

|
|
|
The following design concepts organize replicated data:
|
|
|
A Consistent Distributed Data Set is a set of data that is kept consistent (identical) across two or more databases. A CDDS provides a method of defining and grouping data so that an entire database or parts of databases can be replicated to different target sites.
The CDDS gives the distributed DBA the ability to replicate information according to the needs of the business. Data can be replicated precisely when, where, and how the company requires. Changes to data in a CDDS must only be permitted to take place in full peer targets. This is not strictly enforced by Ingres Replicator, but if not adhered to, can result in collisions or inconsistencies.
A CDDS can consist of:
The whole database is replicated. For example, where two databases are geographically remote, each office accesses the local replicated database and propagates changes to the other database.
Only certain tables in the database are replicated. For example, branch offices do not need all the information that the head office has. For a detailed example, see CDDS Example: Subset of Tables.
Only selected columns in selected tables are replicated. For a detailed example, see CDDS Example: Vertical Partitioning.
Only certain rows from selected tables are replicated based on the values of one or more columns. For example, the branch office in London only gets those rows with London in the location column. Horizontal partitioning can only be done for specific values; data ranges are not allowed. For a detailed example, see CDDS Example: Horizontal Partitioning. For information about setting up horizontal replication, see How You Set Up Horizontal Partitioning.
When assigning tables to a CDDS, be sure to consider logical groupings of data. Keep in mind that if a user transaction crosses two or more CDDSs, for example, update a table in one CDDS and insert into a table in another CDDS, the Replicator Server(s) processes it as two or more separate transactions. For more information, see How Errors Are Handled.
|
|
|
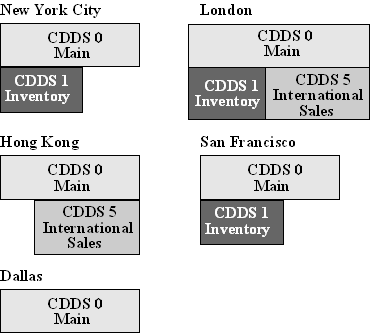
To illustrate CDDS planning, consider the example of 'Round the Earth Publishing (R.E.P.). R.E.P. has a replicated database that is split up into several CDDSs. R.E.P. has its headquarters in New York City and has offices in San Francisco, Dallas, London, and Hong Kong. Most of R.E.P.'s data is in one main CDDS (CDDS 0), which is shared by all locations.
R.E.P.'s inventory information is located in New York, San Francisco, and London, so these locations share an inventory CDDS (CDDS 1).
London and Hong Kong also share an international sales CDDS (CDDS 5).
The following figure illustrates the location of each CDDS:
|
|
|
R.E.P.'s CDDS 0 has a table that contains employee information. The employee table has a salary column. Top Management decides that the salary column must only be accessible to users in New York. Therefore, while the employee table is replicated, its salary column is not. For more information, see the column item in CDDS Definition Dialog.
|
|
|
The inventory CDDS contains information about R.E.P.'s products, but not actual inventory quantities. R.E.P. decides to split up its quantity on hand information into different warehouses.
The New York version has all the information, but the San Francisco and London versions have only the information for their respective locations. To do this, R.E.P. creates three new CDDSs, one for New York, one for San Francisco, and one for London. One of the replicated tables in the three warehouse CDDSs is the warehouse inventory table; it contains a column that specifies the location of the warehouse. The rows belonging in which CDDS is determined by the value in the location column of the warehouse inventory table.
To assign a CDDS by value, you create a lookup table containing the column for CDDS values and its corresponding attribute values. Using Visual DBA or the Replicator Manager, you can associate the lookup table with a base replicated table in your system. For detailed procedures and examples for implementing horizontal partitioning, see How You Set Up Horizontal Partitioning.
|
|
|
Replicator moves information from one database to another according to the data propagation paths for that CDDS. In a data propagation path, a database can be one of the following three types:
The database where a user made a change to a replicated table.
The database that propagates the change to the target.
This is the last database that the change goes through before reaching the target. The local database can be the same as the originator database. A local database must be a target database in another path (it must receive the data as a target) before it can propagate the data as a local database.
The database that receives the change.
Every database in the CDDS must be a target (except the originator in that particular path). The target and the originator database cannot be the same in a given path.
|
|
|
In the R.E.P. scenario described in CDDS Example: Subset of Tables, several databases are allowed to manipulate data. Paths must be defined for each originating database. To do this, a separate data propagation path is defined for each CDDS that resides on an originating database. The path itself consists of separate entries for each target of the originating database.
