Greenplum MapReduce Specification
This specification describes the document format and schema for defining Greenplum MapReduce jobs.
To enable Greenplum to process MapReduce functions, define the functions in a document, then pass the document to the Greenplum MapReduce program, gpmapreduce, for execution by the Greenplum Database parallel engine. The Greenplum Database system distributes the input data, executes the program across a set of machines, handles machine failures, and manages the required inter-machine communication.
See the Greenplum Database Utility Guide for information about gpmapreduce.
Greenplum MapReduce Document Format
This section explains some basics of the Greenplum MapReduce document format to help you get started creating your own Greenplum MapReduce documents. Greenplum uses the YAML 1.1 document format and then implements its own schema for defining the various steps of a MapReduce job.
All Greenplum MapReduce files must first declare the version of the YAML specification they are using. After that, three dashes (---) denote the start of a document, and three dots (...) indicate the end of a document without starting a new one. Comment lines are prefixed with a pound symbol (#). It is possible to declare multiple Greenplum MapReduce documents in the same file:
%YAML 1.1 --- # Begin Document 1 # ... --- # Begin Document 2 # ...
Within a Greenplum MapReduce document, there are three basic types of data structures or nodes: scalars, sequences and mappings.
A scalar is a basic string of text indented by a space. If you have a scalar input that spans multiple lines, a preceding pipe ( | ) denotes a literal style, where all line breaks are significant. Alternatively, a preceding angle bracket ( > ) folds a single line break to a space for subsequent lines that have the same indentation level. If a string contains characters that have reserved meaning, the string must be quoted or the special character must be escaped with a backslash ( \ ).
# Read each new line literally somekey: | this value contains two lines and each line is read literally # Treat each new line as a space anotherkey: > this value contains two lines but is treated as one continuous line # This quoted string contains a special character ThirdKey: "This is a string: not a mapping"
A sequence is a list with each entry in the list on its own line denoted by a dash and a space (- ). Alternatively, you can specify an inline sequence as a comma-separated list within square brackets. A sequence provides a set of data and gives it an order. When you load a list into the Greenplum MapReduce program, the order is kept.
# list sequence - this - is - a list - with - five scalar values # inline sequence [this, is, a list, with, five scalar values]
A mapping is used to pair up data values with indentifiers called keys. Mappings use a colon and space (: ) for each key: value pair, or can also be specified inline as a comma-separated list within curly braces. The key is used as an index for retrieving data from a mapping.
# a mapping of items
title: War and Peace
author: Leo Tolstoy
date: 1865
# same mapping written inline
{title: War and Peace, author: Leo Tolstoy, date: 1865}
Keys are used to associate meta information with each node and specify the expected node type (scalar, sequence or mapping). See Greenplum MapReduce Document Schema for the keys expected by the Greenplum MapReduce program.
The Greenplum MapReduce program processes the nodes of a document in order and uses indentation (spaces) to determine the document hierarchy and the relationships of the nodes to one another. The use of white space is significant. White space should not be used simply for formatting purposes, and tabs should not be used at all.
Greenplum MapReduce Document Schema
Greenplum MapReduce uses the YAML document framework and implements its own YAML schema. The basic structure of a Greenplum MapReduce document is:
%YAML 1.1 --- VERSION: 1.0.0.2 DATABASE: dbname USER: db_username HOST: master_hostname PORT: master_port
DEFINE: - INPUT: NAME: input_name FILE: - hostname:/path/to/file GPFDIST: - hostname:port/file_pattern TABLE: table_name QUERY: SELECT_statement EXEC: command_string COLUMNS: - field_name data_type FORMAT: TEXT | CSV DELIMITER: delimiter_character ESCAPE: escape_character NULL: null_string QUOTE: csv_quote_character ERROR_LIMIT: integer ENCODING: database_encoding
- OUTPUT: NAME: output_name FILE: file_path_on_client TABLE: table_name KEYS: - column_name MODE: REPLACE | APPEND
- MAP: NAME: function_name FUNCTION: function_definition LANGUAGE: perl | python | c LIBRARY: /path/filename.so PARAMETERS: - nametype RETURNS: - nametype OPTIMIZE: STRICT IMMUTABLE MODE: SINGLE | MULTI
- TRANSITION | CONSOLIDATE | FINALIZE: NAME: function_name FUNCTION: function_definition LANGUAGE: perl | python | c LIBRARY: /path/filename.so PARAMETERS: - nametype RETURNS: - nametype OPTIMIZE: STRICT IMMUTABLE MODE: SINGLE | MULTI
- REDUCE: NAME: reduce_job_name TRANSITION: transition_function_name CONSOLIDATE: consolidate_function_name FINALIZE: finalize_function_name INITIALIZE: value KEYS: - key_name
- TASK: NAME: task_name SOURCE: input_name MAP: map_function_name REDUCE: reduce_function_name EXECUTE
- RUN: SOURCE: input_or_task_name TARGET: output_name MAP: map_function_name REDUCE: reduce_function_name...
