struct TimeOfDay {
short hour; // 0 ‑ 23
short minute; // 0 ‑ 59
short second; // 0 ‑ 59
};
interface Clock {
TimeOfDay getTime();
void setTime(TimeOfDay time);
};
This definition defines an interface type called Clock. The interface supports two operations:
getTime and
setTime. Clients access an object supporting the
Clock interface by invoking an operation on the proxy for the object: to read the current time, the client invokes the
getTime operation; to set the current time, the client invokes the
setTime operation, passing an argument of type
TimeOfDay.
Invoking an operation on a proxy instructs the Ice run time to send a message to the target object. The target object can be in another address space or can be collocated (in the same process) as the caller—the location of the target object is transparent to the client. If the target object is in another (possibly remote) address space, the Ice run time invokes the operation via a remote procedure call; if the target is collocated with the client, the Ice run time uses an ordinary function call instead, to avoid the overhead of marshaling.
You can think of an interface definition as the equivalent of the public part of a C++ class definition or as the equivalent of a Java interface, and of operation definitions as (virtual) member functions. Note that nothing but operation definitions are allowed to appear inside an interface definition. In particular, you cannot define a type, an exception, or a data member inside an interface. This does not mean that your object implementation cannot contain state—it can, but how that state is implemented (in the form of data members or otherwise) is hidden from the client and, therefore, need not appear in the object’s interface definition.
An Ice object has exactly one (most derived) Slice interface type (or class type—see
Section 4.11). Of course, you can create multiple Ice objects that have the same type; to draw the analogy with C++, a Slice interface corresponds to a C++ class
definition, whereas an Ice object corresponds to a C++ class
instance (but Ice objects can be implemented in multiple different address spaces).
A Slice interface defines the smallest grain of distribution in Ice: each Ice object has a unique identity (encapsulated in its proxy) that distinguishes it from all other Ice objects; for communication to take place, you must invoke operations on an object’s proxy. There is no other notion of an addressable entity in Ice. You cannot, for example, instantiate a Slice structure and have clients manipulate that structure remotely. To make the structure accessible, you must create an interface that allows clients to access the structure.
The partition of an application into interfaces therefore has profound influence on the overall architecture. Distribution boundaries must follow interface (or class) boundaries; you can spread the implementation of interfaces over multiple address spaces (and you can implement multiple interfaces in the same address space), but you cannot implement parts of interfaces in different address spaces.
An operation definition must contain a return type and zero or more parameter definitions. For example, the
getTime operation on
page 105 has a return type of
TimeOfDay and the
setTime operation has a return type of
void. You must use
void to indicate that an operation returns no value—there is no default return type for Slice operations.
An operation can have one or more input parameters. For example, setTime accepts a single input parameter of type
TimeOfDay called
time. Of course, you can use multiple input parameters, for example:
interface CircadianRhythm {
void setSleepPeriod(TimeOfDay startTime, TimeOfDay stopTime);
// ...
};
interface CircadianRhythm {
void setSleepPeriod(TimeOfDay, TimeOfDay); // Error!
// ...
};
By default, parameters are sent from the client to the server, that is, they are input parameters. To pass a value from the server to the client, you can use an output parameter, indicated by the
out keyword. For example, an alternative way to define the
getTime operation on
page 105 would be:
void getTime(out TimeOfDay time);
interface CircadianRhythm {
void setSleepPeriod(TimeOfDay startTime, TimeOfDay stopTime);
void getSleepPeriod(out TimeOfDay startTime,
out TimeOfDay stopTime);
// ...
};
void changeSleepPeriod( TimeOfDay startTime, // OK
TimeOfDay stopTime,
out TimeOfDay prevStartTime,
out TimeOfDay prevStopTime);
void changeSleepPeriod(out TimeOfDay prevStartTime,
out TimeOfDay prevStopTime,
TimeOfDay startTime, // Error
TimeOfDay stopTime);
Slice does not support parameters that are both input and output parameters (call by reference). The reason is that, for remote calls, reference parameters do not result in the same savings that one can obtain for call by reference in programming languages. (Data still needs to be copied in both directions and any gains in marshaling efficiency are negligible.) Also, reference (or input–output) parameters result in more complex language mappings, with concomitant increases in code size.
