
Compass Core provides an abstraction layer on top of the wonderful Lucene Search Engine. Compass also provides several additional features on top of Lucene, like two phase transaction management, fast updates, and optimizers. When trying to explain how Compass works with the Search Engine, first we need to understand the Search Engine domain model.
Resource represents a collection of properties. You can think about it as a virtual document - a chunk of data, such as a web page, an e-mail message, or a serialization of the Author object. A Resource is always associated with a single Alias and several Resources can have the same Alias. The alias acts as the connection between a Resource and its mapping definitions (OSEM/XSEM/RSEM). A Property is just a place holder for a name and value (both strings). A Property within a Resource represents some kind of meta-data that is associated with the Resource like the author name.
Every Resource is associated with one or more id properties. They are required for Compass to manage Resource loading based on ids and Resource updates (a well known difficulty when using Lucene directly). Id properties are defined either explicitly in RSEM definitions or implicitly in OSEM/XSEM definitions.
For Lucene users, Compass Resource maps to Lucene Document and Compass Property maps to Lucene Field.
When working with RSEM, resources acts as your prime data model. They are used to construct searchable content, as well as manipulate it. When performing a search, resources be used to display the search results.
Another important place where resources can be used, which is often ignored, is with OSEM/XSEM. When manipulating search content through the use of the application domain model (in case of OSEM), or through the use of xml data structures (in case of XSEM), resources are rarely used. They can be used when performing search operations. Based on your mapping definition, the semantic model could be accessed in a uniformed way through resources and properties.
Lets simplify this statement by using an example. If our application has two object types, Recipe and Ingredient, we can map both recipe title and ingredient title into the same semantic meta-data name, title (Resource Property name). This will allow us when searching to display the search results (hits) only on the Resource level, presenting the value of the property title from the list of resources returned.
Analyzers are components that pre-process input text. They are also used when searching (the search string has to be processed the same way that the indexed text was processed). Therefore, it is usually important to use the same Analyzer for both indexing and searching.
Analyzer is a Lucene class (which qualifies to org.apache.lucene.analysis.Analyzer class). Lucene core itself comes with several Analyzers and you can configure Compass to work with either one of them. If we take the following sentence: "The quick brown fox jumped over the lazy dogs", we can see how the different Analyzers handle it:
whitespace (org.apache.lucene.analysis.WhitespaceAnalyzer): [The] [quick] [brown] [fox] [jumped] [over] [the] [lazy] [dogs] simple (org.apache.lucene.analysis.SimpleAnalyzer): [the] [quick] [brown] [fox] [jumped] [over] [the] [lazy] [dogs] stop (org.apache.lucene.analysis.StopAnalyzer): [quick] [brown] [fox] [jumped] [over] [lazy] [dogs] standard (org.apache.lucene.analysis.standard.StandardAnalyzer): [quick] [brown] [fox] [jumped] [over] [lazy] [dogs]
Lucene also comes with an extension library, holding many more analyzer implementations (including language specific analyzers). Compass can be configured to work with all of them as well.
A Compass instance acts as a registry of analyzers, with each analyzer bound to a lookup name. Two internal analyzer names within Compass are: default and search. default is the default analyzer that is used when no other analyzer is configured (configuration of using different analyzer is usually done in the mapping definition by referencing a different analyzer lookup name). search is the analyzer used on a search query string when no other analyzer is configured (configuring a different analyzer when executing a search based on a query string is done through the query builder API). By default, when nothing is configured, Compass will use Lucene standard analyzer as the default analyzer.
The following is an example of configuring two analyzers, one that will replace the default analyzer, and another one registered against myAnalyzer (it will probably later be referenced from within the different mapping definitions).
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<searchEngine>
<analyzer name="deault" type="Snowball" snowballType="Lovins">
<stopWords>
<stopWord value="no" />
</stopWords>
</analyzer>
<analyzer name="myAnalyzer" type="Standard" />
</searchEngine>
</compass>
Compass also supports custom implementations of Lucene Analyzer class (note, the same goal might be achieved by implementing an analyzer filter, described later). If the implementation also implements CompassConfigurable, additional settings (parameters) can be injected to it using the configuration file. Here is an example configuration that registers a custom analyzer implementation that accepts a parameter named threshold:
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<searchEngine>
<analyzer name="deault" type="CustomAnalyzer" analyzerClass="eg.MyAnalyzer">
<setting name="threshold">5</setting>
</analyzer>
</searchEngine>
</compass>
Filters are provided for simpler support for additional filtering (or enrichment) of analyzed streams, without the hassle of creating your own analyzer. Also, filters, can be shared across different analyzers, potentially having different analyzer types.
