Twitter HOWTO¶
Overview¶
This document is an overview of how to use NLTK to collect and process Twitter data. It was written as an IPython notebook, and if you have IPython installed, you can download the source of the notebook from the NLTK GitHub repository and run the notebook in interactive mode.
Most of the tasks that you might want to carry out with 'live' Twitter data require you to authenticate your request by registering for API keys. This is usually a once-only step. When you have registered your API keys, you can store them in a file on your computer, and then use them whenever you want. We explain what's involved in the section First Steps.
If you have already obtained Twitter API keys as part of some earlier project, storing your keys explains how to save them to a file that NLTK will be able to find. Alternatively, if you just want to play around with the Twitter data that is distributed as part of NLTK, head over to the section on using the twitter-samples corpus reader.
Once you have got authentication sorted out, we'll show you how to use NLTK's Twitter class. This is made as simple as possible, but deliberately limits what you can do.
First Steps¶
As mentioned above, in order to collect data from Twitter, you first need to register a new application — this is Twitter's way of referring to any computer program that interacts with the Twitter API. As long as you save your registration information correctly, you should only need to do this once, since the information should work for any NLTK code that you write. You will need to have a Twitter account before you can register. Twitter also insists that you add a mobile phone number to your Twitter profile before you will be allowed to register an application.
These are the steps you need to carry out.
Getting your API keys from Twitter¶
Sign in to your Twitter account at https://apps.twitter.com. You should then get sent to a screen that looks something like this:
Clicking on the Create New App button should take you to the following screen:
The information that you provide for Name, Description and Website can be anything you like.
Make sure that you select Read and Write access for your application (as specified on the Permissions tab of Twitter's Application Management screen):
Go to the tab labeled Keys and Access Tokens. It should look something like this, but with actual keys rather than a string of Xs:
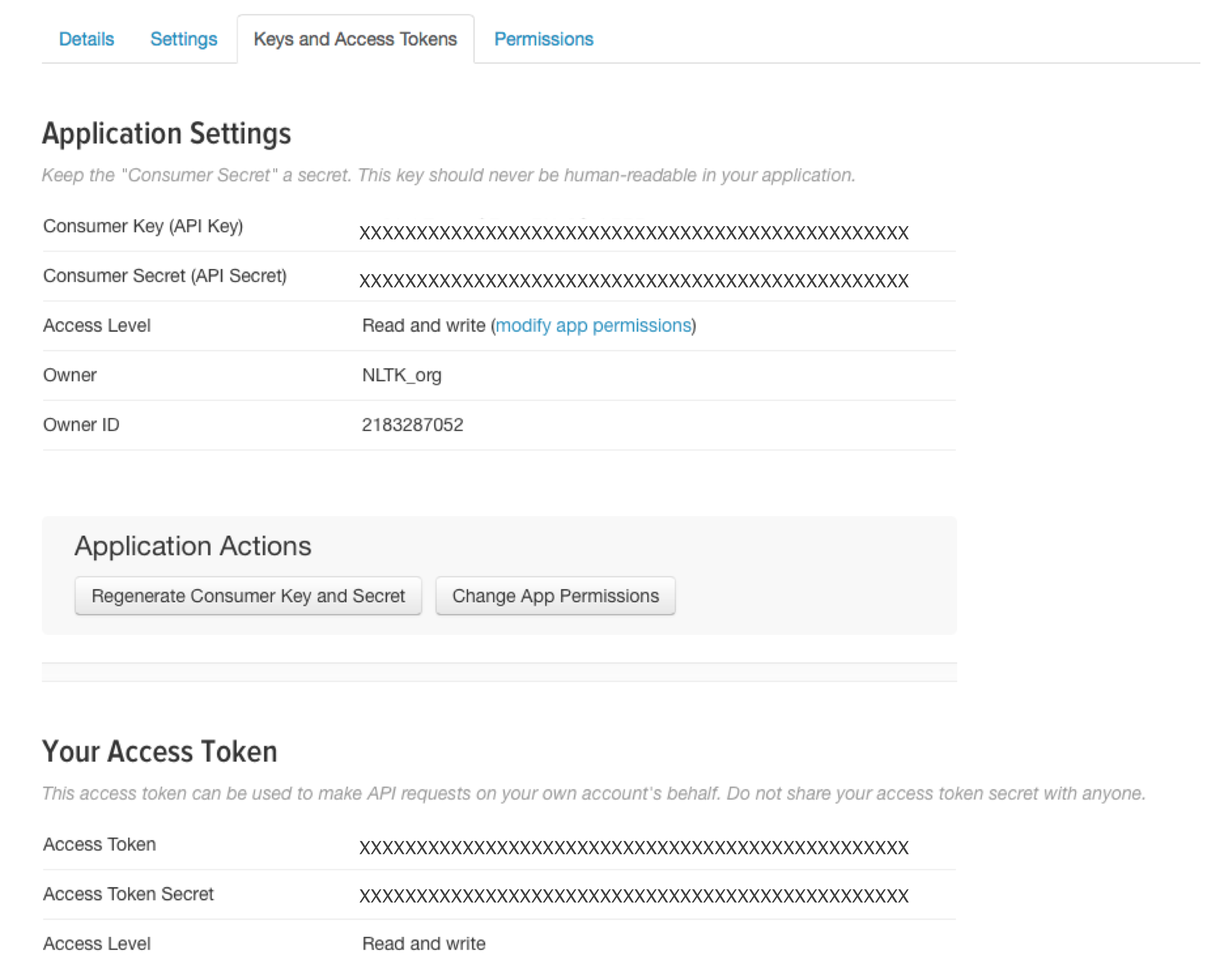 As you can see, this will give you four distinct keys: consumer key, consumer key secret, access token and access token secret.
As you can see, this will give you four distinct keys: consumer key, consumer key secret, access token and access token secret.
Storing your keys¶
Create a folder named
