Job Config Properties
Each ETL graph or Jobflow may have set of config properties, which are applied during the execution. Properties are editable in web GUI section "sandboxes". Select job file and go to tab "Config properties".
The same config properties are editable even for each sandbox. Values specified for sandbox are applied for each job in the sandbox, but with lower priority then config properties specified for the job.
If neither sandbox nor job have config properties specified, defaults from main server configuration are applied. Global config properties related to Job config properties have prefix "executor.". E.g. server property "executor.classpath" is default for Job config property "classpath". (See Part III, “Configuration” for details)
In addition, it is possible to specify additional job parameters, which can be used as placeholders in job XML. Please keep in mind, that these placeholders are resolved during loading and parsing of XML file, thus such job couldn't be pooled.
If you use a relative path, the path is relative to ${SANDBOX_ROOT}.
In path definition, you can use system properties - e.g. ${java.io.tmpdir} -
and some of server config properties: ${sandboxes.home},
${sandboxes.home.partitioned} and ${sandboxes.home.local}.
Table 15.4. Job config parameters
| Property name | Default value | Description |
|---|---|---|
| tracking_interval | 2000 | Interval in ms for sampling nodes status in running transformation. |
| max_running_concurrently | unlimited | Max number of concurrently running instances of this transformation. In cluster environment, the limit is per node. |
| enqueue_executions | false | Boolean value. If it is true, executions above max_running_concurrently are enqueued, if it is false executions above max_running_concurrently fail. |
| log_level | INFO | Log4j log level for this graph executions. (ALL | TRACE | DEBUG | INFO | WARN | ERROR | FATAL) For lower levels (ALL, TRACE or DEBUG), also root logger level must be set to lower level. Root logger log level is INFO by default, thus transformation run log does not contain more detail messages then INFO event if job config parameter "log_level" is set properly. See Chapter 11, Logging for details about log4j configuration. |
| max_graph_instance_age | 0 | A time interval in ms which specifies how long may a transformation instance last in server's cache. 0 means that the transformation is initialized and released for each execution. The transformation cannot be stored in the pool and reused in some cases (a transformation uses placeholders using dynamically specified parameters) |
| classpath | List of paths or jar files which contain external classes used in the job file (transformations, generators, JMS processors). All specified resources will be added to runtime classpath of the transformation job. All Clover Engine libraries and libraries on application-server's classpath are automatically on the classpath. Separator is specified by Engine property "DEFAULT_PATH_SEPARATOR_REGEX". Directory path must always end with a slash character "/", otherwise ClassLoader doesn't recognize it's a directory. Server always automatically adds "trans" subdirectory of job's sandbox, so It doesn't have to be added explicitly. | |
