The key goals of the Ice data encoding are simplicity and efficiency. In keeping with these principles, the encoding does not align primitive types on word boundaries and therefore eliminates the wasted space and additional complexity that alignment requires. The Ice data encoding simply produces a stream of contiguous bytes; data contains no padding bytes and need not be aligned on word boundaries.
Data is always encoded using little-endian byte order for numeric types. (Most machines use a little-endian byte order, so the Ice data encoding is "right" more often than not.) Ice does not use a "receiver makes it right" scheme because of the additional complexity this would introduce. Consider, for example, a chain of receivers that merely forward data along the chain until that data arrives at an ultimate receiver. (Such topologies are common for event distribution services.) The Ice protocol permits all the intermediates to forward the data without requiring it to be unmarshaled: the intermediates can forward requests by simply copying blocks of binary data. With a "receiver makes it right" scheme, the intermediates would have to unmarshal and remarshal the data whenever the byte order of the next receiver in the chain differs from the byte order of the sender, which is inefficient.
Ice requires clients and servers that run on big-endian machines to incur the extra cost of byte swapping data into little-endian layout, but that cost is insignificant compared to the overall cost of sending or receiving a request.
Many of the types involved in the data encoding, as well as several protocol message components, have an associated size or count. A size is a non-negative number. Sizes and counts are encoded in one of two ways:
Using this encoding to indicate sizes is significantly cheaper than always using an int to store the size, especially when marshaling sequences of short strings: counts of up to 254 require only a single byte instead of four. This comes at the expense of counts greater than 254, which require five bytes instead of four. However, for sequences or strings of length greater than 254, the extra byte is insignificant.
An encapsulation is used to contain variable-length data that an intermediate receiver may not be able to decode, but that the receiver can forward to another recipient for eventual decoding. An encapsulation is encoded as if it were the following structure:
The size member specifies the size of the encapsulation in bytes (including the
size,
major, and
minor fields). The
major and
minor fields specify the encoding version of the data contained in the encapsulation (see
Section 34.5.2). The version information is followed by
size‑6 bytes of encoded data.
All the data in an encapsulation is context-free, that is, nothing inside an encapsulation can refer to anything outside the encapsulation. This property allows encapsulations to be forwarded among address spaces as a blob of data.
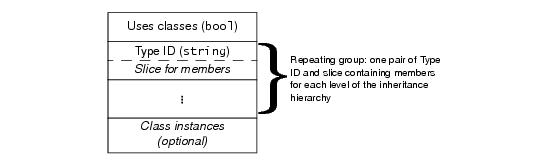
Exceptions and classes are subject to slicing if the receiver of a value only partially understands the received value (that is, only has knowledge of a base type, but not of the actual run-time derived type). To allow the receiver of an exception or class to ignore those parts of a value that it does not understand, exception and class values are marshaled as a sequence of slices (one slice for each level of the inheritance hierarchy). A slice is a byte count encoded as a fixed-length four-byte integer, followed by the data for the slice. (The byte count includes the four bytes occupied by the count itself, so an empty slice has a byte count of four and no data.) The receiver of a value can skip over a slice by reading the byte count
b, and then discarding the next
b−4 bytes in the input stream.
The basic types are encoded as shown in Table 34.1. Integer types (
short,
int,
long) are represented as two’s complement numbers, and floating point types (
float,
double) use the IEEE standard formats
[6]. All numeric types use a little-endian byte order.
Strings are encoded as a size (see Section 34.2.1), followed by the string contents in UTF‑8 format
[23]. Strings are not NUL-terminated. An empty string is encoded with a size of zero.
Sequences are encoded as a size (see Section 34.2.1) representing the number of elements in the sequence, followed by the elements encoded as specified for their type.
Dictionaries are encoded as a size (see Section 34.2.1) representing the number of key–value pairs in the dictionary, followed by the pairs. Each key–value pair is encoded as if it were a
struct containing the key and value as members, in that order.