A custom filter implementation need to implement Compass LuceneAnalyzerTokenFilterProvider, which single method creates a Lucene TokenFilter. Filters are registered against a name as well, which can then be used in the analyzer configuration to reference them. The next example configured two analyzer filters, which are applied on to the default analyzer:
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<searchEngine>
<analyzer name="deafult" type="Standard" filters="test1, test2" />
<analyzerFilter name="test1" type="eg.AnalyzerTokenFilterProvider1">
<setting name="param1" value="value1" />
</analyzerFilter>
<analyzerFilter name="test2" type="eg.AnalyzerTokenFilterProvider2">
<setting name="paramX" value="valueY" />
</analyzerFilter>
</searchEngine>
</compass>
Since synonyms are a common requirement with a search application, Compass comes with a simple synonym analyzer filter: SynonymAnalyzerTokenFilterProvider. The implementation requires as a parameter (setting) an implementation of a SynonymLookupProvider, which can return all the synonyms for a given value. No implementation is provided, though one that goes to a public synonym database, or a file input structure is simple to implement. Here is an example of how to configure it:
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<searchEngine>
<analyzer name="deafult" type="Standard" filters="synonymFilter" />
<analyzerFilter name="synonymFilter" type="synonym">
<setting name="lookup" value="eg.MySynonymLookupProvider" />
</analyzerFilter>
</searchEngine>
</compass>
Note the fact that we did not set the fully qualified class name for the type, and used synonym. This is a simplification that comes with Compass (naturally, you can still use the fully qualified class name of the synonym token filter provider).
Compass can be configured with Lucene Similarity for both indexing and searching. This is advanced configuration level. By default, Lucene DefaultSimilarity is used for both searching and indexing.
In order to globally change the Similarity, the type of the similarity can be set using compass.engine.similarity.default.type. The type can either be the actual class name of the Similarity implementation, or an the class name of SimilarityFactory implementation. Both can optionally implement CompassConfigurble in order to be injected with CompassSettings.
Specifically, the index similarity can be set using compass.engine.similarity.index.type. The search similarity can be set using compass.engine.similarity.search.type.
By default, Compass uses its own query parser based on Lucene query parser. Compass allows to configure several query parsers (registered under a lookup name), as well as override the default Compass query parser (registered under the name default). Custom query parsers can be used to extend the default query language support, to add parsed query caching, and so on. A custom query parser must implement the LuceneQueryParser interface.
Here is an example of configuring a custom query parser registered under the name test:
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<searchEngine>
<queryParser name="test" type="eg.MyQueryParser">
<setting name="param1" value="value1" />
</queryParser>
</searchEngine>
</compass>
It is very important to understand how the Search Engine index is organized so we can than talk about transaction, optimizers, and sub index hashing. The following structure shows the Search Engine Index Structure:
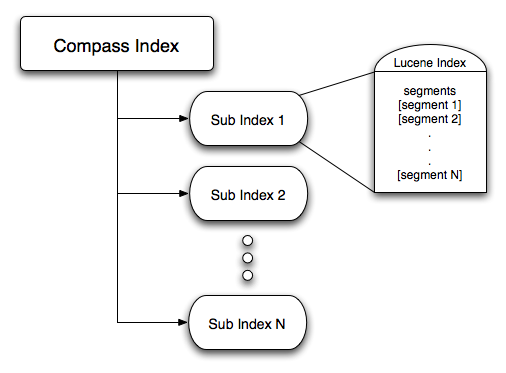
Compass Index Structure
Every sub-index has it's own fully functional index structure (which maps to a single Lucene index). The Lucene index part holds a "meta data" file about the index (called segments) and 0 to N segment files. The segments can be a single file (if the compound setting is enabled) or multiple files (if the compound setting is disable). A segment is close to a fully functional index, which hold the actual inverted index data (see Lucene documentation for a detailed description of these concepts).
Index partitioning is one of Compass main features, allowing for flexible and configurable way to manage complex indexes and performance considerations. The next sections will explain in more details why this feature is important, especially in terms of transaction management.
Compass Search Engine abstraction provides support for transaction management on top of Lucene. The abstraction support the following transaction processors: read_committed, lucene and async. Compass provides two phase commit support for the common transaction levels only.
Compass utilizes Lucene inter and outer process locking mechanism and uses them to establish it's transaction locking. Note that the transaction locking is on the "sub-index" level (the sub index based index), which means that dirty operations only lock their respective sub-index index. So, the more aliases / searchable content map to the same index (next section will explain how to do it - called sub index hashing), the more aliases / searchable content will be locked when performing dirty operations, yet the faster the searches will be. Lucene uses a special lock file to manage the inter and outer process locking which can be set in the Compass configuration. You can manage the transaction timeout and polling interval using Compass configuration.
A Compass transaction acquires a lock only when a dirty operation occurs against the index (for read_committed and lucene this means: create, save or delete), which makes "read only" transactions as fast as they should and can be. The following configuration file shows how to control the two main settings for locking, the locking timeout (which defaults to 10 seconds) and the locking polling interval (how often Compass will check and see if a lock is released or not) (defaults to 100 milli-seconds):
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<transaction lockTimeout="15" lockPollInterval="200" />
</compass>
Read committed transaction processor allows to isolate changes done during a transaction from other transactions until commit. It also allows for load/get/find operations to take into account changes done during the current transaction. This means that a delete that occurs during a transaction will be filtered out if a search is executed within the same transaction just after the delete.
When starting a read_committed transaction, no locks are obtained. Read operation will not obtain a lock either. A lock will be obtained only when a dirty operation is performed. The lock is obtained only on the index of the alias / searchable content that is associated with the dirty operation, i.e the sub-index, and will lock all other aliases / searchable content that map to that sub-index.
