Table of Contents
This chapter describes common development tools and useful complementary tools.
For installation procedure, see annexe "Installing mercurial".
See http://mercurial.selenic.com/wiki/UnderstandingMercurial.
Mercurial is a completely decentralized system. Every cloned repositories contain a working directory and a store of complete project's history, thus allowing offline and parallel development.
The working directory contains a copy of the project's files at a given point in time, ready for editing.
The store contains a sufficient data to provide any file at any revision or tag from any branch.
Mercurial groups related changes to multiple files (commits) into single atomic changesets. Every commit generates a changeset recording the state of the working directory relative to its parents, so merging is really easier and more efficient than with other SCM.
http://mercurial.selenic.com/wiki/Mercurial.
There are “getting started” and “using Mercurial” documentations, even some help for developers used to other SCM systems.
You will find useful tips and scripts in Nuxeo Wiki FAQ: http://doc.nuxeo.org/xwiki/bin/view/FAQ/DownloadingNuxeoSources and some workarounds or guidelines for specific cases.
Since the "nested repositories" came only with Mercurial version 1.3 and are still an experimental feature, we chose to rely on the Forest extension when migrating from Subversion to Mercurial for replacing "svn externals".
This is not mandatory for working with Nuxeo. This extension mainly provides easier way to run a command on a "full" nuxeo repository including its sub-repositories, such as cloning full Nuxeo sources. For example, those repositories have sub-repositories: nuxeo-addons, nuxeo, ...
Although Mercurial is decentralized, Nuxeo hosts “centralized” Mercurial repositories which are the “reference” repositories, they are backed up and changesets made on local repositories must finally be pushed on those remote repositories. The public "centralized" repository is https://hg.nuxeo.org/.
We've set some “hooks” on the central repositories filtering changesets according to whether they comply to the following rules:
Changesets must not be blacklisted.
Even with the Mercurial's two-steps committing process (commit then push), it may happen to push erroneous changesets with really no interest or making trouble in code history. In such cases, it's a good thing to "strip" these changesets, removing them from history.
We usually blacklist a changeset after having stripped it, to be sure nobody will push it again in case it has been pulled before being stripped.
Error message is:
ABORTED: changeset %s has been blacklisted, please strip it from your repository after making sure you don't depend on it: hg strip %s
Changesets are in an allowed branch.
We make an extra use of branches: for long-time developments, prototype or spike solutions, ease parallel changes and give each developer merging responsibility of its code. Branches have "stable/main", "maintenance/release" or "development/test" purpose.
Depending on the project we use white or black lists for branch names.
On some projects, for instance, we blacklist the “default” branch to avoid confusion or lack of information about current version.
Error message:
ABORTED: changesets with branch "%s" are not allowed. The only allowed branches are: %s
Existing branches are given by this command:
hg branches [-a]
Changesets do not result in two heads for the same branch.
Changesets that have a given branch tag, but have no child changesets with that tag are called branch "heads". Mercurial identifies branches depending on their history so there may be two separate branches with the same name in case of concurrent changes made on a branch which were based on different parents. Of course, such situation is abnormal and must be fixed. This hook will prevent a developer from pushing changesets resulting in homonym branch heads.
Rule is: always pull before trying to push. If your local changes drive to multiple heads with same branch name, you must merge them before pushing.
Error message:
ABORTED: branch %s has several heads (%s), you must merge them before pushing.
Existing heads are listed with this command:
hg heads [branchName]
User for changesets must be valid.
For code history readability, usernames must be formatted like “John Doe <[email protected]>”.
Error message:
ABORTED: changesets with user "%s" are not allowed. You need to specify your user name in $HOME/.hgrc as follows: [ui] username = John Smith <[email protected]>
Notifications
This hook will generate a mail to the public mailing list
<[email protected]> for every
changeset.
Build trigger
This hook launches a build in our continuous integration system: http://qa.nuxeo.org/. Using a trigger ran at every commit is saving a lot of bandwidth compared to regularly pulling the repository to check for code changes.
Setting such hooks was not mandatory but they guarantee the developers are following a few basic rules and prevent them from simple mistakes.