- VERSION
-
Required. The version of the Greenplum MapReduce YAML specification. Current versions are 1.0.0.1.
- DATABASE
- Optional. Specifies which database in Greenplum to connect to. If not specified, defaults to the default database or $PGDATABASE if set.
- USER
- Optional. Specifies which database role to use to connect. If not specified, defaults to the current user or $PGUSER if set. You must be a Greenplum superuser to run functions written in untrusted Python and Perl. Regular database users can run functions written in trusted Perl. You also must be a database superuser to run MapReduce jobs that contain FILE, GPFDIST and EXEC input types.
- HOST
- Optional. Specifies Greenplum master host name. If not specified, defaults to localhost or $PGHOST if set.
- PORT
- Optional. Specifies Greenplum master port. If not specified, defaults to 5432 or $PGPORT if set.
- DEFINE
- Required. A sequence of definitions for this MapReduce document. The
DEFINE section must have at least one INPUT
definition.
- INPUT
- Required. Defines the input data. Every MapReduce document must have at least
one input defined. Multiple input definitions are allowed in a document, but each
input definition can specify only one of these access types:a file, a
gpfdist file distribution program, a table in the database, an
SQL command, or an operating system command. See the Greenplum Database Utility
Guide for information about gpfdist.
- NAME
-
A name for this input. Names must be unique with regards to the names of other objects in this MapReduce job (such as map function, task, reduce function and output names). Also, names cannot conflict with existing objects in the database (such as tables, functions or views).
- FILE
- A sequence of one or more input files in the format: seghostname:/path/to/filename. You must be a Greenplum Database superuser to run MapReduce jobs with FILE input. The file must reside on a Greenplum segment host.
- GPFDIST
- A sequence of one or more running gpfdist file distribution programs in the format: hostname[:port]/file_pattern. You must be a Greenplum Database superuser to run MapReduce jobs with GPFDIST input, unless the server configuration parameter Server Configuration Parameters is set to on.
- TABLE
- The name of an existing table in the database.
- QUERY
- A SQL SELECT command to run within the database.
- EXEC
- An operating system command to run on the Greenplum segment hosts. The command is run by all segment instances in the system by default. For example, if you have four segment instances per segment host, the command will be run four times on each host. You must be a Greenplum Database superuser to run MapReduce jobs with EXEC input and the server configuration parameter Server Configuration Parameters is set to on.
- COLUMNS
- Optional. Columns are specified as: column_name [data_type]. If not specified, the default is value text. The DELIMITER character is what separates two data value fields (columns). A row is determined by a line feed character (0x0a).
- FORMAT
-
Optional. Specifies the format of the data - either delimited text (TEXT) or comma separated values (CSV) format. If the data format is not specified, defaults to TEXT.
- DELIMITER
-
Optional for FILE, GPFDIST and EXEC inputs. Specifies a single character that separates data values. The default is a tab character in TEXT mode, a comma in CSV mode.The delimiter character must only appear between any two data value fields. Do not place a delimiter at the beginning or end of a row.
- ESCAPE
- Optional for FILE, GPFDIST and EXEC inputs. Specifies the single character that is used for C escape sequences (such as \n,\t,\100, and so on) and for escaping data characters that might otherwise be taken as row or column delimiters. Make sure to choose an escape character that is not used anywhere in your actual column data. The default escape character is a \ (backslash) for text-formatted files and a " (double quote) for csv-formatted files, however it is possible to specify another character to represent an escape. It is also possible to disable escaping by specifying the value 'OFF' as the escape value. This is very useful for data such as text-formatted web log data that has many embedded backslashes that are not intended to be escapes.
