17.4. EDB-Replication Setup
In order to have replication up and running within a database cluster, we need to have an instance of EnterpriseDB and the EDB-Replication daemon running on all nodes that belong to that cluster.
The installation of EnterpriseDB needs to be done prior to setting up EDB-Replication. You don't need to perform any explicit installation for "EDB-Replication", as it is an integral part of the EDB Database Server distribution.
17.4.1. System Requirements
Any platform that can run EnterpriseDB should be able to run EDB-Replication. Currently EDB-Replication is successfully tested on Linux/Unix flavors and efforts are in progress to make it work on Windows OS. However an EDB Server node running on Windows may be controlled by the corresponding EDB-Replication process executing on a Linux box.
17.4.2. EDB-Replication Software Dependencies
17.4.2.1. Time Synchronization
All the servers used within the replication cluster need to have their Real Time Clocks in sync. This is to ensure that EDB-Replication doesn't generate errors with messages indicating that a subscriber is already ahead of its provider during replication. We recommend you have ntpd running on all nodes, where subscriber nodes using the "master" provider host as their time server.
It is possible for EDB-Replication itself to function even in the face of there being some time discrepancies, but having systems "in sync" is usually pretty important for distributed applications.
In any case, what commonly seems to be the "best practice" with EDB-Replication is for t he postmaster user and/or the user under which "EDB-Replication" runs to use TZ=UTC or TZ=GMT. Those timezones are sure to be supported on any platform, and have the merit over "local" timezones that times never wind up leaping around due to Daylight Savings Time.
17.4.2.2. Network Connectivity
It is necessary that the hosts that are to replicate between one another have bidirectional network communications between the EnterpriseDB instances. That is, if node B is replicating data from node A, it is necessary that there be a path from A to B and from B to A. It is recommended that, as much as possible, all nodes in an EDB-Replication cluster allow this sort of bidirectional communications from any node in the cluster to any other node in the cluster.
17.4.2.3. Setting up EDB-Replication for replication
Let us start out with a sample database in order to see replication in place. As an example we will be replicating the sample "edb" database that is shipped with EnterpriseDB.
You have uncommented the listen_addresses line in your postgresql.conf to enable TCP/IP socket
You have enabled access to all nodes in your cluster(s) via pg_hba.conf
The REPLICATIONUSER needs to be an EnterpriseDB database superuser. The default superuser for EDB is "enterprisedb" although it would be a good idea to define a separate for using EDB-Replication to distinguish between the roles.
You should also set some shell variables. It is not compulsory to do so, but it is recommended as we will be using these shell variables in most of the commands and/or shell scripts later on in this example. These shell variables are as follows:
CLUSTERNAME=edb_asyncreplic_example
MASTERDBNAME=edb_master
SLAVEDBNAME=edb_slave
MASTERDBPORT=5444
SLAVEDBPORT=5488
MASTERHOST=localhost
SLAVEHOST=localhost
REPLICATIONUSER= edb_asyncreplic_user
Here are a couple of examples for setting variables in common shells:
bash, sh, ksh export CLUSTERNAME= edb_asyncreplic_example
setenv CLUSTERNAME edb_asyncreplic_example
17.4.3. Creating a database user for replication
Before proceeding any further you need to create the database superuser on each of the cluster nodes, that we earlier assigned the shell REPLICATIONUSER variable. Please make sure that EDB is up and running on both the master and slave(s).
createuser -A -D $REPLICATIONUSER
17.4.3.1. Preparing the databases
After creating this database superuser you must proceed with creating the database that you will be replicating the data for on both the master and slave node. First you create the database on the master node and then proceed with creating the same database on the slave node. Please note that this just creates a sample database cloned from the template1 database by default without any tables or data apart from the system tables.
createdb -O $ REPLICATIONUSER -h $MASTERHOST -p $MASTERDBPORT $MASTERDBNAME createdb -O $ REPLICATIONUSER -h $SLAVEHOST -p $SLAVEDBPORT $SLAVEDBNAME
Once we are done with creating the database we can now populate it with our sample database tables with data as well as a couple of stored procedures. For this purpose we will store all this in the following database script and name it "edb-sample.sql".
--
-- Script that creates the 'sample' tables, procedures, and
-- triggers.
--
BEGIN; -- Start new transaction - commit all or nothing
--
-- Create and load tables used in the documentation examples.