As you would expect, language mappings follow the style of operation definition you use in Slice: Slice return types map to programming language return types, and Slice parameters map to programming language parameters.
For operations that return only a single value, it is common to return the value from the operation instead of using an out-parameter. This style maps naturally into all programming languages. Note that, if you use an out-parameter instead, you impose a different API style on the client: most programming languages permit the return value of a function to be ignored whereas it is typically not possible to ignore an output parameter.
For operations that return multiple values, it is common to return all values as out-parameters and to use a return type of
void. However, the rule is not all that clear-cut because operations with multiple output values can have one particular value that is considered more “important” than the remainder. A common example of this is an iterator operation that returns items from a collection one-by-one:
bool next(out RecordType r);
The next operation returns two values: the record that was retrieved and a Boolean to indicate the end-of-collection condition. (If the return value is
false, the end of the collection has been reached and the parameter
r has an undefined value.) This style of definition can be useful because it naturally fits into the way programmers write control structures. For example:
while (next(record))
// Process record...
if (next(record))
// Got a valid record...
interface CircadianRhythm {
void modify(TimeOfDay startTime,
TimeOfDay endTime);
void modify( TimeOfDay startTime, // Error
TimeOfDay endTime,
out timeOfDay prevStartTime,
out TimeOfDay prevEndTime);
};
Operations in the same interface must have different names, regardless of what type and number of parameters they have. This restriction exists because overloaded functions cannot sensibly be mapped to languages without built‑in support for overloading.
1
Some operations, such as getTime on
page 105, do not modify the state of the object they operate on. They are the conceptual equivalent of C++
const member functions. Similary,
setTime does modify the state of the object, but is idempotent. You can indicate this in Slice as follows:
interface Clock {
idempotent TimeOfDay getTime();
idempotent void setTime(TimeOfDay time);
};
This marks the getTime and
setTime operations as idempotent. An operation is idempotent if two successive invocations of the operation have the same effect as a single invocation. For example,
x = 1; is an idempotent operation because it does not matter whether it is executed once or twice—either way,
x ends up with the value
1. On the other hand,
x += 1; is not an idempotent operation because executing it twice results in a different value for
x than executing it once. Obviously, any read-only operation is idempotent.
The idempotent keyword is useful because it allows the Ice run time to attempt more aggressive error recovery. Specifically, Ice guarantees
at-most-once semantics for operation invocations:
•
For normal (not idempotent) operations, the Ice run time has to be conservative about how it deals with errors. For example, if a client sends an operation invocation to a server and then loses connectivity, there is no way for the client-side run time to find out whether the request it sent actually made it to the server. This means that the run time cannot attempt to recover from the error by re-establishing a connection and sending the request a second time because that could cause the operation to be invoked a second time and violate at-most-once semantics; the run time has no option but to report the error to the application.
•
For idempotent operations, on the other hand, the client-side run time can attempt to re-establish a connection to the server and safely send the failed request a second time. If the server can be reached on the second attempt, everything is fine and the application never notices the (temporary) failure. Only if the second attempt fails need the run time report the error back to the application. (The number of retries can be increased with an Ice configuration parameter.)
Looking at the setTime operation on
page 105, we find a potential problem: given that the
TimeOfDay structure uses
short as the type of each field, what will happen if a client invokes the
setTime operation and passes a
TimeOfDay value with meaningless field values, such as
‑199 for the minute field, or
42 for the hour? Obviously, it would be nice to provide some indication to the caller that this is meaningless. Slice allows you to define user exceptions to indicate error conditions to the client. For example:
exception Error {}; // Empty exceptions are legal
exception RangeError {
TimeOfDay errorTime;
TimeOfDay minTime;
TimeOfDay maxTime;
};
A user exception is much like a structure in that it contains a number of data members. However, unlike structures, exceptions can have zero data members, that is, be empty.
exception RangeError {
TimeOfDay errorTime;
TimeOfDay minTime;
TimeOfDay maxTime;
string reason = "out of range";
};
The legal syntax for literal values is the same as for Slice constants (see Section 4.9.5). The language mapping guarantees that data members are initialized to their declared default values using a language-specific mechanism.
Exceptions allow you to return an arbitrary amount of error information to the client if an error condition arises in the implementation of an operation. Operations use an exception specification to indicate the exceptions that may be returned to the client:
interface Clock {
idempotent TimeOfDay getTime();
idempotent void setTime(TimeOfDay time)
throws RangeError, Error;
};
This definition indicates that the setTime operation may throw either a
RangeError or an
Error user exception (and no other type of exception). If the client receives a
RangeError exception, the exception contains the
TimeOfDay value that was passed to
setTime and caused the error (in the
errorTime member), as well as the minimum and maximum time values that can be used (in the
minTime and
maxTime members). If
setTime failed because of an error not caused by an illegal parameter value, it throws
Error. Obviously, because
Error does not have data members, the client will have no idea what exactly it was that went wrong—it simply knows that the operation did not work.
An operation can throw only those user exceptions that are listed in its exception specification. If, at run time, the implementation of an operation throws an exception that is not listed in its exception specification, the client receives a run-time exception (see
Section 4.10.4) to indicate that the operation did something illegal. To indicate that an operation does not throw any user exception, simply omit the exception specification. (There is no empty exception specification in Slice.)
The reason for these restrictions is that some implementation languages use a specific and separate type for exceptions (in the same way as Slice does). For such languages, it would be difficult to map exceptions if they could be used as an ordinary data type. (C++ is somewhat unusual among programming languages by allowing arbitrary types to be used as exceptions.)
exception ErrorBase {
string reason;
};
enum RTError {
DivideByZero, NegativeRoot, IllegalNull /* ... */
};
exception RuntimeError extends ErrorBase {
RTError err;
};
enum LError { ValueOutOfRange, ValuesInconsistent, /* ... */ };
exception LogicError extends ErrorBase {
LError err;
};
exception RangeError extends LogicError {
TimeOfDay errorTime;
TimeOfDay minTime;
TimeOfDay maxTime;
};
•
ErrorBase is at the root of the tree and contains a string explaining the cause of the error.
•
Derived from ErrorBase are
RuntimeError and
LogicError. Each of these exceptions contains an enumerated value that further categorizes the error.
•
Finally, RangeError is derived from
LogicError and reports the details of the specific error.
Setting up exception hierarchies such as this not only helps to create a more readable specification because errors are categorized, but also can be used at the language level to good advantage. For example, the Slice C++ mapping preserves the exception hierarchy so you can catch exceptions generically as a base exception, or set up exception handlers to deal with specific exceptions.
Looking at the exception hierarchy on page 112, it is not clear whether, at run time, the application will only throw most derived exceptions, such as
RangeError, or if it will also throw base exceptions, such as
LogicError,
RuntimeError, and
ErrorBase. If you want to indicate that a base exception, interface, or class is abstract (will not be instantiated), you can add a comment to that effect.
Note that, if the exception specification of an operation indicates a specific exception type, at run time, the implementation of the operation may also throw more derived exceptions. For example:
exception Base {
// ...
};
exception Derived extends Base {
// ...
};
interface Example {
void op() throws Base; // May throw Base or Derived
};
In this example, op may throw a
Base or a
Derived exception, that is, any exception that is compatible with the exception types listed in the exception specification can be thrown at run time.
As a system evolves, it is quite common for new, derived exceptions to be added to an existing hierarchy. Assume that we initially construct clients and server with the following definitions:
exception Error {
// ...
};
interface Application {
void doSomething() throws Error;
};
Also assume that a large number of clients are deployed in field, that is, when you upgrade the system, you cannot easily upgrade all the clients. As the application evolves, a new exception is added to the system and the server is redeployed with the new definition:
exception Error {
// ...
};
exception FatalApplicationError extends Error {
// ...
