
The Compass Needle GigaSpaces integration allows to store a Lucene index within GigaSpaces. It also allows to automatically index the data grid using Compass OSEM support and mirror changes done to the data grid into the search engine.
On top of storing the index on GigaSpaces cluster, the integration allows for two automatic indexing and search integration. The first integrates with GigaSpaces mirror service which allows to replicate in a reliable asyncronous manner changes that occur on the space to an external data source implemented by Compass (which, in turn, can store the index on another Space). Searching in this scenario is simple as another Compass instance that connects to the remote Space where the index is stored can be created for search purposes.
The seconds integration allows to perform a collocated indexing where each Space cluster member will have an embedded indexing service that will index changes done on the Space using notifications and store the index only on its local embedded Space. Searching is done using OpenSpaces executor remoting allowing to broadcast the search query to all partitions.
Compass provides a GigaSpaceDirectory which is an implementation of Lucene Directory allowing to store the index within GigaSpaces data grid.
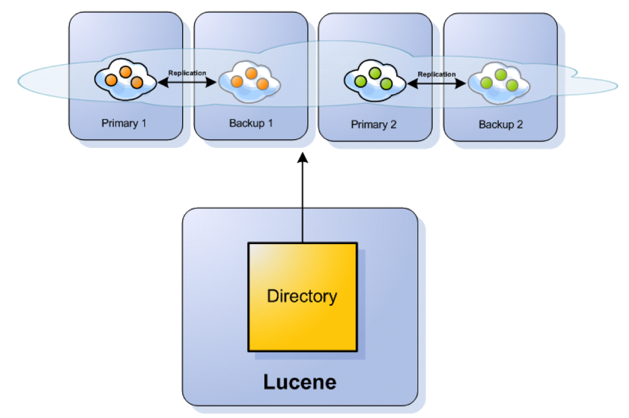
GigaSpaces Lucene Directory Based Store
Here is a simple example of how it can be used:
IJSpace space = SpaceFinder.find("jini://*/*/mySpace");
GigaSpaceDirectory dir = new GigaSpaceDirectory(space, "test");
// ... (use the dir with IndexWriter and IndexSearcher)
In the above example we created a directory on top of GigaSpace's Space with an index named "test". The directory can now be used to create Lucene IndexWriter and IndexSearcher.
The Lucene directory interface represents a virtual file system. Implementing it on top of the Space is done by breaking files into a file header, called FileEntry and one or more FileBucketEntry. The FileEntry holds the meta data of the file, for example, its size and timestamp, while the FileBucketEntry holds a bucket size of the actual file content. The bucket size can be controlled when constructing the GigaSpaceDirectory, but note that it must not be changed if connecting to an existing index.
Note, it is preferable to configure the directory not to use the compound index format as it yields better performance (note, by default, when using Compass, the non compound format will be used). Also, the merge factor for the directory (also applies to Compass optimizers) should be set to a higher value (than the default 10) since it mainly applies to file based optimizations.
The GigaSpaces integration can also use GigaSpaces just as a distributed lock manager without the need to actually store the index on GigaSpaces. The GigaSpaceLockFactory can be used for it.
Compass allows for simple integration with GigaSpaceDirectory as the index storage mechanism. The following example shows how Compass can be configured to work against a GigaSpaces based index with an index named test:
<compass name="default">
<connection>
<space indexName="test" url="jini://*/*/mySpace"/>
</connection>
</compass>
The following shows how to configure it using properties based configuration:
compass.engine.connection=space://test:jini://*/*/mySpace
By default, when using GigaSpaces as the Compass store, the index will be in an uncompound file format. It will also automatically be configured with an expiration time based index deletion policy so multiple clients will work correctly.
Compass can also be configured just to used GigaSpaces as a distributed lock manager without the need to actually store the index on GigaSpaces (note that when configuring GigaSpaces as the actual store, the GigaSpaces lock factory will be used by default). Here is how it can be configured:
compass.engine.store.lockFactory.type=org.compass.needle.gigaspaces.store.GigaSpaceLockFactoryProvider compass.engine.store.lockFactory.path=jini://*/*/mySpace?groups=kimchy
The GigaSpaces integration comes with a built in external data source that can be used with GigaSpaces Mirror Service. Basically, a mirror allows to mirror changes done to the Space (data grid) into the search engine in a reliable asynchronous manner.
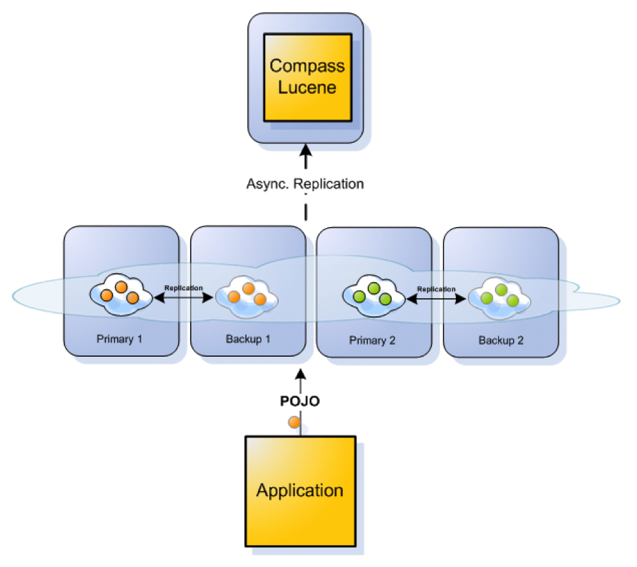
GigaSpaces Mirror Compass Integration
The following is an example of how it can be configured within a mirror processing unit (for more information see here):
<beans xmlns="http://www.springframework.org/schema/beans" ...