| compile_classpath | List of paths or jar files which contain external classes used in the job file (transformations, generators, JMS processors) and related libraries for their compilation. Please note, that libraries on application-server's classpath aren't included automatically. Separator is specified by Engine property "DEFAULT_PATH_SEPARATOR_REGEX". The directory path must always end with a slash character "/", otherwise ClassLoader doesn't recognize it's a directory. Server always automatically adds "SANDBOX_ROOT/trans/" directory and all JARs in "SANDBOX_ROOT/lib/" directory, so they don't have to be added explicitly. | |
| classloader_caching | false | Clover creates new classloaders whenever is necessary to load a class in runtime. For example, Reformat component with a Java transformation has to create a new classloader to load the class. It is worth noting that classloaders for JDBC drivers are not re-created. Classloader cache is used to avoid PermGen out of memory errors (some JDBC drivers automatically register itself to DriverManager, which can cause the classloader cannot be released by garbage collector). This behaviour can be inconvenient for example if you want to share POJO between components. For example, a Reformat component creates an object (from a jar file on runtime classpath) and stores it into a dictionary. Another Reformat component get the object from the dictionary and tries to cast the object to expected class. ClassCastException is thrown due different classloaders used in the Reformat components. Using this flag you can force CloverServer to re-use classloader when possible. |
| skip_check_config | default value is taken from engine property | Switch which specifies whether check config must be performed before transformation execution. |
| password | This property is deprecated. Password for decoding of encoded DB connection passwords. | |
| verbose_mode | true | If true, more descriptive logs of job runs are generated. |
| use_jmx | true | If true, job executor registers jmx mBean of running transformation. |
| debug_mode | false |
If true, edges with debug enabled will store data into files in a debug directory. Without explicit setting, running of a graph from Designer with server integration would set the debug_mode to true. On the other hand, running of a graph from the server console sets the debug_mode to false. |
| delete_obsolete_temp_files | false |
If true, system will remove temporary files produced during previous finished runs of the respective job. This property is useful together with enabled debug mode ensuring that obsolete debug files from previous runs of a job are removed from temp space. This property is set to "true" by default when executing job using designer-server integration. |
| use_local_context_url | false | If true, the context URL of a running job will be a local "file:" URL. Otherwise, a "sandbox:" URL will be used. |
| jobflow_token_tracking | true | If false, token tracking in jobflow executions will be disabled. |
| locale | DEFAULT_LOCALE engine property | Can be used to override the DEFAULT_LOCALE engine property. |
| time_zone | DEFAULT_TIME_ZONE engine property | Can be used to override the DEFAULT_TIME_ZONE engine property. |
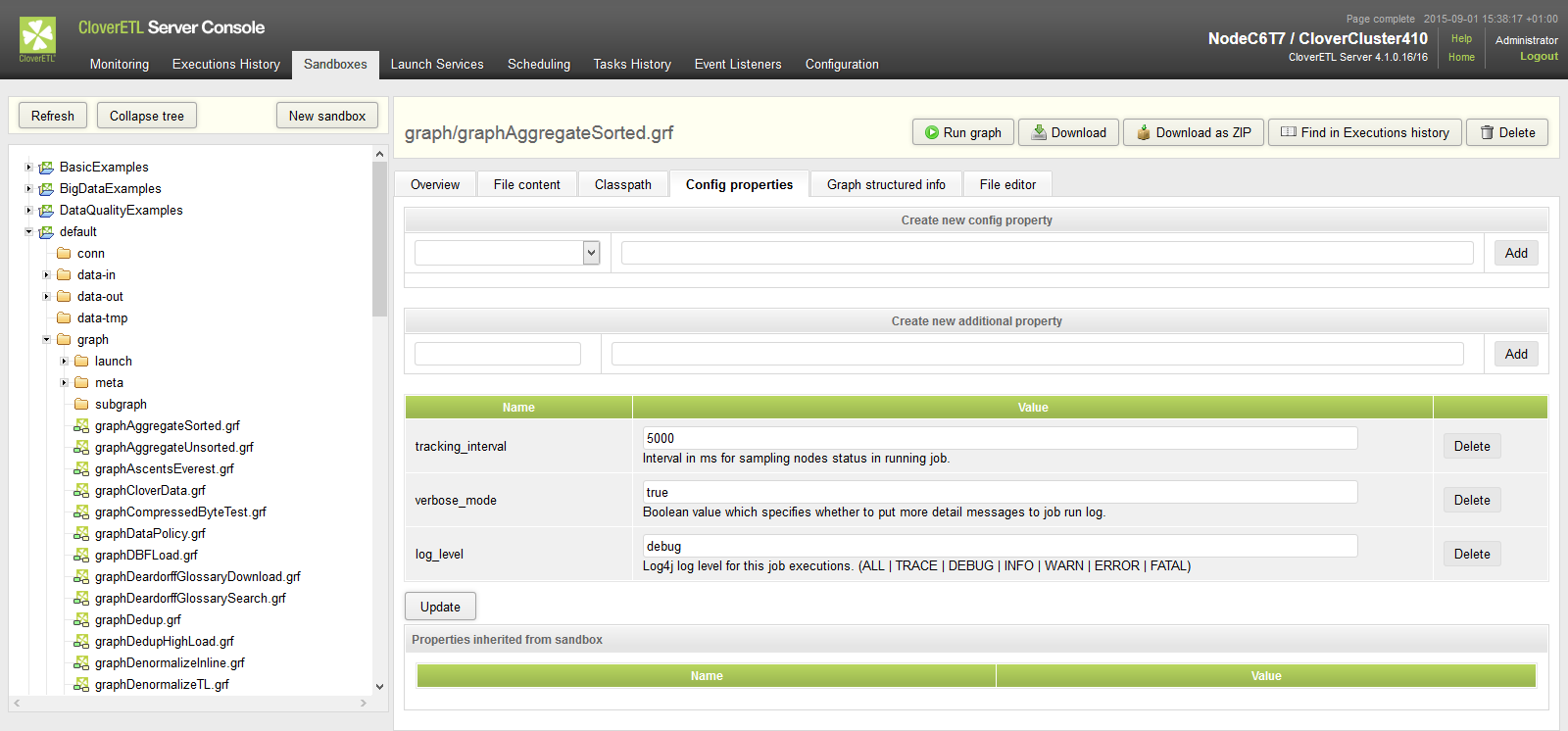 |
Figure 15.9. Job config properties