Every exception instance is preceded by a single byte that indicates whether the exception uses class members: the byte value is
1 if any of the exception members are classes (or if any of the exception members, recursively, contain class members) and
0, otherwise.
Following the header byte, the exception is marshaled as a sequence of pairs: the first member of each pair is the type ID for an exception slice, and the second member of the pair is a slice containing the marshaled members of that slice. The sequence of pairs is marshaled in derived-to-base order, with the most-derived slice first, and ending with the least-derived slice. Within each slice, data members are marshaled as for structures: in the order in which they are defined in the Slice definition.
Following the sequence of pairs, any class instances that are used by the members of the exception are marshaled. This final part is optional: it is present only if the header byte is
1. (See
Section 34.2.11 for a detailed explanation of how class instances are marshaled.)
exception Base {
int baseInt;
string baseString;
};
exception Derived extends Base {
bool derivedBool;
string derivedString;
double derivedDouble;
};
From Table 34.2, we can see that the total size of the members of
Base is 10 bytes, and the total size of the members of
Derived is 16 bytes. None of the exception members are classes. An instance of this exception has the on-the-wire representation shown in
Table 34.3. (The size, type, and byte offset of the marshaled representation is indicated for each component.)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
20 (byte count for slice)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
14 (byte count for slice)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The receiver of this sequence of values uses the header byte to decide whether it eventually must unmarshal any class instances contained in the exception (none in this example) and then examines the first type ID (
::Derived). If the receiver recognizes that type ID, it can unmarshal the contents of the first slice, followed by the remaining slices; otherwise, the receiver reads the byte count that follows the unknown type (20) and then skips 20
−4 bytes in the input stream, which is the start of the type ID for the second slice (
::Base). If the receiver does not recognize that type ID either, it again reads the byte count following the type ID (14), skips 14
−4 bytes, and attempts to read another type ID. (This can happen only if client and server have been compiled with mismatched Slice definitions that disagree in the exception specification of an operation.) In this case, the receiver will eventually encounter an unmarshaling error, which it can report with a
MarshalException.
If an exception contains class members, these members are marshaled following the exception slices as described in the following section.
The marshaling for classes is complex, due to the need to deal with the pointer semantics for graphs of classes, as well as the need for the receiver to slice classes of unknown derived type. In addition, the marshaling for classes uses a type ID compression scheme to avoid repeatedly marshaling the same type IDs for large graphs of class instances.
Classes are marshaled similar to exceptions: each instance is divided into a number of pairs containing a type ID and a slice (one pair for each level of the inheritance hierarchy) and marshaled in derived-to-base order. Only data members are marshaled—no information is sent that would relate to operations. Unlike exceptions, no header byte precedes a class. Instead, each marshaled class instance is preceded by a (non-zero) positive integer that provides an identity for the instance. The sender assigns this identity during marshaling such that each marshaled instance has a different identity. The receiver uses that identity to correctly reconstruct graphs of classes. The overall marshaling format for classes is shown in
Figure 34.2.
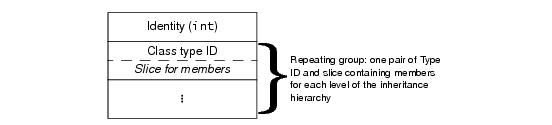
Unlike for exception type IDs, class type IDs are not simple strings. Instead, a class type ID is marshaled as a boolean followed by either a string or a size, to conserve bandwidth. To illustrate this, consider the following class hierarchy:
class Base {
// ...
};
class Derived extends Base {
// ...
};
The type IDs for the class slices are ::Derived and
::Base. Suppose the sender marshals three instances of
::Derived as part of a single request. (For example, two instances could be out-parameters and one instance could be the return value.)
The first instance that is sent on the wire contains the type IDs ::Derived and
::Base preceding their respective slices. Because marshaling proceeds in derived-to-base order, the first type ID that is sent is
::Derived. Every time the sender sends a type ID that it has not sent previously in the same request, it sends the boolean value
false, followed by the type ID. Internally, the sender also assigns a unique positive number to each type ID. These numbers start at
1 and increment by one for each type ID that has not been marshaled previously. This means that the first type ID is encoded as the boolean value
false, followed by
::Derived, and the second type ID is encoded as the boolean value
false, followed by
::Base.