- NULL
- Optional for FILE, GPFDIST and EXEC inputs. Specifies the string that represents a null value. The default is \N in TEXT format, and an empty value with no quotations in CSV format. You might prefer an empty string even in TEXT mode for cases where you do not want to distinguish nulls from empty strings. Any input data item that matches this string will be considered a null value.
- QUOTE
- Optional for FILE, GPFDIST and EXEC inputs. Specifies the quotation character for CSV formatted files. The default is a double quote ("). In CSV formatted files, data value fields must be enclosed in double quotes if they contain any commas or embedded new lines. Fields that contain double quote characters must be surrounded by double quotes, and the embedded double quotes must each be represented by a pair of consecutive double quotes. It is important to always open and close quotes correctly in order for data rows to be parsed correctly.
- ERROR_LIMIT
- If the input rows have format errors they will be discarded provided that the error limit count is not reached on any Greenplum segment instance during input processing. If the error limit is not reached, all good rows will be processed and any error rows discarded.
- ENCODING
- Character set encoding to use for the data. Specify a string constant (such as 'SQL_ASCII'), an integer encoding number, or DEFAULT to use the default client encoding. See Character Set Support for more information.
- OUTPUT
- Optional. Defines where to output the formatted data of this MapReduce job. If
output is not defined, the default is STDOUT (standard output of
the client). You can send output to a file on the client host or to an existing
table in the database.
- NAME
- A name for this output. The default output name is STDOUT. Names must be unique with regards to the names of other objects in this MapReduce job (such as map function, task, reduce function and input names). Also, names cannot conflict with existing objects in the database (such as tables, functions or views).
- FILE
- Specifies a file location on the MapReduce client machine to output data in the format: /path/to/filename.
- TABLE
- Specifies the name of a table in the database to output data. If this table does not exist prior to running the MapReduce job, it will be created using the distribution policy specified with KEYS.
- KEYS
- Optional for TABLE output. Specifies the column(s) to use as the Greenplum Database distribution key. If the EXECUTE task contains a REDUCE definition, then the REDUCE keys will be used as the table distribution key by default. Otherwise, the first column of the table will be used as the distribution key.
- MODE
- Optional for TABLE output. If not specified, the default is to create the table if it does not already exist, but error out if it does exist. Declaring APPEND adds output data to an existing table (provided the table schema matches the output format) without removing any existing data. Declaring REPLACE will drop the table if it exists and then recreate it. Both APPEND and REPLACE will create a new table if one does not exist.
- MAP
- Required. Each MAP function takes data structured in (key, value) pairs, processes each pair, and generates zero or more output (key, value) pairs. The Greenplum MapReduce framework then collects all pairs with the same key from all output lists and groups them together. This output is then passed to the REDUCE task, which is comprised of TRANSITION | CONSOLIDATE | FINALIZE functions. There is one predefined MAP function named IDENTITY that returns (key, value) pairs unchanged. Although (key, value) are the default parameters, you can specify other prototypes as needed.
- TRANSITION | CONSOLIDATE | FINALIZE
- TRANSITION, CONSOLIDATE and FINALIZE are all component pieces of REDUCE. A TRANSITION function is required. CONSOLIDATE and FINALIZE functions are optional. By default, all take state as the first of their input PARAMETERS, but other prototypes can be defined as well.
-
A TRANSITION function iterates through each value of a given key and accumulates values in a state variable. When the transition function is called on the first value of a key, the state is set to the value specified by INITALIZE of a REDUCE job (or the default state value for the data type). A transition takes two arguments as input; the current state of the key reduction, and the next value, which then produces a new state.
- If a CONSOLIDATE function is specified, TRANSITION processing is performed at the segment-level before redistributing the keys across the Greenplum interconnect for final aggregation (two-phase aggregation). Only the resulting state value for a given key is redistributed, resulting in lower interconnect traffic and greater parallelism. CONSOLIDATE is handled like a TRANSITION, except that instead of (state + value) => state, it is (state + state) => state.