};
interface Application {
void doSomething() throws Error;
};
This raises the question of what should happen if the server throws a FatalApplicationError from
doSomething. The answer depends whether the client was built using the old or the updated definition:
•
If the client was built with the original definition, that client has no knowledge that
FatalApplicationError even exists. In this case, the Ice run time automatically slices the exception to the most-derived type that is understood by the receiver (
Error, in this case) and discards the information that is specific to the derived part of the exception. (This is exactly analogous to catching C++ exceptions by value—the exception is sliced to the type used in the
catch-clause.)
As mentioned in Section 2.2.2, in addition to any user exceptions that are listed in an operation’s exception specification, an operation can also throw Ice
run-time exceptions. Run-time exceptions are predefined exceptions that indicate platform-related run-time errors. For example, if a networking error interrupts communication between client and server, the client is informed of this by a run-time exception, such as
ConnectTimeoutException or
SocketException.
The exception specification of an operation must not list any run-time exceptions. (It is understood that all operations can raise run-time exceptions and you are not allowed to restate that.)
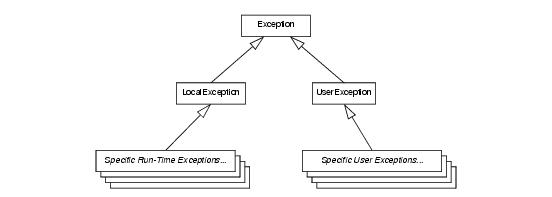
Ice::Exception is at the root of the inheritance hierarchy. Derived from that are the (abstract) types
Ice::LocalException and
Ice::UserException. In turn, all run-time exceptions are derived from
Ice::LocalException, and all user exceptions are derived from
Ice::UserException.
Figure 4.4 shows the complete hierarchy of the Ice run-time exceptions.
2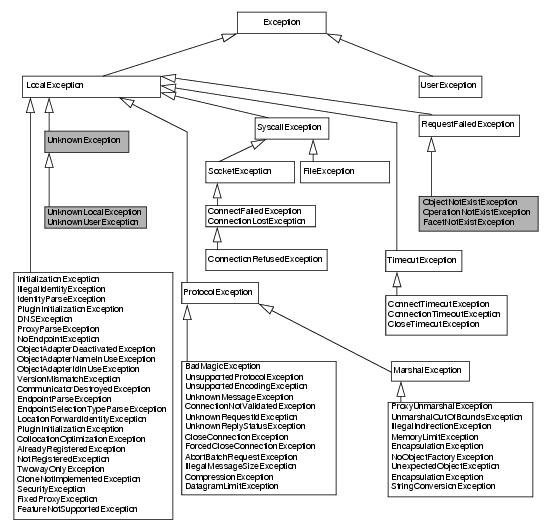
Note that Figure 4.4 groups several exceptions into a single box to save space (which, strictly, is incorrect UML syntax). Also note that some run-time exceptions have data members, which, for brevity, we have omitted in
Figure 4.4. These data members provide additional information about the precise cause of an error.
Many of the run-time exceptions have self-explanatory names, such as MemoryLimitException. Others indicate problems in the Ice run time, such as
EncapsulationException. Still others can arise only through application programming errors, such as
TwowayOnlyException. In practice, you will likely never see most of these exceptions. However, there are a few run-time exceptions you will encounter and whose meaning you should know.
Most error conditions are detected on the client side. For example, if an attempt to contact a server fails, the client-side run time raises a
ConnectTimeoutException. However, there are three specific error conditions (shaded in
Figure 4.4) that are detected by the server and made known explicitly to the client-side run time via the Ice protocol:
An ObjectNotExistException is a death certificate: it indicates that the target object in the server does not exist.
3 Most likely, this is the case because the object existed some time in the past and has since been destroyed, but the same exception is also raised if a client uses a proxy with the identity of an object that has never been created. If you receive this exception, you are expected to clean up whatever resources you might have allocated that relate to the specific object for which you receive this exception.
