| 12.3. Structure of the Deployment Plan | ||
|---|---|---|
 | Chapter 12. Enterprise Java Beans (EJB JARs) [DRAFT (1.0)] |  |
| 12.3. Structure of the Deployment Plan | ||
|---|---|---|
| | Chapter 12. Enterprise Java Beans (EJB JARs) [DRAFT (1.0)] | |
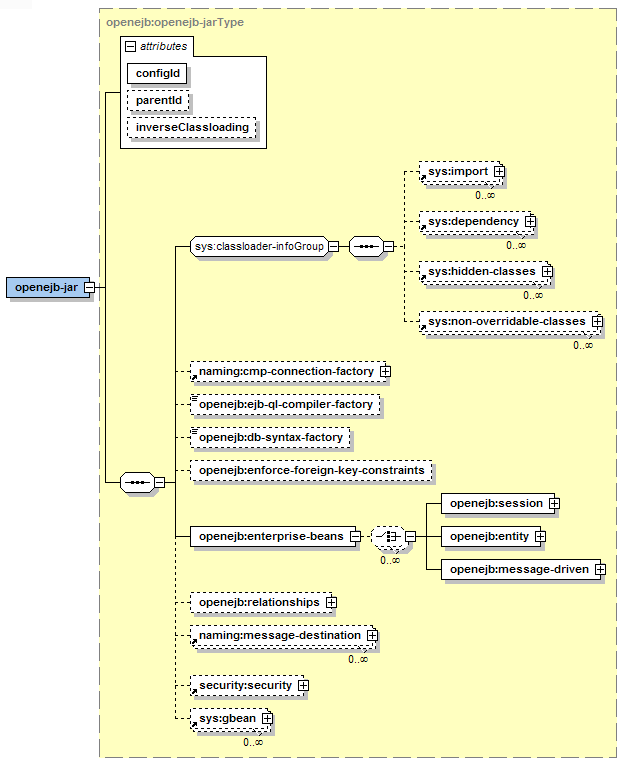
The internal structure of the deployment plan looks like this:
The following sections discuss the elements of the deployment plan in more detail. Note that the order of the elements is fixed as shown in Figure 12.1, “Geronimo EJB Deployment Plan”, and that's the order the elements are discussed in below. Of these elements, only the header (discussed above) and at least one EJB definition are required.
The elements in the classloader-infoGroup are used to customized the EJB JAR's class path.
The elements here are:
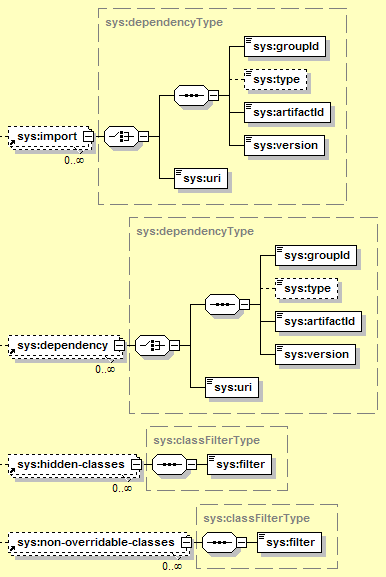
Refers to another configuration deployed in the server. That configuration will be added as a parent of this one (a configuration may have more than one parent). The main effect is that the class loader for the EJB JAR will add the class loader for that configuration as a parent. Additionally, the parent configuration will be started before the EJB JAR.
Adds a third-party library to the class path for the EJB JAR. Any common libraries used in this manner should be located in a subdirectory of the repository/ directory of the main Geronimo installation.
Lists packages or classes that may be in a parent class loader, but should not be exposed from there to the EJB JAR. This is typically used when the EJB JAR wants to use a different version of a library that one of its parent configurations (or Geronimo itself) uses. For example, Geronimo 1.0 uses Log4J 1.2.8. If an EJB wanted to use a newer version, it could include the newer version in a dependency or on the Manifest Class-Path, and then add org.apache.log4j to the list of hidden-classes so that the Log4J classes could not be loaded from a parent class loader.
Lists packages or classes that the EJB JAR should always load from a parent class loader, and never load from its own class loader. This might be used to force an EJB to share the same instance of a common library with other applications or modules, even if they each include it in their own class path.
Used to list classes or packages. The format is a comma-separated list of packages or fully-qualified class names (for example: javax.servlet,javax.ejb).
The import and dependency element both ultimately need to identify a URI. In the case of an import, the URI must match the configId of another deployed module or configuration. In the case of a dependency, the URI must identify an entry in the Geronimo repository.
The Geronimo repository uses URIs divided into four components: the Group ID, Artifact ID, Type, and Version. For example, for Log4J, the Group ID is "log4j", the Type is "jar", the Artifact ID is "log4j", and the version included with Geronimo is "1.2.8". These components correspond to the path to the file in the repository directory of the file system, which is normally repository/groupId/types/artifactId-version.type (so for Log4J, repository/log4j/jars/log4j-1.2.8.jar). The URI format used by the repository looks like groupId/artifactId/version/type (so, log4j/log4j/1.0/jar). Therefore, the dependency element must use a URI of this format, either listing it as a whole string or identifying each of the component parts.
The URIs used by the import element, however, need to match the configId of another module or configuration in the server. The configurations shipped with Geronimo also obey the standard URI format mentioned above, but that is strictly optional. When you provide configIds for your own modules, you may choose to use that format or not as you please. For example, you could use the configId MyEJBJar, or you could use the configId MyCompany/MyEJBJar/1.0.3/jar. Therefore, the import element may list a configId URI as a whole String (matching exactly the configId for the other module). It may instead identify each of the component parts, but only if the configuration it's referring to used the URI syntax described above.
This syntax is used to specify the complete URI as a String:
The value of this element should identify the JAR or configuration, using the syntax described above. For example, specifying regexp/regexp/1.3/jar would select the JAR geronimo/repository/regexp/jars/regexp-1.3.jar. If there is no such JAR available, the module will fail to start.
Instead of a single URI, this creates a URI out of several components. Again, this works for all dependency elements, but only works for an import element if the targeted configuration used a URI composed of all these parts separated by slashes.
Identifies the "group" of the targeted library or configuration, which is usually either the name of the vendor who produced it, or an identifier for the application or project in question.
The name of the specific library or configuration (without any version information).
The version number of the specific library or configuration.
The type of the library or configuration (jar, war, ear, rar, etc.). If omitted, defaults to jar. Note that many of the components shipped with Geronimo use a type of car (for Configuration ARchive), since the Geronimo server is built from a number of separate configurations.
Here are some sample imports and dependencies.
Example 12.1. EJB: Imports and Dependencies
Assume the repository has a file repository/postgresql/jars/postgresql-8.0-314.jdbc3.jar, and the server has a JMS configuration called MessagingResources. An EJB JAR could refer to them like this:
<import><uri>MessagingResources</uri></import> <dependency> <uri>postgresql/postgresql-8.0/314.jdbc3/jar</uri> </dependency>
It's also possible to refer to the dependency using the split-up syntax, but the import cannot use that syntax because the module that's being imported did not use that syntax in its configId. That would look like this:
<import><uri>MessagingResources</uri></import> <dependency> <groupId>postgresql</groupId> <artifactId>postgresql-8.0</artifactId> <version>314.jdbc3</version> </dependency>
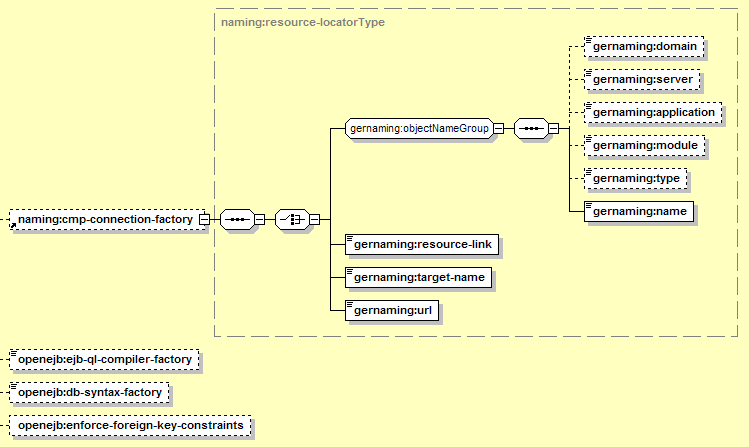
These settings are common to all CMP Entity Beans in this EJB JAR:
The elements here are:
Specifies a JDBC connection pool that should be used by CMP entity beans to connect to the database. There are several styles available to refer to the connection pool, detailed below.
The name of a class that knows how to translate EJB-QL queries into SQL statements for a particular database product. This must be the fully-qualified class name of a class that implements org.tranql.sql.EJBQLCompilerFactory. The default is for the Derby database, though this may work for other database products too.
The name of a class that knows how to customize CMP SQL statements for a particular database product. This must be the fully-qualified class name of a class that implements org.tranql.sql.DBSyntaxFactory. The default is for the Derby database, though this may work for other database products too.
This is effectively a true/false element -- if it's present that means true, and if it's not present, that means false. If true, then Geronimo will make a special effort to execute insert, update, and delete statements in an order consistent with the foreign keys between tables. If false, then Geronimo will execute statements in any order, though still within the same transaction. This element should be present if the underlying database enforces foreign keys at the moment a statement is executed instead of at the end of a transaction.
The cmp-connection-factory element points to a database pool using the same syntax a resource reference uses. There are several ways to identify the database pool. One is to specify the component by a simple name (resource-link), while the other is to use a more complex ObjectName (target-name, or the individual components in the objectNameGroup). The resource-link handles most common resource situations (JDBC pools deployed as J2EE connectors in the same application or deployed standalone in the same server) while the target-name or objectNameGroup can be used for any resource. This might be important if, for example, two resource adapter deployments use the same name for their connection factory, so the resource-link does not uniquely identify one and it must be fully-qualified (though usually its better to avoid this type of naming conflict).
Refers to a database pool deployed in Geronimo using the syntax described in Section 12.3.6.1, “Common Resource Mapping Elements”. The type should be set to JCAManagedConnectionFactory and the name should match the value of the connectiondefinition-instance/name element in the Geronimo deployment plan for the connection pool (or the name selected for the resource when deploying it through the console).
A shortcut to identify a connection pool. This only works if there aren't multiple connection pools with the same name deployed in the server (but that's usually a safe assumption). The value specified here should match the connectiondefinition-instance/name element in the Geronimo deployment plan for the connection pool (or the name selected for the resource when deploying it through the console).
A way to specify any type of resource running in the server. This should be a full JMX ObjectName identifying the resource, such as geronimo.server:J2EEServer=geronimo,J2EEApplication=null, JCAResource=my-db-pool,j2eeType=JCAManagedConnectionFactory,name=MyDatasource
This element is not applicable to connection pools.
A sample CMP configuration might look like this:
Example 12.2. EJB: Basic CMP Configuration
The following configuration selects a database connection pool called PostgreSQLDataSource and enables SQL processing based on foreign keys:
<cmp-connection-factory> <resource-link>PostgreSQLDataSource</resource-link> </cmp-connection-factory> <enforce-foreign-key-constraints />
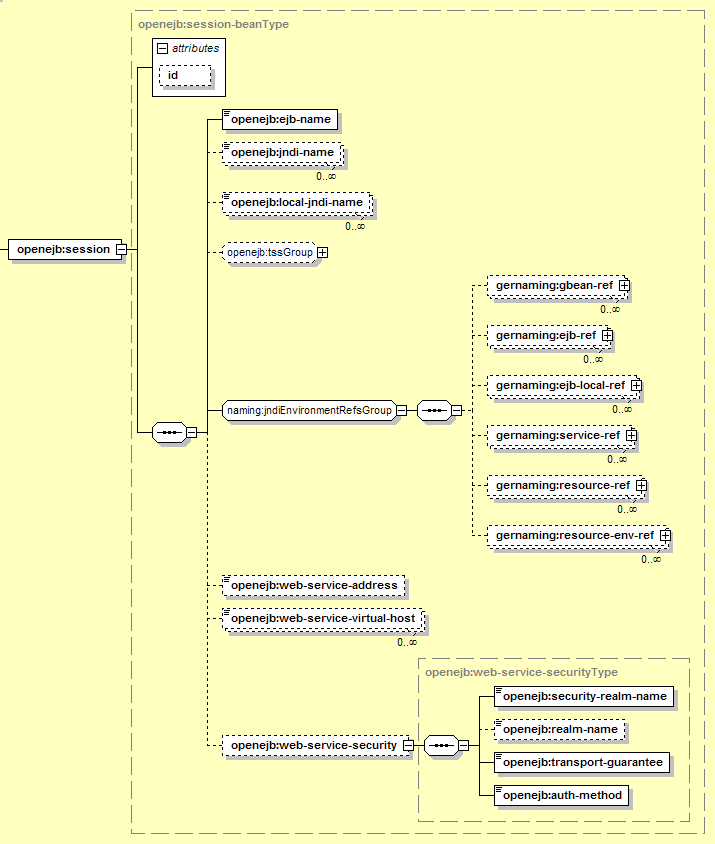
Session Beans settings can include JNDI names used by remote clients, CORBA configuration, resolving references, and web services. The configuration outline for session beans looks like this:
The elements used here are:
Identifies the EJB that these settings apply to. This should match the ejb-name for the EJB in ejb-jar.xml.