- If a FINALIZE function is specified, it takes the final
state produced by CONSOLIDATE (if present) or
TRANSITION and does any final processing before emitting the
final result. TRANSITION and CONSOLIDATE
functions cannot return a set of values. If you need a
REDUCE job to return a set, then a FINALIZE is
necessary to transform the final state into a set of output values.
- NAME
- Required. A name for the function. Names must be unique with regards to the names of other objects in this MapReduce job (such as function, task, input and output names). You can also specify the name of a function built-in to Greenplum Database. If using a built-in function, do not supply LANGUAGE or a FUNCTION body.
- FUNCTION
- Optional. Specifies the full body of the function using the specified LANGUAGE. If FUNCTION is not specified, then a built-in database function corresponding to NAME is used.
- LANGUAGE
- Required when FUNCTION is used. Specifies the implementation language used to interpret the function. This release has language support for perl, python, and C. If calling a built-in database function, LANGUAGE should not be specified.
- LIBRARY
- Required when LANGUAGE is C (not allowed for other language functions). To use this attribute, VERSION must be 1.0.0.2. The specified library file must be installed prior to running the MapReduce job, and it must exist in the same file system location on all Greenplum hosts (master and segments).
- PARAMETERS
- Optional. Function input parameters. The default type is
text.
MAP default - key text, value text
TRANSITION default - state text, value text
CONSOLIDATE default - state1 text, state2 text (must have exactly two input parameters of the same data type)
FINALIZE default - state text (single parameter only)
- RETURNS
- Optional. The default return type is
text.
MAP default - key text, value text
TRANSITION default - state text (single return value only)
CONSOLIDATE default - state text (single return value only)
FINALIZE default - value text
- OPTIMIZE
- Optional optimization parameters for the
function:
STRICT - function is not affected by NULL values
IMMUTABLE - function will always return the same value for a given input
- MODE
- Optional. Specifies the number of rows returned by the function.
MULTI - returns 0 or more rows per input record. The return value of the function must be an array of rows to return, or the function must be written as an iterator using yield in Python or return_next in Perl. MULTI is the default mode for MAP and FINALIZE functions.
SINGLE - returns exactly one row per input record. SINGLE is the only mode supported for TRANSITION and CONSOLIDATE functions. When used with MAP and FINALIZE functions, SINGLE mode can provide modest performance improvement.
- REDUCE
- Required. A REDUCE definition names the TRANSITION | CONSOLIDATE | FINALIZE
functions that comprise the reduction of (key,
value) pairs to the final result set. There are also several
predefined REDUCE jobs you can execute, which all operate over a
column named value:
IDENTITY - returns (key, value) pairs unchanged
SUM - calculates the sum of numeric data
AVG - calculates the average of numeric data
COUNT - calculates the count of input data
MIN - calculates minimum value of numeric data
MAX - calculates maximum value of numeric data
- NAME
- Required. The name of this REDUCE job. Names must be unique with regards to the names of other objects in this MapReduce job (function, task, input and output names). Also, names cannot conflict with existing objects in the database (such as tables, functions or views).
- TRANSITION
- Required. The name of the TRANSITION function.
- CONSOLIDATE
- Optional. The name of the CONSOLIDATE function.
- FINALIZE
- Optional. The name of the FINALIZE function.
- INITIALIZE
- Optional for text and float data types. Required for all other data types. The default value for text is '' . The default value for float is 0.0 . Sets the initial state value of the TRANSITION function.
- KEYS
- Optional. Defaults to [key, *]. When using a multi-column reduce it may be necessary to specify which columns are key columns and which columns are value columns. By default, any input columns that are not passed to the TRANSITION function are key columns, and a column named key is always a key column even if it is passed to the TRANSITION function. The special indicator * indicates all columns not passed to the TRANSITION function. If this indicator is not present in the list of keys then any unmatched columns are discarded.
- TASK
- Optional. A TASK defines a complete end-to-end
INPUT/MAP/REDUCE stage within
a Greenplum MapReduce job pipeline. It is similar to EXECUTE except it is not immediately executed. A task
object can be called as INPUT to
further processing stages.
