about compression in InnoDB. The information presented here may be helpful in tuning for performance, but is not necessary to know for basic use of compression.
Compression Algorithms
Some operating systems implement compression at the file system level. Files are typically divided into fixed-size blocks that are compressed into variable-size blocks, which easily leads into fragmentation. Every time something inside a block is modified, the whole block is recompressed before it is written to disk. These properties make this compression technique unsuitable for use in an update-intensive database system.
InnoDB implements compression with the help of the well-known zlib library, which implements the LZ77 compression algorithm. This compression algorithm is mature, robust, and efficient in both CPU utilization and in reduction of data size. The algorithm is “lossless”, so that the original uncompressed data can always be reconstructed from the compressed form. LZ77 compression works by finding sequences of data that are repeated within the data to be compressed. The patterns of values in your data determine how well it compresses, but typical user data often compresses by 50% or more.
Unlike compression performed by an application, or compression
features of some other database management systems, InnoDB
compression applies both to user data and to indexes. In many
cases, indexes can constitute 40-50% or more of the total database
size, so this difference is significant. When compression is
working well for a data set, the size of the InnoDB data files
(the .idb files) is 25% to 50% of the
uncompressed size or possibly smaller. Depending on the workload,
this smaller database can in turn lead to a reduction in I/O, and
an increase in throughput, at a modest cost in terms of increased
CPU utilization.
InnoDB Data Storage and Compression
All user data in InnoDB is stored in pages comprising a B-tree index (the clustered index). In some other database systems, this type of index is called an “index-organized table”. Each row in the index node contains the values of the (user-specified or system-generated) primary key and all the other columns of the table.
Secondary indexes in InnoDB are also B-trees, containing pairs of values: the index key and a pointer to a row in the clustered index. The pointer is in fact the value of the primary key of the table, which is used to access the clustered index if columns other than the index key and primary key are required. Secondary index records must always fit on a single B-tree page.
The compression of B-tree nodes (of both clustered and secondary
indexes) is handled differently from compression of overflow pages
used to store long VARCHAR,
BLOB, or TEXT columns, as
explained in the following sections.
Compression of B-Tree Pages
Because they are frequently updated, B-tree pages require special treatment. It is important to minimize the number of times B-tree nodes are split, as well as to minimize the need to uncompress and recompress their content.
One technique InnoDB uses is to maintain some system information in the B-tree node in uncompressed form, thus facilitating certain in-place updates. For example, this allows rows to be delete-marked and deleted without any compression operation.
In addition, InnoDB attempts to avoid unnecessary uncompression and recompression of index pages when they are changed. Within each B-tree page, the system keeps an uncompressed “modification log” to record changes made to the page. Updates and inserts of small records may be written to this modification log without requiring the entire page to be completely reconstructed.
When the space for the modification log runs out, InnoDB uncompresses the page, applies the changes and recompresses the page. If recompression fails, the B-tree nodes are split and the process is repeated until the update or insert succeeds.
Generally, InnoDB requires that each B-tree page can accommodate
at least two records. For compressed tables, this requirement has
been relaxed. Leaf pages of B-tree nodes (whether of the primary
key or secondary indexes) only need to accommodate one record, but
that record must fit in uncompressed form, in the per-page
modification log. If InnoDB strict mode is ON,
InnoDB checks the maximum row size during
CREATE TABLE or
CREATE INDEX. If the row does not
fit, the following error message is issued: ERROR HY000:
Too big row.
If you create a table when InnoDB strict mode is OFF, and a
subsequent INSERT or UPDATE
statement attempts to create an index entry that does not fit in
the size of the compressed page, the operation fails with
ERROR 42000: Row size too large. (This error
message does not name the index for which the record is too large,
or mention the length of the index record or the maximum record
size on that particular index page.) To solve this problem,
rebuild the table with ALTER TABLE
and select a larger compressed page size
(KEY_BLOCK_SIZE), shorten any column prefix
indexes, or disable compression entirely with
ROW_FORMAT=DYNAMIC or
ROW_FORMAT=COMPACT.
Compressing BLOB, VARCHAR and TEXT Columns
In a clustered index, BLOB,
VARCHAR and TEXT columns
that are not part of the primary key may be stored on separately
allocated (“overflow”) pages. We call these
off-page columns whose
values are stored on singly-linked lists of overflow pages.
For tables created in ROW_FORMAT=DYNAMIC or
ROW_FORMAT=COMPRESSED, the values of
BLOB, TEXT or
VARCHAR columns may be stored fully off-page,
depending on their length and the length of the entire row. For
columns that are stored off-page, the clustered index record only
contains 20-byte pointers to the overflow pages, one per column.
Whether any columns are stored off-page depends on the page size
and the total size of the row. When the row is too long to fit
entirely within the page of the clustered index, InnoDB chooses
the longest columns for off-page storage until the row fits on the
clustered index page. As noted above, if a row does not fit by
itself on a compressed page, an error occurs.
Tables created in previous versions of InnoDB use the Antelope
file format, which supports only
ROW_FORMAT=REDUNDANT and
ROW_FORMAT=COMPACT. In these formats, InnoDB
stores the first 768 bytes of BLOB,
VARCHAR and TEXT columns in
the clustered index record along with the primary key. The
768-byte prefix is followed by a 20-byte pointer to the overflow
pages that contain the rest of the column value.
When a table is in COMPRESSED format, all data
written to overflow pages is compressed “as is”; that
is, InnoDB applies the zlib compression algorithm to the entire
data item. Other than the data, compressed overflow pages contain
an uncompressed header and trailer comprising a page checksum and
a link to the next overflow page, among other things. Therefore,
very significant storage savings can be obtained for longer
BLOB, TEXT or
VARCHAR columns if the data is highly
compressible, as is often the case with text data (but not
previously compressed images).
The overflow pages are of the same size as other pages. A row containing ten columns stored off-page occupies ten overflow pages, even if the total length of the columns is only 8K bytes. In an uncompressed table, ten uncompressed overflow pages occupy 160K bytes. In a compressed table with an 8K page size, they occupy only 80K bytes. Thus, it is often more efficient to use compressed table format for tables with long column values.
Using a 16K compressed page size can reduce storage and I/O costs
for BLOB, VARCHAR or
TEXT columns, because such data often compress
well, and might therefore require fewer “overflow”
pages, even though the B-tree nodes themselves take as many pages
as in the uncompressed form.
Compression and the InnoDB Buffer Pool
In a compressed InnoDB table, every compressed page (whether 1K, 2K, 4K or 8K) corresponds to an uncompressed page of 16K bytes. To access the data in a page, InnoDB reads the compressed page from disk if it is not already in the buffer pool, then uncompresses the page to its original 16K byte form. This section describes how InnoDB manages the buffer pool with respect to pages of compressed tables.
To minimize I/O and to reduce the need to uncompress a page, at times the buffer pool contains both the compressed and uncompressed form of a database page. To make room for other required database pages, InnoDB may “evict” from the buffer pool an uncompressed page, while leaving the compressed page in memory. Or, if a page has not been accessed in a while, the compressed form of the page may be written to disk, to free space for other data. Thus, at any given time, the buffer pool may contain both the compressed and uncompressed forms of the page, or only the compressed form of the page, or neither.
InnoDB keeps track of which pages to keep in memory and which to evict using a least-recently-used (LRU) list, so that “hot” or frequently accessed data tends to stay in memory. When compressed tables are accessed, InnoDB uses an adaptive LRU algorithm to achieve an appropriate balance of compressed and uncompressed pages in memory. This adaptive algorithm is sensitive to whether the system is running in an I/O-bound or CPU-bound manner. The goal is to avoid spending too much processing time uncompressing pages when the CPU is busy, and to avoid doing excess I/O when the CPU has spare cycles that can be used for uncompressing compressed pages (that may already be in memory). When the system is I/O-bound, the algorithm prefers to evict the uncompressed copy of a page rather than both copies, to make more room for other disk pages to become memory resident. When the system is CPU-bound, InnoDB prefers to evict both the compressed and uncompressed page, so that more memory can be used for “hot” pages and reducing the need to uncompress data in memory only in compressed form.
Compression and the InnoDB Log Files
Before a compressed page is written to a database file, InnoDB writes a copy of the page to the redo log (if it has been recompressed since the last time it was written to the database). This is done to ensure that redo logs will always be usable, even if a future version of InnoDB uses a slightly different compression algorithm. Therefore, some increase in the size of log files, or a need for more frequent checkpoints, can be expected when using compression. The amount of increase in the log file size or checkpoint frequency depends on the number of times compressed pages are modified in a way that requires reorganization and recompression.
Note that compressed tables use a different file format for the redo log and the per-table tablespaces than in MySQL 5.1 and earlier. The MySQL Enterprise Backup product supports this latest Barracuda file format for compressed InnoDB tables. The older InnoDB Hot Backup product can only back up tables using the file format Antelope, and thus does not support InnoDB tables that use compression.
As InnoDB evolves, new on-disk data structures are sometimes
required to support new features. Features such as compressed tables
(see Section 14.2.2.7, “InnoDB Data Compression”), and long variable-length
columns stored off-page (see Section 14.2.2.9, “How InnoDB Stores Variable-Length Columns”)
require data file formats that are not compatible with prior
versions of InnoDB. These features both require use of the new
Barracuda file format.
All other new features are compatible with the original Antelope file format and do not require the Barracuda file format.
This section discusses how to specify the file format for new InnoDB tables, compatibility of different file formats between MySQL releases,
Named File Formats. InnoDB 1.1 has the idea of a named file format and a configuration parameter to enable the use of features that require use of that format. The new file format is the Barracuda format, and the original InnoDB file format is called Antelope. Compressed tables and the new row format that stores long columns “off-page” require the use of the Barracuda file format or newer. Future versions of InnoDB may introduce a series of file formats, identified with the names of animals, in ascending alphabetic order.
The configuration parameter
innodb_file_format controls
whether such statements as CREATE
TABLE and ALTER TABLE
can be used to create tables that depend on support for the
Barracuda file format.
Although Oracle recommends using the Barracuda format for new tables where practical, in MySQL 5.5 the default file format is still Antelope, for maximum compatibility with replication configurations containing different MySQL releases.
The file format is a dynamic, global parameter that can be
specified in the MySQL option file (my.cnf or
my.ini) or changed with the SET
GLOBAL command.
InnoDB 1.1 incorporates several checks to guard against the possible crashes and data corruptions that might occur if you run an older release of the MySQL server on InnoDB data files using a newer file format. These checks take place when the server is started, and when you first access a table. This section describes these checks, how you can control them, and error and warning conditions that might arise.
Backward Compatibility
Considerations of backward compatibility only apply when using a recent version of InnoDB (the InnoDB Plugin, or MySQL 5.5 and higher with InnoDB 1.1) alongside an older one (MySQL 5.1 or earlier, with the built-in InnoDB rather than the InnoDB Plugin). To minimize the chance of compatibility issues, you can standardize on the InnoDB Plugin for all your MySQL 5.1 and earlier database servers.
In general, a newer version of InnoDB may create a table or index that cannot safely be read or written with a prior version of InnoDB without risk of crashes, hangs, wrong results or corruptions. InnoDB 1.1 includes a mechanism to guard against these conditions, and to help preserve compatibility among database files and versions of InnoDB. This mechanism lets you take advantage of some new features of an InnoDB release (such as performance improvements and bug fixes), and still preserve the option of using your database with a prior version of InnoDB, by preventing accidental use of new features that create downward-incompatible disk files.
If a version of InnoDB supports a particular file format (whether or not that format is the default), you can query and update any table that requires that format or an earlier format. Only the creation of new tables using new features is limited based on the particular file format enabled. Conversely, if a tablespace contains a table or index that uses a file format that is not supported by the currently running software, it cannot be accessed at all, even for read access.
The only way to “downgrade” an InnoDB tablespace to
an earlier file format is to copy the data to a new table, in a
tablespace that uses the earlier format. This can be done with the
ALTER TABLE statement, as described
in Section 14.2.2.8.4, “Downgrading the File Format”.
The easiest way to determine the file format of an existing InnoDB
tablespace is to examine the properties of the table it contains,
using the SHOW TABLE STATUS command or querying
the table INFORMATION_SCHEMA.TABLES. If the
Row_format of the table is reported as
'Compressed' or 'Dynamic',
the tablespace containing the table uses the Barracuda format.
Otherwise, it uses the prior InnoDB file format, Antelope.
Internal Details
Every InnoDB per-table tablespace (represented by a
*.ibd file) file is labeled with a file format
identifier. The system tablespace (represented by the
ibdata files) is tagged with the
“highest” file format in use in a group of InnoDB
database files, and this tag is checked when the files are opened.
Creating a compressed table, or a table with
ROW_FORMAT=DYNAMIC, updates the file header for
the corresponding .ibd file and the table type
in the InnoDB data dictionary with the identifier for the
Barracuda file format. From that point forward, the table cannot
be used with a version of InnoDB that does not support this new
file format. To protect against anomalous behavior, InnoDB version
5.0.21 and later performs a compatibility check when the table is
opened. (In many cases, the ALTER
TABLE statement recreates a table and thus changes its
properties. The special case of adding or dropping indexes without
rebuilding the table is described in
Fast Index Creation in the InnoDB Storage Engine.)
Definition of ib-file set
To avoid confusion, for the purposes of this discussion we define the term “ib-file set” to mean the set of operating system files that InnoDB manages as a unit. The ib-file set includes the following files:
The system tablespace (one or more
ibdatafiles) that contain internal system information (including internal catalogs and undo information) and may include user data and indexes.Zero or more single-table tablespaces (also called “file per table” files, named
*.ibdfiles).InnoDB log files; usually two,
ib_logfile0andib_logfile1. Used for crash recovery and in backups.
An “ib-file set” does not include the corresponding
.frm files that contain metadata about InnoDB
tables. The .frm files are created and managed
by MySQL, and can sometimes get out of sync with the internal
metadata in InnoDB.
Multiple tables, even from more than one database, can be stored in a single “ib-file set”. (In MySQL, a “database” is a logical collection of tables, what other systems refer to as a “schema” or “catalog”.)
To prevent possible crashes or data corruptions when InnoDB
opens an ib-file set, it checks that it can fully support the
file formats in use within the ib-file set. If the system is
restarted following a crash, or a “fast shutdown”
(i.e., innodb_fast_shutdown is
greater than zero), there may be on-disk data structures (such
as redo or undo entries, or doublewrite pages) that are in a
“too-new” format for the current software. During
the recovery process, serious damage can be done to your data
files if these data structures are accessed. The startup check
of the file format occurs before any recovery process begins,
thereby preventing consistency issues with the new tables or
startup problems for the MySQL server.
Beginning with version InnoDB 1.0.1, the system tablespace
records an identifier or tag for the “highest” file
format used by any table in any of the tablespaces that is part
of the ib-file set. Checks against this file format tag are
controlled by the configuration parameter
innodb_file_format_check,
which is ON by default.
If the file format tag in the system tablespace is newer or
higher than the highest version supported by the particular
currently executing software and if
innodb_file_format_check is
ON, the following error is issued when the
server is started:
InnoDB: Error: the system tablespace is in a file format that this version doesn't support
You can also set
innodb_file_format to a
file format name. Doing so prevents InnoDB from starting if the
current software does not support the file format specified. It
also sets the “high water mark” to the value you
specify. The ability to set
innodb_file_format_check
will be useful (with future releases of InnoDB) if you manually
“downgrade” all of the tables in an ib-file set (as
described in Downgrading the InnoDB Storage Engine). You can then
rely on the file format check at startup if you subsequently use
an older version of InnoDB to access the ib-file set.
In some limited circumstances, you might want to start the
server and use an ib-file set that is in a “too
new” format (one that is not supported by the software
you are using). If you set the configuration parameter
innodb_file_format_check to
OFF, InnoDB opens the database, but issues
this warning message in the error log:
InnoDB: Warning: the system tablespace is in a file format that this version doesn't support
This is a very dangerous setting, as it permits the recovery
process to run, possibly corrupting your database if the
previous shutdown was a crash or “fast shutdown”.
You should only set
innodb_file_format_check
to OFF if you are sure that the previous
shutdown was done with
innodb_fast_shutdown=0, so that essentially
no recovery process occurs. In a future release, this
parameter setting may be renamed from OFF
to UNSAFE. (However, until there are newer
releases of InnoDB that support additional file formats, even
disabling the startup checking is in fact
“safe”.)
The parameter
innodb_file_format_check
affects only what happens when a database is opened, not
subsequently. Conversely, the parameter
innodb_file_format (which
enables a specific format) only determines whether or not a new
table can be created in the enabled format and has no effect on
whether or not a database can be opened.
The file format tag is a “high water mark”, and as
such it is increased after the server is started, if a table in
a “higher” format is created or an existing table
is accessed for read or write (assuming its format is
supported). If you access an existing table in a format higher
than the format the running software supports, the system
tablespace tag is not updated, but table-level compatibility
checking applies (and an error is issued), as described in
Section 14.2.2.8.2.2, “Compatibility Check When a Table Is Opened”.
Any time the high water mark is updated, the value of
innodb_file_format_check is
updated as well, so the command SELECT
@@innodb_file_format_check; displays the name of the
newest file format known to be used by tables in the currently
open ib-file set and supported by the currently executing
software.
To best illustrate this behavior, consider the scenario described in Table 14.6, “InnoDB Data File Compatibility and Related InnoDB Parameters”. Imagine that some future version of InnoDB supports the Cheetah format and that an ib-file set has been used with that version.
Table 14.6. InnoDB Data File Compatibility and Related InnoDB Parameters
| innodb file format check | innodb file format | Highest file format used in ib-file set | Highest file format supported by InnoDB | Result |
|---|---|---|---|---|
OFF | Antelope or Barracuda | Barracuda | Barracuda | Database can be opened; tables can be created which require Antelope or Barracuda file format |
OFF | Antelope or Barracuda | Cheetah | Barracuda | Database can be opened with a warning, since the database contains files in a “too new” format; tables can be created in Antelope or Barracuda file format; tables in Cheetah format cannot be accessed |
OFF | Cheetah | Barracuda | Barracuda | Database cannot be opened;
innodb_file_format
cannot be set to Cheetah |
ON | Antelope or Barracuda | Barracuda | Barracuda | Database can be opened; tables can be created in Antelope or Barracuda file format |
ON | Antelope or Barracuda | Cheetah | Barracuda | Database cannot be opened, since the database contains files in a “too new” format (Cheetah) |
ON | Cheetah | Barracuda | Barracuda | Database cannot be opened;
innodb_file_format
cannot be set to Cheetah |
When a table is first accessed, InnoDB (including some releases prior to InnoDB 1.0) checks that the file format of the tablespace in which the table is stored is fully supported. This check prevents crashes or corruptions that would otherwise occur when tables using a “too new” data structure are encountered.
All tables using any file format supported by a release can be
read or written (assuming the user has sufficient privileges).
The setting of the system configuration parameter
innodb_file_format can prevent
creating a new table that uses specific file formats, even if
they are supported by a given release. Such a setting might be
used to preserve backward compatibility, but it does not prevent
accessing any table that uses any supported format.
As noted in Named File Formats, versions of MySQL older than 5.0.21 cannot reliably use database files created by newer versions if a new file format was used when a table was created. To prevent various error conditions or corruptions, InnoDB checks file format compatibility when it opens a file (for example, upon first access to a table). If the currently running version of InnoDB does not support the file format identified by the table type in the InnoDB data dictionary, MySQL reports the following error:
ERROR 1146 (42S02): Table 'test.t1' doesn't exist
InnoDB also writes a message to the error log:
InnoDB: tabletest/t1: unknown table type33
The table type should be equal to the tablespace flags, which contains the file format version as discussed in Section 14.2.2.8.3, “Identifying the File Format in Use”.
Versions of InnoDB prior to MySQL 4.1 did not include table format identifiers in the database files, and versions prior to MySQL 5.0.21 did not include a table format compatibility check. Therefore, there is no way to ensure proper operations if a table in a “too new” format is used with versions of InnoDB prior to 5.0.21.
The file format management capability in InnoDB 1.0 and higher (tablespace tagging and run-time checks) allows InnoDB to verify as soon as possible that the running version of software can properly process the tables existing in the database.
If you permit InnoDB to open a database containing files in a
format it does not support (by setting the parameter
innodb_file_format_check to
OFF), the table-level checking described in
this section still applies.
Users are strongly urged not to use database files that contain Barracuda file format tables with releases of InnoDB older than the MySQL 5.1 with the InnoDB Plugin. It is possible to “downgrade” such tables to the Antelope format with the procedure described in Section 14.2.2.8.4, “Downgrading the File Format”.
After you enable a given
innodb_file_format, this
change applies only to newly created tables rather than existing
ones. If you do create a new table, the tablespace containing the
table is tagged with the “earliest” or
“simplest” file format that is required for the
table's features. For example, if you enable file format
Barracuda, and create a new table that is not compressed and does
not use ROW_FORMAT=DYNAMIC, the new tablespace
that contains the table is tagged as using file format Antelope.
It is easy to identify the file format used by a given tablespace
or table. The table uses the Barracuda format if the
Row_format reported by SHOW CREATE
TABLE or INFORMATION_SCHEMA.TABLES is
one of 'Compressed' or
'Dynamic'. (The Row_format
is a separate column; ignore the contents of the
Create_options column, which may contain the
string ROW_FORMAT.) If the table in a
tablespace uses neither of those features, the file uses the
format supported by prior releases of InnoDB, now called file
format Antelope. Then, the Row_format is one of
'Redundant' or 'Compact'.
Internal Details
The file format identifier is written as part of the tablespace
flags (a 32-bit number) in the *.ibd file in
the 4 bytes starting at position 54 of the file, most significant
byte first. (The first byte of the file is byte zero.) On some
systems, you can display these bytes in hexadecimal with the
command od -t x1 -j 54 -N 4
. If all bytes
are zero, the tablespace uses the Antelope file format (which is
the format used by the standard InnoDB storage engine up to
version 5.1). Otherwise, the least significant bit should be set
in the tablespace flags, and the file format identifier is written
in the bits 5 through 11. (Divide the tablespace flags by 32 and
take the remainder after dividing the integer part of the result
by 128.)
tablename.ibd
Each InnoDB tablespace file (with a name matching
*.ibd) is tagged with the file format used to
create its table and indexes. The way to downgrade the tablespace
is to re-create the table and its indexes. The easiest way to
recreate a table and its indexes is to use the command:
ALTER TABLEtROW_FORMAT=COMPACT;
on each table that you want to downgrade. The
COMPACT row format uses the file format
Antelope. It was introduced in MySQL 5.0.3.
The file format used by the standard built-in InnoDB in MySQL 5.1 is the Antelope format. The file format introduced with InnoDB Plugin 1.0 is the Barracuda format. Although no new features have been announced that would require additional new file formats, the InnoDB file format mechanism allows for future enhancements.
For the sake of completeness, these are the file format names that might be used for future file formats: Antelope, Barracuda, Cheetah, Dragon, Elk, Fox, Gazelle, Hornet, Impala, Jaguar, Kangaroo, Leopard, Moose, Nautilus, Ocelot, Porpoise, Quail, Rabbit, Shark, Tiger, Urchin, Viper, Whale, Xenops, Yak and Zebra. These file formats correspond to the internal identifiers 0..25.
This section discusses how certain InnoDB features, such as table
compression and off-page
storage of long columns, are controlled by the
ROW_FORMAT clause of the
CREATE TABLE statement. It discusses
considerations for choosing the right row format and compatibility
of row formats between MySQL releases.
The storage for rows and associated columns affects performance for queries and DML operations. As more rows fit into a single disk page, queries and index lookups can work faster, less cache memory is required in the InnoDB buffer pool, and less I/O is required to write out updated values for the numeric and short string columns.
The data in each InnoDB table is divided into pages. The pages that make up each table are arranged in a tree data structure called a B-tree index. Table data and secondary indexes both use this type of structure. The B-tree index that represents an entire table is known as the clustered index, which is organized according to the primary key columns. The nodes of the index data structure contain the values of all the columns in that row (for the clustered index) or the index columns and the primary key columns (for secondary indexes).
Variable-length columns are an exception to this rule. Columns
such as BLOB and VARCHAR
that are too long to fit on a B-tree page are stored on separately
allocated disk pages called
overflow pages. We call
such columns off-page
columns. The values of these columns are stored in
singly-linked lists of overflow pages, and each such column has
its own list of one or more overflow pages. In some cases, all or
a prefix of the long column value is stored in the B-tree, to
avoid wasting storage and eliminating the need to read a separate
page.
This section describes the clauses you can use with the
CREATE TABLE and
ALTER TABLE statements to control
how these variable-length columns are represented:
ROW_FORMAT and
KEY_BLOCK_SIZE. To use these clauses, you might
also need to change the settings for the
innodb_file_per_table and
innodb_file_format configuration
options.
You specify the row format for a table with the
ROW_FORMAT clause of the
CREATE TABLE and
ALTER TABLE statements.
This section discusses the DYNAMIC and
COMPRESSED row formats for InnoDB tables. You
can only create these kinds of tables when the
innodb_file_format configuration
option is set to Barracuda. (The Barracuda file
format also allows the COMPACT and
REDUNDANT row formats.)
When a table is created with ROW_FORMAT=DYNAMIC
or ROW_FORMAT=COMPRESSED, long column values
are stored fully off-page, and the clustered index record contains
only a 20-byte pointer to the overflow page.
Whether any columns are stored off-page depends on the page size and the total size of the row. When the row is too long, InnoDB chooses the longest columns for off-page storage until the clustered index record fits on the B-tree page.
The DYNAMIC row format maintains the efficiency
of storing the entire row in the index node if it fits (as do the
COMPACT and REDUNDANT
formats), but this new format avoids the problem of filling B-tree
nodes with a large number of data bytes of long columns. The
DYNAMIC format is based on the idea that if a
portion of a long data value is stored off-page, it is usually
most efficient to store all of the value off-page. With
DYNAMIC format, shorter columns are likely to
remain in the B-tree node, minimizing the number of overflow pages
needed for any given row.
The COMPRESSED row format uses similar internal
details for off-page storage as the DYNAMIC row
format, with additional storage and performance considerations
from the table and index data being compressed and using smaller
page sizes. With the COMPRESSED row format, the
option KEY_BLOCK_SIZE controls how much column
data is stored in the clustered index, and how much is placed on
overflow pages. For full details about the
COMPRESSED row format, see
Section 14.2.2.7, “InnoDB Data Compression”.
Early versions of InnoDB used an unnamed file format (now called
Antelope) for database files.
With that file format, tables are defined with
ROW_FORMAT=COMPACT or
ROW_FORMAT=REDUNDANT. InnoDB stores up to the
first 768 bytes of variable-length columns (such as
BLOB and VARCHAR) in the
index record within the B-tree node, with the remainder stored on
the overflow pages.
To preserve compatibility with those prior versions, tables
created with the newest InnoDB default to the
COMPACT row format. See
Section 14.2.2.9.3, “DYNAMIC and COMPRESSED Row Formats” for information about
the newer DYNAMIC and
COMPRESSED row formats.
With the Antelope file format, if the value of a column is 768
bytes or less, no overflow page is needed, and some savings in I/O
may result, since the value is in the B-tree node. This works well
for relatively short BLOBs, but may cause
B-tree nodes to fill with data rather than key values, reducing
their efficiency. Tables with many BLOB columns
could cause B-tree nodes to become too full of data, and contain
too few rows, making the entire index less efficient than if the
rows were shorter or if the column values were stored off-page.
- 14.2.3.1. Creating the
InnoDBTablespace - 14.2.3.2. Adding, Removing, or Resizing
InnoDBData and Log Files - 14.2.3.3. Using Raw Disk Partitions for the Shared Tablespace
- 14.2.3.4. Backing Up and Recovering an
InnoDBDatabase - 14.2.3.5. Moving or Copying
InnoDBTables to Another Machine - 14.2.3.6.
InnoDBand MySQL Replication - 14.2.3.7. Checking InnoDB Availability
- 14.2.3.8. Turning Off InnoDB
Administration tasks related to InnoDB mainly
involve these aspects:
Managing the data files that represent the system tablespace,
InnoDBtables, and their associated indexes. You can change the way these files are laid out and divided, which affects both performance and the features available for specific tables.Managing the redo log files that are used for crash recovery. You can specify the size of these files.
Making sure that
InnoDBis used for the tables where it is intended, rather than a different storage engine.General administrative tasks related to performance. You might consult with application developers during the application design phase, monitor performance on an ongoing basis to ensure the system settings are working well, and diagnose and help fix performance and capacity issues that arise suddenly.
Suppose that you have installed MySQL and have edited your
option file so that it contains the necessary
InnoDB configuration parameters. Before
starting MySQL, verify that the directories you have specified
for InnoDB data files and log files exist and
that the MySQL server has access rights to those directories.
InnoDB does not create directories, only
files. Check also that you have enough disk space for the data
and log files.
It is best to run the MySQL server mysqld
from the command prompt when you first start the server with
InnoDB enabled, not from
mysqld_safe or as a Windows service. When you
run from a command prompt you see what mysqld
prints and what is happening. On Unix, just invoke
mysqld. On Windows, start
mysqld with the
--console option to direct the
output to the console window.
When you start the MySQL server after initially configuring
InnoDB in your option file,
InnoDB creates your data files and log files,
and prints something like this:
InnoDB: The first specified datafile /home/heikki/data/ibdata1 did not exist: InnoDB: a new database to be created! InnoDB: Setting file /home/heikki/data/ibdata1 size to 134217728 InnoDB: Database physically writes the file full: wait... InnoDB: datafile /home/heikki/data/ibdata2 did not exist: new to be created InnoDB: Setting file /home/heikki/data/ibdata2 size to 262144000 InnoDB: Database physically writes the file full: wait... InnoDB: Log file /home/heikki/data/logs/ib_logfile0 did not exist: new to be created InnoDB: Setting log file /home/heikki/data/logs/ib_logfile0 size to 5242880 InnoDB: Log file /home/heikki/data/logs/ib_logfile1 did not exist: new to be created InnoDB: Setting log file /home/heikki/data/logs/ib_logfile1 size to 5242880 InnoDB: Doublewrite buffer not found: creating new InnoDB: Doublewrite buffer created InnoDB: Creating foreign key constraint system tables InnoDB: Foreign key constraint system tables created InnoDB: Started mysqld: ready for connections
At this point InnoDB has initialized its
tablespace and log files. You can connect to the MySQL server
with the usual MySQL client programs like
mysql. When you shut down the MySQL server
with mysqladmin shutdown, the output is like
this:
010321 18:33:34 mysqld: Normal shutdown 010321 18:33:34 mysqld: Shutdown Complete InnoDB: Starting shutdown... InnoDB: Shutdown completed
You can look at the data file and log directories and you see the files created there. When MySQL is started again, the data files and log files have been created already, so the output is much briefer:
InnoDB: Started mysqld: ready for connections
If you add the
innodb_file_per_table option to
my.cnf, InnoDB stores
each table in its own .ibd file, in the
same MySQL database directory where the
.frm file is created. See
Section 14.2.2.1, “Managing InnoDB Tablespaces”.
This section describes what you can do when your
InnoDB
system tablespace
runs out of room or when you want to change the size of the
redo log files.
The easiest way to increase the size of the
InnoDB system tablespace is to configure it
from the beginning to be auto-extending. Specify the
autoextend attribute for the last data file
in the tablespace definition. Then InnoDB
increases the size of that file automatically in 8MB increments
when it runs out of space. The increment size can be changed by
setting the value of the
innodb_autoextend_increment
system variable, which is measured in megabytes.
You can expand the system tablespace by a defined amount by adding another data file:
Shut down the MySQL server.
If the previous last data file is defined with the keyword
autoextend, change its definition to use a fixed size, based on how large it has actually grown. Check the size of the data file, round it down to the closest multiple of 1024 × 1024 bytes (= 1MB), and specify this rounded size explicitly ininnodb_data_file_path.Add a new data file to the end of
innodb_data_file_path, optionally making that file auto-extending. Only the last data file in theinnodb_data_file_pathcan be specified as auto-extending.Start the MySQL server again.
For example, this tablespace has just one auto-extending data
file ibdata1:
innodb_data_home_dir = innodb_data_file_path = /ibdata/ibdata1:10M:autoextend
Suppose that this data file, over time, has grown to 988MB. Here is the configuration line after modifying the original data file to use a fixed size and adding a new auto-extending data file:
innodb_data_home_dir = innodb_data_file_path = /ibdata/ibdata1:988M;/disk2/ibdata2:50M:autoextend
When you add a new data file to the system tablespace
configuration, make sure that the filename does not refer to an
existing file. InnoDB creates and initializes
the file when you restart the server.
Currently, you cannot remove a data file from the system tablespace. To decrease the system tablespace size, use this procedure:
Use mysqldump to dump all your
InnoDBtables.Stop the server.
Remove all the existing tablespace files, including the
ibdataandib_logfiles. If you want to keep a backup copy of the information, then copy all theib*files to another location before the removing the files in your MySQL installation.Remove any
.frmfiles forInnoDBtables.Configure a new tablespace.
Restart the server.
Import the dump files.
If you want to change the number or the size of your
InnoDB log files, use the following
instructions. The procedure to use depends on the value of
innodb_fast_shutdown, which
determines whether or not to bring the system tablespace fully
up-to-date before a shutdown operation:
If
innodb_fast_shutdownis not set to 2: Stop the MySQL server and make sure that it shuts down without errors, to ensure that there is no information for outstanding transactions in the redo log. Copy the old redo log files to a safe place, in case something went wrong during the shutdown and you need them to recover the tablespace. Delete the old log files from the log file directory, editmy.cnfto change the log file configuration, and start the MySQL server again. mysqld sees that noInnoDBlog files exist at startup and creates new ones.If
innodb_fast_shutdownis set to 2: Setinnodb_fast_shutdownto 1:mysql>
SET GLOBAL innodb_fast_shutdown = 1;Then follow the instructions in the previous item.
You can use raw disk partitions as data files in the
InnoDB
system tablespace.
This technique enables nonbuffered I/O on Windows and on some
Linux and Unix systems without file system overhead. Perform
tests with and without raw partitions to verify whether this
change actually improves performance on your system.
When you create a new data file, put the keyword
newraw immediately after the data file size
in innodb_data_file_path. The
partition must be at least as large as the size that you
specify. Note that 1MB in InnoDB is 1024
× 1024 bytes, whereas 1MB in disk specifications usually
means 1,000,000 bytes.
[mysqld] innodb_data_home_dir= innodb_data_file_path=/dev/hdd1:3Gnewraw;/dev/hdd2:2Gnewraw
The next time you start the server, InnoDB
notices the newraw keyword and initializes
the new partition. However, do not create or change any
InnoDB tables yet. Otherwise, when you next
restart the server, InnoDB reinitializes the
partition and your changes are lost. (As a safety measure
InnoDB prevents users from modifying data
when any partition with newraw is specified.)
After InnoDB has initialized the new
partition, stop the server, change newraw in
the data file specification to raw:
[mysqld] innodb_data_home_dir= innodb_data_file_path=/dev/hdd1:3Graw;/dev/hdd2:2Graw
Then restart the server and InnoDB permits
changes to be made.
On Windows, you can allocate a disk partition as a data file like this:
[mysqld] innodb_data_home_dir= innodb_data_file_path=//./D::10Gnewraw
The //./ corresponds to the Windows syntax
of \\.\ for accessing physical drives.
When you use a raw disk partition, ensure that the user ID that
runs the MySQL server has read and write privileges for that
partition. For example, if you run the server as the
mysql user, the partition must be readable
and writeable by mysql. If you run the server
with the --memlock option, the
server must be run as root, so the partition
must be readable and writeable by root.
The key to safe database management is making regular backups. Depending on your data volume, number of MySQL servers, and database workload, you can use these techniques, alone or in combination: hot backup with MySQL Enterprise Backup; cold backup by copying files while the MySQL server is shut down; physical backup for fast operation (especially for restore); logical backup with mysqldump for smaller data volumes or to record the structure of schema objects.
Hot Backups
The mysqlbackup command, part of the MySQL
Enterprise Backup component, lets you back up a running MySQL
instance, including InnoDB and
MyISAM tables, with minimal
disruption to operations while producing a consistent snapshot
of the database. When mysqlbackup is copying
InnoDB tables, reads and writes to both
InnoDB and MyISAM tables
can continue. During the copying of MyISAM
tables, reads (but not writes) to those tables are permitted.
MySQL Enterprise Backup can also create compressed backup files,
and back up subsets of tables and databases. In conjunction with
MySQL’s binary log, users can perform point-in-time recovery.
MySQL Enterprise Backup is part of the MySQL Enterprise
subscription. For more details, see
Section 23.2, “MySQL Enterprise Backup”.
Cold Backups
If you can shut down your MySQL server, you can make a binary
backup that consists of all files used by
InnoDB to manage its tables. Use the
following procedure:
Do a slow shutdown of the MySQL server and make sure that it stops without errors.
Copy all
InnoDBdata files (ibdatafiles and.ibdfiles) into a safe place.Copy all the
.frmfiles forInnoDBtables to a safe place.Copy all
InnoDBlog files (ib_logfilefiles) to a safe place.Copy your
my.cnfconfiguration file or files to a safe place.
Alternative Backup Types
In addition to making binary backups as just described,
regularly make dumps of your tables with
mysqldump. A binary file might be corrupted
without you noticing it. Dumped tables are stored into text
files that are human-readable, so spotting table corruption
becomes easier. Also, because the format is simpler, the chance
for serious data corruption is smaller.
mysqldump also has a
--single-transaction option
for making a consistent snapshot without locking out other
clients. See Section 7.3.1, “Establishing a Backup Policy”.
Replication works with InnoDB tables, so you
can use MySQL replication capabilities to keep a copy of your
database at database sites requiring high availability.
Performing Recovery
To recover your InnoDB database to the
present from the time at which the binary backup was made, you
must run your MySQL server with binary logging turned on, even
before taking the backup. To achieve point-in-time recovery
after restoring a backup, you can apply changes from the binary
log that occurred after the backup was made. See
Section 7.5, “Point-in-Time (Incremental) Recovery Using the Binary Log”.
To recover from a crash of your MySQL server, the only
requirement is to restart it. InnoDB
automatically checks the logs and performs a roll-forward of the
database to the present. InnoDB automatically
rolls back uncommitted transactions that were present at the
time of the crash. During recovery, mysqld
displays output something like this:
InnoDB: Database was not shut down normally. InnoDB: Starting recovery from log files... InnoDB: Starting log scan based on checkpoint at InnoDB: log sequence number 0 13674004 InnoDB: Doing recovery: scanned up to log sequence number 0 13739520 InnoDB: Doing recovery: scanned up to log sequence number 0 13805056 InnoDB: Doing recovery: scanned up to log sequence number 0 13870592 InnoDB: Doing recovery: scanned up to log sequence number 0 13936128 ... InnoDB: Doing recovery: scanned up to log sequence number 0 20555264 InnoDB: Doing recovery: scanned up to log sequence number 0 20620800 InnoDB: Doing recovery: scanned up to log sequence number 0 20664692 InnoDB: 1 uncommitted transaction(s) which must be rolled back InnoDB: Starting rollback of uncommitted transactions InnoDB: Rolling back trx no 16745 InnoDB: Rolling back of trx no 16745 completed InnoDB: Rollback of uncommitted transactions completed InnoDB: Starting an apply batch of log records to the database... InnoDB: Apply batch completed InnoDB: Started mysqld: ready for connections
If your database becomes corrupted or disk failure occurs, you must perform the recovery using a backup. In the case of corruption, first find a backup that is not corrupted. After restoring the base backup, do a point-in-time recovery from the binary log files using mysqlbinlog and mysql to restore the changes that occurred after the backup was made.
In some cases of database corruption, it is enough just to dump,
drop, and re-create one or a few corrupt tables. You can use the
CHECK TABLE SQL statement to
check whether a table is corrupt, although
CHECK TABLE naturally cannot
detect every possible kind of corruption. You can use the
Tablespace Monitor to check the integrity of the file space
management inside the tablespace files.
In some cases, apparent database page corruption is actually due
to the operating system corrupting its own file cache, and the
data on disk may be okay. It is best first to try restarting
your computer. Doing so may eliminate errors that appeared to be
database page corruption. If MySQL still has trouble starting
because of InnoDB consistency problems, see
Section 14.2.5.6, “Starting InnoDB on a Corrupted Database” for steps to start the
instance in a diagnostic mode where you can dump the data.
This section explains various techniques for moving or copying
some or all InnoDB tables to a different
server. For example, you might move an entire MySQL instance to
a larger, faster server; you might clone an entire MySQL
instance to a new replication slave server; you might copy
individual tables to another server to development and test an
application, or to a data warehouse server to produce reports.
Using Lowercase Table Names
On Windows, InnoDB always stores database and
table names internally in lowercase. To move databases in a
binary format from Unix to Windows or from Windows to Unix,
create all databases and tables using lowercase names. A
convenient way to accomplish this is to add the following line
to the [mysqld] section of your
my.cnf or my.ini file
before creating any databases or tables:
[mysqld] lower_case_table_names=1
Using MySQL Enterprise Backup
The MySQL Enterprise Backup product lets you back up a running
MySQL database, including InnoDB and
MyISAM tables, with minimal disruption to
operations while producing a consistent snapshot of the
database. When MySQL Enterprise Backup is copying
InnoDB tables, reads and writes to both
InnoDB and MyISAM tables
can continue. During the copying of MyISAM
and other non-InnoDB tables, reads (but not writes) to those
tables are permitted. In addition, MySQL Enterprise Backup can
create compressed backup files, and back up subsets of
InnoDB tables. In conjunction with the MySQL
binary log, you can perform point-in-time recovery. MySQL
Enterprise Backup is included as part of the MySQL Enterprise
subscription.
For more details about MySQL Enterprise Backup, see MySQL Enterprise Backup User's Guide (Version 3.6.1).
Copying Data Files
Like MyISAM data files,
InnoDB data and log files are
binary-compatible on all platforms having the same
floating-point number format. You can move an
InnoDB database simply by copying all the
relevant files listed in Section 14.2.3.4, “Backing Up and Recovering an InnoDB Database”. If the
floating-point formats differ but you have not used
FLOAT or
DOUBLE data types in your tables,
then the procedure is the same: simply copy the relevant files.
Portability Considerations for .ibd Files
When you move or copy .ibd files, the
database directory name must be the same on the source and
destination systems. The table definition stored in the
InnoDB shared tablespace includes the
database name. The transaction IDs and log sequence numbers
stored in the tablespace files also differ between databases.
To move an .ibd file and the associated
table from one database to another, use a
RENAME TABLE statement:
RENAME TABLEdb1.tbl_nameTOdb2.tbl_name;
If you have a “clean” backup of an
.ibd file, you can restore it to the MySQL
installation from which it originated as follows:
The table must not have been dropped or truncated since you copied the
.ibdfile, because doing so changes the table ID stored inside the tablespace.Issue this
ALTER TABLEstatement to delete the current.ibdfile:ALTER TABLE
tbl_nameDISCARD TABLESPACE;Copy the backup
.ibdfile to the proper database directory.Issue this
ALTER TABLEstatement to tellInnoDBto use the new.ibdfile for the table:ALTER TABLE
tbl_nameIMPORT TABLESPACE;
In this context, a “clean”
.ibd file backup is one for which the
following requirements are satisfied:
There are no uncommitted modifications by transactions in the
.ibdfile.There are no unmerged insert buffer entries in the
.ibdfile.Purge has removed all delete-marked index records from the
.ibdfile.mysqld has flushed all modified pages of the
.ibdfile from the buffer pool to the file.
You can make a clean backup .ibd file using
the following method:
Stop all activity from the mysqld server and commit all transactions.
Wait until
SHOW ENGINE INNODB STATUSshows that there are no active transactions in the database, and the main thread status ofInnoDBisWaiting for server activity. Then you can make a copy of the.ibdfile.
Another method for making a clean copy of an
.ibd file is to use the MySQL Enterprise
Backup product:
Use MySQL Enterprise Backup to back up the
InnoDBinstallation.Start a second mysqld server on the backup and let it clean up the
.ibdfiles in the backup.
Export and Import
If you use mysqldump to dump your tables on one machine and then import the dump files on the other machine, it does not matter whether the formats differ or your tables contain floating-point data.
One way to increase performance is to switch off autocommit mode when importing data, assuming that the tablespace has enough space for the big rollback segment that the import transactions generate. Do the commit only after importing a whole table or a segment of a table.
MySQL replication works for InnoDB tables as
it does for MyISAM tables. It is also
possible to use replication in a way where the storage engine on
the slave is not the same as the original storage engine on the
master. For example, you can replicate modifications to an
InnoDB table on the master to a
MyISAM table on the slave.
To set up a new slave for a master, make a copy of the
InnoDB tablespace and the log files, as well
as the .frm files of the
InnoDB tables, and move the copies to the
slave. If the
innodb_file_per_table option is
enabled, copy the .ibd files as well. For
the proper procedure to do this, see
Section 14.2.3.4, “Backing Up and Recovering an InnoDB Database”.
To make a new slave without taking down the master or an
existing slave, use the
MySQL Enterprise
Backup product. If you can shut down the master or an
existing slave, take a cold
backup of the InnoDB tablespaces and
log files and use that to set up a slave.
Transactions that fail on the master do not affect replication
at all. MySQL replication is based on the binary log where MySQL
writes SQL statements that modify data. A transaction that fails
(for example, because of a foreign key violation, or because it
is rolled back) is not written to the binary log, so it is not
sent to slaves. See Section 13.3.1, “START TRANSACTION,
COMMIT, and
ROLLBACK Syntax”.
Replication and CASCADE.
Cascading actions for InnoDB tables on the
master are replicated on the slave only
if the tables sharing the foreign key relation use
InnoDB on both the master and slave. This
is true whether you are using statement-based or row-based
replication. Suppose that you have started replication, and
then create two tables on the master using the following
CREATE TABLE statements:
CREATE TABLE fc1 (
i INT PRIMARY KEY,
j INT
) ENGINE = InnoDB;
CREATE TABLE fc2 (
m INT PRIMARY KEY,
n INT,
FOREIGN KEY ni (n) REFERENCES fc1 (i)
ON DELETE CASCADE
) ENGINE = InnoDB;
Suppose that the slave does not have InnoDB
support enabled. If this is the case, then the tables on the
slave are created, but they use the MyISAM
storage engine, and the FOREIGN KEY option is
ignored. Now we insert some rows into the tables on the master:
master>INSERT INTO fc1 VALUES (1, 1), (2, 2);Query OK, 2 rows affected (0.09 sec) Records: 2 Duplicates: 0 Warnings: 0 master>INSERT INTO fc2 VALUES (1, 1), (2, 2), (3, 1);Query OK, 3 rows affected (0.19 sec) Records: 3 Duplicates: 0 Warnings: 0
At this point, on both the master and the slave, table
fc1 contains 2 rows, and table
fc2 contains 3 rows, as shown here:
master>SELECT * FROM fc1;+---+------+ | i | j | +---+------+ | 1 | 1 | | 2 | 2 | +---+------+ 2 rows in set (0.00 sec) master>SELECT * FROM fc2;+---+------+ | m | n | +---+------+ | 1 | 1 | | 2 | 2 | | 3 | 1 | +---+------+ 3 rows in set (0.00 sec) slave>SELECT * FROM fc1;+---+------+ | i | j | +---+------+ | 1 | 1 | | 2 | 2 | +---+------+ 2 rows in set (0.00 sec) slave>SELECT * FROM fc2;+---+------+ | m | n | +---+------+ | 1 | 1 | | 2 | 2 | | 3 | 1 | +---+------+ 3 rows in set (0.00 sec)
Now suppose that you perform the following
DELETE statement on the master:
master> DELETE FROM fc1 WHERE i=1;
Query OK, 1 row affected (0.09 sec)
Due to the cascade, table fc2 on the master
now contains only 1 row:
master> SELECT * FROM fc2;
+---+---+
| m | n |
+---+---+
| 2 | 2 |
+---+---+
1 row in set (0.00 sec)
However, the cascade does not propagate on the slave because on
the slave the DELETE for
fc1 deletes no rows from
fc2. The slave's copy of
fc2 still contains all of the rows that were
originally inserted:
slave> SELECT * FROM fc2;
+---+---+
| m | n |
+---+---+
| 1 | 1 |
| 3 | 1 |
| 2 | 2 |
+---+---+
3 rows in set (0.00 sec)
This difference is due to the fact that the cascading deletes
are handled internally by the InnoDB storage
engine, which means that none of the changes are logged.
To determine whether your server supports
InnoDB, use the SHOW
ENGINES statement. (Now that InnoDB
is the default MySQL storage engine, only very specialized
environments might not support it.)
Oracle recommends InnoDB as the preferred storage engine for typical database applications, from single-user wikis and blogs running on a local system, to high-end applications pushing the limits of performance. In MySQL 5.6, InnoDB is is the default storage engine for new tables.
If you do not want to use InnoDB tables:
Start the server with the
--innodb=OFFor--skip-innodboption to disable theInnoDBstorage engine.Because the default storage engine is
InnoDB, the server will not start unless you also use--default-storage-engineand--default-tmp-storage-engineto set the default to some other engine for both permanent andTEMPORARYtables.To prevent the server from crashing when the
InnoDB-relatedinformation_schematables are queried, also disable the plugins associated with those tables. Specify in the[mysqld]section of the MySQL configuration file:loose-innodb-trx=0 loose-innodb-locks=0 loose-innodb-lock-waits=0 loose-innodb-cmp=0 loose-innodb-cmp-per-index=0 loose-innodb-cmp-per-index-reset=0 loose-innodb-cmp-reset=0 loose-innodb-cmpmem=0 loose-innodb-cmpmem-reset=0 loose-innodb-buffer-page=0 loose-innodb-buffer-page-lru=0 loose-innodb-buffer-pool-stats=0 loose-innodb-metrics=0 loose-innodb-ft-default-stopword=0 loose-innodb-ft-inserted=0 loose-innodb-ft-deleted=0 loose-innodb-ft-being-deleted=0 loose-innodb-ft-config=0 loose-innodb-ft-index-cache=0 loose-innodb-ft-index-table=0 loose-innodb-sys-tables=0 loose-innodb-sys-tablestats=0 loose-innodb-sys-indexes=0 loose-innodb-sys-columns=0 loose-innodb-sys-fields=0 loose-innodb-sys-foreign=0 loose-innodb-sys-foreign-cols=0
- 14.2.4.1. The
InnoDBTransaction Model and Locking - 14.2.4.2.
InnoDBLock Modes - 14.2.4.3. Consistent Nonlocking Reads
- 14.2.4.4. Locking Reads (
SELECT ... FOR UPDATEandSELECT ... LOCK IN SHARE MODE) - 14.2.4.5.
InnoDBRecord, Gap, and Next-Key Locks - 14.2.4.6. Avoiding the Phantom Problem Using Next-Key Locking
- 14.2.4.7. Locks Set by Different SQL Statements in
InnoDB - 14.2.4.8. Implicit Transaction Commit and Rollback
- 14.2.4.9. Deadlock Detection and Rollback
- 14.2.4.10. How to Cope with Deadlocks
- 14.2.4.11.
InnoDBMulti-Versioning - 14.2.4.12.
InnoDBTable and Index Structures - 14.2.4.13. The
InnoDBRecovery Process - 14.2.4.14.
InnoDBError Handling
The information in this section provides background to help you
get the most performance and functionality from using
InnoDB tables. It is intended for:
Anyone switching to MySQL from another database system, to explain what things might seem familiar and which might be all-new.
Anyone moving from
MyISAMtables toInnoDB, now thatInnoDBis the default MySQL storage engine.Anyone considering their application architecture or software stack, to understand the design considerations, performance characteristics, and scalability of
InnoDBtables at a detailed level.
In this section, you will learn:
How
InnoDBimplements transactions, and how the inner workings of transactions compare compare with other database systems you might be familiar with.How
InnoDBimplements row-level locking to allow queries and DML statements to read and write the same table simultaneously.How multi-version concurrency control (MVCC) keeps transactions from viewing or modifying each others' data before the appropriate time.
The physical layout of
InnoDB-related objects on disk, such as tables, indexes, tablespaces, undo logs, and the redo log.
To implement a large-scale, busy, or highly reliable database application, to port substantial code from a different database system, or to push MySQL performance to the limits of the laws of physics, you must understand the notions of transactions and locking as they relate to the InnoDB storage engine.
In the InnoDB transaction model, the goal is
to combine the best properties of a multi-versioning database
with traditional two-phase locking. InnoDB
does locking on the row level and runs queries as nonlocking
consistent reads by default, in the style of Oracle. The lock
information in InnoDB is stored so
space-efficiently that lock escalation is not needed: Typically,
several users are permitted to lock every row in
InnoDB tables, or any random subset of the
rows, without causing InnoDB memory
exhaustion.
In InnoDB, all user activity occurs inside a
transaction. If autocommit mode is enabled, each SQL statement
forms a single transaction on its own. By default, MySQL starts
the session for each new connection with autocommit enabled, so
MySQL does a commit after each SQL statement if that statement
did not return an error. If a statement returns an error, the
commit or rollback behavior depends on the error. See
Section 14.2.4.14, “InnoDB Error Handling”.
A session that has autocommit enabled can perform a
multiple-statement transaction by starting it with an explicit
START
TRANSACTION or
BEGIN
statement and ending it with a
COMMIT or
ROLLBACK
statement. See Section 13.3.1, “START TRANSACTION,
COMMIT, and
ROLLBACK Syntax”.
If autocommit mode is disabled within a session with
SET autocommit = 0, the session always has a
transaction open. A COMMIT or
ROLLBACK
statement ends the current transaction and a new one starts.
A COMMIT means that the changes
made in the current transaction are made permanent and become
visible to other sessions. A
ROLLBACK
statement, on the other hand, cancels all modifications made by
the current transaction. Both
COMMIT and
ROLLBACK
release all InnoDB locks that were set during
the current transaction.
In terms of the SQL:1992 transaction
isolation levels,
the default InnoDB level is
REPEATABLE READ.
InnoDB offers all four transaction isolation
levels described by the SQL standard:
READ UNCOMMITTED,
READ COMMITTED,
REPEATABLE READ, and
SERIALIZABLE.
A user can change the isolation level for a single session or
for all subsequent connections with the SET
TRANSACTION statement. To set the server's default
isolation level for all connections, use the
--transaction-isolation option on
the command line or in an option file. For detailed information
about isolation levels and level-setting syntax, see
Section 13.3.6, “SET TRANSACTION Syntax”.
In row-level
locking, InnoDB normally uses next-key
locking. That means that besides index records,
InnoDB can also lock the
gap preceding an index record to
block insertions by other sessions where the indexed values
would be inserted in that gap within the tree data structure. A
next-key lock refers to a lock that locks an index record and
the gap before it. A gap lock refers to a lock that locks only
the gap before some index record.
For more information about row-level locking, and the
circumstances under which gap locking is disabled, see
Section 14.2.4.5, “InnoDB Record, Gap, and Next-Key Locks”.
InnoDB implements standard
row-level locking
where there are two types of locks:
A shared (
S) lock permits the transaction that holds the lock to read a row.An exclusive (
X) lock permits the transaction that holds the lock to update or delete a row.
If transaction T1 holds a shared
(S) lock on row r,
then requests from some distinct transaction
T2 for a lock on row r are
handled as follows:
A request by
T2for anSlock can be granted immediately. As a result, bothT1andT2hold anSlock onr.A request by
T2for anXlock cannot be granted immediately.
If a transaction T1 holds an exclusive
(X) lock on row r,
a request from some distinct transaction T2
for a lock of either type on r cannot be
granted immediately. Instead, transaction T2
has to wait for transaction T1 to release its
lock on row r.
Additionally, InnoDB supports
multiple granularity locking which permits
coexistence of record locks and locks on entire tables. To make
locking at multiple granularity levels practical, additional
types of locks called
intention locks are
used. Intention locks are table locks in
InnoDB that indicate which type of lock
(shared or exclusive) a transaction will require later for a row
in that table. There are two types of intention locks used in
InnoDB (assume that transaction
T has requested a lock of the indicated type
on table t):
Intention shared (
IS): TransactionTintends to setSlocks on individual rows in tablet.Intention exclusive (
IX): TransactionTintends to setXlocks on those rows.
For example, SELECT ...
LOCK IN SHARE MODE sets an
IS lock and
SELECT ... FOR
UPDATE sets an IX lock.
The intention locking protocol is as follows:
Before a transaction can acquire an
Slock on a row in tablet, it must first acquire anISor stronger lock ont.Before a transaction can acquire an
Xlock on a row, it must first acquire anIXlock ont.
These rules can be conveniently summarized by means of the following lock type compatibility matrix.
X | IX | S | IS | |
|---|---|---|---|---|
X | Conflict | Conflict | Conflict | Conflict |
IX | Conflict | Compatible | Conflict | Compatible |
S | Conflict | Conflict | Compatible | Compatible |
IS | Conflict | Compatible | Compatible | Compatible |
A lock is granted to a requesting transaction if it is compatible with existing locks, but not if it conflicts with existing locks. A transaction waits until the conflicting existing lock is released. If a lock request conflicts with an existing lock and cannot be granted because it would cause deadlock, an error occurs.
Thus, intention locks do not block anything except full table
requests (for example, LOCK TABLES ...
WRITE). The main purpose of
IX and IS
locks is to show that someone is locking a row, or going to lock
a row in the table.
The following example illustrates how an error can occur when a lock request would cause a deadlock. The example involves two clients, A and B.
First, client A creates a table containing one row, and then
begins a transaction. Within the transaction, A obtains an
S lock on the row by selecting it in
share mode:
mysql>CREATE TABLE t (i INT) ENGINE = InnoDB;Query OK, 0 rows affected (1.07 sec) mysql>INSERT INTO t (i) VALUES(1);Query OK, 1 row affected (0.09 sec) mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>SELECT * FROM t WHERE i = 1 LOCK IN SHARE MODE;+------+ | i | +------+ | 1 | +------+ 1 row in set (0.10 sec)
Next, client B begins a transaction and attempts to delete the row from the table:
mysql>START TRANSACTION;Query OK, 0 rows affected (0.00 sec) mysql>DELETE FROM t WHERE i = 1;
The delete operation requires an X
lock. The lock cannot be granted because it is incompatible with
the S lock that client A holds, so
the request goes on the queue of lock requests for the row and
client B blocks.
Finally, client A also attempts to delete the row from the table:
mysql> DELETE FROM t WHERE i = 1;
ERROR 1213 (40001): Deadlock found when trying to get lock;
try restarting transaction
Deadlock occurs here because client A needs an
X lock to delete the row. However,
that lock request cannot be granted because client B already has
a request for an X lock and is
waiting for client A to release its S
lock. Nor can the S lock held by A be
upgraded to an X lock because of the
prior request by B for an X lock. As
a result, InnoDB generates an error for one
of the clients and releases its locks. The client returns this
error:
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
At that point, the lock request for the other client can be granted and it deletes the row from the table.
A consistent read
means that InnoDB uses multi-versioning to
present to a query a snapshot of the database at a point in
time. The query sees the changes made by transactions that
committed before that point of time, and no changes made by
later or uncommitted transactions. The exception to this rule is
that the query sees the changes made by earlier statements
within the same transaction. This exception causes the following
anomaly: If you update some rows in a table, a
SELECT sees the latest version of
the updated rows, but it might also see older versions of any
rows. If other sessions simultaneously update the same table,
the anomaly means that you might see the table in a state that
never existed in the database.
If the transaction
isolation level is
REPEATABLE READ (the default
level), all consistent reads within the same transaction read
the snapshot established by the first such read in that
transaction. You can get a fresher snapshot for your queries by
committing the current transaction and after that issuing new
queries.
With READ COMMITTED isolation
level, each consistent read within a transaction sets and reads
its own fresh snapshot.
Consistent read is the default mode in which
InnoDB processes
SELECT statements in
READ COMMITTED and
REPEATABLE READ isolation
levels. A consistent read does not set any locks on the tables
it accesses, and therefore other sessions are free to modify
those tables at the same time a consistent read is being
performed on the table.
Suppose that you are running in the default
REPEATABLE READ isolation
level. When you issue a consistent read (that is, an ordinary
SELECT statement),
InnoDB gives your transaction a timepoint
according to which your query sees the database. If another
transaction deletes a row and commits after your timepoint was
assigned, you do not see the row as having been deleted. Inserts
and updates are treated similarly.
The snapshot of the database state applies to
SELECT statements within a
transaction, not necessarily to
DML statements. If you insert
or modify some rows and then commit that transaction, a
DELETE or
UPDATE statement issued from
another concurrent REPEATABLE READ
transaction could affect those just-committed rows, even
though the session could not query them. If a transaction does
update or delete rows committed by a different transaction,
those changes do become visible to the current transaction.