The Home interface for the EJB is registered in JNDI at the address specified here. This global JNDI name is used by application clients to connect to this EJB, as well as by CORBA clients if this EJB is exposed via CORBA. It is only meaningful if the EJB has a (remote) Home interface.
The LocalHome interface for the EJB is registered in JNDI at the address specified here. It is only meaningful if the EJB has a LocalHome interface. Note that the official Geronimo distributions do not allow access to local EJBs via JNDI (making this setting irrelevant), but a custom Geronimo build may.
This is a set of elements that contains CORBA security settings, for EJBs exposed as CORBA objects. It is not necessary if the EJB will not be accessed via CORBA. The elements in this group are described in Section 12.3.3.2, “Session Bean CORBA Security Settings”.
A set of elements that handle resolving references declared by the current Session bean (including EJB references, Resource references, and Web Service references). Since this group is common to all EJB types, the contents are described in detail in Section 12.3.6, “Resolving References from EJBs”.
There are a few additional settings that are pertinent only to session beans exposed as web services:
Typically when a session beans is exposed as a web service, the WSDL for the service indicates the URL where the web service can be reached. The value specified in this element can be used to override the path to the web service included in the WSDL (that is, the part of the URL after the host and port).
If the web service should only listen on one or more virtual hosts (as opposed to the default listen address configured for the web container), the virtual host names should be listed using this element.
This section holds security settings for a web service, including authentication and SSL encryption.
If the web service is secured, this indicates what Geronimo security realm should be used to authenticate connection attempts. Any users in that realm will be considered valid users of the web service.
For HTTP Basic authentication, this is the realm name used in the authentication challenge. If the web service does not use HTTP Basic authentication, then this element is not necessary.
Indicates whether SSL is required to connect to this web service. The possible values are NONE (no SSL required), INTEGRAL (it must not be possible to alter the data en route, meaning SSL is required), or CONFIDENTIAL (it must not be possible to observe the data en route, meaning SSL is required). If no web-service-security element is present, the default is NONE.
Indicates what type of authentication should be used for secure web services. The possible values are BASIC (HTTP Basic authentication), DIGEST, CLIENT-CERT, and NONE
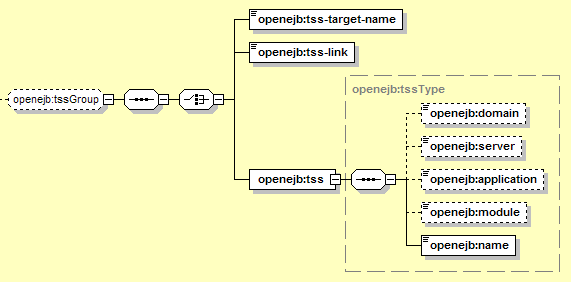
The following settings are used for session beans that should be accessible via CORBA (for more detail, see Chapter 17, CORBA in Geronimo [DRAFT (1.0)]). They identify a Target Security Service (TSS) that applies to this EJB. The TSS includes settings such as whether SSL should be required for the connection.
![[Note]](images/note.png) | Note |
|---|---|
Every EJB exposed via CORBA must have a jndi-name declared, as that is also the name that the EJB is registered under with the CORBA naming service. | |
The Target Security Service is deployed separately, either at the top level of the server, or as a module-scoped service (using the elements described in Section 12.3.9, “Module-Scoped Services”, for example). The elements here reference that separate TSS, similar to the way a resource reference identifies a resource elsewhere in the server (described in Section 12.3.6.4, “Resource References”). That allows several EJBs to refer to the same TSS configuration. There are three ways to refer to a TSS: using the tss-target-name, the tss-link, or the components of the tss element. The tss-link is the easiest to use of the three, assuming that all TSSs deployed in the server use unique names.
The name of the desired TSS. This is used to identify the correct TSS, searching first the current application and then top-level deployments in the server for a TSS with the specified name. This name corresponds to the name= component of the full TSS GBean name. The TSS names available in the geronimo/j2ee-corba/1.0/car configuration that ships with Geronimo are SSLClientCert, SSLClientPassword, SSLIdentityToken, IdentityTokenNoSecurity, and SSLClientCertIdentityToken, though new TSS GBeans can also be deployed and referenced here.
A full GBean Name, containing all that information required identify the TSS. This may even be used to map to a TSS in a different application. It would typically look like: geronimo.server:J2EEApplication=null,J2EEModule=CorbaConfiguration, J2EEServer=geronimo,j2eeType=CORBATSS,name=TSSName
This element holds all the individual components of a GBean name required to identify the desired TSS. The effect is similar to providing an explicit GBean name using the tss-name element, but here the individual components are provided instead. The only exception is the j2eeType component, which in this case is always set to CORBATSS.
The domain name portion of the GBean Name identifying the TSS to map to. This should usually be geronimo.server, and if not specified, it defaults to the domain of the JSR-77 J2EEServer that was configured for the deployer GBean that's deploying the current module -- which is going to be geronimo.server unless you have substantially altered your default configuration.
The J2EE Server portion of the GBean Name identifying the EJB to map to. This should usually be geronimo, and if not specified, it defaults to the name of the JSR-77 J2EEServer that was configured for the deployer GBean that's deploying the current module -- which is going to be geronimo unless you have substantially altered your default configuration.
The name of the application that the target EJB is in. If the EJB JAR was deployed standalone, this would be null. If it was deployed as part of an EAR, this should be the application-name specified for the EAR, or the configId if no application-name was specified.
The configId of the module that the target TSS is in. For server-level TSS references, this is specified in the header of the deployment plan used to deploy the TSS.
The name of the TSS. The name of a TSS is specified in the TSS GBean definition.
This is an example of a complete session bean configuration block:
Example 12.3. EJB: Session Bean Configuration Example
This example binds a session bean to JNDI for clients to access, resolves an EJB reference to an entity bean, and configures how the session bean is exposed as a Web Service.
<session>
<!-- Basic settings -->
<ejb-name>PersonManager</ejb-name>
<jndi-name>ejb/PersonManager</jndi-name>
<!-- Resolve references -->
<ejb-ref>
<ref-name>ejb/Person</ref-name>
<ejb-link>Person</ejb-link>
</ejb-ref>
<!-- Session Bean exposed as Web Service -->
<web-service-address>/services/Person</web-service-address>
<web-service-virtual-host>
services.company.com
</web-service-virtual-host>
<web-service-security>
<security-realm-name>
service-security-realm
</security-realm-name>
<realm-name>PersonService</realm-name>
<transport-guarantee>CONFIDENTIAL</transport-guarantee>
<auth-method>BASIC</auth-method>
</web-service-security>
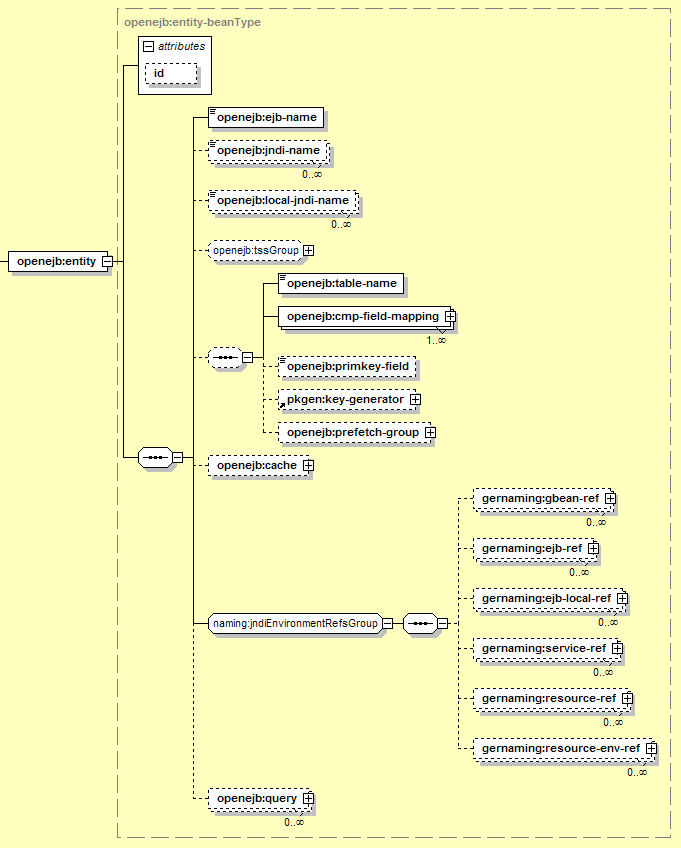
</session>Entity Beans settings can include JNDI names used by remote clients, CORBA configuration, CMP settings, and resolving references. The configuration outline for entity beans looks like this:
The basic elements used here are:
Identifies the EJB that these settings apply to. This should match the ejb-name for the EJB in ejb-jar.xml.
The Home interface for the EJB is registered in JNDI at the address specified here. This global JNDI name is used by application clients to connect to this EJB, as well as by CORBA clients if the EJB is exposed via CORBA. It is only meaningful if the EJB has a (remote) Home interface.
The LocalHome interface for the EJB is registered in JNDI at the address specified here. It is only meaningful if the EJB has a LocalHome interface. Note that the official Geronimo distributions do not allow access to local EJBs via JNDI (making this setting irrelevant), but a custom Geronimo build may.
This is a set of elements that contains CORBA security settings, for EJBs exposed as CORBA objects. It is not necessary if the EJB will not be accessed via CORBA. The elements in this group are described in Section 12.3.4.1, “Entity Bean CORBA Settings”.
A set of elements that handle resolving references declared by the current Session bean (including EJB references, Resource references, and Web Service references). Since this group is common to all EJB types, the contents are described in detail in Section 12.3.6, “Resolving References from EJBs”.
The remaining elements are described in the following sections.
The following settings are used for entity beans that should be accessible via CORBA (for more detail, see Chapter 17, CORBA in Geronimo [DRAFT (1.0)]). They identify a Target Security Service (TSS) that applies for CORBA connections targeting this EJB. The TSS includes settings such as whether SSL should be required for the connection.
| Note |
|---|---|
Every EJB exposed via CORBA must have a jndi-name declared, as that is also the name that the EJB is registered under with the CORBA naming service. | |
The Target Security Service is deployed separately, either at the top level of the server, or as a module-scoped service (using the elements described in Section 12.3.9, “Module-Scoped Services”, for example). The elements here reference that separate TSS, similar to the way a resource reference identifies a resource elsewhere in the server (described in Section 12.3.6.4, “Resource References”). That allows several EJBs to refer to the same TSS configuration. There are three ways to refer to a TSS: using the tss-target-name, the tss-link, or the components of the tss element. The tss-link is the easiest to use of the three, assuming that all TSSs deployed in the server use unique names.
The name of the desired TSS. This is used to identify the correct TSS, searching first the current application and then top-level deployments in the server for a TSS with the specified name. This name corresponds to the name= component of the full TSS GBean name. The TSS names available in the geronimo/j2ee-corba/1.0/car configuration that ships with Geronimo are SSLClientCert, SSLClientPassword, SSLIdentityToken, IdentityTokenNoSecurity, and SSLClientCertIdentityToken, though new TSS GBeans can also be deployed and referenced here.
A full GBean Name, containing all that information required identify the TSS. This may even be used to map to a TSS in a different application. It would typically look like: geronimo.server:J2EEApplication=null,J2EEModule=CorbaConfiguration, J2EEServer=geronimo,j2eeType=CORBATSS,name=TSSName
This element holds all the individual components of a GBean name required to identify the desired TSS. The effect is similar to providing an explicit GBean name using the tss-name element, but here the individual components are provided instead. The only exception is the j2eeType component, which in this case is always set to CORBATSS.
The domain name portion of the GBean Name identifying the TSS to map to. This should usually be geronimo.server, and if not specified, it defaults to the domain of the JSR-77 J2EEServer that was configured for the deployer GBean that's deploying the current module -- which is going to be geronimo.server unless you have substantially altered your default configuration.
The J2EE Server portion of the GBean Name identifying the EJB to map to. This should usually be geronimo, and if not specified, it defaults to the name of the JSR-77 J2EEServer that was configured for the deployer GBean that's deploying the current module -- which is going to be geronimo unless you have substantially altered your default configuration.