- NAME
- Required. The name of this task. Names must be unique with regards to the names of other objects in this MapReduce job (such as map function, reduce function, input and output names). Also, names cannot conflict with existing objects in the database (such as tables, functions or views).
- SOURCE
- The name of an INPUT or another TASK.
- MAP
-
Optional. The name of a MAP function. If not specified, defaults to IDENTITY.
- REDUCE
-
Optional. The name of a REDUCE function. If not specified, defaults to IDENTITY.
- EXECUTE
- Required. EXECUTE defines the final INPUT/MAP/REDUCE stage within a Greenplum MapReduce job pipeline.
Example Greenplum MapReduce Document
# This example MapReduce job processes documents and looks for keywords in them.
# It takes two database tables as input:
# - documents (doc_id integer, url text, data text)
# - keywords (keyword_id integer, keyword text)#
# The documents data is searched for occurences of keywords and returns results of
# url, data and keyword (a keyword can be multiple words, such as "high performance # computing")
%YAML 1.1
---
VERSION:1.0.0.1
# Connect to Greenplum Database using this database and role
DATABASE:webdata
USER:jsmith
# Begin definition section
DEFINE:
# Declare the input, which selects all columns and rows from the
# 'documents' and 'keywords' tables.
- INPUT:
NAME:doc
TABLE:documents
- INPUT:
NAME:kw
TABLE:keywords
# Define the map functions to extract terms from documents and keyword
# This example simply splits on white space, but it would be possible
# to make use of a python library like nltk (the natural language toolkit)
# to perform more complex tokenization and word stemming.
- MAP:
NAME:doc_map
LANGUAGE:python
FUNCTION:|
i = 0 # the index of a word within the document
terms = {}# a hash of terms and their indexes within the document
# Lower-case and split the text string on space
for term in data.lower().split():
i = i + 1# increment i (the index)
# Check for the term in the terms list:
# if stem word already exists, append the i value to the array entry
# corresponding to the term. This counts multiple occurances of the word.
# If stem word does not exist, add it to the dictionary with position i.
# For example:
# data: "a computer is a machine that manipulates data"
# "a" [1, 4]
# "computer" [2]
# "machine" [3]
# …
if term in terms:
terms[term] += ','+str(i)
else:
terms[term] = str(i)
# Return multiple lines for each document. Each line consists of
# the doc_id, a term and the positions in the data where the term appeared.
# For example:
# (doc_id => 100, term => "a", [1,4]
# (doc_id => 100, term => "computer", [2]
# …
for term in terms:
yield([doc_id, term, terms[term]])
OPTIMIZE:STRICT IMMUTABLE
PARAMETERS:
- doc_id integer
- data text
RETURNS:
- doc_id integer
- term text
- positions text
# The map function for keywords is almost identical to the one for documents
# but it also counts of the number of terms in the keyword.
- MAP:
NAME:kw_map
LANGUAGE:python
FUNCTION:|
i = 0
terms = {}
for term in keyword.lower().split():
i = i + 1
if term in terms:
terms[term] += ','+str(i)
else:
terms[term] = str(i)
# output 4 values including i (the total count for term in terms):
yield([keyword_id, i, term, terms[term]])
OPTIMIZE:STRICT IMMUTABLE
PARAMETERS:
- keyword_id integer
- keyword text
RETURNS:
- keyword_id integer
- nterms integer
- term text
- positions text
# A TASK is an object that defines an entire INPUT/MAP/REDUCE stage
# within a Greenplum MapReduce pipeline. It is like EXECUTION, but it is
# executed only when called as input to other processing stages.
# Identify a task called 'doc_prep' which takes in the 'doc' INPUT defined earlier
# and runs the 'doc_map' MAP function which returns doc_id, term, [term_position]
- TASK:
NAME:doc_prep
SOURCE:doc
MAP:doc_map
# Identify a task called 'kw_prep' which takes in the 'kw' INPUT defined earlier
# and runs the kw_map MAP function which returns kw_id, term, [term_position]
- TASK:
