|
GraphLab: Distributed Graph-Parallel API
2.1
|
|
GraphLab: Distributed Graph-Parallel API
2.1
|
A directed graph datastructure which is distributed across multiple machines. More...
#include <graphlab/graph/distributed_graph.hpp>
Classes | |
| class | edge_type |
| The edge represents an edge in the graph and provide access to the data associated with that edge as well as the source and target distributed::vertex_type objects. More... | |
| struct | vertex_type |
| Vertex object which provides access to the vertex data and information about the vertex. More... | |
Public Types | |
| typedef VertexData | vertex_data_type |
| The type of the vertex data stored in the graph. | |
| typedef EdgeData | edge_data_type |
| The type of the edge data stored in the graph. | |
| typedef boost::function< bool(distributed_graph &, const std::string &, const std::string &)> | line_parser_type |
|
typedef fixed_dense_bitset < RPC_MAX_N_PROCS > | mirror_type |
|
typedef graphlab::local_graph < VertexData, EdgeData > | local_graph_type |
| The type of the local graph used to store the graph data. | |
|
typedef graphlab::distributed_graph < VertexData, EdgeData > | graph_type |
| typedef graphlab::vertex_id_type | vertex_id_type |
| typedef graphlab::lvid_type | lvid_type |
| typedef graphlab::edge_id_type | edge_id_type |
| typedef bool | edge_list_type |
| typedef json_parser < VertexData, EdgeData > | json_parser_type |
| Load a distributed graph from a native json output format. This function must be called simultaneously on all machines. | |
|
typedef json_parser_type::edge_parser_type | edge_parser_type |
|
typedef json_parser_type::vertex_parser_type | vertex_parser_type |
Public Member Functions | |
| distributed_graph (distributed_control &dc, const graphlab_options &opts=graphlab_options()) | |
| void | finalize () |
| Commits the graph structure. Once a graph is finalized it may no longer be modified. Must be called on all machines simultaneously. | |
| bool | is_finalized () |
| Returns true if the graph is finalized. | |
| size_t | num_vertices () const |
| Get the number of vertices. | |
| size_t | num_edges () const |
| Get the number of edges. | |
| vertex_type | vertex (vertex_id_type vid) |
| converts a vertex ID to a vertex object. This function should not be used without a deep understanding of the distributed graph representation. | |
| size_t | num_in_edges (const vertex_id_type vid) const |
| Returns the number of in edges of a given global vertex ID. This function should not be used without a deep understanding of the distributed graph representation. | |
| size_t | num_out_edges (const vertex_id_type vid) const |
| Returns the number of out edges of a given global vertex ID. This function should not be used without a deep understanding of the distributed graph representation. | |
| void | add_vertex (const vertex_id_type &vid, const VertexData &vdata=VertexData()) |
| Creates a vertex containing the vertex data. | |
| void | add_edge (vertex_id_type source, vertex_id_type target, const EdgeData &edata=EdgeData()) |
| Creates an edge connecting vertex source, and vertex target(). | |
| template<typename ReductionType , typename MapFunctionType > | |
| ReductionType | map_reduce_vertices (MapFunctionType mapfunction, const vertex_set &vset=complete_set()) |
| Performs a map-reduce operation on each vertex in the graph returning the result. | |
| template<typename ReductionType , typename MapFunctionType > | |
| ReductionType | map_reduce_edges (MapFunctionType mapfunction, const vertex_set &vset=complete_set(), edge_dir_type edir=IN_EDGES) |
| Performs a map-reduce operation on each edge in the graph returning the result. | |
| template<typename TransformType > | |
| void | transform_vertices (TransformType transform_functor, const vertex_set vset=complete_set()) |
| Performs a transformation operation on each vertex in the graph. | |
| template<typename TransformType > | |
| void | transform_edges (TransformType transform_functor, const vertex_set &vset=complete_set(), edge_dir_type edir=IN_EDGES) |
| Performs a transformation operation on each edge in the graph. | |
| void | clear () |
| Clears and resets the graph, releasing all memory used. | |
| void | load_binary (const std::string &prefix) |
| Load a distributed graph from a native binary format previously saved with save_binary(). This function must be called simultaneously on all machines. | |
| void | save_binary (const std::string &prefix) |
| Saves a distributed graph to a native binary format which can be loaded with load_binary(). This function must be called simultaneously on all machines. | |
| template<typename Writer > | |
| void | save_to_posixfs (const std::string &prefix, Writer writer, bool gzip=true, bool save_vertex=true, bool save_edge=true, size_t files_per_machine=4) |
| Saves the graph to the filesystem using a provided Writer object. Like save() but only saves to local filesystem. | |
| template<typename Writer > | |
| void | save_to_hdfs (const std::string &prefix, Writer writer, bool gzip=true, bool save_vertex=true, bool save_edge=true, size_t files_per_machine=4) |
| Saves the graph to HDFS using a provided Writer object. Like save() but only saves to HDFS. | |
| template<typename Writer > | |
| void | save (const std::string &prefix, Writer writer, bool gzip=true, bool save_vertex=true, bool save_edge=true, size_t files_per_machine=4) |
| Saves the graph to the filesystem or to HDFS using a user provided Writer object. This function should be called on all machines simultaneously. | |
| void | save_format (const std::string &prefix, const std::string &format, bool gzip=true, size_t files_per_machine=4) |
| Saves the graph in the specified format. This function should be called on all machines simultaneously. | |
| void | load_from_posixfs (std::string prefix, line_parser_type line_parser) |
| Load a graph from a collection of files in stored on the filesystem using the user defined line parser. Like load(const std::string& path, line_parser_type line_parser) but only loads from the filesystem. | |
| void | load_from_hdfs (std::string prefix, line_parser_type line_parser) |
| Load a graph from a collection of files in stored on the HDFS using the user defined line parser. Like load(const std::string& path, line_parser_type line_parser) but only loads from HDFS. | |
| void | load (std::string prefix, line_parser_type line_parser) |
| Load a the graph from a given path using a user defined line parser. This function should be called on all machines simultaneously. | |
| void | load_synthetic_powerlaw (size_t nverts, bool in_degree=false, double alpha=2.1, size_t truncate=(size_t)(-1)) |
| Constructs a synthetic power law graph. Must be called on all machines simultaneously. | |
| void | load_format (const std::string &path, const std::string &format) |
| load a graph with a standard format. Must be called on all machines simultaneously. | |
| void | load_json (const std::string &prefix, bool gzip=false, edge_parser_type edge_parser=builtin_parsers::empty_edge_parser< EdgeData >, vertex_parser_type vertex_parser=builtin_parsers::empty_vertex_parser< VertexData >) |
| vertex_set | neighbors (const vertex_set &cur, edge_dir_type edir) |
| template<typename FunctionType > | |
| vertex_set | select (FunctionType select_functor, const vertex_set &vset=complete_set()) |
| Constructs a vertex set from a predicate operation which is executed on each vertex. | |
| size_t | vertex_set_size (const vertex_set &vset) |
| Returns the number of vertices in a vertex set. | |
| bool | vertex_set_empty (const vertex_set &vset) |
| Returns true if the vertex set is empty. | |
| local_vertex_type | l_vertex (lvid_type vid) |
| size_t | num_replicas () const |
| size_t | num_local_vertices () const |
| size_t | num_local_edges () const |
| size_t | num_local_own_vertices () const |
| lvid_type | local_vid (const vertex_id_type vid) const |
| vertex_id_type | global_vid (const lvid_type lvid) const |
| local_edge_list_type | l_in_edges (const lvid_type lvid) |
| size_t | l_num_in_edges (const lvid_type lvid) const |
| local_edge_list_type | l_out_edges (const lvid_type lvid) |
| size_t | l_num_out_edges (const lvid_type lvid) const |
| procid_t | procid () const |
| procid_t | numprocs () const |
| distributed_control & | dc () |
| const vertex_record & | get_vertex_record (vertex_id_type vid) const |
| vertex_record & | l_get_vertex_record (lvid_type lvid) |
| const vertex_record & | l_get_vertex_record (lvid_type lvid) const |
| bool | is_master (vertex_id_type vid) const |
| bool | l_is_master (lvid_type lvid) const |
| procid_t | l_master (lvid_type lvid) const |
| local_graph_type & | get_local_graph () |
| const local_graph_type & | get_local_graph () const |
| void | synchronize () |
Static Public Member Functions | |
| static vertex_set | empty_set () |
| Retuns an empty set of vertices. | |
| static vertex_set | complete_set () |
| Retuns a full set of vertices. | |
A directed graph datastructure which is distributed across multiple machines.