For example, you might encounter a situation like the
following:
SELECT COUNT(c1) FROM t1 WHERE c1 = 'xyz'; -- Returns 0: no rows match. DELETE FROM t1 WHERE c1 = 'xyz'; -- Deletes several rows recently committed by other transaction. SELECT COUNT(c2) FROM t1 WHERE c2 = 'abc'; -- Returns 0: no rows match. UPDATE t1 SET c2 = 'cba' WHERE c2 = 'abc'; -- Affects 10 rows: another txn just committed 10 rows with 'abc' values. SELECT COUNT(c2) FROM t1 WHERE c2 = 'cba'; -- Returns 10: this txn can now see the rows it just updated.
You can advance your timepoint by committing your transaction
and then doing another SELECT or
START TRANSACTION WITH
CONSISTENT SNAPSHOT.
This is called multi-versioned concurrency control.
In the following example, session A sees the row inserted by B only when B has committed the insert and A has committed as well, so that the timepoint is advanced past the commit of B.
Session A Session B
SET autocommit=0; SET autocommit=0;
time
| SELECT * FROM t;
| empty set
| INSERT INTO t VALUES (1, 2);
|
v SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
---------------------
| 1 | 2 |
---------------------
1 row in set
If you want to see the “freshest” state of the
database, use either the READ
COMMITTED isolation level or a
locking read:
SELECT * FROM t LOCK IN SHARE MODE;
With READ COMMITTED isolation
level, each consistent read within a transaction sets and reads
its own fresh snapshot. With LOCK IN SHARE
MODE, a locking read occurs instead: A
SELECT blocks until the transaction
containing the freshest rows ends (see
Section 14.2.4.4, “Locking Reads (SELECT ... FOR
UPDATE and
SELECT ... LOCK IN SHARE
MODE)”).
Consistent read does not work over certain DDL statements:
Consistent read does not work over
DROP TABLE, because MySQL cannot use a table that has been dropped andInnoDBdestroys the table.Consistent read does not work over
ALTER TABLE, because that statement makes a temporary copy of the original table and deletes the original table when the temporary copy is built. When you reissue a consistent read within a transaction, rows in the new table are not visible because those rows did not exist when the transaction's snapshot was taken.
The type of read varies for selects in clauses like
INSERT INTO ...
SELECT, UPDATE
... (SELECT), and
CREATE TABLE ...
SELECT that do not specify FOR
UPDATE or LOCK IN SHARE MODE:
By default,
InnoDBuses stronger locks and theSELECTpart acts likeREAD COMMITTED, where each consistent read, even within the same transaction, sets and reads its own fresh snapshot.To use a consistent read in such cases, enable the
innodb_locks_unsafe_for_binlogoption and set the isolation level of the transaction toREAD UNCOMMITTED,READ COMMITTED, orREPEATABLE READ(that is, anything other thanSERIALIZABLE). In this case, no locks are set on rows read from the selected table.
If you query data and then insert or update related data within
the same transaction, the regular SELECT
statement does not give enough protection. Other transactions
can update or delete the same rows you just queried.
InnoDB supports two types of
locking reads that
offer extra safety:
SELECT ... LOCK IN SHARE MODEsets a shared mode lock on any rows that are read. Other sessions can read the rows, but cannot modify them until your transaction commits. If any of these rows were changed by another transaction that has not yet committed, your query waits until that transaction ends and then uses the latest values.For index records the search encounters,
SELECT ... FOR UPDATElocks the rows and any associated index entries, the same as if you issued anUPDATEstatement for those rows. Other transactions are blocked from updating those rows, from doingSELECT ... LOCK IN SHARE MODE, or from reading the data in certain transaction isolation levels. Consistent reads ignore any locks set on the records that exist in the read view. (Old versions of a record cannot be locked; they are reconstructed by applying undo logs on an in-memory copy of the record.)
These clauses are primarily useful when dealing with tree-structured or graph-structured data, either in a single table or split across multiple tables. You traverse edges or tree branches from one place to another, while reserving the right to come back and change any of these “pointer” values.
All locks set by LOCK IN SHARE MODE and
FOR UPDATE queries are released when the
transaction is committed or rolled back.
Locking of rows for update using SELECT FOR
UPDATE only applies when autocommit is disabled
(either by beginning transaction with
START
TRANSACTION or by setting
autocommit to 0. If
autocommit is enabled, the rows matching the specification are
not locked.
Usage Examples
Suppose that you want to insert a new row into a table
child, and make sure that the child row has a
parent row in table parent. Your application
code can ensure referential integrity throughout this sequence
of operations.
First, use a consistent read to query the table
PARENT and verify that the parent row exists.
Can you safely insert the child row to table
CHILD? No, because some other session could
delete the parent row in the moment between your
SELECT and your INSERT,
without you being aware of it.
To avoid this potential issue, perform the
SELECT using LOCK IN
SHARE MODE:
SELECT * FROM parent WHERE NAME = 'Jones' LOCK IN SHARE MODE;
After the LOCK IN SHARE MODE query returns
the parent 'Jones', you can safely add the
child record to the CHILD table and commit
the transaction. Any transaction that tries to read or write to
the applicable row in the PARENT table waits
until you are finished, that is, the data in all tables is in a
consistent state.
For another example, consider an integer counter field in a
table CHILD_CODES, used to assign a unique
identifier to each child added to table
CHILD. Do not use either consistent read or a
shared mode read to read the present value of the counter,
because two users of the database could see the same value for
the counter, and a duplicate-key error occurs if two
transactions attempt to add rows with the same identifier to the
CHILD table.
Here, LOCK IN SHARE MODE is not a good
solution because if two users read the counter at the same time,
at least one of them ends up in deadlock when it attempts to
update the counter.
Here are two ways to implement reading and incrementing the counter without interference from another transaction:
First update the counter by incrementing it by 1, then read it and use the new value in the
CHILDtable. Any other transaction that tries to read the counter waits until your transaction commits. If another transaction is in the middle of this same sequence, your transaction waits until the other one commits.First perform a locking read of the counter using
FOR UPDATE, and then increment the counter:SELECT counter_field FROM child_codes FOR UPDATE; UPDATE child_codes SET counter_field = counter_field + 1;
A SELECT ... FOR
UPDATE reads the latest available data, setting
exclusive locks on each row it reads. Thus, it sets the same
locks a searched SQL UPDATE would
set on the rows.
The preceding description is merely an example of how
SELECT ... FOR
UPDATE works. In MySQL, the specific task of
generating a unique identifier actually can be accomplished
using only a single access to the table:
UPDATE child_codes SET counter_field = LAST_INSERT_ID(counter_field + 1); SELECT LAST_INSERT_ID();
The SELECT statement merely
retrieves the identifier information (specific to the current
connection). It does not access any table.
InnoDB has several types of record-level
locks:
Record lock: This is a lock on an index record.
Gap lock: This is a lock on a gap between index records, or a lock on the gap before the first or after the last index record.
Next-key lock: This is a combination of a record lock on the index record and a gap lock on the gap before the index record.
Record locks always lock index records, even if a table is
defined with no indexes. For such cases,
InnoDB creates a hidden clustered index and
uses this index for record locking. See
Section 14.2.4.12.2, “Clustered and Secondary Indexes”.
By default, InnoDB operates in
REPEATABLE READ transaction
isolation level and with the
innodb_locks_unsafe_for_binlog
system variable disabled. In this case,
InnoDB uses next-key locks for searches and
index scans, which prevents phantom rows (see
Section 14.2.4.6, “Avoiding the Phantom Problem Using Next-Key Locking”).
Next-key locking combines index-row locking with gap locking.
InnoDB performs row-level locking in such a
way that when it searches or scans a table index, it sets shared
or exclusive locks on the index records it encounters. Thus, the
row-level locks are actually index-record locks. In addition, a
next-key lock on an index record also affects the
“gap” before that index record. That is, a next-key
lock is an index-record lock plus a gap lock on the gap
preceding the index record. If one session has a shared or
exclusive lock on record R in an index,
another session cannot insert a new index record in the gap
immediately before R in the index order.
Suppose that an index contains the values 10, 11, 13, and 20.
The possible next-key locks for this index cover the following
intervals, where ( or )
denote exclusion of the interval endpoint and
[ or ] denote inclusion of
the endpoint:
(negative infinity, 10] (10, 11] (11, 13] (13, 20] (20, positive infinity)
For the last interval, the next-key lock locks the gap above the largest value in the index and the “supremum” pseudo-record having a value higher than any value actually in the index. The supremum is not a real index record, so, in effect, this next-key lock locks only the gap following the largest index value.
The preceding example shows that a gap might span a single index value, multiple index values, or even be empty.
Gap locking is not needed for statements that lock rows using a
unique index to search for a unique row. (This does not include
the case that the search condition includes only some columns of
a multiple-column unique index; in that case, gap locking does
occur.) For example, if the id column has a
unique index, the following statement uses only an index-record
lock for the row having id value 100 and it
does not matter whether other sessions insert rows in the
preceding gap:
SELECT * FROM child WHERE id = 100;
If id is not indexed or has a nonunique
index, the statement does lock the preceding gap.
A type of gap lock called an insertion intention gap lock is set
by INSERT operations prior to row
insertion. This lock signals the intent to insert in such a way
that multiple transactions inserting into the same index gap
need not wait for each other if they are not inserting at the
same position within the gap. Suppose that there are index
records with values of 4 and 7. Separate transactions that
attempt to insert values of 5 and 6 each lock the gap between 4
and 7 with insert intention locks prior to obtaining the
exclusive lock on the inserted row, but do not block each other
because the rows are nonconflicting.
Gap locking can be disabled explicitly. This occurs if you
change the transaction isolation level to
READ COMMITTED or enable the
innodb_locks_unsafe_for_binlog
system variable (which is now deprecated). Under these
circumstances, gap locking is disabled for searches and index
scans and is used only for foreign-key constraint checking and
duplicate-key checking.
There are also other effects of using the
READ COMMITTED isolation
level or enabling
innodb_locks_unsafe_for_binlog:
Record locks for nonmatching rows are released after MySQL has
evaluated the WHERE condition. For
UPDATE statements, InnoDB
does a “semi-consistent” read, such that it returns
the latest committed version to MySQL so that MySQL can
determine whether the row matches the WHERE
condition of the UPDATE.
The so-called phantom problem occurs
within a transaction when the same query produces different sets
of rows at different times. For example, if a
SELECT is executed twice, but
returns a row the second time that was not returned the first
time, the row is a “phantom” row.
Suppose that there is an index on the id
column of the child table and that you want
to read and lock all rows from the table having an identifier
value larger than 100, with the intention of updating some
column in the selected rows later:
SELECT * FROM child WHERE id > 100 FOR UPDATE;
The query scans the index starting from the first record where
id is bigger than 100. Let the table contain
rows having id values of 90 and 102. If the
locks set on the index records in the scanned range do not lock
out inserts made in the gaps (in this case, the gap between 90
and 102), another session can insert a new row into the table
with an id of 101. If you were to execute the
same SELECT within the same
transaction, you would see a new row with an
id of 101 (a “phantom”) in the
result set returned by the query. If we regard a set of rows as
a data item, the new phantom child would violate the isolation
principle of transactions that a transaction should be able to
run so that the data it has read does not change during the
transaction.
To prevent phantoms, InnoDB uses an algorithm
called next-key locking that combines
index-row locking with gap locking. InnoDB
performs row-level locking in such a way that when it searches
or scans a table index, it sets shared or exclusive locks on the
index records it encounters. Thus, the row-level locks are
actually index-record locks. In addition, a next-key lock on an
index record also affects the “gap” before that
index record. That is, a next-key lock is an index-record lock
plus a gap lock on the gap preceding the index record. If one
session has a shared or exclusive lock on record
R in an index, another session cannot insert
a new index record in the gap immediately before
R in the index order.
When InnoDB scans an index, it can also lock
the gap after the last record in the index. Just that happens in
the preceding example: To prevent any insert into the table
where id would be bigger than 100, the locks
set by InnoDB include a lock on the gap
following id value 102.
You can use next-key locking to implement a uniqueness check in your application: If you read your data in share mode and do not see a duplicate for a row you are going to insert, then you can safely insert your row and know that the next-key lock set on the successor of your row during the read prevents anyone meanwhile inserting a duplicate for your row. Thus, the next-key locking enables you to “lock” the nonexistence of something in your table.
Gap locking can be disabled as discussed in
Section 14.2.4.5, “InnoDB Record, Gap, and Next-Key Locks”. This may cause
phantom problems because other sessions can insert new rows into
the gaps when gap locking is disabled.
A locking read, an
UPDATE, or a
DELETE generally set record locks
on every index record that is scanned in the processing of the
SQL statement.
It does not matter whether there are WHERE
conditions in the statement that would exclude the row.
InnoDB does not remember the exact
WHERE condition, but only knows which index
ranges were scanned. The locks are normally
next-key locks that
also block inserts into the “gap” immediately
before the record. However, gap
locking can be disabled explicitly, which causes next-key
locking not to be used. For more information, see
Section 14.2.4.5, “InnoDB Record, Gap, and Next-Key Locks”. The transaction
isolation level also can affect which locks are set; see
Section 13.3.6, “SET TRANSACTION Syntax”.
If a secondary index is used in a search and index record locks
to be set are exclusive, InnoDB also
retrieves the corresponding clustered index records and sets
locks on them.
Differences between shared and exclusive locks are described in
Section 14.2.4.2, “InnoDB Lock Modes”.
If you have no indexes suitable for your statement and MySQL must scan the entire table to process the statement, every row of the table becomes locked, which in turn blocks all inserts by other users to the table. It is important to create good indexes so that your queries do not unnecessarily scan many rows.
For SELECT ... FOR
UPDATE or
SELECT ... LOCK IN SHARE
MODE, locks are acquired for scanned rows, and
expected to be released for rows that do not qualify for
inclusion in the result set (for example, if they do not meet
the criteria given in the WHERE clause).
However, in some cases, rows might not be unlocked immediately
because the relationship between a result row and its original
source is lost during query execution. For example, in a
UNION, scanned (and locked) rows
from a table might be inserted into a temporary table before
evaluation whether they qualify for the result set. In this
circumstance, the relationship of the rows in the temporary
table to the rows in the original table is lost and the latter
rows are not unlocked until the end of query execution.
InnoDB sets specific types of locks as
follows.
SELECT ... FROMis a consistent read, reading a snapshot of the database and setting no locks unless the transaction isolation level is set toSERIALIZABLE. ForSERIALIZABLElevel, the search sets shared next-key locks on the index records it encounters.SELECT ... FROM ... LOCK IN SHARE MODEsets shared next-key locks on all index records the search encounters.For index records the search encounters,
SELECT ... FROM ... FOR UPDATEblocks other sessions from doingSELECT ... FROM ... LOCK IN SHARE MODEor from reading in certain transaction isolation levels. Consistent reads will ignore any locks set on the records that exist in the read view.UPDATE ... WHERE ...sets an exclusive next-key lock on every record the search encounters.DELETE FROM ... WHERE ...sets an exclusive next-key lock on every record the search encounters.INSERTsets an exclusive lock on the inserted row. This lock is an index-record lock, not a next-key lock (that is, there is no gap lock) and does not prevent other sessions from inserting into the gap before the inserted row.Prior to inserting the row, a type of gap lock called an insertion intention gap lock is set. This lock signals the intent to insert in such a way that multiple transactions inserting into the same index gap need not wait for each other if they are not inserting at the same position within the gap. Suppose that there are index records with values of 4 and 7. Separate transactions that attempt to insert values of 5 and 6 each lock the gap between 4 and 7 with insert intention locks prior to obtaining the exclusive lock on the inserted row, but do not block each other because the rows are nonconflicting.
If a duplicate-key error occurs, a shared lock on the duplicate index record is set. This use of a shared lock can result in deadlock should there be multiple sessions trying to insert the same row if another session already has an exclusive lock. This can occur if another session deletes the row. Suppose that an
InnoDBtablet1has the following structure:CREATE TABLE t1 (i INT, PRIMARY KEY (i)) ENGINE = InnoDB;
Now suppose that three sessions perform the following operations in order:
Session 1:
START TRANSACTION; INSERT INTO t1 VALUES(1);
Session 2:
START TRANSACTION; INSERT INTO t1 VALUES(1);
Session 3:
START TRANSACTION; INSERT INTO t1 VALUES(1);
Session 1:
ROLLBACK;
The first operation by session 1 acquires an exclusive lock for the row. The operations by sessions 2 and 3 both result in a duplicate-key error and they both request a shared lock for the row. When session 1 rolls back, it releases its exclusive lock on the row and the queued shared lock requests for sessions 2 and 3 are granted. At this point, sessions 2 and 3 deadlock: Neither can acquire an exclusive lock for the row because of the shared lock held by the other.
A similar situation occurs if the table already contains a row with key value 1 and three sessions perform the following operations in order:
Session 1:
START TRANSACTION; DELETE FROM t1 WHERE i = 1;
Session 2:
START TRANSACTION; INSERT INTO t1 VALUES(1);
Session 3:
START TRANSACTION; INSERT INTO t1 VALUES(1);
Session 1:
COMMIT;
The first operation by session 1 acquires an exclusive lock for the row. The operations by sessions 2 and 3 both result in a duplicate-key error and they both request a shared lock for the row. When session 1 commits, it releases its exclusive lock on the row and the queued shared lock requests for sessions 2 and 3 are granted. At this point, sessions 2 and 3 deadlock: Neither can acquire an exclusive lock for the row because of the shared lock held by the other.
INSERT ... ON DUPLICATE KEY UPDATEdiffers from a simpleINSERTin that an exclusive next-key lock rather than a shared lock is placed on the row to be updated when a duplicate-key error occurs.REPLACEis done like anINSERTif there is no collision on a unique key. Otherwise, an exclusive next-key lock is placed on the row to be replaced.INSERT INTO T SELECT ... FROM S WHERE ...sets an exclusive index record without a gap lock on each row inserted intoT. If the transaction isolation level isREAD COMMITTEDorinnodb_locks_unsafe_for_binlogis enabled, and the transaction isolation level is notSERIALIZABLE,InnoDBdoes the search onSas a consistent read (no locks). Otherwise,InnoDBsets shared next-key locks on rows fromS.InnoDBhas to set locks in the latter case: In roll-forward recovery from a backup, every SQL statement must be executed in exactly the same way it was done originally.CREATE TABLE ... SELECT ...performs theSELECTwith shared next-key locks or as a consistent read, as forINSERT ... SELECT.When a
SELECTis used in the constructsREPLACE INTO t SELECT ... FROM s WHERE ...orUPDATE t ... WHERE col IN (SELECT ... FROM s ...),InnoDBsets shared next-key locks on rows from tables.While initializing a previously specified
AUTO_INCREMENTcolumn on a table,InnoDBsets an exclusive lock on the end of the index associated with theAUTO_INCREMENTcolumn. In accessing the auto-increment counter,InnoDBuses a specificAUTO-INCtable lock mode where the lock lasts only to the end of the current SQL statement, not to the end of the entire transaction. Other sessions cannot insert into the table while theAUTO-INCtable lock is held; see Section 14.2.4.1, “TheInnoDBTransaction Model and Locking”.InnoDBfetches the value of a previously initializedAUTO_INCREMENTcolumn without setting any locks.If a
FOREIGN KEYconstraint is defined on a table, any insert, update, or delete that requires the constraint condition to be checked sets shared record-level locks on the records that it looks at to check the constraint.InnoDBalso sets these locks in the case where the constraint fails.LOCK TABLESsets table locks, but it is the higher MySQL layer above theInnoDBlayer that sets these locks.InnoDBis aware of table locks ifinnodb_table_locks = 1(the default) andautocommit = 0, and the MySQL layer aboveInnoDBknows about row-level locks.Otherwise,
InnoDB's automatic deadlock detection cannot detect deadlocks where such table locks are involved. Also, because in this case the higher MySQL layer does not know about row-level locks, it is possible to get a table lock on a table where another session currently has row-level locks. However, this does not endanger transaction integrity, as discussed in Section 14.2.4.9, “Deadlock Detection and Rollback”. See also Section 14.2.8, “Limits onInnoDBTables”.
By default, MySQL starts the session for each new connection
with autocommit mode enabled, so MySQL does a commit after each
SQL statement if that statement did not return an error. If a
statement returns an error, the commit or rollback behavior
depends on the error. See
Section 14.2.4.14, “InnoDB Error Handling”.
If a session that has autocommit disabled ends without explicitly committing the final transaction, MySQL rolls back that transaction.
Some statements implicitly end a transaction, as if you had done
a COMMIT before executing the
statement. For details, see Section 13.3.3, “Statements That Cause an Implicit Commit”.
InnoDB automatically detects transaction
deadlocks and rolls back a
transaction or transactions to break the deadlock.
InnoDB tries to pick small transactions to
roll back, where the size of a transaction is determined by the
number of rows inserted, updated, or deleted.
InnoDB is aware of table locks if
innodb_table_locks = 1 (the default) and
autocommit = 0, and the MySQL
layer above it knows about row-level locks. Otherwise,
InnoDB cannot detect deadlocks where a table
lock set by a MySQL LOCK TABLES
statement or a lock set by a storage engine other than
InnoDB is involved. Resolve these situations
by setting the value of the
innodb_lock_wait_timeout system
variable.
When InnoDB performs a complete rollback of a
transaction, all locks set by the transaction are released.
However, if just a single SQL statement is rolled back as a
result of an error, some of the locks set by the statement may
be preserved. This happens because InnoDB
stores row locks in a format such that it cannot know afterward
which lock was set by which statement.
If a SELECT calls a stored
function in a transaction, and a statement within the function
fails, that statement rolls back. Furthermore, if
ROLLBACK is
executed after that, the entire transaction rolls back.
For techniques to organize database operations to avoid deadlocks, see Section 14.2.4.10, “How to Cope with Deadlocks”.
This section builds on the conceptual information about deadlocks in Section 14.2.4.9, “Deadlock Detection and Rollback”. It explains how to organize database operations to minimize deadlocks and the subsequent error handling required in applications.
Deadlocks are a classic problem in transactional databases, but they are not dangerous unless they are so frequent that you cannot run certain transactions at all. Normally, you must write your applications so that they are always prepared to re-issue a transaction if it gets rolled back because of a deadlock.
InnoDB uses automatic row-level locking. You
can get deadlocks even in the case of transactions that just
insert or delete a single row. That is because these operations
are not really “atomic”; they automatically set
locks on the (possibly several) index records of the row
inserted or deleted.
You can cope with deadlocks and reduce the likelihood of their occurrence with the following techniques:
At any time, issue the
SHOW ENGINE INNODB STATUScommand to determine the cause of the most recent deadlock. That can help you to tune your application to avoid deadlocks.If frequent deadlock warnings cause concern, collect more extensive debugging information by restarting the server with the
innodb_print_all_deadlocksconfiguration option enabled. Information about each deadlock, not just the latest one, is recorded in the MySQL error log. Remove this option and restart the server again once the debugging is finished.Always be prepared to re-issue a transaction if it fails due to deadlock. Deadlocks are not dangerous. Just try again.
Commit your transactions immediately after making a set of related changes. Small transactions are less prone to collision. In particular, do not leave an interactive mysql session open for a long time with an uncommitted transaction.
If you use locking reads (
SELECT ... FOR UPDATEorSELECT ... LOCK IN SHARE MODE), try using a lower isolation level such asREAD COMMITTED.When modifying multiple tables within a transaction, or different sets of rows in the same table, do those operations in a consistent order each time. Then transactions form well-defined queues and do not deadlock. For example, organize database operations into functions within your application, or call stored routines, rather than coding multiple similar sequences of
INSERT,UPDATE, andDELETEstatements in different places.Add well-chosen indexes to your tables. Then your queries need to scan fewer index records and consequently set fewer locks. Use
EXPLAIN SELECTto determine which indexes the MySQL server regards as the most appropriate for your queries.Use less locking. If you can afford to permit a
SELECTto return data from an old snapshot, do not add the clauseFOR UPDATEorLOCK IN SHARE MODEto it. Using theREAD COMMITTEDisolation level is good here, because each consistent read within the same transaction reads from its own fresh snapshot.If nothing else helps, serialize your transactions with table-level locks. The correct way to use
LOCK TABLESwith transactional tables, such asInnoDBtables, is to begin a transaction withSET autocommit = 0(notSTART TRANSACTION) followed byLOCK TABLES, and to not callUNLOCK TABLESuntil you commit the transaction explicitly. For example, if you need to write to tablet1and read from tablet2, you can do this:SET autocommit=0; LOCK TABLES t1 WRITE, t2 READ, ...;
... do something with tables t1 and t2 here ...COMMIT; UNLOCK TABLES;Table-level locks prevent concurrent updates to the table, avoiding deadlocks at the expense of less responsiveness for a busy system.
Another way to serialize transactions is to create an auxiliary “semaphore” table that contains just a single row. Have each transaction update that row before accessing other tables. In that way, all transactions happen in a serial fashion. Note that the
InnoDBinstant deadlock detection algorithm also works in this case, because the serializing lock is a row-level lock. With MySQL table-level locks, the timeout method must be used to resolve deadlocks.
InnoDB is a
multi-versioned storage engine:
it keeps information about old versions of changed rows, to
support transactional features such as concurrency and
rollback. This information
is stored in the tablespace in a data structure called a
rollback segment
(after an analogous data structure in Oracle).
InnoDB uses the information in the rollback
segment to perform the undo operations needed in a transaction
rollback. It also uses the information to build earlier versions
of a row for a consistent
read.
Internal Details of Multi-Versioning
Internally, InnoDB adds three fields to each
row stored in the database. A 6-byte
DB_TRX_ID field indicates the transaction
identifier for the last transaction that inserted or updated the
row. Also, a deletion is treated internally as an update where a
special bit in the row is set to mark it as deleted. Each row
also contains a 7-byte DB_ROLL_PTR field
called the roll pointer. The roll pointer points to an undo log
record written to the rollback segment. If the row was updated,
the undo log record contains the information necessary to
rebuild the content of the row before it was updated. A 6-byte
DB_ROW_ID field contains a row ID that
increases monotonically as new rows are inserted. If
InnoDB generates a clustered index
automatically, the index contains row ID values. Otherwise, the
DB_ROW_ID column does not appear in any
index.
Undo logs in the rollback segment are divided into insert and
update undo logs. Insert undo logs are needed only in
transaction rollback and can be discarded as soon as the
transaction commits. Update undo logs are used also in
consistent reads, but they can be discarded only after there is
no transaction present for which InnoDB has
assigned a snapshot that in a consistent read could need the
information in the update undo log to build an earlier version
of a database row.
Guidelines for Managing Rollback Segments
Commit your transactions regularly, including those transactions
that issue only consistent reads. Otherwise,
InnoDB cannot discard data from the update
undo logs, and the rollback segment may grow too big, filling up
your tablespace.
The physical size of an undo log record in the rollback segment is typically smaller than the corresponding inserted or updated row. You can use this information to calculate the space needed for your rollback segment.
In the InnoDB multi-versioning scheme, a row
is not physically removed from the database immediately when you
delete it with an SQL statement. InnoDB only
physically removes the corresponding row and its index records
when it discards the update undo log record written for the
deletion. This removal operation is called a
purge, and it is quite fast,
usually taking the same order of time as the SQL statement that
did the deletion.
If you insert and delete rows in smallish batches at about the
same rate in the table, the purge thread can start to lag behind
and the table can grow bigger and bigger because of all the
“dead” rows, making everything disk-bound and very
slow. In such a case, throttle new row operations, and allocate
more resources to the purge thread by tuning the
innodb_max_purge_lag system
variable. See Section 14.2.7, “InnoDB Startup Options and System Variables” for more
information.
This section describes how InnoDB tables,
indexes, and their associated metadata is represented at the
physical level. This information is primarily useful for
performance tuning and troubleshooting.
MySQL stores its data dictionary information for tables in
.frm files in database
directories. Unlike other MySQL storage engines,
InnoDB also encodes information about the
table in its own internal data dictionary inside the
tablespace. When MySQL drops a table or a database, it deletes
one or more .frm files as well as the
corresponding entries inside the InnoDB
data dictionary. You cannot move InnoDB
tables between databases simply by moving the
.frm files.
Every InnoDB table has a special index
called the clustered
index where the data for the rows is stored. Typically,
the clustered index is synonymous with the
primary key. To get
the best performance from queries, inserts, and other database
operations, you must understand how InnoDB uses the clustered
index to optimize the most common lookup and DML operations
for each table.
When you define a
PRIMARY KEYon your table,InnoDBuses it as the clustered index. Define a primary key for each table that you create. If there is no logical unique and non-null column or set of columns, add a new auto-increment column, whose values are filled in automatically.If you do not define a
PRIMARY KEYfor your table, MySQL locates the firstUNIQUEindex where all the key columns areNOT NULLandInnoDBuses it as the clustered index.If the table has no
PRIMARY KEYor suitableUNIQUEindex,InnoDBinternally generates a hidden clustered index on a synthetic column containing row ID values. The rows are ordered by the ID thatInnoDBassigns to the rows in such a table. The row ID is a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the row ID are physically in insertion order.
How the Clustered Index Speeds Up Queries
Accessing a row through the clustered index is fast because
the index search leads directly to the page with all the row
data. If a table is large, the clustered index architecture
often saves a disk I/O operation when compared to storage
organizations that store row data using a different page from
the index record. (For example, MyISAM uses
one file for data rows and another for index records.)
How Secondary Indexes Relate to the Clustered Index
All indexes other than the clustered index are known as
secondary indexes.
In InnoDB, each record in a secondary index
contains the primary key columns for the row, as well as the
columns specified for the secondary index.
InnoDB uses this primary key value to
search for the row in the clustered index.
If the primary key is long, the secondary indexes use more space, so it is advantageous to have a short primary key.
For coding guidelines to take advantage of
InnoDB clustered and secondary indexes, see
Section 8.3.2, “Using Primary Keys”
Section 8.3, “Optimization and Indexes”
Section 8.5, “Optimizing for InnoDB Tables”
Section 8.3.2, “Using Primary Keys”.
A special kind of index, the FULLTEXT
index, helps InnoDB deal with queries and
DML operations involving text-based columns and the words they
contain. These indexes are physically represented as entire
InnoDB tables, which are acted upon by SQL
keywords such as the FULLTEXT clause of the
CREATE INDEX statement, the
MATCH() ... AGAINST syntax in a
SELECT statement, and the
OPTIMIZE TABLE statement. For
usage information, see Section 12.9, “Full-Text Search Functions”.
You can examine FULLTEXT indexes by
querying tables in the INFORMATION_SCHEMA
database. You can see basic index information for
FULLTEXT indexes by querying
INNODB_SYS_INDEXES. Although
InnoDB FULLTEXT indexes
are represented by tables, which show up in
INNODB_SYS_TABLES queries, the
way to monitor the special text-processing aspects of a
FULLTEXT index is to query the tables
INNODB_FT_CONFIG,
INNODB_FT_INDEX_TABLE,
INNODB_FT_INDEX_CACHE,
INNODB_FT_DEFAULT_STOPWORD,
INNODB_FT_INSERTED,
INNODB_FT_DELETED, and
INNODB_FT_BEING_DELETED.
InnoDB FULLTEXT indexes
are updated by the OPTIMIZE
TABLE command, using a special mode controlled by
the configuration options
innodb_ft_num_word_optimize
and
innodb_optimize_fulltext_only.
All InnoDB indexes are
B-trees where the index
records are stored in the leaf pages of the tree. The default
size of an index page is 16KB. When new records are inserted,
InnoDB tries to leave 1/16 of the page free
for future insertions and updates of the index records.
If index records are inserted in a sequential order (ascending
or descending), the resulting index pages are about 15/16
full. If records are inserted in a random order, the pages are
from 1/2 to 15/16 full. If the fill factor of an index page
drops below 1/2, InnoDB tries to contract
the index tree to free the page.
You can specify the page
size for all InnoDB tablespaces in
a MySQL instance by setting the
innodb_page_size
configuration option before creating the instance. Once the
page size for a MySQL instance is set, you cannot change it.
Supported sizes are 16KB, 8KB, and 4KB, corresponding to the
option values 16k, 8k,
and 4k.
A MySQL instance using a particular
InnoDB page size cannot use data files or
log files from an instance that uses a different page size.
Database applications often insert new rows in the ascending order of the primary key. In this case, due to the layout of the clustered index in the same order as the primary key, insertions into an InnoDB table do not require random reads from a disk.
On the other hand, secondary indexes are usually nonunique,
and insertions into secondary indexes happen in a relatively
random order. In the same way, deletes and updates can affect
data pages that are not adjacent in secondary indexes. This
would cause a lot of random disk I/O operations without a
special mechanism used in InnoDB.
When an index record is inserted, marked for deletion, or
deleted from a nonunique secondary index,
InnoDB checks whether the secondary index
page is in the buffer
pool. If that is the case, InnoDB
applies the change directly to the index page. If the index
page is not found in the buffer pool,
InnoDB records the change in a special
structure known as the
insert buffer. The
insert buffer is kept small so that it fits entirely in the
buffer pool, and changes can be applied very quickly. This
process is known as
change buffering.
(Formerly, it applied only to inserts and was called insert
buffering. The data structure is still called the insert
buffer.)
Disk I/O for Flushing the Insert Buffer
Periodically, the insert buffer is merged into the secondary index trees in the database. Often, it is possible to merge several changes into the same page of the index tree, saving disk I/O operations. It has been measured that the insert buffer can speed up insertions into a table up to 15 times.
The insert buffer merging may continue to happen
after the transaction has been committed.
In fact, it may continue to happen after a server shutdown and
restart (see Section 14.2.5.6, “Starting InnoDB on a Corrupted Database”).
Insert buffer merging may take many hours when many secondary
indexes must be updated and many rows have been inserted.
During this time, disk I/O will be increased, which can cause
significant slowdown on disk-bound queries. Another
significant background I/O operation is the
purge thread (see
Section 14.2.4.11, “InnoDB Multi-Versioning”).
The feature known as the
adaptive hash
index (AHI) lets InnoDB perform more
like an in-memory database on systems with appropriate
combinations of workload and ample memory for the
buffer pool, without
sacrificing any transactional features or reliability. This
feature is enabled by the
innodb_adaptive_hash_index
option, or turned off by the
--skip-innodb_adaptive_hash_index at server
startup.
Based on the observed pattern of searches, MySQL builds a hash index using a prefix of the index key. The prefix of the key can be any length, and it may be that only some of the values in the B-tree appear in the hash index. Hash indexes are built on demand for those pages of the index that are often accessed.
If a table fits almost entirely in main memory, a hash index
can speed up queries by enabling direct lookup of any element,
turning the index value into a sort of pointer.
InnoDB has a mechanism that monitors index
searches. If InnoDB notices that queries
could benefit from building a hash index, it does so
automatically.
With some workloads, the
speedup from hash index lookups greatly outweighs the extra
work to monitor index lookups and maintain the hash index
structure. Sometimes, the read/write lock that guards access
to the adaptive hash index can become a source of contention
under heavy workloads, such as multiple concurrent joins.
Queries with LIKE operators and
% wildcards also tend not to benefit from
the AHI. For workloads where the adaptive hash index is not
needed, turning it off reduces unnecessary performance
overhead. Because it is difficult to predict in advance
whether this feature is appropriate for a particular system,
consider running benchmarks with it both enabled and disabled,
using a realistic workload. The architectural changes in MySQL
5.6 and higher make more workloads suitable for disabling the
adaptive hash index than in earlier releases, although it is
still enabled by default.
The hash index is always built based on an existing
B-tree index on the table.
InnoDB can build a hash index on a prefix
of any length of the key defined for the B-tree, depending on
the pattern of searches that InnoDB
observes for the B-tree index. A hash index can be partial,
covering only those pages of the index that are often
accessed.
You can monitor the use of the adaptive hash index and the
contention for its use in the SEMAPHORES
section of the output of the
SHOW ENGINE
INNODB STATUS command. If you see many threads
waiting on an RW-latch created in
btr0sea.c, then it might be useful to
disable adaptive hash indexing.
For more information about the performance characteristics of hash indexes, see Section 8.3.8, “Comparison of B-Tree and Hash Indexes”.
The physical row structure for an InnoDB
table depends on the row format specified when the table was
created. By default, InnoDB uses the
Antelope file format and
its COMPACT row format. The
REDUNDANT format is available to retain
compatibility with older versions of MySQL. When you enable
the innodb_file_per_table
setting, you can also make use of the newer Barracuda file
format, with its DYNAMIC and
COMPRESSED row formats, as explained in
Section 14.2.2.9, “How InnoDB Stores Variable-Length Columns” and
Section 14.2.2.7, “InnoDB Data Compression”.
To check the row format of an InnoDB table,
use SHOW TABLE STATUS.
The COMPACT row format decreases row
storage space by about 20% at the cost of increasing CPU use
for some operations. If your workload is a typical one that is
limited by cache hit rates and disk speed,
COMPACT format is likely to be faster. If
the workload is a rare case that is limited by CPU speed,
COMPACT format might be slower.
Rows in InnoDB tables that use
REDUNDANT row format have the following
characteristics:
Each index record contains a 6-byte header. The header is used to link together consecutive records, and also in row-level locking.
Records in the clustered index contain fields for all user-defined columns. In addition, there is a 6-byte transaction ID field and a 7-byte roll pointer field.
If no primary key was defined for a table, each clustered index record also contains a 6-byte row ID field.
Each secondary index record also contains all the primary key fields defined for the clustered index key that are not in the secondary index.
A record contains a pointer to each field of the record. If the total length of the fields in a record is less than 128 bytes, the pointer is one byte; otherwise, two bytes. The array of these pointers is called the record directory. The area where these pointers point is called the data part of the record.
Internally,
InnoDBstores fixed-length character columns such asCHAR(10)in a fixed-length format.InnoDBdoes not truncate trailing spaces fromVARCHARcolumns.An SQL
NULLvalue reserves one or two bytes in the record directory. Besides that, an SQLNULLvalue reserves zero bytes in the data part of the record if stored in a variable length column. In a fixed-length column, it reserves the fixed length of the column in the data part of the record. Reserving the fixed space forNULLvalues enables an update of the column fromNULLto a non-NULLvalue to be done in place without causing fragmentation of the index page.
Rows in InnoDB tables that use
COMPACT row format have the following
characteristics:
Each index record contains a 5-byte header that may be preceded by a variable-length header. The header is used to link together consecutive records, and also in row-level locking.
The variable-length part of the record header contains a bit vector for indicating
NULLcolumns. If the number of columns in the index that can beNULLisN, the bit vector occupiesCEILING(bytes. (For example, if there are anywhere from 9 to 15 columns that can beN/8)NULL, the bit vector uses two bytes.) Columns that areNULLdo not occupy space other than the bit in this vector. The variable-length part of the header also contains the lengths of variable-length columns. Each length takes one or two bytes, depending on the maximum length of the column. If all columns in the index areNOT NULLand have a fixed length, the record header has no variable-length part.For each non-
NULLvariable-length field, the record header contains the length of the column in one or two bytes. Two bytes will only be needed if part of the column is stored externally in overflow pages or the maximum length exceeds 255 bytes and the actual length exceeds 127 bytes. For an externally stored column, the 2-byte length indicates the length of the internally stored part plus the 20-byte pointer to the externally stored part. The internal part is 768 bytes, so the length is 768+20. The 20-byte pointer stores the true length of the column.The record header is followed by the data contents of the non-
NULLcolumns.Records in the clustered index contain fields for all user-defined columns. In addition, there is a 6-byte transaction ID field and a 7-byte roll pointer field.
If no primary key was defined for a table, each clustered index record also contains a 6-byte row ID field.
Each secondary index record also contains all the primary key fields defined for the clustered index key that are not in the secondary index. If any of these primary key fields are variable length, the record header for each secondary index will have a variable-length part to record their lengths, even if the secondary index is defined on fixed-length columns.
Internally,
InnoDBstores fixed-length, fixed-width character columns such asCHAR(10)in a fixed-length format.InnoDBdoes not truncate trailing spaces fromVARCHARcolumns.Internally,
InnoDBattempts to store UTF-8CHAR(columns inN)Nbytes by trimming trailing spaces. (WithREDUNDANTrow format, such columns occupy 3 ×Nbytes.) Reserving the minimum spaceNin many cases enables column updates to be done in place without causing fragmentation of the index page.
InnoDB
crash recovery
consists of several steps:
The first step, applying the redo
log, is performed during initialization, before accepting
any connections. If all changes were flushed from the
buffer pool to the
tablespaces
(ibdata* and *.ibd
files) at the time of the shutdown or crash, the redo log
application can be skipped. If the redo log files are missing at
startup, InnoDB skips the redo log
application.
The remaining steps after redo log application do not depend on the redo log (other than for logging the writes) and are performed in parallel with normal processing. These include:
Rolling back incomplete transactions: Any transactions that were active at the time of crash or fast shutdown.
Insert buffer merge: Applying changes from the insert buffer (part of the system tablespace) to leaf pages of secondary indexes, as the index pages are read to the buffer pool.
Purge: Deleting delete-marked records that are no longer visible for any active transaction.
Of these, only rollback of incomplete transactions is special to crash recovery. The insert buffer merge and the purge are performed during normal processing.
In most situations, even if the MySQL server was killed
unexpectedly in the middle of heavy activity, the recovery
process happens automatically and no action is needed from the
DBA. If a hardware failure or severe system error corrupted
InnoDB data, MySQL might refuse to start. In
that case, see Section 14.2.5.6, “Starting InnoDB on a Corrupted Database” for the
steps to troubleshoot such an issue.
Error handling in InnoDB is not always the
same as specified in the SQL standard. According to the
standard, any error during an SQL statement should cause
rollback of that statement. InnoDB sometimes
rolls back only part of the statement, or the whole transaction.
The following items describe how InnoDB
performs error handling:
If you run out of file space in a tablespace, a MySQL
Table is fullerror occurs andInnoDBrolls back the SQL statement.A transaction deadlock causes
InnoDBto roll back the entire transaction. Retry the whole transaction when this happens.A lock wait timeout causes
InnoDBto roll back only the single statement that was waiting for the lock and encountered the timeout. (To have the entire transaction roll back, start the server with the--innodb_rollback_on_timeoutoption.) Retry the statement if using the current behavior, or the entire transaction if using--innodb_rollback_on_timeout.Both deadlocks and lock wait timeouts are normal on busy servers and it is necessary for applications to be aware that they may happen and handle them by retrying. You can make them less likely by doing as little work as possible between the first change to data during a transaction and the commit, so the locks are held for the shortest possible time and for the smallest possible number of rows. Sometimes splitting work between different transactions may be practical and helpful.
When a transaction rollback occurs due to a deadlock or lock wait timeout, it cancels the effect of the statements within the transaction. But if the start-transaction statement was
START TRANSACTIONorBEGINstatement, rollback does not cancel that statement. Further SQL statements become part of the transaction until the occurrence ofCOMMIT,ROLLBACK, or some SQL statement that causes an implicit commit.A duplicate-key error rolls back the SQL statement, if you have not specified the
IGNOREoption in your statement.A
row too long errorrolls back the SQL statement.Other errors are mostly detected by the MySQL layer of code (above the
InnoDBstorage engine level), and they roll back the corresponding SQL statement. Locks are not released in a rollback of a single SQL statement.
During implicit rollbacks, as well as during the execution of an
explicit
ROLLBACK SQL
statement, SHOW PROCESSLIST
displays Rolling back in the
State column for the relevant connection.
The following is a nonexhaustive list of common
InnoDB-specific errors that you may
encounter, with information about why each occurs and how to
resolve the problem.
1005 (ER_CANT_CREATE_TABLE)Cannot create table. If the error message refers to error 150, table creation failed because a foreign key constraint was not correctly formed. If the error message refers to error –1, table creation probably failed because the table includes a column name that matched the name of an internal
InnoDBtable.1016 (ER_CANT_OPEN_FILE)Cannot find the
InnoDBtable from theInnoDBdata files, although the.frmfile for the table exists. See Section 14.2.5.7, “TroubleshootingInnoDBData Dictionary Operations”.1114 (ER_RECORD_FILE_FULL)InnoDBhas run out of free space in the tablespace. Reconfigure the tablespace to add a new data file.1205 (ER_LOCK_WAIT_TIMEOUT)Lock wait timeout expired. Transaction was rolled back.
1206 (ER_LOCK_TABLE_FULL)The total number of locks exceeds the amount of memory
InnoDBdevotes to managing locks. To avoid this error, increase the value ofinnodb_buffer_pool_size. Within an individual application, a workaround may be to break a large operation into smaller pieces. For example, if the error occurs for a largeINSERT, perform several smallerINSERToperations.1213 (ER_LOCK_DEADLOCK)The transaction encountered a deadlock and was automatically rolled back so that your application could take corrective action. To recover from this error, run all the operations in this transaction again. A deadlock occurs when requests for locks arrive in inconsistent order between transactions. Since the transaction that was not rolled back now has all the locks it requested, the situation typically does not recur; your transaction might just have to wait for the other transaction to finish. If you encounter frequent deadlocks, make the sequence of locking operations (
LOCK TABLES,SELECT ... FOR UPDATE, and so on) consistent between the different transactions or applications that experience the issue.1216 (ER_NO_REFERENCED_ROW)You are trying to add a row but there is no parent row, and a foreign key constraint fails. Add the parent row first.
1217 (ER_ROW_IS_REFERENCED)You are trying to delete a parent row that has children, and a foreign key constraint fails. Delete the children first.
To print the meaning of an operating system error number, use the perror program that comes with the MySQL distribution.
The following table provides a list of some common Linux system error codes. For a more complete list, see Linux source code.
Number Macro Description 1 EPERMOperation not permitted 2 ENOENTNo such file or directory 3 ESRCHNo such process 4 EINTRInterrupted system call 5 EIOI/O error 6 ENXIONo such device or address 7 E2BIGArg list too long 8 ENOEXECExec format error 9 EBADFBad file number 10 ECHILDNo child processes 11 EAGAINTry again 12 ENOMEMOut of memory 13 EACCESPermission denied 14 EFAULTBad address 15 ENOTBLKBlock device required 16 EBUSYDevice or resource busy 17 EEXISTFile exists 18 EXDEVCross-device link 19 ENODEVNo such device 20 ENOTDIRNot a directory 21 EISDIRIs a directory 22 EINVALInvalid argument 23 ENFILEFile table overflow 24 EMFILEToo many open files 25 ENOTTYInappropriate ioctl for device 26 ETXTBSYText file busy 27 EFBIGFile too large 28 ENOSPCNo space left on device 29 ESPIPEFile descriptor does not allow seeking 30 EROFSRead-only file system 31 EMLINKToo many links The following table provides a list of some common Windows system error codes. For a complete list, see the Microsoft Web site.
Number Macro Description 1 ERROR_INVALID_FUNCTIONIncorrect function. 2 ERROR_FILE_NOT_FOUNDThe system cannot find the file specified. 3 ERROR_PATH_NOT_FOUNDThe system cannot find the path specified. 4 ERROR_TOO_MANY_OPEN_FILESThe system cannot open the file. 5 ERROR_ACCESS_DENIEDAccess is denied. 6 ERROR_INVALID_HANDLEThe handle is invalid. 7 ERROR_ARENA_TRASHEDThe storage control blocks were destroyed. 8 ERROR_NOT_ENOUGH_MEMORYNot enough storage is available to process this command. 9 ERROR_INVALID_BLOCKThe storage control block address is invalid. 10 ERROR_BAD_ENVIRONMENTThe environment is incorrect. 11 ERROR_BAD_FORMATAn attempt was made to load a program with an incorrect format. 12 ERROR_INVALID_ACCESSThe access code is invalid. 13 ERROR_INVALID_DATAThe data is invalid. 14 ERROR_OUTOFMEMORYNot enough storage is available to complete this operation. 15 ERROR_INVALID_DRIVEThe system cannot find the drive specified. 16 ERROR_CURRENT_DIRECTORYThe directory cannot be removed. 17 ERROR_NOT_SAME_DEVICEThe system cannot move the file to a different disk drive. 18 ERROR_NO_MORE_FILESThere are no more files. 19 ERROR_WRITE_PROTECTThe media is write protected. 20 ERROR_BAD_UNITThe system cannot find the device specified. 21 ERROR_NOT_READYThe device is not ready. 22 ERROR_BAD_COMMANDThe device does not recognize the command. 23 ERROR_CRCData error (cyclic redundancy check). 24 ERROR_BAD_LENGTHThe program issued a command but the command length is incorrect. 25 ERROR_SEEKThe drive cannot locate a specific area or track on the disk. 26 ERROR_NOT_DOS_DISKThe specified disk or diskette cannot be accessed. 27 ERROR_SECTOR_NOT_FOUNDThe drive cannot find the sector requested. 28 ERROR_OUT_OF_PAPERThe printer is out of paper. 29 ERROR_WRITE_FAULTThe system cannot write to the specified device. 30 ERROR_READ_FAULTThe system cannot read from the specified device. 31 ERROR_GEN_FAILUREA device attached to the system is not functioning. 32 ERROR_SHARING_VIOLATIONThe process cannot access the file because it is being used by another process. 33 ERROR_LOCK_VIOLATIONThe process cannot access the file because another process has locked a portion of the file. 34 ERROR_WRONG_DISKThe wrong diskette is in the drive. Insert %2 (Volume Serial Number: %3) into drive %1. 36 ERROR_SHARING_BUFFER_EXCEEDEDToo many files opened for sharing. 38 ERROR_HANDLE_EOFReached the end of the file. 39 ERROR_HANDLE_DISK_FULLThe disk is full. 87 ERROR_INVALID_PARAMETERThe parameter is incorrect. 112 ERROR_DISK_FULLThe disk is full. 123 ERROR_INVALID_NAMEThe file name, directory name, or volume label syntax is incorrect. 1450 ERROR_NO_SYSTEM_RESOURCESInsufficient system resources exist to complete the requested service.
- 14.2.5.1.
InnoDBPerformance Tuning Tips - 14.2.5.2. InnoDB Performance and Scalability Enhancements
- 14.2.5.3.
InnoDBINFORMATION_SCHEMAtables - 14.2.5.4.
SHOW ENGINE INNODB STATUSand theInnoDBMonitors - 14.2.5.5.
InnoDBGeneral Troubleshooting - 14.2.5.6. Starting
InnoDBon a Corrupted Database - 14.2.5.7. Troubleshooting
InnoDBData Dictionary Operations
This section explains the actions to take for
InnoDB issues. Because much of the
InnoDB focus is on performance, many issues are
performance-related. You can use the tips here to track down
problems after they occur, or do advance planning to avoid the
problems entirely.
With InnoDB becoming the default storage
engine in MySQL 5.5 and higher, the tips and guidelines for
InnoDB tables are now part of the main
optimization chapter. See Section 8.5, “Optimizing for InnoDB Tables”.
This section discusses recent InnoDB enhancements to performance and scalability, covering the performance features in MySQL 5.5 and higher, and in the InnoDB Plugin for MySQL 5.1. This information is useful to any DBA or developer who is concerned with performance and scalability. Although some of the enhancements do not require any action on your part, knowing this information can still help you diagnose performance issues more quickly and modernize systems and applications that rely on older, inefficient behavior.
InnoDB has always been highly efficient, and includes several unique architectural elements to assure high performance and scalability. The latest InnoDB storage engine includes new features that take advantage of advances in operating systems and hardware platforms, such as multi-core processors and improved memory allocation systems. In addition, new configuration options let you better control some InnoDB internal subsystems to achieve the best performance with your workload.
Starting with MySQL 5.5 and InnoDB 1.1, the built-in InnoDB
storage engine within MySQL is upgraded to the full feature set
and performance of the former InnoDB Plugin. This change makes
these performance and scalability enhancements available to a much
wider audience than before, and eliminates the separate
installation step of the InnoDB Plugin. After learning about the
InnoDB performance features in this section, continue with
Chapter 8, Optimization to learn the best practices for
overall MySQL performance, and Section 8.5, “Optimizing for InnoDB Tables”
in particular for InnoDB tips and guidelines.
When a transaction is known to be read-only,
InnoDB can avoid the overhead associated with
setting up the transaction
ID (TRX_ID field). The transaction ID is
only needed for a
transaction that might
perform write operations or
locking reads such as
SELECT ... FOR UPDATE. Eliminating these
unnecessary transaction IDs reduces the size of internal data
structures that are consulted each time a query or DML statement
constructs a read view.
Currently, InnoDB detects the read-only nature
of the transaction and applies this optimization when any of the
following conditions are met:
The transaction is started with the
START TRANSACTION READ ONLYstatement. In this case, attempting to make any changes to the database (forInnoDB,MyISAM, or other types of tables) causes an error, and the transaction continues in read-only state:ERROR 1792 (25006): Cannot execute statement in a READ ONLY transaction.
You can still make changes to session-specific temporary tables in a read-only transaction, or issue locking queries for them, because those changes and locks are not visible to any other transaction.
The autocommit setting is turned on, so that the transaction is guaranteed to be a single statement, and the single statement making up the transaction is a “non-locking”
SELECTstatement. That is, aSELECTthat does not use aFOR UPDATEorLOCK IN SHARED MODEclause.
Thus, for a read-intensive application such as a report generator,
you can tune a sequence of InnoDB queries by
grouping them inside START TRANSACTION READ
ONLY and COMMIT, or by turning on the
autocommit setting before running the
SELECT statements, or simply by avoiding any
DML statements interspersed with
the queries.
Because these optimized transactions are kept out of certain
internal InnoDB data structures, they are not
listed in SHOW
ENGINE INNODB STATUS output.
This feature optionally moves the InnoDB
undo log out of the
system tablespace
into one or more separate
tablespaces. The I/O
patterns for the undo log make these new tablespaces good
candidates to move to SSD storage, while keeping the system
tablespace on hard disk storage. Users cannot drop the separate
tablespaces created to hold InnoDB undo logs,
or the individual segments
inside those tablespaces.
Because these files handle I/O operations formerly done inside the system tablespace, we broaden the definition of system tablespace to include these new files.
The undo logs are also known as the rollback segments.
This feature involves the following new or renamed configuration options:
innodb_rollback_segmentsbecomesinnodb_undo_logs. The old name is still available for compatibility.
Usage Notes
To use this feature, follow these steps:
Decide on a path on a fast storage device to hold the undo logs. You will specify that path as the argument to the
innodb_undo_directoryoption in your MySQL configuration file or startup script.Decide on a non-zero starting value for the
innodb_undo_logsoption. You can start with a relatively low value and increase it over time to examine the effect on performance.Decide on a non-zero value for the
innodb_undo_tablespacesoption. The multiple undo logs specified by theinnodb_undo_logsvalue are divided between this many separate tablespaces (represented by.ibdfiles). This value is fixed for the life of the MySQL instance, so if you are uncertain about the optimal value, estimate on the high side.Set up an entirely new MySQL instance for testing, using the values you chose in the configuration file or in your MySQL startup script. Use a realistic workload with data volume similar to your production servers.
Benchmark the performance of I/O intensive workloads.
Periodically increase the value of
innodb_undo_logsand re-do the performance tests. Find the value where you stop experiencing gains in I/O performance.Deploy a new production instance using the ideal settings for these options. Set it up as a slave server in a replication configuration, or transfer data from an earlier production instance.
Performance and Scalability Considerations
Keeping the undo logs in separate files allows the MySQL team to
implement I/O and memory optimizations related to this
transactional data. For example, because the undo data is written
to disk and then rarely used (only in case of crash recovery), it
does not need to be kept in the filesystem memory cache, in turn
allowing a higher percentage of system memory to be devoted to the
InnoDB buffer
pool.
The typical SSD best practice of keeping the
InnoDB system tablespace on a hard drive and
moving the per-table tablespaces to SSD, is assisted by moving the
undo information into separate tablespace files.
Internals
The physical tablespace files are named
undo, where
NN is the space ID, including leading
zeros.
Currently, MySQL instances containing separate undo tablespaces cannot be downgraded to earlier releases such as MySQL 5.5 or 5.1.
The benefits of the InnoDB
file-per-table setting
come with the tradeoff that each
.ibd
file is extended as the data inside the table grows. This I/O
operation can be a bottleneck for busy systems with many
InnoDB tables. When all
InnoDB tables are stored inside the
system tablespace,
this extension operation happens less frequently, as space freed
by DELETE or TRUNCATE
operations within one table can be reused by another table.
MySQL 5.6 improves the concurrency of the extension operation, so
that multiple .ibd files can be extended
simultaneously, and this operation does not block read or write
operations performed by other threads.
The code that detects
deadlocks in
InnoDB
transactions has been
modified to use a fixed-size work area rather than a recursive
algorithm. The resulting detection operation is faster as a
result. You do not need to do anything to take advantage of this
enhancement.
Under both the old and new detection mechanisms, you might
encounter a search too deep error that is not a
true deadlock, but requires you to re-try the transaction the same
way as with a deadlock.
You can enable the configuration option
innodb_checksum_algorithm=crc32
configuration setting to change the
checksum algorithm to a
faster one that scans the block 32 bits at a time rather than 8
bits at a time. When the CRC32 algorithm is enabled, data blocks
that are written to disk by InnoDB contain
different values in their checksum fields than before. This
process could be gradual, with a mix of old and new checksum
values within the same table or database.
For maximum downward compatibility, this setting is off by default:
Current versions of MySQL Enterprise Backup (up to 3.8.0) do not support backing up tablespaces that use crc32 checksums.
.ibdfiles containing crc32 checksums could cause problems downgrading to MySQL versions prior to 5.6.3. MySQL 5.6.3 and up recognizes either the new or old checksum values for the block as correct when reading the block from disk, ensuring that data blocks are compatible during upgrade and downgrade regardless of the algorithm setting. If data written with new checksum values is processed by an level of MySQL earlier than 5.6.3, it could be reported as corrupted.
When you set up a new MySQL instance, and can be sure that all the
InnoDB data is created using the CRC32 checksum
algorithm, you can use the setting
innodb_checksum_algorithm=strict_crc32,
which can be faster than the crc32 setting
because it does not do the extra checksum calculations to support
both old and new values.
The innodb_checksum_algorithm
option has other values that allow it to replace the
innodb_checksums option.
innodb_checksum_algorithm=none is the same as
innodb_checksums=OFF.
innodb_checksum_algorithm=innodb is the same as
innodb_checksums=ON. To avoid conflicts, remove
references to innodb_checksums from your
configuration file and MySQL startup scripts. The new option also
accepts values strict_none and
strict_innodb, again offering better
performance in situations where all InnoDB data
in an instance is created with the same checksum algorithm.
The following table illustrates the difference between the
none, innodb, and
crc32 option values, and their
strict_ counterparts. none,
innodb, and crc32 write the
specified type checksum value into each data block, but for
compatibility accept any of the other checksum values when
verifying a block during a read operation. The
strict_ form of each parameter only recognizes
one kind of checksum, which makes verification faster but requires
that all InnoDB data files in an instance be
created under the identical
innodb_checksum_algorithm value.
Table 14.7. Allowed Settings for innodb_checksum_algorithm
| Value | Generated checksum (when writing) | Allowed checksums (when reading) |
|---|---|---|
| none | A constant number. | Any of the checksums generated by none,
innodb, or crc32. |
| innodb | A checksum calculated in software, using the original algorithm from
InnoDB. | Any of the checksums generated by none,
innodb, or crc32. |
| crc32 | A checksum calculated using the crc32 algorithm,
possibly done with a hardware assist. | Any of the checksums generated by none,
innodb, or crc32. |
| strict_none | A constant number | Only the checksum generated by none. |
| strict_innodb | A checksum calculated in software, using the original algorithm from
InnoDB. | Only the checksum generated by innodb. |
| strict_crc32 | A checksum calculated using the crc32 algorithm,
possibly done with a hardware assist. | Only the checksum generated by crc32. |
After you restart a busy server, there is typically a
warmup period with steadily
increasing throughput, as disk pages that were in the
InnoDB buffer
pool are brought back into memory as the same data is
queried, updated, and so on. Once the buffer pool holds a similar
set of pages as before the restart, many operations are performed
in memory rather than involving disk I/O, and throughput
stabilizes at a high level.
This feature shortens the warmup period by immediately reloading disk pages that were in the buffer pool before the restart, rather than waiting for DML operations to access the corresponding rows. The I/O requests can be performed in large batches, making the overall I/O faster. The page loading happens in the background, and does not delay the database startup.
In addition to saving the buffer pool state at shutdown and restoring it at startup, you can also save or restore the state at any time. For example, you might save the state of the buffer pool after reaching a stable throughput under a steady workload. You might restore the previous buffer pool state after running reports or maintenance jobs that bring data pages into the buffer pool that are only needed during the time period for those operations, or after some other period with a non-typical workload.
Although the buffer pool itself could be many gigabytes in size,
the data that InnoDB saves on disk to restore
the buffer pool is tiny by comparison: just the tablespace and
page IDs necessary to locate the appropriate pages on disk. This
information is derived from the
information_schema table
innodb_buffer_page_lru.
Because the data is cached in and aged out of the buffer pool the same as with regular database operations, there is no problem if the disk pages were updated recently, or if a DML operation involves data that has not yet been loaded. The loading mechanism skips any requested pages that no longer exist.