NAME:kw_prep
SOURCE:kw
MAP:kw_map
# One advantage of Greenplum MapReduce is that MapReduce tasks can be
# used as input to SQL operations and SQL can be used to process a MapReduce task.
# This INPUT defines a SQL query that joins the output of the 'doc_prep'
# TASK to that of the 'kw_prep' TASK. Matching terms are output to the 'candidate'
# list (any keyword that shares at least one term with the document).
- INPUT:
NAME: term_join
QUERY: |
SELECT doc.doc_id, kw.keyword_id, kw.term, kw.nterms,
doc.positions as doc_positions,
kw.positions as kw_positions
FROM doc_prep doc INNER JOIN kw_prep kw ON (doc.term = kw.term)
# In Greenplum MapReduce, a REDUCE function is comprised of one or more functions.
# A REDUCE has an initial 'state' variable defined for each grouping key. that is
# A TRANSITION function adjusts the state for every value in a key grouping.
# If present, an optional CONSOLIDATE function combines multiple
# 'state' variables. This allows the TRANSITION function to be executed locally at
# the segment-level and only redistribute the accumulated 'state' over
# the network. If present, an optional FINALIZE function can be used to perform
# final computation on a state and emit one or more rows of output from the state.
#
# This REDUCE function is called 'term_reducer' with a TRANSITION function
# called 'term_transition' and a FINALIZE function called 'term_finalizer'
- REDUCE:
NAME:term_reducer
TRANSITION:term_transition
FINALIZE:term_finalizer
- TRANSITION:
NAME:term_transition
LANGUAGE:python
PARAMETERS:
- state text
- term text
- nterms integer
- doc_positions text
- kw_positions text
FUNCTION: |
# 'state' has an initial value of '' and is a colon delimited set
# of keyword positions. keyword positions are comma delimited sets of
# integers. For example, '1,3,2:4:'
# If there is an existing state, split it into the set of keyword positions
# otherwise construct a set of 'nterms' keyword positions - all empty
if state:
kw_split = state.split(':')
else:
kw_split = []
for i in range(0,nterms):
kw_split.append('')
# 'kw_positions' is a comma delimited field of integers indicating what
# position a single term occurs within a given keyword.
# Splitting based on ',' converts the string into a python list.
# add doc_positions for the current term
for kw_p in kw_positions.split(','):
kw_split[int(kw_p)-1] = doc_positions
# This section takes each element in the 'kw_split' array and strings
# them together placing a ':' in between each element from the array.
# For example: for the keyword "computer software computer hardware",
# the 'kw_split' array matched up to the document data of
# "in the business of computer software software engineers"
# would look like: ['5', '6,7', '5', '']
# and the outstate would look like: 5:6,7:5:
outstate = kw_split[0]
for s in kw_split[1:]:
outstate = outstate + ':' + s
return outstate
- FINALIZE:
NAME: term_finalizer
LANGUAGE: python
RETURNS:
- count integer
MODE:MULTI
FUNCTION:|
if not state:
return 0
kw_split = state.split(':')