This class implements a distributed directed graph datastructure where vertices and edges may contain arbitrary user-defined datatypes as templatized by the VertexData and EdgeData template parameters.
To declare a distributed graph you write:
where vdata is the type of data to be stored on vertices, and edata is the type of data to be stored on edges. The constructor must be called simultaneously on all machines. dc is a graphlab::distributed_control object that must be constructed at the start of the program, and clopts is a graphlab::graphlab_options object that is used to pass graph construction runtime options to the graph. See the code examples for further details.
Each vertex is uniquely identified by an unsigned numeric ID of the type graphlab::vertex_id_type. Vertex IDs need not be sequential. However, the ID corresponding to (vertex_id_type)(-1) is reserved. (This is the largest possible ID, corresponding to 0xFFFFFFFF when using 32-bit IDs).
Edges are not numbered, but are uniquely identified by its source->target pair. In other words, there can only be two edges between any pair of vertices, the edge going in the forward direction, and the edge going in the backward direction.
The distributed graph can be constructed in two different ways. The first, and the preferred method, is to construct the graph from files located on a shared filesystem (NFS mounts for instance) , or from files on HDFS (HDFS support must be compiled).
To construct from files, the load_format() function provides built-in parsers to construct the graph structure from various graph file formats on disk or HDFS. Alternatively, the load() function provides generalized parsing capabilities allowing you to construct from your own defined file format. Alternatively, load_binary() may be used to perform an extremely rapid load of a graph previously saved with save_binary(). The caveat being that the number of machines used to save the graph must match the number of machines used to load the graph.
The second construction strategy is to call the add_vertex() and add_edge() functions directly. These functions are parallel reentrant, and are also distributed. Each vertex and each edge should be added no more than once across all machines.
add_vertex() calls are not strictly required since add_edge(i, j) will implicitly construct vertices i and j. The data on these vertices will be default constructed.
After all vertices and edges are inserted into the graph via either load from file functions or direct calls to add_vertex() and add_edge(), for the graph to the useable, it must be finalized.
This is performed by calling
on all machines simultaneously. None of the load* functions perform finalization so multiple load operations could be performed (reading from different file groups) before finalization.
The finalize() operation partitions the graph and synchronizes all internal graph datastructures. After this point, all graph computation operations such as engine, map_reduce and transform operations will function.
The graph is partitioned across the machines using a "vertex separator" strategy where edges are assigned to machines, while vertices may span multiple machines. There are three partitioning strategies implemented. These can be selected by setting –graph_opts="ingress=[partition_method]" on the command line.
"random" The most naive and the fastest partitioner. Random places edges on machines. "oblivious" Runs at roughly half the speed of random. Machines indepedently partitions the segment of the graph it read. Improves partitioning quality and will reduce runtime memory consumption. "batch" Runs at roughly half the speed of oblivious. Machines cooperate in partitioning the graph. This obtains the highest quality partition, reducing runtime memory consumption significantly, at load-time penalty."grid" Runs at rouphly the same speed of random. Randomly places edges on machines with a grid constraint. This obtains quality partition, close to oblivious, but currently only works with perfect square number of machines."pds" Runs at roughly the speed of random. Randomly places edges on machines with a sparser constraint generated by perfect difference set. This obtains the close to batch highest quality partition, reducing runtime memory consumption significantly, without load-time penalty. Currently only works with p^2+p+1 number of machines (p prime).vertex_type and edge_type objects. These objects are light-weight copyable opaque references to vertices and edges in the distributed graph. The vertex_type object provides capabilities such as:
vertex_type::id() Returns the ID of the vertex vertex_type::num_in_edges() Returns the number of in edges vertex_type::num_out_edges() Returns the number of out edges vertex_type::data() Returns a reference to the data on the vertexNo traversal operations are currently provided and there there is no single method to return a list of adjacent edges to the vertex.