The read committed transaction support concurrent commit where if operations are performed against several sub indexes, the commit process will happen concurrently on the different sub indexes. It uses Compass internal Execution Manager where the number of threads as well as the type of the execution manager (concurrent or work manager) can be configured. Concurrent commits are used only if the relevant store supports it.
By default, read committed transactions work in an asynchronous manner (if allowed by the search engine store). Compass executor service is used to execute the destructive operations using several threads. This allows for much faster execution and the ability to continue process application level logic while objects are being indexed or removed from the search engine. In order to disable this, the compass.transaction.processor.read_committed.concurrentOperations setting should be set to false. The read committed semantic is still maintained by waiting for all current operation to complete once a read/search operation occurs. Note, when asynchronous operation is enabled, problems with indexing objects will be raised not as a result of the actual operation that caused it, but on commit, flush or read/search time. ComapssSession flush operation can also be used to wait for all current operation to be performed.
There are several settings that control the asynchronous execution (javadoc at LuceneEnvironment.Transaction.Processor.ReadCommitted). The compass.transaction.processor.read_committed.concurrencyLevel control the number of threads used (per transaction) to process dirty operations (defaults to 5). compass.transaction.processor.read_committed.hashing controls how operations are hashed to a respective thread to be processed, and can be either by uid or subindex (defaults to uid). The compass.transaction.processor.read_committed.backlog controls the number of pending destructive operations allowed. If full, dirty operations will block until space becomes available (defaults to 100). Last, the compass.transaction.processor.read_committed.addTimeout controls the time to wait in order to add dirty operations to the backlog if the backlog is full. It defaults to 10 seconds and accepts Compass time format (10millis, 30s, ...). Note, all settings are also runtime settings that can control specific transaction using CompassSession#getSettings() and then setting the respective ones.
Read committed transaction processor works against a transaction log (which is simply another Lucene index). The transaction log can either be stored in memory or on the file system. By default the transaction log is stored in memory. Here is how it can be configured:
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<transaction processor="read_committed">
<processors>
<readCommitted transLog="ram://" />
</processors>
</transaction>
</compass>
compass.engine.connection=target/test-index compass.transaction.readcommitted.translog.connection=ram://
Using the read committed transaction processor can also be done in runtime using the following code:
CompassSession session = compass.openSession();
session.getSettings().setSetting(LuceneEnvironment.Transaction.Processor.TYPE,
LuceneEnvironment.Transaction.Processor.ReadCommitted.NAME);
The FS transaction log stores the transactional data on the file system. This allows for bigger transactions (bigger in terms of data) to be run when compared with the ram transaction log though on account of performance. The fs transaction log can be configured with a path where to store the transaction log (defaults to java.io.tmpdir system property). The path is then appended with compass/translog and for each transaction a new unique directory is created. Here is an example of how the FS transaction can be configured:
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<transaction processor="read_committed">
<processors>
<readCommitted transLog="file://" />
</processors>
</transaction>
</compass>
compass.engine.connection=target/test-index compass.transaction.readcommitted.translog.connection=file://
CompassSession and CompassIndexSession provides the flushCommit operation. The operation, when used with the read_committed transaction processor, means that the current changes to the search engine will be flushed and committed. The operation will be visible to other sessions / compass instances and rollback operation on the transaction will not roll them back. The flushCommit is handy when there is a long running session that performs the indexing and transactionality is not as important as making the changes made available to other sessions intermittently.
Transactional log settings are one of the session level settings that can be set. This allows to change how Compass would save the transaction log per session, and not globally on the Compass instance level configuration. Note, this only applies on the session that is responsible for creating the transaction. The following is an example of how it can be done:
CompassSession session = compass.openSession();
session.getSettings().setSetting(LuceneEnvironment.Transaction.Processor.ReadCommitted.TransLog.CONNECTION,
"file://tmp/");
A special transaction processor, lucene (previously known as batch_insert) transaction processor is similar to the read_committed isolation level except dirty operations done during a transaction are not visible to get/load/find operations that occur within the same transaction. This isolation level is very handy for long running batch dirty operations and can be faster than read_committed. Most usage patterns of Compass (such as integration with ORM tools) can work perfectly well with the lucene isolation level.
It is important to understand this transaction isolation level in terms of merging done during commit time. Lucene might perform some merges during commit time depending on the merge factor configured using compass.engine.mergeFactor. This is different from the read_committed processor where no merges are performed during commit time. Possible merges can cause commits to take some time, so one option is to configure a large merge factor and let the optimizer do its magic (you can configure a different merge factor for the optimizer).
Another important parameter when using this transaction isolation level is compass.engine.ramBufferSize (defaults to 16.0 Mb) which replaces the max buffered docs parameter and controls the amount of transactional data stored in memory. Larger values will yield better performance and it is best to allocate as much as possible.
By default, lucene transactions work in an asynchronous manner (if allowed by the index store). Compass executor service is used to execute theses destructive operations using several threads. This allows for much faster execution and the ability to continue process application level logic while objects are being indexed or removed from the search engine. In order to disable this, the compass.transaction.processor.lucene.concurrentOperations setting should be set to false. Note, when asynchronous operation is enabled, problems with indexing objects will be raised not as a result of the actual operation that caused it, but on commit or flush time. ComapssSession flush operation can also be used to wait for all current operation to be performed. Also note, that unlike read committed transaction (and because of the semantics of lucene transaction processor, that do not reflect current transaction operations in read/search operations), there is no need to wait for asynchronous dirty operation to be processed during search/read operation.
There are several settings that control the asynchronous execution (javadoc at LuceneEnvironment.Transaction.Processor.Lucene). The compass.transaction.processor.lucene.concurrencyLevel control the number of threads used (per transaction) to process dirty operations (defaults to 5). compass.transaction.processor.lucene.hashing controls how operations are hashed to a respective thread to be processed, and can be either by uid or subindex (defaults to uid). The compass.transaction.processor.lucene.backlog controls the number of pending destructive operations allowed. If full, dirty operations will block until space is available (defaults to 100). Last, the compass.transaction.processor.lucene.addTimeout controls the time to wait in order to add dirty operations to the backlog if the backlog is full. It defaults to 10 seconds and accepts Compass time format (10millis, 30s, ...). Note, all settings are also runtime settings that can control specific transaction using CompassSession#getSettings() and then setting the respective ones.
The lucene transaction support concurrent commit where if operations are performed against several sub indexes, the commit process will happen concurrently on the different sub indexes. It uses Compass internal Execution Manager where the number of threads as well as the type of the execution manager (concurrent or work manager) can be configured.
CompassSession and CompassIndexSession provides the flushCommit operation. The operation, when used with the lucene transaction processor, means that the current changes to the search engine will be flushed and committed. The operation will be visible to other sessions / compass instances and rollback operation on the transaction will not roll them back. The flushCommit is handy when there is a long running session that performs the indexing and transactionality is not as important as making the changes made available to other sessions intermittently.
Here is how the transaction isolation level can be configured to be used as the default one:
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<transaction processor="lucene" />
</compass>
compass.engine.connection=target/test-index compass.transaction.processor=lucene
Using the lucene transaction processor can also be done in runtime using the following code:
CompassSession session = compass.openSession();
session.getSettings().setSetting(LuceneEnvironment.Transaction.Processor.TYPE,
LuceneEnvironment.Transaction.Processor.Lucene.NAME);
The async transaction processor allows to asynchronously process transactions without incurring any overhead on the thread that actually executes the transaction. Transactions (each transaction consists of one or more destructive operation - create/upgrade/delete) are accumulated and processed asynchronously and concurrently. Note, async transaction processor does not obtain a lock when a dirty operation occurs within a transaction.
Note, when several instances of Compass are running using this transaction processor, order of transactions is not maintained, which might result in out of order transaction being applied to the index. When there is a single instance running, by default, order of transaction is maintained by obtaining an order lock once a dirty operation occurs against the sub index (similar to Lucene write lock) which is released once the transaction commits / rolls back. In order to disable even this ordering, the compass.transaction.processor.async.maintainOrder can be set to false.
The number of transactions that have not been processed (backlog) are bounded and default to 10. If the processor is falling behind in processing transactions, commit operations will block until the backlog lowers below its threshold. The backlog can be set using the compass.transaction.processor.async.backlog setting. Commit operations will block by default for 10 seconds in order for the backlog to lower below its threshold. It can be changed using the compass.transaction.processor.async.addTimeout setting (which accepts the time format setting).
Processing of transactions is done by a background thread that waits for transactions. Once there is a transaction to process, it will first try to wait for additional transactions. It will block for 100 milliseconds (configurable using compass.transaction.processor.async.batchJobTimeout), and if one was added, will wait again up to 5 times (configurable using compass.transaction.processor.async.batchJobSize setting). Once batch jobs based on timeout is done, the processor will try to get up to 5 more transactions in a non blocking manner (configurable using compass.transaction.processor.async.nonBlockingBatchJobSize setting).
When all transaction jobs are accumulated, the processor starts up to 5 threads (configurable using compass.transaction.processor.async.concurrencyLevel) in order to process all the transaction jobs against the index. Hashing of actual operation (create/update/delete) can either be done based on uid (of the resource) or subindex. By default, hashing is done based on uid and can be configured using compass.transaction.processor.async.hashing setting.
CompassSession and CompassIndexSession provides the flushCommit operation. The operation, when used with the async transaction processor, means that all the changes accumulated up to this point will be passed to be processed (similar to commit) except that the session is still open for additional changes. This allows, for long running indexing sessions, to periodically flush and commit the changes (otherwise memory consumption will continue to grow) instead of committing and closing the current session, and opening a new session.
When the transaction processor closes, by default it will wait for all the transactions to finish. In order to disable it, the compass.transaction.processor.async.processBeforeClose setting should be set to false.
