|
GraphLab: Distributed Graph-Parallel API
2.1
|
|
GraphLab: Distributed Graph-Parallel API
2.1
|
The distributed_graph requires each vertex to have a numeric ID of type graphlab::vertex_id_type : at a moment a 32-bit integer (this will be lengthened to 64-bits or greater in the near future so you should not depend on it being 32-bits). Vertices do not need to be consecutively numbered. The ID corresponding to (graphlab::vertex_id_type)(-1) (or the maximum integer value) is reserved for internal use and should not be assigned.
To load graph data from a file, we need to implement a line parser for the distributed_graph's graphlab::distributed_graph::load(std::string path, line_parser_type line_parser) load() function.
The load() load works in a simple straight-forward way. It assumes that each line in the file is "independent"; i.e. the order in which lines in the file appear do not matter. Each line is then passed into the user provided line-parsing function which then proceeds to add vertices or edges to the graph.
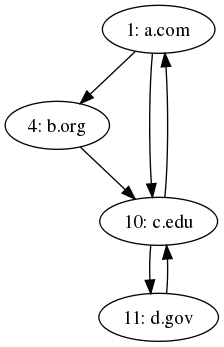
For instance, we could describe the following input file for our pagerank task.
1 a.com 4 10 4 b.org 10 10 c.edu 11 1 11 d.gov 10
Where each contains first an ID for the page, then the name of the page, and finally a list of all the IDs the page links to. Thus describing the following graph:
We can then implement the following line parser:
To load this file, we simply construct a graph,
The key behind the load() function is that its actual behavior is to load all files which begin with the name provided. In other words, if the graph file is cut into many smaller pieces such as graph.txt.1 graph.txt.2, graph.txt.3, etc, the system will load all the files matching graph.txt*, and possibly in parallel (if running in a distributed environment, it is important to ensure that all machines can access the same set of files). Furthermore, the load() function automatically supports HDFS loading and obeys the same rules. Finally, if a filename ends with the .gz extension, it is automatically treated as a gzip compressed file and will be automatically decompressed for reading.
will load all files on the name node hdfsnamenode, and matching the pattern /data/graph*.
Multiple calls may be made to load() to load different sets of files: each call may use a different line parser. The only requirement is that each edge and each vertex be added no more than once.
Once all graph data is loaded, a call to
is necessary to commit the graph structure. This will reorganize the graph datastructures for optimal run-time access.
At this point, your code will look like this:
The distributed graph provides several built-in formats which can be used to save/load graph structure. See distributed_graph::save_format() and distributed_graph::load_format() for more details.
The distributed_graph takes as a second option, a graphlab::graphlab_options datastructure which contains runtime options that can affect the behavior and performance of GraphLab. See the constructor for more details.
GraphLab provides a convenient command line parser in graphlab::command_line_options (really, a wrapper around boost::program_options simpler features). The parser is easy to use and automatically exposes GraphLab's runtime options on the command line.
 1.8.1.1
1.8.1.1 