The edge_type object has similar capabilities:
edge_type::data() Returns a reference to the data on the edge edge_type::source() Returns a vertex_type of the source vertex edge_type::target() Returns a vertex_type of the target vertexThis permits the use of edge.source().data() for instance, to obtain the vertex data on the source vertex.
See the documentation for vertex_type and edge_type for further details.
Due to the distributed nature of the graph, There is at the moment, no way to obtain a reference to arbitrary vertices or edges. The only way to obtain a reference to vertices or edges, is if one is passed to you via a callback (for instance in map_reduce_vertices() / map_reduce_edges() or in an update function). To manipulate the graph at a more fine-grained level will require a more intimate understanding of the underlying distributed graph representation.
After computation is complete, the graph structure can be saved via save_format() which provides built-in writers to write various graph formats to disk or HDFS. Alternatively, save() provides generalized writing capabilities allowing you to write your own graph output to disk or HDFS.
The graph is partitioned over machines using vertex separators. In other words, each edge is assigned to a unique machine while vertices are allowed to span multiple machines.
The image below demonstrates the procedure. The example graph on the left is to be separated among 4 machines where the cuts are denoted by the dotted red lines. After partitioning, (the image on the right), each vertex along the cut is now separated among multiple machines. For instance, the central vertex spans 4 different machines.
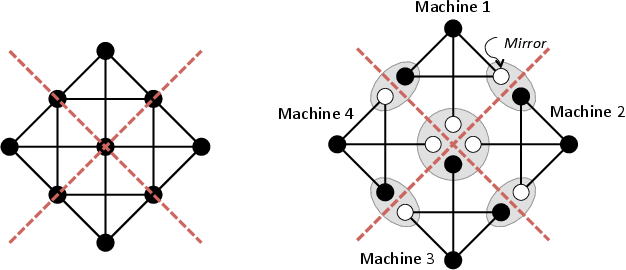
Each vertex which span multiple machines, has a master machine (a black vertex), and all other instances of the vertex are called mirrors. For instance, we observe that the central vertex spans 4 machines, where machine 3 holds the master copy, while all remaining machines hold mirrored copies.
This concept of vertex separators allow us to easily manage large power-law graphs where vertices may have extremely high degrees, since the adjacency information for even the high degree vertices can be separated across multiple machines.
Each machine maintains its local section of the graph in a graphlab::local_graph object. The local_graph object assigns each vertex a sequential vertex ID called the local vertex ID. A hash table is used to provide a mapping between the local vertex IDs and their corresponding global vertex IDs. Additionally, each local vertex is associated with a vertex_record which provides information about global ID of the vertex, the machine which holds the master instance of the vertex, as well as a list of all machines holding a mirror of the vertex.
To support traversal of the local graph, two additional types, the local_vertex_type and the local_edge_type is provided which provide references to vertices and edges on the local graph. These behave similarly to the vertex_type and edge_type types and have similar functionality. However, since these reference the local graph, there is substantially more flexility. In particular, the function l_vertex() may be used to obtain a reference to a local vertex from a local vertex ID. Also unlike the vertex_type , the local_vertex_type support traversal operations such as returning a list of all in_edges (local_vertex_type::in_edges()). However, the list only contains the edges which are local to the current machine. See local_vertex_type and local_edge_type for more details.
| VertexData | Type of data stored on vertices. Must be Copyable, Default Constructable, Copy Constructable and Serializable. |
| EdgeData | Type of data stored on edges. Must be Copyable, Default Constructable, Copy Constructable and Serializable. |
Definition at line 303 of file distributed_graph.hpp.
| typedef json_parser<VertexData, EdgeData> graphlab::distributed_graph< VertexData, EdgeData >::json_parser_type |
Load a distributed graph from a native json output format. This function must be called simultaneously on all machines.
This function loads a sequence of files numbered
These files must be previously saved using external graphbuilder library, and must be saved using the same number of machines.
A graph loaded using load_json() is already finalized and structure modifications are not permitted after loading.