This feature involves the configuration variables:
and the status variables:
To save the current state of the InnoDB buffer
pool, issue the statement:
SET innodb_buffer_pool_dump_now=ON;
The underlying mechanism involves a background thread that is dispatched to perform the dump and load operations.
By default, the buffer pool state is saved in a file
ib_buffer_pool in the
InnoDB data directory.
Disk pages from compressed tables are loaded into the buffer pool in their compressed form. Uncompression happens as usual when the page contents are accessed in the course of DML operations. Because decompression is a CPU-intensive process, it is more efficient for concurrency to perform that operation in one of the connection threads rather than the single thread that performs the buffer pool restore operation.
Example 14.8. Examples of Dumping and Restoring the InnoDB Buffer Pool
Triggering a dump of the buffer pool manually:
SET innodb_buffer_pool_dump_now=ON;
Specifying that a dump should be taken at shutdown:
SET innodb_buffer_pool_dump_at_shutdown=ON;
Specifying that a dump should be loaded at startup:
mysql> SET innodb_buffer_pool_load_at_startup=ON;
Trigger a load of the buffer pool manually:
mysql> SET innodb_buffer_pool_load_now=ON;
Specify which filename to use for storing the dump to and loading the dump from:
mysql> SET innodb_buffer_pool_filename='filename';
Display progress of dump:
mysql> SHOW STATUS LIKE 'innodb_buffer_pool_dump_status';
or:
SELECT variable_value FROM information_schema.global_status WHERE variable_name = 'INNODB_BUFFER_POOL_DUMP_STATUS';
Outputs any of: not started, Dumping buffer pool 5/7, page 237/2873, Finished at 110505 12:18:02
Display progress of load:
SHOW STATUS LIKE 'innodb_buffer_pool_load_status';
or:
SELECT variable_value FROM information_schema.global_status WHERE variable_name = 'INNODB_BUFFER_POOL_LOAD_STATUS';
Outputs any of: not started, Loaded 123/22301 pages, Finished at 110505 12:23:24
Abort a buffer pool load:
SET innodb_buffer_pool_load_abort=ON;
The new configuration options
innodb_flush_neighbors and
innodb_lru_scan_depth let you
fine-tune certain aspects of the
flushing process for the
InnoDB buffer
pool. These options primarily help write-intensive
workloads. With heavy
DML activity, flushing can fall
behind if it is not aggressive enough, resulting in excessive
memory use in the buffer pool; or, disk writes due to flushing can
saturate your I/O capacity if that mechanism is too aggressive.
The ideal settings depend on your workload, data access patterns,
and storage configuration (for example, whether data is stored on
HDD or
SSD devices).
For systems with constant heavy
workloads, or workloads that
fluctuate widely, several new configuration options let you
fine-tune the flushing behavior
for InnoDB tables:
innodb_adaptive_flushing_lwm,
innodb_max_dirty_pages_pct_lwm,
innodb_io_capacity_max, and
innodb_flushing_avg_loops. These
options feed into an improved formula used by the
innodb_adaptive_flushing option.
The existing
innodb_adaptive_flushing,
innodb_io_capacity and
innodb_max_dirty_pages_pct
options work as before, except that they are limited or extended
by other options:
innodb_adaptive_flushing_lwm,
innodb_io_capacity_max and
innodb_max_dirty_pages_pct_lwm:
The
InnoDBadaptive flushing mechanism is not appropriate in all cases. It gives the most benefit when the redo log is in danger of filling up. Theinnodb_adaptive_flushing_lwmoption specifies a percentage of redo log capacity; when that threshold is crossed,InnoDBturns on adaptive flushing even if not specified by theinnodb_adaptive_flushingoption.If flushing activity falls far behind,
InnoDBcan flush more aggressively than specified byinnodb_io_capacity.innodb_io_capacity_maxrepresents an upper limit on the I/O capacity used in such emergency situations, so that the spike in I/O does not consume all the capacity of the server.When the
innodb_max_dirty_pages_pctthreshold is crossed,InnoDBcan begin aggressively flushing pages to disk. Theinnodb_adaptive_flushing_lwmoption specifies a higher value at whichInnoDBbegins gently flushing pages, ideally preventing the percentage of dirty pages from reachinginnodb_max_dirty_pages_pct. A value ofinnodb_max_dirty_pages_pct_lwm=0disables this “preflushing” behavior.
All of these options are most applicable for servers running heavy
workloads for long periods of time, when there is rarely enough
idle time to catch up with changes waiting to be written to disk.
The innodb_flushing_avg_loops
lets you distinguish between a server that is running at full
capacity 24x7 and one that experiences periodic spikes in
workload. For a server with a consistently high workload, keep
this value high so that the adaptive flushing algorithm responds
immediately to changes in the I/O rate. For a server that
experiences peaks and troughs in its workload, keep this value low
so that InnoDB does not overreact to sudden
spikes in DML activity.
Plan stability is a desirable goal for your biggest and most important queries. InnoDB has always computed statistics for each InnoDB table to help the optimizer find the most efficient query execution plan. Now you can make these statistics persistent, so that the index usage and join order for a particular query is less likely to change.
This feature is on by default, enabled by the configuration option
innodb_stats_persistent.
You control how much sampling is done to collect the statistics by
setting the configuration options
innodb_stats_persistent_sample_pages
and
innodb_stats_transient_sample_pages.
The configuration option
innodb_stats_auto_recalc
determines whether the statistics are calculated automatically
whenever a table undergoes substantial changes (to more than 10%
of the rows). If that setting is disabled, ensure the accuracy of
optimizer statistics by issuing the ANALYZE
TABLE statement for each applicable table after creating
an index or making substantial changes to indexed columns. You
might run this statement in your setup scripts after
representative data has been loaded into the table, and run it
periodically after DML operations significantly change the
contents of indexed columns, or on a schedule at times of low
activity.
To ensure statistics are gathered when a new index is created,
either enable the
innodb_stats_auto_recalc
option, or run ANALYZE TABLE
after creating each new index when the persistent statistics
mode is enabled.
You can also set
innodb_stats_persistent,
innodb_stats_auto_recalc, and
innodb_stats_sample_pages options at the
session level before creating a table, or use the
STATS_PERSISTENT,
STATS_AUTO_RECALC, and
STATS_SAMPLE_PAGES clauses on the
CREATE TABLE and
ALTER TABLE statements, to override
the system-wide setting and configure persistent statistics for
individual tables.
Formerly, these statistics were cleared on each server restart and after some other operations, and recomputed when the table was next accessed. The statistics are computed using a random sampling technique that could produce different estimates the next time, leading to different choices in the execution plan and thus variations in query performance.
To revert to the previous method of collecting statistics that are
periodically erased, run the command ALTER TABLE
.
tbl_name STATS_PERSISTENT=0
The persistent statistics feature relies on the internally managed
tables in the mysql database, named
innodb_table_stats and
innodb_index_stats. These tables are set up
automatically in all install, upgrade, and build-from-source
procedures.
If you manually update the statistics in the tables during
troubleshooting or tuning, issue the command FLUSH TABLE
to make MySQL reload
the updated statistics.
tbl_name
In MySQL and InnoDB, multiple threads of execution access shared data structures. InnoDB synchronizes these accesses with its own implementation of mutexes and read/write locks. InnoDB has historically protected the internal state of a read/write lock with an InnoDB mutex. On Unix and Linux platforms, the internal state of an InnoDB mutex is protected by a Pthreads mutex, as in IEEE Std 1003.1c (POSIX.1c).
On many platforms, there is a more efficient way to implement mutexes and read/write locks. Atomic operations can often be used to synchronize the actions of multiple threads more efficiently than Pthreads. Each operation to acquire or release a lock can be done in fewer CPU instructions, and thus result in less wasted time when threads are contending for access to shared data structures. This in turn means greater scalability on multi-core platforms.
InnoDB implements mutexes and read/write locks with the
built-in
functions provided by the GNU Compiler Collection (GCC) for atomic
memory access instead of using the Pthreads approach
previously used. More specifically, an InnoDB that is compiled
with GCC version 4.1.2 or later uses the atomic builtins instead
of a pthread_mutex_t to implement InnoDB
mutexes and read/write locks.
On 32-bit Microsoft Windows, InnoDB has implemented mutexes (but not read/write locks) with hand-written assembler instructions. Beginning with Microsoft Windows 2000, functions for Interlocked Variable Access are available that are similar to the built-in functions provided by GCC. On Windows 2000 and higher, InnoDB makes use of the Interlocked functions. Unlike the old hand-written assembler code, the new implementation supports read/write locks and 64-bit platforms.
Solaris 10 introduced library functions for atomic operations, and InnoDB uses these functions by default. When MySQL is compiled on Solaris 10 with a compiler that does not support the built-in functions provided by the GNU Compiler Collection (GCC) for atomic memory access, InnoDB uses the library functions.
This change improves the scalability of InnoDB on multi-core systems. This feature is enabled out-of-the-box on the platforms where it is supported. You do not have to set any parameter or option to take advantage of the improved performance. On platforms where the GCC, Windows, or Solaris functions for atomic memory access are not available, InnoDB uses the traditional Pthreads method of implementing mutexes and read/write locks.
When MySQL starts, InnoDB writes a message to the log file
indicating whether atomic memory access is used for mutexes, for
mutexes and read/write locks, or neither. If suitable tools are
used to build InnoDB and the target CPU supports the atomic
operations required, InnoDB uses the built-in functions for
mutexing. If, in addition, the compare-and-swap operation can be
used on thread identifiers (pthread_t), then
InnoDB uses the instructions for read-write locks as well.
Note: If you are building from source, ensure that the build process properly takes advantage of your platform capabilities.
For more information about the performance implications of locking, see Section 8.10, “Optimizing Locking Operations”.
When InnoDB was developed, the memory allocators supplied with
operating systems and run-time libraries were often lacking in
performance and scalability. At that time, there were no memory
allocator libraries tuned for multi-core CPUs. Therefore, InnoDB
implemented its own memory allocator in the mem
subsystem. This allocator is guarded by a single mutex, which may
become a bottleneck. InnoDB
also implements a wrapper interface around the system allocator
(malloc and free) that is
likewise guarded by a single mutex.
Today, as multi-core systems have become more widely available,
and as operating systems have matured, significant improvements
have been made in the memory allocators provided with operating
systems. New memory allocators perform better and are more
scalable than they were in the past. The leading high-performance
memory allocators include Hoard,
libumem, mtmalloc,
ptmalloc, tbbmalloc, and
TCMalloc. Most workloads, especially those
where memory is frequently allocated and released (such as
multi-table joins), benefit from using a more highly tuned memory
allocator as opposed to the internal, InnoDB-specific memory
allocator.
You can control whether InnoDB uses its own memory allocator or an
allocator of the operating system, by setting the value of the
system configuration parameter
innodb_use_sys_malloc in the
MySQL option file (my.cnf or
my.ini). If set to ON or
1 (the default), InnoDB uses the
malloc and free functions of
the underlying system rather than manage memory pools itself. This
parameter is not dynamic, and takes effect only when the system is
started. To continue to use the InnoDB memory allocator, set
innodb_use_sys_malloc to
0.
When the InnoDB memory allocator is disabled, InnoDB ignores the
value of the parameter
innodb_additional_mem_pool_size.
The InnoDB memory allocator uses an additional memory pool for
satisfying allocation requests without having to fall back to
the system memory allocator. When the InnoDB memory allocator is
disabled, all such allocation requests are fulfilled by the
system memory allocator.
On Unix-like systems that use dynamic linking, replacing the
memory allocator may be as easy as making the environment
variable LD_PRELOAD or
LD_LIBRARY_PATH point to the dynamic library
that implements the allocator. On other systems, some relinking
may be necessary. Please refer to the documentation of the
memory allocator library of your choice.
Since InnoDB cannot track all memory use when the system memory
allocator is used
(innodb_use_sys_malloc is
ON), the section “BUFFER POOL AND
MEMORY” in the output of the SHOW ENGINE INNODB
STATUS command only includes the buffer pool
statistics in the “Total memory allocated”. Any
memory allocated using the mem subsystem or
using ut_malloc is excluded.
For more information about the performance implications of InnoDB memory usage, see Section 8.9, “Buffering and Caching”.
When INSERT, UPDATE, and
DELETE operations are done to a table, often
the values of indexed columns (particularly the values of
secondary keys) are not in sorted order, requiring substantial I/O
to bring secondary indexes up to date. InnoDB has an
insert buffer that
caches changes to secondary index entries when the relevant
page is not in the
buffer pool, thus
avoiding I/O operations by not reading in the page from the disk.
The buffered changes are merged when the page is loaded to the
buffer pool, and the updated page is later flushed to disk using
the normal mechanism. The InnoDB main thread merges buffered
changes when the server is nearly idle, and during a
slow shutdown.
Because it can result in fewer disk reads and writes, this feature is most valuable for workloads that are I/O-bound, for example applications with a high volume of DML operations such as bulk inserts.
However, the insert buffer occupies a part of the buffer pool, reducing the memory available to cache data pages. If the working set almost fits in the buffer pool, or if your tables have relatively few secondary indexes, it may be useful to disable insert buffering. If the working set entirely fits in the buffer pool, insert buffering does not impose any extra overhead, because it only applies to pages that are not in the buffer pool.
You can control the extent to which InnoDB performs insert
buffering with the system configuration parameter
innodb_change_buffering. You can
turn on and off buffering for inserts, delete operations (when
index records are initially marked for deletion) and purge
operations (when index records are physically deleted). An update
operation is represented as a combination of an insert and a
delete. In MySQL 5.5 and higher, the default value is changed from
inserts to all.
The allowed values of
innodb_change_buffering
are:
allThe default value: buffer inserts, delete-marking operations, and purges.
noneDo not buffer any operations.
insertsBuffer insert operations.
deletesBuffer delete-marking operations.
changesBuffer both inserts and delete-marking.
purgesBuffer the physical deletion operations that happen in the background.
You can set the value of this parameter in the MySQL option file
(my.cnf or my.ini) or change
it dynamically with the SET GLOBAL command,
which requires the SUPER privilege. Changing
the setting affects the buffering of new operations; the merging
of already buffered entries is not affected.
For more information about speeding up INSERT,
UPDATE, and DELETE
statements, see Section 8.2.2, “Optimizing DML Statements”.
If a table fits almost entirely in main memory, the fastest way to
perform queries on it is to use
hash indexes rather
than B-tree lookups. MySQL
monitors searches on each index defined for an InnoDB table. If it
notices that certain index values are being accessed frequently,
it automatically builds an in-memory hash table for that index.
See Section 14.2.4.12.6, “Adaptive Hash Indexes” for background
information and usage guidelines for the
adaptive hash
index feature and the
innodb_adaptive_hash_index
configuration option.
InnoDB uses operating system threads to process requests from user transactions. (Transactions may issue many requests to InnoDB before they commit or roll back.) On modern operating systems and servers with multi-core processors, where context switching is efficient, most workloads run well without any limit on the number of concurrent threads. Scalability improvements in MySQL 5.5 and up reduce the need to limit the number of concurrently executing threads inside InnoDB.
In situations where it is helpful to minimize context switching between threads, InnoDB can use a number of techniques to limit the number of concurrently executing operating system threads (and thus the number of requests that are processed at any one time). When InnoDB receives a new request from a user session, if the number of threads concurrently executing is at a pre-defined limit, the new request sleeps for a short time before it tries again. A request that cannot be rescheduled after the sleep is put in a first-in/first-out queue and eventually is processed. Threads waiting for locks are not counted in the number of concurrently executing threads.
You can limit the number of concurrent threads by setting the
configuration parameter
innodb_thread_concurrency.
Once the number of executing threads reaches this limit,
additional threads sleep for a number of microseconds, set by the
configuration parameter
innodb_thread_sleep_delay,
before being placed into the queue.
Previously, it required experimentation to find the optimal value
for innodb_thread_sleep_delay, and the optimal
value could change depending on the workload. In MySQL 5.6.3 and
higher, you can set the configuration option
innodb_adaptive_max_sleep_delay
to the highest value you would allow for
innodb_thread_sleep_delay, and InnoDB
automatically adjusts innodb_thread_sleep_delay
up or down depending on the current thread-scheduling activity.
This dynamic adjustment helps the thread scheduling mechanism to
work smoothly during times when the system is lightly loaded and
when it is operating near full capacity.
The default value for
innodb_thread_concurrency
and the implied default limit on the number of concurrent threads
has been changed in various releases of MySQL and InnoDB.
Currently, the default value of
innodb_thread_concurrency is
0, so that by default there is no limit on the
number of concurrently executing threads, as shown in
Table 14.8, “Changes to innodb_thread_concurrency”.
Table 14.8. Changes to innodb_thread_concurrency
| InnoDB Version | MySQL Version | Default value | Default limit of concurrent threads | Value to allow unlimited threads |
|---|---|---|---|---|
| Built-in | Earlier than 5.1.11 | 20 | No limit | 20 or higher |
| Built-in | 5.1.11 and newer | 8 | 8 | 0 |
| InnoDB before 1.0.3 | (corresponding to Plugin) | 8 | 8 | 0 |
| InnoDB 1.0.3 and newer | (corresponding to Plugin) | 0 | No limit | 0 |
Note that InnoDB causes threads to sleep only when the number of
concurrent threads is limited. When there is no limit on the
number of threads, all contend equally to be scheduled. That is,
if innodb_thread_concurrency is
0, the value of
innodb_thread_sleep_delay is
ignored.
When there is a limit on the number of threads, InnoDB reduces
context switching overhead by permitting multiple requests made
during the execution of a single SQL statement to enter InnoDB
without observing the limit set by
innodb_thread_concurrency.
Since an SQL statement (such as a join) may comprise multiple row
operations within InnoDB, InnoDB assigns “tickets”
that allow a thread to be scheduled repeatedly with minimal
overhead.
When a new SQL statement starts, a thread has no tickets, and it
must observe
innodb_thread_concurrency.
Once the thread is entitled to enter InnoDB, it is assigned a
number of tickets that it can use for subsequently entering
InnoDB. If the tickets run out,
innodb_thread_concurrency
is observed again and further tickets are assigned. The number of
tickets to assign is specified by the global option
innodb_concurrency_tickets,
which is 500 by default. A thread that is waiting for a lock is
given one ticket once the lock becomes available.
The correct values of these variables depend on your environment and workload. Try a range of different values to determine what value works for your applications. Before limiting the number of concurrently executing threads, review configuration options that may improve the performance of InnoDB on multi-core and multi-processor computers, such as innodb_use_sys_malloc and innodb_adaptive_hash_index.
For general performance information about MySQL thread handling, see Section 8.11.5.1, “How MySQL Uses Threads for Client Connections”.
A read-ahead request is an I/O request to prefetch multiple pages in the buffer pool asynchronously, in anticipation that these pages will be needed soon. The requests bring in all the pages in one extent. InnoDB uses two read-ahead algorithms to improve I/O performance:
Linear read-ahead is a
technique that predicts what pages might be needed soon based on
pages in the buffer pool being accessed sequentially. You control
when InnoDB performs a read-ahead operation by adjusting the
number of sequential page accesses required to trigger an
asynchronous read request, using the configuration parameter
innodb_read_ahead_threshold.
Before this parameter was added, InnoDB would only calculate
whether to issue an asynchronous prefetch request for the entire
next extent when it read in the last page of the current extent.
The new configuration parameter
innodb_read_ahead_threshold
controls how sensitive InnoDB is in detecting patterns of
sequential page access. If the number of pages read sequentially
from an extent is greater than or equal to
innodb_read_ahead_threshold,
InnoDB initiates an asynchronous read-ahead operation of the
entire following extent. It can be set to any value from 0-64. The
default value is 56. The higher the value, the more strict the
access pattern check. For example, if you set the value to 48,
InnoDB triggers a linear read-ahead request only when 48 pages in
the current extent have been accessed sequentially. If the value
is 8, InnoDB would trigger an asynchronous read-ahead even if as
few as 8 pages in the extent were accessed sequentially. You can
set the value of this parameter in the MySQL
configuration file,
or change it dynamically with the SET GLOBAL
command, which requires the SUPER privilege.
Random read-ahead is a
technique that predicts when pages might be needed soon based on
pages already in the buffer pool, regardless of the order in which
those pages were read. If 13 consecutive pages from the same
extent are found in the buffer pool, InnoDB asynchronously issues
a request to prefetch the remaining pages of the extent. This
feature was initially turned off in MySQL 5.5. It is available
once again starting in MySQL 5.1.59 and 5.5.16 and higher, turned
off by default. To enable this feature, set the configuration
variable
innodb_random_read_ahead.
The SHOW ENGINE INNODB STATUS command displays
statistics to help you evaluate the effectiveness of the
read-ahead algorithm. With the return of random read-ahead in
MySQL 5.6, the SHOW ENGINE INNODB STATUS
command once again includes
Innodb_buffer_pool_read_ahead_rnd.
Innodb_buffer_pool_read_ahead keeps its current
name. (In earlier releases, it was listed as
Innodb_buffer_pool_read_ahead_seq.) See
Section 14.2.6.11, “More Read-Ahead Statistics” for more
information.
For more information about I/O performance, see
Section 8.5.7, “Optimizing InnoDB Disk I/O” and
Section 8.11.3, “Optimizing Disk I/O”.
InnoDB uses background threads
to service various types of I/O requests. You can configure the
number of background threads that service read and write I/O on
data pages, using the configuration parameters
innodb_read_io_threads and
innodb_write_io_threads. These
parameters signify the number of background threads used for read
and write requests respectively. They are effective on all
supported platforms. You can set the value of these parameters in
the MySQL option file (my.cnf or
my.ini); you cannot change them dynamically.
The default value for these parameters is 4 and
the permissible values range from 1-64.
The purpose of this change is to make InnoDB more scalable on high
end systems. Each background thread can handle up to 256 pending
I/O requests. A major source of background I/O is
theread-ahead
requests. InnoDB tries to balance the load of incoming requests in
such way that most of the background threads share work equally.
InnoDB also attempts to allocate read requests from the same
extent to the same thread to increase the chances of coalescing
the requests together. If you have a high end I/O subsystem and
you see more than 64 ×
innodb_read_io_threads pending
read requests in SHOW ENGINE INNODB STATUS, you
might gain by increasing the value of
innodb_read_io_threads.
For more information about InnoDB I/O performance, see
Section 8.5.7, “Optimizing InnoDB Disk I/O”.
Starting in InnoDB 1.1 with MySQL 5.5, the
asynchronous I/O
capability that InnoDB has had on Windows systems is now available
on Linux systems. (Other Unix-like systems continue to use
synchronous I/O calls.) This feature improves the scalability of
heavily I/O-bound systems, which typically show many pending
reads/writes in the output of the command SHOW ENGINE
INNODB STATUS\G.
Running with a large number of InnoDB I/O
threads, and especially running multiple such instances on the
same server machine, can exceed capacity limits on Linux systems.
In this case, you can fix the error:
EAGAIN: The specified maxevents exceeds the user's limit of available events.
by writing a higher limit to
/proc/sys/fs/aio-max-nr.
In general, if a problem with the asynchronous I/O subsystem in
the OS prevents InnoDB from starting, set the option
innodb_use_native_aio=0 in the
configuration file. This new configuration option applies to Linux
systems only, and cannot be changed once the server is running.
For more information about InnoDB I/O performance, see
Section 8.5.7, “Optimizing InnoDB Disk I/O”.
InnoDB, like any other ACID-compliant database engine, flushes the redo log of a transaction before it is committed. Historically, InnoDB used group commit functionality to group multiple such flush requests together to avoid one flush for each commit. With group commit, InnoDB issues a single write to the log file to perform the commit action for multiple user transactions that commit at about the same time, significantly improving throughput.
Group commit in InnoDB worked until MySQL 4.x, and works once again with MySQL 5.1 with the InnoDB Plugin, and MySQL 5.5 and higher. The introduction of support for the distributed transactions and Two Phase Commit (2PC) in MySQL 5.0 interfered with the InnoDB group commit functionality. This issue is now resolved.
The group commit functionality inside InnoDB works with the Two
Phase Commit protocol in MySQL. Re-enabling of the group commit
functionality fully ensures that the ordering of commit in the
MySQL binlog and the InnoDB logfile is the same as it was before.
It means it is totally safe to use the
MySQL Enterprise Backup product with InnoDB 1.0.4 (that
is, the InnoDB Plugin with MySQL 5.1) and above. When the binlog
is enabled, you typically also set the configuration option
sync_binlog=0, because group commit for the
binary log is only supported if it is set to 0.
Group commit is transparent; you do not need to do anything to take advantage of this significant performance improvement.
For more information about performance of
COMMIT and other transactional operations, see
Section 8.5.2, “Optimizing InnoDB Transaction Management”.
The master thread in InnoDB is a thread that performs various tasks in the background. Most of these tasks are I/O related, such as flushing dirty pages from the buffer pool or writing changes from the insert buffer to the appropriate secondary indexes. The master thread attempts to perform these tasks in a way that does not adversely affect the normal working of the server. It tries to estimate the free I/O bandwidth available and tune its activities to take advantage of this free capacity. Historically, InnoDB has used a hard coded value of 100 IOPs (input/output operations per second) as the total I/O capacity of the server.
The parameter
innodb_io_capacity
indicates the overall I/O capacity available to InnoDB. This
parameter should be set to approximately the number of I/O
operations that the system can perform per second. The value
depends on your system configuration. When
innodb_io_capacity is set,
the master threads estimates the I/O bandwidth available for
background tasks based on the set value. Setting the value to
100 reverts to the old behavior.
You can set the value of
innodb_io_capacity to any
number 100 or greater. The default value is
200, reflecting that the performance of typical
modern I/O devices is higher than in the early days of MySQL.
Typically, values around the previous default of 100 are
appropriate for consumer-level storage devices, such as hard
drives up to 7200 RPMs. Faster hard drives, RAID configurations,
and SSDs benefit from higher values.
You can set the value of this parameter in the MySQL option file
(my.cnf or my.ini) or change
it dynamically with the SET GLOBAL command,
which requires the SUPER privilege.
Formerly, the InnoDB master thread also
performed any needed purge
operations. In MySQL 5.6.5 and higher, those I/O operations are
moved to other background threads, whose number is controlled by
the innodb_purge_threads
configuration option.
For more information about InnoDB I/O performance, see
Section 8.5.7, “Optimizing InnoDB Disk I/O”.
InnoDB performs certain tasks in the background, including
flushing of
dirty pages (those
pages that have been changed but are not yet written to the
database files) from the
buffer pool, a task
performed by the master
thread. Currently, InnoDB aggressively flushes buffer pool
pages if the percentage of dirty pages in the buffer pool exceeds
innodb_max_dirty_pages_pct.
InnoDB uses a new algorithm to estimate the required rate of flushing, based on the speed of redo log generation and the current rate of flushing. The intent is to smooth overall performance by ensuring that buffer flush activity keeps up with the need to keep the buffer pool “clean”. Automatically adjusting the rate of flushing can help to avoid steep dips in throughput, when excessive buffer pool flushing limits the I/O capacity available for ordinary read and write activity.
InnoDB uses its log files in a circular fashion. Before reusing a
portion of a log file, InnoDB flushes to disk all dirty buffer
pool pages whose redo entries are contained in that portion of the
log file, a process known as a
sharp checkpoint. If
a workload is write-intensive, it generates a lot of redo
information, all written to the log file. If all available space
in the log files is used up, a sharp checkpoint occurs, causing a
temporary reduction in throughput. This situation can happen even
though innodb_max_dirty_pages_pct
is not reached.
InnoDB uses a heuristic-based algorithm to avoid such a scenario, by measuring the number of dirty pages in the buffer pool and the rate at which redo is being generated. Based on these numbers, InnoDB decides how many dirty pages to flush from the buffer pool each second. This self-adapting algorithm is able to deal with sudden changes in the workload.
Internal benchmarking has also shown that this algorithm not only maintains throughput over time, but can also improve overall throughput significantly.
Because adaptive flushing is a new feature that can significantly
affect the I/O pattern of a workload, a new configuration
parameter lets you turn off this feature. The default value of the
boolean parameter
innodb_adaptive_flushing is
TRUE, enabling the new algorithm. You can set
the value of this parameter in the MySQL option file
(my.cnf or my.ini) or change
it dynamically with the SET GLOBAL command,
which requires the SUPER privilege.
For more information about InnoDB I/O performance, see
Section 8.5.7, “Optimizing InnoDB Disk I/O”.
Synchronization inside InnoDB frequently involves the use of
spin loops: while waiting,
InnoDB executes a tight loop of instructions repeatedly to avoid
having the InnoDB process and
threads be rescheduled by the
operating system. If the spin loops are executed too quickly,
system resources are wasted, imposing a performance penalty on
transaction throughput. Most modern processors implement the
PAUSE instruction for use in spin loops, so the
processor can be more efficient.
InnoDB uses a PAUSE instruction in its spin
loops on all platforms where such an instruction is available.
This technique increases overall performance with CPU-bound
workloads, and has the added benefit of minimizing power
consumption during the execution of the spin loops.
You do not have to do anything to take advantage of this performance improvement.
For performance considerations for InnoDB locking operations, see Section 8.10, “Optimizing Locking Operations”.
Many InnoDB mutexes and rw-locks are reserved for a short time. On a multi-core system, it can be more efficient for a thread to continuously check if it can acquire a mutex or rw-lock for a while before sleeping. If the mutex or rw-lock becomes available during this polling period, the thread can continue immediately, in the same time slice. However, too-frequent polling by multiple threads of a shared object can cause “cache ping pong”, different processors invalidating portions of each others' cache. InnoDB minimizes this issue by waiting a random time between subsequent polls. The delay is implemented as a busy loop.
You can control the maximum delay between testing a mutex or
rw-lock using the parameter
innodb_spin_wait_delay. The
duration of the delay loop depends on the C compiler and the
target processor. (In the 100MHz Pentium era, the unit of delay
was one microsecond.) On a system where all processor cores share
a fast cache memory, you might reduce the maximum delay or disable
the busy loop altogether by setting
innodb_spin_wait_delay=0. On a system with
multiple processor chips, the effect of cache invalidation can be
more significant and you might increase the maximum delay.
The default value of
innodb_spin_wait_delay is
6. The spin wait delay is a dynamic global
parameter that you can specify in the MySQL option file
(my.cnf or my.ini) or change
at runtime with the command SET GLOBAL
innodb_spin_wait_delay=,
where delaydelaySUPER privilege.
For performance considerations for InnoDB locking operations, see Section 8.10, “Optimizing Locking Operations”.
Rather than using a strictly LRU algorithm, InnoDB uses a technique to minimize the amount of data that is brought into the buffer pool and never accessed again. The goal is to make sure that frequently accessed (“hot”) pages remain in the buffer pool, even as read-ahead and full table scans bring in new blocks that might or might not be accessed afterward.
Newly read blocks are inserted into the middle of the list
representing the buffer pool. of the LRU list. All newly read
pages are inserted at a location that by default is
3/8 from the tail of the LRU list. The pages
are moved to the front of the list (the most-recently used end)
when they are accessed in the buffer pool for the first time. Thus
pages that are never accessed never make it to the front portion
of the LRU list, and “age out” sooner than with a
strict LRU approach. This arrangement divides the LRU list into
two segments, where the pages downstream of the insertion point
are considered “old” and are desirable victims for
LRU eviction.
For an explanation of the inner workings of the InnoDB buffer pool
and the specifics of its LRU replacement algorithm, see
Section 8.9.1, “The InnoDB Buffer Pool”.
You can control the insertion point in the LRU list, and choose
whether InnoDB applies the same optimization to blocks brought
into the buffer pool by table or index scans. The configuration
parameter
innodb_old_blocks_pct
controls the percentage of “old” blocks in the LRU
list. The default value of
innodb_old_blocks_pct is
37, corresponding to the original fixed ratio
of 3/8. The value range is 5 (new pages in the
buffer pool age out very quickly) to 95 (only
5% of the buffer pool is reserved for hot pages, making the
algorithm close to the familiar LRU strategy).
The optimization that keeps the buffer pool from being churned by
read-ahead can avoid similar problems due to table or index scans.
In these scans, a data page is typically accessed a few times in
quick succession and is never touched again. The configuration
parameter innodb_old_blocks_time
specifies the time window (in milliseconds) after the first access
to a page during which it can be accessed without being moved to
the front (most-recently used end) of the LRU list. The default
value of innodb_old_blocks_time
is 0, corresponding to the original behavior of
moving a page to the most-recently used end of the buffer pool
list when it is first accessed in the buffer pool. Increasing this
value makes more and more blocks likely to age out faster from the
buffer pool.
Both innodb_old_blocks_pct and
innodb_old_blocks_time are
dynamic, global and can be specified in the MySQL option file
(my.cnf or my.ini) or
changed at runtime with the SET GLOBAL command.
Changing the setting requires the SUPER
privilege.
To help you gauge the effect of setting these parameters, the
SHOW ENGINE INNODB STATUS command reports
additional statistics. The BUFFER POOL AND
MEMORY section looks like:
Total memory allocated 1107296256; in additional pool allocated 0 Dictionary memory allocated 80360 Buffer pool size 65535 Free buffers 0 Database pages 63920 Old database pages 23600 Modified db pages 34969 Pending reads 32 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 414946, not young 2930673 1274.75 youngs/s, 16521.90 non-youngs/s Pages read 486005, created 3178, written 160585 2132.37 reads/s, 3.40 creates/s, 323.74 writes/s Buffer pool hit rate 950 / 1000, young-making rate 30 / 1000 not 392 / 1000 Pages read ahead 1510.10/s, evicted without access 0.00/s LRU len: 63920, unzip_LRU len: 0 I/O sum[43690]:cur[221], unzip sum[0]:cur[0]
Old database pagesis the number of pages in the “old” segment of the LRU list.Pages made youngandnot youngis the total number of “old” pages that have been made young or not respectively.youngs/sandnon-young/sis the rate at which page accesses to the “old” pages have resulted in making such pages young or otherwise respectively since the last invocation of the command.young-making rateandnotprovides the same rate but in terms of overall buffer pool accesses instead of accesses just to the “old” pages.
Because the effects of these parameters can vary widely based on your hardware configuration, your data, and the details of your workload, always benchmark to verify the effectiveness before changing these settings in any performance-critical or production environment.
In mixed workloads where most of the activity is OLTP type with
periodic batch reporting queries which result in large scans,
setting the value of
innodb_old_blocks_time
during the batch runs can help keep the working set of the normal
workload in the buffer pool.
When scanning large tables that cannot fit entirely in the buffer
pool, setting
innodb_old_blocks_pct to a
small value keeps the data that is only read once from consuming a
significant portion of the buffer pool. For example, setting
innodb_old_blocks_pct=5 restricts this data
that is only read once to 5% of the buffer pool.
When scanning small tables that do fit into memory, there is less
overhead for moving pages around within the buffer pool, so you
can leave innodb_old_blocks_pct
at its default value, or even higher, such as
innodb_old_blocks_pct=50.
The effect of the
innodb_old_blocks_time
parameter is harder to predict than the
innodb_old_blocks_pct
parameter, is relatively small, and varies more with the workload.
To arrive at an optimal value, conduct your own benchmarks if the
performance improvement from adjusting
innodb_old_blocks_pct is
not sufficient.
For more information about the InnoDB buffer pool, see
Section 8.9.1, “The InnoDB Buffer Pool”.
A number of optimizations speed up certain steps of the recovery that happens on the next startup after a crash. In particular, scanning the redo log and applying the redo log are faster than in MySQL 5.1 and earlier, due to improved algorithms for memory management. You do not need to take any actions to take advantage of this performance enhancement. If you kept the size of your redo log files artificially low because recovery took a long time, you can consider increasing the file size.
For more information about InnoDB recovery, see
Section 14.2.4.13, “The InnoDB Recovery Process”.
Starting with InnoDB 1.1 with MySQL 5.5, you can profile certain internal InnoDB operations using the MySQL Performance Schema feature. This type of tuning is primarily for expert users, those who push the limits of MySQL performance, read the MySQL source code, and evaluate optimization strategies to overcome performance bottlenecks. DBAs can also use this feature for capacity planning, to see whether their typical workload encounters any performance bottlenecks with a particular combination of CPU, RAM, and disk storage; and if so, to judge whether performance can be improved by increasing the capacity of some part of the system.
To use this feature to examine InnoDB performance:
You must be running MySQL 5.5 or higher. You must build the database server from source, enabling the Performance Schema feature by building with the
--with-perfschemaoption. Since the Performance Schema feature introduces some performance overhead, you should use it on a test or development system rather than on a production system.You must be running InnoDB 1.1 or higher.
You must be generally familiar with how to use the Performance Schema feature, for example to query tables in the
performance_schemadatabase.Examine the following kinds of InnoDB objects by querying the appropriate
performance_schematables. The items associated with InnoDB all contain the substringinnodbin theNAMEcolumn.For the definitions of the
*_instancestables, see Section 20.9.2, “Performance Schema Instance Tables”. For the definitions of the*_summary_*tables, see Section 20.9.8, “Performance Schema Summary Tables”. For the definition of thethreadtable, see Section 20.9.9, “Performance Schema Miscellaneous Tables”. For the definition of the*_current_*and*_history_*tables, see Section 20.9.3, “Performance Schema Wait Event Tables”.Mutexes in the
mutex_instancestable. (Mutexes and RW-locks related to theInnoDBbuffer pool are not included in this coverage; the same applies to the output of theSHOW ENGINE INNODB MUTEXcommand.)RW-locks in the
rwlock_instancestable.RW-locks in the
rwlock_instancestable.File I/O operations in the
file_instances,file_summary_by_event_name, andfile_summary_by_instancetables.Threads in the
PROCESSLISTtable.
During performance testing, examine the performance data in the
events_waits_currentandevents_waits_history_longtables. If you are interested especially in InnoDB-related objects, use the clausewhere name like "%innodb%"to see just those entries; otherwise, examine the performance statistics for the overall MySQL server.You must be running MySQL 5.5, with the Performance Schema enabled by building with the
--with-perfschemabuild option.
For more information about the MySQL Performance Schema, see Chapter 20, MySQL Performance Schema.
This performance enhancement is primarily useful for people with a
large buffer pool size,
typically in the multi-gigabyte range. To take advantage of this
speedup, you must set the new
innodb_buffer_pool_instances
configuration option, and you might also adjust the
innodb_buffer_pool_size value.
When the InnoDB buffer pool is large, many data requests can be satisfied by retrieving from memory. You might encounter bottlenecks from multiple threads trying to access the buffer pool at once. Starting in InnoDB 1.1 and MySQL 5.5, you can enable multiple buffer pools to minimize this contention. Each page that is stored in or read from the buffer pool is assigned to one of the buffer pools randomly, using a hashing function. Each buffer pool manages its own free lists, flush lists, LRUs, and all other data structures connected to a buffer pool, and is protected by its own buffer pool mutex.
To enable this feature, set the
innodb_buffer_pool_instances configuration
option to a value greater than 1 (the default) up to 64 (the
maximum). This option takes effect only when you set the
innodb_buffer_pool_size to a size of 1 gigabyte
or more. The total size you specify is divided among all the
buffer pools. For best efficiency, specify a combination of
innodb_buffer_pool_instances and
innodb_buffer_pool_size so that
each buffer pool instance is at least 1 gigabyte.
For more information about the InnoDB buffer pool, see
Section 8.9.1, “The InnoDB Buffer Pool”.
Starting in InnoDB 1.1 with MySQL 5.5, the limit on concurrent transactions is greatly expanded, removing a bottleneck with the InnoDB rollback segment that affected high-capacity systems. The limit applies to concurrent transactions that change any data; read-only transactions do not count against that maximum.
The single rollback segment is now divided into 128 segments, each of which can support up to 1023 transactions that perform writes, for a total of approximately 128K concurrent transactions. The original transaction limit was 1023.
Each transaction is assigned to one of the rollback segments, and remains tied to that rollback segment for the duration. This enhancement improves both scalability (higher number of concurrent transactions) and performance (less contention when different transactions access the rollback segments).
To take advantage of this feature, you do not need to create any new database or tables, or reconfigure anything. You must do a slow shutdown before upgrading from MySQL 5.1 or earlier, or some time afterward. InnoDB makes the required changes inside the system tablespace automatically, the first time you restart after performing a slow shutdown.
If your workload was not constrained by the original limit of 1023
concurrent transactions, you can reduce the number of rollback
segments used within a MySQL instance or within a session by
setting the configuration option
innodb_rollback_segments.
For more information about performance of InnoDB under high
transactional load, see
Section 8.5.2, “Optimizing InnoDB Transaction Management”.
The purge operations (a type of garbage collection) that InnoDB performs automatically is now done in one or more separate threads, rather than as part of the master thread. This change improves scalability, because the main database operations run independently from maintenance work happening in the background.
To control this feature, increase the value of the configuration
option
innodb_purge_threads=.
If DML action is concentrated on a single table or a few tables,
keep the setting low so that the threads do not contend with each
other for access to the busy tables. If DML operations are spread
across many tables, increase the setting. Its maximum is 32.
n
There is another related configuration option,
innodb_purge_batch_size with a default of 20
and maximum of 5000. This option is mainly intended for
experimentation and tuning of purge operations, and should not be
interesting to typical users.
For more information about InnoDB I/O performance, see
Section 8.5.7, “Optimizing InnoDB Disk I/O”.
This is another performance improvement that comes for free, with no user action or configuration needed. The details here are intended for performance experts who delve into the InnoDB source code, or interpret reports with keywords such as “mutex” and “log_sys”.
The mutex known as the log sys
mutex has historically done double duty, controlling access to
internal data structures related to log records and the
LSN, as well as pages in the
buffer pool that are
changed when a
mini-transaction is
committed. Starting in InnoDB 1.1 with MySQL 5.5, these two kinds
of operations are protected by separate mutexes, with a new
log_buf mutex controlling writes to buffer pool
pages due to mini-transactions.
For performance considerations for InnoDB locking operations, see Section 8.10, “Optimizing Locking Operations”.
Starting with InnoDB 1.1 with MySQL 5.5, concurrent access to the buffer pool is faster. Operations involving the flush list, a data structure related to the buffer pool, are now controlled by a separate mutex and do not block access to the buffer pool. You do not need to configure anything to take advantage of this speedup; it is fully automatic.
For more information about the InnoDB buffer pool, see
Section 8.9.1, “The InnoDB Buffer Pool”.
The mutex controlling concurrent
access to the InnoDB kernel is now divided into
separate mutexes and rw-locks
to reduce contention. You do not need to configure anything to
take advantage of this speedup; it is fully automatic.
To ease the memory load on systems with huge numbers of tables,
InnoDB now frees up the memory associated with an opened table,
using an LRU algorithm to select tables that have gone the longest
without being accessed. To reserve more memory to hold metadata
for open InnoDB tables, increase the value of the
table_definition_cache
configuration option. InnoDB treats this value as a “soft
limit”. The actual number of tables with cached metadata
could be higher, because metadata for InnoDB system tables, and
parent and child tables in foreign key relationships, is never
evicted from memory.
Several new features extend the file-per-table mode enabled by the
innodb_file_per_table
configuration option, allowing more flexibility in how the
.ibd files are placed, exported, and
restored. We characterize this as a performance enhancement
because it solves the common customer request to put data from
different tables onto different storage devices, for best
price/performance depending on the access patterns of the data.
For example, tables with high levels of random reads and writes
might be placed on an SSD device,
while less-often-accessed data or data processed with large
batches of sequential I/O might be placed on an
HDD device. See
Section 14.2.2.1, “Managing InnoDB Tablespaces” for details.
The memcached daemon is frequently used as an
in-memory caching layer in front of a MySQL database server. Now
MySQL allows direct access to InnoDB tables
using the familiar memcached protocol and
client libraries. Instead of formulating queries in SQL, you can
perform simple get, set, and increment operations that avoid the
performance overhead of SQL parsing and constructing a query
optimization plan. You can also access the underlying
InnoDB tables through SQL to load data,
generate reports, or perform multi-step transactional
computations.
This technique allows the data to be stored in MySQL for reliability and consistency, while coding application logic that uses the database as a fast key-value store.
This feature combines the best of both worlds:
Data that is written using the memcached protocol is transparently written to an InnoDB table, without going through the MySQL SQL layer. You can control the frequency of writes to achieve higher raw performance when updating non-critical data.
Data that is requested data through the memcached protocol is transparently queried from an InnoDB table, without going through the MySQL SQL layer.
Subsequent requests for the same data will be served from the
InnoDBbuffer pool. The buffer pool handles the in-memory caching. You can tune the performance of data-intensive operations using the familiarInnoDBconfiguration options.InnoDB can handle composing and decomposing multiple column values into a single memcached item value, reducing the amount of string parsing and concatenation required in your application. For example, you might store a string value
2|4|6|8in the memcached cache, and InnoDB splits that value based on a separator character, then stores the result into four numeric columns.
For details on using this NoSQL-style interface to MySQL, see
Section 14.2.10, “InnoDB Integration with memcached”. For additional background on
memcached and considerations for writing
applications for its API, see Section 15.6, “Using MySQL with memcached”.
This feature is a continuation of the “Fast Index Creation” feature introduced in Fast Index Creation in the InnoDB Storage Engine. Now you can perform other kinds of DDL operations on InnoDB tables online: that is, with minimal delay for operations on that table, without rebuilding the entire table, or both. This enhancement improves responsiveness and availability in busy production environments, where making a table unavailable for minutes or hours whenever its column definitions change is not practical.
For full details, see Section 14.2.2.6, “Online DDL for InnoDB Tables”.
The DDL operations enhanced by this feature are these variations
on the ALTER TABLE statement:
Create secondary indexes:
CREATE INDEXornameONtable(col_list)ALTER TABLE. (Creating a primary key or atableADD INDEXname(col_list)FULLTEXTindex still requires locking the table.)Drop secondary indexes:
DROP INDEXornameONtable;ALTER TABLEtableDROP INDEXnameCreating and dropping secondary indexes on
InnoDBtables has avoided the table-copying behavior since the days of MySQL 5.1 with theInnoDBPlugin. Now, the table remains available for read and write operations while the index is being created or dropped. TheCREATE TABLEorDROP TABLEstatement only finishes after all transactions that are modifying the table are completed, so that the initial state of the index reflects the most recent contents of the table.Previously, modifying the table while an index was being created or dropped typically resulted in a deadlock that cancelled the insert, update, or delete statement on the table.
Changing the auto-increment value for a column:
ALTER TABLEtableAUTO_INCREMENT=next_value;Especially in a distributed system using replication or sharding, you sometimes reset the auto-increment counter for a table to a specific value. The next row inserted into the table uses the specified value for its auto-increment column. You might also use this technique in a data warehousing environment where you periodically empty all the tables and reload them, and you can restart the auto-increment sequence from 1.
Adding or dropping a foreign key constraint:
ALTER TABLE
tbl1ADD CONSTRAINTfk_nameFOREIGN KEYindex(col1) REFERENCEStbl2(col2)referential_actions; ALTER TABLEtblDROP FOREIGN KEYfk_name;Dropping a foreign key can be performed online with the
foreign_key_checksoption enabled or disabled. Creating a foreign key online requiresforeign_key_checksto be disabled.If you do not know the names of the foreign key constraints on a particular table, issue the following statement and find the constraint name in the
CONSTRAINTclause for each foreign key:show create table
table\GOr, query the
information_schema.table_constraintstable and use theconstraint_nameandconstraint_typecolumns to identify the foreign key names.As a consequence of this enhancement, you can now also drop a foreign key and its associated index in a single statement, which previously required separate statements in a strict order:
ALTER TABLE
tableDROP FOREIGN KEYconstraint, DROP INDEXindex;Renaming a column:
ALTER TABLEtblCHANGEold_col_namenew_col_namedatatypeWhen you keep the same data type and only change the column name, this operation can always be performed online. As part of this enhancement, you can now rename a column that is part of a foreign key constraint, which was not allowed before.
Some other
ALTER TABLEoperations are non-blocking, and are faster than before because the table-copying operation is optimized, even though a table copy is still required:Changing the
ROW_FORMATorKEY_BLOCK_SIZEproperties for a table.Changing the nullable status for a column.
Adding, dropping, or reordering columns.
As your database schema evolves with new columns, data types,
constraints, indexes, and so on, keep your
CREATE TABLE statements up to
date with the latest table definitions. Even with the
performance improvements of online DDL, it is more efficient to
create stable database structures at the beginning, rather than
creating part of the schema and then issuing
ALTER TABLE statements afterward.
The main exception to this guideline is for secondary indexes on tables with large numbers of rows. It is typically most efficient to create the table with all details specified except the secondary indexes, load the data, then create the secondary indexes.
Whatever sequence of CREATE
TABLE, CREATE INDEX,
ALTER TABLE, and similar
statements went into putting a table together, you can capture
the SQL needed to reconstruct the current form of the table by
issuing the statement SHOW CREATE TABLE
(uppercase
table\G\G required for tidy formatting). This output
shows clauses such as numeric precision, NOT
NULL, and CHARACTER SET that are
sometimes added behind the scenes, and you might otherwise leave
out when cloning the table on a new system or setting up foreign
key columns with identical type.
The
INFORMATION_SCHEMA
is a MySQL feature that helps you monitor server activity to
diagnose capacity and performance issues. Several InnoDB-related
INFORMATION_SCHEMA tables
(INNODB_CMP,
INNODB_CMP_RESET,
INNODB_CMPMEM,
INNODB_CMPMEM_RESET,
INNODB_TRX,
INNODB_LOCKS
and
INNODB_LOCK_WAITS)
contain live information about compressed InnoDB tables, the
compressed InnoDB buffer pool, all transactions currently executing
inside InnoDB, the locks that transactions hold and those that are
blocking transactions waiting for access to a resource (a table or
row).
This section describes the InnoDB-related Information Schema tables and shows some examples of their use.
Two new pairs of Information Schema tables can give you some insight into how well compression is working overall. One pair of tables contains information about the number of compression operations and the amount of time spent performing compression. Another pair of tables contains information on the way memory is allocated for compression.
The tables
INNODB_CMP
and
INNODB_CMP_RESET
contain status information on the operations related to
compressed tables, which are covered in
Section 14.2.2.7, “InnoDB Data Compression”. The compressed
page size is in the column
PAGE_SIZE.
These two tables have identical contents, but reading from
INNODB_CMP_RESET
resets the statistics on compression and uncompression
operations. For example, if you archive the output of
INNODB_CMP_RESET
every 60 minutes, you see the statistics for each hourly period.
If you monitor the output of
INNODB_CMP
(making sure never to read INNODB_CMP_RESET),
you see the cumulated statistics since InnoDB was started.
For the table definition, see
Table 19.1, “Columns of INNODB_CMP and
INNODB_CMP_RESET”.
The tables
INNODB_CMPMEM
and
INNODB_CMPMEM_RESET
contain status information on the compressed pages that reside
in the buffer pool. Please consult
Section 14.2.2.7, “InnoDB Data Compression” for further information on
compressed tables and the use of the buffer pool. The tables
INNODB_CMP
and
INNODB_CMP_RESET
should provide more useful statistics on compression.
InnoDB uses a buddy allocator system to manage memory allocated to pages of various sizes, from 1KB to 16KB. Each row of the two tables described here corresponds to a single page size.
These two tables have identical contents, but reading from
INNODB_CMPMEM_RESET
resets the statistics on relocation operations. For example, if
every 60 minutes you archived the output of
INNODB_CMPMEM_RESET,
it would show the hourly statistics. If you never read
INNODB_CMPMEM_RESET
and monitored the output of
INNODB_CMPMEM
instead, it would show the cumulated statistics since InnoDB was
started.
For the table definition, see Table 19.3, “Columns of INNODB_CMPMEM and INNODB_CMPMEM_RESET”.
Example 14.9. Using the Compression Information Schema Tables
The following is sample output from a database that contains
compressed tables (see Section 14.2.2.7, “InnoDB Data Compression”,
INNODB_CMP,
and
INNODB_CMPMEM).
The following table shows the contents of
INFORMATION_SCHEMA.INNODB_CMP under a light
workload. The only
compressed page size that the buffer pool contains is 8K.
Compressing or uncompressing pages has consumed less than a
second since the time the statistics were reset, because the
columns COMPRESS_TIME and
UNCOMPRESS_TIME are zero.
| page size | compress ops | compress ops ok | compress time | uncompress ops | uncompress time |
|---|---|---|---|---|---|
| 1024 | 0 | 0 | 0 | 0 | 0 |
| 2048 | 0 | 0 | 0 | 0 | 0 |
| 4096 | 0 | 0 | 0 | 0 | 0 |
| 8192 | 1048 | 921 | 0 | 61 | 0 |
| 16384 | 0 | 0 | 0 | 0 | 0 |
According to
INNODB_CMPMEM,
there are 6169 compressed 8KB pages in the buffer pool. The
only other allocated block size is 64 bytes. The smallest
PAGE_SIZE in
INNODB_CMPMEM
is used for block descriptors of those compressed pages for
which no uncompressed page exists in the buffer pool. We see
that there are 5910 such pages. Indirectly, we see that 259
(6169-5910) compressed pages also exist in the buffer pool in
uncompressed form.
The following table shows the contents of
INFORMATION_SCHEMA.INNODB_CMPMEM under a
light workload. Some
memory is unusable due to fragmentation of the InnoDB memory
allocator for compressed pages:
SUM(PAGE_SIZE*PAGES_FREE)=6784. This is
because small memory allocation requests are fulfilled by
splitting bigger blocks, starting from the 16K blocks that are
allocated from the main buffer pool, using the buddy
allocation system. The fragmentation is this low, because some
allocated blocks have been relocated (copied) to form bigger
adjacent free blocks. This copying of
SUM(PAGE_SIZE*RELOCATION_OPS) bytes has
consumed less than a second
(SUM(RELOCATION_TIME)=0).
Three InnoDB-related Information Schema tables make it easy to
monitor transactions and diagnose possible locking problems. The
three tables are
INNODB_TRX,
INNODB_LOCKS
and
INNODB_LOCK_WAITS.
Contains information about every transaction currently executing inside InnoDB, including whether the transaction is waiting for a lock, when the transaction started, and the particular SQL statement the transaction is executing.
For the table definition, see
Table 19.4, “INNODB_TRX Columns”.
Each transaction in InnoDB that is waiting for another
transaction to release a lock
(INNODB_TRX.TRX_STATE='LOCK WAIT') is blocked
by exactly one “blocking lock request”. That
blocking lock request is for a row or table lock held by another
transaction in an incompatible mode. The waiting or blocked
transaction cannot proceed until the other transaction commits
or rolls back, thereby releasing the requested lock. For every
blocked transaction,
INNODB_LOCKS
contains one row that describes each lock the transaction has
requested, and for which it is waiting.
INNODB_LOCKS
also contains one row for each lock that is blocking another
transaction, whatever the state of the transaction that holds
the lock ('RUNNING', 'LOCK
WAIT', 'ROLLING BACK' or
'COMMITTING'). The lock that is blocking a
transaction is always held in a mode (read vs. write, shared vs.
exclusive) incompatible with the mode of requested lock.
For the table definition, see
Table 19.5, “INNODB_LOCKS Columns”.
Using this table, you can tell which transactions are waiting
for a given lock, or for which lock a given transaction is
waiting. This table contains one or more rows for each
blocked transaction, indicating the lock it
has requested and the lock(s) that is (are) blocking that
request. The REQUESTED_LOCK_ID refers to the
lock that a transaction is requesting, and the
BLOCKING_LOCK_ID refers to the lock (held by
another transaction) that is preventing the first transaction
from proceeding. For any given blocked transaction, all rows in
INNODB_LOCK_WAITS
have the same value for REQUESTED_LOCK_ID and
different values for BLOCKING_LOCK_ID.
For the table definition, see
Table 19.6, “INNODB_LOCK_WAITS Columns”.
Example 14.10. Identifying Blocking Transactions
It is sometimes helpful to be able to identify which transaction is blocking another. You can use the Information Schema tables to find out which transaction is waiting for another, and which resource is being requested.
Suppose you have the following scenario, with three users running concurrently. Each user (or session) corresponds to a MySQL thread, and executes one transaction after another. Consider the state of the system when these users have issued the following commands, but none has yet committed its transaction:
User A:BEGIN; SELECT a FROM t FOR UPDATE; SELECT SLEEP(100);
User B:SELECT b FROM t FOR UPDATE;
User C:SELECT c FROM t FOR UPDATE;
In this scenario, you can use this query to see who is waiting for whom:
SELECT r.trx_id waiting_trx_id,
r.trx_mysql_thread_id waiting_thread,
r.trx_query waiting_query,
b.trx_id blocking_trx_id,
b.trx_mysql_thread_id blocking_thread,
b.trx_query blocking_query
FROM information_schema.innodb_lock_waits w
INNER JOIN information_schema.innodb_trx b ON
b.trx_id = w.blocking_trx_id
INNER JOIN information_schema.innodb_trx r ON
r.trx_id = w.requesting_trx_id;
| waiting trx id | waiting thread | waiting query | blocking trx id | blocking thread | blocking query |
|---|---|---|---|---|---|
A4 | 6 | SELECT b FROM t FOR UPDATE | A3 | 5 | SELECT SLEEP(100) |
A5 | 7 | SELECT c FROM t FOR UPDATE | A3 | 5 | SELECT SLEEP(100) |
A5 | 7 | SELECT c FROM t FOR UPDATE | A4 | 6 | SELECT b FROM t FOR UPDATE |
In the above result, you can identify users by the “waiting query” or “blocking query”. As you can see:
User B (trx id
'A4', thread6) and User C (trx id'A5', thread7) are both waiting for User A (trx id'A3', thread5).User C is waiting for User B as well as User A.
You can see the underlying data in the tables
INNODB_TRX,
INNODB_LOCKS,
and
INNODB_LOCK_WAITS.
The following table shows some sample contents of INFORMATION_SCHEMA.INNODB_TRX.
| trx id | trx state | trx started | trx requested lock id | trx wait started | trx weight | trx mysql thread id | trx query |
|---|---|---|---|---|---|---|---|
A3 | RUNNING | 2008-01-15 16:44:54 | NULL | NULL | 2 | 5 | SELECT SLEEP(100) |
A4 | LOCK WAIT | 2008-01-15 16:45:09 | A4:1:3:2 | 2008-01-15 16:45:09 | 2 | 6 | SELECT b FROM t FOR UPDATE |
A5 | LOCK WAIT | 2008-01-15 16:45:14 | A5:1:3:2 | 2008-01-15 16:45:14 | 2 | 7 | SELECT c FROM t FOR UPDATE |
The following table shows some sample contents of
INFORMATION_SCHEMA.INNODB_LOCKS.
| lock id | lock trx id | lock mode | lock type | lock table | lock index | lock space | lock page | lock rec | lock data |
|---|---|---|---|---|---|---|---|---|---|
A3:1:3:2 | A3 | X | RECORD | `test`.`t` | `PRIMARY` | 1 | 3 | 2 | 0x0200 |
A4:1:3:2 | A4 | X | RECORD | `test`.`t` | `PRIMARY` | 1 | 3 | 2 | 0x0200 |
A5:1:3:2 | A5 | X | RECORD | `test`.`t` | `PRIMARY` | 1 | 3 | 2 | 0x0200 |
The following table shows some sample contents of
INFORMATION_SCHEMA.INNODB_LOCK_WAITS.
Example 14.11. More Complex Example of Transaction Data in Information Schema Tables
Sometimes you would like to correlate the internal InnoDB locking information with session-level information maintained by MySQL. For example, you might like to know, for a given InnoDB transaction ID, the corresponding MySQL session ID and name of the user that may be holding a lock, and thus blocking another transaction.
The following output from the
INFORMATION_SCHEMA tables is taken from a
somewhat loaded system.
As can be seen in the following tables, there are several transactions running.
The following INNODB_LOCKS and
INNODB_LOCK_WAITS tables shows that:
Transaction
77F(executing anINSERT) is waiting for transactions77E,77Dand77Bto commit.Transaction
77E(executing an INSERT) is waiting for transactions77Dand77Bto commit.Transaction
77D(executing an INSERT) is waiting for transaction77Bto commit.Transaction
77B(executing an INSERT) is waiting for transaction77Ato commit.Transaction
77Ais running, currently executingSELECT.Transaction
E56(executing anINSERT) is waiting for transactionE55to commit.Transaction
E55(executing anINSERT) is waiting for transaction19Cto commit.Transaction
19Cis running, currently executing anINSERT.
Note that there may be an inconsistency between queries shown
in the two tables INNODB_TRX.TRX_QUERY and
PROCESSLIST.INFO. The current transaction
ID for a thread, and the query being executed in that
transaction, may be different in these two tables for any
given thread. See
Section 14.2.5.3.4.3, “Possible Inconsistency with PROCESSLIST”
for an explanation.