Any error condition on the server side that is not described by one of the three preceding exceptions is made known to the client as one of three generic exceptions (shaded in
Figure 4.4):
If an operation implementation raises a run-time exception other than ObjectNotExistException,
FacetNotExistException, or
OperationNotExistException (such as a
NotRegisteredException), the client receives an
UnknownLocalException. In other words, the Ice protocol does not transmit the exact exception that was encountered in the server, but simply returns a bit to the client in the reply to indicate that the server encountered a run-time exception.
A common cause for a client receiving an UnknownLocalException is failure to catch and handle all exceptions in the server. For example, if the implementation of an operation encounters an exception it does not handle, the exception propagates all the way up the call stack until the stack is unwound to the point where the Ice run time invoked the operation. The Ice run time catches all Ice exceptions that “escape” from an operation invocation and returns them to the client as an
UnknownLocalException.
All other run-time exceptions (not shaded in Figure 4.4) are detected by the client-side run time and are raised locally.
It is possible for the implementation of an operation to throw Ice run-time exceptions (as well as user exceptions). For example, if a client holds a proxy to an object that no longer exists in the server, your server application code is required to throw an
ObjectNotExistException. If you do throw run-time exceptions from your application code, you should take care to throw a run-time exception only if appropriate, that is, do not use run-time exceptions to indicate something that really should be a user exception. Doing so can be very confusing to the client: if the application “hijacks” some run-time exceptions for its own purposes, the client can no longer decide whether the exception was thrown by the Ice run time or by the server application code. This can make debugging very difficult.
Building on the Clock example, we can create definitions for a world-time server:
exception GenericError {
string reason;
};
struct TimeOfDay {
short hour; // 0 ‑ 23
short minute; // 0 ‑ 59
short second; // 0 ‑ 59
};
exception BadTimeVal extends GenericError {};
interface Clock {
idempotent TimeOfDay getTime();
idempotent void setTime(TimeOfDay time) throws BadTimeVal;
};
dictionary<string, Clock*> TimeMap; // Time zone name to clock map
exception BadZoneName extends GenericError {};
interface WorldTime {
idempotent void addZone(string zoneName, Clock* zoneClock);
void removeZone(string zoneName) throws BadZoneName;
idempotent Clock* findZone(string zoneName)
throws BadZoneName;
idempotent TimeMap listZones();
idempotent void setZones(TimeMap zones);
};
The WorldTime interface acts as a collection manager for clocks, one for each time zone. In other words, the
WorldTime interface manages a collection of pairs. The first member of each pair is a time zone name; the second member of the pair is the clock that provides the time for that zone. The interface contains operations that permit you to add or remove a clock from the map (
addZone and
removeZone), to search for a particular time zone by name (
findZone), and to read or write the entire map (
listZones and
setZones).
The WorldTime example illustrates an important Slice concept: note that
addZone accepts a parameter of type
Clock* and
findZone returns a parameter of type
Clock*. In other words, interfaces are types in their own right and can be passed as parameters. The
* operator is known as the
proxy operator. Its left-hand argument must be an interface (or class—see
Section 4.11) and its return type is a proxy. A proxy is like a pointer that can denote an object. The semantics of proxies are very much like those of C++ class instance pointers:
When a client passes a Clock proxy to the
addZone operation, the proxy denotes an actual
Clock object in a server. The
Clock Ice object denoted by that proxy may be implemented in the same server process as the
WorldTime interface, or in a different server process. Where the
Clock object is physically implemented matters neither to the client nor to the server implementing the
WorldTime interface; if either invokes an operation on a particular clock, such as
getTime, an RPC call is sent to whatever server implements that particular clock. In other words, a proxy acts as a local “ambassador” for the remote object; invoking an operation on the proxy forwards the invocation to the actual object implementation. If the object implementation is in a different address space, this results in a remote procedure call; if the object implementation is collocated in the same address space, the Ice run time uses an ordinary local function call from the proxy to the object implementation.
Note that proxies also act very much like pointers in their sharing semantics: if two clients have a proxy to the same object, a state change made by one client (such as setting the time) will be visible to the other client.