twitter-filesin your home directory. Within this folder, use a text editor to create a new file calledcredentials.txt. Make sure that this file is just a plain text file. In it, you should create which you should store in a text file with the following structure:app_key=YOUR CONSUMER KEY app_secret=YOUR CONSUMER SECRET oauth_token=YOUR ACCESS TOKEN oauth_token_secret=YOUR ACCESS TOKEN SECRETType the part up to and includinge the '=' symbol exactly as shown. The values on the right-hand side of the '=' — that is, everything in caps — should be cut-and-pasted from the relevant API key information shown on the Twitter Keys and Access Tokens. Save the file and that's it.
It's going to be important for NLTK programs to know where you have stored your credentials. We'll assume that this folder is called
twitter-files, but you can call it anything you like. We will also assume that this folder is where you save any files containing tweets that you collect. Once you have decided on the name and location of this folder, you will need to set theTWITTERenvironment variable to this value.On a Unix-like system (including MacOS), you will set the variable something like this:
export TWITTER="/path/to/your/twitter-files"
Rather than having to give this command each time you start a new session, it's advisable to add it to your shell's configuration file, e.g. to
.bashrc.On a Windows machine, right click on “My Computer” then select
Properties > Advanced > Environment Variables > User Variables > New...One important thing to remember is that you need to keep your
credentials.txtfile private. So do not share yourtwitter-filesfolder with anyone else, and do not upload it to a public repository such as GitHub.Finally, read through Twitter's Developer Rules of the Road. As far as these rules are concerned, you count as both the application developer and the user.
Install Twython¶
The NLTK Twitter package relies on a third party library called Twython. Install Twython via pip:
$ pip install twython
or with easy_install:
$ easy_install twython
We're now ready to get started. The next section will describe how to use the Twitter class to talk to the Twitter API.
More detail: Twitter offers are two main authentication options. OAuth 1 is for user-authenticated API calls, and allows sending status updates, direct messages, etc, whereas OAuth 2 is for application-authenticated calls, where read-only access is sufficient. Although OAuth 2 sounds more appropriate for the kind of tasks envisaged within NLTK, it turns out that access to Twitter's Streaming API requires OAuth 1, which is why it's necessary to obtain Read and Write access for your application.
Using the simple `Twitter` class¶
Dipping into the Public Stream¶
The Twitter class is intended as a simple means of interacting with the Twitter data stream. Later on, we'll look at other methods which give more fine-grained control.