The following table shows the contents of
INFORMATION_SCHEMA.PROCESSLIST in a system
running a heavy workload.
| ID | USER | HOST | DB | COMMAND | TIME | STATE | INFO |
|---|---|---|---|---|---|---|---|
384 | root | localhost | test | Query | 10 | update | insert into t2 values … |
257 | root | localhost | test | Query | 3 | update | insert into t2 values … |
130 | root | localhost | test | Query | 0 | update | insert into t2 values … |
61 | root | localhost | test | Query | 1 | update | insert into t2 values … |
8 | root | localhost | test | Query | 1 | update | insert into t2 values … |
4 | root | localhost | test | Query | 0 | preparing | SELECT * FROM processlist |
2 | root | localhost | test | Sleep | 566 | | NULL |
The following table shows the contents of
INFORMATION_SCHEMA.INNODB_TRX in a system
running a heavy workload.
| trx id | trx state | trx started | trx requested lock id | trx wait started | trx weight | trx mysql thread id | trx query |
|---|---|---|---|---|---|---|---|
77F | LOCK WAIT | 2008-01-15 13:10:16 | 77F:806 | 2008-01-15 13:10:16 | 1 | 876 | insert into t09 (D, B, C) values … |
77E | LOCK WAIT | 2008-01-15 13:10:16 | 77E:806 | 2008-01-15 13:10:16 | 1 | 875 | insert into t09 (D, B, C) values … |
77D | LOCK WAIT | 2008-01-15 13:10:16 | 77D:806 | 2008-01-15 13:10:16 | 1 | 874 | insert into t09 (D, B, C) values … |
77B | LOCK WAIT | 2008-01-15 13:10:16 | 77B:733:12:1 | 2008-01-15 13:10:16 | 4 | 873 | insert into t09 (D, B, C) values … |
77A | RUNNING | 2008-01-15 13:10:16 | NULL | NULL | 4 | 872 | select b, c from t09 where … |
E56 | LOCK WAIT | 2008-01-15 13:10:06 | E56:743:6:2 | 2008-01-15 13:10:06 | 5 | 384 | insert into t2 values … |
E55 | LOCK WAIT | 2008-01-15 13:10:06 | E55:743:38:2 | 2008-01-15 13:10:13 | 965 | 257 | insert into t2 values … |
19C | RUNNING | 2008-01-15 13:09:10 | NULL | NULL | 2900 | 130 | insert into t2 values … |
E15 | RUNNING | 2008-01-15 13:08:59 | NULL | NULL | 5395 | 61 | insert into t2 values … |
51D | RUNNING | 2008-01-15 13:08:47 | NULL | NULL | 9807 | 8 | insert into t2 values … |
The following table shows the contents of
INFORMATION_SCHEMA.INNODB_LOCK_WAITS in a
system running a heavy
workload.
| requesting trx id | requested lock id | blocking trx id | blocking lock id |
|---|---|---|---|
77F | 77F:806 | 77E | 77E:806 |
77F | 77F:806 | 77D | 77D:806 |
77F | 77F:806 | 77B | 77B:806 |
77E | 77E:806 | 77D | 77D:806 |
77E | 77E:806 | 77B | 77B:806 |
77D | 77D:806 | 77B | 77B:806 |
77B | 77B:733:12:1 | 77A | 77A:733:12:1 |
E56 | E56:743:6:2 | E55 | E55:743:6:2 |
E55 | E55:743:38:2 | 19C | 19C:743:38:2 |
The following table shows the contents of
INFORMATION_SCHEMA.INNODB_LOCKS in a system
running a heavy workload.
| lock id | lock trx id | lock mode | lock type | lock table | lock index | lock space | lock page | lock rec | lock data |
|---|---|---|---|---|---|---|---|---|---|
77F:806 | 77F | AUTO_INC | TABLE | `test`.`t09` | NULL | NULL | NULL | NULL | NULL |
77E:806 | 77E | AUTO_INC | TABLE | `test`.`t09` | NULL | NULL | NULL | NULL | NULL |
77D:806 | 77D | AUTO_INC | TABLE | `test`.`t09` | NULL | NULL | NULL | NULL | NULL |
77B:806 | 77B | AUTO_INC | TABLE | `test`.`t09` | NULL | NULL | NULL | NULL | NULL |
77B:733:12:1 | 77B | X | RECORD | `test`.`t09` | `PRIMARY` | 733 | 12 | 1 | supremum pseudo-record |
77A:733:12:1 | 77A | X | RECORD | `test`.`t09` | `PRIMARY` | 733 | 12 | 1 | supremum pseudo-record |
E56:743:6:2 | E56 | S | RECORD | `test`.`t2` | `PRIMARY` | 743 | 6 | 2 | 0, 0 |
E55:743:6:2 | E55 | X | RECORD | `test`.`t2` | `PRIMARY` | 743 | 6 | 2 | 0, 0 |
E55:743:38:2 | E55 | S | RECORD | `test`.`t2` | `PRIMARY` | 743 | 38 | 2 | 1922, 1922 |
19C:743:38:2 | 19C | X | RECORD | `test`.`t2` | `PRIMARY` | 743 | 38 | 2 | 1922, 1922 |
A set of related INFORMATION_SCHEMA tables
contains information about FULLTEXT search
indexes on InnoDB tables:
When a transaction updates a row in a table, or locks it with
SELECT FOR UPDATE, InnoDB establishes a list
or queue of locks on that row. Similarly, InnoDB maintains a
list of locks on a table for table-level locks transactions
hold. If a second transaction wants to update a row or lock a
table already locked by a prior transaction in an incompatible
mode, InnoDB adds a lock request for the row to the
corresponding queue. For a lock to be acquired by a transaction,
all incompatible lock requests previously entered into the lock
queue for that row or table must be removed (the transactions
holding or requesting those locks either commit or roll back).
A transaction may have any number of lock requests for different
rows or tables. At any given time, a transaction may be
requesting a lock that is held by another transaction, in which
case it is blocked by that other transaction. The requesting
transaction must wait for the transaction that holds the
blocking lock to commit or rollback. If a transaction is not
waiting for a a lock, it is in the 'RUNNING'
state. If a transaction is waiting for a lock, it is in the
'LOCK WAIT' state.
The table
INNODB_LOCKS
holds one or more row for each 'LOCK WAIT'
transaction, indicating the lock request(s) that is (are)
preventing its progress. This table also contains one row
describing each lock in a queue of locks pending for a given row
or table. The table
INNODB_LOCK_WAITS
shows which locks already held by a transaction are blocking
locks requested by other transactions.
The data exposed by the transaction and locking tables represent a glimpse into fast-changing data. This is not like other (user) tables, where the data only changes when application-initiated updates occur. The underlying data is internal system-managed data, and can change very quickly.
For performance reasons, and to minimize the chance of
misleading JOINs between the
INFORMATION_SCHEMA tables, InnoDB collects
the required transaction and locking information into an
intermediate buffer whenever a SELECT on any
of the tables is issued. This buffer is refreshed only if more
than 0.1 seconds has elapsed since the last time the buffer was
read. The data needed to fill the three tables is fetched
atomically and consistently and is saved in this global internal
buffer, forming a point-in-time “snapshot”. If
multiple table accesses occur within 0.1 seconds (as they almost
certainly do when MySQL processes a join among these tables),
then the same snapshot is used to satisfy the query.
A correct result is returned when you JOIN
any of these tables together in a single query, because the data
for the three tables comes from the same snapshot. Because the
buffer is not refreshed with every query of any of these tables,
if you issue separate queries against these tables within a
tenth of a second, the results are the same from query to query.
On the other hand, two separate queries of the same or different
tables issued more than a tenth of a second apart may see
different results, since the data come from different snapshots.
Because InnoDB must temporarily stall while the transaction and locking data is collected, too frequent queries of these tables can negatively impact performance as seen by other users.
As these tables contain sensitive information (at least
INNODB_LOCKS.LOCK_DATA and
INNODB_TRX.TRX_QUERY), for security reasons,
only the users with the PROCESS privilege are
allowed to SELECT from them.
As just described, while the transaction and locking data is
correct and consistent when these
INFORMATION_SCHEMA tables are populated, the
underlying data changes so fast that similar glimpses at other,
similarly fast-changing data, may not be in sync. Thus, you
should be careful in comparing the data in the InnoDB
transaction and locking tables with that in the
MySQL table
PROCESSLIST. The data from the
PROCESSLIST table does not come from the same
snapshot as the data about locking and transactions. Even if you
issue a single SELECT
(JOINing
INNODB_TRX
and PROCESSLIST, for example), the content of
those tables is generally not consistent.
INNODB_TRX
may reference rows that are not present in
PROCESSLIST or the currently executing SQL
query of a transaction, shown in
INNODB_TRX.TRX_QUERY may be different from
the one in PROCESSLIST.INFO. The query in
INNODB_TRX
is always consistent with the rest of
INNODB_TRX,
INNODB_LOCKS
and
INNODB_LOCK_WAITS
when the data comes from the same snapshot.
InnoDB Monitors provide information about the
InnoDB internal state. This information is
useful for performance tuning. Each Monitor can be enabled by
creating a table with a special name, which causes
InnoDB to write Monitor output periodically.
Also, output for the standard InnoDB Monitor
is available on demand through the
SHOW ENGINE INNODB
STATUS SQL statement.
There are several types of InnoDB Monitors:
The standard
InnoDBMonitor displays the following types of information:Table and record locks held by each active transaction.
Lock waits of a transaction.
Semaphore waits of threads.
Pending file I/O requests.
Buffer pool statistics.
Purge and insert buffer merge activity of the main
InnoDBthread.
For a discussion of
InnoDBlock modes, see Section 14.2.4.2, “InnoDBLock Modes”.To enable the standard
InnoDBMonitor for periodic output, create a table namedinnodb_monitor. To obtain Monitor output on demand, use theSHOW ENGINE INNODB STATUSSQL statement to fetch the output to your client program. If you are using the mysql interactive client, the output is more readable if you replace the usual semicolon statement terminator with\G:mysql>
SHOW ENGINE INNODB STATUS\GThe
InnoDBLock Monitor is like the standard Monitor but also provides extensive lock information. To enable this Monitor for periodic output, create a table namedinnodb_lock_monitor.The
InnoDBTablespace Monitor prints a list of file segments in the shared tablespace and validates the tablespace allocation data structures. To enable this Monitor for periodic output, create a table namedinnodb_tablespace_monitor.The
InnoDBTable Monitor prints the contents of theInnoDBinternal data dictionary. To enable this Monitor for periodic output, create a table namedinnodb_table_monitor.NoteAs of MySQL 5.6.3, the
innodb_table_monitortable is deprecated and will be removed in a future MySQL release. Similar information can be obtained fromInnoDBINFORMATION_SCHEMAtables. See Section 19.30, “INFORMATION_SCHEMATables forInnoDB”.
To enable an InnoDB Monitor for periodic
output, use a CREATE TABLE statement to
create the table associated with the Monitor. For example, to
enable the standard InnoDB Monitor, create
the innodb_monitor table:
CREATE TABLE innodb_monitor (a INT) ENGINE=INNODB;
To stop the Monitor, drop the table:
DROP TABLE innodb_monitor;
The CREATE TABLE syntax is just a
way to pass a command to the InnoDB engine
through MySQL's SQL parser: The only things that matter are the
table name innodb_monitor and that it be an
InnoDB table. The structure of the table is
not relevant at all for the InnoDB Monitor.
If you shut down the server, the Monitor does not restart
automatically when you restart the server. Drop the Monitor
table and issue a new CREATE
TABLE statement to start the Monitor. (This syntax may
change in a future release.)
The PROCESS privilege is required
to start or stop the InnoDB Monitor tables.
When you enable InnoDB Monitors for periodic
output, InnoDB writes their output to the
mysqld server standard error output
(stderr). In this case, no output is sent to
clients. When switched on, InnoDB Monitors
print data about every 15 seconds. Server output usually is
directed to the error log (see Section 5.2.2, “The Error Log”).
This data is useful in performance tuning. On Windows, start the
server from a command prompt in a console window with the
--console option if you want to
direct the output to the window rather than to the error log.
InnoDB sends diagnostic output to
stderr or to files rather than to
stdout or fixed-size memory buffers, to avoid
potential buffer overflows. As a side effect, the output of
SHOW ENGINE INNODB
STATUS is written to a status file in the MySQL data
directory every fifteen seconds. The name of the file is
innodb_status.,
where pidpid is the server process ID.
InnoDB removes the file for a normal
shutdown. If abnormal shutdowns have occurred, instances of
these status files may be present and must be removed manually.
Before removing them, you might want to examine them to see
whether they contain useful information about the cause of
abnormal shutdowns. The
innodb_status.
file is created only if the configuration option
pidinnodb-status-file=1 is set.
InnoDB Monitors should be enabled only when
you actually want to see Monitor information because output
generation does result in some performance decrement. Also, if
you enable monitor output by creating the associated table, your
error log may become quite large if you forget to remove the
table later.
For additional information about InnoDB
monitors, see:
Mark Leith: InnoDB Table and Tablespace Monitors
Each monitor begins with a header containing a timestamp and the monitor name. For example:
================================================ 090407 12:06:19 INNODB TABLESPACE MONITOR OUTPUT ================================================
The header for the standard Monitor (INNODB MONITOR
OUTPUT) is also used for the Lock Monitor because the
latter produces the same output with the addition of extra lock
information.
The following sections describe the output for each Monitor.
The Lock Monitor is the same as the standard Monitor except
that it includes additional lock information. Enabling either
monitor for periodic output by creating the associated
InnoDB table turns on the same output
stream, but the stream includes the extra information if the
Lock Monitor is enabled. For example, if you create the
innodb_monitor and
innodb_lock_monitor tables, that turns on a
single output stream. The stream includes extra lock
information until you disable the Lock Monitor by removing the
innodb_lock_monitor table.
Example InnoDB Monitor output:
mysql> SHOW ENGINE INNODB STATUS\G
*************************** 1. row ***************************
Status:
=====================================
030709 13:00:59 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 18 seconds
----------
BACKGROUND THREAD
----------
srv_master_thread loops: 53 1_second, 44 sleeps, 5 10_second, 7 background,
7 flush
srv_master_thread log flush and writes: 48
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 413452, signal count 378357
--Thread 32782 has waited at btr0sea.c line 1477 for 0.00 seconds the
semaphore: X-lock on RW-latch at 41a28668 created in file btr0sea.c line 135
a writer (thread id 32782) has reserved it in mode wait exclusive
number of readers 1, waiters flag 1
Last time read locked in file btr0sea.c line 731
Last time write locked in file btr0sea.c line 1347
Mutex spin waits 0, rounds 0, OS waits 0
RW-shared spins 2, rounds 60, OS waits 2
RW-excl spins 0, rounds 0, OS waits 0
Spin rounds per wait: 0.00 mutex, 20.00 RW-shared, 0.00 RW-excl
------------------------
LATEST FOREIGN KEY ERROR
------------------------
030709 13:00:59 Transaction:
TRANSACTION 0 290328284, ACTIVE 0 sec, process no 3195
inserting
15 lock struct(s), heap size 2496, undo log entries 9
MySQL thread id 25, query id 4668733 localhost heikki update
insert into ibtest11a (D, B, C) values (5, 'khDk' ,'khDk')
Foreign key constraint fails for table test/ibtest11a:
,
CONSTRAINT `0_219242` FOREIGN KEY (`A`, `D`) REFERENCES `ibtest11b` (`A`,
`D`) ON DELETE CASCADE ON UPDATE CASCADE
Trying to add in child table, in index PRIMARY tuple:
0: len 4; hex 80000101; asc ....;; 1: len 4; hex 80000005; asc ....;; 2:
len 4; hex 6b68446b; asc khDk;; 3: len 6; hex 0000114e0edc; asc ...N..;; 4:
len 7; hex 00000000c3e0a7; asc .......;; 5: len 4; hex 6b68446b; asc khDk;;
But in parent table test/ibtest11b, in index PRIMARY,
the closest match we can find is record:
RECORD: info bits 0 0: len 4; hex 8000015b; asc ...[;; 1: len 4; hex
80000005; asc ....;; 2: len 3; hex 6b6864; asc khd;; 3: len 6; hex
0000111ef3eb; asc ......;; 4: len 7; hex 800001001e0084; asc .......;; 5:
len 3; hex 6b6864; asc khd;;
------------------------
LATEST DETECTED DEADLOCK
------------------------
030709 12:59:58
*** (1) TRANSACTION:
TRANSACTION 0 290252780, ACTIVE 1 sec, process no 3185
inserting
LOCK WAIT 3 lock struct(s), heap size 320, undo log entries 146
MySQL thread id 21, query id 4553379 localhost heikki update
INSERT INTO alex1 VALUES(86, 86, 794,'aA35818','bb','c79166','d4766t',
'e187358f','g84586','h794',date_format('2001-04-03 12:54:22','%Y-%m-%d
%H:%i'),7
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290252780 lock mode S waiting
Record lock, heap no 324 RECORD: info bits 0 0: len 7; hex 61613335383138;
asc aa35818;; 1:
*** (2) TRANSACTION:
TRANSACTION 0 290251546, ACTIVE 2 sec, process no 3190
inserting
130 lock struct(s), heap size 11584, undo log entries 437
MySQL thread id 23, query id 4554396 localhost heikki update
REPLACE INTO alex1 VALUES(NULL, 32, NULL,'aa3572','','c3572','d6012t','',
NULL,'h396', NULL, NULL, 7.31,7.31,7.31,200)
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290251546 lock_mode X locks rec but not gap
Record lock, heap no 324 RECORD: info bits 0 0: len 7; hex 61613335383138;
asc aa35818;; 1:
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 48310 n bits 568 table test/alex1 index
symbole trx id 0 290251546 lock_mode X locks gap before rec insert intention
waiting
Record lock, heap no 82 RECORD: info bits 0 0: len 7; hex 61613335373230;
asc aa35720;; 1:
*** WE ROLL BACK TRANSACTION (1)
------------
TRANSACTIONS
------------
Trx id counter 0 290328385
Purge done for trx's n:o < 0 290315608 undo n:o < 0 17
History list length 20
Total number of lock structs in row lock hash table 70
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 0 0, not started, process no 3491
MySQL thread id 32, query id 4668737 localhost heikki
show innodb status
---TRANSACTION 0 290328384, ACTIVE 0 sec, process no 3205
38929 inserting
1 lock struct(s), heap size 320
MySQL thread id 29, query id 4668736 localhost heikki update
insert into speedc values (1519229,1, 'hgjhjgghggjgjgjgjgjggjgjgjgjgjgggjgjg
jlhhgghggggghhjhghgggggghjhghghghghghhhhghghghjhhjghjghjkghjghjghjghjfhjfh
---TRANSACTION 0 290328383, ACTIVE 0 sec, process no 3180
28684 committing
1 lock struct(s), heap size 320, undo log entries 1
MySQL thread id 19, query id 4668734 localhost heikki update
insert into speedcm values (1603393,1, 'hgjhjgghggjgjgjgjgjggjgjgjgjgjgggjgj
gjlhhgghggggghhjhghgggggghjhghghghghghhhhghghghjhhjghjghjkghjghjghjghjfhjf
---TRANSACTION 0 290328327, ACTIVE 0 sec, process no 3200
36880 starting index read
LOCK WAIT 2 lock struct(s), heap size 320
MySQL thread id 27, query id 4668644 localhost heikki Searching rows for
update
update ibtest11a set B = 'kHdkkkk' where A = 89572
------- TRX HAS BEEN WAITING 0 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 65556 n bits 232 table test/ibtest11a index
PRIMARY trx id 0 290328327 lock_mode X waiting
Record lock, heap no 1 RECORD: info bits 0 0: len 9; hex 73757072656d756d00;
asc supremum.;;
------------------
---TRANSACTION 0 290328284, ACTIVE 0 sec, process no 3195
34831 rollback of SQL statement
ROLLING BACK 14 lock struct(s), heap size 2496, undo log entries 9
MySQL thread id 25, query id 4668733 localhost heikki update
insert into ibtest11a (D, B, C) values (5, 'khDk' ,'khDk')
---TRANSACTION 0 290327208, ACTIVE 1 sec, process no 3190
32782
58 lock struct(s), heap size 5504, undo log entries 159
MySQL thread id 23, query id 4668732 localhost heikki update
REPLACE INTO alex1 VALUES(86, 46, 538,'aa95666','bb','c95666','d9486t',
'e200498f','g86814','h538',date_format('2001-04-03 12:54:22','%Y-%m-%d
%H:%i'),
---TRANSACTION 0 290323325, ACTIVE 3 sec, process no 3185
30733 inserting
4 lock struct(s), heap size 1024, undo log entries 165
MySQL thread id 21, query id 4668735 localhost heikki update
INSERT INTO alex1 VALUES(NULL, 49, NULL,'aa42837','','c56319','d1719t','',
NULL,'h321', NULL, NULL, 7.31,7.31,7.31,200)
--------
FILE I/O
--------
I/O thread 0 state: waiting for i/o request (insert buffer thread)
I/O thread 1 state: waiting for i/o request (log thread)
I/O thread 2 state: waiting for i/o request (read thread)
I/O thread 3 state: waiting for i/o request (write thread)
Pending normal aio reads: 0, aio writes: 0,
ibuf aio reads: 0, log i/o's: 0, sync i/o's: 0
Pending flushes (fsync) log: 0; buffer pool: 0
151671 OS file reads, 94747 OS file writes, 8750 OS fsyncs
25.44 reads/s, 18494 avg bytes/read, 17.55 writes/s, 2.33 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf for space 0: size 1, free list len 19, seg size 21,
85004 inserts, 85004 merged recs, 26669 merges
Hash table size 207619, used cells 14461, node heap has 16 buffer(s)
1877.67 hash searches/s, 5121.10 non-hash searches/s
---
LOG
---
Log sequence number 18 1212842764
Log flushed up to 18 1212665295
Last checkpoint at 18 1135877290
0 pending log writes, 0 pending chkp writes
4341 log i/o's done, 1.22 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total memory allocated 84966343; in additional pool allocated 1402624
Buffer pool size 3200
Free buffers 110
Database pages 3074
Modified db pages 2674
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages read 171380, created 51968, written 194688
28.72 reads/s, 20.72 creates/s, 47.55 writes/s
Buffer pool hit rate 999 / 1000
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
Main thread process no. 3004, id 7176, state: purging
Number of rows inserted 3738558, updated 127415, deleted 33707, read 755779
1586.13 inserts/s, 50.89 updates/s, 28.44 deletes/s, 107.88 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
InnoDB Monitor output is limited to 1MB
when produced using the
SHOW ENGINE
INNODB STATUS statement. This limit does not apply
to output written to the server's error output.
Some notes on the output sections:
BACKGROUND
THREAD
The srv_master_thread lines shows work done
by the main background thread.
SEMAPHORES
This section reports threads waiting for a semaphore and
statistics on how many times threads have needed a spin or a
wait on a mutex or a rw-lock semaphore. A large number of
threads waiting for semaphores may be a result of disk I/O, or
contention problems inside InnoDB.
Contention can be due to heavy parallelism of queries or
problems in operating system thread scheduling. Setting the
innodb_thread_concurrency
system variable smaller than the default value might help in
such situations. The Spin rounds per wait
line shows the number of spinlock rounds per OS wait for a
mutex.
LATEST FOREIGN KEY
ERROR
This section provides information about the most recent foreign key constraint error. It is not present if no such error has occurred. The contents include the statement that failed as well as information about the constraint that failed and the referenced and referencing tables.
LATEST DETECTED
DEADLOCK
This section provides information about the most recent
deadlock. It is not present if no deadlock has occurred. The
contents show which transactions are involved, the statement
each was attempting to execute, the locks they have and need,
and which transaction InnoDB decided to
roll back to break the deadlock. The lock modes reported in
this section are explained in
Section 14.2.4.2, “InnoDB Lock Modes”.
TRANSACTIONS
If this section reports lock waits, your applications might have lock contention. The output can also help to trace the reasons for transaction deadlocks.
FILE I/O
This section provides information about threads that
InnoDB uses to perform various types of
I/O. The first few of these are dedicated to general
InnoDB processing. The contents also
display information for pending I/O operations and statistics
for I/O performance.
The number of these threads are controlled by the
innodb_read_io_threads and
innodb_write_io_threads
parameters. See Section 14.2.7, “InnoDB Startup Options and System Variables”.
INSERT BUFFER AND ADAPTIVE HASH
INDEX
This section shows the status of the InnoDB
insert buffer and adaptive hash index. (See
Section 14.2.4.12.5, “Insert Buffering”, and
Section 14.2.4.12.6, “Adaptive Hash Indexes”.) The contents include
the number of operations performed for each, plus statistics
for hash index performance.
LOG
This section displays information about the
InnoDB log. The contents include the
current log sequence number, how far the log has been flushed
to disk, and the position at which InnoDB
last took a checkpoint. (See
Section 5.3.3, “InnoDB Checkpoints”.) The section also
displays information about pending writes and write
performance statistics.
BUFFER POOL AND
MEMORY
This section gives you statistics on pages read and written. You can calculate from these numbers how many data file I/O operations your queries currently are doing.
For additional information about the operation of the buffer
pool, see Section 8.9.1, “The InnoDB Buffer Pool”.
ROW
OPERATIONS
This section shows what the main thread is doing, including the number and performance rate for each type of row operation.
In MySQL 5.6, output from the standard Monitor includes additional sections compared to the output for previous versions. For details, see Diagnostic and Monitoring Capabilities.
The InnoDB Tablespace Monitor prints
information about the file segments in the shared tablespace
and validates the tablespace allocation data structures. If
you use individual tablespaces by enabling
innodb_file_per_table, the
Tablespace Monitor does not describe those tablespaces.
Example InnoDB Tablespace Monitor output:
================================================ 090408 21:28:09 INNODB TABLESPACE MONITOR OUTPUT ================================================ FILE SPACE INFO: id 0 size 13440, free limit 3136, free extents 28 not full frag extents 2: used pages 78, full frag extents 3 first seg id not used 0 23845 SEGMENT id 0 1 space 0; page 2; res 96 used 46; full ext 0 fragm pages 32; free extents 0; not full extents 1: pages 14 SEGMENT id 0 2 space 0; page 2; res 1 used 1; full ext 0 fragm pages 1; free extents 0; not full extents 0: pages 0 SEGMENT id 0 3 space 0; page 2; res 1 used 1; full ext 0 fragm pages 1; free extents 0; not full extents 0: pages 0 ... SEGMENT id 0 15 space 0; page 2; res 160 used 160; full ext 2 fragm pages 32; free extents 0; not full extents 0: pages 0 SEGMENT id 0 488 space 0; page 2; res 1 used 1; full ext 0 fragm pages 1; free extents 0; not full extents 0: pages 0 SEGMENT id 0 17 space 0; page 2; res 1 used 1; full ext 0 fragm pages 1; free extents 0; not full extents 0: pages 0 ... SEGMENT id 0 171 space 0; page 2; res 592 used 481; full ext 7 fragm pages 16; free extents 0; not full extents 2: pages 17 SEGMENT id 0 172 space 0; page 2; res 1 used 1; full ext 0 fragm pages 1; free extents 0; not full extents 0: pages 0 SEGMENT id 0 173 space 0; page 2; res 96 used 44; full ext 0 fragm pages 32; free extents 0; not full extents 1: pages 12 ... SEGMENT id 0 601 space 0; page 2; res 1 used 1; full ext 0 fragm pages 1; free extents 0; not full extents 0: pages 0 NUMBER of file segments: 73 Validating tablespace Validation ok --------------------------------------- END OF INNODB TABLESPACE MONITOR OUTPUT =======================================
The Tablespace Monitor output includes information about the shared tablespace as a whole, followed by a list containing a breakdown for each segment within the tablespace.
In this example using the default page size, the tablespace consists of database pages that are 16KB each. The pages are grouped into extents of size 1MB (64 consecutive pages).
The initial part of the output that displays overall tablespace information has this format:
FILE SPACE INFO: id 0 size 13440, free limit 3136, free extents 28 not full frag extents 2: used pages 78, full frag extents 3 first seg id not used 0 23845
Overall tablespace information includes these values:
id: The tablespace ID. A value of 0 refers to the shared tablespace.size: The current tablespace size in pages.free limit: The minimum page number for which the free list has not been initialized. Pages at or above this limit are free.free extents: The number of free extents.not full frag extents,used pages: The number of fragment extents that are not completely filled, and the number of pages in those extents that have been allocated.full frag extents: The number of completely full fragment extents.first seg id not used: The first unused segment ID.
Individual segment information has this format:
SEGMENT id 0 15 space 0; page 2; res 160 used 160; full ext 2 fragm pages 32; free extents 0; not full extents 0: pages 0
Segment information includes these values:
id: The segment ID.
space, page: The
tablespace number and page within the tablespace where the
segment “inode” is located. A tablespace number
of 0 indicates the shared tablespace.
InnoDB uses inodes to keep track of
segments in the tablespace. The other fields displayed for a
segment (id, res, and so
forth) are derived from information in the inode.
res: The number of pages allocated
(reserved) for the segment.
used: The number of allocated pages in use
by the segment.
full ext: The number of extents allocated
for the segment that are completely used.
fragm pages: The number of initial pages
that have been allocated to the segment.
free extents: The number of extents
allocated for the segment that are completely unused.
not full extents: The number of extents
allocated for the segment that are partially used.
pages: The number of pages used within the
not-full extents.
When a segment grows, it starts as a single page, and
InnoDB allocates the first pages for it one
at a time, up to 32 pages (this is the fragm
pages value). After that, InnoDB
allocates complete extents. InnoDB can add
up to 4 extents at a time to a large segment to ensure good
sequentiality of data.
For the example segment shown earlier, it has 32 fragment pages, plus 2 full extents (64 pages each), for a total of 160 pages used out of 160 pages allocated. The following segment has 32 fragment pages and one partially full extent using 14 pages for a total of 46 pages used out of 96 pages allocated:
SEGMENT id 0 1 space 0; page 2; res 96 used 46; full ext 0 fragm pages 32; free extents 0; not full extents 1: pages 14
It is possible for a segment that has extents allocated to it
to have a fragm pages value less than 32 if
some of the individual pages have been deallocated subsequent
to extent allocation.
The InnoDB Table Monitor prints the
contents of the InnoDB internal data
dictionary.
The output contains one section per table. The
SYS_FOREIGN and
SYS_FOREIGN_COLS sections are for internal
data dictionary tables that maintain information about foreign
keys. There are also sections for the Table Monitor table and
each user-created InnoDB table. Suppose
that the following two tables have been created in the
test database:
CREATE TABLE parent
(
par_id INT NOT NULL,
fname CHAR(20),
lname CHAR(20),
PRIMARY KEY (par_id),
UNIQUE INDEX (lname, fname)
) ENGINE = INNODB;
CREATE TABLE child
(
par_id INT NOT NULL,
child_id INT NOT NULL,
name VARCHAR(40),
birth DATE,
weight DECIMAL(10,2),
misc_info VARCHAR(255),
last_update TIMESTAMP,
PRIMARY KEY (par_id, child_id),
INDEX (name),
FOREIGN KEY (par_id) REFERENCES parent (par_id)
ON DELETE CASCADE
ON UPDATE CASCADE
) ENGINE = INNODB;Then the Table Monitor output will look something like this (reformatted slightly):
===========================================
090420 12:09:32 INNODB TABLE MONITOR OUTPUT
===========================================
--------------------------------------
TABLE: name SYS_FOREIGN, id 0 11, columns 7, indexes 3, appr.rows 1
COLUMNS: ID: DATA_VARCHAR DATA_ENGLISH len 0;
FOR_NAME: DATA_VARCHAR DATA_ENGLISH len 0;
REF_NAME: DATA_VARCHAR DATA_ENGLISH len 0;
N_COLS: DATA_INT len 4;
DB_ROW_ID: DATA_SYS prtype 256 len 6;
DB_TRX_ID: DATA_SYS prtype 257 len 6;
INDEX: name ID_IND, id 0 11, fields 1/6, uniq 1, type 3
root page 46, appr.key vals 1, leaf pages 1, size pages 1
FIELDS: ID DB_TRX_ID DB_ROLL_PTR FOR_NAME REF_NAME N_COLS
INDEX: name FOR_IND, id 0 12, fields 1/2, uniq 2, type 0
root page 47, appr.key vals 1, leaf pages 1, size pages 1
FIELDS: FOR_NAME ID
INDEX: name REF_IND, id 0 13, fields 1/2, uniq 2, type 0
root page 48, appr.key vals 1, leaf pages 1, size pages 1
FIELDS: REF_NAME ID
--------------------------------------
TABLE: name SYS_FOREIGN_COLS, id 0 12, columns 7, indexes 1, appr.rows 1
COLUMNS: ID: DATA_VARCHAR DATA_ENGLISH len 0;
POS: DATA_INT len 4;
FOR_COL_NAME: DATA_VARCHAR DATA_ENGLISH len 0;
REF_COL_NAME: DATA_VARCHAR DATA_ENGLISH len 0;
DB_ROW_ID: DATA_SYS prtype 256 len 6;
DB_TRX_ID: DATA_SYS prtype 257 len 6;
INDEX: name ID_IND, id 0 14, fields 2/6, uniq 2, type 3
root page 49, appr.key vals 1, leaf pages 1, size pages 1
FIELDS: ID POS DB_TRX_ID DB_ROLL_PTR FOR_COL_NAME REF_COL_NAME
--------------------------------------
TABLE: name test/child, id 0 14, columns 10, indexes 2, appr.rows 201
COLUMNS: par_id: DATA_INT DATA_BINARY_TYPE DATA_NOT_NULL len 4;
child_id: DATA_INT DATA_BINARY_TYPE DATA_NOT_NULL len 4;
name: DATA_VARCHAR prtype 524303 len 40;
birth: DATA_INT DATA_BINARY_TYPE len 3;
weight: DATA_FIXBINARY DATA_BINARY_TYPE len 5;
misc_info: DATA_VARCHAR prtype 524303 len 255;
last_update: DATA_INT DATA_UNSIGNED DATA_BINARY_TYPE DATA_NOT_NULL len 4;
DB_ROW_ID: DATA_SYS prtype 256 len 6;
DB_TRX_ID: DATA_SYS prtype 257 len 6;
INDEX: name PRIMARY, id 0 17, fields 2/9, uniq 2, type 3
root page 52, appr.key vals 201, leaf pages 5, size pages 6
FIELDS: par_id child_id DB_TRX_ID DB_ROLL_PTR name birth weight misc_info last_update
INDEX: name name, id 0 18, fields 1/3, uniq 3, type 0
root page 53, appr.key vals 210, leaf pages 1, size pages 1
FIELDS: name par_id child_id
FOREIGN KEY CONSTRAINT test/child_ibfk_1: test/child ( par_id )
REFERENCES test/parent ( par_id )
--------------------------------------
TABLE: name test/innodb_table_monitor, id 0 15, columns 4, indexes 1, appr.rows 0
COLUMNS: i: DATA_INT DATA_BINARY_TYPE len 4;
DB_ROW_ID: DATA_SYS prtype 256 len 6;
DB_TRX_ID: DATA_SYS prtype 257 len 6;
INDEX: name GEN_CLUST_INDEX, id 0 19, fields 0/4, uniq 1, type 1
root page 193, appr.key vals 0, leaf pages 1, size pages 1
FIELDS: DB_ROW_ID DB_TRX_ID DB_ROLL_PTR i
--------------------------------------
TABLE: name test/parent, id 0 13, columns 6, indexes 2, appr.rows 299
COLUMNS: par_id: DATA_INT DATA_BINARY_TYPE DATA_NOT_NULL len 4;
fname: DATA_CHAR prtype 524542 len 20;
lname: DATA_CHAR prtype 524542 len 20;
DB_ROW_ID: DATA_SYS prtype 256 len 6;
DB_TRX_ID: DATA_SYS prtype 257 len 6;
INDEX: name PRIMARY, id 0 15, fields 1/5, uniq 1, type 3
root page 50, appr.key vals 299, leaf pages 2, size pages 3
FIELDS: par_id DB_TRX_ID DB_ROLL_PTR fname lname
INDEX: name lname, id 0 16, fields 2/3, uniq 2, type 2
root page 51, appr.key vals 300, leaf pages 1, size pages 1
FIELDS: lname fname par_id
FOREIGN KEY CONSTRAINT test/child_ibfk_1: test/child ( par_id )
REFERENCES test/parent ( par_id )
-----------------------------------
END OF INNODB TABLE MONITOR OUTPUT
==================================For each table, Table Monitor output contains a section that displays general information about the table and specific information about its columns, indexes, and foreign keys.
The general information for each table includes the table name
(in
db_name/tbl_name
The COLUMNS part of a table section lists
each column in the table. Information for each column
indicates its name and data type characteristics. Some
internal columns are added by InnoDB, such
as DB_ROW_ID (row ID),
DB_TRX_ID (transaction ID), and
DB_ROLL_PTR (a pointer to the rollback/undo
data).
DATA_: These symbols indicate the data type. There may be multiplexxxDATA_symbols for a given column.xxxprtype: The column's “precise” type. This field includes information such as the column data type, character set code, nullability, signedness, and whether it is a binary string. This field is described in theinnobase/include/data0type.hsource file.len: The column length in bytes.
Each INDEX part of the table section
provides the name and characteristics of one table index:
name: The index name. If the name isPRIMARY, the index is a primary key. If the name isGEN_CLUST_INDEX, the index is the clustered index that is created automatically if the table definition doesn't include a primary key or non-NULLunique index. See Section 14.2.4.12.2, “Clustered and Secondary Indexes”.id: The index ID.fields: The number of fields in the index, as a value inm/nmis the number of user-defined columns; that is, the number of columns you would see in the index definition in aCREATE TABLEstatement.nis the total number of index columns, including those added internally. For the clustered index, the total includes the other columns in the table definition, plus any columns added internally. For a secondary index, the total includes the columns from the primary key that are not part of the secondary index.
uniq: The number of leading fields that are enough to determine index values uniquely.type: The index type. This is a bit field. For example, 1 indicates a clustered index and 2 indicates a unique index, so a clustered index (which always contains unique values), will have atypevalue of 3. An index with atypevalue of 0 is neither clustered nor unique. The flag values are defined in theinnobase/include/dict0mem.hsource file.root page: The index root page number.appr. key vals: The approximate index cardinality.leaf pages: The approximate number of leaf pages in the index.size pages: The approximate total number of pages in the index.FIELDS: The names of the fields in the index. For a clustered index that was generated automatically, the field list begins with the internalDB_ROW_ID(row ID) field.DB_TRX_IDandDB_ROLL_PTRare always added internally to the clustered index, following the fields that comprise the primary key. For a secondary index, the final fields are those from the primary key that are not part of the secondary index.
The end of the table section lists the FOREIGN
KEY definitions that apply to the table. This
information appears whether the table is a referencing or
referenced table.
The following general guidelines apply to troubleshooting
InnoDB problems:
When an operation fails or you suspect a bug, look at the MySQL server error log (see Section 5.2.2, “The Error Log”).
If the failure is related to a deadlock, run with the
innodb_print_all_deadlocksoption enabled so that details about eachInnoDBdeadlock are printed to the MySQL server error log.Issues relating to the
InnoDBdata dictionary include failedCREATE TABLEstatements (orphaned table files), inability to open.InnoDBfiles, and system cannot find the path specified errors. For information about these sorts of problems and errors, see Section 14.2.5.7, “TroubleshootingInnoDBData Dictionary Operations”.When troubleshooting, it is usually best to run the MySQL server from the command prompt, rather than through mysqld_safe or as a Windows service. You can then see what mysqld prints to the console, and so have a better grasp of what is going on. On Windows, start mysqld with the
--consoleoption to direct the output to the console window.Use the
InnoDBMonitors to obtain information about a problem (see Section 14.2.5.4, “SHOW ENGINE INNODB STATUSand theInnoDBMonitors”). If the problem is performance-related, or your server appears to be hung, use the standard Monitor to print information about the internal state ofInnoDB. If the problem is with locks, use the Lock Monitor. If the problem is in creation of tables or other data dictionary operations, use the Table Monitor to print the contents of theInnoDBinternal data dictionary. To see tablespace information use the Tablespace Monitor.If you suspect that a table is corrupt, run
CHECK TABLEon that table.
The troubleshooting steps for InnoDB I/O
problems depend on when the problem occurs: during startup of
the MySQL server, or during normal operations when a DML or
DDL statement fails due to problems at the file system level.
Initialization Problems
If something goes wrong when InnoDB
attempts to initialize its tablespace or its log files, delete
all files created by InnoDB: all
ibdata files and all
ib_logfile files. If you already created
some InnoDB tables, also delete the
corresponding .frm files for these
tables, and any .ibd files if you are
using multiple tablespaces, from the MySQL database
directories. Then try the InnoDB database
creation again. For easiest troubleshooting, start the MySQL
server from a command prompt so that you see what is
happening.
Runtime Problems
If InnoDB prints an operating system error
during a file operation, usually the problem has one of the
following solutions:
Make sure the
InnoDBdata file directory and theInnoDBlog directory exist.Make sure mysqld has access rights to create files in those directories.
Make sure mysqld can read the proper
my.cnformy.inioption file, so that it starts with the options that you specified.Make sure the disk is not full and you are not exceeding any disk quota.
Make sure that the names you specify for subdirectories and data files do not clash.
Doublecheck the syntax of the
innodb_data_home_dirandinnodb_data_file_pathvalues. In particular, anyMAXvalue in theinnodb_data_file_pathoption is a hard limit, and exceeding that limit causes a fatal error.
To investigate database page corruption, you might dump your
tables from the database with
SELECT ... INTO
OUTFILE. Usually, most of the data obtained in this
way is intact. Serious corruption might cause SELECT *
FROM statements or
tbl_nameInnoDB background operations to crash or
assert, or even cause InnoDB roll-forward
recovery to crash. In such cases, use the
innodb_force_recovery option to
force the InnoDB storage engine to start up
while preventing background operations from running, so that you
can dump your tables. For example, you can add the following
line to the [mysqld] section of your option
file before restarting the server:
[mysqld] innodb_force_recovery = 4
innodb_force_recovery is 0 by
default (normal startup without forced recovery). The
permissible nonzero values for
innodb_force_recovery follow. A
larger number includes all precautions of smaller numbers. If
you can dump your tables with an option value of at most 4, then
you are relatively safe that only some data on corrupt
individual pages is lost. A value of 6 is more drastic because
database pages are left in an obsolete state, which in turn may
introduce more corruption into B-trees and other database
structures.
1(SRV_FORCE_IGNORE_CORRUPT)Lets the server run even if it detects a corrupt page. Tries to make
SELECT * FROMjump over corrupt index records and pages, which helps in dumping tables.tbl_name2(SRV_FORCE_NO_BACKGROUND)Prevents the master thread and any purge threads from running. If a crash would occur during the purge operation, this recovery value prevents it.
3(SRV_FORCE_NO_TRX_UNDO)Does not run transaction rollbacks after crash recovery.
4(SRV_FORCE_NO_IBUF_MERGE)Prevents insert buffer merge operations. If they would cause a crash, does not do them. Does not calculate table statistics.
5(SRV_FORCE_NO_UNDO_LOG_SCAN)Does not look at undo logs when starting the database:
InnoDBtreats even incomplete transactions as committed.6(SRV_FORCE_NO_LOG_REDO)Does not do the redo log roll-forward in connection with recovery.
With this value, you might not be able to do queries other than a basic
SELECT * FROM t, with noWHERE,ORDER BY, or other clauses. More complex queries could encounter corrupted data structures and fail.If corruption within the table data prevents you from dumping the entire table contents, a query with an
ORDER BYclause might be able to dump the portion of the table after the corrupted part.primary_keyDESC
The database must not otherwise be used with any
nonzero value of
innodb_force_recovery.
As a safety measure, InnoDB prevents
INSERT,
UPDATE, or
DELETE operations when
innodb_force_recovery is
greater than 0.
You can SELECT from tables to
dump them, or DROP or
CREATE tables even if forced recovery is
used. If you know that a given table is causing a crash on
rollback, you can drop it. You can also use this to stop a
runaway rollback caused by a failing mass import or
ALTER TABLE: kill the
mysqld process and set
innodb_force_recovery to
3 to bring the database up without the
rollback, then DROP the table that is causing
the runaway rollback.
Information about table definitions is stored both in the
.frm files, and in the InnoDB
data dictionary. If
you move .frm files around, or if the
server crashes in the middle of a data dictionary operation,
these sources of information can become inconsistent.
Problem with CREATE TABLE
A symptom of an out-of-sync data dictionary is that a
CREATE TABLE statement fails. If
this occurs, look in the server's error log. If the log says
that the table already exists inside the
InnoDB internal data dictionary, you have an
orphaned table inside the InnoDB tablespace
files that has no corresponding .frm file.
The error message looks like this:
InnoDB: Error: table test/parent already exists in InnoDB internal InnoDB: data dictionary. Have you deleted the .frm file InnoDB: and not used DROP TABLE? Have you used DROP DATABASE InnoDB: for InnoDB tables in MySQL version <= 3.23.43? InnoDB: See the Restrictions section of the InnoDB manual. InnoDB: You can drop the orphaned table inside InnoDB by InnoDB: creating an InnoDB table with the same name in another InnoDB: database and moving the .frm file to the current database. InnoDB: Then MySQL thinks the table exists, and DROP TABLE will InnoDB: succeed.
You can drop the orphaned table by following the instructions
given in the error message. If you are still unable to use
DROP TABLE successfully, the
problem may be due to name completion in the
mysql client. To work around this problem,
start the mysql client with the
--skip-auto-rehash
option and try DROP TABLE again.
(With name completion on, mysql tries to
construct a list of table names, which fails when a problem such
as just described exists.)
Problem Opening Table
Another symptom of an out-of-sync data dictionary is that MySQL
prints an error that it cannot open a
.InnoDB file:
ERROR 1016: Can't open file: 'child2.InnoDB'. (errno: 1)
In the error log you can find a message like this:
InnoDB: Cannot find table test/child2 from the internal data dictionary InnoDB: of InnoDB though the .frm file for the table exists. Maybe you InnoDB: have deleted and recreated InnoDB data files but have forgotten InnoDB: to delete the corresponding .frm files of InnoDB tables?
This means that there is an orphaned .frm
file without a corresponding table inside
InnoDB. You can drop the orphaned
.frm file by deleting it manually.
Problem with Temporary Table
If MySQL crashes in the middle of an ALTER
TABLE operation, you may end up with an orphaned
temporary table inside the InnoDB tablespace.
Using the Table Monitor, you can see listed a table with a name
that begins with #sql-. You can perform SQL
statements on tables whose name contains the character
“#” if you enclose the name
within backticks. Thus, you can drop such an orphaned table like
any other orphaned table using the method described earlier. To
copy or rename a file in the Unix shell, you need to put the
file name in double quotation marks if the file name contains
“#”.
Problem with Missing Tablespace
With innodb_file_per_table
enabled, the following message might occur if the
.frm or .ibd files (or
both) are missing:
InnoDB: in InnoDB data dictionary has tablespace id N,
InnoDB: but tablespace with that id or name does not exist. Have
InnoDB: you deleted or moved .ibd files?
InnoDB: This may also be a table created with CREATE TEMPORARY TABLE
InnoDB: whose .ibd and .frm files MySQL automatically removed, but the
InnoDB: table still exists in the InnoDB internal data dictionary.
If this occurs, try the following procedure to resolve the problem:
Create a matching
.frmfile in some other database directory and copy it to the database directory where the orphan table is located.Issue
DROP TABLEfor the original table. That should successfully drop the table andInnoDBshould print a warning to the error log that the.ibdfile was missing.
- 14.2.6.1. Support for Read-Only Media
- 14.2.6.2. Larger Size Limit for Redo Log Files
- 14.2.6.3. 2-Byte Collation IDs for
InnoDBTables - 14.2.6.4. The Barracuda File Format
- 14.2.6.5. Dynamic Control of System Configuration Parameters
- 14.2.6.6.
TRUNCATE TABLEReclaims Space - 14.2.6.7.
InnoDBStrict Mode - 14.2.6.8. Controlling Optimizer Statistics Estimation
- 14.2.6.9. Better Error Handling when Dropping Indexes
- 14.2.6.10. More Compact Output of
SHOW ENGINE INNODB MUTEX - 14.2.6.11. More Read-Ahead Statistics
This section describes several recently added InnoDB features that
offer new flexibility and improve ease of use, reliability and
performance. The Barracuda
file format improves efficiency for storing large variable-length
columns, and enables table
compression. Configuration
options that once were unchangeable after startup, are now flexible
and can be changed dynamically. Some improvements are automatic,
such as faster and more efficient TRUNCATE TABLE.
Others allow you the flexibility to control InnoDB behavior; for
example, you can control whether certain problems cause errors or
just warnings. And informational messages and error reporting
continue to be made more user-friendly.
You can now query InnoDB tables where the MySQL
data directory is on read-only media, by enabling the
--innodb-read-only configuration
option at server startup.
How to Enable
To prepare an instance for read-only operation, make sure all the
necessary information is flushed
to the data files before storing it on the read-only medium. Run
the server with change buffering disabled
(innodb_change_buffering=0) and
do a slow shutdown.
To enable read-only mode for an entire MySQL instance, specify the following configuration options at server startup:
If the instance is on read-only media such as a DVD or CD, or the
/vardirectory is not writeable by all:--pid-file=andpath_on_writeable_media--event-scheduler=disabled
Usage Scenarios
This mode of operation is appropriate in situations such as:
Distributing a MySQL application, or a set of MySQL data, on a read-only storage medium such as a DVD or CD.
Multiple MySQL instances querying the same data directory simultaneously, typically in a data warehousing configuration. You might use this technique to avoid bottlenecks that can occur with a heavily loaded MySQL instance, or you might use different configuration options for the various instances to tune each one for particular kinds of queries.
Querying data that has been put into a read-only state for security or data integrity reasons, such as archived backup data.
This feature is mainly intended for flexibility in distribution and deployment, rather than raw performance based on the read-only aspect. See Section 14.2.5.2.2, “Optimizations for Read-Only Transactions” for ways to tune the performance of read-only queries, which do not require making the entire server read-only.
How It Works
When the server is run in read-only mode through the
--innodb-read-only option,
certain InnoDB features and components are
reduced or turned off entirely:
No change buffering is done, in particular no merges from the change buffer. To make sure the change buffer is empty when you prepare the instance for read-only operation, disable change buffering (
innodb_change_buffering=0) and do a slow shutdown first.There is no crash recovery phase at startup. The instance must have performed a slow shutdown before being put into the read-only state.
Because the redo log is not used in read-only operation, you can set
innodb_log_file_sizeto the smallest size possible (1 MB) before making the instance read-only.All background threads other than I/O read threads are turned off. As a consequence, a read-only instance cannot encounter any deadlocks.
Information about deadlocks, monitor output, and so on is not written to temporary files. As a consequence,
SHOW ENGINE INNODB STATUSdoes not produce any output.If the MySQL server is started with
--innodb-read-onlybut the data directory is still on writeable media, the root user can still perform DCL operations such asGRANTandREVOKE.Changes to configuration option settings that would normally change the the behavior of write operations, have no effect when the server is in read-only mode.
The MVCC processing to enforce isolation levels is turned off. All queries read the latest version of a record, because update and deletes are not possible.
The undo log is not used. Disable any settings for the
innodb_undo_tablespacesandinnodb_undo_directoryconfiguration options.
Formerly, the combined size of the InnoDB
redo log files was limited to
4 gigabytes. Starting in MySQL 5.6.3, this size limit is raised to
512GB.
You do not need any special upgrade process or file format to take
advantage of this feature. The bytes that record the extra size
information were already reserved and set to zero in the
InnoDB
system tablespace.
If you develop applications that interact with the
InnoDB logical
sequence number (LSN) value, change your code to use
guaranteed 64-bit variables to store and compare LSN values,
rather than 32-bit variables.
InnoDB tables can now use collation IDs greater
than 255. Currently, the collation IDs in this range are all
user-defined. For example, the following InnoDB
table can now be created, where formerly the collation ID of 359
was beyond the range supported by InnoDB.
sql> show collation like 'ucs2_vn_ci'; +------------+---------+-----+---------+----------+---------+ | Collation | Charset | Id | Default | Compiled | Sortlen | +------------+---------+-----+---------+----------+---------+ | ucs2_vn_ci | ucs2 | 359 | | | 8 | +------------+---------+-----+---------+----------+---------+ 1 row in set (0.00 sec) mysql> create table two_byte_collation (c1 char(1) character set ucs2 collate ucs2_vn_ci) -> engine = InnoDB; Query OK, 0 rows affected (0.16 sec)
InnoDB has started using named file formats to improve
compatibility in upgrade and downgrade situations, or
heterogeneous systems running different levels of MySQL. Many
important InnoDB features, such as table compression and the
DYNAMIC row format for more efficient BLOB
storage, require creating tables in the
Barracuda file format.
The original file format, which previously didn't have a name, is
known now as Antelope.
To create new tables that take advantage of the Barracuda
features, enable that file format using the configuration
parameter innodb_file_format. The
value of this parameter determines whether a newly created table
or index can use compression or the new DYNAMIC
row format.
To preclude the use of new features that would make your database
inaccessible to the built-in InnoDB in MySQL 5.1 and prior
releases, omit innodb_file_format
or set it to Antelope.
You can set the value of
innodb_file_format on the
command line when you start mysqld, or in the
option file my.cnf (Unix operating systems) or
my.ini (Windows). You can also change it
dynamically with the SET GLOBAL statement.
For more information about managing file formats, see
Section 14.2.2.8, “InnoDB File-Format Management”.
In MySQL 5.5 and higher, you can change certain system configuration parameters without shutting down and restarting the server, as was necessary in MySQL 5.1 and lower. This increases uptime, and makes it easier to test and prototype new SQL and application code. The following sections explain these parameters.
Since MySQL version 4.1, InnoDB has provided two alternatives
for how tables are stored on disk. You can create a new table
and its indexes in the shared
system
tablespace, physically stored in the
ibdata files. Or, you
can store a new table and its indexes in a separate tablespace
(a .ibd file). The storage
layout for each InnoDB table is determined by the the
configuration parameter
innodb_file_per_table at
the time the table is created.
In MySQL 5.5 and higher, the configuration parameter
innodb_file_per_table is
dynamic, and can be set ON or
OFF using the SET GLOBAL.
Previously, the only way to set this parameter was in the MySQL
configuration
file (my.cnf or
my.ini), and changing it required shutting
down and restarting the server.
The default setting is OFF, so new tables and
indexes are created in the system tablespace. Dynamically
changing the value of this parameter requires the
SUPER privilege and immediately affects the
operation of all connections.
Tables created when
innodb_file_per_table is
enabled can use the
Barracuda file format, and
TRUNCATE returns the disk space for those
tables to the operating system. The Barracuda file format in
turn enables features such as table compression and the
DYNAMIC row format. Tables created when
innodb_file_per_table is off
cannot use these features. To take advantage of those features
for an existing table, you can turn on the file-per-table
setting and run ALTER TABLE
for that
table.
t ENGINE=INNODB
When you redefine the primary key for an InnoDB table, the table
is re-created using the current settings for
innodb_file_per_table and
innodb_file_format. This
behavior does not apply when adding or dropping InnoDB secondary
indexes, as explained in Fast Index Creation in the InnoDB Storage Engine.
When a secondary index is created without rebuilding the table,
the index is stored in the same file as the table data,
regardless of the current
innodb_file_per_table setting.
In MySQL 5.5 and higher, you can change the setting of
innodb_stats_on_metadata
dynamically at runtime, to control whether or not InnoDB
performs statistics gathering when metadata statements are
executed. To change the setting, issue the statement
SET GLOBAL
innodb_stats_on_metadata=,
where modemodeON or OFF (or
1 or 0). Changing this
setting requires the SUPER privilege and
immediately affects the operation of all connections.
This setting is related to the feature described in Section 14.2.6.8, “Controlling Optimizer Statistics Estimation”.
The length of time a transaction waits for a resource, before
giving up and rolling back the statement, is determined by the
value of the configuration parameter
innodb_lock_wait_timeout.
(In MySQL 5.0.12 and earlier, the entire transaction was rolled
back, not just the statement.) Your application can try the
statement again (usually after waiting for a while), or roll
back the entire transaction and restart.
The error returned when the timeout period is exceeded is:
ERROR HY000: Lock wait timeout exceeded; try restarting transaction
In MySQL 5.5 and higher, the configuration parameter
innodb_lock_wait_timeout can be
set at runtime with the SET GLOBAL or
SET SESSION statement. Changing the
GLOBAL setting requires the
SUPER privilege and affects the operation of
all clients that subsequently connect. Any client can change the
SESSION setting for
innodb_lock_wait_timeout, which
affects only that client.
In MySQL 5.1 and earlier, the only way to set this parameter was
in the MySQL
configuration
file (my.cnf or
my.ini), and changing it required shutting
down and restarting the server.
As described in Section 14.2.5.2.13, “Controlling Adaptive Hash Indexing”, it may be desirable, depending on your workload, to dynamically enable or disable the adaptive hash indexing scheme InnoDB uses to improve query performance.
The configuration option
innodb_adaptive_hash_index lets
you disable the adaptive hash index. It is enabled by default.
You can modify this parameter through the SET
GLOBAL statement, without restarting the server.
Changing the setting requires the SUPER
privilege.
Disabling the adaptive hash index empties the hash table immediately. Normal operations can continue while the hash table is emptied, and executing queries that were using the hash table access the index B-trees directly instead. When the adaptive hash index is re-enabled, the hash table is populated again during normal operation.
When you truncate a table
that is stored in a
.ibd file
of its own (because
innodb_file_per_table was enabled
when the table was created), and if the table is not referenced in
a FOREIGN KEY constraint, the table is dropped
and re-created in a new .ibd file. This
operation is much faster than deleting the rows one by one. The
operating system can reuse the disk space, in contrast to tables
within the InnoDB system
tablespace, where only InnoDB can use the space after they
are truncated. Physical
backups can also be smaller, without big blocks of unused
space in the middle of the system tablespace.
MySQL 5.1 and earlier would re-use the existing
.ibd file, thus releasing the space only to
InnoDB for storage management, but not to the operating system.
Note that when the table is truncated, the count of rows affected
by the TRUNCATE TABLE statement is an arbitrary
number.
If there is a foreign key constraint between two columns in the same table, that table can still be truncated using this fast technique.
If there are foreign key constraints between the table being
truncated and other tables, the truncate operation fails. This
is a change to the previous behavior, which would transform the
TRUNCATE operation to a
DELETE operation that removed all the rows
and triggered ON DELETE operations on
child tables.
To guard against ignored typos and syntax errors in SQL, or other
unintended consequences of various combinations of operational
modes and SQL statements, InnoDB provides a
strict mode of
operations. In this mode, InnoDB raises error conditions in
certain cases, rather than issuing a warning and processing the
specified statement (perhaps with unintended behavior). This is
analogous to
sql_mode in
MySQL, which controls what SQL syntax MySQL accepts, and
determines whether it silently ignores errors, or validates input
syntax and data values. Since InnoDB strict mode is relatively
new, some statements that execute without errors with earlier
versions of MySQL might generate errors unless you disable strict
mode.
The setting of InnoDB strict mode affects the handling of syntax
errors on the CREATE TABLE,
ALTER TABLE and
CREATE INDEX statements. The
strict mode also enables a record size check, so that an
INSERT or UPDATE never fails
due to the record being too large for the selected page size.
Oracle recommends enabling
innodb_strict_mode when using the
ROW_FORMAT and
KEY_BLOCK_SIZE clauses on
CREATE TABLE,
ALTER TABLE, and
CREATE INDEX statements. Without
strict mode, InnoDB ignores conflicting clauses and creates the
table or index, with only a warning in the message log. The
resulting table might have different behavior than you intended,
such as having no compression when you tried to create a
compressed table. When InnoDB strict mode is on, such problems
generate an immediate error and the table or index is not created,
avoiding a troubleshooting session later.
InnoDB strict mode is set with the configuration parameter
innodb_strict_mode, which can be
specified as ON or OFF. You
can set the value on the command line when you start
mysqld, or in the
configuration file
my.cnf or my.ini. You
can also enable or disable InnoDB strict mode at run time with the
statement SET [GLOBAL|SESSION]
innodb_strict_mode=,
where modemodeON or OFF. Changing the
GLOBAL setting requires the
SUPER privilege and affects the operation of
all clients that subsequently connect. Any client can change the
SESSION setting for
innodb_strict_mode, and the
setting affects only that client.
The MySQL query optimizer uses estimated
statistics about key
distributions to choose the indexes for an execution plan, based
on the relative
selectivity of the index.
Certain operations cause InnoDB to sample random pages from each
index on a table to estimate the
cardinality of the index.
(This technique is known as
random dives.) These
operations include the ANALYZE
TABLE statement, the SHOW TABLE
STATUS statement, and accessing the table for the first
time after a restart.
To give you control over the quality of the statistics estimate
(and thus better information for the query optimizer), you can now
change the number of sampled pages using the parameter
innodb_stats_sample_pages.