The name of the application that the target EJB is in. If the EJB JAR was deployed standalone, this would be null. If it was deployed as part of an EAR, this should be the application-name specified for the EAR, or the configId if no application-name was specified.
The configId of the module that the target TSS is in. For server-level TSS references, this is specified in the header of the deployment plan used to deploy the TSS.
The name of the TSS. The name of a TSS is specified in the TSS GBean definition.
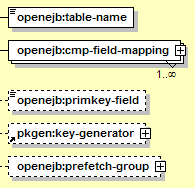
The elements used for CMP entity beans are:
These elements are:
Identifies the table that this EJB maps to. Each EJB can be mapped to only one table.
This element must appear once for each CMP field, to map it to a database column. See Section 12.3.4.2.1, “CMP Field Mapping”.
If the entity bean uses an unknown primary key type, this field can be used to indicate which CMP field stores the actual primary key. The value here should match the cmp-field-name value in the cmp-field-mapping block for that field.
This feature can be used to automatically generate primary key IDs for new entities. This typically uses an underlying database feature such as a Sequence, AUTO_INCREMENT column, or trigger. See Section 12.3.4.2.2, “Automatic Primary Key Generators”.
Holds all the settings related to prefetch groups for this entity bean. Prefetch groups control which columns or relationships are loaded for the entity when it is initially accessed (see Section 12.3.4.2.3, “Prefetch Groups”).
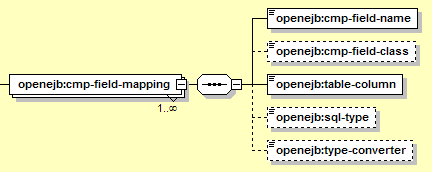
The elements used for CMP field mapping look like this:
The elements shown here are:
This element must appear once for each CMP field. The child elements map the CMP field to a column in the table named in the table-name element above.
Identifies the field that this configuration block applies to. This must match the cmp-field/field-name in ejb-jar.xml.
The fully-qualified class name for the Java type of this CMP field. Normally this is not necessary as it's defined by the EJB implementation. However it is necessary for the primary key field(s) of Entities with an unknown primary key type (if new CMP fields need to be defined in order to support the "actual" primary key values). Note that the use of unknown primary key types is quite rare.
The column in the table above that this CMP field maps to.
The name of the java.sql.Types constant that identifies the SQL data type to use for this field. Generally, the defaults are sufficient. However, it may be necessary to override this manually to enforce custom mappings. For example, if a CHAR(1) type column with Y/N values is mapped to a boolean Java property, the default mapping would assume that the database stores a BOOLEAN, but this element could be used to force a mapping to type CHAR instead.
Generally Geronimo is able to map Java types to SQL types and vice versa. However, a custom type converter can be used if special conversion logic is required (for example, to handle BLOBs, to map a boolean to Y or N in the example above, or to map a Java type of InetAddress to a database type of VARCHAR). This converter should implement org.tranql.sql.TypeConverter.
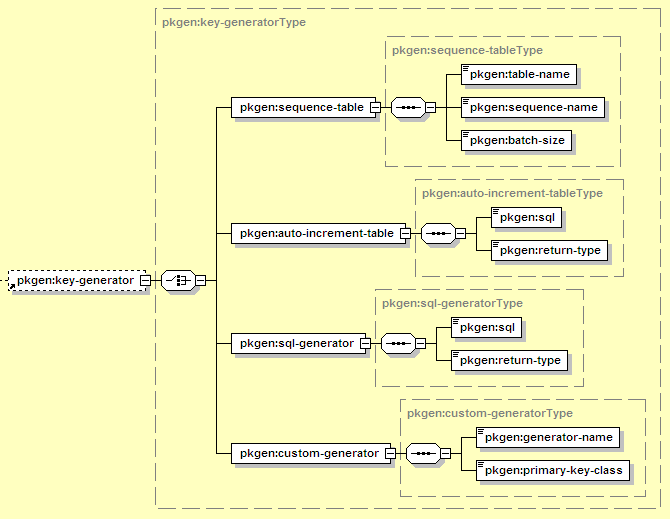
Automatic primary key generation means that EJB developers are not responsible for providing primary key values when new entities of this type are created. Usually the database provides primary key values, though Geronimo can calculate them and keep track of them in an extra database table as well. The standard configuration includes three automatic key generator options, but custom implementations of org.tranql.pkgenerator.PrimaryKeyGenerator may also be used. The configuration syntax looks like this:
The elements introduced here are:
Holds the elements describing the primary key generation strategy for this entity bean. This element should only be present if the entity uses automatic key generation, and one of its child elements must be present.
Uses a separate table that maintains the next ID to use for the EJB. This can be used for databases that do not support any other mechanism of automatically generating primary keys, or for additional portability across database products that may use different generation strategies. It requires a table with columns name (VARCHAR) and value (a numeric type such as INTEGER). With this structure, one such table can hold several sequences, each identified by a unique name.
The name of the database table that stores the sequence rows. It should have two columns, name and value, as described above.
The name used for the row in the sequence table that represents this entity bean. A row should be present in the table with this name, and the value set to whatever the first generated key value should be (e.g. name=MyEntity, value=10).
The number of IDs that should be collected every time Geronimo checks the sequence table in the database. Setting this number higher than 1 may improve performance by reducing visits to the sequence table. However, it may cause entities to receive non-contiguous IDs (for example, if the server fetches a block of 10 IDs, gives out 3 of them to new entity instances, and then is restarted and begins later with a new block of 10 IDs).
Assumes that the table the EJB is mapped to will automatically generate IDs and populate the primary key fields. This would be used for a situation like a MySQL table using the AUTO_INCREMENT flag on its primary key field, a table with a trigger to populate primary keys, etc.
For an auto-increment-table, this is a SQL INSERT statement used to add a new row to the table. Without auto-increment enabled, the server calculates what SQL to use, but in this case you need to specify it manually (this requirement may be removed in a future release). For a sql-generator, this is a SQL SELECT statement that returns the ID to use for the next entity. It should return a result set with one row and one column (the next ID).
Indicates the fully-qualified Java type that should be used for the returned primary key value. This will be used to determine how to extract the ID from the result set that returned it. In many cases, this should be set to java.lang.Integer.
Uses a provided SQL statement to generate the next ID. This might be used to pull the next ID from an Oracle, PostgreSQL, or Axion sequence, for example.
If none of the key generators above fits, a custom key generator class may be provided. It should be deployed separately as a GBean (possibly at the top level of the server, but more likely in the gbean section of this file -- see Section 12.3.9, “Module-Scoped Services”). That GBean should implement the org.tranql.pkgenerator.PrimaryKeyGenerator interface.
The full GBean name of the custom primary key generator GBean.
Indicates the fully-qualified Java type that should be used for the returned primary key value. In many cases, this should be set to java.lang.Integer, though it depends on the values produced by the custom primary key generator.
A prefetch group controls which CMP fields and/or CMR relationships are loaded together. For example, one finder may preload only the values necessary to display basic information about an entity, whereas another finder may preload both entity data and the list of related entity beans for a container-managed relationship.
This has two main effects:
Normally, when a finder is executed or a CMR field is accessed, the primary keys of all matching entities are loaded, but no actual entity data is loaded. As each element in the resulting collection is accessed, all the data for that entity is loaded. This results in 1 SQL query to load the IDs and 1 SQL query for each entity accessed. If a prefetch group is used, all the data in the prefetch group is loaded when the finder or CMR query is executed, which means if that includes the fields that will subsequently be accessed, no additional SQL queries are required (1 SQL total vs. 1 plus 1 per entity). However, if the query returns a large number of rows and only a small subset will actually be accessed, the volume of data brought back by the initial query may result in worse performance than a number of collectively smaller queries.
Normally when an entity is loaded, only the data for that entity is loaded. As CMR fields are accessed, related EJBs are loaded in the manner described above (starting with PKs, etc.). Geronimo has the ability to include CMR fields in prefetch groups, and name prefetch groups for the related entities, and so on. The result is that loading a single entity may result in the loading of a tree of related entities, all in a single SQL query. Again, this may substantially improve performance if all the related entities are about to be accessed anyway. However, it may significantly reduce performance if this results in the loading of a very large number of entities, only a few of which will actually be accessed.
The bottom line is that prefetch groups may significantly improve performance, but they must be carefully configured based on the patterns of access for the application. It may be best to start by limiting prefetch groups to special-purpose finders where the usage scenarios are well-known and a relatively large number of entities are going to be loaded.
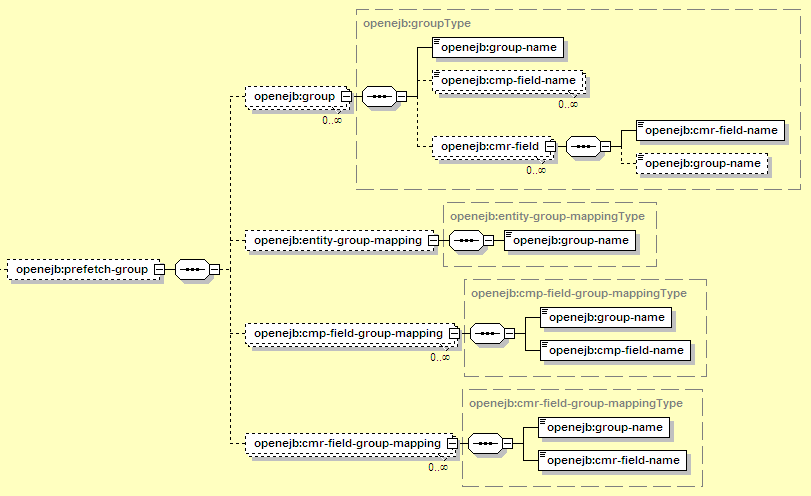
The prefetch configuration block looks like this:
The elements introduced here are:
Holds all the settings related to prefetch groups for this entity bean -- both defining the groups, and to some extent indicating when they should be used.
Defines a prefetch group, with a name, and a list of CMP fields and CMR fields to include in the group
When used in the group element, defines a name for that group. When used elsewhere, refers to a specific group by name.
Identifies a CMP field for this entity bean. This should match the cmp-field/field-name in the ejb-jar.xml file.
Indicates that the prefetch group includes a container-managed relationship (identified by the CMR field that the entity uses to navigate to it). In addition, the group may specify a nested group-name for the entity on the other side of the relationship. This means that when the current prefetch group is loaded, all the related beans should be loaded, and if the group-name is provided, those fields for that entity will be loaded too. If that group-name identifies a group that itself includes cmr-field elements, this may result in several levels of related entities all being loaded at the same time. Note this may actually reduce performance if too many entities are loaded together (and they won't all be accessed).
Identifies a specific CMR field. This should match the cmr-field/cmr-field-name in the ejb-jar.xml file. In the case of a group element, this indicates that the relationship navigated by this CMR field should be included in the group. In the case of a cmr-field-group-mapping, this means the named group should be loaded when this field is accessed.
The default group to load when a CMP or CMR field is accessed and that field has not already been loaded and no other group mapping applies.
For a specific CMP field, indicates which group to load when that CMP field is accessed for the first time and it's not already available (as a result of some different group being loaded). The group must contain the CMP field in question.
For a specific CMR field, indicates which group to load when that CMR field is accessed for the first time and it's not already available (as a result of some different group being loaded). The group must contain the CMR field in question.
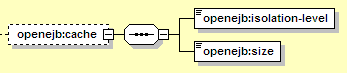
The cache element is used to configure a data cache for CMP entity beans, which means certain database data may be kept in memory and reused to limit the number of database round trips required. This is not the same as an entity bean cache that holds actual entity beans in memory -- it only serves as a local cache for the underlying database data.
The elements here are:
Groups the cache settings for the current entity bean
Controls the data caching strategy. May be set to one of read-uncommitted, read-committed, or repeatable-read. Read uncommitted means that all transactions share the same cache state. Read committed means that any transaction only sees its own changes, or those that have been committed by another transaction. Repeatable read means that each transaction sees each cache entry exactly as it was when the transaction began, no matter what other transactions might do in the mean time.
The number of database rows that the cache should hold. The most recently used instances are kept in the cache, and when the size is exceeded, the least recently used instances are flushed. A large operation that accesses more instances that will fit in the cache may fully cycle through the cache multiple times, making the cache less effective. Note that the cache size applies to the cache as a whole, not the number of records cached for a particular transaction.