Here is how the transaction isolation level can be configured to be used as the default one:
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<transaction processor="async" />
</compass>
compass.engine.connection=target/test-index compass.transaction.processor=async
Using the async transaction processor can also be done in runtime using the following code:
CompassSession session = compass.openSession();
session.getSettings().setSetting(LuceneEnvironment.Transaction.Processor.TYPE,
LuceneEnvironment.Transaction.Processor.Async.NAME);
The mt transaction processor is a thread safe transaction processor effectively allowing to use the same CompassIndexSession (or CompassSession) across multiple threads. The transaction processor is very handy when several threads are updating the index during a single logical indexing session.
Once a dirty operation is performed using the mt transaction processor, its respective sub index is locked and no dirty operation from other session is allowed until the session is committed, rolled back, or closed. Because of the nature of the mt transaction processor, the flushCommit operation can be very handy. It effectively commits all the changes up to the point it was called without closing or committing the session, making it visible for other sessions when searching. Note, it also means that the operations that were flush committed will not rollback on a rollback operation.
It is important to understand this transaction isolation level in terms of merging done during commit and indexing time. Lucene might perform some merges during commit time depending on the merge factor configured using compass.engine.mergeFactor. This is different from the read_committed processor where no merges are performed during commit time. Possible merges can cause commits to take some time, so one option is to configure a large merge factor and let the optimizer do its magic (you can configure a different merge factor for the optimizer).
Another important parameter when using this transaction isolation level is compass.engine.ramBufferSize (defaults to 16.0 Mb) which replaces the max buffered docs parameter and controls the amount of transactional data stored in memory. Larger values will yield better performance and it is best to allocate as much as possible.
If using the search / read API with the mt transaction processor, it basically acts in a similar manner to the lucene transaction processor, meaning the search operations will see the latest version of the index, without the current changes done during the transaction. There is an exception to the rule, where if the flushCommit operation was called, and the internal cache of Compass was invalidated (either asynchronously or explicitly by calling the refresh or clear cache API), then the search results will reflect that changes done up to the point when the flushCommit operation.
Here is how the transaction isolation level can be configured to be used as the default one:
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<transaction processor="mt" />
</compass>
compass.engine.connection=target/test-index compass.transaction.processor=mt
Using the mt transaction processor can also be done in runtime using the following code:
CompassSession session = compass.openSession();
session.getSettings().setSetting(LuceneEnvironment.Transaction.Processor.TYPE,
LuceneEnvironment.Transaction.Processor.MT.NAME);
An optimized transaction processor that only provides search capabilities. The transaction processor is automatically used when setting the session to read only (using CompassSession#setReadOnly()), or when opening a search session (using Compass#openSearchSession()).
Compass supports master worker like processing of transactions using Terracotta. For more information see here.
Implementing a custom Transaction Processor is very simple. Compass provides simple API and simple base classes that should make implementing one a snap. For more information on how to do it, please check the currently implemented transaction processors and ask questions on the forum. Proper documentation will arrive soon.
When indexing an Object, XML, or a plain Resource, their respective properties are added to the index. These properties can later be searched explicitly, for example: title:fang. Most times users wish to search on all the different properties. For this reason, Compass, by default, supports the notion of an "all" property. The property is actually a combination of the different properties mapped to the search engine.
The all property provides advance features such using declared mappings of given properties. For example, if a property is marked with a certain analyzer, that analyzer will be usde to add the property to the all property. If it is untokenized, it will be added without analyzing it. If it is configured with a certain boost value, that part of the all property, when "hit", will result in higher ranking of the result.
The all property allows for global configuration and per mapping configuration. The global configuration allows to disable the all feature completely (compass.property.all.enabled=false). It allows to exclude the alias from the all proeprty (compass.property.all.excludeAlias=true), and can set the term vector for the all property (compass.property.all.termVector=yes for example).
The per mapping definitions allow to configure the above settings on a mapping level (they override the global ones). They are included in an all tag that should be the first one within the different mappings. Here is an example for OSEM:
<compass-core-mapping> <[mapping] alias="test-alias"> <all enable="true" exclude-alias="true" term-vector="yes" omit-norms="yes" /> </[mapping]> </compass-core-mapping>
Searchable content is mapped to the search engine using Compass different mapping definitions (OSEM/XSEM/RSEM). Compass provides the ability to partition the searchable content into different sub indexes, as shown in the next diagram:
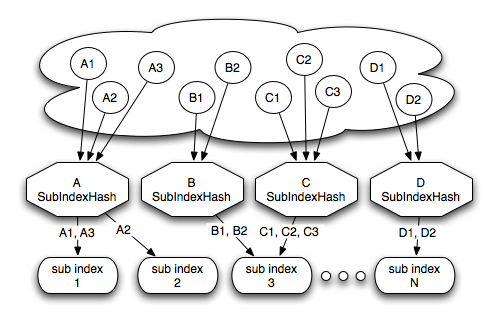
Sub Index Hashing
In the above diagram A, B, C, and D represent aliases which in turn stands for the mapping definitions of the searchable content. A1, B2, and so on, are actual instances of the mentioned searchable content. The diagram shows the different options of mapping searchable content into different sub indexes.