Previously, the number of sampled pages was always 8, which could
be insufficient to produce an accurate estimate, leading to poor
index choices by the query optimizer. This technique is especially
important for large tables and tables used in
joins. Unnecessary
full table scans for
such tables can be a substantial performance issue. See
Section 8.2.1.4, “How to Avoid Full Table Scans” for tips on tuning such
queries.
You can set the global parameter
innodb_stats_sample_pages, at
run time. The default value for this parameter is 8, preserving
the same behavior as in past releases.
The value of
innodb_stats_sample_pages
affects the index sampling for all InnoDB
tables and indexes. There are the following potentially
significant impacts when you change the index sample size:
Small values like 1 or 2 can result in very inaccurate estimates of cardinality.
Increasing the
innodb_stats_sample_pagesvalue might require more disk reads. Values much larger than 8 (say, 100), can cause a big slowdown in the time it takes to open a table or executeSHOW TABLE STATUS.The optimizer might choose very different query plans based on different estimates of index selectivity.
To disable the cardinality estimation for metadata statements such
as SHOW TABLE STATUS, execute the statement
SET GLOBAL innodb_stats_on_metadata=OFF (or
0). The ability to set this option dynamically
is also relatively new.
All InnoDB tables are opened, and the statistics are re-estimated for all associated indexes, when the mysql client starts if the auto-rehash setting is set on (the default). To improve the start up time of the mysql client, you can turn auto-rehash off. The auto-rehash feature enables automatic name completion of database, table, and column names for interactive users.
Whatever value of
innodb_stats_sample_pages works
best for a system, set the option and leave it at that value.
Choose a value that results in reasonably accurate estimates for
all tables in your database without requiring excessive I/O.
Because the statistics are automatically recalculated at various
times other than on execution of ANALYZE
TABLE, it does not make sense to increase the index
sample size, run ANALYZE TABLE,
then decrease sample size again. The more accurate statistics
calculated by ANALYZE running with a high value
of innodb_stats_sample_pages can
be wiped away later.
Although it is not possible to specify the sample size on a
per-table basis, smaller tables generally require fewer index
samples than larger tables do. If your database has many large
tables, consider using a higher value for
innodb_stats_sample_pages than if
you have mostly smaller tables.
For optimal performance with DML statements, InnoDB requires an
index to exist on foreign
key columns, so that UPDATE and
DELETE operations on a
parent table can easily
check whether corresponding rows exist in the
child table. MySQL creates
or drops such indexes automatically when needed, as a side-effect
of CREATE TABLE,
CREATE INDEX, and
ALTER TABLE statements.
When you drop an index, InnoDB checks whether the index is not used for checking a foreign key constraint. It is still OK to drop the index if there is another index that can be used to enforce the same constraint. InnoDB prevents you from dropping the last index that can enforce a particular referential constraint.
The message that reports this error condition is:
ERROR 1553 (HY000): Cannot drop index 'fooIdx':
needed in a foreign key constraint
This message is friendlier than the earlier message it replaces:
ERROR 1025 (HY000): Error on rename of './db2/#sql-18eb_3' to './db2/foo'(errno: 150)
A similar change in error reporting applies to an attempt to drop
the primary key index. For tables without an explicit
PRIMARY KEY, InnoDB creates an implicit
clustered index using
the first columns of the table that are declared
UNIQUE and NOT NULL. When
you drop such an index, InnoDB automatically copies the table and
rebuilds the index using a different UNIQUE NOT
NULL group of columns or a system-generated key. Since
this operation changes the primary key, it uses the slow method of
copying the table and re-creating the index, rather than the Fast
Index Creation technique from
Section 14.2.2.6.6, “Implementation Details of Online DDL”.
Previously, an attempt to drop an implicit clustered index (the
first UNIQUE NOT NULL index) failed if the
table did not contain a PRIMARY KEY:
ERROR 42000: This table type requires a primary key
The statement SHOW ENGINE INNODB MUTEX displays
information about InnoDB mutexes
and rw-locks. Although this
information is useful for tuning on multi-core systems, the amount
of output can be overwhelming on systems with a big
buffer pool. There is one
mutex and one rw-lock in each 16K buffer pool block, and there are
65,536 blocks per gigabyte. It is unlikely that a single block
mutex or rw-lock from the buffer pool could become a performance
bottleneck.
SHOW ENGINE INNODB MUTEX now skips the mutexes
and rw-locks of buffer pool blocks. It also does not list any
mutexes or rw-locks that have never been waited on
(os_waits=0). Thus, SHOW ENGINE INNODB
MUTEX only displays information about mutexes and
rw-locks outside of the buffer pool that have caused at least one
OS-level wait.
As described in Section 14.2.5.2.15, “Changes in the Read-Ahead Algorithm”, a
read-ahead request is an asynchronous I/O request issued in
anticipation that a page will be used in the near future. Knowing
how many pages are read through this read-ahead mechanism, and how
many of them are evicted from the buffer pool without ever being
accessed, can be useful to help fine-tune the parameter
innodb_read_ahead_threshold.
SHOW ENGINE INNODB STATUS output displays the
global status variables
Innodb_buffer_pool_read_ahead
and
Innodb_buffer_pool_read_ahead_evicted.
These variables indicate the number of pages brought into the
buffer pool by read-ahead
requests, and the number of such pages
evicted from the buffer pool
without ever being accessed respectively. These counters provide
global values since the last server restart.
SHOW ENGINE INNODB STATUS also shows the rate
at which the read-ahead pages are read in and the rate at which
such pages are evicted without being accessed. The per-second
averages are based on the statistics collected since the last
invocation of SHOW ENGINE INNODB STATUS and are
displayed in the BUFFER POOL AND MEMORY section
of the output.
This section describes the InnoDB-related
command options and system variables. System variables that are
true or false can be enabled at server startup by naming them, or
disabled by using a --skip- prefix. For
example, to enable or disable InnoDB checksums,
you can use --innodb_checksums or
--skip-innodb_checksums
on the command line, or
innodb_checksums or
skip-innodb_checksums in an option file. System
variables that take a numeric value can be specified as
--
on the command line or as
var_name=valuevar_name=value
Certain options control the locations and layout of the
InnoDB data files.
Section 14.2.1.2, “Configuring InnoDB” explains how to use these
options. Many other options, that you might not use initially,
help to tune InnoDB performance characteristics
based on machine capacity and your database
workload. The
performance-related options are explained in
Section 14.2.5, “InnoDB Performance Tuning and Troubleshooting” and
Section 14.2.5.2, “InnoDB Performance and Scalability Enhancements”.
Table 14.9. InnoDB Option/Variable
Reference
InnoDB Command Options
-
Command-Line Format --ignore-builtin-innodbOption-File Format ignore-builtin-innodbOption Sets Variable Yes, ignore_builtin_innodbVariable Name ignore-builtin-innodbVariable Scope Global Dynamic Variable No Deprecated 5.2.22 Permitted Values Type booleanIn MySQL 5.1, this option caused the server to behave as if the built-in
InnoDBwere not present, which enabledInnoDB Pluginto be used instead. In MySQL 5.6,InnoDBis the default storage engine andInnoDB Pluginis not used, so this option has no effect. As of MySQL 5.6.5, it is ignored. Controls loading of the
InnoDBstorage engine, if the server was compiled withInnoDBsupport. This option has a tristate format, with possible values ofOFF,ON, orFORCE. See Section 5.1.8.1, “Installing and Uninstalling Plugins”.To disable
InnoDB, use--innodb=OFFor--skip-innodb. In this case, because the default storage engine isInnoDB, the server will not start unless you also use--default-storage-engineand--default-tmp-storage-engineto set the default to some other engine for both permanent andTEMPORARYtables.-
Command-Line Format --innodb-status-fileOption-File Format innodb-status-filePermitted Values Type booleanDefault OFFControls whether
InnoDBcreates a file namedinnodb_status.in the MySQL data directory. If enabled,pidInnoDBperiodically writes the output ofSHOW ENGINE INNODB STATUSto this file.By default, the file is not created. To create it, start mysqld with the
--innodb-status-file=1option. The file is deleted during normal shutdown. Disable the
InnoDBstorage engine. See the description of--innodb.
InnoDB System Variables
daemon_memcached_enable_binlogVersion Introduced 5.6.6 Command-Line Format --daemon_memcached_enable_binlog=#Option-File Format daemon_memcached_enable_binlogOption Sets Variable Yes, daemon_memcached_enable_binlogVariable Name daemon_memcached_enable_binlogVariable Scope Global Dynamic Variable No Permitted Values Type booleanDefault falseSee Section 14.2.10, “
InnoDBIntegration with memcached” for usage details for this option.daemon_memcached_engine_lib_nameVersion Introduced 5.6.6 Command-Line Format --daemon_memcached_engine_lib_name=libraryOption-File Format daemon_memcached_engine_lib_nameOption Sets Variable Yes, daemon_memcached_engine_lib_nameVariable Name daemon_memcached_engine_lib_nameVariable Scope Global Dynamic Variable No Permitted Values Type stringDefault innodb_engine.soSpecifies the shared library that implements the
InnoDBmemcached plugin.See Section 14.2.10, “
InnoDBIntegration with memcached” for usage details for this option.daemon_memcached_engine_lib_pathVersion Introduced 5.6.6 Command-Line Format --daemon_memcached_engine_lib_path=directoryOption-File Format daemon_memcached_engine_lib_pathOption Sets Variable Yes, daemon_memcached_engine_lib_pathVariable Name daemon_memcached_engine_lib_pathVariable Scope Global Dynamic Variable No Permitted Values Type stringDefault The path of the directory containing the shared library that implements the
InnoDBmemcached plugin.See Section 14.2.10, “
InnoDBIntegration with memcached” for usage details for this option.-
Version Introduced 5.6.6 Command-Line Format --daemon_memcached_option=optionsOption-File Format daemon_memcached_optionOption Sets Variable Yes, daemon_memcached_optionVariable Name daemon_memcached_optionVariable Scope Global Dynamic Variable No Permitted Values Type stringDefault Space-separated options that are passed to the underlying memcached daemon on startup.
See Section 14.2.10, “
InnoDBIntegration with memcached” for usage details for this option. -
Version Introduced 5.6.6 Command-Line Format --daemon_memcached_r_batch_size=#Option-File Format daemon_memcached_r_batch_sizeOption Sets Variable Yes, daemon_memcached_r_batch_sizeVariable Name daemon_memcached_r_batch_sizeVariable Scope Global Dynamic Variable No Permitted Values Type numericDefault 1Specifies how many memcached read operations (
get) to perform before doing aCOMMITto start a new transaction. Counterpart ofdaemon_memcached_w_batch_size.This value is set to 1 by default, so that any changes made to the table through SQL statements are immediately visible to the memcached operations. You might increase it to reduce the overhead from frequent commits on a system where the underlying table is only being accessed through the memcached interface. If you set the value too large, the amount of undo or redo data could impose some storage overhead, as with any long-running transaction.
See Section 14.2.10, “
InnoDBIntegration with memcached” for usage details for this option. -
Version Introduced 5.6.6 Command-Line Format --daemon_memcached_w_batch_size=#Option-File Format daemon_memcached_w_batch_sizeOption Sets Variable Yes, daemon_memcached_w_batch_sizeVariable Name daemon_memcached_w_batch_sizeVariable Scope Global Dynamic Variable No Permitted Values Type numericDefault 1Specifies how many memcached write operations, such as
add,set, orincr, to perform before doing aCOMMITto start a new transaction. Counterpart ofdaemon_memcached_r_batch_size.This value is set to 1 by default, on the assumption that any data being stored is important to preserve in case of an outage and should immediately be committed. When storing non-critical data, you might increase this value to reduce the overhead from frequent commits; but then the last
N-1 uncommitted write operations could be lost in case of a crash.See Section 14.2.10, “
InnoDBIntegration with memcached” for usage details for this option. Whether the server was started with the
--ignore-builtin-innodboption, which causes the server to behave as if the built-inInnoDBis not present. For more information, see the description of--ignore-builtin-innodbunder “InnoDBCommand Options” earlier in this section.-
Command-Line Format --innodb_adaptive_flushing=#Option-File Format innodb_adaptive_flushingOption Sets Variable Yes, innodb_adaptive_flushingVariable Name innodb_adaptive_flushingVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault ONSpecifies whether to dynamically adjust the rate of flushing dirty pages in the
InnoDBbuffer pool based on the workload. Adjusting the flush rate dynamically is intended to avoid bursts of I/O activity. This setting is enabled by default. For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”. -
Version Introduced 5.6.6 Command-Line Format --innodb_adaptive_flushing_lwm=#Option-File Format innodb_adaptive_flushing_lwmOption Sets Variable Yes, innodb_adaptive_flushing_lwmVariable Name innodb_adaptive_flushing_lwmVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 10Range 0 .. 70Low water mark representing percentage of redo log capacity at which adaptive flushing is enabled.
-
Command-Line Format --innodb_adaptive_hash_index=#Option-File Format innodb_adaptive_hash_indexOption Sets Variable Yes, innodb_adaptive_hash_indexVariable Name innodb_adaptive_hash_indexVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault ONWhether the
InnoDBadaptive hash index is enabled or disabled. The adaptive hash index feature is useful for some workloads, and not for others; conduct benchmarks with it both enabled and disabled, using realistic workloads. See Section 14.2.4.12.6, “Adaptive Hash Indexes” for details. This variable is enabled by default. Use--skip-innodb_adaptive_hash_indexat server startup to disable it. innodb_adaptive_max_sleep_delayVersion Introduced 5.6.3 Command-Line Format --innodb_adaptive_max_sleep_delay=#Option-File Format innodb_adaptive_max_sleep_delayOption Sets Variable Yes, innodb_adaptive_max_sleep_delayVariable Name innodb_adaptive_max_sleep_delayVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 0Range 0 .. 1000000Allows
InnoDBto automatically adjust the value ofinnodb_thread_concurrencyup or down according to the current workload. Any non-zero value enables automated, dynamic adjustment of theinnodb_thread_concurrencyvalue, up to the maximum value specified in theinnodb_adaptive_max_sleep_delayoption. The value represents the number of microseconds. This option can be useful in busy systems, with greater than 16InnoDBthreads. (In practice, it is most valuable for MySQL systems with hundreds or thousands of simultaneous connections.)innodb_additional_mem_pool_sizeVersion Deprecated 5.6.3 Command-Line Format --innodb_additional_mem_pool_size=#Option-File Format innodb_additional_mem_pool_sizeOption Sets Variable Yes, innodb_additional_mem_pool_sizeVariable Name innodb_additional_mem_pool_sizeVariable Scope Global Dynamic Variable No Deprecated 5.6.3 Permitted Values Type numericDefault 8388608Range 2097152 .. 4294967295The size in bytes of a memory pool
InnoDBuses to store data dictionary information and other internal data structures. The more tables you have in your application, the more memory you allocate here. IfInnoDBruns out of memory in this pool, it starts to allocate memory from the operating system and writes warning messages to the MySQL error log. The default value is 8MB.As of MySQL 5.6.3,
innodb_additional_mem_pool_sizeis deprecated and will be removed in a future MySQL release.-
Version Introduced 5.6.7 Command-Line Format --innodb_api_bk_commit_interval=#Option-File Format innodb_api_bk_commit_intervalOption Sets Variable Yes, innodb_api_bk_commit_intervalVariable Name innodb_api_bk_commit_intervalVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 5Range 1 .. 1073741824Specifies how often to auto-commit idle connections that use the
InnoDBmemcached interface. See Section 14.2.10, “InnoDBIntegration with memcached” for usage details for this option. -
Version Introduced 5.6.6 Command-Line Format --innodb_api_disable_rowlock=#Option-File Format innodb_api_disable_rowlockOption Sets Variable Yes, innodb_api_disable_rowlockVariable Name innodb_api_disable_rowlockVariable Scope Global Dynamic Variable No Permitted Values Type booleanDefault OFFSee Section 14.2.10, “
InnoDBIntegration with memcached” for usage details for this option. -
Version Introduced 5.6.6 Command-Line Format --innodb_api_enable_binlog=#Option-File Format innodb_api_enable_binlogOption Sets Variable Yes, innodb_api_enable_binlogVariable Name innodb_api_enable_binlogVariable Scope Global Dynamic Variable No Permitted Values Type booleanDefault OFFLets you use the
InnoDBmemcached plugin with the MySQL binary log. See Section 14.2.10, “InnoDBIntegration with memcached” for usage details for this option. -
Version Introduced 5.6.6 Command-Line Format --innodb_api_enable_mdl=#Option-File Format innodb_api_enable_mdlOption Sets Variable Yes, innodb_api_enable_mdlVariable Name innodb_api_enable_mdlVariable Scope Global Dynamic Variable No Permitted Values Type booleanDefault OFFLocks the table used by the
InnoDBmemcached plugin, so that it cannot be dropped or altered by DDL through the SQL interface. See Section 14.2.10, “InnoDBIntegration with memcached” for usage details for this option. -
Version Introduced 5.6.6 Command-Line Format --innodb_api_trx_level=#Option-File Format innodb_api_trx_levelOption Sets Variable Yes, innodb_api_trx_levelVariable Name innodb_api_trx_levelVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 0Lets you control the transaction isolation level on queries processed by the memcached interface. See Section 14.2.10, “
InnoDBIntegration with memcached” for usage details for this option. -
Command-Line Format --innodb_autoextend_increment=#Option-File Format innodb_autoextend_incrementOption Sets Variable Yes, innodb_autoextend_incrementVariable Name innodb_autoextend_incrementVariable Scope Global Dynamic Variable Yes Permitted Values (<= 5.6.5) Type numericDefault 8Range 1 .. 1000Permitted Values (>= 5.6.6) Type numericDefault 64Range 1 .. 1000The increment size (in MB) for extending the size of an auto-extend
InnoDBsystem tablespace file when it becomes full. The default value is 64 as of MySQL 5.6.6, 8 before that. This variable does not affect the per-table tablespace files that are created if you useinnodb_file_per_table=1. Those files are auto-extending regardless of the value ofinnodb_autoextend_increment. The initial extensions are by small amounts, after which extensions occur in increments of 4MB. -
Command-Line Format --innodb_autoinc_lock_mode=#Option-File Format innodb_autoinc_lock_modeOption Sets Variable Yes, innodb_autoinc_lock_modeVariable Name innodb_autoinc_lock_modeVariable Scope Global Dynamic Variable No Permitted Values Type numericDefault 1Valid Values 012The lock mode to use for generating auto-increment values. The permissible values are 0, 1, or 2, for “traditional”, “consecutive”, or “interleaved” lock mode, respectively. Section 14.2.2.4, “
AUTO_INCREMENTHandling inInnoDB”, describes the characteristics of these modes.This variable has a default of 1 (“consecutive” lock mode).
innodb_buffer_pool_dump_at_shutdownVersion Introduced 5.6.3 Command-Line Format --innodb_buffer_pool_dump_at_shutdown=#Option-File Format innodb_buffer_pool_dump_at_shutdownOption Sets Variable Yes, innodb_buffer_pool_dump_at_shutdownVariable Name innodb_buffer_pool_dump_at_shutdownVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault OFFSpecifies whether to record the pages cached in the InnoDB buffer pool when the MySQL server is shut down, to shorten the warmup process at the next restart. Typically used in combination with
innodb_buffer_pool_load_at_startup.-
Version Introduced 5.6.3 Command-Line Format --innodb_buffer_pool_dump_now=#Option-File Format innodb_buffer_pool_dump_nowOption Sets Variable Yes, innodb_buffer_pool_dump_nowVariable Name innodb_buffer_pool_dump_nowVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault ONImmediately records the pages cached in the InnoDB buffer pool. Typically used in combination with
innodb_buffer_pool_load_now. -
Version Introduced 5.6.3 Command-Line Format --innodb_buffer_pool_filename=fileOption-File Format innodb_buffer_pool_filenameOption Sets Variable Yes, innodb_buffer_pool_filenameVariable Name innodb_buffer_pool_filenameVariable Scope Global Dynamic Variable Yes Permitted Values Type stringDefault ib_buffer_poolSpecifies the file that holds the list of page numbers produced by
innodb_buffer_pool_dump_at_shutdownorinnodb_buffer_pool_dump_now. -
Version Introduced 5.6.3 Command-Line Format --innodb_buffer_pool_load_abort=#Option-File Format innodb_buffer_pool_load_abortOption Sets Variable Yes, innodb_buffer_pool_load_abortVariable Name innodb_buffer_pool_load_abortVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault ONInterrupts the process of restoring InnoDB buffer pool contents triggered by
innodb_buffer_pool_load_at_startuporinnodb_buffer_pool_load_now. innodb_buffer_pool_load_at_startupVersion Introduced 5.6.3 Command-Line Format --innodb_buffer_pool_load_at_startup=#Option-File Format innodb_buffer_pool_load_at_startupOption Sets Variable Yes, innodb_buffer_pool_load_at_startupVariable Name innodb_buffer_pool_load_at_startupVariable Scope Global Dynamic Variable No Permitted Values Type booleanDefault OFFSpecifies that, on MySQL server startup, the InnoDB buffer pool is automatically warmed up by loading the same pages it held at an earlier time. Typically used in combination with
innodb_buffer_pool_dump_at_shutdown.-
Version Introduced 5.6.3 Command-Line Format --innodb_buffer_pool_load_now=#Option-File Format innodb_buffer_pool_load_nowOption Sets Variable Yes, innodb_buffer_pool_load_nowVariable Name innodb_buffer_pool_load_nowVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault ONImmediately warms up the InnoDB buffer pool by loading a set of data pages, without waiting for a server restart. Can be useful to bring cache memory back to a known state during benchmarking, or to ready the MySQL server to resume its normal workload after running queries for reports or maintenance.
-
Command-Line Format --innodb_buffer_pool_instances=#Option-File Format innodb_buffer_pool_instancesOption Sets Variable Yes, innodb_buffer_pool_instancesVariable Name innodb_buffer_pool_instancesVariable Scope Global Dynamic Variable No Permitted Values (<= 5.6.5) Type numericDefault 1Range 1 .. 64Permitted Values (>= 5.6.6) Type numericDefault -1 (autosized)Range 1 .. 64The number of regions that the
InnoDBbuffer pool is divided into. For systems with buffer pools in the multi-gigabyte range, dividing the buffer pool into separate instances can improve concurrency, by reducing contention as different threads read and write to cached pages. Each page that is stored in or read from the buffer pool is assigned to one of the buffer pool instances randomly, using a hashing function. Each buffer pool manages its own free lists, flush lists, LRUs, and all other data structures connected to a buffer pool, and is protected by its own buffer pool mutex.This option takes effect only when you set the
innodb_buffer_pool_sizeto a size of 1 gigabyte or more. The total size you specify is divided among all the buffer pools. For best efficiency, specify a combination ofinnodb_buffer_pool_instancesandinnodb_buffer_pool_sizeso that each buffer pool instance is at least 1 gigabyte.Before MySQL 5.6.6, the default is 1. As of MySQL 5.6.6, the default is 8, except on 32-bit Windows systems, where the default depends on the value of
innodb_buffer_pool_size:If
innodb_buffer_pool_sizeis greater than 1.3GB, the default forinnodb_buffer_pool_instancesisinnodb_buffer_pool_size/128MB, with individual memory allocation requests for each chunk. 1.3MB was chosen as the boundary at which there is significant risk for 32-bit Windows to be unable to allocate the contiguous address space needed for a single buffer pool.Otherwise, the default is 1.
-
Command-Line Format --innodb_buffer_pool_size=#Option-File Format innodb_buffer_pool_sizeOption Sets Variable Yes, innodb_buffer_pool_sizeVariable Name innodb_buffer_pool_sizeVariable Scope Global Dynamic Variable No Permitted Values Platform Bit Size 32Type numericDefault 134217728Range 1048576 .. 2**32-1The size in bytes of the buffer pool, the memory area where
InnoDBcaches table and index data. The default value is 128MB, increased from a historical default of 8MB. The maximum value depends on the CPU architecture, 32-bit or 64-bit. For 32-bit systems, the CPU architecture and operating system sometimes impose a lower practical maximum size. When the size of the buffer pool is greater than 1GB, settinginnodb_buffer_pool_instancesto a value greater than 1 can improve the scalability on a busy server.The larger you set this value, the less disk I/O is needed to access the same data in tables more than once. On a dedicated database server, you might set this to up to 80% of the machine physical memory size. Be prepared to scale back this value if these other issues occur:
Competition for physical memory might cause paging in the operating system.
InnoDBreserves additional memory for buffers and control structures, so that the total allocated space is approximately 10% greater than the specified size.The address space must be contiguous, which can be an issue on Windows systems with DLLs that load at specific addresses.
The time to initialize the buffer pool is roughly proportional to its size. On large installations, this initialization time might be significant. For example, on a modern Linux x86_64 server, initialization of a 10GB buffer pool takes approximately 6 seconds. See Section 8.9.1, “The
InnoDBBuffer Pool”.
-
Version Introduced 5.6.2 Command-Line Format --innodb_change_buffer_max_size=#Option-File Format innodb_change_buffer_max_sizeOption Sets Variable Yes, innodb_change_buffer_max_sizeVariable Name innodb_change_buffer_max_sizeVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 25Range 0 .. 50Maximum size for the InnoDB change buffer, as a percentage of the total size of the buffer pool. You might increase this value for a MySQL server with heavy insert, update, and delete activity, or decrease it for a MySQL server with unchanging data used for reporting. For general I/O tuning advice, see Section 8.5.7, “Optimizing
InnoDBDisk I/O”. -
Command-Line Format --innodb_change_buffering=#Option-File Format innodb_change_bufferingOption Sets Variable Yes, innodb_change_bufferingVariable Name innodb_change_bufferingVariable Scope Global Dynamic Variable Yes Permitted Values Type enumerationDefault allValid Values insertsdeletespurgeschangesallnoneWhether
InnoDBperforms change buffering, an optimization that delays write operations to secondary indexes so that the I/O operations can be performed sequentially. The permitted values areinserts(buffer insert operations),deletes(buffer delete operations; strictly speaking, the writes that mark index records for later deletion during a purge operation),changes(buffer insert and delete-marking operations),purges(buffer purge operations, the writes when deleted index entries are finally garbage-collected),all(buffer insert, delete-marking, and purge operations) andnone(do not buffer any operations). The default isall. For details, see Section 14.2.5.2.12, “Controlling InnoDB Change Buffering”. For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”. -
Version Introduced 5.6.3 Command-Line Format --innodb_checksum_algorithm=#Option-File Format innodb_checksum_algorithmOption Sets Variable Yes, innodb_checksum_algorithmVariable Name innodb_checksum_algorithmVariable Scope Global Dynamic Variable Yes Permitted Values (<= 5.6.5) Type enumerationDefault innodbValid Values innodbcrc32nonestrict_innodbstrict_crc32strict_nonePermitted Values (>= 5.6.6, <= 5.6.6) Type enumerationDefault crc32Valid Values innodbcrc32nonestrict_innodbstrict_crc32strict_nonePermitted Values (>= 5.6.7) Type enumerationDefault innodbValid Values innodbcrc32nonestrict_innodbstrict_crc32strict_noneSpecifies how to generate and verify the checksum stored in each disk block of each
InnoDBtablespace. Replaces theinnodb_checksumsoption.The value
innodbis backward-compatible with all versions of MySQL. The valuecrc32uses an algorithm that is faster to compute the checksum for every modified block, and to check the checksums for each disk read. The valuenonewrites a constant value in the checksum field rather than computing a value based on the block data. The blocks in a tablespace can use a mix of old, new, and no checksum values, being updated gradually as the data is modified; once any blocks in a tablespace are modified to use thecrc32algorithm, the associated tables cannot be read by earlier versions of MySQL.The default value was changed from
innodbto crc32 in MySQL 5.6.6, but switched back toinnodbin 5.6.7 for improved compatibility ofInnoDBdata files during a downgrade to an earlier MySQL version, and for use of MySQL Enterprise Backup for backups.The
strict_*forms work the same asinnodb,crc32, andnone, except thatInnoDBhalts if it encounters a mix of checksum values in the same tablespace. You can only use these options in a completely new instance, to set up all tablespaces for the first time. Thestrict_*settings are somewhat faster, because they do not need to compute both new and old checksum values to accept both during disk reads.For usage information, including a matrix of valid combinations of checksum values during read and write operations, see Section 14.2.5.2.6, “Fast CRC32 Checksum Algorithm”.
-
Command-Line Format --innodb_checksumsOption-File Format innodb_checksumsOption Sets Variable Yes, innodb_checksumsVariable Name innodb_checksumsVariable Scope Global Dynamic Variable No Permitted Values Type booleanDefault ONInnoDBcan use checksum validation on all tablespace pages read from the disk to ensure extra fault tolerance against hardware faults or corrupted data files. This validation is enabled by default. Under specialized circumstances (such as when running benchmarks) this extra safety feature can be disabled with--skip-innodb-checksums. You can specify the method of calculating the checksum withinnodb_checksum_algorithm.In MySQL 5.6.3 and higher, this option is deprecated, replaced by
innodb_checksum_algorithm.innodb_checksum_algorithm=innodbis the same asinnodb_checksums=ON(the default).innodb_checksum_algorithm=noneis the same asinnodb_checksums=OFF. Remove anyinnodb_checksumsoptions from your configuration files and startup scripts, to avoid conflicts withinnodb_checksum_algorithm:innodb_checksums=OFFwould automatically setinnodb_checksum_algorithm=none;innodb_checksums=ONwould be ignored and overridden by any other setting forinnodb_checksum_algorithm. -
Version Introduced 5.6.7 Command-Line Format --innodb_cmp_per_index_enabled=#Option-File Format innodb_cmp_per_index_enabledOption Sets Variable Yes, innodb_cmp_per_index_enabledVariable Name innodb_cmp_per_index_enabledVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault OFFValid Values OFFONEnables per-index compression-related statistics in the
INFORMATION_SCHEMA.INNODB_CMP_PER_INDEXtable. Because these statistics can be expensive to gather, only enable this option on development, test, or slave instances during performance tuning related toInnoDBcompressed tables. -
Command-Line Format --innodb_commit_concurrency=#Option-File Format innodb_commit_concurrencyOption Sets Variable Yes, innodb_commit_concurrencyVariable Name innodb_commit_concurrencyVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 0Range 0 .. 1000The number of threads that can commit at the same time. A value of 0 (the default) permits any number of transactions to commit simultaneously.
The value of
innodb_commit_concurrencycannot be changed at runtime from zero to nonzero or vice versa. The value can be changed from one nonzero value to another. innodb_compression_failure_threshold_pctVersion Introduced 5.6.7 Command-Line Format --innodb_compression_failure_threshold_pct=#Option-File Format innodb_compression_failure_threshold_pctOption Sets Variable Yes, innodb_compression_failure_threshold_pctVariable Name innodb_compression_failure_threshold_pctVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 5Range 0 .. 100Specifies the level of zlib compression to use for
InnoDBcompressed tables and indexes.-
Version Introduced 5.6.7 Command-Line Format --innodb_compression_level=#Option-File Format innodb_compression_levelOption Sets Variable Yes, innodb_compression_levelVariable Name innodb_compression_levelVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 6Range 0 .. 9Specifies the level of zlib compression to use for
InnoDBcompressed tables and indexes. innodb_compression_pad_pct_maxVersion Introduced 5.6.7 Command-Line Format --innodb_compression_pad_pct_max=#Option-File Format innodb_compression_pad_pct_maxOption Sets Variable Yes, innodb_compression_pad_pct_maxVariable Name innodb_compression_pad_pct_maxVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 50Range 0 .. 75Specifies the maximum percentage that can be reserved within each
InnoDBpage for storing delta information when a compressed table or index is updated.-
Command-Line Format --innodb_concurrency_tickets=#Option-File Format innodb_concurrency_ticketsOption Sets Variable Yes, innodb_concurrency_ticketsVariable Name innodb_concurrency_ticketsVariable Scope Global Dynamic Variable Yes Permitted Values (<= 5.6.5) Type numericDefault 500Range 1 .. 4294967295Permitted Values (>= 5.6.6) Type numericDefault 5000Range 1 .. 4294967295Determines the number of threads that can enter
InnoDBconcurrently. A thread is placed in a queue when it tries to enterInnoDBif the number of threads has already reached the concurrency limit. When a thread is permitted to enterInnoDB, it is given a number of “free tickets” equal to the value ofinnodb_concurrency_tickets, and the thread can enter and leaveInnoDBfreely until it has used up its tickets. After that point, the thread again becomes subject to the concurrency check (and possible queuing) the next time it tries to enterInnoDB. The default value is 5000 as of MySQL 5.6.6, 500 before that. -
Command-Line Format --innodb_data_file_path=nameOption-File Format innodb_data_file_pathVariable Name innodb_data_file_pathVariable Scope Global Dynamic Variable No Permitted Values Type file nameThe paths to individual
InnoDBdata files and their sizes. The full directory path to each data file is formed by concatenatinginnodb_data_home_dirto each path specified here. The file sizes are specified in KB, MB, or GB (1024MB) by appendingK,M, orGto the size value. The sum of the sizes of the files must be at least 10MB. If you do not specifyinnodb_data_file_path, the default behavior is to create a single 10MB auto-extending data file namedibdata1. The size limit of individual files is determined by your operating system. You can set the file size to more than 4GB on those operating systems that support big files. You can also use raw disk partitions as data files. For detailed information on configuringInnoDBtablespace files, see Section 14.2.1.2, “ConfiguringInnoDB”. -
Command-Line Format --innodb_data_home_dir=pathOption-File Format innodb_data_home_dirOption Sets Variable Yes, innodb_data_home_dirVariable Name innodb_data_home_dirVariable Scope Global Dynamic Variable No Permitted Values Type file nameThe common part of the directory path for all
InnoDBdata files in the system tablespace. This setting does not affect the location offile-per-table tablespaces wheninnodb_file_per_tableis enabled. The default value is the MySQL data directory. If you specify the value as an empty string, you can use absolute file paths ininnodb_data_file_path. -
Command-Line Format --innodb-doublewriteOption-File Format innodb_doublewriteOption Sets Variable Yes, innodb_doublewriteVariable Name innodb_doublewriteVariable Scope Global Dynamic Variable No Permitted Values Type booleanIf this variable is enabled (the default),
InnoDBstores all data twice, first to the doublewrite buffer, then to the actual data files. This variable can be turned off with--skip-innodb_doublewritefor benchmarks or cases when top performance is needed rather than concern for data integrity or possible failures. -
Command-Line Format --innodb_fast_shutdown[=#]Option-File Format innodb_fast_shutdownOption Sets Variable Yes, innodb_fast_shutdownVariable Name innodb_fast_shutdownVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 1Valid Values 012The
InnoDBshutdown mode. If the value is 0,InnoDBdoes a slow shutdown, a full purge and an insert buffer merge before shutting down. If the value is 1 (the default),InnoDBskips these operations at shutdown, a process known as a fast shutdown. If the value is 2,InnoDBflushes its logs and shuts down cold, as if MySQL had crashed; no committed transactions are lost, but the crash recovery operation makes the next startup take longer.The slow shutdown can take minutes, or even hours in extreme cases where substantial amounts of data are still buffered. Use the slow shutdown technique before upgrading or downgrading between MySQL major releases, so that all data files are fully prepared in case the upgrade process updates the file format.
Use
innodb_fast_shutdown=2in emergency or troubleshooting situations, to get the absolute fastest shutdown if data is at risk of corruption. -
Command-Line Format --innodb_file_format=#Option-File Format innodb_file_formatOption Sets Variable Yes, innodb_file_formatVariable Name innodb_file_formatVariable Scope Global Dynamic Variable Yes Permitted Values Type stringDefault AntelopeValid Values AntelopeBarracudaThe file format to use for new
InnoDBtables. Currently,AntelopeandBarracudaare supported. This applies only for tables that have their own tablespace, so for it to have an effect,innodb_file_per_tablemust be enabled. The Barracuda file format is required for certain InnoDB features such as table compression. -
Command-Line Format --innodb_file_format_check=#Option-File Format innodb_file_format_checkOption Sets Variable Yes, innodb_file_format_checkVariable Name innodb_file_format_checkVariable Scope Global Dynamic Variable No Permitted Values Type booleanDefault ONAs of MySQL 5.5.5, this variable can be set to 1 or 0 at server startup to enable or disable whether
InnoDBchecks the file format tag in the system tablespace (for example,AntelopeorBarracuda). If the tag is checked and is higher than that supported by the current version ofInnoDB, an error occurs andInnoDBdoes not start. If the tag is not higher,InnoDBsets the value ofinnodb_file_format_maxto the file format tag.Before MySQL 5.5.5, this variable can be set to 1 or 0 at server startup to enable or disable whether
InnoDBchecks the file format tag in the system tablespace. If the tag is checked and is higher than that supported by the current version ofInnoDB, an error occurs andInnoDBdoes not start. If the tag is not higher,InnoDBsets the value ofinnodb_file_format_checkto the file format tag, which is the value seen at runtime.NoteDespite the default value sometimes being displayed as
ONorOFF, always use the numeric values 1 or 0 to turn this option on or off in your configuration file or command line. -
Command-Line Format --innodb_file_format_max=#Option-File Format innodb_file_format_maxOption Sets Variable Yes, innodb_file_format_maxVariable Name innodb_file_format_maxVariable Scope Global Dynamic Variable Yes Permitted Values Type stringDefault AntelopeValid Values AntelopeBarracudaAt server startup,
InnoDBsets the value of this variable to the file format tag in the system tablespace (for example,AntelopeorBarracuda). If the server creates or opens a table with a “higher” file format, it sets the value ofinnodb_file_format_maxto that format.This variable was added in MySQL 5.5.5.
-
Command-Line Format --innodb_file_per_tableOption-File Format innodb_file_per_tableVariable Name innodb_file_per_tableVariable Scope Global Dynamic Variable Yes Permitted Values (<= 5.6.5) Type booleanDefault OFFPermitted Values (>= 5.6.6) Type booleanDefault ONWhen
innodb_file_per_tableis enabled (the default in 5.6.6 and higher),InnoDBstores the data and indexes for each newly created table in a separate.ibdfile, rather than in the system tablespace. The storage for theseInnoDBtables is reclaimed when such tables are dropped or truncated. This setting enables several otherInnoDBfeatures, such as table compression. See Section 14.2.2.1, “Managing InnoDB Tablespaces” for details about such features.When
innodb_file_per_tableis disabled,InnoDBstores the data for all tables and indexes in the ibdata files that make up the system tablespace. This setting reduces the performance overhead of filesystem operations for operations such asDROP TABLEorTRUNCATE TABLE. It is most appropriate for a server environment where entire storage devices are devoted to MySQL data. Because the system tablespace never shrinks, and is shared across all databases in an instance, avoid loading huge amounts of temporary data on a space-constrained system wheninnodb_file_per_table=OFF. Set up a separate instance in such cases, so that you can drop the entire instance to reclaim the space.By default,
innodb_file_per_tableis enabled as of MySQL 5.6.6, disabled before that. Consider disabling it if backward compatibility with MySQL 5.5 or 5.1 is a concern. This will preventALTER TABLEfrom movingInnoDBtables from the system tablespace to individual.ibdfiles. -
Version Introduced 5.6.6 Variable Name innodb_flush_log_at_timeoutVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 1Range 0 .. 27000Write and flush the logs every
Nseconds. This setting has an effect only wheninnodb_flush_log_at_trx_commithas a value of 2.This variable was added in MySQL 5.6.6.
innodb_flush_log_at_trx_commitCommand-Line Format --innodb_flush_log_at_trx_commit[=#]Option-File Format innodb_flush_log_at_trx_commitOption Sets Variable Yes, innodb_flush_log_at_trx_commitVariable Name innodb_flush_log_at_trx_commitVariable Scope Global Dynamic Variable Yes Permitted Values Type enumerationDefault 1Valid Values 012Controls the balance between strict ACID compliance for commit operations, and higher performance that is possible when commit-related I/O operations are rearranged and done in batches. You can achieve better performance by changing the default value, but then you can lose up to one second worth of transactions in a crash.
The default value of 1 is required for full ACID compliance. With this value, the log buffer is written out to the log file at each transaction commit and the flush to disk operation is performed on the log file.
With a value of 0, any mysqld process crash can erase the last second of transactions. The log buffer is written out to the log file once per second and the flush to disk operation is performed on the log file, but no writes are done at a transaction commit.
With a value of 2, only an operating system crash or a power outage can erase the last second of transactions. The log buffer is written out to the file at each commit, but the flush to disk operation is not performed on it. Before MySQL 5.6.6, the flushing on the log file takes place once per second. Note that the once-per-second flushing is not 100% guaranteed to happen every second, due to process scheduling issues. As of MySQL 5.6.6, flushing frequency is is controlled by
innodb_flush_log_at_timeoutinstead.InnoDB's crash recovery works regardless of the value. Transactions are either applied entirely or erased entirely.
For the greatest possible durability and consistency in a replication setup using
InnoDBwith transactions, useinnodb_flush_log_at_trx_commit=1andsync_binlog=1in your master servermy.cnffile.CautionMany operating systems and some disk hardware fool the flush-to-disk operation. They may tell mysqld that the flush has taken place, even though it has not. Then the durability of transactions is not guaranteed even with the setting 1, and in the worst case a power outage can even corrupt
InnoDBdata. Using a battery-backed disk cache in the SCSI disk controller or in the disk itself speeds up file flushes, and makes the operation safer. You can also try using the Unix command hdparm to disable the caching of disk writes in hardware caches, or use some other command specific to the hardware vendor.-
Command-Line Format --innodb_flush_method=nameOption-File Format innodb_flush_methodOption Sets Variable Yes, innodb_flush_methodVariable Name innodb_flush_methodVariable Scope Global Dynamic Variable No Permitted Values Type (solaris) enumerationDefault fdatasyncValid Values O_DSYNCO_DIRECTControls the system calls used to flush data to the
InnoDBdata files and log files, which can influence I/O throughput. This variable is relevant only for Unix and Linux systems. On Windows systems, the flush method is alwaysasync_unbufferedand cannot be changed.By default,
InnoDBuses thefsync()system call to flush both the data and log files. Ifinnodb_flush_methodoption is set toO_DSYNC,InnoDBusesO_SYNCto open and flush the log files, andfsync()to flush the data files. IfO_DIRECTis specified (available on some GNU/Linux versions, FreeBSD, and Solaris),InnoDBusesO_DIRECT(ordirectio()on Solaris) to open the data files, and usesfsync()to flush both the data and log files. Note thatInnoDBusesfsync()instead offdatasync(), and it does not useO_DSYNCby default because there have been problems with it on many varieties of Unix.Depending on hardware configuration, setting
innodb_flush_methodtoO_DIRECTcan either have either a positive or negative effect on performance. Benchmark your particular configuration to decide which setting to use. Examine theInnodb_data_fsyncsstatus variable to see the overall number offsync()calls done with each setting. The mix of read and write operations in your workload can also affect which setting performs better for you. For example, on a system with a hardware RAID controller and battery-backed write cache,O_DIRECTcan help to avoid double buffering between theInnoDBbuffer pool and the operating system's filesystem cache. On some systems whereInnoDBdata and log files are located on a SAN, the default value orO_DSYNCmight be faster for a read-heavy workload with mostlySELECTstatements. Always test this parameter with the same type of hardware and workload that reflects your production environment. For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”.Formerly, a value of
fdatasyncalso specified the default behavior. This value was removed, due to confusion that a value offdatasynccausedfsync()system calls rather thanfdatasync()for flushing. To obtain the default value now, do not set any value forinnodb_flush_methodat startup. -
Version Introduced 5.6.3 Command-Line Format --innodb_flush_neighborsOption-File Format innodb_flush_neighborsOption Sets Variable Yes, innodb_flush_neighborsVariable Name innodb_flush_neighborsVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault ONSpecifies whether flushing a page from the InnoDB buffer pool also flushes other dirty pages in the same extent. When the table data is stored on a traditional HDD storage device, flushing such neighbor pages in one operation reduces I/O overhead (primarily for disk seek operations) compared to flushing individual pages at different times. For table data stored on SSD, seek time is not a significant factor and you can turn this setting off to spread out the write operations. For general I/O tuning advice, see Section 8.5.7, “Optimizing
InnoDBDisk I/O”. -
Version Introduced 5.6.6 Command-Line Format --innodb_flushing_avg_loops=#Option-File Format innodb_flushing_avg_loopsOption Sets Variable Yes, innodb_flushing_avg_loopsVariable Name innodb_flushing_avg_loopsVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 30Range 1 .. 1000Number of iterations for which InnoDB keeps the previously calculated snapshot of the flushing state, controlling how quickly adaptive flushing responds to changing workloads. Increasing the value makes the the rate of flush operations change smoothly and gradually as the workload changes. Decreasing the value makes adaptive flushing adjust quickly to workload changes, which can cause spikes in flushing activity if the workload increases and decreases suddenly.
-
Version Introduced 5.6.3 Command-Line Format --innodb_force_load_corruptedOption-File Format innodb_force_load_corruptedOption Sets Variable Yes, innodb_force_load_corruptedVariable Name innodb_force_load_corruptedVariable Scope Global Dynamic Variable No Permitted Values Type booleanDefault OFFLets InnoDB load tables at startup that are marked as corrupted. Use only during troubleshooting, to recover data that is otherwise inaccessible. When troubleshooting is complete, turn this setting back off and restart the server.
-
Command-Line Format --innodb_force_recovery=#Option-File Format innodb_force_recoveryOption Sets Variable Yes, innodb_force_recoveryVariable Name innodb_force_recoveryVariable Scope Global Dynamic Variable No Permitted Values Type enumerationDefault 0Valid Values 0123456The crash recovery mode, typically only changed in serious troubleshooting situations. Possible values are from 0 to 6. The meanings of these values are described in Section 14.2.5.6, “Starting
InnoDBon a Corrupted Database”.WarningOnly set this variable greater than 0 in an emergency situation, to dump your tables from a corrupt database. As a safety measure,
InnoDBprevents any changes to its data when this variable is greater than 0. This restriction also prohibits some queries that useWHEREorORDER BYclauses, because high values can prevent queries from using indexes, to guard against possible corrupt index data. -
Version Introduced 5.6.4 Command-Line Format --innodb_ft_aux_table=db_name/table_nameOption-File Format innodb_ft_aux_tableOption Sets Variable Yes, innodb_ft_aux_tableVariable Name innodb_ft_aux_tableVariable Scope Global Dynamic Variable Yes Permitted Values Type stringSpecifies the qualified name of an
InnoDBtable containing aFULLTEXTindex. After you set this variable to a name in the formatdb_name/table_nameinformation_schematablesinnodb_ft_index_table,innodb_ft_index_cache,innodb_ft_config,innodb_ft_inserted,innodb_ft_deleted, andinnodb_ft_being_deletedthen reflect information about the search index for the specified table. -
Version Introduced 5.6.4 Command-Line Format --innodb_ft_cache_size=#Option-File Format innodb_ft_cache_sizeOption Sets Variable Yes, innodb_ft_cache_sizeVariable Name innodb_ft_cache_sizeVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 33554432Size of the cache that holds a parsed document in memory while creating an InnoDB
FULLTEXTindex. -
Version Introduced 5.6.4 Command-Line Format --innodb_ft_enable_stopword=#Option-File Format innodb_ft_enable_stopwordOption Sets Variable Yes, innodb_ft_enable_stopwordVariable Name innodb_ft_enable_stopwordVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault ONSpecifies that a set of stopwords is associated with an
InnoDBFULLTEXTindex at the time the index is created. If theinnodb_ft_user_stopword_tableoption is set, the stopwords are taken from that table. Else, if theinnodb_ft_server_stopword_tableoption is set, the stopwords are taken from that table. Otherwise, a built-in set of default stopwords is used. -
Version Introduced 5.6.4 Command-Line Format --innodb_ft_max_token_size=#Option-File Format innodb_ft_max_token_sizeOption Sets Variable Yes, innodb_ft_max_token_sizeVariable Name innodb_ft_max_token_sizeVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 84Range 10 .. 252Maximum length of words that are stored in an InnoDB
FULLTEXTindex. Setting a limit on this value reduces the size of the index, thus speeding up queries, by omitting long keywords or arbitrary collections of letters that are not real words and are not likely to be search terms. -
Version Introduced 5.6.4 Command-Line Format --innodb_ft_min_token_size=#Option-File Format innodb_ft_min_token_sizeOption Sets Variable Yes, innodb_ft_min_token_sizeVariable Name innodb_ft_min_token_sizeVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 3Range 0 .. 16Minimum length of words that are stored in an InnoDB
FULLTEXTindex. Increasing this value reduces the size of the index, thus speeding up queries, by omitting common word that are unlikely to be significant in a search context, such as the English words “a” and “to”. For content using a CJK (Chinese, Japanese, Korean) character set, specify a value of 1. -
Version Introduced 5.6.4 Command-Line Format --innodb_ft_num_word_optimize=#Option-File Format innodb_ft_num_word_optimizeOption Sets Variable Yes, innodb_ft_num_word_optimizeVariable Name innodb_ft_num_word_optimizeVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 2000Number of words to process during each
OPTIMIZE TABLEoperation on anInnoDBFULLTEXTindex. Because a bulk insert or update operation to a table containing a full-text search index could require substantial index maintenance to incorporate all changes, you might do a series ofOPTIMIZE TABLEstatements, each picking up where the last left off. innodb_ft_server_stopword_tableVersion Introduced 5.6.4 Command-Line Format --innodb_ft_server_stopword_table=db_name/table_nameOption-File Format innodb_ft_server_stopword_tableOption Sets Variable Yes, innodb_ft_server_stopword_tableVariable Name innodb_ft_server_stopword_tableVariable Scope Global Dynamic Variable Yes Permitted Values Type stringDefault NULLName of the table containing a list of words to ignore when creating an InnoDB
FULLTEXTindex, in the formatdb_name/table_nameNoteThe stopword table must be an
InnoDBtable, containing a singleVARCHARcolumn namedVALUE. The stopword table must exist before you specify its name in the configuration option value.-
Version Introduced 5.6.4 Command-Line Format --innodb_ft_sort_pll_degree=#Option-File Format innodb_ft_sort_pll_degreeOption Sets Variable Yes, innodb_ft_sort_pll_degreeVariable Name innodb_ft_sort_pll_degreeVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 2Range 1 .. 32Number of threads used in parallel to index and tokenize text in an
InnoDBFULLTEXTindex, when building a search index for a large table. -
Version Introduced 5.6.4 Command-Line Format --innodb_ft_user_stopword_table=db_name/table_nameOption-File Format innodb_ft_user_stopword_tableOption Sets Variable Yes, innodb_ft_user_stopword_tableVariable Name innodb_ft_user_stopword_tableVariable Scope Global Dynamic Variable Yes Permitted Values Type stringDefault NULLName of the table containing a list of words to ignore when creating an InnoDB
FULLTEXTindex, in the formatdb_name/table_nameNoteThe stopword table must be an
InnoDBtable, containing a singleVARCHARcolumn namedVALUE. The stopword table must exist before you specify its name in the configuration option value. -
Command-Line Format --innodb_io_capacity=#Option-File Format innodb_io_capacityOption Sets Variable Yes, innodb_io_capacityVariable Name innodb_io_capacityVariable Scope Global Dynamic Variable Yes Permitted Values Platform Bit Size 32Type numericDefault 200Range 100 .. 2**32-1Permitted Values Platform Bit Size 64Type numericDefault 200Range 100 .. 2**64-1An upper limit on the I/O activity performed by the
InnoDBbackground tasks, such as flushing pages from the buffer pool and merging data from the insert buffer. The default value is 200. For busy systems capable of higher I/O rates, you can set a higher value at server startup, to help the server handle the background maintenance work associated with a high rate of row changes. For systems with individual 5400 RPM or 7200 RPM drives, you might lower the value to the former default of100.This parameter should be set to approximately the number of I/O operations that the system can perform per second. Ideally, keep this setting as low as practical, but not so low that these background activities fall behind. If the value is too high, data is removed from the buffer pool and insert buffer too quickly to provide significant benefit from the caching.
The value represents an estimated proportion of the I/O operations per second (IOPS) available to older-generation disk drives that could perform about 100 IOPS. The current default of 200 reflects that modern storage devices are capable of much higher I/O rates.
In general, you can increase the value as a function of the number of drives used for
InnoDBI/O, particularly fast drives capable of high numbers of IOPS. For example, systems that use multiple disks or solid-state disks forInnoDBare likely to benefit from the ability to control this parameter.Although you can specify a very high number, in practice such large values cease to have any benefit; for example, a value of one million would be considered very high.
You can set the
innodb_io_capacityvalue to any number 100 or greater, and the default value is200. You can set the value of this parameter in the MySQL option file (my.cnformy.ini) or change it dynamically with theSET GLOBALcommand, which requires theSUPERprivilege.See Section 14.2.5.2.19, “Controlling the InnoDB Master Thread I/O Rate” for more guidelines about this option. For general information about InnoDB I/O performance, see Section 8.5.7, “Optimizing
InnoDBDisk I/O”. -
Version Introduced 5.6.6 Command-Line Format --innodb_io_capacity_max=#Option-File Format innodb_io_capacity_maxOption Sets Variable Yes, innodb_io_capacity_maxVariable Name innodb_io_capacity_maxVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault see formula in descriptionMin Value 2000Permitted Values Platform Bit Size 64Type numericMax Value 18446744073709547520The limit up to which
InnoDBis allowed to extend theinnodb_io_capacitysetting in case of emergency. Its default value is twice the default value ofinnodb_io_capacity, with a lower limit of 2000. It is inoperative if you have specified any value forinnodb_io_capacityat server startup.For a brief period during MySQL 5.6 development, this variable was known as
innodb_max_io_capacity. -
Version Introduced 5.6.3 Command-Line Format --innodb_large_prefixOption-File Format innodb_large_prefixOption Sets Variable Yes, innodb_large_prefixVariable Name innodb_large_prefixVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault OFFEnable this option to allow index key prefixes longer than 767 bytes (up to 3072 bytes), for
InnoDBtables that use theDYNAMICandCOMPRESSEDrow formats. (Creating such tables also requires the option valuesinnodb_file_format=barracudaandinnodb_file_per_table=true.) See Section 14.2.8, “Limits onInnoDBTables” for the relevant maximums associated with index key prefixes under various settings.For tables using the
REDUNDANTandCOMPACTrow formats, this option does not affect the allowed key prefix length. It does introduce a new error possibility. When this setting is enabled, attempting to create an index prefix with a key length greater than 3072 for aREDUNDANTorCOMPACTtable causes an errorER_INDEX_COLUMN_TOO_LONG(1727). -
Command-Line Format --innodb_lock_wait_timeout=#Option-File Format innodb_lock_wait_timeoutOption Sets Variable Yes, innodb_lock_wait_timeoutVariable Name innodb_lock_wait_timeoutVariable Scope Global, Session Dynamic Variable Yes Permitted Values Type numericDefault 50Range 1 .. 1073741824The timeout in seconds an
InnoDBtransaction waits for a row lock before giving up. The default value is 50 seconds. A transaction that tries to access a row that is locked by anotherInnoDBtransaction waits at most this many seconds for write access to the row before issuing the following error:ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
When a lock wait timeout occurs, the current statement is rolled back (not the entire transaction). To have the entire transaction roll back, start the server with the
--innodb_rollback_on_timeoutoption. See also Section 14.2.4.14, “InnoDBError Handling”.You might decrease this value for highly interactive applications or OLTP systems, to display user feedback quickly or put the update into a queue for processing later. You might increase this value for long-running back-end operations, such as a transform step in a data warehouse that waits for other large insert or update operations to finish.
innodb_lock_wait_timeoutapplies toInnoDBrow locks only. A MySQL table lock does not happen insideInnoDBand this timeout does not apply to waits for table locks.The lock wait timeout value does not apply to deadlocks, because
InnoDBdetects them immediately and rolls back one of the deadlocked transactions. innodb_locks_unsafe_for_binlogVersion Deprecated 5.6.3 Command-Line Format --innodb_locks_unsafe_for_binlogOption-File Format innodb_locks_unsafe_for_binlogOption Sets Variable Yes, innodb_locks_unsafe_for_binlogVariable Name innodb_locks_unsafe_for_binlogVariable Scope Global Dynamic Variable No Deprecated 5.6.3 Permitted Values Type booleanDefault OFFThis variable affects how
InnoDBuses gap locking for searches and index scans. As of MySQL 5.6.3,innodb_locks_unsafe_for_binlogis deprecated and will be removed in a future MySQL release.Normally,
InnoDBuses an algorithm called next-key locking that combines index-row locking with gap locking.InnoDBperforms row-level locking in such a way that when it searches or scans a table index, it sets shared or exclusive locks on the index records it encounters. Thus, the row-level locks are actually index-record locks. In addition, a next-key lock on an index record also affects the “gap” before that index record. That is, a next-key lock is an index-record lock plus a gap lock on the gap preceding the index record. If one session has a shared or exclusive lock on recordRin an index, another session cannot insert a new index record in the gap immediately beforeRin the index order. See Section 14.2.4.5, “InnoDBRecord, Gap, and Next-Key Locks”.By default, the value of
innodb_locks_unsafe_for_binlogis 0 (disabled), which means that gap locking is enabled:InnoDBuses next-key locks for searches and index scans. To enable the variable, set it to 1. This causes gap locking to be disabled:InnoDBuses only index-record locks for searches and index scans.Enabling
innodb_locks_unsafe_for_binlogdoes not disable the use of gap locking for foreign-key constraint checking or duplicate-key checking.The effect of enabling
innodb_locks_unsafe_for_binlogis similar to but not identical to setting the transaction isolation level toREAD COMMITTED:Enabling
innodb_locks_unsafe_for_binlogis a global setting and affects all sessions, whereas the isolation level can be set globally for all sessions, or individually per session.innodb_locks_unsafe_for_binlogcan be set only at server startup, whereas the isolation level can be set at startup or changed at runtime.
READ COMMITTEDtherefore offers finer and more flexible control thaninnodb_locks_unsafe_for_binlog. For additional details about the effect of isolation level on gap locking, see Section 13.3.6, “SET TRANSACTIONSyntax”.Enabling
innodb_locks_unsafe_for_binlogmay cause phantom problems because other sessions can insert new rows into the gaps when gap locking is disabled. Suppose that there is an index on theidcolumn of thechildtable and that you want to read and lock all rows from the table having an identifier value larger than 100, with the intention of updating some column in the selected rows later:SELECT * FROM child WHERE id > 100 FOR UPDATE;
The query scans the index starting from the first record where
idis greater than 100. If the locks set on the index records in that range do not lock out inserts made in the gaps, another session can insert a new row into the table. Consequently, if you were to execute the sameSELECTagain within the same transaction, you would see a new row in the result set returned by the query. This also means that if new items are added to the database,InnoDBdoes not guarantee serializability. Therefore, ifinnodb_locks_unsafe_for_binlogis enabled,InnoDBguarantees at most an isolation level ofREAD COMMITTED. (Conflict serializability is still guaranteed.) For additional information about phantoms, see Section 14.2.4.6, “Avoiding the Phantom Problem Using Next-Key Locking”.Enabling
innodb_locks_unsafe_for_binloghas additional effects:For
UPDATEorDELETEstatements,InnoDBholds locks only for rows that it updates or deletes. Record locks for nonmatching rows are released after MySQL has evaluated theWHEREcondition. This greatly reduces the probability of deadlocks, but they can still happen.For
UPDATEstatements, if a row is already locked,InnoDBperforms a “semi-consistent” read, returning the latest committed version to MySQL so that MySQL can determine whether the row matches theWHEREcondition of theUPDATE. If the row matches (must be updated), MySQL reads the row again and this timeInnoDBeither locks it or waits for a lock on it.
Consider the following example, beginning with this table:
CREATE TABLE t (a INT NOT NULL, b INT) ENGINE = InnoDB; INSERT INTO t VALUES (1,2),(2,3),(3,2),(4,3),(5,2); COMMIT;
In this case, table has no indexes, so searches and index scans use the hidden clustered index for record locking (see Section 14.2.4.12.2, “Clustered and Secondary Indexes”).