The Twitter live public stream is a sample (approximately 1%) of all Tweets that are currently being published by users. They can be on any topic and in any language. In your request, you can give keywords which will narrow down the Tweets that get delivered to you. Our first example looks for Tweets which include either the word love or hate. We limit the call to finding 10 tweets. When you run this code, it will definitely produce different results from those shown below!
from nltk.twitter import Twitter
tw = Twitter()
tw.tweets(keywords='love, hate', limit=10) #sample from the public stream
The next example filters the live public stream by looking for specific user accounts. In this case, we 'follow' two news organisations, namely @CNN and @BBCNews. As advised by Twitter, we use numeric userIDs for these accounts. If you run this code yourself, you'll see that Tweets are arriving much more slowly than in the previous example. This is because even big new organisations don't publish Tweets that often.
A bit later we will show you how to use Python to convert usernames such as @CNN to userIDs such as 759251, but for now you might find it simpler to use a web service like TweeterID if you want to experiment with following different accounts than the ones shown below.
tw = Twitter()
tw.tweets(follow=['759251', '612473'], limit=10) # see what CNN and BBC are talking about
Saving Tweets to a File¶
By default, the Twitter class will just print out Tweets to your computer terminal. Although it's fun to view the Twitter stream zipping by on your screen, you'll probably want to save some tweets in a file. We can tell the tweets() method to save to a file by setting the flag to_screen to False.
The Twitter class will look at the value of your environmental variable TWITTER to determine which folder to use to save the tweets, and it will put them in a date-stamped file with the prefix tweets.
tw = Twitter()
tw.tweets(to_screen=False, limit=25)
So far, we've been taking data from the live public stream. However, it's also possible to retrieve past tweets, for example by searching for specific keywords, and setting stream=False:
tw.tweets(keywords='hilary clinton', stream=False, limit=10)
Onwards and Upwards¶
In this section, we'll look at how to get more fine-grained control over processing Tweets. To start off, we will import a bunch of stuff from the twitter package.
from nltk.twitter import Query, Streamer, Twitter, TweetViewer, TweetWriter, credsfromfile
In the following example, you'll see the line
oauth = credsfromfile()
This gets hold of your stored API key information. The function credsfromfile() by default looks for a file called credentials.txt in the directory set by the environment variable TWITTER, reads the contents and returns the result as a dictionary. We then pass this dictionary as an argument when initializing our client code. We'll be using two classes to wrap the clients: Streamer and Query; the first of these calls the Streaming API and the second calls Twitter's Search API (also called the REST API).
More detail: For more detail, see this blog post on The difference between the Twitter Firehose API, the Twitter Search API, and the Twitter Streaming API
After initializing a client, we call the register() method to specify whether we want to view the data on a terminal or write it to a file. Finally, we call a method which determines the API endpoint to address; in this case, we use sample() to get a random sample from the the Streaming API.
oauth = credsfromfile()
client = Streamer(**oauth)
client.register(TweetViewer(limit=10))
client.sample()
The next example is similar, except that we call the filter() method with the track parameter followed by a string literal. The string is interpreted as a list of search terms where comma indicates a logical OR. The terms are treated as case-insensitive.
client = Streamer(**oauth)
client.register(TweetViewer(limit=10))
client.filter(track='refugee, germany')
Whereas the Streaming API lets us access near real-time Twitter data, the Search API lets us query for past Tweets. In the following example, the value tweets returned by search_tweets() is a generator; the expression next(tweets) gives us the first Tweet from the generator.
Although Twitter delivers Tweets as JSON objects, the Python client encodes them as dictionaries, and the example pretty-prints a portion of the dictionary corresponding the Tweet in question.
client = Query(**oauth)
tweets = client.search_tweets(keywords='nltk', limit=10)
tweet = next(tweets)
from pprint import pprint
pprint(tweet, depth=1)
Twitter's own documentation provides a useful overview of all the fields in the JSON object and it may be helpful to look at this visual map of a Tweet object.
Since each Tweet is converted into a Python dictionary, it's straightforward to just show a selected field, such as the value of the 'text' key.
for tweet in tweets:
print(tweet['text'])
client = Query(**oauth)
client.register(TweetWriter())
client.user_tweets('timoreilly', 10)
Given a list of user IDs, the following example shows how to retrieve the screen name and other information about the users.
userids = ['759251', '612473', '15108702', '6017542', '2673523800']
client = Query(**oauth)
user_info = client.user_info_from_id(userids)
for info in user_info:
name = info['screen_name']
followers = info['followers_count']
following = info['friends_count']
print("{}, followers: {}, following: {}".format(name, followers, following))
A list of user IDs can also be used as input to the Streaming API client.
client = Streamer(**oauth)
client.register(TweetViewer(limit=10))
client.statuses.filter(follow=userids)
To store data that Twitter sents by the Streaming API, we register a TweetWriter instance.
client = Streamer(**oauth)
client.register(TweetWriter(limit=10))
client.statuses.sample()
Here's the full signature of the Tweetwriter's __init__() method:
def __init__(self, limit=2000, upper_date_limit=None, lower_date_limit=None,
fprefix='tweets', subdir='twitter-files', repeat=False,
gzip_compress=False):
If the repeat parameter is set to True, then the writer will write up to the value of limit in file file1, then open a new file file2 and write to it until the limit is reached, and so on indefinitely. The parameter gzip_compress can be used to compress the files once they have been written.
Using a Tweet Corpus¶
NLTK's Twitter corpus currently contains a sample of 20k Tweets (named 'twitter_samples')
retrieved from the Twitter Streaming API, together with another 10k which are divided according to sentiment into negative and positive.
from nltk.corpus import twitter_samples
twitter_samples.fileids()
We follow standard practice in storing full Tweets as line-separated
JSON. These data structures can be accessed via tweets.docs(). However, in general it
is more practical to focus just on the text field of the Tweets, which
are accessed via the strings() method.
strings = twitter_samples.strings('tweets.20150430-223406.json')
for string in strings[:15]:
print(string)
The default tokenizer for Tweets (casual.py) is specialised for 'casual' text, and
the tokenized() method returns a list of lists of tokens.
tokenized = twitter_samples.tokenized('tweets.20150430-223406.json')
for toks in tokenized[:5]:
print(toks)
Extracting Parts of a Tweet¶
If we want to carry out other kinds of analysis on Tweets, we have to work directly with the file rather than via the corpus reader. For demonstration purposes, we will use the same file as the one in the preceding section, namely tweets.20150430-223406.json. The abspath() method of the corpus gives us the full pathname of the relevant file. If your NLTK data is installed in the default location on a Unix-like system, this pathname will be '/usr/share/nltk_data/corpora/twitter_samples/tweets.20150430-223406.json'.
from nltk.corpus import twitter_samples
input_file = twitter_samples.abspath("tweets.20150430-223406.json")
The function json2csv() takes as input a file-like object consisting of Tweets as line-delimited JSON objects and returns a file in CSV format. The third parameter of the function lists the fields that we want to extract from the JSON. One of the simplest examples is to extract just the text of the Tweets (though of course it would have been even simpler to use the strings() method of the corpus reader).
from nltk.twitter.util import json2csv
with open(input_file) as fp:
json2csv(fp, 'tweets_text.csv', ['text'])
We've passed the filename 'tweets_text.csv' as the second argument of json2csv(). Unless you provide a complete pathname, the file will be created in the directory where you are currently executing Python.
If you open the file 'tweets_text.csv', the first 5 lines should look as follows:
RT @KirkKus: Indirect cost of the UK being in the EU is estimated to be costing Britain £170 billion per year! #BetterOffOut #UKIP
VIDEO: Sturgeon on post-election deals http://t.co/BTJwrpbmOY
RT @LabourEoin: The economy was growing 3 times faster on the day David Cameron became Prime Minister than it is today.. #BBCqt http://t.co…
RT @GregLauder: the UKIP east lothian candidate looks about 16 and still has an msn addy http://t.co/7eIU0c5Fm1
RT @thesundaypeople: UKIP's housing spokesman rakes in £800k in housing benefit from migrants. http://t.co/GVwb9Rcb4w http://t.co/c1AZxcLh…However, in some applications you may want to work with Tweet metadata, e.g., the creation date and the user. As mentioned earlier, all the fields of a Tweet object are described in the official Twitter API.