The simplest way to map aliases (stands for the mapping definitions of a searchable content) is by mapping all its searchable content instances into the same sub index. Defining how searchable content mapping to the search engine (OSEM/XSEM/RSEM) is done within the respectable mapping definitions. There are two ways to define a constant mapping to a sub index, the first one (which is simpler) is:
<compass-core-mapping>
<[mapping] alias="test-alias" sub-index="test-subindex">
<!-- ... -->
</[mapping]>
</compass-core-mapping>
The mentioned [mapping] that is represented by the alias test-alias will map all its instances to test-subindex. Note, if sub-index is not defined, it will default to the alias value.
Another option, which probably will not be used to define constant sub index hashing, but shown here for completeness, is by specifying the constant implementation of SubIndexHash within the mapping definition (explained in details later in this section):
<compass-core-mapping>
<[mapping] alias="test-alias">
<sub-index-hash type="org.compass.core.engine.subindex.ConstantSubIndexHash">
<setting name="subIndex" value="test-subindex" />
</sub-index-hash>
<!-- ... -->
</[mapping]>
</compass-core-mapping>
Here is an example of how three different aliases: A, B and C can be mapped using constant sub index hashing:
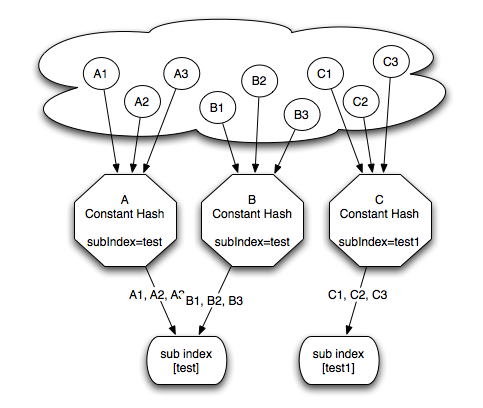
Modulo Sub Index Hashing
Constant sub index hashing allows to map an alias (and all its searchable instances it represents) into the same sub index. The modulo sub index hashing allows for partitioning an alias into several sub indexes. The partitioning is done by hashing the alias value with all the string values of the searchable content ids, and then using the modulo operation against a specified size. It also allows setting a constant prefix for the generated sub index value. This is shown in the following diagram:
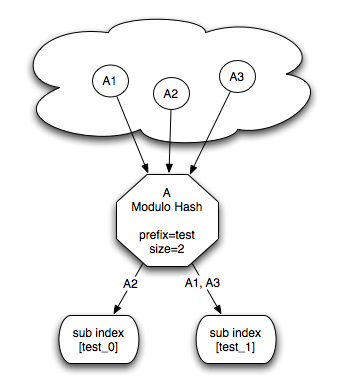
Modulo Sub Index Hashing
Here, A1, A2 and A3 represent different instances of alias A (let it be a mapped Java class in OSEM, a Resource in RSEM, or an XmlObject in XSEM), with a single id mapping with the value of 1, 2, and 3. A modulo hashing is configured with a prefix of test, and a size of 2. This resulted in the creation of 2 sub indexes, called test_0 and test_1. Based on the hashing function (the alias String hash code and the different ids string hash code), instances of A will be directed to their respective sub index. Here is how A alias would be configured:
<compass-core-mapping>
<[mapping] alias="A">
<sub-index-hash type="org.compass.core.engine.subindex.ModuloSubIndexHash">
<setting name="prefix" value="test" />
<setting name="size" value="2" />
</sub-index-hash>
<!-- ... -->
</[mapping]>
</compass-core-mapping>
Naturally, more than one mapping definition can map to the same sub indexes using the same modulo configuration:
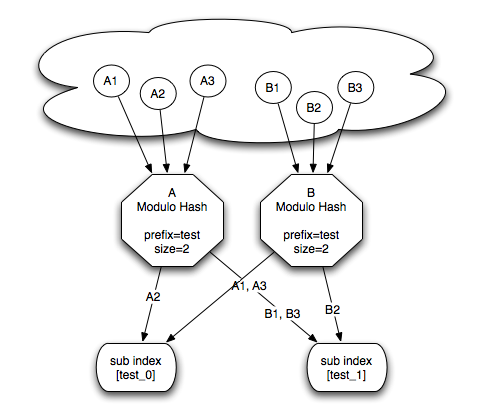
Complex Modulo Sub Index Hashing
ConstantSubIndexHash and ModuloSubIndexHash are implementation of Compass SubIndexHash interface that comes built in with Compass. Naturally, a custom implementation of the SubIndexHash interface can be configured in the mapping definition.
An implementation of SubIndexHash must provide two operations. The first, getSubIndexes, must return all the possible sub indexes the sub index hash implementation can produce. The second, mapSubIndex(String alias, Property[] ids) uses the provided aliases and ids in order to compute the given sub index. If the sub index hash implementation also implements the CompassConfigurable interface, different settings can be injected to it. Here is an example of a mapping definition with custom sub index hash implementation:
<compass-core-mapping>
<[mapping] alias="A">
<sub-index-hash type="eg.MySubIndexHash">
<setting name="param1" value="value1" />
<setting name="param2" value="value2" />
</sub-index-hash>
<!-- ... -->
</[mapping]>
</compass-core-mapping>
As mentioned in the read_committed section, every dirty transaction that is committed successfully creates another segment in the respective sub index. The more segments the index has, the slower the fetching operations take. That's why it is important to keep the index optimized and with a controlled number of segments. We do this by merging small segments into larger segments.
The optimization process works on a sub index level, performing the optimization for each one. During the optimization process, optimizers will lock the sub index for dirty operations (only if optimization is required). This causes a tradeoff between having an optimized index, and spending less time on the optimization process in order to allow for other dirty operations.
Compass comes with a single default optimizer implementation. The default optimizer will try and maintain no more than a configured maximum number of segments (defaults to 10). This applies when using the optimize() and optimizer(subIndex) API, as well as when the optimizer is scheduled to run periodically (which is the default). It also provides support for specific, API level, optimization with a provided maximum number of segments.
Here is an example of a configuration of the default optimizer to run with 20 maximum number of segments, and work in a scheduled manner with an interval of 90 seconds (default is 10 seconds):
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<searchEngine>
<optimizer scheduleInterval="90" schedule="true" maxNumberOfSegments="20" />
</searchEngine>
</compass>
compass.engine.connection=target/test-index compass.engine.optimizer.schedule=true compass.engine.optimizer.schedule.period=90 compass.engine.optimizer.maxNumberOfSegments=20
Lucene perfoms merges of different segments after certain operaitons are done on the index. The less merges you have, the faster the searching is. The more merges you do, the slower certain operations will be. Compass allows for fine control over when merges will occur. This depends greatly on the transaction isolation level and the optimizer used and how they are configured.
Merge policy controls which merges are supposed to happen for a ceratin index. Compass allows to simply configure the two merge policies that come with Lucene, the LogByteSize (the default) and LogDoc, as well as configure custom implementations. Configuring the type can be done usign compass.engine.merge.policy.type and has possible values of logbytesize, logdoc, or the fully qualified class name of a MergePolicyProvider.
The LogByteSize can be further configured using compass.engine.merge.policy.maxMergeMB and compass.engine.merge.policy.minMergeMB.
Merge scheduler controls how merge operations happen once a merge is needed. Lucene comes with built in ConcurrentMergeSchduler (executes merges concurrently on newly created threads) and SerialMergeScheduler that executes the merge operations on the same therad. Compass extends Lucene and provide ExecutorMergeScheduler allowing to utlize Compass internal exdecutor pool (either concurrent or work manager backed) with no overhead of creating new threads. This is the default merge scheduler that comes with Compass.
Configuring the type of the merge scheduler can be done using compass.engine.merge.scheduler.type with the following possible values: executor (the default), concurrent (Lucene Concurrent merge scheduler), and serial (Lucene serial merge scheduler). It can also have a fully qualified name of an implementation of MergeSchedulerProvider.
Lucene allows to define an IndexDeletionPolicy which allows to control when commit points are deleted from the index storage. Index deletion policy mainly aim at allowing to keep old Lucene commit points relevant for a certain parameter (such as expiration time or number of commits), which allows for better NFS support for example. Compass allows to easily control the index deletion policy to use and comes built in with several index deletion policy implementations. Here is an example of its configuration using the default index deletion policy which keeps only the last commit point:
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<searchEngine>
<indexDeletionPolicy>
<keepLastCommit />
</indexDeletionPolicy>
</searchEngine>
</compass>
Here is the same configuration using properties based configuration:
<compass name="default">
<connection>
<file path="target/test-index" />
</connection>
<settings>
<setting name="compass.engine.store.indexDeletionPolicy.type" value="keeplastcommit" />
</settings>
</compass>
Compass comes built in with several additional deletion policies including: keepall which keeps all commit points. keeplastn which keeps the last N commit points. expirationtime which keeps commit points for X number of seconds (with a default expiration time of "cache invalidation interval * 3").
By default, the index deletion policy is controlled by the actual index storage. For most (ram, file) the deletion policy is keep last committed (which should be changed when working over a shared disk). For distributed ones (such as coherence, gigaspaces, terrracotta), the index deletion policy is the expiration time one.
Compass comes with built in support for spell check support. It allows to suggest queries (did you mean feature) as well as allow to get possible suggestions for given words. By default, the spell check support is disabled. In other to enable it, the following property need to be set:
compass.engine.spellcheck.enable=true
Once spell check is enabled, a special spell check index will be built based on the "all" property (more on that later). It can then be used in the following simple manner:
CompassQuery query = session.queryBuilder().queryString("jack london").toQuery();
CompassHits hits = query.hits();
System.out.println("Original Query: " + hits.getQuery());
if (hits.getSuggestedQuery().isSuggested()) {
System.out.println("Did You Mean: " + hits.getSuggestedQuery());
}
In order to perform spell index level operations, Compass exposes now a getSpellCheckManager() in order to perform them. Note, this method will return null in case spell check is disabled. The spell check manager also allows to get suggestions for a given word.
By default, when the spell check index is enabled, two scheduled tasks will kick in. The first scheduled task is responsible for monitoring the spell check index, and if changed (for example, by a different Compass instance), will reload the latest changes into the index. The interval for this scheduled task can be controlled using the setting compass.engine.cacheIntervalInvalidation (which is used by Compass for the actual index as well), and defaults to 5 seconds (it is set in milliseconds).
The second scheduler is responsible for identifying that the actual index was changed, and rebuild the spell check index for the relevant sub indexes that were changed. It is important to understand that the spell check index will not be updated when operations are performed against the actual index. It will only be updated if explicitly called for rebuild or concurrentRebuild using the Spell Check Manager, or through the scheduler (which calls the same methods). By default, the scheduler will run every 10 minutes (no sense in rebuilding the spell check index very often), and can be controlled using the following setting: compass.engine.spellcheck.scheduleInterval (resolution in seconds).
Compass by default will build a spell index using the same configured index storage simply under a different "sub context" name called spellcheck (the compass index is built under sub context index). For each sub index in Compass, a spell check sub index will be created. By default, a scheduler will kick in (by default each 10 minutes) and will check if the spell index needs to be rebuilt, and if it does, it will rebuild it. The spell check manager also exposes API in order to perform the rebuild operations as well as checking if the spell index needs to be rebuilt. Here is an example of how the scheduler can be configured:
compass.engine.spellcheck.enable=true # the default it true, just showing the setting compass.engine.spellcheck.schedule=true # the schedule, in minutes (defaults to 10) compass.engine.spellcheck.scheduleInterval=10
The spell check index can be configured to be stored on a different location than the Compass index. Any index related parameters can be set as well. Here is an example (for example, if the index is stored in the database, and spell index should be stored on the file system):
compass.engine.spellcheck.enable=true compass.engine.spellcheck.engine.connection=file://target/spellindex compass.engine.spellcheck.engine.ramBufferSize=40
In the above example we also configure the indexing process of the spell check index to use more memory (40) so the indexing process will be faster. As seen here, settings that control the index can be used (compass.engine. settings) can apply to the spell check index by prepending the compass.engine.spellcheck setting.
So, what is actually being included in the spell check index. Out of the box, by just enabling spell check, the all field is going to be used to get the terms for the spell check index. In this case, things that are excluded from the all field will be excluded from the spell check index as well
Compass allows for great flexibility in what is going to be included or excluded in the spell check index. The first two important settings are: compass.engine.spellcheck.defaultMode and the spell-check resource mapping level definition (for class/resource/xml-object). By default, both are set to NA, which results in including the all property. The all property can be excluded by setting the spell-check to exclude on the all mapping definition.
Each resource mapping (resource/class/xml-object) can have a spell-check definition of include, exclude, and na. If set to na, the global default mode will be used for it (which can be set to include, exclude and na as well).
When the resource mapping ends up with spell-check of include, it will automatically include all the properties for the given mapping, except for the "all" property. Properties can be excluded by specifically setting their respective spell-check to exclude.
When the resource mapping ends up with spell-check of exclude, it will automatically exclude all the properties for the given mapping, as well as the "all" property. Properties can be included by specifically setting their respective spell-check to include.
On top of specific mapping definition. Compass can be configured with compass.engine.spellcheck.globablIncludeProperties which is a comma separated list of properties that will always be included. And compass.engine.spellcheck.globablExcludeProperties which is a comma separated list of properties that will always be excluded.
If you wish to know which properties end up being included for certain sub index, turn the debug logging level on for org.compass.core.lucene.engine.spellcheck.DefaultLuceneSpellCheckManager and it will print out the list of properties that will be used for each sub index.
Compass provides a helpful abstraction layer on top of Lucene, but it also acknowledges that there are cases where direct Lucene access, both in terms of API and constructs, is required. Most of the direct Lucene access is done using the LuceneHelper class. The next sections will describe its main features, for a complete list, please consult its javadoc.
Compass wraps some of Lucene classes, like Query and Filter. There are cases where a Compass wrapper will need to be created out of an actual Lucene class, or an actual Lucene class need to be accessed out of a wrapper.
Here is an example for wrapping the a custom implementation of a Lucene Query with a CompassQuery:
CompassSession session = // obtain a compass session Query myQ = new MyQuery(param1, param2); CompassQuery myCQ = LuceneHelper.createCompassQuery(session, myQ); CompassHits hits = myCQ.hits();
The next sample shows how to get Lucene Explanation, which is useful to understand how a query works and executes:
CompassSession session = // obtain a compass session
CompassHits hits = session.find("london");
for (int i = 0; i < hits.length(); i++) {
Explanation exp = LuceneHelper.getLuceneSearchEngineHits(hits).explain(i);
System.out.println(exp.toString());
}
When performing read operations against the index, most of the time Compass abstraction layer is enough. Sometimes, direct access to Lucene own IndexReader and Searcher are required. Here is an example of using the reader to get all the available terms for the category property name (Note, this is a prime candidate for future inclusion as part of Compass API):
CompassSession session = // obtain a compass session
LuceneSearchEngineInternalSearch internalSearch = LuceneHelper.getLuceneInternalSearch(session);
TermEnum termEnum = internalSearch.getReader().terms(new Term("category", ""));
try {
ArrayList tempList = new ArrayList();
while ("category".equals(termEnum.term().field())) {
tempList.add(termEnum.term().text());
if (!termEnum.next()) {
break;
}
}
} finally {
termEnum.close();
}