Definition at line 2104 of file distributed_graph.hpp.
| typedef boost::function<bool(distributed_graph&, const std::string&, const std::string&)> graphlab::distributed_graph< VertexData, EdgeData >::line_parser_type |
The line parse is any function (or functor) that has the form:
bool line_parser(distributed_graph& graph, const std::string& filename, const std::string& textline);
the line parser returns true if the line is parsed successfully and calls graph.add_vertex(...) or graph.add_edge(...)
See load() for details.
Definition at line 375 of file distributed_graph.hpp.
|
inline |
Constructs a distributed graph. All machines must call this constructor simultaneously.
Value graph options are:
ingress The graph partitioning method to use. May be "random" "oblivious" or "batch". The methods are in increasing complexity. "random" is the simplest and produces the worst partitions, while "batch" takes longer, but produces a significantly better result. Improved partitioning has direct impacts on GraphLab runtime performance. userecent An optimization that can decrease memory utilization of oblivious and batch quite significantly (especially when there are a large number of machines) at a small partitioning penalty. Defaults to 0. Set to 1 to enable. bufsize The batch size used by the batch ingress method. Defaults to 50,000. Increasing this number will decrease partitioning time with a penalty to partitioning quality.| [in] | dc | Distributed controller to associate with |
| [in] | opts | A graphlab::graphlab_options object specifying engine parameters. This is typically constructed using graphlab::command_line_options. |
Definition at line 590 of file distributed_graph.hpp.
|
inline |
Creates an edge connecting vertex source, and vertex target().
Creates a edge connecting two vertex IDs.
This function is parallel and distributed. i.e. It does not matter which machine, or which thread on which machines calls add_edge() for a particular ID.
However, each edge direction may only be added exactly once. i.e. if edge 5->6 is added already, no other calls to add edge 5->6 should be made.
Definition at line 779 of file distributed_graph.hpp.
|
inline |
Creates a vertex containing the vertex data.
Creates a vertex with a particular vertex ID and containing a particular vertex data. Vertex IDs need not be sequential, and may arbitrarily span the unsigned integer range of vertex_id_type with the exception of (vertex_id_type)(-1), or corresponding to 0xFFFFFFFF on 32-bit vertex IDs.
This function is parallel and distributed. i.e. It does not matter which machine, or which thread on which machines calls add_vertex() for a particular ID.
However, each vertex may only be added exactly once.
Definition at line 747 of file distributed_graph.hpp.
|
inline |
Commits the graph structure. Once a graph is finalized it may no longer be modified. Must be called on all machines simultaneously.
Finalize is used to complete graph ingress by resolving vertex ownship and completing local data structures. Once a graph is finalized its structure may not be modified. Repeated calls to finalize() do nothing.
Definition at line 653 of file distributed_graph.hpp.
|
inline |
Load a the graph from a given path using a user defined line parser. This function should be called on all machines simultaneously.
This functions loads all files in the filesystem or on HDFS matching the pattern "[prefix]*".
Examples:
prefix = "webgraph.txt"
will load the file webgraph.txt if such a file exists. It will also load all files in the current directory which begins with "webgraph.txt". For instance, webgraph.txt.0, webgraph.txt.1, etc.
prefix = "graph/data"
will load all files in the "graph" directory which begin with "data"
prefix = "hdfs:///hdfs_server/graph/data"
will load all files from the HDFS server in the "/graph/" directory which begin with "data".
If files have the ".gz" suffix, it is automatically decompressed.
The line_parser is a user defined function matching the following prototype:
The load() function will call the parser one line at a time, and the paser function should process the line and call add_vertex / add_edge functions in the graph. It should return true on success, and false on failure. Since the parsing may be parallelized, the parser should treat each line independently and not depend on a sequential pass through a file.
For instance, if the graph is in a simple edge list format, a parser could be:
| prefix | The file prefix to read from. All files matching the pattern "[prefix]*" are loaded. If prefix begins with "hdfs://" the files are read from hdfs. |
| line_parser | A user defined parsing function |
Definition at line 1984 of file distributed_graph.hpp.
|
inline |
Load a distributed graph from a native binary format previously saved with save_binary(). This function must be called simultaneously on all machines.
This function loads a sequence of files numbered
These files must be previously saved using save_binary(), and must be saved using the same number of machines. This function uses the graphlab serialization system, so the user must ensure that the vertex data and edge data serialization formats have not changed since the graph was saved.