It is sometimes possible to force a push in spite of the hooks, when you know the hook message is not an error but a warning and it can be securely circumvented.
We usually define stable, maintenance and development branches.
Stable, next to release branch
Often called "main" branch, this named branch is hosting the most-recent code.
Stable branch is of course under continuous integration. Merge and commits must be double-checked; as much as possible, changes have been firstly tested and validated on a development branch or in developer's working directory.
Nuxeo uses two stable branches: 5.1 and 5.2. New features, eventually breaking API, are developed on 5.2. There's quite no new feature on 5.1 which has both stable and maintenance purpose and is gathering fixes from 5.1.x releases.
I.e. 5.2 branch is hosting 5.2-SNAPSHOT code which will lead to 5.2.x release.
Special case of 5.1 branch: it is hosting 5.1.X-SNAPSHOT code and may lead to 5.1.x release.
Maintenance, patch branch
When releasing, a dedicated branch is created and then tagged. This branch is used for creating minor versions releases.
Fixes done on it will be merge on stable branch; fixes from stable branch may be backported on this maintenance branch to generate patches or minor releases.
Maintenance branch are rarely under continuous integration as there is no more work on them except fixes and backports.
I.e. 5.1.6 branch is hosting 5.1.6 code, tagged as release-5.1.6, and may lead to minor versions releases such as 5.1.6.x
Development branches
Developers are strongly encouraged to use as much branches as they need (one per JIRA issue or per development iteration). Those branches may or not be automatically tested, their purpose is code isolation while it is unstable: they are merged to stable branch after being fully tested.
I.e. 5.2-NXP-9999-some_user_story will host code linked to implement some user story until the end of the iteration (or some point the code is considered stable and usable).
Here are some recommended practices using Mercurial at Nuxeo.
Update and commit often. It will ease future merge tasks.
Always reference a Jira issue at the beginning of commit comments: i.e. “NXP-9999 – sample task, remove code using deprecated API”.
Long time work should be done in a separate branch; named with the associated Jira issue and a short description: i.e. “NXP-9999_longtime_work”
Check what you've changed before committing and what you've committed before pushing.
hg status hg diff hg outgoing
Never “force” a push unless being sure it has to be done.
The following Mercurial commands are given with useful parameters into brackets, other parameters may be available. See “hg help [COMMAND]” for available commands listing or help on a specific command.
They are mainly used for Nuxeo repositories which are constructed as a forest of sub-repositories. Forest extension provides quite equivalent functions but both are complementary.
hgf function runs a hg command into current and nuxeo-* subdirectories:
hgf() {
for dir in . nuxeo-*; do
if [ -d "$dir"/.hg ]; then
echo;echo "[$dir]"
(cd "$dir" && hg "$@")
fi
done
}
hgf.bat:
@echo off set PWD=%CD% echo [.] hg %* for /d %%D in (nuxeo-*) do ( echo [%%D] cd %PWD%\%%D hg %* ) cd %PWD%
hgx function is a little more complex and tied to nuxeo repositories as it runs a hg command into current and nuxeo-* subdirectories managing with the two version numbers we have on nuxeo (i.e. 5.2/1.5). It uses inverted polish notation.
hgx() {
NXP=$1
NXC=$2
shift 2;
if [ -d .hg ]; then
echo $PWD
hg $@ $NXP
# NXC
(echo nuxeo-common ; cd nuxeo-common; hg $@ $NXC || true)
(echo nuxeo-runtime ; cd nuxeo-runtime; hg $@ $NXC || true)
(echo nuxeo-core ; cd nuxeo-core; hg $@ $NXC || true)
# NXP
(echo nuxeo-theme ; cd nuxeo-theme; hg $@ $NXP || true)
[ -d nuxeo-shell ] && (echo nuxeo-shell ; cd nuxeo-shell; hg $@ $NXP || true) || (echo ignore nuxeo-shell)
[ -d nuxeo-platform ] && (echo nuxeo-platform ; cd nuxeo-platform && hg $@ $NXP || true) || (echo ignore nuxeo-platform)
[ -d nuxeo-services ] && (echo nuxeo-services ; cd nuxeo-services && hg $@ $NXP || true) || (echo ignore nuxeo-services)
[ -d nuxeo-jsf ] && (echo nuxeo-jsf ; cd nuxeo-jsf && hg $@ $NXP || true) || (echo ignore nuxeo-jsf)
[ -d nuxeo-features ] && (echo nuxeo-features ; cd nuxeo-features && hg $@ $NXP || true) || (echo ignore nuxeo-features)
[ -d nuxeo-dm ] && (echo nuxeo-dm ; cd nuxeo-dm && hg $@ $NXP || true) || (echo ignore nuxeo-dm)
[ -d nuxeo-webengine ] && (echo nuxeo-webengine ; cd nuxeo-webengine; hg $@ $NXP || true) || (echo ignore nuxeo-webengine)
[ -d nuxeo-gwt ] && (echo nuxeo-gwt ; cd nuxeo-gwt; hg $@ $NXP || true) || (echo ignore nuxeo-gwt)
(echo nuxeo-distribution ; cd nuxeo-distribution; hg $@ $NXP || true)
fi
}
hgx.bat:
@echo off set PWD=%CD% set NXP=%1 set NXC=%2 echo [.] hg %3 %NXP% for /d %%D in (nuxeo-platform nuxeo-distribution nuxeo-theme nuxeo-shell nuxeo- webengine nuxeo-gwt nuxeo-services nuxeo-jsf nuxeo-features nuxeo-dm) do ( echo [%%D] cd %PWD%\%%D hg %3 %NXP% ) for /d %%D in (nuxeo-core nuxeo-common nuxeo-runtime) do ( echo [%%D] cd %PWD%\%%D hg %3 %NXC% ) cd %PWD%
hg st [--rev REVISION]
This gives you modified (M), added (A), removed (R) and uncontrolled files (?).
Use “hg add”, “hg rm”, “hg addremove” and/or “hg ci” to commit these changes.
hg id [-inbt]
This gives you current revision (with a “+” if it has been locally modified but not yet committed), current branch name and, if you current revision is the latest modified head, the “tip” keyword.
hg parents [-r REVISION]
Show the parents of the working directory or revision.
hg tip [-p]
This gives you the log of the latest modified head, aka “tip”.
hg branches [-a]
Branches marked as “inactive” are not considered as “heads”, they haven't been modified since they were merged into another branch (i.e. Nuxeo 5.1 branch is always “inactive” as we ask the developers to always merge — forward port — their changeset from 5.1 to 5.2).
hg heads [-r REVISION] [REVISION|BRANCH_NAME]
This is useful for example to identify multiple heads with same name that must be merged.
hg tags
Gives all available tags and their corresponding revision and branch.
hg log [-r REVISION] [-l LIMIT] [-p]
Show revision history of entire repository or files.
hg glog [-r REVISION] [-l LIMIT] [-p]
Same as log but with a graphic view (requires GraphLog extension).
hg ann [-r] [-f] [-u] [-d] [-n] [-l]
Show changeset information per file line. Useful when you need to know who changed a specific part of a file.
hg strip REVISION
Strip a revision and all later revisions on the same branch.
hg unbundle FILE...
Apply one or more changegroup files. Used to revert a strip.
hg backout
Reverse effect of earlier changeset. Contrary to strip, backout only removes one changeset, not the children revisions.
hg rollback
Roll back the last transaction.
hg revert [-a] [-r REVISION] FILE...
Restore individual files or directories to an earlier state.
Merge stable branch on your development one as much as possible. It can be automated at morning and then manually done day by day each time there is some work merged on stable.
hg pull && hg up -C devbranch hg merge stablebranch && hg ci -m”automated merge from stablebranch” [-u...] && hg push
See http://svn.nuxeo.org/nuxeo/tools/mercurial/automerge.sh.
It happens at the end of a development iteration, when code to merge is implementing a group of User Stories/Use Cases.
Unit tests are up-to-date to valid the new code (see test-driven development recommendations).
