

This chapter introduces Ingres Replicator and describes its benefits. It covers the following topics:
|
|
|
Replication is the act of maintaining identical copies of a defined set of data in more than one database. Replication allows continuous access to your databases, protects against catastrophic failures, improves performance, and is an excellent means of maintaining data across different database systems.
|
|
|
Ingres Replicator is a database connectivity system that manages replication. It provides transparent replication of data across databases on local or remote sites.
You can replicate between different databases on the same machine or on different machines on the other side of the world, as long as they are in a distributed network. So instead of having all your users throughout the world access the same database in one location, you can have a replicated database in every region.
Data from a transaction are not available for replication until the transaction has committed locally.
Ingres Replicator works behind the scenes to replicate data asynchronously by transaction. Designed as a layer that sits between the database and an application, Ingres Replicator is transparent to users.
Ingres Replicator queues each replicated transaction and uses two-phase commit to move the transaction from the Ingres Replicator queues to the target database. In the event of a source, target, or network failure, data integrity is enforced through this two-phase commit protocol by ensuring that either the whole transaction is replicated, or none of it is.
If the replication fails during two-phase commit, it remains in the queue and is tried again. Therefore, if one replicated database goes down, all the transactions that must be replicated to it remain queued and is sent again in the correct order as soon as it becomes available. For more information, see How Two-Phase Commit Works.
Note: Two-phase commit is not available for installations running the Ingres Cluster Solution. For information on how to turn off two-phase commit and use Ingres Replicator with clusters, see the appendix "Cluster Support."
Ingres Replicator also allows you to monitor your replicated transactions and run reports on your replication system.
|
|
|
Specific advantages of using Ingres Replicator include:
When multiple sites need access to the same data, providing replicated copies of the data at each local site reduces network traffic and improves response times. Also, by distributing the users over more than one machine, the load on any single machine is reduced, overcoming system bottlenecks.
If a node in the network becomes unavailable, replicated changes to be sent to that node are queued in order and are sent when the node comes back online. You can also configure Ingres Replicator so that if a particular machine fails, users can switch to another machine and continue working. If two databases do become inconsistent, Ingres Replicator has procedures for reconciling them that work in conjunction with the normal recovery procedures. Because your data exists in more than one location, loss of data on one machine is not catastrophic.
Ingres Replicator offers existing and future database connectivity solutions in an ever-changing computing environment. If your system operates over a number of different databases, you can use Ingres Replicator to connect them. Ingres Replicator interoperates with non-Ingres databases through Enterprise Access products. You can maintain your legacy systems, or use Ingres Replicator to complete a controlled migration to an Ingres database system. Thus users of the legacy system can access data created on desktop or other heterogeneous environments.
|
|
|
Ingres Replicator gives you significant control over the flow of data. You can configure Ingres Replicator to fit your specific needs. Because Ingres Replicator has great flexibility, the key to achieving the results you want is planning your replication scheme.
You can control:
You can replicate any combination of the following sets of data:
You can configure Ingres Replicator so that data is replicated in:
You must specify the route the replicated data takes to get to all its targets.
You can specify whether you want Ingres Replicator to propagate changes continuously, once a day, or on demand.
You can use Ingres databases in any capacity with Ingres Replicator. Certain Enterprise Access databases can be used as both source and target databases; others, however, can be used only as a target database in a read-only capacity.
|
|
|
Like Ingres Replicator, Ingres Star maintains data across two or more distributed databases.
However, Ingres Star uses two-phase commit between the local and remote databases. During an update by a local user, Ingres Star takes locks on the local database and the remote databases, and does not release the locks until the two-phase commit procedure has been successfully completed. Holding locks can cause delays for the local user.
Unlike Ingres Star, Ingres Replicator updates the local database asynchronously, and takes locks on the Ingres Replicator queues and each remote database in turn for the duration of the two-phase commit procedure. Thus, using Ingres Replicator instead of Ingres Star results in significant performance gains.
With Ingres Replicator, you can customize your replication environment in ways that are not available with Ingres Star.
With Ingres Star, either the transaction is completed in all databases or in none of them. With Ingres Replicator, however, two users can update the same record in different replicated databases. This can result in a collision. For more information, see Collision Design.
|
|
|
Security for Ingres Replicator is provided through Ingres Net, a database connection program that uses industry-standard networking protocols. Ingres Net provides security by requiring authorization before a user can access the system. Through Ingres Net, security is controlled by the operating system's password or by using Ingres Net passwords. For more information, see the Connectivity Guide.
|
|
|
To use Ingres Replicator, each location that requires data replication must have the following Ingres products:
A local DBMS server is required to support the local database. The server interprets client component requests and interacts or manipulates the database accordingly.
Ingres Net is required to access data on remote nodes on your network. It is an interface to your existing network setup and protocols. The remote transmission of replicated data among source and target databases is handled completely by Ingres Net and is transparent to the user.
|
|
|
Ingres Replicator can also be used with Enterprise Access products, including Oracle, MS SQL, DB2 UDB, RMS, RDB, or EDBC products, including CA-Datacom/DB, IBM DB2, and IMS. Ingres Replicator is compatible with all Enterprise Access products, EDBC products, and the abstract date data type, providing the database product that underlies your Enterprise Access Server or EDBC Server and your Enterprise Access product or EDBC product supports it. If your legacy system relies on data from a heterogeneous system, you can designate replicated data to be sent through the gateway.
The following figure illustrates the components of a sample Ingres Replicator environment consisting of a development tool, an Ingres DBMS Server and database, the Ingres Replicator Server, Ingres Net, two additional Ingres databases, and an Enterprise Access database:
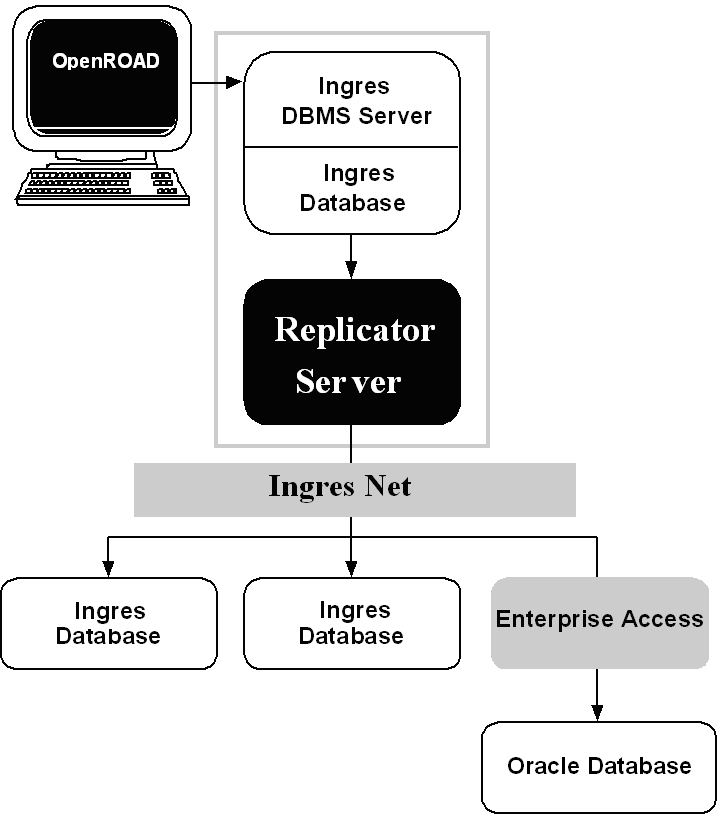
|
|
|
To create a successful replication scheme, it is important to understand concepts and terms used in Replicator.
Key Ingres Replicator concepts are as follows:
A collision is an event that occurs when more than one user updates the same replicated row in different databases. Ingres Replicator can preserve the history of changes made to each replicated row. If the same rows in two databases do not match in the last transaction, Ingres Replicator detects a collision.
For more information, see Collision Design.
A CDDS defines what data is replicated and where it resides.
The CDDS is the unit of organization in Ingres Replicator. Various processes, such as collision and error handling, are specified at the CDDS level.
For more information, see Consistent Distributed Data Set (CDDS).
A target type defines which database within a CDDS is allowed to alter the data and how Ingres Replicator acts on each database within the CDDS.
The target types are:
A CDDS has a target type defined in every database that is contained in the CDDS. You must define target types for each CDDS. For more information, see CDDS Target Types.
A data propagation path defines what route the data takes to reach target databases within a CDDS.
For more information, see Data Propagation Paths in the CDDS.
To identify information specific to Ingres Replicator during processing of a replicated row, the system generates a key for each such row.
The key consists of:
For more information, see Change Recorder.
Replicator Components defines the terms change recorder, distribution threads, and Replicator Server. Replicator Processing Tables defines the terms base table, shadow table, archive table, input queue, and distribution queue.