Suppose that one client performs an
UPDATEusing these statements:SET autocommit = 0; UPDATE t SET b = 5 WHERE b = 3;
Suppose also that a second client performs an
UPDATEby executing these statements following those of the first client:SET autocommit = 0; UPDATE t SET b = 4 WHERE b = 2;
As
InnoDBexecutes eachUPDATE, it first acquires an exclusive lock for each row, and then determines whether to modify it. IfInnoDBdoes not modify the row andinnodb_locks_unsafe_for_binlogis enabled, it releases the lock. Otherwise,InnoDBretains the lock until the end of the transaction. This affects transaction processing as follows.If
innodb_locks_unsafe_for_binlogis disabled, the firstUPDATEacquires x-locks and does not release any of them:x-lock(1,2); retain x-lock x-lock(2,3); update(2,3) to (2,5); retain x-lock x-lock(3,2); retain x-lock x-lock(4,3); update(4,3) to (4,5); retain x-lock x-lock(5,2); retain x-lock
The second
UPDATEblocks as soon as it tries to acquire any locks (because first update has retained locks on all rows), and does not proceed until the firstUPDATEcommits or rolls back:x-lock(1,2); block and wait for first UPDATE to commit or roll back
If
innodb_locks_unsafe_for_binlogis enabled, the firstUPDATEacquires x-locks and releases those for rows that it does not modify:x-lock(1,2); unlock(1,2) x-lock(2,3); update(2,3) to (2,5); retain x-lock x-lock(3,2); unlock(3,2) x-lock(4,3); update(4,3) to (4,5); retain x-lock x-lock(5,2); unlock(5,2)
For the second
UPDATE,InnoDBdoes a “semi-consistent” read, returning the latest committed version of each row to MySQL so that MySQL can determine whether the row matches theWHEREcondition of theUPDATE:x-lock(1,2); update(1,2) to (1,4); retain x-lock x-lock(2,3); unlock(2,3) x-lock(3,2); update(3,2) to (3,4); retain x-lock x-lock(4,3); unlock(4,3) x-lock(5,2); update(5,2) to (5,4); retain x-lock
-
Command-Line Format --innodb_log_buffer_size=#Option-File Format innodb_log_buffer_sizeOption Sets Variable Yes, innodb_log_buffer_sizeVariable Name innodb_log_buffer_sizeVariable Scope Global Dynamic Variable No Permitted Values Type numericDefault 8388608Range 262144 .. 4294967295The size in bytes of the buffer that
InnoDBuses to write to the log files on disk. The default value is 8MB. A large log buffer enables large transactions to run without a need to write the log to disk before the transactions commit. Thus, if you have transactions that update, insert, or delete many rows, making the log buffer larger saves disk I/O. For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”. -
Version Introduced 5.6.7 Command-Line Format --innodb_log_compressed_pages=#Option-File Format innodb_log_compressed_pagesOption Sets Variable Yes, innodb_log_compressed_pagesVariable Name innodb_log_compressed_pagesVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault OFFValid Values ONOFFSpecifies whether images of re-compressed pages are stored in
InnoDBredo logs. -
Command-Line Format --innodb_log_file_size=#Option-File Format innodb_log_file_sizeOption Sets Variable Yes, innodb_log_file_sizeVariable Name innodb_log_file_sizeVariable Scope Global Dynamic Variable No Permitted Values (>= 5.6.3) Type numericDefault 5242880Range 1048576 .. 512GB / innodb_log_files_in_groupThe size in bytes of each log file in a log group. The combined size of log files (
innodb_log_file_size*innodb_log_files_in_group) can be up to 512GB. The default value is 5MB. Sensible values range from 1MB to 1/N-th of the size of the buffer pool, whereNis the number of log files in the group. The larger the value, the less checkpoint flush activity is needed in the buffer pool, saving disk I/O. Larger log files also make crash recovery slower, although improvements to recovery performance in MySQL 5.5 and higher make the log file size less of a consideration. For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”. -
Command-Line Format --innodb_log_files_in_group=#Option-File Format innodb_log_files_in_groupOption Sets Variable Yes, innodb_log_files_in_groupVariable Name innodb_log_files_in_groupVariable Scope Global Dynamic Variable No Permitted Values Type numericDefault 2Range 2 .. 100The number of log files in the log group.
InnoDBwrites to the files in a circular fashion. The default (and recommended) value is 2. The location of these files is specified byinnodb_log_group_home_dir. The combined size of log files (innodb_log_file_size*innodb_log_files_in_group) can be up to 512GB. -
Command-Line Format --innodb_log_group_home_dir=pathOption-File Format innodb_log_group_home_dirOption Sets Variable Yes, innodb_log_group_home_dirVariable Name innodb_log_group_home_dirVariable Scope Global Dynamic Variable No Permitted Values Type file nameThe directory path to the
InnoDBredo log files, whose number is specified byinnodb_log_files_in_group. If you do not specify anyInnoDBlog variables, the default is to create two 5MB files namedib_logfile0andib_logfile1in the MySQL data directory. -
Version Introduced 5.6.3 Command-Line Format --innodb_lru_scan_depth=#Option-File Format innodb_lru_scan_depthOption Sets Variable Yes, innodb_lru_scan_depthVariable Name innodb_lru_scan_depthVariable Scope Global Dynamic Variable Yes Permitted Values Platform Bit Size 32Type numericDefault 1024Range 100 .. 2**32-1Permitted Values Platform Bit Size 64Type numericDefault 1024Range 100 .. 2**64-1A parameter that influences the algorithms and heuristics for the flush operation for the
InnoDBbuffer pool. Primarily of interest to performance experts tuning I/O-intensive workloads. It specifies how far down the buffer pool LRU list thepage_cleanerthread scans looking for dirty pages to flush. This is a background operation performed once a second. If you have spare I/O capacity under a typical workload, increase the value. If a write-intensive workload saturates your I/O capacity, decrease the value, especially if you have a large buffer pool. For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”. -
Command-Line Format --innodb_max_dirty_pages_pct=#Option-File Format innodb_max_dirty_pages_pctOption Sets Variable Yes, innodb_max_dirty_pages_pctVariable Name innodb_max_dirty_pages_pctVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 75Range 0 .. 99InnoDBtries to flush data from the buffer pool so that the percentage of dirty pages does not exceed this value. Specify an integer in the range from 0 to 99. The default value is 75. For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”. innodb_max_dirty_pages_pct_lwmVersion Introduced 5.6.6 Command-Line Format --innodb_max_dirty_pages_pct_lwm=#Option-File Format innodb_max_dirty_pages_pct_lwmOption Sets Variable Yes, innodb_max_dirty_pages_pct_lwmVariable Name innodb_max_dirty_pages_pct_lwmVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 0Range 0 .. 99Low water mark representing percentage of dirty pages where preflushing is enabled to control the dirty page ratio. The default of 0 disables the preflushing behavior entirely.
-
Command-Line Format --innodb_max_purge_lag=#Option-File Format innodb_max_purge_lagOption Sets Variable Yes, innodb_max_purge_lagVariable Name innodb_max_purge_lagVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 0Range 0 .. 4294967295This variable controls how to delay
INSERT,UPDATE, andDELETEoperations when purge operations are lagging (see Section 14.2.4.11, “InnoDBMulti-Versioning”). The default value is 0 (no delays).The
InnoDBtransaction system maintains a list of transactions that have index records delete-marked byUPDATEorDELETEoperations. The length of this list represents thepurge_lagvalue. Whenpurge_lagexceedsinnodb_max_purge_lag, eachINSERT,UPDATE, andDELETEoperation is delayed.The amount of the delay is ((
purge_lag/innodb_max_purge_lag)*10)-5 milliseconds. To prevent excessive delays in extreme situations wherepurge_lagbecomes huge, you can put a cap on the amount of delay by setting theinnodb_max_purge_lag_delayconfiguration option. The delay is computed in the beginning of a purge batch, every ten seconds. The operations are not delayed if purge cannot run because of an old consistent read view that could see the rows to be purged.A typical setting for a problematic workload might be 1 million, assuming that transactions are small, only 100 bytes in size, and it is permissible to have 100MB of unpurged
InnoDBtable rows.The lag value is displayed as the history list length in the
TRANSACTIONSsection of InnoDB Monitor output. For example, if the output includes the following lines, the lag value is 20:------------ TRANSACTIONS ------------ Trx id counter 0 290328385 Purge done for trx's n:o < 0 290315608 undo n:o < 0 17 History list length 20
For general I/O tuning advice, see Section 8.5.7, “Optimizing
InnoDBDisk I/O”. -
Version Introduced 5.6.5 Command-Line Format --innodb_max_purge_lag_delay=#Option-File Format innodb_max_purge_lag_delayOption Sets Variable Yes, innodb_max_purge_lag_delayVariable Name innodb_max_purge_lag_delayVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 0Min Value 0Specifies the maximum delay in milliseconds for the delay imposed by the
innodb_max_purge_lagconfiguration option. Any non-zero value represents an upper limit on the delay period computed from the formula based on the value ofinnodb_max_purge_lag. The default of zero means that there is no upper limit imposed on the delay interval.For general I/O tuning advice, see Section 8.5.7, “Optimizing
InnoDBDisk I/O”. The number of identical copies of log groups to keep for the database. Always set this value to 1.
-
Version Introduced 5.6.2 Command-Line Format --innodb_monitor_disable=[counter|module|pattern|all]Option-File Format innodb_monitor_disableOption Sets Variable Yes, innodb_monitor_disableVariable Name innodb_monitor_disableVariable Scope Global Dynamic Variable Yes Permitted Values Type stringTurns off one or more counters in the
information_schema.innodb_metricstable. For usage information, see Section 19.30.17, “TheINFORMATION_SCHEMA INNODB_METRICSTable”. -
Version Introduced 5.6.2 Command-Line Format --innodb_monitor_enable=nameOption-File Format innodb_monitor_enableOption Sets Variable Yes, innodb_monitor_enableVariable Name innodb_monitor_enableVariable Scope Global Dynamic Variable Yes Permitted Values Type stringTurns on one or more counters in the
information_schema.innodb_metricstable. For usage information, see Section 19.30.17, “TheINFORMATION_SCHEMA INNODB_METRICSTable”. -
Version Introduced 5.6.2 Command-Line Format --innodb_monitor_reset=[counter|module|pattern|all]Option-File Format innodb_monitor_resetOption Sets Variable Yes, innodb_monitor_resetVariable Name innodb_monitor_resetVariable Scope Global Dynamic Variable Yes Permitted Values Type stringResets to zero the count value for one or more counters in the
information_schema.innodb_metricstable. For usage information, see Section 19.30.17, “TheINFORMATION_SCHEMA INNODB_METRICSTable”. -
Version Introduced 5.6.2 Command-Line Format --innodb_monitor_reset_all=[counter|module|pattern|all]Option-File Format innodb_monitor_reset_allOption Sets Variable Yes, innodb_monitor_reset_allVariable Name innodb_monitor_reset_allVariable Scope Global Dynamic Variable Yes Permitted Values Type stringResets all values (minimum, maximum, and so on) for one or more counters in the
information_schema.innodb_metricstable. For usage information, see Section 19.30.17, “TheINFORMATION_SCHEMA INNODB_METRICSTable”. -
Command-Line Format --innodb_old_blocks_pct=#Option-File Format innodb_old_blocks_pctVariable Name innodb_old_blocks_pctVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 37Range 5 .. 95Specifies the approximate percentage of the
InnoDBbuffer pool used for the old block sublist. The range of values is 5 to 95. The default value is 37 (that is, 3/8 of the pool). Often used in combination withinnodb_old_blocks_time. See Section 8.9.1, “TheInnoDBBuffer Pool” for information about buffer pool management, such as the LRU algorithm and eviction policies. -
Command-Line Format --innodb_old_blocks_time=#Option-File Format innodb_old_blocks_timeVariable Name innodb_old_blocks_timeVariable Scope Global Dynamic Variable Yes Permitted Values (<= 5.6.5) Type numericDefault 0Range 0 .. 2**32-1Permitted Values (>= 5.6.6) Type numericDefault 1000Range 0 .. 2**32-1Non-zero values protect against the buffer pool being filled up by data that is referenced only for a brief period, such as during a full table scan. Increasing this value offers more protection against full table scans interfering with data cached in the buffer pool.
Specifies how long in milliseconds (ms) a block inserted into the old sublist must stay there after its first access before it can be moved to the new sublist. If the value is 0, a block inserted into the old sublist moves immediately to the new sublist the first time it is accessed, no matter how soon after insertion the access occurs. If the value is greater than 0, blocks remain in the old sublist until an access occurs at least that many ms after the first access. For example, a value of 1000 causes blocks to stay in the old sublist for 1 second after the first access before they become eligible to move to the new sublist.
The default value is 1000 as of MySQL 5.6.6, 0 before that.
This variable is often used in combination with
innodb_old_blocks_pct. See Section 8.9.1, “TheInnoDBBuffer Pool” for information about buffer pool management, such as the LRU algorithm and eviction policies. innodb_online_alter_log_max_sizeVersion Introduced 5.6.6 Command-Line Format --innodb_online_alter_log_max_size=#Option-File Format innodb_online_alter_log_max_sizeOption Sets Variable Yes, innodb_online_alter_log_max_sizeVariable Name innodb_online_alter_log_max_sizeVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 134217728Range 65536 .. 2**64-1Specifies an upper limit on the size of the temporary log files used during online DDL operations for
InnoDBtables. There is one such log file for each index being created or table being altered. This log file stores data inserted, updated, or deleted in the table during the DDL operation. The temporary log file is extended when needed by the value ofinnodb_sort_buffer_size, up to the maximum specified byinnodb_online_alter_log_max_size. If any temporary log file exceeds the upper size limit, theALTER TABLEoperation fails and all uncommitted concurrent DML operations are rolled back. Thus, a large value for this option allows more DML to happen during an online DDL operation, but also causes a longer period at the end of the DDL operation when the table is locked to apply the data from the log.-
Command-Line Format --innodb_open_files=#Option-File Format innodb_open_filesVariable Name innodb_open_filesVariable Scope Global Dynamic Variable No Permitted Values (<= 5.6.5) Type numericDefault 300Range 10 .. 4294967295Permitted Values (>= 5.6.6) Type numericDefault -1 (autosized)Range 10 .. 4294967295This variable is relevant only if you use multiple
InnoDBtablespaces. It specifies the maximum number of.ibdfiles that MySQL can keep open at one time. The minimum value is 10. As of MySQL 5.6.6, the default value is 300 ifinnodb_file_per_tableis enabled, and the higher of 300 andtable_open_cacheotherwise. Before 5.6.6, the default value is 300.The file descriptors used for
.ibdfiles are forInnoDBtables only. They are independent of those specified by the--open-files-limitserver option, and do not affect the operation of the table cache. For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”. -
Version Introduced 5.6.4 Command-Line Format --innodb_optimize_fulltext_only=#Option-File Format innodb_optimize_fulltext_onlyOption Sets Variable Yes, innodb_optimize_fulltext_onlyVariable Name innodb_optimize_fulltext_onlyVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault OFFChanges the way the
OPTIMIZE TABLEstatement operates onInnoDBtables. Intended to be enabled temporarily, during maintenance operations forInnoDBtables withFULLTEXTindexes.By default,
OPTIMIZE TABLEreorganizes the data in the clustered index of the table. When this option is enabled,OPTIMIZE TABLEskips this reorganization of the table data, and instead processes the newly added, deleted, and updated token data for aFULLTEXTindex, See Section 14.2.4.12.3, “FULLTEXTIndexes” for more information aboutFULLTEXTindexes forInnoDBtables. -
Version Introduced 5.6.4 Command-Line Format --innodb_page_size=#kOption-File Format innodb_page_sizeOption Sets Variable Yes, innodb_page_sizeVariable Name innodb_page_sizeVariable Scope Global Dynamic Variable No Permitted Values Type enumerationDefault 16384Valid Values 4k8k16k4096819216384Specifies the page size for all
InnoDBtablespaces in a MySQL instance. This value is set when the instance is created and remains constant afterwards. You can specify page size using the values16k(the default),8k, or4k.The default, with the largest page size, is appropriate for a wide range of workloads, particularly for queries involving table scans and DML operations involving bulk updates. Smaller page sizes might be more efficient for OLTP workloads involving many small writes, where contention can be an issue when a single page contains many rows. Smaller pages might also be efficient with SSD storage devices, which typically use small block sizes. Keeping the
InnoDBpage size close to the storage device block size minimizes the amount of unchanged data that is rewritten to disk. For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”. -
Version Introduced 5.6.2 Command-Line Format --innodb_print_all_deadlocks=#Option-File Format innodb_print_all_deadlocksOption Sets Variable Yes, innodb_print_all_deadlocksVariable Name innodb_print_all_deadlocksVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault OFFWhen this option is enabled, information about all deadlocks in
InnoDBuser transactions is recorded in themysqlderror log. Otherwise, you see information about only the last deadlock, using theSHOW ENGINE INNODB STATUScommand. An occasionalInnoDBdeadlock is not necessarily an issue, becauseInnoDBdetects the condition immediately, and rolls back one of the transactions automatically. You might use this option to troubleshoot why deadlocks are happening if an application does not have appropriate error-handling logic to detect the rollback and retry its operation. A large number of deadlocks might indicate the need to restructure transactions that issue DML orSELECT ... FOR UPDATEstatements for multiple tables, so that each transaction accesses the tables in the same order, thus avoiding the deadlock condition. -
Command-Line Format --innodb_purge_batch_size=#Option-File Format innodb_purge_batch_sizeVariable Name innodb_purge_batch_sizeVariable Scope Global Dynamic Variable No Permitted Values (>= 5.6.3) Type numericDefault 300Range 1 .. 5000The granularity of changes, expressed in units of redo log records, that trigger a purge operation, flushing the changed buffer pool blocks to disk. This option is intended for tuning performance in combination with the setting
innodb_purge_threads=, and typical users do not need to modify it.n -
Command-Line Format --innodb_purge_threads=#Option-File Format innodb_purge_threadsVariable Name innodb_purge_threadsVariable Scope Global Dynamic Variable No Permitted Values (>= 5.6.2) Type numericDefault 0Range 0 .. 32Permitted Values (>= 5.6.5) Type numericDefault 1Range 1 .. 32The number of background threads devoted to the InnoDB purge operation. The new default and minimum value of 1 in MySQL 5.6.5 signifies that the purge operation is always performed by background threads, never as part of the master thread. Non-zero values runs the purge operation in one or more background threads, which can reduce internal contention within InnoDB, improving scalability. Increasing the value to greater than 1 creates that many separate purge threads, which can improve efficiency on systems where DML operations are performed on multiple tables. The maximum is 32.
-
Version Introduced 5.6.3 Command-Line Format --innodb_random_read_ahead=#Option-File Format innodb_random_read_aheadOption Sets Variable Yes, innodb_random_read_aheadVariable Name innodb_random_read_aheadVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault OFFEnables the random read-ahead technique for optimizing
InnoDBI/O. This is a setting that was originally on by default, then was removed in MySQL 5.5, and now is available but turned off by default. See Section 14.2.5.2.15, “Changes in the Read-Ahead Algorithm” for details about the performance considerations for the different types of read-ahead requests. For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”. -
Command-Line Format --innodb_read_ahead_threshold=#Option-File Format innodb_read_ahead_thresholdOption Sets Variable Yes, innodb_read_ahead_thresholdVariable Name innodb_read_ahead_thresholdVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 56Range 0 .. 64Controls the sensitivity of linear read-ahead that
InnoDBuses to prefetch pages into the buffer pool. IfInnoDBreads at leastinnodb_read_ahead_thresholdpages sequentially from an extent (64 pages), it initiates an asynchronous read for the entire following extent. The permissible range of values is 0 to 64. The default is 56:InnoDBmust read at least 56 pages sequentially from an extent to initiate an asynchronous read for the following extent. For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”. -
Command-Line Format --innodb_read_io_threads=#Option-File Format innodb_read_io_threadsOption Sets Variable Yes, innodb_read_io_threadsVariable Name innodb_read_io_threadsVariable Scope Global Dynamic Variable No Permitted Values Type numericDefault 4Range 1 .. 64The number of I/O threads for read operations in
InnoDB. The default value is 4. Its counterpart for write threads isinnodb_read_io_threads. For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”.NoteOn Linux systems, running multiple MySQL servers (typically more than 12) with default settings for
innodb_read_io_threads,innodb_write_io_threads, and the Linuxaio-max-nrsetting can exceed system limits. Ideally, increase theaio-max-nrsetting; as a workaround, you might reduce the settings for one or both of the MySQL configuration options. -
Version Introduced 5.6.7 Command-Line Format --innodb_read_only=#Option-File Format innodb_read_onlyOption Sets Variable Yes, innodb_read_onlyVariable Name innodb_read_onlyVariable Scope Global Dynamic Variable No Permitted Values Type booleanDefault OFFStarts the server in read-only mode. For distributing database applications or data sets on read-only media. Can also be used in data warehouses to share the same data directory between multiple instances. See Section 14.2.6.1, “Support for Read-Only Media” for usage instructions.
-
Command-Line Format --innodb_replication_delay=#Option-File Format innodb_replication_delayOption Sets Variable Yes, innodb_replication_delayVariable Name innodb_replication_delayVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 0Range 0 .. 4294967295The replication thread delay (in ms) on a slave server if
innodb_thread_concurrencyis reached. -
Command-Line Format --innodb_rollback_on_timeoutOption-File Format innodb_rollback_on_timeoutOption Sets Variable Yes, innodb_rollback_on_timeoutVariable Name innodb_rollback_on_timeoutVariable Scope Global Dynamic Variable No Permitted Values Type booleanDefault OFFIn MySQL 5.6,
InnoDBrolls back only the last statement on a transaction timeout by default. If--innodb_rollback_on_timeoutis specified, a transaction timeout causesInnoDBto abort and roll back the entire transaction (the same behavior as in MySQL 4.1). -
Version Introduced 5.6.2 Command-Line Format --innodb_rollback_segments=#Option-File Format innodb_rollback_segmentsOption Sets Variable Yes, innodb_rollback_segmentsVariable Name innodb_rollback_segmentsVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 128Range 1 .. 128Defines how many of the rollback segments in the system tablespace that InnoDB uses within a transaction. You might reduce this value from its default of 128 if a smaller number of rollback segments performs better for your workload. For general I/O tuning advice, see Section 8.5.7, “Optimizing
InnoDBDisk I/O”. -
Version Introduced 5.6.4 Command-Line Format --innodb_sort_buffer_size=#Option-File Format innodb_sort_buffer_sizeOption Sets Variable Yes, innodb_sort_buffer_sizeVariable Name innodb_sort_buffer_sizeVariable Scope Global Dynamic Variable Yes Permitted Values (>= 5.6.4) Type numericDefault 1048576Range 524288 .. 67108864Permitted Values (>= 5.6.5) Type numericDefault 1048576Range 65536 .. 67108864Specifies the sizes of several buffers used for sorting data during creation of an
InnoDBindex. Before this setting was made configurable, the size was hardcoded to 1MB, and that value remains the default. This sort area is only used for merge sorts during index creation, not during later index maintenance operations. During anALTER TABLEorCREATE TABLEstatement that creates an index, 3 buffers are allocated, each with a size defined by this option. These buffers are deallocated when the index creation completes.The value of this option also controls the amount by which the temporary log file is extended, to record concurrent DML during online DDL operations.
-
Command-Line Format --innodb_spin_wait_delay=#Option-File Format innodb_spin_wait_delayOption Sets Variable Yes, innodb_spin_wait_delayVariable Name innodb_spin_wait_delayVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 6Range 0 .. 4294967295The maximum delay between polls for a spin lock. The low-level implementation of this mechanism varies depending on the combination of hardware and operating system, so the delay does not correspond to a fixed time interval. The default value is 6.
-
Version Introduced 5.6.6 Command-Line Format --innodb_stats_auto_recalc=#Option-File Format innodb_stats_auto_recalcOption Sets Variable Yes, innodb_stats_auto_recalcVariable Name innodb_stats_auto_recalcVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault ONCauses
InnoDBto automatically recalculate persistent statistics after the data in a table is changed substantially. The threshold value is currently 10% of the rows in the table. This setting applies to tables created when theinnodb_stats_persistentoption is enabled, or where the clauseSTATS_PERSISTENT=1is enabled by aCREATE TABLEorALTER TABLEstatement. The amount of data sampled to produce the statistics is controlled by theinnodb_stats_persistent_sample_pagesconfiguration option. -
Version Introduced 5.6.2 Command-Line Format --innodb_stats_method=nameOption-File Format innodb_stats_methodOption Sets Variable Yes, innodb_stats_methodVariable Name innodb_stats_methodVariable Scope Global Dynamic Variable Yes Permitted Values Type enumerationDefault nulls_equalValid Values nulls_equalnulls_unequalnulls_ignoredHow the server treats
NULLvalues when collecting statistics about the distribution of index values forInnoDBtables. This variable has three possible values,nulls_equal,nulls_unequal, andnulls_ignored. Fornulls_equal, allNULLindex values are considered equal and form a single value group that has a size equal to the number ofNULLvalues. Fornulls_unequal,NULLvalues are considered unequal, and eachNULLforms a distinct value group of size 1. Fornulls_ignored,NULLvalues are ignored.The method that is used for generating table statistics influences how the optimizer chooses indexes for query execution, as described in Section 8.3.7, “
InnoDBandMyISAMIndex Statistics Collection”. -
Command-Line Format --innodb_stats_on_metadataOption-File Format innodb_stats_on_metadataOption Sets Variable Yes, innodb_stats_on_metadataVariable Name innodb_stats_on_metadataVariable Scope Global Dynamic Variable Yes Permitted Values (<= 5.6.5) Type booleanDefault ONPermitted Values (>= 5.6.6) Type booleanDefault OFFWhen this variable is enabled,
InnoDBupdates statistics during metadata statements such asSHOW TABLE STATUSorSHOW INDEX, or when accessing theINFORMATION_SCHEMAtablesTABLESorSTATISTICS. (These updates are similar to what happens forANALYZE TABLE.) When disabled,InnoDBdoes not update statistics during these operations. Leaving this setting disabled can improve access speed for schemas that have a large number of tables or indexes. It can also improve the stability of execution plans for queries that involveInnoDBtables.This variable is disabled by default as of MySQL 5.6.6, enabled before that.
-
Version Introduced 5.6.6 Command-Line Format --innodb_stats_persistent=settingOption-File Format innodb_stats_persistentOption Sets Variable Yes, innodb_stats_persistentVariable Name innodb_stats_persistentVariable Scope Global Dynamic Variable Yes Permitted Values Type enumerationDefault OFFValid Values OFFON01defaultSpecifies whether the
InnoDBindex statistics produced by theANALYZE TABLEcommand are stored on disk, remaining consistent until a subsequentANALYZE TABLE. Otherwise, the statistics are recalculated more frequently, such as at each server restart, which can lead to variations in query execution plans. This setting is stored with each table when the table is created. You can specify or change it through SQL with theSTATS_PERSISTENTclause of theCREATE TABLEandALTER TABLEcommands. innodb_stats_persistent_sample_pagesVersion Introduced 5.6.2 Command-Line Format --innodb_stats_persistent_sample_pages=#Option-File Format innodb_stats_persistent_sample_pagesOption Sets Variable Yes, innodb_stats_persistent_sample_pagesVariable Name innodb_stats_persistent_sample_pagesVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 20The number of index pages to sample when estimating cardinality and other statistics for an indexed column, such as those calculated by
ANALYZE TABLE. Increasing the value improves the accuracy of index statistics, which can improve the query execution plan, at the expense of increased I/O during the execution ofANALYZE TABLEfor anInnoDBtable.This option only applies when the
innodb_stats_persistentsetting is turned on for a table; when that option is turned off for a table, theinnodb_stats_transient_sample_pagessetting applies instead. For more information, see Section 14.2.6, “InnoDBFeatures for Flexibility, Ease of Use and Reliability”.-
Version Deprecated 5.6.3 Command-Line Format --innodb_stats_sample_pages=#Option-File Format innodb_stats_sample_pagesOption Sets Variable Yes, innodb_stats_sample_pagesVariable Name innodb_stats_sample_pagesVariable Scope Global Dynamic Variable Yes Deprecated 5.6.3 Permitted Values Type numericDefault 8Range 1 .. 2**64-1Deprecated, use
innodb_stats_transient_sample_pagesinstead. innodb_stats_transient_sample_pagesVersion Introduced 5.6.2 Command-Line Format --innodb_stats_transient_sample_pages=#Option-File Format innodb_stats_transient_sample_pagesOption Sets Variable Yes, innodb_stats_transient_sample_pagesVariable Name innodb_stats_transient_sample_pagesVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 8The number of index pages to sample when estimating cardinality and other statistics for an indexed column, such as those calculated by
ANALYZE TABLE. The default value is 8. Increasing the value improves the accuracy of index statistics, which can improve the query execution plan, at the expense of increased I/O when opening anInnoDBtable or recalculating statistics.This option only applies when the
innodb_stats_persistentsetting is turned off for a table; when this option is turned on for a table, theinnodb_stats_persistent_sample_pagessetting applies instead. Takes the place of theinnodb_stats_sample_pagesoption. For more information, see Section 14.2.6, “InnoDBFeatures for Flexibility, Ease of Use and Reliability”.-
Command-Line Format --innodb_strict_mode=#Option-File Format innodb_strict_modeOption Sets Variable Yes, innodb_strict_modeVariable Name innodb_strict_modeVariable Scope Global, Session Dynamic Variable Yes Permitted Values Type booleanDefault OFFWhether
InnoDBreturns errors rather than warnings for certain conditions. This is analogous to strict SQL mode. The default value isOFF. See Section 14.2.6.7, “InnoDBStrict Mode” for a list of the conditions that are affected. -
Command-Line Format --innodb_support_xaOption-File Format innodb_support_xaOption Sets Variable Yes, innodb_support_xaVariable Name innodb_support_xaVariable Scope Global, Session Dynamic Variable Yes Permitted Values Type booleanDefault TRUEEnables
InnoDBsupport for two-phase commit in XA transactions, causing an extra disk flush for transaction preparation. This setting is the default. The XA mechanism is used internally and is essential for any server that has its binary log turned on and is accepting changes to its data from more than one thread. If you turn it off, transactions can be written to the binary log in a different order from the one in which the live database is committing them. This can produce different data when the binary log is replayed in disaster recovery or on a replication slave. Do not turn it off on a replication master server unless you have an unusual setup where only one thread is able to change data.For a server that is accepting data changes from only one thread, it is safe and recommended to turn off this option to improve performance for
InnoDBtables. For example, you can turn it off on replication slaves where only the replication SQL thread is changing data.You can also turn off this option if you do not need it for safe binary logging or replication, and you also do not use an external XA transaction manager.
-
Version Introduced 5.6.3 Command-Line Format --innodb_sync_array_size=#Option-File Format innodb_sync_array_sizeOption Sets Variable Yes, innodb_sync_array_sizeVariable Name innodb_sync_array_sizeVariable Scope Global Dynamic Variable No Permitted Values Type numericDefault 1024Min Value 1Splits an internal data structure used to coordinate threads, for higher concurrency in workloads with large numbers of waiting threads. This setting must be configured when the MySQL instance is starting up, and cannot be changed afterward. Increasing this option value is recommended for workloads that frequently produce a large number of waiting threads, typically greater than 768.
-
Command-Line Format --innodb_sync_spin_loops=#Option-File Format innodb_sync_spin_loopsOption Sets Variable Yes, innodb_sync_spin_loopsVariable Name innodb_sync_spin_loopsVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 30Range 0 .. 4294967295The number of times a thread waits for an
InnoDBmutex to be freed before the thread is suspended. The default value is 30. -
Command-Line Format --innodb_table_locksOption-File Format innodb_table_locksOption Sets Variable Yes, innodb_table_locksVariable Name innodb_table_locksVariable Scope Global, Session Dynamic Variable Yes Permitted Values Type booleanDefault TRUEIf
autocommit = 0,InnoDBhonorsLOCK TABLES; MySQL does not return fromLOCK TABLES ... WRITEuntil all other threads have released all their locks to the table. The default value ofinnodb_table_locksis 1, which means thatLOCK TABLEScauses InnoDB to lock a table internally ifautocommit = 0.In MySQL 5.6,
innodb_table_locks = 0has no effect for tables locked explicitly withLOCK TABLES ... WRITE. It does have an effect for tables locked for read or write byLOCK TABLES ... WRITEimplicitly (for example, through triggers) or byLOCK TABLES ... READ. -
Command-Line Format --innodb_thread_concurrency=#Option-File Format innodb_thread_concurrencyOption Sets Variable Yes, innodb_thread_concurrencyVariable Name innodb_thread_concurrencyVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 0Range 0 .. 1000InnoDBtries to keep the number of operating system threads concurrently insideInnoDBless than or equal to the limit given by this variable. Once the number of threads reaches this limit, additional threads are placed into a wait state within a FIFO queue for execution. Threads waiting for locks are not counted in the number of concurrently executing threads.The correct value for this variable is dependent on environment and workload. Try a range of different values to determine what value works for your applications. A recommended value is 2 times the number of CPUs plus the number of disks.
The range of this variable is 0 to 1000. A value of 0 (the default) is interpreted as infinite concurrency (no concurrency checking). Disabling thread concurrency checking enables InnoDB to create as many threads as it needs. A value of 0 also disables the
queries inside InnoDBandqueries in queue countersin theROW OPERATIONSsection ofSHOW ENGINE INNODB STATUSoutput. -
Command-Line Format --innodb_thread_sleep_delay=#Option-File Format innodb_thread_sleep_delayOption Sets Variable Yes, innodb_thread_sleep_delayVariable Name innodb_thread_sleep_delayVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 10000How long
InnoDBthreads sleep before joining theInnoDBqueue, in microseconds. The default value is 10,000. A value of 0 disables sleep. -
Version Introduced 5.6.3 Command-Line Format --innodb_undo_directory=nameOption-File Format innodb_undo_directoryOption Sets Variable Yes, innodb_undo_directoryVariable Name innodb_undo_directoryVariable Scope Global Dynamic Variable No Permitted Values Type stringDefault .The relative or absolute directory path where
InnoDBcreates separate tablespaces for the undo logs. Typically used to place those logs on a different storage device. Used in conjunction withinnodb_undo_logsandinnodb_undo_tablespaces, which determine the disk layout of the undo logs outside the system tablespace. Its default value of.represents the same directory whereInnoDBcreates its other log files by default. -
Version Introduced 5.6.3 Command-Line Format --innodb_undo_logs=#Option-File Format innodb_undo_logsOption Sets Variable Yes, innodb_undo_logsVariable Name innodb_undo_logsVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 0Range 0 .. 128Defines how many of the rollback segments in the system tablespace that
InnoDBuses within a transaction. This setting is appropriate for tuning performance if you observe mutex contention related to the undo logs. Replaces theinnodb_rollback_segmentssetting. For the total number of available undo logs, rather than the number of active ones, see theInnodb_available_undo_logsstatus variable.Although you can increase or decrease how many rollback segments are used within a transaction, the number of rollback segments physically present in the system never decreases. Thus you might start with a low value for this parameter and gradually increase it, to avoid allocating rollback segments that are not needed later.
-
Version Introduced 5.6.3 Command-Line Format --innodb_undo_tablespaces=#Option-File Format innodb_undo_tablespacesOption Sets Variable Yes, innodb_undo_tablespacesVariable Name innodb_undo_tablespacesVariable Scope Global Dynamic Variable Yes Permitted Values Type numericDefault 2**64Min Value 0The number of tablespace files that the undo logs are divided between, when you use a non-zero
innodb_undo_logssetting. By default, all the undo logs are part of the system tablespace. Because the undo logs can become large during long-running transactions, splitting the undo logs between multiple tablespaces reduces the maximum size of any one tablespace. The tablespace files are created in the location defined byinnodb_undo_directory, with names of the forminnodb, whereNNis a sequential series of integers, including leading zeros. -
Command-Line Format --innodb_use_native_aio=#Option-File Format innodb_use_native_aioOption Sets Variable Yes, innodb_use_native_aioVariable Name innodb_use_native_aioVariable Scope Global Dynamic Variable No Permitted Values Type booleanDefault ONSpecifies whether to use the Linux asynchronous I/O subsystem. This variable applies to Linux systems only, and cannot be changed while the server is running.
Normally, you do not need to touch this option, because it is enabled by default. If a problem with the asynchronous I/O subsystem in the OS prevents
InnoDBfrom starting, start the server with this variable disabled (useinnodb_use_native_aio=0in the option file). This option could also be turned off automatically during startup, ifInnoDBdetects a potential problem such as a combination oftmpdirlocation,tmpfsfilesystem, and Linux kernel that that does not support AIO ontmpfs.This variable was added in MySQL 5.5.4.
-
Version Deprecated 5.6.3 Command-Line Format --innodb_use_sys_malloc=#Option-File Format innodb_use_sys_mallocOption Sets Variable Yes, innodb_use_sys_mallocVariable Name innodb_use_sys_mallocVariable Scope Global Dynamic Variable No Deprecated 5.6.3 Permitted Values Type booleanDefault ONWhether
InnoDBuses the operating system memory allocator (ON) or its own (OFF). The default value isON.As of MySQL 5.6.3,
innodb_use_sys_mallocis deprecated and will be removed in a future MySQL release. The
InnoDBversion number.-
Command-Line Format --innodb_write_io_threads=#Option-File Format innodb_write_io_threadsOption Sets Variable Yes, innodb_write_io_threadsVariable Name innodb_write_io_threadsVariable Scope Global Dynamic Variable No Permitted Values Type numericDefault 4Range 1 .. 64The number of I/O threads for write operations in
InnoDB. The default value is 4. Its counterpart for read threads isinnodb_read_io_threads. For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”.NoteOn Linux systems, running multiple MySQL servers (typically more than 12) with default settings for
innodb_read_io_threads,innodb_write_io_threads, and the Linuxaio-max-nrsetting can exceed system limits. Ideally, increase theaio-max-nrsetting; as a workaround, you might reduce the settings for one or both of the MySQL configuration options. sync_binlogCommand-Line Format --sync-binlog=#Option-File Format sync_binlogOption Sets Variable Yes, sync_binlogVariable Name sync_binlogVariable Scope Global Dynamic Variable Yes Permitted Values Platform Bit Size 32Type numericDefault 0Range 0 .. 4294967295Permitted Values Platform Bit Size 64Type numericDefault 0Range 0 .. 18446744073709547520If the value of this variable is greater than 0, the MySQL server synchronizes its binary log to disk (using
fdatasync()) after everysync_binlogwrites to the binary log. There is one write to the binary log per statement if autocommit is enabled, and one write per transaction otherwise. The default value ofsync_binlogis 0, which does no synchronizing to disk. A value of 1 is the safest choice, because in the event of a crash you lose at most one statement or transaction from the binary log. However, it is also the slowest choice (unless the disk has a battery-backed cache, which makes synchronization very fast). For general I/O tuning advice, see Section 8.5.7, “OptimizingInnoDBDisk I/O”.
Throughout the course of development, InnoDB 1.1 and its predecessor the InnoDB Plugin introduced new configuration parameters.
The following InnoDB-related configuration
parameters were added between MySQL 5.5 and 5.6:
innodb_adaptive_max_sleep_delay,
innodb_buffer_pool_dump_at_shutdown,
innodb_buffer_pool_dump_now,
innodb_buffer_pool_filename,
innodb_buffer_pool_load_abort,
innodb_buffer_pool_load_at_startup,
innodb_buffer_pool_load_now,
innodb_change_buffer_max_size,
innodb_checksum_algorithm,
innodb_disable_sort_file_cache,
innodb_flush_neighbors,
innodb_force_load_corrupted,
innodb_ft_aux_table,
innodb_ft_cache_size,
innodb_ft_enable_diag_print,
innodb_ft_enable_stopword,
innodb_ft_max_token_size,
innodb_ft_min_token_size,
innodb_ft_num_word_optimize,
innodb_ft_server_stopword_table,
innodb_ft_sort_pll_degree,
innodb_ft_user_stopword_table,
innodb_large_prefix,
innodb_lru_scan_depth,
innodb_monitor_disable,
innodb_monitor_enable,
innodb_monitor_reset,
innodb_monitor_reset_all,
innodb_optimize_fulltext_only,
innodb_page_size,
innodb_print_all_deadlocks,
innodb_random_read_ahead,
innodb_sort_buf_size,
innodb_stats_persistent_sample_pages,
innodb_stats_transient_sample_pages,
innodb_sync_array_size,
innodb_undo_directory,
innodb_undo_logs,
innodb_undo_tablespaces
For better out-of-the-box performance, the following InnoDB configuration parameters have new default values since MySQL 5.1:
Table 14.10. InnoDB Parameters with New Defaults
| Name | Old Default | New Default |
|---|---|---|
innodb_additional_mem_pool_size | 1MB | 8MB |
innodb_buffer_pool_size | 8MB | 128MB |
innodb_change_buffering | inserts | all |
innodb_file_format_check | ON | 1 |
innodb_log_buffer_size | 1MB | 8MB |
innodb_max_dirty_pages_pct | 90 | 75 |
innodb_sync_spin_loops | 20 | 30 |
innodb_thread_concurrency | 8 | 0 |
Do not convert MySQL system tables in the
mysql database from MyISAM
to InnoDB tables! This is an unsupported
operation. If you do this, MySQL does not restart until you
restore the old system tables from a backup or re-generate them
with the mysql_install_db script.
It is not a good idea to configure InnoDB to
use data files or log files on NFS volumes. Otherwise, the files
might be locked by other processes and become unavailable for
use by MySQL.
Maximums and Minimums
A table can contain a maximum of 1000 columns.
A table can contain a maximum of 64 secondary indexes.
By default, an index key for a single-column index can be up to 767 bytes. The same length limit applies to any index key prefix. See Section 13.1.11, “
CREATE INDEXSyntax”. For example, you might hit this limit with a column prefix index of more than 255 characters on aTEXTorVARCHARcolumn, assuming a UTF-8 character set and the maximum of 3 bytes for each character. When theinnodb_large_prefixconfiguration option is enabled, this length limit is raised to 3072 bytes, forInnoDBtables that use theDYNAMICandCOMPRESSEDrow formats.When you attempt to specify an index prefix length longer than allowed, the length is silently reduced to the maximum length for a nonunique index. For a unique index, exceeding the index prefix limit produces an error. To avoid such errors for replication configurations, avoid setting the
innodb_large_prefixoption on the master if it cannot also be set on the slaves, and the slaves have unique indexes that could be affected by this limit.This configuration option changes the error handling for some combinations of row format and prefix length longer than the maximum allowed. See
innodb_large_prefixfor details.The
InnoDBinternal maximum key length is 3500 bytes, but MySQL itself restricts this to 3072 bytes. This limit applies to the length of the combined index key in a multi-column index.If you reduce the
InnoDBpage size to 8KB or 4KB by specifying theinnodb_page_sizeoption when creating the MySQL instance, the maximum length of the index key is lowered proportionally, based on the limit of 3072 bytes for a 16KB page size. That is, the maximum index key length is 1536 bytes when the page size is 8KB, and 768 bytes when the page size is 4KB.The maximum row length, except for variable-length columns (
VARBINARY,VARCHAR,BLOBandTEXT), is slightly less than half of a database page. That is, the maximum row length is about 8000 bytes for the default page size of 16KB; if you reduce the page size by specifying theinnodb_page_sizeoption when creating the MySQL instance, the maximum row length is 4000 bytes for 8KB pages and 2000 bytes for 4KB pages.LONGBLOBandLONGTEXTcolumns must be less than 4GB, and the total row length, includingBLOBandTEXTcolumns, must be less than 4GB.If a row is less than half a page long, all of it is stored locally within the page. If it exceeds half a page, variable-length columns are chosen for external off-page storage until the row fits within half a page, as described in Section 5.3.2, “File Space Management”.
Although
InnoDBsupports row sizes larger than 65,535 bytes internally, MySQL itself imposes a row-size limit of 65,535 for the combined size of all columns:mysql>
CREATE TABLE t (a VARCHAR(8000), b VARCHAR(10000),->c VARCHAR(10000), d VARCHAR(10000), e VARCHAR(10000),->f VARCHAR(10000), g VARCHAR(10000)) ENGINE=InnoDB;ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBsSee Section E.10.4, “Table Column-Count and Row-Size Limits”.
On some older operating systems, files must be less than 2GB. This is not a limitation of
InnoDBitself, but if you require a large tablespace, you will need to configure it using several smaller data files rather than one or a file large data files.The combined size of the
InnoDBlog files can be up to 512GB.The minimum tablespace size is 10MB. The maximum tablespace size is four billion database pages (64TB). This is also the maximum size for a table.
The default database page size in
InnoDBis 16KB, or you can lower the page size to 8KB or 4KB by specifying theinnodb_page_sizeoption when creating the MySQL instance.NoteIncreasing the page size is not a supported operation: there is no guarantee that
InnoDBwill function normally with a page size greater than 16KB. Problems compiling or running InnoDB may occur. In particular,ROW_FORMAT=COMPRESSEDin the Barracuda file format assumes that the page size is at most 16KB and uses 14-bit pointers.A MySQL instance using a particular
InnoDBpage size cannot use data files or log files from an instance that uses a different page size. This limitation could affect restore or downgrade operations using data from MySQL 5.6, which does support page sizes other than 16KB.
Index Types
InnoDBtables supportFULLTEXTindexes, starting in MySQL 5.6.4. See Section 14.2.4.12.3, “FULLTEXTIndexes” for details.InnoDBtables support spatial data types, but not indexes on them.
Restrictions on InnoDB Tables
ANALYZE TABLEdetermines index cardinality (as displayed in theCardinalitycolumn ofSHOW INDEXoutput) by doing random dives to each of the index trees and updating index cardinality estimates accordingly. Because these are only estimates, repeated runs ofANALYZE TABLEcould produce different numbers. This makesANALYZE TABLEfast onInnoDBtables but not 100% accurate because it does not take all rows into account.You can make the statistics collected by
ANALYZE TABLEmore precise and more stable by turning on theinnodb_stats_persistentconfiguration option, as explained in Section 14.2.5.2.9, “Persistent Optimizer Statistics for InnoDB Tables”. When that setting is enabled, it is important to runANALYZE TABLEafter major changes to indexed column data, because the statistics are not recalculated periodically (such as after a server restart) as they traditionally have been.You can change the number of random dives by modifying the
innodb_stats_persistent_sample_pagessystem variable (if the persistent statistics setting is turned on), or theinnodb_stats_transient_sample_pagessystem variable (if the persistent statistics setting is turned off). For more information, see Section 14.2.6, “InnoDBFeatures for Flexibility, Ease of Use and Reliability”.MySQL uses index cardinality estimates only in join optimization. If some join is not optimized in the right way, you can try using
ANALYZE TABLE. In the few cases thatANALYZE TABLEdoes not produce values good enough for your particular tables, you can useFORCE INDEXwith your queries to force the use of a particular index, or set themax_seeks_for_keysystem variable to ensure that MySQL prefers index lookups over table scans. See Section 5.1.4, “Server System Variables”, and Section C.5.6, “Optimizer-Related Issues”.SHOW TABLE STATUSdoes not give accurate statistics onInnoDBtables, except for the physical size reserved by the table. The row count is only a rough estimate used in SQL optimization.InnoDBdoes not keep an internal count of rows in a table because concurrent transactions might “see” different numbers of rows at the same time. To process aSELECT COUNT(*) FROM tstatement,InnoDBscans an index of the table, which takes some time if the index is not entirely in the buffer pool. If your table does not change often, using the MySQL query cache is a good solution. To get a fast count, you have to use a counter table you create yourself and let your application update it according to the inserts and deletes it does. If an approximate row count is sufficient,SHOW TABLE STATUScan be used. See Section 14.2.5.1, “InnoDBPerformance Tuning Tips”.On Windows,
InnoDBalways stores database and table names internally in lowercase. To move databases in a binary format from Unix to Windows or from Windows to Unix, create all databases and tables using lowercase names.An
AUTO_INCREMENTcolumnai_colmust be defined as part of an index such that it is possible to perform the equivalent of an indexedSELECT MAX(lookup on the table to obtain the maximum column value. Typically, this is achieved by making the column the first column of some table index.ai_col)While initializing a previously specified
AUTO_INCREMENTcolumn on a table,InnoDBsets an exclusive lock on the end of the index associated with theAUTO_INCREMENTcolumn. While accessing the auto-increment counter,InnoDBuses a specificAUTO-INCtable lock mode where the lock lasts only to the end of the current SQL statement, not to the end of the entire transaction. Other clients cannot insert into the table while theAUTO-INCtable lock is held. See Section 14.2.2.4, “AUTO_INCREMENTHandling inInnoDB”.When you restart the MySQL server,
InnoDBmay reuse an old value that was generated for anAUTO_INCREMENTcolumn but never stored (that is, a value that was generated during an old transaction that was rolled back).When an
AUTO_INCREMENTinteger column runs out of values, a subsequentINSERToperation returns a duplicate-key error. This is general MySQL behavior, similar to howMyISAMworks.DELETE FROMdoes not regenerate the table but instead deletes all rows, one by one.tbl_nameCurrently, cascaded foreign key actions do not activate triggers.
You cannot create a table with a column name that matches the name of an internal InnoDB column (including
DB_ROW_ID,DB_TRX_ID,DB_ROLL_PTR, andDB_MIX_ID). The server reports error 1005 and refers to error –1 in the error message. This restriction applies only to use of the names in uppercase.
Locking and Transactions
LOCK TABLESacquires two locks on each table ifinnodb_table_locks=1(the default). In addition to a table lock on the MySQL layer, it also acquires anInnoDBtable lock. Versions of MySQL before 4.1.2 did not acquireInnoDBtable locks; the old behavior can be selected by settinginnodb_table_locks=0. If noInnoDBtable lock is acquired,LOCK TABLEScompletes even if some records of the tables are being locked by other transactions.In MySQL 5.6,
innodb_table_locks=0has no effect for tables locked explicitly withLOCK TABLES ... WRITE. It does have an effect for tables locked for read or write byLOCK TABLES ... WRITEimplicitly (for example, through triggers) or byLOCK TABLES ... READ.All
InnoDBlocks held by a transaction are released when the transaction is committed or aborted. Thus, it does not make much sense to invokeLOCK TABLESonInnoDBtables inautocommit=1mode because the acquiredInnoDBtable locks would be released immediately.You cannot lock additional tables in the middle of a transaction because
LOCK TABLESperforms an implicitCOMMITandUNLOCK TABLES.The limit of 1023 concurrent data-modifying transactions has been raised in MySQL 5.5 and above. The limit is now 128 * 1023 concurrent transactions that generate undo records. You can remove any workarounds that require changing the proper structure of your transactions, such as committing more frequently.
The ACID model is a set of
database design principles that emphasize aspects of reliability
that are important for business data and mission-critical
applications. MySQL includes components such as the
InnoDB storage engine that adhere closely to
the ACID model, so that data is not corrupted and results are not
distorted by exceptional conditions such as software crashes and
hardware malfunctions. When you rely on ACID-compliant features,
you do not need to reinvent the wheel of consistency checking and
crash recovery mechanisms. In cases where you have additional
software safeguards, ultra-reliable hardware, or an application
that can tolerate a small amount of data loss or inconsistency,
you can adjust MySQL settings to trade some of the ACID
reliability for greater performance or throughput.
The following sections discuss how MySQL features, in particular
the InnoDB storage engine, interact with the
categories of the ACID model:
A: atomicity.
C: consistency.
I:: isolation.
D: durability.
Atomicity
The atomicity aspect of the ACID
model mainly involves InnoDB
transactions. Related
MySQL features include:
Consistency
The consistency aspect of the
ACID model mainly involves internal InnoDB
processing to protect data from crashes. Related MySQL features
include:
InnoDBdoublewrite buffer.InnoDBcrash recovery.
Isolation
The isolation aspect of the ACID
model mainly involves InnoDB
transactions, in
particular the isolation
level that applies to each transaction. Related MySQL
features include:
Autocommit setting.
SET ISOLATION LEVELstatement.The low-level details of
InnoDBlocking. During performance tuning, you see these details throughINFORMATION_SCHEMAtables.
Durability
The durability aspect of the ACID model involves MySQL software features interacting with your particular hardware configuration. Because of the many possibilities depending on the capabilities of your CPU, network, and storage devices, this aspect is the most complicated to provide concrete guidelines for. (And those guidelines might take the form of buy “new hardware”.) Related MySQL features include:
InnoDBdoublewrite buffer, turned on and off by theinnodb_doublewriteconfiguration option.Configuration option
innodb_flush_log_at_trx_commit.Configuration option
sync_binlog.Configuration option
innodb_file_per_table.Write buffer in a storage device, such as a disk drive, SSD, or RAID array.
Battery-backed cache in a storage device.
The operating system used to run MySQL, in particular its support for the
fsync()system call.Uninterruptible power supply (UPS) protecting the electrical power to all computer servers and storage devices that run MySQL servers and store MySQL data.
Your backup strategy, such as frequency and types of backups, and backup retention periods.
For distributed or hosted data applications, the particular characteristics of the data centers where the hardware for the MySQL servers is located, and network connections between the data centers.
- 14.2.10.1. Benefits of the
InnoDB/ memcached Combination - 14.2.10.2. Introduction to
InnoDBand memcached Integration - 14.2.10.3. Getting Started with InnoDB Memcached Daemon Plugin
- 14.2.10.4. Using the
InnoDBmemcached Plugin with Replication - 14.2.10.5. Security Considerations for
InnoDBmemcached Plugin - 14.2.10.6. Adapting an Existing MySQL Schema for a memcached Application
- 14.2.10.7. Adapting an Existing memcached Application for the Integrated memcached Daemon
- 14.2.10.8. Tuning Performance of the
InnoDBmemcached Plugin - 14.2.10.9. Controlling Transactional Behavior of the
InnoDBmemcached Plugin - 14.2.10.10. Adapting DML Statements to memcached Operations
- 14.2.10.11. Performing DML and DDL Statements on the Underlying
InnoDBTable - 14.2.10.12. Internals of the
InnoDBmemcached Plugin - 14.2.10.13. Verifying the
InnoDBand memcached Setup - 14.2.10.14. Troubleshooting the
InnoDBmemcached Plugin
The ever-increasing performance demands of web-based services have generated significant interest in simple data access methods that maximize performance. These techniques are broadly classified under the name “NoSQL”: to increase performance and throughput, they take away the overhead of parsing an SQL statement, constructing an execution plan, and dealing with strongly typed data values split into multiple fields.
MySQL 5.6 includes a NoSQL interface, using an
integrated memcached daemon that can
automatically store data and retrieve it from
InnoDB tables, turning the MySQL server into a
fast “key-value store”. You can still also access the
same tables through SQL for convenience, complex queries, and other
strengths of traditional database software.
With this NoSQL interface, you use the familiar
memcached API to speed up database operations,
letting InnoDB handle memory caching using its
buffer pool mechanism. Data
modified through memcached operations such as
ADD, SET,
INCR are stored to disk, using the familiar
InnoDB mechanisms such as
change buffering, the
doublewrite buffer,
and crash recovery. The
combination of memcached simplicity and
InnoDB durability provides users with the best of
both worlds:
Raw performance for simple lookups. Direct access to the
InnoDBstorage engine avoids the parsing and planning overhead of SQL. Running memcached in the same process space as the MySQL server avoids the network overhead of passing requests back and forth.Data is stored in a MySQL database to protect against crashes, outages, and corruption.
The transfer between memory and disk is handled automatically, simplifying application logic.
Data can be unstructured or structured, depending on the type of application. You can make an all-new table for the data, or map the NoSQL-style processing to one or more existing tables.
You can still access the underlying table through SQL, for reporting, analysis, ad hoc queries, bulk loading, set operations such as union and intersection, and other operations well suited to the expressiveness and flexibility of SQL.
You can ensure high availability of the NoSQL data by using this feature in combination with MySQL replication.
The combination of InnoDB tables and
memcached offers advantages over using either
by themselves:
The integration of memcached with MySQL provides a painless way to make the in-memory data persistent, so you can use it for more significant kinds of data. You can put more
add,incr, and similar write operations into your application, without worrying that the data could disappear at any moment. You can bounce the memcached server without losing updates made to the cached data. To guard against unexpected outages, you can take advantage ofInnoDBcrash recovery, replication, and backup procedures.The way
InnoDBdoes fast primary key lookups is a natural fit for memcached single-item queries. The direct, low-level database access path used by the memcached plugin is much more efficient for key-value lookups than equivalent SQL queries.The serialization features of memcached, which can turn complex data structures, binary files, or even code blocks into storeable strings, offer a simple way to get such objects into a database.
Because you can access the underlying data through SQL, you can produce reports, search or update across multiple keys, and call functions such as
AVG()andMAX()on the memcached data. All of these operations are expensive or complicated with the standalone memcached.You do not need to manually load data into memcached at startup. As particular keys are requested by an application, the values are retrieved from the database automatically, and cached in memory using the
InnoDBbuffer pool.Because memcached consumes relatively little CPU, and its memory footprint is easy to control, it can run comfortably alongside a MySQL instance on the same system.
Because data consistency is enforced through the usual mechanism as with regular
InnoDBtables, you do not have to worry about stale memcached data or fallback logic to query the database in the case of a missing key.
When integrated with MySQL Server, memcached is
implemented as a MySQL plugin daemon, accessing the
InnoDB storage engine directly and bypassing
the SQL layer:

Features provided in the current release:
memcached as a daemon plugin of mysqld: both mysqld and memcached run in the same process space, with very low latency access to data.
Direct access to
InnoDBtables, bypassing the SQL parser, the optimizer, and even the Handler API layer.Standard memcached protocols, both the text-based protocol and the binary protocol. The
InnoDB+ memcached combination passes all 55 compatibility tests from the memcapable command.Multi-column support: you can map multiple columns into the “value” part of the key/value store, with column values delimited by a user-specified separator character.
By default, you use the memcached protocol to read and write data directly to
InnoDB, and let MySQL manage the in-memory caching through theInnoDBbuffer pool. Advanced users can also configure the system as a traditional memcached server, with all data cached only in memory, or use a combination of memcached caching andInnoDBpersistent storage. The default settings represent the combination of high reliability with the fewest surprises for database applications. For example, the default settings avoid uncommitted data on the database side, or stale data returned for memcachedgetrequests.You can control how often data is passed back and forth between InnoDB and memcached operations through the
innodb_api_bk_commit_interval,daemon_memcached_r_batch_size, anddaemon_memcached_w_batch_sizeconfiguration options. Both the batch size options default to a value of 1 for maximum reliability.You can specify any memcached configuration options through the MySQL configuration variable
daemon_memcached_option. For example, you might change the port that memcached listens on, reduce the maximum number of simultaneous connections, change the maximum memory size for a key/value pair, or enable debugging messages for the error log.A configuration option
innodb_api_trx_levellets you control the transaction isolation level on queries processed by the memcached interface. Although memcached has concept of transactions, you might use this property to control how soon memcached sees changes caused by SQL statements, if you issue DML statements on the same table that memcached interfaces with. By default, it is set toREAD UNCOMMITTED.Another configuration option is
innodb_api_enable_mdl. “MDL” stands for “metadata locking”. This basically locks the table from the MySQL level, so that the mapped table cannot be dropped or altered by DDL through the SQL interface. Without the lock, the table can be dropped from MySQL layer, but will be kept in the InnoDB storage until memcached or any other user stops using it.
Differences Between Using memcached Standalone or with InnoDB
MySQL users might already be familiar with using
memcached along with MySQL, as described in
Section 15.6, “Using MySQL with memcached”. This section describes the
similarities and differences between the information in that
section, and when using the InnoDB integration
features of the memcached that is built into
MySQL. The link at the start of each item goes to the associated
information about the traditional memcached
server.
Installation: Because the memcached library comes with the MySQL server, installation and setup are straightforward. You run a SQL script to set up a table for memcached to use, issue a one-time
install pluginstatement to enable memcached, and add to the MySQL configuration file or startup script any desired memcached options, for example to use a different port. You might still install the regular memcached distribution to get the additional utilities such as memcp, memcat, and memcapable.Deployment: It is typical to run large numbers of low-capacity memcached servers. Because the
InnoDB+ memcached combination has a 1:1 ratio between database and memcached servers, the typical deployment involves a smaller number of moderate or high-powered servers, machines that were already running MySQL. The benefit of this server configuration is more for improving the efficiency of each individual database server than in tapping into unused memory or distributing lookups across large numbers of servers. In the default configuration, very little memory is used for memcached, and the in-memory lookups are served from theInnoDBbuffer pool, which automatically caches the most recently used and most frequently used data. As in a traditional MySQL server instance, keep the value of theinnodb_buffer_pool_sizeconfiguration option as high as practical (without causing paging at the OS level), so that as much of the workload as possible is done in memory.Expiry: By default (that is, with the caching policy
innodb_only), the latest data from theInnoDBtable is always returned, so the expiry options have no practical effect. If you change the caching policy tocachingorcache-only, the expiry options work as usual, but requested data might be stale if it was updated in the underlying table before it expires from the memory cache.Namespaces: memcached is like a single giant directory, where to keep files from conflicting with each other you might give them elaborate names with prefixes and suffixes. The integrated
InnoDB/ memcached server lets you use these same naming conventions for keys, with one addition. Key names of the format@@.table_id.keytable_idare decoded to reference a specific a table, using mapping data from theinnodb_memcache.containerstable. Thekeyis looked up in or written to the specified table.The
@@notation only works for individual calls to theget,add, andsetfunctions, not the others such asincrordelete. To designate the default table for all subsequent memcached operations within a session, perform agetrequest using the@@notation and a table ID, but without the key portion. For example:get @@table_x
Subsequent
get,set,incr,deleteand other operations use the table designated bytable_xin theinnodb_memcache.containers.namecolumn.Hashing and distribution: The default configuration, with the caching policy
innodb_only, is suitable for the traditional deployment configuration where all data is available on all servers, such as a set of replication slave servers.If you physically divide the data, as in a sharded configuration, you can split the data across several machines running the
InnoDBand memcached combined server, and use the traditional memcached hashing mechanism to route requests to a particular machine. On the MySQL side, typically you would let all the data be inserted byaddrequests to memcached so the appropriate values were stored in the database on the appropriate server.These types of deployment best practices are still being codified.