Functional tests are up-to-date to cover the new functionalities.
The development branch to merge must have been fully tested:
developers have successfully run Unit Tests
developers have functionally validated last developments
automated builds have run on development branch
At this moment, development branch can be merged on stable one:
hg pull && hg up -C stablebranch hg merge devbranch && hg st hg ci -m”merge from devbranch – NXP-9999 ...” hg push [-f]
Use “-f” only if stablebranch was no more a head.
If two developers worked on the same branch with different parents, it may result in two simultaneous branches with the same name (see server-side hooks).
$ hg push pushing to https://hg.nuxeo.org/somerepository searching for changes abort: push creates new remote heads! (did you forget to merge? use push -f to force)
In such case, the developers won't be able to push their changesets until they have merged the two branches. "hg heads branchname" will show the multiple heads and their changeset identifiers.
Simplest way is to switch his working directory to the other developer's revision and merge his own code:
hg up -C otherRevision hg merge ownRevision hg st hg ci -m”merge two heads” hg push
In case of doubts, before pushing, you can check what you've done with multiple commands:
hg out [-p] [-r REVISION] hg glog [-l LIMIT] [|less] hg heads someBranch
Thanks to Mercurial which is decentralized, even if Nuxeo's repositories are not, you can pull from Internet to a local repository and then pull from this repository. Then, you can update the .hg/hgrc file to bind it on the central repository or continue using the local one, pushing on it and then pushing changesets from it to the remote one.
hg clone https://hg.nuxeo.org/somerepository/ ~/repo-remote/ hg clone ~/repo-remote/ ~/repo-local/ cd ~/repo-local/ # some work… hg ci -m”NXP-9999 - some work” && hg push cd ~/repo-remote/ && hg pull # usual checks (heads, merge, …) hg push
Later, to update ~/repo-local/ for instance:
cd ~/repo-remote/ && hg pull cd ~/repo-local/ && hg pull && hg up
“hg fetch” can be used to pull, merge, commit but it is for experienced users, it's recommended to first being familiarized with unitary commands.
Mercurial Queues are an advanced group of Mercurial functions. Whereas not very easy to apprehend, they are powerful tools.
You can for instance transform a group of changesets made on a wrong branch to patches being then re-applied on the right branch, while editing and changing anything in those changesets (user, comments, ...).
See http://mercurial.selenic.com/wiki/MqExtension or Mercurial: The Definitive Guide by Bryan O'Sullivan.
Eclipse can benefit for several plugins for improving code quality, in both adherence to the project's coding standard and in removing bugs.
TODO
If you are already familiar with the Checkstyle Eclipse plugin,
just configure it to use the checkstyle.xml at the
root of the nuxeo sources: http://hg.nuxeo.org/nuxeo/file/5.2/checkstyle.xml.
IDEA doesn't provide an integrated profiler and Eclipse's profiler, provided by the TPTP project, doesn't currently work on Mac OS, one can use NetBeans to profile the Nuxeo platform.
Here is how to do it:
Nuxeo heavily uses extension points. In order to manage them nxPointDoc tool has been created. Its purpose is to explore all XML files and build the documentation of each explored components. Cross links and indexes are also built to ease the navigation.
The NxPointDoc pages are available at
http://svn.nuxeo.org/nxpointdoc/
The tool is written in Python and the following libraries are needed:
Genshi for templating
ElementTree for XML processing
Pygments for code highlighting
A component XML file is structured as follow:
<component ...>
<!--############## Component configuration ############-->
<!-- implementation class (optional) -->
<implementation>...</implementation>
<!-- component properties (optional) -->
<property name="..." value="..."/>
...
<property name="..." value="..."/>
<!--############### Extension points ################-->
<!-- extension points are optional -->
<extension-point ...>
...
</extension-point>
...
<!--############### Contributions ################-->
<!-- contributions are optional -->
<extension ...>
...
</extension>
...
</component>We can see that the only required element is the component element (although it is useless to have an empty component). So there are 3 main sections (any of these sections are optional).
Component configuration: This section defines the component implementation class and some properties to initialize the component (This section content may be modified in future especially when aligning nuxeo components with OSGi services).
Extension points: This sections contains all the extension point declared by the component.
Contributions (extension tag): This section
contains all the contributions made by this component to other
components.
To add documentation to these elements a
<documentation> tag will be used. An element
may have different content depending on what it is documenting. While
some information is already available in other XML elements in the file,
there is no need to duplicate these information inside the documentation
provided though the element. For example the name of the component can
be retrieved from the name attribute of the component element, the
implementation class name from the implementation element etc.
To format the description text, we can use XHTML tags and
javadoc-like markers such as @property,
@schema etc. Javadoc-like links are also supported:
@see points on the javadoc,
@component points on another component documentation.
For example, {@see
org.nuxeo.ecm.core.schema.types.Type} will point on the
http://maven.nuxeo.org/apidocs corresponding page
while {@component
org.nuxeo.ecm.webapp.directory.DirectoryTreeService} will
explicitly insert a link to the related NxPointDoc page. Code
colorization is also supported through the <code
language='xml'> ... </code> tags. If no language is
given, xml is taken by default. Java
(language='java') and many other languages are
supported (see Pygments pages).
Regarding <component> documentation, the following elements
are available:
@author: may be duplicated for multiple
authoring
@version
@property
@see: points to Javadoc
@component: points to nxpointdoc
@deprecated
component@name attribute: the component
name
component/implementation tag: the
implementation class
component/require tag: required
elements
component/documentation tag: the
description
For <extension-point> the following
elements have to be used:
@author: may be duplicated for multiple
authoring
@schema
@deprecated
@see
@component
component/extension-point@name attribute:
the name
component/extension-point/documentation tag
- the description
If the extension point is using object
sub-elements, the DTD should be extracted from
the XMap annotated class, otherwise the user may specify the
DTD using the @schema marker
inside the documentation element
For <extension>, describing contributions to an extension-point, we have
@author: may be duplicated for multiple
authoring
@see
@component
@deprecated
component/extension@target attribute -
rendered as a link to the component documentation
component/extension@point - rendered as a
link to the extension point documentation
component/extension-point/documentation
description
Here is a short example of what a component xml file may look like.
<?xml version="1.0"?>
<component name="org.nuxeo.ecm.MyService">
<documentation>
My demo service
<p/>
This service does nothing
@property home home directory to be used to create temp files
@property timeout the time interval in seconds
@version 1.0
@author Bogdan
</documentation>
<require>org.nuxeo.ecm.Service1</require>
<require>org.nuxeo.ecm.Service2</require>
<implementation class=”org.nuxeo.ecm.core.demo.Service2”/>
<property name=”home” value=”/home/bstefanescu”/>
<property name=”interval” value=”20” type=”Integer”/>
<extension target="org.nuxeo.ecm.SchemaService" point="schema">
<documentation>Common and Dublin Core schemas</documentation>
<schema name="dublincore" src="schema/dublincore.xsd" />
<schema name="common" src="schema/common.xsd" />
</extension>
<extension-point name="repository">
<documentation>Register new repositories</documentation>
<object class="org.nuxeo.ecm.RepositoryDescriptor"/>
</extension-point>
</component>
Feel free to browse the NxPointDoc site and teh corresponding xml file to go deeper. The systematic link to the source code svn repository may help you.
nxpointdoc is a command line program that creates the whole site
from a source repository SOURCE_DIR to a target
publication directory TARGET_DIR. Each component is
analyzed and all related pages created. Index pages are then
created.
$ ./nxpointdoc.py -h usage: nxpointdoc.py [options] options: --version show program's version number and exit -h, --help show this help message and exit --source=SOURCE_DIR Source root directory containing xml component files --target=TARGET_DIR Target directory for the generated documentation --template=TEMPLATE Genshi template for component html file --template-index=TEMPLATE_INDEX Genshi template for index html file --allow-xhtml-comment=ALLOW_XHTML_COMMENT 'no' to not interpret xhtml tags in comment --color=COLOR_CODE 'no' to not color <code> contents
Valid SOURCE_DIR and TARGET_DIR
are mandatory. Template files have to exist. The one delivered have the
.template extension and can be used as is.