A graph loaded using load_binary() is already finalized and structure modifications are not permitted after loading.
Definition at line 1379 of file distributed_graph.hpp.
|
inline |
load a graph with a standard format. Must be called on all machines simultaneously.
The supported graph formats are described in Graph File Formats.
Definition at line 2063 of file distributed_graph.hpp.
|
inline |
Constructs a synthetic power law graph. Must be called on all machines simultaneously.
This function constructs a synthetic out-degree power law of "nverts" vertices with a particular alpha parameter. In other words, the probability that a vertex has out-degree \form#0, is given by:
![\[ P(d) \propto d^{-\alpha} \]](form_1.png)
By default, the out-degree distribution of each vertex
will have power-law distribution, but the in-degrees will be nearly
uniform. This can be reversed by setting the second argument "in_degree"
to true.
\param nverts Number of vertices to generate
\param in_degree If set to true, the graph will have power-law in-degree.
Defaults to false.
\param alpha The alpha parameter in the power law distribution. Defaults
to 2.1
\param truncate Limits the maximum degree of any vertex. (thus generating
a truncated power-law distribution). Necessary
for large number of vertices (hundreds of millions)
since this function allocates a PDF vector of
"nverts" to sample from.
Definition at line 2022 of file distributed_graph.hpp.
|
inline |
Performs a map-reduce operation on each edge in the graph returning the result.
Given a map function, map_reduce_edges() call the map function on all edges in the graph. The return values are then summed together and the final result returned. The map function should only read data and should not make any modifications. map_reduce_edges() must be called on all machines simultaneously.
For instance, if the graph has float vertex data, and float edge data:
To compute an absolute sum over all the edge data, we would write a function which reads in each a edge, and returns the absolute value of the data on the edge.
After which calling:
will call the absolute_edge_data() function on each edge in the graph. absolute_edge_data() reads the value of the edge and returns the absolute result. This return values are then summed together and returned. All machines see the same result.
The template argument <float> is needed to inform the compiler regarding the return type of the mapfunction.
The two optional arguments vset and edir can be used to restrict the set of edges which are map-reduced over.
This function similar to graphlab::distributed_graph::map_reduce_edges() with the difference that this does not take a context and thus cannot influence engine signalling. Finally transform_edges() can be used to perform a similar but may also make modifications to graph data.
| ReductionType | The output of the map function. Must have operator+= defined, and must be Serializable. |
| EdgeMapperType | The type of the map function. Not generally needed. Can be inferred by the compiler. |
| mapfunction | The map function to use. Must take a edge_type, or a reference to a edge_type as its only argument. Returns a ReductionType which must be summable and Serializable . |
| vset | A set of vertices. Combines with edir to identify the set of edges. For instance, if edir == IN_EDGES, map_reduce_edges will map over all in edges of the vertices in vset. Optional. Defaults to complete_set(). |
| edir | An edge direction. Combines with vset to identify the set of edges to map over. For instance, if edir == IN_EDGES, map_reduce_edges will map over all in edges of the vertices in vset. Optional. Defaults to IN_EDGES. |
Definition at line 1004 of file distributed_graph.hpp.
|
inline |
Performs a map-reduce operation on each vertex in the graph returning the result.
Given a map function, map_reduce_vertices() call the map function on all vertices in the graph. The return values are then summed together and the final result returned. The map function should only read the vertex data and should not make any modifications. map_reduce_vertices() must be called on all machines simultaneously.
For instance, if the graph has float vertex data, and float edge data:
To compute an absolute sum over all the vertex data, we would write a function which reads in each a vertex, and returns the absolute value of the data on the vertex.
After which calling:
will call the absolute_vertex_data() function on each vertex in the graph. absolute_vertex_data() reads the value of the vertex and returns the absolute result. This return values are then summed together and returned. All machines see the same result.
The template argument <float> is needed to inform the compiler regarding the return type of the mapfunction.
The optional argument vset can be used to restrict he set of vertices map-reduced over.
