17.3. EDB-Replication Concepts
Before we go into further details about EDB-Replication it is important to come to terms with some basic EDB-Replication jargon.
So let us discuss some of those key concepts:
Cluster
Node
Replication Set
Master, Slaves and Subscribers
edb-replication process
slonik configuration processor
17.3.1. Cluster
An EDB-Replication cluster is a set of EnterpriseDB database instances between which replication is to take place.
Each database instance in which replication is to take place is identified by a node number.
The cluster name is specified in each and every Slonik script via the directive:
cluster name = 'test';
If the Cluster name is test, then EDB-Replication will create, in each database instance in the cluster, a schema with the same name as the cluster prefixed with an underscore character. So for a cluster named "test" we would have a corresponding schema named "_test" created by EDB-Replication.
17.3.2. Node
An EDB-Replication Node is a named EnterpriseDB database that will be participating in replication. Thus, an EDB-Replication cluster consists of:
A cluster name
A set of EDB-Replication nodes, each of which has a namespace based on that cluster name
17.3.3. Replication Set
A replication set is defined as the set of tables and sequences that are to be replicated between the subscribed nodes within an EDB-Replication cluster.
A replication set can replicate the following:
Keys on tables that are to be replicated that have no suitable primary key
Tables to be replicated
Sequences to be replicated
It is possible for multiple sets to exist within the same cluster.
17.3.4. Master, Slaves and Subscribers
Origin indicates the originating node and is also referred to as being the "master" node. The master node is the only node where all the database transactions as in inserts, updates, deletes are made. This is the only node in which the required applications modify the data that is to be replicated across all the other nodes.
All the other nodes that are part of a cluster excluding the origin node are referred to as the "slave" nodes. These "slave" nodes in the cluster subscribe to the replication set, indicating that they want to receive data.
Hence the origin node can never be a "subscriber" because it is the node to which all the slave nodes will be subscribing to.
EDB-Replication also supports the concept of cascaded subscriptions where a subscribed node itself can act as a "provider" to other nodes in the cluster for a particular replication set.
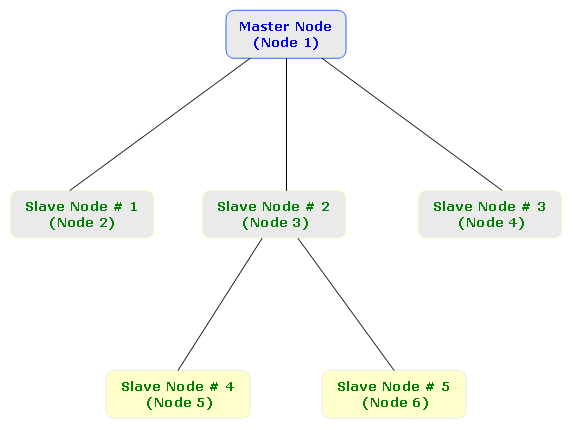
The concept of master, slaves, and subscribers can be further clarified by discussing the example in the screenshot above. In the particular example, Node 1 is the origin or master node, and Nodes 2-6 are all slave nodes. From these Nodes 2-4 have subscribed to Node 1, whereas Nodes 5-6 have subscribed to Node 3 which in turn is subscribed to Node 1, hence illustrating the concept of cascaded subscriptions.
17.3.5. The edb-replication process
The "edb-replication" is the process that manages all replication events on each node be it the master or slave. The EDB-Replication daemons are the actual programs that perform replication.
Currently these events can be either:
Configuration events
SYNC events
Configuration events normally occur when a slonik script is run, which in ends up updating the configuration of the cluster.
SYNC events are composed of a group of transactions on the origin node that are applied together on all the subscriber nodes. For example a bunch of inserts or updates on the origin node will compose a SYNC event.
17.3.6. Slonik Configuration Processor
Slonik is a command line utility that is used to set up and modify configurations of EDB-Replication clusters.
It reads a set of Slonik statements, which are written in a scripting language with syntax similar to that of SQL, and performs the set of configuration changes on the EDB-Replication nodes specified in the script.
The format of the Slonik language is very similar to that of SQL and the slonik command processor processes scripts that are used to submit events to update the configuration of an EDB-Replication cluster. This includes such things as adding and removing nodes, modifying communications paths, adding or removing subscriptions.