

|
|
|
There are a number of possible replication schemes that you can use to propagate transaction data throughout your distributed processing environment. The way you choose to design Ingres Replicator on your network depends on the needs of your business and the purpose of your application.
|
|
|
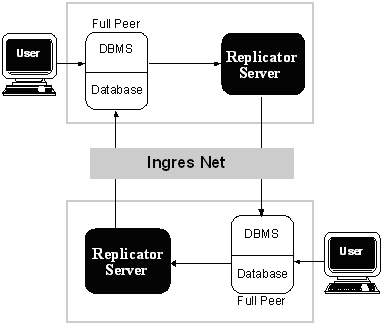
In peer-to-peer replication, illustrated in the following figure, each Ingres Replicator site plays a sending and receiving role on a peer basis with other target databases. There is no hierarchical relationship between the various servers.
The peer-to-peer arrangement implies that each Ingres Replicator site is functioning autonomously, using its own replicated database. All sites have the same information by having their own copies of an enterprise database.
Note: Although the following figure shows only two databases, a peer-to-peer scheme can encompass more than two, with each database transmitting directly to each of the other databases.
|
|
|
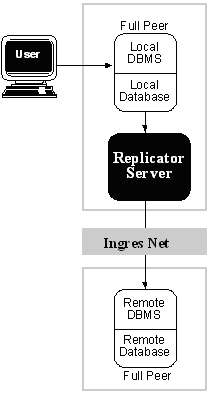
In a central-to-backup or standby design scheme, illustrated in the following figure, if a source database fails, an emergency backup database is available to resume activity.
Using central-to-backup with a peer-to-peer design scheme allows Ingres Replicator to ensure data is replicated to the failed database upon recovery; consistency is thereby restored across databases. Without a peer-to-peer scheme, a DBA must use a copy from a read-only backup and perform manual recovery.
Note: A two-database peer-to-peer backup (or standby) scheme is identical to a two-database peer-to-peer, except that in the standby scheme the backup database is normally not accessed by users.
The central-to-backup configuration can maximize database availability across an enterprise without sacrificing fault tolerance. A central-to-backup configuration can also be used for continuous (24 x 7) operation. When database maintenance tasks such as recreating indexes are necessary on the main database, the users can be switched to access the secondary copy.
|
|
|
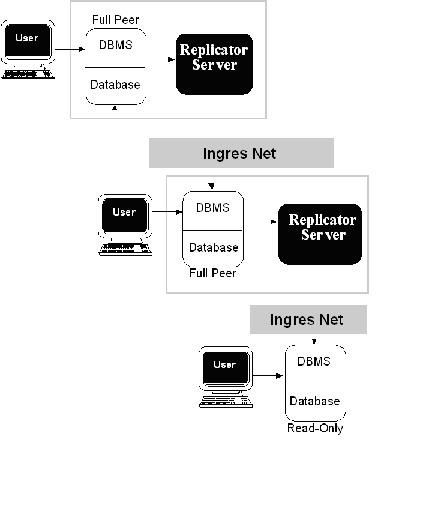
In a cascade replication, illustrated in the following figure, data from a source database is moved to a target database. That target database in turn moves the data to yet another target database. Every database that propagates the replication to another database must be designated as full peer. This scheme is useful in that the source database does not have to be responsible for distributing the data it creates throughout the entire replication system.
|
|
|
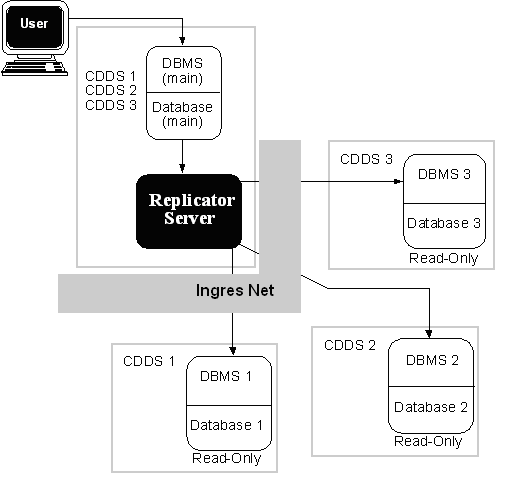
In a central-to-branch scheme, illustrated in the following figure, subsets of a central database are designated for replication to branch sites. The diagram shows read-only targets, but central-to-branch is often combined with peer-to-peer. In this arrangement, branches can update information from headquarters or create their own data and send the new data back to headquarters.
|
|
|
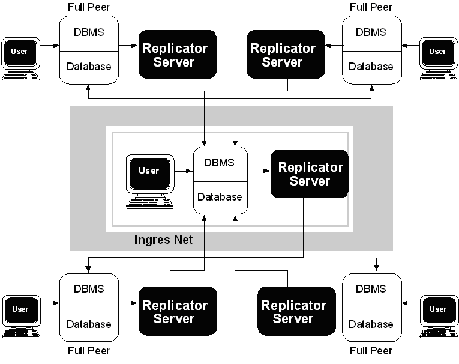
In a hub-and-spoke scheme, illustrated in the following figure, the hub database has a peer-to-peer relationship with each of its spokes. Implicit in this relationship is a cascade replication, in which each of the spokes receives replicated data whenever the hub database or any of the other spoke databases are manipulated.
|
|
|
Because no one technique necessarily accommodates all the needs of your environment, you may need to use more than one design technique.
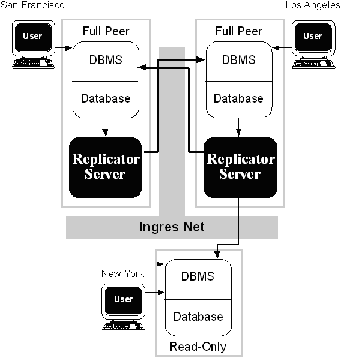
For example, if you have a site that uses data for decision support applications, but requires no updates to data, you can use a fault-tolerant peer-to-peer and cascade scenario, as shown in the following illustration.
Data from San Francisco is replicated to Los Angeles on a peer-to-peer basis and to New York on a protected read-only cascade basis. Data from Los Angeles is replicated to San Francisco on a peer-to-peer basis and to New York on a protected read-only cascade basis. In the event of a failure at New York, decision support is performed at either San Francisco or Los Angeles with a degree of performance impact.
|
|
|
In conventional DBMS installations, a database administrator (DBA) oversees the DBMS at a designated local site and is the owner of the databases created within the DBA's account.
As a distributed database system, Ingres Replicator can span many local and remote locations. Using Ingres Replicator not only requires local DBAs to maintain their own part of the system, including the replicated databases that they own, but also requires a distributed database administrator to: