

In this tutorial we formulate the learning problem for neural networks and describe some learning tasks that they can solve.
Contents:Any application for neural networks involves a neural network itself, a performance functional, and a training strategy. The learning problem is then formulated as to find a neural network which optimizes a performance functional by means of a training strategy.
The following figure depicts an activity diagram for the learning problem.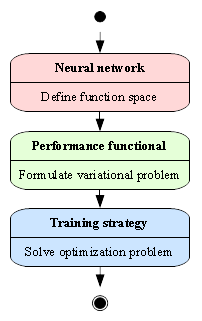
As we will see, the learning problem for neural networks is formulated from a variational point of view. Indeed, learning tasks lie in terms of finding a function which causes some functional to assume an extreme value. Neural networks provide a general framework for solving variational problems.
The data set contains the information for creating the model. It comprises a data matrix in which columns represent variables and rows represent instances. The data is contained in a file with the following format:
d_1_1 d_1_2 ... d_1_q ... ... ... ... d_p_1 d_p_2 ... d_p_q
Here the number of instances is denoted p, while the number of variables is denoted q.
Variables in a data set can be of three types:The crucial point is that testing instances are never used to choose among two or more neural networks. Instances that are used to choose the best of two or more neural networks are, by definition, generalization instances.
A neuron model is a mathematical model of the behaviour of a single neuron in a biological nervous system. The most important neuron model is the so called perceptron. The perceptron neuron model receives information in the form of numerical inputs. This information is then combined with a set of parameters to produce a message in the form of a single numerical output.
Most neural networks, even biological neural networks, exhibit a layered structure. In this work layers are the basis to determine the architecture of a neural network. A layer of perceptrons takes a set of inputs in order to produce a set of outputs.
A multilayer perceptron is built up by organizing layers of perceptrons in a network architecture. In this way, the architecture of a network refers to the number of layers, their arrangement and connectivity. The characteristic network architecture in OpenNN is the so called feed-forward architecture. The multilayer perceptron can then be defined as a network architecture of perceptron layers. This neural network represents a parameterized function of several variables with very good approximation properties.
In order to solve practical applications, different extensions must be added to the multilayer perceptron. Some of them include scaling, unscaling, bounding, probabilistic or conditions layers. Therefore, the neural network in OpenNN is composed by a mutlilayer perceptron plus some additional layers.
The performance functional plays an important role in the use of a neural network. It defines the task the neural network is required to do and provides a measure of the quality of the representation that the neural network is required to learn. The choice of a suitable performance functional depends on the particular application.
A performance functional in OpenNN is composed of three different terms: objective, regularization and constraints. Most of the times, a single objective term will be enough, but some applications will require regularize solutions or will be defined by constraints on the solutions.
Learning tasks such as function regression and pattern recognition will have performance functionals measured on data sets. On the other hand, learning tasks such as optimal control or optimal shape design will have performance functionals measured on mathematical models. Finally, the performance functionals in another learning tasks, such as inverse problems, will be measured in both data sets and mathematical models.
The procedure used to carry out the learning process is called training (or learning) strategy. The training strategy is applied to the neural network to in order to obtain the best possible performance. The type of training is determined by the way in which the adjustment of the parameters in the neural network takes place.
The most general training strategy in OpenNN will include three different training algorithms: initialization, main and refinement. Most applications will only need one training algorithm, but some complex problems might require the combination of two or three of them.
A generally good training strategy includes the quasi-Newton method. However, noisy problems might require an evolutionary algorithm. The first cited training algorithm is several orders of magnitude faster than the second one.
Learning tasks for neural networks can be classified according to the source of information for them. There are basically two sources of information: data sets and mathematical models. In this way, some classes of learning tasks which learn from data sets are function regression, pattern recognition or time series prediction. On the other hand, learning tasks in which learning is performed from mathematical models are optimal control or optimal shape design. Finally, in inverse problems the neural network learns from both data sets and mathematical models.
As we have said, the knowledge for a neural network can be represented in the form of data sets or mathematical models. The neural network learns from data sets in function regression and pattern recognition; it learns from mathematical models in optimal control and optimal shape design; and it learns from both mathematical models and data sets in inverse problems. Please note that other possible applications can be added to these learning tasks.
Figure shows the learning tasks for neural networks described in this section. As we can see, they are capable of dealing with a great range of applications. Any of that learning tasks is formulated as being a variational problem. All of them are solved using the three step approach described in the previous section. Modelling and classification are the most traditional; optimal control, optimal shape design and inverse problems can also be very useful.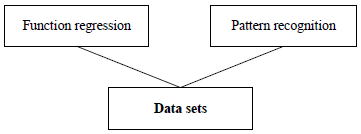
Function regression is the most popular learning task for neural networks. It is also called modelling. The function regression problem can be regarded as the problem of approximating a function from a data set consisting of input-target instances. The targets are a specification of what the response to the inputs should be. While input variables might be quantitative or qualitative, in function regression target variables are quantitative.
Performance measures for function regression are based on a sum of errors between the outputs from the neural network and the targets in the training data. As the training data is usually deficient, a regularization term might be required in order to solve the problem correctly.
An example is to design an instrument that can determine serum cholesterol levels from measurements of spectral content of a blood sample. There are a number of patients for which there are measurements of several wavelengths of the spectrum. For the same patients there are also measurements of several cholesterol levels, based on serum separation.
The learning task of pattern recognition gives raise to artificial intelligence. That problem can be stated as the process whereby a received pattern, characterized by a distinct set of features, is assigned to one of a prescribed number of classes. Pattern recognition is also known as classification. Here the neural network learns from knowledge represented by a training data set consisting of input-target instances. The inputs include a set of features which characterize a pattern, and they can be quantitative or qualitative. The targets specify the class that each pattern belongs to and therefore are qualitative.
Classification problems can be, in fact, formulated as being modelling problems. As a consequence, performance functionals used here are also based on the sum squared error. Anyway, the learning task of pattern recognition is more difficult to solve than that of function regression. This means that a good knowledge of the state of the technique is recommended for success.
A typical example is to distinguish hand-written versions of characters. Images of the characters might be captured and fed to a computer. An algorithm is then seek to which can distinguish as reliably as possible between the characters.
OpenNN Copyright © 2014 Roberto Lopez (Artelnics)