--
-- Create the 'dept' table
--
CREATE TABLE dept (
deptno NUMBER(2) NOT NULL CONSTRAINT dept_pk PRIMARY KEY,
dname VARCHAR2(14) CONSTRAINT dept_dname_uq UNIQUE,
loc VARCHAR2(13)
);
--
-- Create the 'emp' table
--
CREATE TABLE emp (
empno NUMBER(4) NOT NULL CONSTRAINT emp_pk PRIMARY KEY,
ename VARCHAR2(10),
job VARCHAR2(9),
mgr NUMBER(4),
hiredate DATE,
sal NUMBER(7,2) CONSTRAINT emp_sal_ck CHECK (sal > 0),
comm NUMBER(7,2),
deptno NUMBER(2) CONSTRAINT emp_ref_dept_fk
REFERENCES dept(deptno)
);
--
-- Create the 'jobhist' table
--
CREATE TABLE jobhist (
empno NUMBER(4) NOT NULL,
startdate DATE NOT NULL,
enddate DATE,
job VARCHAR2(9),
sal NUMBER(7,2),
comm NUMBER(7,2),
deptno NUMBER(2),
chgdesc VARCHAR2(80),
CONSTRAINT jobhist_pk PRIMARY KEY (empno, startdate),
CONSTRAINT jobhist_ref_emp_fk FOREIGN KEY (empno)
REFERENCES emp(empno) ON DELETE CASCADE,
CONSTRAINT jobhist_ref_dept_fk FOREIGN KEY (deptno)
REFERENCES dept (deptno) ON DELETE SET NULL,
CONSTRAINT jobhist_date_chk CHECK (startdate <= enddate)
);
GRANT ALL ON emp TO PUBLIC;
GRANT ALL ON dept TO PUBLIC;
GRANT ALL ON jobhist TO PUBLIC;
--
-- Load the 'dept' table
--
INSERT INTO dept VALUES (10,'ACCOUNTING','NEW YORK');
INSERT INTO dept VALUES (20,'RESEARCH','DALLAS');
INSERT INTO dept VALUES (30,'SALES','CHICAGO');
INSERT INTO dept VALUES (40,'OPERATIONS','BOSTON');
--
-- Load the 'emp' table
--
INSERT INTO emp VALUES (7369,'SMITH','CLERK',7902,'17-DEC-80',800,NULL,20);
INSERT INTO emp VALUES (7499,'ALLEN','SALESMAN',7698,'20-FEB-81',1600,300,30);
INSERT INTO emp VALUES (7521,'WARD','SALESMAN',7698,'22-FEB-81',1250,500,30);
INSERT INTO emp VALUES (7566,'JONES','MANAGER',7839,'02-APR-81',2975,NULL,20);
INSERT INTO emp VALUES (7654,'MARTIN','SALESMAN',7698,'28-SEP-81',1250,1400,30);
INSERT INTO emp VALUES (7698,'BLAKE','MANAGER',7839,'01-MAY-81',2850,NULL,30);
INSERT INTO emp VALUES (7782,'CLARK','MANAGER',7839,'09-JUN-81',2450,NULL,10);
INSERT INTO emp VALUES (7788,'SCOTT','ANALYST',7566,'19-APR-87',3000,NULL,20);
INSERT INTO emp VALUES (7839,'KING','PRESIDENT',NULL,'17-NOV-81',5000,NULL,10);
INSERT INTO emp VALUES (7844,'TURNER','SALESMAN',7698,'08-SEP-81',1500,0,30);
INSERT INTO emp VALUES (7876,'ADAMS','CLERK',7788,'23-MAY-87',1100,NULL,20);
INSERT INTO emp VALUES (7900,'JAMES','CLERK',7698,'03-DEC-81',950,NULL,30);
INSERT INTO emp VALUES (7902,'FORD','ANALYST',7566,'03-DEC-81',3000,NULL,20);
INSERT INTO emp VALUES (7934,'MILLER','CLERK',7782,'23-JAN-82',1300,NULL,10);
--
-- Load the 'jobhist' table
--
INSERT INTO jobhist VALUES (7369,'17-DEC-80',NULL,'CLERK',800,NULL,20,'New Hire');
INSERT INTO jobhist VALUES (7499,'20-FEB-81',NULL,'SALESMAN',1600,300,30,'New Hire');
INSERT INTO jobhist VALUES (7521,'22-FEB-81',NULL,'SALESMAN',1250,500,30,'New Hire');
INSERT INTO jobhist VALUES (7566,'02-APR-81',NULL,'MANAGER',2975,NULL,20,'New Hire');
INSERT INTO jobhist VALUES (7654,'28-SEP-81',NULL,'SALESMAN',1250,1400,30,'New Hire');
INSERT INTO jobhist VALUES (7698,'01-MAY-81',NULL,'MANAGER',2850,NULL,30,'New Hire');
INSERT INTO jobhist VALUES (7782,'09-JUN-81',NULL,'MANAGER',2450,NULL,10,'New Hire');
INSERT INTO jobhist VALUES (7788,'19-APR-87','12-APR-88','CLERK',1000,NULL,20,'New Hire');
INSERT INTO jobhist VALUES (7788,'13-APR-88','04-MAY-89','CLERK',1040,NULL,20,'Raise');
INSERT INTO jobhist VALUES (7788,'05-MAY-90',NULL,'ANALYST',3000,NULL,20,'Promoted to Analyst');
INSERT INTO jobhist VALUES (7839,'17-NOV-81',NULL,'PRESIDENT',5000,NULL,10,'New Hire');
INSERT INTO jobhist VALUES (7844,'08-SEP-81',NULL,'SALESMAN',1500,0,30,'New Hire');
INSERT INTO jobhist VALUES (7876,'23-MAY-87',NULL,'CLERK',1100,NULL,20,'New Hire');
INSERT INTO jobhist VALUES (7900,'03-DEC-81','14-JAN-83','CLERK',950,NULL,10,'New Hire');
INSERT INTO jobhist VALUES (7900,'15-JAN-83',NULL,'CLERK',950,NULL,30,'Changed to Dept 30');
INSERT INTO jobhist VALUES (7902,'03-DEC-81',NULL,'ANALYST',3000,NULL,20,'New Hire');
INSERT INTO jobhist VALUES (7934,'23-JAN-82',NULL,'CLERK',1300,NULL,10,'New Hire');
--
-- Procedure that lists all employees' numbers and names
-- from the 'emp' table using a cursor.
--
CREATE OR REPLACE PROCEDURE list_emp
IS
v_empno NUMBER(4);
v_ename VARCHAR2(10);
CURSOR emp_cur IS
SELECT empno, ename FROM emp ORDER BY empno;
BEGIN
OPEN emp_cur;
DBMS_OUTPUT.PUT_LINE('EMPNO ENAME');
DBMS_OUTPUT.PUT_LINE('----- -------');
LOOP
FETCH emp_cur INTO v_empno, v_ename;
EXIT WHEN emp_cur%NOTFOUND;
DBMS_OUTPUT.PUT_LINE(v_empno || ' ' || v_ename);
END LOOP;
CLOSE emp_cur;
END;
--
-- Procedure that selects an employee row given the employee
-- number and displays certain columns.
--
CREATE OR REPLACE PROCEDURE select_emp
(
p_empno IN NUMBER
)
IS
v_ename emp.ename%TYPE;
v_hiredate emp.hiredate%TYPE;
v_sal emp.sal%TYPE;
v_comm emp.comm%TYPE;
v_dname dept.dname%TYPE;
v_disp_date VARCHAR2(10);
BEGIN
SELECT ename, hiredate, sal, NVL(comm, 0), dname
INTO v_ename, v_hiredate, v_sal, v_comm, v_dname
FROM emp e, dept d
WHERE empno = p_empno
AND e.deptno = d.deptno;
v_disp_date := TO_CHAR(v_hiredate, 'MM/DD/YYYY');
DBMS_OUTPUT.PUT_LINE('Number : ' || p_empno);
DBMS_OUTPUT.PUT_LINE('Name : ' || v_ename);
DBMS_OUTPUT.PUT_LINE('Hire Date : ' || v_disp_date);
DBMS_OUTPUT.PUT_LINE('Salary : ' || v_sal);
DBMS_OUTPUT.PUT_LINE('Commission: ' || v_comm);
DBMS_OUTPUT.PUT_LINE('Department: ' || v_dname);
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE('Employee ' || p_empno || ' not found');
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('The following is SQLERRM:');
DBMS_OUTPUT.PUT_LINE(SQLERRM);
DBMS_OUTPUT.PUT_LINE('The following is SQLCODE:');
DBMS_OUTPUT.PUT_LINE(SQLCODE);
END;
--
-- Procedure that queries the 'emp' table based on
-- department number and employee number or name. Returns
-- employee number and name as IN OUT parameters and job,
-- hire date, and salary as OUT parameters.
--
CREATE OR REPLACE PROCEDURE emp_query (
p_deptno IN NUMBER,
p_empno IN OUT NUMBER,
p_ename IN OUT VARCHAR2,
p_job OUT VARCHAR2,
p_hiredate OUT DATE,
p_sal OUT NUMBER
)
IS
BEGIN
SELECT empno, ename, job, hiredate, sal
INTO p_empno, p_ename, p_job, p_hiredate, p_sal
FROM emp
WHERE deptno = p_deptno
AND (empno = p_empno
OR ename = UPPER(p_ename));
END;
--
-- Procedure to call 'emp_query_caller' with IN and IN OUT
-- parameters. Displays the results received from IN OUT and
-- OUT parameters.
--
CREATE OR REPLACE PROCEDURE emp_query_caller
IS
v_deptno NUMBER(2);
v_empno NUMBER(4);
v_ename VARCHAR2(10);
v_job VARCHAR2(9);
v_hiredate DATE;
v_sal NUMBER;
BEGIN
v_deptno := 30;
v_empno := 0;
v_ename := 'Martin';
emp_query(v_deptno, v_empno, v_ename, v_job, v_hiredate, v_sal);
DBMS_OUTPUT.PUT_LINE('Department : ' || v_deptno);
DBMS_OUTPUT.PUT_LINE('Employee No: ' || v_empno);
DBMS_OUTPUT.PUT_LINE('Name : ' || v_ename);
DBMS_OUTPUT.PUT_LINE('Job : ' || v_job);
DBMS_OUTPUT.PUT_LINE('Hire Date : ' || v_hiredate);
DBMS_OUTPUT.PUT_LINE('Salary : ' || v_sal);
EXCEPTION
WHEN TOO_MANY_ROWS THEN
DBMS_OUTPUT.PUT_LINE('More than one employee was selected');
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE('No employees were selected');
END;
--
-- After statement-level trigger that displays a message after
-- an insert, update, or deletion to the 'emp' table. One message
-- per SQL command is displayed.
--
CREATE OR REPLACE TRIGGER user_audit_trig
AFTER INSERT OR UPDATE OR DELETE ON emp
DECLARE
v_action VARCHAR2(24);
BEGIN
IF INSERTING THEN
v_action := ' added employee(s) on ';
ELSIF UPDATING THEN
v_action := ' updated employee(s) on ';
ELSIF DELETING THEN
v_action := ' deleted employee(s) on ';
END IF;
DBMS_OUTPUT.PUT_LINE('User ' || USER || v_action || TO_CHAR(SYSDATE,'YYYY-MM-DD'));
END;
/
--
-- Before row-level trigger that displays employee number and
-- salary of an employee that is about to be added, updated,
-- or deleted in the 'emp' table.
--
CREATE OR REPLACE TRIGGER emp_sal_trig
BEFORE DELETE OR INSERT OR UPDATE ON emp
FOR EACH ROW
DECLARE
sal_diff NUMBER;
BEGIN
IF INSERTING THEN
DBMS_OUTPUT.PUT_LINE('Inserting employee ' || :NEW.empno);
DBMS_OUTPUT.PUT_LINE('..New salary: ' || :NEW.sal);
END IF;
IF UPDATING THEN
sal_diff := :NEW.sal - :OLD.sal;
DBMS_OUTPUT.PUT_LINE('Updating employee ' || :OLD.empno);
DBMS_OUTPUT.PUT_LINE('..Old salary: ' || :OLD.sal);
DBMS_OUTPUT.PUT_LINE('..New salary: ' || :NEW.sal);
DBMS_OUTPUT.PUT_LINE('..Raise : ' || sal_diff);
END IF;
IF DELETING THEN
DBMS_OUTPUT.PUT_LINE('Deleting employee ' || :OLD.empno);
DBMS_OUTPUT.PUT_LINE('..Old salary: ' || :OLD.sal);
END IF;
END;
/
COMMIT;
In the following step you run the above sql script ONLY on the master database. We will run this script only on the master and not the slave as we want to populate the sample tables with replication and not with this sql script.
edb-psql -f /edb-sample.sql -h $MASTERHOST -p $MASTERDBPORT -U $REPLICATIONUSER $MASTERDBNAME
EDB-Replication does not automatically copy table definitions from a master when a slave subscribes to it, so we need to import this database schema. We do this with pg_dump. Please note that we only import the database schema and not the data in the database tables.
pg_dump -s -U $REPLICATIONUSER -h $MASTERHOST -p $MASTERDBPORT $MASTERDBNAME | edb-psql -U $REPLICATIONUSER -h $SLAVEHOST -p $SLAVEDBPORT $SLAVEDBNAME
After this step your master and slave node should look something like in the following screenshot.

To ensure that only the sample tables in the master node are populated with data and not the slave node(s) view the data first on the master and then on the slave. You should see the following in case of the master.
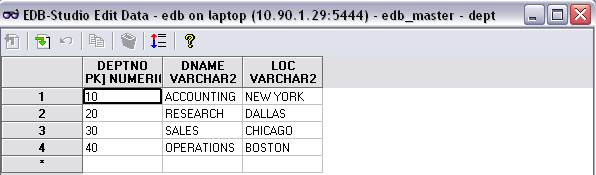
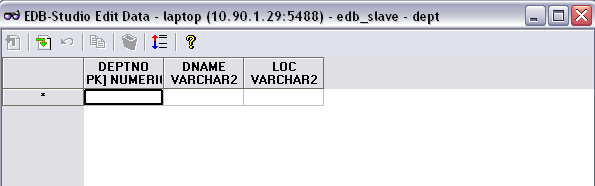
Whereas, if you view the dept table in the slave node(s) it should be unpopulated and something like the following:
17.4.4. Configuring the Database for Replication
Creating the configuration tables, stored procedures, triggers and configuration is all done through the slonik tool. It is a specialized scripting aid that mostly calls stored procedures in the master/slave (node) databases. The script to create the initial configuration for the simple master-slave setup of our "edb" database looks like this:
#!/bin/sh slonik <<_EOF_ #-- # define the namespace the replication system uses in our example it is # slony_example #-- cluster name = $CLUSTERNAME; #-- # admin conninfo's are used by slonik to connect to the nodes one for each # node on each side of the cluster, the syntax is that of PQconnectdb in # the C-API # -- node 1 admin conninfo = 'dbname=$MASTERDBNAME host=$MASTERHOST port=$MASTERDBPORT user=$REPLICATIONUSER'; node 2 admin conninfo = 'dbname=$SLAVEDBNAME host=$SLAVEHOST port=$SLAVEDBPORT user=$REPLICATIONUSER'; #-- # init the first node. Its id MUST be 1. This creates the schema # _$CLUSTERNAME containing all replication system specific database # objects. #-- init cluster ( id=1, comment = 'Master Node'); #-- # Slony-I organizes tables into sets. The smallest unit a node can # subscribe is a set. The following commands create one set containing # all 4 pgbench tables. The master or origin of the set is node 1. #-- create set (id=1, origin=1, comment='All edb sample tables'); set add table (set id=1, origin=1, id=1, fully qualified name = 'public.dept', comment='dept table'); set add table (set id=1, origin=1, id=2, fully qualified name = 'public.emp', comment='emp table'); set add table (set id=1, origin=1, id=3, fully qualified name = 'public.jobhist', comment='jobhist table'); #-- # Create the second node (the slave) tell the 2 nodes how to connect to # each other and how they should listen for events. #-- store node (id=2, comment = 'Slave node'); store path (server = 1, client = 2, conninfo='dbname=$MASTERDBNAME host=$MASTERHOST port=$MASTERDBPORT user=$REPLICATIONUSER'); store path (server = 2, client = 1, conninfo='dbname=$SLAVEDBNAME host=$SLAVEHOST port=$SLAVEDBPORT user=$REPLICATIONUSER'); store listen (origin=1, provider = 1, receiver =2); store listen (origin=2, provider = 2, receiver =1); _EOF_
You can run this script directly via shell or save the script as a shell script. It is recommended that you save it as a shell script, as you can easily make modifications and rerun the script in the event that you are either doing this over again or if you are creating another database cluster over again. Save the script as "init_cluster.sh" and run it. By running the script you are doing the following:
initializing a cluster for replication
identifying the nodes that are to be part of the cluster
creating a sample set for replication
adding the emp, dept and jobhist tables to this sample set
storing the path and connectivity information for the nodes in the cluster
enabling the listening of events on both the slave and master nodes
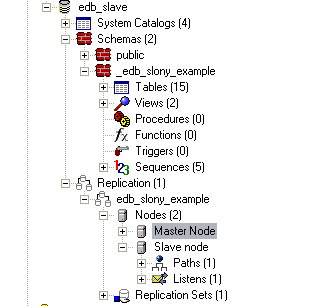
After running the script your master node should look something like:

At this point we have 2 databases that are fully prepared for replication. It's now time to start the replication daemons. On the $MASTERHOST the command to start the replication engine is:
edb-replication $CLUSTERNAME "dbname=$MASTERDBNAME user=$REPLICATIONUSER host=$MASTERHOST port=$MASTERDBPORT"
After running this command you should see something like the following (on the master node):
CONFIG main: edb-replication version 1.1.0 starting up CONFIG main: local node id = 1 CONFIG main: loading current cluster configuration CONFIG storeNode: no_id=2 no_comment='Slave node' CONFIG storePath: pa_server=2 pa_client=1 pa_conninfo="dbname=edb_slave host=localhost port=5488 user=edb_slony" pa_connretry=10 CONFIG storeListen: li_origin=2 li_receiver=1 li_provider=2 CONFIG storeSet: set_id=1 set_origin=1 set_comment='All edb sample tables' CONFIG main: configuration complete - starting threads CONFIG enableNode: no_id=2
Likewise we start the replication system on node 2 (the slave):
edb-replication $CLUSTERNAME "dbname=$SLAVEDBNAME user=$REPLICATIONUSER host=$SLAVEHOST port=$SLAVEDBPORT"
Similarly you should see something like the following upon the execution of this command:
CONFIG main: edb-replication version 1.1.0 starting up CONFIG main: local node id = 2 CONFIG main: loading current cluster configuration CONFIG storeNode: no_id=1 no_comment='Master Node' CONFIG storePath: pa_server=1 pa_client=2 pa_conninfo="dbname=edb_master host=localhost port=5444 user=edb_slony" pa_connretry=10 CONFIG storeListen: li_origin=1 li_receiver=2 li_provider=1 CONFIG storeSet: set_id=1 set_origin=1 set_comment='All edb sample tables' WARN remoteWorker_wakeup: node 1 - no worker thread CONFIG main: configuration complete - starting threads CONFIG enableNode: no_id=1
17.4.5. EDB-Replication Subscribtion
Even though we have the edb-replication process running on both the master and slave, and they are both spitting out diagnostics and other messages, we aren't replicating any data yet. The notices you are seeing is the synchronization of cluster configurations between the 2 EDB-Replication processes (you can see these messages in the window(s) running the edb-replication process.
To start replicating the data in the 3 sample edb tables (defined under set 1) from the master (node id 1) to the slave (node id 2), save the following script as "subscribe_set.sh" and run it.
#!/bin/sh slonik <<_EOF_ # ---- # This defines which namespace the replication system uses # ---- cluster name = $CLUSTERNAME; # ---- # Admin conninfo's are used by the slonik program to connect # to the node databases. So these are the PQconnectdb arguments # that connect from the administrators workstation (where # slonik is executed). # ---- node 1 admin conninfo = 'dbname=$MASTERDBNAME host=$MASTERHOST user=$REPLICATIONUSER'; node 2 admin conninfo = 'dbname=$SLAVEDBNAME host=$SLAVEHOST user=$REPLICATIONUSER'; # ---- # Node 2 subscribes set 1 # ---- subscribe set ( id = 1, provider = 1, receiver = 2, forward = no); _EOF_
Any second now, the replication daemon on $SLAVEHOST will start to copy the current content of all 3 replicated tables. And you should see the following output appended on the window running the the edb-replication process on the slave node(s) indicating that the slave node(s) has successfully subscribed to the master.
CONFIG storeSubscribe: sub_set=1 sub_provider=1 sub_forward='f' CONFIG enableSubscription: sub_set=1
You have now successfully set up your first basic master/slave replication system, and the 2 databases should, once the slave has caught up, contain identical data.