<bean id="compass" class="org.compass.spring.LocalCompassBean">
<property name="classMappings">
<list>
<value>eg.Blog</value>
<value>eg.Post</value>
<value>eg.Comment</value>
</list>
</property>
<property name="compassSettings">
<props>
<prop key="compass.engine.connection">space://blog:jini://*/*/searchContent</prop>
<!-- Configure expiration time so other clients that
haven't refreshed the cache will still see deleted files -->
<prop key="compass.engine.store.indexDeletionPolicy.type">expirationtime</prop>
<prop key="compass.engine.store.indexDeletionPolicy.expirationTimeInSeconds">300</prop>
</props>
</property>
</bean>
<bean id="compassDataSource" class="org.compass.needle.gigaspaces.CompassDataSource">
<property name="compass" ref="compass" />
</bean>
<os-core:space id="mirrodSpace" url="/./mirror-service" schema="mirror"
external-data-source="compassDataSource" />
</beans>
The above configuration will mirror any changes done in the data grid into the search engine through the Compass instance. It will, further more, connect and store the index content on a specific Space called blog.
Compass and be integrated with GigaSpaces allows for seamless indexing of objects and search using an embedded indexing and search service. The integration runs an embedded indexing service within each cluster member that is responsible for indexing only the specific cluster data (and probably storing the relevant index on that embedded space for performance). Search is done by client applications by broadcasting the search request to all partitions and reducing the results back on the client side. Here is a diagram showing the process:
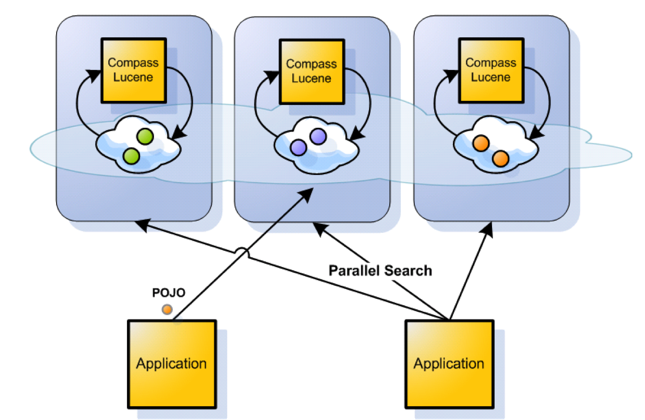
GigaSpaces Service Compass Integration
The integrations builds on top of GigaSpaces OpenSpaces build in components. On the "server" side (the processing unit that starts up the relevant space cluster members), the following configuration should be added:
<beans xmlns="http://www.springframework.org/schema/beans" ...
<os-core:space id="space" url="/./space"" />
<os-core:giga-space id="gigaSpace" space="space"/>
<bean id="compass" class="org.compass.spring.LocalCompassBean" depends-on="space">
<property name="settings">
<map>
<entry key="compass.engine.connection" value="space://test:space"/>
<entry key="space" value-ref="gigaSpace"/>
<entry key="compass.osem.supportUnmarshall" value="false" />
</map>
</property>
<property name="mappingScan" value="com.mycompany" />
</bean>
<bean id="searchService" class="org.compass.needle.gigaspaces.service.ServerCompassSearchService">
<property name="compass" ref="compass"/>
<property name="gigaSpace" ref="gigaSpace"/>
</bean>
<os-remoting:service-exporter id="serviceExporter">
<os-remoting:service ref="searchService"/>
</os-remoting:service-exporter>
<bean id="indexService" class="org.compass.needle.gigaspaces.service.CompassIndexEventListener">
<constructor-arg ref="compass"/>
</bean>
<os-events:notify-container id="eventContainer" giga-space="gigaSpace">
<os-events:batch size="100" time="2000" />
<os-events:notify write="true" lease-expire="true" take="true" update="true"/>
<os-core:template>
<bean class="com.mycompany.model.Order"/>
</os-core:template>
<os-events:listener ref="indexService"/>
</os-events:notify-container>
</beans>
The above configuration starts up an embedded space (the clustering model is chosen during deployment time). It creates a Compass instance that stores the index on the embedded local space cluster member. It uses the notify container to listen for notifications of changes happening on the embedded cluster member and index them using the Compass instance. It also exposes a executor remoting service that implements the CompassSearchService interface. The service performs a search using Compass on top of the collocated space and loads objects back from the collocated space. Note, all operations are done in memory in a collocated manner.
On the client side, both programmatic and Spring based configuration can be used. Here is an example of the spring based configuration:
<beans xmlns="http://www.springframework.org/schema/beans" ...
<os-core:space id="space" url="jini://*/*/space" />
<os-core:giga-space id="gigaSpace" space="space"/>
<bean id="searchService" class="org.compass.needle.gigaspaces.service.ClientCompassSearchService">
<constructor-arg ref="gigaSpace"/>
</bean>
</beans>
The above configuration connects to a remote space. It creates the client side search service that also implements CompassSearchService. The search operation is automatically broadcast to all relevant partitions, performed in a collocated manner on them, and then reduced back on the client side.
Note, exposing other more advance forms of queries, or using other Compass APIs (such as term frequencies), can be done by exposing other remoting services in a similar manner to how the search API is done.