Memory usage: By default (with the caching policy
innodb_only), the memcached protocol passes information back and forth withInnoDBtables, and the fixed-sizeInnoDBbuffer pool handles the in-memory lookups rather than memcached memory usage growing and shrinking. Relatively little memory is used on the memcached side.If you switch the caching policy to
cachingorcache-only, the normal rules of memcached memory usage apply. Memory for the memcached data values is allocated in terms of “slabs”. You can control the slab size and maximum memory used for memcached.Either way, you can monitor and troubleshoot the integrated memcached daemon using the familiar statistics system, accessed through the standard protocol, for example over a telnet session. Because extra utilities are not included with the integrated daemon, to use the
memcached-toolscript, install a full memcached distribution.Thread usage: MySQL threads and memcached threads must co-exist on the same server, so any limits imposed on threads by the operating system apply to this total number.
Log usage: Because the memcached daemon is run alongside the MySQL server and writes to
stderr, the-v,-vv, and-vvvoptions for logging write their output to the MySQL error log.memcached operations: All the familiar operations such as
get,set,add, anddeleteare available. Serialization (that is, the exact string format to represent complex data structures) depends on the language interface. Still to confirm if there are any special nuances for these operations:delete(key, [, time]): Deletes the key and its associated item from the cache. If you supply a time, then adding another item with the specified key is blocked for the specified period. flush_all: Invalidates (or expires) all the current items in the cache. Technically they still exist (they are not deleted), but they are silently destroyed the next time you try to access them.
Using memcached as a MySQL front end: That is what the
InnoDBintegration with memcached is all about. Putting these components together improves the performance of your application. MakingInnoDBhandle data transfers between memory and disk simplifies the logic of your application.Utilities: The MySQL server includes the
libmemcachedlibrary but not the additional command-line utilities. To get the commands such as memcp, memcat, and memcapable commands, install a full memcached distribution. When memrm and memflush remove items from the cache, they are also removed from the underlyingInnoDBtable.Programming interfaces: You can access the MySQL server through the
InnoDBand memcached combination using the same language as always: C and C++, Java, Perl, Python, PHP, Ruby, and MySQL user-defined functions (UDFs). Specify the server hostname and port as with any other memcached server. By default, the integrated memcached server listens on the same port as usual,11211. You can use both the text and binary protocols. You can customize the behavior of the memcached functions at runtime. Serialization (that is, the exact string format to represent complex data structures) depends on the language interface.Frequently asked questions: MySQL has had an extensive memcached FAQ for several releases. In MySQL 5.6, the answers are largely the same, except that using
InnoDBtables as a storage medium for memcached data means that you can use this combination for more write-intensive applications than before, rather than as a read-only cache.
This section provides step-by-step instructions to get the memcached Daemon Plugin up and running.
For a brief introduction on the setup steps, see the file
README-innodb_memcached in the installation
package. This is a more detailed explanation of that procedure.
Platform Support
Currently, the memcached Daemon Plugin is only supported on Linux, Solaris, and OS X platforms.
Software Prerequisites
As a prerequisite, you must have libevent
installed, since it is required by memcached.
The way to get this library is different if you use the MySQL
installer or build from source, as described in the following
sections.
Using a MySQL Installation Package
When you use a MySQL installer, the libevent
library is not included. Use the particular method for your
operating system to download and install
libevent 1.4.3 or later: for example, depending
on the operating system, you might use the command
apt-get, yum, or
port install.
The libraries for memcached and the
InnoDB plugin for memcached
are put into the right place by the MySQL installer. For typical
operation, the files
lib/plugin/libmemcached.so and
lib/plugin/innodb_engine.so are used.
Building from Source
If you have the source code release, then there is a
libevent 1.4.3 included in the package.
Go to the directory
plugin/innodb_memcached/libevent.Issue the following commands to build and install the
libeventlibrary:autoconf ./configure make make install
When building the MySQL Server from source, once
libevent is installed, build the MySQL server
as usual. No special build steps are required.
The source code for the
InnoDB-memcached plugin is
in the plugin/innodb_memcached directory. As
part of the server build, it generates two shared libraries:
libmemcached.so: the memcached daemon plugin to MySQL.innodb_engine.so: anInnoDBAPI plugin to memcached.
Put these two shared libraries in the MySQL plugin directory. To find the MySQL plugin directory, issue the following command:
mysql> select @@plugin_dir; +-----------------------------------------------+ | @@plugin_dir | +-----------------------------------------------+ | /Users/cirrus/sandbox-setup/5.6.6/lib/plugin/ | +-----------------------------------------------+ 1 row in set (0.00 sec)
Setting Operating System Limits
The memcached daemon can sometimes cause the
MySQL server to exceed the OS limit on the number of open files.
See Section 14.2.10.14, “Troubleshooting the InnoDB
memcached Plugin” for the steps
to resolve this issue.
Setting Up Required Tables
To configure the memcached plugin so it can
interact with InnoDB tables, run the
configuration script
scripts/innodb_memcached_config.sql to
install the necessary tables used behind the scenes:
mysql> source MYSQL_HOME/scripts/innodb_memcached_config.sql
For information about the layout and purpose of these tables, see
Section 14.2.10.12, “Internals of the InnoDB memcached
Plugin”.
Installing the Daemon Plugin
To activate the daemon plugin, use the install
plugin statement, just as when installing any other
MySQL plugin:
mysql> install plugin daemon_memcached soname "libmemcached.so";
Once the plugin is installed this way, it is automatically activated each time the MySQL server is booted or restarted.
Specifying memcached Configuration Options
If you have any memcached specific
configuration parameters, specify them during on the
mysqld command line or enter them in the MySQL
configuration file, encoded in the argument to the
daemon_memcached_option MySQL
configuration option. The memcached
configuration options take effect when the plugin is installed,
which you do each time the MySQL server is started.
For example, to make memcached listen on port
11222 instead of the default port 11211, add
-p11222 to the MySQL configuration option
daemon_memcached_option:
mysqld .... --loose-daemon_memcached_option="-p11222"
You can add other memcached command line options to the
daemon_memcached_option string.
The other configuration options are:
daemon_memcached_engine_lib_name(defaultinnodb_engine.so)daemon_memcached_engine_lib_path(default NULL, representing the plugin directory).daemon_memcached_r_batch_size, batch commit size for read operations (get). It specifies after how many memcached read operations the system automatically does a commit. By default, this is set to 1 so that everygetrequest can access the very latest committed data in theInnoDBtable, whether the data was updated through memcached or by SQL. When its value is greater than 1, the counter for read operations is incremented once for everygetcall. Theflush_allcall resets both the read and write counters.daemon_memcached_w_batch_size, batch commit for any write operations (set,replace,append,prepend,incr,decr, and so on) By default, this is set as 1, so that no uncommitted data is lost in case of an outage, and any SQL queries on the underlying table can access the very latest data. When its value is greater than 1, the counter for write operations is incremented once for everyadd,set,incr,decr, anddeletecall. Theflush_allcall resets both the read and write counters.
By default, you do not need to change anything with the first two configuration options. Those options allow you to load any other storage engine for memcached (such as the NDB memcached engine).
Again, please note that you will have these configuration parameter in your MySQL configure file or MySQL boot command line. They take effect when you load the memcached plugin.
Summary
Now you have everything set up. You can directly interact with InnoDB tables through the memcached interface.
Because the InnoDB Memcached Daemon Plugin
supports the MySQL binary
log, any updates through the memcached
interface can be replicated for backup, balancing intensive read
workloads, and high availability. All memcached
commands are supported for binlogging.
The following sections show how to use the binlog capability, to
use the InnoDB + memcached
combination along with MySQL replication. It assumes you have
already done the basic setup described in
Section 14.2.10.3, “Getting Started with InnoDB Memcached Daemon Plugin”.
Enable InnoDB Memcached Binary Log with innodb_api_enable_binlog:
To use the
InnoDBmemcached plugin with the MySQL binary log, enable theinnodb_api_enable_binlogconfiguration option. This option can only be set at server boot time. You must also enable the MySQL binary log with the--log-binoption. You can add these options to your server configuration file such asmy.cnf, or on the mysqld command line.mysqld ... --log-bin -–innodb_api_enable_binlog=1
Then configure your master and slave server, as described in Section 16.1.1, “How to Set Up Replication”.
Use mysqldump to create a master data snapshot, and sync it to the slave server.
master shell > mysqldump --all-databases --lock-all-tables > dbdump.db slave shell > mysql < dbdump.db
On the master server, issue
show master statusto obtain the Master Binary Log Coordinates:mysql> show master status;
On the slave server, use a
change master tostatement to set up a slave server with the above coordinates:mysql> CHANGE MASTER TO MASTER_HOST='localhost', MASTER_USER='root', MASTER_PASSWORD='', MASTER_PORT = 13000, MASTER_LOG_FILE='0.000001, MASTER_LOG_POS=114;
Then start the slave:
mysql>start slave;
If the error log prints output similar to the following, the slave is ready for replication:
111002 18:47:15 [Note] Slave I/O thread: connected to master 'root@localhost:13000', replication started in log '0.000001' at position 114
Test with the memcached telnet interface:
To test the server with the above replication setup, we use the memcached telnet interface, and also query the master and slave servers using SQL to verify the results.
In our configuration setup SQL, one example table
demo_test is created in the
test database for use by
memcached. We will use this default table for
the demonstrations:
Use
setto insert a record, keytest1, valuet1, and flag10:telnet 127.0.0.1 11211 Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'. set test1 10 0 2 t1 STORED
In the master server, you can see that the row is inserted.
c1 maps to the key, c2 maps
to the value, c3 is the flag,
c4 is the cas value, and
c5 is the expiration.
mysql> select * from demo_test;
In the slave server, you will see the same record is inserted by replication:
mysql> select * from demo_test;
Use
setcommand to update the keytest1to a new valuenew:
Connected to 127.0.0.1. Escape character is '^]'. set test1 10 0 3 new STORED
From the slave server, the update is replicated (notice the
cas value also updated):
mysql> select * from demo_test;
Delete the record with a
deletecommand:
Connected to 127.0.0.1. Escape character is '^]'. delete test1 DELETED
The delete is replicated to the slave, the record in slave is also deleted:
mysql> select * from demo_test; Empty set (0.00 sec)
Truncate the table with the
flush_allcommand.
First, insert two records by telnetting to the master server:
Connected to 127.0.0.1. Escape character is '^]' set test2 10 0 5 again STORED set test3 10 0 6 again1 STORED
In the slave server, confirm these two records are replicated:
mysql> select * from demo_test;
Call flush_all in the telnet interface to
truncate the table:
Connected to 127.0.0.1. Escape character is '^]'. flush_all OK
Then check that the truncation operation is replicated on the slave server:
mysql> select * from demo_test; Empty set (0.00 sec)
All memcached commands are supported in terms
of replication.
Notes for the InnoDB Memcached Binlog:
Binlog Format:
Most memcached operations are mapped to DML statements (analogous to insert, delete, update). Since there is no actual SQL statement being processed by the MySQL server, all memcached commands (except for
flush_all) use Row-Based Replication (RBR) logging. This is independent of any serverbinlog_formatsetting.The memcached
flush_allcommand is mapped to theTRUNCATE TABLEcommand. Since DDL commands can only use statement-based logging, thisflush_allcommand is replicated by sending aTRUNCATE TABLEstatement.
Transactions:
The concept of transactions has not typically been part of memcached applications. We use
daemon_memcached_r_batch_sizeanddaemon_memcached_w_batch_sizeto control the read and write transaction batch size for performance considerations. These settings do not affect replication: each SQL operation on the underlying table is replicated right after successful completion.The default value of
daemon_memcached_w_batch_sizeis 1, so each memcached write operation is committed immediately. This default setting incurs a certain amount of performance overhead, to avoid any inconsistency in the data visible on the master and slave servers. The replicated records will always be available immediately on the slave server. If you setdaemon_memcached_w_batch_sizegreater than 1, records inserted or updated through the memcached interface are not immediately visible on the master server; to view these records on the master server before they are committed, issueset transaction isolation level read uncommitted.
Consult this section before deploying the
InnoDB memcached plugin on
any production servers, or even test servers if the MySQL
instance contains any sensitive information.
Because memcached does not use an
authentication mechanism by default, and the optional SASL
authentication is not as strong as traditional DBMS security
measures, make sure to keep only non-sensitive data in the MySQL
instance using the InnoDB
memcached plugin, and wall off any servers
using this configuration from potential intruders. Do not allow
memcached access to such servers from the
Internet, only from within a firewalled intranet, ideally from a
subnet whose membership you can restrict.
SASL support gives you the capability to protect your MySQL database from unauthenticated access through memcached clients. This section explains the steps to enable this option.
Background Info:
SASL stands for “Simple Authentication and Security Layer”, a standard for adding authentication support to connection-based protocols. memcached added SASL support starting in its 1.4.3 release.
For the InnoDB + memcached combination, the
table that stores the memcached data must be
registered in the container system table. And
memcached clients can only access such a
registered table. Even though the DBA can add access
restrictions on such table, they have no control over who can
access it through memcached applications.
This is why we provide a means (through SASL) to control who can
access InnoDB tables associated with the
memcached plugin.
The following section shows how to build, enable, and test an SASL-enabled InnoDB Memcached plugin.
Steps to Build and Enable SASL in InnoDB Memcached Plugin:
By default, SASL-enabled InnoDB memcached is
not included in the release package, since it relies on building
memcached with SASL libraries. To enable this
feature, download the MySQL source and rebuild the
InnoDB memcached plugin
after downloading the SASL libraries. The detail is described in
following sections:
First, get the SASL development and utility libraries. For example, on Ubuntu, you can get these libraries through:
sudo apt-get -f install libsasl2-2 sasl2-bin libsasl2-2 libsasl2-dev libsasl2-modules
Then build the InnoDB Memcached Engine plugin (shared libraries) with SASL capability, by adding
ENABLE_MEMCACHED_SASL=1to the cmake options. In addition, Memcached provides a simple plaintext password support, which is easier to use for testing. To enable this, set the optionENABLE_MEMCACHED_SASL_PWDB=1.So overall, we will need to add following three options to the cmake:
cmake ... -DWITH_INNODB_MEMCACHED=1 -DENABLE_MEMCACHED_SASL=1 -DENABLE_MEMCACHED_SASL_PWDB=1
The third step is to install the InnoDB Memcached Plugin as before, as explained in Section 14.2.10.3, “Getting Started with InnoDB Memcached Daemon Plugin”.
As previously mentioned, memcached provides a simple plaintext password support through SASL, which will be used for this demo. There was a good blog from Thond Norbye describes the steps, so you can follow the instruction there too. I will repeat the important steps here.
Create a user named
testnameand its password astestpasswdin a file:echo "testname:testpasswd:::::::" >/home/jy/memcached-sasl-db
Let memcached know about it by setting the environment variable
MEMCACHED_SASL_PWDB:export MEMCACHED_SASL_PWDB=/home/jy/memcached-sasl-db
Also tell memcached that it is a plaintext password:
echo "mech_list: plain" > /home/jy/work2/msasl/clients/memcached.conf export SASL_CONF_PATH=/home/jy/work2/msasl/clients/memcached.conf
Then reboot the server, and add a
daemon_memcached_optionoption-Sto enable SASL:mysqld ... --daemon_memcached_option="-S"
Now we are done the setup. To test it, you might need an SASL-enabled client, such as the SASL-enabled libmemcached as described in Thond Norbye's blog.
memcp --servers=localhost:11211 --binary --username=testname --password=testpasswd myfile.txt memcat --servers=localhost:11211 --binary --username=testname --password=testpasswd myfile.txt
Without appropriate user name or password, the above operation will be rejected by error message
memcache error AUTHENTICATION FAILURE. Otherwise, the operation will be completed. You can also play with the plaintext password set in thememcached-sasl-dbfile to verify it.
There are other methods to test the SASL with memcached. But the one described above is the most straightforward.
Summary:
In summary, this release provides you a more robust InnoDB Memcached Engine with SASL support. The steps to enable such support are fairly straightforward and almost identical to those you would do to enable SASL for a memcached server. So if you are familiar with using SASL for memcached, then it would just require some name flipping to build and enable it. And if you are not familiar with the operation, the above steps give you a quick start to use it.
Consider these aspects of memcached applications when adapting an existing MySQL schema or application to use the memcached interface:
memcached keys cannot contain spaces or newlines, because those characters are used as separators in the ASCII protocol. If you are using lookup values that contain spaces, transform or hash them into values without spaces before using them as keys in calls to
add(),set(),get()and so on. Although theoretically those characters are allowed in keys in programs that use the binary protocol, you should always restrict the characters used in keys to ensure compatibility with a broad range of clients.If you have a short numeric primary key column in an
InnoDBtable, you can use that as the unique lookup key for memcached by converting the integer to a string value. If the memcached server is being used for more than one application, or with more than oneInnoDBtable, consider modifying the name to make sure it is unique. For example, you might prepend the table name, or the database name and the table name, before the numeric value.You cannot use a partitioned table for data queried or stored through the memcached interface.
The memcached protocol passes numeric values around as strings. To store numeric values in the underlying
InnoDBtable, for example to implement counters that can be used in SQL functions such asSUM()orAVG():Use
VARCHARcolumns with enough characters to hold all the digits of the largest expected number (and additional characters if appropriate for the negative sign, decimal point, or both).In any query that performs arithmetic using the column values, use the
CAST()function to convert from string to integer or other numeric type. For example:-- Alphabetic entries are returned as zero. select cast(c2 as unsigned integer) from demo_test; -- Since there could be numeric values of 0, can't disqualify them. -- Test the string values to find the ones that are actual integers, and average only those. select avg(cast(c2 as unsigned integer)) from demo_test where c2 between '0' and '999999999'; -- Views let you hide the complexity of queries using the same functions and WHERE clauses over and over. create view numbers as select c1 key, cast(c2 as unsigned integer) val from demo_test where c2 between '0' and '9999999999'; select sum(val) from numbers;
Note that any alphabetic values in the result set are turned into 0 by the call to
CAST(). When using functions such asAVG()that depend on the number of rows in the result set, includeWHEREclauses to filter out any non-numeric values.
If the
InnoDBcolumn you use as a key can be longer than 250 bytes, either hash it to a value that is less than 250 bytes, or increase the allowed size for memcached keys.To use an existing table with the memcached interface, define an entry for it in the
innodb_memcache.containerstable. To make that the table used by all requests relayed through memcached, specify the valuedefaultin thenamecolumn, then restart the MySQL server to make that change take effect. If you are using multiple tables for different classes of memcached data, set up multiple entries in theinnodb_memcache.containerstable withnamevalues of your choosing, then issue a memcached request of the formget @@within the application to switch the table used for subsequent requests through the memcached API.nameTo use multiple MySQL column values with memcached key/value pairs, in the
innodb_memcache.containersentry associated with the MySQL table, specify in thevalue_columnsfield several column names separated by comma, semicolon, space, or pipe characters; for example,col1,col2,col3orcol1|col2|col3.Concatenate the column values into a single string using the pipe character as a separator, before passing that string to memcached
addorsetcalls. The string is unpacked automatically into the various columns. Eachgetcall returns a single string with the column values, also delimited by the pipe separator character. you unpack those values using the appropriate syntax depending on your application language.
Example 14.12. Specifying the Table and Column Mapping for an InnoDB + memcached Application
Here is an example showing how to use your own table for a MySQL
application going through the InnoDB
memcached plugin for data manipulation.
First, we set up a table to hold some country data: the
population, area in metric units, and 'R' or
'L' indicating if people drive on the right
or on the left.
use test; CREATE TABLE `multicol` ( `country` varchar(128) NOT NULL DEFAULT '', `population` varchar(10) DEFAULT NULL, `area_sq_km` varchar(9) DEFAULT NULL, `drive_side` varchar(1) DEFAULT NULL, `c3` int(11) DEFAULT NULL, `c4` bigint(20) unsigned DEFAULT NULL, `c5` int(11) DEFAULT NULL, PRIMARY KEY (`country`), ) ENGINE=InnoDB DEFAULT CHARSET=latin1;
Now we make a descriptor for this table so that the
InnoDB memcached plugin
knows how to access it:
The sample entry in the
CONTAINERStable has anamecolumn'aaa', so we set up an identifier'bbb'.We specify the
test.multicoltable through separate schema and table columns.The key column will be our unique
countryvalue. That column was specified as the primary key when we created the table above, so we also specify the index name'PRIMARY'here.Rather than a single column to hold a composite data value, we will divide the data among three table columns, so we specify a comma-separated list of those columns that will be used when storing or retrieving values.
And for the rarely used flags, expire, and CAS values, we specify corresponding columns based on the settings from the sample table
demo.test.
insert into innodb_memcache.containers
(name,db_schema,db_table,key_columns,value_columns,flags,cas_column,expire_time_column,unique_idx_name_on_key)
values
('bbb','test','multicol','country','population,area_sq_km,drive_side','c3','c4','c5','PRIMARY');
commit;Here is a sample Python program showing how we would access this table from a program:
No database authorization is needed, since all data manipulation is done through the memcached interface. All we need to know is the port number the memcached daemon is listening to on the local system.
We load sample values for a few arbitrary countries. (Area and population figures from Wikipedia.)
To make the program use the
multicoltable, we call theswitch_table()function that does a dummyGETrequest using@@notation. The name in the request isbbb, which is the value we stored ininnodb_memcache.containers.name. (In a real application, we would use a more descriptive name. This example just illustrates that you use a table identifier with theGET @@...request rather than the table name.The utility functions to insert and query the data demonstrate how we might turn a Python data structure into pipe-separated values for sending to MySQL with
ADDorSETrequests, and unpack the pipe-separated values returned byGETrequests. This extra processing is only required when mapping the single memcached value to multiple MySQL table columns.
import sys, os
import MySQLdb
import memcache
def connect_to_memcached():
memc = memcache.Client(['127.0.0.1:11211'], debug=0);
print "Connected to memcached."
return memc
def banner(message):
print
print "=" * len(message)
print message
print "=" * len(message)
country_data = [
("Canada","34820000","9984670","R"),
("USA","314242000","9826675","R"),
("Ireland","6399152","84421","L"),
("UK","62262000","243610","L"),
("Mexico","113910608","1972550","R"),
("Denmark","5543453","43094","R"),
("Norway","5002942","385252","R"),
("UAE","8264070","83600","R"),
("India","1210193422","3287263","L"),
("China","1347350000","9640821","R"),
]
def switch_table(memc,table):
key = "@@" + table
print "Switching default table to '" + table + "' by issuing GET request for '" + key + "'."
result = memc.get(key)
def insert_country_data(memc):
banner("Inserting initial data via memcached interface")
for item in country_data:
country = item[0]
population = item[1]
area = item[2]
drive_side = item[3]
key = country
value = "|".join([population,area,drive_side])
print "Key = " + key
print "Value = " + value
if memc.add(key,value):
print "Added new key, value pair."
else:
print "Updating value for existing key."
memc.set(key,value)
def query_country_data(memc):
banner("Retrieving data for all keys (country names)")
for item in country_data:
key = item[0]
result = memc.get(key)
print "Here is the result retrieved from the database for key " + key + ":"
print result
(m_population, m_area, m_drive_side) = result.split("|")
print "Unpacked population value: " + m_population
print "Unpacked area value : " + m_area
print "Unpacked drive side value: " + m_drive_side
if __name__ == '__main__':
memc = connect_to_memcached()
switch_table(memc,"bbb")
insert_country_data(memc)
query_country_data(memc)
sys.exit(0)Here are some SQL queries to illustrate the state of the MySQL data after the script is run, and show how you could access the same data directly through SQL, or from an application written in any language using the appropriate MySQL Connector or API.
The table descriptor 'bbb' is in place,
allowing us to switch to the multicol table
by issuing a memcached request GET
@bbb:
mysql: use innodb_memcache; Database changed mysql: select * from containers; +------+-----------+-----------+-------------+----------------------------------+-------+------------+--------------------+------------------------+ | name | db_schema | db_table | key_columns | value_columns | flags | cas_column | expire_time_column | unique_idx_name_on_key | +------+-----------+-----------+-------------+----------------------------------+-------+------------+--------------------+------------------------+ | aaa | test | demo_test | c1 | c2 | c3 | c4 | c5 | PRIMARY | | bbb | test | multicol | country | population,area_sq_km,drive_side | c3 | c4 | c5 | PRIMARY | +------+-----------+-----------+-------------+----------------------------------+-------+------------+--------------------+------------------------+ 2 rows in set (0.01 sec)
After running the script, the data is in the
multicol table, available for traditional
MySQL queries or
DML statements:
mysql: use test; Database changed mysql: select * from multicol; +---------+------------+------------+------------+------+------+------+ | country | population | area_sq_km | drive_side | c3 | c4 | c5 | +---------+------------+------------+------------+------+------+------+ | Canada | 34820000 | 9984670 | R | 0 | 11 | 0 | | China | 1347350000 | 9640821 | R | 0 | 20 | 0 | | Denmark | 5543453 | 43094 | R | 0 | 16 | 0 | | India | 1210193422 | 3287263 | L | 0 | 19 | 0 | | Ireland | 6399152 | 84421 | L | 0 | 13 | 0 | | Mexico | 113910608 | 1972550 | R | 0 | 15 | 0 | | Norway | 5002942 | 385252 | R | 0 | 17 | 0 | | UAE | 8264070 | 83600 | R | 0 | 18 | 0 | | UK | 62262000 | 243610 | L | 0 | 14 | 0 | | USA | 314242000 | 9826675 | R | 0 | 12 | 0 | +---------+------------+------------+------------+------+------+------+ 10 rows in set (0.00 sec) mysql: desc multicol; +------------+---------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+---------------------+------+-----+---------+-------+ | country | varchar(128) | NO | PRI | | | | population | varchar(10) | YES | | NULL | | | area_sq_km | varchar(9) | YES | | NULL | | | drive_side | varchar(1) | YES | | NULL | | | c3 | int(11) | YES | | NULL | | | c4 | bigint(20) unsigned | YES | | NULL | | | c5 | int(11) | YES | | NULL | | +------------+---------------------+------+-----+---------+-------+ 7 rows in set (0.01 sec)
Allow sufficient size to hold all necessary digits, decimal
points, sign characters, leading zeros, and so on when defining
the length for columns that will be treated as numbers. Too-long
values in a string column such as a VARCHAR
are truncated by removing some characters, which might produce a
nonsensical numeric value.
We can produce reports through SQL queries, doing calculations
and tests across any columns, not just the
country key column. (Because these examples
use data from only a few countries, the numbers are for
illustration purposes only.) Here, we find the average
population of countries where people drive on the right, and the
average size of countries whose names start with
“U”:
mysql: select avg(population) from multicol where drive_side = 'R'; +-------------------+ | avg(population) | +-------------------+ | 261304724.7142857 | +-------------------+ 1 row in set (0.00 sec) mysql: select sum(area_sq_km) from multicol where country like 'U%'; +-----------------+ | sum(area_sq_km) | +-----------------+ | 10153885 | +-----------------+ 1 row in set (0.00 sec)
Because the population and
area_sq_km columns store character data
rather than strongly typed numeric data, functions such as
avg() and sum() work by
converting each value to a number first. This approach
does not work for operators such as
< or >: for example,
when comparing character-based values, 9 >
1000, which is not you expect from a clause such as
ORDER BY population DESC. For the most
accurate type treatment, perform queries against views that cast
numeric columns to the appropriate types. This technique lets
you issue very simple SELECT * queries from
your database applications, while ensuring that all casting,
filtering, and ordering is correct. Here, we make a view that
can be queried to find the top 3 countries in descending order
of population, with the results always reflecting the latest
data from the multicol table, and with the
population and area figures always treated as numbers:
mysql: create view populous_countries as
select
country,
cast(population as unsigned integer) population,
cast(area_sq_km as unsigned integer) area_sq_km,
drive_side from multicol
order by cast(population as unsigned integer) desc
limit 3;
Query OK, 0 rows affected (0.01 sec)
mysql: select * from populous_countries;
+---------+------------+------------+------------+
| country | population | area_sq_km | drive_side |
+---------+------------+------------+------------+
| China | 1347350000 | 9640821 | R |
| India | 1210193422 | 3287263 | L |
| USA | 314242000 | 9826675 | R |
+---------+------------+------------+------------+
3 rows in set (0.00 sec)
mysql: desc populous_countries;
+------------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------------------+------+-----+---------+-------+
| country | varchar(128) | NO | | | |
| population | bigint(10) unsigned | YES | | NULL | |
| area_sq_km | int(9) unsigned | YES | | NULL | |
| drive_side | varchar(1) | YES | | NULL | |
+------------+---------------------+------+-----+---------+-------+
4 rows in set (0.02 sec)
Consider these aspects of MySQL and InnoDB
tables when adapting an existing memcached
application to use the MySQL integration:
If you have key values longer than a few bytes, you might find it more efficient to use a numeric auto-increment column for the primary key in the
InnoDBtable, and create a unique secondary index on the column holding the memcached key values. This is becauseInnoDBperforms best for large-scale insertions if the primary key values are added in sorted order (as they are with auto-increment values), and the primary key values are duplicated in each secondary index, which can take up unnecessary space when the primary key is a long string value.When you use the default caching policy
innodb_only, your calls toadd(),set(),incr(), and so on can succeed but still trigger debugging messages such aswhile expecting 'STORED', got unexpected response 'NOT_STORED. This is because in theinnodb_onlyconfiguration, new and updated values are sent directly to theInnoDBtable without being saved in the memory cache.If you store several different classes of information in memcached, you might set up a separate
InnoDBtable for each kind of data. Define additional table identifiers in theinnodb_memcache.containerstable, and use the notation@@to store or retrieve items from different tables. Physically dividing the items lets you tune the characteristics of each table for best space utilization, performance, and reliability. For example, you might enable compression for a table that holds blog posts, but not for one that holds thumbnail images. You might back up one table more frequently than another because it holds critical data. You might create additional secondary indexes on tables that are frequently used to generate reports through SQL.table_id.keyChanges to the
containerstable take effect the next time that table is queried. The entries in that table are processed at startup, and are consulted whenever an unrecognized table ID is requested by the@@notation. Thus, new entries are visible as soon as you try to use the associated table ID, but changes to existing entries require a server restart before they take effect.
Because using InnoDB in combination with
memcached involves writing all data to disk,
whether immediately or sometime later, understand that raw
performance is expected to be somewhat lower than using
memcached by itself. Focus your tuning goals
for the InnoDB memcached
plugin on achieving higher performance than equivalent SQL
operations.
Benchmarks suggest that both queries and DML operations (inserts, updates, and deletes) are faster going through the memcached interface than with traditional SQL. DML operations typically see a larger speedup. Thus, the types of applications you might adapt to use the memcached interface first are those that are write-intensive. You might also use MySQL as a data store for types of write-intensive applications that formerly used some fast, lightweight mechanism where reliability was not a priority.
Adapting SQL Queries
The types of queries that are most suited to the simple
GET request style are those with a single
clause, or a set of AND conditions, in the
WHERE clause:
SQL: select col from tbl where key = 'key_value'; memcached: GET key_value SQL: select col from tbl where col1 = val1 and col2 = val2 and col3 = val3; memcached: # Since you must always know these 3 values to look up the key, # combine them into a unique string and use that as the key # for all ADD, SET, and GET operations. key_value = val1 + ":" + val2 + ":" + val3 GET key_value SQL: select 'key exists!' from tbl where exists (select col1 from tbl where key = 'key_value') limit 1; memcached: # Test for existence of key by asking for its value and checking if the call succeeds, # ignoring the value itself. For existence checking, you typically only store a very # short value such as "1". GET key_value
Taking Advantage of System Memory
For best performance, deploy the InnoDB
memcached plugin on machines that are
configured like typical database servers: in particular, with the
majority of system RAM devoted to the InnoDB
buffer pool through the
innodb_buffer_pool_size
configuration option. For systems with multi-gigabyte buffer
pools, consider raising the value of the
innodb_buffer_pool_instances
configuration option for maximum throughput when most operations
involve data already cached in memory.
Reducing Redundant I/O
InnoDB has a number of settings that let you
choose the balance between high reliability in case of a crash,
and the amount of I/O overhead during high write workloads. For
example, consider setting the configuration options
innodb_doublewrite=0 and
innodb_flush_log_at_trx_commit=2.
Measure the performance with different settings for the
innodb_flush_method option. If
the binary log is not
turned on for the server, use the setting
innodb_support_xa=0.
For other ways to reduce or tune I/O for table operations, see
Section 8.5.7, “Optimizing InnoDB Disk I/O”.
Reducing Transactional Overhead
The default value of 1 for the configuration options
daemon_memcached_r_batch_size and
daemon_memcached_w_batch_size is
intended for maximum reliability of results and safety of stored
or updated data.
Depending on the type of application, you might increase one or
both of these settings to reduce the overhead of frequent
commit operations. On a busy
system, you might increase
daemon_memcached_r_batch_size,
knowing that changes to the data made through SQL might not become
visible to memcached immediately (that is,
until N more get
operations were processed). When processing data where every write
operation must be reliably stored, you would leave
daemon_memcached_w_batch_size set
to 1. You might increase it when processing large numbers of
updates intended to only be used for statistical analysis, where
it is not critical if the last N
updates are lost in case of a crash.
For example, imagine a system that monitors traffic crossing a
busy bridge, recording approximately 100,000 vehicles each day. If
the application simply counts different types of vehicles to
analyze traffic patterns, it might change
daemon_memcached_w_batch_size
from 1 to 100, reducing the
I/O overhead for commit operations by 99%. In case of an
unexpected outage, only a maximum of 100 records could be lost,
which might be an acceptable margin of error. If instead the
application was doing automated toll collection for each car, it
would keep
daemon_memcached_w_batch_size set
to 1 to ensure that every toll record was
immediately saved to disk.
Because of the way InnoDB organizes the
memcached key values on disk, if you have a
large number of keys to create, it can be faster to sort all the
data items by the key value in your application and
add them in sorted order, rather than creating
them in arbitrary order.
The memslap command, which is part of the regular memcached distribution but not included with the MySQL server, can be useful for benchmarking different configurations. It can also be used to generate sample key/value pairs that you can use in your own benchmarking. See Section 15.6.3.3.6, “libmemcached Command-Line Utilities” for details.
Unlike with the traditional memcached, with the
InnoDB + memcached
combination you can control how “durable” are the
data values produced through calls to add,
set, incr, and so on.
Because MySQL places a high priority on durability and consistency
of data, by default all data written through the
memcached interface is always stored to disk,
and calls to get always return the most recent
value from disk. Although this default setting does not give the
highest possible raw performance, it is still very fast compared
to the traditional SQL interface for InnoDB
tables.
As you gain experience with this feature, you can make the decision to relax the durability settings for non-critical classes of data, at the risk of possibly losing some updated values in case of an outage, or returning data that is slightly out-of-date.
Data Stored on Disk, in Memory, or Both
Table innodb_memcache.cache_policies specifies
whether to store data written through the
memcached on disk
(innodb_only, the default); to store the data
in memory only, as in the traditional memcached
(cache-only); or both
(caching).
With the caching setting, if
memcached cannot find a key in memory, it
searches for the value in an InnoDB table.
Values returned from get calls under the
caching setting could be out-of-date, if they
were updated on disk in the InnoDB table but
not yet expired from the memory cache.
The caching policy can be set independently for
get, set (including
incr and decr),
delete, and flush
operations. For example:
You might allow
getandsetoperations to query or update a table and the memcached memory cache at the same time (through thecachingsetting), while makingdelete,flush, or both operate only on the in-memory copy (through thecache_onlysetting). That way, deleting or flushing an item just expires it from the cache, and the latest value is returned from theInnoDBtable the next time the item is requested.
mysql> desc innodb_memcache.cache_policies;
+---------------+-------------------------------------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------------+-------------------------------------------------------+------+-----+---------+-------+
| policy_name | varchar(40) | NO | PRI | NULL | |
| get_policy | enum('innodb_only','cache_only','caching','disabled') | NO | | NULL | |
| set_policy | enum('innodb_only','cache_only','caching','disabled') | NO | | NULL | |
| delete_policy | enum('innodb_only','cache_only','caching','disabled') | NO | | NULL | |
| flush_policy | enum('innodb_only','cache_only','caching','disabled') | NO | | NULL | |
+---------------+-------------------------------------------------------+------+-----+---------+-------+
mysql> select * from innodb_memcache.cache_policies;
+--------------+-------------+-------------+---------------+--------------+
| policy_name | get_policy | set_policy | delete_policy | flush_policy |
+--------------+-------------+-------------+---------------+--------------+
| cache_policy | innodb_only | innodb_only | innodb_only | innodb_only |
+--------------+-------------+-------------+---------------+--------------+
mysql> update innodb_memcache.cache_policies set set_policy = 'caching'
-> where policy_name = 'cache_policy';
The cache_policies values are only read at
startup, and are tightly integrated with the operation of the
memcached plugin. After changing any of the
values in this table, uninstall the plugin and reinstall it:
mysql> uninstall plugin daemon_memcached; Query OK, 0 rows affected (2.00 sec) mysql> install plugin daemon_memcached soname "libmemcached.so"; Query OK, 0 rows affected (0.00 sec)
Frequency of Commits
When the cache policy is innodb_only or
caching, one tradeoff between durability and
raw performance is how frequently new and changed data is
committed.
When a memcached operation causes an insert,
update, or delete in the underlying InnoDB
table, that change might be committed to the underlying table
instantly (if
daemon_memcached_w_batch_size=1)
or some time later (if that configuration option value is greater
than 1). In either case, the change cannot be rolled back.
When a memcached operation causes an insert or
update in the underlying InnoDB table, the
changed data is immediately visible to other
memcached requests because the new value
remains in the memory cache, even if it is not committed yet on
the MySQL side.
When a memcached operation causes a delete in
the underlying InnoDB table...
When a memcached operation such as
get or incr causes a query
in the underlying InnoDB table...
Transaction Isolation
You can change the setting of the
innodb_api_trx_level
configuration option at startup to control the
isolation level of the
transactions performed by
the InnoDB memcached plugin.
Allowing or Disallowing DDL
By default, you can perform DDL
operations such as ALTER TABLE on
the tables being used by the InnoDB
memcached plugin. To avoid potential slowdowns
when these tables are being used for high-throughput applications,
you can disable DDL operations on these tables by turning on the
innodb_api_enable_mdl
configuration option at startup. This option is less appropriate
when you are accessing the same underlying tables through both the
memcached interface and SQL, because it blocks
CREATE INDEX statements on the
tables, which could be important for configuring the system to run
reporting queries.
Benchmarks suggest that the InnoDB
memcached plugin speeds up
DML operations (inserts, updates,
and deletes) more than it speeds up queries. You might focus your
initial development efforts on write-intensive applications that
are I/O-bound, and look for opportunities to use MySQL for new
kinds of write-intensive applications.
INSERT INTO t1 (key,val) VALUES (
some_key,some_value; SELECT val FROM t1 WHERE key =some_key; UPDATE t1 SET val =new_valueWHERE key =some_key; UPDATE t1 SET val = val + x WHERE key =some_key; DELETE FROM t1 WHERE key =some_key;Single-row DML statements are the most straightforward kinds of statements to turn into
memcachedoperations:INSERTbecomesadd,UPDATEbecomesset,incrordecr, andDELETEbecomesdelete. When issued through the memcached interface, these operations are guaranteed to affect only 1 row becausekeyis unique within the table.In the preceding SQL examples,
t1refers to the table currently being used by theInnoDBmemcached plugin based on the configuration settings in theinnodb_memcache.containerstable,keyrefers to the column listed underkey_columns, andvalrefers to the column listed undervalue_columns.TRUNCATE TABLE t1; DELETE FROM t1;
Corresponds to the
flush_alloperation, whent1is configured as the table for memcached operations as in the previous step. Removes all the rows in the table.
You can access the InnoDB table (by default,
test.demo_test) through the standard SQL
interfaces. However, there are some restrictions:
When query a table through SQL that is also being accessed through the memcached interface, remember that memcached operations can be configured to be committed periodically rather than after every write operation. This behavior is controlled by the
daemon_memcached_w_batch_sizeoption. If this option is set to a value greater than 1, useREAD UNCOMMITTEDqueries to find the just-inserted rows:mysql> set session TRANSACTION ISOLATION LEVEL read uncommitted; Query OK, 0 rows affected (0.00 sec) mysql> select * from demo_test; +------+------+------+------+-----------+------+------+------+------+------+------+ | cx | cy | c1 | cz | c2 | ca | CB | c3 | cu | c4 | C5 | +------+------+------+------+-----------+------+------+------+------+------+------+ | NULL | NULL | a11 | NULL | 123456789 | NULL | NULL | 10 | NULL | 3 | NULL | +------+------+------+------+-----------+------+------+------+------+------+------+ 1 row in set (0.00 sec)
To modify a table through SQL that is also being accessed through the memcached interface, remember that memcached operations can be configured to be start a new transaction periodically rather than for every read operation. This behavior is controlled by the
daemon_memcached_r_batch_sizeoption. If this option is set to a value greater than 1, ...The
InnoDBtable is locked IS (shared intention) or IX (exclusive intentional) for all operations in a transaction. If you increasedaemon_memcached_r_batch_sizeanddaemon_memcached_w_batch_sizesubstantially from their default value of 1, the table is most likely intentionally locked between each operation, preventing you from running DDL statements on the table.
This section explains the details of the underlying tables used by
the InnoDB / memcached
plugin.
The configuration script installs 3 tables needed by the InnoDB
memcached. These tables are created in a
dedicated database innodb_memcache:
mysql> use innodb_memcache; Database changed mysql> show tables; +---------------------------+ | Tables_in_innodb_memcache | +---------------------------+ | cache_policies | | config_options | | containers | +---------------------------+ 3 rows in set (0.01 sec)
The tables are:
containers - This table is the most important
table for the memcached daemon. It describes
the table or tables used to store the memcached
values. You must make changes to this table to start using the
memcached interface with one or more of your
own tables, rather than just experimenting with the
test.demo_test table.
The mapping is done through specifying corresponding column values in the table:
mysql> desc containers; +------------------------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------------------+--------------+------+-----+---------+-------+ | name | varchar(50) | NO | PRI | NULL | | | db_schema | varchar(250) | NO | | NULL | | | db_table | varchar(250) | NO | | NULL | | | key_columns | varchar(250) | NO | | NULL | | | value_columns | varchar(250) | YES | | NULL | | | flags | varchar(250) | NO | | 0 | | | cas_column | varchar(250) | YES | | NULL | | | expire_time_column | varchar(250) | YES | | NULL | | | unique_idx_name_on_key | varchar(250) | NO | | NULL | | +------------------------+--------------+------+-----+---------+-------+ 9 rows in set (0.02 sec)
db_schemaanddb_tablecolumns specify the database and table name for storing the memcached value.key_columnsspecifies the single column name used as the lookup key for memcached operations.value_columnsdescribes the columns (one or more) used as values for memcached operations. To specify multiple columns, separate them with pipe characters (such ascol1|col2|col3and so on).unique_idx_name_on_keyis the name of the index on the key column. It must be a unique index. It can be the primary key or a secondary index. Preferably, make the key column the primary key of theInnoDBtable. Doing so saves a lookup step over using a secondary index for this column. You cannot make a covering index for memcached lookups;InnoDBreturns an error if you try to define a composite secondary index over both the key and value columns.
The above 5 column values (table name, key column, value column and index) must be supplied. Otherwise, the setup will fail.
Although the following values are optional, they are needed for full compliance with the memcached protocol:
flagsspecifies the columns used as flags (a user-defined numeric value that is stored and retrieved along with the main value) for memcached. It is also used as the column specifier for some operations (such asincr,prepend) if memcached value is mapped to multiple columns. So the operation would be done on the specified column. For example, if you have mapped a value to 3 columns, and only want the increment operation performed on one of these columns, you can useflagsto specify which column will be used for these operations.cas_columnandexp_columnare used specifically to store thecas(compare-and-swap) andexp(expiry) value of memcached. Those values are related to the way memcached hashes requests to different servers and caches data in memory. Because theInnoDBmemcached plugin is so tightly integrated with a single memcached daemon, and the in-memory caching mechanism is handled by MySQL and the buffer pool, these columns are rarely needed in this type of deployment.
Table cache_policies specifies whether to use
InnoDB as the data store of
memcached (innodb_only), or
to use the traditional memcached engine as the
backstore (cache-only), or both
(caching). In the last case, if
memcached cannot find a key in memory, it
searches for the value in an InnoDB table.
Table config_options stores
memcached-related settings that are appropriate
to change at runtime, through SQL. Currently, MySQL supports the
following configuration options through this table:
separator: The separator used to separate
values of a long string into smaller values for multiple columns
values. By default, this is the | character.
For example, if you defined col1, col2 as value
columns, And you define | as separator, you
could issue the following command in memcached
to insert values into col1 and
col2 respectively:
set keyx 10 0 19 valuecolx|valuecoly
So valuecol1x is stored in
col1 and valuecoly is stored
in col2.
table_map_delimiter: The character separating
the schema name and the table name when you use the
@@ notation in a key name to access a key in a
specific table. For example, @@t1.some_key and
@@t2.some_key have the same key value, but are
stored in different tables and so do not conflict.
Example Tables
Finally, the configuration script creates a table
demo_test in the test
database as an example. It also allows the Daemon Memcached to
work immediately, without creating any additional tables.
The entries in the container table define which
column is used for what purpose as described above:
mysql> select * from containers; +------+-----------+-----------+-------------+---------------+-------+------------+--------------------+------------------------+ | name | db_schema | db_table | key_columns | value_columns | flags | cas_column | expire_time_column | unique_idx_name_on_key | +------+-----------+-----------+-------------+---------------+-------+------------+--------------------+------------------------+ | aaa | test | demo_test | c1 | c2 | c3 | c4 | c5 | PRIMARY | +------+-----------+-----------+-------------+---------------+-------+------------+--------------------+------------------------+ 1 row in set (0.00 sec) mysql> desc test.demo_test; +-------+---------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------------------+------+-----+---------+-------+ | c1 | varchar(32) | NO | PRI | | | | c2 | varchar(1024) | YES | | NULL | | | c3 | int(11) | YES | | NULL | | | c4 | bigint(20) unsigned | YES | | NULL | | | c5 | int(11) | YES | | NULL | | +-------+---------------------+------+-----+---------+-------+ 5 rows in set (0.01 sec)
When no table ID is requested through the @@
notation in the key name:
If a row has a
namevalue ofdefault, the corresponding table is used by the memcached plugin. Thus, when you make your first entry ininnodb_memcache.containersto move beyond thedemo_testtable, use anamevalue ofdefault.If there is no
innodb_memcache.containers.namevalue ofdefault, the row with the firstnamevalue in alphabetical order is used.
Now that everything is set up, you can experiment with the InnoDB and memcached combination:
Here is an example using the Unix, Linux, or OS X command shell:
# Point memcached-related commands at the memcached attached to the mysqld process. export MEMCACHED_SERVERS=127.0.0.1:11211 # Store the contents of a modestly sized text file in memcached, with the data passed through # to MySQL and stored in an InnoDB table. The key is the basename of the file, 'mime.types'. memcp /etc/apache2/mime.types # Retrieve the data we just stored, from the memory cache. memcat mime.types
Here is an example using telnet to send memcached commands and receive results through the ASCII protocol:
telnet 127.0.0.1 11211set a11 10 0 9123456789STOREDget a11VALUE a11 0 9 123456789 ENDquit
To prove that all the same data has been stored in MySQL, connect to the MySQL server and issue:
mysql> select * from test.demo_test;
Now, shut down the MySQL server, which also shuts off the integrated memcached server. Further attempts to access the memcached data now fail with a connection error. Normally, the memcached data would disappear at this point, and you would write application logic to load the data back into memory when memcached was restarted. But the MySQL / memcached integration automates this process:
Restart the MySQL server.
Run the
install pluginstatement to start thedaemon_memcachedplugin again.Now any memcat commands or
getoperations once again return the key/value pairs you stored in the earlier memcached session. When a key is requested and the associated value is not already in the memory cache, it is automatically queried from the MySQL table, by defaulttest.demo_test.
The following list shows some potential issues you might encounter
using the InnoDB memcached
daemon, and solutions or workarounds where available:
If you see this error in your MySQL error log, the server might fail to start:
failed to set rlimit for open files. Try running as root or requesting smaller maxconns value.
The error message is actually from the memcached daemon. One solution is to raise the OS limit for the number of open files. The command varies depending on the operating system. For example, here are the commands to check and increase the limit on several operating systems:
# OS X Lion (10.6) $ ulimit -n 256 ulimit -n 4096 $ ulimit -n 4096 # OS X Snow Leopard (10.5) ??? # Solaris ??? # Linux ???
The other solution is to reduce the number of concurrent connections available for the memcached daemon, using the
-coption which defaults to 1024. Encode that memcached option using the MySQL optiondaemon_memcached_optioninside the MySQL configuration file:[mysqld] ... loose-daemon_memcached_option='-c 64'
To troubleshoot problems where the memcached daemon is unable to store data in or retrieve data from the
InnoDBtable, specify the memcached option-vvvthrough the MySQL configuration optiondaemon_memcached_option. Examine the MySQL error log for debug output related to memcached operations.If the column specified to hold the memcached item values is the wrong data type, such as a numeric type instead of a string type, attempts to store key/value pairs will fail with no specific error code or message.
If the
daemon_memcachedplugin causes any issues with starting the MySQL server, disable it during troubleshooting by adding this line under the[mysqld]group in your MySQL configuration file:daemon_memcached=OFF
For example, if you run the
install plugincommand before running thescripts/innodb_memcached_config.sqlscript to set up the necessary database and tables, the server might crash and be unable to start. Or, if you set up an incorrect entry in theinnodb_memcache.containerstable, the server might be unable to start.To permanently turn off the memcached plugin for a MySQL instance, issue the following command:
mysql> uninstall plugin daemon_memcached;
If you run more than one instance of MySQL on the same machine, with the memcached daemon plugin enabled in each, make sure to specify a unique memcached port for each one using the
daemon_memcached_optionconfiguration option.As the length of the memcached key and values increase, you encounter size and length limits at different points:
When the key exceeds 250 bytes in size, memcached operations return an error. This is currently a fixed limit within memcached.
You might encounter
InnoDB-related limits when the value exceeds 768 bytes in size, or 3072 bytes in size, or 1/2 of the size specified byinnodb_page_size. These limits primarily apply if you intend to create an index on the value column to run report-generating queries on that column from SQL. See Section 14.2.8, “Limits onInnoDBTables” for details.The maximum size for the combination of the key and the value is 1 MB.
If you share configuration files across MySQL servers with different versions, using the latest configuration options for the memcached plugin could cause startup errors for older MySQL versions. To avoid compatibility problems, use the
looseforms of these option names, for exampleloose-daemon_memcached_option='-c 64'instead ofdaemon_memcached_option='-c 64'.
MyISAM is based on the older (and no longer
available) ISAM storage engine but has many
useful extensions.
Table 14.11. MyISAM Storage Engine
Features
| Storage limits | 256TB | Transactions | No | Locking granularity | Table |
| MVCC | No | Geospatial data type support | Yes | Geospatial indexing support | Yes |
| B-tree indexes | Yes | Hash indexes | No | Full-text search indexes | Yes |
| Clustered indexes | No | Data caches | No | Index caches | Yes |
| Compressed data | Yes[a] | Encrypted data[b] | Yes | Cluster database support | No |
| Replication support[c] | Yes | Foreign key support | No | Backup / point-in-time recovery[d] | Yes |
| Query cache support | Yes | Update statistics for data dictionary | Yes | ||
|
[a] Compressed MyISAM tables are supported only when using the compressed row format. Tables using the compressed row format with MyISAM are read only. [b] Implemented in the server (via encryption functions), rather than in the storage engine. [c] Implemented in the server, rather than in the storage engine. [d] Implemented in the server, rather than in the storage engine. | |||||
Each MyISAM table is stored on disk in three
files. The files have names that begin with the table name and have
an extension to indicate the file type. An .frm
file stores the table format. The data file has an
.MYD (MYData) extension. The
index file has an .MYI
(MYIndex) extension.
To specify explicitly that you want a MyISAM
table, indicate that with an ENGINE table option:
CREATE TABLE t (i INT) ENGINE = MYISAM;
In MySQL 5.6, it is normally necessary to use
ENGINE to specify the MyISAM
storage engine because InnoDB is the default
engine.
You can check or repair MyISAM tables with the
mysqlcheck client or myisamchk
utility. You can also compress MyISAM tables with
myisampack to take up much less space. See
Section 4.5.3, “mysqlcheck — A Table Maintenance Program”, Section 4.6.3, “myisamchk — MyISAM Table-Maintenance Utility”, and
Section 4.6.5, “myisampack — Generate Compressed, Read-Only MyISAM Tables”.
MyISAM tables have the following characteristics:
All data values are stored with the low byte first. This makes the data machine and operating system independent. The only requirements for binary portability are that the machine uses two's-complement signed integers and IEEE floating-point format. These requirements are widely used among mainstream machines. Binary compatibility might not be applicable to embedded systems, which sometimes have peculiar processors.
There is no significant speed penalty for storing data low byte first; the bytes in a table row normally are unaligned and it takes little more processing to read an unaligned byte in order than in reverse order. Also, the code in the server that fetches column values is not time critical compared to other code.
All numeric key values are stored with the high byte first to permit better index compression.
Large files (up to 63-bit file length) are supported on file systems and operating systems that support large files.
There is a limit of (232)2 (1.844E+19) rows in a
MyISAMtable.The maximum number of indexes per
MyISAMtable is 64.The maximum number of columns per index is 16.
The maximum key length is 1000 bytes. This can also be changed by changing the source and recompiling. For the case of a key longer than 250 bytes, a larger key block size than the default of 1024 bytes is used.
When rows are inserted in sorted order (as when you are using an
AUTO_INCREMENTcolumn), the index tree is split so that the high node only contains one key. This improves space utilization in the index tree.Internal handling of one
AUTO_INCREMENTcolumn per table is supported.MyISAMautomatically updates this column forINSERTandUPDATEoperations. This makesAUTO_INCREMENTcolumns faster (at least 10%). Values at the top of the sequence are not reused after being deleted. (When anAUTO_INCREMENTcolumn is defined as the last column of a multiple-column index, reuse of values deleted from the top of a sequence does occur.) TheAUTO_INCREMENTvalue can be reset withALTER TABLEor myisamchk.Dynamic-sized rows are much less fragmented when mixing deletes with updates and inserts. This is done by automatically combining adjacent deleted blocks and by extending blocks if the next block is deleted.
MyISAMsupports concurrent inserts: If a table has no free blocks in the middle of the data file, you canINSERTnew rows into it at the same time that other threads are reading from the table. A free block can occur as a result of deleting rows or an update of a dynamic length row with more data than its current contents. When all free blocks are used up (filled in), future inserts become concurrent again. See Section 8.10.3, “Concurrent Inserts”.You can put the data file and index file in different directories on different physical devices to get more speed with the
DATA DIRECTORYandINDEX DIRECTORYtable options toCREATE TABLE. See Section 13.1.14, “CREATE TABLESyntax”.NULLvalues are permitted in indexed columns. This takes 0 to 1 bytes per key.Each character column can have a different character set. See Section 10.1, “Character Set Support”.
There is a flag in the
MyISAMindex file that indicates whether the table was closed correctly. If mysqld is started with the--myisam-recover-optionsoption,MyISAMtables are automatically checked when opened, and are repaired if the table wasn't closed properly.myisamchk marks tables as checked if you run it with the
--update-stateoption. myisamchk --fast checks only those tables that don't have this mark.myisamchk --analyze stores statistics for portions of keys, as well as for entire keys.
myisampack can pack
BLOBandVARCHARcolumns.
MyISAM also supports the following features:
Additional Resources
A forum dedicated to the
MyISAMstorage engine is available at http://forums.mysql.com/list.php?21.
The following options to mysqld can be used to
change the behavior of MyISAM tables. For
additional information, see Section 5.1.3, “Server Command Options”.
Table 14.12. MyISAM Option/Variable
Reference
| Name | Cmd-Line | Option file | System Var | Status Var | Var Scope | Dynamic |
|---|---|---|---|---|---|---|
| bulk_insert_buffer_size | Yes | Yes | Yes | Both | Yes | |
| concurrent_insert | Yes | Yes | Yes | Global | Yes | |
| delay-key-write | Yes | Yes | Global | Yes | ||
| - Variable: delay_key_write | Yes | Global | Yes | |||
| have_rtree_keys | Yes | Global | No | |||
| key_buffer_size | Yes | Yes | Yes | Global | Yes | |
| log-isam | Yes | Yes | ||||
| myisam-block-size | Yes | Yes | ||||
| myisam_data_pointer_size | Yes | Yes | Yes | Global | Yes | |
| myisam_max_sort_file_size | Yes | Yes | Yes | Global | Yes | |
| myisam_mmap_size | Yes | Yes | Yes | Global | No | |
| myisam-recover-options | Yes | Yes | ||||
| - Variable: myisam_recover_options | ||||||
| myisam_recover_options | Yes | Global | No | |||
| myisam_repair_threads | Yes | Yes | Yes | Both | Yes | |
| myisam_sort_buffer_size | Yes | Yes | Yes | Both | Yes | |
| myisam_stats_method | Yes | Yes | Yes | Both | Yes | |
| myisam_use_mmap | Yes | Yes | Yes | Global | Yes | |
| skip-concurrent-insert | Yes | Yes | ||||
| - Variable: concurrent_insert | ||||||
| tmp_table_size | Yes | Yes | Yes | Both | Yes |
Set the mode for automatic recovery of crashed
MyISAMtables.Don't flush key buffers between writes for any
MyISAMtable.NoteIf you do this, you should not access
MyISAMtables from another program (such as from another MySQL server or with myisamchk) when the tables are in use. Doing so risks index corruption. Using--external-lockingdoes not eliminate this risk.
The following system variables affect the behavior of
MyISAM tables. For additional information, see
Section 5.1.4, “Server System Variables”.
The size of the tree cache used in bulk insert optimization.
NoteThis is a limit per thread!
The maximum size of the temporary file that MySQL is permitted to use while re-creating a
MyISAMindex (duringREPAIR TABLE,ALTER TABLE, orLOAD DATA INFILE). If the file size would be larger than this value, the index is created using the key cache instead, which is slower. The value is given in bytes.Set the size of the buffer used when recovering tables.
Automatic recovery is activated if you start
mysqld with the
--myisam-recover-options option. In
this case, when the server opens a MyISAM
table, it checks whether the table is marked as crashed or whether
the open count variable for the table is not 0 and you are running
the server with external locking disabled. If either of these
conditions is true, the following happens:
The server checks the table for errors.
If the server finds an error, it tries to do a fast table repair (with sorting and without re-creating the data file).
If the repair fails because of an error in the data file (for example, a duplicate-key error), the server tries again, this time re-creating the data file.
If the repair still fails, the server tries once more with the old repair option method (write row by row without sorting). This method should be able to repair any type of error and has low disk space requirements.
If the recovery wouldn't be able to recover all rows from
previously completed statements and you didn't specify
FORCE in the value of the
--myisam-recover-options option,
automatic repair aborts with an error message in the error log:
Error: Couldn't repair table: test.g00pages
If you specify FORCE, a warning like this is
written instead:
Warning: Found 344 of 354 rows when repairing ./test/g00pages
Note that if the automatic recovery value includes
BACKUP, the recovery process creates files with
names of the form
tbl_name-datetime.BAK
MyISAM tables use B-tree indexes. You can
roughly calculate the size for the index file as
(key_length+4)/0.67, summed over all keys. This
is for the worst case when all keys are inserted in sorted order
and the table doesn't have any compressed keys.
String indexes are space compressed. If the first index part is a
string, it is also prefix compressed. Space compression makes the
index file smaller than the worst-case figure if a string column
has a lot of trailing space or is a
VARCHAR column that is not always
used to the full length. Prefix compression is used on keys that
start with a string. Prefix compression helps if there are many
strings with an identical prefix.
In MyISAM tables, you can also prefix compress
numbers by specifying the PACK_KEYS=1 table
option when you create the table. Numbers are stored with the high
byte first, so this helps when you have many integer keys that
have an identical prefix.
MyISAM supports three different storage
formats. Two of them, fixed and dynamic format, are chosen
automatically depending on the type of columns you are using. The
third, compressed format, can be created only with the
myisampack utility (see
Section 4.6.5, “myisampack — Generate Compressed, Read-Only MyISAM Tables”).
