Copyright © 1995-2015 The FreeBSD Documentation Project
Copyright
Redistribution and use in source (XML DocBook) and 'compiled' forms (XML, HTML, PDF, PostScript, RTF and so forth) with or without modification, are permitted provided that the following conditions are met:
Redistributions of source code (XML DocBook) must retain the above copyright notice, this list of conditions and the following disclaimer as the first lines of this file unmodified.
Redistributions in compiled form (transformed to other DTDs, converted to PDF, PostScript, RTF and other formats) must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
Important:
THIS DOCUMENTATION IS PROVIDED BY THE FREEBSD DOCUMENTATION PROJECT "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE FREEBSD DOCUMENTATION PROJECT BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS DOCUMENTATION, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
FreeBSD is a registered trademark of the FreeBSD Foundation.
3Com and HomeConnect are registered trademarks of 3Com Corporation.
3ware is a registered trademark of 3ware Inc.
ARM is a registered trademark of ARM Limited.
Adaptec is a registered trademark of Adaptec, Inc.
Adobe, Acrobat, Acrobat Reader, Flash and PostScript are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States and/or other countries.
Apple, AirPort, FireWire, iMac, iPhone, iPad, Mac, Macintosh, Mac OS, Quicktime, and TrueType are trademarks of Apple Inc., registered in the U.S. and other countries.
Android is a trademark of Google Inc.
Heidelberg, Helvetica, Palatino, and Times Roman are either registered trademarks or trademarks of Heidelberger Druckmaschinen AG in the U.S. and other countries.
IBM, AIX, OS/2, PowerPC, PS/2, S/390, and ThinkPad are trademarks of International Business Machines Corporation in the United States, other countries, or both.
IEEE, POSIX, and 802 are registered trademarks of Institute of Electrical and Electronics Engineers, Inc. in the United States.
Intel, Celeron, Centrino, Core, EtherExpress, i386, i486, Itanium, Pentium, and Xeon are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries.
Intuit and Quicken are registered trademarks and/or registered service marks of Intuit Inc., or one of its subsidiaries, in the United States and other countries.
Linux is a registered trademark of Linus Torvalds.
LSI Logic, AcceleRAID, eXtremeRAID, MegaRAID and Mylex are trademarks or registered trademarks of LSI Logic Corp.
Microsoft, IntelliMouse, MS-DOS, Outlook, Windows, Windows Media and Windows NT are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
Motif, OSF/1, and UNIX are registered trademarks and IT DialTone and The Open Group are trademarks of The Open Group in the United States and other countries.
Oracle is a registered trademark of Oracle Corporation.
RealNetworks, RealPlayer, and RealAudio are the registered trademarks of RealNetworks, Inc.
Red Hat, RPM, are trademarks or registered trademarks of Red Hat, Inc. in the United States and other countries.
Sun, Sun Microsystems, Java, Java Virtual Machine, JDK, JRE, JSP, JVM, Netra, OpenJDK, Solaris, StarOffice, SunOS and VirtualBox are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries.
MATLAB is a registered trademark of The MathWorks, Inc.
SpeedTouch is a trademark of Thomson.
VMware is a trademark of VMware, Inc.
Mathematica is a registered trademark of Wolfram Research, Inc.
XFree86 is a trademark of The XFree86 Project, Inc.
Ogg Vorbis and Xiph.Org are trademarks of Xiph.Org.
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this document, and the FreeBSD Project was aware of the trademark claim, the designations have been followed by the “™” or the “®” symbol.
Welcome to FreeBSD! This handbook covers the installation
and day to day use of
FreeBSD 8.4-RELEASE,
FreeBSD 9.3-RELEASE, and
FreeBSD 10.2-RELEASE. This
manual is a work in progress and is the
work of many individuals. As such, some sections may become
dated and require updating. If you are interested in helping
out with this project, send email to the FreeBSD documentation project mailing list. The latest
version of this document is always available from the FreeBSD web site
(previous versions of this handbook can be obtained from http://docs.FreeBSD.org/doc/).
It may also be downloaded in a variety of formats and
compression options from the FreeBSD
FTP server or one of the numerous
mirror sites. If you would
prefer to have a hard copy of the handbook, you can purchase
one at the
FreeBSD
Mall. You may also want to
search the
handbook.
- Preface
- I. Getting Started
- 1. Introduction
- 2. Installing FreeBSD 9.
Xand Later - 3. Installing FreeBSD 8.
X - 3.1. Synopsis
- 3.2. Hardware Requirements
- 3.3. Pre-installation Tasks
- 3.4. Starting the Installation
- 3.5. Introducing sysinstall(8)
- 3.6. Allocating Disk Space
- 3.7. Choosing What to Install
- 3.8. Choosing the Installation Media
- 3.9. Committing to the Installation
- 3.10. Post-installation
- 3.11. Troubleshooting
- 3.12. Advanced Installation Guide
- 3.13. Preparing Custom Installation Media
- 4. UNIX Basics
- 5. Installing Applications: Packages and Ports
- 6. The X Window System
- II. Common Tasks
- III. System Administration
- 12. Configuration and Tuning
- 12.1. Synopsis
- 12.2. Starting Services
- 12.3. Configuring cron(8)
- 12.4. Managing Services in FreeBSD
- 12.5. Setting Up Network Interface Cards
- 12.6. Virtual Hosts
- 12.7. Configuring System Logging
- 12.8. Configuration Files
- 12.9. Tuning with sysctl(8)
- 12.10. Tuning Disks
- 12.11. Tuning Kernel Limits
- 12.12. Adding Swap Space
- 12.13. Power and Resource Management
- 13. The FreeBSD Booting Process
- 14. Security
- 15. Jails
- 16. Mandatory Access Control
- 17. Security Event Auditing
- 18. Storage
- 18.1. Synopsis
- 18.2. Adding Disks
- 18.3. Resizing and Growing Disks
- 18.4. USB Storage Devices
- 18.5. Creating and Using CD Media
- 18.6. Creating and Using DVD Media
- 18.7. Creating and Using Floppy Disks
- 18.8. Backup Basics
- 18.9. Memory Disks
- 18.10. File System Snapshots
- 18.11. Disk Quotas
- 18.12. Encrypting Disk Partitions
- 18.13. Encrypting Swap
- 18.14. Highly Available Storage (HAST)
- 19. GEOM: Modular Disk Transformation Framework
- 20. The Z File System (ZFS)
- 21. Other File Systems
- 22. Virtualization
- 23. Localization - i18n/L10n Usage and Setup
- 24. Updating and Upgrading FreeBSD
- 25. DTrace
- IV. Network Communication
- 26. Serial Communications
- 27. PPP
- 28. Electronic Mail
- 28.1. Synopsis
- 28.2. Mail Components
- 28.3. Sendmail Configuration Files
- 28.4. Changing the Mail Transfer Agent
- 28.5. Troubleshooting
- 28.6. Advanced Topics
- 28.7. Setting Up to Send Only
- 28.8. Using Mail with a Dialup Connection
- 28.9. SMTP Authentication
- 28.10. Mail User Agents
- 28.11. Using fetchmail
- 28.12. Using procmail
- 29. Network Servers
- 29.1. Synopsis
- 29.2. The inetd Super-Server
- 29.3. Network File System (NFS)
- 29.4. Network Information System (NIS)
- 29.5. Lightweight Directory Access Protocol (LDAP)
- 29.6. Dynamic Host Configuration Protocol (DHCP)
- 29.7. Domain Name System (DNS)
- 29.8. Apache HTTP Server
- 29.9. File Transfer Protocol (FTP)
- 29.10. File and Print Services for Microsoft® Windows® Clients (Samba)
- 29.11. Clock Synchronization with NTP
- 29.12. iSCSI Initiator and Target Configuration
- 30. Firewalls
- 31. Advanced Networking
- V. Appendices
- FreeBSD Glossary
- Index
- 2.1. FreeBSD Boot Loader Menu
- 2.2. FreeBSD Boot Options Menu
- 2.3. Welcome Menu
- 2.4. Keymap Selection
- 2.5. Selecting Keyboard Menu
- 2.6. Enhanced Keymap Menu
- 2.7. Setting the Hostname
- 2.8. Selecting Components to Install
- 2.9. Installing from the Network
- 2.10. Choosing a Mirror
- 2.11. Partitioning Choices on FreeBSD 9.x
- 2.12. Partitioning Choices on FreeBSD 10.x and Higher
- 2.13. Selecting from Multiple Disks
- 2.14. Selecting Entire Disk or Partition
- 2.15. Review Created Partitions
- 2.16. Manually Create Partitions
- 2.17. Manually Create Partitions
- 2.18. Manually Create Partitions
- 2.19. ZFS Partitioning Menu
- 2.20. ZFS Pool Type
- 2.21. Disk Selection
- 2.22. Invalid Selection
- 2.23. Analysing a Disk
- 2.24. Disk Encryption Password
- 2.25. Last Chance
- 2.26. Final Confirmation
- 2.27. Fetching Distribution Files
- 2.28. Verifying Distribution Files
- 2.29. Extracting Distribution Files
- 2.30. Setting the
rootPassword - 2.31. Choose a Network Interface
- 2.32. Scanning for Wireless Access Points
- 2.33. Choosing a Wireless Network
- 2.34. WPA2 Setup
- 2.35. Choose IPv4 Networking
- 2.36. Choose IPv4 DHCP Configuration
- 2.37. IPv4 Static Configuration
- 2.38. Choose IPv6 Networking
- 2.39. Choose IPv6 SLAAC Configuration
- 2.40. IPv6 Static Configuration
- 2.41. DNS Configuration
- 2.42. Select Local or UTC Clock
- 2.43. Select a Region
- 2.44. Select a Country
- 2.45. Select a Time Zone
- 2.46. Confirm Time Zone
- 2.47. Selecting Additional Services to Enable
- 2.48. Enabling Crash Dumps
- 2.49. Add User Accounts
- 2.50. Enter User Information
- 2.51. Exit User and Group Management
- 2.52. Final Configuration
- 2.53. Manual Configuration
- 2.54. Complete the Installation
- 3.1. FreeBSD Boot Loader Menu
- 3.2. Typical Device Probe Results
- 3.3. Selecting Country Menu
- 3.4. Selecting Keyboard Menu
- 3.5. Selecting Usage from Sysinstall Main Menu
- 3.6. Selecting Documentation Menu
- 3.7. Sysinstall Documentation Menu
- 3.8. Sysinstall Main Menu
- 3.9. Sysinstall Keymap Menu
- 3.10. Sysinstall Main Menu
- 3.11. Sysinstall Options
- 3.12. Begin Standard Installation
- 3.13. Select Drive for FDisk
- 3.14. Typical Default FDisk Partitions
- 3.15. Fdisk Partition Using Entire Disk
- 3.16. Sysinstall Boot Manager Menu
- 3.17. Exit Select Drive
- 3.18. Sysinstall Disklabel Editor
- 3.19. Sysinstall Disklabel Editor with Auto Defaults
- 3.20. Free Space for Root Partition
- 3.21. Edit Root Partition Size
- 3.22. Choose the Root Partition Type
- 3.23. Choose the Root Mount Point
- 3.24. Sysinstall Disklabel Editor
- 3.25. Choose Distributions
- 3.26. Confirm Distributions
- 3.27. Choose Installation Media
- 3.28. Selecting an Ethernet Device
- 3.29. Set Network Configuration for
ed0 - 3.30. Editing
inetd.conf - 3.31. Default Anonymous FTP Configuration
- 3.32. Edit the FTP Welcome Message
- 3.33. Editing
exports - 3.34. System Console Configuration Options
- 3.35. Screen Saver Options
- 3.36. Screen Saver Timeout
- 3.37. System Console Configuration Exit
- 3.38. Select the Region
- 3.39. Select the Country
- 3.40. Select the Time Zone
- 3.41. Select Mouse Protocol Type
- 3.42. Set Mouse Protocol
- 3.43. Configure Mouse Port
- 3.44. Setting the Mouse Port
- 3.45. Enable the Mouse Daemon
- 3.46. Test the Mouse Daemon
- 3.47. Select Package Category
- 3.48. Select Packages
- 3.49. Install Packages
- 3.50. Confirm Package Installation
- 3.51. Select User
- 3.52. Add User Information
- 3.53. Exit User and Group Management
- 3.54. Exit Install
- 3.55. Network Configuration Upper-level
- 3.56. Select a Default MTA
- 3.57. Ntpdate Configuration
- 3.58. Network Configuration Lower-level
- 31.1. PXE Booting Process with NFS Root Mount
- 2.1. Partitioning Schemes
- 3.1. Sample Device Inventory
- 3.2. Partition Layout for First Disk
- 3.3. Partition Layout for Subsequent Disks
- 3.4. FreeBSD ISO Image Names and Meanings
- 4.1. Utilities for Managing User Accounts
- 4.2. UNIX® Permissions
- 4.3. Disk Device Names
- 4.4. Common Environment Variables
- 6.1. XDM Configuration Files
- 8.1. Common Error Messages
- 10.1. Output PDLs
- 13.1. Loader Built-In Commands
- 13.2. Kernel Interaction During Boot
- 14.1. Login Class Resource Limits
- 17.1. Default Audit Event Classes
- 17.2. Prefixes for Audit Event Classes
- 23.1. Common Language and Country Codes
- 23.2. Defined Terminal Types for Character Sets
- 23.3. Available Console from Ports Collection
- 23.4. Available Input Methods
- 26.1. RS-232C Signal Names
- 26.2. DB-25 to DB-25 Null-Modem Cable
- 26.3. DB-9 to DB-9 Null-Modem Cable
- 26.4. DB-9 to DB-25 Null-Modem Cable
- 29.1. NIS Terminology
- 29.2. Additional Users
- 29.3. Additional Systems
- 29.4. DNS Terminology
- 30.1. Useful
pfctlOptions - 31.1. Commonly Seen Routing Table Flags
- 31.2. Station Capability Codes
- 31.3. Reserved IPv6 Addresses
- 2.1. Creating Traditional Split File System Partitions
- 3.1. Using an Existing Partition Unchanged
- 3.2. Shrinking an Existing Partition
- 4.1. Install a Program As the Superuser
- 4.2. Adding a User on FreeBSD
- 4.3.
rmuserInteractive Account Removal - 4.4. Using
chpassas Superuser - 4.5. Using
chpassas Regular User - 4.6. Changing Your Password
- 4.7. Changing Another User's Password as the Superuser
- 4.8. Adding a Group Using pw(8)
- 4.9. Adding User Accounts to a New Group Using pw(8)
- 4.10. Adding a New Member to a Group Using pw(8)
- 4.11. Using id(1) to Determine Group Membership
- 4.12. Sample Disk, Slice, and Partition Names
- 4.13. Conceptual Model of a Disk
- 12.1. Sample Log Server Configuration
- 12.2. Creating a Swap File on
FreeBSD 10.
Xand Later - 12.3. Creating a Swap File on
FreeBSD 9.
Xand Earlier - 13.1.
boot0Screenshot - 13.2.
boot2Screenshot - 13.3. Configuring an Insecure Console in
/etc/ttys - 14.1. Create a Secure Tunnel for SMTP
- 14.2. Secure Access of a POP3 Server
- 14.3. Bypassing a Firewall
- 15.1. mergemaster(8) on Untrusted Jail
- 15.2. mergemaster(8) on Trusted Jail
- 15.3. Running BIND in a Jail
- 18.1. Using
dumpover ssh - 18.2. Using
dumpover ssh withRSHSet - 18.3. Backing Up the Current Directory with
tar - 18.4. Restoring Up the Current Directory with
tar - 18.5. Using
lsandcpioto Make a Recursive Backup of the Current Directory - 18.6. Backing Up the Current Directory with
pax - 19.1. Labeling Partitions on the Boot Disk
- 26.1. Configuring Terminal Entries
- 29.1. Reloading the inetd Configuration File
- 29.2. Mounting an Export with amd
- 29.3. Mounting an Export with autofs(5)
- 29.4. Sample
/etc/ntp.conf - 31.1. LACP Aggregation with a Cisco® Switch
- 31.2. Failover Mode
- 31.3. Failover Mode Between Ethernet and Wireless Interfaces
Intended Audience
The FreeBSD newcomer will find that the first section of this book guides the user through the FreeBSD installation process and gently introduces the concepts and conventions that underpin UNIX®. Working through this section requires little more than the desire to explore, and the ability to take on board new concepts as they are introduced.
Once you have traveled this far, the second, far larger, section of the Handbook is a comprehensive reference to all manner of topics of interest to FreeBSD system administrators. Some of these chapters may recommend that you do some prior reading, and this is noted in the synopsis at the beginning of each chapter.
For a list of additional sources of information, please see Appendix B, Bibliography.
Changes from the Third Edition
The current online version of the Handbook represents the cumulative effort of many hundreds of contributors over the past 10 years. The following are some of the significant changes since the two volume third edition was published in 2004:
Chapter 25, DTrace has been added with information about the powerful DTrace performance analysis tool.
Chapter 21, Other File Systems has been added with information about non-native file systems in FreeBSD, such as ZFS from Sun™.
Chapter 17, Security Event Auditing has been added to cover the new auditing capabilities in FreeBSD and explain its use.
Chapter 22, Virtualization has been added with information about installing FreeBSD on virtualization software.
Chapter 2, Installing FreeBSD 9.
Xand Later has been added to cover installation of FreeBSD using the new installation utility, bsdinstall.
Changes from the Second Edition (2004)
The third edition was the culmination of over two years of work by the dedicated members of the FreeBSD Documentation Project. The printed edition grew to such a size that it was necessary to publish as two separate volumes. The following are the major changes in this new edition:
Chapter 12, Configuration and Tuning has been expanded with new information about the ACPI power and resource management, the
cronsystem utility, and more kernel tuning options.Chapter 14, Security has been expanded with new information about virtual private networks (VPNs), file system access control lists (ACLs), and security advisories.
Chapter 16, Mandatory Access Control is a new chapter with this edition. It explains what MAC is and how this mechanism can be used to secure a FreeBSD system.
Chapter 18, Storage has been expanded with new information about USB storage devices, file system snapshots, file system quotas, file and network backed filesystems, and encrypted disk partitions.
A troubleshooting section has been added to Chapter 27, PPP.
Chapter 28, Electronic Mail has been expanded with new information about using alternative transport agents, SMTP authentication, UUCP, fetchmail, procmail, and other advanced topics.
Chapter 29, Network Servers is all new with this edition. This chapter includes information about setting up the Apache HTTP Server, ftpd, and setting up a server for Microsoft® Windows® clients with Samba. Some sections from Chapter 31, Advanced Networking were moved here to improve the presentation.
Chapter 31, Advanced Networking has been expanded with new information about using Bluetooth® devices with FreeBSD, setting up wireless networks, and Asynchronous Transfer Mode (ATM) networking.
A glossary has been added to provide a central location for the definitions of technical terms used throughout the book.
A number of aesthetic improvements have been made to the tables and figures throughout the book.
Changes from the First Edition (2001)
The second edition was the culmination of over two years of work by the dedicated members of the FreeBSD Documentation Project. The following were the major changes in this edition:
A complete Index has been added.
All ASCII figures have been replaced by graphical diagrams.
A standard synopsis has been added to each chapter to give a quick summary of what information the chapter contains, and what the reader is expected to know.
The content has been logically reorganized into three parts: “Getting Started”, “System Administration”, and “Appendices”.
Chapter 3, Installing FreeBSD 8.
Xwas completely rewritten with many screenshots to make it much easier for new users to grasp the text.Chapter 4, UNIX Basics has been expanded to contain additional information about processes, daemons, and signals.
Chapter 5, Installing Applications: Packages and Ports has been expanded to contain additional information about binary package management.
Chapter 6, The X Window System has been completely rewritten with an emphasis on using modern desktop technologies such as KDE and GNOME on XFree86™ 4.X.
Chapter 13, The FreeBSD Booting Process has been expanded.
Chapter 18, Storage has been written from what used to be two separate chapters on “Disks” and “Backups”. We feel that the topics are easier to comprehend when presented as a single chapter. A section on RAID (both hardware and software) has also been added.
Chapter 26, Serial Communications has been completely reorganized and updated for FreeBSD 4.X/5.X.
Chapter 27, PPP has been substantially updated.
Many new sections have been added to Chapter 31, Advanced Networking.
Chapter 28, Electronic Mail has been expanded to include more information about configuring sendmail.
Chapter 11, Linux® Binary Compatibility has been expanded to include information about installing Oracle® and SAP® R/3®.
The following new topics are covered in this second edition:
Organization of This Book
This book is split into five logically distinct sections. The first section, Getting Started, covers the installation and basic usage of FreeBSD. It is expected that the reader will follow these chapters in sequence, possibly skipping chapters covering familiar topics. The second section, Common Tasks, covers some frequently used features of FreeBSD. This section, and all subsequent sections, can be read out of order. Each chapter begins with a succinct synopsis that describes what the chapter covers and what the reader is expected to already know. This is meant to allow the casual reader to skip around to find chapters of interest. The third section, System Administration, covers administration topics. The fourth section, Network Communication, covers networking and server topics. The fifth section contains appendices of reference information.
- Chapter 1, Introduction
Introduces FreeBSD to a new user. It describes the history of the FreeBSD Project, its goals and development model.
- Chapter 2, Installing FreeBSD 9.
Xand Later Walks a user through the entire installation process of FreeBSD 9.
xand later using bsdinstall.- Chapter 3, Installing FreeBSD 8.
X Walks a user through the entire installation process of FreeBSD 8.
xand earlier using sysinstall. Some advanced installation topics, such as installing through a serial console, are also covered.- Chapter 4, UNIX Basics
Covers the basic commands and functionality of the FreeBSD operating system. If you are familiar with Linux® or another flavor of UNIX® then you can probably skip this chapter.
- Chapter 5, Installing Applications: Packages and Ports
Covers the installation of third-party software with both FreeBSD's innovative “Ports Collection” and standard binary packages.
- Chapter 6, The X Window System
Describes the X Window System in general and using X11 on FreeBSD in particular. Also describes common desktop environments such as KDE and GNOME.
- Chapter 7, Desktop Applications
Lists some common desktop applications, such as web browsers and productivity suites, and describes how to install them on FreeBSD.
- Chapter 8, Multimedia
Shows how to set up sound and video playback support for your system. Also describes some sample audio and video applications.
- Chapter 9, Configuring the FreeBSD Kernel
Explains why you might need to configure a new kernel and provides detailed instructions for configuring, building, and installing a custom kernel.
- Chapter 10, Printing
Describes managing printers on FreeBSD, including information about banner pages, printer accounting, and initial setup.
- Chapter 11, Linux® Binary Compatibility
Describes the Linux® compatibility features of FreeBSD. Also provides detailed installation instructions for many popular Linux® applications such as Oracle® and Mathematica®.
- Chapter 12, Configuration and Tuning
Describes the parameters available for system administrators to tune a FreeBSD system for optimum performance. Also describes the various configuration files used in FreeBSD and where to find them.
- Chapter 13, The FreeBSD Booting Process
Describes the FreeBSD boot process and explains how to control this process with configuration options.
- Chapter 14, Security
Describes many different tools available to help keep your FreeBSD system secure, including Kerberos, IPsec and OpenSSH.
- Chapter 15, Jails
Describes the jails framework, and the improvements of jails over the traditional chroot support of FreeBSD.
- Chapter 16, Mandatory Access Control
Explains what Mandatory Access Control (MAC) is and how this mechanism can be used to secure a FreeBSD system.
- Chapter 17, Security Event Auditing
Describes what FreeBSD Event Auditing is, how it can be installed, configured, and how audit trails can be inspected or monitored.
- Chapter 18, Storage
Describes how to manage storage media and filesystems with FreeBSD. This includes physical disks, RAID arrays, optical and tape media, memory-backed disks, and network filesystems.
- Chapter 19, GEOM: Modular Disk Transformation Framework
Describes what the GEOM framework in FreeBSD is and how to configure various supported RAID levels.
- Chapter 21, Other File Systems
Examines support of non-native file systems in FreeBSD, like the Z File System from Sun™.
- Chapter 22, Virtualization
Describes what virtualization systems offer, and how they can be used with FreeBSD.
- Chapter 23, Localization - i18n/L10n Usage and Setup
Describes how to use FreeBSD in languages other than English. Covers both system and application level localization.
- Chapter 24, Updating and Upgrading FreeBSD
Explains the differences between FreeBSD-STABLE, FreeBSD-CURRENT, and FreeBSD releases. Describes which users would benefit from tracking a development system and outlines that process. Covers the methods users may take to update their system to the latest security release.
- Chapter 25, DTrace
Describes how to configure and use the DTrace tool from Sun™ in FreeBSD. Dynamic tracing can help locate performance issues, by performing real time system analysis.
- Chapter 26, Serial Communications
Explains how to connect terminals and modems to your FreeBSD system for both dial in and dial out connections.
- Chapter 27, PPP
Describes how to use PPP to connect to remote systems with FreeBSD.
- Chapter 28, Electronic Mail
Explains the different components of an email server and dives into simple configuration topics for the most popular mail server software: sendmail.
- Chapter 29, Network Servers
Provides detailed instructions and example configuration files to set up your FreeBSD machine as a network filesystem server, domain name server, network information system server, or time synchronization server.
- Chapter 30, Firewalls
Explains the philosophy behind software-based firewalls and provides detailed information about the configuration of the different firewalls available for FreeBSD.
- Chapter 31, Advanced Networking
Describes many networking topics, including sharing an Internet connection with other computers on your LAN, advanced routing topics, wireless networking, Bluetooth®, ATM, IPv6, and much more.
- Appendix A, Obtaining FreeBSD
Lists different sources for obtaining FreeBSD media on CDROM or DVD as well as different sites on the Internet that allow you to download and install FreeBSD.
- Appendix B, Bibliography
This book touches on many different subjects that may leave you hungry for a more detailed explanation. The bibliography lists many excellent books that are referenced in the text.
- Appendix C, Resources on the Internet
Describes the many forums available for FreeBSD users to post questions and engage in technical conversations about FreeBSD.
- Appendix D, OpenPGP Keys
Lists the PGP fingerprints of several FreeBSD Developers.
Conventions used in this book
To provide a consistent and easy to read text, several conventions are followed throughout the book.
Typographic Conventions
- Italic
An italic font is used for filenames, URLs, emphasized text, and the first usage of technical terms.
MonospaceA
monospacedfont is used for error messages, commands, environment variables, names of ports, hostnames, user names, group names, device names, variables, and code fragments.- Bold
A bold font is used for applications, commands, and keys.
User Input
Keys are shown in bold to stand out from
other text. Key combinations that are meant to be typed
simultaneously are shown with `+' between
the keys, such as:
Ctrl+Alt+Del
Meaning the user should type the Ctrl, Alt, and Del keys at the same time.
Keys that are meant to be typed in sequence will be separated with commas, for example:
Ctrl+X, Ctrl+S
Would mean that the user is expected to type the Ctrl and X keys simultaneously and then to type the Ctrl and S keys simultaneously.
Examples
Examples starting with C:\>
indicate a MS-DOS® command. Unless otherwise noted, these
commands may be executed from a “Command Prompt”
window in a modern Microsoft® Windows®
environment.
E:\>tools\fdimage floppies\kern.flp A:
Examples starting with # indicate a command that
must be invoked as the superuser in FreeBSD. You can login as
root to type the
command, or login as your normal account and use su(1) to
gain superuser privileges.
#dd if=kern.flp of=/dev/fd0
Examples starting with % indicate a command that
should be invoked from a normal user account. Unless otherwise
noted, C-shell syntax is used for setting environment variables
and other shell commands.
%top
Acknowledgments
The book you are holding represents the efforts of many hundreds of people around the world. Whether they sent in fixes for typos, or submitted complete chapters, all the contributions have been useful.
Several companies have supported the development of this document by paying authors to work on it full-time, paying for publication, etc. In particular, BSDi (subsequently acquired by Wind River Systems) paid members of the FreeBSD Documentation Project to work on improving this book full time leading up to the publication of the first printed edition in March 2000 (ISBN 1-57176-241-8). Wind River Systems then paid several additional authors to make a number of improvements to the print-output infrastructure and to add additional chapters to the text. This work culminated in the publication of the second printed edition in November 2001 (ISBN 1-57176-303-1). In 2003-2004, FreeBSD Mall, Inc, paid several contributors to improve the Handbook in preparation for the third printed edition.
This part of the FreeBSD Handbook is for users and administrators who are new to FreeBSD. These chapters:
Introduce you to FreeBSD.
Guide you through the installation process.
Teach you UNIX® basics and fundamentals.
Show you how to install the wealth of third party applications available for FreeBSD.
Introduce you to X, the UNIX® windowing system, and detail how to configure a desktop environment that makes you more productive.
We have tried to keep the number of forward references in the text to a minimum so that you can read this section of the Handbook from front to back with the minimum page flipping required.
- 1. Introduction
- 2. Installing FreeBSD 9.
Xand Later - 3. Installing FreeBSD 8.
X - 3.1. Synopsis
- 3.2. Hardware Requirements
- 3.3. Pre-installation Tasks
- 3.4. Starting the Installation
- 3.5. Introducing sysinstall(8)
- 3.6. Allocating Disk Space
- 3.7. Choosing What to Install
- 3.8. Choosing the Installation Media
- 3.9. Committing to the Installation
- 3.10. Post-installation
- 3.11. Troubleshooting
- 3.12. Advanced Installation Guide
- 3.13. Preparing Custom Installation Media
- 4. UNIX Basics
- 5. Installing Applications: Packages and Ports
- 6. The X Window System
Thank you for your interest in FreeBSD! The following chapter covers various aspects of the FreeBSD Project, such as its history, goals, development model, and so on.
After reading this chapter, you will know:
How FreeBSD relates to other computer operating systems.
The history of the FreeBSD Project.
The goals of the FreeBSD Project.
The basics of the FreeBSD open-source development model.
And of course: where the name “FreeBSD” comes from.
FreeBSD is a 4.4BSD-Lite based operating system for Intel (x86 and Itanium®), AMD64, Sun UltraSPARC® computers. Ports to other architectures are also underway. You can also read about the history of FreeBSD, or the current release. If you are interested in contributing something to the Project (code, hardware, funding), see the Contributing to FreeBSD article.
FreeBSD has many noteworthy features. Some of these are:
Preemptive multitasking with dynamic priority adjustment to ensure smooth and fair sharing of the computer between applications and users, even under the heaviest of loads.
Multi-user facilities which allow many people to use a FreeBSD system simultaneously for a variety of things. This means, for example, that system peripherals such as printers and tape drives are properly shared between all users on the system or the network and that individual resource limits can be placed on users or groups of users, protecting critical system resources from over-use.
Strong TCP/IP networking with support for industry standards such as SCTP, DHCP, NFS, NIS, PPP, SLIP, IPsec, and IPv6. This means that your FreeBSD machine can interoperate easily with other systems as well as act as an enterprise server, providing vital functions such as NFS (remote file access) and email services or putting your organization on the Internet with WWW, FTP, routing and firewall (security) services.
Memory protection ensures that applications (or users) cannot interfere with each other. One application crashing will not affect others in any way.
The industry standard X Window System (X11R7) can provide a graphical user interface (GUI) on any machine and comes with full sources.
Binary compatibility with many programs built for Linux, SCO, SVR4, BSDI and NetBSD.
Thousands of ready-to-run applications are available from the FreeBSD ports and packages collection. Why search the net when you can find it all right here?
Thousands of additional and easy-to-port applications are available on the Internet. FreeBSD is source code compatible with most popular commercial UNIX® systems and thus most applications require few, if any, changes to compile.
Demand paged virtual memory and “merged VM/buffer cache” design efficiently satisfies applications with large appetites for memory while still maintaining interactive response to other users.
A full complement of C and C++ development tools. Many additional languages for advanced research and development are also available in the ports and packages collection.
Source code for the entire system means you have the greatest degree of control over your environment. Why be locked into a proprietary solution at the mercy of your vendor when you can have a truly open system?
Extensive online documentation.
And many more!
FreeBSD is based on the 4.4BSD-Lite release from Computer Systems Research Group (CSRG) at the University of California at Berkeley, and carries on the distinguished tradition of BSD systems development. In addition to the fine work provided by CSRG, the FreeBSD Project has put in many thousands of hours in fine tuning the system for maximum performance and reliability in real-life load situations. FreeBSD offers performance and reliability on par with commercial offerings, combined with many cutting-edge features not available anywhere else.
The applications to which FreeBSD can be put are truly limited only by your own imagination. From software development to factory automation, inventory control to azimuth correction of remote satellite antennae; if it can be done with a commercial UNIX® product then it is more than likely that you can do it with FreeBSD too! FreeBSD also benefits significantly from literally thousands of high quality applications developed by research centers and universities around the world, often available at little to no cost. Commercial applications are also available and appearing in greater numbers every day.
Because the source code for FreeBSD itself is generally available, the system can also be customized to an almost unheard of degree for special applications or projects, and in ways not generally possible with operating systems from most major commercial vendors. Here is just a sampling of some of the applications in which people are currently using FreeBSD:
Internet Services: The robust TCP/IP networking built into FreeBSD makes it an ideal platform for a variety of Internet services such as:
Education: Are you a student of computer science or a related engineering field? There is no better way of learning about operating systems, computer architecture and networking than the hands on, under the hood experience that FreeBSD can provide. A number of freely available CAD, mathematical and graphic design packages also make it highly useful to those whose primary interest in a computer is to get other work done!
Research: With source code for the entire system available, FreeBSD is an excellent platform for research in operating systems as well as other branches of computer science. FreeBSD's freely available nature also makes it possible for remote groups to collaborate on ideas or shared development without having to worry about special licensing agreements or limitations on what may be discussed in open forums.
Networking: Need a new router? A name server (DNS)? A firewall to keep people out of your internal network? FreeBSD can easily turn that unused PC sitting in the corner into an advanced router with sophisticated packet-filtering capabilities.
Embedded: FreeBSD makes an excellent platform to build embedded systems upon. With support for the ARM®, MIPS® and PowerPC® platforms, coupled with a robust network stack, cutting edge features and the permissive BSD license FreeBSD makes an excellent foundation for building embedded routers, firewalls, and other devices.
Desktop: FreeBSD makes a fine choice for an inexpensive desktop solution using the freely available X11 server. FreeBSD offers a choice from many open-source desktop environments, including the standard GNOME and KDE graphical user interfaces. FreeBSD can even boot “diskless” from a central server, making individual workstations even cheaper and easier to administer.
Software Development: The basic FreeBSD system comes with a full complement of development tools including a full C/C++ compiler and debugger suite. Support for many other languages are also available through the ports and packages collection.
FreeBSD is available to download free of charge, or can be obtained on either CD-ROM or DVD. Please see Appendix A, Obtaining FreeBSD for more information about obtaining FreeBSD.
FreeBSD's advanced features, proven security, predictable release cycle, and permissive license have led to its use as a platform for building many commercial and open source appliances, devices, and products. Many of the world's largest IT companies use FreeBSD:
Apache - The Apache Software Foundation runs most of its public facing infrastructure, including possibly one of the largest SVN repositories in the world with over 1.4 million commits, on FreeBSD.
Apple - OS X borrows heavily from FreeBSD for the network stack, virtual file system, and many userland components. Apple iOS also contains elements borrowed from FreeBSD.
Cisco - IronPort network security and anti-spam appliances run a modified FreeBSD kernel.
Citrix - The NetScaler line of security appliances provide layer 4-7 load balancing, content caching, application firewall, secure VPN, and mobile cloud network access, along with the power of a FreeBSD shell.
Dell KACE - The KACE system management appliances run FreeBSD because of its reliability, scalability, and the community that supports its continued development.
Experts Exchange - All public facing web servers are powered by FreeBSD and they make extensive use of jails to isolate development and testing environments without the overhead of virtualization.
Isilon - Isilon's enterprise storage appliances are based on FreeBSD. The extremely liberal FreeBSD license allowed Isilon to integrate their intellectual property throughout the kernel and focus on building their product instead of an operating system.
iXsystems - The TrueNAS line of unified storage appliances is based on FreeBSD. In addition to their commercial products, iXsystems also manages development of the open source projects PC-BSD and FreeNAS.
Juniper - The JunOS operating system that powers all Juniper networking gear (including routers, switches, security, and networking appliances) is based on FreeBSD. Juniper is one of many vendors that showcases the symbiotic relationship between the project and vendors of commercial products. Improvements generated at Juniper are upstreamed into FreeBSD to reduce the complexity of integrating new features from FreeBSD back into JunOS in the future.
McAfee - SecurOS, the basis of McAfee enterprise firewall products including Sidewinder is based on FreeBSD.
NetApp - The Data ONTAP GX line of storage appliances are based on FreeBSD. In addition, NetApp has contributed back many features, including the new BSD licensed hypervisor, bhyve.
Netflix - The OpenConnect appliance that Netflix uses to stream movies to its customers is based on FreeBSD. Netflix has made extensive contributions to the codebase and works to maintain a zero delta from mainline FreeBSD. Netflix OpenConnect appliances are responsible for delivering more than 32% of all Internet traffic in North America.
Sandvine - Sandvine uses FreeBSD as the basis of their high performance realtime network processing platforms that make up their intelligent network policy control products.
Sony - The PlayStation 4 gaming console runs a modified version of FreeBSD.
Sophos - The Sophos Email Appliance product is based on a hardened FreeBSD and scans inbound mail for spam and viruses, while also monitoring outbound mail for malware as well as the accidental loss of sensitive information.
Spectra Logic - The nTier line of archive grade storage appliances run FreeBSD and OpenZFS.
The Weather Channel - The IntelliStar appliance that is installed at each local cable providers headend and is responsible for injecting local weather forecasts into the cable TV network's programming runs FreeBSD.
Verisign - Verisign is responsible for operating the .com and .net root domain registries as well as the accompanying DNS infrastructure. They rely on a number of different network operating systems including FreeBSD to ensure there is no common point of failure in their infrastructure.
Voxer - Voxer powers their mobile voice messaging platform with ZFS on FreeBSD. Voxer switched from a Solaris derivative to FreeBSD because of its superior documentation, larger and more active community, and more developer friendly environment. In addition to critical features like ZFS and DTrace, FreeBSD also offers TRIM support for ZFS.
WhatsApp - When WhatsApp needed a platform that would be able to handle more than 1 million concurrent TCP connections per server, they chose FreeBSD. They then proceeded to scale past 2.5 million connections per server.
Wheel Systems - The FUDO security appliance allows enterprises to monitor, control, record, and audit contractors and administrators who work on their systems. Based on all of the best security features of FreeBSD including ZFS, GELI, Capsicum, HAST, and auditdistd.
FreeBSD has also spawned a number of related open source projects:
BSD Router - A FreeBSD based replacement for large enterprise routers designed to run on standard PC hardware.
FreeNAS - A customized FreeBSD designed to be used as a network file server appliance. Provides a python based web interface to simplify the management of both the UFS and ZFS file systems. Includes support for NFS, SMB/CIFS, AFP, FTP, and iSCSI. Includes an extensible plugin system based on FreeBSD jails.
GhostBSD - A desktop oriented distribution of FreeBSD bundled with the Gnome desktop environment.
mfsBSD - A toolkit for building a FreeBSD system image that runs entirely from memory.
NAS4Free - A file server distribution based on FreeBSD with a PHP powered web interface.
PC-BSD - A customized version of FreeBSD geared towards desktop users with graphical utilities to exposing the power of FreeBSD to all users. Designed to ease the transition of Windows and OS X users.
pfSense - A firewall distribution based on FreeBSD with a huge array of features and extensive IPv6 support.
m0n0wall - A stripped down version of FreeBSD bundled with a web server and PHP. Designed as an embedded firewall appliance with a footprint of less than 12 MB.
ZRouter - An open source alternative firmware for embedded devices based on FreeBSD. Designed to replace the proprietary firmware on off-the-shelf routers.
FreeBSD is also used to power some of the biggest sites on the Internet, including:
and many more. Wikipedia also maintains a list of products based on FreeBSD.
The following section provides some background information on the project, including a brief history, project goals, and the development model of the project.
The FreeBSD Project had its genesis in the early part of 1993, partially as an outgrowth of the Unofficial 386BSDPatchkit by the patchkit's last 3 coordinators: Nate Williams, Rod Grimes and Jordan Hubbard.
The original goal was to produce an intermediate snapshot of 386BSD in order to fix a number of problems with it that the patchkit mechanism just was not capable of solving. The early working title for the project was 386BSD 0.5 or 386BSD Interim in reference of that fact.
386BSD was Bill Jolitz's operating system, which had been up to that point suffering rather severely from almost a year's worth of neglect. As the patchkit swelled ever more uncomfortably with each passing day, they decided to assist Bill by providing this interim “cleanup” snapshot. Those plans came to a rude halt when Bill Jolitz suddenly decided to withdraw his sanction from the project without any clear indication of what would be done instead.
The trio thought that the goal remained worthwhile, even without Bill's support, and so they adopted the name "FreeBSD" coined by David Greenman. The initial objectives were set after consulting with the system's current users and, once it became clear that the project was on the road to perhaps even becoming a reality, Jordan contacted Walnut Creek CDROM with an eye toward improving FreeBSD's distribution channels for those many unfortunates without easy access to the Internet. Walnut Creek CDROM not only supported the idea of distributing FreeBSD on CD but also went so far as to provide the project with a machine to work on and a fast Internet connection. Without Walnut Creek CDROM's almost unprecedented degree of faith in what was, at the time, a completely unknown project, it is quite unlikely that FreeBSD would have gotten as far, as fast, as it has today.
The first CD-ROM (and general net-wide) distribution was FreeBSD 1.0, released in December of 1993. This was based on the 4.3BSD-Lite (“Net/2”) tape from U.C. Berkeley, with many components also provided by 386BSD and the Free Software Foundation. It was a fairly reasonable success for a first offering, and they followed it with the highly successful FreeBSD 1.1 release in May of 1994.
Around this time, some rather unexpected storm clouds formed on the horizon as Novell and U.C. Berkeley settled their long-running lawsuit over the legal status of the Berkeley Net/2 tape. A condition of that settlement was U.C. Berkeley's concession that large parts of Net/2 were “encumbered” code and the property of Novell, who had in turn acquired it from AT&T some time previously. What Berkeley got in return was Novell's “blessing” that the 4.4BSD-Lite release, when it was finally released, would be declared unencumbered and all existing Net/2 users would be strongly encouraged to switch. This included FreeBSD, and the project was given until the end of July 1994 to stop shipping its own Net/2 based product. Under the terms of that agreement, the project was allowed one last release before the deadline, that release being FreeBSD 1.1.5.1.
FreeBSD then set about the arduous task of literally re-inventing itself from a completely new and rather incomplete set of 4.4BSD-Lite bits. The “Lite” releases were light in part because Berkeley's CSRG had removed large chunks of code required for actually constructing a bootable running system (due to various legal requirements) and the fact that the Intel port of 4.4 was highly incomplete. It took the project until November of 1994 to make this transition, and in December it released FreeBSD 2.0 to the world. Despite being still more than a little rough around the edges, the release was a significant success and was followed by the more robust and easier to install FreeBSD 2.0.5 release in June of 1995.
Since that time, FreeBSD has made a series of releases each time improving the stability, speed, and feature set of the previous version.
For now, long-term development projects continue to take place in the 10.X-CURRENT (trunk) branch, and snapshot releases of 10.X are continually made available from the snapshot server as work progresses.
The goals of the FreeBSD Project are to provide software that may be used for any purpose and without strings attached. Many of us have a significant investment in the code (and project) and would certainly not mind a little financial compensation now and then, but we are definitely not prepared to insist on it. We believe that our first and foremost “mission” is to provide code to any and all comers, and for whatever purpose, so that the code gets the widest possible use and provides the widest possible benefit. This is, I believe, one of the most fundamental goals of Free Software and one that we enthusiastically support.
That code in our source tree which falls under the GNU General Public License (GPL) or Library General Public License (LGPL) comes with slightly more strings attached, though at least on the side of enforced access rather than the usual opposite. Due to the additional complexities that can evolve in the commercial use of GPL software we do, however, prefer software submitted under the more relaxed BSD copyright when it is a reasonable option to do so.
The development of FreeBSD is a very open and flexible process, being literally built from the contributions of thousands of people around the world, as can be seen from our list of contributors. FreeBSD's development infrastructure allow these thousands of contributors to collaborate over the Internet. We are constantly on the lookout for new developers and ideas, and those interested in becoming more closely involved with the project need simply contact us at the FreeBSD technical discussions mailing list. The FreeBSD announcements mailing list is also available to those wishing to make other FreeBSD users aware of major areas of work.
Useful things to know about the FreeBSD Project and its development process, whether working independently or in close cooperation:
- The SVN repositories
For several years, the central source tree for FreeBSD was maintained by CVS (Concurrent Versions System), a freely available source code control tool. In June 2008, the Project switched to using SVN (Subversion). The switch was deemed necessary, as the technical limitations imposed by CVS were becoming obvious due to the rapid expansion of the source tree and the amount of history already stored. The Documentation Project and Ports Collection repositories also moved from CVS to SVN in May 2012 and July 2012, respectively. Please refer to the Synchronizing your source tree section for more information on obtaining the FreeBSD
src/repository and Using the Ports Collection for details on obtaining the FreeBSD Ports Collection.- The committers list
The committers are the people who have write access to the Subversion tree, and are authorized to make modifications to the FreeBSD source (the term “committer” comes from the source control
commitcommand, which is used to bring new changes into the repository). The best way of making submissions for review is to use the send-pr(1) command, which is included in releases prior to FreeBSD 10.1, or submit issues using the problem report form. If a problem report has not received any attention, please engage the community mailing lists.- The FreeBSD core team
The FreeBSD core team would be equivalent to the board of directors if the FreeBSD Project were a company. The primary task of the core team is to make sure the project, as a whole, is in good shape and is heading in the right directions. Inviting dedicated and responsible developers to join our group of committers is one of the functions of the core team, as is the recruitment of new core team members as others move on. The current core team was elected from a pool of committer candidates in July 2014. Elections are held every 2 years.
Note:
Like most developers, most members of the core team are also volunteers when it comes to FreeBSD development and do not benefit from the project financially, so “commitment” should also not be misconstrued as meaning “guaranteed support.” The “board of directors” analogy above is not very accurate, and it may be more suitable to say that these are the people who gave up their lives in favor of FreeBSD against their better judgement!
- Outside contributors
Last, but definitely not least, the largest group of developers are the users themselves who provide feedback and bug fixes to us on an almost constant basis. The primary way of keeping in touch with FreeBSD's more non-centralized development is to subscribe to the FreeBSD technical discussions mailing list where such things are discussed. See Appendix C, Resources on the Internet for more information about the various FreeBSD mailing lists.
The FreeBSD Contributors List is a long and growing one, so why not join it by contributing something back to FreeBSD today?
Providing code is not the only way of contributing to the project; for a more complete list of things that need doing, please refer to the FreeBSD Project web site.
In summary, our development model is organized as a loose set of concentric circles. The centralized model is designed for the convenience of the users of FreeBSD, who are provided with an easy way of tracking one central code base, not to keep potential contributors out! Our desire is to present a stable operating system with a large set of coherent application programs that the users can easily install and use — this model works very well in accomplishing that.
All we ask of those who would join us as FreeBSD developers is some of the same dedication its current people have to its continued success!
In addition to the base distributions, FreeBSD offers a
ported software collection with thousands of commonly
sought-after programs. At the time of this writing, there
were over 24,000 ports! The list of ports ranges from
http servers, to games, languages, editors, and almost
everything in between. The entire Ports Collection requires
approximately 500 MB. To compile a port, you simply
change to the directory of the program you wish to install,
type make install, and let the system do
the rest. The full original distribution for each port you
build is retrieved dynamically so you need only enough disk
space to build the ports you want. Almost every port is also
provided as a pre-compiled “package”, which can
be installed with a simple command
(pkg install) by those who do not wish to
compile their own ports from source. More information on
packages and ports can be found in
Chapter 5, Installing Applications: Packages and Ports.