Proxies are strongly typed (at least for statically typed languages, such as C++ and Java). This means that you cannot pass something other than a
Clock proxy to the
addZone operation; attempts to do so are rejected at compile time.
interface AlarmClock extends Clock {
idempotent TimeOfDay getAlarmTime();
idempotent void setAlarmTime(TimeOfDay alarmTime)
throws BadTimeVal;
};
The semantics of this are the same as for C++ or Java: AlarmClock is a subtype of
Clock and an
AlarmClock proxy can be substituted wherever a
Clock proxy is expected. Obviously, an
AlarmClock supports the same
getTime and
setTime operations as a
Clock but also supports the
getAlarmTime and
setAlarmTime operations.
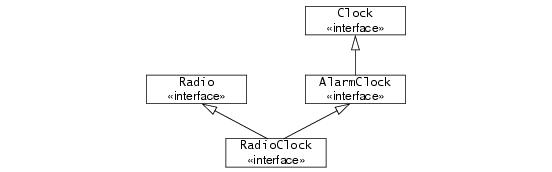
interface Radio {
void setFrequency(long hertz) throws GenericError;
void setVolume(long dB) throws GenericError;
};
enum AlarmMode { RadioAlarm, BeepAlarm };
interface RadioClock extends Radio, AlarmClock {
void setMode(AlarmMode mode);
AlarmMode getMode();
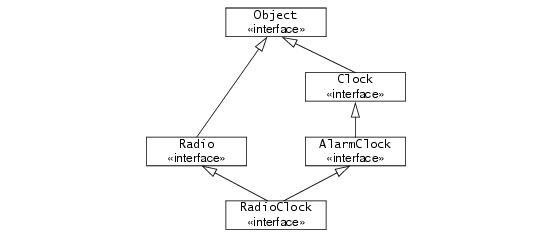
};
RadioClock extends both
Radio and
AlarmClock and can therefore be passed where a
Radio, an
AlarmClock, or a
Clock is expected. The inheritance diagram for this definition looks as follows:
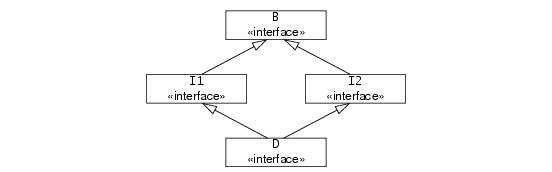
interface B { /* ... */ };
interface I1 extends B { /* ... */ };
interface I2 extends B { /* ... */ };
interface D extends I1, I2 { /* ... */ };
If an interface uses multiple inheritance, it must not inherit the same operation name from more than one base interface. For example, the following definition is illegal:
interface Clock {
void set(TimeOfDay time); // set time
};
interface Radio {
void set(long hertz); // set frequency
};
interface RadioClock extends Radio, Clock { // Illegal!
// ...
};
This definition is illegal because RadioClock inherits two
set operations,
Radio::set and
Clock::set. The Slice compiler makes this illegal because (unlike C++) many programming languages do not have a built‑in facility for disambiguating the different operations. In Slice, the simple rule is that all inherited operations must have unique names. (In practice, this is rarely a problem because inheritance is rarely added to an interface hierarchy “after the fact”. To avoid accidental clashes, we suggest that you use descriptive operation names, such as
setTime and
setFrequency. This makes accidental name clashes less likely.)
All Slice interfaces are ultimately derived from Object. For example, the inheritance hierarchy from
Figure 4.5 would be shown more correctly as in
Figure 4.7.
interface ProxyStore {
idempotent void putProxy(string name, Object* o);
idempotent Object* getProxy(string name);
};
Object is a Slice keyword (note the capitalization) that denotes the root type of the inheritance hierarchy. The
ProxyStore interface is a generic proxy storage facility: the client can call
putProxy to add a proxy of any type under a given name and later retrieve that proxy again by calling
getProxy and supplying that name. The ability to generically store proxies in this fashion allows us to build general-purpose facilities, such as a naming service that can store proxies and deliver them to clients. Such a service, in turn, allows us to avoid hard-coding proxy details into clients and servers (see
Chapter 38).