When you use CREATE TABLE or
ALTER TABLE for a table that has no
BLOB or
TEXT columns, you can force the
table format to FIXED or
DYNAMIC with the ROW_FORMAT
table option.
See Section 13.1.14, “CREATE TABLE Syntax”, for information about
ROW_FORMAT.
You can decompress (unpack) compressed MyISAM
tables using myisamchk
--unpack; see
Section 4.6.3, “myisamchk — MyISAM Table-Maintenance Utility”, for more information.
Static format is the default for MyISAM
tables. It is used when the table contains no variable-length
columns (VARCHAR,
VARBINARY,
BLOB, or
TEXT). Each row is stored using a
fixed number of bytes.
Of the three MyISAM storage formats, static
format is the simplest and most secure (least subject to
corruption). It is also the fastest of the on-disk formats due
to the ease with which rows in the data file can be found on
disk: To look up a row based on a row number in the index,
multiply the row number by the row length to calculate the row
position. Also, when scanning a table, it is very easy to read a
constant number of rows with each disk read operation.
The security is evidenced if your computer crashes while the
MySQL server is writing to a fixed-format
MyISAM file. In this case,
myisamchk can easily determine where each row
starts and ends, so it can usually reclaim all rows except the
partially written one. Note that MyISAM table
indexes can always be reconstructed based on the data rows.
Fixed-length row format is only available for tables without
BLOB or
TEXT columns. Creating a table
with these columns with an explicit
ROW_FORMAT clause will not raise an error
or warning; the format specification will be ignored.
Static-format tables have these characteristics:
CHARandVARCHARcolumns are space-padded to the specified column width, although the column type is not altered.BINARYandVARBINARYcolumns are padded with0x00bytes to the column width.Very quick.
Easy to cache.
Easy to reconstruct after a crash, because rows are located in fixed positions.
Reorganization is unnecessary unless you delete a huge number of rows and want to return free disk space to the operating system. To do this, use
OPTIMIZE TABLEor myisamchk -r.Usually require more disk space than dynamic-format tables.
Dynamic storage format is used if a MyISAM
table contains any variable-length columns
(VARCHAR,
VARBINARY,
BLOB, or
TEXT), or if the table was
created with the ROW_FORMAT=DYNAMIC table
option.
Dynamic format is a little more complex than static format because each row has a header that indicates how long it is. A row can become fragmented (stored in noncontiguous pieces) when it is made longer as a result of an update.
You can use OPTIMIZE TABLE or
myisamchk -r to defragment a table. If you
have fixed-length columns that you access or change frequently
in a table that also contains some variable-length columns, it
might be a good idea to move the variable-length columns to
other tables just to avoid fragmentation.
Dynamic-format tables have these characteristics:
All string columns are dynamic except those with a length less than four.
Each row is preceded by a bitmap that indicates which columns contain the empty string (for string columns) or zero (for numeric columns). Note that this does not include columns that contain
NULLvalues. If a string column has a length of zero after trailing space removal, or a numeric column has a value of zero, it is marked in the bitmap and not saved to disk. Nonempty strings are saved as a length byte plus the string contents.Much less disk space usually is required than for fixed-length tables.
Each row uses only as much space as is required. However, if a row becomes larger, it is split into as many pieces as are required, resulting in row fragmentation. For example, if you update a row with information that extends the row length, the row becomes fragmented. In this case, you may have to run
OPTIMIZE TABLEor myisamchk -r from time to time to improve performance. Use myisamchk -ei to obtain table statistics.More difficult than static-format tables to reconstruct after a crash, because rows may be fragmented into many pieces and links (fragments) may be missing.
The expected row length for dynamic-sized rows is calculated using the following expression:
3 + (
number of columns+ 7) / 8 + (number of char columns) + (packed size of numeric columns) + (length of strings) + (number of NULL columns+ 7) / 8There is a penalty of 6 bytes for each link. A dynamic row is linked whenever an update causes an enlargement of the row. Each new link is at least 20 bytes, so the next enlargement probably goes in the same link. If not, another link is created. You can find the number of links using myisamchk -ed. All links may be removed with
OPTIMIZE TABLEor myisamchk -r.
Compressed storage format is a read-only format that is generated with the myisampack tool. Compressed tables can be uncompressed with myisamchk.
Compressed tables have the following characteristics:
Compressed tables take very little disk space. This minimizes disk usage, which is helpful when using slow disks (such as CD-ROMs).
Each row is compressed separately, so there is very little access overhead. The header for a row takes up one to three bytes depending on the biggest row in the table. Each column is compressed differently. There is usually a different Huffman tree for each column. Some of the compression types are:
Suffix space compression.
Prefix space compression.
Numbers with a value of zero are stored using one bit.
If values in an integer column have a small range, the column is stored using the smallest possible type. For example, a
BIGINTcolumn (eight bytes) can be stored as aTINYINTcolumn (one byte) if all its values are in the range from-128to127.If a column has only a small set of possible values, the data type is converted to
ENUM.A column may use any combination of the preceding compression types.
Can be used for fixed-length or dynamic-length rows.
While a compressed table is read only, and you cannot
therefore update or add rows in the table, DDL (Data
Definition Language) operations are still valid. For example,
you may still use DROP to drop the table,
and TRUNCATE TABLE to empty the
table.
The file format that MySQL uses to store data has been extensively tested, but there are always circumstances that may cause database tables to become corrupted. The following discussion describes how this can happen and how to handle it.
Even though the MyISAM table format is very
reliable (all changes to a table made by an SQL statement are
written before the statement returns), you can still get
corrupted tables if any of the following events occur:
The mysqld process is killed in the middle of a write.
An unexpected computer shutdown occurs (for example, the computer is turned off).
Hardware failures.
You are using an external program (such as myisamchk) to modify a table that is being modified by the server at the same time.
A software bug in the MySQL or
MyISAMcode.
Typical symptoms of a corrupt table are:
You get the following error while selecting data from the table:
Incorrect key file for table: '...'. Try to repair it
Queries don't find rows in the table or return incomplete results.
You can check the health of a MyISAM table
using the CHECK TABLE statement,
and repair a corrupted MyISAM table with
REPAIR TABLE. When
mysqld is not running, you can also check or
repair a table with the myisamchk command.
See Section 13.7.2.2, “CHECK TABLE Syntax”,
Section 13.7.2.5, “REPAIR TABLE Syntax”, and Section 4.6.3, “myisamchk — MyISAM Table-Maintenance Utility”.
If your tables become corrupted frequently, you should try to
determine why this is happening. The most important thing to
know is whether the table became corrupted as a result of a
server crash. You can verify this easily by looking for a recent
restarted mysqld message in the error log. If
there is such a message, it is likely that table corruption is a
result of the server dying. Otherwise, corruption may have
occurred during normal operation. This is a bug. You should try
to create a reproducible test case that demonstrates the
problem. See Section C.5.4.2, “What to Do If MySQL Keeps Crashing”, and
MySQL Internals:
Porting to Other Systems.
Each MyISAM index file
(.MYI file) has a counter in the header
that can be used to check whether a table has been closed
properly. If you get the following warning from
CHECK TABLE or
myisamchk, it means that this counter has
gone out of sync:
clients are using or haven't closed the table properly
This warning doesn't necessarily mean that the table is corrupted, but you should at least check the table.
The counter works as follows:
The first time a table is updated in MySQL, a counter in the header of the index files is incremented.
The counter is not changed during further updates.
When the last instance of a table is closed (because a
FLUSH TABLESoperation was performed or because there is no room in the table cache), the counter is decremented if the table has been updated at any point.When you repair the table or check the table and it is found to be okay, the counter is reset to zero.
To avoid problems with interaction with other processes that might check the table, the counter is not decremented on close if it was zero.
In other words, the counter can become incorrect only under these conditions:
A
MyISAMtable is copied without first issuingLOCK TABLESandFLUSH TABLES.MySQL has crashed between an update and the final close. (Note that the table may still be okay, because MySQL always issues writes for everything between each statement.)
A table was modified by myisamchk --recover or myisamchk --update-state at the same time that it was in use by mysqld.
Multiple mysqld servers are using the table and one server performed a
REPAIR TABLEorCHECK TABLEon the table while it was in use by another server. In this setup, it is safe to useCHECK TABLE, although you might get the warning from other servers. However,REPAIR TABLEshould be avoided because when one server replaces the data file with a new one, this is not known to the other servers.In general, it is a bad idea to share a data directory among multiple servers. See Section 5.4, “Running Multiple MySQL Instances on One Machine”, for additional discussion.
The MEMORY storage engine (formerly known as
HEAP) creates special-purpose tables with
contents that are stored in memory. Because the data is vulnerable
to crashes, hardware issues, or power outages, only use these tables
as temporary work areas or read-only caches for data pulled from
other tables.
Table 14.13. MEMORY Storage Engine
Features
| Storage limits | RAM | Transactions | No | Locking granularity | Table |
| MVCC | No | Geospatial data type support | No | Geospatial indexing support | No |
| B-tree indexes | Yes | Hash indexes | Yes | Full-text search indexes | No |
| Clustered indexes | No | Data caches | N/A | Index caches | N/A |
| Compressed data | No | Encrypted data[a] | Yes | Cluster database support | No |
| Replication support[b] | Yes | Foreign key support | No | Backup / point-in-time recovery[c] | Yes |
| Query cache support | Yes | Update statistics for data dictionary | Yes | ||
|
[a] Implemented in the server (via encryption functions), rather than in the storage engine. [b] Implemented in the server, rather than in the storage engine. [c] Implemented in the server, rather than in the storage engine. | |||||
When to Use MEMORY or MySQL Cluster.
Developers looking to deploy applications that use the
MEMORY storage engine for important, highly
available, or frequently updated data should consider whether
MySQL Cluster is a better choice. A typical use case for the
MEMORY engine involves these characteristics:
Operations involving transient, non-critical data such as session management or caching. When the MySQL server halts or restarts, the data in
MEMORYtables is lost.In-memory storage for fast access and low latency. Data volume can fit entirely in memory without causing the operating system to swap out virtual memory pages.
A read-only or read-mostly data access pattern (limited updates).
MySQL Cluster offers the same features as the
MEMORY engine with higher performance levels, and
provides additional features not available with
MEMORY:
Row-level locking and multiple-thread operation for low contention between clients.
Scalability even with statement mixes that include writes.
Optional disk-backed operation for data durability.
Shared-nothing architecture and multiple-host operation with no single point of failure, enabling 99.999% availability.
Automatic data distribution across nodes; application developers need not craft custom sharding or partitioning solutions.
Support for variable-length data types (including
BLOBandTEXT) not supported byMEMORY.
For a white paper with more detailed comparison of the
MEMORY storage engine and MySQL Cluster, see
Scaling
Web Services with MySQL Cluster: An Alternative to the MySQL Memory
Storage Engine. This white paper includes a performance
study of the two technologies and a step-by-step guide describing
how existing MEMORY users can migrate to MySQL
Cluster.
Performance Characteristics
MEMORY performance is constrained by contention
resulting from single-thread execution and table lock overhead when
processing updates. This limits scalability when load increases,
particularly for statement mixes that include writes.
Despite the in-memory processing for MEMORY
tables, they are not necessarily faster than
InnoDB tables on a busy server, for
general-purpose queries, or under a read/write workload. In
particular, the table locking involved with performing updates can
slow down concurrent usage of MEMORY tables from
multiple sessions.
Depending on the kinds of queries performed on a
MEMORY table, you might create indexes as either
the default hash data structure (for looking up single values based
on a unique key), or a general-purpose B-tree data structure (for
all kinds of queries involving equality, inequality, or range
operators such as less than or greater than). The following sections
illustrate the syntax for creating both kinds of indexes. A common
performance issue is using the default hash indexes in workloads
where B-tree indexes are more efficient.
Physical Characteristics of MEMORY Tables
The MEMORY storage engine associates each table
with one disk file, which stores the table definition (not the
data). The file name begins with the table name and has an extension
of .frm.
MEMORY tables have the following characteristics:
Space for
MEMORYtables is allocated in small blocks. Tables use 100% dynamic hashing for inserts. No overflow area or extra key space is needed. No extra space is needed for free lists. Deleted rows are put in a linked list and are reused when you insert new data into the table.MEMORYtables also have none of the problems commonly associated with deletes plus inserts in hashed tables.MEMORYtables use a fixed-length row-storage format. Variable-length types such asVARCHARare stored using a fixed length.MEMORYincludes support forAUTO_INCREMENTcolumns.Non-
TEMPORARYMEMORYtables are shared among all clients, just like any other non-TEMPORARYtable.
DDL Operations for MEMORY Tables
To create a MEMORY table, specify the clause
ENGINE=MEMORY on the CREATE
TABLE statement.
CREATE TABLE t (i INT) ENGINE = MEMORY;
As indicated by the engine name, MEMORY tables
are stored in memory. They use hash indexes by default, which makes
them very fast for single-value lookups, and very useful for
creating temporary tables. However, when the server shuts down, all
rows stored in MEMORY tables are lost. The tables
themselves continue to exist because their definitions are stored in
.frm files on disk, but they are empty when the
server restarts.
This example shows how you might create, use, and remove a
MEMORY table:
mysql>CREATE TABLE test ENGINE=MEMORY->SELECT ip,SUM(downloads) AS down->FROM log_table GROUP BY ip;mysql>SELECT COUNT(ip),AVG(down) FROM test;mysql>DROP TABLE test;
The maximum size of MEMORY tables is limited by
the max_heap_table_size system
variable, which has a default value of 16MB. To enforce different
size limits for MEMORY tables, change the value
of this variable. The value in effect for
CREATE TABLE, or a subsequent
ALTER TABLE or
TRUNCATE TABLE, is the value used for
the life of the table. A server restart also sets the maximum size
of existing MEMORY tables to the global
max_heap_table_size value. You can
set the size for individual tables as described later in this
section.
Indexes
The MEMORY storage engine supports both
HASH and BTREE indexes. You
can specify one or the other for a given index by adding a
USING clause as shown here:
CREATE TABLE lookup
(id INT, INDEX USING HASH (id))
ENGINE = MEMORY;
CREATE TABLE lookup
(id INT, INDEX USING BTREE (id))
ENGINE = MEMORY;For general characteristics of B-tree and hash indexes, see Section 8.3.1, “How MySQL Uses Indexes”.
MEMORY tables can have up to 64 indexes per
table, 16 columns per index and a maximum key length of 3072 bytes.
If a MEMORY table hash index has a high degree of
key duplication (many index entries containing the same value),
updates to the table that affect key values and all deletes are
significantly slower. The degree of this slowdown is proportional to
the degree of duplication (or, inversely proportional to the index
cardinality). You can use a BTREE index to avoid
this problem.
MEMORY tables can have nonunique keys. (This is
an uncommon feature for implementations of hash indexes.)
Columns that are indexed can contain NULL values.
User-Created and Temporary Tables
MEMORY table contents are stored in memory, which
is a property that MEMORY tables share with
internal temporary tables that the server creates on the fly while
processing queries. However, the two types of tables differ in that
MEMORY tables are not subject to storage
conversion, whereas internal temporary tables are:
If an internal temporary table becomes too large, the server automatically converts it to on-disk storage, as described in Section 8.4.3.3, “How MySQL Uses Internal Temporary Tables”.
User-created
MEMORYtables are never converted to disk tables.
Loading Data
To populate a MEMORY table when the MySQL server
starts, you can use the --init-file
option. For example, you can put statements such as
INSERT INTO ...
SELECT or LOAD
DATA INFILE into this file to load the table from a
persistent data source. See Section 5.1.3, “Server Command Options”, and
Section 13.2.6, “LOAD DATA INFILE
Syntax”.
For loading data into MEMORY tables accessed by
other sessions concurrently, MEMORY supports
INSERT DELAYED. See
Section 13.2.5.2, “INSERT DELAYED Syntax”.
MEMORY Tables and Replication
A server's MEMORY tables become empty when it is
shut down and restarted. If the server is a replication master, its
slaves are not aware that these tables have become empty, so you see
out-of-date content if you select data from the tables on the
slaves. To synchronize master and slave MEMORY
tables, when a MEMORY table is used on a master
for the first time since it was started, a
DELETE statement is written to the
master's binary log, to empty the table on the slaves also. The
slave still has outdated data in the table during the interval
between the master's restart and its first use of the table. To
avoid this interval when a direct query to the slave could return
stale data, use the --init-file
option to populate the MEMORY table on the master
at startup.
Managing Memory Use
The server needs sufficient memory to maintain all
MEMORY tables that are in use at the same time.
Memory is not reclaimed if you delete individual rows from a
MEMORY table. Memory is reclaimed only when the
entire table is deleted. Memory that was previously used for deleted
rows is re-used for new rows within the same table. To free all the
memory used by a MEMORY table when you no longer
require its contents, execute DELETE
or TRUNCATE TABLE to remove all rows,
or remove the table altogether using DROP
TABLE. To free up the memory used by deleted rows, use
ALTER TABLE ENGINE=MEMORY to force a table
rebuild.
The memory needed for one row in a MEMORY table
is calculated using the following expression:
SUM_OVER_ALL_BTREE_KEYS(max_length_of_key+ sizeof(char*) * 4) + SUM_OVER_ALL_HASH_KEYS(sizeof(char*) * 2) + ALIGN(length_of_row+1, sizeof(char*))
ALIGN() represents a round-up factor to cause the
row length to be an exact multiple of the char
pointer size. sizeof(char*) is 4 on 32-bit
machines and 8 on 64-bit machines.
As mentioned earlier, the
max_heap_table_size system variable
sets the limit on the maximum size of MEMORY
tables. To control the maximum size for individual tables, set the
session value of this variable before creating each table. (Do not
change the global
max_heap_table_size value unless
you intend the value to be used for MEMORY tables
created by all clients.) The following example creates two
MEMORY tables, with a maximum size of 1MB and
2MB, respectively:
mysql>SET max_heap_table_size = 1024*1024;Query OK, 0 rows affected (0.00 sec) mysql>CREATE TABLE t1 (id INT, UNIQUE(id)) ENGINE = MEMORY;Query OK, 0 rows affected (0.01 sec) mysql>SET max_heap_table_size = 1024*1024*2;Query OK, 0 rows affected (0.00 sec) mysql>CREATE TABLE t2 (id INT, UNIQUE(id)) ENGINE = MEMORY;Query OK, 0 rows affected (0.00 sec)
Both tables revert to the server's global
max_heap_table_size value if the
server restarts.
You can also specify a MAX_ROWS table option in
CREATE TABLE statements for
MEMORY tables to provide a hint about the number
of rows you plan to store in them. This does not enable the table to
grow beyond the max_heap_table_size
value, which still acts as a constraint on maximum table size. For
maximum flexibility in being able to use
MAX_ROWS, set
max_heap_table_size at least as
high as the value to which you want each MEMORY
table to be able to grow.
Additional Resources
A forum dedicated to the MEMORY storage engine is
available at http://forums.mysql.com/list.php?92.
The CSV storage engine stores data in text files
using comma-separated values format.
The CSV storage engine is always compiled into
the MySQL server.
To examine the source for the CSV engine, look in
the storage/csv directory of a MySQL source
distribution.
When you create a CSV table, the server creates a
table format file in the database directory. The file begins with
the table name and has an .frm extension. The
storage engine also creates a data file. Its name begins with the
table name and has a .CSV extension. The data
file is a plain text file. When you store data into the table, the
storage engine saves it into the data file in comma-separated values
format.
mysql>CREATE TABLE test (i INT NOT NULL, c CHAR(10) NOT NULL)->ENGINE = CSV;Query OK, 0 rows affected (0.12 sec) mysql>INSERT INTO test VALUES(1,'record one'),(2,'record two');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM test;+------+------------+ | i | c | +------+------------+ | 1 | record one | | 2 | record two | +------+------------+ 2 rows in set (0.00 sec)
Creating a CSV table also creates a corresponding Metafile that
stores the state of the table and the number of rows that exist in
the table. The name of this file is the same as the name of the
table with the extension CSM.
If you examine the test.CSV file in the
database directory created by executing the preceding statements,
its contents should look like this:
"1","record one" "2","record two"
This format can be read, and even written, by spreadsheet applications such as Microsoft Excel or StarOffice Calc.
The CSV storage engines supports the CHECK and
REPAIR statements to verify and if possible
repair a damaged CSV table.
When running the CHECK statement, the CSV file
will be checked for validity by looking for the correct field
separators, escaped fields (matching or missing quotation marks),
the correct number of fields compared to the table definition and
the existence of a corresponding CSV metafile. The first invalid
row discovered will report an error. Checking a valid table
produces output like that shown below:
mysql> check table csvtest;
+--------------+-------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+--------------+-------+----------+----------+
| test.csvtest | check | status | OK |
+--------------+-------+----------+----------+
1 row in set (0.00 sec)A check on a corrupted table returns a fault:
mysql> check table csvtest;
+--------------+-------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+--------------+-------+----------+----------+
| test.csvtest | check | error | Corrupt |
+--------------+-------+----------+----------+
1 row in set (0.01 sec)
If the check fails, the table is marked as crashed (corrupt). Once
a table has been marked as corrupt, it is automatically repaired
when you next run CHECK or execute a
SELECT statement. The corresponding
corrupt status and new status will be displayed when running
CHECK:
mysql> check table csvtest;
+--------------+-------+----------+----------------------------+
| Table | Op | Msg_type | Msg_text |
+--------------+-------+----------+----------------------------+
| test.csvtest | check | warning | Table is marked as crashed |
| test.csvtest | check | status | OK |
+--------------+-------+----------+----------------------------+
2 rows in set (0.08 sec)
To repair a table you can use REPAIR, this
copies as many valid rows from the existing CSV data as possible,
and then replaces the existing CSV file with the recovered rows.
Any rows beyond the corrupted data are lost.
mysql> repair table csvtest;
+--------------+--------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+--------------+--------+----------+----------+
| test.csvtest | repair | status | OK |
+--------------+--------+----------+----------+
1 row in set (0.02 sec)
Note that during repair, only the rows from the CSV file up to the first damaged row are copied to the new table. All other rows from the first damaged row to the end of the table are removed, even valid rows.
The CSV storage engine does not support
indexing.
Partitioning is not supported for tables using the
CSV storage engine.
All tables that you create using the CSV
storage engine must have the NOT NULL attribute
on all columns. However, for backward compatibility, you can
continue to use tables with nullable columns that were created in
previous MySQL releases. (Bug #32050)
The ARCHIVE storage engine produces
special-purpose tables that store large amounts of unindexed data in
a very small footprint.
Table 14.14. ARCHIVE Storage Engine
Features
| Storage limits | None | Transactions | No | Locking granularity | Table |
| MVCC | No | Geospatial data type support | Yes | Geospatial indexing support | No |
| B-tree indexes | No | Hash indexes | No | Full-text search indexes | No |
| Clustered indexes | No | Data caches | No | Index caches | No |
| Compressed data | Yes | Encrypted data[a] | Yes | Cluster database support | No |
| Replication support[b] | Yes | Foreign key support | No | Backup / point-in-time recovery[c] | Yes |
| Query cache support | Yes | Update statistics for data dictionary | Yes | ||
|
[a] Implemented in the server (via encryption functions), rather than in the storage engine. [b] Implemented in the server, rather than in the storage engine. [c] Implemented in the server, rather than in the storage engine. | |||||
The ARCHIVE storage engine is included in MySQL
binary distributions. To enable this storage engine if you build
MySQL from source, invoke CMake with the
-DWITH_ARCHIVE_STORAGE_ENGINE
option.
To examine the source for the ARCHIVE engine,
look in the storage/archive directory of a
MySQL source distribution.
You can check whether the ARCHIVE storage engine
is available with the SHOW ENGINES
statement.
When you create an ARCHIVE table, the server
creates a table format file in the database directory. The file
begins with the table name and has an .frm
extension. The storage engine creates other files, all having names
beginning with the table name. The data file has an extension of
.ARZ. An .ARN file may
appear during optimization operations.
The ARCHIVE engine supports
INSERT and
SELECT, but not
DELETE,
REPLACE, or
UPDATE. It does support
ORDER BY operations,
BLOB columns, and basically all but
spatial data types (see Section 12.17.4.1, “MySQL Spatial Data Types”).
The ARCHIVE engine uses row-level locking.
The ARCHIVE engine supports the
AUTO_INCREMENT column attribute. The
AUTO_INCREMENT column can have either a unique or
nonunique index. Attempting to create an index on any other column
results in an error. The ARCHIVE engine also
supports the AUTO_INCREMENT table option in
CREATE TABLE and
ALTER TABLE statements to specify the
initial sequence value for a new table or reset the sequence value
for an existing table, respectively.
The ARCHIVE engine ignores
BLOB columns if they are not
requested and scans past them while reading.
Storage: Rows are compressed as
they are inserted. The ARCHIVE engine uses
zlib lossless data compression (see
http://www.zlib.net/). You can use
OPTIMIZE TABLE to analyze the table
and pack it into a smaller format (for a reason to use
OPTIMIZE TABLE, see later in this
section). The engine also supports CHECK
TABLE. There are several types of insertions that are
used:
An
INSERTstatement just pushes rows into a compression buffer, and that buffer flushes as necessary. The insertion into the buffer is protected by a lock. ASELECTforces a flush to occur, unless the only insertions that have come in wereINSERT DELAYED(those flush as necessary). See Section 13.2.5.2, “INSERT DELAYEDSyntax”.A bulk insert is visible only after it completes, unless other inserts occur at the same time, in which case it can be seen partially. A
SELECTnever causes a flush of a bulk insert unless a normal insert occurs while it is loading.
Retrieval: On retrieval, rows are
uncompressed on demand; there is no row cache. A
SELECT operation performs a complete
table scan: When a SELECT occurs, it
finds out how many rows are currently available and reads that
number of rows. SELECT is performed
as a consistent read. Note that lots of
SELECT statements during insertion
can deteriorate the compression, unless only bulk or delayed inserts
are used. To achieve better compression, you can use
OPTIMIZE TABLE or
REPAIR TABLE. The number of rows in
ARCHIVE tables reported by
SHOW TABLE STATUS is always accurate.
See Section 13.7.2.4, “OPTIMIZE TABLE Syntax”,
Section 13.7.2.5, “REPAIR TABLE Syntax”, and
Section 13.7.5.37, “SHOW TABLE STATUS Syntax”.
Additional Resources
A forum dedicated to the
ARCHIVEstorage engine is available at http://forums.mysql.com/list.php?112.
The BLACKHOLE storage engine acts as a
“black hole” that accepts data but throws it away and
does not store it. Retrievals always return an empty result:
mysql>CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE;Query OK, 0 rows affected (0.03 sec) mysql>INSERT INTO test VALUES(1,'record one'),(2,'record two');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM test;Empty set (0.00 sec)
To enable the BLACKHOLE storage engine if you
build MySQL from source, invoke CMake with the
-DWITH_BLACKHOLE_STORAGE_ENGINE
option.
To examine the source for the BLACKHOLE engine,
look in the sql directory of a MySQL source
distribution.
When you create a BLACKHOLE table, the server
creates a table format file in the database directory. The file
begins with the table name and has an .frm
extension. There are no other files associated with the table.
The BLACKHOLE storage engine supports all kinds
of indexes. That is, you can include index declarations in the table
definition.
You can check whether the BLACKHOLE storage
engine is available with the SHOW
ENGINES statement.
Inserts into a BLACKHOLE table do not store any
data, but if the binary log is enabled, the SQL statements are
logged (and replicated to slave servers). This can be useful as a
repeater or filter mechanism. Suppose that your application requires
slave-side filtering rules, but transferring all binary log data to
the slave first results in too much traffic. In such a case, it is
possible to set up on the master host a “dummy” slave
process whose default storage engine is
BLACKHOLE, depicted as follows:
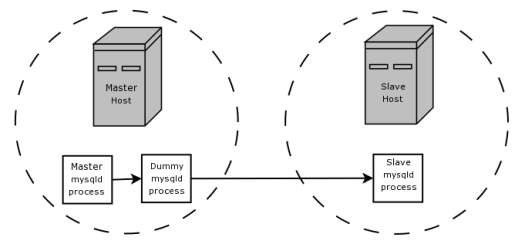
The master writes to its binary log. The “dummy”
mysqld process acts as a slave, applying the
desired combination of replicate-do-* and
replicate-ignore-* rules, and writes a new,
filtered binary log of its own. (See
Section 16.1.4, “Replication and Binary Logging Options and Variables”.) This filtered log is
provided to the slave.
The dummy process does not actually store any data, so there is little processing overhead incurred by running the additional mysqld process on the replication master host. This type of setup can be repeated with additional replication slaves.
INSERT triggers for
BLACKHOLE tables work as expected. However,
because the BLACKHOLE table does not actually
store any data, UPDATE and
DELETE triggers are not activated:
The FOR EACH ROW clause in the trigger definition
does not apply because there are no rows.
Other possible uses for the BLACKHOLE storage
engine include:
Verification of dump file syntax.
Measurement of the overhead from binary logging, by comparing performance using
BLACKHOLEwith and without binary logging enabled.BLACKHOLEis essentially a “no-op” storage engine, so it could be used for finding performance bottlenecks not related to the storage engine itself.
The BLACKHOLE engine is transaction-aware, in the
sense that committed transactions are written to the binary log and
rolled-back transactions are not.
Blackhole Engine and Auto Increment Columns
The Blackhole engine is a no-op engine. Any operations performed on a table using Blackhole will have no effect. This should be born in mind when considering the behavior of primary key columns that auto increment. The engine will not automatically increment field values, and does not retain auto increment field state. This has important implications in replication.
Consider the following replication scenario where all three of the following conditions apply:
On a master server there is a blackhole table with an auto increment field that is a primary key.
On a slave the same table exists but using the MyISAM engine.
Inserts are performed into the master's table without explicitly setting the auto increment value in the
INSERTstatement itself or through using aSET INSERT_IDstatement.
In this scenario replication will fail with a duplicate entry error on the primary key column.
In statement based replication, the value of
INSERT_ID in the context event will always be the
same. Replication will therefore fail due to trying insert a row
with a duplicate value for a primary key column.
In row based replication, the value that the engine returns for the row always be the same for each insert. This will result in the slave attempting to replay two insert log entries using the same value for the primary key column, and so replication will fail.
Column Filtering
When using row-based replication,
(binlog_format=ROW), a slave where
the last columns are missing from a table is supported, as described
in the section
Section 16.4.1.8, “Replication with Differing Table Definitions on Master and Slave”.
This filtering works on the slave side, that is, the columns are copied to the slave before they are filtered out. There are at least two cases where it is not desirable to copy the columns to the slave:
If the data is confidential, so the slave server should not have access to it.
If the master has many slaves, filtering before sending to the slaves may reduce network traffic.
Master column filtering can be achieved using the
BLACKHOLE engine. This is carried out in a way
similar to how master table filtering is achieved - by using the
BLACKHOLE engine and the
--replicate-do-table or
--replicate-ignore-table option.
The setup for the master is:
CREATE TABLE t1 (public_col_1, ..., public_col_N,
secret_col_1, ..., secret_col_M) ENGINE=MyISAM;The setup for the trusted slave is:
CREATE TABLE t1 (public_col_1, ..., public_col_N) ENGINE=BLACKHOLE;
The setup for the untrusted slave is:
CREATE TABLE t1 (public_col_1, ..., public_col_N) ENGINE=MyISAM;
The MERGE storage engine, also known as the
MRG_MyISAM engine, is a collection of identical
MyISAM tables that can be used as one.
“Identical” means that all tables have identical column
and index information. You cannot merge MyISAM
tables in which the columns are listed in a different order, do not
have exactly the same columns, or have the indexes in different
order. However, any or all of the MyISAM tables
can be compressed with myisampack. See
Section 4.6.5, “myisampack — Generate Compressed, Read-Only MyISAM Tables”. Differences in table options such as
AVG_ROW_LENGTH, MAX_ROWS, or
PACK_KEYS do not matter.
An alternative to a MERGE table is a partitioned
table, which stores partitions of a single table in separate files.
Partitioning enables some operations to be performed more
efficiently and is not limited to the MyISAM
storage engine. For more information, see
Chapter 17, Partitioning.
When you create a MERGE table, MySQL creates two
files on disk. The files have names that begin with the table name
and have an extension to indicate the file type. An
.frm file stores the table format, and an
.MRG file contains the names of the underlying
MyISAM tables that should be used as one. The
tables do not have to be in the same database as the
MERGE table.
You can use SELECT,
DELETE,
UPDATE, and
INSERT on MERGE
tables. You must have SELECT,
DELETE, and
UPDATE privileges on the
MyISAM tables that you map to a
MERGE table.
The use of MERGE tables entails the following
security issue: If a user has access to MyISAM
table t, that user can create a
MERGE table m that
accesses t. However, if the user's
privileges on t are subsequently
revoked, the user can continue to access
t by doing so through
m.
Use of DROP TABLE with a
MERGE table drops only the
MERGE specification. The underlying tables are
not affected.
To create a MERGE table, you must specify a
UNION=(
option that indicates which list-of-tables)MyISAM tables to use.
You can optionally specify an INSERT_METHOD
option to control how inserts into the MERGE
table take place. Use a value of FIRST or
LAST to cause inserts to be made in the first or
last underlying table, respectively. If you specify no
INSERT_METHOD option or if you specify it with a
value of NO, inserts into the
MERGE table are not permitted and attempts to do
so result in an error.
The following example shows how to create a MERGE
table:
mysql>CREATE TABLE t1 (->a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,->message CHAR(20)) ENGINE=MyISAM;mysql>CREATE TABLE t2 (->a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,->message CHAR(20)) ENGINE=MyISAM;mysql>INSERT INTO t1 (message) VALUES ('Testing'),('table'),('t1');mysql>INSERT INTO t2 (message) VALUES ('Testing'),('table'),('t2');mysql>CREATE TABLE total (->a INT NOT NULL AUTO_INCREMENT,->message CHAR(20), INDEX(a))->ENGINE=MERGE UNION=(t1,t2) INSERT_METHOD=LAST;
Note that column a is indexed as a
PRIMARY KEY in the underlying
MyISAM tables, but not in the
MERGE table. There it is indexed but not as a
PRIMARY KEY because a MERGE
table cannot enforce uniqueness over the set of underlying tables.
(Similarly, a column with a UNIQUE index in the
underlying tables should be indexed in the MERGE
table but not as a UNIQUE index.)
After creating the MERGE table, you can use it to
issue queries that operate on the group of tables as a whole:
mysql> SELECT * FROM total;
+---+---------+
| a | message |
+---+---------+
| 1 | Testing |
| 2 | table |
| 3 | t1 |
| 1 | Testing |
| 2 | table |
| 3 | t2 |
+---+---------+
To remap a MERGE table to a different collection
of MyISAM tables, you can use one of the
following methods:
DROPtheMERGEtable and re-create it.Use
ALTER TABLEto change the list of underlying tables.tbl_nameUNION=(...)It is also possible to use
ALTER TABLE ... UNION=()(that is, with an emptyUNIONclause) to remove all of the underlying tables.
The underlying table definitions and indexes must conform closely to
the definition of the MERGE table. Conformance is
checked when a table that is part of a MERGE
table is opened, not when the MERGE table is
created. If any table fails the conformance checks, the operation
that triggered the opening of the table fails. This means that
changes to the definitions of tables within a
MERGE may cause a failure when the
MERGE table is accessed. The conformance checks
applied to each table are:
The underlying table and the
MERGEtable must have the same number of columns.The column order in the underlying table and the
MERGEtable must match.Additionally, the specification for each corresponding column in the parent
MERGEtable and the underlying tables are compared and must satisfy these checks:The column type in the underlying table and the
MERGEtable must be equal.The column length in the underlying table and the
MERGEtable must be equal.The column of the underlying table and the
MERGEtable can beNULL.
The underlying table must have at least as many indexes as the
MERGEtable. The underlying table may have more indexes than theMERGEtable, but cannot have fewer.NoteA known issue exists where indexes on the same columns must be in identical order, in both the
MERGEtable and the underlyingMyISAMtable. See Bug #33653.Each index must satisfy these checks:
The index type of the underlying table and the
MERGEtable must be the same.The number of index parts (that is, multiple columns within a compound index) in the index definition for the underlying table and the
MERGEtable must be the same.For each index part:
Index part lengths must be equal.
Index part types must be equal.
Index part languages must be equal.
Check whether index parts can be
NULL.
If a MERGE table cannot be opened or used because
of a problem with an underlying table, CHECK
TABLE displays information about which table caused the
problem.
Additional Resources
A forum dedicated to the
MERGEstorage engine is available at http://forums.mysql.com/list.php?93.
MERGE tables can help you solve the following
problems:
Easily manage a set of log tables. For example, you can put data from different months into separate tables, compress some of them with myisampack, and then create a
MERGEtable to use them as one.Obtain more speed. You can split a large read-only table based on some criteria, and then put individual tables on different disks. A
MERGEtable structured this way could be much faster than using a single large table.Perform more efficient searches. If you know exactly what you are looking for, you can search in just one of the underlying tables for some queries and use a
MERGEtable for others. You can even have many differentMERGEtables that use overlapping sets of tables.Perform more efficient repairs. It is easier to repair individual smaller tables that are mapped to a
MERGEtable than to repair a single large table.Instantly map many tables as one. A
MERGEtable need not maintain an index of its own because it uses the indexes of the individual tables. As a result,MERGEtable collections are very fast to create or remap. (You must still specify the index definitions when you create aMERGEtable, even though no indexes are created.)If you have a set of tables from which you create a large table on demand, you can instead create a
MERGEtable from them on demand. This is much faster and saves a lot of disk space.Exceed the file size limit for the operating system. Each
MyISAMtable is bound by this limit, but a collection ofMyISAMtables is not.You can create an alias or synonym for a
MyISAMtable by defining aMERGEtable that maps to that single table. There should be no really notable performance impact from doing this (only a couple of indirect calls andmemcpy()calls for each read).
The disadvantages of MERGE tables are:
You can use only identical
MyISAMtables for aMERGEtable.Some
MyISAMfeatures are unavailable inMERGEtables. For example, you cannot createFULLTEXTindexes onMERGEtables. (You can createFULLTEXTindexes on the underlyingMyISAMtables, but you cannot search theMERGEtable with a full-text search.)If the
MERGEtable is nontemporary, all underlyingMyISAMtables must be nontemporary. If theMERGEtable is temporary, theMyISAMtables can be any mix of temporary and nontemporary.MERGEtables use more file descriptors thanMyISAMtables. If 10 clients are using aMERGEtable that maps to 10 tables, the server uses (10 × 10) + 10 file descriptors. (10 data file descriptors for each of the 10 clients, and 10 index file descriptors shared among the clients.)Index reads are slower. When you read an index, the
MERGEstorage engine needs to issue a read on all underlying tables to check which one most closely matches a given index value. To read the next index value, theMERGEstorage engine needs to search the read buffers to find the next value. Only when one index buffer is used up does the storage engine need to read the next index block. This makesMERGEindexes much slower oneq_refsearches, but not much slower onrefsearches. For more information abouteq_refandref, see Section 13.8.2, “EXPLAINSyntax”.
The following are known problems with MERGE
tables:
In versions of MySQL Server prior to 5.1.23, it was possible to create temporary merge tables with nontemporary child MyISAM tables.
From versions 5.1.23, MERGE children were locked through the parent table. If the parent was temporary, it was not locked and so the children were not locked either. Parallel use of the MyISAM tables corrupted them.
If you use
ALTER TABLEto change aMERGEtable to another storage engine, the mapping to the underlying tables is lost. Instead, the rows from the underlyingMyISAMtables are copied into the altered table, which then uses the specified storage engine.The
INSERT_METHODtable option for aMERGEtable indicates which underlyingMyISAMtable to use for inserts into theMERGEtable. However, use of theAUTO_INCREMENTtable option for thatMyISAMtable has no effect for inserts into theMERGEtable until at least one row has been inserted directly into theMyISAMtable.A
MERGEtable cannot maintain uniqueness constraints over the entire table. When you perform anINSERT, the data goes into the first or lastMyISAMtable (as determined by theINSERT_METHODoption). MySQL ensures that unique key values remain unique within thatMyISAMtable, but not over all the underlying tables in the collection.Because the
MERGEengine cannot enforce uniqueness over the set of underlying tables,REPLACEdoes not work as expected. The two key facts are:REPLACEcan detect unique key violations only in the underlying table to which it is going to write (which is determined by theINSERT_METHODoption). This differs from violations in theMERGEtable itself.If
REPLACEdetects a unique key violation, it will change only the corresponding row in the underlying table it is writing to; that is, the first or last table, as determined by theINSERT_METHODoption.
Similar considerations apply for
INSERT ... ON DUPLICATE KEY UPDATE.MERGEtables do not support partitioning. That is, you cannot partition aMERGEtable, nor can any of aMERGEtable's underlyingMyISAMtables be partitioned.You should not use
ANALYZE TABLE,REPAIR TABLE,OPTIMIZE TABLE,ALTER TABLE,DROP TABLE,DELETEwithout aWHEREclause, orTRUNCATE TABLEon any of the tables that are mapped into an openMERGEtable. If you do so, theMERGEtable may still refer to the original table and yield unexpected results. To work around this problem, ensure that noMERGEtables remain open by issuing aFLUSH TABLESstatement prior to performing any of the named operations.The unexpected results include the possibility that the operation on the
MERGEtable will report table corruption. If this occurs after one of the named operations on the underlyingMyISAMtables, the corruption message is spurious. To deal with this, issue aFLUSH TABLESstatement after modifying theMyISAMtables.DROP TABLEon a table that is in use by aMERGEtable does not work on Windows because theMERGEstorage engine's table mapping is hidden from the upper layer of MySQL. Windows does not permit open files to be deleted, so you first must flush allMERGEtables (withFLUSH TABLES) or drop theMERGEtable before dropping the table.The definition of the
MyISAMtables and theMERGEtable are checked when the tables are accessed (for example, as part of aSELECTorINSERTstatement). The checks ensure that the definitions of the tables and the parentMERGEtable definition match by comparing column order, types, sizes and associated indexes. If there is a difference between the tables, an error is returned and the statement fails. Because these checks take place when the tables are opened, any changes to the definition of a single table, including column changes, column ordering, and engine alterations will cause the statement to fail.The order of indexes in the
MERGEtable and its underlying tables should be the same. If you useALTER TABLEto add aUNIQUEindex to a table used in aMERGEtable, and then useALTER TABLEto add a nonunique index on theMERGEtable, the index ordering is different for the tables if there was already a nonunique index in the underlying table. (This happens becauseALTER TABLEputsUNIQUEindexes before nonunique indexes to facilitate rapid detection of duplicate keys.) Consequently, queries on tables with such indexes may return unexpected results.If you encounter an error message similar to ERROR 1017 (HY000): Can't find file: '
tbl_name.MRG' (errno: 2), it generally indicates that some of the underlying tables do not use theMyISAMstorage engine. Confirm that all of these tables areMyISAM.The maximum number of rows in a
MERGEtable is 264 (~1.844E+19; the same as for aMyISAMtable). It is not possible to merge multipleMyISAMtables into a singleMERGEtable that would have more than this number of rows.The
MERGEstorage engine does not supportINSERT DELAYEDstatements.Use of underlying
MyISAMtables of differing row formats with a parentMERGEtable is currently known to fail. See Bug #32364.You cannot change the union list of a nontemporary
MERGEtable whenLOCK TABLESis in effect. The following does not work:CREATE TABLE m1 ... ENGINE=MRG_MYISAM ...; LOCK TABLES t1 WRITE, t2 WRITE, m1 WRITE; ALTER TABLE m1 ... UNION=(t1,t2) ...;
However, you can do this with a temporary
MERGEtable.You cannot create a
MERGEtable withCREATE ... SELECT, neither as a temporaryMERGEtable, nor as a nontemporaryMERGEtable. For example:CREATE TABLE m1 ... ENGINE=MRG_MYISAM ... SELECT ...;
Attempts to do this result in an error:
tbl_nameis notBASE TABLE.In some cases, differing
PACK_KEYStable option values among theMERGEand underlying tables cause unexpected results if the underlying tables containCHARorBINARYcolumns. As a workaround, useALTER TABLEto ensure that all involved tables have the samePACK_KEYSvalue. (Bug #50646)
The FEDERATED storage engine lets you access data
from a remote MySQL database without using replication or cluster
technology. Querying a local FEDERATED table
automatically pulls the data from the remote (federated) tables. No
data is stored on the local tables.
To include the FEDERATED storage engine if you
build MySQL from source, invoke CMake with the
-DWITH_FEDERATED_STORAGE_ENGINE
option.
The FEDERATED storage engine is not enabled by
default in the running server; to enable
FEDERATED, you must start the MySQL server binary
using the --federated option.
To examine the source for the FEDERATED engine,
look in the storage/federated directory of a
MySQL source distribution.
When you create a table using one of the standard storage engines
(such as MyISAM, CSV or
InnoDB), the table consists of the table
definition and the associated data. When you create a
FEDERATED table, the table definition is the
same, but the physical storage of the data is handled on a remote
server.
A FEDERATED table consists of two elements:
A remote server with a database table, which in turn consists of the table definition (stored in the
.frmfile) and the associated table. The table type of the remote table may be any type supported by the remotemysqldserver, includingMyISAMorInnoDB.A local server with a database table, where the table definition matches that of the corresponding table on the remote server. The table definition is stored within the
.frmfile. However, there is no data file on the local server. Instead, the table definition includes a connection string that points to the remote table.
When executing queries and statements on a
FEDERATED table on the local server, the
operations that would normally insert, update or delete
information from a local data file are instead sent to the remote
server for execution, where they update the data file on the
remote server or return matching rows from the remote server.
The basic structure of a FEDERATED table setup
is shown in Figure 14.1, “FEDERATED Table Structure”.

When a client issues an SQL statement that refers to a
FEDERATED table, the flow of information
between the local server (where the SQL statement is executed) and
the remote server (where the data is physically stored) is as
follows:
The storage engine looks through each column that the
FEDERATEDtable has and constructs an appropriate SQL statement that refers to the remote table.The statement is sent to the remote server using the MySQL client API.
The remote server processes the statement and the local server retrieves any result that the statement produces (an affected-rows count or a result set).
If the statement produces a result set, each column is converted to internal storage engine format that the
FEDERATEDengine expects and can use to display the result to the client that issued the original statement.
The local server communicates with the remote server using MySQL
client C API functions. It invokes
mysql_real_query() to send the
statement. To read a result set, it uses
mysql_store_result() and fetches
rows one at a time using
mysql_fetch_row().
To create a FEDERATED table you should follow
these steps:
Create the table on the remote server. Alternatively, make a note of the table definition of an existing table, perhaps using the
SHOW CREATE TABLEstatement.Create the table on the local server with an identical table definition, but adding the connection information that links the local table to the remote table.
For example, you could create the following table on the remote server:
CREATE TABLE test_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=MyISAM
DEFAULT CHARSET=latin1;
To create the local table that will be federated to the remote
table, there are two options available. You can either create the
local table and specify the connection string (containing the
server name, login, password) to be used to connect to the remote
table using the CONNECTION, or you can use an
existing connection that you have previously created using the
CREATE SERVER statement.
When you create the local table it must have an identical field definition to the remote table.
You can improve the performance of a
FEDERATED table by adding indexes to the
table on the host. The optimization will occur because the query
sent to the remote server will include the contents of the
WHERE clause and will be sent to the remote
server and subsequently executed locally. This reduces the
network traffic that would otherwise request the entire table
from the server for local processing.
To use the first method, you must specify the
CONNECTION string after the engine type in a
CREATE TABLE statement. For
example:
CREATE TABLE federated_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=FEDERATED
DEFAULT CHARSET=latin1
CONNECTION='mysql://fed_user@remote_host:9306/federated/test_table';
CONNECTION replaces the
COMMENT used in some previous versions of
MySQL.
The CONNECTION string contains the
information required to connect to the remote server containing
the table that will be used to physically store the data. The
connection string specifies the server name, login credentials,
port number and database/table information. In the example, the
remote table is on the server remote_host,
using port 9306. The name and port number should match the host
name (or IP address) and port number of the remote MySQL server
instance you want to use as your remote table.
The format of the connection string is as follows:
scheme://user_name[:password]@host_name[:port_num]/db_name/tbl_name
Where:
scheme: A recognized connection protocol. Onlymysqlis supported as theschemevalue at this point.user_name: The user name for the connection. This user must have been created on the remote server, and must have suitable privileges to perform the required actions (SELECT,INSERT,UPDATE, and so forth) on the remote table.password: (Optional) The corresponding password foruser_name.host_name: The host name or IP address of the remote server.port_num: (Optional) The port number for the remote server. The default is 3306.db_name: The name of the database holding the remote table.tbl_name: The name of the remote table. The name of the local and the remote table do not have to match.
Sample connection strings:
CONNECTION='mysql://username:password@hostname:port/database/tablename' CONNECTION='mysql://username@hostname/database/tablename' CONNECTION='mysql://username:password@hostname/database/tablename'
If you are creating a number of FEDERATED
tables on the same server, or if you want to simplify the
process of creating FEDERATED tables, you can
use the CREATE SERVER statement
to define the server connection parameters, just as you would
with the CONNECTION string.
The format of the CREATE SERVER
statement is:
CREATE SERVERserver_nameFOREIGN DATA WRAPPERwrapper_nameOPTIONS (option[,option] ...)
The server_name is used in the
connection string when creating a new
FEDERATED table.
For example, to create a server connection identical to the
CONNECTION string:
CONNECTION='mysql://fed_user@remote_host:9306/federated/test_table';
You would use the following statement:
CREATE SERVER fedlink FOREIGN DATA WRAPPER mysql OPTIONS (USER 'fed_user', HOST 'remote_host', PORT 9306, DATABASE 'federated');
To create a FEDERATED table that uses this
connection, you still use the CONNECTION
keyword, but specify the name you used in the
CREATE SERVER statement.
CREATE TABLE test_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=FEDERATED
DEFAULT CHARSET=latin1
CONNECTION='fedlink/test_table';
The connection name in this example contains the name of the
connection (fedlink) and the name of the
table (test_table) to link to, separated by a
slash. If you specify only the connection name without a table
name, the table name of the local table is used instead.
For more information on CREATE
SERVER, see Section 13.1.13, “CREATE SERVER Syntax”.
The CREATE SERVER statement
accepts the same arguments as the CONNECTION
string. The CREATE SERVER
statement updates the rows in the
mysql.servers table. See the following table
for information on the correspondence between parameters in a
connection string, options in the CREATE
SERVER statement, and the columns in the
mysql.servers table. For reference, the
format of the CONNECTION string is as
follows:
scheme://user_name[:password]@host_name[:port_num]/db_name/tbl_name
| Description | CONNECTION string | CREATE SERVER option | mysql.servers column |
|---|---|---|---|
| Connection scheme | scheme | wrapper_name | Wrapper |
| Remote user | user_name | USER | Username |
| Remote password | password | PASSWORD | Password |
| Remote host | host_name | HOST | Host |
| Remote port | port_num | PORT | Port |
| Remote database | db_name | DATABASE | Db |
You should be aware of the following points when using the
FEDERATED storage engine:
FEDERATEDtables may be replicated to other slaves, but you must ensure that the slave servers are able to use the user/password combination that is defined in theCONNECTIONstring (or the row in themysql.serverstable) to connect to the remote server.
The following items indicate features that the
FEDERATED storage engine does and does not
support:
The remote server must be a MySQL server.
The remote table that a
FEDERATEDtable points to must exist before you try to access the table through theFEDERATEDtable.It is possible for one
FEDERATEDtable to point to another, but you must be careful not to create a loop.A
FEDERATEDtable does not support indexes per se. Because access to the table is handled remotely, it is the remote table that supports the indexes. Care should be taken when creating aFEDERATEDtable since the index definition from an equivalentMyISAMor other table may not be supported. For example, creating aFEDERATEDtable with an index prefix onVARCHAR,TEXTorBLOBcolumns will fail. The following definition inMyISAMis valid:CREATE TABLE `T1`(`A` VARCHAR(100),UNIQUE KEY(`A`(30))) ENGINE=MYISAM;
The key prefix in this example is incompatible with the
FEDERATEDengine, and the equivalent statement will fail:CREATE TABLE `T1`(`A` VARCHAR(100),UNIQUE KEY(`A`(30))) ENGINE=FEDERATED CONNECTION='MYSQL://127.0.0.1:3306/TEST/T1';
If possible, you should try to separate the column and index definition when creating tables on both the remote server and the local server to avoid these index issues.
Internally, the implementation uses
SELECT,INSERT,UPDATE, andDELETE, but notHANDLER.The
FEDERATEDstorage engine supportsSELECT,INSERT,UPDATE,DELETE,TRUNCATE TABLE, and indexes. It does not supportALTER TABLE, or any Data Definition Language statements that directly affect the structure of the table, other thanDROP TABLE. The current implementation does not use prepared statements.FEDERATEDacceptsINSERT ... ON DUPLICATE KEY UPDATEstatements, but if a duplicate-key violation occurs, the statement fails with an error.Performance on a
FEDERATEDtable when performing bulk inserts (for example, on aINSERT INTO ... SELECT ...statement) is slower than with other table types because each selected row is treated as an individualINSERTstatement on theFEDERATEDtable.Transactions are not supported.
FEDERATEDperforms bulk-insert handling such that multiple rows are sent to the remote table in a batch. This provides a performance improvement and enables the remote table to perform improvement. Also, if the remote table is transactional, it enables the remote storage engine to perform statement rollback properly should an error occur. This capability has the following limitations:The size of the insert cannot exceed the maximum packet size between servers. If the insert exceeds this size, it is broken into multiple packets and the rollback problem can occur.
Bulk-insert handling does not occur for
INSERT ... ON DUPLICATE KEY UPDATE.
There is no way for the
FEDERATEDengine to know if the remote table has changed. The reason for this is that this table must work like a data file that would never be written to by anything other than the database system. The integrity of the data in the local table could be breached if there was any change to the remote database.When using a
CONNECTIONstring, you cannot use an '@' character in the password. You can get round this limitation by using theCREATE SERVERstatement to create a server connection.The
insert_idandtimestampoptions are not propagated to the data provider.Any
DROP TABLEstatement issued against aFEDERATEDtable drops only the local table, not the remote table.FEDERATEDtables do not work with the query cache.User-defined partitioning is not supported for
FEDERATEDtables.
The following additional resources are available for the
FEDERATED storage engine:
A forum dedicated to the
FEDERATEDstorage engine is available at http://forums.mysql.com/list.php?105.
The EXAMPLE storage engine is a stub engine that
does nothing. Its purpose is to serve as an example in the MySQL
source code that illustrates how to begin writing new storage
engines. As such, it is primarily of interest to developers.
To enable the EXAMPLE storage engine if you build
MySQL from source, invoke CMake with the
-DWITH_EXAMPLE_STORAGE_ENGINE
option.
To examine the source for the EXAMPLE engine,
look in the storage/example directory of a
MySQL source distribution.
When you create an EXAMPLE table, the server
creates a table format file in the database directory. The file
begins with the table name and has an .frm
extension. No other files are created. No data can be stored into
the table. Retrievals return an empty result.
mysql>CREATE TABLE test (i INT) ENGINE = EXAMPLE;Query OK, 0 rows affected (0.78 sec) mysql>INSERT INTO test VALUES(1),(2),(3);ERROR 1031 (HY000): Table storage engine for 'test' doesn't » have this option mysql>SELECT * FROM test;Empty set (0.31 sec)
The EXAMPLE storage engine does not support
indexing.
Other storage engines may be available from third parties and community members that have used the Custom Storage Engine interface.
Third party engines are not supported by MySQL. For further information, documentation, installation guides, bug reporting or for any help or assistance with these engines, please contact the developer of the engine directly.
Third party engines that are known to be available include the following:
PrimeBase XT (PBXT): PBXT has been designed for modern, web-based, high concurrency environments.
RitmarkFS: RitmarkFS enables you to access and manipulate the file system using SQL queries. RitmarkFS also supports file system replication and directory change tracking.
Distributed Data Engine: The Distributed Data Engine is an Open Source project that is dedicated to provide a Storage Engine for distributed data according to workload statistics.
mdbtools: A pluggable storage engine that enables read-only access to Microsoft Access
.mdbdatabase files.solidDB for MySQL: solidDB Storage Engine for MySQL is an open source, transactional storage engine for MySQL Server. It is designed for mission-critical implementations that require a robust, transactional database. solidDB Storage Engine for MySQL is a multi-threaded storage engine that supports full ACID compliance with all expected transaction isolation levels, row-level locking, and Multi-Version Concurrency Control (MVCC) with nonblocking reads and writes.
For more information on developing a customer storage engine that can be used with the Pluggable Storage Engine Architecture, see MySQL Internals: Writing a Custom Storage Engine.
The MySQL pluggable storage engine architecture enables a database professional to select a specialized storage engine for a particular application need while being completely shielded from the need to manage any specific application coding requirements. The MySQL server architecture isolates the application programmer and DBA from all of the low-level implementation details at the storage level, providing a consistent and easy application model and API. Thus, although there are different capabilities across different storage engines, the application is shielded from these differences.
The pluggable storage engine architecture provides a standard set of management and support services that are common among all underlying storage engines. The storage engines themselves are the components of the database server that actually perform actions on the underlying data that is maintained at the physical server level.
This efficient and modular architecture provides huge benefits for those wishing to specifically target a particular application need—such as data warehousing, transaction processing, or high availability situations—while enjoying the advantage of utilizing a set of interfaces and services that are independent of any one storage engine.
The application programmer and DBA interact with the MySQL database through Connector APIs and service layers that are above the storage engines. If application changes bring about requirements that demand the underlying storage engine change, or that one or more storage engines be added to support new needs, no significant coding or process changes are required to make things work. The MySQL server architecture shields the application from the underlying complexity of the storage engine by presenting a consistent and easy-to-use API that applies across storage engines.
MySQL Server uses a pluggable storage engine architecture that enables storage engines to be loaded into and unloaded from a running MySQL server.
Plugging in a Storage Engine
Before a storage engine can be used, the storage engine plugin
shared library must be loaded into MySQL using the
INSTALL PLUGIN statement. For
example, if the EXAMPLE engine plugin is
named example and the shared library is named
ha_example.so, you load it with the
following statement:
mysql> INSTALL PLUGIN example SONAME 'ha_example.so';
To install a pluggable storage engine, the plugin file must be
located in the MySQL plugin directory, and the user issuing the
INSTALL PLUGIN statement must
have INSERT privilege for the
mysql.plugin table.
The shared library must be located in the MySQL server plugin
directory, the location of which is given by the
plugin_dir system variable.
Unplugging a Storage Engine
To unplug a storage engine, use the
UNINSTALL PLUGIN statement:
mysql> UNINSTALL PLUGIN example;
If you unplug a storage engine that is needed by existing tables, those tables become inaccessible, but will still be present on disk (where applicable). Ensure that there are no tables using a storage engine before you unplug the storage engine.
A MySQL pluggable storage engine is the component in the MySQL database server that is responsible for performing the actual data I/O operations for a database as well as enabling and enforcing certain feature sets that target a specific application need. A major benefit of using specific storage engines is that you are only delivered the features needed for a particular application, and therefore you have less system overhead in the database, with the end result being more efficient and higher database performance. This is one of the reasons that MySQL has always been known to have such high performance, matching or beating proprietary monolithic databases in industry standard benchmarks.
From a technical perspective, what are some of the unique supporting infrastructure components that are in a storage engine? Some of the key feature differentiations include:
Concurrency: Some applications have more granular lock requirements (such as row-level locks) than others. Choosing the right locking strategy can reduce overhead and therefore improve overall performance. This area also includes support for capabilities such as multi-version concurrency control or “snapshot” read.
Transaction Support: Not every application needs transactions, but for those that do, there are very well defined requirements such as ACID compliance and more.
Referential Integrity: The need to have the server enforce relational database referential integrity through DDL defined foreign keys.
Physical Storage: This involves everything from the overall page size for tables and indexes as well as the format used for storing data to physical disk.
Index Support: Different application scenarios tend to benefit from different index strategies. Each storage engine generally has its own indexing methods, although some (such as B-tree indexes) are common to nearly all engines.
Memory Caches: Different applications respond better to some memory caching strategies than others, so although some memory caches are common to all storage engines (such as those used for user connections or MySQL's high-speed Query Cache), others are uniquely defined only when a particular storage engine is put in play.
Performance Aids: This includes multiple I/O threads for parallel operations, thread concurrency, database checkpointing, bulk insert handling, and more.
Miscellaneous Target Features: This may include support for geospatial operations, security restrictions for certain data manipulation operations, and other similar features.
Each set of the pluggable storage engine infrastructure components are designed to offer a selective set of benefits for a particular application. Conversely, avoiding a set of component features helps reduce unnecessary overhead. It stands to reason that understanding a particular application's set of requirements and selecting the proper MySQL storage engine can have a dramatic impact on overall system efficiency and performance.