The third argument of json2csv() can specified so that the function selects relevant parts of the metadata. For example, the following will generate a CSV file including most of the metadata together with the id of the user who has published it.
with open(input_file) as fp:
json2csv(fp, 'tweets.20150430-223406.tweet.csv',
['created_at', 'favorite_count', 'id', 'in_reply_to_status_id',
'in_reply_to_user_id', 'retweet_count', 'retweeted',
'text', 'truncated', 'user.id'])
for line in open('tweets.20150430-223406.tweet.csv').readlines()[:5]:
print(line)
The first nine elements of the list are attributes of the Tweet, while the last one, user.id, takes the user object associated with the Tweet, and retrieves the attributes in the list (in this case only the id). The object for the Twitter user is described in the Twitter API for users.
from nltk.twitter.util import json2csv_entities
with open(input_file) as fp:
json2csv_entities(fp, 'tweets.20150430-223406.hashtags.csv',
['id', 'text'], 'hashtags', ['text'])
with open(input_file) as fp:
json2csv_entities(fp, 'tweets.20150430-223406.user_mentions.csv',
['id', 'text'], 'user_mentions', ['id', 'screen_name'])
with open(input_file) as fp:
json2csv_entities(fp, 'tweets.20150430-223406.media.csv',
['id'], 'media', ['media_url', 'url'])
with open(input_file) as fp:
json2csv_entities(fp, 'tweets.20150430-223406.urls.csv',
['id'], 'urls', ['url', 'expanded_url'])
with open(input_file) as fp:
json2csv_entities(fp, 'tweets.20150430-223406.place.csv',
['id', 'text'], 'place', ['name', 'country'])
with open(input_file) as fp:
json2csv_entities(fp, 'tweets.20150430-223406.place_bounding_box.csv',
['id', 'name'], 'place.bounding_box', ['coordinates'])
Additionally, when a Tweet is actually a retweet, the original tweet can be also fetched from the same file, as follows:
with open(input_file) as fp:
json2csv_entities(fp, 'tweets.20150430-223406.original_tweets.csv',
['id'], 'retweeted_status', ['created_at', 'favorite_count',
'id', 'in_reply_to_status_id', 'in_reply_to_user_id', 'retweet_count',
'text', 'truncated', 'user.id'])
Here the first id corresponds to the retweeted Tweet, and the second id to the original Tweet.
Using Dataframes¶
Sometimes it's convenient to manipulate CSV files as tabular data, and this is made easy with the Pandas data analysis library. pandas is not currrently one of the dependencies of NLTK, and you will probably have to install it specially.
Here is an example of how to read a CSV file into a pandas dataframe. We use the head() method of a dataframe to just show the first 5 rows.
import pandas as pd
tweets = pd.read_csv('tweets.20150430-223406.tweet.csv', index_col=2, header=0, encoding="utf8")
tweets.head(5)
Using the dataframe it is easy, for example, to first select Tweets with a specific user ID and then retrieve their 'text' value.
tweets.loc[tweets['user.id'] == 557422508]['text']
Expanding a list of Tweet IDs¶
Because the Twitter Terms of Service place severe restrictions on the distribution of Tweets by third parties, a workaround is to instead distribute just the Tweet IDs, which are not subject to the same restrictions. The method expand_tweetids() sends a request to the Twitter API to return the full Tweet (in Twitter's terminology, a hydrated Tweet) that corresponds to a given Tweet ID.
Since Tweets can be deleted by users, it's possible that certain IDs will only retrieve a null value. For this reason, it's safest to use a try/except block when retrieving values from the fetched Tweet.
from nltk.compat import StringIO
ids_f =\
StringIO("""\
588665495492124672
588665495487909888
588665495508766721
588665495513006080
588665495517200384
588665495487811584
588665495525588992
588665495487844352
88665495492014081
588665495512948737""")
oauth = credsfromfile()
client = Query(**oauth)
hydrated = client.expand_tweetids(ids_f)
for tweet in hydrated:
id_str = tweet['id_str']
print('id: {}'.format(id_str))
text = tweet['text']
if text.startswith('@null'):
text = "[Tweet not available]"
print(text + '\n')
Although we provided the list of IDs as a string in the above example, the standard use case is to pass a file-like object as the argument to expand_tweetids().