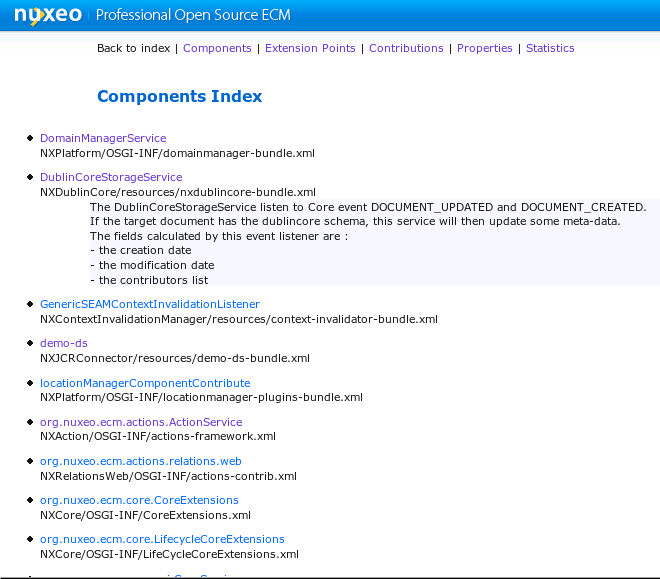
NxPointDoc generates 3 indexes that are the entry points; The
documentation is accessible at
http://svn.nuxeo.org/nxpointdoc/ with 3 indexes related to
components, extension points and contributions. Each one is an entry
point for the documentation. The Indexes give the name and the first
line of the documentation. An hyperlink allows to see the detail of the
examinated item.
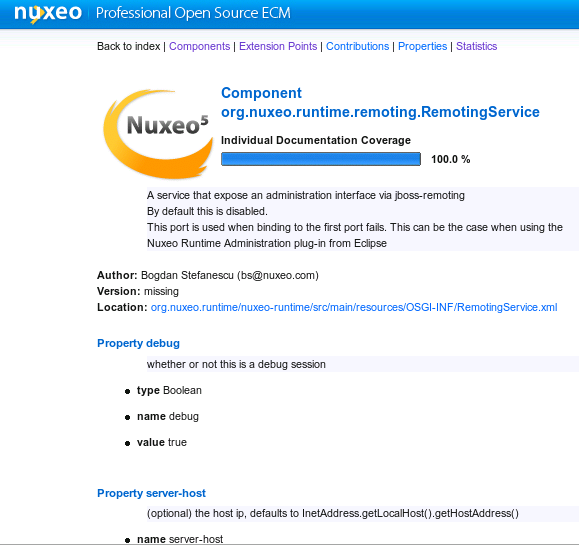
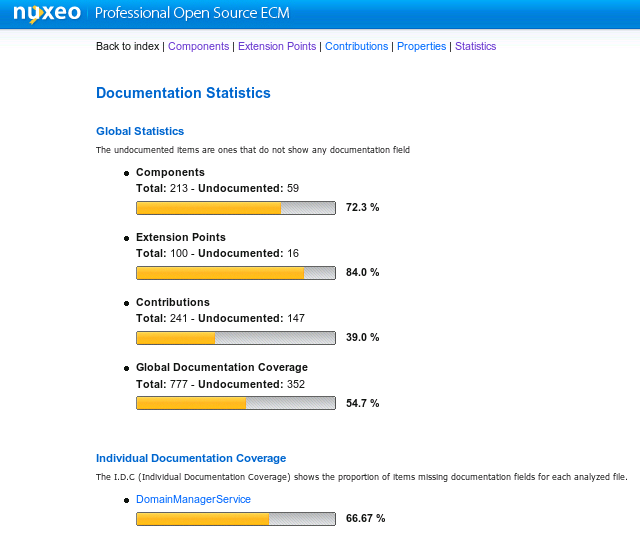
The statistic gives some rough indicators on the documentation
coverage, globally or for each component file. The
G.D.C stands for Global Documentation Coverage while
the I.D.C stands for Individual Documentation
Coverage. They show the ratio between all the information/documentation
that is written over all the entries that are considered as mandatory
(like author, documentation, etc.). The higher these indicators are, the
better it is.