# This function does the following:
# 1) Splits 'kw_split' on ':'
# for example, 1,5,7:2,8 creates '1,5,7' and '2,8'
# 2) For each group of positions in 'kw_split', splits the set on ','
# to create ['1','5','7'] from Set 0: 1,5,7 and
# eventually ['2', '8'] from Set 1: 2,8
# 3) Checks for empty strings
# 4) Adjusts the split sets by subtracting the position of the set
# in the 'kw_split' array
# ['1','5','7'] - 0 from each element = ['1','5','7']
# ['2', '8'] - 1 from each element = ['1', '7']
# 5) Resulting arrays after subtracting the offset in step 4 are
# intersected and their overlaping values kept:
# ['1','5','7'].intersect['1', '7'] = [1,7]
# 6) Determines the length of the intersection, which is the number of
# times that an entire keyword (with all its pieces) matches in the
# document data.
previous = None
for i in range(0,len(kw_split)):
isplit = kw_split[i].split(',')
if any(map(lambda(x): x == '', isplit)):
return 0
adjusted = set(map(lambda(x): int(x)-i, isplit))
if (previous):
previous = adjusted.intersection(previous)
else:
previous = adjusted
# return the final count
if previous:
return len(previous)
# Define the 'term_match' task which is then executed as part
# of the 'final_output' query. It takes the INPUT 'term_join' defined
# earlier and uses the REDUCE function 'term_reducer' defined earlier
- TASK:
NAME:term_match
SOURCE:term_join
REDUCE:term_reducer
- INPUT:
NAME:final_output
QUERY:|
SELECT doc.*, kw.*, tm.count
FROM documents doc, keywords kw, term_match tm
WHERE doc.doc_id = tm.doc_id
AND kw.keyword_id = tm.keyword_id
AND tm.count > 0
# Execute this MapReduce job and send output to STDOUT
EXECUTE:
- RUN:
SOURCE:final_output
TARGET:STDOUT
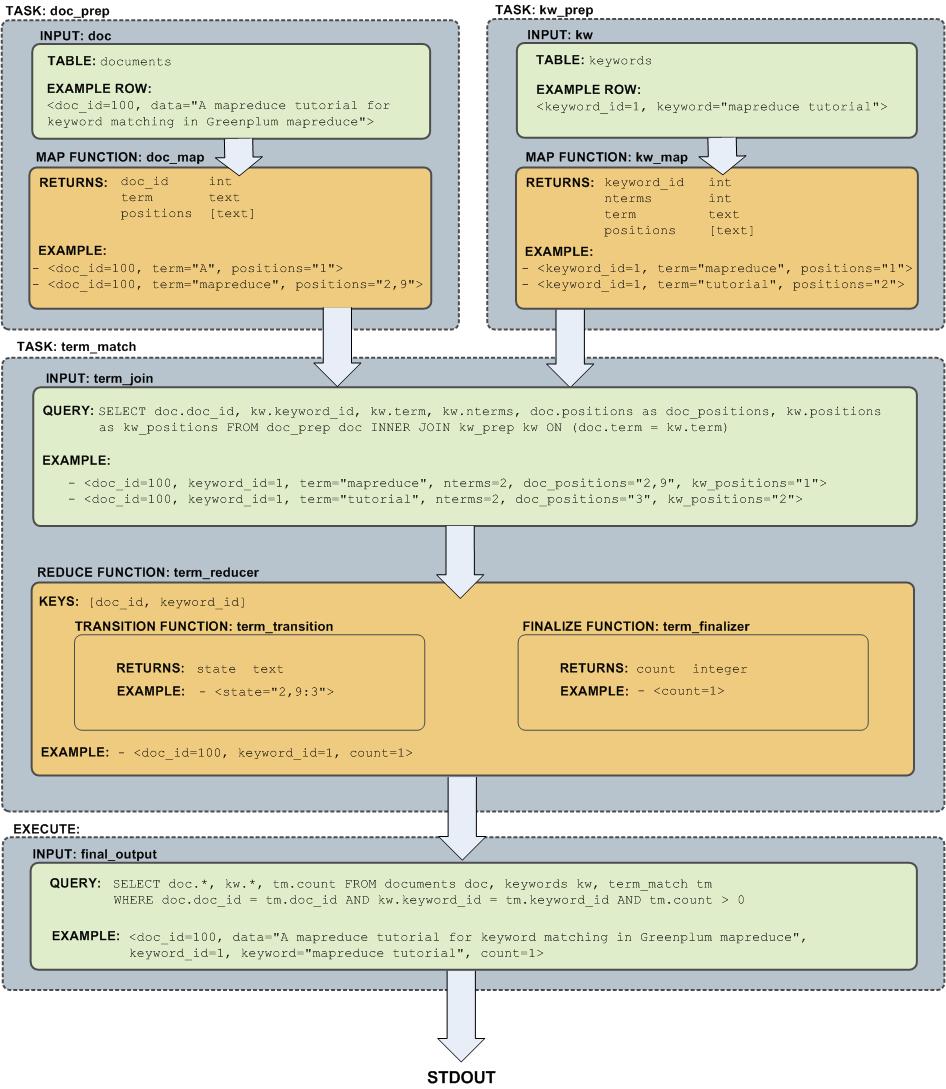
Flow Diagram for MapReduce Example
The following diagram shows the job flow of the MapReduce job defined in the example: