JSONExtract
Available in Community Designer

| Short Description |
| Ports |
| Metadata |
| JSONExtract Attributes |
| Details |
| Best Practices |
| Compatibility |
| See also |
Short Description
JSONExtract reads data from JSON files using SAX technology. It can also read data from compressed files, input port, and dictionary.
| Component | Data source | Input ports | Output ports | Each to all outputs | Different to different outputs | Transformation | Transf. req. | Java | CTL | Auto-propagated metadata |
|---|---|---|---|---|---|---|---|---|---|---|
| JSONExtract | JSON file | 0-1 | 1-n |
 |
 |
|
|
|
|
|
Icon
Ports
| Port type | Number | Required | Description | Metadata |
|---|---|---|---|---|
| Input | 0 | | For port reading. See Reading from Input Port. | One field (byte,
cbyte, string). |
| Output | 0 | | For correct data records | Any |
| 1-n | [2] | For correct data records | Any | |
[2] Other output ports are required if mapping requires that. | ||||
Metadata
JSONExtract does not propagate metadata.
JSONExtract has no metadata template.
Metadata on optional input port must contain string or byte or cbyte field.
Metadata on each output port does not need to be the same.
Each metadata can use Autofilling Functions.
JSONExtract Attributes
| Attribute | Req | Description | Possible values |
|---|---|---|---|
| Basic | |||
| File URL | yes | Attribute specifying what data source(s) will be read (JSON file, input port, dictionary). See Supported File URL Formats for Readers. | |
| Charset | Encoding of records which are read. | any encoding, default system one by default | |
| Mapping | [1] | Mapping of the input JSON structure to output ports. See XMLExtract Mapping Definition for more information. | |
| Mapping URL | [1] | Name of an external file, including its path which defines mapping of the input JSON structure to output ports. See XMLExtract Mapping Definition for more information. | |
| Equivalent XML Schema | URL of the file that should be used for creating the Mapping definition. See JSONExtract Mapping Editor and XSD Schema for more information. | ||
| Use nested nodes | By default, nested elements are also mapped to output
ports automatically. If set to false, an
explicit <Mapping> tag must be
created for each such nested element. | true (default) | false | |
| Trim strings | By default, white spaces from the beginning and the end
of the elements values are removed. If set to
false, they are not removed. | true (default) | false | |
| Advanced | |||
| Number of skipped mappings | Number of mappings to be skipped continuously throughout all source files. See Selecting Input Records. | 0-N | |
| Max number of rows to output | Maximum number of records to be read continuously throughout all source files. See Selecting Input Records. | 0-N | |
[1] One of these must be specified. If both are specified, Mapping URL has higher priority. | |||
Details
JSONExtract reads data from JSON files using SAX technology. This component is faster than JSONReader which can read JSON files too. JSONExtract does not use DOM, so it uses less memory than JSONReader.
JSONExtract reads lists.
![[Note]](figures/note.png) | Note |
|---|---|
Component JSONExtract is very similar to component XMLExtract. The JSONExtract internally transforms JSON to XML and uses XMLExtract to parsing the data. Therefore you can generate xsd file for corresponding xml file. |
Mapping in JSONExtract is almost same as in XMLExtract. The main one difference is, that JSON does not have attributes. See XMLExtract's Details for details.
JSONExtract Mapping Editor and XSD Schema
JSONExtract Mapping Editor serves to setup of mapping from JSON tree structure to one ore more output ports without necessity of being aware how to create mapping of field using xml editor.
To be able to use the editor, the editor needs to have created equivalent xsd schema. The equivalent xsd schema is created automatically. Only the directory for the schema needs to be specified.
Any other operations to set up mapping are described in above mentioned XMLExtract.
Mapping Input Fields to the Output Fields
In JSONExtract, you can map input fields to the output in the same way as you map JSON fields. The input field mapping works in all three processing modes.
Examples
Reading lists
JSON file contains information about employees and orders. Each item contains employee id and list of order ids.
{
"jsonextract_order" : {
"employee" : "Henri",
"orders" : [ "order01", "order08", "order15" ]
},
"jsonextract_order" : {
"employee" : "Jane",
"orders" : [ "order02", "order05", "order09" ]
}
}Read data for further processing.
Solution
Use File URL attribute to point to the source file and use Mapping attribute to define mapping.
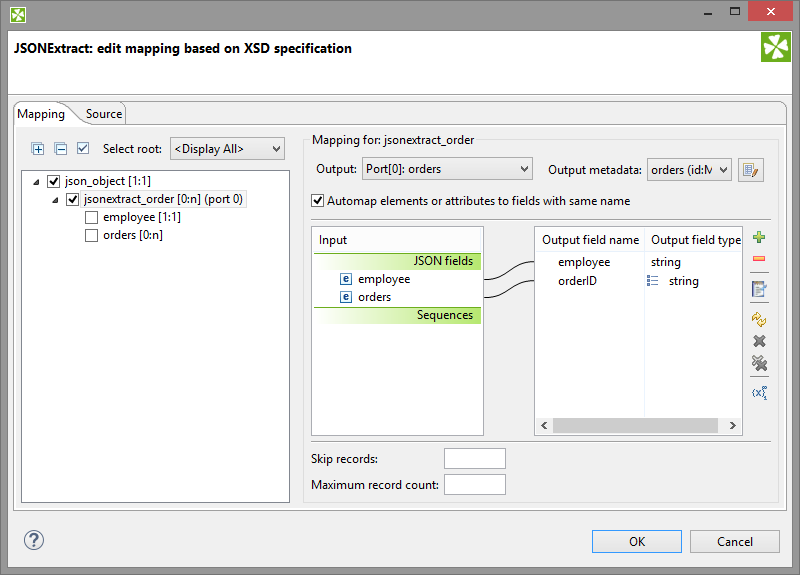 |
Figure 53.10. JSONExtract - mapping the list
Best Practices
We recommend users to explicitly specify Charset.
Compatibility
3.5.0-M2
JSONExtract is available since CloverETL 3.5.0-M2.
4.1.0-M1
Since CloverETL 4.1.0-M1 you can map input fields to the output fields in this component.
4.1.0
Since CloverETL 4.1.0 you can read lists.