All recent FreeBSD versions provide an option in the
installer (either sysinstall(8) or bsdinstall(8)) to
install additional documentation under
/usr/local/share/doc/freebsd during the
initial system setup. Documentation may also be installed at
any later time using packages as described in
Section 24.3.2, “Updating Documentation from Ports”. You may view the
locally installed manuals with any HTML capable browser using
the following URLs:
- The FreeBSD Handbook
- The FreeBSD FAQ
You can also view the master (and most frequently updated)
copies at http://www.FreeBSD.org/.
Beginning with FreeBSD 9.0-RELEASE, FreeBSD provides an easy
to use, text-based installation
program named bsdinstall. This
chapter describes how to install FreeBSD using
bsdinstall. The use of
sysinstall, which is the installation
program used by FreeBSD 8.x, is covered in Chapter 3, Installing FreeBSD 8.X.
In general, the installation instructions in this chapter are written for the i386™ and AMD64 architectures. Where applicable, instructions specific to other platforms will be listed. There may be minor differences between the installer and what is shown here, so use this chapter as a general guide rather than as a set of literal instructions.
Note:
Users who prefer to install FreeBSD using a graphical installer may be interested in pc-sysinstall, the installer used by the PC-BSD Project. It can be used to install either a graphical desktop (PC-BSD) or a command line version of FreeBSD. Refer to the PC-BSD Users Handbook for details (http://wiki.pcbsd.org/index.php/PC-BSD%C2%AE_Users_Handbook/10.1).
After reading this chapter, you will know:
The minimum hardware requirements and FreeBSD supported architectures.
How to create the FreeBSD installation media.
How to start bsdinstall.
The questions bsdinstall will ask, what they mean, and how to answer them.
How to troubleshoot a failed installation.
How to access a live version of FreeBSD before committing to an installation.
Before reading this chapter, you should:
Read the supported hardware list that shipped with the version of FreeBSD to be installed and verify that the system's hardware is supported.
The hardware requirements to install FreeBSD vary by the FreeBSD version and the hardware architecture. Hardware architectures and devices supported by a FreeBSD release are listed on the Release Information page of the FreeBSD web site (http://www.FreeBSD.org/releases/index.html).
A FreeBSD installation will require a minimum 64 MB of RAM and 1.5 GB of free hard drive space for the most minimal installation. However, that is a minimal install, leaving almost no free space. RAM requirements depend on usage. Specialized FreeBSD systems can run in as little as 128MB RAM while desktop systems should have at least 4 GB of RAM.
The processor requirements for each architecture can be summarized as follows:
- amd64
This is the most common type of processor desktop and laptop computers will have. Other vendors may call this architecture x86-64.
There are two primary vendors of amd64 processors: Intel® (which produces Intel64 class processors) and AMD (which produces AMD64).
Examples of amd64 compatible processsors include: AMD Athlon™64, AMD Opteron™, multi-core Intel® Xeon™, and Intel® Core™ 2 and later processors.
- i386
This architecture is the 32-bit x86 architecture.
Almost all i386-compatible processors with a floating point unit are supported. All Intel® processors 486 or higher are supported.
FreeBSD will take advantage of Physical Address Extensions (PAE) support on CPUs that support this feature. A kernel with the PAE feature enabled will detect memory above 4 GB and allow it to be used by the system. This feature places constraints on the device drivers and other features of FreeBSD which may be used; refer to pae(4) for details.
- ia64
Currently supported processors are the Itanium® and the Itanium® 2. Supported chipsets include the HP zx1, Intel® 460GX, and Intel® E8870. Both Uniprocessor (UP) and Symmetric Multi-processor (SMP) configurations are supported.
- pc98
NEC PC-9801/9821 series with almost all i386-compatible processors, including 80486, Pentium®, Pentium® Pro, and Pentium® II, are all supported. All i386-compatible processors by AMD, Cyrix, IBM, and IDT are also supported. EPSON PC-386/486/586 series, which are compatible with NEC PC-9801 series, are supported. The NEC FC-9801/9821 and NEC SV-98 series should be supported.
High-resolution mode is not supported. NEC PC-98XA/XL/RL/XL^2, and NEC PC-H98 series are supported in normal (PC-9801 compatible) mode only. The SMP-related features of FreeBSD are not supported. The New Extend Standard Architecture (NESA) bus used in the PC-H98, SV-H98, and FC-H98 series, is not supported.
- powerpc
All New World ROM Apple® Mac® systems with built-in USB are supported. SMP is supported on machines with multiple CPUs.
A 32-bit kernel can only use the first 2 GB of RAM.
- sparc64
Systems supported by FreeBSD/sparc64 are listed at the FreeBSD/sparc64 Project (http://www.freebsd.org/platforms/sparc.html).
SMP is supported on all systems with more than 1 processor. A dedicated disk is required as it is not possible to share a disk with another operating system at this time.
Once it has been determined that the system meets the minimum hardware requirements for installing FreeBSD, the installation file should be downloaded and the installation media prepared. Before doing this, check that the system is ready for an installation by verifying the items in this checklist:
Back Up Important Data
Before installing any operating system, always backup all important data first. Do not store the backup on the system being installed. Instead, save the data to a removable disk such as a USB drive, another system on the network, or an online backup service. Test the backup before starting the installation to make sure it contains all of the needed files. Once the installer formats the system's disk, all data stored on that disk will be lost.
Decide Where to Install FreeBSD
If FreeBSD will be the only operating system installed, this step can be skipped. But if FreeBSD will share the disk with another operating system, decide which disk or partition will be used for FreeBSD.
In the i386 and amd64 architectures, disks can be divided into multiple partitions using one of two partitioning schemes. A traditional Master Boot Record (MBR) holds a partition table defining up to four primary partitions. For historical reasons, FreeBSD calls these primary partition slices. One of these primary partitions can be made into an extended partition containing multiple logical partitions. The GUID Partition Table (GPT) is a newer and simpler method of partitioning a disk. Common GPT implementations allow up to 128 partitions per disk, eliminating the need for logical partitions.
Warning:
Some older operating systems, like Windows® XP, are not compatible with the GPT partition scheme. If FreeBSD will be sharing a disk with such an operating system, MBR partitioning is required.
The FreeBSD boot loader requires either a primary or GPT partition. If all of the primary or GPT partitions are already in use, one must be freed for FreeBSD. To create a partition without deleting existing data, use a partition resizing tool to shrink an existing partition and create a new partition using the freed space.
A variety of free and commercial partition resizing tools are listed at http://en.wikipedia.org/wiki/List_of_disk_partitioning_software. GParted Live (http://gparted.sourceforge.net/livecd.php) is a free live CD which includes the GParted partition editor. GParted is also included with many other Linux live CD distributions.
Warning:
When used properly, disk shrinking utilities can safely create space for creating a new partition. Since the possibility of selecting the wrong partition exists, always backup any important data and verify the integrity of the backup before modifying disk partitions.
Disk partitions containing different operating systems make it possible to install multiple operating systems on one computer. An alternative is to use virtualization (Chapter 22, Virtualization) which allows multiple operating systems to run at the same time without modifying any disk partitions.
Collect Network Information
Some FreeBSD installation methods require a network connection in order to download the installation files. After any installation, the installer will offer to setup the system's network interfaces.
If the network has a DHCP server, it can be used to provide automatic network configuration. If DHCP is not available, the following network information for the system must be obtained from the local network administrator or Internet service provider:
Check for FreeBSD Errata
Although the FreeBSD Project strives to ensure that each release of FreeBSD is as stable as possible, bugs occasionally creep into the process. On very rare occasions those bugs affect the installation process. As these problems are discovered and fixed, they are noted in the FreeBSD Errata (http://www.freebsd.org/releases/10.2R/errata.html) on the FreeBSD web site. Check the errata before installing to make sure that there are no problems that might affect the installation.
Information and errata for all the releases can be found on the release information section of the FreeBSD web site (http://www.freebsd.org/releases/index.html).
The FreeBSD installer is not an application that can be run from within another operating system. Instead, download a FreeBSD installation file, burn it to the media associated with its file type and size (CD, DVD, or USB), and boot the system to install from the inserted media.
FreeBSD installation files are available at www.freebsd.org/where.html#download.
Each installation file's name includes the release version of
FreeBSD, the architecture, and the type of file. For example, to
install FreeBSD 10.0 on an amd64 system from a
DVD, download
FreeBSD-10.0-RELEASE-amd64-dvd1.iso, burn
this file to a DVD, and boot the system
with the DVD inserted.
Several file types are available, though not all file types are available for all architectures. The possible file types are:
-bootonly.iso: This is the smallest installation file as it only contains the installer. A working Internet connection is required during installation as the installer will download the files it needs to complete the FreeBSD installation. This file should be burned to a CD using a CD burning application.-disc1.iso: This file contains all of the files needed to install FreeBSD, its source, and the Ports Collection. It should be burned to a CD using a CD burning application.-dvd1.iso: This file contains all of the files needed to install FreeBSD, its source, and the Ports Collection. It also contains a set of popular binary packages for installing a window manager and some applications so that a complete system can be installed from media without requiring a connection to the Internet. This file should be burned to a DVD using a DVD burning application.-memstick.img: This file contains all of the files needed to install FreeBSD, its source, and the Ports Collection. It should be burned to a USB stick using the instructions below.
Also download CHECKSUM.SHA256 from
the same directory as the image file and use it to check the
image file's integrity by calculating a
checksum. FreeBSD provides sha256(1)
for this, while other operating systems have similar programs.
Compare the calculated checksum with the one shown in
CHECKSUM.SHA256. The checksums must
match exactly. If the checksums do not match, the file is
corrupt and should be downloaded again.
The *.img file is an
image of the complete contents of a
memory stick. It cannot be copied to
the target device as a file. Several applications are
available for writing the *.img to a
USB stick. This section describes two of
these utilities.
Important:
Before proceeding, back up any important data on the USB stick. This procedure will erase the existing data on the stick.
dd to Write the
ImageWarning:
This example uses /dev/da0 as
the target device where the image will be written. Be
very careful that the correct
device is used as this command will destroy the existing
data on the specified target device.
The dd(1) command-line utility is available on BSD, Linux®, and Mac OS® systems. To burn the image using
dd, insert the USB stick and determine its device name. Then, specify the name of the downloaded installation file and the device name for the USB stick. This example burns the amd64 installation image to the first USB device on an existing FreeBSD system.#dd if=FreeBSD-10.0-RELEASE-amd64-memstick.imgof=/dev/da0bs=64kIf this command fails, verify that the USB stick is not mounted and that the device name is for the disk, not a partition. Some operating systems might require this command to be run with sudo(8). Systems like Linux® might buffer writes. To force all writes to complete, use sync(8).
Warning:
Be sure to give the correct drive letter as the existing data on the specified drive will be overwritten and destroyed.
Obtaining Image Writer for Windows®
Image Writer for Windows® is a free application that can correctly write an image file to a memory stick. Download it from
https://launchpad.net/win32-image-writer/and extract it into a folder.Writing the Image with Image Writer
Double-click the Win32DiskImager icon to start the program. Verify that the drive letter shown under
Deviceis the drive with the memory stick. Click the folder icon and select the image to be written to the memory stick. Click to accept the image file name. Verify that everything is correct, and that no folders on the memory stick are open in other windows. When everything is ready, click to write the image file to the memory stick.
You are now ready to start installing FreeBSD.
Important:
By default, the installation will not make any changes to the disk(s) before the following message:
Your changes will now be written to disk. If you have chosen to overwrite existing data, it will be PERMANENTLY ERASED. Are you sure you want to commit your changes?
The install can be exited at any time prior to this warning. If there is a concern that something is incorrectly configured, just turn the computer off before this point and no changes will be made to the system's disks.
This section describes how to boot the system from the installation media which was prepared using the instructions in Section 2.3.1, “Prepare the Installation Media”. When using a bootable USB stick, plug in the USB stick before turning on the computer. When booting from CD or DVD, turn on the computer and insert the media at the first opportunity. How to configure the system to boot from the inserted media depends upon the architecture.
These architectures provide a BIOS menu for selecting the boot device. Depending upon the installation media being used, select the CD/DVD or USB device as the first boot device. Most systems also provide a key for selecting the boot device during startup without having to enter the BIOS. Typically, the key is either F10, F11, F12, or Escape.
If the computer loads the existing operating system instead of the FreeBSD installer, then either:
The installation media was not inserted early enough in the boot process. Leave the media inserted and try restarting the computer.
The BIOS changes were incorrect or not saved. Double-check that the right boot device is selected as the first boot device.
This system is too old to support booting from the chosen media. In this case, the Plop Boot Manager (http://www.plop.at/en/bootmanagers.html) can be used to boot the system from the selected media.
On most machines, holding C on the
keyboard during boot will boot from the CD.
Otherwise, hold Command+Option+O+F, or
Windows+Alt+O+F on non-Apple® keyboards. At the
0 > prompt, enter
boot cd:,\ppc\loader cd:0Most SPARC64® systems are set up to boot automatically from disk. To install FreeBSD from a CD requires a break into the PROM.
To do this, reboot the system and wait until the boot message appears. The message depends on the model, but should look something like this:
Sun Blade 100 (UltraSPARC-IIe), Keyboard Present Copyright 1998-2001 Sun Microsystems, Inc. All rights reserved. OpenBoot 4.2, 128 MB memory installed, Serial #51090132. Ethernet address 0:3:ba:b:92:d4, Host ID: 830b92d4.
If the system proceeds to boot from disk at this point,
press L1+A
or Stop+A
on the keyboard, or send a BREAK over the
serial console. When using tip or
cu, ~# will
issue a BREAK. The PROM prompt will be
ok on systems with one
CPU and ok {0} on
SMP systems, where the digit indicates the
number of the active CPU.
At this point, place the CD into the
drive and type boot cdrom from the
PROM prompt.
Once the system boots from the installation media, a menu similar to the following will be displayed:
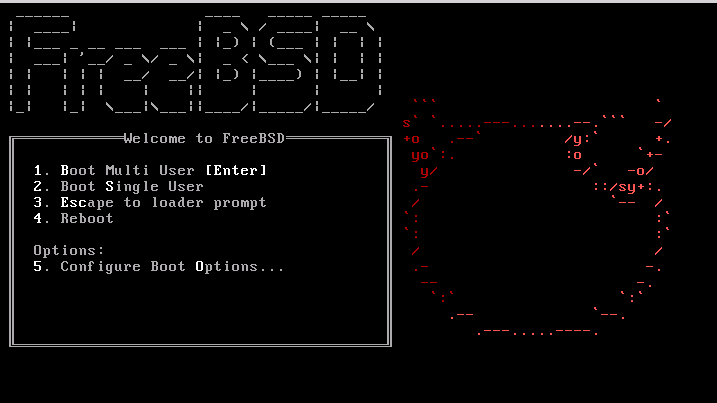
By default, the menu will wait ten seconds for user input before booting into the FreeBSD installer or, if FreeBSD is already installed, before booting into FreeBSD. To pause the boot timer in order to review the selections, press Space. To select an option, press its highlighted number, character, or key. The following options are available.
Boot Multi User: This will continue the FreeBSD boot process. If the boot timer has been paused, press 1, upper- or lower-case B, or Enter.Boot Single User: This mode can be used to fix an existing FreeBSD installation as described in Section 13.2.4.1, “Single-User Mode”. Press 2 or the upper- or lower-case S to enter this mode.Escape to loader prompt: This will boot the system into a repair prompt that contains a limited number of low-level commands. This prompt is described in Section 13.2.3, “Stage Three”. Press 3 or Esc to boot into this prompt.Reboot: Reboots the system.Configure Boot Options: Opens the menu shown in, and described under, Figure 2.2, “FreeBSD Boot Options Menu”.
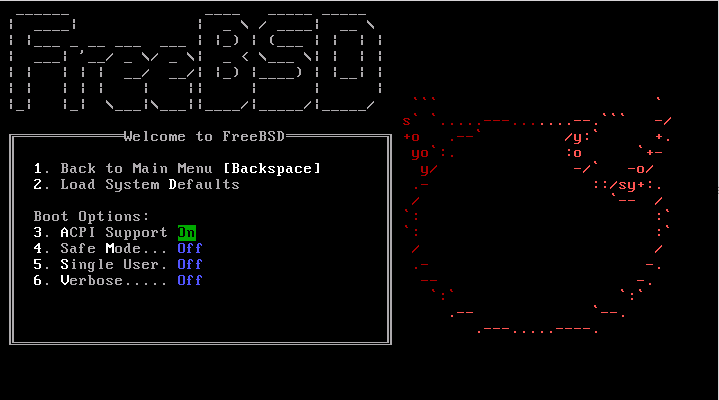
The boot options menu is divided into two sections. The first section can be used to either return to the main boot menu or to reset any toggled options back to their defaults.
The next section is used to toggle the available options
to On or Off by pressing
the option's highlighted number or character. The system will
always boot using the settings for these options until they
are modified. Several options can be toggled using this
menu:
ACPI Support: If the system hangs during boot, try toggling this option toOff.Safe Mode: If the system still hangs during boot even withACPI Supportset toOff, try setting this option toOn.Single User: Toggle this option toOnto fix an existing FreeBSD installation as described in Section 13.2.4.1, “Single-User Mode”. Once the problem is fixed, set it back toOff.Verbose: Toggle this option toOnto see more detailed messages during the boot process. This can be useful when troubleshooting a piece of hardware.
After making the needed selections, press 1 or Backspace to return to the main boot menu, then press Enter to continue booting into FreeBSD. A series of boot messages will appear as FreeBSD carries out its hardware device probes and loads the installation program. Once the boot is complete, the welcome menu shown in Figure 2.3, “Welcome Menu” will be displayed.
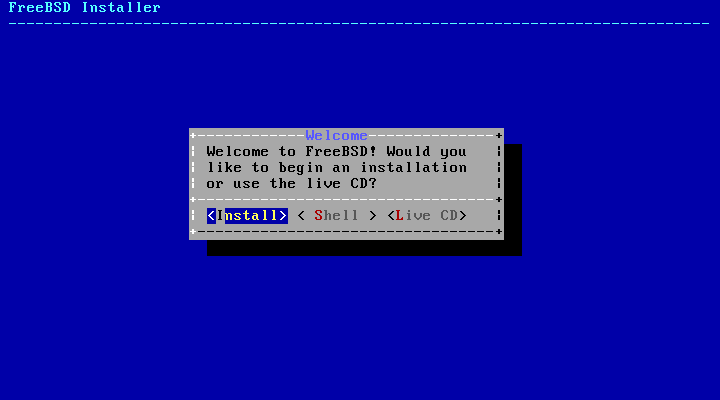
Press Enter to select the default of to enter the installer. The rest of this chapter describes how to use this installer. Otherwise, use the right or left arrows or the colorized letter to select the desired menu item. The can be used to access a FreeBSD shell in order to use command line utilities to prepare the disks before installation. The option can be used to try out FreeBSD before installing it. The live version is described in Section 2.10, “Using the Live CD”.
Tip:
To review the boot messages, including the hardware
device probe, press the upper- or lower-case
S and then Enter to access
a shell. At the shell prompt, type more
/var/run/dmesg.boot and use the space bar to
scroll through the messages. When finished, type
exit to return to the welcome
menu.
This section shows the order of the bsdinstall menus and the type of information that will be asked before the system is installed. Use the arrow keys to highlight a menu option, then Space to select or deselect that menu item. When finished, press Enter to save the selection and move onto the next screen.
Depending on the system console being used, bsdinstall may initially display the menu shown in Figure 2.4, “Keymap Selection”.
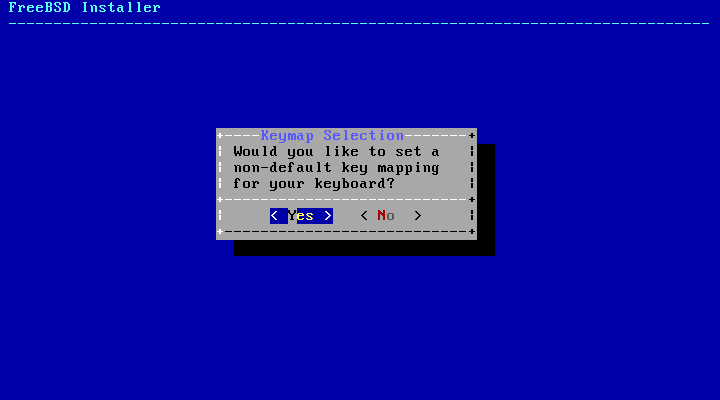
To configure the keyboard layout, press Enter with selected, which will display the menu shown in Figure 2.5, “Selecting Keyboard Menu”. To instead use the default layout, use the arrow key to select and press Enter to skip this menu screen.
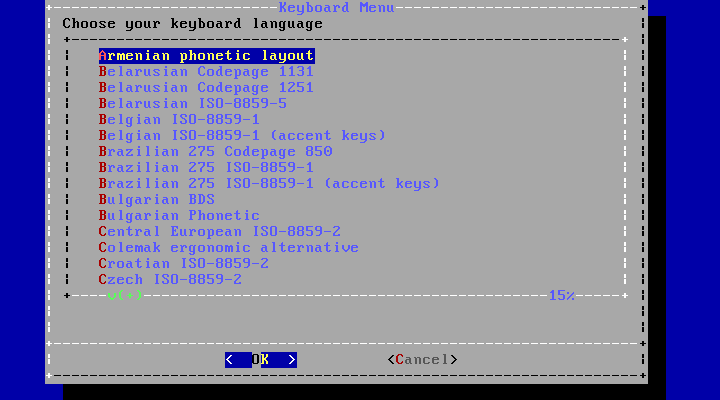
When configuring the keyboard layout, use the up and down arrows to select the keymap that most closely represents the mapping of the keyboard attached to the system. Press Enter to save the selection.
Note:
Pressing Esc will exit this menu and use the default keymap. If the choice of keymap is not clear, is also a safe option.
In FreeBSD 10.0-RELEASE and later, this menu has been enhanced. The full selection of keymaps is shown, with the default preselected. In addition, when selecting a different keymap, a dialog is displayed that allows the user to try the keymap and ensure it is correct before proceeding.
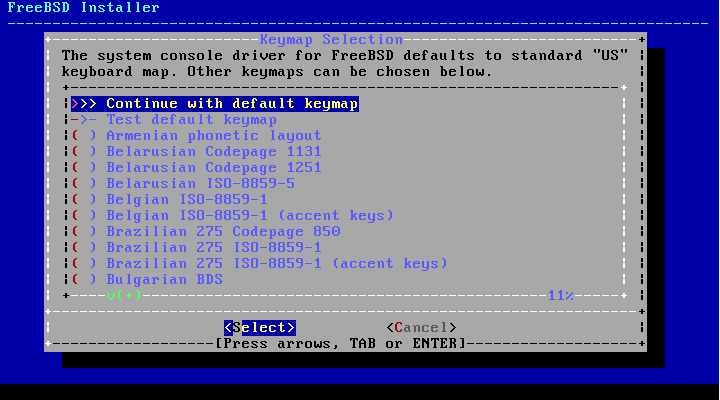
The next bsdinstall menu is used to set the hostname for the newly installed system.
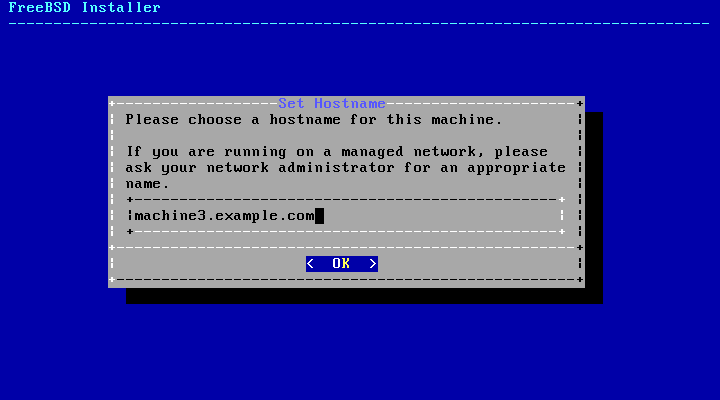
Type in a hostname that is unique for the network. It
should be a fully-qualified hostname, such as machine3.example.com.
Next, bsdinstall will prompt to select optional components to install.
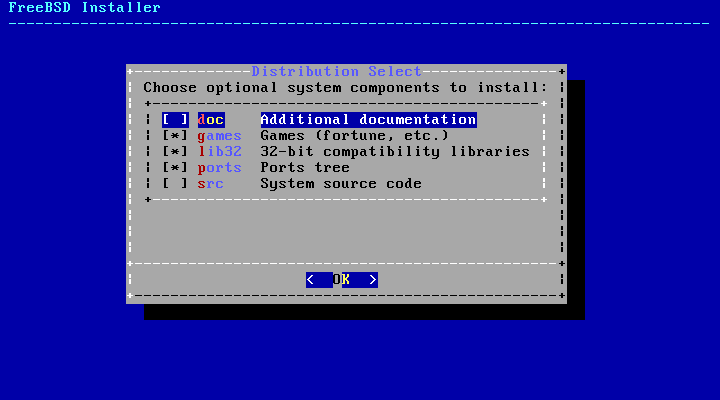
Deciding which components to install will depend largely on the intended use of the system and the amount of disk space available. The FreeBSD kernel and userland, collectively known as the base system, are always installed. Depending on the architecture, some of these components may not appear:
doc- Additional documentation, mostly of historical interest, to install into/usr/share/doc. The documentation provided by the FreeBSD Documentation Project may be installed later using the instructions in Section 24.3, “Updating the Documentation Set”.games- Several traditional BSD games, including fortune, rot13, and others.lib32- Compatibility libraries for running 32-bit applications on a 64-bit version of FreeBSD.ports- The FreeBSD Ports Collection is a collection of files which automates the downloading, compiling and installation of third-party software packages. Chapter 5, Installing Applications: Packages and Ports discusses how to use the Ports Collection.Warning:
The installation program does not check for adequate disk space. Select this option only if sufficient hard disk space is available. The FreeBSD Ports Collection takes up about 500 MB of disk space.
src- The complete FreeBSD source code for both the kernel and the userland. Although not required for the majority of applications, it may be required to build device drivers, kernel modules, or some applications from the Ports Collection. It is also used for developing FreeBSD itself. The full source tree requires 1 GB of disk space and recompiling the entire FreeBSD system requires an additional 5 GB of space.
The menu shown in Figure 2.9, “Installing from the Network” only appears when
installing from a -bootonly.iso
CD as this installation media does not hold
copies of the installation files. Since the installation
files must be retrieved over a network connection, this menu
indicates that the network interface must be first
configured.
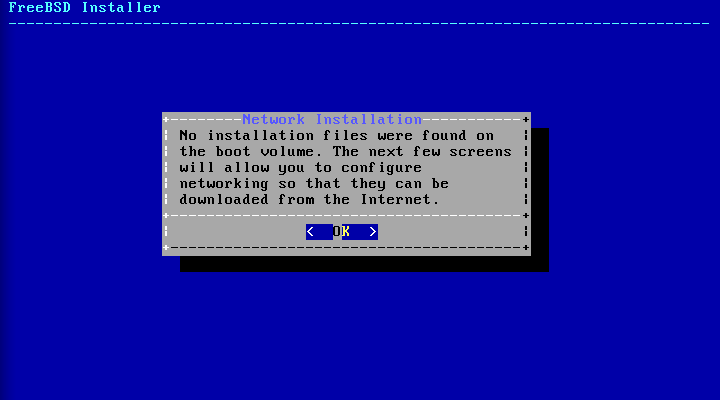
To configure the network connection, press Enter and follow the instructions in Section 2.8.2, “Configuring Network Interfaces”. Once the interface is configured, select a mirror site that is located in the same region of the world as the computer on which FreeBSD is being installed. Files can be retrieved more quickly when the mirror is close to the target computer, reducing installation time.
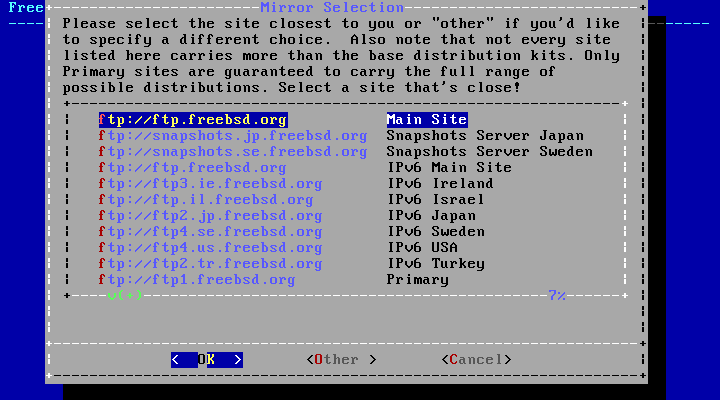
Installation will then continue as if the installation files were located on the local installation media.
The next menu is used to determine the method for allocating disk space. The options available in the menu depend upon the version of FreeBSD being installed.
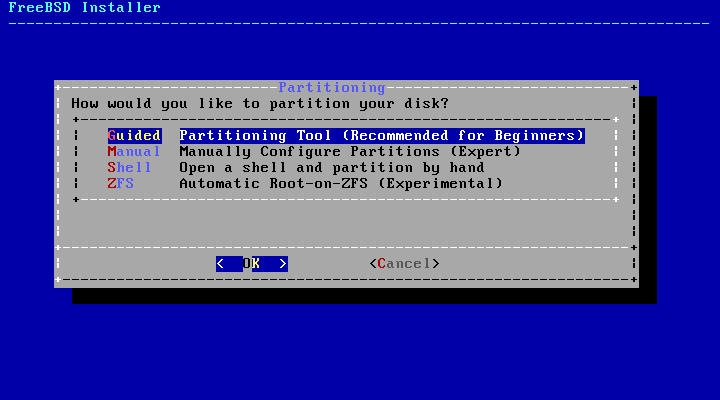
Guided partitioning automatically sets up
the disk partitions, Manual partitioning
allows advanced users to create customized partitions from menu
options, and Shell opens a shell prompt where
advanced users can create customized partitions using
command-line utilities like gpart(8), fdisk(8), and
bsdlabel(8). ZFS partitioning, only
available in FreeBSD 10 and later, creates an optionally encrypted
root-on-ZFS system with support for boot
environments.
This section describes what to consider when laying out the disk partitions. It then demonstrates how to use the different partitioning methods.
When laying out file systems, remember that hard drives
transfer data faster from the outer tracks to the inner.
Thus, smaller and heavier-accessed file systems should be
closer to the outside of the drive, while larger partitions
like /usr should be placed toward the
inner parts of the disk. It is a good idea to create
partitions in an order similar to: /,
swap, /var, and
/usr.
The size of the /var partition
reflects the intended machine's usage. This partition is
used to hold mailboxes, log files, and printer spools.
Mailboxes and log files can grow to unexpected sizes
depending on the number of users and how long log files are
kept. On average, most users rarely need more than about a
gigabyte of free disk space in
/var.
Note:
Sometimes, a lot of disk space is required in
/var/tmp. When new software is
installed, the packaging tools extract a temporary copy of
the packages under /var/tmp. Large
software packages, like Firefox,
OpenOffice or
LibreOffice may be tricky to
install if there is not enough disk space under
/var/tmp.
The /usr partition holds many of the
files which support the system, including the FreeBSD Ports
Collection and system source code. At least 2 gigabytes is
recommended for this partition.
When selecting partition sizes, keep the space requirements in mind. Running out of space in one partition while barely using another can be a hassle.
As a rule of thumb, the swap partition should be about double the size of physical memory (RAM). Systems with minimal RAM may perform better with more swap. Configuring too little swap can lead to inefficiencies in the VM page scanning code and might create issues later if more memory is added.
On larger systems with multiple SCSI disks or multiple IDE disks operating on different controllers, it is recommended that swap be configured on each drive, up to four drives. The swap partitions should be approximately the same size. The kernel can handle arbitrary sizes but internal data structures scale to 4 times the largest swap partition. Keeping the swap partitions near the same size will allow the kernel to optimally stripe swap space across disks. Large swap sizes are fine, even if swap is not used much. It might be easier to recover from a runaway program before being forced to reboot.
By properly partitioning a system, fragmentation
introduced in the smaller write heavy partitions will not
bleed over into the mostly read partitions. Keeping the
write loaded partitions closer to the disk's edge will
increase I/O performance in the
partitions where it occurs the most. While
I/O performance in the larger partitions
may be needed, shifting them more toward the edge of the disk
will not lead to a significant performance improvement over
moving /var to the edge.
When this method is selected, a menu will display the available disk(s). If multiple disks are connected, choose the one where FreeBSD is to be installed.
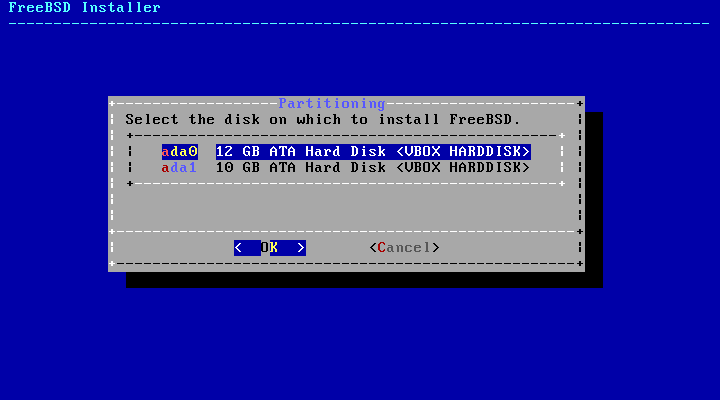
Once the disk is selected, the next menu prompts to install to either the entire disk or to create a partition using free space. If is chosen, a general partition layout filling the whole disk is automatically created. Selecting creates a partition layout from the unused space on the disk.
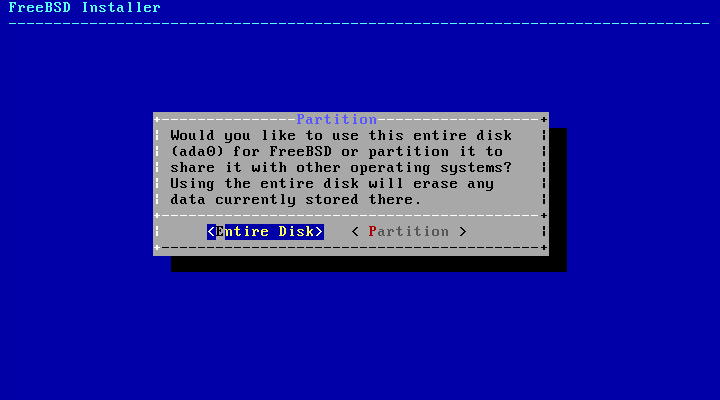
After the partition layout has been created, review it to ensure it meets the needs of the installation. Selecting will reset the partitions to their original values and pressing will recreate the automatic FreeBSD partitions. Partitions can also be manually created, modified, or deleted. When the partitioning is correct, select to continue with the installation.
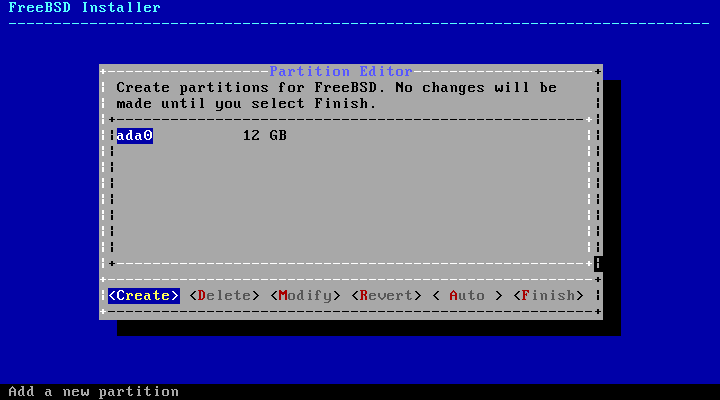
Highlight the installation drive
(ada0 in this example) and select
to display a menu
of available partition schemes:
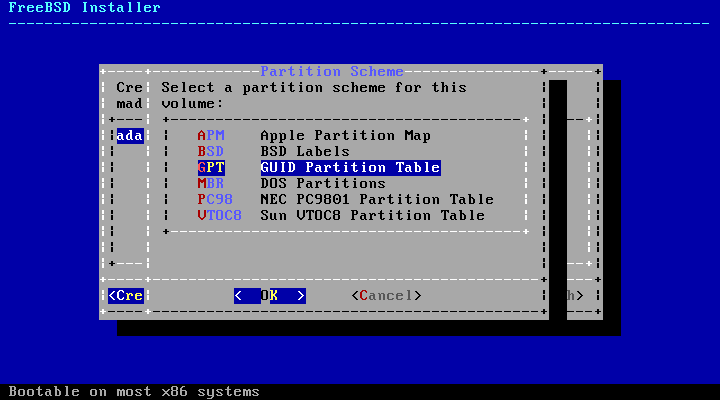
GPT is usually the most appropriate choice for amd64 computers. Older computers that are not compatible with GPT should use MBR. The other partition schemes are generally used for uncommon or older computers.
| Abbreviation | Description |
|---|---|
| APM | Apple Partition Map, used by PowerPC®. |
| BSD | BSD label without an MBR, sometimes called dangerously dedicated mode as non-BSD disk utilities may not recognize it. |
| GPT | GUID Partition Table (http://en.wikipedia.org/wiki/GUID_Partition_Table). |
| MBR | Master Boot Record (http://en.wikipedia.org/wiki/Master_boot_record). |
| PC98 | MBR variant used by NEC PC-98 computers (http://en.wikipedia.org/wiki/Pc9801). |
| VTOC8 | Volume Table Of Contents used by Sun SPARC64 and UltraSPARC computers. |
After the partitioning scheme has been selected and created, select again to create the partitions.
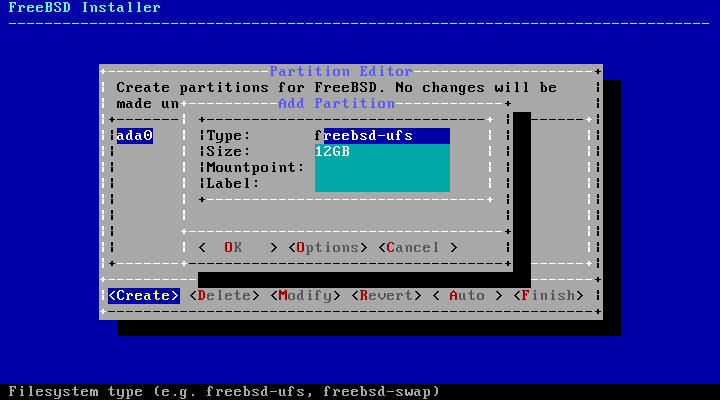
A standard FreeBSD GPT installation uses at least three partitions:
freebsd-boot- Holds the FreeBSD boot code.freebsd-ufs- A FreeBSD UFS file system.freebsd-swap- FreeBSD swap space.
Another partition type worth noting is
freebsd-zfs, used for partitions that will
contain a FreeBSD ZFS file system (Chapter 20, The Z File System (ZFS)). Refer to gpart(8) for
descriptions of the available GPT partition
types.
Multiple file system partitions can be created and some
people prefer a traditional layout with separate partitions
for /, /var,
/tmp, and /usr. See
Example 2.1, “Creating Traditional Split File System
Partitions” for an
example.
The Size may be entered with common
abbreviations: K for kilobytes,
M for megabytes, or
G for gigabytes.
Tip:
Proper sector alignment provides the best performance, and making partition sizes even multiples of 4K bytes helps to ensure alignment on drives with either 512-byte or 4K-byte sectors. Generally, using partition sizes that are even multiples of 1M or 1G is the easiest way to make sure every partition starts at an even multiple of 4K. There is one exception: the freebsd-boot partition should be no larger than 512K due to current boot code limitations.
A Mountpoint is needed if the partition
will contain a file system. If only a single
UFS partition will be created, the
mountpoint should be /.
The Label is a name by which the
partition will be known. Drive names or numbers can change if
the drive is connected to a different controller or port, but
the partition label does not change. Referring to labels
instead of drive names and partition numbers in files like
/etc/fstab makes the system more tolerant
to hardware changes. GPT labels appear in
/dev/gpt/ when a disk is attached. Other
partitioning schemes have different label capabilities and
their labels appear in different directories in
/dev/.
Tip:
Use a unique label on every partition to avoid
conflicts from identical labels. A few letters from the
computer's name, use, or location can be added to the label.
For instance, use labroot or
rootfslab for the UFS
root partition on the computer named
lab.
For a traditional partition layout where the
/, /var,
/tmp, and /usr
directories are separate file systems on their own
partitions, create a GPT partitioning
scheme, then create the partitions as shown. Partition
sizes shown are typical for a 20G target disk. If more
space is available on the target disk, larger swap or
/var partitions may be useful. Labels
shown here are prefixed with ex for
“example”, but readers should use other unique
label values as described above.
By default, FreeBSD's gptboot expects
the first UFS partition to be the
/ partition.
| Partition Type | Size | Mountpoint | Label |
|---|---|---|---|
freebsd-boot | 512K | ||
freebsd-ufs | 2G | / | exrootfs |
freebsd-swap | 4G | exswap | |
freebsd-ufs | 2G | /var | exvarfs |
freebsd-ufs | 1G | /tmp | extmpfs |
freebsd-ufs | accept the default (remainder of the disk) | /usr | exusrfs |
After the custom partitions have been created, select to continue with the installation.
Support for automatic creation of root-on-ZFS
installations was added in FreeBSD 10.0-RELEASE. This
partitioning mode only works with whole disks and will erase
the contents of the entire disk. The installer will
automatically create partitions aligned to 4k boundaries and
force ZFS to use 4k sectors. This is safe
even with 512 byte sector disks, and has the added benefit of
ensuring that pools created on 512 byte disks will be able to
have 4k sector disks added in the future, either as additional
storage space or as replacements for failed disks. The
installer can also optionally employ GELI
disk encryption as described in Section 18.12.2, “Disk Encryption with geli”.
If encryption is enabled, a 2 GB unencrypted boot pool
containing the /boot directory is
created. It holds the kernel and other files necessary to
boot the system. A swap partition of a user selectable size
is also created, and all remaining space is used for the
ZFS pool.
The main ZFS configuration menu offers a number of options to control the creation of the pool.
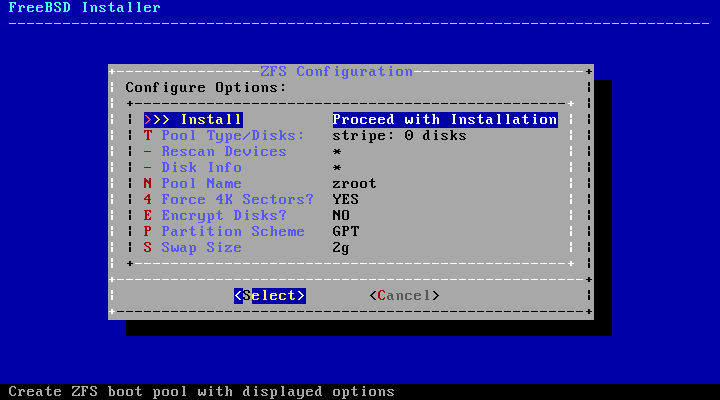
Select T to configure the Pool
Type and the disk(s) that will constitute the
pool. The automatic ZFS installer
currently only supports the creation of a single top level
vdev, except in stripe mode. To create more complex pools,
use the instructions in Section 2.6.5, “Shell Mode Partitioning” to create the pool. The
installer supports the creation of various pool types,
including stripe (not recommended, no redundancy), mirror
(best performance, least usable space), and RAID-Z 1, 2, and 3
(with the capability to withstand the concurrent failure of 1,
2, and 3 disks, respectively). while selecting the pool type,
a tooltip is displayed across the bottom of the screen with
advice about the number of required disks, and in the case of
RAID-Z, the optimal number of disks for each
configuration.
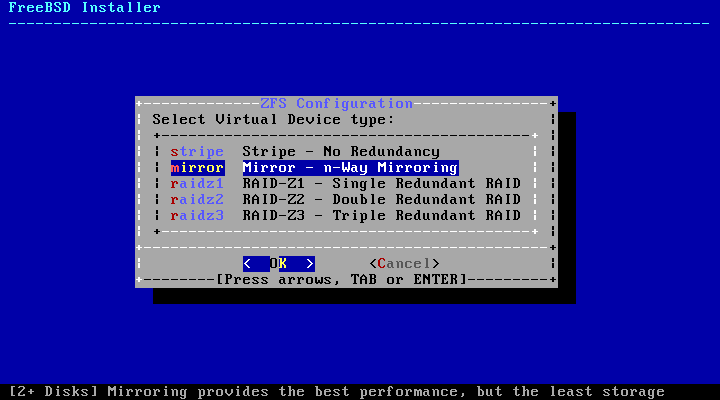
Once a Pool Type has been selected, a
list of available disks is displayed, and the user is prompted
to select one or more disks to make up the pool. The
configuration is then validated, to ensure enough disks are
selected. If not, select to return to the list of disks, or
to change the pool
type.
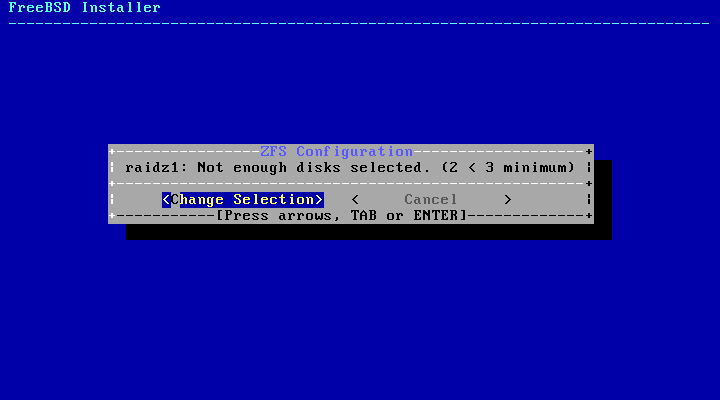
If one or more disks are missing from the list, or if disks were attached after the installer was started, select to repopulate the list of available disks. To ensure that the correct disks are selected, so as not to accidently destroy the wrong disks, the menu can be used to inspect each disk, including its partition table and various other information such as the device model number and serial number, if available.
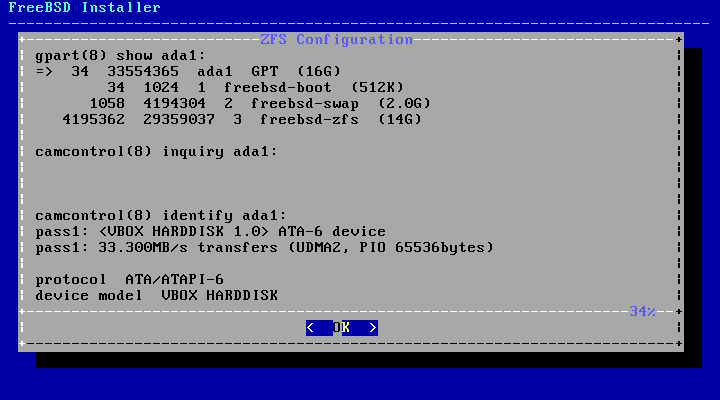
The main ZFS configuration menu also allows the user to enter a pool name, disable forcing 4k sectors, enable or disable encryption, switch between GPT (recommended) and MBR partition table types, and select the amount of swap space. Once all options have been set to the desired values, select the option at the top of the menu.
If GELI disk encryption was enabled, the installer will prompt twice for the passphrase to be used to encrypt the disks.