"Continuous Integration is a software development practice where members of a team integrate their work frequently, usually each person integrates at least daily - leading to multiple integrations per day. Each integration is verified by an automated build (including test) to detect integration errors as quickly as possible. Many teams find that this approach leads to significantly reduced integration problems and allows a team to develop cohesive software more rapidly." | ||
| --Martin Fowler - Continuous Integration (an introduction) | ||
See http://en.wikipedia.org/wiki/Continuous_Integration
It's as important to follow quality processes on development as to maintain this quality among time. Nuxeo is involved in such practices that will guarantee or reinforce its products quality.
Nuxeo products and tools are continuously built over time, at each change and against multiple environments. Nuxeo QA team sets and maintain a QA environment applying CI rules and so providing to developers means to check their code quality and being warned in case of any problem.
Maintain a code repository
Nuxeo sources repositories hg.nuxeo.org and svn.nuxeo.org are under continuous integration.
This includes Nuxeo EP, Nuxeo addons, Nuxeo RCP, Nuxeo WebEngine, Nuxeo Books, tools and plugins and of course all our customers' projects.
Builds are automated
This is done by Hudson on Nuxeo QA Unit, Functional and Integration tests.
Every commit on mainline is integrated
When code is committed, target project is built, as all projects depending on it. The full chain is verified, from build to deployment.
Mainlines on Nuxeo EP and addons are the main branches in development: 5.1 and 5.2 (resp. 1.4 and 1.5 for associated subtrees). For projects under SubVersion, that means the trunk and, if exists, 5.1 branch.
Everyone can see the results of the latest build
Hudson plugins ensure to warn potential responsible(s) of build fail by mail and jabber, so they can react quickly.
Moreover, every build fail is sent on ECM QA mailing list.
Make it easy to get the latest deliverables
Nightly builds are done. Produced artifacts are published on our Maven repositories maven.nuxeo.org. Currently managed with Nexus, our repositories store all released artifacts and recent snapshots.
Keep the build fast
Continuous Integration is done on multiple servers, more or less powerful, using slaves in order to distribute the load.
Thanks to Maven and to Nuxeo modularity, each module is built separately and as a consequence, quickly.
Test in a clone of the production environment
We have two integration levels: unit and functional.
First level checks code compilation and runs Unit tests. A lot of Unit tests simulate target environments (with mock objects). Dependent projects/modules are then added to the CI chain.
Second level runs packaging tools and automated deployment against multiple environments (we aim at covering JVM versions, SQL backends, OS, browsers, performance, ...). Finally we use Selenium tests to check functional integrity. This also indirectly provides a continuous integration on our tools (packaging, convenient scripts, ...).
These practices apply on every script, project or module. They should be strictly followed.
Code must be under continuous integration.
Except for prototype and spike solutions (sandbox projects or temporary branches), all projects must be under CI. If not, ask for it to the QA team, providing the informations mentioned in the following Hudson part.
Automate the build
Think about QA tools that will have to test the project without any human intervention. Provide Maven, Ant or, in the worse case, Shell autonomous configuration.
Make your build self-testing
Think "test-driven development". Simply building a project/module and running its Unit tests should be a valuable measurement of the code stability. Unit tests code coverage often needs to be increased.
Commit every day
Smaller are the commits, lower is the risk of conflicting changes and easier is the bug analysis.
Stay tuned
Be aware of CI builds, particularly failed builds.
Log on http://qa.nuxeo.org/hudson/ and check your profile's informations, especially your jabber address. Hudson will then be able to contact you via Jabber when you are suspected of having broken something.
Subscribe to ECM QA mailing list. Use mail filters to quickly catch and fix problems. Hudson will send you a mail if it detects one of your commits between succeed and failed tests.
If you're used to, RSS feeds are also available.
