The Query Cache Release Strategy Technical Reference
Strategies and MMBase clusters
This software is OSI Certified Open Source Software. OSI Certified is a certification mark of the Open Source Initiative.
The license (Mozilla version 1.0) can be read at the MMBase site. See http://www.mmbase.org/license
Abstract
Technical reference for query cache release strategies
Table of Contents
MMBase uses a lot of caches to improve it's performance. Each time a peace of information can be retrieved from a cache some more costly operation becomes unnessecary, like reading from a database. MMBase has quite a lot of caches in use (it varies a bit from release to release), but there are principally two kinds: query result caches and all the others. The query result caches cache (surprise!) the result sets of various types of queries, and they are the subject of this document.
So the better these caches work, the less often expansive database reads have to be done, and the more rapidly MMBase can respond to requests. The degree to which a cache works 'well' can be seen as the degree to which a cache can keep it's information during changes in the dataset it buffers. When this data changes, the cache will somehow have to decide what the consequence of this change is for each of it's entries. So the more intelligently a cache can assess these changes, and the less often data is flushed from the cache unnecessarily, the better a cache works. For a more detailed explanation of how the MMBase query caches work see Appendix A.
MMBase has a data model who's strength lies in flexibility rather than performance. Also, MMBase tends to create a lot of queries, that are system generated (read: generic) and not performance optimized. When your MMBase website begins to draw serious visitors, and for some reason nodes that are being read a lot are being updated a lot as well, and you want to show these changes right away, database load can become a serious issue, and cache performance becomes vital. For this reason it used to be so that applications like forums or even polls could be challenging against a great load with MMBase. The query caches were not able to make good judgments about what changes in the data should cause flushes on what cache entries, with far to many flushes as consequence, and far to many queries on the database, leading to poor performance. The 'query cache release strategy project' was created to address this problem.
In this project we actually had two goals. First we wanted to improve the query caches by making them 'smarter', so they could evaluate node and relation changes better. We were going to do that by introducing a set of rules that could analyze the events and determine if a query result set needs to be flushed on account of them.
But we also wanted to provide the means to easily and flexibly add rules to caches, so application developers can optimize their specific data models with custom rules. An example: Think of a forum. Usually there are threads and posts. When a post is added to a specific thread, all queries that query the posts of that specific thread should be flushed from the cache, and those alone. It would be hard to create a generic rule for this kind of optimization. This parent-child relation does not exist between all node types that are related, and it is hard to guess. So it would be a good idea for the developer of the forum to create a custom rule that checks the (parent) thread of all posts that generate a node event, and match that thread against the constraints of the queries in the cache, to see if the changed forum post applies to it. If not, don't flush.
So we wanted a system that would allow others to easily create custom cache invalidation rules (from now on called strategies). We also wanted to be able to dynamically load and unload strategies, and we wanted to be able to see some statistics for each strategy on the system, he MMBase admin > tools > cache jsp page being the designated place to access statistics and functionality of the release strategies.
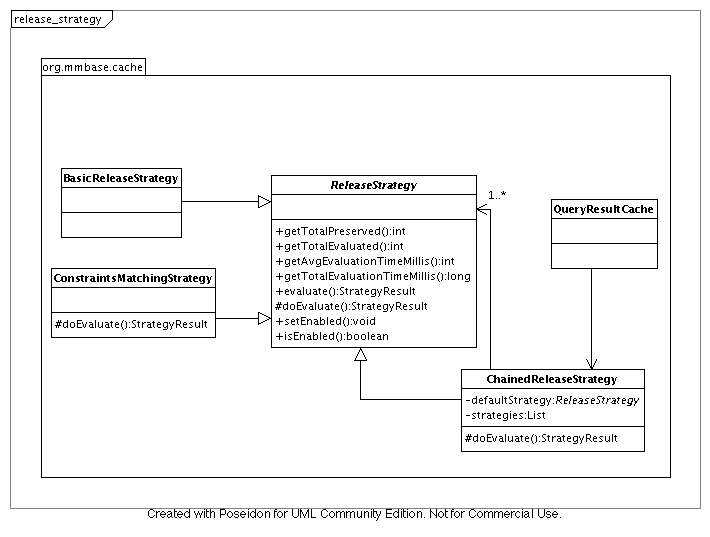
To achieve this a small framework was created, and inserted at the base of all query result caches: org.mmbase.cache.QueryResultCache. All strategies are subclasses of the abstract class ReleaseStrategy. This class provides some services in the nature of performance tracking, so you can show some statistics for every strategy. It also contains a growing collection of utility methods that are there to help you investigate query objects. For more detail, check out the api docs.