This function is similar to graphlab::iengine::map_reduce_vertices() with the difference that this does not take a context and thus cannot influence engine signalling. transform_vertices() can be used to perform a similar but may also make modifications to graph data.
| ReductionType | The output of the map function. Must have operator+= defined, and must be Serializable. |
| VertexMapperType | The type of the map function. Not generally needed. Can be inferred by the compiler. |
| mapfunction | The map function to use. Must take a vertex_type, or a reference to a vertex_type as its only argument. Returns a ReductionType which must be summable and Serializable . |
| vset | The set of vertices to map reduce over. Optional. Defaults to complete_set() |
Definition at line 877 of file distributed_graph.hpp.
|
inline |
Returns the number of in edges of a given global vertex ID. This function should not be used without a deep understanding of the distributed graph representation.
Returns the number of in edges of a given vertex ID. Equivalent to vertex(vid).num_in_edges(). The global vertex ID must exist on this machine or assertion failures will be produced.
Definition at line 714 of file distributed_graph.hpp.
|
inline |
Returns the number of out edges of a given global vertex ID. This function should not be used without a deep understanding of the distributed graph representation.
Returns the number of out edges of a given vertex ID. Equivalent to vertex(vid).num_out_edges(). The global vertex ID must exist on this machine or assertion failures will be produced.
Definition at line 728 of file distributed_graph.hpp.
|
inline |
Saves the graph to the filesystem or to HDFS using a user provided Writer object. This function should be called on all machines simultaneously.
This function saves the current graph to disk using a user provided Writer object. The writer object must implement two functions:
The save_vertex() function will be called on each vertex on the graph, and the output of the function is written to file. Similarly, the save_edge() function is called on each edge in the graph and the output written to file.
For instance, a simple Writer object which saves a file containing a list of edges will be:
The save_edge() function is called on each edge in the graph. It then constructs a string containing "[source] \\t [target] \\n" and returns the string.
This can also be used to data in human readable format. For instance, if the vertex data type is a floating point number (say a PageRank value), to save a list of vertices and their corresponding PageRanks, the following writer could be implemented:
The output files will be written in
To accelerate the saving process, multiple files are be written per machine in parallel. If the gzip option is not set, the ".gz" suffix is not added.
For instance, if there are 4 machines, running:
Will create the files
If HDFS support is compiled in, this function can save to HDFS by adding "hdfs://" to the prefix.
For instance, if there are 4 machines, running:
Will create on the HDFS server, the files
| Writer | The writer object type. This is generally inferred by the compiler and need not be specified. |
| prefix | The file prefix to save the output graph files. The output files will be numbered [prefix].0 , [prefix].1 , etc. If prefix begins with "hdfs://", the output is written to HDFS |
| writer | The writer object to use. |
| gzip | If gzip compression should be used. If set, all files will be appended with the .gz suffix. Defaults to true. |
| save_vertex | If vertices should be saved. Defaults to true. |
| save_edges | If edges should be saved. Defaults to true. |
| files_per_machine | Number of files to write simultaneously in parallel per machine. Defaults to 4. |
Definition at line 1740 of file distributed_graph.hpp.
|
inline |
Saves a distributed graph to a native binary format which can be loaded with load_binary(). This function must be called simultaneously on all machines.
This function saves a sequence of files numbered
This files can be loaded with load_binary() using the same number of machines. This function uses the graphlab serialization system, so the vertex data and edge data serialization formats must not change between the use of save_binary() and load_binary().
If the graph is not alreasy finalized before save_binary() is called, this function will finalize the graph.
Definition at line 1436 of file distributed_graph.hpp.
|
inline |
Saves the graph in the specified format. This function should be called on all machines simultaneously.
The output files will be written in
To accelerate the saving process, multiple files are be written per machine in parallel. If the gzip option is not set, the ".gz" suffix is not added.
For instance, if there are 4 machines, running:
Will create the files
The supported formats are described in Graph File Formats.
| prefix | The file prefix to save the output graph files. The output files will be numbered [prefix].0 , [prefix].1 , etc. If prefix begins with "hdfs://", the output is written to HDFS. |
| format | The file format to save in. Either "tsv", "snap", "graphjrl" or "bin". |
| gzip | If gzip compression should be used. If set, all files will be appended with the .gz suffix. Defaults to true. Ignored if format == "bin". |
| files_per_machine | Number of files to write simultaneously in parallel per machine. Defaults to 4. Ignored if format == "bin". |
Definition at line 1791 of file distributed_graph.hpp.
|
inline |
Constructs a vertex set from a predicate operation which is executed on each vertex.
This function selects a subset of vertices on which the predicate evaluates to true. For instance if vertices contain an integer, the following code will construct a set of vertices containing only vertices with data which are a multiple of 2.
select() also takes a second argument which restricts the set of vertices queried. For instance,
will select from the set of even vertices, all vertices which are also divisible by 3. The resultant set is therefore the set of all vertices which are divisible by 6.
| select_functor | A function/functor which takes a const vertex_type& argument and returns a boolean denoting of the vertex is to be included in the returned set |
| vset | Optional. The set of vertices to evaluate the selection on. Defaults to complete_set() |
Definition at line 2201 of file distributed_graph.hpp.
|
inline |
Performs a transformation operation on each edge in the graph.
Given a mapfunction, transform_edges() calls mapfunction on every edge in graph. The map function may make modifications to the data on the edge. transform_edges() must be called on all machines simultaneously.
For instance, if the graph has integer vertex data, and integer edge data:
To set each edge value to be the number of out-going edges of the target vertex, we may write the following:
Calling transform_edges():
will run the set_edge_value() function on each edge in the graph, setting its new value.
The two optional arguments vset and edir may be used to restrict the set of edges operated upon.
map_reduce_edges() provide similar signalling functionality, but should not make modifications to graph data. graphlab::iengine::transform_edges() provide the same graph modification capabilities, but with a context and thus can perform signalling.
| EdgeMapperType | The type of the map function. Not generally needed. Can be inferred by the compiler. |
| mapfunction | The map function to use. Must take an icontext_type& as its first argument, and a edge_type, or a reference to a edge_type as its second argument. Returns void. |
| vset | A set of vertices. Combines with edir to identify the set of edges. For instance, if edir == IN_EDGES, map_reduce_edges will map over all in edges of the vertices in vset. Optional. Defaults to complete_set(). |
| edir | An edge direction. Combines with vset to identify the set of edges to map over. For instance, if edir == IN_EDGES, map_reduce_edges will map over all in edges of the vertices in vset. Optional. Defaults to IN_EDGES. |
Definition at line 1216 of file distributed_graph.hpp.
|
inline |
Performs a transformation operation on each vertex in the graph.
Given a mapfunction, transform_vertices() calls mapfunction on every vertex in graph. The map function may make modifications to the data on the vertex. transform_vertices() must be called by all machines simultaneously.
The optional vset argument may be used to restrict the set of vertices operated upon.
For instance, if the graph has integer vertex data, and integer edge data:
To set each vertex value to be the number of out-going edges, we may write the following function:
Calling transform_vertices():
will run the set_vertex_value() function on each vertex in the graph, setting its new value.
map_reduce_vertices() provide similar signalling functionality, but should not make modifications to graph data. graphlab::iengine::transform_vertices() provide the same graph modification capabilities, but with a context and thus can perform signalling.
| VertexMapperType | The type of the map function. Not generally needed. Can be inferred by the compiler. |
| mapfunction | The map function to use. Must take an icontext_type& as its first argument, and a vertex_type, or a reference to a vertex_type as its second argument. Returns void. |
| vset | The set of vertices to transform. Optional. Defaults to complete_set() |
Definition at line 1134 of file distributed_graph.hpp.
|
inline |
converts a vertex ID to a vertex object. This function should not be used without a deep understanding of the distributed graph representation.
This functions converts a global vertex ID to a vertex_type object. The global vertex ID must exist on this machine or assertion failures will be produced.
Definition at line 681 of file distributed_graph.hpp.
|
inline |
Returns true if the vertex set is empty.
This function must be called on all machines and returns true if the vertex set is empty
Definition at line 2249 of file distributed_graph.hpp.
|
inline |
Returns the number of vertices in a vertex set.
This function must be called on all machines and returns the number of vertices contained in the vertex set.
For instance:
will always evaluate to graph.num_vertices();
Definition at line 2232 of file distributed_graph.hpp.
 1.8.1.1
1.8.1.1 