Here is the example for CDDS 1 in San Francisco, which is set up to transmit inventory information to New York and London.
Data Propagation Paths for CDDS 1 in San Francisco:
Originator DB |
Local DB |
Target DB |
SFO |
SFO |
NYC |
SFO |
NYC |
LON |
Note that the local database is part of all path definitions. It is used to differentiate between a direct and indirect path to a target. In the first entry of the example, the originator and local databases are both SFO; this refers to the start of the replication path. In the second entry, the originator and local databases differ; this indicates that the local database, NYC, is responsible for cascading replication to the target, LON. As a result of cascades, a data propagation path can run through many databases.
Data Propagation Paths for CDDS 1 in New York:
Originator DB |
Local DB |
Target DB |
NYC |
NYC |
SFO |
NYC |
NYC |
LON |
Note that in this example, New York sends inventory data directly to San Francisco and London. The choice between the cascading paths in the SFO example and the direct paths in the NYC example can be influenced by various factors, such as communications infrastructure, transaction volumes at each site, and processor capacities.
Remember that a CDDS is simply a piece of a larger database. These individual pieces can reside at any site in an enterprise. In the R.E.P. scenario, international sales information (CDDS 5) from Hong Kong does not get copied to the master database in New York. Thus, no path definition for Hong Kong to New York for CDDS 5 is required. The New York inventory CDDS (CDDS 1) maintains the same standard, sharing only with the necessary remote sites.
|
|
|
CDDS target type refers to the function a database performs within a CDDS. The target type determines whether changes to databases can be replicated and whether collisions are detected. Target types are defined separately for each CDDS; therefore, a database can have more than one target type if it is contained in more than one CDDS.
Ingres Replicator currently supports the following types of CDDS target types to carry out replication:
A database provides services of a particular target type based on the CDDSs it contains. To plan database replication, you need to decide what role you want each database to play within each CDDS and assign one of the three target types. Your decision is based on the type of replication behavior you want the database to perform and the computing resources available in your system. By carefully analyzing how various work groups use data, you can determine which targets require full peer or read-only capabilities.
|
|
|
A full peer designation is required for production CDDSs where interactive users or other processes first manipulate data. Full peer CDDS targets make full use of the Ingres Replicator processing capabilities and maintain shadow tables, archive tables, as well as the input and distribution queues.
In a full peer CDDS target, each replicated table has a shadow table. Each change to a row designated for replication is tracked through a shadow record entry in the shadow table. Before-images of updates and deletes are maintained in the archive table. The shadow table itself contains the information necessary to allow the propagation of row changes to other targets.
If a row change is an update or a delete, the old image of the row is stored in an archive table. The archive table makes it possible to re-run the transactions that occurred in a database, in the proper order with the proper data, even if the replicated row has been changed many times. For each change in a replicated table of a full peer target, an entry is also made in the input queue table.
If a full peer source sends information to a full peer CDDS target (in a peer-to-peer configuration), database procedures are used to transmit the data, while the DBMS captures local changes to the database. As a result, all replicated tables in this CDDS must be registered with Ingres Replicator, not only to transmit information to other replicated CDDS targets, but to receive information as well.
As the workhorse of the Ingres Replicator system, a full peer target consumes more disk space than any other target type; it makes use of all support tables and many of the CPU cycles available in the Ingres Replicator system to process its replication.
|
|
|
A protected read-only target is used to receive information from a full peer source. The term protected means that this target contains sufficient information to detect collisions against the source copy of the data. Users must not make changes to the data in a protected read-only target, although Ingres Replicator does not prevent this. The ability to detect and resolve collisions provides a protection against any change that is made to a replicated table from another source. Note that collisions resulting from updating data directly at the protected read-only target are generally not detectable.
A protected mode is important because more than one source can be transmitting to a single protected read-only target. If the target is not protected, transactions can arrive out of order. A protected read-only target maintains a shadow table for each replicated table but does not maintain archive tables or input and distribution queues. This allows the target to only accept replicated rows in order, thus ensuring that consistent data is available to users. Other sources replicate data to this target by database procedures; so although this target does not send data, all replicated tables in the protected read-only target must be registered with Ingres Replicator, and most Ingres Replicator support objects must be present.
|
|
|
In unprotected mode, there is no safeguard against any change that is made to a replicated table from another source (or locally); hence, use unprotected read-only target only if one full peer source sends information to the read-only target. Because the unprotected read-only target does not maintain any support objects within the database, no table registration is required for the target's tables. Collisions cannot be detected because of the absence of the shadow table.
All Enterprise Access and EDBC databases can only be designated as unprotected read-only.