One of the first implementations was ChainedReleaseStrategy. This class is basically a wrapper class for a collection of strategies, with functionality to dynamically add and remove strategies. This class is actually the default strategy for every query cache, and is always loaded with the default strategy(s). Which the default strategies are will change over time, and the default strategies themselves will also get better over time, as more rules are added. Currently there are two global strategies that are always loaded:
This strategy, in spite of it's lousy name, performs quite a number of checks on queries to discover if a node/relation event actually applies to it, and so prevents a major amount of un necessary cache flushes. Here are some examples of the things this strategy checks:
If a node is new, and the query has more steps than one: don't flush. A new node has no relations yet, so can not be part of the dataset of a query over more tables than one.
If the event is a relation event. Check if the source type, role and destination type actually occur in the query. If not: don't flush (a relation event is received by an Observer if that observer's type matches either source type or destination type of the relation event, so most of these events are bound to have no full match with the queries of this Observer.
This strategy goes one step further. If the BetterStrategy can not find reason not to flush a query, the ConstraintsMatchingStrategy will try to find a constraint in the query for the step that matches the event. then it checks the values of the changed node against those constraints to see if now falls within the query where it did not before or the other way around (for more information about query objects take a look at the SeachQuery documentation).
To add your own strategy class you have to do two things: Create the class and deploy it.
To create your own strategy class you have to extend ReleaseStrategy and override it's abstract method doEvaluate(NodeEvent event, SearchQuery query, List cachedResult) (This is not the method actually called by the query cache, but it is a template method. The method evaluate(NodeEvent event, SearchQuery query, List cachedResult), which is called by the cache should not be overridden, because it takes care of the statistics gathering business). Here you define your specific rules.
Then you have to deploy it. Make sure the class is on the class path of your application server and add and entry in the configuration file caches.xml, to configure which of the query caches are loaded with your strategy (the strategies are loaded in the order they are listed). If the query cache that you want to configure with your cache is not listed in caches.xml, just add an entry for it.
<cache name="MultilevelCache">
<strategy name=”org.something.mystrategy”/>
<status>active</status>
<size>300</size>
</cache>It is also possible to configure for a strategy to be loaded on all query caches. Just add it in the top of the configuration file, just below the <caches> element.
<caches>
<releaseStrategies>
<strategy>org.something.mystrategy</strategy>
</releaseStrategies>Then after starting up MMBase you can go to [url to your mmbase]mmbase/admin/. Then choose 'tools' and then 'cache'. Here you can see how your query caches are performing. You can monitor the cost (processing time in milliseconds) and performance (queries evaluated and flushes prevented). Of every strategy on every individual query cache. You can also disable your strategy here.
It is possible to make strategies that do very elaborate checks, which can in turn become rather costly in terms of CPU. It could well be that you are overshooting your target when this happens. One interesting point though is that mmbase applications are easily up scaled through clustering. This is not necessarily the same for your database application. So in some situations it could well make sense to do very costly checking on the application server layer to avoid some extra queries on the database.
The QueryResultCache is the base class for all caches that store queries and their result sets. It has a static inner class called Observer. An Observer listens to the node events of a specific type of builder. When a query is cached, all steps are iterated over, and if an Observer instance for the type of that step does not exist, it is created. Then the query is registered with this Observer instance. This creates a matrix where a query is registered with all the observers that correspond to it´s steps, and an Observer hold reference to all queries containing a step of it´s type.
When an observer receives a node event, it Iterates over all queries it holds reference to, evaluates if the query should be flushed, and then removes it from the cache.

This is part of the MMBase documentation.
For questions and remarks about this documentation mail to: [email protected]