Inheritance from type Object is always implicit. For example, the following Slice definition is illegal:
interface MyInterface extends Object { /* ... */ }; // Error!
Type Object is mapped to an abstract type by the various language mappings, so you cannot instantiate an Ice object of that type.
Looking at the ProxyStore interface once more, we notice that
getProxy does not have an exception specification. The question then is what should happen if a client calls
getProxy with a name under which no proxy is stored? Obviously, we could add an exception to indicate this condition to
getProxy. However, another option is to return a
null proxy. Ice has the built‑in notion of a null proxy, which is a proxy that “points nowhere”. When such a proxy is returned to the client, the client can test the value of the returned proxy to check whether it is null or denotes a valid object.
A more interesting question is: “which approach is more appropriate, throwing an exception or returning a null proxy?” The answer depends on the expected usage pattern of an interface. For example, if, in normal operation, you do not expect clients to call
getProxy with a non-existent name, it is better to throw an exception. (This is probably the case for our
ProxyStore interface: the fact that there is no
list operation makes it clear that clients are expected to know which names are in use.)
On the other hand, if you expect that clients will occasionally try to look up something that is not there, it is better to return a null proxy. The reason is that throwing an exception breaks the normal flow of control in the client and requires special handling code. This means that you should throw exceptions only in exceptional circumstances. For example, throwing an exception if a database lookup returns an empty result set is wrong; it is expected and normal that a result set is occasionally empty.
It is worth paying attention to such design issues: well-designed interfaces that get these details right are easier to use and easier to understand. Not only do such interfaces make life easier for client developers, they also make it less likely that latent bugs cause problems later.
interface Link {
idempotent SomeType getValue();
idempotent Link* next();
};
The Link interface contains a
next operation that returns a proxy to a
Link interface. Obviously, this can be used to create a chain of interfaces; the final link in the chain returns a null proxy from its
next operation.
The Slice compiler will compile this definition without complaint. An interesting question is: “why would I need an empty interface?” In most cases, empty interfaces are an indication of design errors. Here is one example:
interface ThingBase {};
interface Thing1 extends ThingBase {
// Operations here...
};
interface Thing2 extends ThingBase {
// Operations here...
};
•
Thing1 and
Thing2 have a common base and are therefore related.
Of course, looking at ThingBase, we find that
Thing1 and
Thing2 do not share any operations at all because
ThingBase is empty. Given that we are using an object-oriented paradigm, this is definitely strange: in the object-oriented model, the
only way to communicate with an object is to send a message to the object. But, to send a message, we need an operation. Given that
ThingBase has no operations, we cannot send a message to it, and it follows that
Thing1 and
Thing2 are
not related because they have no common operations. But of course, seeing that
Thing1 and
Thing2 have a common base, we conclude that they
are related, otherwise the common base would not exist. At this point, most programmers begin to scratch their head and wonder what is going on here.
One common use of the above design is a desire to treat Thing1 and
Thing2 polymorphically. For example, we might continue the previous definition as follows:
interface ThingUser {
void putThing(ThingBase* thing);
};
Now the purpose of having the common base becomes clear: we want to be able to pass both
Thing1 and
Thing2 proxies to
putThing. Does this justify the empty base interface? To answer this question, we need to think about what happens in the implementation of
putThing. Obviously,
putThing cannot possibly invoke an operation on a
ThingBase because there are no operations. This means that
putThing can do one of two things:
1. putThing can simply remember the value of thing.
2.
putThing can try to down-cast to either
Thing1 or
Thing2 and then invoke an operation. The pseudo-code for the implementation of
putThing would look something like this:
void putThing(ThingBase thing)
{
if (is_a(Thing1, thing)) {
// Do something with Thing1...
} else if (is_a(Thing2, thing)) {
// Do something with Thing2...
} else {
// Might be a ThingBase?
// ...
}
}
If you find yourself writing operations such as putThing that rely on artificial base interfaces, ask yourself whether you really need to do things this way. For example, a more appropriate design might be:
interface Thing1 {
// Operations here...
};
interface Thing2 {
// Operations here...