When the sender marshals the remaining two instances, it consults a lookup table of previously-marshaled type IDs. Because both type IDs were sent previously in the same request (or reply), the sender encodes all further occurrences of
::Derived as the value
true followed by the number
1 encoded as a size (see
Section 34.2.1), and it encodes all further occurrences of
::Base as the value
true followed by the number
2 encoded as a size.
•
If the boolean is false, the receiver reads a string and enters that string into a lookup table that maps integers to strings. The first new class type ID received in a request is numbered
1, the second new class type ID is numbered
2, and so on.
•
If the boolean value is true, the receiver reads a number encoded as a size and uses that number to index into the lookup table to retrieve the corresponding class type ID.
Note that this numbering scheme is re-established for each new encapsulation. (As we will see in
Section 34.3, parameters, return values, and exceptions are always marshaled inside an enclosing encapsulation.) For subsequent or nested encapsulation, the numbering scheme restarts, with the first new type ID being assigned the value
1. In other words, each encapsulation uses its own independent numbering scheme for class type IDs to satisfy the constraint that encapsulations must not depend on their surrounding context.
Encoding class type IDs in this way provides significant savings in bandwidth: whenever an ID is marshaled a second and subsequent time, it is marshaled as a two-byte value (assuming no more than 254 distinct type IDs per request) instead of as a string. Because type IDs can be long, especially if you are using nested modules, the savings are considerable.
interface SomeInterface {
void op1();
};
class Base {
int baseInt;
void op2();
string baseString;
};
class Derived extends Base implements SomeInterface {
bool derivedBool;
string derivedString;
void op3();
double derivedDouble;
};
Note that Base and
Derived have operations, and that
Derived also implements the interface
SomeInterface. Because marshaling of classes is concerned with state, not behavior, the operations
op1,
op2, and
op3 are simply ignored during marshaling and the on-the-wire representation is as if the classes had been defined as follows:
class Base {
int baseInt;
string baseString;
};
class Derived extends Base {
bool derivedBool;
string derivedString;
double derivedDouble;
};
Suppose the sender marshals two instances of Derived (for example, as two in-parameters in the same request). The member values are as shown in
Table 34.4.
The sender arbitrarily assigns a non-zero identity (see page 1122) to each instance. Typically, the sender will simply consecutively number the instances starting at
1. For this example, assume that the two instances have the identities
1 and
2. The marshaled representation for the two instances (assuming that they are marshaled immediately following each other) is shown in
Table 34.5.
|
|
|
|
|
|
|
|
|
|
0 (marker for class type ID)
|
|
|
|
"::Derived" (class type ID)
|
|
|
|
20 (byte count for slice)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 (marker for class type ID)
|
|
|
|
|
|
|
|
|
14 (byte count for slice)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 (marker for class type ID)
|
|
|
|
"::Ice::Object" (class type ID)
|
|
|
|
|
|
|
|
|
0 (number of dictionary entries)
|
|
|
|
|
|
|
|
|
1 (marker for class type ID)
|
|
|
|
|
|
|
|
|
19 (byte count for slice)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 (marker for class type ID)
|
|
|
|
|
|
|
|
|
13 (byte count for slice)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 (marker for class type ID)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 (number of dictionary entries)
|
|
|
|
Note that, because classes (like exceptions) are sent as a sequence of slices, the receiver of a class can slice off any derived parts of a class it does not understand. Also note that (as shown in
Table 34.5) each class instance contains three slices. The third slice is for the type
::Ice::Object, which is the base type of all classes. The class type ID
::Ice::Object has the number
3 in this example because it is the third distinct type ID that is marshaled by the sender. (See entries at byte offsets 58 and 118 in
Table 34.5.) All class instances have this final slice of type
::Ice::Object.
Marshaling a separate slice for ::Ice::Object dates back to Ice versions 1.3 and earlier. In those versions, classes carried a facet map that was marshaled as if it were defined as follows:
module Ice {
class Object;
dictionary<string, Object> FacetMap;
class Object {
FacetMap facets; // No longer exists
};
};
As of Ice version 1.4, this facet map is always empty, that is, the count of entries for the dictionary that is marshaled in the
::Ice::Object slice is always zero. If a receiver receives a class instance with a non-empty facet map, it must throw a
MarshalException.
Note that if a class has no data members, a type ID and slice for that class is still marshaled. The byte count of the slice will be 4 in this case, indicating that the slice contains no data.
Classes support pointer semantics, that is, you can construct graphs of classes. It follows that classes can arbitrarily point at each other. The class identity (see
page 1122) is used to distinguish instances and pointers as follows:
Identity values less than zero are pointers. For example, if the receiver receives the identity
−57, this means that the corresponding class member that is currently being unmarshaled will eventually point at the instance with identity 57.
For structures, classes, exceptions, sequences, and dictionary members that do not contain class members, the Ice protocol uses a simple depth-first traversal algorithm to marshal the members. For example, structure members are marshaled in the order of their Slice definition; if a structure member itself is of complex type, such as a sequence, the sequence is marshaled in toto where it appears inside its enclosing structure. For complex types that contain class members, this depth-first marshaling is suspended: instead of marshaling the actual class instance at this point, a negative identity is marshaled that indicates which class instance that member must eventually denote. For example, consider the following definitions:
class C {
// ...
};
struct S {
int i;
C firstC;
C secondC;
C thirdC;
int j;
};
S myS;
myS.i = 99;
myS.firstC = new C; // New instance
myS.secondC = 0; // null
myS.thirdC = myS.firstC; // Same instance as previously
myS.j = 100;
When this structure is marshaled, the contents of the three class members are not marshaled in‑line. Instead, the sender marshals the negative identities of the corresponding instances. Assuming that the sender has assigned the identity 78 to the instance assigned to
myS.firstC,
myS is marshaled as shown in
Table 34.6.
Note that myS.firstC and
myS.thirdC both use the identity
−78. This allows the receiver to recognize that
firstC and
thirdC point at the same class instance (rather than at two different instances that happen to have the same contents).
Marshaling the negative identities instead of the contents of an instance allows the receiver to accurately reconstruct the class graph that was sent by the sender. However, this begs the question of
when the actual instances are to be marshaled as described at the beginning of this section. As we will see in
Section 34.3, parameters and return values are marshaled as if they were members of a structure. For example, if an operation invocation has five input parameters, the client marshals the five parameters end-to-end as if they were members of a single structure. If any of the five parameters are class instances, or are of complex type (recursively) containing class instances, the sender marshals the parameters in multiple passes: the first pass marshals the parameters end-to-end, using the usual depth-first algorithm:
Once the first pass ends, the sender has marshaled all the parameters, but has not yet marshaled any of the class instances that may be pointed at by various parameters or members. The identity table at this point contains all those instances for which negative identities (pointers) were marshaled, so whatever is in the identity table at this point are the classes that the receiver still needs. The sender now marshals those instances in the identity table, but with positive identities and followed by their contents, as described on
page 1124. The outstanding instances are marshaled as a sequence, that is, the sender marshals the number of instances as a size (see
Section 34.2.1), followed by the actual instances.
In turn, the instances just sent may themselves contain class members; when those class members are marshaled, the sender assigns an identity to new instances or uses a negative identity for previously marshaled instances as usual. This means that, by the end of the second pass, the identity table may have grown, necessitating a third pass. That third pass again marshals the outstanding class instances as a size followed by the actual instances. The third pass contains all those instances that were not marshaled in the second pass. Of course, the third pass may trigger yet more passes until, finally, the sender has sent all outstanding instances, that is, marshaling is complete. At this point, the sender terminates the sequence of passes by marshaling an empty sequence (the value
0 encoded as a size).
enum UnaryOp { UnaryPlus, UnaryMinus, Not };
enum BinaryOp { Plus, Minus, Multiply, Divide, And, Or };
class Node {
idempotent long eval();
};
class UnaryOperator extends Node {
UnaryOp operator;
Node operand;
};
class BinaryOperator extends Node {
BinaryOp op;
Node operand1;
Node operand2;
};
class Operand {
long val;
};
These definitions allow us to construct expression trees. Suppose the client initializes a tree to the shape shown in
Figure 34.3, representing the expression
(1 + 6 / 2) ∗ (9 − 3). The values outside the nodes are the identities assigned by the client.
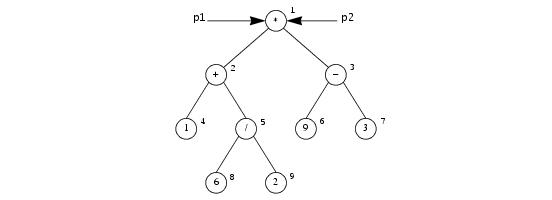
The client passes the root of the tree to the following operation in the parameters p1 and
p2, as shown on
page 1131. (Even though it does not make sense to pass the same parameter value twice, we do it here for illustration purposes):
interface Tree {
void sendTree(Node p1, Node p2);
};
The client now marshals the two parameters p1 and
p2 to the server, resulting in the value
‑1 being sent twice in succession. (The client arbitrarily assigns an identity to each node. The value of the identity does not matter, as long as each node has a unique identity. For simplicity, the Ice implementation numbers instances with a counter that starts counting at
1 and increments by one for each unique instance.) This completes the marshaling of the parameters and results in a single instance with identity 1 in the identity table. The client now marshals a sequence containing a single element, node 1, as described on
page 1124. In turn, node 1 results in nodes 2 and 3 being added to the identity table, so the next sequence of nodes contains two elements, nodes 2 and 3. The next sequence of nodes contains nodes 4, 5, 6, and 7, followed by another sequence containing nodes 8 and 9. At this point, no more class instances are outstanding, and the client marshals an empty sequence to indicate to the receiver that the final sequence has been marshaled.
Within each sequence, the order in which class instances are marshaled is irrelevant. For example, the third sequence could equally contain nodes 7, 6, 4, and 5, in that order. What is important here is that each sequence contains nodes that are an equal number of "hops" away from the initial node: the first sequence contains the initial node(s), the second sequence contains all nodes that can be reached by traversing a single link from the initial node(s), the third sequence contains all nodes that can be reached by traversing two links from the initial node(s), and so on.
Now consider the same example once more, but with different parameter values for
sendTree:
p1 denotes the root of the tree, and
p2 denotes the
− operator of the right-hand sub-tree, as shown in
Figure 34.4.
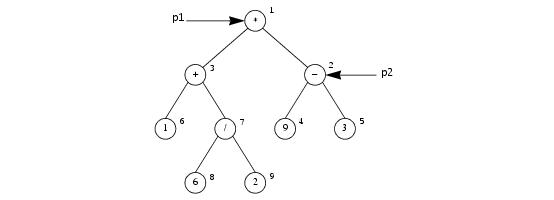
In this way, any graph of nodes can be transmitted (including graphs that contain cycles). The receiver reconstructs the graph by filling in a patch table during unmarshaling:
Note that the receiver may receive negative identities that denote class instances that have been unmarshaled already (that is, point "backward" in the unmarshaling stream), as well as instances that are yet to be unmarshaled (that is, point "forward" in the unmarshaling stream). Both scenarios are possible, depending on the order in which instances are marshaled, as well as their in‑degree.
class C {
// ...
};
sequence<C> CSeq;
Suppose the client marshals a sequence of 100 C instances to the server, with each instance being distinct. (That is, the sequence contains 100 pointers to 100 different instances, not 100 pointers to the same single instance.) In that case, the sequence is marshaled as a size of 100, followed by 100 negative identities,
‑1 to
‑100. Following that, the client marshals a single sequence containing the 100 instances, each instance with its positive identity in the range
1 to
100, and completes by marshaling an empty sequence.
On the other hand, if the client sends a sequence of 100 elements that all point to the same single class instance, the client marshals the sequence as a size of 100, followed by 100 negative identities, all with the value
‑1. The client then marshals a sequence containing a single element, namely instance
1, and completes by marshaling an empty sequence.
It is important to note that when a graph of class instances is sent, it always forms a connected graph. However, when the receiver rebuilds the graph, it may end up with a disconnected graph, due to slicing. Consider:
class Base {
// ...
};
class Derived extends Base {
// ...
Base b;
};
interface Example {
void op(Base p);
};
Suppose the client has complete type knowledge, that is, understands both types Base and
Derived, but the server only understands type
Base, so the derived part of a
Derived instance is sliced. The client can instantiate classes to be sent as parameter
p as follows:
DerivedPtr p = new Derived;
p‑>b = new Derived;
ExamplePrx e = ...;
e‑>op(p);
However, the server does not understand the derived part of the instances and slices them. Yet, the server unmarshals all the class instances, leading to the situation where the class graph has become disconnected, as shown in
Figure 34.6.

If an exception contains class members, its header byte (see page 1119) is
1 and the exception members are followed by the outstanding class instances as described on the preceding pages, that is, the actual exception members are followed by one or more sequences that contain the outstanding class instances, followed by an empty sequence that serves as an end marker.
Interfaces can be marshaled by value (see Section 4.11.12). For an interface marshaled by value (as opposed to a class instance derived from that interface), only the type ID of the most-derived interface is encoded. Here are the Slice definitions once more:
interface Base { /* ... */ };
interface Derived extends Base { /* ... */ };
interface Example {
void doSomething(Base b);
};
If the client passes a class instance to doSomething that does not have a Slice definition (but derives from
Derived), the on-the-wire representation of the interface is as follows:
|
|
|
|
|
|
|
|
|
|
0 (marker for class type ID)
|
|
|
|
"::Derived" (class type ID)
|
|
|
|
|
|
|
|
|
0 (marker for class type ID)
|
|
|
|
"::Ice::Object" (class type ID)
|
|
|
|
|
|
|
|
|
0 (number of dictionary entries)
|
|
|
|
The first component of an encoded proxy is a value of type Ice::Identity. If the proxy is a nil value, the
category and
name members are empty strings, and no additional data is encoded. The encoding for a non-null proxy consists of general parameters followed by endpoint parameters.
|
|
|
|
|
|
|
|
|
|
|
The proxy mode (0=twoway, 1=oneway, 2=batch oneway, 3=datagram, 4=batch datagram)
|
|
|
true if secure endpoints are required, otherwise false
|
The facet field has either zero elements or one element. An empty sequence denotes the default facet, and a one-element sequence provides the facet name in its first member. If a receiver receives a proxy with a
facet field with more than one element, it must throw a
ProxyUnmarshalException.
Type-specific endpoint parameters are encapsulated because a receiver may not be capable of decoding them. For example, a receiver can only decode SSL endpoint parameters if it is configured with the SSL plug‑in (see
Chapter 38). However, the receiver must be able to re-encode the proxy with all of its original endpoints, in the order they were received, even if the receiver does not understand the type-specific parameters for an endpoint. Encapsulation of the parameters allows the receiver to do this.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
true if compression should be used (if possible), otherwise false
|
See Section 34.4 for more information on compression.
struct UDPEndpointData { string host;
int port;
byte protocolMajor;
byte protocolMinor;
byte encodingMajor;
byte encodingMinor;
bool compress;
};
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
true if compression should be used (if possible), otherwise false
|
See Section 34.4 for more information on compression.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
true if compression should be used (if possible), otherwise false
|
See Section 34.4 for more information on compression.