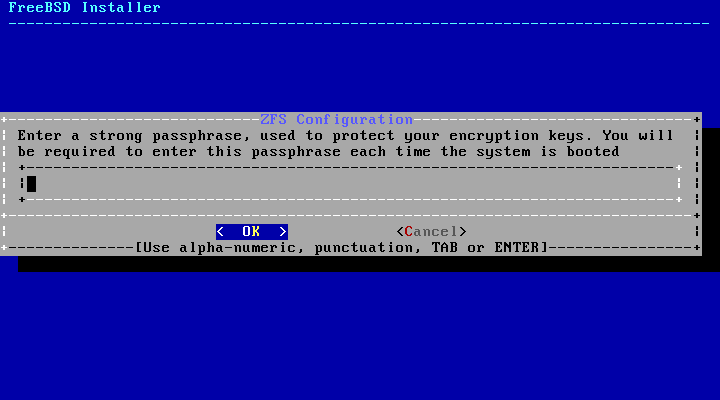
The installer then offers a last chance to cancel before the contents of the selected drives are destroyed to create the ZFS pool.
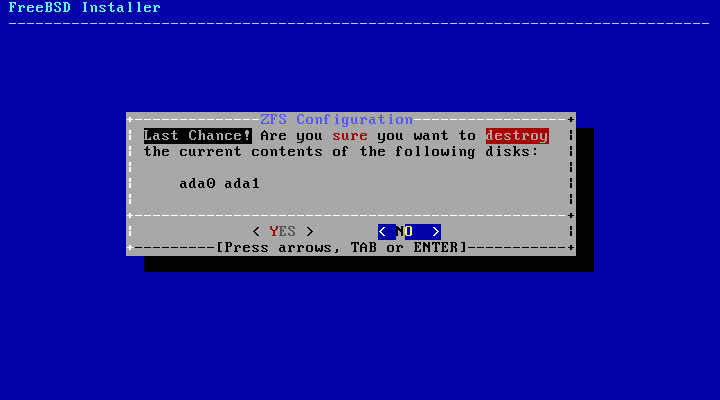
The installation then proceeds normally.
When creating advanced installations, the
bsdinstall paritioning menus may
not provide the level of flexibility required. Advanced users
can select the option from the
partitioning menu in order to manually partition the drives,
create the file system(s), populate
/tmp/bsdinstall_etc/fstab, and mount the
file systems under /mnt. Once this is
done, type exit to return to
bsdinstall and continue the
installation.
Once the disks are configured, the next menu provides the last chance to make changes before the selected hard drive(s) are formatted. If changes need to be made, select to return to the main partitioning menu. will exit the installer without making any changes to the hard drive.
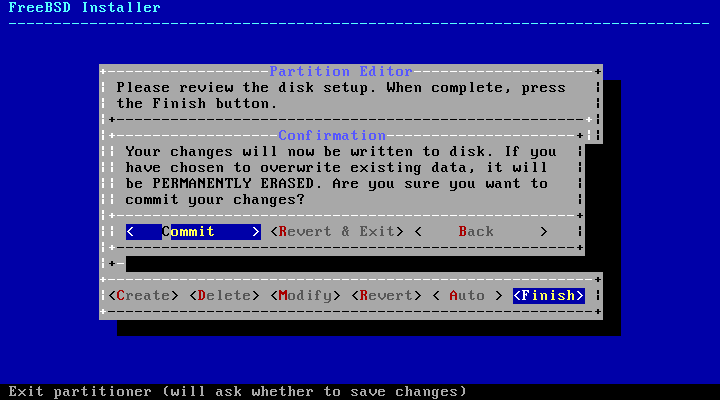
To instead start the actual installation, select and press Enter.
Installation time will vary depending on the distributions chosen, installation media, and speed of the computer. A series of messages will indicate the progress.
First, the installer formats the selected disk(s) and initializes the partitions. Next, in the case of a bootonly media, it downloads the selected components:
Next, the integrity of the distribution files is verified to ensure they have not been corrupted during download or misread from the installation media:
Finally, the verified distribution files are extracted to the disk:
Once all requested distribution files have been extracted, bsdinstall displays the first post-installation configuration screen. The available post-configuration options are described in the next section.
Once FreeBSD is installed, bsdinstall will prompt to configure several options before booting into the newly installed system. This section describes these configuration options.
Tip:
Once the system has booted,
bsdconfig provides a menu-driven method for
configuring the system using these and additional
options.
First, the root
password must be set. While entering the password, the
characters being typed are not displayed on the screen. After
the password has been entered, it must be entered again. This
helps prevent typing errors.
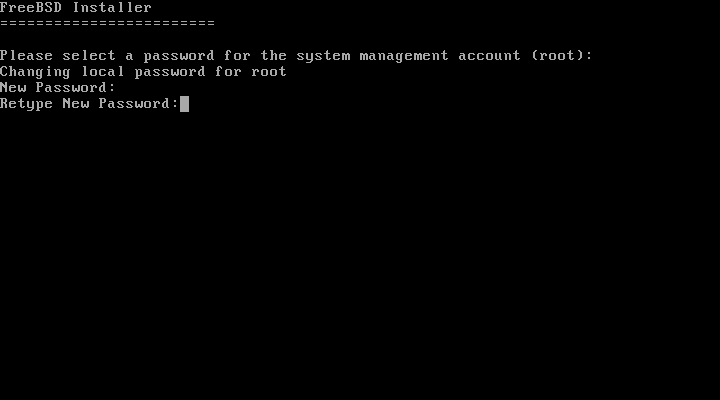
Next, a list of the network interfaces found on the computer is shown. Select the interface to configure.
Note:
The network configuration menus will be skipped if the network was previously configured as part of a bootonly installation.
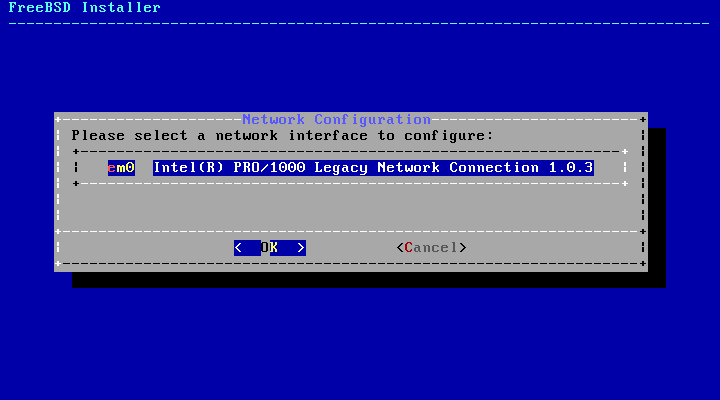
If an Ethernet interface is selected, the installer will skip ahead to the menu shown in Figure 2.35, “Choose IPv4 Networking”. If a wireless network interface is chosen, the system will instead scan for wireless access points:
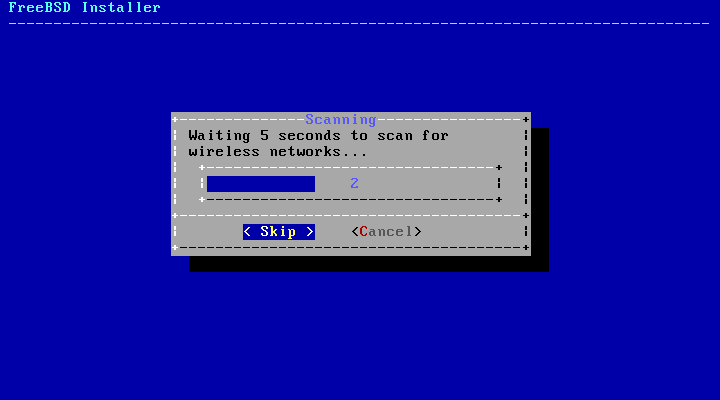
Wireless networks are identified by a Service Set Identifier (SSID), a short, unique name given to each network. SSIDs found during the scan are listed, followed by a description of the encryption types available for that network. If the desired SSID does not appear in the list, select to scan again. If the desired network still does not appear, check for problems with antenna connections or try moving the computer closer to the access point. Rescan after each change is made.
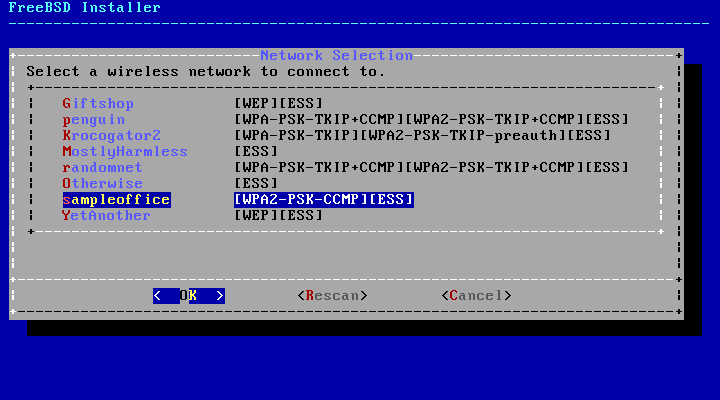
Next, enter the encryption information for connecting to the selected wireless network. WPA2 encryption is strongly recommended as older encryption types, like WEP, offer little security. If the network uses WPA2, input the password, also known as the Pre-Shared Key (PSK). For security reasons, the characters typed into the input box are displayed as asterisks.
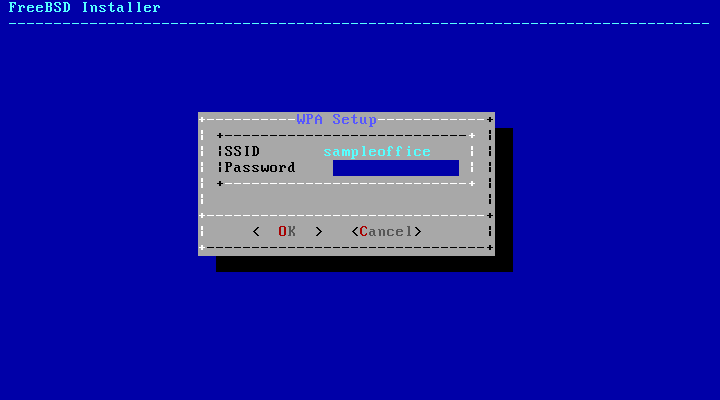
Next, choose whether or not an IPv4 address should be configured on the Ethernet or wireless interface:
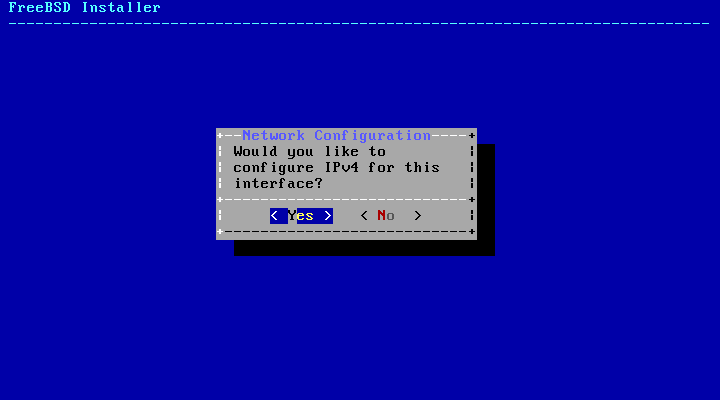
There are two methods of IPv4 configuration. DHCP will automatically configure the network interface correctly and should be used if the network provides a DHCP server. Otherwise, the addressing information needs to be input manually as a static configuration.
Note:
Do not enter random network information as it will not work. If a DHCP server is not available, obtain the information listed in Required Network Information from the network administrator or Internet service provider.
If a DHCP server is available, select in the next menu to automatically configure the network interface. The installer will appear to pause for a minute or so as it finds the DHCP server and obtains the addressing information for the system.
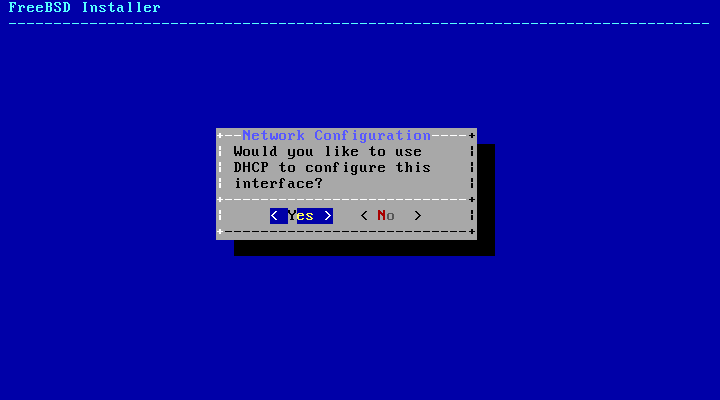
If a DHCP server is not available, select and input the following addressing information in this menu:
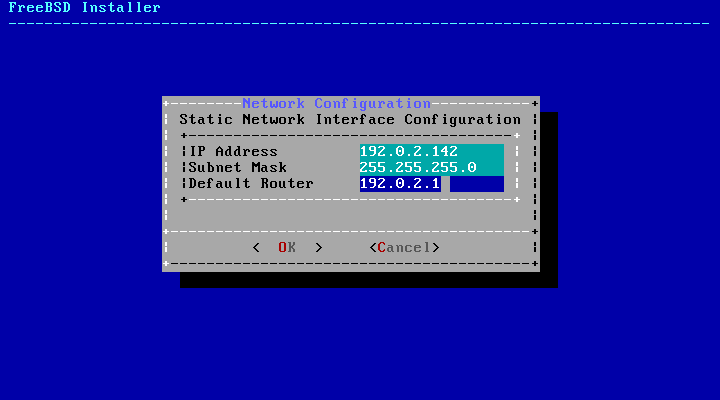
IP Address- The IPv4 address assigned to this computer. The address must be unique and not already in use by another piece of equipment on the local network.Subnet Mask- The subnet mask for the network.Default Router- The IP address of the network's default gateway.
The next screen will ask if the interface should be configured for IPv6. If IPv6 is available and desired, choose to select it.
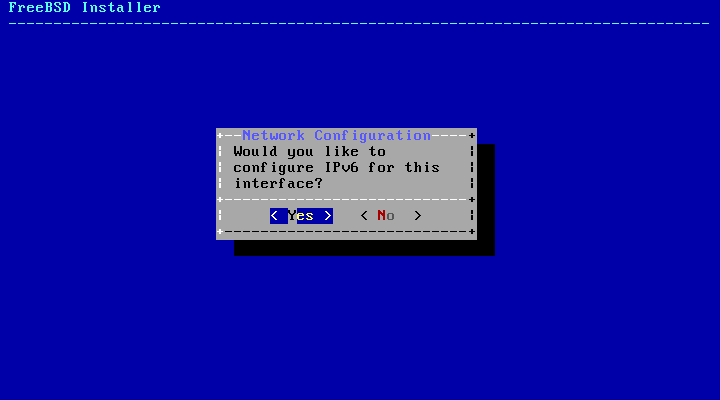
IPv6 also has two methods of configuration. StateLess Address AutoConfiguration (SLAAC) will automatically request the correct configuration information from a local router. Refer to http://tools.ietf.org/html/rfc4862 for more information. Static configuration requires manual entry of network information.
If an IPv6 router is available, select in the next menu to automatically configure the network interface. The installer will appear to pause for a minute or so as it finds the router and obtains the addressing information for the system.
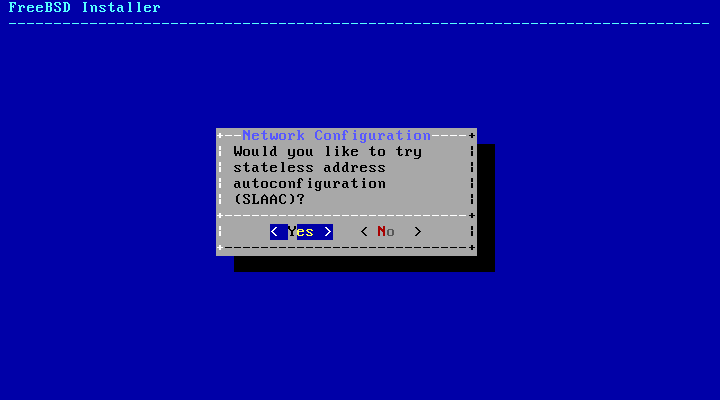
If an IPv6 router is not available, select and input the following addressing information in this menu:
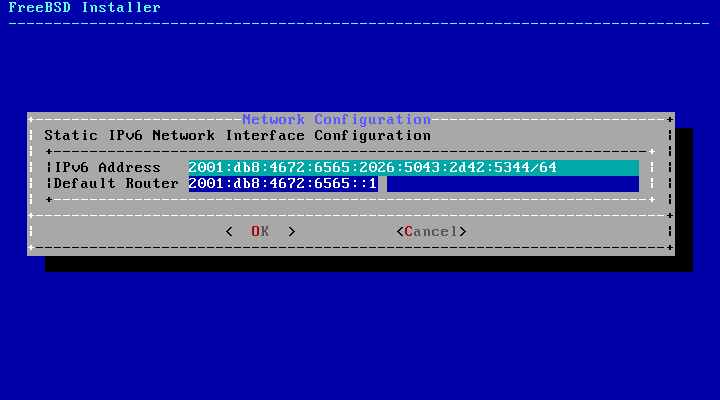
IPv6 Address- The IPv6 address assigned to this computer. The address must be unique and not already in use by another piece of equipment on the local network.Default Router- The IPv6 address of the network's default gateway.
The last network configuration menu is used to configure
the Domain Name System (DNS) resolver,
which converts hostnames to and from network addresses. If
DHCP or SLAAC was used
to autoconfigure the network interface, the Resolver
Configuration values may already be filled in.
Otherwise, enter the local network's domain name in the
Search field. DNS #1
and DNS #2 are the IPv4
and/or IPv6 addresses of the
DNS servers. At least one
DNS server is required.
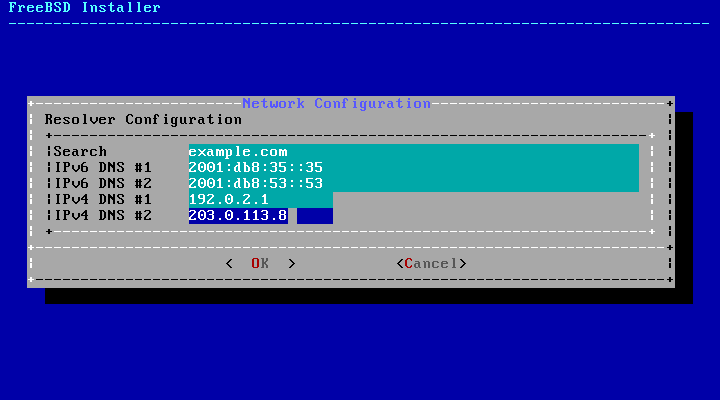
The next menu asks if the system clock uses UTC or local time. When in doubt, select to choose the more commonly-used local time.
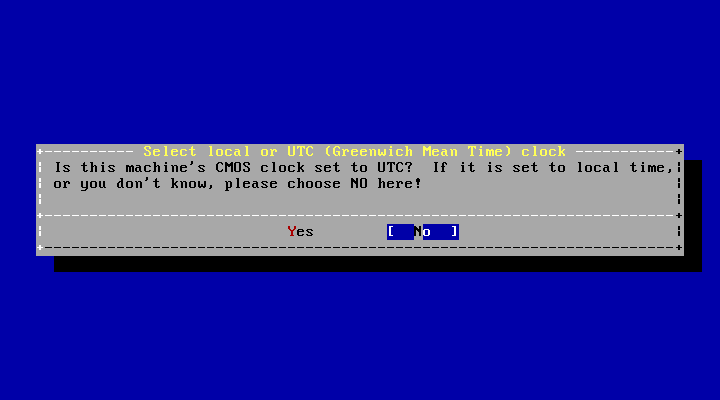
The next series of menus are used to determine the correct local time by selecting the geographic region, country, and time zone. Setting the time zone allows the system to automatically correct for regional time changes, such as daylight savings time, and perform other time zone related functions properly.
The example shown here is for a machine located in the Eastern time zone of the United States. The selections will vary according to the geographical location.
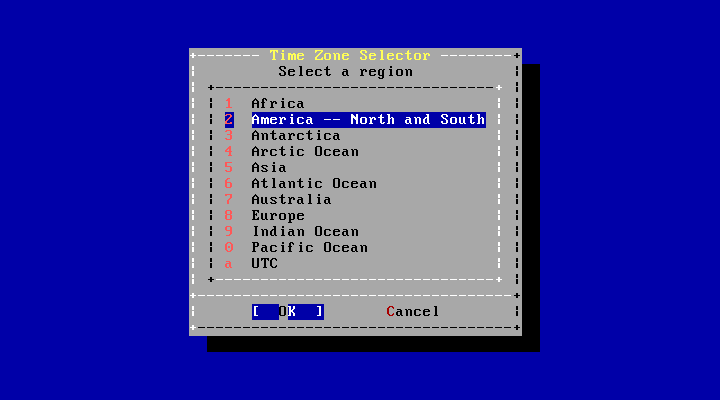
The appropriate region is selected using the arrow keys and then pressing Enter.
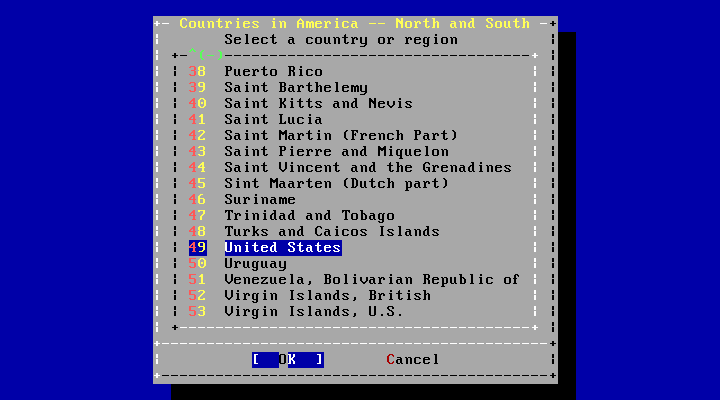
Select the appropriate country using the arrow keys and press Enter.
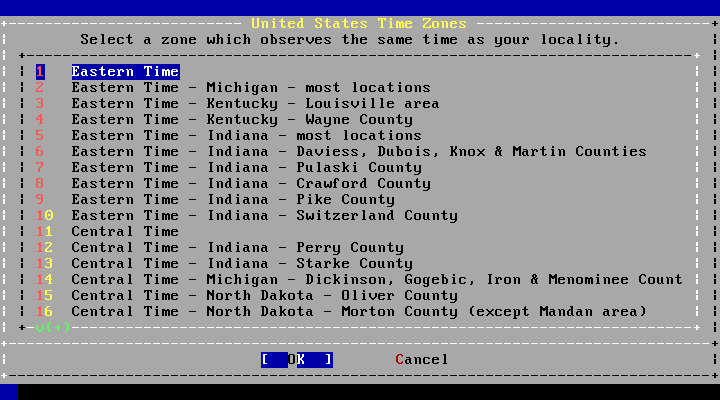
The appropriate time zone is selected using the arrow keys and pressing Enter.
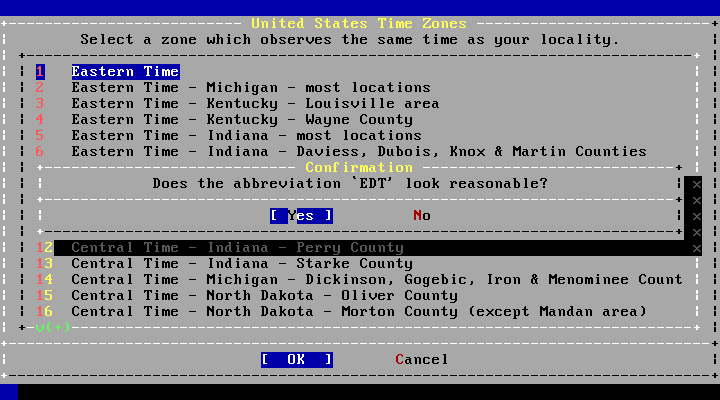
Confirm the abbreviation for the time zone is correct. If it is, press Enter to continue with the post-installation configuration.
The next menu is used to configure which system services will be started whenever the system boots. All of these services are optional. Only start the services that are needed for the system to function.
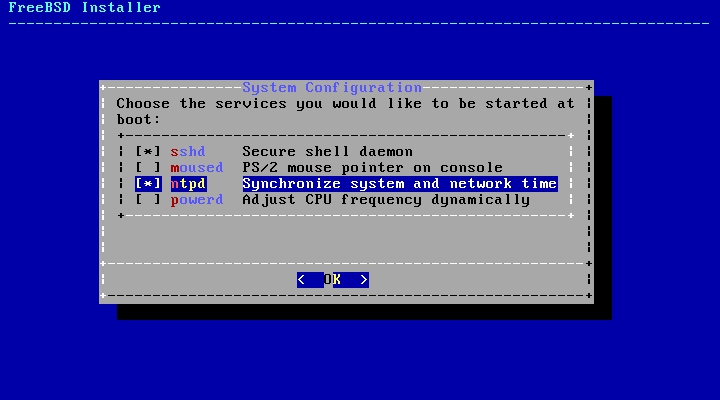
Here is a summary of the services which can be enabled in this menu:
sshd- The Secure Shell (SSH) daemon is used to remotely access a system over an encrypted connection. Only enable this service if the system should be available for remote logins.moused- Enable this service if the mouse will be used from the command-line system console.ntpd- The Network Time Protocol (NTP) daemon for automatic clock synchronization. Enable this service if there is a Windows®, Kerberos, or LDAP server on the network.powerd- System power control utility for power control and energy saving.
The next menu is used to configure whether or not crash dumps should be enabled. Enabling crash dumps can be useful in debugging issues with the system, so users are encouraged to enable crash dumps.
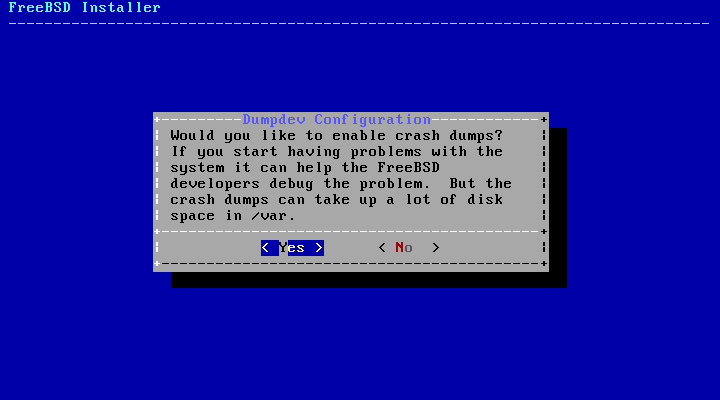
The next menu prompts to create at least one user account.
It is recommended to login to the system using a user account
rather than as root.
When logged in as root, there are essentially no
limits or protection on what can be done. Logging in as a
normal user is safer and more secure.
Select to add new users.
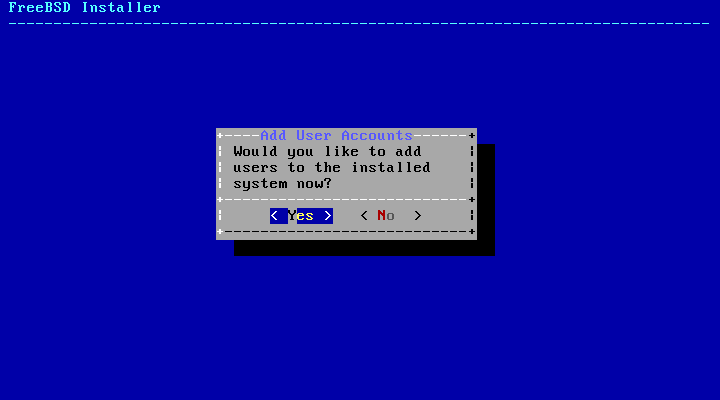
Follow the prompts and input the requested information for
the user account. The example shown in Figure 2.50, “Enter User Information” creates the asample user account.
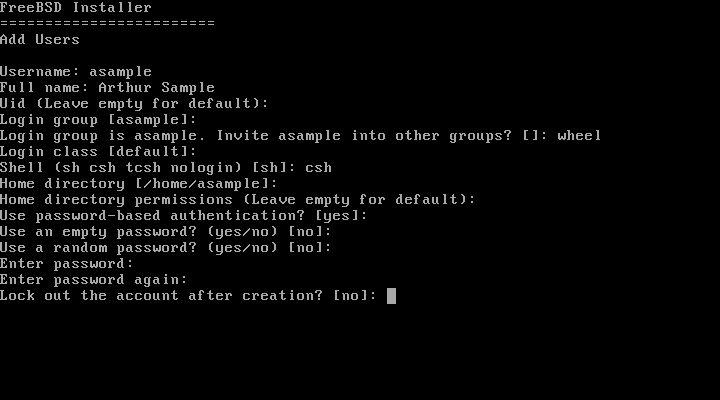
Here is a summary of the information to input:
Username- The name the user will enter to log in. A common convention is to use the first letter of the first name combined with the last name, as long as each username is unique for the system. The username is case sensitive and should not contain any spaces.Full name- The user's full name. This can contain spaces and is used as a description for the user account.Uid- User ID. Typically, this is left blank so the system will assign a value.Login group- The user's group. Typically this is left blank to accept the default.Invite- Additional groups to which the user will be added as a member. If the user needs administrative access, typeuserinto other groups?wheelhere.Login class- Typically left blank for the default.Shell- Type in one of the listed values to set the interactive shell for the user. Refer to Section 4.9, “Shells” for more information about shells.Home directory- The user's home directory. The default is usually correct.Home directory permissions- Permissions on the user's home directory. The default is usually correct.Use password-based authentication?- Typicallyyesso that the user is prompted to input their password at login.Use an empty password?- Typicallynoas it is insecure to have a blank password.Use a random password?- Typicallynoso that the user can set their own password in the next prompt.Enter password- The password for this user. Characters typed will not show on the screen.Enter password again- The password must be typed again for verification.Lock out the account after creation?- Typicallynoso that the user can login.
After entering everything, a summary is shown for review.
If a mistake was made, enter no and try
again. If everything is correct, enter yes
to create the new user.
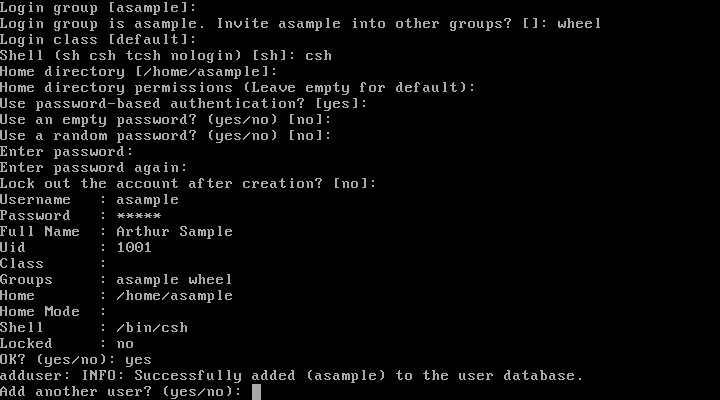
If there are more users to add, answer the Add
another user? question with
yes. Enter no to finish
adding users and continue the installation.
For more information on adding users and user management, see Section 4.3, “Users and Basic Account Management”.
After everything has been installed and configured, a final chance is provided to modify settings.
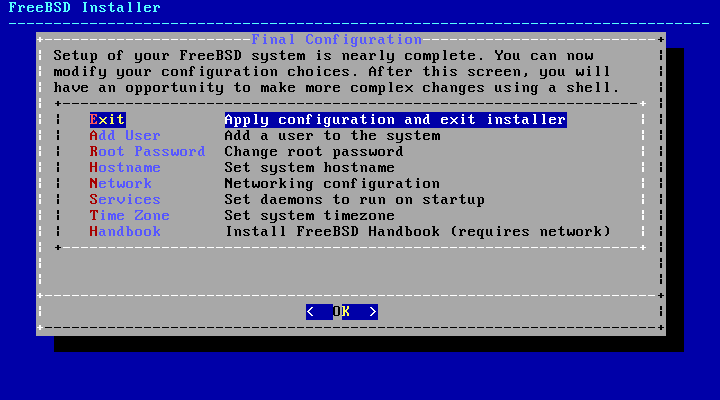
Use this menu to make any changes or do any additional configuration before completing the installation.
Add User- Described in Section 2.8.6, “Add Users”.Root Password- Described in Section 2.8.1, “Setting therootPassword”.Hostname- Described in Section 2.5.2, “Setting the Hostname”.Network- Described in Section 2.8.2, “Configuring Network Interfaces”.Services- Described in Section 2.8.4, “Enabling Services”.Time Zone- Described in Section 2.8.3, “Setting the Time Zone”.Handbook- Download and install the FreeBSD Handbook.
After any final configuration is complete, select .
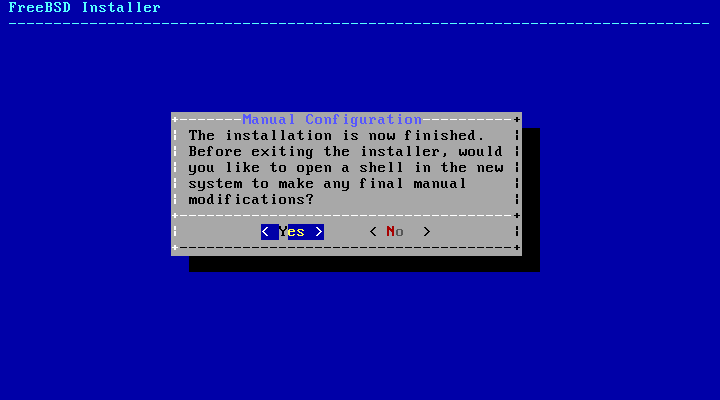
bsdinstall will prompt if there are any additional configuration that needs to be done before rebooting into the new system. Select to exit to a shell within the new system or to proceed to the last step of the installation.
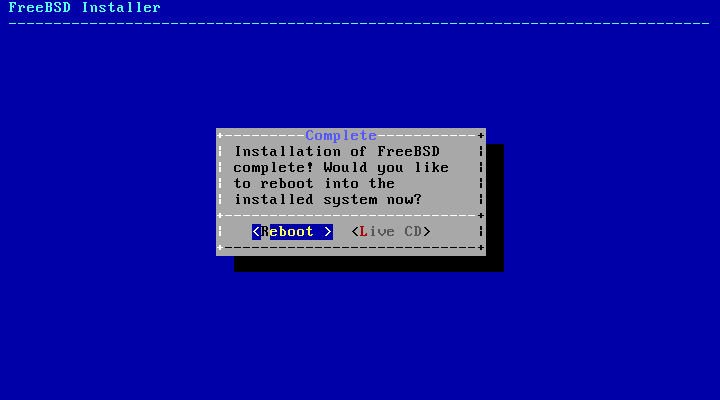
If further configuration or special setup is needed, select to boot the install media into Live CD mode.
If the installation is complete, select to reboot the computer and start the new FreeBSD system. Do not forget to remove the FreeBSD install media or the computer may boot from it again.
As FreeBSD boots, informational messages are displayed.
After the system finishes booting, a login prompt is
displayed. At the login: prompt, enter the
username added during the installation. Avoid logging in as
root. Refer to
Section 4.3.1.3, “The Superuser Account” for instructions on how to
become the superuser when administrative access is
needed.
The messages that appeared during boot can be reviewed by
pressing Scroll-Lock to turn on the
scroll-back buffer. The PgUp,
PgDn, and arrow keys can be used to scroll
back through the messages. When finished, press
Scroll-Lock again to unlock the display and
return to the console. To review these messages once the
system has been up for some time, type less
/var/run/dmesg.boot from a command prompt. Press
q to return to the command line after
viewing.
If sshd was enabled in Figure 2.47, “Selecting Additional Services to Enable”, the first boot may be a bit slower as the system will generate the RSA and DSA keys. Subsequent boots will be faster. The fingerprints of the keys will be displayed, as seen in this example:
Generating public/private rsa1 key pair. Your identification has been saved in /etc/ssh/ssh_host_key. Your public key has been saved in /etc/ssh/ssh_host_key.pub. The key fingerprint is: 10:a0:f5:af:93:ae:a3:1a:b2:bb:3c:35:d9:5a:b3:f3 [email protected] The key's randomart image is: +--[RSA1 1024]----+ | o.. | | o . . | | . o | | o | | o S | | + + o | |o . + * | |o+ ..+ . | |==o..o+E | +-----------------+ Generating public/private dsa key pair. Your identification has been saved in /etc/ssh/ssh_host_dsa_key. Your public key has been saved in /etc/ssh/ssh_host_dsa_key.pub. The key fingerprint is: 7e:1c:ce:dc:8a:3a:18:13:5b:34:b5:cf:d9:d1:47:b2 [email protected] The key's randomart image is: +--[ DSA 1024]----+ | .. . .| | o . . + | | . .. . E .| | . . o o . . | | + S = . | | + . = o | | + . * . | | . . o . | | .o. . | +-----------------+ Starting sshd.
Refer to Section 14.8, “OpenSSH” for more information about fingerprints and SSH.
FreeBSD does not install a graphical environment by default. Refer to Chapter 6, The X Window System for more information about installing and configuring a graphical window manager.
Proper shutdown of a FreeBSD computer helps protect data and
hardware from damage. Do not turn off the power
before the system has been properly shut down! If
the user is a member of the wheel group, become the
superuser by typing su at the command line
and entering the root password. Then, type
shutdown -p now and the system will shut
down cleanly, and if the hardware supports it, turn itself
off.
This section covers basic installation troubleshooting, such as common problems people have reported.
Check the Hardware Notes (http://www.freebsd.org/releases/index.html)
document for the version of FreeBSD to make sure the hardware is
supported. If the hardware is supported and lock-ups or other
problems occur, build a custom kernel using the instructions in
Chapter 9, Configuring the FreeBSD Kernel to add support for devices which
are not present in the GENERIC kernel. The
default kernel assumes that most hardware devices are in their
factory default configuration in terms of
IRQs, I/O addresses, and
DMA channels. If the hardware has been
reconfigured, a custom kernel configuration file can tell FreeBSD
where to find things.
Note:
Some installation problems can be avoided or alleviated by updating the firmware on various hardware components, most notably the motherboard. Motherboard firmware is usually referred to as the BIOS. Most motherboard and computer manufacturers have a website for upgrades and upgrade information.
Manufacturers generally advise against upgrading the motherboard BIOS unless there is a good reason for doing so, like a critical update. The upgrade process can go wrong, leaving the BIOS incomplete and the computer inoperative.
If the system hangs while probing hardware during boot, or
it behaves strangely during install, ACPI may
be the culprit. FreeBSD makes extensive use of the system
ACPI service on the i386,
amd64, and ia64 platforms to aid in system configuration
if it is detected during boot. Unfortunately, some bugs still
exist in both the ACPI driver and within
system motherboards and BIOS firmware.
ACPI can be disabled by setting the
hint.acpi.0.disabled hint in the third stage
boot loader:
set hint.acpi.0.disabled="1"This is reset each time the system is booted, so it is
necessary to add hint.acpi.0.disabled="1" to
the file /boot/loader.conf. More
information about the boot loader can be found in Section 13.1, “Synopsis”.
The welcome menu of bsdinstall, shown in Figure 2.3, “Welcome Menu”, provides a option. This is useful for those who are still wondering whether FreeBSD is the right operating system for them and want to test some of the features before installing.
The following points should be noted before using the :
To gain access to the system, authentication is required. The username is
rootand the password is blank.As the system runs directly from the installation media, performance will be significantly slower than that of a system installed on a hard disk.
This option only provides a command prompt and not a graphical interface.
- 3.1. Synopsis
- 3.2. Hardware Requirements
- 3.3. Pre-installation Tasks
- 3.4. Starting the Installation
- 3.5. Introducing sysinstall(8)
- 3.6. Allocating Disk Space
- 3.7. Choosing What to Install
- 3.8. Choosing the Installation Media
- 3.9. Committing to the Installation
- 3.10. Post-installation
- 3.11. Troubleshooting
- 3.12. Advanced Installation Guide
- 3.13. Preparing Custom Installation Media
FreeBSD provides a text-based, easy to use installation
program. FreeBSD 9.0-RELEASE and later use the installation
program known as bsdinstall(8) while
FreeBSD 8.X uses
sysinstall(8). This chapter describes how to use
sysinstall(8). The use of bsdinstall(8) is covered in
Chapter 2, Installing FreeBSD 9.X and
Later.
After reading this chapter, you will know:
How to create the FreeBSD installation media.
How FreeBSD refers to and subdivides hard disks.
How to start sysinstall(8).
The questions sysinstall(8) asks, what they mean, and how to answer them.
Before reading this chapter, you should:
Read the supported hardware list that shipped with the version of FreeBSD to install, and verify that the system's hardware is supported.
Note:
In general, these installation instructions are written for the i386™ and FreeBSD/amd64 architectures. Where applicable, instructions specific to other platforms will be listed. There may be minor differences between the installer and what is shown here. This chapter should be used as a general guide rather than a literal installation manual.
The minimal configuration to install FreeBSD varies with the FreeBSD version and the hardware architecture.
A summary of this information is given in the following sections. Depending on the method chosen to install FreeBSD, a floppy drive, CDROM drive, or network adapter may be needed. Instructions on how to prepare the installation media can be found in Section 3.3.7, “Prepare the Boot Media”.
Both FreeBSD/i386 and FreeBSD/pc98 require a 486 or better processor, at least 24 MB of RAM, and at least 150 MB of free hard drive space for the most minimal installation.
Note:
In the case of older hardware, installing more RAM and more hard drive space is often more important than a faster processor.
There are two classes of processors capable of running FreeBSD/amd64. The first are AMD64 processors, including the AMD Athlon™64, AMD Athlon™64-FX, and AMD Opteron™ or better processors.
The second class of processors includes those using the Intel® EM64T architecture. Examples of these processors include the Intel® Core™ 2 Duo, Quad, Extreme processor families, and the Intel® Xeon™ 3000, 5000, and 7000 sequences of processors.
If the machine is based on an nVidia nForce3 Pro-150, the BIOS setup must be used to disable the IO APIC. If this option does not exist, disable ACPI instead as there are bugs in the Pro-150 chipset.
To install FreeBSD/sparc64, use a supported platform (see Section 3.2.2, “Supported Hardware”).
A dedicated disk is needed for FreeBSD/sparc64 as it is not possible to share a disk with another operating system at this time.
A list of supported hardware is provided with each FreeBSD
release in the FreeBSD Hardware Notes. This document can usually
be found in a file named HARDWARE.TXT, in
the top-level directory of a CDROM or FTP distribution, or in
sysinstall(8)'s documentation menu. It lists, for a
given architecture, which hardware devices are known to be
supported by each release of FreeBSD. Copies of the supported
hardware list for various releases and architectures can also
be found on the Release
Information page of the FreeBSD website.
Before installing FreeBSD it is recommended to inventory the components in the computer. The FreeBSD installation routines will show components such as hard disks, network cards, and CDROM drives with their model number and manufacturer. FreeBSD will also attempt to determine the correct configuration for these devices, including information about IRQ and I/O port usage. Due to the vagaries of computer hardware, this process is not always completely successful, and FreeBSD may need some manual configuration.
If another operating system is already installed, use the
facilities provided by that operating systems to view the
hardware configuration. If the settings of an expansion card
are not obvious, check if they are printed on the card itself.
Popular IRQ numbers are 3, 5, and 7, and I/O port addresses
are normally written as hexadecimal numbers, such as
0x330.
It is recommended to print or write down this information before installing FreeBSD. It may help to use a table, as seen in this example:
| Device Name | IRQ | I/O port(s) | Notes |
|---|---|---|---|
| First hard disk | N/A | N/A | 40 GB, made by Seagate, first IDE master |
| CDROM | N/A | N/A | First IDE slave |
| Second hard disk | N/A | N/A | 20 GB, made by IBM, second IDE master |
| First IDE controller | 14 | 0x1f0 | |
| Network card | N/A | N/A | Intel® 10/100 |
| Modem | N/A | N/A | 3Com® 56K faxmodem, on COM1 |
| … |
Once the inventory of the components in the computer is complete, check if it matches the hardware requirements of the FreeBSD release to install.
If the computer contains valuable data, ensure it is backed up, and that the backup has been tested before installing FreeBSD. The FreeBSD installer will prompt before writing any data to disk, but once that process has started, it cannot be undone.
If FreeBSD is to be installed on the entire hard disk, skip this section.
However, if FreeBSD will co-exist with other operating systems, a rough understanding of how data is laid out on the disk is useful.
A PC disk can be divided into discrete chunks known as partitions. Since FreeBSD also has partitions, naming can quickly become confusing. Therefore, these disk chunks are referred to as slices in FreeBSD. For example, the FreeBSD version of fdisk(8) refers to slices instead of partitions. By design, the PC only supports four partitions per disk. These partitions are called primary partitions. To work around this limitation and allow more than four partitions, a new partition type was created, the extended partition. A disk may contain only one extended partition. Special partitions, called logical partitions, can be created inside this extended partition.
Each partition has a partition
ID, which is a number used to identify the
type of data on the partition. FreeBSD partitions have the
partition ID of 165.
In general, each operating system will identify
partitions in a particular way. For example, Windows®,
assigns each primary and logical partition a
drive letter, starting with
C:.
FreeBSD must be installed into a primary partition. If there are multiple disks, a FreeBSD partition can be created on all, or some, of them. When FreeBSD is installed, at least one partition must be available. This might be a blank partition or it might be an existing partition whose data can be overwritten.
If all the partitions on all the disks are in use, free
one of them for FreeBSD using the tools provided by an existing
operating system, such as Windows®
fdisk.
If there is a spare partition, use that. If it is too small, shrink one or more existing partitions to create more available space.
A minimal installation of FreeBSD takes as little as 100 MB of disk space. However, that is a very minimal install, leaving almost no space for files. A more realistic minimum is 250 MB without a graphical environment, and 350 MB or more for a graphical user interface. If other third-party software will be installed, even more space is needed.
You can use a tool such as GParted to resize your partitions and make space for FreeBSD. GParted is known to work on NTFS and is available on a number of Live CD Linux distributions, such as SystemRescueCD.
Warning:
Incorrect use of a shrinking tool can delete the data on the disk. Always have a recent, working backup before using this type of tool.
Consider a computer with a single 4 GB disk that
already has a version of Windows® installed, where the
disk has been split into two drive letters,
C: and D:, each
of which is 2 GB in size. There is 1 GB of data
on C:, and 0.5 GB of data on
D:.
This disk has two partitions, one per drive letter.
Copy all existing data from D: to
C:, which will free up the second
partition, ready for FreeBSD.
Consider a computer with a single 4 GB disk that
already has a version of Windows® installed. When
Windows® was installed, it created one large partition,
a C: drive that is 4 GB in size.
Currently, 1.5 GB of space is used, and FreeBSD should
have 2 GB of space.
In order to install FreeBSD, either:
Backup the Windows® data and then reinstall Windows®, asking for a 2 GB partition at install time.
Use one of the tools described above to shrink your Windows® partition.
Before installing from an FTP site or an NFS server, make note of the network configuration. The installer will prompt for this information so that it can connect to the network to complete the installation.
If using an Ethernet network or an Internet connection using an Ethernet adapter via cable or DSL, the following information is needed:
IP address
IP address of the default gateway
Hostname
DNS server IP addresses
Subnet Mask
If this information is unknown, ask the system administrator or service provider. Make note if this information is assigned automatically using DHCP.
If using a dialup modem, FreeBSD can still be installed over the Internet, it will just take a very long time.
You will need to know:
The phone number to dial the Internet Service Provider (ISP)
The COM: port the modem is connected to
The username and password for the ISP account
Although the FreeBSD Project strives to ensure that each release of FreeBSD is as stable as possible, bugs do occasionally creep into the process. On rare occasions those bugs affect the installation process. As these problems are discovered and fixed, they are noted in the FreeBSD Errata, which is found on the FreeBSD website. Check the errata before installing to make sure that there are no late-breaking problems to be aware of.
Information about all releases, including the errata for each release, can be found on the release information section of the FreeBSD website.
The FreeBSD installer can install FreeBSD from files located in any of the following places:
A CDROM or DVD
A USB Memory Stick
A MS-DOS® partition on the same computer
Floppy disks (FreeBSD/pc98 only)
An FTP site through a firewall or using an HTTP proxy
An NFS server
A dedicated parallel or serial connection
If installing from a purchased FreeBSD CD/DVD, skip ahead to Section 3.3.7, “Prepare the Boot Media”.
To obtain the FreeBSD installation files, skip ahead to Section 3.13, “Preparing Custom Installation Media” which explains how to prepare the installation media. After reading that section, come back here and read on to Section 3.3.7, “Prepare the Boot Media”.
The FreeBSD installation process is started by booting the computer into the FreeBSD installer. It is not a program that can be run within another operating system. The computer normally boots using the operating system installed on the hard disk, but it can also be configured to boot from a CDROM or from a USB disk.
Tip:
If installing from a CD/DVD to a computer whose BIOS supports booting from the CD/DVD, skip this section. The FreeBSD CD/DVD images are bootable and can be used to install FreeBSD without any other special preparation.
To create a bootable memory stick, follow these steps:
Acquire the Memory Stick Image
Memory stick images for FreeBSD 8.
Xcan be downloaded from theISO-IMAGES/directory atftp://ftp.FreeBSD.org/pub/FreeBSD/releases/. Replacearch/ISO-IMAGES/version/FreeBSD-version-RELEASE-arch-memstick.imgarchandversionwith the architecture and the version number to install. For example, the memory stick images for FreeBSD/i386 9.3-RELEASE are available fromftp://ftp.FreeBSD.org/pub/FreeBSD/releases/i386/ISO-IMAGES/9.3/FreeBSD-9.3-RELEASE-i386-memstick.img.Tip:
A different directory path is used for FreeBSD 9.0-RELEASE and later versions. How to download and install FreeBSD 9.
Xis covered in Chapter 2, Installing FreeBSD 9.Xand Later.The memory stick image has a
.imgextension. TheISO-IMAGES/directory contains a number of different images and the one to use depends on the version of FreeBSD and the type of media supported by the hardware being installed to.Important:
Before proceeding, back up the data on the USB stick, as this procedure will erase it.
Write the Image File to the Memory Stick
Procedure 3.1. Using FreeBSD to Write the ImageWarning:
The example below lists
/dev/da0as the target device where the image will be written. Be very careful that you have the correct device as the output target, or you may destroy your existing data.Writing the Image with dd(1)
The
.imgfile is not a regular file that can just be copied to the memory stick. It is an image of the complete contents of the disk. This means that dd(1) must be used to write the image directly to the disk:#dd if=FreeBSD-9.3-RELEASE-i386-memstick.img of=/dev/da0bs=64kIf an
Operation not permittederror is displayed, make certain that the target device is not in use, mounted, or being automounted by another program. Then try again.
Procedure 3.2. Using Windows® to Write the ImageWarning:
Make sure to use the correct drive letter as the output target, as this command will overwrite and destroy any existing data on the specified device.
Obtaining Image Writer for Windows
Image Writer for Windows is a free application that can correctly write an image file to a memory stick. Download it from
https://launchpad.net/win32-image-writer/and extract it into a folder.Writing the Image with Image Writer
Double-click the Win32DiskImager icon to start the program. Verify that the drive letter shown under
Deviceis the drive with the memory stick. Click the folder icon and select the image to be written to the memory stick. Click to accept the image file name. Verify that everything is correct, and that no folders on the memory stick are open in other windows. Finally, click to write the image file to the drive.
To create the boot floppy images for a FreeBSD/pc98 installation, follow these steps:
Acquire the Boot Floppy Images
The FreeBSD/pc98 boot disks can be downloaded from the floppies directory,
ftp://ftp.FreeBSD.org/pub/FreeBSD/releases/pc98/. Replaceversion-RELEASE/floppies/versionwith the version number to install.The floppy images have a
.flpextension.floppies/contains a number of different images. Downloadboot.flpas well as the number of files associated with the type of installation, such askern.small*orkern*.Important:
The FTP program must use binary mode to download these disk images. Some web browsers use text or ASCII mode, which will be apparent if the disks are not bootable.
Prepare the Floppy Disks
Prepare one floppy disk per downloaded image file. It is imperative that these disks are free from defects. The easiest way to test this is to reformat the disks. Do not trust pre-formatted floppies. The format utility in Windows® will not tell about the presence of bad blocks, it simply marks them as “bad” and ignores them. It is advised to use brand new floppies.
Important:
If the installer crashes, freezes, or otherwise misbehaves, one of the first things to suspect is the floppies. Write the floppy image files to new disks and try again.
Write the Image Files to the Floppy Disks
The
.flpfiles are not regular files that can be copied to the disk. They are images of the complete contents of the disk. Specific tools must be used to write the images directly to the disk.FreeBSD provides a tool called
rawritefor creating the floppies on a computer running Windows®. This tool can be downloaded fromftp://ftp.FreeBSD.org/pub/FreeBSD/releases/pc98/on the FreeBSD FTP site. Download this tool, insert a floppy, then specify the filename to write to the floppy drive:version-RELEASE/tools/C:\>rawrite boot.flp A:Repeat this command for each
.flpfile, replacing the floppy disk each time, being sure to label the disks with the name of the file. Adjust the command line as necessary, depending on where the.flpfiles are located.When writing the floppies on a UNIX®-like system, such as another FreeBSD system, use dd(1) to write the image files directly to disk. On FreeBSD, run:
#dd if=boot.flp of=/dev/fd0On FreeBSD,
/dev/fd0refers to the first floppy disk. Other UNIX® variants might have different names for the floppy disk device, so check the documentation for the system as necessary.
You are now ready to start installing FreeBSD.
Important:
By default, the installer will not make any changes to the disk(s) until after the following message:
Last Chance: Are you SURE you want continue the installation? If you're running this on a disk with data you wish to save then WE STRONGLY ENCOURAGE YOU TO MAKE PROPER BACKUPS before proceeding! We can take no responsibility for lost disk contents!
The install can be exited at any time prior to this final warning without changing the contents of the hard drive. If there is a concern that something is configured incorrectly, turn the computer off before this point, and no damage will be done.
Turn on the computer. As it starts it should display an option to enter the system set up menu, or BIOS, commonly reached by keys like F2, F10, Del, or Alt+S. Use whichever keystroke is indicated on screen. In some cases the computer may display a graphic while it starts. Typically, pressing Esc will dismiss the graphic and display the boot messages.
Find the setting that controls which devices the system boots from. This is usually labeled as the “Boot Order” and commonly shown as a list of devices, such as
Floppy,CDROM,First Hard Disk, and so on.If booting from the CD/DVD, make sure that the CDROM drive is selected. If booting from a USB disk, make sure that it is selected instead. When in doubt, consult the manual that came with the computer or its motherboard.
Make the change, then save and exit. The computer should now restart.
If using a prepared a “bootable” USB stick, as described in Section 3.3.7, “Prepare the Boot Media”, plug in the USB stick before turning on the computer.
If booting from CD/DVD, turn on the computer, and insert the CD/DVD at the first opportunity.
Note:
For FreeBSD/pc98, installation boot floppies are available and can be prepared as described in Section 3.3.7, “Prepare the Boot Media”. The first floppy disc will contain
boot.flp. Put this floppy in the floppy drive to boot into the installer.If the computer starts up as normal and loads the existing operating system, then either:
The disks were not inserted early enough in the boot process. Leave them in, and try restarting the computer.
The BIOS changes did not work correctly. Redo that step until the right option is selected.
That particular BIOS does not support booting from the desired media.
FreeBSD will start to boot. If booting from CD/DVD, messages will be displayed, similar to these:
Booting from CD-Rom... 645MB medium detected CD Loader 1.2 Building the boot loader arguments Looking up /BOOT/LOADER... Found Relocating the loader and the BTX Starting the BTX loader BTX loader 1.00 BTX version is 1.02 Consoles: internal video/keyboard BIOS CD is cd0 BIOS drive C: is disk0 BIOS drive D: is disk1 BIOS 636kB/261056kB available memory FreeBSD/i386 bootstrap loader, Revision 1.1 Loading /boot/defaults/loader.conf /boot/kernel/kernel text=0x64daa0 data=0xa4e80+0xa9e40 syms=[0x4+0x6cac0+0x4+0x88e9d] \
If booting from floppy disc, a display similar to this will be shown:
Booting from Floppy... Uncompressing ... done BTX loader 1.00 BTX version is 1.01 Console: internal video/keyboard BIOS drive A: is disk0 BIOS drive C: is disk1 BIOS 639kB/261120kB available memory FreeBSD/i386 bootstrap loader, Revision 1.1 Loading /boot/defaults/loader.conf /kernel text=0x277391 data=0x3268c+0x332a8 | Insert disk labelled "Kernel floppy 1" and press any key...
Remove the
boot.flpfloppy, insert the next floppy, and press Enter. When prompted, insert the other disks as required.The boot process will then display the FreeBSD boot loader menu:
Either wait ten seconds, or press Enter.
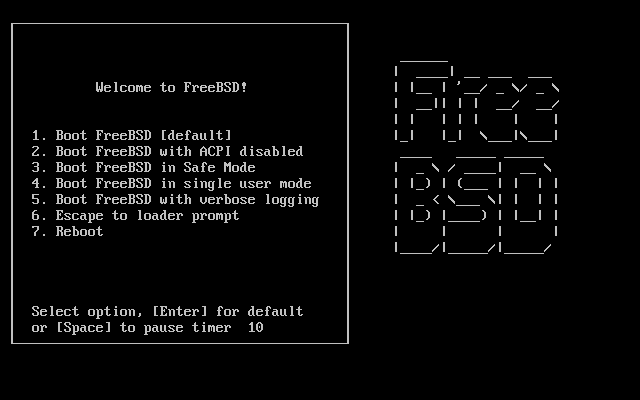
Most SPARC64® systems are set to boot automatically from disk. To install FreeBSD, boot over the network or from a CD/DVD and wait until the boot message appears. The message depends on the model, but should look similar to:
Sun Blade 100 (UltraSPARC-IIe), Keyboard Present Copyright 1998-2001 Sun Microsystems, Inc. All rights reserved. OpenBoot 4.2, 128 MB memory installed, Serial #51090132. Ethernet address 0:3:ba:b:92:d4, Host ID: 830b92d4.
If the system proceeds to boot from disk, press
L1+A
or Stop+A
on the keyboard, or send a BREAK over the
serial console using ~# in tip(1) or
cu(1) to get to the PROM prompt. It looks like
this:
ok
ok {0}This is the prompt used on systems with just one CPU.

This is the prompt used on SMP systems and the digit indicates the number of the active CPU.
At this point, place the CD/DVD into the drive and from
the PROM prompt, type boot cdrom.
The last few hundred lines that have been displayed on screen are stored and can be reviewed.
To review this buffer, press Scroll Lock to turn on scrolling in the display. Use the arrow keys or PageUp and PageDown to view the results. Press Scroll Lock again to stop scrolling.
Do this now, to review the text that scrolled off the screen when the kernel was carrying out the device probes. Text similar to Figure 3.2, “Typical Device Probe Results” will be displayed, although it will differ depending on the devices in the computer.
avail memory = 253050880 (247120K bytes) Preloaded elf kernel "kernel" at 0xc0817000. Preloaded mfs_root "/mfsroot" at 0xc0817084. md0: Preloaded image </mfsroot> 4423680 bytes at 0xc03ddcd4 md1: Malloc disk Using $PIR table, 4 entries at 0xc00fde60 npx0: <math processor> on motherboard npx0: INT 16 interface pcib0: <Host to PCI bridge> on motherboard pci0: <PCI bus> on pcib0 pcib1:<VIA 82C598MVP (Apollo MVP3) PCI-PCI (AGP) bridge> at device 1.0 on pci0 pci1: <PCI bus> on pcib1 pci1: <Matrox MGA G200 AGP graphics accelerator> at 0.0 irq 11 isab0: <VIA 82C586 PCI-ISA bridge> at device 7.0 on pci0 isa0: <iSA bus> on isab0 atapci0: <VIA 82C586 ATA33 controller> port 0xe000-0xe00f at device 7.1 on pci0 ata0: at 0x1f0 irq 14 on atapci0 ata1: at 0x170 irq 15 on atapci0 uhci0 <VIA 83C572 USB controller> port 0xe400-0xe41f irq 10 at device 7.2 on pci 0 usb0: <VIA 83572 USB controller> on uhci0 usb0: USB revision 1.0 uhub0: VIA UHCI root hub, class 9/0, rev 1.00/1.00, addr1 uhub0: 2 ports with 2 removable, self powered pci0: <unknown card> (vendor=0x1106, dev=0x3040) at 7.3 dc0: <ADMtek AN985 10/100BaseTX> port 0xe800-0xe8ff mem 0xdb000000-0xeb0003ff ir q 11 at device 8.0 on pci0 dc0: Ethernet address: 00:04:5a:74:6b:b5 miibus0: <MII bus> on dc0 ukphy0: <Generic IEEE 802.3u media interface> on miibus0 ukphy0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, auto ed0: <NE2000 PCI Ethernet (RealTek 8029)> port 0xec00-0xec1f irq 9 at device 10. 0 on pci0 ed0 address 52:54:05:de:73:1b, type NE2000 (16 bit) isa0: too many dependant configs (8) isa0: unexpected small tag 14 orm0: <Option ROM> at iomem 0xc0000-0xc7fff on isa0 fdc0: <NEC 72065B or clone> at port 0x3f0-0x3f5,0x3f7 irq 6 drq2 on isa0 fdc0: FIFO enabled, 8 bytes threshold fd0: <1440-KB 3.5” drive> on fdc0 drive 0 atkbdc0: <Keyboard controller (i8042)> at port 0x60,0x64 on isa0 atkbd0: <AT Keyboard> flags 0x1 irq1 on atkbdc0 kbd0 at atkbd0 psm0: <PS/2 Mouse> irq 12 on atkbdc0 psm0: model Generic PS/@ mouse, device ID 0 vga0: <Generic ISA VGA> at port 0x3c0-0x3df iomem 0xa0000-0xbffff on isa0 sc0: <System console> at flags 0x100 on isa0 sc0: VGA <16 virtual consoles, flags=0x300> sio0 at port 0x3f8-0x3ff irq 4 flags 0x10 on isa0 sio0: type 16550A sio1 at port 0x2f8-0x2ff irq 3 on isa0 sio1: type 16550A ppc0: <Parallel port> at port 0x378-0x37f irq 7 on isa0 pppc0: SMC-like chipset (ECP/EPP/PS2/NIBBLE) in COMPATIBLE mode ppc0: FIFO with 16/16/15 bytes threshold plip0: <PLIP network interface> on ppbus0 ad0: 8063MB <IBM-DHEA-38451> [16383/16/63] at ata0-master UDMA33 acd0: CD-RW <LITE-ON LTR-1210B> at ata1-slave PIO4 Mounting root from ufs:/dev/md0c /stand/sysinstall running as init on vty0
Check the probe results carefully to make sure that FreeBSD
found all the devices. If a device was not found, it will
not be listed. A custom kernel can be used to
add in support for devices which are not in the
GENERIC kernel.
After the device probe, the menu shown in Figure 3.3, “Selecting Country Menu” will be displayed. Use the arrow key to choose a country, region, or group. Then press Enter to set the country.
If is selected as the country, the standard American keyboard map will be used. If a different country is chosen, the following menu will be displayed. Use the arrow keys to choose the correct keyboard map and press Enter.
After the country selection, the sysinstall(8) main menu will display.
3.5. Introducing sysinstall(8)
The FreeBSD 8.X installer,
sysinstall(8), is console based and is divided into a
number of menus and screens that can be used to configure and
control the installation process.
This menu system is controlled by the arrow keys, Enter, Tab, Space, and other keys. To view a detailed description of these keys and what they do, ensure that the entry is highlighted and that the button is selected, as shown in Figure 3.5, “Selecting Usage from Sysinstall Main Menu”, then press Enter.
The instructions for using the menu system will be displayed. After reviewing them, press Enter to return to the Main Menu.
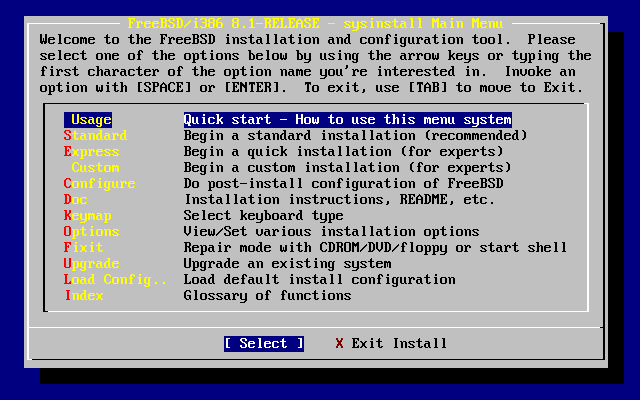
From the Main Menu, select with the arrow keys and press Enter.
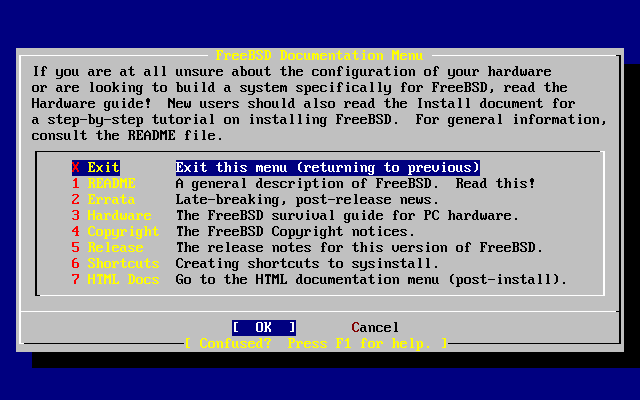
It is important to read the documents provided. To view a document, select it with the arrow keys and press Enter. When finished reading a document, press Enter to return to the Documentation Menu.
To return to the Main Installation Menu, select with the arrow keys and press Enter.
To change the keyboard mapping, use the arrow keys to select from the menu and press Enter. This is only required when using a non-standard or non-US keyboard.
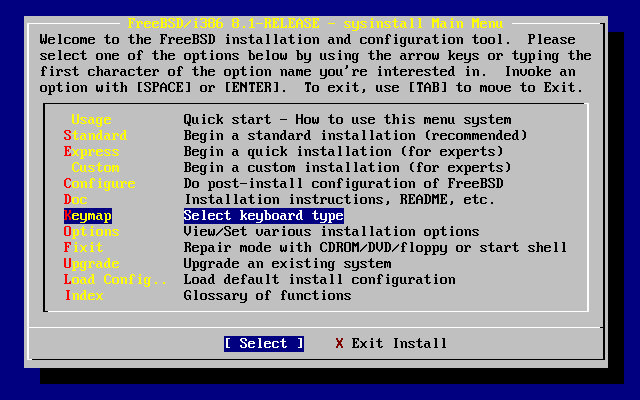
A different keyboard mapping may be chosen by selecting the menu item using the up and down arrow keys and pressing Space. Pressing Space again will unselect the item. When finished, choose the using the arrow keys and press Enter.
Only a partial list is shown in this screen representation. Selecting by pressing Tab will use the default keymap and return to the Main Install Menu.
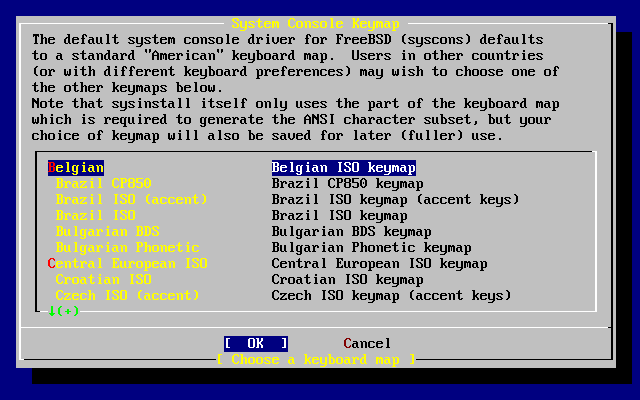
Select and press Enter.
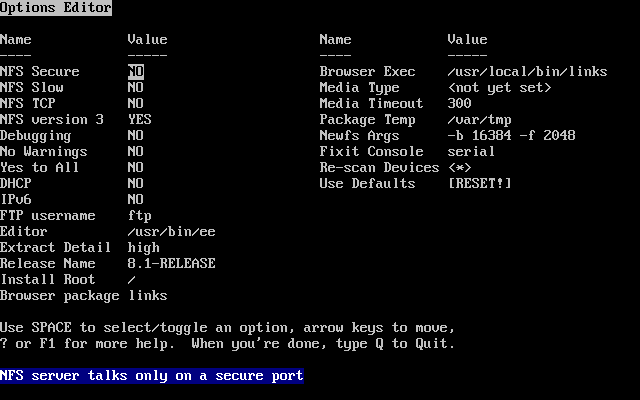
The default values are usually fine for most users and do not need to be changed. The release name will vary according to the version being installed.
The description of the selected item will appear at the bottom of the screen highlighted in blue. Notice that one of the options is to reset all values to startup defaults.
Press F1 to read the help screen about the various options.
Press Q to return to the Main Install menu.
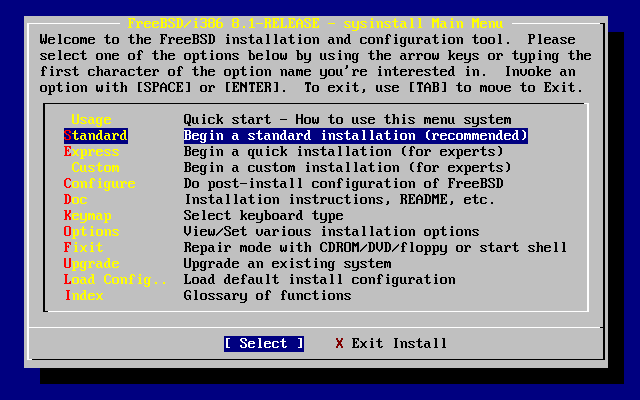
The first task is to allocate disk space for FreeBSD, and label that space so that sysinstall(8) can prepare it. In order to do this you need to know how FreeBSD expects to find information on the disk.
Before installing and configuring FreeBSD it is important to be aware how FreeBSD deals with BIOS drive mappings.
In a PC running a BIOS-dependent operating system such as Microsoft® Windows®, the BIOS is able to abstract the normal disk drive order and the operating system goes along with the change. This allows the user to boot from a disk drive other than the "primary master". This is especially convenient for users buy an identical second hard drive, and perform routine copies of the first drive to the second drive. If the first drive fails, is attacked by a virus, or is scribbled upon by an operating system defect, they can easily recover by instructing the BIOS to logically swap the drives. It is like switching the cables on the drives, without having to open the case.
Systems with SCSI controllers often include BIOS extensions which allow the SCSI drives to be re-ordered in a similar fashion for up to seven drives.
A user who is accustomed to taking advantage of these features may become surprised when the results with FreeBSD are not as expected. FreeBSD does not use the BIOS, and does not know the “logical BIOS drive mapping”. This can lead to perplexing situations, especially when drives are physically identical in geometry and have been made as data clones of one another.
When using FreeBSD, always restore the BIOS to natural drive numbering before installing FreeBSD, and then leave it that way. If drives need to be switched around, take the time to open the case and move the jumpers and cables.
After choosing to begin a standard installation in sysinstall(8), this message will appear:
Message
In the next menu, you will need to set up a DOS-style ("fdisk")
partitioning scheme for your hard disk. If you simply wish to devote
all disk space to FreeBSD (overwriting anything else that might be on
the disk(s) selected) then use the (A)ll command to select the default
partitioning scheme followed by a (Q)uit. If you wish to allocate only
free space to FreeBSD, move to a partition marked "unused" and use the
(C)reate command.
[ OK ]
[ Press enter or space ]Press Enter and a list of all the hard
drives that the kernel found when it carried out the device
probes will be displayed. Figure 3.13, “Select Drive for FDisk” shows an example from a
system with two IDE disks called ad0 and
ad2.
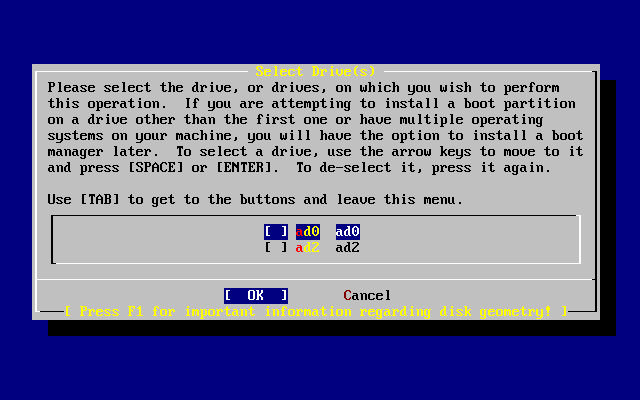
Note that ad1 is not listed
here.
Consider two IDE hard disks where one is the master on the
first IDE controller and one is the master on the second IDE
controller. If FreeBSD numbered these as
ad0 and ad1,
everything would work.
But if a third disk is later added as the slave device on
the first IDE controller, it would now be
ad1, and the previous
ad1 would become
ad2. Because device names are used to
find filesystems, some filesystems may no longer appear
correctly, requiring a change to the FreeBSD
configuration.
To work around this, the kernel can be configured to name
IDE disks based on where they are and not the order in which
they were found. With this scheme, the master disk on the
second IDE controller will always be
ad2, even if there are no
ad0 or ad1
devices.
This configuration is the default for the FreeBSD kernel,
which is why the display in this example shows
ad0 and ad2. The
machine on which this screenshot was taken had IDE disks on
both master channels of the IDE controllers and no disks on
the slave channels.
Select the disk on which to install FreeBSD, and then press . FDisk will start, with a display similar to that shown in Figure 3.14, “Typical Default FDisk Partitions”.
The FDisk display is broken into three sections.
The first section, covering the first two lines of the display, shows details about the currently selected disk, including its FreeBSD name, the disk geometry, and the total size of the disk.
The second section shows the slices that are currently on
the disk, where they start and end, how large they are, the
name FreeBSD gives them, and their description and sub-type.
This example shows two small unused slices which are artifacts
of disk layout schemes on the PC. It also shows one large
FAT slice, which appears as
C: in Windows®, and an extended slice,
which may contain other drive letters in Windows®.
The third section shows the commands that are available in FDisk.
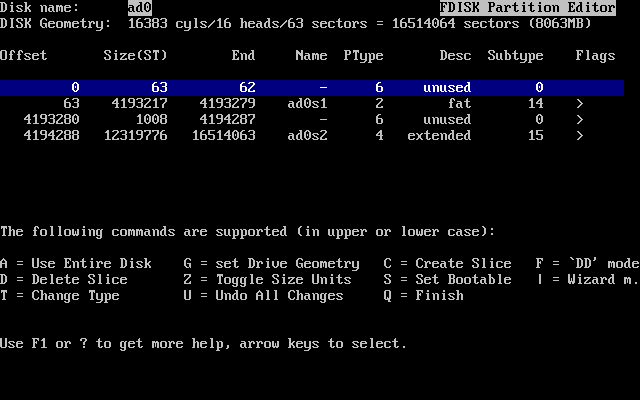
This step varies, depending on how the disk is to be sliced.
To install FreeBSD to the entire disk, which will delete all
the other data on this disk, press A, which
corresponds to the
option. The existing slices will be removed and replaced with
a small area flagged as unused and one
large slice for FreeBSD. Then, select the newly created FreeBSD
slice using the arrow keys and press S to
mark the slice as being bootable. The screen will then look
similar to Figure 3.15, “Fdisk Partition Using Entire Disk”. Note the
A in the Flags column,
which indicates that this slice is
active, and will be booted from.
If an existing slice needs to be deleted to make space for FreeBSD, select the slice using the arrow keys and press D. Then, press C to be prompted for the size of the slice to create. Enter the appropriate value and press Enter. The default value in this box represents the largest possible slice to make, which could be the largest contiguous block of unallocated space or the size of the entire hard disk.
If you have already made space for FreeBSD then you can press C to create a new slice. Again, you will be prompted for the size of slice you would like to create.
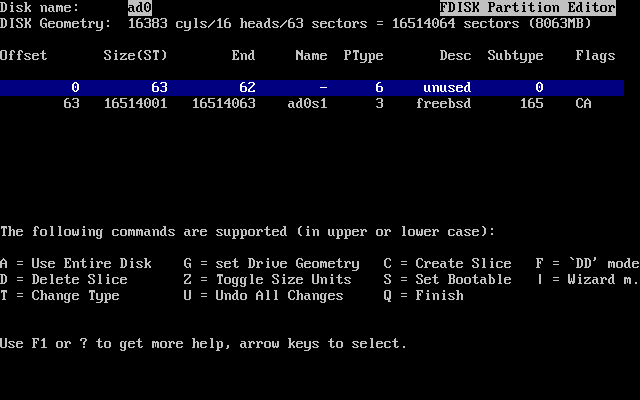
When finished, press Q. Any changes will be saved in sysinstall(8), but will not yet be written to disk.
The next menu provides the option to install a boot manager. In general, install the FreeBSD boot manager if:
There is more than one drive and FreeBSD will be installed onto a drive other than the first one.
FreeBSD will be installed alongside another operating system on the same disk, and you want to choose whether to start FreeBSD or the other operating system when the computer starts.
If FreeBSD is going to be the only operating system on this machine, installed on the first hard disk, then the boot manager will suffice. Choose if using a third-party boot manager capable of booting FreeBSD.
Make a selection and press Enter.
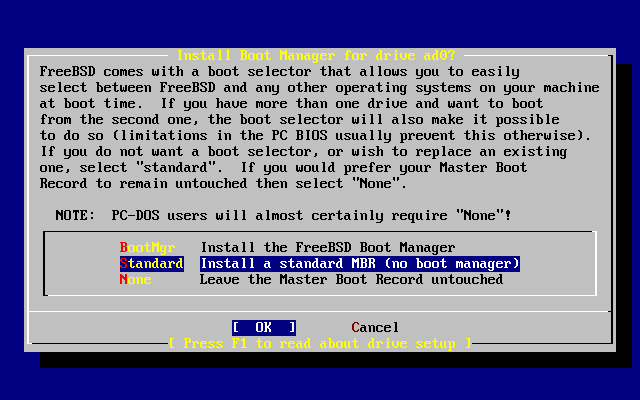
The help screen, reached by pressing F1, discusses the problems that can be encountered when trying to share the hard disk between operating systems.
If there is more than one drive, it will return to the Select Drives screen after the boot manager selection. To install FreeBSD on to more than one disk, select another disk and repeat the slice process using FDisk.
Important:
If installing FreeBSD on a drive other than the first drive, the FreeBSD boot manager needs to be installed on both drives.
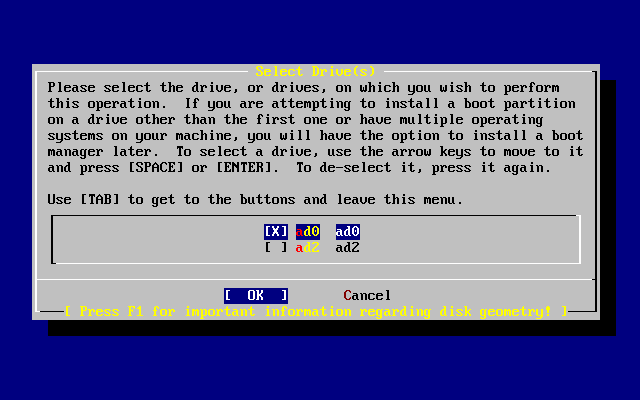
Use Tab to toggle between the last drive selected, , and .
Press Tab once to toggle to , then press Enter to continue with the installation.
Next, create some partitions inside each slice.
Remember that each partition is lettered, from
a through to h, and that
partitions b, c, and
d have conventional meanings that should be
adhered to.
Certain applications can benefit from particular partition schemes, especially when laying out partitions across more than one disk. However, for a first FreeBSD installation, do not give too much thought to how to partition the disk. It is more important to install FreeBSD and start learning how to use it. You can always re-install FreeBSD to change the partition scheme after becoming more familiar with the operating system.
The following scheme features four partitions: one for swap space and three for filesystems.
| Partition | Filesystem | Size | Description |
|---|---|---|---|
a | / | 1 GB | This is the root filesystem. Every other filesystem will be mounted somewhere under this one. 1 GB is a reasonable size for this filesystem as user files should not be stored here and a regular FreeBSD install will put about 128 MB of data here. |
b | N/A | 2-3 x RAM | The system's swap space is kept on the
|
e | /var | 512 MB to 4096 MB | /var contains files that are
constantly varying, such as log files and other
administrative files. Many of these files are read
from or written to extensively during FreeBSD's
day-to-day running. Putting these files on another
filesystem allows FreeBSD to optimize the access of these
files without affecting other files in other
directories that do not have the same access
pattern. |
f | /usr | Rest of disk (at least 8 GB) | All other files will typically be stored in
/usr and its
subdirectories. |
Warning:
The values above are given as example and should be used
by experienced users only. Users are encouraged to use the
automatic partition layout called Auto
Defaults by the FreeBSD partition editor.
If installing FreeBSD on to more than one disk, create partitions in the other configured slices. The easiest way to do this is to create two partitions on each disk, one for the swap space, and one for a filesystem.
| Partition | Filesystem | Size | Description |
|---|---|---|---|
b | N/A | See description | Swap space can be split across each disk. Even
though the a partition is free,
convention dictates that swap space stays on the
b partition. |
e | /diskn | Rest of disk | The rest of the disk is taken up with one big
partition. This could easily be put on the
a partition, instead of the
e partition. However, convention
says that the a partition on a
slice is reserved for the filesystem that will be the
root (/) filesystem. Following
this convention is not necessary, but
sysinstall(8) uses it, so following it makes the
installation slightly cleaner. This filesystem can be
mounted anywhere; this example mounts it as /disk,
where n is a number that
changes for each disk. |
Having chosen the partition layout, create it using sysinstall(8).
Message
Now, you need to create BSD partitions inside of the fdisk
partition(s) just created. If you have a reasonable amount of disk
space (1GB or more) and don't have any special requirements, simply
use the (A)uto command to allocate space automatically. If you have
more specific needs or just don't care for the layout chosen by
(A)uto, press F1 for more information on manual layout.
[ OK ]
[ Press enter or space ]Press Enter to start the FreeBSD partition editor, called Disklabel.
Figure 3.18, “Sysinstall Disklabel Editor” shows the display when Disklabel starts. The display is divided into three sections.
The first few lines show the name of the disk being
worked on and the slice that contains the partitions to
create. At this point, Disklabel
calls this the Partition name rather than
slice name. This display also shows the amount of free space
within the slice; that is, space that was set aside in the
slice, but that has not yet been assigned to a
partition.
The middle of the display shows the partitions that have been created, the name of the filesystem that each partition contains, their size, and some options pertaining to the creation of the filesystem.
The bottom third of the screen shows the keystrokes that are valid in Disklabel.
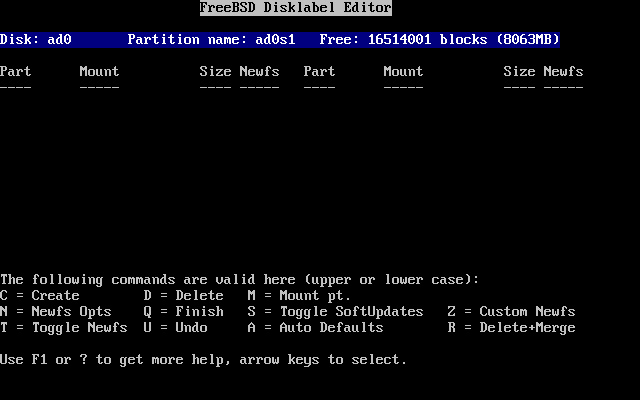
Disklabel can automatically create partitions and assign them default sizes. The default sizes are calculated with the help of an internal partition sizing algorithm based on the disk size. Press A to see a display similar to that shown in Figure 3.19, “Sysinstall Disklabel Editor with Auto Defaults”. Depending on the size of the disk, the defaults may or may not be appropriate.
Note:
The default partitioning assigns
/tmp its own partition instead of
being part of the / partition. This
helps avoid filling the / partition
with temporary files.
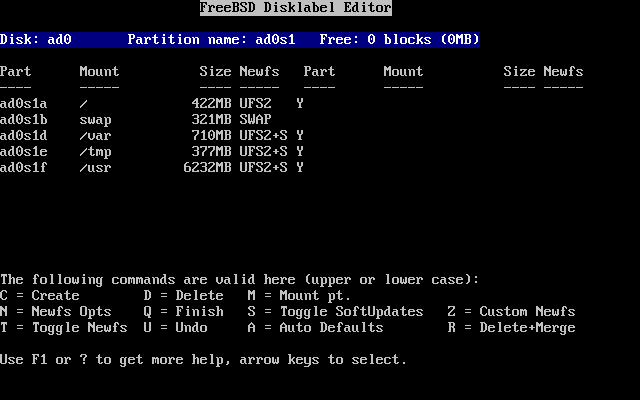
To replace the default partitions, use the arrow keys to select the first partition and press D to delete it. Repeat this to delete all the suggested partitions.
To create the first partition, a,
mounted as /, make sure the proper disk
slice at the top of the screen is selected and press
C. A dialog box will appear, prompting for
the size of the new partition, as shown in Figure 3.20, “Free Space for Root Partition”. The size can be entered
as the number of disk blocks to use or as a number followed by
either M for megabytes,
G for gigabytes, or C
for cylinders.
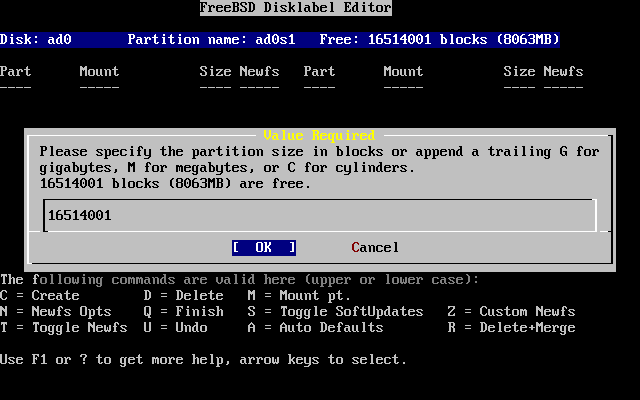
The default size shown will create a partition that takes
up the rest of the slice. If using the partition sizes
described in the earlier example, delete the existing figure
using Backspace, and then type in
512M, as shown in Figure 3.21, “Edit Root Partition Size”. Then press
.
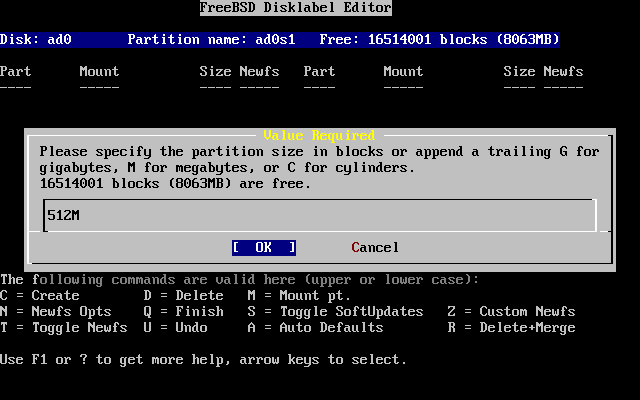
After choosing the partition's size, the installer will ask whether this partition will contain a filesystem or swap space. The dialog box is shown in Figure 3.22, “Choose the Root Partition Type”. This first partition will contain a filesystem, so check that is selected and press Enter.
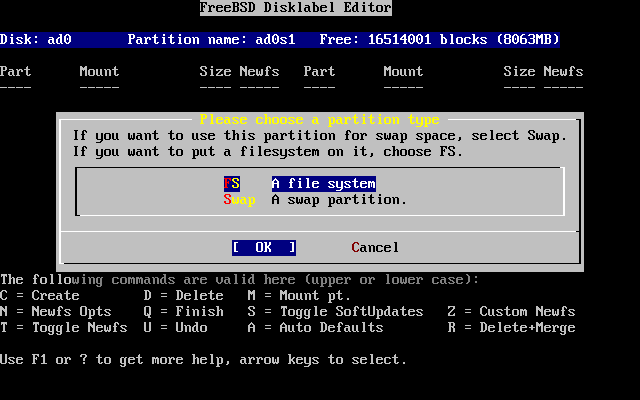
Finally, tell Disklabel where
the filesystem will be mounted. The dialog box is shown in
Figure 3.23, “Choose the Root Mount Point”. Type
/, and then press
Enter.
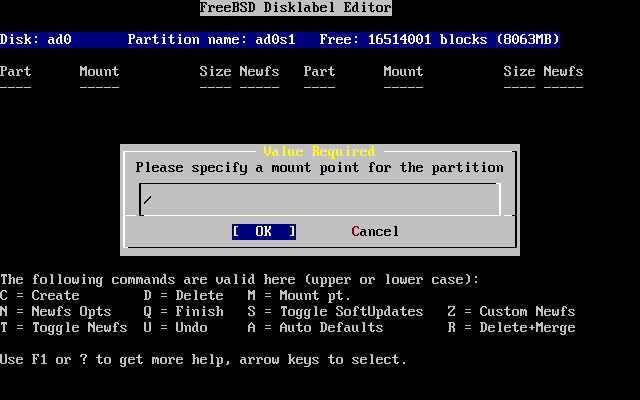
The display will then update to show the newly created
partition. Repeat this procedure for the other partitions.
When creating the swap partition, it will not prompt for the
filesystem mount point. When creating the final partition,
/usr, leave the suggested size as is to
use the rest of the slice.
The final FreeBSD DiskLabel Editor screen will appear similar to Figure 3.24, “Sysinstall Disklabel Editor”, although the values chosen may be different. Press Q to finish.
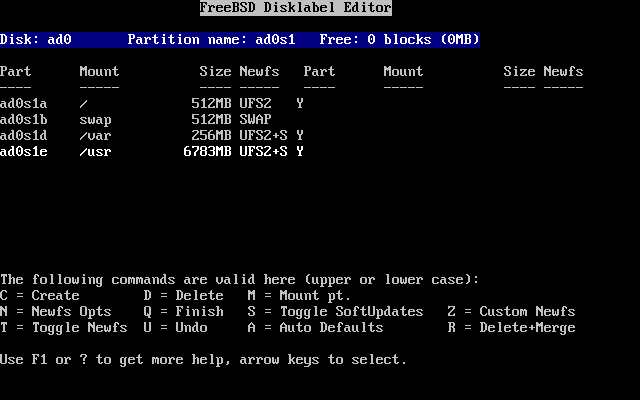
Deciding which distribution set to install will depend largely on the intended use of the system and the amount of disk space available. The predefined options range from installing the smallest possible configuration to everything. Those who are new to UNIX® or FreeBSD should select one of these canned options. Customizing a distribution set is typically for the more experienced user.
Press F1 for more information on the distribution set options and what they contain. When finished reviewing the help, press Enter to return to the Select Distributions Menu.
If a graphical user interface is desired, the configuration of Xorg and selection of a default desktop must be done after the installation of FreeBSD. More information regarding the installation and configuration of a Xorg can be found in Chapter 6, The X Window System.
If compiling a custom kernel is anticipated, select an option which includes the source code. For more information on why a custom kernel should be built or how to build a custom kernel, see Chapter 9, Configuring the FreeBSD Kernel.
The most versatile system is one that includes everything. If there is adequate disk space, select , as shown in Figure 3.25, “Choose Distributions”, by using the arrow keys and pressing Enter. If there is a concern about disk space, consider using an option that is more suitable for the situation. Do not fret over the perfect choice, as other distributions can be added after installation.
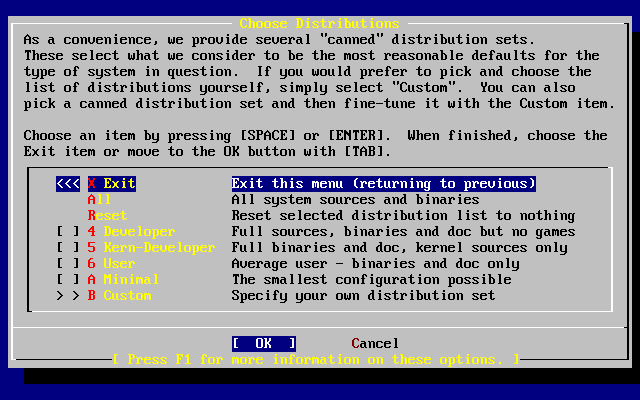
After selecting the desired distribution, an opportunity to install the FreeBSD Ports Collection is presented. The Ports Collection is an easy and convenient way to install software as it provides a collection of files that automate the downloading, compiling, and installation of third-party software packages. Chapter 5, Installing Applications: Packages and Ports discusses how to use the Ports Collection.
The installation program does not check to see if you have adequate space. Select this option only if you have adequate hard disk space. As of FreeBSD 10.2, the FreeBSD Ports Collection takes up about 500 MB of disk space. You can safely assume a larger value for more recent versions of FreeBSD.
User Confirmation Requested
Would you like to install the FreeBSD ports collection?
This will give you ready access to over 24,000 ported software packages,
at a cost of around 500 MB of disk space when "clean" and possibly much
more than that if a lot of the distribution tarballs are loaded
(unless you have the extra CDs from a FreeBSD CD/DVD distribution
available and can mount it on /cdrom, in which case this is far less
of a problem).
The Ports Collection is a very valuable resource and well worth having
on your /usr partition, so it is advisable to say Yes to this option.
For more information on the Ports Collection & the latest ports,
visit:
http://www.FreeBSD.org/ports
[ Yes ] NoSelect with the arrow keys to install the Ports Collection or to skip this option. Press Enter to continue. The Choose Distributions menu will redisplay.
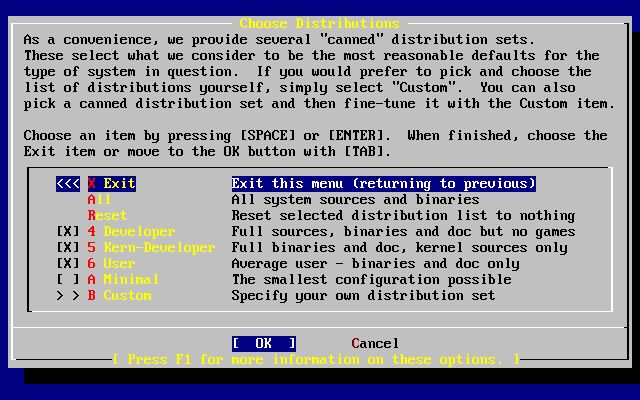
Once satisfied with the options, select with the arrow keys, ensure that is highlighted, and press Enter to continue.
If installing from a CD/DVD, use the arrow keys to highlight . Ensure that is highlighted, then press Enter to proceed with the installation.
For other methods of installation, select the appropriate option and follow the instructions.
Press F1 to display the Online Help for installation media. Press Enter to return to the media selection menu.
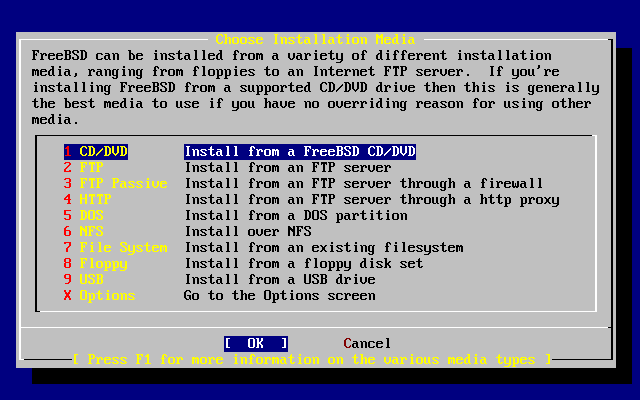
FTP Installation Modes:
There are three FTP installation modes to choose from: active FTP, passive FTP, or via a HTTP proxy.
- FTP Active:
This option makes all FTP transfers use “Active” mode. This will not work through firewalls, but will often work with older FTP servers that do not support passive mode. If the connection hangs with passive mode (the default), try using active mode.
- FTP Passive:
This option instructs sysinstall(8) to use passive mode for all FTP operations. This allows the user to pass through firewalls that do not allow incoming connections on random TCP ports.
- FTP via a HTTP proxy:
This option instructs sysinstall(8) to use the HTTP protocol to connect to a proxy for all FTP operations. The proxy will translate the requests and send them to the FTP server. This allows the user to pass through firewalls that do not allow FTP, but offer a HTTP proxy. In this case, specify the proxy in addition to the FTP server.
For a proxy FTP server, give the name of the server as
part of the username, after an “@” sign. The
proxy server then “fakes” the real server. For
example, to install from ftp.FreeBSD.org, using the
proxy FTP server foo.example.com, listening
on port 1234, go to the options menu, set the FTP username to
[email protected] and the password to an
email address. As the installation media, specify FTP (or
passive FTP, if the proxy supports it), and the URL
ftp://foo.example.com:1234/pub/FreeBSD.
Since /pub/FreeBSD from ftp.FreeBSD.org is proxied
under foo.example.com, the proxy
will fetch the files from ftp.FreeBSD.org as the
installer requests them.
The installation can now proceed if desired. This is also the last chance for aborting the installation to prevent changes to the hard drive.
User Confirmation Requested
Last Chance! Are you SURE you want to continue the installation?
If you're running this on a disk with data you wish to save then WE
STRONGLY ENCOURAGE YOU TO MAKE PROPER BACKUPS before proceeding!
We can take no responsibility for lost disk contents!
[ Yes ] NoSelect and press Enter to proceed.
The installation time will vary according to the distribution chosen, installation media, and the speed of the computer. There will be a series of messages displayed, indicating the status.
The installation is complete when the following message is displayed:
Message
Congratulations! You now have FreeBSD installed on your system.
We will now move on to the final configuration questions.
For any option you do not wish to configure, simply select No.
If you wish to re-enter this utility after the system is up, you may
do so by typing: /usr/sbin/sysinstall.
[ OK ]
[ Press enter or space ]Press Enter to proceed with post-installation configurations.
Selecting and pressing Enter will abort the installation so no changes will be made to the system. The following message will appear:
Message
Installation complete with some errors. You may wish to scroll
through the debugging messages on VTY1 with the scroll-lock feature.
You can also choose "No" at the next prompt and go back into the
installation menus to retry whichever operations have failed.
[ OK ]This message is generated because nothing was installed. Pressing Enter will return to the Main Installation Menu to exit the installation.
Configuration of various options can be performed after a successful installation. An option can be configured by re-entering the configuration menus before booting the new FreeBSD system or after boot using sysinstall(8) and then selecting the menu.
If PPP was previously configured for an FTP install, this screen will not display and can be configured after boot as described above.
For detailed information on Local Area Networks and configuring FreeBSD as a gateway/router refer to the Advanced Networking chapter.
User Confirmation Requested
Would you like to configure any Ethernet or PPP network devices?
[ Yes ] NoTo configure a network device, select and press Enter. Otherwise, select to continue.
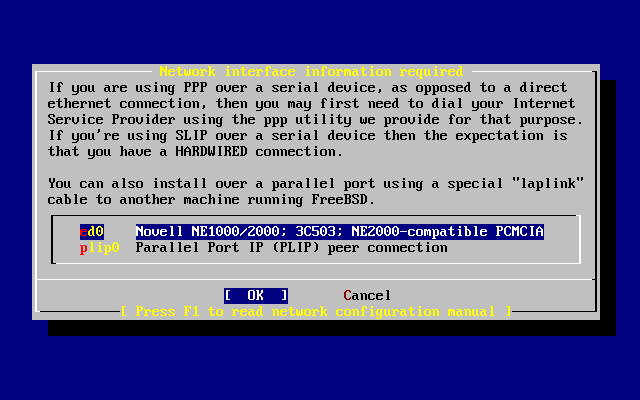
Select the interface to be configured with the arrow keys and press Enter.
User Confirmation Requested
Do you want to try IPv6 configuration of the interface?
Yes [ No ]In this private local area network, the current Internet type protocol (IPv4) was sufficient and was selected with the arrow keys and Enter pressed.
If connected to an existing IPv6 network with an RA server, choose and press Enter. It will take several seconds to scan for RA servers.
User Confirmation Requested
Do you want to try DHCP configuration of the interface?
Yes [ No ]If Dynamic Host Configuration Protocol DHCP) is not required, select with the arrow keys and press Enter.
Selecting will execute dhclient(8) and, if successful, will fill in the network configuration information automatically. Refer to Section 29.6, “Dynamic Host Configuration Protocol (DHCP)” for more information.
The following Network Configuration screen shows the configuration of the Ethernet device for a system that will act as the gateway for a Local Area Network.
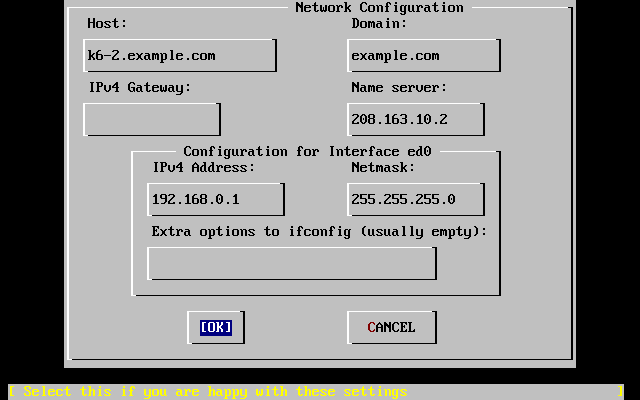
Use Tab to select the information fields and fill in appropriate information:
- Host
The fully-qualified hostname, such as
k6-2.example.comin this case.- Domain
The name of the domain that the machine is in, such as
example.comfor this case.- IPv4 Gateway
IP address of host forwarding packets to non-local destinations. This must be filled in if the machine is a node on the network. Leave this field blank if the machine is the gateway to the Internet for the network. The IPv4 Gateway is also known as the default gateway or default route.
- Name server
IP address of the local DNS server. There is no local DNS server on this private local area network so the IP address of the provider's DNS server (
208.163.10.2) was used.- IPv4 address
The IP address to be used for this interface was
192.168.0.1- Netmask
The address block being used for this local area network is
192.168.0.0-192.168.0.255with a netmask of255.255.255.0.- Extra options to ifconfig(8)
Any additional interface-specific options to ifconfig(8). There were none in this case.
Use Tab to select when finished and press Enter.
User Confirmation Requested
Would you like to bring the ed0 interface up right now?
[ Yes ] NoChoosing and pressing Enter will bring the machine up on the network so it is ready for use. However, this does not accomplish much during installation, since the machine still needs to be rebooted.
User Confirmation Requested
Do you want this machine to function as a network gateway?
[ Yes ] NoIf the machine will be acting as the gateway for a local area network and forwarding packets between other machines, select and press Enter. If the machine is a node on a network, select and press Enter to continue.
User Confirmation Requested
Do you want to configure inetd and the network services that it provides?
Yes [ No ]If is selected, various services will not be
enabled. These services can be enabled after installation by
editing /etc/inetd.conf with a text
editor. See Section 29.2.1, “Configuration File” for more
information.
Otherwise, select to configure these services during install. An additional confirmation will display:
User Confirmation Requested
The Internet Super Server (inetd) allows a number of simple Internet
services to be enabled, including finger, ftp and telnetd. Enabling
these services may increase risk of security problems by increasing
the exposure of your system.
With this in mind, do you wish to enable inetd?
[ Yes ] NoSelect to continue.
User Confirmation Requested
inetd(8) relies on its configuration file, /etc/inetd.conf, to determine
which of its Internet services will be available. The default FreeBSD
inetd.conf(5) leaves all services disabled by default, so they must be
specifically enabled in the configuration file before they will
function, even once inetd(8) is enabled. Note that services for
IPv6 must be separately enabled from IPv4 services.
Select [Yes] now to invoke an editor on /etc/inetd.conf, or [No] to
use the current settings.
[ Yes ] NoSelecting allows services to be enabled by
deleting the # at the beginning of the
lines representing those services.
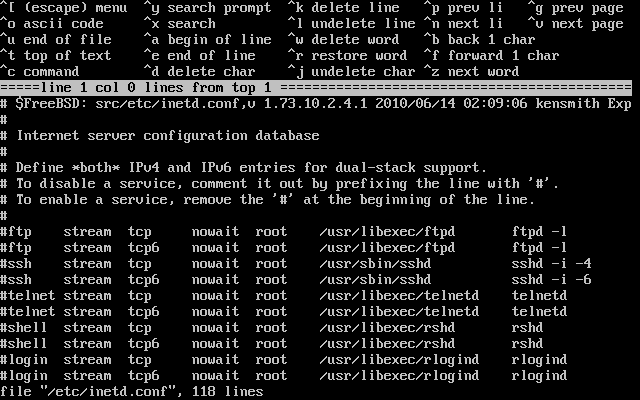
Once the edits are complete, press Esc to display a menu which will exit the editor and save the changes.
User Confirmation Requested
Would you like to enable SSH login?
Yes [ No ]Selecting will enable sshd(8), the daemon for OpenSSH. This allows secure remote access to the machine. For more information about OpenSSH, see Section 14.8, “OpenSSH”.
User Confirmation Requested
Do you want to have anonymous FTP access to this machine?
Yes [ No ]Selecting the default and pressing Enter will still allow users who have accounts with passwords to use FTP to access the machine.
Anyone can access the machine if anonymous FTP connections are allowed. The security implications should be considered before enabling this option. For more information about security, see Chapter 14, Security.
To allow anonymous FTP, use the arrow keys to select and press Enter. An additional confirmation will display:
User Confirmation Requested
Anonymous FTP permits un-authenticated users to connect to the system
FTP server, if FTP service is enabled. Anonymous users are
restricted to a specific subset of the file system, and the default
configuration provides a drop-box incoming directory to which uploads
are permitted. You must separately enable both inetd(8), and enable
ftpd(8) in inetd.conf(5) for FTP services to be available. If you
did not do so earlier, you will have the opportunity to enable inetd(8)
again later.
If you want the server to be read-only you should leave the upload
directory option empty and add the -r command-line option to ftpd(8)
in inetd.conf(5)
Do you wish to continue configuring anonymous FTP?
[ Yes ] NoThis message indicates that the FTP service will also
have to be enabled in /etc/inetd.conf
to allow anonymous FTP connections. Select and
press Enter to continue. The following
screen will display:
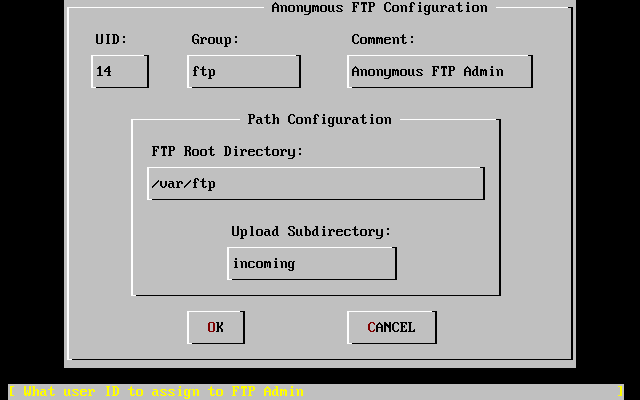
Use Tab to select the information fields and fill in appropriate information:
- UID
The user ID to assign to the anonymous FTP user. All files uploaded will be owned by this ID.
- Group
Which group to place the anonymous FTP user into.
- Comment
String describing this user in
/etc/passwd.- FTP Root Directory
Where files available for anonymous FTP will be kept.
- Upload Subdirectory
Where files uploaded by anonymous FTP users will go.
The FTP root directory will be put in
/var by default. If there is not
enough room there for the anticipated FTP needs, use
/usr instead by setting the FTP root
directory to /usr/ftp.
Once satisfied with the values, press Enter to continue.
User Confirmation Requested
Create a welcome message file for anonymous FTP users?
[ Yes ] NoIf is selected, press Enter and the ee(1) editor will automatically start.
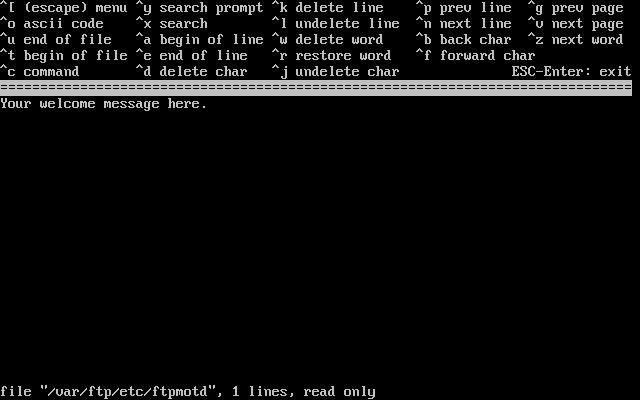
Use the instructions to change the message. Note the file name location at the bottom of the editor screen.
Press Esc and a pop-up menu will default to . Press Enter to exit and continue. Press Enter again to save any changes.
The Network File System (NFS) allows sharing of files across a network. A machine can be configured as a server, a client, or both. Refer to Section 29.3, “Network File System (NFS)” for more information.
User Confirmation Requested
Do you want to configure this machine as an NFS server?
Yes [ No ]If there is no need for a NFS server, select and press Enter.
If is chosen, a message will pop-up indicating
that /etc/exports must be
created.
Message
Operating as an NFS server means that you must first configure an
/etc/exports file to indicate which hosts are allowed certain kinds of
access to your local filesystems.
Press [Enter] now to invoke an editor on /etc/exports
[ OK ]Press Enter to continue. A text editor
will start, allowing /etc/exports to be
edited.
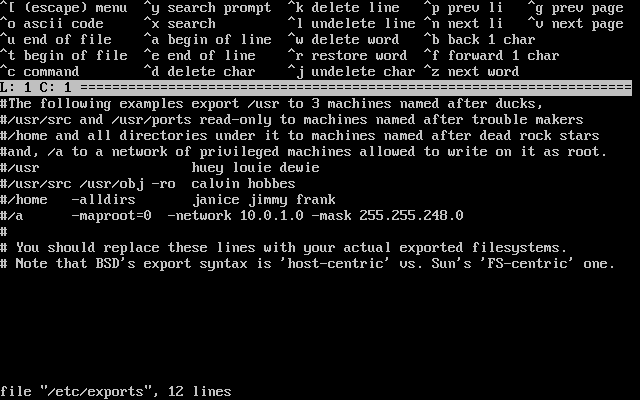
Use the instructions to add the exported filesystems. Note the file name location at the bottom of the editor screen.
Press Esc and a pop-up menu will default to . Press Enter to exit and continue.
There are several options available to customize the system console.
User Confirmation Requested
Would you like to customize your system console settings?
[ Yes ] NoTo view and configure the options, select and press Enter.
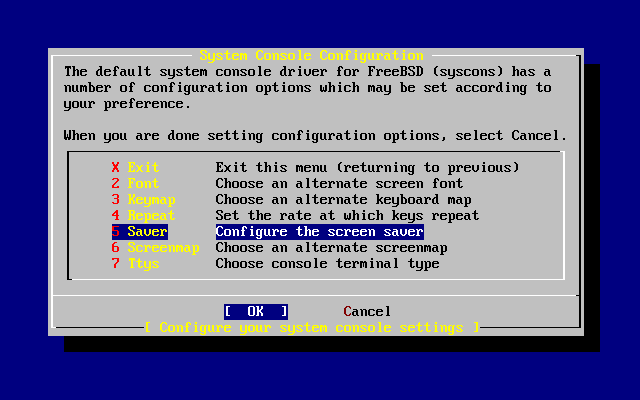
A commonly used option is the screen saver. Use the arrow keys to select and then press Enter.

Select the desired screen saver using the arrow keys and then press Enter. The System Console Configuration menu will redisplay.
The default time interval is 300 seconds. To change the time interval, select again. At the Screen Saver Options menu, select using the arrow keys and press Enter. A pop-up menu will appear:
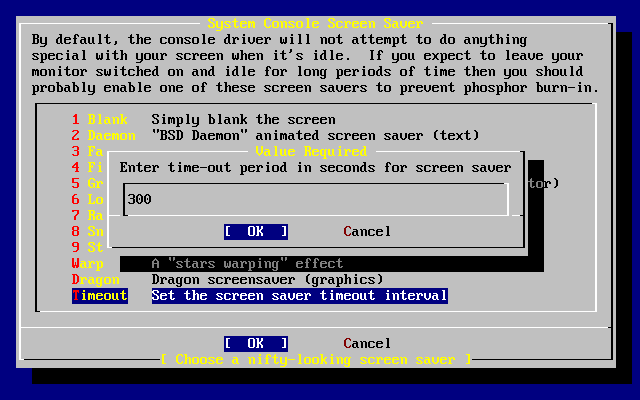
The value can be changed, then select and press Enter to return to the System Console Configuration menu.
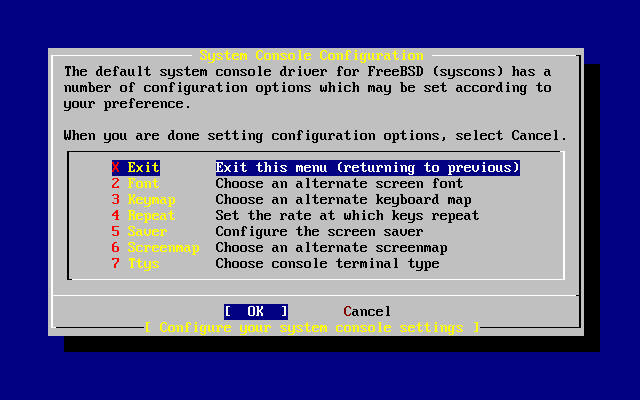
Select and press Enter to continue with the post-installation configuration.
Setting the time zone allows the system to automatically correct for any regional time changes and perform other time zone related functions properly.
The example shown is for a machine located in the Eastern time zone of the United States. The selections will vary according to the geographic location.
User Confirmation Requested
Would you like to set this machine's time zone now?
[ Yes ] NoSelect and press Enter to set the time zone.
User Confirmation Requested
Is this machine's CMOS clock set to UTC? If it is set to local time
or you don't know, please choose NO here!
Yes [ No ]Select or according to how the machine's clock is configured, then press Enter.
The appropriate region is selected using the arrow keys and then pressing Enter.
Select the appropriate country using the arrow keys and press Enter.
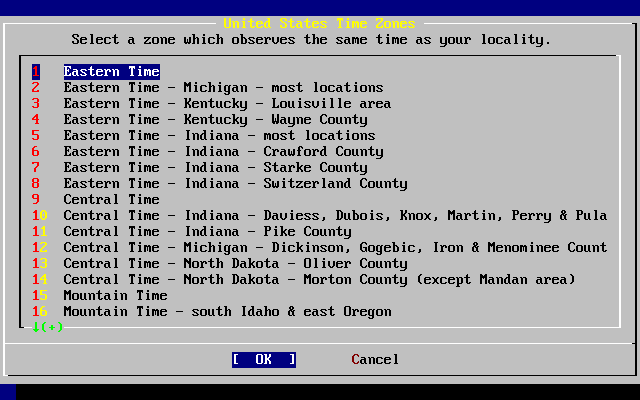
The appropriate time zone is selected using the arrow keys and pressing Enter.
Confirmation
Does the abbreviation 'EDT' look reasonable?
[ Yes ] NoConfirm that the abbreviation for the time zone is correct. If it looks okay, press Enter to continue with the post-installation configuration.
This option allows cut and paste in the console and user programs using a 3-button mouse. If using a 2-button mouse, refer to moused(8) for details on emulating the 3-button style. This example depicts a non-USB mouse configuration:
User Confirmation Requested
Does this system have a PS/2, serial, or bus mouse?
[ Yes ] No Select for a PS/2, serial, or bus mouse, or for a USB mouse, then press Enter.
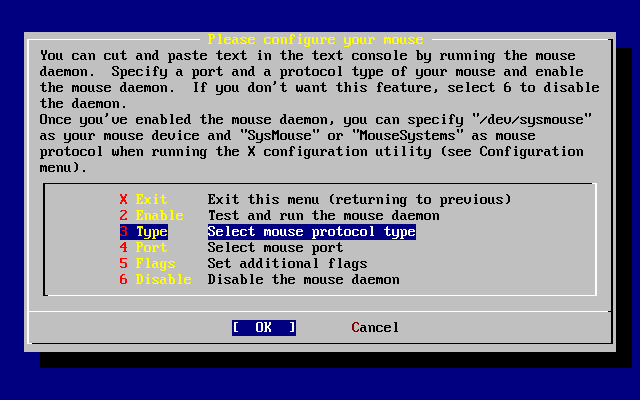
Use the arrow keys to select and press Enter.
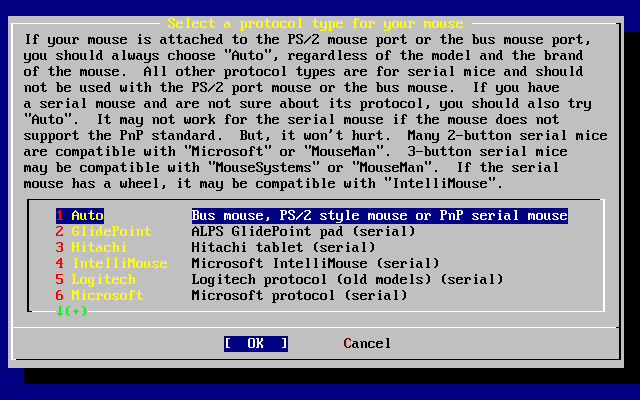
The mouse used in this example is a PS/2 type, so the default is appropriate. To change the mouse protocol, use the arrow keys to select another option. Ensure that is highlighted and press Enter to exit this menu.
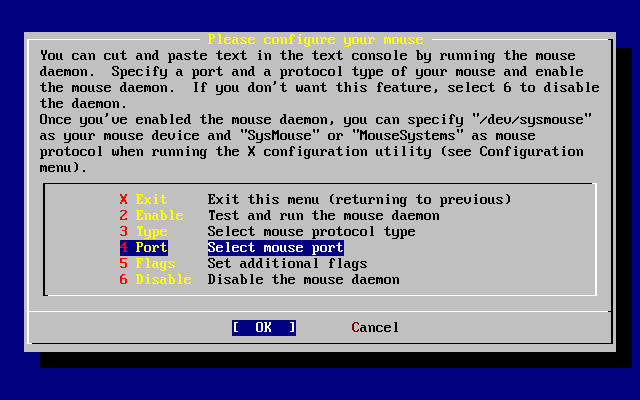
Use the arrow keys to select and press Enter.
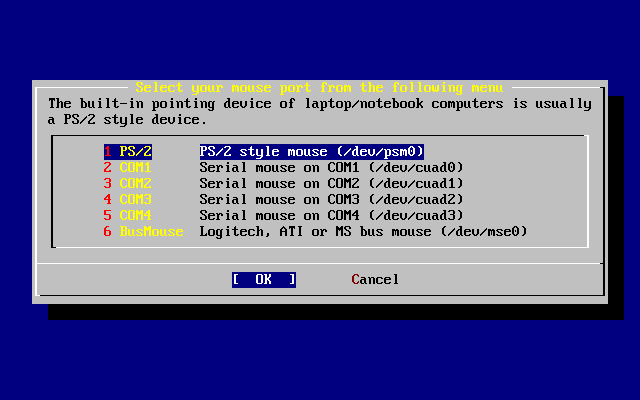
This system had a PS/2 mouse, so the default is appropriate. To change the port, use the arrow keys and then press Enter.
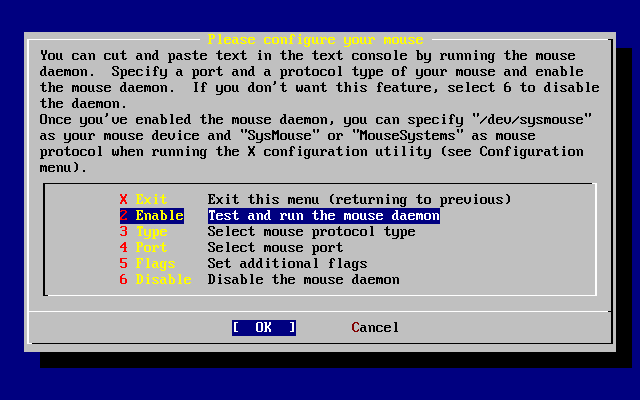
Last, use the arrow keys to select , and press Enter to enable and test the mouse daemon.
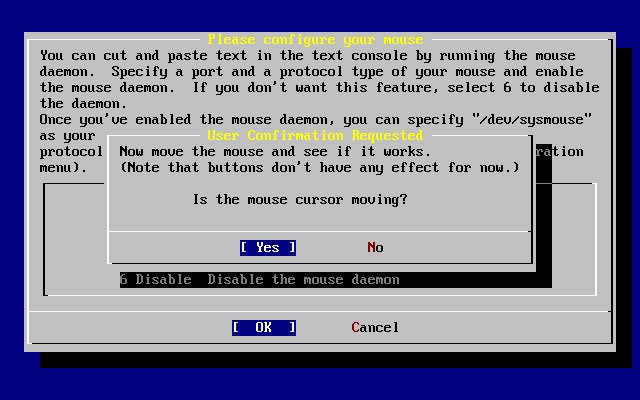
Move the mouse around the screen to verify that the cursor responds properly. If it does, select and press Enter. If not, the mouse has not been configured correctly. Select and try using different configuration options.
Select with the arrow keys and press Enter to continue with the post-installation configuration.
Packages are pre-compiled binaries and are a convenient way to install software.
Installation of one package is shown for purposes of illustration. Additional packages can also be added at this time if desired. After installation, sysinstall(8) can be used to add additional packages.
User Confirmation Requested
The FreeBSD package collection is a collection of hundreds of
ready-to-run applications, from text editors to games to WEB servers
and more. Would you like to browse the collection now?
[ Yes ] NoSelect and press Enter to be presented with the Package Selection screens:
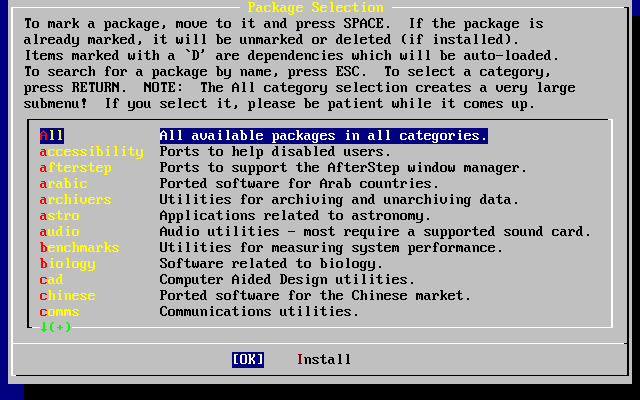
Only packages on the current installation media are available for installation at any given time.
All packages available will be displayed if is selected. Otherwise, select a particular category. Highlight the selection with the arrow keys and press Enter.
A menu will display showing all the packages available for the selection made:
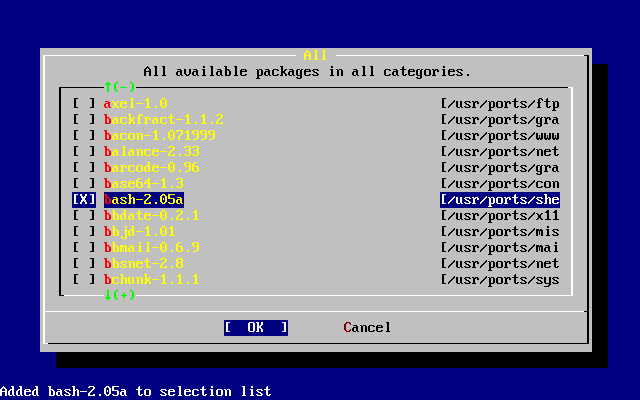
The bash shell is shown as selected. Select as many packages as desired by highlighting the package and pressing Space. A short description of each package will appear in the lower left corner of the screen.
Press Tab to toggle between the last selected package, , and .
Once finished marking the packages for installation, press Tab once to toggle to and press Enter to return to the Package Selection menu.
The left and right arrow keys will also toggle between and . This method can also be used to select and press Enter to return to the Package Selection menu.
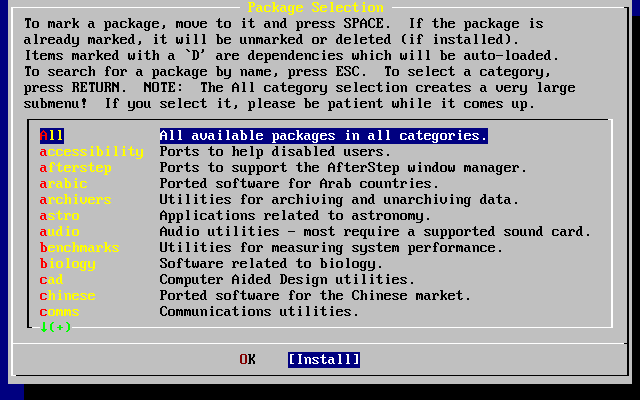
Use the Tab and arrow keys to select and press Enter to see the installation confirmation message:
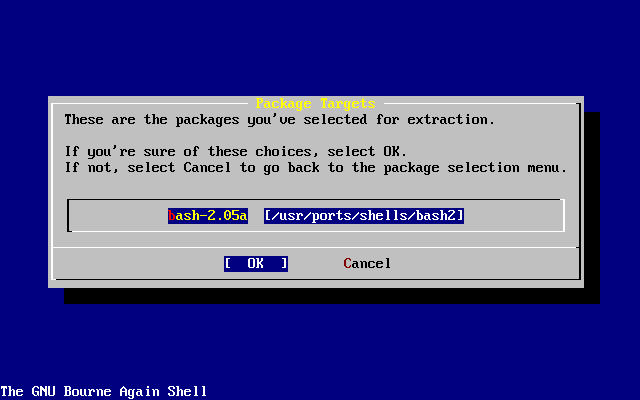
Select and press Enter to start the package installation. Installation messages will appear until all of the installations have completed. Make note if there are any error messages.
The final configuration continues after packages are installed. If no packages are selected, select to return to the final configuration.
Add at least one user during the installation so that the
system can be used without logging in as root. The root partition is
generally small and running applications as root can quickly fill it. A
bigger danger is noted below:
User Confirmation Requested
Would you like to add any initial user accounts to the system? Adding
at least one account for yourself at this stage is suggested since
working as the "root" user is dangerous (it is easy to do things which
adversely affect the entire system).
[ Yes ] NoSelect and press Enter to continue with adding a user.
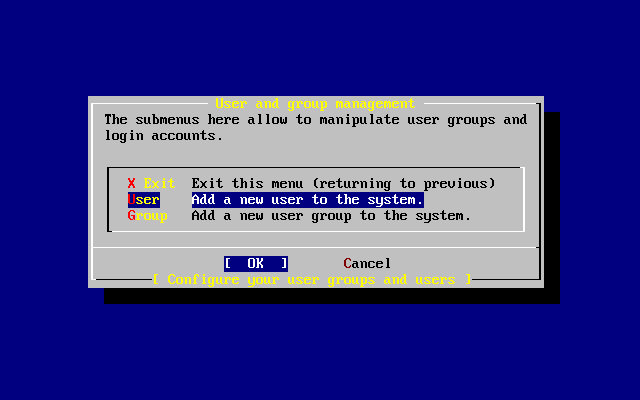
Select with the arrow keys and press Enter.
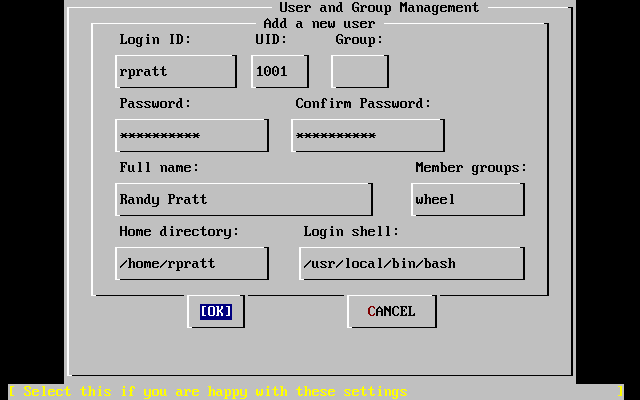
The following descriptions will appear in the lower part of the screen as the items are selected with Tab to assist with entering the required information:
- Login ID
The login name of the new user (mandatory).
- UID
The numerical ID for this user (leave blank for automatic choice).
- Group
The login group name for this user (leave blank for automatic choice).
- Password
The password for this user (enter this field with care!).
- Full name
The user's full name (comment).
- Member groups
The groups this user belongs to.
- Home directory
The user's home directory (leave blank for default).
- Login shell
The user's login shell (leave blank for default of
/bin/sh).
In this example, the login shell was changed from
/bin/sh to
/usr/local/bin/bash to use the
bash shell that was previously
installed as a package. Do not use a shell that does not
exist or the user will not be able to login. The most common
shell used in FreeBSD is the C shell,
/bin/tcsh.
The user was also added to the wheel group to be able to
become a superuser with root privileges.
Once satisfied, press and the User and Group Management menu will redisplay:
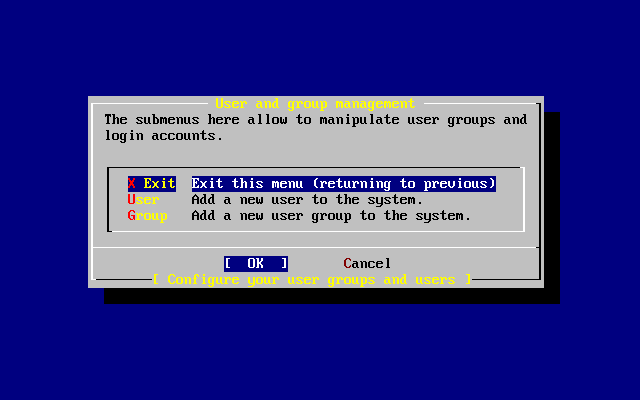
Groups can also be added at this time. Otherwise, this menu may be accessed using sysinstall(8) at a later time.
When finished adding users, select with the arrow keys and press Enter to continue the installation.
Message
Now you must set the system manager's password.
This is the password you'll use to log in as "root".
[ OK ]
[ Press enter or space ]Press Enter to set the root password.
The password will need to be typed in twice correctly. Do not forget this password. Notice that the typed password is not echoed, nor are asterisks displayed.
New password: Retype new password :
The installation will continue after the password is successfully entered.
A message will ask if configuration is complete:
User Confirmation Requested
Visit the general configuration menu for a chance to set any last
options?
Yes [ No ]Select with the arrow keys and press Enter to return to the Main Installation Menu.
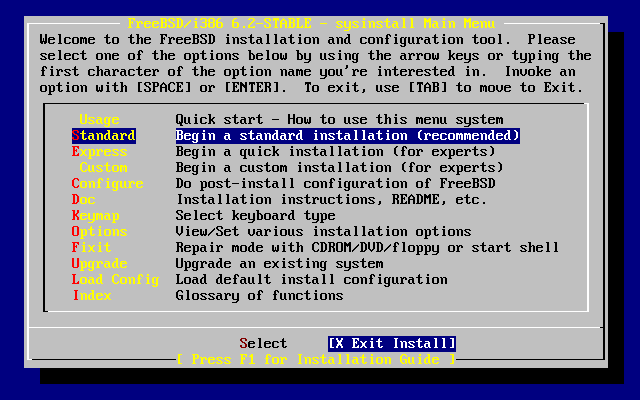
Select with the arrow keys and press Enter. The installer will prompt to confirm exiting the installation:
User Confirmation Requested
Are you sure you wish to exit? The system will reboot.
[ Yes ] NoSelect . If booting from the CDROM drive, the following message will remind you to remove the disk:
Message
Be sure to remove the media from the drive.
[ OK ]
[ Press enter or space ]The CDROM drive is locked until the machine starts to reboot, then the disk can quickly be removed from the drive. Press to reboot.
The system will reboot so watch for any error messages that may appear, see Section 3.10.15, “FreeBSD Bootup” for more details.
Configuring network services can be a daunting task for users that lack previous knowledge in this area. Since networking and the Internet are critical to all modern operating systems, it is useful to have some understanding of FreeBSD's extensive networking capabilities.
Network services are programs that accept input from
anywhere on the network. Since there have been cases where
bugs in network services have been exploited by attackers, it
is important to only enable needed network services. If in
doubt, do not enable a network service until it is needed.
Services can be enabled with sysinstall(8) or by editing
/etc/rc.conf.
Selecting the option will display a menu similar to the one below:
The first option, , is covered in Section 3.10.1, “Network Device Configuration”.
Selecting the option adds support for amd(8). This is usually used in conjunction with NFS for automatically mounting remote filesystems.
Next is the option. When selected, a menu will pop up where specific AMD flags can be entered. The menu already contains a set of default options:
-a /.amd_mnt -l syslog /host /etc/amd.map /net /etc/amd.map
-a sets the default mount location which
is specified here as /.amd_mnt.
-l specifies the default
log; however, when syslogd(8) is
used, all log activity will be sent to the system log daemon.
/host is used to mount an exported file
system from a remote host, while /net
is used to mount an exported filesystem from an
IP address. The default options for
AMD exports are defined in
/etc/amd.map.
The option permits anonymous FTP connections. Select this option to make this machine an anonymous FTP server. Be aware of the security risks involved with this option. Another menu will be displayed to explain the security risks and configuration in depth.
The menu will configure the machine to be a gateway. This menu can also be used to unset the option if it was accidentally selected during installation.
The option can be used to configure or completely disable inetd(8).
The option is used to configure the system's default Mail Transfer Agent (MTA). Selecting this option will bring up the following menu:
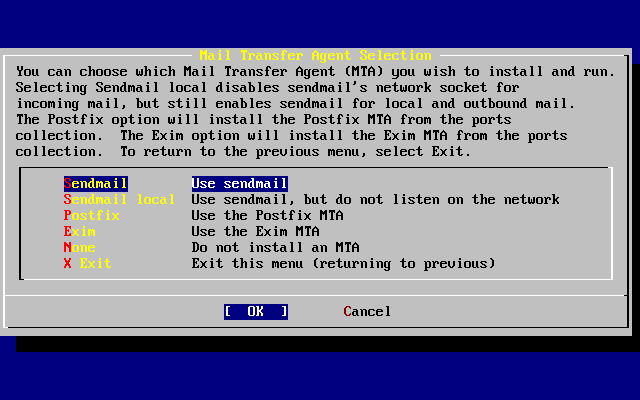
This menu offers a choice as to which MTA to install and set as the default. An MTA is a mail server which delivers email to users on the system or the Internet.
Select to install Sendmail as the default MTA. Select to set Sendmail as the default MTA, but disable its ability to receive incoming email from the Internet. The other options, and , provide alternatives to Sendmail.
The next menu after the MTA menu is . This menu is used to configure the system to communicate with a NFS server which in turn is used to make filesystems available to other machines on the network over the NFS protocol. See Section 29.3, “Network File System (NFS)” for more information about client and server configuration.
Below that option is the option, for setting the system up as an NFS server. This adds the required information to start up the Remote Procedure Call RPC services. RPC is used to coordinate connections between hosts and programs.
Next in line is the option, which deals with time synchronization. When selected, a menu like the one below shows up:
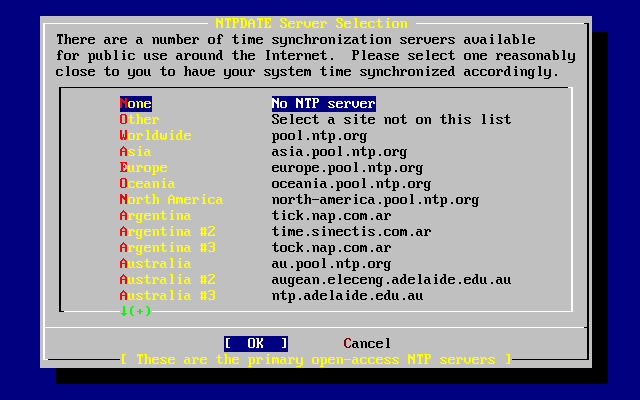
From this menu, select the server which is geographically closest. This will make the time synchronization more accurate as a farther server may have more connection latency.
The next option is the PCNFSD selection. This option will install the net/pcnfsd package from the Ports Collection. This is a useful utility which provides NFS authentication services for systems which are unable to provide their own, such as Microsoft's MS-DOS® operating system.
Now, scroll down a bit to see the other options:
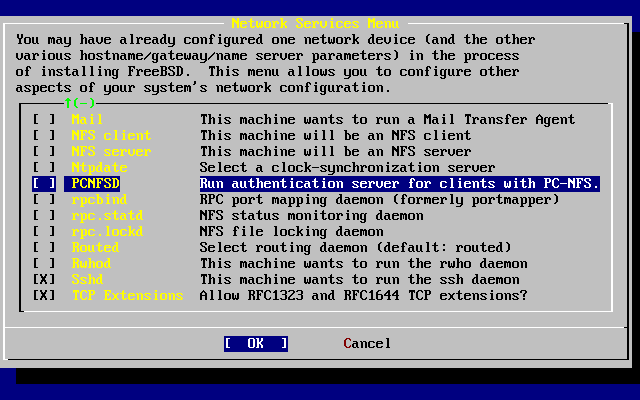
RPC communication between
NFS servers and clients is managed by
rpcbind(8) which is required for NFS
servers to operate correctly. Status monitoring is provided
by rpc.statd(8) and the reported status is usually held
in /var/db/statd.status. The next option
is for rpc.lockd(8) which provides file locking
services. This is usually used with rpc.statd(8) to
monitor which hosts are requesting locks and how frequently
they request them. While these last two options are useful
for debugging, they are not required for
NFS servers and clients to operate
correctly.
The next menu, ,
configures the routing daemon. routed(8), manages
network routing tables, discovers multicast routers, and
supplies a copy of the routing tables to any physically
connected host on the network upon request. This is mainly
used for machines which act as a gateway for the local
network. If selected, a menu will request the default
location of the utility. To accept the default location,
press Enter. Yet another menu will ask for
the flags to pass to routed(8). The default of
-q should appear on the screen.
The next menu, , starts rwhod(8) during system initialization. This utility broadcasts system messages across the network periodically, or collects them when in “consumer” mode. More information can be found in ruptime(1) and rwho(1).
The next to last option in the list is for sshd(8), the secure shell server for OpenSSH. It is highly recommended over the standard telnetd(8) and ftpd(8) servers as it is used to create a secure, encrypted connection from one host to another.
The final option is which are defined in RFC 1323 and RFC 1644. While on many hosts this can speed up connections, it can also cause some connections to be dropped. It is not recommended for servers, but may be beneficial for stand alone machines.
Once the network services are configured, scroll up to the very top item which is and continue on to the next configuration item or simply exit sysinstall(8) by selecting twice then .
If everything went well, messages will scroll along the screen and a login prompt will appear. To view these messages, press Scroll-Lock then use PgUp and PgDn. Press Scroll-Lock again to return to the prompt.
All of the messages may not display due to buffer limitations, but they can be read after logging using dmesg(8).
Login using the username and password which were set
during installation. Avoid logging in as root except when
necessary.
Typical boot messages (version information omitted):
Copyright (c) 1992-2002 The FreeBSD Project.
Copyright (c) 1979, 1980, 1983, 1986, 1988, 1989, 1991, 1992, 1993, 1994
The Regents of the University of California. All rights reserved.
Timecounter "i8254" frequency 1193182 Hz
CPU: AMD-K6(tm) 3D processor (300.68-MHz 586-class CPU)
Origin = "AuthenticAMD" Id = 0x580 Stepping = 0
Features=0x8001bf<FPU,VME,DE,PSE,TSC,MSR,MCE,CX8,MMX>
AMD Features=0x80000800<SYSCALL,3DNow!>
real memory = 268435456 (262144K bytes)
config> di sn0
config> di lnc0
config> di le0
config> di ie0
config> di fe0
config> di cs0
config> di bt0
config> di aic0
config> di aha0
config> di adv0
config> q
avail memory = 256311296 (250304K bytes)
Preloaded elf kernel "kernel" at 0xc0491000.
Preloaded userconfig_script "/boot/kernel.conf" at 0xc049109c.
md0: Malloc disk
Using $PIR table, 4 entries at 0xc00fde60
npx0: <math processor> on motherboard
npx0: INT 16 interface
pcib0: <Host to PCI bridge> on motherboard
pci0: <PCI bus> on pcib0
pcib1: <VIA 82C598MVP (Apollo MVP3) PCI-PCI (AGP) bridge> at device 1.0 on pci0
pci1: <PCI bus> on pcib1
pci1: <Matrox MGA G200 AGP graphics accelerator> at 0.0 irq 11
isab0: <VIA 82C586 PCI-ISA bridge> at device 7.0 on pci0
isa0: <ISA bus> on isab0
atapci0: <VIA 82C586 ATA33 controller> port 0xe000-0xe00f at device 7.1 on pci0
ata0: at 0x1f0 irq 14 on atapci0
ata1: at 0x170 irq 15 on atapci0
uhci0: <VIA 83C572 USB controller> port 0xe400-0xe41f irq 10 at device 7.2 on pci0
usb0: <VIA 83C572 USB controller> on uhci0
usb0: USB revision 1.0
uhub0: VIA UHCI root hub, class 9/0, rev 1.00/1.00, addr 1
uhub0: 2 ports with 2 removable, self powered
chip1: <VIA 82C586B ACPI interface> at device 7.3 on pci0
ed0: <NE2000 PCI Ethernet (RealTek 8029)> port 0xe800-0xe81f irq 9 at
device 10.0 on pci0
ed0: address 52:54:05:de:73:1b, type NE2000 (16 bit)
isa0: too many dependant configs (8)
isa0: unexpected small tag 14
fdc0: <NEC 72065B or clone> at port 0x3f0-0x3f5,0x3f7 irq 6 drq 2 on isa0
fdc0: FIFO enabled, 8 bytes threshold
fd0: <1440-KB 3.5" drive> on fdc0 drive 0
atkbdc0: <keyboard controller (i8042)> at port 0x60-0x64 on isa0
atkbd0: <AT Keyboard> flags 0x1 irq 1 on atkbdc0
kbd0 at atkbd0
psm0: <PS/2 Mouse> irq 12 on atkbdc0
psm0: model Generic PS/2 mouse, device ID 0
vga0: <Generic ISA VGA> at port 0x3c0-0x3df iomem 0xa0000-0xbffff on isa0
sc0: <System console> at flags 0x1 on isa0
sc0: VGA <16 virtual consoles, flags=0x300>
sio0 at port 0x3f8-0x3ff irq 4 flags 0x10 on isa0
sio0: type 16550A
sio1 at port 0x2f8-0x2ff irq 3 on isa0
sio1: type 16550A
ppc0: <Parallel port> at port 0x378-0x37f irq 7 on isa0
ppc0: SMC-like chipset (ECP/EPP/PS2/NIBBLE) in COMPATIBLE mode
ppc0: FIFO with 16/16/15 bytes threshold
ppbus0: IEEE1284 device found /NIBBLE
Probing for PnP devices on ppbus0:
plip0: <PLIP network interface> on ppbus0
lpt0: <Printer> on ppbus0
lpt0: Interrupt-driven port
ppi0: <Parallel I/O> on ppbus0
ad0: 8063MB <IBM-DHEA-38451> [16383/16/63] at ata0-master using UDMA33
ad2: 8063MB <IBM-DHEA-38451> [16383/16/63] at ata1-master using UDMA33
acd0: CDROM <DELTA OTC-H101/ST3 F/W by OIPD> at ata0-slave using PIO4
Mounting root from ufs:/dev/ad0s1a
swapon: adding /dev/ad0s1b as swap device
Automatic boot in progress...
/dev/ad0s1a: FILESYSTEM CLEAN; SKIPPING CHECKS
/dev/ad0s1a: clean, 48752 free (552 frags, 6025 blocks, 0.9% fragmentation)
/dev/ad0s1f: FILESYSTEM CLEAN; SKIPPING CHECKS
/dev/ad0s1f: clean, 128997 free (21 frags, 16122 blocks, 0.0% fragmentation)
/dev/ad0s1g: FILESYSTEM CLEAN; SKIPPING CHECKS
/dev/ad0s1g: clean, 3036299 free (43175 frags, 374073 blocks, 1.3% fragmentation)
/dev/ad0s1e: filesystem CLEAN; SKIPPING CHECKS
/dev/ad0s1e: clean, 128193 free (17 frags, 16022 blocks, 0.0% fragmentation)
Doing initial network setup: hostname.
ed0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 192.168.0.1 netmask 0xffffff00 broadcast 192.168.0.255
inet6 fe80::5054::5ff::fede:731b%ed0 prefixlen 64 tentative scopeid 0x1
ether 52:54:05:de:73:1b
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x8
inet6 ::1 prefixlen 128
inet 127.0.0.1 netmask 0xff000000
Additional routing options: IP gateway=YES TCP keepalive=YES
routing daemons:.
additional daemons: syslogd.
Doing additional network setup:.
Starting final network daemons: creating ssh RSA host key
Generating public/private rsa1 key pair.
Your identification has been saved in /etc/ssh/ssh_host_key.
Your public key has been saved in /etc/ssh/ssh_host_key.pub.
The key fingerprint is:
cd:76:89:16:69:0e:d0:6e:f8:66:d0:07:26:3c:7e:2d [email protected]
creating ssh DSA host key
Generating public/private dsa key pair.
Your identification has been saved in /etc/ssh/ssh_host_dsa_key.
Your public key has been saved in /etc/ssh/ssh_host_dsa_key.pub.
The key fingerprint is:
f9:a1:a9:47:c4:ad:f9:8d:52:b8:b8:ff:8c:ad:2d:e6 [email protected].
setting ELF ldconfig path: /usr/lib /usr/lib/compat /usr/X11R6/lib
/usr/local/lib
a.out ldconfig path: /usr/lib/aout /usr/lib/compat/aout /usr/X11R6/lib/aout
starting standard daemons: inetd cron sshd usbd sendmail.
Initial rc.i386 initialization:.
rc.i386 configuring syscons: blank_time screensaver moused.
Additional ABI support: linux.
Local package initialization:.
Additional TCP options:.
FreeBSD/i386 (k6-2.example.com) (ttyv0)
login: rpratt
Password:Generating the RSA and DSA keys may take some time on slower machines. This happens only on the initial boot-up of a new installation. Subsequent boots will be faster.
If Xorg has been configured
and a default desktop chosen, it can be started by typing
startx at the command line.
It is important to properly shutdown the operating system.
Do not just turn off the power. First, become the superuser
using su(1) and entering the root password. This will work
only if the user is a member of wheel. Otherwise, login as
root. To shutdown
the system, type shutdown -h now.
The operating system has halted. Please press any key to reboot.
It is safe to turn off the power after the shutdown command has been issued and the message “Please press any key to reboot” appears. If any key is pressed instead of turning off the power switch, the system will reboot.
The Ctrl+Alt+Del key combination can also be used to reboot the system; however, this is not recommended.
This section covers basic installation troubleshooting of common problems. There are also a few questions and answers for people wishing to dual-boot FreeBSD with Windows®.
Due to various limitations of the PC architecture, it is impossible for device probing to be 100% reliable. However, there are a few things to try if it fails.
Check the Hardware Notes document for the version of FreeBSD to make sure the hardware is supported.
If the hardware is supported but still experiences
lock-ups or other problems, build a custom kernel to add in
support for devices which are not present in the
GENERIC kernel. The default kernel
assumes that most hardware devices are in their factory
default configuration in terms of IRQs, I/O addresses, and
DMA channels. If the hardware has been reconfigured, create a
custom kernel configuration file and recompile to tell FreeBSD
where to find things.
It is also possible that a probe for a device not present will cause a later probe for another device that is present to fail. In that case, the probes for the conflicting driver(s) should be disabled.
Note:
Some installation problems can be avoided or alleviated by updating the firmware on various hardware components, most notably the motherboard BIOS. Most motherboard and computer manufacturers have a website where upgrade information may be located.
Most manufacturers strongly advise against upgrading the motherboard BIOS unless there is a good reason for doing so, such as a critical update. The upgrade process can go wrong, causing permanent damage to the BIOS chip.
At this time, FreeBSD does not support file systems compressed with the Double Space™ application. Therefore the file system will need to be uncompressed before FreeBSD can access the data. This can be done by running the Compression Agent located in the > > menu.
FreeBSD can support MS-DOS® file systems (sometimes called
FAT file systems). The mount_msdosfs(8) command grafts
such file systems onto the existing directory hierarchy,
allowing the file system's contents to be accessed. The
mount_msdosfs(8) program is not usually invoked directly;
instead, it is called by the system through a line in
/etc/fstab or by using mount(8) with
the appropriate parameters.
A typical line in /etc/fstab
is:
/dev/ad0sN /dos msdosfs rw 0 0
Note:
/dos must already exist for this to
work. For details about the format of
/etc/fstab, see fstab(5).
A typical call to mount(8) for a FAT filesystem looks like:
#mount -t msdosfs /dev/ad0s1 /mnt
In this example, the FAT filesystem is located on the first partition of the primary hard disk. The output from dmesg(8) and mount(8) should produce enough information to give an idea of the partition layout.
Note:
FreeBSD may number FAT partitions differently than other operating systems. In particular, extended partitions are usually given higher slice numbers than primary partitions. Use fdisk(8) to help determine which slices belong to FreeBSD and which belong to other operating systems.
- 3.11.3.1. My system hangs while probing hardware during boot or it behaves strangely during install.
- 3.11.3.2. When booting from the hard disk for the first time after installing FreeBSD, the kernel loads and probes hardware, but stops with messages like:
- 3.11.3.3. When booting from the hard disk for the first time after installing FreeBSD, the Boot Manager prompt just prints F? at the boot menu and the boot will not go any further.
- 3.11.3.4. The system finds the ed(4) network card but continuously displays device timeout errors.
- 3.11.3.5. When sysinstall(8) is usedin an Xorg terminal, the yellow font is difficult to read against the light gray background. Is there a way to provide higher contrast for this application?
3.11.3.1. | My system hangs while probing hardware during boot or it behaves strangely during install. |
FreeBSD makes extensive use of the system ACPI service
on the i386, amd64, and ia64 platforms to aid in system
configuration if it is detected during boot.
Unfortunately, some bugs still exist in the ACPI driver
and various system motherboards. The use of ACPI can be
disabled by setting
This is reset each time the system is booted, so it
is necessary to add
| |
3.11.3.2. | When booting from the hard disk for the first time after installing FreeBSD, the kernel loads and probes hardware, but stops with messages like: changing root device to ad1s1a panic: cannot mount root What is wrong? |
This can occur when the boot disk is not the first disk in the system. The BIOS uses a different numbering scheme to FreeBSD, and working out which numbers correspond to which is difficult to get right. If this occurs, tell FreeBSD where the root filesystem is by specifying the BIOS disk number, the disk type, and the FreeBSD disk number for that type. Consider two IDE disks, each configured as the
master on their respective IDE bus, where FreeBSD should be
booted from the second disk. The BIOS sees these as
disk 0 and disk 1, while FreeBSD sees them as
If FreeBSD is on BIOS disk 1, of type
Note that if there is a slave on the primary bus, the above is not necessary and is effectively wrong. The second situation involves booting from a SCSI
disk when there are one or more IDE disks in the system.
In this case, the FreeBSD disk number is lower than the
BIOS disk number. For two IDE disks and a SCSI disk,
where the SCSI disk is BIOS disk 2, type
This tells FreeBSD to boot from BIOS disk 2, which is
the first SCSI disk in the system. If there is only IDE
disk, use Once the correct value to use is determined, put the
command in | |
3.11.3.3. | When booting from the hard disk for the first time
after installing FreeBSD, the Boot Manager prompt just
prints |
The hard disk geometry was set incorrectly in the partition editor when FreeBSD was installed. Go back into the partition editor and specify the actual geometry of the hard disk. FreeBSD must be reinstalled again from the beginning with the correct geometry. For a dedicated FreeBSD system that does not need future compatibility with another operating system, use the entire disk by selecting in the installer's partition editor. | |
3.11.3.4. | The system finds the ed(4) network card but continuously displays device timeout errors. |
The card is probably on a different IRQ from what
is specified in
Either move the jumper on the card to the
configuration setting or specify the IRQ as
Another possibility is that the card is at IRQ 9, which is shared by IRQ 2 and frequently a cause of problems, especially if a VGA card is using IRQ 2. Do not use IRQ 2 or 9 if at all possible. | |
3.11.3.5. | When sysinstall(8) is usedin an Xorg terminal, the yellow font is difficult to read against the light gray background. Is there a way to provide higher contrast for this application? |
If the default colors chosen by sysinstall(8)
make text illegible while using
x11/xterm or
x11/rxvt, add the following to
|
This section describes how to install FreeBSD in exceptional cases.
This type of installation is called a “headless install” because the machine to be installed does not have either an attached monitor or a VGA output. This type of installation is possible using a serial console, another machine which acts as the main display and keyboard. To do this, follow the steps to create an installation USB stick, explained in Section 3.3.7, “Prepare the Boot Media”, or download the correct installation ISO image as described in Section 3.13.1, “Creating an Installation ISO”.
To modify the installation media to boot into a serial console, follow these steps. If using a CD/DVD media, skip the first step):
Enabling the Installation USB Stick to Boot into a Serial Console
By default, booting into the USB stick boots into the installer. To instead boot into a serial console, mount the USB disk onto a FreeBSD system using mount(8):
#mount /dev/da0a/mntNote:
Adapt the device node and the mount point to the situation.
Once the USB stick is mounted, set it to boot into a serial console. Add this line to
/boot/loader.confon the USB stick:#echo 'console="comconsole"' >>/mnt/boot/loader.confNow that the USB is stick configured correctly, unmount the disk using umount(8):
#umount/mntNow, unplug the USB stick and jump directly to the third step of this procedure.
Enabling the Installation CD/DVD to Boot into a Serial Console
By default, when booting into the installation CD/DVD, FreeBSD boots into its normal install mode. To instead boot into a serial console, extract, modify, and regenerate the ISO image before burning it to the CD/DVD media.
From the FreeBSD system with the saved installation ISO image, use tar(1) to extract all the files:
#mkdir/path/to/headless-iso#tar -C/path/to/headless-iso-pxvf FreeBSD-10.2-RELEASE-i386-disc1.isoNext, set the installation media to boot into a serial console. Add this line to the
/boot/loader.confof the extracted ISO image:#echo 'console="comconsole"' >>/path/to/headless-iso/boot/loader.confThen, create a new ISO image from the modified tree. This example uses mkisofs(8) from the sysutils/cdrtools package or port:
#mkisofs -v -b boot/cdboot -no-emul-boot -r -J -V "Headless_install" \ -oHeadless-FreeBSD-9.3-RELEASE-i386-disc1.iso/path/to/headless-isoNow that the ISO image is configured correctly, burn it to a CD/DVD media using a burning application.
Connecting the Null-modem Cable
Connect a null-modem cable to the serial ports of the two machines. A normal serial cable will not work. A null-modem cable is required.
Booting Up for the Install
It is now time to go ahead and start the install. Plug in the USB stick or insert the CD/DVD media in the headless install machine and power it on.
Connecting to the Headless Machine
Next, connect to that machine with cu(1):
#cu -l /dev/cuau0
The headless machine can now be controlled using cu(1). It will load the kernel and then display a selection of which type of terminal to use. Select the FreeBSD color console and proceed with the installation.
Some situations may require a customized FreeBSD installation media and/or source. This might be physical media or a source that sysinstall(8) can use to retrieve the installation files. Some example situations include:
A local network with many machines has a private FTP server hosting the FreeBSD installation files which the machines should use for installation.
FreeBSD does not recognize the CD/DVD drive but Windows® does. In this case, copy the FreeBSD installation files to a Windows® partition on the same computer, and then install FreeBSD using those files.
The computer to install does not have a CD/DVD drive or a network card, but can be connected using a null-printer cable to a computer that does.
A tape will be used to install FreeBSD.
As part of each release, the FreeBSD Project provides ISO images for each supported architecture. These images can be written (“burned”) to CD or DVD media using a burning application, and then used to install FreeBSD. If a CD/DVD writer is available, this is the easiest way to install FreeBSD.
Download the Correct ISO Images
The ISO images for each release can be downloaded from
ftp://ftp.FreeBSD.org/pub/FreeBSD/ISO-IMAGES-or the closest mirror. Substitutearch/versionarchandversionas appropriate.An image directory normally contains the following images:
Table 3.4. FreeBSD ISO Image Names and MeaningsFilename Contents FreeBSD-version-RELEASE-arch-bootonly.isoThis CD image starts the installation process by booting from a CD-ROM drive but it does not contain the support for installing FreeBSD from the CD itself. Perform a network based install, such as from an FTP server, after booting from this CD. FreeBSD-version-RELEASE-arch-dvd1.iso.gzThis DVD image contains everything necessary to install the base FreeBSD operating system, a collection of pre-built packages, and the documentation. It also supports booting into a “livefs” based rescue mode. FreeBSD-version-RELEASE-arch-memstick.imgThis image can be written to a USB memory stick in order to install machines capable of booting from USB drives. It also supports booting into a “livefs” based rescue mode. The only included package is the documentation package. FreeBSD-version-RELEASE-arch-disc1.isoThis image can be written to a USB memory stick in order to install machines capable of booting from USB drives. Similar to the bootonly.isoimage, it does not contain the distribution sets on the medium itself, but does support network-based installations (for example, via ftp).FreeBSD-version-RELEASE-arch-disc1.isoThis CD image contains the base FreeBSD operating system and the documentation package but no other packages. FreeBSD-version-RELEASE-arch-disc2.isoA CD image with as many third-party packages as would fit on the disc. This image is not available for FreeBSD 9. X.FreeBSD-version-RELEASE-arch-disc3.isoAnother CD image with as many third-party packages as would fit on the disc. This image is not available for FreeBSD 9. X.FreeBSD-version-RELEASE-arch-livefs.isoThis CD image contains support for booting into a “livefs” based rescue mode but does not support doing an install from the CD itself. When performing a CD installation, download either the
bootonlyISO image ordisc1. Do not download both, sincedisc1contains everything that thebootonlyISO image contains.Use the
bootonlyISO to perform a network install over the Internet. Additional software can be installed as needed using the Ports Collection as described in Chapter 5, Installing Applications: Packages and Ports.Use
dvd1to install FreeBSD and a selection of third-party packages from the disc.Burn the Media
Next, write the downloaded image(s) to disc. If using another FreeBSD system, refer to Section 18.5.2, “Burning a CD” for instructions.
If using another platform, use any burning utility that exists for that platform. The images are in the standard ISO format which most CD writing applications support.
Note:
To build a customized release of FreeBSD, refer to the Release Engineering Article.
FreeBSD discs are laid out in the same way as the FTP site. This makes it easy to create a local FTP site that can be used by other machines on a network to install FreeBSD.
On the FreeBSD computer that will host the FTP site, ensure that the CD/DVD is in the drive and mounted:
#mount /cdromCreate an account for anonymous FTP. Use vipw(8) to insert this line:
ftp:*:99:99::0:0:FTP:/cdrom:/nonexistent
Ensure that the FTP service is enabled in
/etc/inetd.conf.
Anyone with network connectivity to the machine can now
chose a media type of FTP and type in
ftp:// after picking
“Other” in the FTP sites menu during the
install.your
machine
Note:
If the boot media for the FTP clients is not precisely the same version as that provided by the local FTP site, sysinstall(8) will not complete the installation. To override this, go into the menu and change the distribution name to .
Warning:
This approach is acceptable for a machine on the local network which is protected by a firewall. Offering anonymous FTP services to other machines over the Internet exposes the computer to increased security risks. It is strongly recommended to follow good security practices when providing services over the Internet.
To prepare for an installation from a Windows® partition,
copy the files from the distribution into a directory in the
root directory of the partition, such as
c:\freebsd. Since the directory
structure must be reproduced, it is recommended to use
robocopy when copying from a CD/DVD. For
example, to prepare for a minimal installation of FreeBSD:
C:\>md c:\freebsdC:\>robocopy e:\bin c:\freebsd\bin\ /sC:\>robocopy e:\manpages c:\freebsd\manpages\ /s
This example assumes that C: has
enough free space and E: is where the
CD/DVD is mounted.
Alternatively, download the distribution from ftp.FreeBSD.org. Each distribution is in its own directory; for example, the base distribution can be found in the 9.3/base/ directory.
Copy the distributions to install from a Windows®
partition to c:\freebsd. Both the
base and kernel
distributions are needed for the most minimal
installation.
There are three types of network installations available: Ethernet, PPP, and PLIP.
For the fastest possible network installation, use an Ethernet adapter. FreeBSD supports most common Ethernet cards. A list of supported cards is provided in the Hardware Notes for each release of FreeBSD. If using a supported PCMCIA Ethernet card, be sure that it is plugged in before the system is powered on as FreeBSD does not support hot insertion of PCMCIA cards during installation.
Make note of the system's IP address, subnet mask, hostname, default gateway address, and DNS server addresses if these values are statically assigned. If installing by FTP through a HTTP proxy, make note of the proxy's address. If you do not know these values, ask the system administrator or ISP before trying this type of installation.
If using a dialup modem, have the service provider's PPP information handy as it is needed early in the installation process.
If PAP or CHAP are used to connect to the
ISP without using a script, type
dial at the FreeBSD
ppp prompt. Otherwise, know how to
dial the ISP using the “AT
commands” specific to the modem, as the PPP dialer
provides only a simple terminal emulator. Refer to Section 27.2, “Configuring PPP” and ../../../../doc/en_US.ISO8859-1/books/faq/ppp.html
for further information. Logging can be directed to the
screen using set log local ....
If a hard-wired connection to another FreeBSD machine is available, the installation can occur over a null-modem parallel port cable. The data rate over the parallel port is higher than what is typically possible over a serial line.
To perform an NFS installation, copy the needed FreeBSD distribution files to an NFS server and then point the installer's NFS media selection to it.
If the server supports only a “privileged
port”, set the option NFS Secure
in the menu so that the
installation can proceed.
If using a poor quality Ethernet card which suffers
from slow transfer rates, toggle the
NFS Slow flag to on.
In order for an NFS installation to
work, the server must support subdir mounts. For example,
if the FreeBSD 10.2 distribution lives on:
ziggy:/usr/archive/stuff/FreeBSD,
ziggy will have to allow the direct
mounting of /usr/archive/stuff/FreeBSD,
not just /usr or
/usr/archive/stuff.
In FreeBSD, this is controlled by using
-alldirs in
/etc/exports. Other
NFS servers may have different
conventions. If the server is displaying
permission denied messages, it is
likely that this is not enabled properly.
This chapter covers the basic commands and functionality of the FreeBSD operating system. Much of this material is relevant for any UNIX®-like operating system. New FreeBSD users are encouraged to read through this chapter carefully.
After reading this chapter, you will know:
How to use and configure virtual consoles.
How to create and manage users and groups on FreeBSD.
How UNIX® file permissions and FreeBSD file flags work.
The default FreeBSD file system layout.
The FreeBSD disk organization.
How to mount and unmount file systems.
What processes, daemons, and signals are.
What a shell is, and how to change the default login environment.
How to use basic text editors.
What devices and device nodes are.
How to read manual pages for more information.
Unless FreeBSD has been configured to automatically start a graphical environment during startup, the system will boot into a command line login prompt, as seen in this example:
FreeBSD/amd64 (pc3.example.org) (ttyv0) login:
The first line contains some information about the system.
The amd64 indicates that the system in this
example is running a 64-bit version of FreeBSD. The hostname is
pc3.example.org, and
ttyv0 indicates that this is the
“system console”. The second line is the login
prompt.
Since FreeBSD is a multiuser system, it needs some way to distinguish between different users. This is accomplished by requiring every user to log into the system before gaining access to the programs on the system. Every user has a unique name “username” and a personal “password”.
To log into the system console, type the username that was configured during system installation, as described in Section 2.8.6, “Add Users”, and press Enter. Then enter the password associated with the username and press Enter. The password is not echoed for security reasons.
Once the correct password is input, the message of the
day (MOTD) will be displayed followed
by a command prompt. Depending upon the shell that was
selected when the user was created, this prompt will be a
#, $, or
% character. The prompt indicates that
the user is now logged into the FreeBSD system console and ready
to try the available commands.
While the system console can be used to interact with the system, a user working from the command line at the keyboard of a FreeBSD system will typically instead log into a virtual console. This is because system messages are configured by default to display on the system console. These messages will appear over the command or file that the user is working on, making it difficult to concentrate on the work at hand.
By default, FreeBSD is configured to provide several virtual consoles for inputting commands. Each virtual console has its own login prompt and shell and it is easy to switch between virtual consoles. This essentially provides the command line equivalent of having several windows open at the same time in a graphical environment.
The key combinations
Alt+F1
through
Alt+F8
have been reserved by FreeBSD for switching between virtual
consoles. Use
Alt+F1
to switch to the system console
(ttyv0),
Alt+F2
to access the first virtual console
(ttyv1),
Alt+F3
to access the second virtual console
(ttyv2), and so on.
When switching from one console to the next, FreeBSD manages the screen output. The result is an illusion of having multiple virtual screens and keyboards that can be used to type commands for FreeBSD to run. The programs that are launched in one virtual console do not stop running when the user switches to a different virtual console.
Refer to syscons(4), atkbd(4), vidcontrol(1) and kbdcontrol(1) for a more technical description of the FreeBSD console and its keyboard drivers.
In FreeBSD, the number of available virtual consoles is
configured in this section of
/etc/ttys:
# name getty type status comments # ttyv0 "/usr/libexec/getty Pc" xterm on secure # Virtual terminals ttyv1 "/usr/libexec/getty Pc" xterm on secure ttyv2 "/usr/libexec/getty Pc" xterm on secure ttyv3 "/usr/libexec/getty Pc" xterm on secure ttyv4 "/usr/libexec/getty Pc" xterm on secure ttyv5 "/usr/libexec/getty Pc" xterm on secure ttyv6 "/usr/libexec/getty Pc" xterm on secure ttyv7 "/usr/libexec/getty Pc" xterm on secure ttyv8 "/usr/X11R6/bin/xdm -nodaemon" xterm off secure
To disable a virtual console, put a comment symbol
(#) at the beginning of the line
representing that virtual console. For example, to reduce the
number of available virtual consoles from eight to four, put a
# in front of the last four lines
representing virtual consoles ttyv5
through ttyv8.
Do not comment out the line for the
system console ttyv0. Note that the last
virtual console (ttyv8) is used to access
the graphical environment if Xorg
has been installed and configured as described in
Chapter 6, The X Window System.
For a detailed description of every column in this file and the available options for the virtual consoles, refer to ttys(5).
The FreeBSD boot menu provides an option labelled as
“Boot Single User”. If this option is selected,
the system will boot into a special mode known as
“single user mode”. This mode is typically used
to repair a system that will not boot or to reset the
root password when
it is not known. While in single user mode, networking and
other virtual consoles are not available. However, full
root access to the
system is available, and by default, the
root password is not
needed. For these reasons, physical access to the keyboard is
needed to boot into this mode and determining who has physical
access to the keyboard is something to consider when securing
a FreeBSD system.
The settings which control single user mode are found in
this section of /etc/ttys:
# name getty type status comments # # If console is marked "insecure", then init will ask for the root password # when going to single-user mode. console none unknown off secure
By default, the status is set to
secure. This assumes that who has physical
access to the keyboard is either not important or it is
controlled by a physical security policy. If this setting is
changed to insecure, the assumption is that
the environment itself is insecure because anyone can access
the keyboard. When this line is changed to
insecure, FreeBSD will prompt for the
root password when a
user selects to boot into single user mode.
Note:
Be careful when changing this setting to
insecure! If the
root password is
forgotten, booting into single user mode is still possible,
but may be difficult for someone who is not familiar with
the FreeBSD booting process.
The FreeBSD console default video mode may be adjusted to
1024x768, 1280x1024, or any other size supported by the
graphics chip and monitor. To use a different video mode
load the VESA module:
#kldload vesa
To determine which video modes are supported by the hardware, use vidcontrol(1). To get a list of supported video modes issue the following:
#vidcontrol -i mode
The output of this command lists the video modes that are
supported by the hardware. To select a new video mode,
specify the mode using vidcontrol(1) as the
root user:
#vidcontrol MODE_279
If the new video mode is acceptable, it can be permanently
set on boot by adding it to
/etc/rc.conf:
allscreens_flags="MODE_279"
FreeBSD allows multiple users to use the computer at the same time. While only one user can sit in front of the screen and use the keyboard at any one time, any number of users can log in to the system through the network. To use the system, each user should have their own user account.
This chapter describes:
The different types of user accounts on a FreeBSD system.
How to add, remove, and modify user accounts.
How to set limits to control the resources that users and groups are allowed to access.
How to create groups and add users as members of a group.
Since all access to the FreeBSD system is achieved using accounts and all processes are run by users, user and account management is important.
There are three main types of accounts: system accounts, user accounts, and the superuser account.
System accounts are used to run services such as DNS, mail, and web servers. The reason for this is security; if all services ran as the superuser, they could act without restriction.
Examples of system accounts are
daemon,
operator,
bind,
news, and
www.
nobody is the
generic unprivileged system account. However, the more
services that use
nobody, the more
files and processes that user will become associated with,
and hence the more privileged that user becomes.
User accounts are assigned to real people and are used to log in and use the system. Every person accessing the system should have a unique user account. This allows the administrator to find out who is doing what and prevents users from clobbering the settings of other users.
Each user can set up their own environment to accommodate their use of the system, by configuring their default shell, editor, key bindings, and language settings.
Every user account on a FreeBSD system has certain information associated with it:
- User name
The user name is typed at the
login:prompt. Each user must have a unique user name. There are a number of rules for creating valid user names which are documented in passwd(5). It is recommended to use user names that consist of eight or fewer, all lower case characters in order to maintain backwards compatibility with applications.- Password
Each account has an associated password.
- User ID (UID)
The User ID (UID) is a number used to uniquely identify the user to the FreeBSD system. Commands that allow a user name to be specified will first convert it to the UID. It is recommended to use a UID less than 65535, since higher values may cause compatibility issues with some software.
- Group ID (GID)
The Group ID (GID) is a number used to uniquely identify the primary group that the user belongs to. Groups are a mechanism for controlling access to resources based on a user's GID rather than their UID. This can significantly reduce the size of some configuration files and allows users to be members of more than one group. It is recommended to use a GID of 65535 or lower as higher GIDs may break some software.
- Login class
Login classes are an extension to the group mechanism that provide additional flexibility when tailoring the system to different users. Login classes are discussed further in Section 14.13.1, “Configuring Login Classes”.
- Password change time
By default, passwords do not expire. However, password expiration can be enabled on a per-user basis, forcing some or all users to change their passwords after a certain amount of time has elapsed.
- Account expiry time
By default, FreeBSD does not expire accounts. When creating accounts that need a limited lifespan, such as student accounts in a school, specify the account expiry date using pw(8). After the expiry time has elapsed, the account cannot be used to log in to the system, although the account's directories and files will remain.
- User's full name
The user name uniquely identifies the account to FreeBSD, but does not necessarily reflect the user's real name. Similar to a comment, this information can contain spaces, uppercase characters, and be more than 8 characters long.
- Home directory
The home directory is the full path to a directory on the system. This is the user's starting directory when the user logs in. A common convention is to put all user home directories under
/home/username/usr/home/username- User shell
The shell provides the user's default environment for interacting with the system. There are many different kinds of shells and experienced users will have their own preferences, which can be reflected in their account settings.
The superuser account, usually called
root, is used to
manage the system with no limitations on privileges. For
this reason, it should not be used for day-to-day tasks like
sending and receiving mail, general exploration of the
system, or programming.
The superuser, unlike other user accounts, can operate without limits, and misuse of the superuser account may result in spectacular disasters. User accounts are unable to destroy the operating system by mistake, so it is recommended to login as a user account and to only become the superuser when a command requires extra privilege.
Always double and triple-check any commands issued as the superuser, since an extra space or missing character can mean irreparable data loss.
There are several ways to gain superuser privilege.
While one can log in as
root, this is
highly discouraged.
Instead, use su(1) to become the superuser. If
- is specified when running this command,
the user will also inherit the root user's environment. The
user running this command must be in the
wheel group or
else the command will fail. The user must also know the
password for the
root user
account.
In this example, the user only becomes superuser in
order to run make install as this step
requires superuser privilege. Once the command completes,
the user types exit to leave the
superuser account and return to the privilege of their user
account.
%configure%make%su -Password:#make install#exit%
The built-in su(1) framework works well for single systems or small networks with just one system administrator. An alternative is to install the security/sudo package or port. This software provides activity logging and allows the administrator to configure which users can run which commands as the superuser.
FreeBSD provides a variety of different commands to manage user accounts. The most common commands are summarized in Table 4.1, “Utilities for Managing User Accounts”, followed by some examples of their usage. See the manual page for each utility for more details and usage examples.
| Command | Summary |
|---|---|
| adduser(8) | The recommended command-line application for adding new users. |
| rmuser(8) | The recommended command-line application for removing users. |
| chpass(1) | A flexible tool for changing user database information. |
| passwd(1) | The command-line tool to change user passwords. |
| pw(8) | A powerful and flexible tool for modifying all aspects of user accounts. |
The recommended program for adding new users is
adduser(8). When a new user is added, this program
automatically updates /etc/passwd and
/etc/group. It also creates a home
directory for the new user, copies in the default
configuration files from
/usr/share/skel, and can optionally
mail the new user a welcome message. This utility must be
run as the superuser.
The adduser(8) utility is interactive and walks
through the steps for creating a new user account. As seen
in Example 4.2, “Adding a User on FreeBSD”, either input
the required information or press Return
to accept the default value shown in square brackets.
In this example, the user has been invited into the
wheel group,
allowing them to become the superuser with su(1).
When finished, the utility will prompt to either
create another user or to exit.
#adduserUsername:jruFull name:J. Random UserUid (Leave empty for default): Login group [jru]: Login group is jru. Invite jru into other groups? []:wheelLogin class [default]: Shell (sh csh tcsh zsh nologin) [sh]:zshHome directory [/home/jru]: Home directory permissions (Leave empty for default): Use password-based authentication? [yes]: Use an empty password? (yes/no) [no]: Use a random password? (yes/no) [no]: Enter password: Enter password again: Lock out the account after creation? [no]: Username : jru Password : **** Full Name : J. Random User Uid : 1001 Class : Groups : jru wheel Home : /home/jru Shell : /usr/local/bin/zsh Locked : no OK? (yes/no):yesadduser: INFO: Successfully added (jru) to the user database. Add another user? (yes/no):noGoodbye!#
Note:
Since the password is not echoed when typed, be careful to not mistype the password when creating the user account.
To completely remove a user from the system, run rmuser(8) as the superuser. This command performs the following steps:
Removes the user's crontab(1) entry, if one exists.
Removes any at(1) jobs belonging to the user.
Kills all processes owned by the user.
Removes the user from the system's local password file.
Optionally removes the user's home directory, if it is owned by the user.
Removes the incoming mail files belonging to the user from
/var/mail.Removes all files owned by the user from temporary file storage areas such as
/tmp.Finally, removes the username from all groups to which it belongs in
/etc/group. If a group becomes empty and the group name is the same as the username, the group is removed. This complements the per-user unique groups created by adduser(8).
rmuser(8) cannot be used to remove superuser accounts since that is almost always an indication of massive destruction.
By default, an interactive mode is used, as shown in the following example.
rmuser Interactive Account
Removal#rmuser jruMatching password entry: jru:*:1001:1001::0:0:J. Random User:/home/jru:/usr/local/bin/zsh Is this the entry you wish to remove?yRemove user's home directory (/home/jru)?yRemoving user (jru): mailspool home passwd.#
Any user can use chpass(1) to change their default shell and personal information associated with their user account. The superuser can use this utility to change additional account information for any user.
When passed no options, aside from an optional username, chpass(1) displays an editor containing user information. When the user exits from the editor, the user database is updated with the new information.
Note:
This utility will prompt for the user's password when exiting the editor, unless the utility is run as the superuser.
In Example 4.4, “Using chpass as
Superuser”, the
superuser has typed chpass jru and is
now viewing the fields that can be changed for this user.
If jru runs this
command instead, only the last six fields will be displayed
and available for editing. This is shown in
Example 4.5, “Using chpass as Regular
User”.
chpass as
Superuser#Changing user database information for jru. Login: jru Password: * Uid [#]: 1001 Gid [# or name]: 1001 Change [month day year]: Expire [month day year]: Class: Home directory: /home/jru Shell: /usr/local/bin/zsh Full Name: J. Random User Office Location: Office Phone: Home Phone: Other information:
chpass as Regular
User#Changing user database information for jru. Shell: /usr/local/bin/zsh Full Name: J. Random User Office Location: Office Phone: Home Phone: Other information:
Note:
The commands chfn(1) and chsh(1) are links
to chpass(1), as are ypchpass(1),
ypchfn(1), and ypchsh(1). Since
NIS support is automatic, specifying
the yp before the command is not
necessary. How to configure NIS is covered in Chapter 29, Network Servers.
Any user can easily change their password using passwd(1). To prevent accidental or unauthorized changes, this command will prompt for the user's original password before a new password can be set:
%passwdChanging local password for jru. Old password: New password: Retype new password: passwd: updating the database... passwd: done
The superuser can change any user's password by specifying the username when running passwd(1). When this utility is run as the superuser, it will not prompt for the user's current password. This allows the password to be changed when a user cannot remember the original password.
#passwd jruChanging local password for jru. New password: Retype new password: passwd: updating the database... passwd: done
Note:
As with chpass(1), yppasswd(1) is a link to passwd(1), so NIS works with either command.
The pw(8) utility can create, remove, modify, and display users and groups. It functions as a front end to the system user and group files. pw(8) has a very powerful set of command line options that make it suitable for use in shell scripts, but new users may find it more complicated than the other commands presented in this section.
A group is a list of users. A group is identified by its group name and GID. In FreeBSD, the kernel uses the UID of a process, and the list of groups it belongs to, to determine what the process is allowed to do. Most of the time, the GID of a user or process usually means the first group in the list.
The group name to GID mapping is listed
in /etc/group. This is a plain text file
with four colon-delimited fields. The first field is the
group name, the second is the encrypted password, the third
the GID, and the fourth the comma-delimited
list of members. For a more complete description of the
syntax, refer to group(5).
The superuser can modify /etc/group
using a text editor. Alternatively, pw(8) can be used to
add and edit groups. For example, to add a group called
teamtwo and then
confirm that it exists:
In this example, 1100 is the
GID of
teamtwo. Right
now, teamtwo has no
members. This command will add
jru as a member of
teamtwo.
#pw groupmod teamtwo -M jru#pw groupshow teamtwoteamtwo:*:1100:jru
The argument to -M is a comma-delimited
list of users to be added to a new (empty) group or to replace
the members of an existing group. To the user, this group
membership is different from (and in addition to) the user's
primary group listed in the password file. This means that
the user will not show up as a member when using
groupshow with pw(8), but will show up
when the information is queried via id(1) or a similar
tool. When pw(8) is used to add a user to a group, it
only manipulates /etc/group and does not
attempt to read additional data from
/etc/passwd.
#pw groupmod teamtwo -m db#pw groupshow teamtwoteamtwo:*:1100:jru,db
In this example, the argument to -m is a
comma-delimited list of users who are to be added to the
group. Unlike the previous example, these users are appended
to the group and do not replace existing users in the
group.
%id jruuid=1001(jru) gid=1001(jru) groups=1001(jru), 1100(teamtwo)
In this example,
jru is a member of
the groups jru and
teamtwo.
For more information about this command and the format of
/etc/group, refer to pw(8) and
group(5).
In FreeBSD, every file and directory has an associated set of permissions and several utilities are available for viewing and modifying these permissions. Understanding how permissions work is necessary to make sure that users are able to access the files that they need and are unable to improperly access the files used by the operating system or owned by other users.
This section discusses the traditional UNIX® permissions used in FreeBSD. For finer grained file system access control, refer to Section 14.9, “Access Control Lists”.
In UNIX®, basic permissions are assigned using
three types of access: read, write, and execute. These access
types are used to determine file access to the file's owner,
group, and others (everyone else). The read, write, and execute
permissions can be represented as the letters
r, w, and
x. They can also be represented as binary
numbers as each permission is either on or off
(0). When represented as a number, the
order is always read as rwx, where
r has an on value of 4,
w has an on value of 2
and x has an on value of
1.
Table 4.1 summarizes the possible numeric and alphabetic
possibilities. When reading the “Directory
Listing” column, a - is used to
represent a permission that is set to off.
| Value | Permission | Directory Listing |
|---|---|---|
| 0 | No read, no write, no execute | --- |
| 1 | No read, no write, execute | --x |
| 2 | No read, write, no execute | -w- |
| 3 | No read, write, execute | -wx |
| 4 | Read, no write, no execute | r-- |
| 5 | Read, no write, execute | r-x |
| 6 | Read, write, no execute | rw- |
| 7 | Read, write, execute | rwx |
Use the -l argument to ls(1) to view a
long directory listing that includes a column of information
about a file's permissions for the owner, group, and everyone
else. For example, a ls -l in an arbitrary
directory may show:
%ls -ltotal 530 -rw-r--r-- 1 root wheel 512 Sep 5 12:31 myfile -rw-r--r-- 1 root wheel 512 Sep 5 12:31 otherfile -rw-r--r-- 1 root wheel 7680 Sep 5 12:31 email.txt
The first (leftmost) character in the first column indicates
whether this file is a regular file, a directory, a special
character device, a socket, or any other special pseudo-file
device. In this example, the - indicates a
regular file. The next three characters, rw-
in this example, give the permissions for the owner of the file.
The next three characters, r--, give the
permissions for the group that the file belongs to. The final
three characters, r--, give the permissions
for the rest of the world. A dash means that the permission is
turned off. In this example, the permissions are set so the
owner can read and write to the file, the group can read the
file, and the rest of the world can only read the file.
According to the table above, the permissions for this file
would be 644, where each digit represents the
three parts of the file's permission.
How does the system control permissions on devices? FreeBSD
treats most hardware devices as a file that programs can open,
read, and write data to. These special device files are
stored in /dev/.
Directories are also treated as files. They have read, write, and execute permissions. The executable bit for a directory has a slightly different meaning than that of files. When a directory is marked executable, it means it is possible to change into that directory using cd(1). This also means that it is possible to access the files within that directory, subject to the permissions on the files themselves.
In order to perform a directory listing, the read permission must be set on the directory. In order to delete a file that one knows the name of, it is necessary to have write and execute permissions to the directory containing the file.
There are more permission bits, but they are primarily used in special circumstances such as setuid binaries and sticky directories. For more information on file permissions and how to set them, refer to chmod(1).
Symbolic permissions use characters instead of octal values to assign permissions to files or directories. Symbolic permissions use the syntax of (who) (action) (permissions), where the following values are available:
| Option | Letter | Represents |
|---|---|---|
| (who) | u | User |
| (who) | g | Group owner |
| (who) | o | Other |
| (who) | a | All (“world”) |
| (action) | + | Adding permissions |
| (action) | - | Removing permissions |
| (action) | = | Explicitly set permissions |
| (permissions) | r | Read |
| (permissions) | w | Write |
| (permissions) | x | Execute |
| (permissions) | t | Sticky bit |
| (permissions) | s | Set UID or GID |
These values are used with chmod(1), but with
letters instead of numbers. For example, the following
command would block other users from accessing
FILE:
%chmod go= FILE
A comma separated list can be provided when more than one
set of changes to a file must be made. For example, the
following command removes the group and
“world” write permission on
FILE, and adds the execute
permissions for everyone:
%chmod go-w,a+xFILE
In addition to file permissions, FreeBSD supports the use of
“file flags”. These flags add an additional
level of security and control over files, but not directories.
With file flags, even
root can be
prevented from removing or altering files.
File flags are modified using chflags(1). For
example, to enable the system undeletable flag on the file
file1, issue the following
command:
#chflags sunlink file1
To disable the system undeletable flag, put a
“no” in front of the
sunlink:
#chflags nosunlink file1
To view the flags of a file, use -lo with
ls(1):
#ls -lo file1
-rw-r--r-- 1 trhodes trhodes sunlnk 0 Mar 1 05:54 file1
Several file flags may only be added or removed by the
root user. In other
cases, the file owner may set its file flags. Refer to
chflags(1) and chflags(2) for more
information.
Other than the permissions already discussed, there are
three other specific settings that all administrators should
know about. They are the setuid,
setgid, and sticky
permissions.
These settings are important for some UNIX® operations as they provide functionality not normally granted to normal users. To understand them, the difference between the real user ID and effective user ID must be noted.
The real user ID is the UID who owns
or starts the process. The effective UID
is the user ID the process runs as. As an example,
passwd(1) runs with the real user ID when a user changes
their password. However, in order to update the password
database, the command runs as the effective ID of the
root user. This
allows users to change their passwords without seeing a
Permission Denied error.
The setuid permission may be set by prefixing a permission set with the number four (4) as shown in the following example:
#chmod 4755 suidexample.sh
The permissions on
suidexample.sh
-rwsr-xr-x 1 trhodes trhodes 63 Aug 29 06:36 suidexample.sh
Note that a s is now part of the
permission set designated for the file owner, replacing the
executable bit. This allows utilities which need elevated
permissions, such as passwd(1).
Note:
The nosuid mount(8) option will
cause such binaries to silently fail without alerting
the user. That option is not completely reliable as a
nosuid wrapper may be able to circumvent
it.
To view this in real time, open two terminals. On
one, type passwd as a normal user.
While it waits for a new password, check the process
table and look at the user information for
passwd(1):
In terminal A:
Changing local password for trhodes Old Password:
In terminal B:
#ps aux | grep passwd
trhodes 5232 0.0 0.2 3420 1608 0 R+ 2:10AM 0:00.00 grep passwd root 5211 0.0 0.2 3620 1724 2 I+ 2:09AM 0:00.01 passwd
Although passwd(1) is run as a normal user, it is
using the effective UID of
root.
The setgid permission performs the
same function as the setuid permission;
except that it alters the group settings. When an application
or utility executes with this setting, it will be granted the
permissions based on the group that owns the file, not the
user who started the process.
To set the setgid permission on a
file, provide chmod(1) with a leading two (2):
#chmod 2755 sgidexample.sh
In the following listing, notice that the
s is now in the field designated for the
group permission settings:
-rwxr-sr-x 1 trhodes trhodes 44 Aug 31 01:49 sgidexample.sh
Note:
In these examples, even though the shell script in question is an executable file, it will not run with a different EUID or effective user ID. This is because shell scripts may not access the setuid(2) system calls.
The setuid and
setgid permission bits may lower system
security, by allowing for elevated permissions. The third
special permission, the sticky bit, can
strengthen the security of a system.
When the sticky bit is set on a
directory, it allows file deletion only by the file owner.
This is useful to prevent file deletion in public directories,
such as /tmp, by users
who do not own the file. To utilize this permission, prefix
the permission set with a one (1):
#chmod 1777 /tmp
The sticky bit permission will display
as a t at the very end of the permission
set:
#ls -al / | grep tmp
drwxrwxrwt 10 root wheel 512 Aug 31 01:49 tmp
The FreeBSD directory hierarchy is fundamental to obtaining an overall understanding of the system. The most important directory is root or, “/”. This directory is the first one mounted at boot time and it contains the base system necessary to prepare the operating system for multi-user operation. The root directory also contains mount points for other file systems that are mounted during the transition to multi-user operation.
A mount point is a directory where additional file systems
can be grafted onto a parent file system (usually the root file
system). This is further described in
Section 4.6, “Disk Organization”. Standard mount points
include /usr/, /var/,
/tmp/, /mnt/, and
/cdrom/. These directories are usually
referenced to entries in /etc/fstab. This
file is a table of various file systems and mount points and is
read by the system. Most of the file systems in
/etc/fstab are mounted automatically at
boot time from the script rc(8) unless their entry includes
noauto. Details can be found in
Section 4.7.1, “The fstab File”.
A complete description of the file system hierarchy is available in hier(7). The following table provides a brief overview of the most common directories.
| Directory | Description |
|---|---|
/ | Root directory of the file system. |
/bin/ | User utilities fundamental to both single-user and multi-user environments. |
/boot/ | Programs and configuration files used during operating system bootstrap. |
/boot/defaults/ | Default boot configuration files. Refer to loader.conf(5) for details. |
/dev/ | Device nodes. Refer to intro(4) for details. |
/etc/ | System configuration files and scripts. |
/etc/defaults/ | Default system configuration files. Refer to rc(8) for details. |
/etc/mail/ | Configuration files for mail transport agents such as sendmail(8). |
/etc/namedb/ | named(8) configuration files. |
/etc/periodic/ | Scripts that run daily, weekly, and monthly, via cron(8). Refer to periodic(8) for details. |
/etc/ppp/ | ppp(8) configuration files. |
/mnt/ | Empty directory commonly used by system administrators as a temporary mount point. |
/proc/ | Process file system. Refer to procfs(5), mount_procfs(8) for details. |
/rescue/ | Statically linked programs for emergency recovery as described in rescue(8). |
/root/ | Home directory for the
root
account. |
/sbin/ | System programs and administration utilities fundamental to both single-user and multi-user environments. |
/tmp/ | Temporary files which are usually
not preserved across a system
reboot. A memory-based file system is often mounted
at /tmp. This can be automated
using the tmpmfs-related variables of rc.conf(5)
or with an entry in /etc/fstab;
refer to mdmfs(8) for details. |
/usr/ | The majority of user utilities and applications. |
/usr/bin/ | Common utilities, programming tools, and applications. |
/usr/include/ | Standard C include files. |
/usr/lib/ | Archive libraries. |
/usr/libdata/ | Miscellaneous utility data files. |
/usr/libexec/ | System daemons and system utilities executed by other programs. |
/usr/local/ | Local executables and libraries. Also used as
the default destination for the FreeBSD ports framework.
Within
/usr/local, the
general layout sketched out by hier(7) for
/usr should be
used. Exceptions are the man directory, which is
directly under /usr/local rather than
under /usr/local/share, and
the ports documentation is in share/doc/. |
/usr/obj/ | Architecture-specific target tree produced by
building the /usr/src
tree. |
/usr/ports/ | The FreeBSD Ports Collection (optional). |
/usr/sbin/ | System daemons and system utilities executed by users. |
/usr/share/ | Architecture-independent files. |
/usr/src/ | BSD and/or local source files. |
/var/ | Multi-purpose log, temporary, transient, and
spool files. A memory-based file system is sometimes
mounted at
/var. This can
be automated using the varmfs-related variables in
rc.conf(5) or with an entry in
/etc/fstab; refer to
mdmfs(8) for details. |
/var/log/ | Miscellaneous system log files. |
/var/mail/ | User mailbox files. |
/var/spool/ | Miscellaneous printer and mail system spooling directories. |
/var/tmp/ | Temporary files which are usually preserved
across a system reboot, unless
/var is a
memory-based file system. |
/var/yp/ | NIS maps. |
The smallest unit of organization that FreeBSD uses to find
files is the filename. Filenames are case-sensitive, which
means that readme.txt and
README.TXT are two separate files. FreeBSD
does not use the extension of a file to determine whether the
file is a program, document, or some other form of data.
Files are stored in directories. A directory may contain no files, or it may contain many hundreds of files. A directory can also contain other directories, allowing a hierarchy of directories within one another in order to organize data.
Files and directories are referenced by giving the file or
directory name, followed by a forward slash,
/, followed by any other directory names that
are necessary. For example, if the directory
foo contains a directory
bar which contains the
file readme.txt, the full name, or
path, to the file is
foo/bar/readme.txt. Note that this is
different from Windows® which uses \ to
separate file and directory names. FreeBSD does not use drive
letters, or other drive names in the path. For example, one
would not type c:\foo\bar\readme.txt on
FreeBSD.
Directories and files are stored in a file system. Each
file system contains exactly one directory at the very top
level, called the root directory for that
file system. This root directory can contain other directories.
One file system is designated the
root file system or /.
Every other file system is mounted under
the root file system. No matter how many disks are on the FreeBSD
system, every directory appears to be part of the same
disk.
Consider three file systems, called A,
B, and C. Each file
system has one root directory, which contains two other
directories, called A1, A2
(and likewise B1, B2 and
C1, C2).
Call A the root file system. If
ls(1) is used to view the contents of this directory,
it will show two subdirectories, A1 and
A2. The directory tree looks like
this:

A file system must be mounted on to a directory in another
file system. When mounting file system B
on to the directory A1, the root directory
of B replaces A1, and
the directories in B appear
accordingly:

Any files that are in the B1 or
B2 directories can be reached with the path
/A1/B1 or
/A1/B2 as necessary. Any
files that were in /A1
have been temporarily hidden. They will reappear if
B is unmounted from
A.
If B had been mounted on
A2 then the diagram would look like
this:

and the paths would be
/A2/B1 and
/A2/B2
respectively.
File systems can be mounted on top of one another.
Continuing the last example, the C file
system could be mounted on top of the B1
directory in the B file system, leading to
this arrangement:

Or C could be mounted directly on to the
A file system, under the
A1 directory:
It is entirely possible to have one large root file system, and not need to create any others. There are some drawbacks to this approach, and one advantage.
Different file systems can have different mount options. For example, the root file system can be mounted read-only, making it impossible for users to inadvertently delete or edit a critical file. Separating user-writable file systems, such as
/home, from other file systems allows them to be mounted nosuid. This option prevents the suid/guid bits on executables stored on the file system from taking effect, possibly improving security.FreeBSD automatically optimizes the layout of files on a file system, depending on how the file system is being used. So a file system that contains many small files that are written frequently will have a different optimization to one that contains fewer, larger files. By having one big file system this optimization breaks down.
FreeBSD's file systems are robust if power is lost. However, a power loss at a critical point could still damage the structure of the file system. By splitting data over multiple file systems it is more likely that the system will still come up, making it easier to restore from backup as necessary.
File systems are a fixed size. If you create a file system when you install FreeBSD and give it a specific size, you may later discover that you need to make the partition bigger. This is not easily accomplished without backing up, recreating the file system with the new size, and then restoring the backed up data.
Important:
FreeBSD features the growfs(8) command, which makes it possible to increase the size of file system on the fly, removing this limitation.
File systems are contained in partitions. This does not
have the same meaning as the common usage of the term partition
(for example, MS-DOS® partition), because of FreeBSD's UNIX®
heritage. Each partition is identified by a letter from
a through to h. Each
partition can contain only one file system, which means that
file systems are often described by either their typical mount
point in the file system hierarchy, or the letter of the
partition they are contained in.
FreeBSD also uses disk space for swap space to provide virtual memory. This allows your computer to behave as though it has much more memory than it actually does. When FreeBSD runs out of memory, it moves some of the data that is not currently being used to the swap space, and moves it back in (moving something else out) when it needs it.
Some partitions have certain conventions associated with them.
| Partition | Convention |
|---|---|
a | Normally contains the root file system. |
b | Normally contains swap space. |
c | Normally the same size as the enclosing slice.
This allows utilities that need to work on the entire
slice, such as a bad block scanner, to work on the
c partition. A file system would not
normally be created on this partition. |
d | Partition d used to have a
special meaning associated with it, although that is now
gone and d may work as any normal
partition. |
Disks in FreeBSD are divided into slices, referred to in Windows® as partitions, which are numbered from 1 to 4. These are then divided into partitions, which contain file systems, and are labeled using letters.
Slice numbers follow the device name, prefixed with an
s, starting at 1. So
“da0s1” is the first slice on
the first SCSI drive. There can only be four physical slices on
a disk, but there can be logical slices inside physical slices
of the appropriate type. These extended slices are numbered
starting at 5, so “ada0s5” is
the first extended slice on the first SATA disk. These devices
are used by file systems that expect to occupy a slice.
Slices, “dangerously dedicated” physical
drives, and other drives contain
partitions, which are represented as
letters from a to h. This
letter is appended to the device name, so
“da0a” is the
a partition on the first
da drive, which is
“dangerously dedicated”.
“ada1s3e” is the fifth
partition in the third slice of the second SATA disk
drive.
Finally, each disk on the system is identified. A disk name starts with a code that indicates the type of disk, and then a number, indicating which disk it is. Unlike slices, disk numbering starts at 0. Common codes are listed in Table 4.3, “Disk Device Names”.
When referring to a partition, include the disk name,
s, the slice number, and then the partition
letter. Examples are shown in
Example 4.12, “Sample Disk, Slice, and Partition Names”.
Example 4.13, “Conceptual Model of a Disk” shows a conceptual model of a disk layout.
When installing FreeBSD, configure the disk slices, create partitions within the slice to be used for FreeBSD, create a file system or swap space in each partition, and decide where each file system will be mounted.
| Drive Type | Drive Device Name |
|---|---|
| SATA and IDE hard drives | ada or
ad |
| SCSI hard drives and USB storage devices | da |
| SATA and IDE CD-ROM drives | cd or
acd |
| SCSI CD-ROM drives | cd |
| Floppy drives | fd |
| Assorted non-standard CD-ROM drives | mcd for Mitsumi
CD-ROM and scd for
Sony CD-ROM devices |
| SCSI tape drives | sa |
| IDE tape drives | ast |
| RAID drives | Examples include aacd for
Adaptec® AdvancedRAID, mlxd and
mlyd for Mylex®,
amrd for AMI MegaRAID®,
idad for Compaq Smart RAID,
twed for 3ware® RAID. |
| Name | Meaning |
|---|---|
ada0s1a | The first partition (a) on the
first slice (s1) on the first IDE
disk (ada0). |
da1s2e | The fifth partition (e) on the
second slice (s2) on the second
SCSI disk (da1). |
This diagram shows FreeBSD's view of the first IDE disk
attached to the system. Assume that the disk is 4 GB in
size, and contains two 2 GB slices (MS-DOS® partitions).
The first slice contains a MS-DOS® disk,
C:, and the second slice contains a
FreeBSD installation. This example FreeBSD installation has three
data partitions, and a swap partition.
The three partitions will each hold a file system.
Partition a will be used for the root file
system, e for the
/var/ directory
hierarchy, and f for the
/usr/ directory
hierarchy.
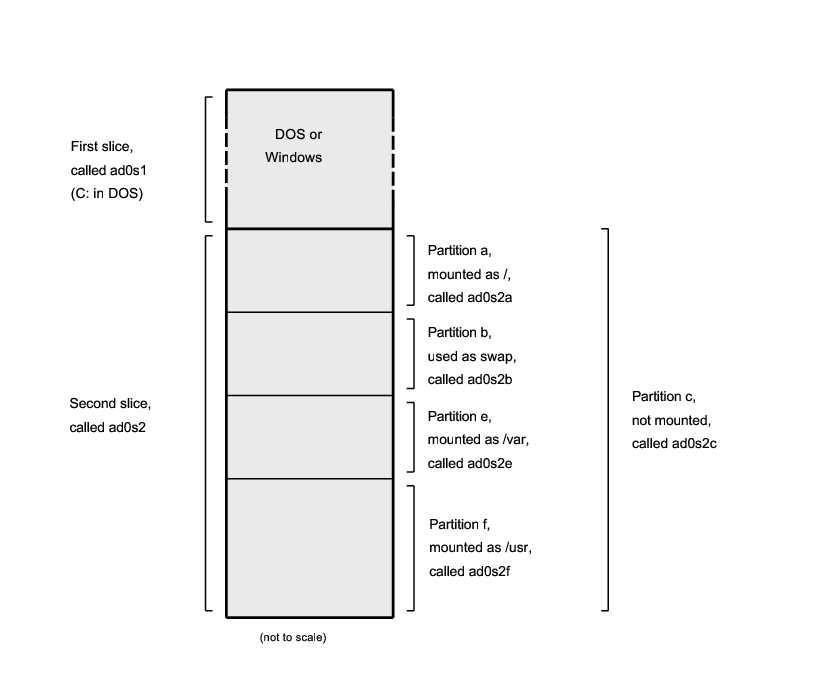
The file system is best visualized as a tree, rooted, as it
were, at /.
/dev,
/usr, and the other
directories in the root directory are branches, which may have
their own branches, such as
/usr/local, and so
on.
There are various reasons to house some of these
directories on separate file systems.
/var contains the
directories log/,
spool/, and various types
of temporary files, and as such, may get filled up. Filling up
the root file system is not a good idea, so splitting
/var from
/ is often
favorable.
Another common reason to contain certain directory trees on other file systems is if they are to be housed on separate physical disks, or are separate virtual disks, such as Network File System mounts, described in Section 29.3, “Network File System (NFS)”, or CDROM drives.
During the boot process (Chapter 13, The FreeBSD Booting Process), file
systems listed in /etc/fstab are
automatically mounted except for the entries containing
noauto. This file contains entries in the
following format:
device/mount-pointfstypeoptionsdumpfreqpassno
deviceAn existing device name as explained in Table 4.3, “Disk Device Names”.
mount-pointAn existing directory on which to mount the file system.
fstypeThe file system type to pass to mount(8). The default FreeBSD file system is
ufs.optionsEither
rwfor read-write file systems, orrofor read-only file systems, followed by any other options that may be needed. A common option isnoautofor file systems not normally mounted during the boot sequence. Other options are listed in mount(8).dumpfreqUsed by dump(8) to determine which file systems require dumping. If the field is missing, a value of zero is assumed.
passnoDetermines the order in which file systems should be checked. File systems that should be skipped should have their
passnoset to zero. The root file system needs to be checked before everything else and should have itspassnoset to one. The other file systems should be set to values greater than one. If more than one file system has the samepassno, fsck(8) will attempt to check file systems in parallel if possible.
Refer to fstab(5) for more information on the format
of /etc/fstab and its options.
4.7.2. Using mount(8)
File systems are mounted using mount(8). The most basic syntax is as follows:
#mountdevicemountpoint
This command provides many options which are described in mount(8), The most commonly used options include:
-aMount all the file systems listed in
/etc/fstab, except those marked as “noauto”, excluded by the-tflag, or those that are already mounted.-dDo everything except for the actual mount system call. This option is useful in conjunction with the
-vflag to determine what mount(8) is actually trying to do.-fForce the mount of an unclean file system (dangerous), or the revocation of write access when downgrading a file system's mount status from read-write to read-only.
-rMount the file system read-only. This is identical to using
-o ro.-tfstypeMount the specified file system type or mount only file systems of the given type, if
-ais included. “ufs” is the default file system type.-uUpdate mount options on the file system.
-vBe verbose.
-wMount the file system read-write.
The following options can be passed to -o
as a comma-separated list:
- nosuid
Do not interpret setuid or setgid flags on the file system. This is also a useful security option.
4.7.3. Using umount(8)
To unmount a file system use umount(8). This command
takes one parameter which can be a mountpoint, device name,
-a or -A.
All forms take -f to force unmounting,
and -v for verbosity. Be warned that
-f is not generally a good idea as it might
crash the computer or damage data on the file system.
To unmount all mounted file systems, or just the file
system types listed after -t, use
-a or -A. Note that
-A does not attempt to unmount the root file
system.
FreeBSD is a multi-tasking operating system. Each program running at any one time is called a process. Every running command starts at least one new process and there are a number of system processes that are run by FreeBSD.
Each process is uniquely identified by a number called a
process ID (PID).
Similar to files, each process has one owner and group, and
the owner and group permissions are used to determine which
files and devices the process can open. Most processes also
have a parent process that started them. For example, the
shell is a process, and any command started in the shell is a
process which has the shell as its parent process. The
exception is a special process called init(8) which is
always the first process to start at boot time and which always
has a PID of 1.
Some programs are not designed to be run with continuous user input and disconnect from the terminal at the first opportunity. For example, a web server responds to web requests, rather than user input. Mail servers are another example of this type of application. These types of programs are known as daemons. The term daemon comes from Greek mythology and represents an entity that is neither good nor evil, and which invisibly performs useful tasks. This is why the BSD mascot is the cheerful-looking daemon with sneakers and a pitchfork.
There is a convention to name programs that normally run as
daemons with a trailing “d”. For example,
BIND is the Berkeley Internet Name
Domain, but the actual program that executes is
named. The
Apache web server program is
httpd and the line printer spooling daemon
is lpd. This is only a naming convention.
For example, the main mail daemon for the
Sendmail application is
sendmail, and not
maild.
To see the processes running on the system, use ps(1) or top(1). To display a static list of the currently running processes, their PIDs, how much memory they are using, and the command they were started with, use ps(1). To display all the running processes and update the display every few seconds in order to interactively see what the computer is doing, use top(1).
By default, ps(1) only shows the commands that are running and owned by the user. For example:
%psPID TT STAT TIME COMMAND 8203 0 Ss 0:00.59 /bin/csh 8895 0 R+ 0:00.00 ps
The output from ps(1) is organized into a number of
columns. The PID column displays the
process ID. PIDs are assigned starting at
1, go up to 99999, then wrap around back to the beginning.
However, a PID is not reassigned if it is
already in use. The TT column shows the
tty the program is running on and STAT
shows the program's state. TIME is the
amount of time the program has been running on the CPU. This
is usually not the elapsed time since the program was started,
as most programs spend a lot of time waiting for things to
happen before they need to spend time on the CPU. Finally,
COMMAND is the command that was used to
start the program.
A number of different options are available to change the
information that is displayed. One of the most useful sets is
auxww, where a displays
information about all the running processes of all users,
u displays the username and memory usage of
the process' owner, x displays
information about daemon processes, and ww
causes ps(1) to display the full command line for each
process, rather than truncating it once it gets too long to
fit on the screen.
The output from top(1) is similar:
%toplast pid: 9609; load averages: 0.56, 0.45, 0.36 up 0+00:20:03 10:21:46 107 processes: 2 running, 104 sleeping, 1 zombie CPU: 6.2% user, 0.1% nice, 8.2% system, 0.4% interrupt, 85.1% idle Mem: 541M Active, 450M Inact, 1333M Wired, 4064K Cache, 1498M Free ARC: 992M Total, 377M MFU, 589M MRU, 250K Anon, 5280K Header, 21M Other Swap: 2048M Total, 2048M Free PID USERNAME THR PRI NICE SIZE RES STATE C TIME WCPU COMMAND 557 root 1 -21 r31 136M 42296K select 0 2:20 9.96% Xorg 8198 dru 2 52 0 449M 82736K select 3 0:08 5.96% kdeinit4 8311 dru 27 30 0 1150M 187M uwait 1 1:37 0.98% firefox 431 root 1 20 0 14268K 1728K select 0 0:06 0.98% moused 9551 dru 1 21 0 16600K 2660K CPU3 3 0:01 0.98% top 2357 dru 4 37 0 718M 141M select 0 0:21 0.00% kdeinit4 8705 dru 4 35 0 480M 98M select 2 0:20 0.00% kdeinit4 8076 dru 6 20 0 552M 113M uwait 0 0:12 0.00% soffice.bin 2623 root 1 30 10 12088K 1636K select 3 0:09 0.00% powerd 2338 dru 1 20 0 440M 84532K select 1 0:06 0.00% kwin 1427 dru 5 22 0 605M 86412K select 1 0:05 0.00% kdeinit4
The output is split into two sections. The header (the
first five or six lines) shows the PID of
the last process to run, the system load averages (which are a
measure of how busy the system is), the system uptime (time
since the last reboot) and the current time. The other
figures in the header relate to how many processes are
running, how much memory and swap space has been used, and how
much time the system is spending in different CPU states. If
the ZFS file system module has been loaded,
an ARC line indicates how much data was
read from the memory cache instead of from disk.
Below the header is a series of columns containing similar information to the output from ps(1), such as the PID, username, amount of CPU time, and the command that started the process. By default, top(1) also displays the amount of memory space taken by the process. This is split into two columns: one for total size and one for resident size. Total size is how much memory the application has needed and the resident size is how much it is actually using now.
top(1) automatically updates the display every two
seconds. A different interval can be specified with
-s.
One way to communicate with any running process or daemon
is to send a signal using kill(1).
There are a number of different signals; some have a specific
meaning while others are described in the application's
documentation. A user can only send a signal to a process
they own and sending a signal to someone else's process will
result in a permission denied error. The exception is the
root user, who can
send signals to anyone's processes.
The operating system can also send a signal to a process.
If an application is badly written and tries to access memory
that it is not supposed to, FreeBSD will send the process the
“Segmentation Violation” signal
(SIGSEGV). If an application has been
written to use the alarm(3) system call to be alerted
after a period of time has elapsed, it will be sent the
“Alarm” signal
(SIGALRM).
Two signals can be used to stop a process:
SIGTERM and SIGKILL.
SIGTERM is the polite way to kill a process
as the process can read the signal, close any log files it may
have open, and attempt to finish what it is doing before
shutting down. In some cases, a process may ignore
SIGTERM if it is in the middle of some task
that can not be interrupted.
SIGKILL can not be ignored by a
process. Sending a SIGKILL to a
process will usually stop that process there and then.
[1].
Other commonly used signals are SIGHUP,
SIGUSR1, and SIGUSR2.
Since these are general purpose signals, different
applications will respond differently.
For example, after changing a web server's configuration
file, the web server needs to be told to re-read its
configuration. Restarting httpd would
result in a brief outage period on the web server. Instead,
send the daemon the SIGHUP signal. Be
aware that different daemons will have different behavior, so
refer to the documentation for the daemon to determine if
SIGHUP will achieve the desired
results.
This example shows how to send a signal to
inetd(8). The inetd(8) configuration file is
/etc/inetd.conf, and inetd(8) will
re-read this configuration file when it is sent a
SIGHUP.
Find the PID of the process to send the signal to using pgrep(1). In this example, the PID for inetd(8) is 198:
%pgrep -l inetd198 inetd -wWUse kill(1) to send the signal. Because inetd(8) is owned by
root, use su(1) to becomerootfirst.%suPassword:#/bin/kill -s HUP 198Like most UNIX® commands, kill(1) will not print any output if it is successful. If a signal is sent to a process not owned by that user, the message kill:
PID: Operation not permitted will be displayed. Mistyping the PID will either send the signal to the wrong process, which could have negative results, or will send the signal to a PID that is not currently in use, resulting in the error kill:PID: No such process.Why Use
/bin/kill?:Many shells provide
killas a built in command, meaning that the shell will send the signal directly, rather than running/bin/kill. Be aware that different shells have a different syntax for specifying the name of the signal to send. Rather than try to learn all of them, it can be simpler to specify/bin/kill.
When sending other signals, substitute
TERM or KILL with the
name of the signal.
A shell provides a command line
interface for interacting with the operating system. A shell
receives commands from the input channel and executes them.
Many shells provide built in functions to help with everyday
tasks such as file management, file globbing, command line
editing, command macros, and environment variables. FreeBSD comes
with several shells, including the Bourne shell (sh(1)) and
the extended C shell (tcsh(1)). Other shells are available
from the FreeBSD Ports Collection, such as
zsh and bash.
The shell that is used is really a matter of taste. A C
programmer might feel more comfortable with a C-like shell such
as tcsh(1). A Linux® user might prefer
bash. Each shell has unique properties that
may or may not work with a user's preferred working environment,
which is why there is a choice of which shell to use.
One common shell feature is filename completion. After a
user types the first few letters of a command or filename and
presses Tab, the shell completes the rest of
the command or filename. Consider two files called
foobar and football.
To delete foobar, the user might type
rm foo and press Tab to
complete the filename.
But the shell only shows rm foo. It was
unable to complete the filename because both
foobar and football
start with foo. Some shells sound a beep or
show all the choices if more than one name matches. The user
must then type more characters to identify the desired filename.
Typing a t and pressing Tab
again is enough to let the shell determine which filename is
desired and fill in the rest.
Another feature of the shell is the use of environment variables. Environment variables are a variable/key pair stored in the shell's environment. This environment can be read by any program invoked by the shell, and thus contains a lot of program configuration. Table 4.4, “Common Environment Variables” provides a list of common environment variables and their meanings. Note that the names of environment variables are always in uppercase.
| Variable | Description |
|---|---|
USER | Current logged in user's name. |
PATH | Colon-separated list of directories to search for binaries. |
DISPLAY | Network name of the Xorg display to connect to, if available. |
SHELL | The current shell. |
TERM | The name of the user's type of terminal. Used to determine the capabilities of the terminal. |
TERMCAP | Database entry of the terminal escape codes to perform various terminal functions. |
OSTYPE | Type of operating system. |
MACHTYPE | The system's CPU architecture. |
EDITOR | The user's preferred text editor. |
PAGER | The user's preferred utility for viewing text one page at a time. |
MANPATH | Colon-separated list of directories to search for manual pages. |
How to set an environment variable differs between shells.
In tcsh(1) and csh(1), use
setenv to set environment variables. In
sh(1) and bash, use
export to set the current environment
variables. This example sets the default EDITOR
to /usr/local/bin/emacs for the
tcsh(1) shell:
%setenv EDITOR /usr/local/bin/emacs
The equivalent command for bash
would be:
%export EDITOR="/usr/local/bin/emacs"
To expand an environment variable in order to see its
current setting, type a $ character in front
of its name on the command line. For example,
echo $TERM displays the current
$TERM setting.
Shells treat special characters, known as meta-characters,
as special representations of data. The most common
meta-character is *, which represents any
number of characters in a filename. Meta-characters can be used
to perform filename globbing. For example, echo
* is equivalent to ls because
the shell takes all the files that match *
and echo lists them on the command
line.
To prevent the shell from interpreting a special character,
escape it from the shell by starting it with a backslash
(\). For example, echo
$TERM prints the terminal setting whereas
echo \$TERM literally prints the string
$TERM.
The easiest way to permanently change the default shell is
to use chsh. Running this command will
open the editor that is configured in the
EDITOR environment variable, which by default
is set to vi(1). Change the Shell:
line to the full path of the new shell.
Alternately, use chsh -s which will set
the specified shell without opening an editor. For example,
to change the shell to bash:
%chsh -s /usr/local/bin/bash
Note:
The new shell must be present in
/etc/shells. If the shell was
installed from the FreeBSD Ports Collection as described in
Chapter 5, Installing Applications: Packages and Ports, it should be automatically added
to this file. If it is missing, add it using this command,
replacing the path with the path of the shell:
#echo/usr/local/bin/bash>> /etc/shells
Then, rerun chsh(1).
The UNIX® shell is not just a command interpreter, it acts as a powerful tool which allows users to execute commands, redirect their output, redirect their input and chain commands together to improve the final command output. When this functionality is mixed with built in commands, the user is provided with an environment that can maximize efficiency.
Shell redirection is the action of sending the output or the input of a command into another command or into a file. To capture the output of the ls(1) command, for example, into a file, simply redirect the output:
%ls > directory_listing.txt
The directory_listing.txt file will
now contain the directory contents. Some commands allow you
to read input in a similar one, such as sort(1). To sort
this listing, redirect the input:
%sort < directory_listing.txt
The input will be sorted and placed on the screen. To redirect that input into another file, one could redirect the output of sort(1) by mixing the direction:
%sort < directory_listing.txt > sorted.txt
In all of the previous examples, the commands are performing redirection using file descriptors. Every unix system has file descriptors; however, here we will focus on three, so named as Standard Input, Standard Output, and Standard Error. Each one has a purpose, where input could be a keyboard or a mouse, something that provides input. Output could be a screen or paper in a printer for example. And error would be anything that is used for diagnostic or error messages. All three are considered I/O based file descriptors and sometimes considered streams.
Through the use of these descriptors, short named stdin, stdout, and stderr, the shell allows output and input to be passed around through various commands and redirected to or from a file. Another method of redirection is the pipe operator.
The UNIX® pipe operator, “|” allows the output of one command to be directly passed, or directed to another program. Basically a pipe will allow the standard output of a command to be passed as standard input to another command, for example:
%cat directory_listing.txt | sort | less
In that example, the contents of
directory_listing.txt will be sorted and
the output passed to less(1). This allows the user to
scroll through the output at their own pace and prevent it
from scrolling off the screen.
Most FreeBSD configuration is done by editing text files. Because of this, it is a good idea to become familiar with a text editor. FreeBSD comes with a few as part of the base system, and many more are available in the Ports Collection.
A simple editor to learn is ee(1), which stands for
easy editor. To start this editor, type ee
where
filenamefilename is the name of the file to
be edited. Once inside the editor, all of the commands for
manipulating the editor's functions are listed at the top of the
display. The caret (^) represents
Ctrl, so ^e expands to
Ctrl+e. To leave ee(1), press Esc,
then choose the “leave editor” option from the main
menu. The editor will prompt to save any changes if the file
has been modified.
FreeBSD also comes with more powerful text editors, such as vi(1), as part of the base system. Other editors, like editors/emacs and editors/vim, are part of the FreeBSD Ports Collection. These editors offer more functionality at the expense of being more complicated to learn. Learning a more powerful editor such as vim or Emacs can save more time in the long run.
Many applications which modify files or require typed input
will automatically open a text editor. To change the default
editor, set the EDITOR environment
variable as described in Section 4.9, “Shells”.
A device is a term used mostly for hardware-related
activities in a system, including disks, printers, graphics
cards, and keyboards. When FreeBSD boots, the majority of the boot
messages refer to devices being detected. A copy of the boot
messages are saved to
/var/run/dmesg.boot.
Each device has a device name and number. For example,
ada0 is the first SATA hard drive,
while kbd0 represents the
keyboard.
Most devices in a FreeBSD must be accessed through special
files called device nodes, which are located in
/dev.
The most comprehensive documentation on FreeBSD is in the form
of manual pages. Nearly every program on the system comes with
a short reference manual explaining the basic operation and
available arguments. These manuals can be viewed using
man:
%mancommand
where command is the name of the
command to learn about. For example, to learn more about
ls(1), type:
%man ls
Manual pages are divided into sections which represent the type of topic. In FreeBSD, the following sections are available:
User commands.
System calls and error numbers.
Functions in the C libraries.
Device drivers.
File formats.
Games and other diversions.
Miscellaneous information.
System maintenance and operation commands.
System kernel interfaces.
In some cases, the same topic may appear in more than one
section of the online manual. For example, there is a
chmod user command and a
chmod() system call. To tell man(1)
which section to display, specify the section number:
%man 1 chmod
This will display the manual page for the user command chmod(1). References to a particular section of the online manual are traditionally placed in parenthesis in written documentation, so chmod(1) refers to the user command and chmod(2) refers to the system call.
If the name of the manual page is unknown, use man
-k to search for keywords in the manual page
descriptions:
%man -k
This command displays a list of commands that have the keyword “mail” in their descriptions. This is equivalent to using apropos(1).
To read the descriptions for all of the commands in
/usr/bin, type:
%cd /usr/bin%man -f * | more
or
%cd /usr/bin%whatis * |more
FreeBSD includes several applications and utilities produced
by the Free Software Foundation (FSF). In addition to manual
pages, these programs may include hypertext documents called
info files. These can be viewed using
info(1) or, if editors/emacs is
installed, the info mode of
emacs.
To use info(1), type:
%info
For a brief introduction, type h. For
a quick command reference, type ?.
[1] There are a few tasks that can not be interrupted. For example, if the process is trying to read from a file that is on another computer on the network, and the other computer is unavailable, the process is said to be “uninterruptible”. Eventually the process will time out, typically after two minutes. As soon as this time out occurs the process will be killed.
FreeBSD is bundled with a rich collection of system tools as part of the base system. In addition, FreeBSD provides two complementary technologies for installing third-party software: the FreeBSD Ports Collection, for installing from source, and packages, for installing from pre-built binaries. Either method may be used to install software from local media or from the network.
After reading this chapter, you will know:
The difference between binary packages and ports.
How to find third-party software that has been ported to FreeBSD.
How to manage binary packages using pkg.
How to build third-party software from source using the Ports Collection.
How to find the files installed with the application for post-installation configuration.
What to do if a software installation fails.
The typical steps for installing third-party software on a UNIX® system include:
Find and download the software, which might be distributed in source code format or as a binary.
Unpack the software from its distribution format. This is typically a tarball compressed with compress(1), gzip(1), or bzip2(1).
Locate the documentation in
INSTALL,READMEor some file in adoc/subdirectory and read up on how to install the software.If the software was distributed in source format, compile it. This may involve editing a
Makefileor running aconfigurescript.Test and install the software.
If the software package was not deliberately ported, or tested to work, on FreeBSD, the source code may need editing in order for it to install and run properly. At the time of this writing, over 24,000 third-party applications have been ported to FreeBSD.
A FreeBSD package contains pre-compiled copies of all the
commands for an application, as well as any configuration files
and documentation. A package can be manipulated with the
pkg commands, such as
pkg install.
A FreeBSD port is a collection of files designed to automate the process of compiling an application from source code. The files that comprise a port contain all the necessary information to automatically download, extract, patch, compile, and install the application.
The ports system can also be used to generate packages which can be manipulated with the FreeBSD package management commands.
Both packages and ports understand dependencies. If a package or port is used to install an application and a dependent library is not already installed, the library will automatically be installed first.
While the two technologies are similar, packages and ports each have their own strengths. Select the technology that meets your requirements for installing a particular application.
A compressed package tarball is typically smaller than the compressed tarball containing the source code for the application.
Packages do not require compilation time. For large applications, such as Mozilla, KDE, or GNOME, this can be important on a slow system.
Packages do not require any understanding of the process involved in compiling software on FreeBSD.
Packages are normally compiled with conservative options because they have to run on the maximum number of systems. By compiling from the port, one can change the compilation options.
Some applications have compile-time options relating to which features are installed. For example, Apache can be configured with a wide variety of different built-in options.
In some cases, multiple packages will exist for the same application to specify certain settings. For example, Ghostscript is available as a
ghostscriptpackage and aghostscript-nox11package, depending on whether or not Xorg is installed. Creating multiple packages rapidly becomes impossible if an application has more than one or two different compile-time options.The licensing conditions of some software forbid binary distribution. Such software must be distributed as source code which must be compiled by the end-user.
Some people do not trust binary distributions or prefer to read through source code in order to look for potential problems.
Source code is needed in order to apply custom patches.
To keep track of updated ports, subscribe to the FreeBSD ports mailing list and the FreeBSD ports bugs mailing list.
Warning:
Before installing any application, check http://vuxml.freebsd.org/
for security issues related to the application or type
pkg audit -F to check all installed
applications for known vulnerabilities.
The remainder of this chapter explains how to use packages and ports to install and manage third-party software on FreeBSD.
FreeBSD's list of available applications is growing all the time. There are a number of ways to find software to install:
The FreeBSD web site maintains an up-to-date searchable list of all the available applications, at http://www.FreeBSD.org/ports/. The ports can be searched by application name or by software category.
Dan Langille maintains FreshPorts.org which provides a comprehensive search utility and also tracks changes to the applications in the Ports Collection. Registered users can create a customized watch list in order to receive an automated email when their watched ports are updated.
If finding a particular application becomes challenging, try searching a site like SourceForge.net or GitHub.com then check back at the FreeBSD site to see if the application has been ported.
To search the binary package repository for an application:
#pkg searchgit-subversion-subversion1.9.2java-subversion-1.8.8_2p5-subversion-1.8.8_2py27-hgsubversion-1.6py27-subversion-1.8.8_2ruby-subversion-1.8.8_2subversion-1.8.8_2subversion-book-4515subversion-static-1.8.8_2subversion16-1.6.23_4subversion17-1.7.16_2Package names include the version number and in case of ports based on python, the version number of the version of python the package was built with. Some ports also have multiple versions available. In case of subversion there are different versions available, as well as different compile options. In this case, the staticly linked version of subversion. When indicating which package to install, it is best to specify the application by the port origin, which is the path in the ports tree. Repeat the
pkg searchwith-oto list the origin of each package:#pkg search -odevel/git-subversion java/java-subversion devel/p5-subversion devel/py-hgsubversion devel/py-subversion devel/ruby-subversion devel/subversion16 devel/subversion17 devel/subversion devel/subversion-book devel/subversion-staticsubversionSearching by shell globs, regular expressions, exact match, by description, or any other field in the repository database is also supported by
pkg search. After installing ports-mgmt/pkg or ports-mgmt/pkg-devel, see pkg-search(8) for more details.If the Ports Collection is already installed, there are several methods to query the local version of the ports tree. To find out which category a port is in, type
whereis, wherefilefileis the program to be installed:#whereis lsoflsof: /usr/ports/sysutils/lsofAlternately, an echo(1) statement can be used:
#echo /usr/ports/*/*lsof*/usr/ports/sysutils/lsofNote that this will also return any matched files downloaded into the
/usr/ports/distfilesdirectory.Another way to find software is by using the Ports Collection's built-in search mechanism. To use the search feature, cd to
/usr/portsthen runmake search name=program-namewhereprogram-nameis the name of the software. For example, to search forlsof:#cd /usr/ports#make search name=lsofPort: lsof-4.88.d,8 Path: /usr/ports/sysutils/lsof Info: Lists information about open files (similar to fstat(1)) Maint: [email protected] Index: sysutils B-deps: R-deps:Tip:
The built-in search mechanism uses a file of index information. If a message indicates that the
INDEXis required, runmake fetchindexto download the current index file. With theINDEXpresent,make searchwill be able to perform the requested search.The “Path:” line indicates where to find the port.
To receive less information, use the
quicksearchfeature:#cd /usr/ports#make quicksearch name=lsofPort: lsof-4.88.d,8 Path: /usr/ports/sysutils/lsof Info: Lists information about open files (similar to fstat(1))For more in-depth searching, use
make search key=orstringmake quicksearch key=, wherestringstringis some text to search for. The text can be in comments, descriptions, or dependencies in order to find ports which relate to a particular subject when the name of the program is unknown.When using
searchorquicksearch, the search string is case-insensitive. Searching for “LSOF” will yield the same results as searching for “lsof”.
pkg is the next generation replacement for the traditional FreeBSD package management tools, offering many features that make dealing with binary packages faster and easier.
pkg is not a replacement for port management tools like ports-mgmt/portmaster or ports-mgmt/portupgrade. These tools can be used to install third-party software from both binary packages and the Ports Collection, while pkg installs only binary packages.
FreeBSD 8.4 and later includes a bootstrap utility which can be used to download and install pkg, along with its manual pages.
To bootstrap the system, run:
#/usr/sbin/pkg
For earlier FreeBSD versions, pkg must instead be installed from the Ports Collection or as a binary package.
To install the port, run:
#cd /usr/ports/ports-mgmt/pkg#make#make install clean
When upgrading an existing system that originally used the older package system, the database must be converted to the new format, so that the new tools are aware of the already installed packages. Once pkg has been installed, the package database must be converted from the traditional format to the new format by running this command:
#pkg2ng
Note:
This step is not required for new installations that do not yet have any third-party software installed.
Important:
This step is not reversible. Once the package database
has been converted to the pkg
format, the traditional pkg_* tools
should no longer be used.
Note:
The package database conversion may emit errors as the
contents are converted to the new version. Generally, these
errors can be safely ignored. However, a list of
third-party software that was not successfully converted
will be listed after pkg2ng has finished
and these applications must be manually reinstalled.
To ensure that the FreeBSD Ports Collection registers
new software with pkg, and not
the traditional packages format, FreeBSD versions earlier than
10.X require this line in
/etc/make.conf:
WITH_PKGNG= yes
By default pkg uses the FreeBSD package mirrors. For information about building a custom package repository, see Section 5.6, “Building Packages with Poudriere”
Additional pkg configuration options are described in pkg.conf(5).
Usage information for pkg is
available in the pkg(8) manpage or by running
pkg without additional arguments.
Each pkg command argument is
documented in a command-specific manual page. To read the
manual page for pkg install, for example,
run either of these commands:
#pkg help install
#man pkg-install
The rest of this section demonstrates common binary package management tasks which can be performed using pkg. Each demonstrated command provides many switches to customize its use. Refer to a command's help or man page for details and more examples.
Information about the packages installed on a system
can be viewed by running pkg info which,
when run without any switches, will list the package version
for either all installed packages or the specified
package.
For example, to see which version of pkg is installed, run:
#pkg info pkgpkg-1.1.4_1
To install a binary package use the following command,
where packagename is the name of
the package to install:
#pkg installpackagename
This command uses repository data to determine which version of the software to install and if it has any uninstalled dependencies. For example, to install curl:
#pkg install curlUpdating repository catalogue /usr/local/tmp/All/curl-7.31.0_1.txz 100% of 1181 kB 1380 kBps 00m01s /usr/local/tmp/All/ca_root_nss-3.15.1_1.txz 100% of 288 kB 1700 kBps 00m00s Updating repository catalogue The following 2 packages will be installed: Installing ca_root_nss: 3.15.1_1 Installing curl: 7.31.0_1 The installation will require 3 MB more space 0 B to be downloaded Proceed with installing packages [y/N]:yChecking integrity... done [1/2] Installing ca_root_nss-3.15.5_1... done [2/2] Installing curl-7.31.0_1... done Cleaning up cache files...Done
The new package and any additional packages that were installed as dependencies can be seen in the installed packages list:
#pkg infoca_root_nss-3.15.5_1 The root certificate bundle from the Mozilla Project curl-7.31.0_1 Non-interactive tool to get files from FTP, GOPHER, HTTP(S) servers pkg-1.1.4_6 New generation package manager
Packages that are no longer needed can be removed with
pkg delete. For example:
#pkg delete curlThe following packages will be deleted: curl-7.31.0_1 The deletion will free 3 MB Proceed with deleting packages [y/N]:y[1/1] Deleting curl-7.31.0_1... done
Installed packages can be upgraded to their latest versions by running:
#pkg upgrade
This command will compare the installed versions with those available in the repository catalogue and upgrade them from the repository.
Occasionally, software vulnerabilities may be discovered in third-party applications. To address this, pkg includes a built-in auditing mechanism. To determine if there are any known vulnerabilities for the software installed on the system, run:
#pkg audit -F
Removing a package may leave behind dependencies which are no longer required. Unneeded packages that were installed as dependencies can be automatically detected and removed using:
#pkg autoremovePackages to be autoremoved: ca_root_nss-3.13.5 The autoremoval will free 723 kB Proceed with autoremoval of packages [y/N]:yDeinstalling ca_root_nss-3.15.1_1... done
Unlike the traditional package management system, pkg includes its own package database backup mechanism. This functionality is enabled by default.
Tip:
To disable the periodic script from backing up the
package database, set
daily_backup_pkgdb_enable="NO" in
periodic.conf(5).
To restore the contents of a previous package database
backup, run the following command replacing
/path/to/pkg.sql with the location
of the backup:
#pkg backup -r/path/to/pkg.sql
Note:
If restoring a backup taken by the periodic script, it must be decompressed prior to being restored.
To run a manual backup of the
pkg database, run the following
command, replacing /path/to/pkg.sql
with a suitable file name and location:
#pkg backup -d/path/to/pkg.sql
By default, pkg stores
binary packages in a cache directory defined by
PKG_CACHEDIR in pkg.conf(5). Only copies
of the latest installed packages are kept. Older versions of
pkg kept all previous packages. To
remove these outdated binary packages, run:
#pkg clean
The entire cache may be cleared by running:
#pkg clean -a
Software within the FreeBSD Ports Collection can
undergo major version number changes. To address this,
pkg has a built-in command to
update package origins. This can be useful, for example, if
lang/php5 is renamed to
lang/php53 so that
lang/php5 can now
represent version 5.4.
To change the package origin for the above example, run:
#pkg set -o lang/php5:lang/php53
As another example, to update lang/ruby18 to lang/ruby19, run:
#pkg set -o lang/ruby18:lang/ruby19
As a final example, to change the origin of the
libglut shared libraries from
graphics/libglut to
graphics/freeglut, run:
#pkg set -o graphics/libglut:graphics/freeglut
Note:
When changing package origins, it is important to reinstall packages that are dependent on the package with the modified origin. To force a reinstallation of dependent packages, run:
#pkg install -Rfgraphics/freeglut
The Ports Collection is a set of
Makefiles, patches, and description files
stored in /usr/ports. This set of files is
used to compile and install applications on FreeBSD. Before an
application can be compiled using a port, the Ports Collection
must first be installed. If it was not installed during the
installation of FreeBSD, use one of the following methods to
install it:
The base system of FreeBSD includes Portsnap. This is a fast and user-friendly tool for retrieving the Ports Collection and is the recommended choice for most users. This utility connects to a FreeBSD site, verifies the secure key, and downloads a new copy of the Ports Collection. The key is used to verify the integrity of all downloaded files.
To download a compressed snapshot of the Ports Collection into
/var/db/portsnap:#portsnap fetchWhen running Portsnap for the first time, extract the snapshot into
/usr/ports:#portsnap extractAfter the first use of Portsnap has been completed as shown above,
/usr/portscan be updated as needed by running:#portsnap fetch#portsnap updateWhen using
fetch, theextractor theupdateoperation may be run consecutively, like so:#portsnap fetch update
If more control over the ports tree is needed or if local changes need to be maintained, Subversion can be used to obtain the Ports Collection. Refer to the Subversion Primer for a detailed description of Subversion.
Subversion must be installed before it can be used to check out the ports tree. If a copy of the ports tree is already present, install Subversion like this:
#cd /usr/ports/devel/subversion#make install cleanIf the ports tree is not available, or pkg is being used to manage packages, Subversion can be installed as a package:
#pkg install subversionCheck out a copy of the ports tree. For better performance, replace
svn0.us-east.FreeBSD.orgwith a Subversion mirror close to your geographic location:#svn checkout https://svn0.us-east.FreeBSD.org/ports/head /usr/portsAs needed, update
/usr/portsafter the initial Subversion checkout:#svn update /usr/ports
The Ports Collection installs a series of directories representing software categories with each category having a subdirectory for each application. Each subdirectory, also referred to as a ports skeleton, contains a set of files that tell FreeBSD how to compile and install that program. Each port skeleton includes these files and directories:
Makefile: contains statements that specify how the application should be compiled and where its components should be installed.distinfo: contains the names and checksums of the files that must be downloaded to build the port.files/: this directory contains any patches needed for the program to compile and install on FreeBSD. This directory may also contain other files used to build the port.pkg-descr: provides a more detailed description of the program.pkg-plist: a list of all the files that will be installed by the port. It also tells the ports system which files to remove upon deinstallation.
Some ports include pkg-message or
other files to handle special situations. For more details
on these files, and on ports in general, refer to the FreeBSD
Porter's Handbook.
The port does not include the actual source code, also
known as a distfile. The extract portion
of building a port will automatically save the downloaded
source to /usr/ports/distfiles.
This section provides basic instructions on using the
Ports Collection to install or remove software. The detailed
description of available make targets and
environment variables is available in ports(7).
Warning:
Before compiling any port, be sure to update the Ports
Collection as described in the previous section. Since
the installation of any third-party software can introduce
security vulnerabilities, it is recommended to first check
http://vuxml.freebsd.org/
for known security issues related to the port. Alternately,
run pkg audit -F before installing a new
port. This command can be configured to automatically
perform a security audit and an update of the vulnerability
database during the daily security system check. For more
information, refer to pkg-audit(8) and
periodic(8).
Using the Ports Collection assumes a working Internet connection. It also requires superuser privilege.
To compile and install the port, change to the directory
of the port to be installed, then type make
install at the prompt. Messages will indicate
the progress:
#cd /usr/ports/sysutils/lsof#make install>> lsof_4.88D.freebsd.tar.gz doesn't seem to exist in /usr/ports/distfiles/. >> Attempting to fetch from ftp://lsof.itap.purdue.edu/pub/tools/unix/lsof/. ===> Extracting for lsof-4.88 ... [extraction output snipped] ... >> Checksum OK for lsof_4.88D.freebsd.tar.gz. ===> Patching for lsof-4.88.d,8 ===> Applying FreeBSD patches for lsof-4.88.d,8 ===> Configuring for lsof-4.88.d,8 ... [configure output snipped] ... ===> Building for lsof-4.88.d,8 ... [compilation output snipped] ... ===> Installing for lsof-4.88.d,8 ... [installation output snipped] ... ===> Generating temporary packing list ===> Compressing manual pages for lsof-4.88.d,8 ===> Registering installation for lsof-4.88.d,8 ===> SECURITY NOTE: This port has installed the following binaries which execute with increased privileges. /usr/local/sbin/lsof#
Since lsof is a program that runs
with increased privileges, a security warning is displayed
as it is installed. Once the installation is complete, the
prompt will be returned.
Some shells keep a cache of the commands that are
available in the directories listed in the
PATH environment variable, to speed up lookup
operations for the executable file of these commands. Users
of the tcsh shell should type
rehash so that a newly installed command
can be used without specifying its full path. Use
hash -r instead for the
sh shell. Refer to the documentation
for the shell for more information.
During installation, a working subdirectory is created which contains all the temporary files used during compilation. Removing this directory saves disk space and minimizes the chance of problems later when upgrading to the newer version of the port:
#make clean===> Cleaning for lsof-88.d,8#
Note:
To save this extra step, instead use make
install clean when compiling the port.
Some ports provide build options which can be used to
enable or disable application components, provide security
options, or allow for other customizations. Examples
include www/firefox,
security/gpgme, and
mail/sylpheed-claws.
If the port depends upon other ports which have configurable
options, it may pause several times for user interaction
as the default behavior is to prompt the user to select
options from a menu. To avoid this, run make
config-recursive within the port skeleton to do
this configuration in one batch. Then, run make
install [clean] to compile and install the
port.
Tip:
When using
config-recursive, the list of
ports to configure are gathered by the
all-depends-list target. It is
recommended to run make
config-recursive until all dependent ports
options have been defined, and ports options screens no
longer appear, to be certain that all dependency options
have been configured.
There are several ways to revisit a port's build options
menu in order to add, remove, or change these options after
a port has been built. One method is to
cd into the directory containing the
port and type make config. Another
option is to use make showconfig.
Another option is to execute make
rmconfig which will remove all selected options
and allow you to start over. All of these options, and
others, are explained in great detail in
ports(7).
The ports system uses fetch(1) to download the
source files, which supports various environment variables.
The FTP_PASSIVE_MODE,
FTP_PROXY, and FTP_PASSWORD
variables may need to be set if the FreeBSD system is behind
a firewall or FTP/HTTP proxy. See fetch(3) for the
complete list of supported variables.
For users who cannot be connected to the Internet all
the time, make fetch can be run within
/usr/ports, to fetch all distfiles, or
within a category, such as
/usr/ports/net, or within the specific
port skeleton. Note that if a port has any dependencies,
running this command in a category or ports skeleton will
not fetch the distfiles of ports from
another category. Instead, use make
fetch-recursive to also fetch the distfiles for
all the dependencies of a port.
In rare cases, such as when an organization has a local
distfiles repository, the MASTER_SITES
variable can be used to override the download locations
specified in the Makefile. When using,
specify the alternate location:
#cd /usr/ports/directory#make MASTER_SITE_OVERRIDE= \ftp://ftp.organization.org/pub/FreeBSD/ports/distfiles/fetch
The WRKDIRPREFIX and
PREFIX variables can override the default
working and target directories. For example:
#make WRKDIRPREFIX=/usr/home/example/ports install
will compile the port in
/usr/home/example/ports and install
everything under /usr/local.
#make PREFIX=/usr/home/example/local install
will compile the port in /usr/ports
and install it in
/usr/home/example/local. And:
#make WRKDIRPREFIX=../ports PREFIX=../local install
will combine the two.
These can also be set as environmental variables. Refer to the manual page for your shell for instructions on how to set an environmental variable.
Installed ports can be uninstalled using pkg
delete. Examples for using this command can be
found in the pkg-delete(8) manpage.
Alternately, make deinstall can be
run in the port's directory:
#cd /usr/ports/sysutils/lsofmake deinstall===> Deinstalling for sysutils/lsof ===> Deinstalling Deinstallation has been requested for the following 1 packages: lsof-4.88.d,8 The deinstallation will free 229 kB [1/1] Deleting lsof-4.88.d,8... done
It is recommended to read the messages as the port is uninstalled. If the port has any applications that depend upon it, this information will be displayed but the uninstallation will proceed. In such cases, it may be better to reinstall the application in order to prevent broken dependencies.
Over time, newer versions of software become available in the Ports Collection. This section describes how to determine which software can be upgraded and how to perform the upgrade.
To determine if newer versions of installed ports are available, ensure that the latest version of the ports tree is installed, using the updating command described in either Procedure 5.1, “Portsnap Method” or Procedure 5.2, “Subversion Method”. On FreeBSD 10 and later, or if the system has been converted to pkg, the following command will list the installed ports which are out of date:
#pkg version -l "<"
For FreeBSD 9.X and lower, the
following command will list the installed ports that are out
of date:
#pkg_version -l "<"
Important:
Before
attempting an upgrade, read
/usr/ports/UPDATING from the top of
the file to the date closest to the last time ports were
upgraded or the system was installed. This file describes
various issues and additional steps users may encounter and
need to perform when updating a port, including such things
as file format changes, changes in locations of
configuration files, or any incompatibilities with previous
versions. Make note of any instructions which match any of
the ports that need upgrading and follow these instructions
when performing the upgrade.
To perform the actual upgrade, use either Portmaster or Portupgrade.
The ports-mgmt/portmaster package or
port is the recommended tool for upgrading installed ports
as it is designed to use the tools installed with FreeBSD
without depending upon other ports. It uses the
information in /var/db/pkg/ to
determine which ports to upgrade. To install this utility
as a port:
#cd /usr/ports/ports-mgmt/portmaster#make install clean
Portmaster defines four categories of ports:
Root port: has no dependencies and is not a dependency of any other ports.
Trunk port: has no dependencies, but other ports depend upon it.
Branch port: has dependencies and other ports depend upon it.
Leaf port: has dependencies but no other ports depend upon it.
To list these categories and search for updates:
#portmaster -L===>>> Root ports (No dependencies, not depended on) ===>>> ispell-3.2.06_18 ===>>> screen-4.0.3 ===>>> New version available: screen-4.0.3_1 ===>>> tcpflow-0.21_1 ===>>> 7 root ports ... ===>>> Branch ports (Have dependencies, are depended on) ===>>> apache22-2.2.3 ===>>> New version available: apache22-2.2.8 ... ===>>> Leaf ports (Have dependencies, not depended on) ===>>> automake-1.9.6_2 ===>>> bash-3.1.17 ===>>> New version available: bash-3.2.33 ... ===>>> 32 leaf ports ===>>> 137 total installed ports ===>>> 83 have new versions available
This command is used to upgrade all outdated ports:
#portmaster -a
Note:
By default, Portmaster will
make a backup package before deleting the existing port.
If the installation of the new version is successful,
Portmaster will delete the
backup. Using -b will instruct
Portmaster not to automatically
delete the backup. Adding -i will start
Portmaster in interactive mode,
prompting for confirmation before upgrading each port.
Many other options are available. Read through the
manual page for portmaster(8) for details regarding
their usage.
If errors are encountered during the upgrade process,
add -f to upgrade and rebuild all
ports:
#portmaster -af
Portmaster can also be used to install new ports on the system, upgrading all dependencies before building and installing the new port. To use this function, specify the location of the port in the Ports Collection:
#portmastershells/bash
Another utility that can be used to upgrade ports is Portupgrade, which is available as the ports-mgmt/portupgrade package or port. This utility installs a suite of applications which can be used to manage ports. However, it is dependent upon Ruby. To install the port:
#cd /usr/ports/ports-mgmt/portupgrade#make install clean
Before performing an upgrade using this utility, it is
recommended to scan the list of installed ports using
pkgdb -F and to fix all the
inconsistencies it reports.
To upgrade all the outdated ports installed on the
system, use portupgrade -a. Alternately,
include -i to be asked for confirmation
of every individual upgrade:
#portupgrade -ai
To upgrade only a specified application instead of all
available ports, use portupgrade
. It is very
important to include pkgname-R to first upgrade
all the ports required by the given application:
#portupgrade -R firefox
If
-P is included,
Portupgrade searches for
available packages in the local directories listed in
PKG_PATH. If none are available locally, it
then fetches packages from a remote site. If packages can
not be found locally or fetched remotely,
Portupgrade will use ports. To
avoid using ports entirely, specify -PP.
This last set of options tells
Portupgrade to abort if no
packages are available:
#portupgrade -PP gnome2
To just fetch the port distfiles, or packages, if
-P is specified, without building or
installing anything, use -F. For further
information on all of the available switches, refer to the
manual page for portupgrade.
Using the Ports Collection will use up disk space over
time. After building and installing a port, running
make clean within the ports skeleton will
clean up the temporary work directory.
If Portmaster is used to install a
port, it will automatically remove this directory unless
-K is specified. If
Portupgrade is installed, this
command will remove all work directories
found within the local copy of the Ports Collection:
#portsclean -C
In addition, a lot of out-dated source distribution files
will collect in /usr/ports/distfiles over
time. If Portupgrade is installed,
this command will delete all the distfiles that are no longer
referenced by any ports:
#portsclean -D
To use Portupgrade to remove all distfiles not referenced by any port currently installed on the system:
#portsclean -DD
If Portmaster is installed, use:
#portmaster --clean-distfiles
By default, this command is interactive and will prompt the user to confirm if a distfile should be deleted.
In addition to these commands, the ports-mgmt/pkg_cutleaves package or port automates the task of removing installed ports that are no longer needed.
Poudriere is a BSD-licensed utility for creating and testing FreeBSD packages. It uses FreeBSD jails to set up isolated compilation environments. These jails can be used to build packages for versions of FreeBSD that are different from the system on which it is installed, and also to build packages for i386 if the host is an amd64 system. Once the packages are built, they are in a layout identical to the official mirrors. These packages are usable by pkg(8) and other package management tools.
Poudriere is installed using
the ports-mgmt/poudriere package
or port. The installation includes a sample configuration
file /usr/local/etc/poudriere.conf.sample.
Copy this file to
/usr/local/etc/poudriere.conf. Edit the
copied file to suit the local configuration.
While ZFS is not required on the system
running poudriere, it is beneficial.
When ZFS is used,
ZPOOL must be specified in
/usr/local/etc/poudriere.conf and
FREEBSD_HOST should be set to a nearby
mirror. Defining CCACHE_DIR enables the use
of devel/ccache to cache
compilation and reduce build times for frequently-compiled code.
It may be convenient to put
poudriere datasets in an isolated
tree mounted at /poudriere. Defaults for the
other configuration values are adequate.
The number of processor cores detected is used to define how many builds should run in parallel. Supply enough virtual memory, either with RAM or swap space. If virtual memory runs out, compiling jails will stop and be torn down, resulting in weird error messages.
After configuration, initialize
poudriere so that it installs a
jail with the required FreeBSD tree and a ports tree. Specify a
name for the jail using -j and the FreeBSD
version with -v. On systems running
FreeBSD/amd64, the architecture can be set with
-a to either i386 or
amd64. The default is the
architecture shown by uname.
#poudriere jail -c -j====>> Creating 10amd64 fs... done ====>> Fetching base.txz for FreeBSD 10.0-RELEASE amd64 /poudriere/jails/10amd64/fromftp/base.txz 100% of 59 MB 1470 kBps 00m42s ====>> Extracting base.txz... done ====>> Fetching src.txz for FreeBSD 10.0-RELEASE amd64 /poudriere/jails/10amd64/fromftp/src.txz 100% of 107 MB 1476 kBps 01m14s ====>> Extracting src.txz... done ====>> Fetching games.txz for FreeBSD 10.0-RELEASE amd64 /poudriere/jails/10amd64/fromftp/games.txz 100% of 865 kB 734 kBps 00m01s ====>> Extracting games.txz... done ====>> Fetching lib32.txz for FreeBSD 10.0-RELEASE amd64 /poudriere/jails/10amd64/fromftp/lib32.txz 100% of 14 MB 1316 kBps 00m12s ====>> Extracting lib32.txz... done ====>> Cleaning up... done ====>> Jail 10amd64 10.0-RELEASE amd64 is ready to be used10amd64-v10.0-RELEASE
#poudriere ports -c -p====>> Creating local fs... done ====>> Extracting portstree "local"... Looking up portsnap.FreeBSD.org mirrors... 7 mirrors found. Fetching public key from ec2-eu-west-1.portsnap.freebsd.org... done. Fetching snapshot tag from ec2-eu-west-1.portsnap.freebsd.org... done. Fetching snapshot metadata... done. Fetching snapshot generated at Tue Feb 11 01:07:15 CET 2014: 94a3431f0ce567f6452ffde4fd3d7d3c6e1da143efec76100% of 69 MB 1246 kBps 00m57s Extracting snapshot... done. Verifying snapshot integrity... done. Fetching snapshot tag from ec2-eu-west-1.portsnap.freebsd.org... done. Fetching snapshot metadata... done. Updating from Tue Feb 11 01:07:15 CET 2014 to Tue Feb 11 16:05:20 CET 2014. Fetching 4 metadata patches... done. Applying metadata patches... done. Fetching 0 metadata files... done. Fetching 48 patches. (48/48) 100.00% done. done. Applying patches... done. Fetching 1 new ports or files... done. /poudriere/ports/tester/CHANGES /poudriere/ports/tester/COPYRIGHT [...] Building new INDEX files... done.local
On a single computer, poudriere can build ports with multiple configurations, in multiple jails, and from different port trees. Custom configurations for these combinations are called sets. See the CUSTOMIZATION section of poudriere(8) for details after ports-mgmt/poudriere or ports-mgmt/poudriere-devel is installed.
The basic configuration shown here puts a single jail-,
port-, and set-specific make.conf in
/usr/local/etc/poudriere.d.
The filename in this example is created by combining the jail
name, port name, and set name:
10amd64-local-workstation-make.confmake.conf and this new file
are combined at build time to create the
make.conf used by the build jail.
Packages to be built are entered in
10amd64-local-workstation-pkglist
editors/emacs devel/git ports-mgmt/pkg ...
Options and dependencies for the specified ports are configured:
#poudriere options -j10amd64-plocal-zworkstation-f10amd64-local-workstation-pkglist
Finally, packages are built and a package repository is created:
#poudriere bulk -j10amd64-plocal-zworkstation-f10amd64-local-workstation-pkglist
Ctrl+t
displays the current state of the build.
Poudriere also builds files in
/poudriere/logs/bulk/
that can be used with a web server to display build
information.jailname
Packages are now available for installation from the poudriere repository.
For more information on using poudriere, see poudriere(8) and the main web site, https://github.com/freebsd/poudriere/wiki.
While it is possible to use both a custom repository along
side of the official repository, sometimes it is useful to
disable the official repository. This is done by creating a
configuration file that overrides and disables the official
configuration file. Create
/usr/local/etc/pkg/repos/FreeBSD.conf
that contains the following:
FreeBSD: {
enabled: no
}Usually it is easiest to serve a poudriere repository to
the client machines via HTTP. Setup a webserver to serve up
the package directory, usually something like:
/usr/local/poudriere/data/packages/.
Where 10amd6410amd64 is the name of the
build.
If the URL to the package repository is:
http://pkg.example.com/10amd64, then the
repository configuration file in
/usr/local/etc/pkg/repos/custom.conf
would look like:
custom: {
url: "http://pkg.example.com/10amd64",
mirror_type: "http",
enabled: yes,
}Regardless of whether the software was installed from a binary package or port, most third-party applications require some level of configuration after installation. The following commands and locations can be used to help determine what was installed with the application.
Most applications install at least one default configuration file in
/usr/local/etc. In the case where an application has a large number of configuration files, a subdirectory will be created to hold them. Often, sample configuration files are installed which end with a suffix such as.sample. The configuration files should be reviewed and possibly edited to meet the system's needs. To edit a sample file, first copy it without the.sampleextension.Applications which provide documentation will install it into
/usr/local/share/docand many applications also install manual pages. This documentation should be consulted before continuing.Some applications run services which must be added to
/etc/rc.confbefore starting the application. These applications usually install a startup script in/usr/local/etc/rc.d. See Starting Services for more information.Users of csh(1) should run
rehashto rebuild the known binary list in the shellsPATH.Use
pkg infoto determine which files, man pages, and binaries were installed with the application.
When a port does not build or install, try the following:
Search to see if there is a fix pending for the port in the Problem Report database. If so, implementing the proposed fix may fix the issue.
Ask the maintainer of the port for help. Type
make maintainerin the ports skeleton or read the port'sMakefileto find the maintainer's email address. Remember to include the$FreeBSD:line from the port'sMakefileand the output leading up to the error in the email to the maintainer.Note:
Some ports are not maintained by an individual but instead by a mailing list. Many, but not all, of these addresses look like
<[email protected]>. Take this into account when sending an email.In particular, ports shown as maintained by
<[email protected]>are not maintained by a specific individual. Instead, any fixes and support come from the general community who subscribe to that mailing list. More volunteers are always needed!If there is no response to the email, use Bugzilla to submit a bug report using the instructions in Writing FreeBSD Problem Reports.
Fix it! The Porter's Handbook includes detailed information on the ports infrastructure so that you can fix the occasional broken port or even submit your own!
Install the package instead of the port using the instructions in Section 5.4, “Using pkg for Binary Package Management”.
An installation of FreeBSD using bsdinstall does not automatically install a graphical user interface. This chapter describes how to install and configure Xorg, which provides the open source X Window System used to provide a graphical environment. It then describes how to find and install a desktop environment or window manager.
Note:
Users who prefer an installation method that automatically configures the Xorg and offers a choice of window managers during installation should refer to the pcbsd.org website.
For more information on the video hardware that Xorg supports, refer to the x.org website.
After reading this chapter, you will know:
The various components of the X Window System, and how they interoperate.
How to install and configure Xorg.
How to install and configure several window managers and desktop environments.
How to use TrueType® fonts in Xorg.
How to set up your system for graphical logins (XDM).
Before reading this chapter, you should:
Know how to install additional third-party software as described in Chapter 5, Installing Applications: Packages and Ports.
While it is not necessary to understand all of the details of the various components in the X Window System and how they interact, some basic knowledge of these components can be useful:
- X server
X was designed from the beginning to be network-centric, and adopts a “client-server” model. In this model, the “X server” runs on the computer that has the keyboard, monitor, and mouse attached. The server's responsibility includes tasks such as managing the display, handling input from the keyboard and mouse, and handling input or output from other devices such as a tablet or a video projector. This confuses some people, because the X terminology is exactly backward to what they expect. They expect the “X server” to be the big powerful machine down the hall, and the “X client” to be the machine on their desk.
- X client
Each X application, such as XTerm or Firefox, is a “client”. A client sends messages to the server such as “Please draw a window at these coordinates”, and the server sends back messages such as “The user just clicked on the OK button”.
In a home or small office environment, the X server and the X clients commonly run on the same computer. It is also possible to run the X server on a less powerful computer and to run the X applications on a more powerful system. In this scenario, the communication between the X client and server takes place over the network.
- window manager
X does not dictate what windows should look like on screen, how to move them around with the mouse, which keystrokes should be used to move between windows, what the title bars on each window should look like, whether or not they have close buttons on them, and so on. Instead, X delegates this responsibility to a separate window manager application. There are dozens of window managers available. Each window manager provides a different look and feel: some support virtual desktops, some allow customized keystrokes to manage the desktop, some have a “Start” button, and some are themeable, allowing a complete change of the desktop's look-and-feel. Window managers are available in the
x11-wmcategory of the Ports Collection.Each window manager uses a different configuration mechanism. Some expect configuration file written by hand while others provide graphical tools for most configuration tasks.
- desktop environment
KDE and GNOME are considered to be desktop environments as they include an entire suite of applications for performing common desktop tasks. These may include office suites, web browsers, and games.
- focus policy
The window manager is responsible for the mouse focus policy. This policy provides some means for choosing which window is actively receiving keystrokes and it should also visibly indicate which window is currently active.
One focus policy is called “click-to-focus”. In this model, a window becomes active upon receiving a mouse click. In the “focus-follows-mouse” policy, the window that is under the mouse pointer has focus and the focus is changed by pointing at another window. If the mouse is over the root window, then this window is focused. In the “sloppy-focus” model, if the mouse is moved over the root window, the most recently used window still has the focus. With sloppy-focus, focus is only changed when the cursor enters a new window, and not when exiting the current window. In the “click-to-focus” policy, the active window is selected by mouse click. The window may then be raised and appear in front of all other windows. All keystrokes will now be directed to this window, even if the cursor is moved to another window.
Different window managers support different focus models. All of them support click-to-focus, and the majority of them also support other policies. Consult the documentation for the window manager to determine which focus models are available.
- widgets
Widget is a term for all of the items in the user interface that can be clicked or manipulated in some way. This includes buttons, check boxes, radio buttons, icons, and lists. A widget toolkit is a set of widgets used to create graphical applications. There are several popular widget toolkits, including Qt, used by KDE, and GTK+, used by GNOME. As a result, applications will have a different look and feel, depending upon which widget toolkit was used to create the application.
Xorg is the implementation of the open source X Window System released by the X.Org Foundation. In FreeBSD, it can be installed as a package or port. The meta-port for the complete distribution which includes X servers, clients, libraries, and fonts is located in x11/xorg. A minimal distribution is located in x11/xorg-minimal, with separate ports available for docs, libraries, and apps. The examples in this section install the complete Xorg distribution.
To build and install Xorg from the Ports Collection:
#cd /usr/ports/x11/xorg#make install clean
Note:
To build Xorg in its entirety, be sure to have at least 4 GB of free disk space available.
Alternatively, Xorg can be installed directly from packages with this command:
#pkg install xorg
In most cases, Xorg is self-configuring. When started without any configuration file, the video card and input devices are automatically detected and used. Autoconfiguration is the preferred method, and should be tried first.
Check if HAL is used by the X server:
%pkg info xorg-server | grep HALIf the output shows HAL is
off, skip to the next step. If HAL ison, enable needed services by adding two entries to/etc/rc.conf. Then start the services:hald_enable="YES" dbus_enable="YES"
#service hald start ; service dbus startRename or delete old versions of
xorg.conf:#mv /etc/X11/xorg.conf ~/xorg.conf.etc#mv /usr/local/etc/X11/xorg.conf ~/xorg.conf.localetcStart the X system:
%startxTest the system by moving the mouse and typing text into the windows. If both mouse and keyboard work as expected, see Section 6.8, “Desktop Environments” and Section 6.7, “The X Display Manager”.
If the mouse or keyboard do not work, continue with Section 6.5, “Xorg Configuration”.
Those with older or unusual equipment may find it helpful to gather some hardware information before beginning configuration.
Monitor sync frequencies
Video card chipset
Video card memory
Screen resolution and refresh rate are determined by the monitor's horizontal and vertical sync frequencies. Almost all monitors support electronic autodetection of these values. A few monitors do not provide these values, and the specifications must be determined from the printed manual or manufacturer web site.
The video card chipset is also autodetected, and used to select the proper video driver. It is beneficial for the user to be aware of which chipset is installed for when autodetection does not provide the desired result.
Video card memory determines the maximum resolution and color depth which can be displayed.
The ability to configure optimal resolution is dependent upon the video hardware and the support provided by its driver. At this time, driver support includes:
Intel: as of FreeBSD 9.3 and FreeBSD 10.1, 3D acceleration on most Intel graphics, including IronLake, SandyBridge, and IvyBridge, is supported. Support for switching between X and virtual consoles is provided by vt(4).
ATI/Radeon: 2D and 3D acceleration is supported on most Radeon cards up to the HD6000 series.
NVIDIA: several NVIDIA drivers are available in the
x11category of the Ports Collection. Install the driver that matches the video card.Optimus: currently there is no switching support between the two graphics adapters provided by Optimus. Optimus implementations vary, and FreeBSD will not be able to drive all versions of the hardware. Some computers provide a BIOS option to disable one of the graphics adapters or select a discrete mode.
By default, Xorg uses
HAL to autodetect keyboards and mice. The
sysutils/hal and
devel/dbus ports are automatically
installed as dependencies of x11/xorg, but
must be enabled by adding these entries to
/etc/rc.conf:
hald_enable="YES" dbus_enable="YES"
Start these services before configuring Xorg:
#service hald start#service dbus start
Once the services have been started, check whether Xorg auto-configures itself by typing:
#Xorg -configure
This will generate a file named
/root/xorg.conf.new which attempts to
load the proper drivers for the detected hardware. Next, test
that the automatically generated configuration file works with
the graphics hardware by typing:
#Xorg -config xorg.conf.new -retro
If a black and grey grid and an X mouse cursor appear, the
configuration was successful. To exit the test, switch to the
virtual console used to start it by pressing Ctrl+Alt+Fn
(F1 for the first virtual console) and press
Ctrl+C.
Note:
The Ctrl+Alt+Backspace key combination may also be used to break out of Xorg. To enable it, you can either type the following command from any X terminal emulator:
%setxkbmap -option terminate:ctrl_alt_bksp
or create a keyboard configuration file for
hald called
x11-input.fdi and saved in the
/usr/local/etc/hal/fdi/policy
directory. This file should contain the following
lines:
<?xml version="1.0" encoding="iso-8859-1"?>
<deviceinfo version="0.2">
<device>
<match key="info.capabilities" contains="input.keyboard">
<merge key="input.x11_options.XkbOptions" type="string">terminate:ctrl_alt_bksp</merge>
</match>
</device>
</deviceinfo>You will have to reboot your machine to force hald to read this file.
The following line will also have to be added to
xorg.conf.new, in the
ServerLayout or
ServerFlags section:
Option "DontZap" "off"
If the test is unsuccessful, skip ahead to Section 6.10, “Troubleshooting”. Once the test is successful,
copy the configuration file to
/etc/X11/xorg.conf:
#cp xorg.conf.new /etc/X11/xorg.conf
Note:
Desktop environments like GNOME, KDE or Xfce provide graphical tools to set parameters such as video resolution. If the default configuration works, skip to Section 6.8, “Desktop Environments” for examples on how to install a desktop environment.
The default fonts that ship with Xorg are less than ideal for typical desktop publishing applications. Large presentation fonts show up jagged and unprofessional looking, and small fonts are almost completely unintelligible. However, there are several free, high quality Type1 (PostScript®) fonts available which can be readily used with Xorg. For instance, the URW font collection (x11-fonts/urwfonts) includes high quality versions of standard type1 fonts (Times Roman®, Helvetica®, Palatino® and others). The Freefonts collection (x11-fonts/freefonts) includes many more fonts, but most of them are intended for use in graphics software such as the Gimp, and are not complete enough to serve as screen fonts. In addition, Xorg can be configured to use TrueType® fonts with a minimum of effort. For more details on this, see the X(7) manual page or Section 6.6.2, “TrueType® Fonts”.
To install the above Type1 font collections from the Ports Collection, run the following commands:
#cd /usr/ports/x11-fonts/urwfonts#make install clean
And likewise with the freefont or other collections. To
have the X server detect these fonts, add an appropriate line
to the X server configuration file
(/etc/X11/xorg.conf), which reads:
FontPath "/usr/local/share/fonts/urwfonts/"
Alternatively, at the command line in the X session run:
%xset fp+ /usr/local/share/fonts/urwfonts%xset fp rehash
This will work but will be lost when the X session is
closed, unless it is added to the startup file
(~/.xinitrc for a normal
startx session, or
~/.xsession when logging in through a
graphical login manager like XDM).
A third way is to use the new
/usr/local/etc/fonts/local.conf as
demonstrated in Section 6.6.3, “Anti-Aliased Fonts”.
Xorg has built in support for
rendering TrueType® fonts. There are two different modules
that can enable this functionality. The freetype module is
used in this example because it is more consistent with the
other font rendering back-ends. To enable the freetype module
just add the following line to the "Module"
section of /etc/X11/xorg.conf.
Load "freetype"
Now make a directory for the TrueType® fonts (for
example,
/usr/local/share/fonts/TrueType) and
copy all of the TrueType® fonts into this directory. Keep in
mind that TrueType® fonts cannot be directly taken from an
Apple® Mac®; they must be in UNIX®/MS-DOS®/Windows®
format for use by Xorg. Once the
files have been copied into this directory, use
ttmkfdir to create a
fonts.dir, so that the X font renderer
knows that these new files have been installed.
ttmkfdir is available from the FreeBSD
Ports Collection as
x11-fonts/ttmkfdir.
#cd /usr/local/share/fonts/TrueType#ttmkfdir -o fonts.dir
Now add the TrueType® directory to the font path. This is just the same as described in Section 6.6.1, “Type1 Fonts”:
%xset fp+ /usr/local/share/fonts/TrueType%xset fp rehash
or add a FontPath line to
xorg.conf.
Now Gimp, OpenOffice, and all of the other X applications should now recognize the installed TrueType® fonts. Extremely small fonts (as with text in a high resolution display on a web page) and extremely large fonts (within StarOffice™) will look much better now.
All fonts in Xorg that are
found in /usr/local/share/fonts/ and
~/.fonts/ are automatically made
available for anti-aliasing to Xft-aware applications. Most
recent applications are Xft-aware, including
KDE,
GNOME, and
Firefox.
In order to control which fonts are anti-aliased, or to
configure anti-aliasing properties, create (or edit, if it
already exists) the file
/usr/local/etc/fonts/local.conf. Several
advanced features of the Xft font system can be tuned using
this file; this section describes only some simple
possibilities. For more details, please see
fonts-conf(5).
This file must be in XML format. Pay careful attention to
case, and make sure all tags are properly closed. The file
begins with the usual XML header followed by a DOCTYPE
definition, and then the <fontconfig>
tag:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>As previously stated, all fonts in
/usr/local/share/fonts/ as well as
~/.fonts/ are already made available to
Xft-aware applications. If you wish to add another directory
outside of these two directory trees, add a line similar to
the following to
/usr/local/etc/fonts/local.conf:
<dir>/path/to/my/fonts</dir>
After adding new fonts, and especially new font directories, you should run the following command to rebuild the font caches:
#fc-cache -f
Anti-aliasing makes borders slightly fuzzy, which makes very small text more readable and removes “staircases” from large text, but can cause eyestrain if applied to normal text. To exclude font sizes smaller than 14 point from anti-aliasing, include these lines:
<match target="font"> <test name="size" compare="less"> <double>14</double> </test> <edit name="antialias" mode="assign"> <bool>false</bool> </edit> </match> <match target="font"> <test name="pixelsize" compare="less" qual="any"> <double>14</double> </test> <edit mode="assign" name="antialias"> <bool>false</bool> </edit> </match>
Spacing for some monospaced fonts may also be inappropriate with anti-aliasing. This seems to be an issue with KDE, in particular. One possible fix for this is to force the spacing for such fonts to be 100. Add the following lines:
<match target="pattern" name="family"> <test qual="any" name="family"> <string>fixed</string> </test> <edit name="family" mode="assign"> <string>mono</string> </edit> </match> <match target="pattern" name="family"> <test qual="any" name="family"> <string>console</string> </test> <edit name="family" mode="assign"> <string>mono</string> </edit> </match>
(this aliases the other common names for fixed fonts as
"mono"), and then add:
<match target="pattern" name="family"> <test qual="any" name="family"> <string>mono</string> </test> <edit name="spacing" mode="assign"> <int>100</int> </edit> </match>
Certain fonts, such as Helvetica, may have a problem when
anti-aliased. Usually this manifests itself as a font that
seems cut in half vertically. At worst, it may cause
applications to crash. To avoid this, consider adding the
following to local.conf:
<match target="pattern" name="family"> <test qual="any" name="family"> <string>Helvetica</string> </test> <edit name="family" mode="assign"> <string>sans-serif</string> </edit> </match>
Once you have finished editing
local.conf make sure you end the file
with the </fontconfig> tag. Not
doing this will cause your changes to be ignored.
Finally, users can add their own settings via their
personal .fonts.conf files. To do this,
each user should simply create a
~/.fonts.conf. This file must also be in
XML format.
One last point: with an LCD screen, sub-pixel sampling may
be desired. This basically treats the (horizontally
separated) red, green and blue components separately to
improve the horizontal resolution; the results can be
dramatic. To enable this, add the line somewhere in
local.conf:
<match target="font"> <test qual="all" name="rgba"> <const>unknown</const> </test> <edit name="rgba" mode="assign"> <const>rgb</const> </edit> </match>
Note:
Depending on the sort of display,
rgb may need to be changed to
bgr, vrgb or
vbgr: experiment and see which works
best.
Xorg provides an X Display Manager, XDM, which can be used for login session management. XDM provides a graphical interface for choosing which display server to connect to and for entering authorization information such as a login and password combination.
This section demonstrates how to configure the X Display Manager on FreeBSD. Some desktop environments provide their own graphical login manager. Refer to Section 6.8.1, “GNOME” for instructions on how to configure the GNOME Display Manager and Section 6.8.2, “KDE” for instructions on how to configure the KDE Display Manager.
To install XDM, use the
x11/xdm package or port. Once installed,
XDM can be configured to run when
the machine boots up by editing this entry in
/etc/ttys:
ttyv8 "/usr/local/bin/xdm -nodaemon" xterm off secure
Change the off to on
and save the edit. The ttyv8 in this entry
indicates that XDM will run on the
ninth virtual terminal.
The XDM configuration directory
is located in /usr/local/lib/X11/xdm.
This directory contains several files used to change the
behavior and appearance of XDM, as
well as a few scripts and programs used to set up the desktop
when XDM is running. Table 6.1, “XDM Configuration Files” summarizes the function of each
of these files. The exact syntax and usage of these files is
described in xdm(1).
| File | Description |
|---|---|
Xaccess | The protocol for connecting to XDM is called the X Display Manager Connection Protocol (XDMCP) This file is a client authorization ruleset for controlling XDMCP connections from remote machines. By default, this file does not allow any remote clients to connect. |
Xresources | This file controls the look and feel of the XDM display chooser and login screens. The default configuration is a simple rectangular login window with the hostname of the machine displayed at the top in a large font and “Login:” and “Password:” prompts below. The format of this file is identical to the app-defaults file described in the Xorg documentation. |
Xservers | The list of local and remote displays the chooser should provide as login choices. |
Xsession | Default session script for logins which is run by
XDM after a user has logged
in. Normally each user will have a customized session
script in ~/.xsession that
overrides this script |
Xsetup_* | Script to automatically launch applications
before displaying the chooser or login interfaces.
There is a script for each display being used, named
Xsetup_*, where
* is the local display number.
Typically these scripts run one or two programs in the
background such as
xconsole. |
xdm-config | Global configuration for all displays running on this machine. |
xdm-errors | Contains errors generated by the server program.
If a display that XDM is
trying to start hangs, look at this file for error
messages. These messages are also written to the
user's ~/.xsession-errors on a
per-session basis. |
xdm-pid | The running process ID of XDM. |
By default, only users on the same system can login using XDM. To enable users on other systems to connect to the display server, edit the access control rules and enable the connection listener.
To configure XDM to listen for
any remote connection, comment out the
DisplayManager.requestPort line in
/usr/local/lib/X11/xdm/xdm-config by
putting a ! in front of it:
! SECURITY: do not listen for XDMCP or Chooser requests ! Comment out this line if you want to manage X terminals with xdm DisplayManager.requestPort: 0
Save the edits and restart XDM.
To restrict remote access, look at the example entries in
/usr/local/lib/X11/xdm/Xaccess and refer
to xdm(1) for further information.
This section describes how to install three popular desktop
environments on a FreeBSD system. A desktop environment can range
from a simple window manager to a complete suite of desktop
applications. Over a hundred desktop environments are available
in the x11-wm category of the Ports
Collection.
GNOME is a user-friendly desktop environment. It includes a panel for starting applications and displaying status, a desktop, a set of tools and applications, and a set of conventions that make it easy for applications to cooperate and be consistent with each other. More information regarding GNOME on FreeBSD can be found at http://www.FreeBSD.org/gnome. That web site contains additional documentation about installing, configuring, and managing GNOME on FreeBSD.
This desktop environment can be installed from a package:
#pkg install gnome2
To instead build GNOME from ports, use the following command. GNOME is a large application and will take some time to compile, even on a fast computer.
#cd /usr/ports/x11/gnome2#make install clean
For proper operation, GNOME
requires /proc to be mounted. Add this
line to /etc/fstab to mount this file
system automatically during system startup:
proc /proc procfs rw 0 0
Once GNOME is installed,
configure Xorg to start
GNOME. The easiest way to do this
is to enable the GNOME Display Manager,
GDM, which is installed as part of
the GNOME package or port. It can
be enabled by adding this line to
/etc/rc.conf:
gdm_enable="YES"
It is often desirable to also start all
GNOME services. To achieve this,
add a second line to /etc/rc.conf:
gnome_enable="YES"
GDM will now start automatically when the system boots.
A second method for starting
GNOME is to type
startx from the command-line after
configuring ~/.xinitrc. If this file
already exists, replace the line that starts the current
window manager with one that starts
/usr/local/bin/gnome-session. If this
file does not exist, create it with this command:
%echo "exec /usr/local/bin/gnome-session" > ~/.xinitrc
A third method is to use XDM as
the display manager. In this case, create an executable
~/.xsession:
%echo "#!/bin/sh" > ~/.xsession%echo "exec /usr/local/bin/gnome-session" >> ~/.xsession%chmod +x ~/.xsession
KDE is another easy-to-use desktop environment. This desktop provides a suite of applications with a consistent look and feel, a standardized menu and toolbars, keybindings, color-schemes, internationalization, and a centralized, dialog-driven desktop configuration. More information on KDE can be found at http://www.kde.org/. For FreeBSD-specific information, consult http://freebsd.kde.org.
To install the KDE package, type:
#pkg install x11/kde4
To instead build the KDE port, use the following command. Installing the port will provide a menu for selecting which components to install. KDE is a large application and will take some time to compile, even on a fast computer.
#cd /usr/ports/x11/kde4#make install clean
KDE requires
/proc to be mounted. Add this line to
/etc/fstab to mount this file system
automatically during system startup:
proc /proc procfs rw 0 0
The installation of KDE
includes the KDE Display Manager,
KDM. To enable this display
manager, add this line to
/etc/rc.conf:
kdm4_enable="YES"
A second method for launching
KDE is to type
startx from the command line. For this to
work, the following line is needed in
~/.xinitrc:
exec /usr/local/bin/startkde
A third method for starting KDE
is through XDM. To do so, create
an executable ~/.xsession as
follows:
%echo "#!/bin/sh" > ~/.xsession%echo "exec /usr/local/bin/startkde" >> ~/.xsession%chmod +x ~/.xsession
Once KDE is started, refer to its built-in help system for more information on how to use its various menus and applications.
Xfce is a desktop environment based on the GTK+ toolkit used by GNOME. However, it is more lightweight and provides a simple, efficient, easy-to-use desktop. It is fully configurable, has a main panel with menus, applets, and application launchers, provides a file manager and sound manager, and is themeable. Since it is fast, light, and efficient, it is ideal for older or slower machines with memory limitations. More information on Xfce can be found at http://www.xfce.org.
To install the Xfce package:
#pkg install xfce
Alternatively, to build the port:
#cd /usr/ports/x11-wm/xfce4#make install clean
Unlike GNOME or
KDE,
Xfce does not provide its own login
manager. In order to start Xfce
from the command line by typing startx,
first add its entry to ~/.xinitrc:
%echo "exec /usr/local/bin/startxfce4" > ~/.xinitrc
An alternate method is to use
XDM. To configure this method,
create an executable ~/.xsession:
%echo "#!/bin/sh" > ~/.xsession%echo "exec /usr/local/bin/startxfce4" >> ~/.xsession%chmod +x ~/.xsession
One way to increase the pleasantness of using a desktop computer is by having nice 3D effects.
Installing the Compiz Fusion package is easy, but configuring it requires a few steps that are not described in the port's documentation.
Desktop effects can cause quite a load on the graphics
card. For an nVidia-based graphics card, the proprietary
driver is required for good performance. Users of other
graphics cards can skip this section and continue with the
xorg.conf configuration.
To determine which nVidia driver is needed see the FAQ question on the subject.
Having determined the correct driver to use for your card, installation is as simple as installing any other package.
For example, to install the latest driver:
#pkg install x11/nvidia-driver
The driver will create a kernel module, which needs to be
loaded at system startup. Add the following line to
/boot/loader.conf:
nvidia_load="YES"
Note:
To immediately load the kernel module into the running
kernel by issuing a command like kldload
nvidia, however it has been noted that the some
versions of Xorg will not
function properly if the driver is not loaded at boot time.
After editing /boot/loader.conf, a
reboot is recommended.
With the kernel module loaded, you normally only need to
change a single line in xorg.conf
to enable the proprietary driver:
Find the following line in
/etc/X11/xorg.conf:
Driver "nv"
and change it to:
Driver "nvidia"
Start the GUI as usual, and you should be greeted by the nVidia splash. Everything should work as usual.
To enable Compiz Fusion,
/etc/X11/xorg.conf needs to be
modified:
Add the following section to enable composite effects:
Section "Extensions"
Option "Composite" "Enable"
EndSectionLocate the “Screen” section which should look similar to the one below:
Section "Screen"
Identifier "Screen0"
Device "Card0"
Monitor "Monitor0"
...and add the following two lines (after “Monitor” will do):
DefaultDepth 24
Option "AddARGBGLXVisuals" "True"Locate the “Subsection” that refers to the screen resolution that you wish to use. For example, if you wish to use 1280x1024, locate the section that follows. If the desired resolution does not appear in any subsection, you may add the relevant entry by hand:
SubSection "Display"
Viewport 0 0
Modes "1280x1024"
EndSubSectionA color depth of 24 bits is needed for desktop composition, change the above subsection to:
SubSection "Display"
Viewport 0 0
Depth 24
Modes "1280x1024"
EndSubSectionFinally, confirm that the “glx” and “extmod” modules are loaded in the “Module” section:
Section "Module"
Load "extmod"
Load "glx"
...The preceding can be done automatically with x11/nvidia-xconfig by running (as root):
#nvidia-xconfig --add-argb-glx-visuals#nvidia-xconfig --composite#nvidia-xconfig --depth=24
Installing Compiz Fusion is as simple as any other package:
#pkg install x11-wm/compiz-fusion
When the installation is finished, start your graphic desktop and at a terminal, enter the following commands (as a normal user):
%compiz --replace --sm-disable --ignore-desktop-hints ccp &%emerald --replace &
Your screen will flicker for a few seconds, as your window manager (e.g. Metacity if you are using GNOME) is replaced by Compiz Fusion. Emerald takes care of the window decorations (i.e. close, minimize, maximize buttons, title bars and so on).
You may convert this to a trivial script and have it run at startup automatically (e.g. by adding to “Sessions” in a GNOME desktop):
#! /bin/sh
compiz --replace --sm-disable --ignore-desktop-hints ccp &
emerald --replace &Save this in your home directory as, for example,
start-compiz and make it
executable:
%chmod +x ~/start-compiz
Then use the GUI to add it to (located in , , on a GNOME desktop).
To actually select all the desired effects and their settings, execute (again as a normal user) the Compiz Config Settings Manager:
%ccsm
Note:
In GNOME, this can also be found in the , menu.
If you have selected “gconf support” during
the build, you will also be able to view these settings using
gconf-editor under
apps/compiz.
If the mouse does not work, you will need to first configure
it before proceeding. See Section 3.10.9, “Mouse Settings” in the FreeBSD
install chapter. In recent Xorg
versions, the InputDevice sections in
xorg.conf are ignored in favor of the
autodetected devices. To restore the old behavior, add the
following line to the ServerLayout or
ServerFlags section of this file:
Option "AutoAddDevices" "false"
Input devices may then be configured as in previous versions, along with any other options needed (e.g., keyboard layout switching).
Note:
As previously explained the hald daemon will, by default, automatically detect your keyboard. There are chances that your keyboard layout or model will not be correct, desktop environments like GNOME, KDE or Xfce provide tools to configure the keyboard. However, it is possible to set the keyboard properties directly either with the help of the setxkbmap(1) utility or with a hald's configuration rule.
For example if, one wants to use a PC 102 keys keyboard
coming with a french layout, we have to create a keyboard
configuration file for hald
called x11-input.fdi and saved in the
/usr/local/etc/hal/fdi/policy
directory. This file should contain the following
lines:
<?xml version="1.0" encoding="iso-8859-1"?>
<deviceinfo version="0.2">
<device>
<match key="info.capabilities" contains="input.keyboard">
<merge key="input.x11_options.XkbModel" type="string">pc102</merge>
<merge key="input.x11_options.XkbLayout" type="string">fr</merge>
</match>
</device>
</deviceinfo>If this file already exists, just copy and add to your file the lines regarding the keyboard configuration.
You will have to reboot your machine to force hald to read this file.
It is possible to do the same configuration from an X terminal or a script with this command line:
%setxkbmap -model pc102 -layout fr
/usr/local/share/X11/xkb/rules/base.lst
lists the various keyboard, layouts and options
available.
The xorg.conf.new configuration file
may now be tuned to taste. Open the file in a text editor
such as emacs(1) or ee(1). If the monitor is an
older or unusual model that does not support autodetection of
sync frequencies, those settings can be added to
xorg.conf.new under the
"Monitor" section:
Section "Monitor" Identifier "Monitor0" VendorName "Monitor Vendor" ModelName "Monitor Model" HorizSync 30-107 VertRefresh 48-120 EndSection
Most monitors support sync frequency autodetection, making manual entry of these values unnecessary. For the few monitors that do not support autodetection, avoid potential damage by only entering values provided by the manufacturer.
X allows DPMS (Energy Star) features to be used with capable monitors. The xset(1) program controls the time-outs and can force standby, suspend, or off modes. If you wish to enable DPMS features for your monitor, you must add the following line to the monitor section:
Option "DPMS"
While the xorg.conf.new configuration
file is still open in an editor, select the default resolution
and color depth desired. This is defined in the
"Screen" section:
Section "Screen" Identifier "Screen0" Device "Card0" Monitor "Monitor0" DefaultDepth 24 SubSection "Display" Viewport 0 0 Depth 24 Modes "1024x768" EndSubSection EndSection
The DefaultDepth keyword describes the
color depth to run at by default. This can be overridden with
the -depth command line switch to
Xorg(1). The Modes keyword describes
the resolution to run at for the given color depth. Note that
only VESA standard modes are supported as defined by the
target system's graphics hardware. In the example above, the
default color depth is twenty-four bits per pixel. At this
color depth, the accepted resolution is 1024 by 768
pixels.
Finally, write the configuration file and test it using the test mode given above.
Note:
One of the tools available to assist you during
troubleshooting process are the
Xorg log files, which contain
information on each device that the
Xorg server attaches to.
Xorg log file names are in the
format of /var/log/Xorg.0.log. The
exact name of the log can vary from
Xorg.0.log to
Xorg.8.log and so forth.
If all is well, the configuration file needs to be
installed in a common location where Xorg(1) can find it.
This is typically /etc/X11/xorg.conf or
/usr/local/etc/X11/xorg.conf.
#cp xorg.conf.new /etc/X11/xorg.conf
The Xorg configuration process is now complete. Xorg may be now started with the startx(1) utility. The Xorg server may also be started with the use of xdm(1).
Configuration with Intel® i810 integrated chipsets
requires the agpgart AGP programming
interface for Xorg to drive the
card. See the agp(4) driver manual page for more
information.
This will allow configuration of the hardware as any
other graphics board. Note on systems without the
agp(4) driver compiled in the kernel, trying to load
the module with kldload(8) will not work. This driver
has to be in the kernel at boot time through being compiled
in or using /boot/loader.conf.
This section assumes a bit of advanced configuration knowledge. If attempts to use the standard configuration tools above have not resulted in a working configuration, there is information enough in the log files to be of use in getting the setup working. Use of a text editor will be necessary.
Current widescreen (WSXGA, WSXGA+, WUXGA, WXGA, WXGA+, et.al.) formats support 16:10 and 10:9 formats or aspect ratios that can be problematic. Examples of some common screen resolutions for 16:10 aspect ratios are:
2560x1600
1920x1200
1680x1050
1440x900
1280x800
At some point, it will be as easy as adding one of these
resolutions as a possible Mode in the
Section "Screen" as such:
Section "Screen" Identifier "Screen0" Device "Card0" Monitor "Monitor0" DefaultDepth 24 SubSection "Display" Viewport 0 0 Depth 24 Modes "1680x1050" EndSubSection EndSection
Xorg is smart enough to pull the resolution information from the widescreen via I2C/DDC information so it knows what the monitor can handle as far as frequencies and resolutions.
If those ModeLines do not exist in
the drivers, one might need to give
Xorg a little hint. Using
/var/log/Xorg.0.log one can extract
enough information to manually create a
ModeLine that will work. Simply look for
information resembling this:
(II) MGA(0): Supported additional Video Mode: (II) MGA(0): clock: 146.2 MHz Image Size: 433 x 271 mm (II) MGA(0): h_active: 1680 h_sync: 1784 h_sync_end 1960 h_blank_end 2240 h_border: 0 (II) MGA(0): v_active: 1050 v_sync: 1053 v_sync_end 1059 v_blanking: 1089 v_border: 0 (II) MGA(0): Ranges: V min: 48 V max: 85 Hz, H min: 30 H max: 94 kHz, PixClock max 170 MHz
This information is called EDID information. Creating a
ModeLine from this is just a matter of
putting the numbers in the correct order:
ModeLine <name> <clock> <4 horiz. timings> <4 vert. timings>
So that the ModeLine in
Section "Monitor" for this example would
look like this:
Section "Monitor" Identifier "Monitor1" VendorName "Bigname" ModelName "BestModel" ModeLine "1680x1050" 146.2 1680 1784 1960 2240 1050 1053 1059 1089 Option "DPMS" EndSection
Now having completed these simple editing steps, X should start on your new widescreen monitor.
- 6.10.3.1. I have installed Compiz Fusion, and after running the commands you mention, my windows are left without title bars and buttons. What is wrong?
- 6.10.3.2. When I run the command to start Compiz Fusion, the X server crashes and I am back at the console. What is wrong?
6.10.3.1. | I have installed Compiz Fusion, and after running the commands you mention, my windows are left without title bars and buttons. What is wrong? |
You are probably missing a setting in
| |
6.10.3.2. | When I run the command to start Compiz Fusion, the X server crashes and I am back at the console. What is wrong? |
If you check
(EE) NVIDIA(0): Failed to initialize the GLX module; please check in your X
(EE) NVIDIA(0): log file that the GLX module has been loaded in your X
(EE) NVIDIA(0): server, and that the module is the NVIDIA GLX module. If
(EE) NVIDIA(0): you continue to encounter problems, Please try
(EE) NVIDIA(0): reinstalling the NVIDIA driver.This is usually the case when you upgrade Xorg. You will need to reinstall the x11/nvidia-driver package so glx is built again. |