};
interface ThingUser {
void putThing1(Thing1* thing);
void putThing2(Thing2* thing);
};
With this design, Thing1 and
Thing2 are not related, and
ThingUser offers a separate operation for each type of proxy. The implementation of these operations does not need to use any down-casts, and all is well in our object-oriented world.
interface PersistentObject {};
interface Thing1 extends PersistentObject {
// Operations here...
};
interface Thing2 extends PersistentObject {
// Operations here...
};
Clearly, the intent of this design is to place persistence functionality into the PersistentObject base
implementation and require objects that want to have persistent state to inherit from
PersistentObject. On the face of things, this is reasonable: after all, using inheritance in this way is a well-established design pattern, so what can possibly be wrong with it? As it turns out, there are a number of things that are wrong with this design:
•
The above inheritance hierarchy is used to add behavior to
Thing1 and
Thing2. However, in a strict OO model, behavior can be invoked only by sending messages. But, because
PersistentObject has no operations, no messages can be sent.
This raises the question of how the implementation of PersistentObject actually goes about doing its job; presumably, it knows something about the implementation (that is, the internal state) of
Thing1 and
Thing2, so it can write that state into a database. But, if so,
PersistentObject,
Thing1, and
Thing2 can no longer be implemented in different address spaces because, in that case,
PersistentObject can no longer get at the state of
Thing1 and
Thing2.
Alternatively, Thing1 and
Thing2 use some functionality provided by
PersistentObject in order to make their internal state persistent. But
PersistentObject does not have any operations, so how would
Thing1 and
Thing2 actually go about achieving this? Again, the only way that can work is if
PersistentObject,
Thing1, and
Thing2 are implemented in a single address space and share implementation state behind the scenes, meaning that they cannot be implemented in different address spaces.
• Suppose you have an existing application with already implemented, non-persistent objects. Requirements change over time and you find that you now would like to make some of your objects persistent. With the above design, you cannot do this unless you change the type of your objects because they now must inherit from
PersistentObject. Of course, this is extremely bad news: not only do you have to change the implementation of your objects in the server, you also need to locate and update all the clients that are currently using your objects because they suddenly have a completely new type. What is worse, there is no way to keep things backward compatible: either all clients change with the server, or none of them do. It is impossible for some clients to remain “unupgraded”.
• The design does not scale to multiple features. Imagine that we have a number of additional behaviors that objects can inherit, such as serialization, fault-tolerance, persistence, and the ability to be searched by a search engine. We quickly end up in a mess of multiple inheritance. What is worse, each possible combination of features creates a completely separate type hierarchy. This means that you can no longer write operations that generically operate on a number of object types. For example, you cannot pass a persistent object to something that expects a non-persistent object,
even if the receiver of the object does not care about the persistence aspects of the object. This quickly leads to fragmented and hard-to-maintain type systems. Before long, you will either find yourself rewriting your application or end up with something that is both difficult to use and difficult to maintain.
The foregoing discussion will hopefully serve as a warning: Slice is an interface definition language that has nothing to do with
implementation (but empty interfaces almost always indicate that implementation state is shared via mechanisms other than defined interfaces). If you find yourself writing an empty interface definition, at least step back and think about the problem at hand; there may be a more appropriate design that expresses your intent more cleanly. If you do decide to go ahead with an empty interface regardless, be aware that, almost certainly, you will lose the ability to later change the distribution of the object model over physical server processes because you cannot place an address space boundary between interfaces that share hidden state.
Keep in mind that Slice interface inheritance applies only to interfaces. In particular, if two interfaces are in an inheritance relationship, this in no way implies that the implementations of those interfaces must also inherit from each other. You can choose to use implementation inheritance when you implement your interfaces, but you can also make the implementations independent of each other. (To C++ programmers, this often comes as a surprise because C++ uses implementation inheritance by default, and interface inheritance requires extra effort to implement.)
In summary, Slice inheritance simply establishes type compatibility. It says nothing about how interfaces are implemented and, therefore, keeps implementation choices open to whatever is most appropriate for your application.