![[Tip]](images/tip.png) | Tip |
|---|---|
If no cache element is provided for an EJB, caching is not used. That typically increases the amount of database traffic, but avoids any overhead that might be caused by the cache logic, and is generally safer if other applications may be updating the database at the same time as Geronimo. A cache is most beneficial if the same data may be accessed multiple times within a single transaction, so that the cached data can be used instead of repeated database calls. | |
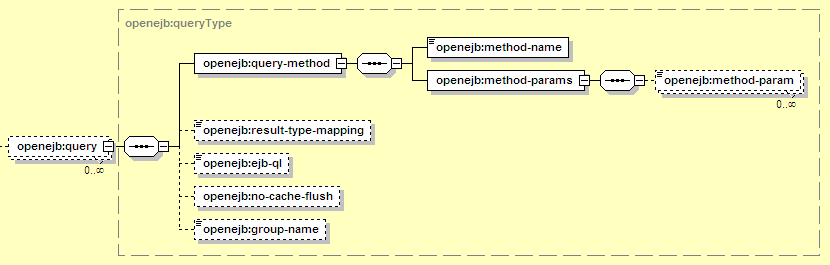
The elements used to customize CMP Queries (including finders and selectors) are:
The elements introduced here are:
Holds all the custom settings for a single query.
The elements in this block identify the query that this configuration applies to. It must match the same query identification in ejb-jar.xml.
The name of the finder or selector method.
Holds a list of method argument types. The order of the entries is important (it must match the order of arguments to the method). Together, the method name and parameter list uniquely identify the query method. If the method takes no parameters, then the method-params element should be present but empty.
The fully-qualified Java class name of a single argument to the method. Note that method arguments are identified by their type, not by their name.
This value overrides the same value specified in ejb-jar.xml for this query.
This is used for EJB 1.1 entity beans that did not have a standard query syntax. It provides no advantage over the same setting in ejb-jar.xml for EJB 2.x entity beans.
Normally, if a finder is about to be executed, the CMP engine executes any pending changes against the database. That way, if you alter an EJB in such a way that it would affect the query results, then execute the finder later in the same transaction, the finder will see the earlier changes. If this element is present, the cache flush will step will not be performed before this query is executed, which will improve performance, but will cause finders to miss any updates contained only in the cache. This is normally not recommended, as the resulting behavior may be unpredictable (depending on whether there's enough data to cause a cache flush, etc.), but it can be used if you know that no earlier work can affect the results of the query.
Indicates that when this query is executed, the named prefetch group should be applied to all the results. In other words, instead of initially loading just the primary key IDs for the results, a group of CMP and CMR fields for the entity should be loaded as well. This often cuts down on the total number of queries executed, at the expense of each one returning substantially more data. Whether this is a good idea depends on how many of the query results will actually be accessed by the application. For more on prefetch groups, see Section 12.3.4.2.3, “Prefetch Groups”.
This is an example of a complete entity bean configuration for a BMP entity bean:
Example 12.4. EJB: BMP Entity Bean Configuration Example
The excerpt below binds a BMP entity bean to JNDI for clients to access. If the entity bean is not going to be accessed by remote clients, this entity bean could be omitted from the Geronimo plan altogether!
<entity> <ejb-name>LDAPAccount</ejb-name> <jndi-name>ejb/LDAPAccount</jndi-name> </entity>
This is an example of a complete entity bean configuration for a CMP entity bean:
Example 12.5. EJB: CMP Entity Bean Configuration Example
The except below configures the CMP settings for the entity bean, including database mapping, an automatic primary key generator, prefetch groups and a query that uses one of the prefetch groups, and a cache.
<entity>
<ejb-name>Person</ejb-name>
<table-name>person</table-name>
<cmp-field-mapping>
<cmp-field-name>id</cmp-field-name>
<table-column>id</table-column>
</cmp-field-mapping>
<cmp-field-mapping>
<cmp-field-name>username</cmp-field-name>
<table-column>username</table-column>
</cmp-field-mapping>
<cmp-field-mapping>
<cmp-field-name>firstName</cmp-field-name>
<table-column>first_name</table-column>
</cmp-field-mapping>
<cmp-field-mapping>
<cmp-field-name>lastName</cmp-field-name>
<table-column>last_name</table-column>
</cmp-field-mapping>
<key-generator>
<sql-generator>
<sql>select nextval('person_seq')</sql>
<return-type>java.lang.Integer</return-type>
</sql-generator>
</key-generator>
<prefetch-group>
<group>
<group-name>Default</group-name>
<!-- All CMP fields, no CMR fields -->
<cmp-field-name>id</cmp-field-name>
<cmp-field-name>username</cmp-field-name>
<cmp-field-name>first_name</cmp-field-name>
<cmp-field-name>last_name</cmp-field-name>
</group>
<group>
<group-name>All</group-name>
<!-- All CMP and CMR fields -->
<cmp-field-name>id</cmp-field-name>
<cmp-field-name>username</cmp-field-name>
<cmp-field-name>first_name</cmp-field-name>
<cmp-field-name>last_name</cmp-field-name>
<!-- When this group is loaded, load the related addresses,
including whatever's in the "All" group for that EJB -->
<cmr-field>
<cmr-field-name>addresses</cmr-field-name>
<group-name>Default</group-name>
</cmr-field>
</group>
<entity-group-mapping>All</entity-group-mapping>
</prefetch-group>
<cache>
<isolation-level>read-committed</isolation-level>
<size>100</size>
</cache>
<query>
<!-- For this method, load the "All" prefetch group -->
<query-method>
<method-name>findByUsername</method-name>
<method-params>
<method-param>java.lang.String</method-param>
</method-params>
</query-method>
<group-name>All</group-name>
</query>
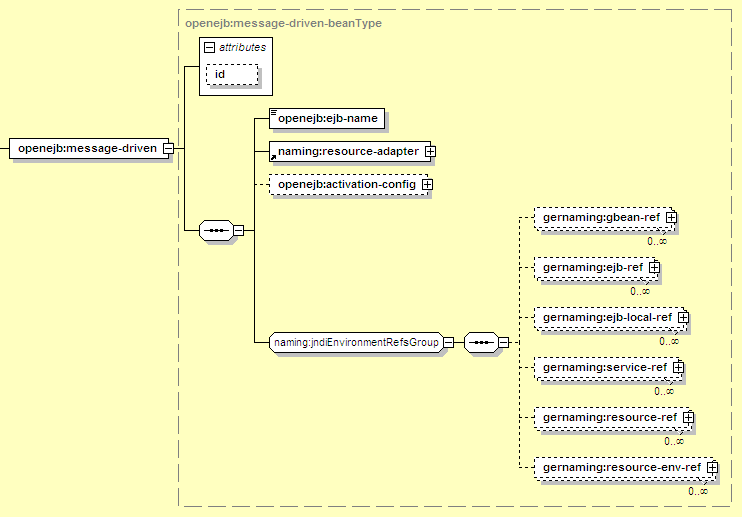
</entity>Message-driven bean settings include mapping the MDB to a specific message destination (usually a JMS Topic or Queue), as well as resolving references to other EJBs, resources, or web services.
The key elements here are:
Identifies the EJB that these settings apply to. This should match the ejb-name for the EJB in ejb-jar.xml.
Identifies the resource adapter instance that this MDB should use to connect to its destination. For example, a specific ActiveMQ broker may have several resource adapter instances set up, with different authentication settings, and this identifies the specific instance to use. For more detail, see Section 12.3.5.1, “Resource Adapter Settings”.
Holds any configuration data (in the form of name/value pairs) required by the resource adapter in order to supply messages to the MDB. For more detail, see Section 12.3.5.2, “Identifying a Messaging Destination”.
A set of elements that handle resolving references declared for the current message-driven bean (including EJB references, Resource references, and Web Service references). Since this group is common to all EJB types, the contents are described in detail in Section 12.3.6, “Resolving References from EJBs”.
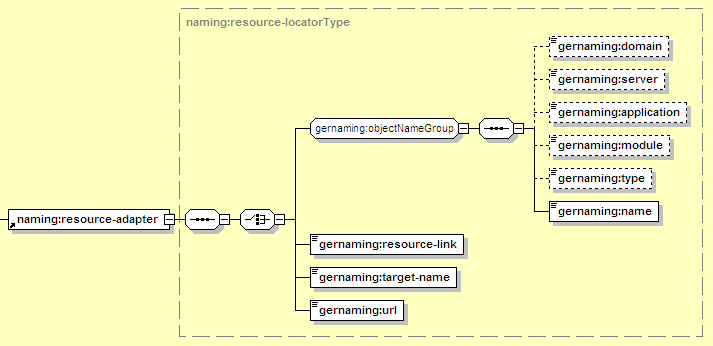
The resource-adapter element identifies the resource adapter that this message-driven bean connects to. This is typically a JMS server, meaning ActiveMQ for the default Geronimo JMS provider.
There are several ways to identify the resource adapter. One is to specify the component by a simple name (resource-link), while the other is to use a more complex GBean Name (target-name, or the individual components in the objectNameGroup). The resource-link handles most common resource situations (a JMS resource adapter deployed as part of the same EAR or in the top level of the server) while the target-name or objectNameGroup can be used for any resource. This might be important if, for example, two resource adapter deployments use the same name, so the resource-link does not uniquely identify one and it must be fully-qualified.
Refers to the resource adapter deployed in Geronimo using the syntax described in Section 12.3.6.1, “Common Resource Mapping Elements”. Note that the type should be set to JCAResourceAdapter and the name should match the resourceadapter-name specified for the resource adapter instance in its Geronimo deployment plan.
Can be used to identify any resource adapter in the same EAR or at the top level in the server. The value specified here should match the resourceadapter-name specified for the resource adapter instance in its Geronimo deployment plan.
A way to specify any resource adapter running in the server. This should be a GBean Name identifying the resource, such as geronimo.server:J2EEServer=geronimo,J2EEApplication=null, JCAResource=MyJMS,j2eeType=JCAResourceAdapter,name=JMS_RA
Not applicable here.
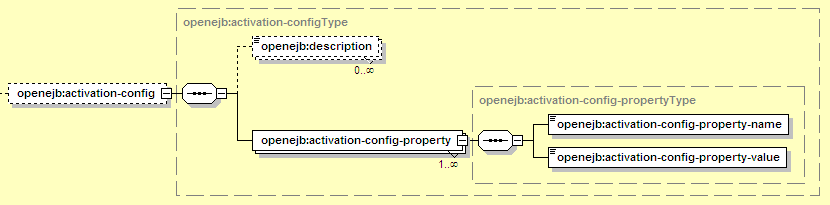
The activation-config element provides the configuration necessary for the resource adapter to deliver messages to the MDB. For the normal case of JMS, this typically selects the JMS destination (Queue or Topic) that the MDB should receive messages from.
The elements here are:
Holds a single configuration property (name and value in child elements).
Identifies the specific property that is being configured here.
The value to set for the current configuration property. This must make sense based on the data type of the property (which is actually controlled by a Java Bean implementing ActivationSpec, but the messaging provider should provide a list of properties and their corresponding data types).
| Tip |
|---|---|
Each resource adapter uses its own ActivationSpec class, and therefore its own list of activation-config properties. The values for the default ActiveMQ provider are listed below. For other JMS or inbound messaging providers, the list of available config properties will be different. | |
The following activation-config properties are available for Message-Driven Beans connected to ActiveMQ JMS destinations:
Table 12.1. ActiveMQ Activation Config Properties
| Property Name | Data Type | Required | Description |
|---|---|---|---|
| destination | String | Yes | The name of the Topic or Queue that the MDB should be connected to. This should match the physical name of the underlying ActiveMQ destination (it does not need to match the name of any configured admin objects). This overrides any message-destination-link specified for the MDB in ejb-jar.xml. |
| destinationType | String | Yes | javax.jms.Topic or javax.jms.Queue. This overrides any message-destination-type specified for the MDB in ejb-jar.xml. |
| userName | String | The username that should be used to connect to the ActiveMQ broker. | |
| password | String | The password that should be used to connect to the ActiveMQ broker. | |
| messageSelector | String | The message selector used to identify a specific subset of messages that this MDB should receive. This uses standard JMS message selector syntax (for example, color='red' and value>20) | |
| noLocal | boolean | Used for and MDB that subscribes to the same topic it receives. If set to true, then messages published by the MDB will not be delivered to the same MDB. (This may break down in a cluster where copies of the same MDB on other cluster nodes may still receive the message.) | |
| acknowledgeMode | String | How messages should be acknowledged. Possible values are Auto-acknowledge (the default) and Dups-ok-acknowledge. | |
| clientId | String | A unique identifier for a client, used to identify the durable connection state associated with the client. This should be set to a unique value for each MDB that uses a durable subscription. | |
| subscriptionDurability | String | Whether subscriptions should be durable. Possible values are Durable and NonDurable (the default). | |
| subscriptionName | String | Identifies the client's subscription to the destination in question. This should be set to a unique value for each MDB that uses a durable subscription. | |
| maxSessions | Integer | Limits the number of threads used to deliver messages to the MDB (or equivalently, the number of JMS Sessions used for the MDB). | |
| maxMessagesPerSessions | Integer | Not currently used (though the intent is to limit pre-fetching of messages on behalf of the client). |
This is an example of a complete message-driven bean configuration block:
Example 12.6. EJB: Message-Driven Configuration Example
This excerpt configures the resource adapter and destination for a message-driven bean, as well as a database resource reference.
<message-driven>
<ejb-name>EventReceiver</ejb-name>
<resource-adapter>
<resource-link>ActiveMQ RA</resource-link>
</resource-adapter>
<activation-config>
<activation-config-property>
<activation-config-property-name>
destination
</activation-config-property-name>
<activation-config-property-value>
EventQueue
</activation-config-property-value>
<activation-config-property-name>
destinationType
</activation-config-property-name>
<activation-config-property-value>
javax.jms.Queue
</activation-config-property-value>
</activation-config-property>
</activation-config>
<resource-ref>
<ref-name>jdbc/DatabasePool</ref-name>
<resource-link>PostgreSQLDataSource</resource-link>
</resource-ref>
</message-driven> | Note |
|---|---|
A message-driven bean independently selects the resource adapter and the JMS destination (or other message source) that it should connect to. That means it's possible to select Resource Adapter A as the target RA, and then a destination deployed with Resource Adapter B as the target destination. This may or may not make sense. In the case of ActiveMQ, this works as expected if both resource adapter deployments point to the same ActiveMQ broker (otherwise, it will create the destination named from Resource Adapter B in the broker referred to by Resource Adapter A, which is probably not the desired result). But some other resource adapters may not support selecting a destination that was not deployed in conjunction with the same resource adapter. | |
EJBs can declare references to other EJBs (via either local or remote interfaces), to resources of various types (such as database pools or JMS connection factories), to message destinations, and to web services. In most cases, the references are declared in the ejb-jar.xml deployment descriptor, and those references are resolved to specific targets in the Geronimo openejb-jar.xml deployment plan.
The following sections describe how the various types of references are resolved. These are applicable to all EJB types (Session, Entity, and Message-Driven) -- they can all declare references of any of these types.
| Note |
|---|---|
The schema includes a placeholder element (gbean-ref) for GBean references (that is, putting a reference to an arbitrary GBean in the component's java:comp/env JNDI space), but that is not yet working in Geronimo 1.0 so it is not covered here. | |
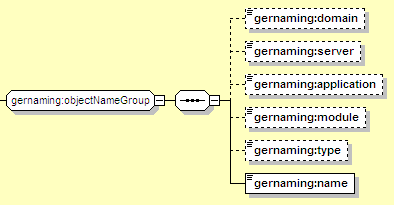
All of the resource types use common elements to refer to components (GBeans) running elsewhere in the server. These elements are known as the objectNameGroup, and look like this:
The elements introduced here are:
The domain name portion of the GBean Name identifying the EJB or resource to map to. This should usually be geronimo.server, and if not specified, it defaults to the domain of the JSR-77 J2EEServer that was configured for the deployer GBean that's deploying the current module -- which is going to be geronimo.server unless you have substantially altered your default configuration.
The J2EE Server portion of the GBean Name identifying the EJB or resource to map to. This should usually be geronimo, and if not specified, it defaults to the name of the JSR-77 J2EEServer that was configured for the deployer GBean that's deploying the current module -- which is going to be geronimo unless you have substantially altered your default configuration.
The name of the application that the target EJB or resource is in. If the target module was deployed standalone, this would be null. If it was deployed as part of an EAR, this should be the application-name specified for the EAR, or the configId if no application-name was specified.
The configId of the module that the target EJB or resource is in.
Should identify the type of the EJB or resource that this is pointing to. For EJBs, this should be one of StatefulSessionBean, StatelessSessionBean, EntityBean, or MessageDrivenBean, depending on the type of the target EJB. For a typical connection factory resource (such as a JDBC pool or JMS connection factory), this should be JCAManagedConnectionFactory. For a CORBA CSS, this should be CORBACSS.
The JSR-77 name of the target object. This would be the ejb-name for an EJB, the connectiondefinition-instance/name for a connection factory, or the GBean name for a CORBA CSS.
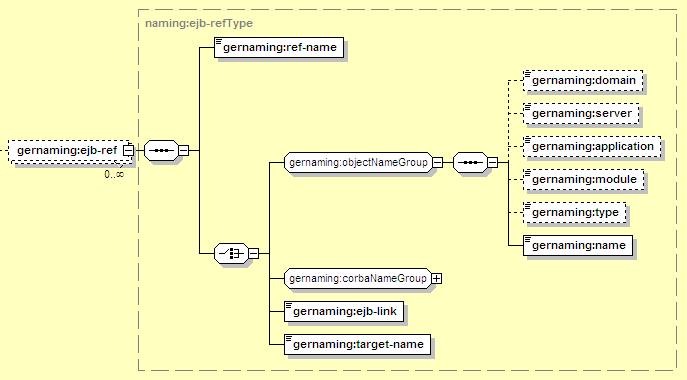
An EJB reference points to the remote interface of an EJB, usually deployed elsewhere in the local Geronimo server. It can also refer to EJBs running elsewhere, using CORBA to connect to the remote server. When EJB references are configured, the client EJB looks in its local java:comp/env/... JNDI space to access the referenced EJB.
The elements used to resolve an EJB reference are:
As shown in Figure 12.18, “EJB: EJB References”, there are four ways to resolve an EJB reference. The simplest is the ejb-link, which is just the name of an EJB elsewhere in the same application, or deployed in a standalone EJB JAR in Geronimo. The target-name or objectNameGroup can be used to specify the EJB by its full GBean Name, either as a single String or as separate GBean Name components. Finally, the corbaNameGroup is used to configure references to EJBs via CORBA.
Groups all the settings for a reference to another EJB (via its remote interface)
Each reference must have a ref-name, which is used to match the definition here to the EJB reference declared in ejb-jar.xml. The value here must match the ejb-ref-name in the ejb-ref in ejb-jar.xml.
Refers to the EJB deployed in Geronimo using the syntax described in Section 12.3.6.1, “Common Resource Mapping Elements”. The type should be one of StatefulSessionBean, StatelessSessionBean, EntityBean, or MessageDrivenBean, depending on the type of the target EJB.
Refers to an EJB using CORBA as the lookup and communication mechanism. The corbaNameGroup is described in detail in the next section.
An ejb-link can be specified here to identify an EJB in the same application EAR by name (must match the ejb-name for the EJB in its ejb-jar.xml). A value specified here overrides any ejb-link specified for the same EJB reference in ejb-jar.xml.
Instead of splitting out all the components using the objectNameGroup, this element holds a single GBean Name containing all that information required to identify the EJB. This may be used to map an EJB in a different application. It would typically look like: geronimo.server:J2EEApplication=ear-name,EJBModule=ejb-jar-name.jar, J2EEServer=geronimo,j2eeType=StatelessSessionBean,name=EJBName
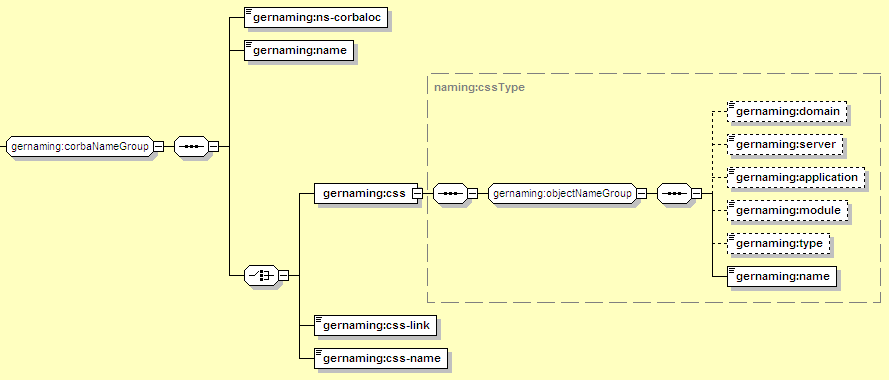
The corbaNameGroup allows an EJB reference to point to a remote EJB via CORBA:
Besides identifying a specific remote EJB, this block selects a Client Security Service (CSS) to be used to manage security settings for the CORBA connection. The CSS is a GBean deployed elsewhere in Geronimo, so that multiple EJB references can share the same CSS settings by pointing to the same CSS. There are several ways to identify a CSS. The simplest is the css-link, which selects a CSS by name, assuming it is deployed in the same application or in a standalone plan. Otherwise the CSS can be identified by its GBean Name, either as a single String (using css-name) or split into the various components (under the css element).
Identifies the CORBA name server that has a reference to the target object. This would typically look like: corbaloc::localhost:1050/NameService
The name of the target EJB as known to the CORBA name server. For EJBs exposed via CORBA in Geronimo, this is usually the ejb-name of the EJB.
Holds a series of individual GBean Name components, which are used together to build a GBean Name to identify the target CSS.
Refers to the CSS deployed in Geronimo using the syntax described in Section 12.3.6.1, “Common Resource Mapping Elements”. The type should be CORBACSS.
Identifies a CSS by its name alone (the same as the name= component of its GBean Name). This searches for a CSS with a matching name in the same application, and then deployed at the top level of the server (outside of any application). If this would result in multiple matches, the CSS must be identified by its full GBean Name (using the css-name or css) instead.
The full GBean Name of the target CSS. This may be used to map to a CSS in a different application. It would typically look like: geronimo.server:J2EEApplication=ear-name,J2EEModule=module-name.jar, J2EEServer=geronimo,j2eeType=CORBACSS,name=MyCSSConfig
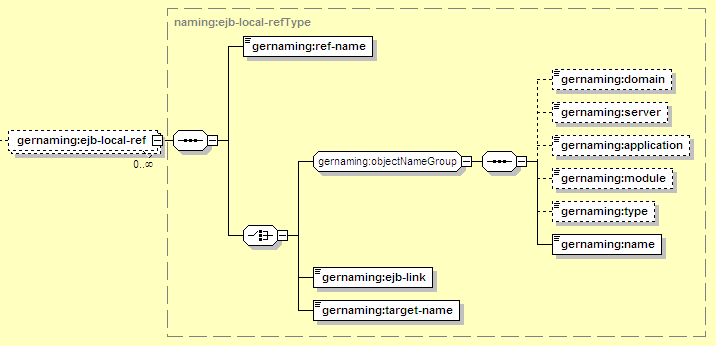
A local EJB reference points to the local interface of an EJB, deployed elsewhere in the local Geronimo server. When local EJB references are configured, the client EJB looks in its local java:comp/env/... JNDI space to access the referenced EJB.
The elements used to resolve a local EJB reference are:
As shown in Figure 12.20, “EJB: Local EJB References”, there are several ways to resolve an EJB reference. The simplest is the ejb-link, which is just the name of an EJB elsewhere in the same application, or deployed in a standalone EJB JAR in Geronimo. Alternatively, the target-name or objectNameGroup can be used to specify the EJB by its full GBean Name, either as a single String or as separate GBean Name components.
Groups all the settings for a reference to another EJB (via its local interface)
Each reference must have a ref-name, which is used to match the definition here to the EJB reference declared in ejb-jar.xml. The value here must match the ejb-ref-name in the ejb-local-ref in ejb-jar.xml.
Refers to the EJB deployed in Geronimo using the syntax described in Section 12.3.6.1, “Common Resource Mapping Elements”. The type should be one of StatefulSessionBean, StatelessSessionBean, EntityBean, or MessageDrivenBean, depending on the type of the target EJB.
An ejb-link can be specified here to identify an EJB in the same application EAR by name (must match the ejb-name for the EJB in its ejb-jar.xml). A value specified here overrides any ejb-link specified for the same EJB reference in ejb-jar.xml.
Instead of splitting out all the components using the objectNameGroup, this element holds a single GBean Name containing all that information required to identify the EJB. This may be used to map an EJB in a different application. It would typically look like: geronimo.server:J2EEApplication=ear-name,EJBModule=ejb-jar-name.jar, J2EEServer=geronimo,j2eeType=StatelessSessionBean,name=EJBName
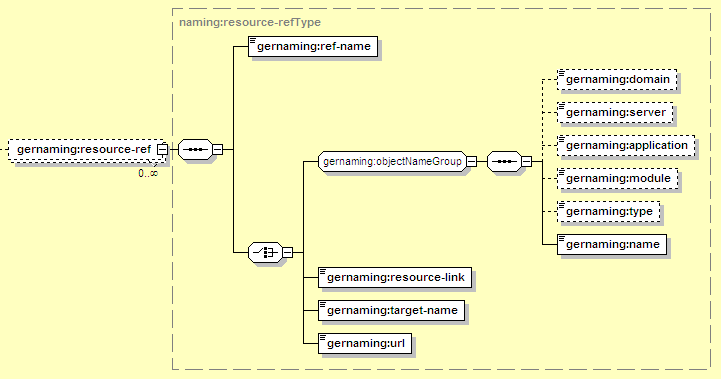
The resource-ref element is used to map resource references (typically JDBC resources, JMS resources, or URLs) to specific resources available in the server. The elements available for mapping resource references are:
There are several ways to identify a targeted resource. One is to specify the component by a simple name (resource-link), while the other is to use a more complex GBean Name (target-name, or the individual components in the objectNameGroup). The resource-link handles most common resource situations (J2EE connectors in the same application or deployed standalone, including JDBC pools and JMS connection factories) while the target-name or objectNameGroup can be used for any resource. This might be important if, for example, two resource adapter deployments use the same name for their connection factory, so the resource-link does not uniquely identify one and it must be fully-qualified. Finally, in the special case of URL resources, the url element provides a value for the resource (instead of looking something else up in the server environment).
Each reference must have a ref-name, which is used to match the definition here to the resource reference in ejb-jar.xml. Specifically, the value here must match the res-ref-name in the resource-ref in ejb-jar.xml.
Refers to the resource deployed in Geronimo using the syntax described in Section 12.3.6.1, “Common Resource Mapping Elements”. For a typical connection factory (such as a JDBC pool or JMS connection factory), the type should be JCAManagedConnectionFactory and the name should match the value of the connectiondefinition-instance/name element in the Geronimo deployment plan for the resource adapter (or the name selected for the resource when deploying it through the console). Note: other resource types may use different types and names.
Can be used to identify any resource deployed as a J2EE connector (including JDBC pools and JMS connection factories). The value specified here should match the connectiondefinition-instance/name element in the Geronimo deployment plan for the connector.
A way to specify any type of resource running in the server. This should be a GBean Name identifying the resource, such as geronimo.server:J2EEServer=geronimo,J2EEApplication=null, JCAModule=my-db-pool,j2eeType=JCAManagedConnectionFactory,name=MyDatasource
If the resource type was java.net.URL, this element can be used to provide a value for the URL reference (such as http://www.amazon.com/). This element should not be used for other resource types.
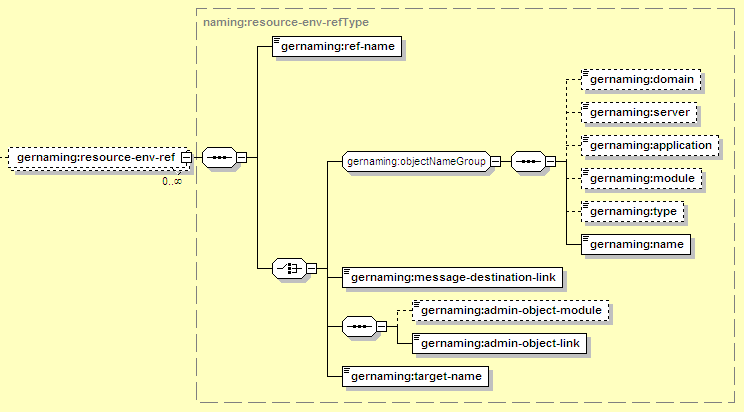
The resource-env-ref is used for administered objects deployed as part of a J2EE Connector. In J2EE 1.3-style configurations, it's also used for JMS topics and queues. The elements available for mapping resource environment references are:
There are several ways to identify a targeted admin object or messaging destination. One is to specify the component by a simple name (message-destination-link), while the other is to use a more complex GBean Name (target-name, or the individual components in the objectNameGroup). The message-destination-link handles most common situations (where the target is in the same application or deployed at the top level of the server), while the target-name or objectNameGroup can be used for any resource. This might be important if, for example, two resource adapter deployments use the same name for their admin objects, so the resource-link does not uniquely identify one and it must be fully-qualified.
Each reference must have a ref-name, which is used to match the definition here to the resource env reference in ejb-jar.xml. Specifically, the value here must match the resource-env-ref-name in the resource-env-ref in ejb-jar.xml.
Refers to the resource deployed in Geronimo using the syntax described in Section 12.3.6.1, “Common Resource Mapping Elements”. For a typical admin object (such as a JMS topic or queue), the type should be JCAAdminObject and the name should match the message-destination-name for the admin object in the Geronimo deployment plan for the JMS resource adapter.
Can be used to identify any admin object deployed as part a J2EE connector (typically JMS topics and queues). The message-destination-link value specified here should match the message-destination-name element in the admin object section of the Geronimo deployment plan for the connector. This element is deprecated and will be removed in a future release in favor of admin-object-link.
Due to a bug, this mapping style does not work in releases earlier than Geronimo 1.0.1. If the admin-object-link is used, this can be used to identify the module that the admin object was deployed in. If admin-object-link is used but this element is left out, the current module will be searched for a matching admin object, as well as any connectors deployed at the top level of the server (e.g. not in an EAR).
Due to a bug, this mapping style does not work in releases earlier than Geronimo 1.0.1. Can be used to identify any admin object deployed as part a J2EE connector. The value specified here should match the message-destination-name element in the admin object section of the Geronimo deployment plan for the connector.
A way to specify any type of resource running in the server. This should be a GBean Name identifying the resource, such as geronimo.server:J2EEServer=geronimo,J2EEApplication=null, JCAModule=my-jms-plan,j2eeType=JCAAdminObject,name=MyQueue
JMS destination references are an odd case because the preferred syntax changed between J2EE 1.3 and J2EE 1.4. The advantage to the newer syntax is that there is usually no Geronimo-specific configuration required in the EJB JAR, whereas J2EE 1.3 requires settings in both the ejb-jar.xml and openejb-jar.xml files. In either case, the references need to be matched up to the settings used when the JMS destination was deployed (for more information on deploying JMS resources, see Chapter 7, JMS Configuration [DRAFT (1.0)]).
As of J2EE 1.4, a reference to a topic or queue can be configured specifically in the ejb-jar.xml file, like this:
META-INF/ejb-jar.xml
<ejb-jar xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/ejb-jar_2_1.xsd"
version="2.1">
<enterprise-beans>
<session>
...
<message-destination-ref>
<message-destination-ref-name>
jms/ATopic
</message-destination-ref-name>
<message-destination-type>
javax.jms.Topic
</message-destination-type>
<message-destination-usage>
Produces
</message-destination-usage>
<message-destination-link>
MyTopic
</message-destination-link>
</message-destination-ref>
</session>
</enterprise-beans>
<assembly-descriptor>
<message-destination>
<message-destination-name>
MyTopic
</message-destination-name>
</message-destination>
</assembly-descriptor>
</ejb-jar>The message-destination element declares the Topic, and the message-destination-ref in a particular EJB declares a reference to it and places the destination into the java:comp/env JNDI space for the web application components. This works automatically in Geronimo if the message-destination-name specified above matches the adminobject/message-destination-name in the Geronimo deployment plan for the JMS destination (though the message destination should have been deployed already). In this case there's no need for any more configuration in the EJB JAR -- in particular, no settings are necessary in the openejb-jar.xml deployment plan.
For reference, here's a snippet from a JMS connector deployment plan that matches the EJB JAR configuration above:
META-INF/geronimo-ra.xml
<connector
xmlns="http://geronimo.apache.org/xml/ns/j2ee/connector-1.0"
version="1.5"
configId="MyJMSResources"
parentId="MyJMSServer">
...
<adminobject>
<adminobject-interface>
javax.jms.Topic
</adminobject-interface>
<adminobject-class>
org.codehaus.activemq.message.ActiveMQTopic
</adminobject-class>
<adminobject-instance>
<message-destination-name>
MyTopic
</message-destination-name>
<config-property-setting name="PhysicalName">
ServerTopicName
</config-property-setting>
</adminobject-instance>
</adminobject>
</connector>If the message-destination-name values don't match, then the following Geronimo configuration block can be used:
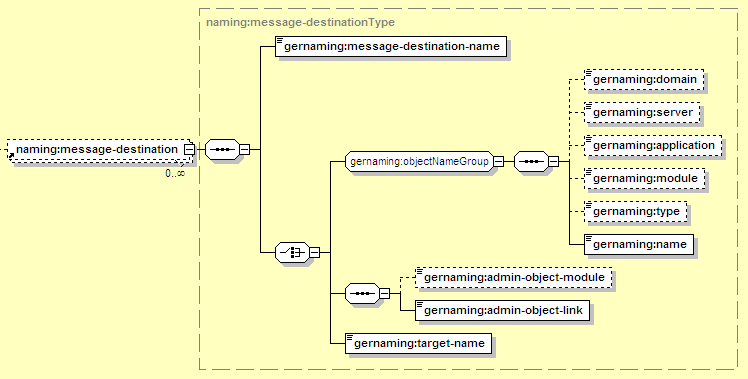
Note that there are several possible ways to resolve a message destination. The elements used here are:
Each reference must have a message-destination-name, which is used to match the definition here to the message destination declared in ejb-jar.xml. Specifically, the value here must match the message-destination-name in the message-destination in ejb-jar.xml.
See Section 12.3.6.1, “Common Resource Mapping Elements” for a full description of the elements in the objectNameGroup. This can be used to identify an admin object GBean to map the message destination reference to. For a typical admin object (such as a JMS topic or queue), the type should be JCAAdminObject and the name should match the message-destination-name for the admin object in the Geronimo deployment plan for the JMS resource adapter.
If the admin-object-link is used, this can be used to identify the module that the admin object was deployed in. If admin-object-link is used but this element is left out, the current module will be searched for a matching admin object, as well as any connectors deployed at the top level of the server (e.g. not in an EAR).
Can be used to identify any admin object deployed as part a J2EE connector. The value specified here should match the message-destination-name element in the admin object section of the Geronimo deployment plan for the JMS resource adapter.
Uniquely identifies an admin object running elsewhere in Geronimo. This should be a GBean Name identifying the admin object, such as geronimo.server:J2EEServer=geronimo,J2EEApplication=null, J2EEModule=some-ra.rar,j2eeType=JCAAdminObject,name=MyQueue
| Note |
|---|---|
The message-destination element is specified at the EJB JAR level, as opposed to other references which are resolved at the individual EJB level. This is because the message-destination element in ejb-jar.xml is included in the assembly-descriptor, not in the section for any particular EJB. | |
Using this syntax, the message-destination declared in ejb-jar.xml above could be mapped like this:
META-INF/openejb-jar.xml
<openejb-jar
xmlns="http://www.openejb.org/xml/ns/openejb-jar-2.0"
xmlns:naming="http://geronimo.apache.org/xml/ns/naming-1.0"
configId="MyEJBJAR">
<naming:message-destination>
<naming:message-destination-name>
MyTopic
</naming:message-destination-name>
<naming:admin-object-link>
MyApplicationTopic
</naming:admin-object-link>
</naming:resource-env-ref>
</openejb-jar>This means that the destination known to the EJB JAR as MyTopic (and present in JNDI for the session bean at java:comp/env/jms/ATopic) will actually connect to a topic configured using an admin object named MyApplicationTopic in the JMS connector deployment plan (and may have still another physical name in the underlying JMS server!).
The message-destination and message-destination-ref elements didn't exist in J2EE 1.3. Instead, JMS destination references were declared using resource-env-ref elements, and these would be resolved in the Geronimo deployment plan. For example, the same Topic reference in J2EE 1.3 would look like this:
META-INF/ejb-jar.xml
<!DOCTYPE ejb-jar PUBLIC
"-//Sun Microsystems, Inc.//DTD Enterprise JavaBeans 2.0//EN"
"http://java.sun.com/dtd/ejb-jar_2_0.dtd">
<ejb-jar>
<enterprise-beans>
<session>
...
<resource-env-ref>
<resource-env-ref-name>jms/ATopic</resource-env-ref-name>
<resource-env-ref-type>
javax.jms.Topic
</resource-env-ref-type>
</resource-env-ref>
</session>
</enterprise-beans>
</ejb-jar>Then this would be mapped as described in Section 12.3.6.5, “Resource Environment References”:
META-INF/openejb-jar.xml
<openejb-jar
xmlns="http://www.openejb.org/xml/ns/openejb-jar-2.0"
xmlns:naming="http://geronimo.apache.org/xml/ns/naming-1.0"
configId="MyEJBJAR">
<enterprise-beans>
<session>
...
<naming:resource-env-ref>
<naming:ref-name>jms/ATopic</naming:ref-name>
<naming:message-destination-link>
MyTopic
</naming:message-destination-link>
</naming:resource-env-ref>
</session>
</enterprise-beans>
</openejb-jar>Note that you're still depending on the definition of the JMS destination in the Geronimo deployment plan for the JMS resource -- the message-destination-link above needs to match the same adminobject/message-destination-name value.
As of J2EE 1.4, EJBs can declare reference to web services, which may be running in Geronimo or elsewhere. Fully configuring web services references is somewhat complex (involving separate files), and is addressed in more detail in Chapter 16, Web Services [DRAFT(1.0)]. This section describes the elements that appear in the openejb-jar.xml deployment plan.
In order to make sense of this configuration scheme, there are several important things to understand about web services references:
One web service may include multiple "ports", each of which is a mapping of a connection URL to a "binding" (ultimately consisting of one or more operations and associated configuration within the service). A web service reference points to one or more ports. So for a web service with multiple ports, there might be several references to the same service but targeting different ports, or there may be one service reference with several ports the client can use.
Normally, the WSDL file for a web service specifies all the ports that the service provides, including accurate connectivity information to access the port. This is contained in a service element in the WSDL, which also specifies a name for the service.
Not all WSDL files are complete -- they may be missing the service element, and the ports may not have a correct URL to connect to the web service. However the WSDL must always include the bindings.
Therefore, there are two possible approaches to resolving web services references. One is to select one or more existing ports from the WSDL (using service-ref/port), potentially overriding the URL to the server hosting the web service (in case, for example, the WSDL incorrectly specifies "localhost" for the server name). The other approach is used for incomplete WSDL files, and is used to fill out all the missing information for the service and the ports it contains (using service-ref/service-completion). This latter approach is not preferred, since it requires including a lot of information that should be in the WSDL in the openejb-jar.xml plan instead, but it can be used when the WSDL is incomplete and cannot be changed (because it is provided by a third party, etc.).
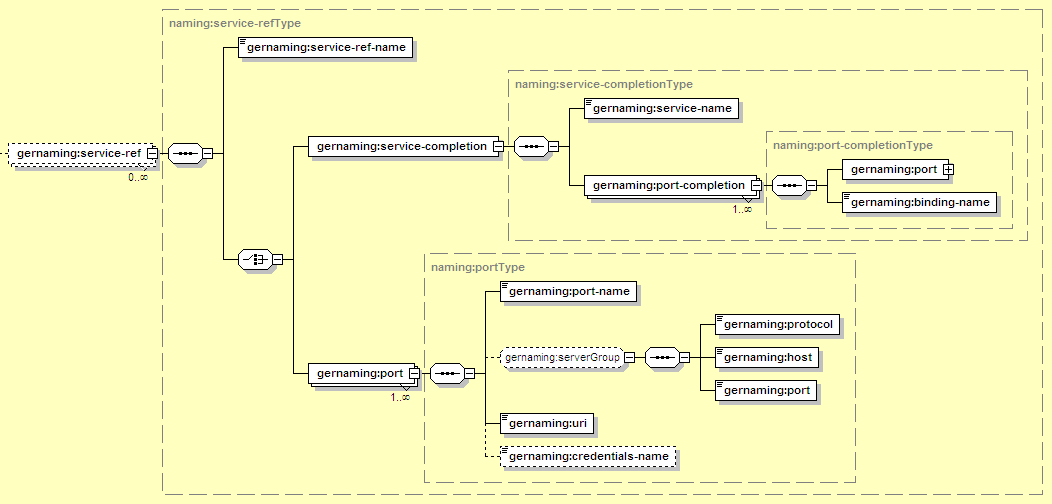
Each reference must have a service-ref-name, which is used to match the definition here to the web service reference in ejb-jar.xml. Specifically, the value here must match the service-ref-name in the service-ref in ejb-jar.xml.
If the WSDL for the web service is not complete, this element holds missing information. The service reference will be configured to target all ports defined here. If this element is not used, the WSDL must be complete, and the service reference will target the subset of ports listed instead.
Specifies the name of the service, which normally would have been specified in the missing service block of the WSDL file.
If specified within a service-completion element, fully defines a port by providing all the data missing from the WSDL file. If specified directly under the service-ref element, designates the ports that should be available through this service reference. In either case, the port specifies some or all of the URL used to connect to the web service. This is split into several child elements, so the actual URL would look like protocol://host:port/uri. If this is not in a service-completion, the protocol, host, and network port default to the values provided in the WSDL.
The name that identifies this port.
Part of the connection information used to connect to the port. This is the network protocol, typically http or https.
Part of the connection information used to connect to the port. This is the host that the port runs on.
Part of the connection information used to connect to the port. This is the network port used to connect to the web service port.
Part of the connection information used to connect to the port. This is the path information used once the server connection is established.
When a caller invokes a secure web service, their current Geronimo security information is used to authenticate. In case the web service uses different logins than the Geronimo application, the Geronimo security information may include multiple sets of authentication information (credentials), each with a name that identifies it. If that's the case, the name provided here identifies which set of credentials should be passed to the web service. So for example, a user may sign on as "jsmith" and get set up in Geronimo as (jsmith with password foo) and also a second credential (john_smith with password bar) where that second credential is named "ws_credentials". Then if the credentials_name field isn't present they'd log into a secure web service as jsmith, or if the credentials-name was set to ws_credentials they'd log in to the web service as john_smith. Of course, the Geronimo security realm must be configured properly to support this (see Chapter 9, Security Configuration [DRAFT (1.0-pre)]).
A port is essentially a mapping of a binding to a URL. The other components in the port element specify the URL, and the value here names the binding. There must be a binding with this name in the WSDL file.
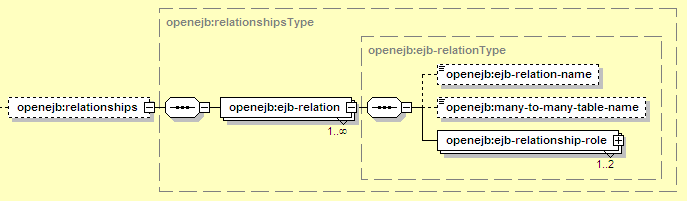
Container-managed relationships are initially defined in the ejb-jar.xml deployment descriptor, but the mappings to specific database elements are defined here. The mapping strategy is different depending on the type of relationship: one-to-one, one-to-many, or many-to-many. The high-level elements used to map container-managed relationships are:
The elements introduced here are:
Holds all container-managed relationship settings.
Holds all the settings pertinent to a specific container-managed relationship.
Can be used as a convenience to indicate which relation this block applies to, in which case it ought to match the ejb-relation/ejb-relation-name value from ejb-jar.xml. However, Geronimo does not actually pay attention to this field, so it's more for documentation purposes.
In the case of a many-to-many relationship, Geronimo requires an intermediate mapping table containing nothing but foreign keys to the two entity tables. This element holds the name of that table.
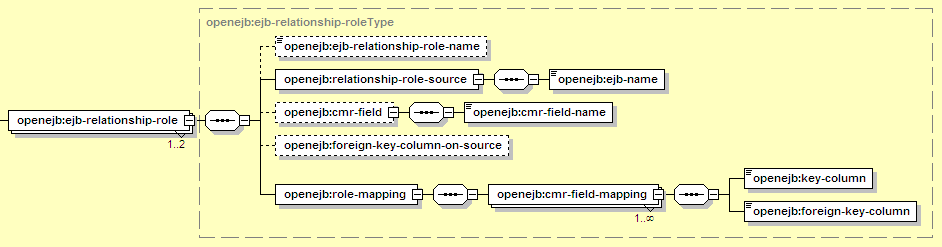
Each relationship is composed of two entities, each of which is represented in the configuration by an ejb-relationship-role. The detailed settings for each side of the relationship are shown below. For one-to-one and one-to-many relationships, it may be the case that only one of the two relationships need additional settings here, so there may only be one ejb-relationship-role block in this file.
The elements introduced here are:
Can be used as a convenience to indicate which relationship role this block applies to, in which case it ought to match the ejb-relationship-role/ejb-relationship-role-name in ejb-jar.xml. However, Geronimo does not actually pay attention to this element, so it's more for documentation purposes. The relationship in question will be uniquely identified by the combination of relationship-role-source and cmr-field instead (or by the relationship-role-source if only the other ejb-relationship-role in the relationship has a cmr-field).
Identifies the EJB that is associated with this relationship role. With cmr-field, (or if this ejb-relationship-role is paired with another ejb-relationship-role that has a cmr-field), this field uniquely identifies the relationship role which these settings apply to.
Holds the name of the EJB that forms this relationship role. This must match the relationship-role-source/ejb-name for this ejb-relationship-role in ejb-jar.xml.
If the ejb-relationship-role in ejb-jar.xml includes a cmr-field, this element can be used with the relationship-role-source to uniquely identify the relationship role these settings apply to. Otherwise, this must be one of two ejb-relationship-role blocks for this ejb-relation, and the other ejb-relationship-role must include a cmr-field.
The name of the cmr-field on the EJB. This must match the cmr-field/cmr-field-name for this relationship role in ejb-jar.xml.
For one-to-one and one-to-many relationships, the server normally expects that if an EJB (say, Person) declares a CMR field (say, getAddress()), then the underlying ADDRESS table has a column like PERSON_ID on it (referring to the primary key of the PERSON table, say PERSON.ID). So the EJB declaring the CMR field has the table with the primary key, and the other EJB has the foreign key. If that is true, then this element should not be present.
However, if the CMR field is still Person.getAddress() but it's instead the PERSON table that has a column like ADDRESS_ID on it (referring to say, ADDRESS.ID), then this element should be present to indicate that it's actually the case that the EJB with the CMR field has the foreign key, and the other EJB has the primary key.
This element never has any content; the data is conveyed by whether it's present or not. It should never be used for many-to-many mappings.
This element holds the data that maps the relationship to specific database columns (typically based on foreign keys, though Geronimo does not actually require that the database include actual foreign key constraints).
Holds a single primary-key to foreign-key mapping. There should be one cmr-field-mapping element for each column in the primary key (and therefore the foreign key that refers to it).
The primary key column in the database. If foreign-key-column-on-source is not present, then this should be a column on the table for the EJB named in the relationship-role-source element. Otherwise, this should be a column on the table for the other EJB in the relationship.
The foreign key column in the database. If foreign-key-column-on-source is present, then this should be a column on the table for the EJB named in the relationship-role-source element. Otherwise, this should be a column on the table for the other EJB in the relationship.
The following examples walk through CMR mapping for a relationship between a Person and an Address. This is done in three different ways:
One to One: Each person has exactly one address, and addresses are not reused across people (two people at the same address would have two distinct address records with similar data)
One to Many: A person may have multiple addresses (home, work, etc.) and addresses are not reused across people
Many to Many: A person may have multiple addresses, and an address may be shared by multiple people. For example, everyone in a family may share the same home address, while everyone in an office may share the same work address.
The database structure looks slightly different for each, so a representative SQL script is included with each example.
Example 12.7. One-To-One CMR Mapping
This example assumes that each Person has one Address and vice versa. In this case we also assume that the person table has a foreign key to the address table. So the SQL might look like this:
CREATE TABLE ADDRESS (
ADD_ID INTEGER NOT NULL PRIMARY KEY,
STREET_1 VARCHAR(30),
...
);
CREATE TABLE PERSON (
PER_ID INTEGER NOT NULL PRIMARY KEY,
ADDRESS_ID INTEGER NOT NULL,
FIRST_NAME VARCHAR(30),
...
CONSTRAINT FK_PERSON_ADDRESS FOREIGN KEY (ADDRESS_ID)
REFERENCES ADDRESS(ADD_ID)
);The Person EJB might have a CMR field address corresponding to a getAddress method, and the Address EJB might have a CMR field person corresponding to a getPerson method. If both CMR fields are present, this relationship can be mapped in one of two ways. If only one EJB has a CMR field, the mapping must use the EJB with the CMR field available.
Option 1: openejb-jar.xml mapping based on Person with address CMR field:
<relationships>
<ejb-relation>
<ejb-relationship-role>
<relationship-role-source>
<ejb-name>Person</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>address</cmr-field-name>
</cmr-field>
<foreign-key-column-on-source />
<role-mapping>
<cmr-field-mapping>
<key-column>ADD_ID</key-column>
<foreign-key-column>ADDRESS_ID</foreign-key-column>
</cmr-field-mapping>
</role-mapping>
</ejb-relationship-role>
</ejb-relation>
...
</relationships>Note that this option includes the foreign-key-column-on-source element, as the foreign key column (ADDRESS_ID) appears on the table associated with the relationship-role-source EJB (Person).
Option 2: openejb-jar.xml mapping based on Address with person CMR field:
<relationships>
<ejb-relation>
<ejb-relationship-role>
<relationship-role-source>
<ejb-name>Address</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>person</cmr-field-name>
</cmr-field>
<role-mapping>
<cmr-field-mapping>
<key-column>ADD_ID</key-column>
<foreign-key-column>ADDRESS_ID</foreign-key-column>
</cmr-field-mapping>
</role-mapping>
</ejb-relationship-role>
</ejb-relation>
...
</relationships>In this case the foreign-key-column-on-source element does not appear, as the primary key column (ADD_ID) appears on the table associated with the relationship-role-source EJB (Address).
Example 12.8. One-To-Many CMR Mapping
This example assumes that each Person has several Addresses, but an Address is only associated with one Person. In this case we assume that the address table has a foreign key to the person table. So the SQL might look like this:
CREATE TABLE ADDRESS (
ADD_ID INTEGER NOT NULL PRIMARY KEY,
PERSON_ID INTEGER NOT NULL,
STREET_1 VARCHAR(30),
...
CONSTRAINT FK_ADDRESS_PERSON FOREIGN KEY (PERSON_ID)
REFERENCES PERSON(PER_ID)
);
CREATE TABLE PERSON (
PER_ID INTEGER NOT NULL PRIMARY KEY,
FIRST_NAME VARCHAR(30),
...
);The Person EJB might have a CMR field addresses corresponding to a getAddresses method, and the Address EJB might have a CMR field person corresponding to a getPerson method. If both CMR fields are present, this relationship can be mapped in one of two ways. If only one EJB has a CMR field, the mapping must use the EJB with the CMR field available.
Option 1: openejb-jar.xml mapping based on Person with addresses CMR field:
<relationships>
<ejb-relation>
<ejb-relationship-role>
<relationship-role-source>
<ejb-name>Person</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>addresses</cmr-field-name>
</cmr-field>
<role-mapping>
<cmr-field-mapping>
<key-column>PER_ID</key-column>
<foreign-key-column>PERSON_ID</foreign-key-column>
</cmr-field-mapping>
</role-mapping>
</ejb-relationship-role>
</ejb-relation>
...
</relationships>Note that this option does not include the foreign-key-column-on-source element, as the primary key column (PER_ID) appears on the table associated with the relationship-role-source EJB (Person).
Option 2: openejb-jar.xml mapping based on Address with person CMR field:
<relationships>
<ejb-relation>
<ejb-relationship-role>
<relationship-role-source>
<ejb-name>Address</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>person</cmr-field-name>
</cmr-field>
<foreign-key-column-on-source />
<role-mapping>
<cmr-field-mapping>
<key-column>PER_ID</key-column>
<foreign-key-column>PERSON_ID</foreign-key-column>
</cmr-field-mapping>
</role-mapping>
</ejb-relationship-role>
</ejb-relation>
...
</relationships>In this case the foreign-key-column-on-source is present, as the foreign key column (PERSON_ID) appears on the table associated with the relationship-role-source EJB (Address).
Example 12.9. Many-To-Many CMR Mapping
This example assumes that each Person has several Addresses, and each Address may have several associated people. In this case we assume that there's a mapping table that refers to both the person and address tables. So the SQL might look like this:
CREATE TABLE ADDRESS (
ADD_ID INTEGER NOT NULL PRIMARY KEY,
STREET_1 VARCHAR(30),
...
);
CREATE TABLE PERSON (
PER_ID INTEGER NOT NULL PRIMARY KEY,
FIRST_NAME VARCHAR(30),
...
);
CREATE TABLE PERSON_ADDRESS_MAP (
PERSON_ID INTEGER NOT NULL,
ADDRESS_ID INTEGER NOT NULL,
CONSTRAINT FK_MAP_ADDRESS FOREIGN KEY (ADDRESS_ID)
REFERENCES ADDRESS(ADD_ID),
CONSTRAINT FK_MAP_PERSON FOREIGN KEY (PERSON_ID)
REFERENCES PERSON(PER_ID)
);The Person EJB might have a CMR field addresses corresponding to a getAddresses method, and the Address EJB might have a CMR field persons corresponding to a getPersons method. There is only one way to map this and both relationship roles must be included, but if only one EJB has a CMR field, then only one of the relationship roles will include a cmr-field element. Note that neither relationship role can have the foreign-key-column-on-source element, as the foreign keys must live in the mapping table and the primary keys must live in the EJB tables. However a many-to-many-table-name element is required.
<relationships>
<ejb-relation>
<many-to-many-table-name>
PERSON_ADDRESS_MAP
</many-to-many-table-name>
<ejb-relationship-role>
<relationship-role-source>
<ejb-name>Person</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>addresses</cmr-field-name>
</cmr-field>
<role-mapping>
<cmr-field-mapping>
<key-column>PER_ID</key-column>
<foreign-key-column>PERSON_ID</foreign-key-column>
</cmr-field-mapping>
</role-mapping>
</ejb-relationship-role>
<ejb-relationship-role>
<relationship-role-source>
<ejb-name>Address</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>person</cmr-field-name>
</cmr-field>
<role-mapping>
<cmr-field-mapping>
<key-column>ADD_ID</key-column>
<foreign-key-column>ADDRESS_ID</foreign-key-column>
</cmr-field-mapping>
</role-mapping>
</ejb-relationship-role>
</ejb-relation>
...
</relationships>The security element maps security roles declared in the openejb-jar.xml deployment descriptor to specific users or groups in the security realms configured in Geronimo. It also allows you to specify a default user or group to be used when the end user has not yet logged in.
| Tip |
|---|---|
If the EJB JAR is in an EAR, its best to put the roles in the EAR's application.xml and the security settings in the EAR's geronimo-application.xml. That way the same settings will be used by all modules in the EAR, instead of needing to repeat them in the configuration for each. If the security settings are specified in the EAR containing this EJB JAR, it is not necessary to include a security element here at all. | |
Note that the description elements are the standard J2EE 1.4 -- there may be many of them at each appropriate location (typically with different languages for each occurrence in the group).
The other elements here are:
The name of the Geronimo security realm that will authenticate user logins. This should match the name specified for the security realm GBean. (The standard security realm in Geronimo is named geronimo-properties-realm -- to deploy additional security realms, see Chapter 9, Security Configuration [DRAFT (1.0-pre)].)
Groups the security role mapping settings for the EJB JAR.
May be true or false. If set to true, any work done by EJBs in this JAR will be performed as the calling Subject, instead of "as the application server". This can be used to hook into the Java JVM security sandbox (for example, to only allow trusted users to access the server filesystem). It is not usually necessary, as the application-level security features are typically sufficient. When it is enabled, you may want to adjust the security policy used for the server to control certain permissions by subject. This element is optional and the default is false.
May be true or false. The default is false, but advanced JACC users may enable it to insert their own code in the JACC processing chain.
Controls security restrictions on EJB methods that do not have explicit security settings in ejb-jar.xml. The value for this element is the name of a J2EE security role (which must be itself listed in ejb-jar.xml). If present, any EJB method without an explicit security setting will require the specified role for access. If this element is omitted, any EJB method without an explicit security setting will effectively be marked as unchecked (that is, open to unauthenticated access).
Holds a principal which will be used any time an unauthenticated user accesses an unchecked EJB. Normally this would result in no principal being used, but you can specify a default here. This would, for example, allow an insecure EJB to itself access a secured EJB. This element is described in more detail below.
Holds the information mapping roles declared in the ejb-jar.xml deployment descriptor to specific principals present in the security realms available to Geronimo.
Holds the set of principals that map to a single role from ejb-jar.xml. This is described in more detail below.
The default-principal element looks like this:
Configures a principal using simple principal mapping. Principal elements are discussed in the next section.
Configures a principal using login domain specific mapping. Principal elements are discussed in the next section.
Configures a principal using login domain and realm specific mapping. Principal elements are discussed in the next section.
Named credentials are used by external resources (e.g. a J2EE Connector or Web Service) that use per-user authentication, but require different authentication than the calling web application. So for example, a the default principal may be a user "jsmith" and this element can be used to set up a second credential ("john_smith" with password "foo") where that second credential is named "ws_credentials". Then when the user invokes a web service, the web service reference can be configured to look for and use a credential named "ws_credentials" instead of the normal principal. Normally named credentials are added by the Geronimo security realm, but in the case of the default principal, they must be manually configured here.
The name to store this credential under (ws_credentials in the example above)
The username that this credential should contain.
The password that this credential should contain.
The role element used for role mapping looks like this:
The elements used here are:
Holds the set of principals that map to a single role from ejb-jar.xml.
The name used to identify this role. Must match a role-name specified in ejb-jar.xml.
Configures a principal using simple principal mapping. Principal elements are discussed in the next section.
Configures a principal using login domain specific mapping. Principal elements are discussed in the next section.
Configures a principal using login domain and realm specific mapping. Principal elements are discussed in the next section.
Used for client certificate authentication.
The value here is matched against the distinguished name on the certificate presented by the client.
This boolean attribute is used to indicate which principal should be used if an EJB has a run-as role set (in ejb-jar.xml). If the run-as is set to the role that this principal is a member of, and this principal's designated-run-as is set to true, then this principal will be used to represent the user for the duration of the run-as call.
There are three types of principal elements available to specify either a default principal or the principals that should be included in a role.
Principals are normally identified by their principal class and principal name. Both values must match one of the principals for the current user in order for the user to successfully qualify for the application role. However, if the Support Advanced Mapping flag is enabled for the login modules used by the security realm that produced the principals (see Chapter 9, Security Configuration [DRAFT (1.0-pre)]), those principals are also identified by their login domain name and realm name, and the security mapping process can distinguish based on those characteristics of the principal as well.
The principal element is the most straightforward of the three:
The attributes used here are:
Each principal is represented by an object of a particular class by the security realm (e.g. an LDAP realm might use the classes com.foo.LDAPUser and com.foo.LDAPGroup). This attribute holds the fully qualified Java class name of the principal class. The class is necessary to distinguish between different types of principals that may have the same name (such as a group Administrator and a user Administrator). The principal classes used by the default Geronimo security realms are org.apache.geronimo.security.realm.providers.GeronimoUserPrincipal (for users) and org.apache.geronimo.security.realm.providers.GeronimoGroupPrincipal (for groups).
This attribute holds the name of the principal, which should be unique among principals of a particular class if you're using simple mapping.
This boolean attribute is used to indicate which principal should be used if an EJB has a run-as role set (in ejb-jar.xml). If the run-as is set to the role that this principal is a member of, and this principal's designated-run-as is set to true, then this principal will be used to represent the user for the duration of the run-as call. This attribute should not be used for principals within the default-principal element.
The login-domain-principal element let principals be identified by the login module that produced them, as well as by their class and name:
This includes all the same attributes as the principal element, plus:
Must match the login-domain-name set for the JAAS Login Module that produced this principal in order for the principal to qualify the user to be in the current role. Additionally, the LoginModule must have its advanced mapping (also known as principal wrapping) flag enabled.
The realm-principal element let principals be identified by the realm that they came from, as well as by their class, name, and login domain:
This includes all the same attributes as the login-domain-principal element, plus:
Must match the realm-name set for the Geronimo security realm that produced this principal in order for the principal to qualify the user to be in the current role. Additionally, the LoginModule that produced this principal must have its advanced mapping (also known as principal wrapping) flag enabled.
Here's an example of the security block from a Geronimo EJB deployment plan, using simple mapping:
Example 12.10. EJB Security Example
<security xmlns="http://geronimo.apache.org/xml/ns/security-1.1">
<default-principal>
<principal class="com.example.LDAPUserPrincipal"
name="Anonymous" />
</default-principal>
<role-mappings>
<role name="Administrator">
<principal class="com.example.LDAPUserPrincipal"
name="Aaron" />
</role>
<role name="User">
<principal class="com.example.LDAPGroupPrincipal"
name="ApplicationUsers" />
<principal class="com.example.LDAPUserPrincipal"
name="Bob" designated-run-as="true" />
</role>
</role-mappings>
</security>In this example, there is only one realm in use (an LDAP realm). When an unauthenticated user accesses an unsecured EJB, they will be treated as the user Anonymous. If they log in they may end up in the Administrator role or the User role. The LDAP user Aaron would be an administrator, while the LDAP user Bob or anyone in the LDAP group ApplicationUsers would be a user. Anyone else would not get any application roles, which means they will not be able to access any secured EJBs. If an EJB declares a run-as role of User, then the server will behave as if the user Bob was logged in while that EJB executes.
The gbean element lets you configure additional Geronimo services which will be deployed when the web application is deployed. Normally, the implementation classes for these services are still included at the server level, and referenced using a dependency element (see Section 12.3.1, “Customizing the Class Path”). But the required code or libraries can also be packaged in the EAR, usually referenced from the Manifest of the EJB JAR.
The full syntax for deploying GBeans is covered in Chapter 18, GBeans: Adding New Services to Geronimo [EMPTY]. In general, the gbean element and its attributes define a GBean, and the child elements are used to configure the GBean.
| |  | |
| 12.2. The Geronimo EJB Deployment Plan |  | Chapter 13. J2EE Connectors (RARs) [DRAFT (1.0)] |