Check regularly your projects health on our QA sites. Inform QA team if you notice any issue.
Always consider a build failed as an emergency.
Maven Parent POM file gives a lot of useful information. Take care
to fill in you project's pom.xml file:
main tags
<name>Nuxeo ECM Projects</name>
<description>Nuxeo ECM Platform and related components</description>
<organization>
<name>Nuxeo SAS</name>
<url>http://www.nuxeo.com/</url>
</organization>
<licenses>
<license>
<name>GNU LESSER GENERAL PUBLIC LICENSE, Version 2.1</name>
<url>http://www.gnu.org/copyleft/lesser.txt</url>
</license>
</licenses>
<mailingLists>
<mailingList>
<name>Nuxeo ECM list</name>
<subscribe>http://lists.nuxeo.com/mailman/listinfo/ECM</subscribe>
<unsubscribe>http://lists.nuxeo.com/mailman/listinfo/ECM</unsubscribe>
<archive>http://lists.nuxeo.com/pipermail/ecm/</archive>
</mailingList>
</mailingLists>
<issueManagement>
<system>jira</system>
<url>http://jira.nuxeo.org/browse/NXP</url>
</issueManagement>
<ciManagement>
<system>Hudson</system>
<url>http://qa.nuxeo.org/hudson/</url>
</ciManagement>
"scm" tag
<scm> <connection>scm:hg:http://hg.nuxeo.org/addons/nuxeo-samples</connection> <developerConnection>scm:hg:https://hg.nuxeo.org/addons/nuxeo-samples</developerConnection> <url>http://trac.nuxeo.org/nuxeo/browser/nuxeo_samples</url> </scm>
"developers" tag (there's no rule for tags within the "developer" tag, feel free to add useful information such as "role", "url", "organization" or "module")
<developers>
<developer>
<name>John Doe</name>
<email>[email protected]</email>
</developer>
</developers>
You also have to add <repositories> section in the project's parent POM in order to make your project fully autonomous.
<repositories>
<repository>
<id>public</id>
<url>http://maven.nuxeo.org/public</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>public-snapshot</id>
<url>http://maven.nuxeo.org/public-snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
All these tags are intelligently inherited so that, if you're project's Maven parent is nuxeo-ecm or one of its children, you don't have to repeat informations such as "organization", "licenses", "mailingLists", "issueManagement". Also, when working on a project with sub-modules, it's only necessary to set "scm" on the parent POM.
Adding a project under continuous integration in Hudson requires:
SCM URL
Build command
In case of Maven, it's the goals to run (usually, it will be "clean install"). Consider using Maven "Profiles" to manage different behaviors like development versus production environment.
In case of Ant, you may need to provide some parameters on the
command line (equivalent to what can be set by a human user in a
build.properties).
In case of Shell (avoid it as much as possible), it's a simple command with working default values in case of required parameters. If needed, some environment constants may be set.
Notification target(s): eg, the team mailing list.
Release process is managed and tested by multiple tools:
Hudson continuous integration which generates a candidate release every night based on snapshots.
When a release is wanted, all continuous integration chain must be satisfied, nightly builds are manually tested to complete automated tests and candidate release is "promoted" to public release (code is tagged, artifacts are uploaded to the maven repository and packages are published on Nuxeo web site.
For now, continuous integration covers those configurations:
Nuxeo DM.
Linux Ubuntu (Debian).
Sun Java 5, Sun Java 6.
JBoss application server.
VCS backend on H2.
VCS backend on PostgreSQL.
Not automatically tested at integration level (full deployment and tests):
Nuxeo EP.
Nuxeo-shell and scripts.
JCR backend with various databases: H2, Derby, PostgreSQL, MySQL, Oracle, ...
VCS backend with various databases: Derby, MySQL, Oracle, ...
Various application servers: Jetty, GlassFish (GF3) and Tomcat.
Various Windows OS.
Various Java providers.
You can download nightly candidate releases from IT-nuxeo-5.2-build, test and send feedback on our ECM mailing list or, in case of bugs confirmed, in our Issue Tracker (Jira).